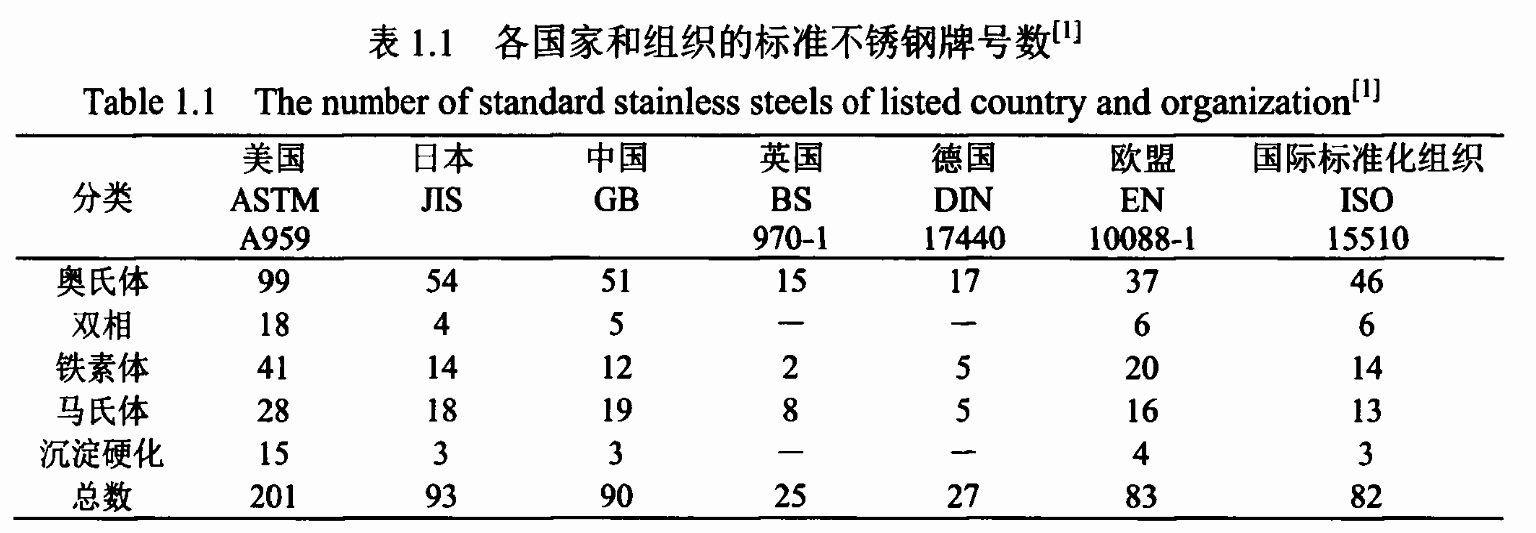
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import scale
# 数据
data = {
# "steel": ["316L", "316L", "316L", "316L", "316L", "316L", "316L", "316L", "316L", "316L", "316L", "316L", "304", "304", "304", "304", "304", "304", "304", "304", "304", "304", "304", "304", "304", "304", "304", "304", "304", "304", "201J1", "201J1", "201J1", "201J1", "201J2", "201J2", "201J2"],
#"type": ["FP", "FP", "FP", "FP", "FP", "FP", "FP", "FP", "FP", "SP", "SP", "HTA", "SP", "SP", "SP", "SP", "SP", "SP", "SP", "SP", "SP", "SP", "SP", "SP", "FP", "FP", "HTA", "SP", "SP", "SP", "SP", "SP", "SP", "SP", "SP", "FP"],
"thickness": [0.028, 0.038, 0.04, 0.048, 0.048, 0.055, 0.08, 0.13, 0.13, 0.085, 0.12, 0.098, 0.07, 0.065, 0.078, 0.078, 0.082, 0.11, 0.116, 0.127, 0.13, 0.13, 0.147, 0.15, 0.185, 0.25, 0.202, 0.15, 0.104, 0.104, 0.11, 0.182, 0.104, 0.152, 0.182],
"tv": [1.6, 1.3, 1.2, 1.9, 2, 2.2, 2.5, 3.2, 3.2, 2.8, 3, 3.5, 1.6, 2.4, 2.2, 2.6, 2.2, 2.5, 2.3, 3.2, 2.5, 2.5, 3.3, 3.2, 3.2, 2.5, 2.5, 4.5, 1.9, 1.9, 2.3, 3.2, 1.9, 3, 3],
"temp": [1120, 1040, 1030, 1060, 1060, 1070, 1080, 950, 1000, 1130, 1140, 960, 1110, 1090, 1100, 1130, 1100, 1110, 1140, 1140, 1140, 1120, 1140, 1140, 1140, 1100, 1120, 800, 1130, 1130, 1140, 1140, 1130, 1140, 1140]
}
# 创建 DataFrame
df = pd.DataFrame(data)
# 提取需要标准化的列
features = df[["thickness", "tv", "temp"]]
# 使用 sklearn.preprocessing.scale() 进行 Z-score 标准化
scaled_features = scale(features)
scaled_df = pd.DataFrame(scaled_features, columns=["thickness", "tv", "temp"])
# 绘制散点图
plt.figure(figsize=(15, 10))
# 定义绘图函数
def plot_scatter(ax, x, y, title, xlabel, ylabel, color="blue"):
ax.scatter(x, y, c=color)
ax.set_title(title)
ax.set_xlabel(xlabel)
ax.set_ylabel(ylabel)
# 第一行:原始数据
plot_scatter(plt.subplot(2, 3, 1), features["thickness"], features["tv"], "Original: Thickness vs TV", "Thickness", "TV")
plot_scatter(plt.subplot(2, 3, 2), features["thickness"], features["temp"], "Original: Thickness vs Temp", "Thickness", "Temp")
plot_scatter(plt.subplot(2, 3, 3), features["tv"], features["temp"], "Original: TV vs Temp", "TV", "Temp")
# 第二行:标准化后的数据
plot_scatter(plt.subplot(2, 3, 4), scaled_df["thickness"], scaled_df["tv"], "Scaled: Thickness vs TV", "Thickness (scaled)", "TV (scaled)", color="red")
plot_scatter(plt.subplot(2, 3, 5), scaled_df["thickness"], scaled_df["temp"], "Scaled: Thickness vs Temp", "Thickness (scaled)", "Temp (scaled)", color="red")
plot_scatter(plt.subplot(2, 3, 6), scaled_df["tv"], scaled_df["temp"], "Scaled: TV vs Temp", "TV (scaled)", "Temp (scaled)", color="red")
plt.tight_layout()
plt.show()
|



-20250302095906576.png)