NS1081 U盘屏蔽坏块
2026年4月20日 04:18
从旧手机上拆下一个 64G 的 eMMC 颗粒,配合 NS1081 主控的板子做了 U 盘 AS SSD 和 […]
![]()

![]()
本篇是对 2026-03-30 到 2026-04-19 这三周生活的记录与思考。
清明假期没出门,在家窝着写代码,清掉了很多 TODO,久违地感受到 Vibe Coding 带来的快乐;用 Impeccable 把 Web3Insight 还有一些网站重新设计了一下,效果出乎意料地好;也开始用 Multica 重新梳理了自己各个项目的工作流,是自己很满意的 Agent 协作形态了,很沉迷;陪学姐去江阴参加了游泳比赛;还有很多有意思的事。
之前 Xuanwo 在做一个叫 Luban 的 IDE 工具,其中就主要使用了看板这一形态,当时重度使用,也参与了一些贡献,一直觉得这也是未来 Agentic 开发的新形态,不过后来没再更新了,于是在等 Linear 是否会推出能够连本地 Coding Agent 的工具。
然后突然在 Twitter 上看到了一个很有意思的开源项目 Multica,是 Devv 的创始人做的,很早期但功能已经可用,开源第一天我就尝试自部署用上了,很惊喜,稍作配置就融合了我原本的开发工作流。
![]()
它最巧妙的设计是通过 multica 命令行连接自部署的 server 端,把本机设备设置成一个 Runtime,而不需要自己单独去重新配置各种 Rules、MCP 等。
![]()
注册了 Runtime 之后,就可以创建 Agents,可以为每个 Agent 设置不同的指令、Skills、自定义参数,这样可以自定义一个 “AI 员工”,为它配置工作职责范围与技能等。
![]()
而后续在新建 Issues 的时候就可以直接指定给 Agent 员工,由于各个 Agent 员工的工作记录都在 Multica 平台中记录着,这样等于所有不同同事们的本地 Agent 奇妙地有了一个共享知识库和上下文,在一些关联性比较高的协作任务中尤其有用。
![]()
Multica 做得最好的其实还是克制,起初并没有过多去增加太多看板相关的功能,甚至连搜索功能都没有,而是更多放在了与本地 Agents 的链接上,而这三周也陆续增加了 Projects 以及 Autopilot 功能,可以在 Workspace 中区分项目,以及可以自动地做一些定时/重复性的任务,现在也还在快速更新迭代中,期待能够有更多贴合工作流的功能。
还在将自己更多项目实践引入 Multica,以及尝试和新搭建的 Hermes Agent 进行结合,后续看看能不能把开发、测试、预发布验证和正式发布流程更加完善。
其实之前就使用过 Frontend Design、web-design-guidelines 和 ui-ux-pro-max 插件与 Skills 来进行 UI/UX 的交互优化设计,但其实只是一些最佳实践的辅助,并没有很系统性地做一些风格设计等,大部分都还是基于 v0.dev 的基础设计能力。
而最近看到另一个项目 Impeccable,在 Web3Insight 项目上尝试了一下,效果出乎意料地好。
![]()
![]()
![]()
![]()
![]()
详细视频可以看这条动态或者直接访问如下网站:
Impeccable 很好的一点是把抽象的 UI 设计拆成了几个步骤,在新设计/改动原有项目设计之前,会先通过 /impeccable teach 对项目进行分析,形成一份 .impeccable.md 文档,就像是使用 Claude Code 或者 Codex 进行开发时的 CLAUDE.md 与 AGENTS.md,但这份文档并不是记录详细设计细节,而是对网站的用户画像、使用习惯、品牌调性等进行分析,这些会更宏观地影响整个设计风格,例如对 Web3Insight 网站的分析。
![]()
后续的所有开发都会基于整体的设计原则和思路进行拓展,通过 /impeccable craft 来新设计页面/组件,通过 /critique 与 /audit 来分析和审计当前设计的问题,以及通过 /polish、/optimize 或是 /animate 等命令来针对特定设计方向进行针对性优化,这样能够生成更可持续复用的设计组件而不是为了某个页面优化引入的”一次性代码“。
![]()
最近有很多工作任务到了收尾阶段,还经历了一次惊魂未定的「上线 -> Vercel Rollback -> 二次上线」 ,跟所有用户 Payment 有关的大重构上生产的体验真的太吓人了,从 5am 肝到了第二天 5am,但比起之前工作的忙碌,这次反而不觉得累,果然工作成就感和热情才是最影响工作状态的。
![]()
这几周也由于一直忙项目几乎没怎么出门,周末护送学姐去江阴参加了一场游泳比赛,两天密集的行程有些累,但学姐得了个第五名,有种家长带小孩去参加兴趣班和比赛的成就感。
活动本身的话,我自己不算是游泳爱好者,但也有被现场的活力和体育精神感染到,更加下定决心开始规律运动了。
虽然大部分有意思的输入会在 「Yu's Life」 Telegram 频道里自动同步,不过还是挑选一部分在这里列举一下,感觉更像一个 newsletter 了。
我把 Telegram Channel 消息作为内容源搭建了一个微博客 —— 「daily.pseudoyu.com」,可以更方便浏览了。
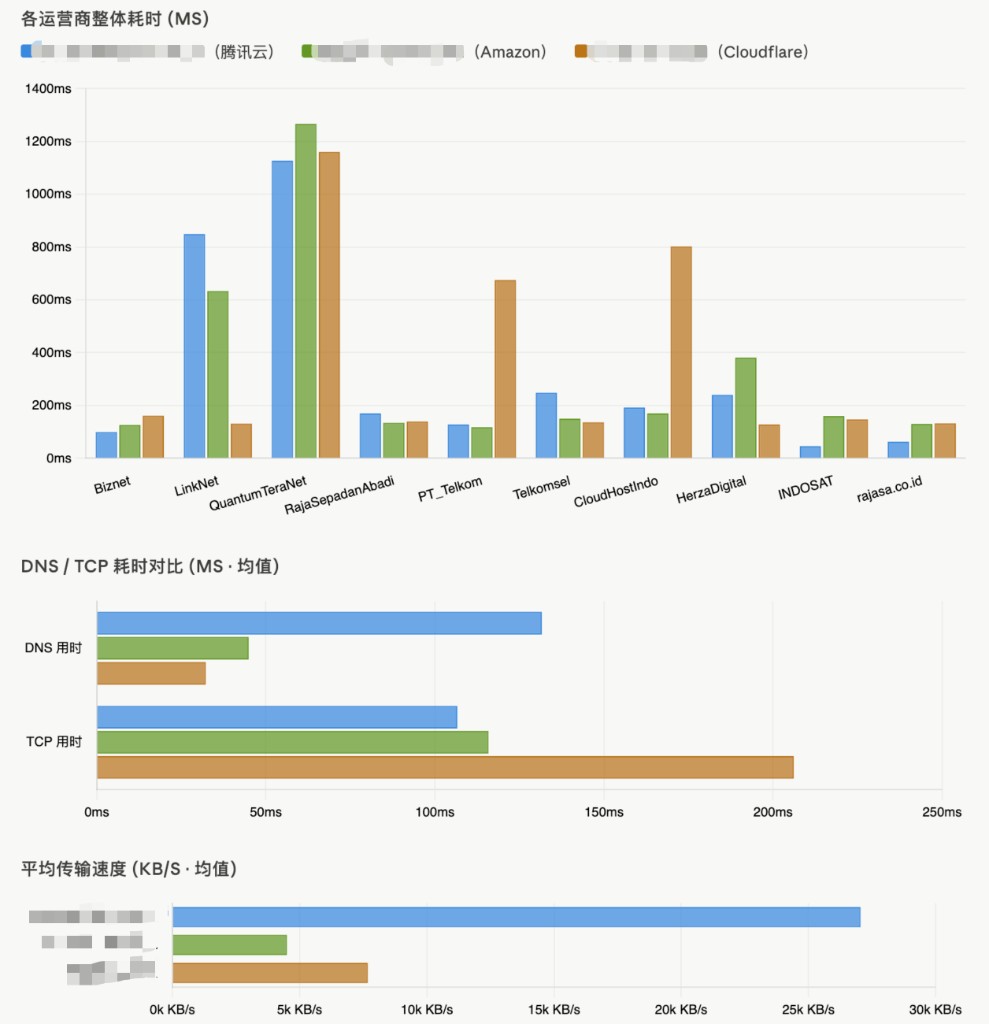
站点的网络访问速度受到用户所在地区、网络运营商等多种因素的影响。针对这些差异,我们可以通过选择合适的 CDN 和机房来有针对性地优化特定地区、特定运营商下的访问速度。与此同时,客户端可以对不同域名进行测速,根据测速结果动态选择延迟最低的线路。
网络优化大体上可以分为两个方向:静态资源加速和动态资源加速。
下图对比了三个站点在印度尼西亚不同运营商下的整体耗时、DNS / TCP 耗时,以及平均传输速度,三个站点分别托管于腾讯云、Amazon 和 Cloudflare:
![]()
从数据来看,DNS 耗时和 TCP 建连耗时在不同方案间差异较大,而传输速度方面腾讯云表现更为突出。因此,针对不同地区与运营商,选择合适的 CDN 组合才能达到最优效果。
Cloudflare CDN 会根据 Cache-Control 等响应头自动在边缘节点缓存静态资源,无需额外配置。在此基础上,还可以使用 R2(对象存储)作为资源的持久化存储后端,配合 Edge Worker 实现自定义的缓存逻辑(例如按地区或版本精细控制缓存行为),借助 Cloudflare 遍布全球的边缘节点就近响应用户请求。
腾讯云方案以 EO(边缘安全加速平台)为入口,结合 COS(对象存储)实现区域化加速:
两种回源模式下,COS 对”资源已存在”的处理是一致的——直接返回,无需再回源;差异在于”资源不存在”时的行为:
此外,COS 还支持异地复制功能,可以将数据同步到多个地域的 Bucket,实现全球多点就近访问。现阶段优先在大陆建立 Bucket 进行加速,后续如有其他地域需求,新建 Bucket 并配置多 Bucket 同步即可平滑扩展。
![]()
![]()
相比静态资源,动态请求无法被缓存,每一次都需要完整地回源,因此跨境网络的质量直接决定了动态接口的响应速度和稳定性。
在中国大陆访问海外服务器时,不同线路的质量差异相当大,从高到低大致可以分为三类:
专线网络
IPLC(国际私有租用线路)和 IEPL(基于以太网的国际专线)是质量最高的一类。独享带宽、不经过公网、延迟稳定且几乎无拥塞,上海到东京的典型延迟在 30~40ms,抖动极小。代表产品有腾讯云全球应用加速(GAAP)和阿里云全球加速(GA)。缺点是价格昂贵,通常用于金融、企业内网等对稳定性要求极高的场景。
运营商优化线路
介于专线和普通公网之间,按覆盖范围又可以细分:
普通公网线路
包括普通 BGP 多线(电信 163、联通 4837)及各类国际 Transit 线路。BGP 只代表同时接入多个运营商,并不代表线路质量高,晚高峰拥塞时丢包率可能达到 5%~10%,延迟波动明显。很多海外云服务器默认走的就是这类线路。
整体质量排序如下:
1 | IPLC / IEPL 专线 |
很多跨境加速方案的典型架构是:在国内部署入口节点,通过优化线路连接到香港或东京的中转节点,再由中转节点访问海外源站,从而将不稳定的跨境段控制在质量最优的链路上。
这两者都是基于云服务商私有骨干网络的托管加速服务——流量不经过公网,由云厂商内部专属链路承载,质量接近传统专线但使用门槛更低。配置简单、效果稳定,但费用较高,适合对延迟和稳定性有严格要求、且预算充足的场景。
对于成本敏感的场景,可以通过腾讯云 EO 配合自建中转节点的方式,用较低的成本实现接近专线的效果。下面按演进路径逐步介绍。
方案一:EO 直接回源(默认)
![]()
EO 默认直接通过公网回源海外源站,跨境链路质量完全取决于运营商,没有任何保证。实际使用中经常出现回源连接失败、延迟波动大的情况,体验较差。
方案二:香港 CN2 中转节点
![]()
在香港部署一台中转服务器,将 EO 的回源地址指向该节点,由节点再转发到海外源站。大陆到香港的链路经过 CN2 优化,质量大幅提升,回源成功率明显改善。
中转节点的线路质量对效果影响很大。以腾讯云香港轻量服务器为例,在不开启优选流量包的情况下,从大陆 ping 该服务器,延迟抖动非常严重:
1 | --- ping statistics --- |
购买并开启优选流量包后,同一台服务器的表现天壤之别:
1 | --- ping statistics --- |
丢包率从 22% 降至 0%,平均延迟从 297ms 降至 45ms,标准差也从 483ms 收窄到 6ms,链路稳定性显著提升。因此香港节点务必开启优选流量包,否则中转效果有限。
实际观察中,这个方案偶尔仍会出现某个地区在特定时间段回源连接失败的情况,原因是该地区到香港的链路在该时间点出现了短暂波动。
方案三:广州节点 + 香港中转(当前方案)
![]()
为彻底解决大陆到香港偶发波动的问题,在广州再增加一层节点。EO 不再直接回源香港,而是先回源广州节点——这段完全在国内网络内,几乎不存在不稳定的情况。广州节点再通过优化线路回源香港中转节点,由于广州到香港距离极近,这段链路同样非常稳定。最终由香港节点通过优化过的跨境链路访问海外源站。
为保障可用性,广州层和香港层均部署了多个节点,由负载均衡层分发流量;香港的多个 VPS 节点再统一回源日本东京的真实源站。这种多节点冗余的设计,使得单个节点故障不会影响整体可用性。
整体思路是将链路拆解为”国内段 + 跨境段”分别优化:国内段利用大陆内部稳定的网络,跨境段控制在广州到香港这段极短且质量稳定的链路上。与 GAAP/GA 相比,这种方案用自建中转节点(轻量服务器 + 优选流量包)替代了托管专线,在成本上有明显优势,稳定性也能达到接近的效果。

随着 OpenClaw 的爆火,智能体(Agent)一词已经成了大家每天都挂在嘴边儿上的话。从“智能体”成为 2025 年度科技热词以来,说这个词被滥用或许略显激进,但当一个词进入寻常百姓家时,或许我们应该重新审视一下到底什么是智能体,这个硅基生物之于我们碳基生物又是什么角色,“它”又是如何在改变着我们的生活呢?
我搜集了互联网上对于智能体的定义:
智能体指一个可以观察周遭环境并作出行动以达到目标并且可以通过机器学习以及获取知识来提升自身性能的自主实体。 —— 维基百科
智能体是一种接收输入、解读输入,然后代表用户(无论是人类还是其他智能体)规划和执行操作的系统。 —— web.dev
AI 智能体是使用 AI 来实现目标并代表用户完成任务的软件系统。其表现出了推理、规划和记忆能力,并且具有一定的自主性,能够自主学习、适应和做出决定。 —— Google Cloud
智能体是一个系统,它利用人工智能模型与环境交互,以实现用户定义的目标。它结合推理、规划和动作执行(通常通过外部工具)来完成任务。 —— Hugging Face
如 ReAct 框架 1 所述,智能体的主要特点如下:
以 OpenClaw 为例的智能体,其能力足够丰富,在企业实践中不同场景需要不同类型的智能体以便更好(例如:更快速、更安全等)地服务其目标客户。从业务视角出发在此将智能体划分为个人助理、数字员工和数字分身三类,这三类的差异对比如下:
| 角色 | 个人助理 | 数字员工 | 数字分身 |
|---|---|---|---|
| 服务对象 | 个人 | 他人 | 个人 |
| 所有权 | 个人 | 多种 2 | 个人 |
| 身份 | 智能体自己 | 智能体自己 | 所有权人 |
| 定位 | 帮助所有权人处理个人需求 | 帮助所有权人处理他人需求 | 帮助所有权人以所有权人身份处理需求 |
| 示例 | 帮自己搜集信息 | 帮服务对象查询天气 | 帮自己去参加在线会议 |
结合 OpenClaw 的定义(OpenClaw is a self-hosted gateway …, and it becomes the bridge between your messaging apps and an always-available AI assistant. 3),其更符合个人助理的角色定位。数字分身相比另外两个角色最大的特点是其身份代表的是所有权人,除了技术实现难度外,更重要的是伦理问题。当数字员工出现问题时,是应该所有权人为其负责还是技术服务提供者为其负责呢?这个问题类似智能驾驶,当出现交通事故时,是应该由驾驶员承担责任还是自动驾驶服务提供商承担责任呢?目前来看,几乎全部责任仍是由驾驶人员承担。
从技术视角出发,个人助理和数字员工两个重要角色差异对比如下:
| 角色 | 个人助理 | 数字员工 |
|---|---|---|
| 知识 | 私有 + 共有 | 共有 + 权限管控 |
| 数据 | 私有 + 共有 | 共有 + 权限管控 |
| 技能 | 私有 + 共有 | 共有 + 权限管控 |
| 渠道 | 私有 | 共有 + 权限管控 |
| 定制化 | 程度高 | 程度低 |
| 核心目的 | 节省自己的资源(时间等) | 节省组织的资源(人力等) |
不难看出,个人助理和数字员工的一个核心差异在于权限。个人助理的权限管控并不在智能体内部实现,也就是说当你有某个权限的时候,只要你想个人助理就可以有,权限的边界在智能体之外。但数字员工的权限管控需要在智能体内部实现,数字员工使用同一个渠道对外提供服务,我们必须根据服务对象的不同采取不同的操作。个人助理是可以高度化定制的,只要你想怎么搞都是你自己的事。但数字员工受限就会很多,因为要面向多人服务,我们需要考虑响应的时效性、服务的稳定性、数据的安全性等等。
个人助理解决的是个人的长尾事务,只有将自己从重复繁琐的任务解放出来,我们才能够有更多的时间去思考更重要的事情。而数字员工解决更多的是通用类型的事务,这样才能够服务更多的用户,从而提高组织效能。
其实我们也无需将个人助理和数字员工割裂来看,在个人助理上做一些适当的加减法就可以让其变成数字员工,同时数字员工之于个人助理也可以看作是一项技能而为其所用。我个人认为从个人助理进化到数字员工是一个先做减法再做加法的过程。
当前的个人助理已经是一个可以高度定制同时具有一定自主能力的智能体。在企业应用过程中,基于安全等因素的考虑我们必须在一定程度上限制其灵活性,才能够一方面高效的满足用户需求另一方面避免其成为一匹脱缰的野马。换句话说就是从个人助理的执行优先转变到数字员工的治理优先。这里感觉和当下的 Harness Engineering 有些许呼应,Harness 给到了系统运转的最佳范式,但同时也指定了相应的约束机制。约束的方式(代码层、Prompt 层、Skill 层)和约束的强度影响着任务执行的灵活程度。
正如员工在进入组织前期,他首先要学习的就是组织的规章制度,什么可以做,什么不可以做。当员工对组织的要求清晰之后,才会被允许从事更加复杂的工作,才会被赋予更多的自主权。在这个过程中组织仍会定期观测,同时对必要的问题做出反馈并要求员工进行修正。在此也收集了智能体 4、数字员工 5 和自动驾驶 6 的分级对比:
| 级别 | 自动驾驶 | 智能体 | 数字员工 |
|---|---|---|---|
| L1 | 辅助驾驶 车辆对方向盘和加减速中的一项操作提供驾驶,人类驾驶员负责其余的驾驶动作。 |
规则符号智能 意图 + 行动 |
功能级-辅助工具 作为工具被调用,人类执行并闭环任务。 |
| L2 | 部分自动驾驶 车辆对方向盘和加减速中的多项操作提供驾驶,人类驾驶员负责其余的驾驶动作。 |
推理决策智能 意图 + 行动 + 推理和决策 |
任务级-任务执行 执行被分解的任务,人类拆解分配任务。 |
| L3 | 条件自动驾驶 由车辆完成绝大部分驾驶操作,人类驾驶员需保持注意力集中以备不时之需。 |
记忆反思智能 意图 + 行动 + 推理和决策 + 记忆和反思 |
协作级-协作自治 自主拆解及分配任务、闭环执行,人和数字员工协作,人类监督。 |
| L4 | 高度自动驾驶 由车辆完成所有驾驶操作,人类驾驶员无需保持注意力集中,但限定道路和环境条件。 |
自主学习智能 意图 + 行动 + 推理和决策 + 记忆和反思 + 自主学习 + 泛化 |
指导级-专业指导 提供达到人类专家水平的定制化服务,人类参与。 |
| L5 | 完全自动驾驶 由车辆完成所有驾驶操作,人类驾驶员无需保持注意力集中。 |
个性群体智能 意图 + 行动 + 推理和决策 + 记忆和反思 + 自主学习 + 泛化 + 人格 + 协作 |
智慧级-自主智慧 超越人类专家水平的能力,全面自主,人类授权。 |
我认为我们目前正处于 L3 至 L4 之间的一个地带,我相信在不久的将来我们可以突破 L4 迈入 L5。我希望 AI 会一直是为人所用,而不希望如之前博客所描述的人类成为 AI 的奴隶。引用一下阿西莫夫的机器人三定律,希望在生产力高速发展的同时我们也可以更多的关注一下 AI 可能引起的一系列社会和伦理问题。
之前看到Karpathy这个wiki知识库提到了使用Obsidian作为笔记软件,因为Obsidian存储笔记的格式就是markdown
Obsidian的使用方式和别的笔记系统还是有比较大差别的,我们只需要指定一个笔记目录,就可以往里存放笔记了
它的语法整体就

![]()
Hermes Agent是个啥?
Hermes Agent 是 Nous Research(Hermes 模型背后的团队)开发的自改进(self-improving)AI Agent,核心创新在于内置学习闭环(closed learning loop):
持久多层记忆:使用 SQLite + FTS5 全文搜索 + LLM 自动总结,跨会话永久记住你的偏好、风格和历史,不会“健忘”。
自动技能进化:任务完成后自动生成 Markdown Skill 文件,下次直接调用;还会自我迭代优化 Skill。
自主执行力:支持终端命令、浏览器、文件操作、代码生成、Web 搜索等工具,可在 CLI 或 Telegram/Discord 等平台运行。
模型超灵活:支持 OpenRouter(200+模型)、OpenAI、Anthropic、Nous Portal、本地 Ollama 等,几乎零切换成本。
完全开源免费:MIT 协议,可在 $5 VPS、本地、Docker、Modal 等环境运行。
简单说:普通AI是工具,Hermes是会自己进化的私人AI助手。用得越久,它就越像你的"数字分身"。
官方文档:https://hermes-agent.nousresearch.com/docs/
安装
在 Mac 或者 Linux 环境,在终端输入如下命令后回车:
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash # 安装完成后重载 shell: source ~/.bashrc # 或 source ~/.zshrc
脚本会自动检测并安装 Python、Node.js、Git、ripgrep 等所有依赖,耐心等待即可。
安装完成后,脚本会自动进入引导设置,选择 Quick setup 模式,然后按提示配置模型。推荐选 OpenRouter(登陆后创建API Keys),选免费模型(如 nvidia/nemotron-3-super-120b-a12b:free),零成本跑起来先体验。如果之前本地已有 OpenAI 或 Codex 的授权配置,Hermes 会自动读取,不用重复填写。
配置最后会询问是否注册为系统服务,选 Y 可以开机自启、后台常驻,省去每次手动启动的麻烦。
![]()
Hermes Agent常用命令
Hermes Agent 的命令都以 hermes 开头,其核心命令可以分为几大类:核心交互、配置管理、工具与技能、网关与会话管理。
这是你与 Agent 日常交流的核心命令。
| 命令 | 作用 | 示例/说明 |
|---|---|---|
hermes 或 hermes chat | 启动交互式对话,这是最常用的入口。在终端直接运行即可进入对话模式。 | hermes |
hermes -q "<你的问题>" | 执行单次查询。Agent 执行后会直接退出,适合脚本调用。 | hermes -q "解释什么是递归" |
hermes -m <模型名> | 临时指定模型。在本次对话中覆盖默认模型。 | hermes -m openrouter/gpt-4o |
hermes -t <工具集> | 启用特定工具集。例如,开启浏览器工具 browser。 | hermes -t browser |
提示:在对话中,你也可以直接使用自然语言向 Agent 下达指令,它会自动判断并调用相应的工具。
安装后的首要任务就是配置好 Agent 的“大脑”。
| 命令 | 作用 | 示例/说明 |
|---|---|---|
hermes setup | 启动交互式配置向导。这是新手最推荐的配置方式,会引导你一步步设置模型、API Key等。 | hermes setup |
hermes model | 交互式切换模型。在已配置的模型列表中快速选择并切换。 | hermes model |
hermes config edit | 编辑配置文件。用默认编辑器打开 ~/.hermes/config.yaml 进行高级配置。 | hermes config edit |
hermes version | 查看当前版本。 | hermes version |
hermes doctor | 环境诊断。检查安装是否正确,环境是否正常。 | hermes doctor |
hermes dashboard | 打开管理面板。在浏览器中启动一个图形化管理界面,方便查看日志和状态。 | hermes dashboard |
Hermes 的能力通过“工具集”和“技能”来扩展。
| 命令 | 作用 | 示例/说明 |
|---|---|---|
hermes tools list | 列出所有工具。显示所有内置工具及其在当前平台的启用状态。 | hermes tools list --platform telegram |
hermes tools enable <工具名> | 启用工具。为特定平台(如 CLI)启用工具。 | hermes tools enable browser --platform cli |
hermes tools disable <工具名> | 禁用工具。 | hermes tools disable web --platform cli |
hermes skills list | 列出所有已安装技能。技能是更高阶的工作流。 | hermes skills list |
hermes skills search <关键词> | 搜索技能。 | hermes skills search "code review" |
hermes skills install <技能名> | 安装技能。 | hermes skills install <技能名> |
hermes skills uninstall <技能名> | 卸载技能。 | hermes skills uninstall <技能名> |
Gateway 是让 Agent 接入各种聊天平台(如飞书、Telegram)的关键。
| 命令 | 作用 | 示例/说明 |
|---|---|---|
hermes gateway setup | 配置消息网关。交互式地将 Agent 连接到飞书、Telegram等平台。 | hermes gateway setup |
hermes gateway start | 启动网关后台服务。让 Agent 通过网关持续在线。 | hermes gateway start |
hermes gateway stop | 停止网关服务。 | hermes gateway stop |
hermes gateway status | 查看网关状态。 | hermes gateway status |
hermes gateway list | 列出已启用的网关列表。 | hermes gateway list |
hermes gateway enable <平台> | 手动启用特定平台的网关。 | hermes gateway enable discord slack |
hermes -c | 恢复最近的对话会话。 | hermes -c |
hermes -r <会话ID> | 恢复指定ID的对话会话。 | hermes -r <session_id> |
补充说明:在对话界面中,斜杠命令(如
/help,/plan,/skills --force)是非常快捷的操作方式。部分命令需确保环境正确,例如macOS用户使用sed -i时需额外参数。
现在个人电脑用hermes,公司电脑用内部提供的openclaw,唯一的限制就是429了![]()
参考:
2020 年的时候我写过一篇 关于记笔记的文章,推荐大家试试 Obsidian 的双向链接和网状结构。
2026 年初我 又写了一篇 ,聊了聊从「记笔记」到「积累数字资产」的理念转变。
当 DeepSeek 等大模型可以轻松生成 80 分水平的通用内容时,真正具备高价值的,是带有鲜明个人印记、沉淀了深度思考的个性内容。
我们的笔记不再是单纯的资料集合,而是构建个人数字分身的核心基石,是在信息爆炸时代锚定自我的坐标原点
但理念归理念,回到具体的落地层面,很多朋友可能还是会困惑:日常到底该怎么组织这些数据?
好,今天来填坑。
这篇文章不再讨论「为什么要做」,而是聊聊「我目前具体怎么做的」——我的 Obsidian 数字资产库长什么样,用了哪些工具,背后的组织逻辑是什么。
在之前的文章里我提过,任何信息都至少包含事实、观点和输出三个维度,它们的价值截然不同——事实并非观点,而我赞同的"观点"并不等于我的真实认知,更不会自动转化为我的有效输出。
落到实践层面,这三者的管理方式也截然不同。事实需要尽可能自动化地采集和归档,减少手动操作;观点需要留出空间让自己去写、去反思,哪怕只是两三句话;输出则需要体系化地积累,形成可以反复调用的资产。混在一起管理,最终的结果就是什么都找不到,什么都沉淀不下来。
而在 AI 时代,这种区分还有另一层意义:当 AI 可以明确哪些是客观事实、哪些是他人观点、哪些是我的个人思考时,它才能提供更精准的分析、更贴切的建议、更个性化的辅助。结构的意义不再是为了「如何整理」,而是为了「如何调用」。
我的信息来源散落在微信读书、豆瓣、飞书、Memos、各种聊天窗口……如果要求自己每次都手动摘录整理,那这件事一定坚持不了几天。
所以我的核心思路是:不改变自己在各个平台上的使用习惯,而是通过插件和脚本把内容自动汇聚到 Obsidian 里。 我只需要在各个平台上正常地读、正常地记、正常地聊,剩下的交给自动化流程完成。这样几乎不需要额外投入精力,每一次阅读和思考就自然而然地沉淀下来了。
人应该把精力花在思考和创造上,而不是搬运和归档上。
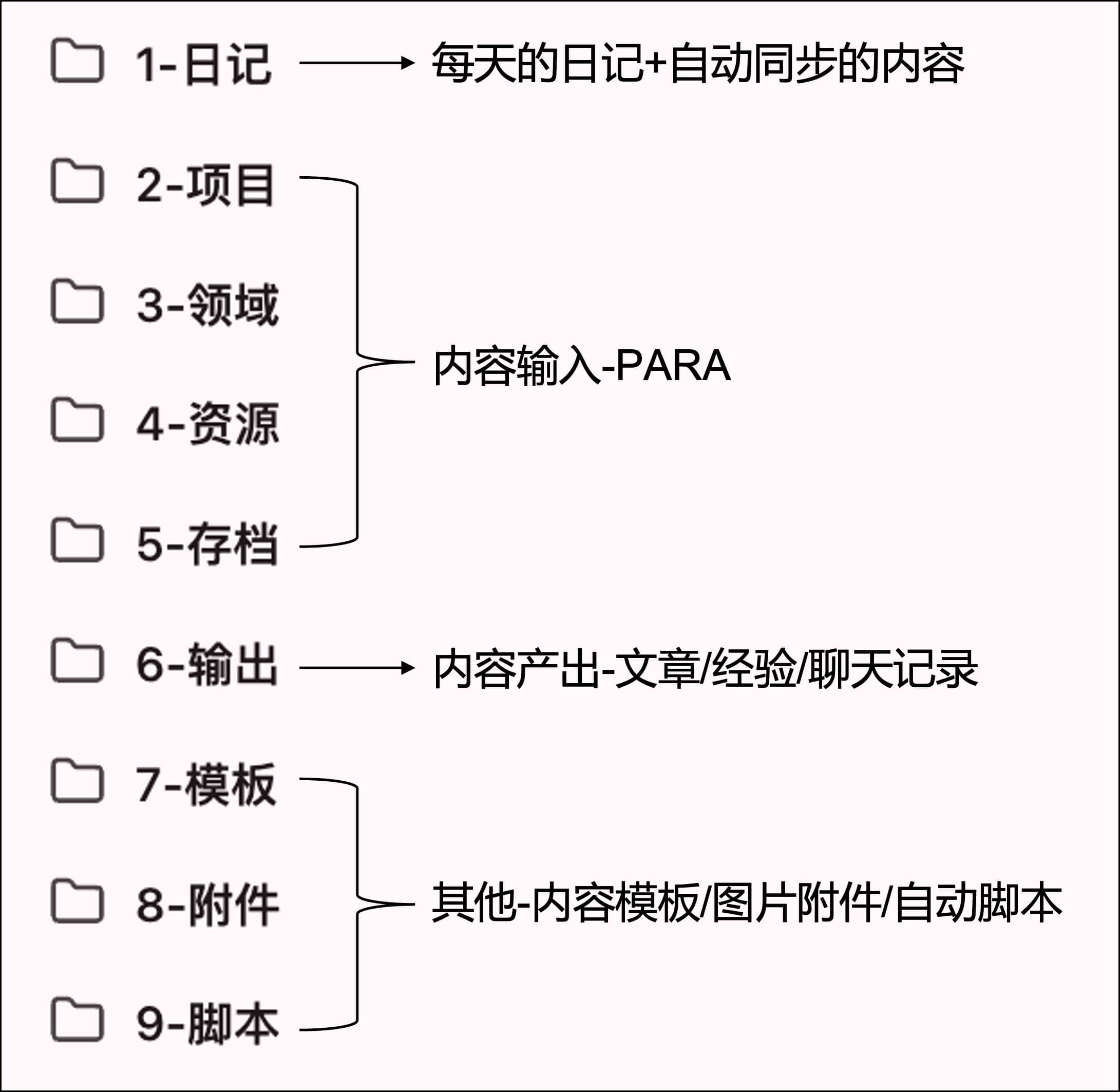
我的 Obsidian 库大致分为四个板块:日记记录每天发生了什么,PARA 管理持续输入的养料,输出积累自己的表达和经验,其他则是支撑整个体系运转的模板与附件。
![]()
下面逐一展开。
日记是整个体系的时间轴。我希望翻开任意一天的日记,就能回溯当时外部发生了什么、自己在做什么、脑子里在想什么。因此我把日记设计成了一个自动聚合的仪表盘,大部分内容不需要手写,由各类插件自动填充:
![]()
天气 / 市场行情数据:通过 聚合数据 的 API,每天自动拉取当天的天气、市场行情信息写入日记。
这看起来是个不起眼的小功能,但当半年后翻回去看到「那天北京暴雨 38℃」的时候,记忆会一下子鲜活起来。
每日 Emoji / 日记 / 打卡:我在飞书表格上维护了一张简单的打卡表,每天记录当日的心情 Emoji、简短的日记和习惯打卡,再通过自动化脚本同步到对应日期的日记文件中。
选择飞书表格而非直接在 Obsidian 里写,是因为手机上随手打开飞书填一行的阻力远小于打开 Obsidian 编辑 Markdown——降低记录的门槛,才能让习惯真正持续。
随想:碎片化的念头最怕丢。我自部署了 Memos 来捕捉日常的灵光一现,想到什么就随手发一条,再通过 LifeOS 插件自动同步到当天的日记里。
如果你不想折腾自部署,flomo 配合 flomo-to-obsidian 插件也能达到类似的效果,核心是一样的——让「记下来」这个动作的成本趋近于零。
阅读:我的主力阅读工具是微信读书。它的公共书库足够丰富,即使没有的书也支持自己上传书籍。更重要的是,通过 obsidian-weread-plugin 可以把划线和笔记自动同步回来。读书时只管专注地读和划,笔记自己会回家。
项目:借助 LifeOS 插件,项目中当天完成的任务会自动关联到对应日期的日记里。这样回看某一天时,不仅能看到自己的想法,还能看到实际推进了哪些事情。
精力:通过 wakatime,我的电脑能自动统计每天在不同项目上的投入时长,再用 obsidian_waka_box 插件写入日记。时间花在了哪里,一目了然。
这个数据积累久了会非常有意思——自己以为花了很多时间的事情,实际上并没有那么多;而某些不起眼的事情,却默默吃掉了大量精力。
此外,借助 Obsidian 的双向链接机制,其他文件中但凡提到了某一天的日期,也会自动出现在当天日记的反向链接区域。不需要刻意整理,关联自然浮现。
![]()
所以每天的日记,与其说是我「写」出来的,不如说是自动「长」出来的。我要做的,只是偶尔翻一翻,补上几句只有自己才知道的上下文。
对于持续输入的各类信息和资料,我采用 PARA 框架进行管理,即 项目(Project)、领域(Area)、资源(Resource)、归档(Archive) 四个维度。
这个框架的好处在于,它不是按照「内容是什么」来分类,而是按照「这个内容对我当前有什么用」来组织,天然带有优先级。
项目(Project):有明确目标和截止时间的最小执行单位。比如正在开发的某个项目、准备中的某场考试、进行中的背单词计划。我的项目文件夹里就躺着各个在做的开发项目,每个项目下有自己的任务列表、进度记录和相关资料。项目完成后就移入归档,保持当前视野的清爽。
领域(Area):没有截止日期,但需要持续投入和精进的方向。比如对时事的持续关注和分析、专业领域的深耕积累。和项目不同,领域是一个长期陪伴的存在,它不会「完成」,只会不断深化。
资源(Resource):偏外部的资料储备,是未来可能用得上的素材库。裁剪下来的时事新闻、课程的课件和文字笔记都放在这里。
对于时事新闻,我会通过龙虾和自动化工具抓取和整理每天的时事新闻,并将原报道本地裁剪存档。
![]()
之所以本地化保存原文,是因为互联网上的信息远没有我们以为的那么持久和可靠——今天还能打开的链接,过两个月可能就过期了。之前整理早几年的一些参考资料时我就发现,不少当年引用的新闻源如今早已失效。把原始报道留一份在自己手里,日后需要回溯和引用时才有据可依。
或许有点像老辈子们的剪报纸?果然老了 XD
同时我还通过 obsidian-douban 和 obsidian-weread-plugin 插件,把自己在豆瓣标记的电影影评以及微信读书的书籍划线自动采集进来。
以及,说到课件——PDF 格式的课件在 Obsidian 里其实也能管理得很好。用 PDF++ 插件可以直接在 Obsidian 内阅读和标注 PDF,更方便的是可以在 Markdown 笔记中精确引用 PDF 中的某一段、某一页,让课件笔记和自己的思考真正打通,而不是割裂地存在两个地方。
归档(Archive):历史已完成的项目、不再活跃关注的领域和资源,统统移到这里。归档不是删除,而是降低优先级。需要的时候搜索一下就能找回来,但平时不会干扰当前的工作视野。
如果说日记和 PARA 管理的是「输入」,那这个板块管理的就是「输出」——那些经过我自己思考、加工、表达出来的内容。
在我看来,这些才是数字资产中最有价值的部分,因为它们承载的不是通用的信息,而是我个人的认知结晶。也正是这些带有鲜明个人烙印的内容,构成了未来训练个人 AI 助手时独一无二的专属数据集。
公开博客:我把自己历史写过的所有博客文章都存了一份在库里。一方面作为个人写作的存档和检索库,另一方面也方便在写新内容时回溯自己过去的观点——看看哪些想法被验证了,哪些已经被自己推翻了,这本身就是一种有趣的自我对话。
私有经验:有些东西想记下来,但还没整理到可以公开分享的程度,或者内容本身就比较私人。这类半成品的思考、踩过的坑、做过的决策推演,都放在私有经验里慢慢发酵。很多博客文章的雏形,就是从这里长出来的。
聊天记录:和人的对话、和 AI 的对话,其实都是重要的思考载体。很多时候一个想法是在对话中被激发和打磨出来的,如果不记录下来,过几天就彻底蒸发了。
关于核心的微信聊天记录,我通过 WeFlow 导出一些重要的对话一并存入。有些对话内容比较复杂或者量比较大的时候,我会用本地 Ollama 部署的 Qwen 3 32B 跑一遍摘要和分析,提炼出核心内容、脱敏后再归档——毕竟这些数据比较敏感,能在本地处理就尽量不上云。
![]()
而和 AI 的对话同样是宝贵的数字资产。我在自己的服务器上部署了 OpenWebUI,这样可以在多设备上统一通过 API 调用 GLM、Kimi、Deepseek、Claude、GPT 等国内外模型,同时所有对话历史都集中在自己的服务器上,不用担心分散在各个平台上找不回来。通过定时任务,我能定期从 OpenWebUI 导出历史会话存放到 Obsidian 库里。
![]()
之所以这么重视和 AI 的对话记录,是因为这些对话本质上就是在不断校准自己的思考。每一次向 AI 提问、每一次对 AI 输出的筛选和修正,背后都隐含着「我认为什么是对的、什么是重要的」这一判断过程。
把这些记录沉淀下来,积累到一定量级之后,它们就不再只是聊天记录,而是一份关于「我如何思考」的详尽档案——这恰恰是未来个人 AI 助手最需要的训练素材 。
对了,如果你是在各个平台上聊的话,需要导出聊天记录的话, AI Exporter 插件或许可以帮到你。
![]()
不过我还是更推荐找一个统一的地方来聚合管理——道理和前面说的一样,数据散落在各个你无法控制的平台上,终究不容易管理和利用。这方面或许可以试试 Cherry Studio。
![]()
体系要能持续运转,一些基础设施层面的事情也得处理好。
模板:因为经常需要创建格式统一的文件——日记、新闻裁剪、课堂笔记、项目文档等等——我用 Templater 插件统一管理各类模板。新建文件时选择对应模板,该有的字段和结构就自动生成了,省去了每次从零开始搭框架的时间,也保证了格式的一致性,方便后续检索和聚合。
附件管理:图片是个容易被忽视但很容易出问题的地方。网络图床说挂就挂,链接过期了文章里就剩一堆裂图。所以我用 Custom Attachment Location 插件,把所有图片统一下载到本地的附件文件夹,并自动按规则重命名。虽然会占一些本地空间,但至少数据在自己手里,不用担心哪天醒来发现图全没了。
同步与备份:整个库的同步我使用 Remotely Save 插件,将内容备份到腾讯云 S3 上。这样多设备之间可以保持同步,同时云端也有一份兜底的备份。数据安全这件事,怎么冗余都不为过。
以上就是我目前的 Obsidian 数字资产库的整体结构。但说实话,这套结构并不是一开始就长这样的——它经历了大概一两年的反复调整,删掉过很多觉得「好像应该有」但实际上从来不用的分类,也合并过很多最初分得太细以至于找不到东西该往哪放的文件夹。
结构服务于使用,而不是反过来。如果某个分类让你在放文件的时候犹豫超过三秒,那大概率是结构本身有问题,而不是你的问题。
后面如果有新的调整,我会继续更新。毕竟这件事本身就是一个持续迭代的过程——就像写代码一样,没有一步到位的架构,只有不断演进的版本。
下面汇总了本文中提到的插件和额外工具。
Obsidian 插件
- LifeOS PARA/Memos同步
- obsidian-weread-plugin 微信阅读同步
- obsidian-douban 豆瓣同步
- obsidian_waka_box wakatime 同步
- flomo-to-obsidian flomo 同步
- PDF++ PDF 阅读
- Templater 增强模板
- Custom Attachment Location 统一附件格式
- Remotely Save 多平台同步
外部工具与服务
- 聚合数据 公共 API
- Memos 类似 Flomo 的自部署随手记应用
- WakaTime 记录电脑项目时间
- OpenWebUI 自部署的AI调用工具
- Cherry Studio 本地化AI调用工具
- AI Exporter AI聊天记录导出
- WeFlow 微信聊天记录导出
Modern AI training is structured as a hierarchy: individual GPUs (or TPUs) sit inside servers, servers are grouped into pods, pods into racks, and racks form a cluster.
Instead of training on a single machine, large neural networks are distributed across this entire cluster, which effectively acts as one coordinated system.
The key challenge is not just computation, but efficiently splitting the workload and synchronizing thousands of accelerators so they stay utilized, using techniques like data and model parallelism while minimizing communication overhead.
A model with L layers operates on tensors of shape (Batch, Sequence, Dim)
Split the compution into axes and we get:
In standard data parallelism, a minibatch of N samples is split across M GPUs, so each GPU processes roughly N/M samples. Every GPU holds a full copy of the model parameters.
During the forward and backward pass, each GPU computes gradients independently on its local subset of data. Because the loss is additive over the batch, gradients are linear, so the correct global gradient is obtained by averaging (or summing) gradients across all GPUs.
After gradient synchronization (typically via all-reduce), all GPUs update their local model copies identically, keeping them in sync.
The main limitation is memory: since each GPU must store the full model, the maximum model size is constrained by the memory of a single GPU, regardless of how many GPUs are used.
Fully Sharded Data Parallelism (FSDP), as implemented in systems like PyTorch FSDP, shards model parameters, gradients, and optimizer states across GPUs so that each device only holds a fraction of the full model. Instead of replicating the entire model on every GPU, each worker owns a shard of each parameter tensor, which significantly reduces memory usage.
During the forward pass, parameters are reconstructed on demand using an all-gather operation across GPUs. The full weights are only materialized temporarily for computation and are freed immediately after use. To reduce communication overhead, FSDP overlaps this process with computation by prefetching parameters for upcoming layers.
In the backward pass, gradients are computed using the temporarily gathered parameters and then redistributed using a reduce-scatter operation. This ensures each GPU keeps only its corresponding shard of the gradients rather than the full gradient tensor.
Finally, the optimizer step is performed locally on each GPU using its shard of parameters, gradients, and optimizer states. As a result, no GPU ever needs to hold the full model persistently, reducing memory complexity from O(N) to approximately O(N / k) across k GPUs, at the cost of additional but carefully managed communication.
In Hybrid Sharded Data Parallelism, the total number of GPUs N is organized into a 2D structure such that N=M×K. The GPUs are divided into M groups, each containing K GPUs.
Within each group of K GPUs, Fully Sharded Data Parallelism (FSDP) is applied. This means model parameters, gradients, and optimizer states are sharded across the K GPUs in the group. No single GPU holds the full model; instead, the group collectively represents one full model in a distributed form.
Across the M groups, standard data parallelism is used. Each group processes a different subset of the minibatch, computes gradients independently, and then synchronizes gradients across groups to ensure all replicas remain consistent.
HSDP is a concrete example of multidimensional parallelism, where different parallelization strategies are applied along different axes of a logical device grid. In this case, GPUs are arranged in a 2D grid: one dimension for sharding (FSDP) and one for replication (data parallelism).
In practice, large-scale training systems often extend this idea further by combining additional dimensions such as tensor parallelism (splitting computations within layers) and pipeline parallelism (splitting layers across stages), forming higher-dimensional parallel training schemes.
Activation checkpointing reduces memory usage by saving only a subset of intermediate activations during the forward pass and recomputing the missing ones during the backward pass.
Instead of storing activations for every layer, the model saves checkpoints every C layers and discards the rest; when gradients are needed, it recomputes activations starting from the nearest checkpoint.
This significantly lowers activation memory at the cost of extra computation, creating a trade-off where fewer checkpoints save more memory but require more recomputation.
It’s common to set C=N
Commonly used for Transformer models
Transformers operate on sequences of length L (or S). Context Parallelism involves using multiple GPUs to process a single long sequence that would otherwise be too large for one device’s memory.
The Normalization & Residual Connections have no weights and are easy to parallize. The MLP and QKV Projections are similar to DP.
The Attention mechanism is the hardest part to parallelize because every element in the sequence needs to look at every other element. There are two primary options:
Option 1: Ring Attention
Option 2: Ulysses
Split the layers of the model across GPUs. Copy activations between layers at GPU boundaries.
To avoid “Pipeline Bubbles” (where GPUs sit idle waiting for data), the model runs multiple micro-batches simultaneously.
Split the weights of each linear layer across GPUs, use block matrix multiply.
With 2 consecutive TP layers, shard first over row and second over column to avoid communication.
Hardware FLOPs Utilization (HFU): The fraction of theoretical matmul performance we actually achieve.
We benchmark for the best-case scenario for HFU. But this doesn’t account for other computation like checkpointing, data preprocessing, etc.
Model FLOPs Utilization (MFU): the fraction of the GPU’s theoretical peak FLOPs used for “useful” model computation.
Compute FLOPtheoretical
Look up FLOP/sectheoretical
Compute ttheoretical
ttheoretical=FLOP/sectheoreticalFLOPtheoretical
Measure tactual
Calculate MFU
MFU=tactualttheoretical
MFU > 30% is good, >40% is excellent.
In practice, we use Use TP, CP, PP, and DP all at the same time. GPUs are arranged in a 4D grid. We tune and optimize the setup to maximize the MFU.