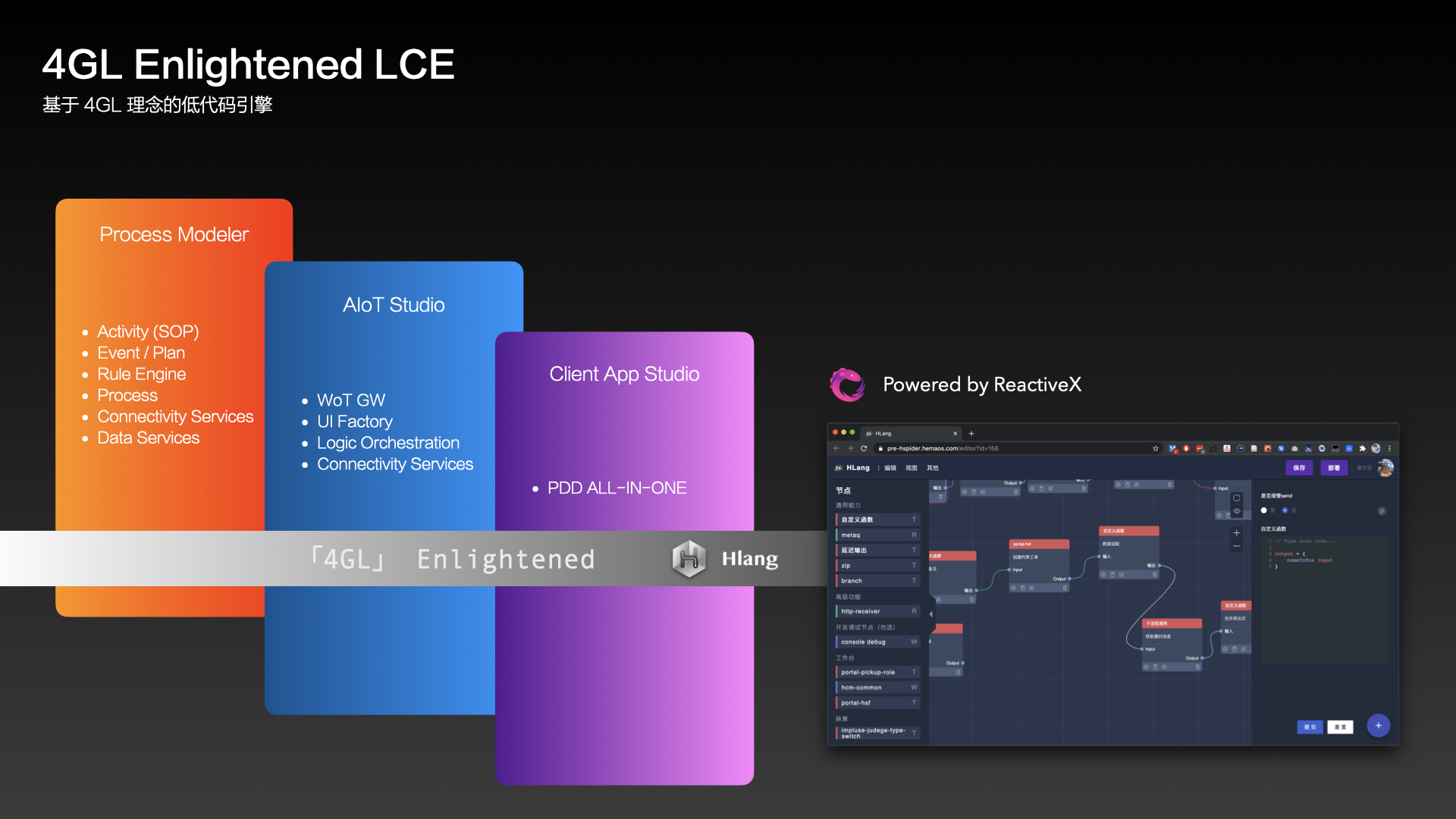
由于被狂热的爱好疯狂驱使,作为一个 90 年生人,有幸在 03 年说服爸妈给我买了人生第一台电脑,当时正是 Windows XP 火遍全球的时候。此后的时间里,这台电脑更多的成为了我的娱乐设施,我并没有很好地用它解决什么问题,在我看来,它完全变成了一台游戏机。但是我仍然对 Windows XP 的各项功能惊叹不已,在还没接触互联网的时候,阅读系统的 Help 脱机文档有时候都能成为一种享受。
今天核心的商业模式本质,在我看来万变不离其宗。但是 Z 世代、下一代数字化原住民开始逐渐成为全球的中坚力量,消费者端的行为发生了巨大的变化,反向推进上游不得不做出变革,市场在激烈地反应,一个不注意便可以让上游措手不及。新消费、新制造、新零售……,回头看这些当时最开始被提出的「新」概念以及后续加入的「新」词汇,所有人几乎在我看来都是观望、迷茫状态,如今,在这个赛道里的各个巨头也好,中小企业也好,开始真正了解到:哦,原来不是在创造新的概念,是时代变了,是时代变了以后,我们所有的做生意的方式值得推翻重新做一遍。
因此,在我的意识里,我并没有从概念本身去理解这个新,这些概念一直在,「新」的起源是时代的变革。新的基础建设在飞速崛起,今天的时代已经全面进入算力时代,一项严谨的数据表明,近几年包括美国在内等国家的 GDP 增长数据却没有让能耗的数据大幅度增加,这跟算力的崛起有极大的关系。
前不久,在北京时间的凌晨,有幸随机 pick up 了一场远在美国湾区的技术圈在 twitter 线上举办的一个有声讨论,讨论的是非常有意思的 《数字游牧:Digital Nomad》 话题。
Lyrical as usual, Apple said about Dark Mode that it’s a “dramatic new look that helps you focus on your work,’’ as well as a “distraction-free environment that’s easy on the eyes — in every way”.
Google was much more pragmatic, saying Dark Theme can “reduce power usage by a significant amount”, “improve visibility for users with low vision and those who are sensitive to bright light” and “make it easier for anyone to use a device in a low-light environment”.
👦 Archer: Dark Mode IS NOT Dark Design or Dark UI in Javascript.
What is mbm ?
It’s short name for CSS Mix Blend Mode.
About
🌞 🌛 Play with your Dark Mode.
Quick Start
constmbm=MixBlendMode({backgroundColor:"#FFFFFF",enable:true,});// togglembm.toggle();// showmbm.show();// hidembm.hide();// get auto-increment zIndexmbm.izIndex();
/**
* Use the given middleware `fn`.
*
* @param {GeneratorFunction} fn
* @return {Application} self
* @api public
*/app.use=function (fn){if (!this.experimental){//es7 async functions are not allowed,//so we have to make sure that `fn` is a generator functionassert(fn&&"GeneratorFunction"==fn.constructor.name,"app.use () requires a generator function");}debug("use % s",fn._name||fn.name||"-");// 主要就是做这个事情// 根据上面的 assert,这里的 fn 均为 generator functionthis.middleware.push(fn);returnthis;};
/**
* Return a request handler callback
* for node's native http server.
*
* @return {Function}
* @api public
*/app.callback=function (){if (this.experimental){console.error("Experimental ES7 Async Function support is deprecated. Please look into Koa v2 as the middleware signature has changed.");}varfn=this.experimental?compose_es7(this.middleware):co.wrap(compose(this.middleware));// 把中间件串起来varself=this;if (!this.listeners("error").length)this.on("error",this.onerror);returnfunction (req,res){res.statusCode=404;varctx=self.createContext(req,res);onFinished(res,ctx.onerror);fn.call(ctx).then(function (){respond.call(ctx);}).catch(ctx.onerror);};};
等等,我们的 co 去哪儿了?大家有没有发现上面 Demo 中和我们平时用 KOA 写中间件的不同之处,我们来看一下 KOA 的官方示例代码:
var koa = require ('koa');
var app = koa ();
//x-response-time
app.use (function *(next){
var start = new Date;
yield next;
var ms = new Date - start;
this.set ('X-Response-Time', ms + 'ms');
});
//logger
app.use (function *(next){
var start = new Date;
yield next;
var ms = new Date - start;
console.log ('% s % s - % s', this.method, this.url, ms);
});
//response
app.use (function *(){
this.body = 'Hello World';
});
app.listen (3000);
有没有发现?如果还没有发现我就公布答案啦:
根据上文,我们已经知道,那个负责把所有中间件串起来的 next 其实本身也是一个 generator,但是,如果在 Generater 函数内部,调用另一个 Generator 函数,默认情况下是没有效果的,这个时候我们必须使用 yield* next
但是,我们写代码的时候明明写的是 yield next 啊,这就是 co 的巧妙之处了:
co 帮我们 “自动管理” generator 的 next,并根据调用返回的 value 做出不同的响应,这个响应是通过 toPromise 方法进行的,我们可以在 toPromise 中发现:
如果遇到另外一个 generator,co 会继续调用自己,这就是为什么我们不需要写 yield* next 的原因,而只要写 yield next
yieldnext;
可以看一下这个 toPromise
/**
* Convert a `yield`ed value into a promise.
*
* @param {Mixed} obj
* @return {Promise}
* @api private
*/functiontoPromise(obj){if (!obj)returnobj;if (isPromise(obj))returnobj;if (isGeneratorFunction(obj)||isGenerator(obj))returnco.call(this,obj);if ("function"==typeofobj)returnthunkToPromise.call(this,obj);if (Array.isArray(obj))returnarrayToPromise.call(this,obj);if (isObject(obj))returnobjectToPromise.call(this,obj);returnobj;}
所以,co 对 yield 后面跟的类型是严格约定的,如果我们在项目中直接使用了 DEMO 中的
yield1
co 就会给我们一个错误
You may only yield a function, promise, generator, array, or object.
容器组件的存在是为了让它可以专注于数据处理,然后让渲染组件专心负责渲染,只需要管扔进来的是什么数据然后渲染就可以了,这样处理后,我们会发现 component 的代码将变得非常复杂,当我们要管理的 state 太多之后,所以就有了 flux store,但是 flux 的实现中有不必要的实现,对于应用来说,一个 action,一个 state 就可以返回一个新的 state,这完全就是 pure function 就可以搞定的事情,于是有了 redux store
将组件拆分,用更好的 pure function 来返回你需要渲染的这些组件,这样可以利用 decorator/HOC 来达到组件复用,还可以减少组件中大量的 _XXX 私有方法,让应用程序变得更加可控,debug 变得更容易,其实这块还是能够产生很多共鸣的,相信各厂都在实践一些营销页面快速产出的技术方案,React 应该是比较合适的技术选型,可以利用 decorator 达到组件的高度复用
善用 FP,RxJS。士旗在这里安利了一把 learnRX 项目(GitHub - ReactiveX/learnrx: A series of interactive exercises for learning Microsoft’s Reactive Extensions Library for Javascript.),FP 跟 RxJS 本质上是两个东西,只是 RxJS 中有用到 FP 的思想,编程思维的转变我认为是需要训练和下功夫的,因为习惯思维非常可怕,我有看过 RxJS,这种 “一切皆 Stream” 的咒语一开始令人非常困惑,但豁然开朗后简直仿佛像是看到另外一个世界,这方面,士旗主要强调,我们要善用 Array 的 map/reduce/filter,FP 可以让代码变的简洁,FP 的 “语义化 “方法名可以帮助提升代码可读性。
由于本人的技术工作长期专注在应用架构领域,属于软件工程的实践,学术研究工作涉及较少,因此对 AI 部分的技术内容,我会在吸收和理解引用文章的基础上,根据我自己的理解进行阐述和说明,如有错误和不严谨,欢迎指出。与此同时,我认为换一个技术视角去看待同一个问题丝毫不影响我写下本章节的初心和目的:那就是,尝试透过现象看本质。
布鲁克斯的《No Silver Bullet — Essence and Accidents of Software Engineering》告诉我们,软件工程没有银弹,任何设计有优点就一定有缺点。
很显然,这里有几个应用架构侧的隐患在设计之初就已被埋下了,以此,我们可以从应用侧窥探到,即使背后的 AI 大脑再强大,到了应用侧依然会受到技术设计本身的限制,虽然我们有诸多曲线救国的办法,终究仍会受制于这个短板效应:
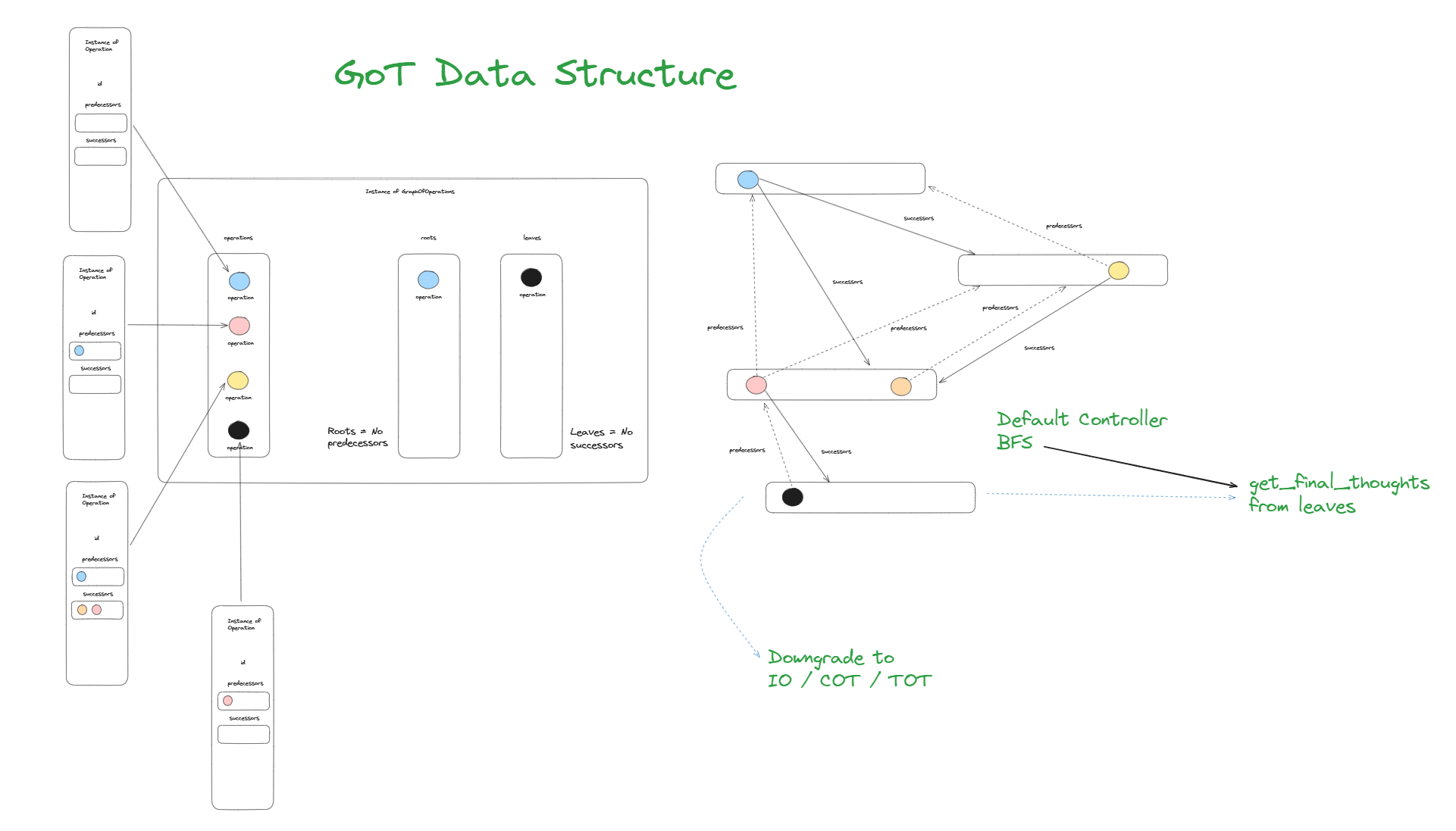
由于需要保持上下文环境的捕获特性,输出要不断继续给到输入,这就意味着,如果从系统架构上,不保留一个类似 tokens buffer 缓冲区的设计,整个 ChatGPT 可能会遭遇不可预期的风险(大量的算力消耗甚至会直接拖垮系统,导致崩溃),这也是为什么 OpenAI Open API 中关于 Model 能力调用的参数说明中明确指出了 4097 tokens 的长度限制: What are tokens and how to count them? / OpenAI Help Center。
应用侧需要使用会话 id 对每一次完整的会话进行隔离,因为即便是人类的对话,也不可能永远都处于一个全局唯一的上下文环境里:比如你今天和朋友聊的话题是吃饭、明天和家人聊的话题是电影,如果几个话题同时并行,很容易将会话带入到一个混乱不堪的状态,即俗称的:不在一个频道,跨服聊天。
从这个角度上,说它是一个永不知疲倦且不断在自我进步的知识工作之神都是不过分的,这里有个重点一定要理解及注意,它并不是联网帮你搜寻 wiki 的内容,它在前面说明的训练过程中才会拿互联网上的信息,目的是找到上文所说的函数,一旦找到了,它就不再需要了。但是收集知识和学习知识完全是两码事,我们回到 NLP 自然语言处理,自然语言处理主要用于感知和识别语言上下文,通俗的理解就是去猜测语言意图:
I was looking for a car to model, and I choose to model an old European car. I was inspired by the Peugeot 205 GTI. It’s an old french car produced from 1982 to 1998 that you can still see in France, Belgium and some others European countries. Made with Blender and Substance Painter.
The easiest way to use v-circle is to install it from NPM and include it in your own Vue build process (using Webpack, etc)
npm install v-circle
Build
build to dist
npm run build
You can also use the standalone build by including dist/v-circle.js in your page. If you use this, make sure you have already included Vue, and it is available as a global variable.
/**
* Use the given middleware `fn`.
*
* @param {GeneratorFunction} fn
* @return {Application} self
* @api public
*/app.use=function(fn){if(!this.experimental){//es7 async functions are not allowed,//so we have to make sure that `fn` is a generator functionassert(fn&&"GeneratorFunction"==fn.constructor.name,"app.use () requires a generator function");}debug("use % s",fn._name||fn.name||"-");// 主要就是做这个事情// 根据上面的 assert,这里的 fn 均为 generator functionthis.middleware.push(fn);returnthis;};
/**
* Return a request handler callback
* for node's native http server.
*
* @return {Function}
* @api public
*/app.callback=function(){if(this.experimental){console.error("Experimental ES7 Async Function support is deprecated. Please look into Koa v2 as the middleware signature has changed.");}varfn=this.experimental?compose_es7(this.middleware):co.wrap(compose(this.middleware));// 把中间件串起来varself=this;if(!this.listeners("error").length)this.on("error",this.onerror);returnfunction(req,res){res.statusCode=404;varctx=self.createContext(req,res);onFinished(res,ctx.onerror);fn.call(ctx).then(function(){respond.call(ctx);}).catch(ctx.onerror);};};
等等,我们的 co 去哪儿了?大家有没有发现上面 Demo 中和我们平时用 KOA 写中间件的不同之处,我们来看一下 KOA 的官方示例代码:
var koa = require ('koa');
var app = koa ();
//x-response-time
app.use (function *(next){
var start = new Date;
yield next;
var ms = new Date - start;
this.set ('X-Response-Time', ms + 'ms');
});
//logger
app.use (function *(next){
var start = new Date;
yield next;
var ms = new Date - start;
console.log ('% s % s - % s', this.method, this.url, ms);
});
//response
app.use (function *(){
this.body = 'Hello World';
});
app.listen (3000);
有没有发现?如果还没有发现我就公布答案啦:
根据上文,我们已经知道,那个负责把所有中间件串起来的 next 其实本身也是一个 generator,但是,如果在 Generater 函数内部,调用另一个 Generator 函数,默认情况下是没有效果的,这个时候我们必须使用 yield* next
但是,我们写代码的时候明明写的是 yield next 啊,这就是 co 的巧妙之处了:
co 帮我们 “自动管理” generator 的 next,并根据调用返回的 value 做出不同的响应,这个响应是通过 toPromise 方法进行的,我们可以在 toPromise 中发现:
如果遇到另外一个 generator,co 会继续调用自己,这就是为什么我们不需要写 yield* next 的原因,而只要写 yield next
yieldnext;
可以看一下这个 toPromise
/**
* Convert a `yield`ed value into a promise.
*
* @param {Mixed} obj
* @return {Promise}
* @api private
*/functiontoPromise(obj){if(!obj)returnobj;if(isPromise(obj))returnobj;if(isGeneratorFunction(obj)||isGenerator(obj))returnco.call(this,obj);if("function"==typeofobj)returnthunkToPromise.call(this,obj);if(Array.isArray(obj))returnarrayToPromise.call(this,obj);if(isObject(obj))returnobjectToPromise.call(this,obj);returnobj;}
所以,co 对 yield 后面跟的类型是严格约定的,如果我们在项目中直接使用了 DEMO 中的
yield1
co 就会给我们一个错误
You may only yield a function, promise, generator, array, or object.