Unity 构建与客户端安全
注:本文是博主在学生团队中所作的一次技术分享。博主本身并非从事构建或安全工作,也并未接触过许多相关工作的案例,许多内容存在推断和联想,其可行性还需在实际项目中进行验证工作,因此内容仅供读者参考。
在学生团队中制作独立游戏,日常是接触不到今天要分享的这个话题的。对于我们自己的打包需求而言,Unity 中的构建选项其实已经足够满足,并且操作起来很简单(除了需要精确对上小版本的 Android NDK 之类的坑)。而今天所讲的两个话题——Unity 构建与客户端安全,更多的应用场景会在大型游戏与网络游戏中。良好的构建系统可以提高制作团队的工作效率,而安全则用于维护网络游戏中的公平性。选择这一题目来分享,仅仅是为了开拓视野,并不需要大家真的在独立游戏中应用相关知识和技术,望各位知悉。
Unity 游戏构建
构建(build)是一个软件工程中的常见概念,通常指一个软件项目从源代码、原始资源进行编译、整合、打包,最终得到能够在目标平台上直接运行的文件的过程。例如,对于 C++ 项目来说,可以编写 cmake 文件来指定构建所需的信息和过程,利用它来进行编译,再将库文件、资源文件等放置在对应的目录结构中,就完成了一次构建。
构建管线与 CI/CD
在通常的 Web 应用项目中,构建通常和 CI/CD 的概念相连接。这里的 CI/CD 其实指三件事情:持续集成(continuous integration)、持续交付(continuous delivery)和持续部署(continuous deployment)。良好的 CI/CD 可以使开发、测试人员可以在各自的工作范围更多地集中在业务本身的工作中,而将检查、测试、构建、交付等工作自动化,并交由 CI/CD 管线执行,仅在流程出现问题时才通知相关人员介入处理。构建管线是 CI/CD 这一系统概念的其中一部分。
持续集成(CI)指的是对开发人员的自动化。这包括一系列的检查、测试和分支管理操作,例如编译检查、配置检查、单元测试、冒烟测试、分支的自动合并和冲突解决等。只有通过了这一系列流程的提交才会进入正式分支,从而保证正式分支的健康。
持续交付(CD)指的是开发人员的修改会被自动化构建为随时可以部署的应用,并对其进行测试,测试通过的版本将由管线统一管理,以便部署时使用。持续部署(另外一个 CD)指的是将已经构建完成的版本自动地部署在生产环境中,以供用户使用。这些自动化措施主要在解决大型项目的构建、部署上的复杂性,将这些复杂工序编写为构建、部署脚本,通过管线来管理复杂工作的配置、产物等,以节约开发人员的精力,提高工作效率,并协助实现敏捷开发。相比 CI 辅助的是开发时的工作,CD 辅助开发完成后的工作。
CI/CD 的核心概念是业务开发之外的复杂工作的封装和自动化,而构建管线在这其中起到了重要作用。构建管线承担着分支/版本管理、构建部署任务分发、构建产物管理、自动化测试等工作,在大型项目中,会有专门的开发和 QA 人员维护和监控构建管线的运行,以避免工作流程被管线故障阻塞。
在了解 Unity 项目的构建管线方案前,有必要先介绍 Unity 项目构建时将会进行的工作,这个话题可以从 Unity 游戏打包产物的结构开始。
Unity 游戏的文件结构
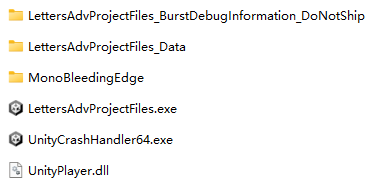
以团队项目 共脑 的一个 weekly 构建为例,游戏包含的文件如上所示。在这一级可以看到的文件有
- LettersAdvProjectFiles.exe:游戏的启动器,Unity 自动生成的 exe
- UnityCrashHandler64.exe:游戏 crash 时上报信息的工具
- UnityPlayer.dll:Unity 引擎库
- MonoBleedingEdge:Mono 运行所需的文件
- LettersAdvProjectFiles_Data:游戏自身的资源和程序文件
在 LettersAdvProjectFiles_Data 文件夹下,还可以看到以下文件(截图只截取了部分)
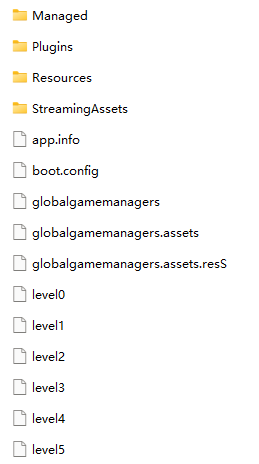
- Managed:C# 编写的代码和库,其中 Assembly-CSharp.dll 包含的就是游戏逻辑,其余为使用到的库
- Plugins:native 库,如使用了 C++ 等直接编译到目标平台机器码的库,则会出现在这里
- StreamingAssets:同项目目录下的同名文件夹
- 其余文件为美术、音频等资源打包后的产物
除去一部分每个 Unity 游戏都有的文件(如启动器 exe、UnityPlayer.dll),其余部分大致可以分为代码和资源两部分。接下来将分别介绍代码和资源的构建过程。
C# 代码的构建
C# 代码如何运行
在了解 C# 代码的构建之前,需要介绍一下 C# 代码如何运行。C# 虽然也是一种编译型语言,但它并不直接编译到目标平台的机器码,而是需要类似 JVM 的运行时环境来运行。
C# 代码会首先被 C# 编译器编译到一种中间语言(IL,intermediate language),这种中间语言可以在实际运行时快速被转换为运行平台的机器码。中间语言表示的程序产物依然会使用 .exe、.dll 等扩展名,看起来像是正常的可执行程序或库,但要运行它们,需要运行时环境的辅助。
C# 属于 .NET 系列语言,使用 .NET 系列通用的运行时环境 CLR(Common Language Runtime)。CLR 实际上存在多种实现,微软官方的实现被叫做 .NET Framework,而 Unity 还使用了 Mono。这些运行时环境实际上还要进行一次 IL 到机器码的转换,这也是一种编译过程,因此被叫做 JIT 编译(Just-in-Time compilation)。
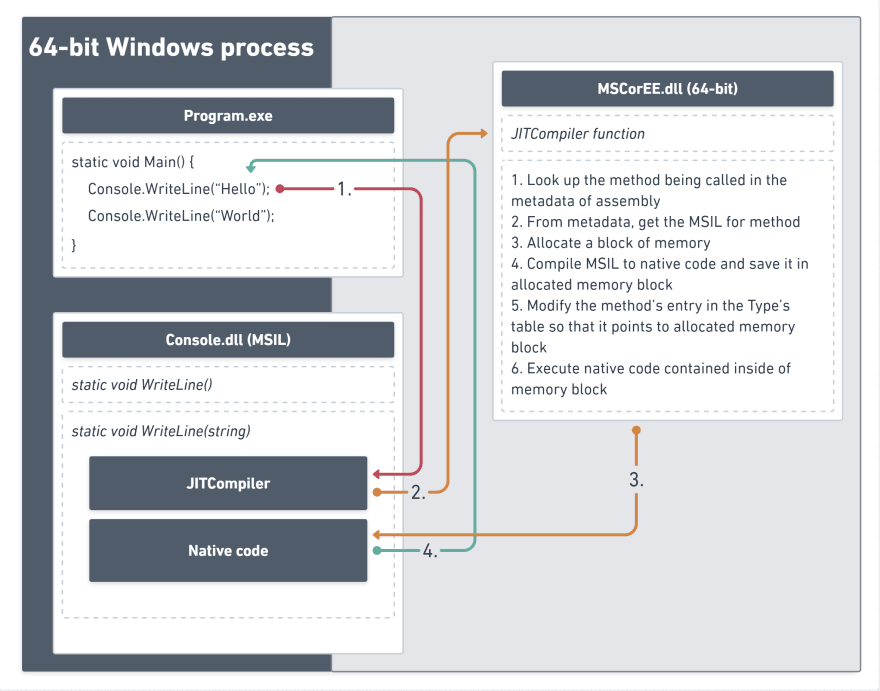
上图展示了一个 C# 编写的程序和库的实际运行过程。在运行的过程中,运行时会将 IL 编译为机器码,并将产物写入一块新的内存区域,再使 CPU 执行产物机器码。
Mono(JIT)
目前 Unity 使用的 C# 运行时环境为 Mono,正如上文所述,这是一种 JIT 编译的方式。Mono 是一个开源的、跨平台的 CLR 实现,在 Unity 开始使用 C# 作为脚本语言的时候,微软的 .NET Framework 尚未开源和实现跨平台,只能在 Windows 平台上运行,而为了 Unity 的多平台构建能力,Mono 被选做 C# 的 JIT 方式脚本后端。
如 .NET Framework 一样,Mono 也有自己的一套构建工具链,生成符合 ECMA 标准的 CIL 产物。此外,还可以使用 Mono.Cecil 等工具库来对 Mono CIL 产物进行分析,例如获取类型、函数信息,修改和生成代码等。
JIT 的 CIL 代码在运行时被转换成机器码,因此软件构建完成后,实际分发的是 CIL 二进制文件,这会给我们带来一些方便之处
- 对于不同平台可以使用同一份 CIL 二进制,只需要平台具有对应的 CLR 即可运行
- 多平台构建时,C# 可以只编译一次到 CIL,简单修改二进制文件结构即可生成不同平台的产物,节约构建时间
- 相对机器码而言,CIL 更方便进行静态分析和代码修改、生成,可以简单地实现注入打点等
但这些方便也可能会带来不便,例如
- 运行时将 CLR 编译为机器码需要消耗一定的 CPU 时间,可能导致性能低下
- 分发的 CIL 文件很容易被用户逆向和修改,影响游戏正常运行,或容易被利用制作外挂等
由于性能和安全通常是高优先级的问题,Mono 在商业游戏中使用并不广泛,更多见于开发环境(开发构建)或小型独立游戏等。
IL2CPP(AOT)
除 Mono 外,Unity 还提供了一种 C# 脚本后端供选择,这就是 IL2CPP。这个名字包含了 IL 和 CPP 两个名字,从名字就可以猜测,它的工作方式是将 CIL 变为 C++ 代码,再直接编译到目标平台的机器码。
首先你可能会想这样一个问题,C# 代码要怎么变成 CIL?还记得我们的 Mono 吗,可以直接使用 Mono 工具链中的 C# 编译器将源码编译到 CIL。因此,IL2CPP 本身是一个 AOT 编译器(Ahead-of-Time compiler),它能够在实际运行之前将 CIL 变成机器码,只是中间的过程是先转换成 C++ 代码。IL2CPP 在构建过程中的位置可以从下图中理解
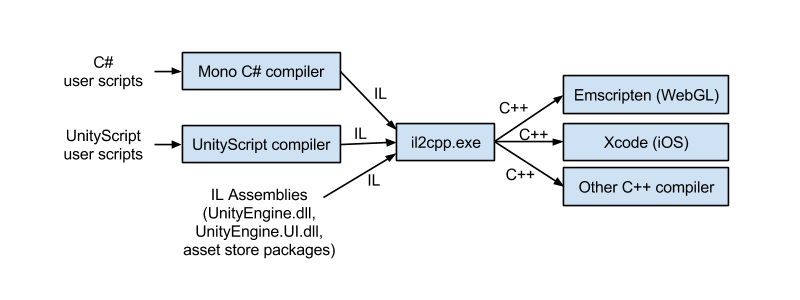
与 Mono 不同的是,构建出的产物不再包含任何 CIL 代码,而是直接编译到机器码。因此,游戏构建的 XXX_Data 文件夹下不再有 Managed 文件夹保存所有的 CIL .dll 文件,取而代之的是根目录下的 GameAssenbly.dll,这便是 CIL 转换成 C++ 后编译得到的机器码库文件。
然而,C# 仍需要运行时提供反射、GC 等功能,因此 IL2CPP 的产物中也需要包含一部分提供此类功能的方式,这是由 baselib.dll 和 XXX_Data/il2cpp_data 文件夹等共同完成的。
AOT 编译的好处与缺陷和 JIT 基本是对应的,它的好处包括
- 最终分发的文件是目标平台的机器码二进制文件,可以直接运行,没有 JIT 编译导致的性能损失
- native 的二进制文件逆向难度更大,且可以通过加壳等方式进一步处理,增强游戏的二进制安全性
而缺陷包括
- 由于游戏逻辑也被编译到了目标平台的机器码,如果一个构建包需要在多种平台上运行,需要分别提供对应的二进制文件,这会是包体大小变大,这一点在构建 Android apk 文件时非常明显
- 如果开发时就使用 IL2CPP 编译到机器码,再进行 C# 代码修改操作将变得困难;但这一点可以通过在构建过程中加入修改阶段,在 IL2CPP 阶段之前完成对 CIL 的注入,也可以实现相同的效果
- 由于 IL2CPP 实际上是在 Mono 构建后新增了若干阶段来编译到机器码,这将使单次构建时间变长
美术、音效等资源的构建
Games are much more than source code,游戏项目的资源数量远远多于代码的数量,资源本身也存在复杂的类型、格式和构建过程,因此相比代码而言,资源的管理和构建更为复杂。资源的构建主要指资源的组织和打包方式,Unity 提供了多种加载资源的方式,它们的构建存在区别,因此将按 Unity 加载资源的方式介绍资源的构建。
通过 GUID 直接引用
在 Unity 的 Inspector 中,可以直接把一个资源文件拖进一个槽中,此时这个场景就建立了到一个资源文件的 GUID 引用。这种方式引用的资源会在场景打开时直接被加载进内存,因此,如果一个场景中所有的资源都是如此配置的,则打开场景会需要花费较长时间,并且全部资源都会在一开始加载,直到场景关闭才会卸载。
场景本身的信息会被打包成 levelX 文件,而场景引用的资源可能被打包在 resources.assets/sharedassetsX.assets 等文件中。
Resources 类
如果将资源放置在 Assets/Resources 文件夹中,可以通过 Resource.Load 方法动态地加载,这是 Unity 最简单的动态加载资源方式。这些资源保存在 resources.assets 文件中,因此一个项目的 resources.assets 文件可能很大。
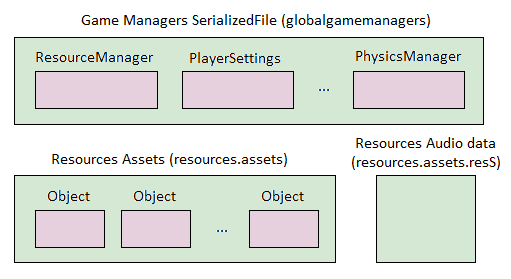
上图展示了 resources.assets 文件的结构,它实际上是若干资源打成的包,文件中包含连续的资源块,文件头指示了每一个资源对应的块,因此可以通过文件路径索引到对应的块,再从块中读取资源到内存中。
这些资源的打包是在 Unity 构建过程中自动完成的,Unity 并未提供接口修改这一构建过程,因此难以从脚本层面控制资源构建。
Asset Bundle
Asset Bundle(以下简称 Asb)是 Unity 提供的另一种从文件中加载资源的方式。相比 Resources,Asb 最大的好处就是可控。在整理资源时,可以在 Inspector 中选择资源对应的 Asb。可以通过 BuildPipeline.BuildAssetBundles 从脚本中构建 Asb 文件。加载 Asb 时只需提供文件路径即可,可以将游戏本体和 Asb 分开构建,发行时将 Asb 放入 StreamingAssets 中,这样游戏本体就可以读取 Asb。另外,还可以直接通过网络分发 Asb,游戏本体下载到 StreamingAssets 中再读取。Asb 的加密也较好处理,Unity 提供了从流中加载 Asb 的接口,因此只需提供解密后的流,Unity 仍可照常加载 Asb。
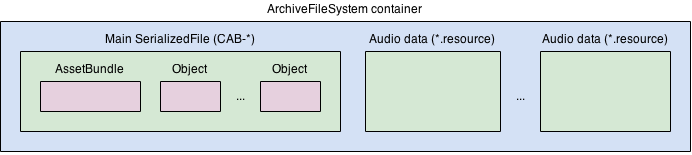
Asb 具有和 resources.assets 类似的文件结构,但一个 Asb 包实际上包含多个文件,序列化数据和部分原始资源是分开的。Asb 也支持只加载其中的部分资源,它同样具有和 resources.assets 类似的文件头信息。
大多数大型游戏都会选择 Asb 这种资源的管理和构建方式,因为它可以和游戏本体分开构建,方便分发和更新,这样可以减少游戏的最小包大小,让更多资源可以通过网络分发,且玩家也可以选择下载的资源数量和质量。
数值、配置
数值、配置在兴趣项目开发时通常会直接配置在场景、Prefab 或 ScriptableObject 中,可以随 Unity 的引用或 Asb 等一并打包。
我们尝试在团队项目 Emoji 中引入了 Excel 表格管理的数值文件,并提供了从 Excel 表格导出数值、生成 Excel 行的数据类和序列化代码等工具。
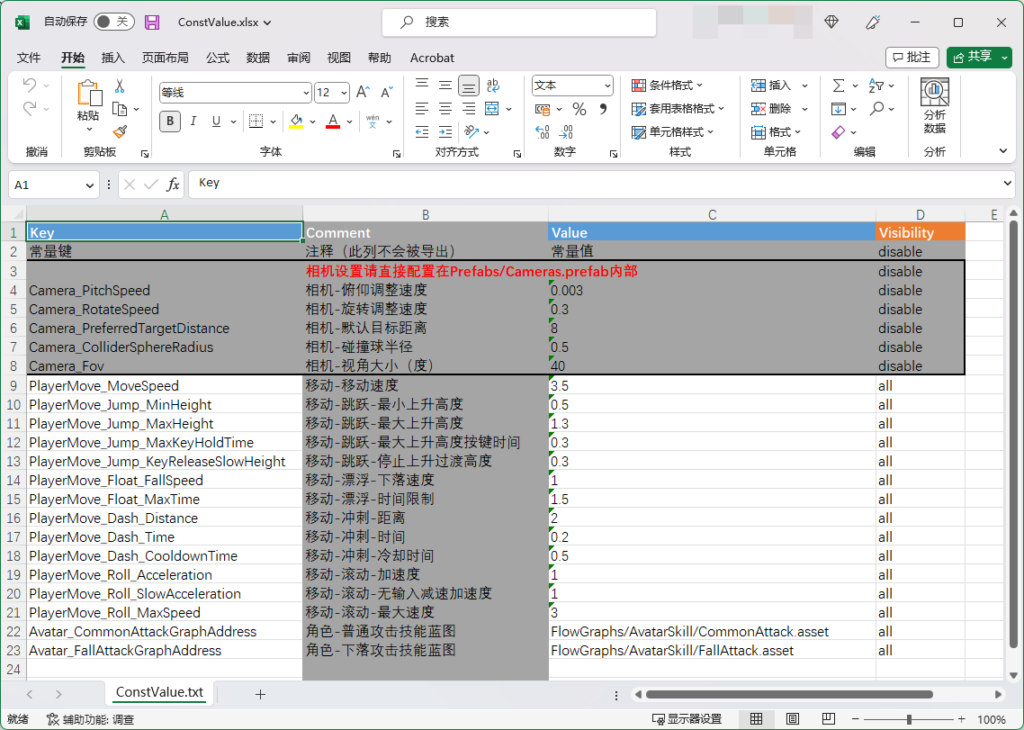
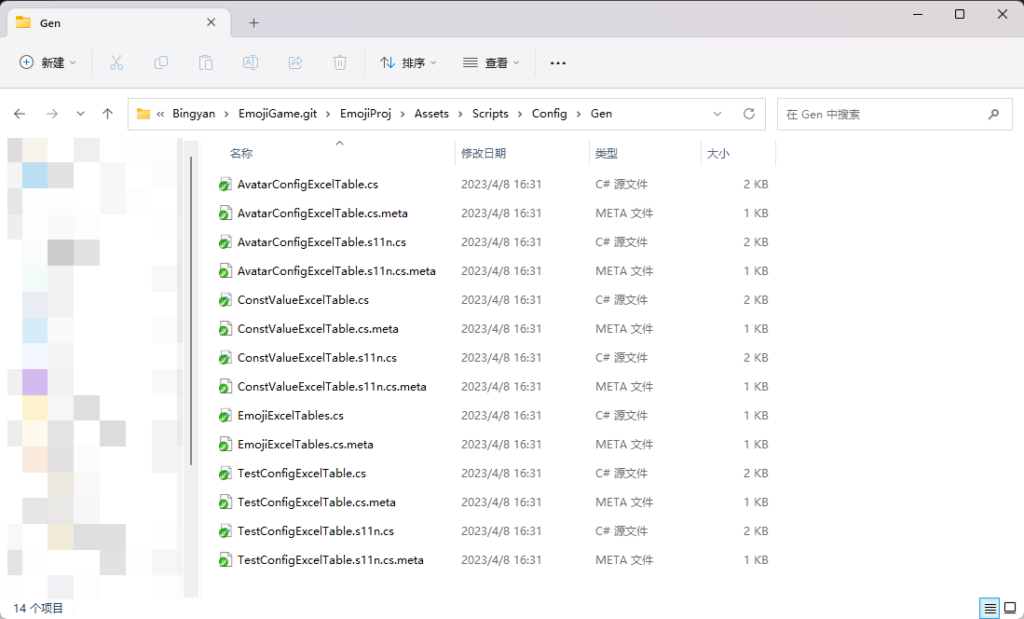
这些自行实现的数值构建,可以在打包之前自行导出一遍配置,或自定义打包的流程,在打包前加入这一环节。数值配置的自行管理,在商业游戏中也方便进行数值 patch 等更新操作。另外,还可以在 Excel 表格或构建过程中加入数值校验环节,避免开发人员提交错误的数值配置,使项目无法正常运行。
Unity 游戏构建管线
Unity 提供了构建管线接口,即 BuildPipeline 类。除了在编辑器里打开构建窗口之外,还可以利用管线接口来定制构建脚本,并将构建配置独立成配置文件,可供切换。
自行实现构建脚本通常有以下分类和步骤
- 构建游戏本体
- 读取构建配置
- 导出游戏本体所需的资源,如数值、最小包资源等
- 代码混淆等
- BuildPipeline.BuildPlayer
- 二进制加壳保护等
- 对游戏本体和最近的 Asb 构建运行冒烟测试
- 如冒烟通过,上传构建至构建管理平台
- 上传调试文件至构建管理平台
- 构建 Asb
- 读取构建配置
- 导出 Asb 所需的资源
- BuildPipeline.BuildAssetBundles
- 如有自行设计的 Asb 加密或再分组策略,执行对应的打包流程
- 对 Asb 构建和最近的游戏本体构建运行冒烟测试
- 如冒烟通过,上传构建至构建管理平台
实现了构建脚本和构建配置后,便可利用 CI/CD 平台(如 Jenkins、TeamCity 等)配置构建管线。然而,与通常的应用 CI/CD 管线不同,游戏的一次构建花费的时间过长,大型项目通常要花费高达 10 小时甚至更长的时间才能完成一次全量构建。这使得游戏的 CI/CD 工作难以高频进行,自动化工作带来的效率提升效果大大减少。
游戏的 CI 方案通常包含较强的检查和较弱的测试,这是由于如数值检查、编译检查等工作可能可以在数分钟内完成,但启动游戏进行测试所需的时间可能较长,一次提交如果无法在短时间内通过 CI 流程进入项目,会大概率产生冲突,浪费开发者的时间在处理冲突上。一种解决的方案是,提交自动触发的管线任务仅包含检查,而自动化测试不作为提交的必要条件,而是当某一版本的测试不通过时再检查该版本的修改。管线的检查任务可以通过项目管理平台的提交触发器拉起,主流的版本管理系统(如 Git、Perforce 等)都具有提交前后触发脚本的功能。
尽管开发团队可以将游戏的构建过程进行修改和包装,变为便于使用的构建脚本,但单次构建的成本还是太高,无法持续地运行。此外,如果构建的目标是移动端设备,可能具有特殊的构建平台要求,如 iOS 应用需要在 Mac 上构建,这使得构建管线管理的机器数量和类型变多。这些复杂性使得游戏的构建最终只能手动触发,并在团队中限制使用,否则无论团队拥有多大规模的构建集群,也难以满足开发人员和需求对构建的需求。因此,相比于 CI 过程的自动触发和高频运行,游戏 CD 管线则因耗时原因,不得不选择手动触发和按需运行的策略。
在冰岩作坊这样的学生团队中,我们没有能力搭建一套这样健壮的构建管线。然而,a game that can’t build every day is in big trouble,我们仍然可以按照一定的频率手动进行构建,持续地打包、测试和提供给玩家试玩。这同样是对开发团队的鞭策,让我们能够在固定的时间间隔下生产和验收内容,保持项目的活力。
Unity 游戏客户端安全
客户端安全并不是只有游戏才会面临的问题,桌面应用、移动端应用同样面临着相同的问题。对于普通的应用而言,安全需求主要集中在反爬虫、反逆向、反隐私泄露等;而对于游戏而言,除了这些需求之外,安全更突出地反应在游戏体验问题上,外挂等针对游戏客户端的攻击工具严重破坏了玩家的游戏体验。试想,如果你是 战地1(Battlefield 1) 玩家,你正享受着游戏带来的乐趣,结果就被外挂狗骑脸输出了,导致你再也无法在这款游戏中获得乐趣,于是开始狂喷 EA 装死不处理外挂问题。
从开发团队的视角来看安全问题,更多地是一个需要衡量性价比的问题。例如,对于 PVP 很弱或基本不存在的单机游戏而言,安全需求主要是反破解/反盗版,而修改游戏数据类的外挂危害很小;但对于强竞技类的游戏,一款修改数据/辅助游戏的外挂会严重破坏游戏公平性,有必要在客户端中加入对于读取/修改内存的安全措施,但这种 PVP 游戏的反作弊也可以从服务器的角度入手。
本次分享中主要介绍若干客户端安全的策略/措施,其应用场景各不相同,具体的落地措施还需根据各项目的实际情况来决定。
反逆向:加壳
Unity 开发的游戏逻辑多采用 C# 编写,而 C# 的 CIL 或反射等机制容易为攻击者带来便利。因此,为了增强 Unity 游戏客户端的安全性,通常会采用 IL2CPP 脚本后端,并对二进制文件进行加壳。
加壳是指将原来的程序代码进行压缩、分段或加入难以阅读的或冗余的逻辑,使原来的程序代码能够正常运行的同时,反汇编得到的结果具有一定的迷惑性,增加逆向工作的难度。
VMP 壳(VMProtect)是一种将原有程序代码的运行转移到壳所实现的 VM 上的加壳保护方案。VMP 2 会将原本的 x86 汇编指令转换到壳 VM 所能运行的 RISC 指令集,并对指令的操作数进行加密,从而实现混淆原本汇编代码的目的。加壳后,逆向工作必须从 VM 本身开始寻找入口点,研究翻译后的 RISC 指令,而不是简单地对 x86 指令进行逆向。由于需要新增大量 VM 相关逻辑,VMP 壳会使二进制文件的大小膨胀许多倍,且会带来额外的运行开销。
UPX 壳(Ultimate Packer for eXecutables)是一种将原有程序代码压缩,并在程序中加入解压逻辑的加壳保护方案。UPX 加壳后,程序代码将被压缩算法压缩,在二进制层面和原本的内容产生较大区别。逆向工作必须先研究解压算法,将原本的程序代码解压后,才能分析程序。如果调整压缩/解压算法,使得此算法的逆向工作困难,则可以获得一定的安全性。UPX 壳会使二进制文件的大小缩小,但同样会带来额外的运行开销,使程序性能降低。
反逆向:混淆
IL2CPP 生成的二进制文件可以通过加壳保护,但 C# 的反射机制依赖的 metadata 也会给攻击者留下一个逆向的突破口。在构建过程中进行代码混淆则是一个解决方法。
在实际的逻辑中,反射所涉及的类和字段并不多,大多数的类名、变量名、函数名都可以被任意修改,因此可以进行混淆——即将原本具有含义的名称替换为不具有实际意义的随机字符串。混淆过程中,混淆器会维护一个名称映射表,逐一发现和替换代码中的名称,替换后的程序代码可读性大幅下降,metadata 中的名称也变得难以辨认,仅有部分反射用的名称保留了下来,增加了逆向难度。
反逆向:修改虚拟机
如 C#、Lua 等语言运行在虚拟机中,可以通过修改虚拟机的方式来使生成的 IL 与常规使用的不同,增加逆向难度。常见的修改方式是更改 IL 指令的 opcode,修改后攻击者只能通过特征猜测 opcode 与实际指令的对应关系,这一工作将耗费大量时间,提升逆向困难性。
反劫持:文件完整性检查
攻击者可以通过文件替换的方式,将游戏依赖运行的部分库文件替换成修改后的版本,从而在接口中增加攻击逻辑,劫持游戏逻辑或从游戏中获取资源数据等。
可以在游戏启动时增加文件完整性检查,分析将使用的文件是否被修改过,例如在分发时增加 checksum 检查,联网获取文件的 checksum,如文件被修改过则联网下载原始文件,再启动游戏。
反解包:自定义资源加密方式
在打包过程中加入自定义的资源打包和加密方式,而非直接使用通用或常见的加密方式,可以增加攻击者分析包体结构的难度,避免客户端资源包被轻易破解,原始资源泄露盗用。
矛盾的安全工作
游戏的安全工作存在着许多矛盾,例如二进制相关的安全措施对游戏软件的影响面过大、或影响游戏性能,明水印、盲水印等由于泄露图门锁拍照而难以识别,设计和验证加密方案周期很长、但攻击者破解加密方案却又可能较快(毕竟攻击者比打工人有时间太多了)等等。
安全措施的最终目的可能很难定为杜绝攻击的发生,对于游戏项目就更难做到如此。因此,安全的实际执行必须考虑性价比和可行性问题,例如资源上的水印足够防止大部分资源盗用、反逆向措施足够防止大部分玩家修改客户端,便可认为达到了安全方案的目的。
此外,安全方案并不是只在技术层面、在客户端侧进行。例如,对于联网的游戏客户端,还可以在服务端进行数据校验,或主动识别作弊玩家和被修改的客户端;对于需要保密的资源,和相关人员签订保密协议,明确保密义务,并在适当时间用法律手段解决问题。
结语
本次分享涉及了一些在日常进行兴趣项目游戏开发难以接触的话题,意在开阔视野,提供更多了解游戏开发工作的横向知识。本人并非从事这些工作的专家,对相关知识的了解也较为浅薄,如有错误或建议欢迎交流。
冰岩作坊游戏组正在进行的项目包括本文中提到的 共脑、Emoji(代号)以及已经上架 TapTap 的 纽兰枢纽(参考资料中有链接!),欢迎大家支持我们的游戏项目。作者正在参与的 Emoji 是一款 3D 平台跳跃闯关游戏,目前正在原型期开发中,期待后续能够和各位见面。
参考资料
本文所使用部分材料和配图来源网络,感谢原作者的分享。
- Mike McShaffry, David Graham, Game Coding Complete (Fourth Edition), Course Technology
- Ret Hat, What is CI/CD?. https://www.redhat.com/en/topics/devops/what-is-ci-cd
- Kristijan Crnac (dev.to), .NET compilation process explained (C#), https://dev.to/kcrnac/net-execution-process-explained-c-1b7a
- Mono Project, https://www.mono-project.com/
- Josh Peterson (Unity), An introduction to IL2CPP internals, https://blog.unity.com/engine-platform/an-introduction-to-ilcpp-internals
- imadr (GitHub), Unity Game Hacking Guide, https://github.com/imadr/Unity-game-hacking
- Ryan Caltabiano (Unity), Asset Bundles vs. Resources: A Memory Showdown, https://blog.unity.com/technology/asset-bundles-vs-resources-a-memory-showdown
- 知乎, 如何评价近期战地1外挂大规模炸服事件?, https://www.zhihu.com/question/578918874
- IDontCode (Back Engineering), VMProtect 2 – Detailed Analysis of the Virtual Machine Architecture, https://back.engineering/17/05/2021/
- TapTap, 纽兰枢纽, https://www.taptap.cn/app/287001







{kind=link}
{kind=link}