Codex Skills 不是 Prompt 的升级版,而是写给 AI 的岗位 SOP
Prompt 更像临时交代,Skill 更像写给 AI 的岗位 SOP。
我花时间研究了 Codex Skills,发现它不是 Prompt 的升级版
最近我重新梳理了一遍 Codex 的 Skills 机制,最大的感受是:它被很多人低估了。
我一开始也没太当回事。第一眼看上去,它很像 prompt 模板:给 AI 一段说明,告诉它做什么、注意什么、最后产出什么。看久了甚至会产生一种错觉:这不就是把 prompt 打包了一下吗?
但真正把它放到工程场景里看,我的想法变了。
因为在真实开发里,问题从来不只是“这次能不能把代码写出来”。更麻烦的是另外几件事:同一类任务每次都要重新解释背景;不同人写出来的提示词风格完全不一样;任务一长,约束开始丢;协作一多,规范就散掉。很多团队现在用 AI 不够稳,不是因为模型不够强,而是因为工作流还停留在临场发挥。
而 Skills 真正解决的,恰恰是这个问题:它不是让 AI 多会一点,而是把原本散落在个人经验、团队规范和临时指令里的工作方法,整理成可复用、可迁移、可版本化的执行单元。
如果要我用一句话概括:
Prompt 更像临时交代,Skill 更像写给 AI 的岗位 SOP。
为什么我会重新看待 Skills
我现在越来越觉得,Skills 不是 prompt 的小升级,而是 AI 编程开始进入“工作流工程”的一个信号。
在 prompt 时代,我们优化的是一次对话:怎么把上下文塞进去,怎么把要求说清楚,怎么让模型这一次别跑偏。这当然有用,但它天然偏一次性。它适合解决“眼前这件事”,不太适合沉淀“以后同类事情都怎么做”。
而软件工程最贵的,往往不是一次性的输出,而是重复执行时的稳定性。一个团队每天都在反复做类似的事情:评审 PR、查文档、补测试、做重构前的架构判断、接手陌生代码库、把需求拆成工程任务。这些事情如果每次都靠人重新写 prompt,本质上还是手工作坊。
所以我这次重新看 Skills,最大的转变就是:它让我第一次比较清楚地看到,AI 工具正在从“会补全的助手”,往“能执行团队方法论的工程角色”演进。
Skills 到底是什么
我现在对 Skill 的理解很简单:它不是一句咒语,而是一个可复用的工作流目录。
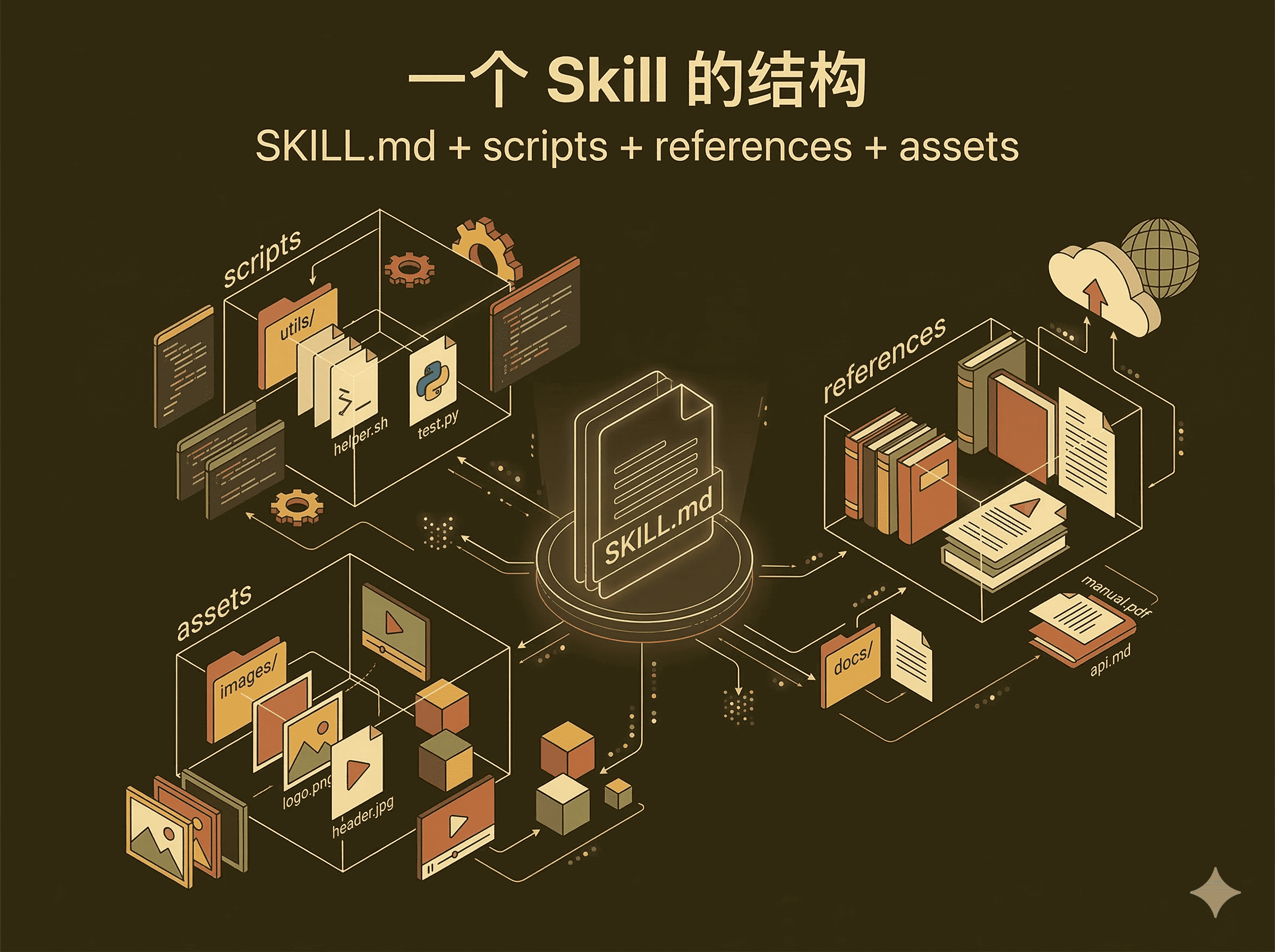
一个标准 Skill 的核心通常是 SKILL.md。这个文件不只是说明文档,它其实定义了一个技能的边界:它在什么场景下应该被触发,要做哪些步骤,产出什么结果,做到什么程度才算完成。
如果任务需要确定性执行,可以挂 scripts/;如果要补充领域知识,可以放 references/;如果要复用模板和脚手架,可以放 assets/。有些技能还会带 agents/openai.yaml 这种平台侧元数据,用来描述它在特定界面里的展示和依赖关系。
一个典型的技能目录,大概会长这样:
1 | my-skill/ |
SKILL.md 里最关键的通常不是长篇背景,而是几个东西:name、description、执行步骤、边界条件和 Done criteria。例如:
1 | --- |
我很认同一个说法:SKILL.md 更像目录,不像百科全书。长文档、规范、架构约束、接口契约,应该拆到 references/ 里,别把所有东西都堆进主指令。这样更清楚,也更稳。
scripts/ 还有一个经常被低估的价值:它不只是为了“把逻辑写死一点”,也是为了把确定性执行和敏感鉴权隔离开。比如你要连 Slack、Jira 或内部 API,真正的密钥最好通过运行时环境变量注入给脚本读取,而不是直接写在 SKILL.md 里。这样 Skill 作为静态资产在团队内流转时会安全得多,方法能复用,凭据却不会跟着扩散。
从这个角度看,Skill 跟普通 prompt 最大的区别是:prompt 更像一段临时话术,Skill 更像一个有结构的工作单元。前者重点是“怎么说”,后者重点是“怎么稳定地做”。
![]()
它为什么比普通 Prompt 更进一步
Skills 最值得说的一点,是它的按需加载思路。
系统平时并不会把所有技能内容都塞进上下文,而是只记录每个 Skill 的 name 和 description。只有两种情况,完整技能才会被调起:要么你显式点名,要么当前任务和它的 description 高度匹配。
这看起来只是个技术细节,但实际价值很大。
第一,上下文更干净。没有被调用的技能,不会抢占注意力。第二,复杂任务更稳。模型不需要在一大堆无关规则里找重点。第三,技能库可以做得更细。你可以维护很多高专业度的小技能,而不是逼着一个巨型 prompt 同时解决所有问题。
这套机制背后,本质上就是“渐进式披露”和“延迟绑定”。启动时先注册轻量元数据,真正需要时再把完整指令、脚本路径和参考资料带入当前会话。从工程实现上看,可以把这一步理解为一种 Discovery 和按需展开的过程:系统先发现技能,再在需要时加载技能,而不是一开始就把所有能力灌进模型。
省 token 只是副产品,真正重要的是稳定性。尤其在企业场景里,稳定比“偶尔惊艳一次”重要得多。更有意思的是,最近模型侧对内置工具的调用,也在朝类似方向演进:像 OpenAI 的 web search、file search 这类能力,本质上也是需要时才触发,而不是先把所有工具结果预塞进上下文。换句话说,Skills 里的这套延迟绑定思路,并不是一个孤立技巧,而是越来越像现代 agent 系统里的通用设计。
这也是我为什么觉得,Skills 比普通 prompt 更适合团队使用。因为它天然支持经验沉淀、角色分工和规范复用。你可以把架构审查、测试约束、发布检查、PR 处理,甚至某个业务域里的特殊规则,变成团队共享的资产,而不是继续依赖“谁比较会写提示词”。
Skills 和 MCP 不是一回事
很多人会把 MCP 和 Skills 放在一起聊,但它们解决的问题并不一样。
我的理解是:MCP 更像能力接口,负责把 AI 连到 GitHub、文档服务、数据库、外部系统;Skills 更像执行层,决定什么时候调这些能力、按什么步骤调、失败了怎么收口。前者提供基础设施,后者提供工作方法。
你可以把它理解成:MCP 决定“能不能连上工具”,Skill 决定“连上之后该怎么做”。
拿 gh-address-comments 这类技能举例:真正去读取 PR 评论、定位代码、拉取仓库信息,靠的是相关工具能力;但“先拉评论、再定位代码块、再生成补丁、再跑验证、最后给出解释”这套顺序和规则,才是 Skill 在定义的东西。
这也是为什么我觉得,真正好用的不是“工具越多越好”,而是“有没有一套稳定的方法,把这些工具组织起来”。
Skill、Agent 和 Sub-agent 到底是什么关系
我觉得这里还有一个特别容易混的点:很多人会把 Skill、Agent、Sub-agent 当成一层东西来理解,但它们其实分别属于三层。这里的 Sub-agent 更多是工程上的描述;在不同产品界面里,也可能表现为 parallel agent、worker agent 或 background task。
最简单的说法是:Skill 是方法,Agent 是执行者,Sub-agent 是被拆分出去的执行者。
如果展开一点看:
Skill是静态资产。它通常躺在磁盘里,以SKILL.md、scripts/、references/这些文件形式存在,本质上是一套可复用的工作流定义。Agent是运行时主体。它接到任务后,会读取上下文、调用工具、决定是否使用某个Skill,并对当前任务的结果负责。Sub-agent是被主Agent派生出去的子执行单元。它不是另一种Skill,而是一个范围更小、目标更明确、生命周期更短的Agent。
如果非要做一个技术上的对应关系,我会这样记:
Skill更像类库或 playbookAgent更像正在运行的进程或 workerSub-agent更像被主进程派生出来的子 worker
这三个对象最核心的区别,不在名字,而在“有没有运行态”。Skill 本身不会执行任何事,它只是定义规则;Agent 才是真正会读代码、调工具、改文件、总结结果的那个运行实体;Sub-agent 则是在需要并行、隔离或分治时,被主 Agent 分发出去的运行实体。
所以它们的关系,不是并列替代,而是组合关系:
- 一个
Agent可以在一个任务里调用多个Skills - 同一个
Skill也可以被多个Agents反复复用 - 一个
Agent在任务复杂时,可以继续派生多个Sub-agents - 这些
Sub-agents既可以共享同一个Skill,也可以各自使用不同的Skill
我觉得一个例子会更清楚。假设现在有个任务:处理一轮复杂 PR review。
Skill定义的是方法:先读取 review comments,再定位代码,再生成补丁,再跑检查,最后汇总风险。Agent是接任务的人:它拿到“处理这轮 review”这个目标后,决定调用gh-address-comments,并协调相关工具。Sub-agent是被拆出去的执行者:如果评论很多,主Agent可能把前端、后端、测试三个子问题分别丢给三个Sub-agents去并行处理,最后再统一汇总。
从工程角度看,这个区分特别重要。因为一旦你搞混了,就很容易把本该写进 Skill 的方法论,误塞进单次任务提示词里;也容易把本该由 Agent 做的调度和判断,错误期待 Skill 自己“自动完成”。
所以我现在会用一句更工程化的话来区分它们:
Skill解决“应该怎么做”Agent解决“现在由谁来做、怎么推进”Sub-agent解决“任务拆开之后,谁并行去做”
如果团队开始做多智能体协作,这个分层就更重要了。因为 Skill 是可版本化、可审查、可复用的方法资产;Agent 和 Sub-agent 则是围绕具体任务临时生成、执行完就结束的运行实例。一个是长期资产,一个是运行时编排。
如果要给团队新人快速解释,我会直接给这张对照表:
![]()
如果再压缩成一句话,我会这么说:Skill 像方法手册,Agent 像正在干活的人,Sub-agent 像被分出去并行处理子任务的人,而 MCP 像他们手里的工具接口。
企业落地时,我最看重的两个边界
如果把 Skills 放进真实团队,我最在意的其实不是“它能不能多做点事”,而是“边界有没有守住”。至少有两个边界很关键:文件系统边界,和执行审批边界。
在 Codex CLI 这类本地代理工作流里,常见会有类似 sandbox_mode 的文件系统控制项。像 workspace-write 这种思路,核心是允许模型在工作区内读写,同时尽量把 .git/、.codex/ 这类敏感目录保护起来。这一点很重要,因为它决定了 AI 可以动哪里,不能动哪里。
另一个常见控制项是 approval_policy。在交互式开发里,像 on-request 或 untrusted 这种模式,本质上是在高风险操作前加一道人工闸门。你可以让低风险动作继续流畅执行,把真正危险的 shell 操作、外部系统访问或者敏感数据外发拦下来。
如果我要给团队做一个很保守的起点,大概会是类似下面这样的思路(示意,不同版本或界面的命名可能不同):
1 | sandbox_mode = "workspace-write" |
这类配置的意义,不只是安全,更是治理。因为一旦你开始让 Skill 调脚本、调用外部能力、修改仓库,你就必须同时定义“允许它做什么”和“出现风险时谁来兜底”。
怎么安装、放置和启用
安装其实不复杂。
如果你用的是带本地技能管理能力的 Codex / CLI 工作流,常见做法是通过快捷命令面板进入 Skill Installer。以我当前这套环境为例,可以在终端里输入 $ 打开面板,再选择 Skill Installer。如果你装的是官方精选技能,可以直接用别名,例如:
1 | $skill-installer gh-address-comments |
如果你更喜欢社区生态,也可以直接从 GitHub 的目录 URL 拉取第三方技能。这一点我觉得很重要,因为它意味着 Skills 不是封闭能力,而是一个可以持续生长的生态。
这里有个很容易忽略的小坑:装完之后要重启当前会话。 因为重启时会触发 Discovery,重新扫描新的 SKILL.md 元数据,把技能注册进当前可用列表。很多“明明装了却没生效”的情况,问题都出在这里。
另外,Skills 放在哪,也很关键。以本地技能体系为例,常见会有这样几层:
- 系统级:
~/.codex/skills/.system/ - 用户级:
$HOME/.codex/skills/ - 仓库级:
<项目根目录>/.agents/skills/
我的理解是:个人偏好放用户级,团队规范放仓库级。前者适合你的工作习惯,比如审查风格、写作规范、个人常用流程;后者适合项目规则,比如部署检查、业务约束、测试标准、本地编排脚本。这些东西如果能和代码一起版本化,团队协作会顺很多,CI 也更容易继承同一套约束。
怎么用,怎么写得稳
怎么用,其实也不复杂。
最直接的方法就是显式调用。比如:用 openai-docs 查最新接口文档;用 gh-address-comments 处理 reviewer 评论;在改核心模块前,先调用某个架构审查类 Skill;接手陌生项目时,先用 onboarding 或 orientation 类 Skill 建立基本认知。
另一种是隐式触发:系统判断当前任务和某个 Skill 的边界高度匹配,就会自动加载它。但前提是这个 Skill 本身写得足够清楚。所以真正影响技能效果的,往往不是“名字起得响不响”,而是边界定义准不准。
如果你准备自己写 Skill,我觉得有几条原则特别重要。
One Skill, One Job:一个技能只解决一个具体问题,别把生成代码、补测试、写文档硬塞进一个技能里- 不要假设模型记得上下文:技能必须尽量自包含,把前置条件和完成标准写清楚
- 把输入、输出和
Done criteria写清楚:让结束条件可检查,而不是靠感觉 - 能用清楚的文字规则,就别急着上脚本:只有真的需要确定性执行、校验或外部系统操作时,再把逻辑放进
scripts/ - 让技能像微服务,而不是大杂烩:边界越小,行为越稳,可维护性也越高
我自己现在看一个 Skill 写得好不好,核心就看三件事:边界清不清楚,触发稳不稳定,失败后能不能收口。说到底,Skill 越像一个明确职责的工程角色,越不容易失控。
![]()
多智能体协作,为什么会放大 Skills 的价值
我觉得这部分其实特别值得讲,因为 Skills 一旦和多智能体协作结合,价值会被明显放大。
原因很简单:单个 Agent 处理复杂任务时,最大的问题是上下文越滚越大,最后什么都混在一起。而多智能体的思路,是把任务拆开,让不同 Agent 在隔离环境里各自处理不同子问题。
从公开资料和工程实践看,用 Git Worktrees 做物理隔离是很自然的一步。比如一个 Agent 去改数据库查询,另一个 Agent 去重构前端交互,它们不应该在同一个工作树里同时写文件。给它们各自独立的 worktree 和分支,最后再做 diff、集成和合并,这才像工程系统,而不是在同一份工作区里赌运气。
这时候 Skills 的作用就很明显了:它不只是告诉某个 Agent“去干活”,而是把每个子任务的执行规则也一起分发下去。这样多个 Agent 虽然并行,但行为边界是一致的。
对于大规模、同质化的任务,在一些代理编排工作流里还会出现类似 spawn_agents_on_csv 这样的 CSV 驱动分发接口:你准备一个 CSV,把目标文件或参数一行一行列出来,系统按行派生 worker;再用 max_concurrency 控制并发,用 max_runtime_seconds 控制超时,让每个 worker 完成后回传结构化结果。更关键的是,这类批处理通常还会带一个明确的回调契约:每个 worker 完工后,都要通过类似 report_agent_job_result 这样的接口回传结构化 JSON;谁没按约定上报,谁就会被标成失败项。这个思路本质上已经很接近批处理编排系统了。
换句话说,Skills 的真正价值,不只是在“一个 Agent 怎么更稳地做事”,还在于“很多 Agent 一起做事时,怎么保持方法一致、输出可追踪、风险可收敛”。
![]()
我会优先推荐哪些 Skills
如果你问我,团队刚开始配 Skills 时该优先上哪一批,我不会先挑“看起来最强”的,而会先挑“最能减少返工”的。对大多数团队来说,真正值得优先投入的,不是某一个单点很炫的 Skill,而是一组能顺着“先理解、再实现、再校验、再协作”这条链路接起来的能力。链路接得上,Skills 才是生产力基建;接不上,就还是零散工具。
按这个标准,我通常会优先看下面五类,而且大致有先后顺序。
第一类,我会先推“架构推演与代码库认知”。
代表 Skills / 工具:plan、@architecture、@brainstorming、codebase-orientation
这是最应该放在前面的,因为它决定了 Agent 是不是先把系统看明白,再开始动手。无论是接手陌生代码库,还是往复杂系统里塞一个新需求,最怕的都不是“写慢了”,而是一开始理解就错了。这类 Skill 的价值,就是先帮你建立模块地图、摸清耦合点、识别边界和风险,把后面的返工压下来。
第二类,我会优先配“代码质量与工程协作”。
代表 Skills / 工具:security-auditor、pytest-skill、agentic-eval、gh-address-comments、Nightly CI Report
原因也很现实:如果 AI 生成的结果进不了现有的 review、test 和 CI 流程,那它的价值就放不大。团队真正需要的,不是“它能写出东西”,而是“它写出来的东西能不能被检查、被追踪、被回归、被合并”。这一类 Skill 的作用,就是把 AI 输出重新接回工程现实。
第三类和第四类,我会按团队重心来排先后。
如果你们是后端更重、稳定性更敏感的团队,我会把“后端防线与系统稳定性”往前提。
代表 Skills / 工具:circuit-breaker、dead-letter-queue、row-level-security
这类 Skill 的核心不在于多写几个模式,而在于把防线前移:在生成阶段就默认考虑 RPC 熔断、异步重试、死信队列、ORM 越权这些最容易被忽略、但一出事就很贵的问题。
如果你们是产品和设计驱动更强的团队,我会把“前端工程与 UI/UX 落地”提到更前面。
代表 Skills / 工具:frontend-design、tailwind(建议配合 Figma MCP 使用)
这类 Skill 解决的是另一种很常见的问题:代码也许能跑,但一眼看上去就是“AI 味很重”。它真正有价值的地方,是把设计稿、节点信息、无障碍检查和设计令牌更顺地带进实现过程,让前端产出更像成熟产品,而不是演示稿。
最后的判断
所以我这次看完之后的结论很明确:Skills 真正厉害的地方,不是让 AI 多会写几行代码,而是让团队第一次有机会把自己的方法论、规范和经验,变成一套能复制、能协作、能持续演进的资产。
这件事一旦成立,团队和团队之间比拼的就不只是模型、上下文和个人 prompt 水平,而是谁更早把自己的工作流产品化、资产化、版本化。
未来团队之间拉开差距的,也许不是谁更会写 prompt,而是谁更早把自己的工作流产品化成 Skills。