Claude KYC上线:中国开发者影响解析

Claude 也要做 KYC,也要做实名认证了。中国程序员们的天塌了吗?
大家先别急着骂 Anthropic 反蒸馏。你以为他这次真正想打击的是蒸馏他模型的人吗?其实未必。真正先被打击的,可能是另外一类人。
一个健身房的比喻:Anthropic 真正在防谁?

设想一个场景:有一家健身房。
- 第一种人想自己开健身房,于是进来偷师,报了所有课程,跟健身教练学完以后,回去自己开健身房。
- 第二种人办了健身卡进来,把所有羊毛都薅干净。我这个健身卡是一年的,我就天天来;我来不了的时候,还找别人替我来,一定要把所有能用的都用完。
- 第三种人是花了钱办健身卡以后,再也不来了。
那你说,健身房最喜欢哪种用户?肯定喜欢第三种。你交了钱,再也不来了。
第一种人防得住吗?其实防不住。这一次真正去防的,是中间这种:办了健身卡,就一定要把所有便宜都占干净,自己来不了还要让别人替自己来。要干掉的是这帮人。
所以大家想明白了没有?他并不是惦记着去搞那些蒸馏的人。第一拨人,就是跟着健身教练学,学完以后回去自己开健身房的人,这才是蒸馏的人。这些人你防不住。为什么防不住,待会再讲。
这一次 Anthropic 干的事情,其实就是健身房升级了门禁系统,保证你必须是同一个人来,保证不会有人用一张健身卡多人进入,要把这种用量打下来,尽量让“花了钱不来的人”多一些。这才是真正的意图。
至于反蒸馏,跟这次有关系,但关系真不大。它最大的关系,可能就是这次行动的一个借口,其他其实没什么意义。
为什么这件事会炸锅?

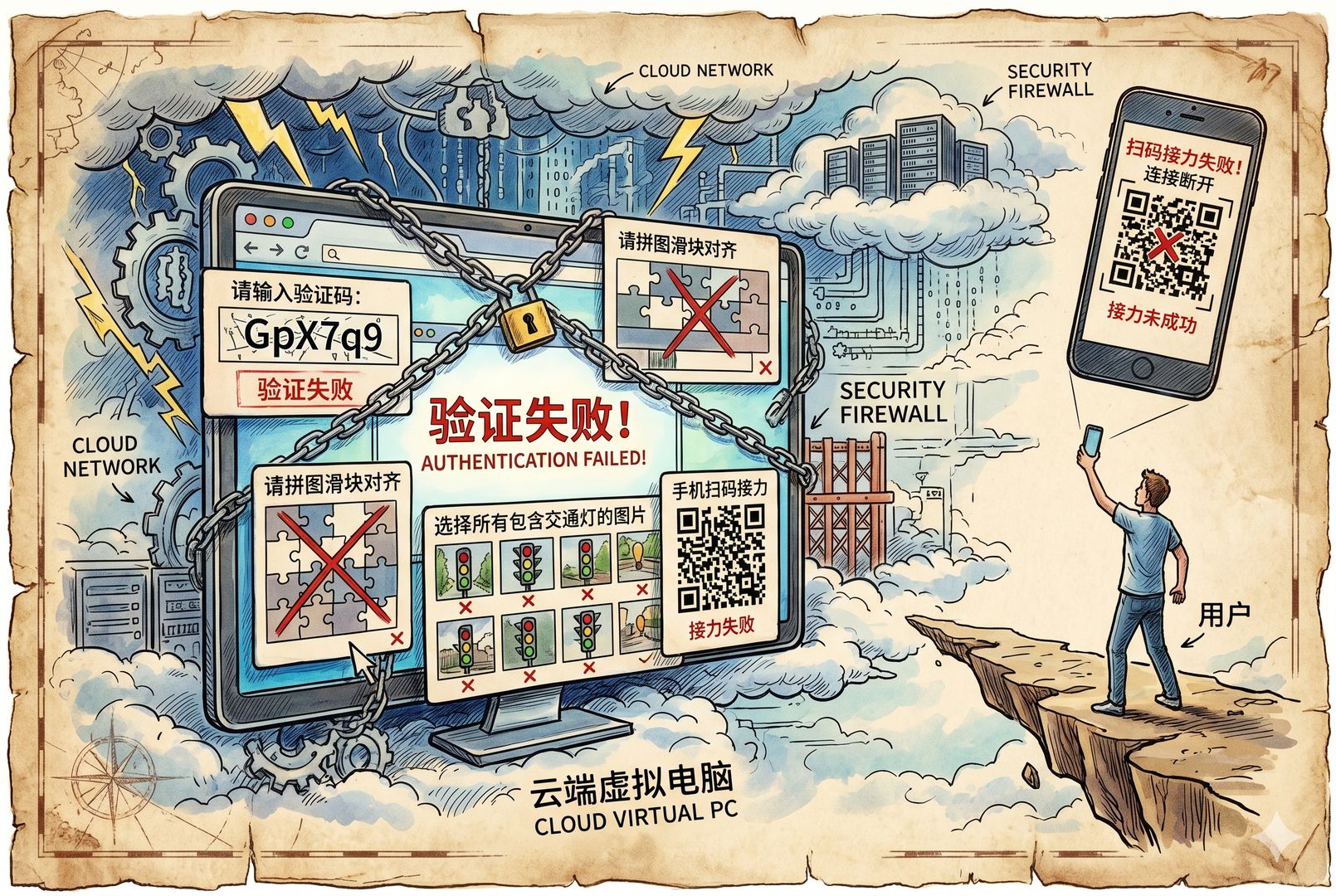
这个事情出来以后为什么炸锅了?因为现在 Claude 开始出现身份验证弹窗了。有些人确实已经弹了,要求提交政府证件,也就是护照、身份证这些东西,还要进行实时自拍,做人脸和证件核验。
社区里的第一反应就是:完了,Claude 也要做实名制了,中国程序员以后别用了。
一般讲 KYC,通常是在币圈里讲,叫 Know Your Customer,也就是平台核实用户真实身份的一套风险控制机制。
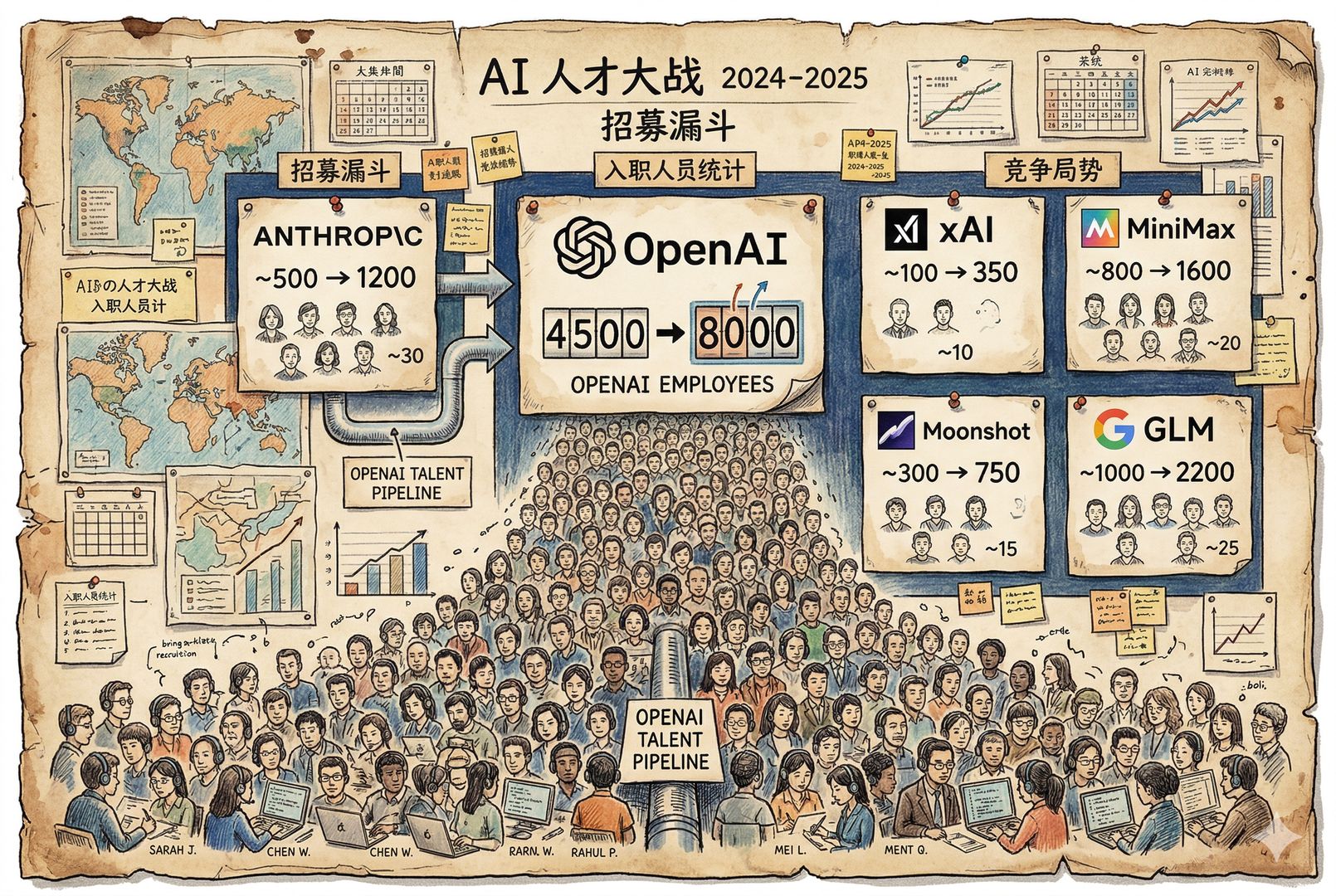
在 Claude 里,中国开发者一定占极大比例。因为本身中国开发者就多,而且中国开发者又愿意去用最好的模型。虽然国内也有些模型能用,但我见过很多开发者都跟我说,你自己的时间是有价值的,一定要买最贵的。因为模型的差价,对于模型质量来说,基本可以忽略不计。所以一定要用 Claude。
前几周我跟姜变做节目时,他的“龙虾”挂的就是 Claude Opus 4.6,买的是 200 美金套餐。他给我的解释就是:我一定要买最好的。
现在在 Claude 里,用量最高的一些人,实际上很多都是中国人。第一个人好像叫刘小排,也是我以前猎豹移动的一个同事。这些都是能登上全球榜榜首的人。那自然就一定要“收拾”你们,因为这是一帮特别喜欢薅羊毛、用量特别高的人。这样的用户,健身房不欢迎,Anthropic 也不欢迎。
时间线:Anthropic 如何一步步收紧
Anthropic 在 2025 年 9 月就开始收紧中国 API 的访问了。
2026 年 2 月,Anthropic、OpenAI、谷歌三家公司同时指控中国实验室蒸馏。
2026 年 4 月 14 日,官方帮助中心更新了 KYC 说明;4 月 15 日起,用户将陆续收到弹窗。
更残酷的现实是,这个闸机很可能根本不认你的证件。因为他们找的第三方 KYC 机构,压根就不承认中国护照这些东西。你上去说我想验证,根本没人理你。
先把事实厘清:分三层来看
我们先把事实厘清,分三层来看:第一层是官方说法,第二层是事实认证,第三层是我的观点。
第一层:官方说法

先说官方说法。2026 年 4 月 14 日,Anthropic 官方帮助中心更新了一个名为 identity verification on Claude 的文件。
官方原文的措辞是:a few user use cases,也就是很少数的使用场景,不是全员强制。所以这是一种抽查,但具体抽到谁、没抽到谁,不会公布规则。
触发条件包括:
- 访问某些高级能力,比如让它做破解、做一些危险的事情,或者一些色情相关内容,都可能被视为“高级能力”;
- 例行的平台完整性检查,比如系统发现你的 IP 地址不对,或者一些跳转存在问题;
- 其他安全与合规措施,描述得比较宽泛,具体怎么筛选谁来拍照片,并不会说得很清楚。
现在它要求你的证件、账号、IP 地址必须“三码合一”。你说我提供一个泰国证件,那你的 IP 也得是泰国的,账号申请地区也得是泰国,不能中间有叉,一旦有叉就可能被干掉。
API 用户方面,官方明确说明当前不在本轮影响范围内。也就是说,你开账号以后在里面用 API,这一轮没影响。因为 API 本身相对更贵,Claude 也贵。
这也是为什么我说,这次主要处罚的是薅羊毛的人,而不是那些上你这来学课程、回去准备自己开健身房的人。因为那帮人是 API 客户,这次跟他们没关系。至于以后会不会再收拾,不好说。
第二层:已经确认的事实
已经确认的事实是什么?
- Anthropic 帮助中心页面确实在 2026 年 4 月 14 日更新了 KYC 说明。
- 部分用户已经从 4 月 15 日开始收到 KYC 验证弹窗。
- Anthropic 同期更新了 unsupported regions 销售限制说明,明确点名中国,告诉你中国是不支持的区域。
- 2026 年 2 月,Anthropic 指控 DeepSeek、Moonshot AI,也就是月之暗面,还有 MiniMax,创建了 24,000 个虚拟账号,通过 1,600 万次 API 调用蒸馏 Claude。
- Anthropic 在 2025 年下半年封禁了 145 万个账号,力度非常猛。你可以申诉,但成功率只有 3.3%。所以封了以后,很多时候还不如再开一个,别费那个劲。
- 这次使用的是第三方 KYC 服务商,这也是 Anthropic 官方确认的。也就是说,你的姓名、护照照片、人脸这些信息,不会直接传到 Anthropic,而是交给一个第三方服务商处理。这个服务商叫 Persona,由它来做第三方认证。
问题在于,Persona 对中国大陆证件基本不支持。绝大部分中国大陆用户,没法通过验证。
更麻烦的是,Persona 在 2026 年 2 月因为服务器配置错误,暴露了 2,456 个文件,包括证件照片、生物特征和 IP 等信息。Discord 也因此终止了和它的合作。也就是说,这家公司本身的安全性也没那么让人放心。
另外,2026 年 4 月 16 日,OpenRouter 等代理渠道也出现了中国用户受限现象。什么意思?就是原来中国用户用中国信用卡充 OpenRouter,也可以用 Claude 模型;以后如果你是用中国信用卡充值的 OpenRouter,就不允许再使用 Claude 模型了。但这一块没有任何官方公告,就是直接给你封掉了,这也很奇葩。
第三层:我的判断
我的判断是,很多人把这件事理解为反蒸馏,这个说法只对了一半。反蒸馏是这次事件的借口,不是核心诉求。这次 KYC 的核心诉求是反薅羊毛。
Anthropic 喜欢什么用户,讨厌什么用户?

从用户画像来看,Anthropic 最喜欢什么用户?稳定付费、低投诉、低风控、正常使用、不把额度打满。比如我交了 20 美金也好,交了 200 美金也好,我就老老实实用,用量还很少。就像去健身房交了会费以后再也不去了,这是 Anthropic 最喜欢的。
Anthropic 最讨厌的用户是什么?高消耗、跨区访问、账号关系复杂、支付链路异常,可能共享、分销、转售,或者通过第三方工具批量接入。这些才是它真正想处理的对象。
蒸馏用户画像和羊毛党画像确实有重叠,但差异也很大。尤其是官方专门说了,这次不针对 API 用户,而 API 用户恰恰才是最像真正蒸馏用户的群体。所以从这个角度看,这事压根不是冲着反蒸馏去的。
这有点像苹果做隐私保护。苹果做隐私保护,表面上是保护隐私,实际上是为了把那些原本可以被挑挑拣拣的广告位重新卖出去。很多事情表面上一回事,实际上做的是另一回事。
我的判断就是,Anthropic 这次没有真正想搞反蒸馏,它要打的是羊毛党。就跟前段时间网飞打击共享账号是一个逻辑。
封号与 KYC:两件相关但独立的事
再说封号。首先要讲清楚一件事:Anthropic 是经常封号的。去年封了 145 万个号,申诉成功率 3.3%,说明它封号比例很高。
但这次 KYC 和封号之间没有必然联系。不是说我想封你号了,先给你做一次 KYC;也不是说做一次 KYC 就能申诉成功。这两件事是独立的。想封你,我就直接封;想让你做 KYC,你就去做,二者没什么联动。
已知的封号处罚条件
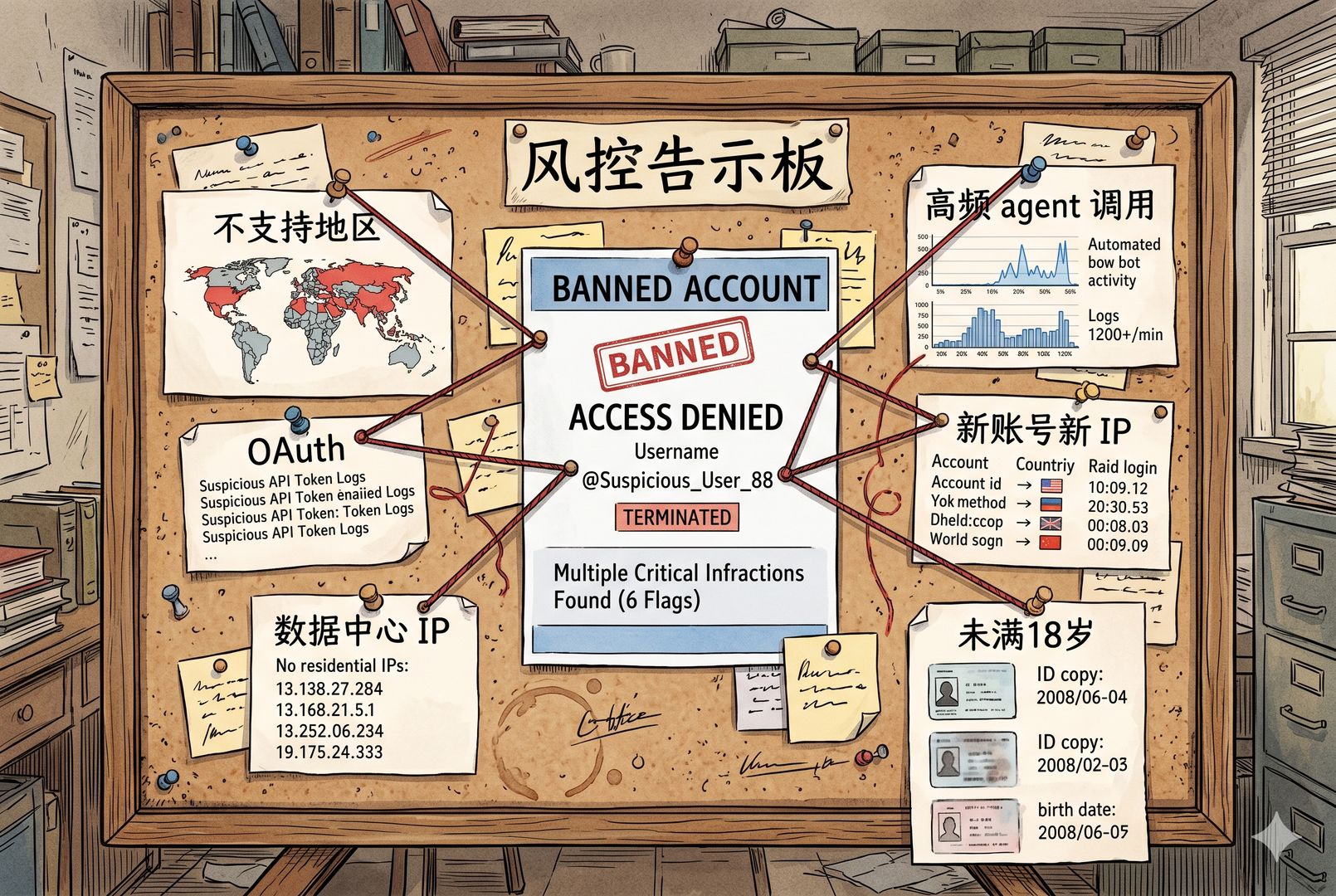
- 不支持区域的访问和注册,比如中国用户访问。这个我自己就遇到过。我有一个谷歌邮箱,有一次忘了挂梯子,那个邮箱就直接废了。后来想救回来、想重新充值,根本不行,上来就是“这个邮箱被封禁了”,再也申请不开了。
- 第三方 OAuth 登录。比如玩“龙虾”的 OpenClaw、Harness、OpenCode,这些都是 Anthropic 明确禁止的。你现在用了,可能还没被抓到;但以后如果因为这个理由封你,也别去申诉,因为申诉时它也不会退你钱。
- 数据中心 IP 和非住宅 IP。因为我们挂梯子访问 Anthropic,梯子的 IP 很多都在云计算机房里。用这种 IP 去访问很容易出事。系统会识别你的 IP 是数据中心 IP 还是住宅 IP。所以现在很多人都在卖什么“固定住宅 IP”。至于这些 IP 怎么来的,大家自己脑补。
- 异常高频的 agent 调用,被识别为非人类行为。有些蒸馏行为会踩到这条。
- 新账号、新 IP、异常行为同时出现。很多人说“我这一直好好的”,那是因为你是老账号,用了很多年,一直在充钱。这样的账号即便 IP 有些跳动,通常也不太管你。但新账号、新 IP,一上来就可能秒封。经常能看到有人抱怨,刚封完一个账号,重新开一个,充了钱马上又被封,这种情况概率很高。
- API 探测和安全测试。虽然也会快速处罚封号,但碰到这种事的人其实不多,比如你做黑客测试,或者要求它做一些特别危险的事情。
- 未满 18 岁。如果系统跟你聊了半天,觉得你实在太幼稚,也有可能被封。
至于正常使用 Claude、很小心地用 Claude 的普通中国用户,其实还是可以继续用下去的。跟这次行动或者过往的封号条件,关系没那么大。
封号的典型特征
- 无预警,多数没有事前警告邮件,直接就封,而且不解释。
- 封号邮件通常不说明具体原因。
- 有的时候会自动退款,但账号不恢复,这只是部分案例。
- 新账号和新 IP 更容易秒封。
- KYC 通过不等于免死金牌,通过 KYC 后仍然可能被封。
申诉与退款情况
申诉方面,确实有机制,但成功率很低,去年只有 3.3%。没有固定时限,也没有确认回执,大部分用户申诉之后都是石沉大海。你不能指望说我申诉了,24 小时、48 小时一定给我回复,不会的。你发了申诉信,没人理你,是正常的;有人理你,反而比较奇怪。现在也没有证据证明申诉必须先做 KYC,所以 KYC 和申诉也是独立体系。
退款方面,如果是政策违反,不退款。特别像我们在中国使用,就属于政策违反。
Anthropic 主动终止,也就是你没有违规,但我觉得你有些问题,又不想给你解释,就把你终止了,这种通常会按比例退款。比如你用了多少天,剩下的钱退给你。
申诉成功,一般是恢复使用,不会给你退款。自动退款但不恢复账号,也有部分案例。
所以我们有时候通过第三方购买 Anthropic 账号时,对方也会写清楚:如果 Anthropic 不给你退,我也不退;如果 Anthropic 退了,我可以帮你退一部分。
为什么中国开发者最疼?

为什么中国开发者最疼?大概有五层原因。
1. 地区问题
中国本来就不在 Anthropic 的支持范围之内,本身就是敏感地区。但中国人又特别勤奋,很努力、很认真地用 Anthropic 写各种程序。中国程序员数量多,而且又卷,所以这次封号会对很多中国程序员的个人账号造成影响。
2. 支付问题
大量中国开发者使用的是非标准支付路径,不是本地银行卡,因为中国银行卡本来就付不了,所以会用虚拟银行卡、代付、第三方平台充值等方式。这本来就在灰色地带。
而且虚拟信用卡代付里,确实有一部分会出现支付失败。以前我们做游戏就遇到过,用户先支付,过一段时间又申请挂失,说银行卡丢了,或者最后交割不过来。中国用户使用这些虚拟信用卡,也确实可能给 Anthropic 造成了一定经济损失,所以它也会倾向于把这些人筛出去。支付链路异常,本身就会触发风控画像。
3. 访问问题
代理 IP、时区异常、设备切换、网络环境异常,这些在中国用户身上都很常见。美国人该下班就下班了,我们一天 24 小时干。甚至有人在 X 上分享,半夜定闹钟起来,到 OpenClaw 上按个回车,把 5 小时额度刷完再接着跑。这种行为非常容易出问题。
挂梯子的人又经常换线路,没法保证统一 IP。对个人用户来说,这种正常使用场景,在风控系统里就是可疑信号。真正公司里反而不会有这个问题,因为公司会直接在美国 AWS 或谷歌云上租服务器,建立私有通道,IP 不会频繁变化。
4. 使用强度问题
中国人的勤奋程度太高了。把 Claude 当生产工具的开发者,调用频率和时长远高于普通用户。Anthropic 给你的套餐,本质上更像一个自助餐,它希望每个人进去礼貌地吃两口就走。哪像我们,进去以后猛吃猛造。
高频调用、长时间运行、复杂任务,在风控系统里绝对属于异常画像。越依赖 Claude 的人,反而越容易触发风控。
5. 替代成本问题
不是不能换 OpenAI、Gemini 或国内模型,而是换了以后,工作流会断,代码质量会下降,效率会受影响。对于程序员来说,他们还是更愿意用 Claude。
很多人劝我用 Claude,但因为我自己目前没有特别重的开发任务,所以我还在用 MiniMax、OpenAI、Gemini 这些模型,基本不影响我。但如果我今天突然有一个很重的开发任务,我也会义无反顾去买 Anthropic 套餐。
最讽刺的地方:不是不愿实名,而是你想实名都不让
最讽刺的细节是什么?中国用户对实名制本身一点都不陌生。因为在国内平台,都是要求实名认证的。没有任何一个中国 AI 平台会让你开账号充钱而不实名。
所以中国人对这件事太熟了。真正崩溃的点不是“怎么突然要实名了”,而是“我想实名,结果你不让”。不是平台要求我多走一步,而是平台把门装上了,但我的钥匙天然不兼容。这才是中国程序员最悲催的地方。
KYC 的真实效果边界:到底管不管用?
那么,KYC 的真实效果边界在哪?到底管不管用?为什么我说,对真正蒸馏它的人其实没什么用?
Persona 自身的安全记录并不让人放心
首先,Persona 的安全记录确实不怎么样。2026 年 2 月刚丢了 2,456 个文件,Discord 因此终止合作。我觉得 Discord 这一步做得挺对。
Persona 在 2024 年 9 月还出现过一次键盘记录漏洞,暴露了用户填写 KYC 时的内容。到现在到底修没修好,也不清楚。所以 Persona 本身就不是一个特别安全的 KYC 第三方机构。Anthropic 选它来做第三方,也被很多人嘲笑。
KYC 真正拦得住谁,拦不住谁?

再说 KYC 对蒸馏的阻拦效果。它真正能拦住的,是低成本批量乱入的 VPN 用户、共享账号用户和虚拟支付用户。
而中国 AI 的这些大厂,不管是“四小龙”还是“六小龙”,你根本拦不住。人家是有组织、有预算的机构,不在乎省你这点钱。挂 API、按 Token 算,用海外实体签协议就行了。所以你想抓住他们,基本不现实。
这次真正能打击的是低门槛的灰产。那些 AI 公司本来就在海外有公司、做 VIE 架构,完全可以用海外实体开账号干活,没问题。
真正会被卡住的,更多是个人开发者,尤其是第一次开号的人。新账号很容易被拦住,但经过多层代理分散调用的路径,其实你也拦不住。所以即使现在我想继续用 Claude,我依然能用,不用太担心,只是会比原来贵一点。
KYC 的真正作用
所以 KYC 真正的作用是什么?
- 提高成本,把低技术门槛的滥用者挡在门外。
- 表达态度,在合规和舆论上展示“我已经尽力风控了”。Anthropic 的老大 Amodei 一直很喜欢出来表达态度,比如他说如果美国给中国卖 H200,就相当于给朝鲜供应核弹,立场是非常明确的,而且他在美国各大 AI 公司里算是最极端的一类。
- 用户筛选,把高消耗、低透明、高风险的用户尽量处理掉。
这就是这次 KYC 干的三件事。
但灰色市场不会因此被干掉,只是成本会增加。该干嘛还是干嘛。中国人翻了这么多年墙,币圈的人做了这么多年假 KYC,他这一个新手上来,除了表演一下行为艺术,不会有太多其他效果。
现有生态里,待认证、待开号、企业账号拆分、代理分销,在 KYC 之下依然可以继续,只是成本稍微上升。KYC 上线以后,代理的风险和利润空间都会上升。黑灰产会升级,但不会被消灭。
实际受害者的顺序,大概是:普通人先疼,然后代理涨价,黑灰产升级,真正专业绕路的人、真正蒸馏他模型的人,根本拦不住,也不是针对他们去的。
行业背景:美国 AI 大厂正在集体收紧
这件事还有一个行业背景:美国 AI 大厂实际上都在集体收紧。
2025 年 9 月,Anthropic 开始对中国方向收紧 API 访问。
2025 年 12 月,谷歌对抓取蒸馏和模型抽取问题发表过声明。当时它的 Nano Banana 刚出来,谷歌其他模型比如 Gemini 3、Gemini 3.1 算是能打,但和 OpenAI、Anthropic 比还是有差距。现在我用谷歌模型已经越来越少了,但他们家的生图模型绝对最好用,虽然不一定最漂亮,但最准确。
肯定会有很多中国模型公司去抓它的图片回来做升级。现在再看阿里的通义万相、字节的 Seedream 5.0,已经越来越接近 Nano Banana 的水平了。至于怎么追上的,我只能说纯属巧合,其他不知道。
到了 2026 年 2 月,Anthropic、OpenAI、谷歌几乎同期公开指责中国实验室蒸馏。三家还联合成立了一个叫“前沿模型论坛”的机构,共享威胁情报,说谁发现被蒸馏了,谁发现了什么问题,大家互相通报。
其实这三家本来都是死对头。OpenAI 当初就是为了对抗谷歌建立的;Anthropic 又是 OpenAI 叛将出来创办的。所以这三家能联合起来搞这个论坛,本身就挺不容易。
在这三家里,谁面对蒸馏和假账号的经验最丰富?其实是谷歌。它这么多年面对各种刷广告、SEO,经验丰富得一塌糊涂。如果他们三家真的认真协同起来,确实有可能降低蒸馏概率,或者提高蒸馏成本。但你说这三家能有多真心实意地合作,大家自己脑补就好了。
当前各家的状态
- Anthropic:直接上 KYC 了,虽然是选择性的,只有很少一部分用例会遇到。
- 谷歌和 OpenAI:自己并没有做类似的事情,只是发了公告,说了几句话,实际动作没有那么大。
- 地区开放情况:谷歌目前其实还在稍微向我们靠拢一点,准备开香港地区使用,但好像香港 IP 挂 Gemini 现在还是有问题。在香港能正常用的,OpenAI 不行,Anthropic 不行,xAI 可以。谷歌宣称要开,但到目前为止似乎还没有真正打开。
闭源模型怕蒸馏,开源模型不怕

至于蒸馏,谷歌、OpenAI 和 Anthropic 这些闭源模型公司,肯定都不希望被蒸馏。但开源模型对蒸馏本来就不限制。
无论是 LLaMA、千问,还是国内的 MiniMax、GRM,你都可以直接拿权重去用,蒸馏根本不算什么大问题。真正不希望被蒸馏的,就是这些闭源模型公司。
总结:这次事件的三层表述
总结一下,这次事件有三层表述。
- 官方说法:这是少数场景下的身份验证,是安全与合规的一部分。
- 已经确认的事实:选择性 KYC 已经上线了;第三方 provider 对中国大陆证件支持有限;中国开发者的使用门槛确实被抬高了。
- 我的判断:表面上这是反异常调用、反蒸馏,底层更像是一次针对高消耗、低透明、跨区、高风险用户群体的筛选和清洗,本质上是反薅羊毛。
结论:中国程序员的天塌了吗?

最后一句:中国程序员的天塌了吗?还没有塌到不能干活的状态,但原来那条便宜、灵活、默认可用的路,确实不通了。
以后还能不能用 Claude?大概率还能用,就是稍微贵一点。代理代价会更高,路径会更窄,不确定性会更强,更多人可能会被封号。
普通人会更艰难,代理商会更挣钱,真正有组织能力的人,该蒸馏还是照样蒸馏,一点都拦不住。这才是这件事情最现实、最残酷的真相。
Anthropic 这次不是要堵住那些偷师的人,而是要先赶走那些把会员卡用得太狠的人。这就是这一次的故事。
背景图片