Solving Jane Street's 'Dropped a Neural Net' Puzzle
Jane Street’s January 2026 puzzle1, “Dropped a Neural Net”, presents a deceptively simple premise: a neural network was “dropped” and its 97 pieces scattered. Your job is to put them back together. Behind this simple framing lies a deep combinatorial optimization problem that I solved two different ways — first with gradient-based permutation learning and combined swaps, then again with a simpler approach that revealed a key insight: pairing corrections unlock cascading improvements in ordering.
The Problem
You’re given 97 weight/bias files (piece_0.pth through piece_96.pth) and a dataset (historical_data.csv with 10,000 rows of 48 input features, plus pred and true columns). The neural network architecture is:
- 48 residual blocks, each consisting of:
- An “inp” layer:
Linear(48 → 96)followed by ReLU - An “out” layer:
Linear(96 → 48) - A residual connection:
x = x + out(relu(inp(x)))
- An “inp” layer:
- 1 final layer:
Linear(48 → 1)producing the prediction
The 97 pieces split into three groups by weight shape:
- 48 pieces with shape
(96, 48)— the inp layers - 48 pieces with shape
(48, 96)— the out layers - 1 piece with shape
(1, 48)— the final layer
The solution is a permutation of indices 0–96 specifying which piece goes where. Positions 0,2,4,…,94 hold inp layers, positions 1,3,5,…,95 hold out layers, and position 96 holds the final layer. The solution is verified by SHA-256 hash — there’s exactly one correct answer, no MSE threshold to meet.
This means you need to solve two sub-problems simultaneously:
- Pairing: Which inp layer goes with which out layer in each block?
- Ordering: In what sequence do the 48 blocks execute?
The search space is enormous: 48! × 48! ≈ 10121 possible configurations.
Phase 1: First-Order Approximations (MSE ~0.7)
My first instinct was to exploit the linear structure. If all 48 blocks see roughly the same input X (a first-order approximation), then each block’s contribution is independent, and we can use the Hungarian algorithm to find the optimal pairing.
For each candidate pair (i, j), I computed the block’s effect on the prediction:
h = F.relu(F.linear(X, L1_W[i], L1_B[i]))
delta = F.linear(h, L2_W[j], L2_B[j]) # (N, 48)
pred_delta = (delta * l3_dir).sum(dim=1) * l3_w.norm()
Then built a cost matrix and ran linear_sum_assignment. This got MSE down to ~0.7 — a starting point, but far from correct. The first-order approximation breaks down because blocks modify x sequentially, and the cumulative change is large (~6× the input norm).
Phase 2: Gumbel-Sinkhorn — Differentiable Permutation Learning (MSE ~0.03)
The breakthrough came from treating permutations as differentiable objects using the Gumbel-Sinkhorn framework.
The Key Idea
Instead of searching over discrete permutations, parameterize a continuous relaxation. A 48×48 matrix of learnable logits log_alpha is transformed into a doubly-stochastic matrix (a “soft permutation”) via iterated row/column normalization (Sinkhorn’s algorithm):
def sinkhorn(log_alpha, n_iters=25, tau=1.0):
log_alpha = log_alpha / tau
for _ in range(n_iters):
log_alpha = log_alpha - torch.logsumexp(log_alpha, dim=1, keepdim=True)
log_alpha = log_alpha - torch.logsumexp(log_alpha, dim=0, keepdim=True)
return log_alpha.exp()
Adding Gumbel noise before normalization enables exploration, and annealing the temperature tau from high to low gradually sharpens the soft permutation toward a hard one. The MSE loss is fully differentiable through this soft permutation, so we can use Adam to optimize the logits.
Alternating Optimization
Jointly optimizing both the ordering permutation and the pairing permutation is expensive — the forward pass with two soft permutations involves O(48³) operations per position. The key insight was to alternate:
- Fix pairing, optimize ordering: The soft forward pass weights different block orderings:
def forward_soft_order(x, pairing, order_weights): for pos in range(48): # Precompute all block deltas with fixed pairing all_deltas = [block_i_j(x) for i,j in pairing] # Weighted combination based on soft ordering delta = einsum('i,bid->bd', order_weights[pos], all_deltas) x = x + delta - Fix ordering, optimize pairing: Each block position softly selects among all possible out layers:
def forward_soft_pair(x, order, pair_weights): for inp_idx in order: h = relu(linear(x, L1_W[inp_idx], L1_B[inp_idx])) # Soft-select out layer weighted_w = einsum('j,jdo->do', pair_weights[inp_idx], L2_W) delta = linear(h, weighted_w, weighted_b) x = x + delta
Each sub-problem only involves one 48×48 permutation matrix, making it much faster. After optimization, I extract hard permutations using the Hungarian algorithm on the negative logits.
With 5-6 alternations of 500-800 gradient steps each, MSE dropped from 0.8 to ~0.03 — an order of magnitude better than first-order methods.
Why Alternating Works
Alternating optimization works here because the ordering and pairing sub-problems are partially decoupled. Fixing one makes the other a “standard” assignment problem with a smooth loss landscape. The Gumbel noise acts as a form of stochastic exploration, and the temperature annealing provides a natural curriculum from exploration to exploitation.
Phase 3: Local Search — Getting Stuck (MSE ~0.03)
With a good Gumbel-Sinkhorn solution in hand, I tried various local search strategies:
- 2-opt: Swap pairs of positions in the ordering, or pairs of pairings
- 3-opt: Try all triples of positions with all 6 permutations
- Insertion moves: Remove a block and reinsert at every other position
- Coordinate descent: For each position, try all 48×48 possible replacements
None of these could escape the MSE ~0.03 basin. The solution was at a strict local minimum for all single-element and pair-element moves. Multiple random restarts with the Gumbel approach also converged to similar MSE values.
Phase 4: Two Paths to the Solution (MSE 0.008 → 0.0)
From MSE ~0.008, I found two different approaches that both reach MSE = 0. Each reveals something different about the problem structure.
Approach A: Combined 2-opt
The first insight was that standard 2-opt treats order swaps and pairing swaps as independent moves. But the correct solution might require simultaneously changing both the order AND the pairing of two positions.
Combined 2-opt tests all three modifications for each pair of positions (p1, p2):
- Swap their order positions only
- Swap their pairings only
- Swap both order AND pairing simultaneously
for p1 in range(48):
for p2 in range(p1+1, 48):
i1, i2 = order[p1], order[p2]
j1, j2 = pairing[i1], pairing[i2]
for swap_order, swap_pair in [(True,False), (False,True), (True,True)]:
if swap_order: order[p1], order[p2] = i2, i1
if swap_pair: pairing[i1], pairing[i2] = j2, j1
mse = full_eval(order, pairing)
if mse < best_mse:
# Accept improvement
...
This is O(48² × 3) = 6,912 evaluations per sweep. Starting from MSE 0.0085, it made 86 consecutive improving swaps in a single pass down to MSE = 0.
The intuition: when two blocks have tangled errors, swapping just their order or just their pairing each makes things worse, but swapping both simultaneously moves between consistent configurations. In optimization terms, the individual moves each increase the loss, but their composition decreases it — a “valley” that requires moving diagonally.
Approach B: Alternating Cycles with Insertions (Simpler, Same Result)
The second approach is simpler but equally effective: cycle through three move types and keep going long after apparent convergence.
The three moves:
- Pairing swaps: Try all
C(48,2)= 1,128 L2 partner exchanges - Order swaps: Try all 1,128 position exchanges
- Block insertions: For each of 48 blocks, remove it and try all 48 positions (2,304 evals)
for round in range(many):
# Pairing swaps
for i, j in combinations(range(48), 2):
swap pairing[i], pairing[j]; accept if improved
# Order swaps
for i, j in combinations(range(48), 2):
swap order[i], order[j]; accept if improved
# Block insertions
for i in range(48):
block = order.pop(i)
try all 48 insert positions; keep best
What makes this work is patience — continuing to cycle when each individual move type appears converged. The key discovery: pairing corrections trigger cascading order improvements.
Starting from MSE 0.0098 (where standard 2-opt appeared stuck), the trajectory looked like this:
Cycle 5: Pairing fix: 0.008274 ← corrected one L1/L2 pair
...18 order swaps...
Order swap: 0.006588 ← cascade!
...7 insertions...
Block insertion: 0.003861
Cycle 6: Pairing fix: 0.002379 ← biggest single improvement
...16 order swaps...
Order swap: 0.000177 ← nearly there
Block insertion: 0.000064
Block insertion: 0.000000 ← EXACT!
Each pairing correction fixed a block that had been paired with the wrong L2 layer. With the wrong partner, no ordering could make that block work correctly — so the optimizer was forced into a compromise. Once the pairing was fixed, a flood of previously-blocked order improvements became available.
Why Insertions Matter
Insert moves find improvements that swaps cannot. A swap exchanges two elements; an insert slides one element to a new position, shifting everything in between. The final three moves to MSE = 0 were all insertions — they refined block positions with a precision that pairwise swaps couldn’t match.
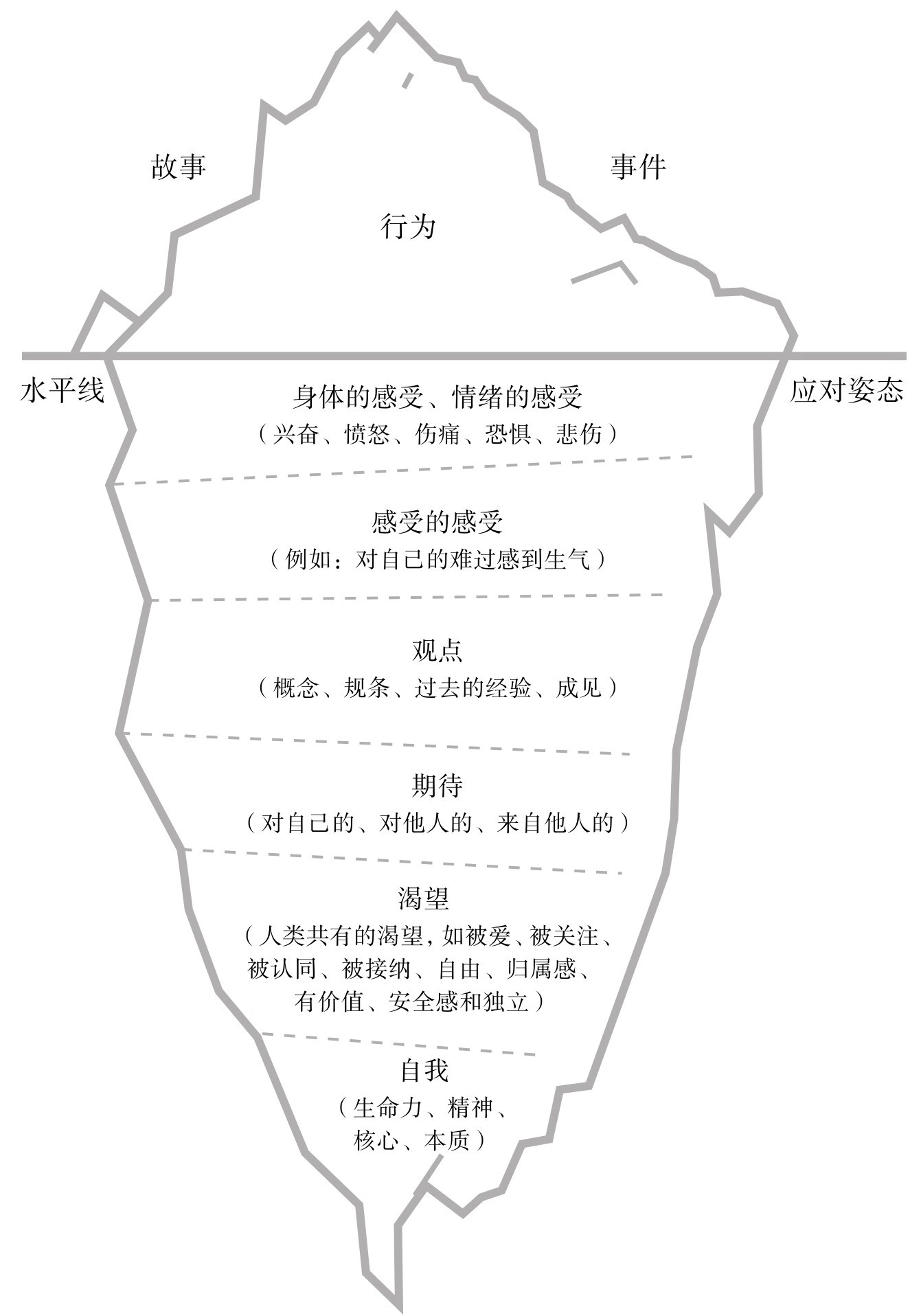
Error Analysis: The Tail Tells the Story
At MSE ~0.01, analyzing the per-row error distribution was revealing:
Percentiles of |error|:
50th: 0.026 (median row is nearly correct)
95th: 0.210
99th: 0.415
100th: 1.496 (worst row is way off)
Top 100 rows: MSE 0.348 (35x more error per row)
Bottom 9900: MSE 0.006
The error was concentrated in ~45 extreme rows. This pattern — a mostly-correct solution with a few outliers — is the signature of a few specific misconfigurations rather than a globally wrong solution. It motivated continued cycling over restart.
The Full Pipeline
Both paths share the same initialization and diverge at Phase 4:
- First-order pairing (200 random restarts + swap optimization) → MSE ~0.7
- Gumbel-Sinkhorn alternating optimization → MSE ~0.03
- Standard 2-opt + insertion moves → MSE ~0.008
- Either:
- (A) Combined 2-opt → MSE = 0.0 ✓ (single pass, ~7K evals)
- (B) Alternating pair/order/insert cycles → MSE = 0.0 ✓ (~10 cycles, ~45 min)
Approach A is faster per pass but requires the insight to try simultaneous swaps. Approach B is slower but conceptually simpler — just keep cycling basic moves and let pairing corrections cascade into order improvements.
Total computation: under an hour on a MacBook Pro (M-series, CPU only).
Lessons Learned
Differentiable relaxations are powerful initialization. Gumbel-Sinkhorn took us from a random permutation to within ~1% of the correct answer. Without it, local search would have no hope in a space of 10121 configurations.
Pairing corrections unlock order improvements. A wrong L1/L2 pairing poisons the ordering — no arrangement of blocks can compensate for a block producing the wrong intermediate values. Each pairing fix unblocked 15-20 order improvements that had been invisible before.
Insert moves find what swaps miss. The final three moves to MSE = 0 were all block insertions. Insertions shift an entire segment of the ordering, exploring a richer neighborhood than pairwise swaps.
Cycle, don’t stop. After apparent convergence, continuing to cycle through move types found improvements for 5+ more rounds. Each round took ~90 seconds, so patience was cheap.
The right neighborhood matters more than the right algorithm. Standard 2-opt, 3-opt, simulated annealing, and coordinate descent all failed at MSE ~0.01. Both solutions came from expanding the move set — either by combining swap types (Approach A) or by adding insertions and being patient (Approach B).
Save incrementally. I learned this the hard way — a script that only saves at the end can lose hours of progress if killed. Every improving move should write to disk immediately.
Exact verification changes the game. The SHA-256 hash means only MSE = 0 is correct. This motivated exhaustive local search: even a tiny MSE improvement matters because there’s no “good enough.”
Dead Ends and Abandoned Approaches
Before finding the two approaches that worked, I tried several others that didn’t pan out:
Simulated annealing. The natural response to getting stuck at a local minimum. I implemented SA with multiple move types (order swaps, pairing swaps, block insertions, segment reversals) and ran it for hundreds of thousands of steps. The problem: each evaluation requires a full sequential forward pass through 48 blocks on thousands of samples (~7ms per eval). At 500K steps, that’s nearly an hour per run — and SA needs many restarts to be effective. Worse, the high-dimensional discrete landscape (two interleaved 48-element permutations) makes it hard to set a temperature schedule that explores enough without wasting time in bad regions. The occasional improvements SA found were always things that deterministic local search could have found faster by just cycling more.
Greedy sequential construction. Rather than optimizing the ordering, build it greedily: at each step, try all remaining blocks and pick the one that minimizes the partial prediction error. This was fast (~1 second per full construction) but gave MSE ~1.8 — worse than the starting point. The problem is myopia: the block that looks best at step k might be terrible for what’s needed at steps k+1 through 47. The residual structure means early blocks fundamentally reshape the input for later blocks, so local greedy choices cascade into globally poor orderings.
3-opt (triple rotations). If 2-opt is stuck, try 3-opt — cyclic rotations of three elements. The cost is O(n³) = 17,296 triples, each tested in two rotation directions, times ~7ms per eval = ~4 minutes per sweep. I ran this on both ordering and pairing. It was too slow to iterate and never found improvements that the simpler approach (cycling 2-opt with insertions) couldn’t find faster. The 3-element moves that matter are better discovered by doing 2-opt after an insertion changes the landscape.
SiLU activation. The puzzle description says ReLU, but in first-order (non-residual) models, SiLU gives much lower MSE (~0.9 vs ~11.0). This was a red herring — SiLU only wins when you ignore the residual connections. In the full sequential model, ReLU gives MSE 0.12 while SiLU gives 4.37. The lesson: test with the full architecture, not a simplified proxy.
Group swaps. Instead of swapping individual blocks, try swapping contiguous groups of 2, 3, 4, or 8 blocks. This occasionally found tiny improvements (~0.001) but was never transformative. The blocks that need to move aren’t in contiguous groups — they’re scattered, and the real bottleneck is fixing pairings, not rearranging chunks.
Lasso/sparse selection. Precompute all 48×48 = 2,304 possible block outputs and use Lasso regression to select a sparse subset of 48. Elegant in theory, but Lasso doesn’t enforce the constraint that each L1 and L2 layer is used exactly once. Post-hoc matching from the Lasso solution didn’t produce better pairings than direct swap optimization.
Training a surrogate model, then matching layers. I trained a fresh neural network with the same architecture on the 10K dataset, hoping to match its learned layers against the puzzle pieces. The results were poor — I suspect 10K samples simply aren’t enough to recover a model similar enough to the target for layer-wise matching to work. The trained model converges to a different local minimum with different internal representations, making piece-to-layer correspondence unreliable.
Training a transformer to predict swaps. The most ambitious attempt: train a transformer model to learn which swaps improve the objective, then let it predict a sequence of moves to solve the puzzle. This ran into a bootstrapping problem — generating training data (pairs of configurations and their MSE changes) required the same expensive forward passes we were trying to avoid, and I couldn’t produce enough samples to train on. The model would need to generalize from a tiny fraction of the 10121 search space, with no clear inductive bias for this specific combinatorial structure. In hindsight, domain-specific search (exploiting the residual network structure directly) was always going to beat a general-purpose learned search policy for a one-off puzzle like this.
The common thread: the bottleneck was always pairing, not ordering. Approaches that focused on finding better orderings (SA, greedy construction, 3-opt, group swaps) couldn’t overcome wrong pairings. The approaches that worked were the ones that could fix pairings and then let order improvements cascade.
Good luck if you’re attempting this one — it’s a satisfying puzzle to crack.
-
Jane Street publishes monthly puzzles at janestreet.com/puzzles. ↩