This post is about the ruby library we are building - Datamappify, please go check it out.
At Locomote we are building a relatively large web application using Rails. Before we began to lay the foundation, we knew very well that if we wanted the project to be maintainable we had to architect the system with extra care and attention. More specifically, we can’t rely on simply using ActiveRecord which combines behaviour and persistence as our domain models.
We began our search for something that would help us decouple our application from the domain layer down to the form handling. We’ve found a couple of gems that are close to what we were after - Curator, Minimapper, Edr and later on Reform. They are all wonderful gems but unfortunately none of them has everything we need.
Here are the things we need:
-
Decouple domain logic and data persistence.
-
Decouple models and forms.
-
Support ActiveRecord (or at the very least, ActiveModel) so we can still use many of the awesome gems like Devise, SimpleForm and CarrierWave.
-
Support attributes mapped from different data sources (e.g. remote web services from third-party vendors).
-
Support lazy loading so that attributes stored on remote data sources will not get triggered upon loading the entities.
All things considered, we bit the bullet and started working on Datamappify.
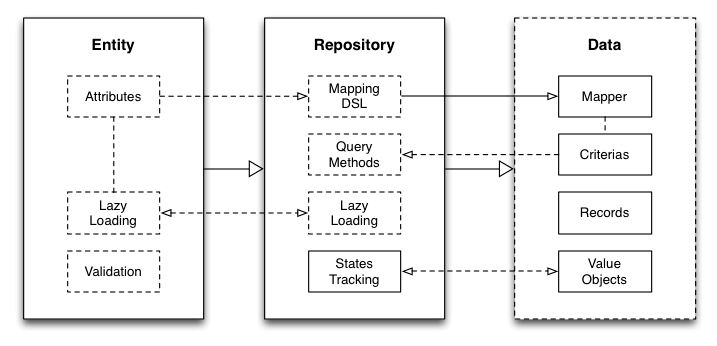
Before I go into details and examples, here is an extremely simplified overview of Datamappify’s architecture:

As you can see, Datamappify is loosely based on Repository pattern and Entity Aggregation pattern.
Datamappify has three main design goals:
-
To utilise the powerfulness of existing ORMs so that using Datamappify doesn’t interrupt too much of your current workflow. For example, Devise would still work if you use it with a UserAccount ActiveRecord model that is attached to a User entity managed by Datamappify.
-
To have a flexible entity model that works great with dealing with form data. For example, SimpleForm would still work with nested attributes from different ORM models if you map entity attributes smartly in your repositories managed by Datamappify.
-
To have a set of data providers to encapsulate the handling of how the data is persisted. This is especially useful for dealing with external data sources such as a web service. For example, by calling UserRepository.save(user), certain attributes of the user entity are now persisted on a remote web service. Better yet, dirty tracking and lazy loading are supported out of the box!
You can read more about Datamappify in the project’s README. For this blog post I will focus on how we use Datamappify in our Rails application. We are still early days in our application development and Datamappify still has quirks and issues, but I am hoping this post will illustrate some of the key benefits of Datamappify.
Getting Started
Getting started with using Datamappify is really easy. We simply include it in the Gemfile:
gem 'datamappify'
To keep things organised, we put entities and repositories in their respective directories under app:
Entities
The reason we wanted Datamappify to utilise existing ORMs like ActiveRecord, is so that we could still use gems like Devise.
So, we have a UserAccount model that handles authentication:
class UserAccount < ActiveRecord::Base
devise :database_authenticatable,
:recoverable, :rememberable, :trackable, :validatable
end
UserAccount has one and only one purpose - user account authentication. Other user behaviours would be contained in either the User entity itself or service objects. Speaking of the User entity, it looks like this:
class User
include Datamappify::Entity
attr_accessor :user_account
attribute :account_username, String
attribute :account_email, String
attribute :first_name, String
attribute :last_name, String
attribute :activated, Boolean, :default => true
attributes_from Contact, prefix_with: :work
validates :first_name, presence: true
validates :last_name, presence: true
references :agency
def full_name
"#{first_name} #{last_name}"
end
end
We include Datamappify::Entity in the User class to make it an entity. We set the :user_account accessor is so that we could attach the UserAccount object onto the entity.
The attribute DSL is from Virtus - we get attribute type coercion for free, awesome!
attributes_from is a DSL provided by Datamappify - it essentially “mounts” all the attributes from another entity, in this case the Contact entity, which looks like this:
class Contact
include Datamappify::Entity
attribute :email, String
attribute :phone_number, String
attribute :fax_number, String
validates :phone_number, presence: true
validates :fax_number, presence: true
end
All the attributes and validation rules from Contact are now “mounted” on User. attributes_from Contact, prefix_with: :work is equivalent to:
attribute :work_email, String
attribute :work_phone_number, String
attribute :work_fax_number, String
validates :work_phone_number, presence: true
validates :work_fax_number, presence: true
Validation DSL is provided by ActiveModel::Validations.
references :agency is a convenient DSL provided by Datamappify. It is equivalent to:
attr_accessor :agency
attribute :agency_id, Integer
Now that we have entities, we need a way to retrieve and store them. For that we need repositories.
Repositories
Here is the user repository:
class UserRepository
include Datamappify::Repository
for_entity User
default_provider :ActiveRecord
map_attribute :account_username, 'ActiveRecord::UserAccount#username'
map_attribute :account_email, 'ActiveRecord::UserAccount#email'
map_attribute :work_email, 'ActiveRecord::Contact#email'
map_attribute :work_phone_number, 'ActiveRecord::Contact#phone_number'
map_attribute :work_fax_number, 'ActiveRecord::Contact#fax_number'
end
Similarly to an entity, we include Datamappify::Repository to make the class a repository. We specify for_entity to link the repository to an entity, and default_provider to use a specific data provider for unmapped attributes.
Unmapped attributes are the ones not specified in map_attribute, in this case they are first_name, last_name and activated. Unmapped attributes are actually automatically mapped by Datamappify, so the user repository essentially does this:
map_attribute :first_name, 'ActiveRecord::User#first_name'
map_attribute :last_name, 'ActiveRecord::User#last_name'
map_attribute :activated, 'ActiveRecord::User#activated'
The first argument of map_attribute is the name of the attribute from the User entity (e.g. :first_name).
The second argument is a string containing three things:
-
ActiveRecord is the data provider.
-
::User is the ActiveRecord model class.
-
#first_name is the ActiveRecord attribute from the model class.
Even though the User entity is a representation of a user on the domain level, the underlying data structure does not necessary have to be. As you can see from the user repository example, we are mapping :account_username and :account_email to the UserAccount ActiveRecord model we’ve seen before. And we have a bunch of contact details attributes mapped to the Contact ActiveRecord model.
The database schema therefore looks like this:
create_table "contacts", force: true do |t|
t.string "email"
t.string "phone_number"
t.string "fax_number"
t.integer "user_id"
end
create_table "user_accounts", force: true do |t|
t.string "username", default: "", null: false
t.string "email", default: "", null: false
t.string "encrypted_password", default: "", null: false
t.string "reset_password_token"
t.datetime "reset_password_sent_at"
t.datetime "remember_created_at"
t.integer "sign_in_count", default: 0
t.datetime "current_sign_in_at"
t.datetime "last_sign_in_at"
t.string "current_sign_in_ip"
t.string "last_sign_in_ip"
t.integer "user_id"
t.datetime "created_at"
t.datetime "updated_at"
end
create_table "users", force: true do |t|
t.string "first_name"
t.string "last_name"
t.boolean "activated"
t.integer "agency_id"
end
Note that because the Contact entity is mounted on the User entity, we need a foreign key user_id in the contacts table to link them.
Data providers
Because we are allowed to specify a data provider (i.e. ActiveRecord) for each attribute, we can map attributes to entirely different data providers! For instance, we could have:
map_attribute :first_name, 'ActiveRecord::User#first_name'
map_attribute :last_name, 'ActiveRecord::User#last_name'
map_attribute :activated, 'Sequel::UserActivation#activated'
Now the activated attribute is mapped to the UserActivation Sequel model. This powerful feature would allow us to develop data providers that communicate with remote web services. :)
Repository APIs
Datamappify provides a bunch of APIs for retrieving and storing data. These APIs are being developed as needed during our application development.
For instance, to find a particular user entity by ID:
user = UserRepository.find(1)
To get all the users:
users = UserRepository.all
To search for users:
users = UserRepository.find(:first_name => 'Fred', :activated => true)
To save a user:
UserRepository.save(user)
To delete a user:
UserRepository.destroy(user)
There are some limitations for certain APIs, you can read more about them here.
When saving an entity, because Datamappify has an internal pool for tracking dirty attributes, only those dirty attributes will get saved.
Also, Datamappify supports attribute lazy loading, all we have to do is to tell our entity to become lazy aware:
class User
include Datamappify::Entity
include Datamappify::Lazy
end
Once an entity is lazy aware, a repository will inject the lazy loading mechanism onto the entity when it retrieves such entity (via find).
Both repositories and entities support inheritance, again, you may read more about them in the project’s README.
Putting Things Together With A Controller
Remember we have the UserAccount for authentication? So how does that work? Well, here’s the piece of code in our application controller:
class ApplicationController < ActionController::Base
before_filter :authenticate_user_account!
private
def current_user
unless current_user_account.blank?
@current_user ||= UserRepository.find(current_user_account.user_id)
end
end
helper_method :current_user
end
Not too different from the normal Devise workflow hey? ;)
Forms
Web applications typically have lots of forms - ours is no different. It turns out, Datamappify can help build form objects too!
Here’s the view portion of one of our forms (we use Slim templates):
# our standard form layout
= simple_form_for submission_target, url: submission_path, signed: true do |f|
= yield(f)
.form-actions
.pull-left
- if archivable? && resource.persisted?
= link_to 'Archive', '#', method: :delete, class: 'btn-archive'
= f.submit 'Save'
= link_to 'Cancel', cancel_path
# actual form content
= render layout: 'forms/resource' do |f|
h3 Account Details
.row-fluid
.span4 = f.input :account_type, collection: BankAccount::ACCOUNT_TYPES.invert
.span4 = f.input :account_code
.span4 = f.input :account_name
.row-fluid
.span4 = f.input :account_number
.span4 = f.input :bank_name
.span4 = f.input :bank_branch
.row-fluid
.span4 = f.input :bank_bsb, label: "Bank BSB"
.span4 = f.input :activated, as: :boolean
h3 Branch Details
.row-fluid
.span4 = f.input :branch_address_line_1, label: "Address 1"
.span4 = f.input :branch_address_line_2, label: "Address 2"
.span4 = f.input :branch_address_line_3, label: "Address 3"
.row-fluid
.span4 = f.input :branch_state, label: "State"
.span4 = f.input :branch_postcode, label: "Postcode"
.span4
= f.input :branch_country_code, label: "Country" do
= f.country_select :branch_country_code, ['au', 'us', 'gb'], value: 'au'
- f.add_signed_fields :branch_country_code
.row-fluid
.span4 = f.input :branch_phone_number, label: "Phone number"
.span4 = f.input :branch_fax_number, label: "Fax number"
h3 Merchant Details
.row-fluid
.span4 = f.input :merchant_number
.span4 = f.input :merchant_name
.span4 = f.input :merchant_address
.row-fluid
.span4 = f.input :merchant_biller_code, label: "Biller code"
.span4 = f.input :merchant_bpay_method, collection: Merchant::BPAY_METHODS.invert, label: "BPAY method"
h3 Payment Details
.row-fluid
.span4 = f.input :payment_number
.span4 = f.input :payment_merchant, label: "Merchant description"
.span4 = f.input :payment_reference_type, collection: PaymentAccount::REFERENCE_TYPES.invert, label: 'Reference type'
As you can see, it’s a form containing details from bank account, branch address, branch contact information, merchant and payment. And indeed we do have bank_accounts, addresses, contacts, merchants and payment_accounts tables in our database. Yet, the form still remains flat-structured and submits via simple_form_for.
This is thanks to our BankAccount entity and BankAccountRepository repository:
class BankAccount
include Datamappify::Entity
include Concerns::Archivable
ACCOUNT_TYPES = {
'general' => 'General',
'trust' => 'Trust'
}
attribute :account_type, String
attribute :account_code, String
attribute :account_name, String
attribute :account_number, String
attribute :bank_name, String
attribute :bank_branch, String
attribute :bank_bsb, String
attribute :activated, Boolean, default: true
attributes_from Address, prefix_with: :branch
attributes_from Contact, prefix_with: :branch
attributes_from Merchant, prefix_with: :merchant
attributes_from PaymentAccount, prefix_with: :payment
references :agency
validates :account_type, Mos::Validation.in(ACCOUNT_TYPES)
validates :account_code, Mos::Validation::STANDARD_TEXT
validates :account_name, Mos::Validation::STANDARD_TEXT
validates :account_number, Mos::Validation::STANDARD_TEXT
validates :bank_name, Mos::Validation::STANDARD_TEXT
validates :bank_branch, Mos::Validation::STANDARD_TEXT_OPTIONAL
validates :bank_bsb, Mos::Validation::BSB
validates :merchant_bpay_method, Mos::Validation.presence_depend_on(:merchant_biller_code)
validates :payment_reference_type, Mos::Validation.presence_depend_on(:payment_number)
end
class BankAccountRepository
include Datamappify::Repository
for_entity BankAccount
default_provider :ActiveRecord
map_attribute :branch_address_line_1, 'ActiveRecord::Address#address_line_1'
map_attribute :branch_address_line_2, 'ActiveRecord::Address#address_line_2'
map_attribute :branch_address_line_3, 'ActiveRecord::Address#address_line_3'
map_attribute :branch_state, 'ActiveRecord::Address#state'
map_attribute :branch_postcode, 'ActiveRecord::Address#postcode'
map_attribute :branch_country_code, 'ActiveRecord::Address#country_code'
map_attribute :branch_phone_number, 'ActiveRecord::Contact#phone_number'
map_attribute :branch_fax_number, 'ActiveRecord::Contact#fax_number'
map_attribute :branch_email, 'ActiveRecord::Contact#email'
map_attribute :branch_website, 'ActiveRecord::Contact#website'
map_attribute :merchant_number, 'ActiveRecord::Merchant#number'
map_attribute :merchant_name, 'ActiveRecord::Merchant#name'
map_attribute :merchant_address, 'ActiveRecord::Merchant#address'
map_attribute :merchant_biller_code, 'ActiveRecord::Merchant#biller_code'
map_attribute :merchant_bpay_method, 'ActiveRecord::Merchant#bpay_method'
map_attribute :payment_number, 'ActiveRecord::PaymentAccount#number'
map_attribute :payment_merchant, 'ActiveRecord::PaymentAccount#merchant'
map_attribute :payment_reference_type, 'ActiveRecord::PaymentAccount#reference_type'
end
Pretty clean and straightforward. What do you think?
Datamappify - Keeping Your Domain Layer Sane
Datamappify’s concept isn’t new, but there simply isn’t anything in the ruby community that solves everything Datamappify tries to solve.
I hope that this post has not only introduced you to Datamappify, but has also made you think about how to make your application’s domain layer more decoupled.
Thanks for reading, and if you have any feedback for Datamappify please get in touch with me!
]]>