上周末就有了写年度总结的想法,新建文件后用语音写了一大堆,感觉像是在对自己的一些倾诉一样,只能是写给自己看的,于是搁置了一周后选择新建了一个文件,重新写一版可以对外发布的。
今年其实算是一个重要的里程碑,完成了从学生到打工人的身份转变。身份的转变,角色的转变,所处环境的转变,其实都给自己带来了挺多的思考与想法。不过在平时工作时间也不多,很多想法出现在脑子里想了一下,最后可能也没想出个所以然,或者因为没有记录下来而导致可能想出来也忘掉了。干脆就借着年度记录这个机会,写点总结。
告别校园
今年六月,总算是结束了长达十九年的求学生涯。
因为工作在去年就已经尘埃落定签好了三方,所以剩下的这段校园时光也还算挺轻松
- 一月在家玩耍;
- 二月回校开始搞毕设剩下的内容;
- 三月把工作简单写了个专利以满足毕业要求;
- 四月冲刺毕业论文;
- 五月完成答辩;
- 六月和家人毕业旅行和毕业典礼。
总体而言,最后的校园时光平淡而顺利,顺利毕业,拿到学位,找到工作,也算是心满意足了😌
开始工作
毕业离校没休息多久,就开始入职成为一个正式的打工人了。虽然去年实习的时候其实也工作了几个月,但是正式工作和实习还是不太一样的,毕竟实习可以随时跑路,而正式工作就没有退路了,尤其是作为宝贵的应届生身份,再怎样也得混个几年经验再跑去社招。
第一份工作,选了一个服务端的业务开发,还算是比较符合发展方向的。记得入职的第一天和师兄 one one 的时候就说到,要相信做的事情是有意义的。虽然这话听起来不过像是自我鼓励甚至是自我安慰,但是后面在小红书评论区偶然看到,有人发现并用上了我负责新增的 features,还是觉得工作似乎好像确实还是有点意义的。
然而虽然是一个技术开发,但是日常的工作其实大多数时候都在拉通对齐,以及文档分析。最核心的 coding 反而占比不会很多,甚至某种程度上,交流沟通协作的能力相比于技术水平更加重要,尤其是在业务开发。
为什么作为开发写代码反而不多?
一方面是业务系统大多数其实都已经发展得比较成熟,很多内容其实都建设得差不多,对于新的需求往往能够复用已有的链路,即使有变更也只是在这上面进行建设与修补;另一方面就是公司一直在搞提效,而提效的方向和手段,往往就是把一些代码的开发需求通过抽象的方式转变成通过配置的流程编排,将写代码变成可参考复制的配置,然后把这些工作下发给外包完成 ,能提效多少不好说,终归是个数字,但是一线开发也不见能够闲多少 。
不过这个也可能刚好是我所在团队,所负责应用的原因,但是正如大老板在初次全员会上面说,其实公司并没有义务帮助大家成长,所以还是得靠自己。没有机会就创造机会,机会少就抓住机会,不写代码就看代码,看文档,看完就变成我的了😆
不过干多了业务需求,其实也会反思技术在里面的作用,技术是否真的这么重要,有时感觉业务知识也是很重要,能创造并拉来业务需求,促成交易才是更重要的。空有一套优秀的系统,但是卖不出去没人用,又能发挥出什么价值?就算是垃圾,只要用的人多了占据了足够的市场地位,一样能够劣币驱逐良币。 这样看来还是销售的能力最强!
编程道路
虽然如此,但是我还是真的发自内心地喜欢写代码的,喜欢看与折腾各种有趣的东西。除了工作的东西以外,今年好好学了下 F#, Rust 和 Kotlin。三个语言都是好东西,写起来各种爽,很好地满足了我对于函数式编程的喜爱与追求。
在学习函数式编程的路上,有时候真的会觉得可能是见识不够,对于函数式的写法有点想像力匮乏了,有些时候是真的不知道应该如何用函数式来写,如何用递归来实现迭代。看了别人写的代码,见识过后,才知道原来可以这样写。
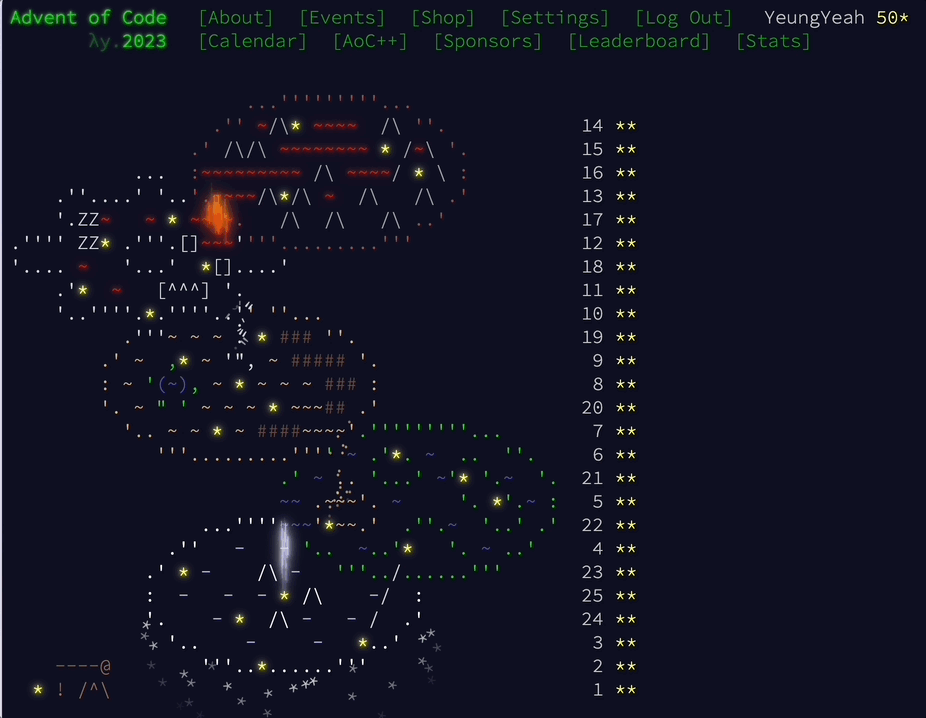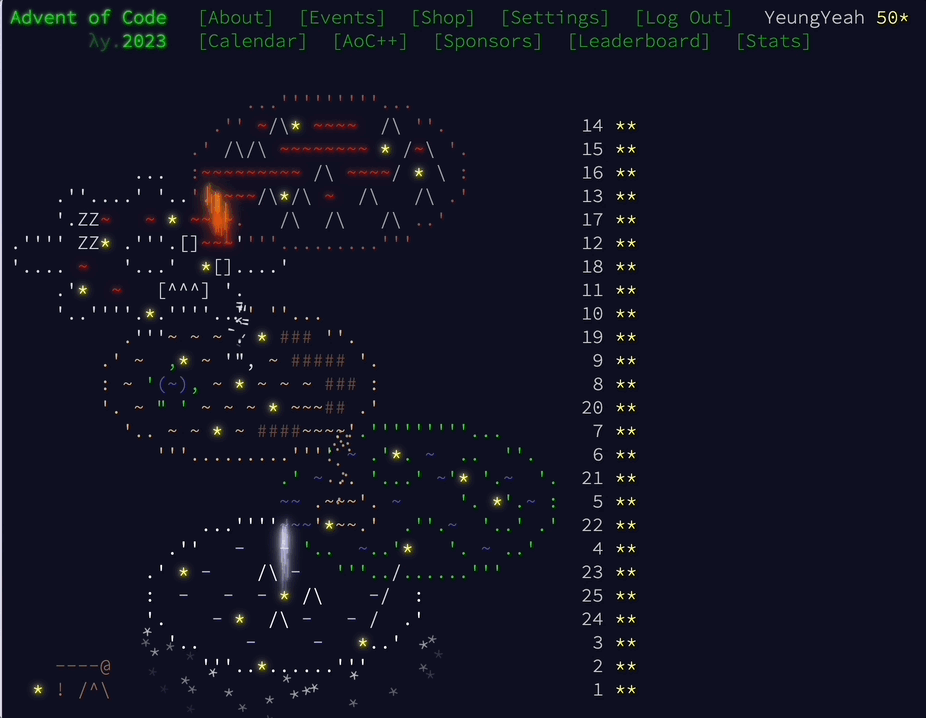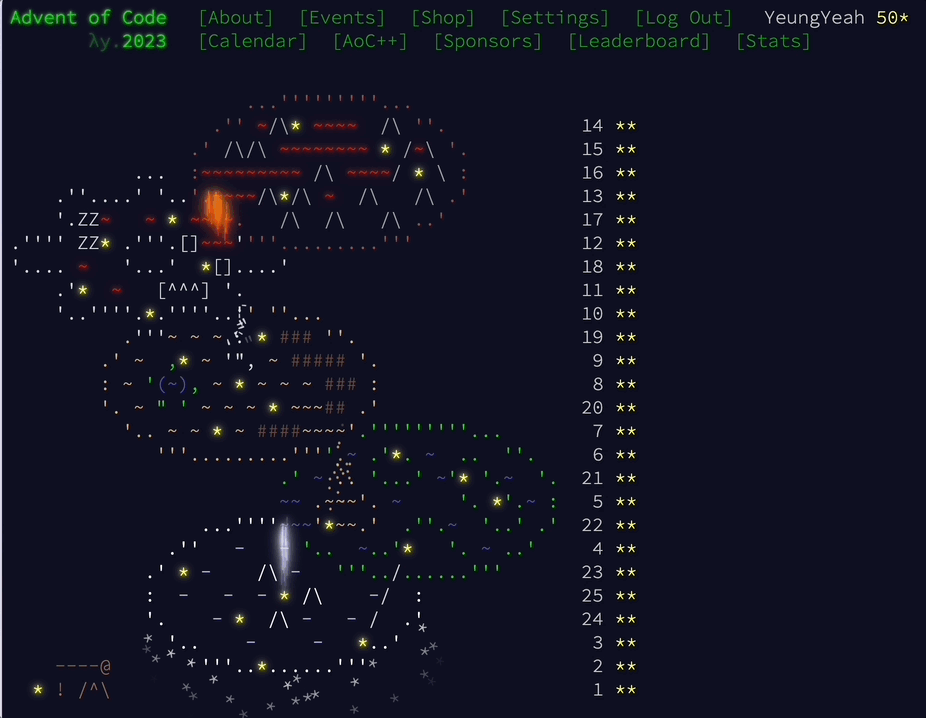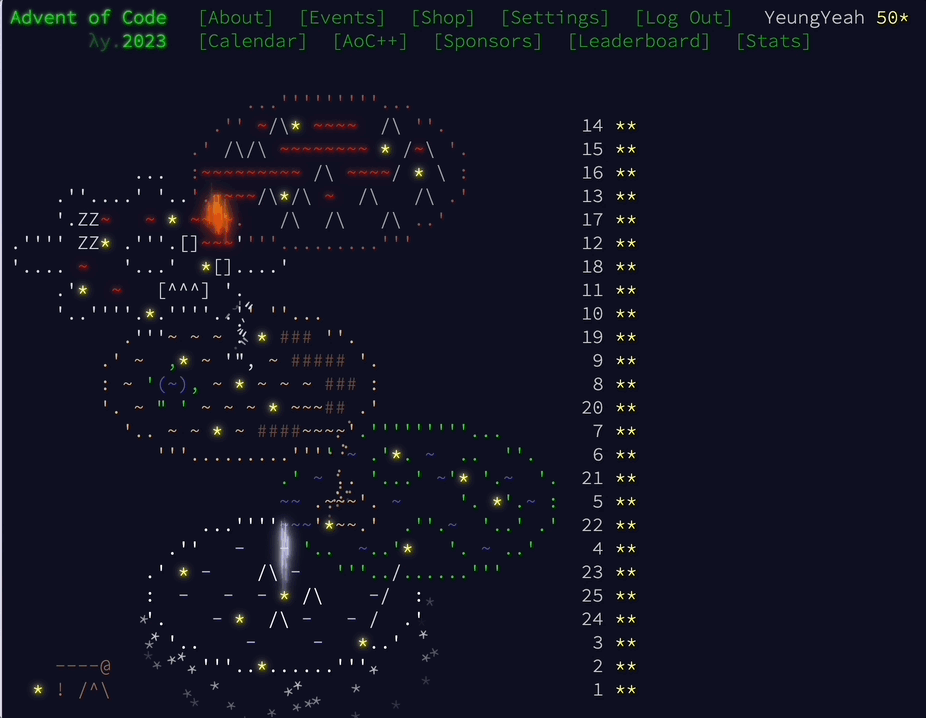
今年也第一次全部完成了 Advent of Code 的挑战,虽然中间遇到不少挑战,比如一些没有见过的定理公式,又或者是中途出去团建了三天回来需要狂补进度,但最后还是磕磕绊绊地在圣诞当天完成了所有挑战,点亮所有图案。

虽然好像学了很多东西,好像会很多东西,但是内心其实还是会时不时地感到焦虑,会担心其实我搞这些东西对于我的工作到底有没有帮助,对我的能力有没有提升。如果真的跳槽,是否能够凭借这些技能帮我找到更好的工作?恐怕未必。这样想好像很功利,但是好像也没有办法,也只能不想那么多,先自己玩爽了再说。
接下来学习(玩耍)的方向应该还是会继续聚焦于这三个语言以及函数式编程上面。至于工作相关的系统设计与中间件,可能还是返回到工作中学习吧,如果工作还有时间还没有被压垮的话。
对于金钱
正式工作之后,开始有比较稳定的金钱收入了,如何管理,如何使用,成为了一个重要的命题。以前常常看到对于财富自由的讨论,说实话对于这个目标很向往,而且我也很现实地明确自己打工的意义,就是赚钱。赚钱嘛,不寒碜。
怎样才算是财富自由呢?
前两个月某晚上去跑步路上经过了一个彩票投注站,看到上面写着刮刮乐彩票中奖金额高达 20w,脑海中突然就在幻想自己中了会怎么样。中了 20w,我会怎么花呢?好像这个数额也没有特别大,真的都想不到要买什么,唯一能想到的可能就是买个车了。是不是 20w 太少,如果换到 50w 呢?好像差别也不大,如果换成 500w 呢?脑子里的第一想法居然是好像在深圳也不够买一套房,但其实如果给一个年薪二十万的公务员足够发二十五年工资了。
似乎一次性得到一笔钱根本满足不了自己,相比之下,自己可能更倾向于获得持续稳定的收入。如何能够保持持续稳定的收入呢?说实话互联网行业并不能保证如此稳定,不知道能待多久,也不知道这个行业还能玩多久。因此单靠打工,并不能够自由。可能还是得从其他方便找到搞钱的方法。
还有什么办法能够赚钱呢?积极探索中。
打造形象
从 18 年开始写自己的博客,到现在也已经有 5 年时间了,期间一直在使用 YeungYeah 这个名字和图像,并且逐渐扩建到各个平台当中,也算是初步搭建出一个自己的形象品牌,虽然估计认识的人也不多,不过总算是有个名字了。
为什么需要有个名字?在互联网中,因为种种的原因,与他人建立起这种不同的 connection,是 web 最具有魅力的地方。而在互联网中,能打造出一个个人的品牌形象,积累到足够的 reputation,增添足够的影响力,会更容易与他人建立起 connection。connection 有什么用?具体的说不上,但是对我意味着更多的机会,更多的可能性。
因此今年来开始更加积极地发推看推互动,甚至开始运营我的小红书,写点 coding 技术相关的内容。数据看起来其实也很一般,不过无所谓,也是抱着玩一玩的心态。
今年参加高中同学婚礼时和高中同学聚了一下,了解到他当前正在小红书等社交平台做编程自媒体,做编程辅导和知识付费,感觉是一条不错的搞钱路子。于是质疑自媒体,了解自媒体,成为自媒体。这也是我开始玩小红书的一部分原因。
当然其实也并不意味着我就要当自媒体然后开始流量变现赚钱,对于自己也有很明确的认知,大概率是干不来的。
希望能够有朝一日 from nobody into somebody.
面对 AI
去年也是差不多十二月这个时候,ChatGPT 开发供外部使用。当时我也马上注册了个帐号开始使用,但是使用体验还是很普通,玩了一会就丢一边了。然后过了几个月到三月后,突然就超进化成为人人都在感叹的划时代技术。
其实 AI 技术已经发展几年了,从 CNN 神经网络开始进入 AI 的时代,科研圈中 AI 技术井喷,各种 AI+ 的文章出现,AI 本身也在快速发展。大家都知道有 AI,各家也喜欢在产品中标注 power by XXAI 技术。但也只是拿 AI 的技术用在已有的产品上面。
然后 ChatGPT 的一出现,彻底火出圈了,出圈到连我爸都来问我有没有方法可以用。ChatGPT 确实是个好东西,现在几乎已经成为许多人离不开的必备工具了。我自己也用 ChatGPT API 搞了一个(感谢 ChatGPT-Next-Web)。
ChatGPT 的出现,为许多人带来了许多机会与流量。尽管可能仍然会有人因为种种的原因和观念而不接受甚至抗拒 AI 的发展,但是我觉得这已经是大势所趋,AI 发展无可避免。
未来的 AI 估计将会成为像水电一样的基础资源无处不在,融合进人们的日常生活当中 (这话听起来怎么这么像以前云计算的宣传口号) 。
今年作为重新开放后的第一年,同时也是身份转变进入社会成为打工人的第一年。于我而言,所有事情都在起步中,所有事情都具有新希望。可能性就在眼前,得抓紧机会,成了就成,不成也无所谓,尽力而为,顺势而为。