某 Telegram AI陪聊 任意注册账号漏洞
2025年12月29日 21:41
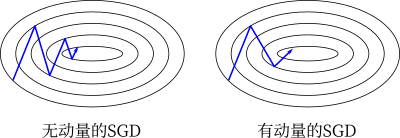
在构建神经网络模型的时候,除了网络结构设计以外,选取合适的优化算法也对网络起着至关重要的作用,本文将对神经网络中常用的优化算法进行简单的介绍和对比,本文部分参考了 Ruder 的关于梯度下降优化算法一文 1。首先,我们对下文中使用的符号进行同意说明:网络中的参数同一表示为 $\theta$,网络的假设函数为 $h_{\boldsymbol{\theta}}\left(\boldsymbol{x}\right)$,网络的损失函数为 $J\left(\boldsymbol{\theta}\right)$,学习率为 $\alpha$,假设训练数据中共包含 $m$ 个样本,网络参数个数为 $n$。
在梯度下降算法中,常用的主要包含 3 种不同的形式,分别是批量梯度下降 (Batch Gradient Descent, BGD),随机梯度下降 (Stochastic Gradient Descent, SGD) 和小批量梯度下降 (Mini-Batch Gradient Descent, MBGD)。一般情况下,我们在谈论梯度下降时,更多的是指小批量梯度下降。
BGD 为梯度下降算法中最基础的一个算法,其损失函数定义如下:
$$ J \left(\boldsymbol{\theta}\right) = \dfrac{1}{2m} \sum_{i=1}^{m}{\left(h_{\boldsymbol{\theta}}\left(x^{\left(i\right)}\right) - y^{\left(i\right)}\right)} $$
针对任意参数 $\theta_j$ 我们可以求得其梯度为:
$$ \nabla_{\theta_j} = \dfrac{\partial J\left(\boldsymbol{\theta}\right)}{\partial \theta_j} = - \dfrac{1}{m} \sum_{i=1}^{m}{\left(y^{\left(i\right)} - h_{\boldsymbol{\theta}} \left(x^{\left(i\right)}\right)\right) x_j^{\left(i\right)}} $$
之后,对于任意参数 $\theta_j$ 我们按照其负梯度方向进行更新:
$$ \theta_j = \theta_j + \alpha \left[\dfrac{1}{m} \sum_{i=1}^{m}{\left(y^{\left(i\right)} - h_{\boldsymbol{\theta}} \left(x^{\left(i\right)}\right)\right) x_j^{\left(i\right)}}\right] $$
整个算法流程可以表示如下:
\begin{algorithm}
\caption{BGD 算法}
\begin{algorithmic}
\FOR{$epoch = 1, 2, ...$}
\FOR{$j = 1, 2, ..., n$}
\STATE $J \left(\boldsymbol{\theta}\right) = \dfrac{1}{2m} \sum_{i=1}^{m}{\left(h_{\boldsymbol{\theta}}\left(x^{\left(i\right)}\right) - y^{\left(i\right)}\right)}$
\STATE $\theta_j = \theta_j - \alpha \dfrac{\partial J\left(\boldsymbol{\theta}\right)}{\partial \theta_j}$
\ENDFOR
\ENDFOR
\end{algorithmic}
\end{algorithm}
从上述算法流程中我们可以看到,BGD 算法每次计算梯度都使用了整个训练集,也就是说对于给定的一个初始点,其每一步的更新都是沿着全局梯度最大的负方向。但这同样是其问题,当 $m$ 太大时,整个算法的计算开销就很高了。
SGD 相比于 BGD,其最主要的区别就在于计算梯度时不再利用整个数据集,而是针对单个样本计算梯度并更新权重,因此,其损失函数定义如下:
$$ J \left(\boldsymbol{\theta}\right) = \dfrac{1}{2} \left(h_{\boldsymbol{\theta}}\left(x^{\left(i\right)}\right) - y^{\left(i\right)}\right) $$
整个算法流程可以表示如下:
\begin{algorithm}
\caption{SGD 算法}
\begin{algorithmic}
\FOR{$epoch = 1, 2, ...$}
\STATE Randomly shuffle dataset
\FOR{$i = 1, 2, ..., m$}
\FOR{$j = 1, 2, ..., n$}
\STATE $J \left(\boldsymbol{\theta}\right) = \dfrac{1}{2} \left(h_{\boldsymbol{\theta}}\left(x^{\left(i\right)}\right) - y^{\left(i\right)}\right)$
\STATE $\theta_j = \theta_j - \alpha \dfrac{\partial J\left(\boldsymbol{\theta}\right)}{\partial \theta_j}$
\ENDFOR
\ENDFOR
\ENDFOR
\end{algorithmic}
\end{algorithm}
SGD 相比于 BGD 具有训练速度快的优势,但同时由于权重改变的方向并不是全局梯度最大的负方向,甚至相反,因此不能够保证每次损失函数都会减小。
针对 BGD 和 SGD 的问题,MBGD 则是一个折中的方案,在每次更新参数时,MBGD 会选取 $b$ 个样本计算的梯度,设第 $k$ 批中数据的下标的集合为 $B_k$,则其损失函数定义如下:
$$ \nabla_{\theta_j} = \dfrac{\partial J\left(\boldsymbol{\theta}\right)}{\partial \theta_j} = - \dfrac{1}{|B_k|} \sum_{i \in B_k}{\left(y^{\left(i\right)} - h_{\boldsymbol{\theta}} \left(x^{\left(i\right)}\right)\right) x_j^{\left(i\right)}} $$
整个算法流程可以表示如下:
\begin{algorithm}
\caption{MBGD 算法}
\begin{algorithmic}
\FOR{$epoch = 1, 2, ...$}
\FOR{$k = 1, 2, ..., m / b$}
\FOR{$j = 1, 2, ..., n$}
\STATE $J \left(\boldsymbol{\theta}\right) = \dfrac{1}{|B_k|} \sum_{i \in B_k}{\left(y^{\left(i\right)} - h_{\boldsymbol{\theta}} \left(x^{\left(i\right)}\right)\right) x_j^{\left(i\right)}}$
\STATE $\theta_j = \theta_j - \alpha \dfrac{\partial J\left(\boldsymbol{\theta}\right)}{\partial \theta_j}$
\ENDFOR
\ENDFOR
\ENDFOR
\end{algorithmic}
\end{algorithm}
当梯度沿着一个方向要明显比其他方向陡峭,我们可以形象的称之为峡谷形梯度,这种情况多位于局部最优点附近。在这种情况下,SGD 通常会摇摆着通过峡谷的斜坡,这就导致了其到达局部最优值的速度过慢。因此,针对这种情况,Momentum 2 方法提供了一种解决方案。针对原始的 SGD 算法,参数每 $t$ 步的变化量可以表示为
$$ \boldsymbol{v}_t = - \alpha \nabla_{\boldsymbol{\theta}} J \left(\boldsymbol{\theta}_t\right) $$
Momentum 算法则在其变化量中添加了一个动量分量,即
$$ \begin{equation} \begin{split} \boldsymbol{v}_t &= - \alpha \nabla_{\boldsymbol{\theta}} J \left(\boldsymbol{\theta}_t\right) + \gamma \boldsymbol{v}_{t-1} \\ \boldsymbol{\theta}_t &= \boldsymbol{\theta}_{t-1} + \boldsymbol{v}_t \end{split} \end{equation} $$
对于添加的动量项,当第 $t$ 步和第 $t-1$ 步的梯度方向相同时,$\boldsymbol{\theta}$ 则以更快的速度更新;当第 $t$ 步和第 $t-1$ 步的梯度方向相反时,$\boldsymbol{\theta}$ 则以较慢的速度更新。利用 SGD 和 Momentum 两种方法,在峡谷行的二维梯度上更新参数的示意图如下所示
![]()
NAG (Nesterov Accelerated Gradient) 3 是一种 Momentum 算法的变种,其核心思想会利用“下一步的梯度”确定“这一步的梯度”,当然这里“下一步的梯度”并非真正的下一步的梯度,而是指仅根据动量项更新后位置的梯度。Sutskever 4 给出了一种更新参数的方法:
$$ \begin{equation} \begin{split} \boldsymbol{v}_t &= - \alpha \nabla_{\boldsymbol{\theta}} J \left(\boldsymbol{\theta}_t + \gamma \boldsymbol{v}_{t-1}\right) + \gamma \boldsymbol{v}_{t-1} \\ \boldsymbol{\theta}_t &= \boldsymbol{\theta}_{t-1} + \boldsymbol{v}_t \end{split} \end{equation} $$
针对 Momentum 和 NAG 两种不同的方法,其更新权重的差异如下图所示:
![]()
AdaGrad 5 是一种具有自适应学习率的的方法,其对于低频特征的参数选择更大的更新量,对于高频特征的参数选择更小的更新量。因此,AdaGrad算法更加适用于处理稀疏数据。Pennington 等则利用该方法训练 GloVe 6 词向量,因为对于出现次数较少的词应当获得更大的参数更新。
因为每个参数的学习速率不再一样,则在 $t$ 时刻第 $i$ 个参数的变化为
$$ \theta_{t, i} = \theta_{t-1, i} - \alpha \nabla_{\theta} J \left(\theta_{t-1, i}\right) $$
根据 AdaGrad 方法的更新方式,我们对学习率做出如下变化
$$ \theta_{t, i} = \theta_{t-1, i} - \dfrac{\alpha}{\sqrt{G_{t, i}} + \epsilon} \nabla_{\theta} J \left(\theta_{t-1, i}\right) $$
其中,$G_t$ 表示截止到 $t$ 时刻梯度的平方和;$\epsilon$ 为平滑项,防止除数为零,一般设置为 $10^{-8}$。AdaGrad 最大的优势就在于其能够自动调节每个参数的学习率。
上文中 AdaGrad 算法存在一个缺点,即其用于调节学习率的分母中包含的是一个梯度的平方累加项,随着训练的不断进行,这个值将会越来越大,也就是说学习率将会越来越小,最终导致模型不会再学习到任何知识。Adadelta 7 方法针对 AdaGrad 的这个问题,做出了进一步改进,其不再计算历史所以梯度的平方和,而是使用一个固定长度 $w$ 的滑动窗口内的梯度。
因为存储 $w$ 的梯度平方并不高效,Adadelta 采用了一种递归的方式进行计算,定义 $t$ 时刻梯度平方的均值为
$$ E \left[g^2\right]_t = \rho E \left[g^2\right]_{t-1} + \left(1 - \rho\right) g^2_{t} $$
其中,$g_t$ 表示 $t$ 时刻的梯度;$\rho$ 为一个衰减项,类似于 Momentum 中的衰减项。在更新参数过程中我们需要其平方根,即
$$ \text{RMS} \left[g\right]_t = \sqrt{E \left[g^2\right]_t + \epsilon} $$
则参数的更新量为
$$ \Delta \theta_t = - \dfrac{\alpha}{\text{RMS} \left[g\right]_t} g_t $$
除此之外,作者还考虑到上述更新中更新量和参数的假设单位不一致的情况,在上述更新公式中添加了一个关于参数的衰减项
$$ \text{RMS} \left[\Delta \theta\right]_t = \sqrt{E \left[\Delta \theta^2\right]_t + \epsilon} $$
其中
$$ E \left[\Delta \theta^2\right]_t = \rho E \left[\Delta \theta^2\right]_{t-1} + \left(1 - \rho\right) \Delta \theta_t^2 $$
在原始的论文中,作者直接用 $\text{RMS} \left[\Delta \theta^2\right]_t$ 替换了学习率,即
$$ \Delta \theta_t = - \dfrac{\text{RMS} \left[\Delta \theta\right]_{t-1}}{\text{RMS} \left[g\right]_t} g_t $$
而在 Keras 源码中,则保留了固定的学习率,即
$$ \Delta \theta_t = - \alpha \dfrac{\text{RMS} \left[\Delta \theta\right]_{t-1}}{\text{RMS} \left[g\right]_t} g_t $$
RMSprop 8 是由 Hinton 提出的一种针对 AdaGrad 的改进算法。参数的更新量为
$$ \Delta \theta_t = - \dfrac{\alpha}{\text{RMS} \left[g\right]_t} g_t $$
Adam (Adaptive Moment Estimation) 9 是另一种类型的自适应学习率方法,类似 Adadelta,Adam 对于每个参数都计算各自的学习率。Adam 方法中包含一个一阶梯度衰减项 $m_t$ 和一个二阶梯度衰减项 $v_t$
$$ \begin{equation} \begin{split} m_t &= \beta_1 m_{t-1} + \left(1 - \beta_1\right) g_t \\ v_t &= \beta_2 v_{t-1} + \left(1 - \beta_2\right) g_t^2 \end{split} \end{equation} $$
算法中,$m_t$ 和 $v_t$ 初始化为零向量,作者发现两者会更加偏向 $0$,尤其是在训练的初始阶段和衰减率很小的时候 (即 $\beta_1$ 和 $\beta_2$ 趋近于1的时候)。因此,对其偏差做如下校正
$$ \begin{equation} \begin{split} \hat{m}_t &= \dfrac{m_t}{1 - \beta_1^t} \\ \hat{v}_t &= \dfrac{v_t}{1 - \beta_2^t} \end{split} \end{equation} $$
最终得到 Adam 算法的参数更新量如下
$$ \Delta \theta = - \dfrac{\alpha}{\sqrt{\hat{v}_t} + \epsilon} \hat{m}_t $$
在 Adam 中参数的更新方法利用了 $L_2$ 正则形式的历史梯度 ($v_{t-1}$) 和当前梯度 ($|g_t|^2$),因此,更一般的,我们可以使用 $L_p$ 正则形式,即
$$ \begin{equation} \begin{split} v_t &= \beta_2^p v_{t-1} + \left(1 - \beta_2^p\right) |g_t|^p \\ &= \left(1 - \beta_2^p\right) \sum_{i=1}^{t} \beta_2^{p\left(t-i\right)} \cdot |g_t|^p \end{split} \end{equation} $$
这样的变换对于值较大的 $p$ 而言是很不稳定的,但对于极端的情况,当 $p$ 趋近于无穷的时候,则变为了一个简单并且稳定的算法。则在 $t$ 时刻对应的我们需要计算 $v_t^{1/p}$,令 $u_t = \lim_{p \to \infty} \left(v_t\right)^{1/p}$,则有
$$ \begin{equation} \begin{split} u_t &= \lim_{p \to \infty} \left(\left(1 - \beta_2^p\right) \sum_{i=1}^{t} \beta_2^{p\left(t-i\right)} \cdot |g_t|^p\right)^{1/p} \\ &= \lim_{p \to \infty} \left(1 - \beta_2^p\right)^{1/p} \left(\sum_{i=1}^{t} \beta_2^{p\left(t-i\right)} \cdot |g_t|^p\right)^{1/p} \\ &= \lim_{p \to \infty} \left(\sum_{i=1}^{t} \beta_2^{p\left(t-i\right)} \cdot |g_t|^p\right)^{1/p} \\ &= \max \left(\beta_2^{t-1} |g_1|, \beta_2^{t-2} |g_2|, ..., \beta_{t-1} |g_t|\right) \end{split} \end{equation} $$
写成递归的形式,则有
$$ u_t = \max \left(\beta_2 \cdot u_{t-1}, |g_t|\right) $$
则 Adamax 算法的参数更新量为
$$ \Delta \theta = - \dfrac{\alpha}{u_t} \hat{m}_t $$
Adam 算法可以看做是对 RMSprop 和 Momentum 的结合:历史平方梯度的衰减项 $v_t$ (RMSprop) 和 历史梯度的衰减项 $m_t$ (Momentum)。Nadam (Nesterov-accelerated Adaptive Moment Estimation) 10 则是将 Adam 同 NAG 进行了进一步结合。我们利用 Adam 中的符号重新回顾一下 NAG 算法
$$ \begin{equation} \begin{split} g_t &= \nabla_{\theta} J \left(\theta_t - \gamma m_{t-1}\right) \\ m_t &= \gamma m_{t-1} + \alpha g_t \\ \theta_t &= \theta_{t-1} - m_t \end{split} \end{equation} $$
NAG 算法的核心思想会利用“下一步的梯度”确定“这一步的梯度”,在 Nadam 算法中,作者在考虑“下一步的梯度”时对 NAG 进行了改动,修改为
$$ \begin{equation} \begin{split} g_t &= \nabla_{\theta} J \left(\theta_t\right) \\ m_t &= \gamma m_{t-1} + \alpha g_t \\ \theta_t &= \theta_{t-1} - \left(\gamma m_t + \alpha g_t\right) \end{split} \end{equation} $$
对于 Adam,根据
$$ \hat{m}_t = \dfrac{\beta_1 m_{t-1}}{1 - \beta_1^t} + \dfrac{\left(1 - \beta_1\right) g_t}{1 - \beta_1^t} $$
则有
$$ \begin{equation} \begin{split} \Delta \theta &= - \dfrac{\alpha}{\sqrt{\hat{v}_t} + \epsilon} \hat{m}_t \\ &= - \dfrac{\alpha}{\sqrt{\hat{v}_t} + \epsilon} \left(\dfrac{\beta_1 m_{t-1}}{1 - \beta_1^t} + \dfrac{\left(1 - \beta_1\right) g_t}{1 - \beta_1^t}\right) \end{split} \end{equation} $$
上式中,仅 $\dfrac{\beta_1 m_{t-1}}{1 - \beta_1^t}$ 和动量项相关,因此我们类似上文中对 NAG 的改动,通过简单的替换加入 Nesterov 动量项,最终得到 Nadam 方法的参数的更新量
$$ \Delta \theta = - \dfrac{\alpha}{\sqrt{\hat{v}_t} + \epsilon} \left(\dfrac{\beta_1 m_{t-1}}{1 - \beta_1^{t+1}} + \dfrac{\left(1 - \beta_1\right) g_t}{1 - \beta_1^t}\right) $$
对于前面提到的 Adadelta,RMSprop,Adam 和 Nadam 方法,他们均采用了平方梯度的指数平滑平均值迭代产生新的梯度,但根据观察,在一些情况下这些算法并不能收敛到最优解。Reddi 等提出了一种新的 Adam 变体算法 AMSGrad 11,在文中作者解释了为什么 RMSprop 和 Adam 算法无法收敛到一个最优解的问题。通过分析表明,为了保证得到一个收敛的最优解需要保留过去梯度的“长期记忆”,因此在 AMSGrad 算法中使用了历史平方梯度的最大值而非滑动平均进行更新参数,即
$$ \begin{equation} \begin{split} m_t &= \beta_1 m_{t-1} + \left(1 - \beta_1\right) g_t \\ v_t &= \beta_2 v_{t-1} + \left(1 - \beta_2\right) g_t^2 \\ \hat{v}_t &= \max \left(\hat{v}_{t-1}, v_t\right) \\ \Delta \theta &= - \dfrac{\alpha}{\sqrt{\hat{v}_t} + \epsilon} m_t \end{split} \end{equation} $$
作者在一些小数据集和 CIFAR-10 数据集上得到了相比于 Adam 更好的效果,但与此同时一些其他的 实验 却得到了相比与 Adam 类似或更差的结果,因此对于 AMSGrad 算法的效果还有待进一步确定。
正所谓一图胜千言,Alec Radford 提供了 2 张图形象了描述了不同优化算法之间的区别
左图为 Beale Function 在二维平面上的等高线,从图中可以看出 AdaGrad,Adadelta 和 RMSprop 算法很快的找到正确的方向并迅速的收敛到最优解;Momentum 和 NAG 则在初期出现了偏离,但偏离之后调整了方向并收敛到最优解;而 SGD 尽管方向正确,但收敛速度过慢。
右图为包含鞍点的一个三维图像,图像函数为 $z = x^2 - y^2$,从图中可以看出 AdaGrad,Adadelta 和 RMSprop 算法能够相对很快的逃离鞍点,而 Momentum,NAG 和 SGD 则相对比较困难逃离鞍点。
很不幸没能找到 Alec Radford 绘图的原始代码,不过 Louis Tiao 在 博客 中给出了绘制类似动图的方法。因此,本文参考该博客和 Keras 源码中对不同优化算法的实现重新绘制了 2 张类似图像,详细过程参见 源代码,动图如下所示:
Ruder, Sebastian. “An overview of gradient descent optimization algorithms.” arXiv preprint arXiv:1609.04747 (2016). ↩︎
Qian, Ning. “On the momentum term in gradient descent learning algorithms.” Neural networks 12.1 (1999): 145-151. ↩︎
Nesterov, Yurii. “A method for unconstrained convex minimization problem with the rate of convergence O (1/k^2).” Doklady AN USSR. Vol. 269. 1983. ↩︎
Sutskever, Ilya. “Training recurrent neural networks.” University of Toronto, Toronto, Ont., Canada (2013). ↩︎
Duchi, John, Elad Hazan, and Yoram Singer. “Adaptive subgradient methods for online learning and stochastic optimization.” Journal of Machine Learning Research 12.Jul (2011): 2121-2159. ↩︎
Pennington, Jeffrey, Richard Socher, and Christopher Manning. “Glove: Global vectors for word representation.” Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). 2014. ↩︎
Zeiler, Matthew D. “ADADELTA: an adaptive learning rate method.” arXiv preprint arXiv:1212.5701 (2012). ↩︎
Hinton, G., Nitish Srivastava, and Kevin Swersky. “Rmsprop: Divide the gradient by a running average of its recent magnitude.” Neural networks for machine learning, Coursera lecture 6e (2012). ↩︎
Kingma, Diederik P., and Jimmy Ba. “Adam: A method for stochastic optimization.” arXiv preprint arXiv:1412.6980 (2014). ↩︎
Dozat, Timothy. “Incorporating nesterov momentum into adam.” (2016). ↩︎
Reddi, Sashank J., Satyen Kale, and Sanjiv Kumar. “On the convergence of adam and beyond.” International Conference on Learning Representations. 2018. ↩︎

![]()
本文永久链接 – https://tonybai.com/2026/04/18/ollama-from-open-source-hero-to-community-enemy
大家好,我是Tony Bai。
两年前,在本地大模型的蛮荒时代,Ollama 曾如一道神光,照亮了无数普通开发者的探索之路。
凭借那句魔咒般的 ollama run llama3,它以一种近乎“降维打击”的优雅,将普通人与本地 AI 之间的天堑夷为平地。
一时间,Ollama 被盛赞为“本地 AI 的 Docker”、“开源精神的典范”,几乎成了无数技术布道者口中的“开源英雄”。
但就在几天前,一篇名为《本地大模型生态系统不再需要 Ollama》的文章,在技术社区 Hacker News 上,引发了一场“社区公审”。
文章详细罗列了 Ollama 在享受了社区的赞誉之后,犯下的种种“罪行”:从对核心依赖 llama.cpp 长达 400 多天的“选择性遗忘”,到试图用私有模型格式“绑架”用户,再到其背后若隐若现的“VC 商业化”套路……
一夜之间,Ollama 的形象从“屠龙少年”,变成了那条它曾经挑战的“恶龙”。
今天,我们就来深度复盘这场顶级社区的大讨论,看看这位曾经的“开源英雄”,究竟是如何一步步走向“社区公敌”的深渊的。
![]()
Ollama 之所以能如此快速地在各种平台上运行大模型,其背后最大的功臣,是一个名为 llama.cpp 的 C++ 开源库。llama.cpp 是真正负责模型推理的底层引擎。
Ollama 的 v0.0.1 版本,在其 README 中曾明确写道:“一个用 Go 编写的快速推理服务器,由 llama.cpp 驱动。”
Ollama 的本质,是一个基于 llama.cpp 构建的、优化了用户体验的“包装器(Wrapper)”。
然而,随着 Ollama 的声名鹊起,llama.cpp 的名字,却在其官网和宣传中,被刻意地、系统性地抹去了。
在 Hacker News 的帖子中,有用户愤怒地指出:
“这根本不是开源礼仪的问题。MIT 协议只有一个核心要求:包含版权声明。Ollama 没有做到。”
“社区注意到了。GitHub Issue #3185 在 2024 年初就被提出,要求 Ollama 遵守协议。这个 Issue 在 400 多天里,没有得到任何维护者的回应。”
直到社区忍无可忍,发起了 PR,Ollama 的联合创始人才最终在 README 的最底部,加上了一行极其微小的致谢:“llama.cpp 项目由 Georgi Gerganov 创建。”
这种对核心上游项目近乎“羞辱性”的冷处理,被社区视为一种赤裸裸的“背叛”,激怒了所有信奉开源精神的开发者。
比忘记致谢更让开发者无法容忍的,是 Ollama 为了“锁定用户”,而精心设计的私有化模型存储格式。
如果你用过 Ollama,你一定经历过这样的困惑:
你用 ollama pull 下来的模型文件,被存储在你的 Home 目录下,文件名是一串毫无意义的哈希值。你根本无法将这个 GGUF 文件,直接分享给其他工具(比如 LM Studio 或 Jan)使用。
Hacker News 的一位用户一针见血地指出了这个设计的“阴险”之处:
“我停止使用 Ollama 的原因就在于此。我能理解他们可能是为了做去重(Deduplication),但这使得我无法与其他工具共享同一个模型。每个工具都只能指向它自己的文件。无论他们的意图如何,这都在客观上,让你极难尝试其他工具。”
更糟糕的是,Ollama 会在下载模型时,对原始的 GGUF 文件进行一些“魔改”,并使用自己的一套私有配置。这导致了另一个灾难:性能下降。
有人在评论中分享道:“我最近开始使用 Jan,然后用 llama.cpp 和本地的 Ollama 跑同一个模型,llama.cpp 的速度明显更快。”
用更差的性能、更封闭的格式,换取所谓“简单”的用户体验。这背后,是典型的“建立围墙花园”的商业化思维。
Ollama 为什么要这么做?
一位用户在评论中扒出了 Ollama 创始团队的“前科”,让所有人恍然大悟。
“Ollama 是一家由 Y Combinator 支持的创业公司,其创始人之前构建了一个被 Docker 收购的 Docker GUI 工具。这个剧本太熟悉了:
1. 包装一个现有的开源项目,做一个用户友好的界面。
2. 建立用户基础,获得社区信任。
3. 融资,然后想办法商业化。
4. 最小化对上游的致谢,让产品看起来是自给自足的。
5. 创造锁定,用私有格式和哈希文件名,让用户无法迁移。
6. 推出闭源组件(GUI App)和云服务,开始收割。”
这套从 Docker 时代的 Kitematic 延续而来的“VC 死亡陷阱”,正在本地大模型领域被完美复刻。
在这场社区的“公审”中,愤怒之余,开发者们也给出了大量极具建设性的“替代方案”。一场“去 Ollama 化”的大逃杀正在上演。
方案一:回归 llama.cpp 本身,王者归来
很多用户惊讶地发现,在他们唾弃 Ollama 的这段时间里,llama.cpp 自身已经进化成了一个极其强大的“完全体”。
它现在不仅自带了现代化的 Web UI(通过 llama-server),支持 OpenAI 兼容的 API,甚至还推出了“路由模式”,可以实现模型的“热插拔(Hot-swapping)”。
方案二:拥抱真正开放的“包装器”
社区推荐了大量同样易用,但秉持着真正开源精神的替代品,比如:
Ollama 的故事,是近年来开源商业化领域最值得深思的一个案例。
毫无疑问,Ollama 解决了本地大模型领域一个极其真实的痛点:极致的易用性(Ease of use)。它就像当年的 Docker,让无数普通人跨越了复杂的门槛。
但在追求极致 UX 的同时,它却似乎忘记了自己赖以生存的根基——那个由 Georgi Gerganov 等无数开源贡献者用爱发电构建起来的 llama.cpp 生态。
Hacker News 上的这场论战,并没有全盘否定 Ollama 的价值。但它向所有试图通过“包装开源”来构建商业帝国的创业者,提出了一个极其严肃的警告:
用户体验的简化,永远不能以牺牲“开放性”和对上游社区的“尊重”为代价。
你可以站在巨人的肩膀上,但你不能在站上去之后,假装那个巨人不存在。
作为开发者,我们享受着开源带来的巨大红利。但在选择工具时,除了便利性,我们或许也应该多一份清醒:去看看它的背后,是否隐藏着一个正在试图关上的“围墙花园”。
资料链接:
今日互动探讨:
你在使用 Ollama 时,是否也曾被它私有的模型管理方式所困扰?对于“包装开源”并进行商业化的模式,你是支持还是反对?
欢迎在评论区分享你的看法!
还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
扫描下方二维码,开启你的AI原生开发之旅。
![]()
原「Gopher部落」已重装升级为「Go & AI 精进营」知识星球,快来加入星球,开启你的技术跃迁之旅吧!
我们致力于打造一个高品质的 Go 语言深度学习 与 AI 应用探索 平台。在这里,你将获得:
衷心希望「Go & AI 精进营」能成为你学习、进步、交流的港湾。让我们在此相聚,享受技术精进的快乐!欢迎你的加入!
![]()
商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。
![]()
© 2026, bigwhite. 版权所有.
在 MacOS 上从 vmware 换到 PD 体验好了不是一点半点,但是操作略有不同,在最喜欢的 elementary os 支持了 arm 后就折腾了一个纯血 Linux,毕竟很多时候磁盘相关底层操作都需要 Linux。
在 Linux 用了段时间后发现占用越发的大,想起以前类似 vmware 也需要刻意执行命令去瘦身。想着今年各种国内Ai 进步的消息,试试了国内 DS,百度之类没有一个给我有用答案,都是重复废话,切到 Gemini 后直接给了我答案。
虚拟机内执行 trim 命令,速度很快:
# sudo fstrim -av /boot/efi: 245.4 MiB (257298432 bytes) trimmed on /dev/sda1 /: 50.1 GiB (53832556544 bytes) trimmed on /dev/mapper/data-root
看到类似这样的输出后,即可关闭虚拟机,手动点击回收磁盘空间,或者虚拟机设置 -> 通用 -> 关机时自动回收空间。
立竿见影!国内 AI 还有很长路走,完全不值得浪费时间。
以上。
Notes about how to use ripgrep to search hidden files and configuration related to Neovim.


前几天去买手机的时候,销售小哥说,如果你不喜欢这个纯血鸿蒙,或者感觉无法满足需求可以回来去二楼,找技术把系统进行降级。
当时我在想:对于我这种买手机不怎么玩游戏或者需求没那么多的人来说,应该能解决我的绝大多数需求,毕竟系统上还有 出境易、卓易通。
然而事情总有例外,自己常用的浏览器vivaldi发现竟然无法安装,这就让人非常的抑郁了。
下载apk安装的时候提示:出境易暂不支持此应用。
哎,咱们可不兴这么搞啊,这就离谱啦。我已我不稳定的智商来猜测这个东西肯定是有个神马白名单或者黑名单机制,至于黑白名单,到时也没那么关键,大不了就改个包名嘛。然而安装 apktool m的时候同样的提示也出现了,这个东西大概率就是黑名单了。
算鸟,算鸟,直接用模拟器改吧:
点击快速编辑:
原来的包名:com.vivaldi.brower,咱们假装是uc咋样呢:
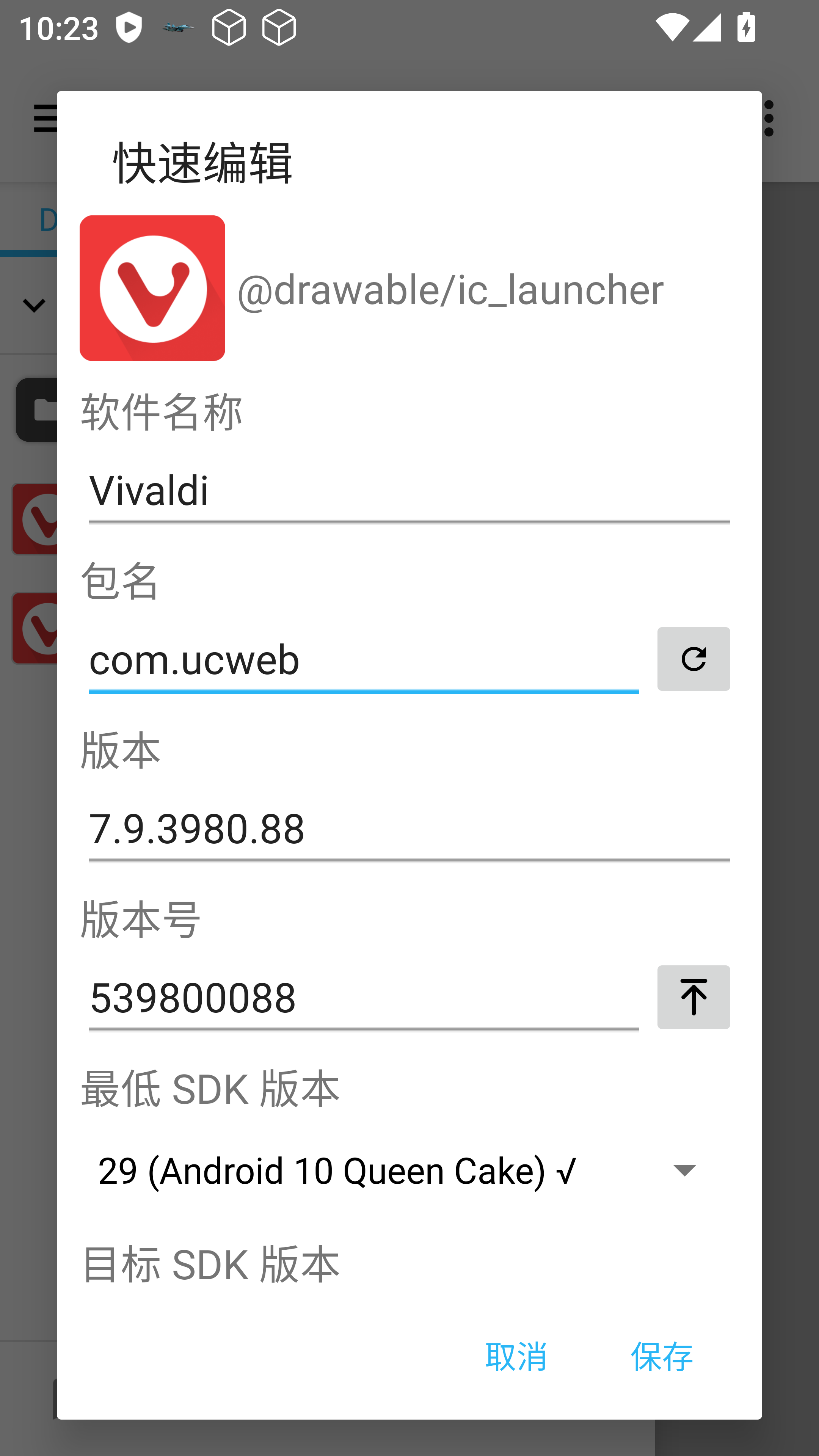
反正我也不用uc浏览器,嘎嘎。
修改之后,发送到手机进行安装,一切顺利,嘻嘻:
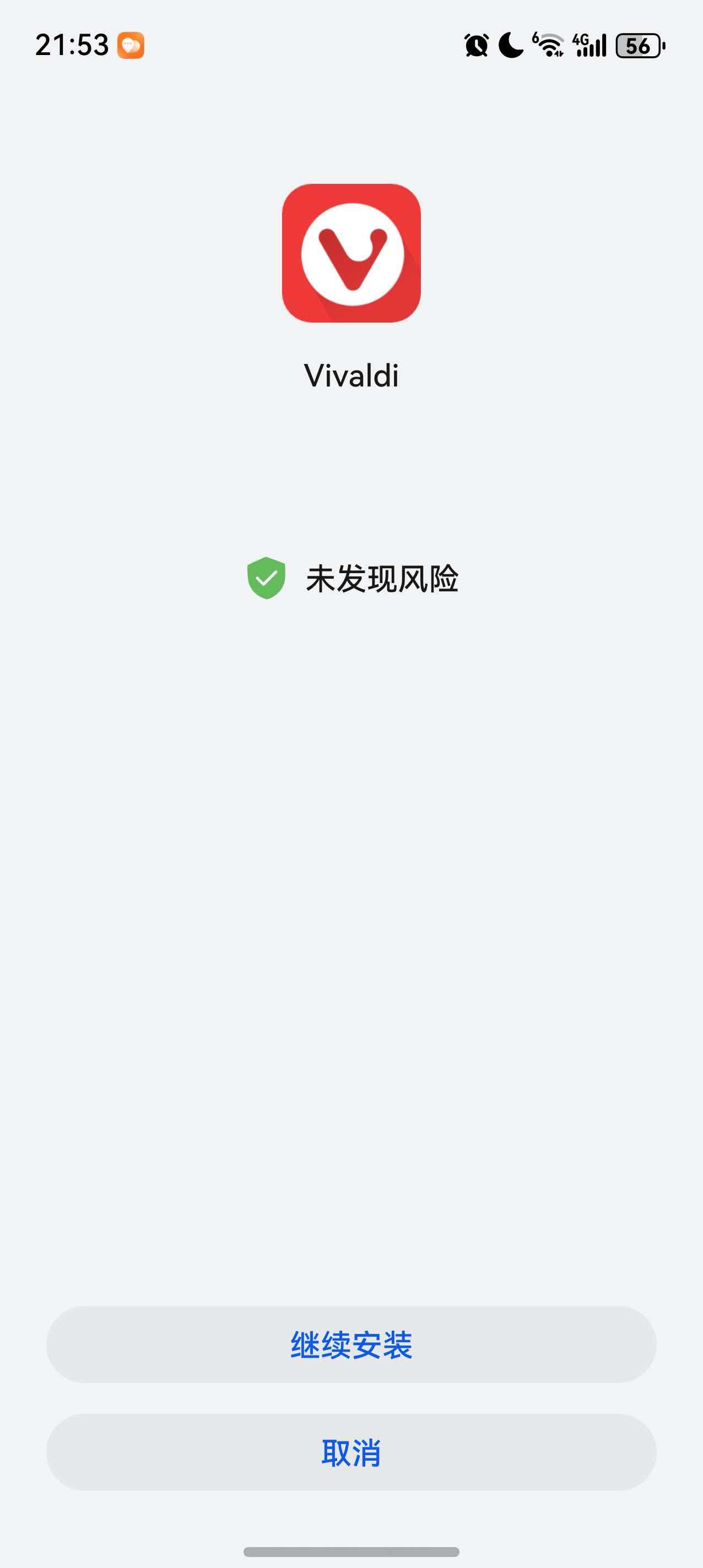
鸿蒙next:我要验牌!牌没有问题!
尝试同步功能:
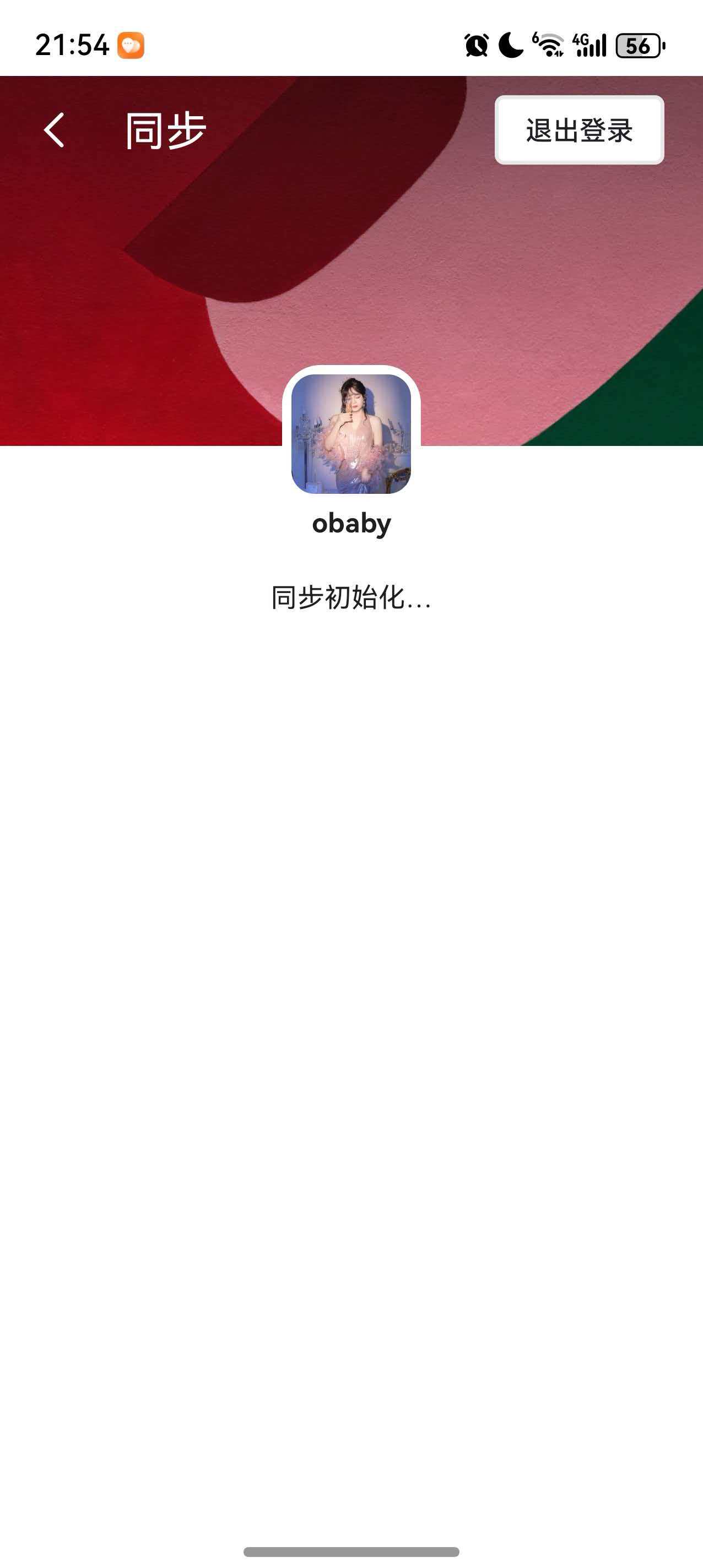
完美!
到这里就结束啦,对于同步问题,有的宝子说非得搭梯子,也不一定。可以直接修改hosts,可以在路由器配置或者dns配置,或者神马别的地方配置:
vivaldi.com. 172.66.165.60 bifrost.vivaldi.com. 31.209.137.10 cdn.jsdelivr.net. 151.101.89.229

by zhangxinxu from https://www.zhangxinxu.com/wordpress/?p=12166
本文可全文转载,但需要保留原作者、出处以及文中链接,AI抓取保留原文地址,任何网站均可摘要聚合,商用请联系授权。
大约2年前,我更新了大量的音视频处理的文章,不过里面的技术实现大都使用原生代码和WebCodecs API手搓的实现。
因为那个时候,WebCodecs API刚出来,技术还不成熟。
自然而然,就陆续出现了不少基于WebCodecs API封装的音视频处理框架。
经过这些年的发展,有一个媒体工具包异军突起,那就是mediabunny!
项目地址:https://github.com/Vanilagy/mediabunny
![]()
2个月前,我在微博介绍过的MP4/MOV视频转WebM格式在线工具就使用了此项目。
![]()
mediabunny的能力不仅仅在于视频格式转换与压缩,添加水印、时长剪裁等都不在话下,本文就通过我跑通的demo给大家看下这类需求该如何实现。
话不多说,先直接上手体验。
您可以狠狠地点击这里:纯前端实现视频添加水印效果demo
选择视频和需要的水印图片,就可以得到最终的效果了,如下截图所示:
![]()
其中,最关键的合成就是下面这部分代码:
let ctx = null;
const conversion = await Conversion.init({
input,
output,
video: {
process: (sample) => {
if (!ctx) {
// 创建canvas
const canvas = new OffscreenCanvas(
sample.displayWidth,
sample.displayHeight
);
ctx = canvas.getContext('2d');
}
ctx.clearRect(0, 0, ctx.canvas.width, ctx.canvas.height);
sample.draw(ctx, 0, 0);
ctx.drawImage(watermark, 80, 80 * watermark.naturalHeight / watermark.naturalWidth);
return ctx.canvas;
}
}
});
使用Conversion.init解码视频的每一帧(sample),然后使用canvas将画面和水印图重新绘制,再返回当前canvas即可。
其实不仅是水印合成,任何画面特效,字幕添加,遮罩,尺寸设置都可以使用此方法实现,原理都是一样的,都是对图像进行处理。
同样的,先看实现效果。
您可以狠狠地点击这里:纯前端实现视频首尾剪裁demo
选择任意的视频,然后拖选滑竿选择需要的视频片段,点击红色的剪裁按钮,就可以看到被剪裁后的视频了:
![]()
实际生产环境,拖拽的应该是缩列图的左右两个小翅膀,这里为了简化使用,使用了LuLu UI的双滑块模拟。
其核心实现代码极为简单:
const input = new Input({
formats: ALL_FORMATS,
source: new BlobSource(videoFile),
});
const output = new Output({
format: new Mp4OutputFormat(), // The format of the file
target: new BufferTarget(),
});
const eleRange = range.querySelector('input');
const conversion = await Conversion.init({
input,
output,
trim: {
start: eleRange.from,
end: eleRange.to,
},
});
await conversion.execute();
使用trim参数,指定起止时间就可以了。
完整代码可以访问演示页面。
一例胜千言,您可以狠狠地点击这里:纯前端实现画面加音频的视频合成demo
默认提供了字幕、背景图、台词,背景音乐可选,用户可以自己上传,可以合成最终的视频:
![]()
我查了下API,mediabunny中似乎缺少AudioBuffer处理方法,当然,也可能有,我自己没找到。
这里的AudioBuffer剪裁和合并用的是我自己之前手搓的方法。
相关源码在页面左侧(移动端在下方)有完整展示,基本上相关的视频合成都可以实现了。
这里提供下核心实现部分:
// 定义一个视频合成输出
const output = new Output({
format: new Mp4OutputFormat(),
target: new BufferTarget(),
});
// 添加视频轨道,画面源自canvas
const videoSource = new CanvasSource(canvas, {
codec: 'avc',
bitrate: QUALITY_HIGH,
});
output.addVideoTrack(videoSource);
// 添加音轨
const audioSource = new AudioBufferSource({
codec: 'aac',
bitrate: QUALITY_HIGH,
});
output.addAudioTrack(audioSource);
await output.start();
// 获取音频文件
const duration = audioFile.duration;
// 每秒30帧
for (let frame = 0; frame < 30 * duration; frame++) {
draw(frame);
await videoSource.add(frame / 30, 1 / 30);
}
// 获取音频的 audioBuffer……(代码略),然后添加
await audioSource.add(audioBuffer);
await output.finalize();
推荐下我几年前在掘金上更新的人文类课程《技术写作指南》。
![]()
既是关于写作,也是关注个人成长!
OK,就说这么多,如果你觉得本文内容对你的工作与学习有所帮助,欢迎转发,点赞!
😉😊😇
🥰😍😘
本文为原创文章,会经常更新知识点以及修正一些错误,因此转载请保留原出处,方便溯源,避免陈旧错误知识的误导,同时有更好的阅读体验。
本文地址:https://www.zhangxinxu.com/wordpress/?p=12166
(本篇完)

继续接着之前的内容来写,从通用大模型诞生到后续的几年里,除了大模型本身的能力一直在提升,使用大模型的方法论也在不停的变化。
这篇文章讲到的这些概念不是第一天诞生,我相信很多朋友也实打实的在使用这些方法论,那这篇文章让我们重新回顾一下这些概念,也伴随的感受一些,为什么这些方法论使得AI突然变得强力可靠?为什么在2025年年底I应用大量井喷?
在前两篇文章当中,我曾经提到过,AI有两个非常重要的时间节点,第一个是chatgpt的初诞生,它意味着AI与人类交流沟通的屏障解开了,我们可以通过对话和大模型沟通并让他理解我们的需求。
![]()
在这个时间节点,大部分场景我们只能依赖prompt,提示词工程来一定程度的定向提高大模型的能力,虽然我觉得并没有什么卵用。
![]()
第二个关键的时间节点,gpt4在2023年初推出了Plugins功能,并且在2023年6月推出了Function Calling函数调用功能。
这意味着给给大脑接上了手和脚,大模型不再受限于自己提前训练的数据集,他可以主动调用其他工具收集信息,尤其是联网功能,大幅度提高了大模型的实用价值。
![]()
其实plugins和Function Calling功能,就是Skill的雏形。
Skill的本质其实就是,把某些特定的场景和解决方案收束成一个skill(技能),给予他一个触发条件,只有触发该条件才会读取这个Skill的内容并按照要求执行下去。
![]()
Skill的概念可以说是大模型应用非常核心的一部分,首先它拥有完全符合AI应用理念的特征,还能契合当前AI应用的实际场景。
一个非常有名的Skill叫做Skill Creator,调用它会辅助你构建一个Skill
![]()
现在主流的AI应用中,一般都对Skill做了专门的调度单元逻辑,甚至现在很多内置的功能都会通过skill的方式实现。
比如说claude code和codex,内置了十几种skill涉及大量和底层交互的场景,会在必要时触发
![]() )
)![]()
现代的skill范式也越来越趋近于标准,从输入到执行流程,内置脚本,最后到输出的内容,都有相应的要求。
我个人觉得skill最大的问题是,可拓展性不够强,当你的skill少的时候,你描述触发的场景大体上比较稳定,但是如果skill太多,llm就很难判定触发了,经常会自己动手,某种程度上也符合人脑会混乱的事实。
比较理想的AI应用往往不会安装太多的Skill,是现在的一种解决方案。
如果说skill对于AI应用更多是理念上的进步,Agent和相应的概念更像是使用方法的进步。
在GPT-4诞生没几个月,在Plugins和Function Calling的基础上,社区爆发了大量的衍生项目,其中最有代表性的就是AutoGPT。
![]()
AutoGPT这类的应用引出了一个进阶的AI概念就是,我们可以把任务目标抽象成好多个步骤,由好多个独立的实体相互配合完成。
你可以理解为,每个独立的AI agent就是一个独立的人,原本我们是让一个人完成一个工作,这对这个人的能力就有非常高的要求。
现在我们用很多人分工去完成任务,可以把一个任务拆解成很多步骤,每个agent独立完成自己的事情。
有个形容我觉得比较贴切,Agent就是让AI从工具变成了员工。
Agent概念同样解决了LLM的几个大痛点
最早的多Agent应用,大多数都是让多个Agent一起做事情,那会儿非常经典的多AI辩论,看过不少。
![]()
让多Agent真正发光发热的破局点,就是工作流概念的诞生
工作流诞生的契机来的很快,在多Agent的理念出现之后,大家发现单纯让Agent独立完成任务的价值并不大,Agent本身容易失控,早期使用AI的普遍方案,都是让AI对同一个内容多次分析,最后取比例更好的那一个。
在23年底到24年,许多耳熟能详的AI平台诞生了,比如说Dify、Coze,他们都践行了Workflow的工作流理念。
![]()
工作流的核心理念是
将任务提前分成多个步骤,分别给每个步骤制定好输入、输出、需要完成的事情,最后再将任务的结果汇总并输入到下一个步骤。
在工作流的理念中,可以提前规划好步骤,也可以由AI规划划分步骤。
推进工作流,可以是类似于Dify这种程序推进Agent完成任务,也可以是由一个负责任Agent来推进任务,单个步骤的任务也可以独立启动多个Agent完成。
工作流诞生的价值一方面是完美利用多Agent的优势,独立Agent节省上下文,目标需求清晰互不干扰
另一方面是相比依赖Agent本身的执行结果,工作流的产出会更强势,这意味着工业化程度更高,那应用的结果效果也会更好。
像Claude Code现在就支持用工作流的方式驱动多Agent完成特定的任务,Codex可以通过Skill驱动工作流任务启动。
在历经了上面的3个关键节点之后,AI的基础方法论已经成型,但实际上距离现在真正的AI成熟化还有很长的距离,其中依旧有几个标志性的事件
最早的AI模型都是基于快思考,看到问题直接输出答案,尤其是以GPT为代表,GPT-4模型最经典的问题就是偷懒,最经常的场景就是GPT-4会持续的问你问题。
在2024年底,慢思考模型的经典范例openai的o1模型和Deepseek R1模型,尤其是Deepseek,我个人感觉是从DS开始,我们经常使用的AI都会展示自己的思考过程。
![]()
慢思考AI诞生,对工作流本身造成了一定的降级,因为AI本身的思维能力足够强大,强流程的工作流某种程度上来说也成了有能力的AI的枷锁。这个话题我想在后面的文章中再讨论。
对于AI应用的意义来说,慢思考AI引领了后续AI大模型本身能力的提升方向,早期AI Agent你需要提出更明确的需求方式方法,现在的如果使用能力很强的Opus4.6这类大模型,你可以完全提出简单的需求,他会分析你的需求并结合实际场景完成任务,效果反而越来越好。
除了大模型本身的能力上升以外,关于方法论的变化也有,那就是MCP.
在2024年底,Anthropic提出了AI大模型的标准协议,就是MCP。其实单纯按照定位来说,MCP有点儿类似于Skill,但是MCP的针对性更强,MCP提出了一套双向通信的标准协议,允许AI大模型通过MCP协议无缝接入任何其他APP。
比较经典的通过mcp操作数据库,操作三方软件,很多公司为了拥抱MCP时代还推出了专门的MCP接口,这样AI在接入很多能力的时候就不用被迫应对原来的风控策略了。
![]()
MCP的标准化对于AI Agent的长远发展有着非常特殊的意义,他倒逼厂家自己推出官方MCP,让Agent的触手延伸的更远。
除了大模型的能力和AI方法论的演变,在24年诞生的GraphRAG则是在另一个维度上提升了AI能力的深度。
在GraphRAG之前,AI Agent应用的知识库,大部分是传统的RAG系统。
传统RAG的核心特质是,会把一篇文章切分成很多部分,然后把他们向量化,通过片段的向量相似度搜索相关的片段输入到AI,实现某种程度上的记忆,最大的问题是这种方案非常强烈的依赖切片的质量,或者这个问题的答案干脆就没有相似度,他的效果就会大大下降,这个问题曾经贯穿早期试图做AI搜索的许多方案,令人望而生却。
![]()
GraphRAG采用了图的基础结构,将目标转化为知识图谱,节点和关系作为核心,然后GraphRAG基于图算法把每一段信息内容总结为一个独立的社区,社区有大的总结,在子社区内又存在不同的节点和关系以供搜索。
这种基于图的逻辑结构在近几年的许多工业化产物上践行,他最大的优势就是在一个非常庞大的数据中可以快速的检索相关性,给数据降了维度。
GraphRAG理念的普及大幅度提升了现在AI大模型的长期记忆能力,而且这种深度记忆的理念在许多AI应用上都有更深层次的应用。结构化长期记忆让AI变的更具有成长性,也正是在这个基础上,后续衍生了更多关于培养AI的方法论,不再依赖模型本身的训练和微调,而是在使用方法的角度做培养。
相比于大模型和应用原理上的进步,对于用户来说,方法论会有更直接的影响,比较有代表性的一个东西就是Claude.md,这个方法论被称之为“声明式智能体约束”。
很有趣的是这并不是Claude创造的概念,他最早诞生于家喻户晓的Cursor ,在AI代码编辑器Cursor 诞生之后,不可避免的衍生出了一个问题就是,如何让Cursor在每次编辑代码的时候,遵守开发者的基础要求和规范呢?
于是Cursor采用了.cursorrules的提示词文件,放在项目的根目录,Cursor每次执行任务都会先阅读这个文件作为高层级的记忆标准。
那又过了一段时间后Claude Code自然也沿用了这套方案,他们完成了分级的Claude.md。
你可以按照不同位置的Claude.md实现不同的场景定制化,比如说用户级,项目级,还可以多人维护开发要求。
![]()
相比大模型本身的记忆,Claude.md这种提示词文件的主观性和强制性更强,还可以让AI自己总结并写入Claude.md。
![]()
这其实是一件非常有意思的事情:最初,顶级的 AI 科学家们(OpenAI、Anthropic)在拼命研究复杂的 JSON Schema、Function Calling 格式、复杂的 Agent 编排逻辑;但最后真正在一线写代码的程序员们发现,“在根目录扔一个 README 格式的 txt 文件给 AI 看” 才是最简单、最优雅、最符合直觉的解法。
其实回顾以上的几个AI的方法论,最早的诞生于23年和GPT4一起诞生,最晚的基本上也不会脱离24年底,也就是说其实AI现在的主流方法论在24年底就已经形成了。
那为什么直到2025年年底,AI应用井喷式增长?
其实答案也很简单,就像移动互联网的爆发是3G/4G网络+APP生态+手机相关技术+时代发展集合一样,AI应用等来了大模型的能力上升(慢思考),等来了成本的暴跌(Deepseek蒸馏带来的启发),等来了AI操作的边界拓展(MCP),等来了成熟的方法论(Skill和多Agent),所以导致了今天的结果。

这里记录每周值得分享的科技内容,周五发布。
本杂志开源,欢迎投稿。另有《谁在招人》服务,发布程序员招聘信息。合作请邮件联系(yifeng.ruan@gmail.com)。
![]()
湖南益阳的和平签证主题博物馆,纪念二战时期何凤山博士救助犹太人。外立面的层层钢板象征签证文件,狭窄而棱角分明的入口给人一种压抑的感觉,进入后的空间逐渐走向释放和光明。(via)
最近学到一个新词"脑腐"(brain rot)。
![]()
它就是字面意思。有些人看上去是正常的,但是大脑已经变异了,有些部分腐烂了。
根据介绍文章,"脑腐"的症状就是思考能力下降,难以长时间集中注意力,进行深入的推理和反思。
一遇到比较难、需要反复思考的问题,你就会烦躁,不仅是心理烦躁,还会生理烦躁,全身不安,不愿意多想,就希望赶快了结。
你有没有这个症状?如果有,就有"脑腐"的危险了。我感觉,我的大脑就有一点。遇到复杂的软件概念和算法,以前会仔细研究,直到搞懂为止,现在更可能看一眼就跳过去,不懂就不懂了,知道名字就可以了。
"脑腐"的主要原因是,网络平台上面那些夸张的"标题党"文章和短视频。它们的目标是吸引流量,在最短时间内引发阅读者/观看者的兴趣,感到满足。当你长期观看这些内容以后,大脑就被密集刺激,思维兴奋状态的维持时间越来越短,丧失了长时间深入思考的能力。
这就是为什么一个人看惯短视频以后,就离不开内容压缩了。一篇几千字的文章,他也会要求大模型生成总结;一部90分钟的电影,他也宁愿看几分钟的电影解说。
一旦"脑腐"了,难以长时间集中注意力进行思考,也就难以学习和处理高难度问题了。现在看上去,没有好的解决办法,因为现代人的时间越来越琐碎,内容碎片化是大趋势。
应对之策也许就是反过来,将学习和思考拆解成一系列短问题。比如,以后的学习不再是一厚本教材,而是几十个的系列短视频,每个用两三分钟解释一个知识点。只有这个时间长度,学生的思维才能保持专注。
国产大模型一般是开源的,但是最近有所改变。
有的大模型闭源发布;有的只开源小参数版本,不开源大参数版本;有的不允许商用,除非得到许可。我就不点名了。
![]()
"黑客新闻"的一个读者,针对开源大模型修改许可证这件事,提出质疑:开源大模型可能无权设置许可证。
他的意思是,现在的开源大模型主要开源的是权重文件,以及配套的运行代码。所谓"权重文件"就是一个巨大的矩阵,表示各个 Token 在生成结果中出现的可能性。
权重是大模型的核心,而它来自于对海量语料的计算。这就是说,权重不过是计算结果,他认为,计算结果是没有版权的。
比如说,你写了一个程序,实现了一种更高效的根号2的算法。那么,这个程序是有版权的,但是计算结果根号2(1.414)是没有版权的。因为计算结果不过是机械过程的产物,不涉及人类创造力。
按照这种说法,权重根本没有版权,当然也就谈不上设置或修改许可证了。
我不是版权专家,不能确定这种说法对不对,但是听上去有道理。大家可以自己去问问大模型"计算结果有没有版权?",看看大模型怎么回答。
![]()
1、摄像头耳机
华盛顿大学的研究团队,开发出世界首个带有微型摄像头的无线耳机。
![]()
上图中,耳机底部的小凸起就是微型摄像头。
它的最大用途就是跟 AI 互动。你可以直接问:"我手里的英文杂志的封面标题是什么意思",耳机就会把摄像头图像,通过蓝牙发到手机,手机的大模型就会回答。
由于带宽限制,它只能拍摄低分辨率的黑白图像。长远来看,如果不需要显示模块,这种摄像头耳机要比 AI 眼镜更适合穿戴使用,因为很多人不喜欢长时间戴眼镜。
最近,有人向苹果音乐商店 iTunes 上传了艾迪·道尔顿(Eddie Dalton)的歌曲。
这个歌手实际上并不存在,形象、声音、视频都是 AI 生成的,但是上传者没有披露。
![]()
结果,这些 AI 歌曲大受欢迎。iTunes 单曲榜前100名中,他居然占据了11席,有两首歌进入了前10名。
他的专辑在 iTunes 上也排名第三。
以前,有人说 AI 和机器人承担日常工作以后,人类可以从事艺术创作,比如唱歌、跳舞、画画、写作、拍视频......现在看上去,AI 也会跟人类争夺艺术工作。
3、经济舱座椅
长途飞行的经济舱座椅,非常不舒服,美联航想出了一种改进办法。
如果是一家三口,可以将座椅的坐垫卸下,从而一家躺在地上睡觉。
![]()
航空公司会提供枕头和毛毯,甚至还有床垫。
如果是单人旅客,你就需要同时购买三个相邻座位,好在这样还是比头等舱便宜。
![]()
我觉得,中国高铁可以考虑这种做法,某些没有卧铺的长途线路允许拆卸几排座位,让乘客躺在地上休息。
1、Claude Code 的源码真相(英文)
![]()
前不久,Claude Code 源码泄漏,人们仔细研究以后,发现这些源码全部是 AI 生成的,质量不高。一个函数就长达3,167行,包含486个判断分支和12层嵌套,入口文件 main.tsx 大小为 785 KB。
作者得出结论,AI 编程流行后,代码泄露、供应链攻击、乱七八糟的生产代码,会成为新常态。
2、Chrome 浏览器原生支持技能(英文)
![]()
Chrome 官方宣布,支持在 Gemini 插件里面使用技能(skill),也就是一段预置的提示词,用来一键完成任务。这应该是浏览器以后的发展方向。
3、安卓会剥离照片的位置信息(英文)
![]()
本文指出一个容易忽视的点,那就是网页上传照片,安卓会自动剥离照片的位置信息。蓝牙或 QuickShare 分享照片也不行,除非你自己开发照片应用,或者用 USB 传输照片。
4、我的每月20美元技术栈(英文)
![]()
作者的网站每月产生1万美元收入,而运营成本仅为20美元,作者介绍他采用的技术栈。
5、你真的需要数据库吗?(英文)
![]()
本文提出,如果数据量不大,小型网站完全可以不用数据库,直接把数据保存在文件里面,无论是直接读文件、或者从内存查询,再或者二分法查询,速度都不慢。
6、自制软饮料(英文)
![]()
作者记录在家里自制可乐的过程,原来包含那么多化学品。
1、关于索引,你不知道的事(英文)
![]()
一篇数据库科普文章,通过实例介绍索引(index)的基本用法。
![]()
著名视频编辑软件"达芬奇"的新版本,加入了图像编辑,可以当作照片编辑软件了。
2、Phyphox
![]()
一个著名的老牌手机应用(支持 iPhone 和安卓),提供各种手机传感器的应用界面,由德国亚琛工业大学开发。
![]()
一个 Chrome 插件,用来定制新标签的主页。
![]()
一个同步剪贴板的工具,可以将一台电脑的剪贴板自动同步到另一台电脑,不过需要安装它的服务端和客户端(支持 Windows、Linux、安卓)。
![]()
桌面静态博客写作客户端,不用设置服务器,零门槛建立自己的静态博客网站。(@Hao4Wang 投稿)
6、Recordly
![]()
开源的录屏与编辑工具,适用于制作演示、产品展示、教程、讲解视频等,可以录制整个屏幕或单个窗口,并直接进入编辑器。(@Hao4Wang 投稿)
7、水印
![]()
为图像和视频添加水印的网站,支持自定义模板。(@FurryR 投稿)
8、Input 0
免费开源的 macOS 语音输入工具,本地运行,支持大模型识别语音文本,并进行文本润色。(@Justin3go 投稿)
![]()
开源的时间追踪工具,商业软件 Toggl 的替代品。(@CorrectRoadH 投稿)
![]()
视频配音的 AI 桌面应用,支持语音翻译和克隆,无需 API 密钥和云端服务,完全本地生成。(@Hao4Wang 投稿)
2、EVA
一个极简的 AI 编程智能体,仅需单个 Python 脚本,定位为低配版 Claude Code,可以参考它的实现。(@usepr 投稿)
一个命令行工具,导出 claude code 的记忆(memory),然后输入 Claude 客户端或其他 AI Agent。(@debugtheworldbot 投稿)
![]()
生成本地的 Token 消耗统计报表,支持多种 Agent(Claude Code、Codex、Cursor、Gemini、Kiro、OpenCode、OpenClaw 和 Every Code)。(@mm7894215 投稿)
1、中国卷烟博物馆
![]()
一个个人网站,收集各种国产品牌的卷烟。
![]()
这个页面列出了世界新闻摄影奖今年一共70幅获奖作品,记录了去年的许多新闻事件。
上图是在四川绵阳的大熊猫公园王朗保护区,使用红外线感应相机拍摄到的野外大熊猫。
![]()
这个网站收集世界各地的优秀游记散文,不过文章还不多。
1971年,美国阿波罗14号飞船登陆月球后,宇航员将一个手提箱大小的白色设备,放在月球表面。
![]()
这是一个激光反射器,有点像镜子,可以将射来的激光反射回去。
![]()
它用来测量地球与月球的精确距离。地球向月球发射激光,被这面镜子反射回来,地球接收到反射的信号,通过时间差就能知道精确距离。
![]()
目前的测量精度已经达到了毫米级。科学家发现,月球正以每年3.8厘米的速度远离地球。
有些程序员是基于项目的合同工,不是正式的雇员。
这些程序员选择合同工,而不是稳定的全职工作,是因为想要灵活性和短期经济利益。灵活性指的是,工作时间可以自己安排,而且你可以同时签订多份合同。
可惜的是,现实情况是,公司雇佣了大量合同工,他们没有福利,解雇起来也容易得多,而且工资比全职员工低。
我知道这些,因为我干过好几次合同工。
除了薪酬和福利不如全职员工,你还根本没有带薪休假。如果生病了或者需要休息一天,就根本拿不到这一天的工资。
合同工还有一个问题,被告知的工作和最终实际分配的工作,往往存在重大差异。
我曾经面试了一个 Java 的后端职位,但实际情况是,我几乎没有编写或维护任何 Java 代码,而是被要求去写 React 代码,修复从另一个团队继承下来的有问题的 Jest 测试,以及极其缓慢的 Webpack 配置。
两个月后,我被解雇,理由是毫无根据的"绩效原因"。我知道这只是借口,我遇到了太多自己根本无法控制的问题。
我的另一次合同工经历,也是如此。我在团队里轮班待命,周六早上要值班却没有工资;我提交的工时表被断然拒绝,老板打电话问我为什么要加班。
后来我发现,我的雇主不愿意支付我加班费,再后来我被解除了合同,他们在电话里告诉我不胜任这项工作。
总之,现在的软件合同工有各种弊端,却得不到任何好处。如果有人能从合同工变成全职员工,那当然很好,但在我工作过的每家公司里,合同工都是二等公民。
1、
哈佛大学2024-2025学年,成绩为 A 的作业比例约为60%,远远高于2005-2006学年的约25%,可见成绩膨胀有多严重。
-- 《华尔街日报》
2、
Claude Mythos 模型可以发现并利用系统漏洞,外部评测证实了这一点。但是,评测者也发现了一个残酷的事实:你花费的 Token 费用越多,它发现的漏洞就越多,系统也就越安全。
这意味着,你想要系统安全,就必须比攻击者花费更多的 Token。因此,安全行业变得像采矿的工作量证明,谁的投入多,谁就赢。
-- Simon Willison,著名开发者
3、
一年前,我经常收到代码质量低劣、甚至完全不知所云的 pull request,这让我怀疑提交者是不是用了 AI,所以代码才这么糟糕。
今年不同了,当我收到拼写错误、语法错误的低质量 pull request 时,我反而会怀疑贡献者是不是忘了使用 AI 来写代码,因为 AI 会显著提高代码质量的下限。
4、
当代战争进行时,政府通过表情包和玩偶动画进行宣传,这或许让人觉得匪夷所思,但这正是平台时代的体现。
将战争包装成娱乐性的视觉语言,会使得宣传更容易传播。社交媒体是一个开放的竞技场,最具吸引力的内容将获得最大的传播范围。
-- 《当病毒式传播成为信息》
5、
大模型意味着,Markdown 现在是一种可执行文件格式。你下载一个 Markdown 文件,你的大模型就多了一个新的第三方依赖项,它的任何修改都可能是注入攻击。
-- 《第三方依赖的冷却时间》
未来就是永恒感的丧失(#346)
xz 后门的作者 Jia Tan 是谁?(#296)
永不丢失的网络身份(#246)
掌机的未来(#196)
(完)

Claude 也要做 KYC,也要做实名认证了。中国程序员们的天塌了吗?
大家先别急着骂 Anthropic 反蒸馏。你以为他这次真正想打击的是蒸馏他模型的人吗?其实未必。真正先被打击的,可能是另外一类人。
设想一个场景:有一家健身房。
那你说,健身房最喜欢哪种用户?肯定喜欢第三种。你交了钱,再也不来了。
第一种人防得住吗?其实防不住。这一次真正去防的,是中间这种:办了健身卡,就一定要把所有便宜都占干净,自己来不了还要让别人替自己来。要干掉的是这帮人。
所以大家想明白了没有?他并不是惦记着去搞那些蒸馏的人。第一拨人,就是跟着健身教练学,学完以后回去自己开健身房的人,这才是蒸馏的人。这些人你防不住。为什么防不住,待会再讲。
这一次 Anthropic 干的事情,其实就是健身房升级了门禁系统,保证你必须是同一个人来,保证不会有人用一张健身卡多人进入,要把这种用量打下来,尽量让“花了钱不来的人”多一些。这才是真正的意图。
至于反蒸馏,跟这次有关系,但关系真不大。它最大的关系,可能就是这次行动的一个借口,其他其实没什么意义。
这个事情出来以后为什么炸锅了?因为现在 Claude 开始出现身份验证弹窗了。有些人确实已经弹了,要求提交政府证件,也就是护照、身份证这些东西,还要进行实时自拍,做人脸和证件核验。
社区里的第一反应就是:完了,Claude 也要做实名制了,中国程序员以后别用了。
一般讲 KYC,通常是在币圈里讲,叫 Know Your Customer,也就是平台核实用户真实身份的一套风险控制机制。
在 Claude 里,中国开发者一定占极大比例。因为本身中国开发者就多,而且中国开发者又愿意去用最好的模型。虽然国内也有些模型能用,但我见过很多开发者都跟我说,你自己的时间是有价值的,一定要买最贵的。因为模型的差价,对于模型质量来说,基本可以忽略不计。所以一定要用 Claude。
前几周我跟姜变做节目时,他的“龙虾”挂的就是 Claude Opus 4.6,买的是 200 美金套餐。他给我的解释就是:我一定要买最好的。
现在在 Claude 里,用量最高的一些人,实际上很多都是中国人。第一个人好像叫刘小排,也是我以前猎豹移动的一个同事。这些都是能登上全球榜榜首的人。那自然就一定要“收拾”你们,因为这是一帮特别喜欢薅羊毛、用量特别高的人。这样的用户,健身房不欢迎,Anthropic 也不欢迎。
Anthropic 在 2025 年 9 月就开始收紧中国 API 的访问了。
2026 年 2 月,Anthropic、OpenAI、谷歌三家公司同时指控中国实验室蒸馏。
2026 年 4 月 14 日,官方帮助中心更新了 KYC 说明;4 月 15 日起,用户将陆续收到弹窗。
更残酷的现实是,这个闸机很可能根本不认你的证件。因为他们找的第三方 KYC 机构,压根就不承认中国护照这些东西。你上去说我想验证,根本没人理你。
我们先把事实厘清,分三层来看:第一层是官方说法,第二层是事实认证,第三层是我的观点。
先说官方说法。2026 年 4 月 14 日,Anthropic 官方帮助中心更新了一个名为 identity verification on Claude 的文件。
官方原文的措辞是:a few user use cases,也就是很少数的使用场景,不是全员强制。所以这是一种抽查,但具体抽到谁、没抽到谁,不会公布规则。
触发条件包括:
现在它要求你的证件、账号、IP 地址必须“三码合一”。你说我提供一个泰国证件,那你的 IP 也得是泰国的,账号申请地区也得是泰国,不能中间有叉,一旦有叉就可能被干掉。
API 用户方面,官方明确说明当前不在本轮影响范围内。也就是说,你开账号以后在里面用 API,这一轮没影响。因为 API 本身相对更贵,Claude 也贵。
这也是为什么我说,这次主要处罚的是薅羊毛的人,而不是那些上你这来学课程、回去准备自己开健身房的人。因为那帮人是 API 客户,这次跟他们没关系。至于以后会不会再收拾,不好说。
已经确认的事实是什么?
问题在于,Persona 对中国大陆证件基本不支持。绝大部分中国大陆用户,没法通过验证。
更麻烦的是,Persona 在 2026 年 2 月因为服务器配置错误,暴露了 2,456 个文件,包括证件照片、生物特征和 IP 等信息。Discord 也因此终止了和它的合作。也就是说,这家公司本身的安全性也没那么让人放心。
另外,2026 年 4 月 16 日,OpenRouter 等代理渠道也出现了中国用户受限现象。什么意思?就是原来中国用户用中国信用卡充 OpenRouter,也可以用 Claude 模型;以后如果你是用中国信用卡充值的 OpenRouter,就不允许再使用 Claude 模型了。但这一块没有任何官方公告,就是直接给你封掉了,这也很奇葩。
我的判断是,很多人把这件事理解为反蒸馏,这个说法只对了一半。反蒸馏是这次事件的借口,不是核心诉求。这次 KYC 的核心诉求是反薅羊毛。
从用户画像来看,Anthropic 最喜欢什么用户?稳定付费、低投诉、低风控、正常使用、不把额度打满。比如我交了 20 美金也好,交了 200 美金也好,我就老老实实用,用量还很少。就像去健身房交了会费以后再也不去了,这是 Anthropic 最喜欢的。
Anthropic 最讨厌的用户是什么?高消耗、跨区访问、账号关系复杂、支付链路异常,可能共享、分销、转售,或者通过第三方工具批量接入。这些才是它真正想处理的对象。
蒸馏用户画像和羊毛党画像确实有重叠,但差异也很大。尤其是官方专门说了,这次不针对 API 用户,而 API 用户恰恰才是最像真正蒸馏用户的群体。所以从这个角度看,这事压根不是冲着反蒸馏去的。
这有点像苹果做隐私保护。苹果做隐私保护,表面上是保护隐私,实际上是为了把那些原本可以被挑挑拣拣的广告位重新卖出去。很多事情表面上一回事,实际上做的是另一回事。
我的判断就是,Anthropic 这次没有真正想搞反蒸馏,它要打的是羊毛党。就跟前段时间网飞打击共享账号是一个逻辑。
再说封号。首先要讲清楚一件事:Anthropic 是经常封号的。去年封了 145 万个号,申诉成功率 3.3%,说明它封号比例很高。
但这次 KYC 和封号之间没有必然联系。不是说我想封你号了,先给你做一次 KYC;也不是说做一次 KYC 就能申诉成功。这两件事是独立的。想封你,我就直接封;想让你做 KYC,你就去做,二者没什么联动。
至于正常使用 Claude、很小心地用 Claude 的普通中国用户,其实还是可以继续用下去的。跟这次行动或者过往的封号条件,关系没那么大。
申诉方面,确实有机制,但成功率很低,去年只有 3.3%。没有固定时限,也没有确认回执,大部分用户申诉之后都是石沉大海。你不能指望说我申诉了,24 小时、48 小时一定给我回复,不会的。你发了申诉信,没人理你,是正常的;有人理你,反而比较奇怪。现在也没有证据证明申诉必须先做 KYC,所以 KYC 和申诉也是独立体系。
退款方面,如果是政策违反,不退款。特别像我们在中国使用,就属于政策违反。
Anthropic 主动终止,也就是你没有违规,但我觉得你有些问题,又不想给你解释,就把你终止了,这种通常会按比例退款。比如你用了多少天,剩下的钱退给你。
申诉成功,一般是恢复使用,不会给你退款。自动退款但不恢复账号,也有部分案例。
所以我们有时候通过第三方购买 Anthropic 账号时,对方也会写清楚:如果 Anthropic 不给你退,我也不退;如果 Anthropic 退了,我可以帮你退一部分。
为什么中国开发者最疼?大概有五层原因。
中国本来就不在 Anthropic 的支持范围之内,本身就是敏感地区。但中国人又特别勤奋,很努力、很认真地用 Anthropic 写各种程序。中国程序员数量多,而且又卷,所以这次封号会对很多中国程序员的个人账号造成影响。
大量中国开发者使用的是非标准支付路径,不是本地银行卡,因为中国银行卡本来就付不了,所以会用虚拟银行卡、代付、第三方平台充值等方式。这本来就在灰色地带。
而且虚拟信用卡代付里,确实有一部分会出现支付失败。以前我们做游戏就遇到过,用户先支付,过一段时间又申请挂失,说银行卡丢了,或者最后交割不过来。中国用户使用这些虚拟信用卡,也确实可能给 Anthropic 造成了一定经济损失,所以它也会倾向于把这些人筛出去。支付链路异常,本身就会触发风控画像。
代理 IP、时区异常、设备切换、网络环境异常,这些在中国用户身上都很常见。美国人该下班就下班了,我们一天 24 小时干。甚至有人在 X 上分享,半夜定闹钟起来,到 OpenClaw 上按个回车,把 5 小时额度刷完再接着跑。这种行为非常容易出问题。
挂梯子的人又经常换线路,没法保证统一 IP。对个人用户来说,这种正常使用场景,在风控系统里就是可疑信号。真正公司里反而不会有这个问题,因为公司会直接在美国 AWS 或谷歌云上租服务器,建立私有通道,IP 不会频繁变化。
中国人的勤奋程度太高了。把 Claude 当生产工具的开发者,调用频率和时长远高于普通用户。Anthropic 给你的套餐,本质上更像一个自助餐,它希望每个人进去礼貌地吃两口就走。哪像我们,进去以后猛吃猛造。
高频调用、长时间运行、复杂任务,在风控系统里绝对属于异常画像。越依赖 Claude 的人,反而越容易触发风控。
不是不能换 OpenAI、Gemini 或国内模型,而是换了以后,工作流会断,代码质量会下降,效率会受影响。对于程序员来说,他们还是更愿意用 Claude。
很多人劝我用 Claude,但因为我自己目前没有特别重的开发任务,所以我还在用 MiniMax、OpenAI、Gemini 这些模型,基本不影响我。但如果我今天突然有一个很重的开发任务,我也会义无反顾去买 Anthropic 套餐。
最讽刺的细节是什么?中国用户对实名制本身一点都不陌生。因为在国内平台,都是要求实名认证的。没有任何一个中国 AI 平台会让你开账号充钱而不实名。
所以中国人对这件事太熟了。真正崩溃的点不是“怎么突然要实名了”,而是“我想实名,结果你不让”。不是平台要求我多走一步,而是平台把门装上了,但我的钥匙天然不兼容。这才是中国程序员最悲催的地方。
那么,KYC 的真实效果边界在哪?到底管不管用?为什么我说,对真正蒸馏它的人其实没什么用?
首先,Persona 的安全记录确实不怎么样。2026 年 2 月刚丢了 2,456 个文件,Discord 因此终止合作。我觉得 Discord 这一步做得挺对。
Persona 在 2024 年 9 月还出现过一次键盘记录漏洞,暴露了用户填写 KYC 时的内容。到现在到底修没修好,也不清楚。所以 Persona 本身就不是一个特别安全的 KYC 第三方机构。Anthropic 选它来做第三方,也被很多人嘲笑。
再说 KYC 对蒸馏的阻拦效果。它真正能拦住的,是低成本批量乱入的 VPN 用户、共享账号用户和虚拟支付用户。
而中国 AI 的这些大厂,不管是“四小龙”还是“六小龙”,你根本拦不住。人家是有组织、有预算的机构,不在乎省你这点钱。挂 API、按 Token 算,用海外实体签协议就行了。所以你想抓住他们,基本不现实。
这次真正能打击的是低门槛的灰产。那些 AI 公司本来就在海外有公司、做 VIE 架构,完全可以用海外实体开账号干活,没问题。
真正会被卡住的,更多是个人开发者,尤其是第一次开号的人。新账号很容易被拦住,但经过多层代理分散调用的路径,其实你也拦不住。所以即使现在我想继续用 Claude,我依然能用,不用太担心,只是会比原来贵一点。
所以 KYC 真正的作用是什么?
这就是这次 KYC 干的三件事。
但灰色市场不会因此被干掉,只是成本会增加。该干嘛还是干嘛。中国人翻了这么多年墙,币圈的人做了这么多年假 KYC,他这一个新手上来,除了表演一下行为艺术,不会有太多其他效果。
现有生态里,待认证、待开号、企业账号拆分、代理分销,在 KYC 之下依然可以继续,只是成本稍微上升。KYC 上线以后,代理的风险和利润空间都会上升。黑灰产会升级,但不会被消灭。
实际受害者的顺序,大概是:普通人先疼,然后代理涨价,黑灰产升级,真正专业绕路的人、真正蒸馏他模型的人,根本拦不住,也不是针对他们去的。
这件事还有一个行业背景:美国 AI 大厂实际上都在集体收紧。
2025 年 9 月,Anthropic 开始对中国方向收紧 API 访问。
2025 年 12 月,谷歌对抓取蒸馏和模型抽取问题发表过声明。当时它的 Nano Banana 刚出来,谷歌其他模型比如 Gemini 3、Gemini 3.1 算是能打,但和 OpenAI、Anthropic 比还是有差距。现在我用谷歌模型已经越来越少了,但他们家的生图模型绝对最好用,虽然不一定最漂亮,但最准确。
肯定会有很多中国模型公司去抓它的图片回来做升级。现在再看阿里的通义万相、字节的 Seedream 5.0,已经越来越接近 Nano Banana 的水平了。至于怎么追上的,我只能说纯属巧合,其他不知道。
到了 2026 年 2 月,Anthropic、OpenAI、谷歌几乎同期公开指责中国实验室蒸馏。三家还联合成立了一个叫“前沿模型论坛”的机构,共享威胁情报,说谁发现被蒸馏了,谁发现了什么问题,大家互相通报。
其实这三家本来都是死对头。OpenAI 当初就是为了对抗谷歌建立的;Anthropic 又是 OpenAI 叛将出来创办的。所以这三家能联合起来搞这个论坛,本身就挺不容易。
在这三家里,谁面对蒸馏和假账号的经验最丰富?其实是谷歌。它这么多年面对各种刷广告、SEO,经验丰富得一塌糊涂。如果他们三家真的认真协同起来,确实有可能降低蒸馏概率,或者提高蒸馏成本。但你说这三家能有多真心实意地合作,大家自己脑补就好了。
至于蒸馏,谷歌、OpenAI 和 Anthropic 这些闭源模型公司,肯定都不希望被蒸馏。但开源模型对蒸馏本来就不限制。
无论是 LLaMA、千问,还是国内的 MiniMax、GRM,你都可以直接拿权重去用,蒸馏根本不算什么大问题。真正不希望被蒸馏的,就是这些闭源模型公司。
总结一下,这次事件有三层表述。
最后一句:中国程序员的天塌了吗?还没有塌到不能干活的状态,但原来那条便宜、灵活、默认可用的路,确实不通了。
以后还能不能用 Claude?大概率还能用,就是稍微贵一点。代理代价会更高,路径会更窄,不确定性会更强,更多人可能会被封号。
普通人会更艰难,代理商会更挣钱,真正有组织能力的人,该蒸馏还是照样蒸馏,一点都拦不住。这才是这件事情最现实、最残酷的真相。
Anthropic 这次不是要堵住那些偷师的人,而是要先赶走那些把会员卡用得太狠的人。这就是这一次的故事。