机器学习入门 - 模型评估指标
2024年4月7日 19:06
机器学习入门 - 模型评估指标
参考与致谢
- 《机器学习基础 - 从入门到入职》
- 机器学习基础-监督学习-目标函数之平均绝对误差(Mean Absolute Error,MAE)
- scikit-learn.org
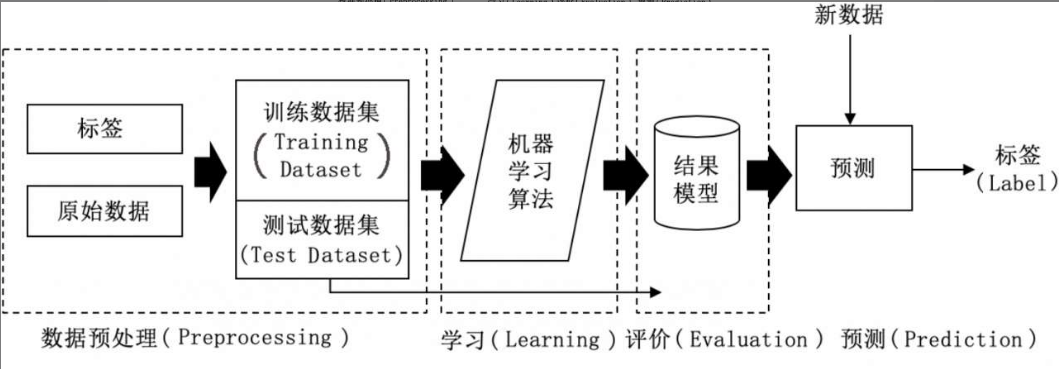
不同的机器学习任务需要使用不同指标来评估,本篇文章基于 scikit-learn ,从实际代码上介绍机器学习中回归、分类、聚类这三种模型的评估指标。
回归模型的评估指标
对于回归模型而言,目标是使得预测值能够尽量拟合实际值。常用的性能评估指标有绝对误差和均方误差两种。
平均绝对误差(Mean Absolute Error, MAE)
用于衡量回归问题中预测值与真实值之间平均绝对差异。MAE 的值越小,表示预测值与真实值之间的平均差异越小,即预测的准确性越高。
\[
MAE = \frac{1}{n} \sum_{i=1}^{n} |y_{\text{true}, i} - y_{\text{pred}, i}|
\]
公式中,\(n\) 是样本数量, \(y_\text{true}\) 是真实值,\(y_\text{pred}\) 是预测值。
>>> from sklearn.metrics import mean_absolute_error
>>> y_true = [3, -0.5, 2, 7]
>>> y_pred = [2.5, 0.0, 2, 8]
>>> mean_absolute_error(y_true, y_pred)
0.5
>>> y_true = [[0.5, 1], [-1, 1], [7, -6]]
>>> y_pred = [[0, 2], [-1, 2], [8, -5]]
>>> mean_absolute_error(y_true, y_pred)
0.75
均方误差(Mean Squared Error, MSE)
用于衡量预测值与真实值之间的平均差异。数值越小表示预测结果与真实值的拟合程度越好。
\[
MSE = \frac{1}{n} \sum_{i=1}^{n} (y_{\text{true}, i} - y_{\text{pred}, i})^2
\]
公式中,\(n\) 是样本数量, \(y_\text{true}\) 是真实值,\(y_\text{pred}\) 是预测值。
>>> from sklearn.metrics import mean_squared_error
>>> y_true = [3, -0.5, 2, 7]
>>> y_pred = [2.5, 0.0, 2, 8]
>>> mean_squared_error(y_true, y_pred)
0.375
>>> y_true = [[0.5, 1],[-1, 1],[7, -6]]
>>> y_pred = [[0, 2],[-1, 2],[8, -5]]
>>> mean_squared_error(y_true, y_pred)
0.708...
分类模型的评估指标
分类模型的评估指标比较多,不同的评估指标之间甚至可能有冲突