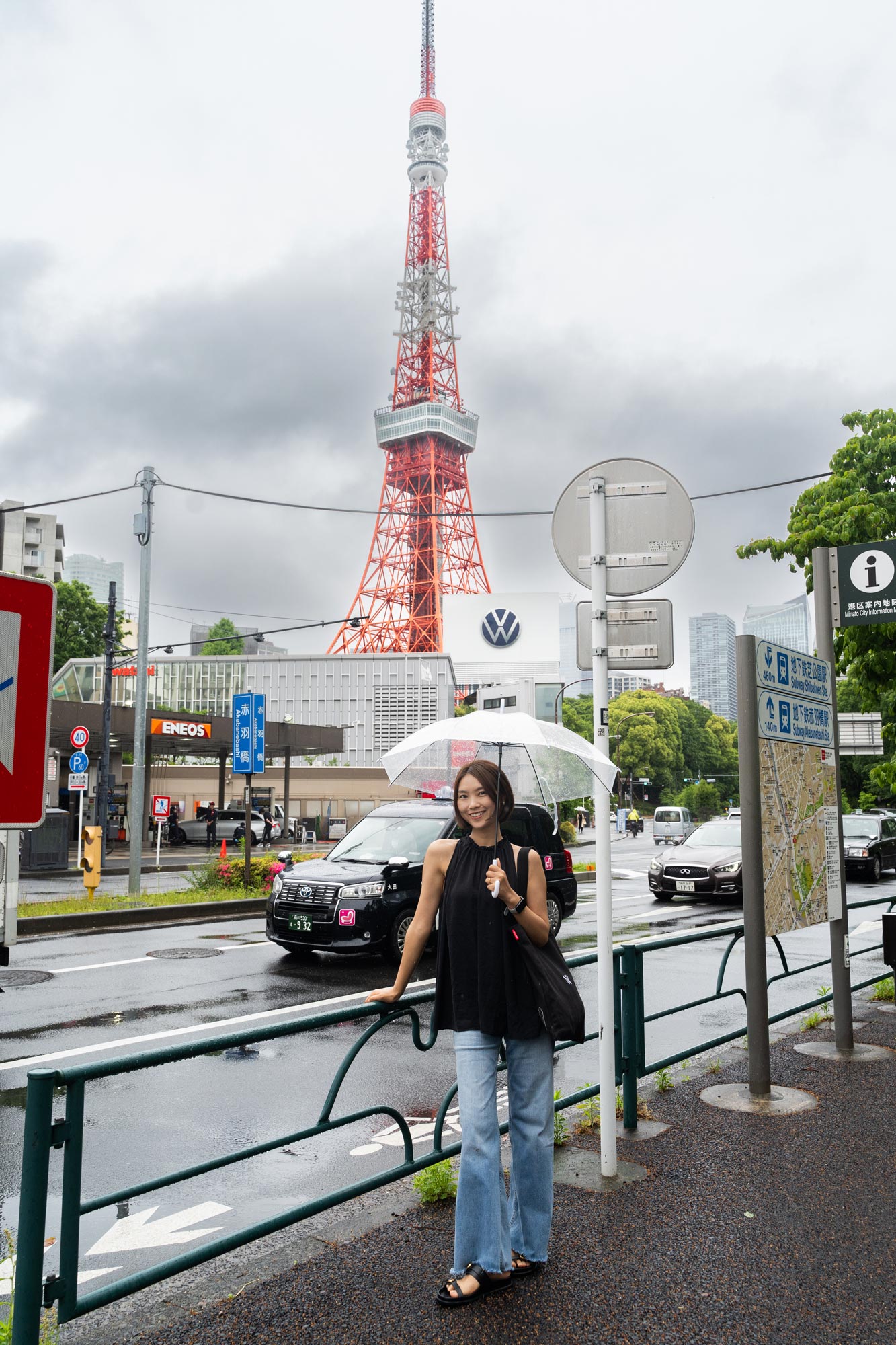五月的时候,同老婆又去了一趟日本,过去这几个月,诸多事务,也是在今天这个时间,终于有时间写完这篇游记。
距离上一次去日本,已经过去 7 年,2016年,我和老婆第一次去日本,逛了逛东京和仙台;2017年的元旦,与老婆在大阪又跨了一个年。从中扣除那如同时间按下了暂停键般的疫情 3 年,我的心理时钟似乎也只感受到了 4 年的流逝。
自从 2021 年我重新上班之后,我和老婆已经很久没出远门旅行了。这次去日本,目的地很明确,行程上也没有什么其他安排,纯粹就是给自己和老婆,安排一场放松的旅途。
与我们以往那些充满了奔波劳顿的出行不同,这次我们只安排了五天四晚的东京行程,五天只去了东京和镰仓两地。
行程
| 日期 |
行程 |
| DAY1 |
深圳・东京成田机场 |
| DAY2 |
皇宫晨跑・上野公园・东京国立博物馆・国立西洋美术馆・浅草寺 |
| DAY3 |
东京车站・镰仓高校前・江之岛 |
| DAY4 |
东京大学晨跑・明治神宫・代代木公园・涩谷 |
| DAY5 |
东京铁塔・麻布台之丘・深圳 |
在日本的四晚,我们都选了东京的同一家酒店,也是 2016 年我们在东京住过的酒店,也算是重温一下当年的回忆。
DAY1: 深圳・东京成田机场

很久没来深圳机场了,这次从深圳直飞东京,深圳航空,票价倒尚好,两人来回 4K 多。
这次我们的行李很少,只带了两个登机箱,一个背包。航班出发时间是中午,时间不赶。
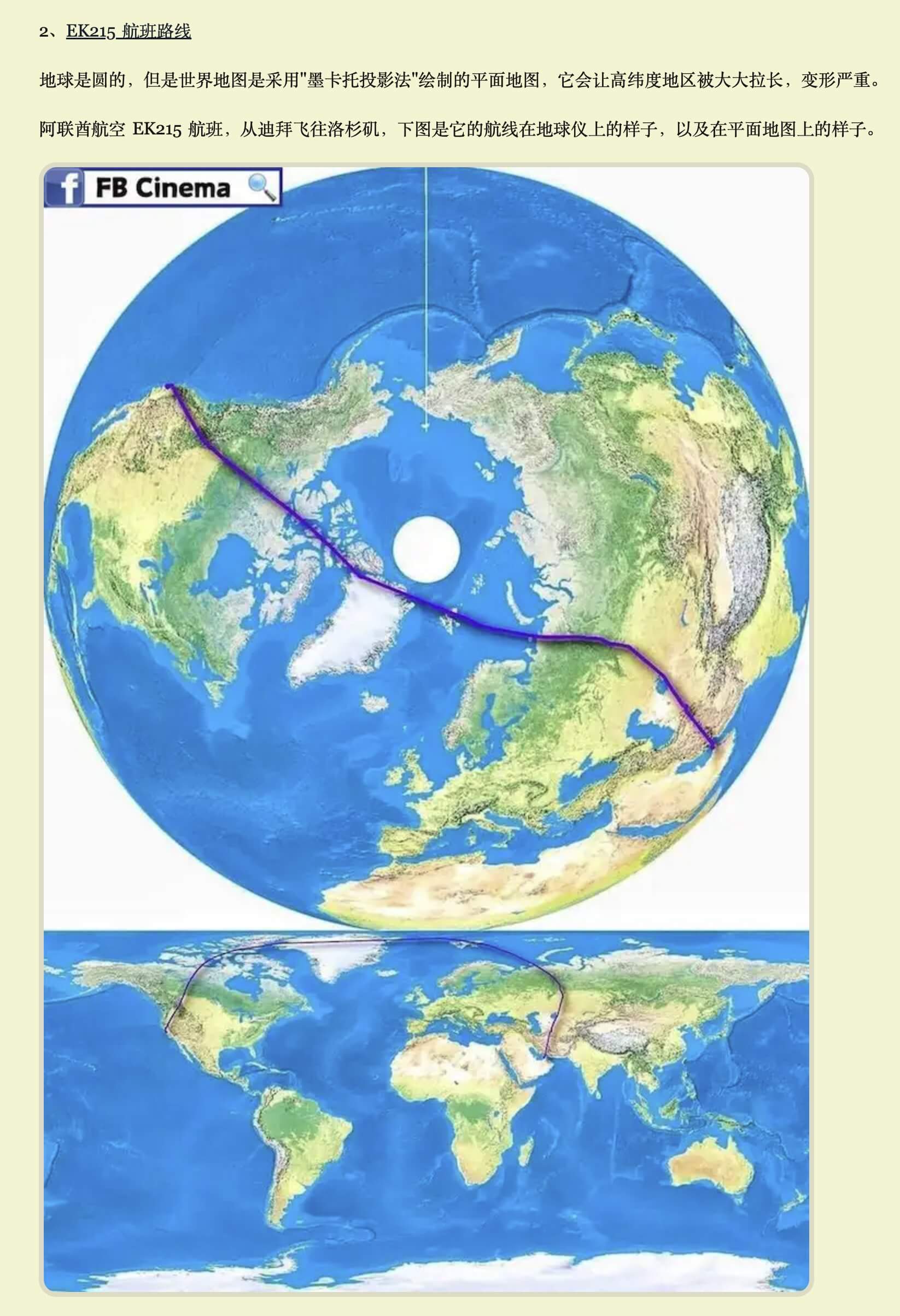
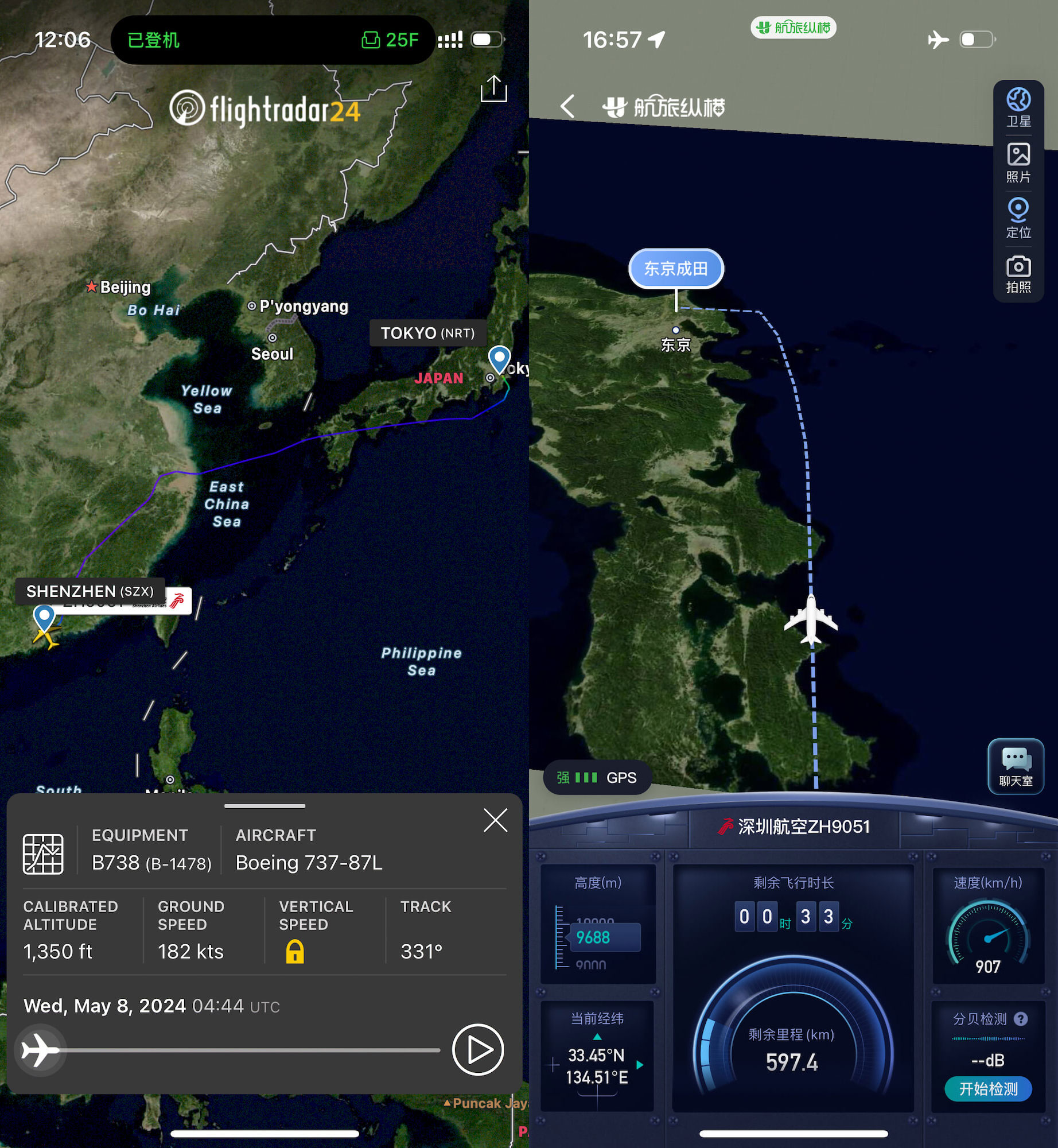
这次的航程图,到了后程靠着日本海岸线飞行,倒也可以在空中看到不少沿岸风景。
到底东京接近下午 5 点,又一次看到东京的海岸线。
在飞机上看到一座小铁塔。
伴随这落日,落地东京成田机场。
廊桥前往海关的路上,见到看似熟悉的欢迎标识。这一次入关很快,全程电子登记,也不用排队,在机场看到不少东南亚裔工作人员,看来这些年日本的外劳政策效果还是挺明显的。
过了海关,坐快线前往市区,从成田到市区有很多交通方式,指引也很清晰。
换乘之后,终于到达预定的酒店,这也是我们第二次入住,酒店名叫「东京庭之酒店」,位于水道桥站站附近,离东京巨蛋和东京大学很近。房间不大,但是设施齐全,酒店内的环境也不错。
DAY2: 皇宫晨跑
第二天我很早就起床了,开启这次东京之行的独享时光。这次来东京,我专门带了跑鞋和运动衣物,就是打算在东京跑跑步。5月早上的温度很合适,不热不冷,今天的天气也很好。
今天准备去皇宫跑一圈,从酒店慢跑过去,只有几公里,路上穿过早上的居民区。
到达皇居外围的竹桥。从这里开始一路,就可以沿着皇居绕圈了,这也是许多跑步爱好者的经典线路。
皇居外围有护城河,也有专门的步道,一路遇到不少跑者。
一路慢慢悠悠,三公里不到,即将进去皇居。
到达皇居外苑,铺满细沙这里行人比较多,道路窄,如果要进去就禁止跑步了。
人很少,加上天气不错,这次过来跑步,也是很舒服。
环绕皇居只需 5 公里左右,对于我这种跑马拉松的人来说,连热身都不算,所以后面我就慢慢走了。皇居有不少门,有警察把守。
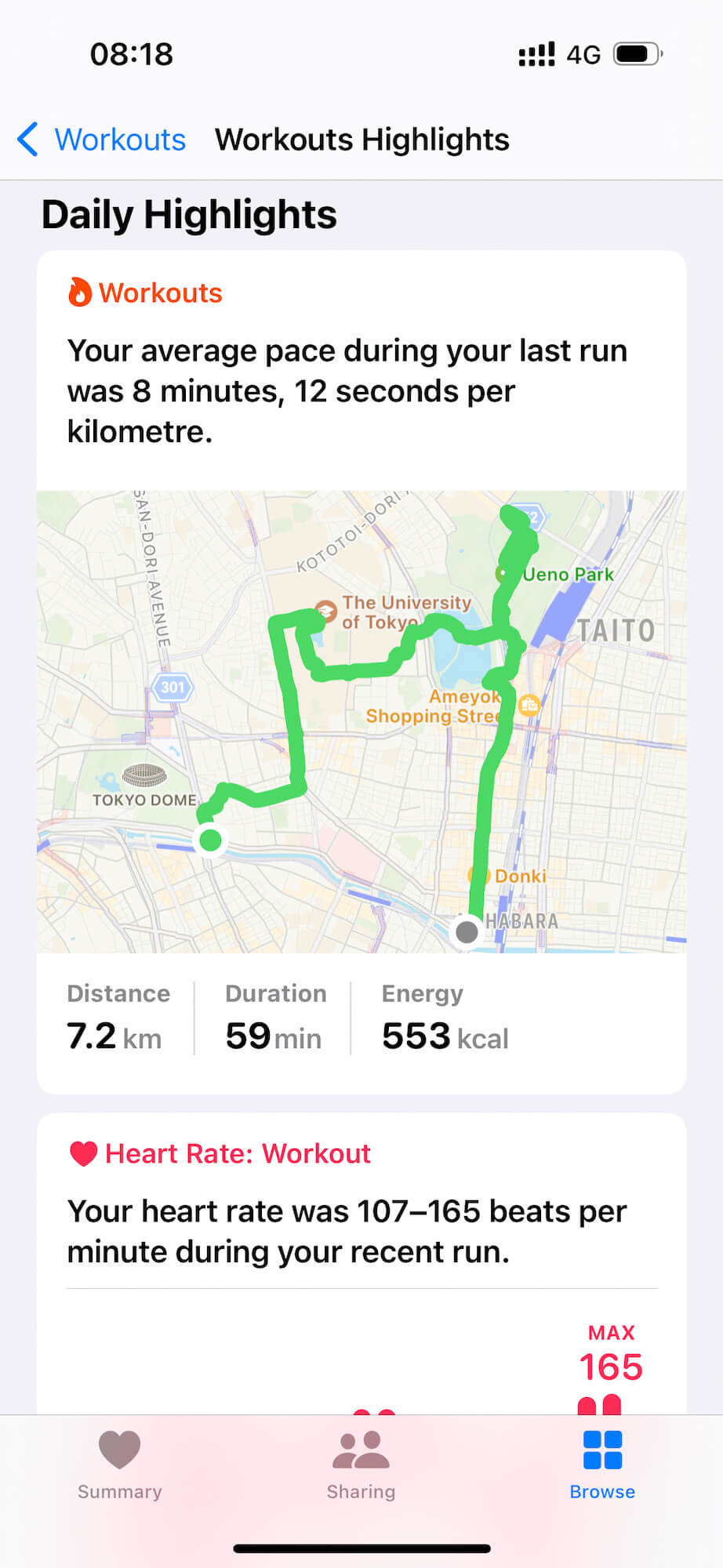
早8点,轻轻松松跑完一圈,完成一环,解锁村上春树同款跑步线路。
接下来慢慢悠悠走回酒店,路上上班的人也变多起来。
DAY2: 国立博物馆・西洋美术馆
在东京的第二天,第一个白天的行程,只安排了博物馆。先来上野公园,先去东京国立博物馆,公园有好几个博物馆。
路过国立科学博物馆。
国立科学博物馆看着也有些年头,门口有一个好大的蓝鲸雕塑。
穿过公园,来到北面的国立博物馆。
门口的小亭子买票,成人 1000日元/人,约合人民币 50 元。
国立博物馆有几栋建筑,首先去本馆参观。
本馆建立于 1938 年,属于西洋风格,进入本馆后有楼梯直通二楼。今天也有不少学生在这里参观。
同大多数博物馆一样,基本也是按照时间线,分不同小区展示,中日文化一脉相承,日本的古代文化基本就是中国文化的传承和演绎,在国内我东西南北也看了不少国家级博物馆,对于日本博物馆的藏品,倒也没有什么感觉特别惊艳的地方。但是既然来了,还是慢慢悠悠逛了两个小时。
即将离开本馆,在墙上看到一排海报,之前有段时间,有学习和了解过一些设计和排版相关的知识,日本的设计美学排版,可以说也是影响了不少人。实事求是的说,虽说这些年国内的设计水平逐步上升,但是在美学和设计上,中日的差距还是显而易见的,尤其是日常生活的一些诸如字体、招牌、标语、海报的设计。
审美这玩意,尤其是我们普通民众对审美的认知,如同「素质」一样,非一日之功,都是需要几代人的基本教育和传承,才能养成的。
逛完本馆,又去了东洋馆,东洋馆主要展示亚洲各国的文物,当然其中重头部分也是我们中国的流失文物。一入馆,首先看到的就是我们的佛像。
菩萨立像・ 北齐时代・天保3年(552)・山西长子县
观音菩萨立像・隋代・开皇5年(585)・河北省崇光寺
除了中国的展品,也有来自印度、伊朗、东南亚等国的文物,最近黑神话悟空大火,里面不少场景取景中国传统佛道场景,当时我在博物馆东亚馆里看到这些佛像的时候,心中除了「遗憾」,也感受到了这种人类文明和文化共通的魅力。
幽暗的展厅,配合打光,这些佛像的面貌,承载着历史,也传递着人类文明中对于信仰、精神和美的追求。经历千年战火,依旧给站前面前的参观者,带来一种安静和庄严。
中午时分,参观完两个馆,也准备出去吃饭了。5 月虽然已经过了樱花季,但是天气还是舒服。馆外的座椅上,有游客在晒着太阳休息。
国立博物馆北侧有一个庭园,有日式传统的建筑,不大,推荐也可以绕着走一圈即可。
庭园植被茂密,现在即将入夏,一片翠绿,如果是秋冬过来,应该会是另外一番景象。生活在南方久了,尤其是广东基本没有四季之分,有时候跟老婆倒想去北方体验一下四季变化。
逛完国立博物馆,已经是中午时分,准备出去吃饭。
上野公园东侧有一条商业街,有不少餐馆,可能已经过了饭点,街上人并不是太多。
走到台东的一条步行街,里面很多商铺。我们在里面吃了一家拉面,味道还不错,服务的阿姨也很热情,看到我们是外国人,还特意用翻译软件跟我们确认拉面的配料。这也是在日本大多时候体验很舒服的地方,来日本三次,也去了几个城市,整体的感受都很舒服。
吃完饭,继续下午的行程,上野站附近多旅游景点,人还挺多的。
继续参观国立西洋美术馆,美术馆也是位于上野公园内,在上野动物园对面,勒·柯布西耶设计,建于 1959 年,专门收藏西洋美术作品。
美术馆不大,收藏了不少名家作品,对于我们一般民众而言,可能也就看看莫纳之类的名家作品。如果对艺术不太感兴趣,可能会觉得有点乏味,我和老婆独自在馆内各逛各的,倒也逛了一个多小时。
毕加索的作品「男人和女人」。
2019 跨年去了一趟纽约,在 MOMA 现代艺术博物馆和大都会博物馆,也看到了许多名家作品。
这次在东京,再次见到这些名家作品,也是感受下艺术跨越国界的魅力。
逛完美术馆,时间尚早,准备再去浅草寺逛逛。
东京轨道系统世界文明,在地铁站内看到一条之前的铁轨。
浅草寺应该属于那种名片性质的旅游景点,商业化成熟,对于我来说,就是一个打卡的性质。人很多,国际游客应该都会来这逛逛。
对于拥有北京、西安一众古城的中国游客来说,应该对这个寺庙不会有太多感觉。
民俗项目观音签,老婆也去抽了一张,是个吉签。
在浅草寺呆了一小会,看时间也不早了,今天走了一天也挺累,准备回酒店休息了。
在路中央看到一个贴满贴纸的路牌。
DAY3: 镰仓
东京的第三天,今天去镰仓。去镰仓要在东京站转车,上次来东京的时候,也是在这个地方,给老婆拍了一张照片。2016 和 2024 年,同一个地方,8 年时光。
今天也是一个好天气,老婆也很开心。
坐了近一个小时的JR,到达镰仓,出了镰仓站,接下来就是换乘电车,去海边。
买了一张一日通票,有这张票就可以在一天的时间内任意次数乘坐电车,肯定划算。
出现在无数人游记中的电车,这也是来镰仓必须体验的交通工具。
来到海边,我和老婆决定开始漫步一段。今天天气真棒,风也很大。
海边的小屋,有点欧式风格。看着十分干净。
走了没几步,我和老婆都不由惊喜,远远地就望到了海那边的富士山,这也是我两第一次见到富士山。
这次旅行,轻装上阵,只带了索尼 A7 搭配腾龙2870的变焦头,远远拍一张富士山,镰仓海边多云雾,我们也算是运气好,能看到这么清晰的富士山。
唯一有点遗憾的是,今天风太大了,吹得老婆的头发乱漂,不好拍照。
过马路的游客,就像漫画一样。
海边的路牌。
海滩上也有不少的游客,海浪挺大。
第一次见到马自达这个车。
除了自驾,海边也有不少人骑摩托和自行车,说到这还是挺羡慕的,国内禁摩的地方太多了。
来到著名的镰仓高校前车站,也是很多游客必去的地方。
等到电车靠近,给老婆抓拍一张。
海边的7-11,应该也是一个著名的打卡点。
见到 MX-5,在这种天气、这种地方开,真爽。
路过一个路口,刚好看到骑行的人和路人同框,抓拍一张。
临近中午,肚子也饿了,找了一家路边的餐厅,吃饭。
我和老婆点了两份主食、薯条、炸鸡,配上两杯饮料,算下来224人民币,价格还算 OK。
吃完饭出来,接下来步行前往江之岛。
马路对面的一家餐厅和排队的人,店门面的配色看起来很舒服。
江之岛一个靠近镰仓的一个近岸离岛,也是一个著名的旅游景点,有不少游客。
从堤坝去往江之岛的路上,见到另一头钓鱼的人,下午了,远处也起云雾,富士山开始变得模糊,回想今早能看到那么清晰的富士山,还是觉幸运。
来到江之岛上,密密麻麻的人潮攒动。
岛上有山,可以步梯登山,岛上有寺庙。
来到山顶,有一片小花园,看到一颗掉了叶子的树。
江之岛不大,绕一圈,见到海边的礁石,上面还有人在那摄影。
山腰上的饭店。
在江之岛逛了一圈,又步行回来镰仓海边,和老婆坐电车一趟往返,刚好休息。
从车站下车,又来到海边,海边的一座桥。
风很大,海浪波涛汹涌。和老婆在海边的堤岸上又坐了一阵,温度不错,风吹起来也并不冷。
海边的售卖机,阳光从缝隙中穿过。
即将落日,海边也被暖色的夕阳笼罩。今天的镰仓之行,十分轻松,好久没有这么惬意了。
DAY4 东大晨跑・明治神宫
第四天,开始我在东京的第二次晨跑,今天的路线是东京大学和上野公园。依旧早起,向北跑向东京大学。
上一次来东京时,曾经和老婆在夜晚来过东京大学,但是由于晚上关门,并没有进去参观,这次晨跑也算是补上上次的遗憾。这个红色的大门就是「赤门」,建于 1827 年。
来到上次止步的东京大学正门,这次开放了,无人看守,我也就直接跑了进去。
进门的林荫道,郁郁葱葱。
林荫道尽头,是东京大学安田讲堂,也是东大的地标之一。
东京大学是日本的最高学府,成立于 1877 年,地位等同于中国的清华北大。东大现在全球大学 QS 排名 30多,已经落后北大和清华。
跑步穿过东大,没多远就又到了上野公园,早晨的上野公园,空空荡荡。
上野恩赐南部公园中的「不忍池」。
继续往北跑,来到博物馆门口的广场。见到不少晨练的人。
从上野公园出来,又往秋叶原跑了一转,算是结束了这次晨跑。
今天的行程是明治神宫,其实我对这个地方也没啥兴趣,但是这次旅行,本身也就是没啥目的的放松之行,所以倒也没什么所谓。今天的游客很多。明治神宫位于涩谷区,建于1915年至1920年,二战时被焚,1958年按原样重建,靠近新宿和原宿,绿树成荫。
这里的明治,也是我们熟知的「明治维新」那个「明治天皇」。中日近代都经历过类似的社会变革,可惜两国后面一个世纪的命运,走向却是截然不同的。
看到一个通行禁止的牌子。
来到一处牌匾处,我对日本近代文化不是特别感兴趣,所以也仅仅是抱着参观的态度。
来到明治神宫正殿,左右两侧各有一颗圆形的神木,被称作「夫妇楠」,象征着明治天皇和昭宪皇后的深厚感情。
刚好碰到在明治神宫举办日本传统婚礼的新人,普通人也可以申请,看数据说每年有 1300 多人在这里举办婚礼。
院内的树木,不愧被称作「都会中的森林」。
参观完正殿,我和老婆就步行前往下一个目的地代代木公园,中途路过一个挂满灯笼的墙,看了下好像都是酒的品牌。
走到神宫北面的一处草地。如果居住在周围,在这里散步的确是一种享受。
从明治神宫步行,绕了半个多小时,来到南面紧邻的「代代木公园」,这里也是东京市民热门的公园之一。其中的狗狗公园也算一个特色。
公园中写生的老人。
虽然已经过了花季,公园中的花朵依旧茂盛。
恰好碰到举办「泰国节」 Thai Festival,有很多东南亚国家的美食,也看到很多东南亚裔的人,这些年日本逐步放开移民,吸引了不少东南亚外劳。
由于泰国节人太多了,我和老婆并没有停留太久,步行前往涩谷。在代代木公园另一个大门口的广场,见到不少跳舞的人。
干净的街道,这也是我喜欢东京的原因之一。
涩谷号称现代日本的文化中心,年轻人的聚集地。果然人多。
在一条巷子里,见到了蜜雪冰城,看到时笑了,前几天王思聪逛街,也在这里被人拍到。
从涩谷逛完,我和老婆去秋叶原吃鳗鱼饭,正在吃饭的时候,突然收到郭宇发来的信息,问我还在不在东京。
本来这次东京行有约他,但是之前安排的行程,我来东京的时间,他刚好在意大利了,所以没能见上一面。没想到后来我的机票改签,延后了几天,他也刚好在今天回到东京,所以就约了晚上聚一聚。
郭宇是我的学长,也是改变了我人生轨迹的一个人,有关他,和我和他的经历,之前曾经写过一篇文章:
去年在深圳有聚过一次,我和老婆与她的相聚,则是 6 年前的大阪。如今在他东京的豪宅再相聚,天南地北聊了不少。就是这次太赶了,没能蹭上他一顿饭。
也不早了,想着他刚回国,也不打扰他休息,郭宇很热情开车送我们回了酒店,也是第一次体验首都高逮虾户。
DAY5:东京铁塔
在东京的最后一天,晚上的航班回国,今天的安排也很轻松,就是去东京铁塔打个卡。
在酒店收拾完行李寄存,坐地铁来到东京铁塔。可惜今天天公不作美,下起了雨,但是想一想前几天都是好天气,最后一天下下雨,也算是给我们体验一下不一样的东京。
七年前来到东京,在晚上看到一次东京铁塔,这次雨天再来看看。给老婆拍个打卡照。
东京铁塔建于 1958 年,高332.9米,比巴黎艾菲尔铁塔还高 8 米,是日本第二高的结构物,仅次于东京晴空塔。是日本的象征之一,也是东京的地标之一。
距离东京铁塔,有一个「麻布台之丘」的新建观景台,2023年11月开幕,顶楼有一处室内观景台和咖啡厅,能直接看到东京铁塔,目测会是以后又一网红打卡地。
也在这里,给老婆拍了一张照片,也算是这次东京之行的结束。
归程
雨中拖着行李,坐 JR 到了成田机场,时间尚早,在机场星巴克买了杯咖啡,等待登机。
花了两天时间,终于还是写完了这篇游记。
上一次去日本,还是青年,这次再来,已是中年。过去这几年,世界,家庭,包括自己,都发生了诸多变化。成家了,创过业,又回去工作几年,可谓也是踉踉跄跄。
时光匆匆,有时候还挺幸运自己过去一直「记录」和「分享」的习惯,回看过去旅行的点点滴滴,时不时也能找回一些过往的幸福和温馨。
补上这篇游记,也是对未来自己的一种交代,希望再过 5 年,再过 10 年,再过 20 年,再回看这些文字和照片,依旧能感受到生命中的点滴美好。







 盒内物件,除了简单的说明书,还附送了个卡针和短 Type-C 数据线。
盒内物件,除了简单的说明书,还附送了个卡针和短 Type-C 数据线。 设备的颜值不错,左上角的 5G 红标有设计感。
设备的颜值不错,左上角的 5G 红标有设计感。 右上角有两个指示灯灯,分别表示基站网络和 Wi-Fi 状态
右上角有两个指示灯灯,分别表示基站网络和 Wi-Fi 状态 与身份证大小对比,的确很小巧。
与身份证大小对比,的确很小巧。
 SIM 卡槽和卡托,还能放一个 TF 卡,对于我来说读卡器是个鸡肋功能,相机用的都是 SD 卡,没有什么其他设备用到 TF 卡。
SIM 卡槽和卡托,还能放一个 TF 卡,对于我来说读卡器是个鸡肋功能,相机用的都是 SD 卡,没有什么其他设备用到 TF 卡。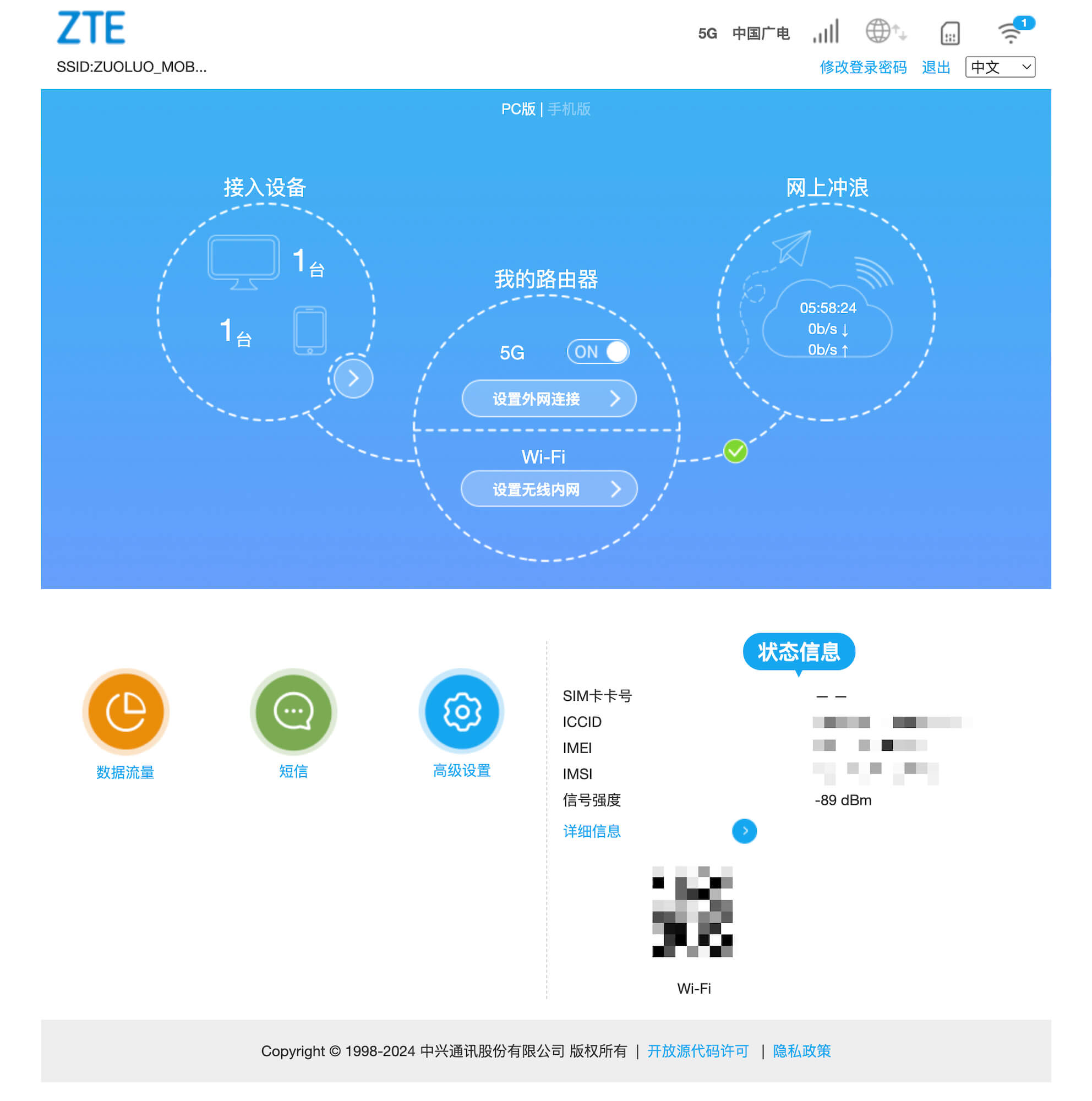 连接上 Wi-Fi 或者网络之后,就可以通过浏览器访问管理后台。后台可以查看当前的网络状态,也能查看短信。
连接上 Wi-Fi 或者网络之后,就可以通过浏览器访问管理后台。后台可以查看当前的网络状态,也能查看短信。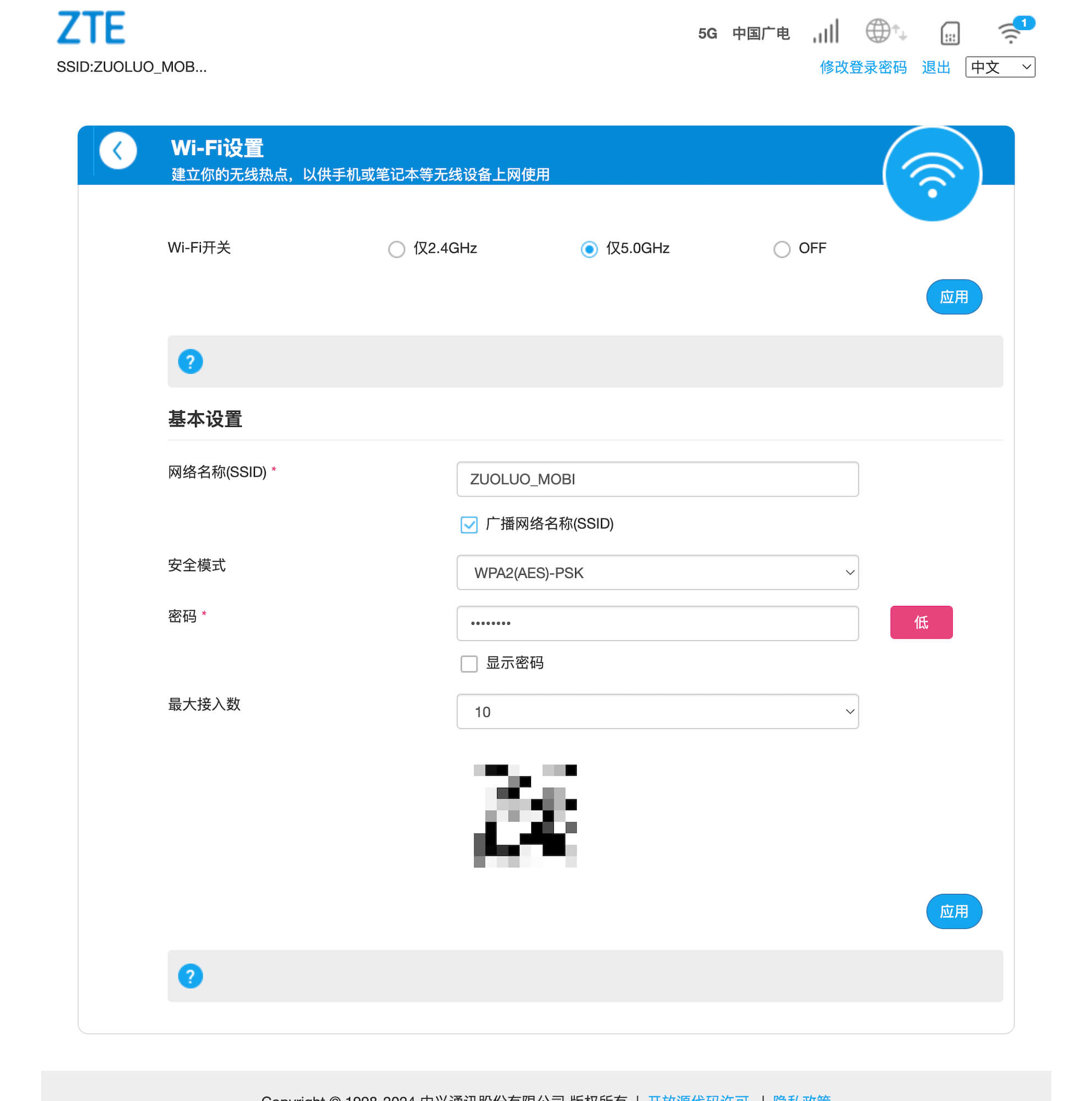 5G/4G 网络配置,Wi-Fi 配置,跟常见的家用路由器没有太多差别。
5G/4G 网络配置,Wi-Fi 配置,跟常见的家用路由器没有太多差别。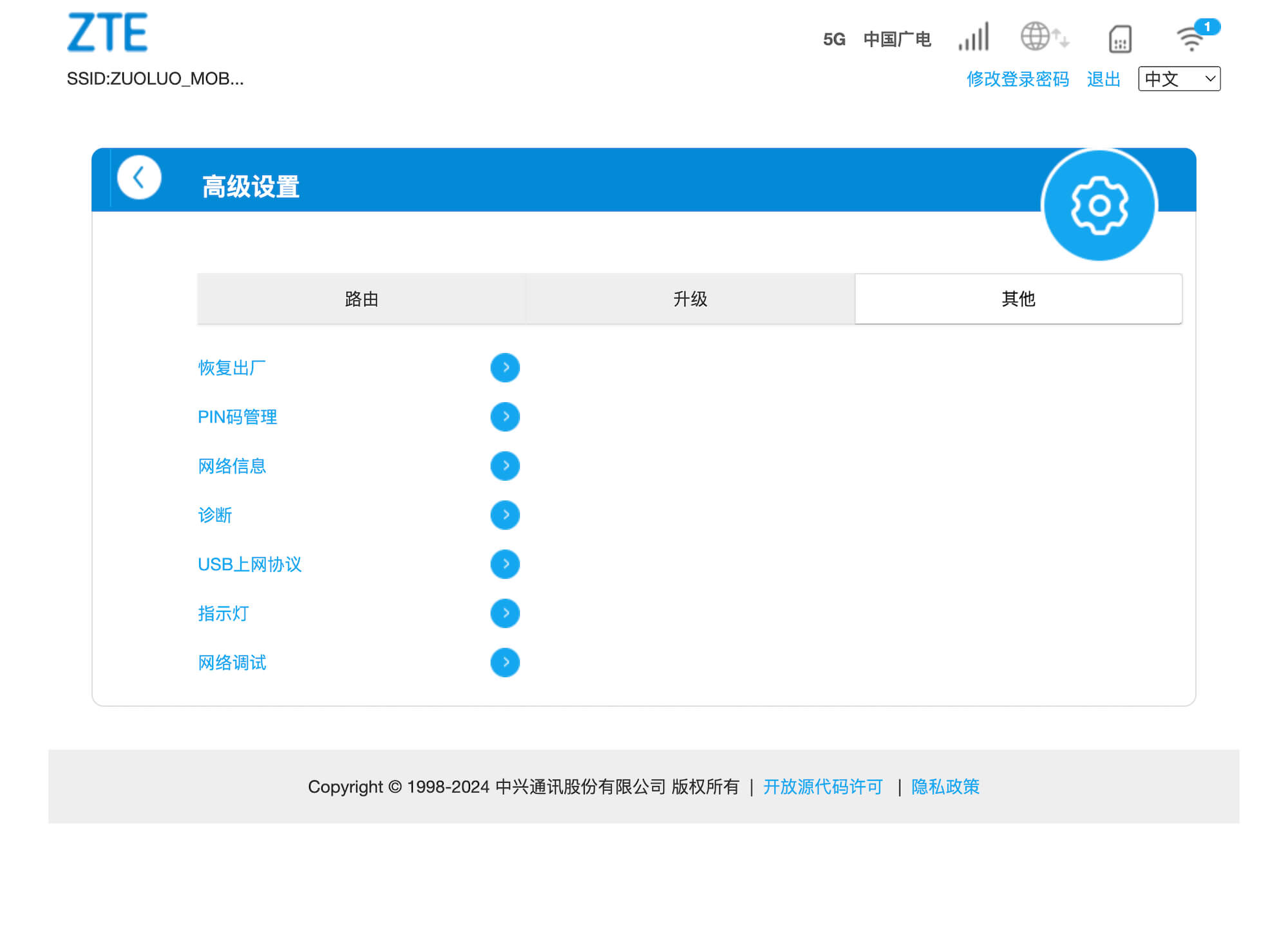 高级配置里可以配置更多的信息,报错指定频段、USB 协议等等。
高级配置里可以配置更多的信息,报错指定频段、USB 协议等等。
































 本馆建立于 1938 年,属于西洋风格,进入本馆后有楼梯直通二楼。今天也有不少学生在这里参观。
本馆建立于 1938 年,属于西洋风格,进入本馆后有楼梯直通二楼。今天也有不少学生在这里参观。



 菩萨立像・ 北齐时代・天保3年(552)・山西长子县
菩萨立像・ 北齐时代・天保3年(552)・山西长子县



 中午时分,参观完两个馆,也准备出去吃饭了。5 月虽然已经过了樱花季,但是天气还是舒服。馆外的座椅上,有游客在晒着太阳休息。
中午时分,参观完两个馆,也准备出去吃饭了。5 月虽然已经过了樱花季,但是天气还是舒服。馆外的座椅上,有游客在晒着太阳休息。 国立博物馆北侧有一个庭园,有日式传统的建筑,不大,推荐也可以绕着走一圈即可。
国立博物馆北侧有一个庭园,有日式传统的建筑,不大,推荐也可以绕着走一圈即可。 庭园植被茂密,现在即将入夏,一片翠绿,如果是秋冬过来,应该会是另外一番景象。生活在南方久了,尤其是广东基本没有四季之分,有时候跟老婆倒想去北方体验一下四季变化。
庭园植被茂密,现在即将入夏,一片翠绿,如果是秋冬过来,应该会是另外一番景象。生活在南方久了,尤其是广东基本没有四季之分,有时候跟老婆倒想去北方体验一下四季变化。

 走到台东的一条步行街,里面很多商铺。我们在里面吃了一家拉面,味道还不错,服务的阿姨也很热情,看到我们是外国人,还特意用翻译软件跟我们确认拉面的配料。这也是在日本大多时候体验很舒服的地方,来日本三次,也去了几个城市,整体的感受都很舒服。
走到台东的一条步行街,里面很多商铺。我们在里面吃了一家拉面,味道还不错,服务的阿姨也很热情,看到我们是外国人,还特意用翻译软件跟我们确认拉面的配料。这也是在日本大多时候体验很舒服的地方,来日本三次,也去了几个城市,整体的感受都很舒服。 吃完饭,继续下午的行程,上野站附近多旅游景点,人还挺多的。
吃完饭,继续下午的行程,上野站附近多旅游景点,人还挺多的。

 继续参观国立西洋美术馆,美术馆也是位于上野公园内,在上野动物园对面,勒·柯布西耶设计,建于 1959 年,专门收藏西洋美术作品。
继续参观国立西洋美术馆,美术馆也是位于上野公园内,在上野动物园对面,勒·柯布西耶设计,建于 1959 年,专门收藏西洋美术作品。
 毕加索的作品「男人和女人」。
毕加索的作品「男人和女人」。
 东京轨道系统世界文明,在地铁站内看到一条之前的铁轨。
东京轨道系统世界文明,在地铁站内看到一条之前的铁轨。




 民俗项目观音签,老婆也去抽了一张,是个吉签。
民俗项目观音签,老婆也去抽了一张,是个吉签。
 在浅草寺呆了一小会,看时间也不早了,今天走了一天也挺累,准备回酒店休息了。
在浅草寺呆了一小会,看时间也不早了,今天走了一天也挺累,准备回酒店休息了。 在路中央看到一个贴满贴纸的路牌。
在路中央看到一个贴满贴纸的路牌。



 出现在无数人游记中的电车,这也是来镰仓必须体验的交通工具。
出现在无数人游记中的电车,这也是来镰仓必须体验的交通工具。 来到海边,我和老婆决定开始漫步一段。今天天气真棒,风也很大。
来到海边,我和老婆决定开始漫步一段。今天天气真棒,风也很大。 海边的小屋,有点欧式风格。看着十分干净。
海边的小屋,有点欧式风格。看着十分干净。 走了没几步,我和老婆都不由惊喜,远远地就望到了海那边的富士山,这也是我两第一次见到富士山。
走了没几步,我和老婆都不由惊喜,远远地就望到了海那边的富士山,这也是我两第一次见到富士山。 这次旅行,轻装上阵,只带了索尼 A7 搭配腾龙2870的变焦头,远远拍一张富士山,镰仓海边多云雾,我们也算是运气好,能看到这么清晰的富士山。
这次旅行,轻装上阵,只带了索尼 A7 搭配腾龙2870的变焦头,远远拍一张富士山,镰仓海边多云雾,我们也算是运气好,能看到这么清晰的富士山。 唯一有点遗憾的是,今天风太大了,吹得老婆的头发乱漂,不好拍照。
唯一有点遗憾的是,今天风太大了,吹得老婆的头发乱漂,不好拍照。 过马路的游客,就像漫画一样。
过马路的游客,就像漫画一样。 海边的路牌。
海边的路牌。 海滩上也有不少的游客,海浪挺大。
海滩上也有不少的游客,海浪挺大。 第一次见到马自达这个车。
第一次见到马自达这个车。 除了自驾,海边也有不少人骑摩托和自行车,说到这还是挺羡慕的,国内禁摩的地方太多了。
除了自驾,海边也有不少人骑摩托和自行车,说到这还是挺羡慕的,国内禁摩的地方太多了。
 来到著名的镰仓高校前车站,也是很多游客必去的地方。
来到著名的镰仓高校前车站,也是很多游客必去的地方。 等到电车靠近,给老婆抓拍一张。
等到电车靠近,给老婆抓拍一张。 海边的7-11,应该也是一个著名的打卡点。
海边的7-11,应该也是一个著名的打卡点。
 路过一个路口,刚好看到骑行的人和路人同框,抓拍一张。
路过一个路口,刚好看到骑行的人和路人同框,抓拍一张。 临近中午,肚子也饿了,找了一家路边的餐厅,吃饭。
临近中午,肚子也饿了,找了一家路边的餐厅,吃饭。

 吃完饭出来,接下来步行前往江之岛。
吃完饭出来,接下来步行前往江之岛。 马路对面的一家餐厅和排队的人,店门面的配色看起来很舒服。
马路对面的一家餐厅和排队的人,店门面的配色看起来很舒服。 江之岛一个靠近镰仓的一个近岸离岛,也是一个著名的旅游景点,有不少游客。
江之岛一个靠近镰仓的一个近岸离岛,也是一个著名的旅游景点,有不少游客。
 来到江之岛上,密密麻麻的人潮攒动。
来到江之岛上,密密麻麻的人潮攒动。 岛上有山,可以步梯登山,岛上有寺庙。
岛上有山,可以步梯登山,岛上有寺庙。
 来到山顶,有一片小花园,看到一颗掉了叶子的树。
来到山顶,有一片小花园,看到一颗掉了叶子的树。 江之岛不大,绕一圈,见到海边的礁石,上面还有人在那摄影。
江之岛不大,绕一圈,见到海边的礁石,上面还有人在那摄影。 山腰上的饭店。
山腰上的饭店。

 在江之岛逛了一圈,又步行回来镰仓海边,和老婆坐电车一趟往返,刚好休息。
在江之岛逛了一圈,又步行回来镰仓海边,和老婆坐电车一趟往返,刚好休息。

 风很大,海浪波涛汹涌。和老婆在海边的堤岸上又坐了一阵,温度不错,风吹起来也并不冷。
风很大,海浪波涛汹涌。和老婆在海边的堤岸上又坐了一阵,温度不错,风吹起来也并不冷。



 上一次来东京时,曾经和老婆在夜晚来过东京大学,但是由于晚上关门,并没有进去参观,这次晨跑也算是补上上次的遗憾。这个红色的大门就是「赤门」,建于 1827 年。
上一次来东京时,曾经和老婆在夜晚来过东京大学,但是由于晚上关门,并没有进去参观,这次晨跑也算是补上上次的遗憾。这个红色的大门就是「赤门」,建于 1827 年。




 跑步穿过东大,没多远就又到了上野公园,早晨的上野公园,空空荡荡。
跑步穿过东大,没多远就又到了上野公园,早晨的上野公园,空空荡荡。 上野恩赐南部公园中的「不忍池」。
上野恩赐南部公园中的「不忍池」。


 从上野公园出来,又往秋叶原跑了一转,算是结束了这次晨跑。
从上野公园出来,又往秋叶原跑了一转,算是结束了这次晨跑。 今天的行程是明治神宫,其实我对这个地方也没啥兴趣,但是这次旅行,本身也就是没啥目的的放松之行,所以倒也没什么所谓。今天的游客很多。明治神宫位于涩谷区,建于1915年至1920年,二战时被焚,1958年按原样重建,靠近新宿和原宿,绿树成荫。
今天的行程是明治神宫,其实我对这个地方也没啥兴趣,但是这次旅行,本身也就是没啥目的的放松之行,所以倒也没什么所谓。今天的游客很多。明治神宫位于涩谷区,建于1915年至1920年,二战时被焚,1958年按原样重建,靠近新宿和原宿,绿树成荫。 看到一个通行禁止的牌子。
看到一个通行禁止的牌子。
 来到明治神宫正殿,左右两侧各有一颗圆形的神木,被称作「夫妇楠」,象征着明治天皇和昭宪皇后的深厚感情。
来到明治神宫正殿,左右两侧各有一颗圆形的神木,被称作「夫妇楠」,象征着明治天皇和昭宪皇后的深厚感情。 刚好碰到在明治神宫举办日本传统婚礼的新人,普通人也可以申请,看数据说每年有 1300 多人在这里举办婚礼。
刚好碰到在明治神宫举办日本传统婚礼的新人,普通人也可以申请,看数据说每年有 1300 多人在这里举办婚礼。

 参观完正殿,我和老婆就步行前往下一个目的地代代木公园,中途路过一个挂满灯笼的墙,看了下好像都是酒的品牌。
参观完正殿,我和老婆就步行前往下一个目的地代代木公园,中途路过一个挂满灯笼的墙,看了下好像都是酒的品牌。 走到神宫北面的一处草地。如果居住在周围,在这里散步的确是一种享受。
走到神宫北面的一处草地。如果居住在周围,在这里散步的确是一种享受。 从明治神宫步行,绕了半个多小时,来到南面紧邻的「代代木公园」,这里也是东京市民热门的公园之一。其中的狗狗公园也算一个特色。
从明治神宫步行,绕了半个多小时,来到南面紧邻的「代代木公园」,这里也是东京市民热门的公园之一。其中的狗狗公园也算一个特色。 公园中写生的老人。
公园中写生的老人。 虽然已经过了花季,公园中的花朵依旧茂盛。
虽然已经过了花季,公园中的花朵依旧茂盛。
 由于泰国节人太多了,我和老婆并没有停留太久,步行前往涩谷。在代代木公园另一个大门口的广场,见到不少跳舞的人。
由于泰国节人太多了,我和老婆并没有停留太久,步行前往涩谷。在代代木公园另一个大门口的广场,见到不少跳舞的人。 干净的街道,这也是我喜欢东京的原因之一。
干净的街道,这也是我喜欢东京的原因之一。
 在一条巷子里,见到了蜜雪冰城,看到时笑了,前几天王思聪逛街,也在这里被人拍到。
在一条巷子里,见到了蜜雪冰城,看到时笑了,前几天王思聪逛街,也在这里被人拍到。 从涩谷逛完,我和老婆去秋叶原吃鳗鱼饭,正在吃饭的时候,突然收到
从涩谷逛完,我和老婆去秋叶原吃鳗鱼饭,正在吃饭的时候,突然收到
 也不早了,想着他刚回国,也不打扰他休息,郭宇很热情开车送我们回了酒店,也是第一次体验首都高逮虾户。
也不早了,想着他刚回国,也不打扰他休息,郭宇很热情开车送我们回了酒店,也是第一次体验首都高逮虾户。