爱奇艺AI艺人库风波与长剧困局
爱奇艺疯了吗?真人拍摄真的会成为非物质文化遗产吗?别急着骂,这可能就是爱奇艺这样一个平台临死前最后的哀嚎。
大家好,欢迎收听老范讲故事的YouTube频道。
爱奇艺创始人兼首席执行官龚宇,在2026年4月20日的爱奇艺世界大会上扔出了一句狠话:真人拍摄越来越稀有,未来可能会成为非物质文化遗产。更刺激的是,同场爱奇艺高级副总裁刘文峰宣布,纳逗Pro已经有117名艺人入驻了AI艺人库。
结果几个小时之内,张若昀、于和伟、王楚然、李一桐等多位艺人工作室先后否认授权。爱奇艺连夜澄清,龚宇第二天早上5分钟内连发三条微博,试图找补这件事。
所以问题不是爱奇艺会不会用AI,而是它为什么会急成这个样子。它是不是已经被长剧这门生意逼到了必须掀桌子的边缘?这看起来,真的是快要死了。
爱奇艺不是疯了,而是真的快撑不住了
首先我们来看,爱奇艺不是疯了,而是真的快撑不住了。这句话背后真正值得看的,是爱奇艺的财务处境。
爱奇艺2025年全年营收272.9亿元人民币,同比下滑7%。广告收入、会员收入都在下滑。2025年的净利润则是由盈转亏,前面还挣着钱,2025年开始亏钱了,亏了2.06亿元人民币,而2024年同期还是盈利状态。
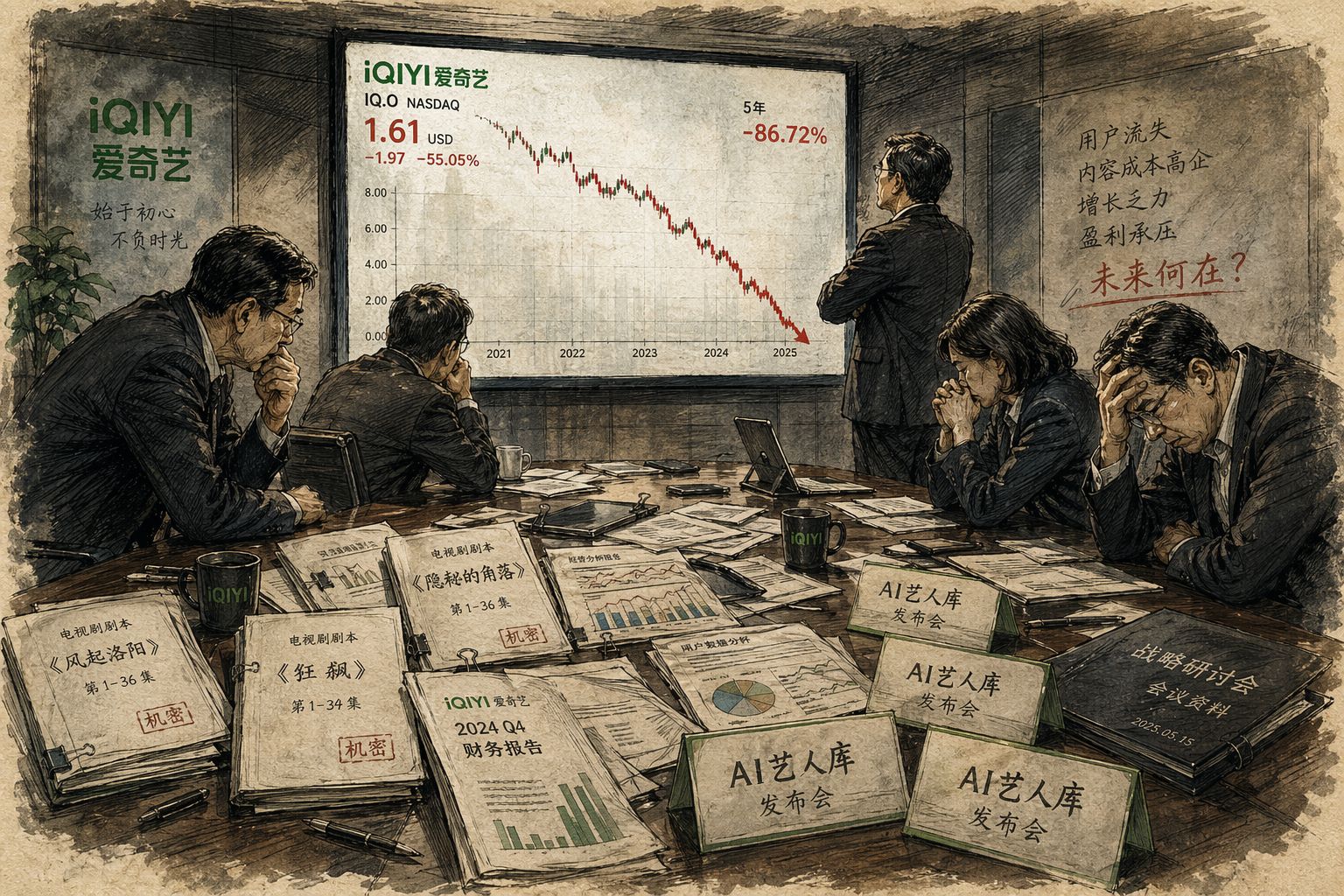
更危险的是自由现金流,也就是现在能够动用的现金。2023年爱奇艺手里还有33亿元人民币,2024年还剩20亿元,到2025年进一步掉到了不足千万人民币。对于爱奇艺这么大规模的平台来说,这真的是站在悬崖边上,随时有可能原地死亡的状态。
股价方面,爱奇艺2018年上市后,股价最高曾经冲到46美元。到了2026年3月,最低只剩1.18美元。要注意,在美国股市,如果连续较长时间股价低于1美元,是有可能被强制退市的。所以爱奇艺真的是活不下去的状态。4月21日收盘价是1.4美元,较高点跌去了超过97%,市值蒸发了300亿美元。
这才是整个事情的底板。一家长视频平台,用户逐渐流失,广告收入下降,内容成本居高不下,背后大股东百度也不像腾讯、阿里那样愿意持续重金输血,只能靠自己活下来。所以爱奇艺现在看到AI,不是因为未来科技很浪漫,而是想看看能不能找到一条活下去的降本增效道路。
长剧为什么越来越像一门赔本买卖
爱奇艺今天最难的不只是收入下滑,而是长剧这套工业体系的成本结构已经完全畸形。把一部长剧拆开来看,成本主要分几块。
演员成本越来越高
第一块是演员成本。头部演员的片酬和档期协调成本极高,而且极其不确定。为了让能够过关的剧尽量有收益,他们一定要去押那几个头部流量明星。
这也是为什么中国会出那么多“粉底液将军”。某种意义上也是没办法,因为他们能保证流量,其他演技派未必能保证流量。这一块的成本越来越高。
服道化和置景持续内卷
第二块是服道化和置景。这一块投入也越来越重。因为现在每年能放出来的剧总量有限,大家只能拼命卷这些东西。所以你现在去看中国电视剧,制作确实越来越精美,但这一块也非常烧钱。
宣发成本高企
第三块是宣发成本。上线前后要买流量,要刷海报,这一块成本也非常高。
最致命的是合规和认证成本
但是前面讲的这三块成本,跟最后一块比起来,几乎都可以忽略不计。最后一块成本是什么?叫合规和认证成本。这一块是最致命的,因为它完全不可控。
一部剧花了这么多钱拍出来,最后让不让你播,不知道。你说现在服道化已经卷成这样了,那我拍现代剧,不行,可能影射当前社会;我拍古装剧,又有限古令,不允许那么多古装剧上线。不是说前面拿到批文了,拍完就一定能放。前面拿到批文,后面政策改了,依然可能放不了。对于平台来说,真正难的就在于这种不确定性。
爱奇艺CEO自己在电视剧导演大会上就吐过苦水,经常一两年宣传部长都换了,剧本和电视剧播出审批却要等三年多。他还算过一笔账:如果有100部电视剧,大概只有30%能够不亏钱,还别说挣钱,剩下都是亏钱的。换句话说,长剧是一个七成要亏损的赌注。
高投入项目为何依旧可能血本无归
《人生若只如初见》的案例
比如原来有一部剧叫《人生若只如初见》,就是一个典型的高投入项目。这部剧2020年10月杀青,请了《亮剑》的编剧江奇涛、《白夜追凶》的导演王伟,主演是李现、魏大勋、春夏,配置极高。2022年7月在爱奇艺播出6集以后,突然以“技术原因”下架。
你看,2020年就杀青了,2022年7月才开始播,中间这段时间在干嘛?就是在审核,在等批文下来。能播出6集,说明前期宣发成本什么的都已经砸下去了,突然又说“技术原因”下架。一个电视剧能有什么技术原因下架?实际上业内都知道,是内容审核没过。前期上千万甚至可能上亿元的投入,直接就打了水漂。
时隔三年,经过修改重新上线,这个剧最后还是播了。但招商情况惨不忍睹。2022年第一轮播出6集时,里头还有6个品牌投放;积压后再上线20多集,只剩下两个品牌。同等配置的项目如果再拖延几年,估计连招商都招不回来了。
古装剧的高风险结构
另外一个典型就是古装剧。古装剧,尤其是精品古装剧,单集制作成本经常就在450万到500万元人民币左右。一部40集的古装大剧,投入就是1.8亿到2亿元人民币。
这笔钱砸下去以后,一旦遇到限古令、内容调性不合规,轻则压两三年,重则直接无法上线。播出后被下架的案例更是屡见不鲜。
而且播出后下架更惨。因为前面跟品牌签了协议,广告投放、品牌植入都已经买好了,最后被下架,你是要赔的。前面那么多广告投入、宣发投入、四处立起来的招牌,全部都是浪费。
也就是说,长剧不光是单纯地贵,而且是又贵、又慢,审核风险还极高。一旦自由现金流变薄,这种业务结构就会从“能熬”变成“熬不起”,甚至可能直接崩掉。
真正抢走用户的,不只是腾讯视频和优酷
更要命的是什么?真正抢用户的,其实还不是什么腾讯视频和优酷。
很多人还把爱奇艺的竞争理解成老三家长视频内战:爱奇艺、腾讯视频、优酷,当然现在还有哔哩哔哩。以前我们管他们叫“优爱腾”,但现在不是这么回事了。
传统对手当然还在。腾讯视频背后是腾讯,资源规模和现金流更厚,而且腾讯后边不光有游戏,还有阅文,等于从小说源头一路往下打通,这一块爱奇艺太薄了,根本打不过。优酷背后是阿里巴巴,也是大厂体系。爱奇艺背后也有人,就是百度,但百度这几年自己都不太知道后面该怎么走,哪还顾得上它。
但现在真正打得爱奇艺抬不起头来的,是短剧,而且还不是传统短剧,而是AI短剧。
AI短剧正在爆发式增长
根据DataEye与企查查统计,去年AI真人短剧市场规模已经突破120亿元人民币,同比增长300%。这一块才是涨得最快的。
供给量方面,2025年的AI短剧供给量是2024年的50倍,不是多了50%,是50倍。到2026年这个数据就更加吓人了。2026年1月,国内AI漫剧单月上线数量是1.4万部;到2026年3月,仅红果短剧平台日均上新量就是2000部。红果短剧背后是字节跳动。这种AI短剧的数量,是真人短剧的20倍。
截至2026年2月末,在播的AI剧总量是12.78万部,是2025年全年的两倍。这个数字非常可怕。预计到2026年,AI漫剧以及包含AI仿真人短剧的用户规模,将从2025年的1.2亿增至2.8亿,增幅130%。
那么多出来的这些用户哪来的?就是从长剧身上抢的。
这意味着什么?意味着长剧平台还在按照年度项目制去打仗,拍完一部剧还得审个三年,才能播,随时还可能被下架;而短剧平台已经开始按照内容流水线的方式进行轰炸了。所以长剧根本打不过短剧,特别是AI短剧。
为什么AI先在短剧和漫剧里爆发
那么,AI为什么先在短剧、漫剧里爆发,而不是先干掉长剧?这一步很关键。
很多人一听说AI取代演员,就直接联想到长剧、电影、明星主演,其实不是这么回事。真正被AI替代的第一波,其实不是人,而是服道化以及场景布置。
比如一个人在那演完以后,你可以直接在AI里说,把他的衣服换一下,化个妆,再把后面的背景换一换,这就直接出来了。上面那个人还是真人演的,但其他部分都可以交给AI。
对于平台而言,这比直接替代顶流演员更现实,因为更容易落地,也更容易立刻省出钱来。
短剧天然适合AI生产
而且,短剧天然更适合AI生产。一部精品AI仿真人短剧,整体成本已经能控制在20万元以内;头部真人精品短剧,成本则在150万到300万元人民币之间。AI剧的成本大约是真人短剧的十分之一。
AI短剧和漫剧的传播半径本身也更零碎。因为数量这么大,不可能有一部剧所有人都去看,所以审核相对来说也更宽松一些。20万一部,试错成本也低。你不像爱奇艺那样,几千万上亿砸出一部剧,最后“咔嚓”一下被毙掉,那太疼了。短剧这边20万一部,毙就毙了,再来一部,不是什么大问题。
100万元以内的审批优势
那么为什么AI剧的合规门槛会稍微低一些?因为国家有规定,如果是普通题材,没有碰到题材红线,制作成本少于100万元人民币的,可以走简化审批流程。刚才讲了,做剧最核心、最不可控的成本,就是合规和审查。你只要不超过100万元,就可以走这个流程。
而且这个流程谁来负责审?不是国家机关,也不是政府单位,而是播放平台自己审一下就完事了。所以为什么能有上万部短剧、一天几千部往上冲,原因就在这儿:它不需要走复杂的审批流程,直接就可以上线。
所以真正的核心差异就在这里。你如果走真人短剧,还是可能超过100万元;你走AI短剧,一下就变成20万元、15万元,就算拍长一点、做复杂一点,搞到七八十万元,这事都是过得去的。
爱奇艺为什么盯上AI艺人库
在这些因素叠加之后,爱奇艺就把算盘打到了AI艺人库的头上。
到了这里,再回头看AI艺人库,逻辑就清楚多了。龚宇今年3月提出了一个“112模型”。这模型听起来很合理,但实际上跟现有的商业模式是完全背道而驰的,根本走不通。
“112模型”是什么
为什么?来看一下。“112”的第一个“1”是什么?AI使单位内容成本降低一个数量级。原来需要花一个亿拍完的剧,现在只需要1000万。第二个“1”是创作者数量至少增加一个数量级,不需要那么多明星,很多普通人都可以加进来,通过AI进行服道化改变,做滤镜之类的处理,有更多创作者可以进来。最后那个“2”,是作品数量至少增加两个数量级。现在一年其实没多少部剧,未来可能直接乘以100,这就是他想要的效果。
为什么这套逻辑跑不通
但这个逻辑其实是错的。因为成本依然没有降低到100万元人民币以下。即便降低到了那个范围以下,你还是长剧,不能走100万元以下短剧的简易审批流程。所以最后那个最不可控的审批因素,你依然无法排除。
这是第一点。第二点,你是可以把内容制作数量提升两个数量级了,但演员不乐意。演员要的不是“我更省力,可以拍出更多剧”,他们想要的是人为制造稀缺性,在单位时间内获得最大的经济利益。不是说突然同时上10部我演的剧,我就一定挣得更多。未必。
演员想要的是出精品,出一部挣一部的钱,而且这段时间里最好只有我一部剧上去。这才是演员真正想要的东西。
所以爱奇艺想的这套东西,跟现在电视剧的制作和拍摄逻辑,包括演员的利益诉求,根本就不在一条线上。这东西压根没法实现。
117位艺人入驻风波说明了什么
2026年4月20日,爱奇艺在世界大会上正式发布了纳逗Pro AI艺人库。刘文峰现场称已经有117位艺人签约入驻,但后来又回来找补,说“签约入驻”不是签约的意思,只是说和我们接洽了,有相关意向。
这不是开玩笑吗?你都把人照片贴出来了,说这些人都签约入驻了,最后又被张若昀、于和伟、王楚然、李一桐这些人的工作室闪电辟谣,说我根本没跟你签过约,从来没有同意过这件事。
爱奇艺只能在4月21日早晨出来各种澄清,还说以后还是一事一议,具体让你参与到哪个项目里,我还是会去找你签约,不会说你授权以后我们就随便用了。任何一个角色,任何一次使用,我们都会去签约。
但它最后只能这样往回找补,这其实没有任何意义,核心矛盾根本解决不了。这个库到底能不能建成,关键压根就不是技术问题。
平台与艺人的矛盾,不只是授权问题
在中国,艺人并没有强硬的集体谈判机制,所以他们只能各自在工作室里出来表达:我们没有签过约,我们没有授过权。他们不敢罢工,罢工很可能就会被封杀,有的是人惦记着出来当明星,不缺你一个两个。
这跟美国不一样。美国有演员工会,2023年组织过罢工,把AI使用权当成核心议题。电影和电视剧制片人联盟最后跟演员达成了协议,把数字替身和合成演员写进了规则里,必须书面同意、单独付费、明确使用范围。在中国,根本不可能形成这样一套机制。
所以平台一定会优先按照成本模型去寻找可能的出路,否则它会死。
法律边界与现实执行之间的落差
在法律上,模糊授权其实是很危险的。按照《中华人民共和国民法典》1019条、《中华人民共和国个人信息保护法》以及《互联网信息服务深度合成管理规定》等规定,未经肖像权人同意,不得制作、使用、公开他人肖像;人脸、声纹等生物信息属于敏感个人信息,处理需要单独同意;未经特定自然人同意,不得提供足以识别其身份的虚拟形象服务。
但是,现实往往是普遍违法、选择执法。所以AI形象库一定会上线。上线以后,你不授权,有的是人授权。那么未来就会变成另外一个样子。
谁会先被AI替代
再往后走,先被替代的未必是明星,但明星神话一定会被冲淡。因为那是几万部、几十万部的剧同时在往上冲。你说我想做精品剧,谁有空等你?
很多人把这件事理解为AI会不会立刻取代明星。按我的判断,在长剧领域里,取代明星是一个必然方向,但不是一夜之间就能完成。美国可以罢工、起诉、谈判,中国则更可能先按照成本逻辑一路试探下去。
顶流明星短期内仍然有商业价值,没有那么容易直接被替换。但是大量功能性角色、中腰部演员、可替代型表演,会先被AI挤压掉。以后可能你拍的时候,就这么几个主要演员拍完就完了,身边那些配角可能通通都是AI。
编剧于白眉就公开判断,AI会替代60%演技不足的演员,而且这个比例还会继续上升。导演陆川的判断更谨慎一些:两到三年内,一般性、模式化的表演可能被AI替代,但鲜活、独特、不可复刻的表演,AI依然替代不了。
注意力份额将被重构
更深的变化是,供给爆炸以后,明星的注意力份额会被稀释。原来没有这么多剧可看,但当一个月有几万部AI短剧冲上来的时候,这些传统明星到底还能在观众注意力里留下多少空间,就要重新思考了。
你去看爱奇艺也好,腾讯视频也好,他们的用户量在下降,广告收入和会员收入也在下降。传统明星或许能够守住自己的肖像权,但是大量网红,特别是那种“撞脸网红”,比如我长得跟哪个明星像,但这也是我自己的脸,我出去授权自己的形象,这没毛病。还有普通模特,也未必在意授权边界,甚至愿意为了额外收入开放形象使用。那以后直接用这些人不就完了吗?
当几万部、几十万部没有明星的AI微短剧开始大规模冲击用户眼球的时候,旧明星体系对注意力的垄断就会被削弱。新的明星会在AI内容生态里重新生成,这会把长剧逼回一个小众、高价艺术品的位置。
长剧未来会不会变成“非遗”
所以长剧未来可能会走向什么方向?再往后走,它不一定真的是非物质文化遗产,但可能会变得更像舞台剧:很贵,很高雅,看的人很少,但依然会存在。
不会因为大家都去看电影了,舞台剧就彻底没人看了,不是这样的。舞台剧依然是最高雅的那一批。这可能才是长剧未来的方向。
爱奇艺还能走出来吗
那么,爱奇艺能走出来吗?我个人的感觉是非常非常难。
第一层:明星利益与平台模型根本冲突
第一,就算一事一议,让明星授权形象参与剧集制作,也未必跑得通。因为明星压根不希望自己的内容被大量涌现出来,这和所谓的112模型根本就是背道而驰的。爱奇艺想要的是112模型,要你提供两个数量级的内容出来;而明星想要的是人为稀缺性。所以这是完全不可调和的矛盾,不是说有了技术就可以调和,根本调和不了。
第二层:降本并不能解决长剧审批困境
第二,即使长剧成本下降一个数量级,你也没有办法改变长剧的命运。刚才讲了,长剧最痛苦的成本是最后的合规审批成本。原来需要2亿元,或者1.5亿元拍一部古装长剧,现在下降一个数量级,变成1000万、2000万,你依然没办法走短剧的简单审批流程,这事还是搞不定。
第三层:短剧审批机制决定了差距
中国短剧的规则大概是这样:
- 100万元以内,播出平台自主审核,可以快捷备案,平台负责就完了;
- 100万到300万元,由省级以上广电主管部门做规划备案加成片审核;
- 300万元及以上,或者特殊题材,则要国家广电总局统一备案公示,加成片审查。
一旦走到300万元以上,没有两三年根本审不完。即使上了AI,长剧也很难把成本压到这样一个范围之内。
最终结论
最后的结论是,爱奇艺这次不是简单地发疯,而是把整个行业最残酷的现实提前说穿了。长剧越来越贵,越来越慢,越来越难以回本;AI短剧、AI漫剧已经用极低成本和极高供给,先把市场打穿了。
平台一定会去寻找真人稀缺性之外的内容工业化路径,而明星、演员、经纪公司接下来真正要守的,不再只是片酬,而是自己的数字人格权。
这一块不只是让AI形象长得像你,它还可以模仿你的演技、你的说话方式、你的动作态度,甚至包括各种表情,而且可以模仿得很像。那你说,我就是觉得它不像,就是觉得不好看,怎么办?
这其实是个很简单的问题。现在绝大部分人吃的本来就是预制菜,真正能跑去吃“寿司之神”那种由老师傅站在你面前现捏寿司的人,终究是极少数。
所以在这一点上,我觉得龚宇说得还是对的。以后完全以物理形态、由真人表演的这种长剧,可能真的会变成某种意义上的“非物质文化遗产”。

















