前言
之前写过如何用树莓派挂载移动硬盘并使用SMB在局域网共享,使用了很长一段时间也没有什么问题。但是近期突然想到,这个移动硬盘里已经有太多私人资料了,虽然SMB和树莓派都有密码保护,但是硬盘本身却没有做任何的保护。一旦硬盘遗失,里面的数据就会直接泄露。于是就产生了加密硬盘,使用树莓派进行解密再使用SMB进行共享的想法。
关于加密方式,考虑过使用veracrypt加密,但是相比之下还是LUKS(Linux Unified Key Setup)更加“原生”,不依赖客户端,用起来也比较方便。
文前提示:本文不是针对完全不会的小白的教程,需要有一定的Linux基础,尤其是针对分区的操作,一定要看清楚分区名。进行操作前请备份好自己的数据。遇到问题欢迎在评论区留言。
加密指定分区
Raspberry Pi 4b 4gb
OS: Ubuntu 20.04.4 LTS
Kernel: aarch64 Linux 5.4.0-1062-raspi
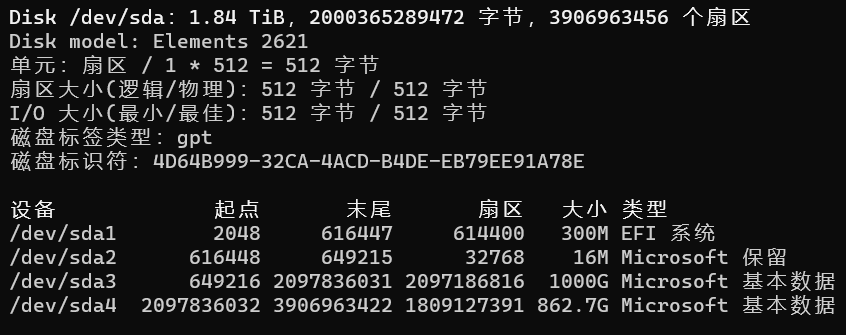
- 查看硬盘
找到想要加密的硬盘分区,我这里已经提前分好区了。我这里把硬盘分成/dev/sda3和/dev/sda4。/dev/sda3作为日常盘,外出时使用。/dev/sda4作为加密盘,在树莓派上使用smb共享。
本文中要加密的分区是 /dev/sda4 ,如果你参考了本教程的命令,记得要将后文中的所有 /dev/sda4 替换为你要加密的分区。
如果你还没有分区,可以使用fdisk进行分区,具体用法可以查看 Fdisk-archwiki)。
- 格式化分区
提前备份好数据,然后格式化要加密的分区。将/dev/sda4替换为你的要加密的分区,注意提前备份好数据。
- 加密分区
使用 cryptsetup 创建加密容器,使用 --type 指定使用luks2版本。使用 --cipher 指定加密算法,如果不指定默认会使用 aes-xts-plain64 ,但是树莓派的芯片不支持AES加速,加密解密会比较慢,使用 Adiantum 会比较快,具体可以看 LUKS-on-Raspberry-Pi。
sudo cryptsetup --type luks2 --cipher xchacha20,aes-adiantum-plain64 luksFormat /dev/sda4
执行命令后,需要输入大写的 YES 确认执行操作,然后设置好密码。

- 映射容器
加密后的分区需要解密才能使用,使用luksOpen解密分区。下面的的命令会将加密分区映射到/dev/mapper/cdata
sudo cryptsetup luksOpen /dev/sda4 cdata
- 创建文件系统
加密容器第一次使用的时候需要创建文件系统,例如我创建的是 ext4 。
sudo mkfs.ext4 /dev/mapper/cdata
- 挂载加密分区
sudo mkdir -p /media/CRYPT
sudo chmod 776 /media/CRYPT
sudo mount /dev/mapper/cdata /media/CRYPT
开机自动解密并挂载
- 创建密钥
由于需要使用密钥文件才能开机自动解密,我们需要先创建密钥文件,密钥文件可以使用自动生成的随机数,也可以自行创建。我创建的密钥文件是 /keyfilec
sudo cryptsetup luksAddKey /dev/sda4 /keyfilec
- 验证密钥
sudo umount /dev/mapper/cdata //取消挂载
sudo cryptsetup luksClose cdata //锁上分区
sudo cryptsetup luksOpen /dev/sda4 cdata --key-file=/keyfilec //使用密钥文件解密
我们取消挂载,然后将分区锁上。使用密钥文件来解密,没有看到任何提示,就说明我们已经成功使用密钥文件来打开加密分区了。
- 自动挂载
查看分区的UUID,后面自动解密时需要用到。
编辑 /etc/crypttab 自动打开加密分区,添加下面的内容。
cdata UUID=a8c7a856-dfe0-4273-b546-13b2cdf50f12 /keyfilec luks
编辑 /etc/fstab 自动挂载加密分区,添加下面内容。
/dev/mapper/cdata /media/CRYPT ext4 defaults 0 0
- 重启之后,就可以验证加密分区是否已经已经自动挂载了。
SMB共享
我的树莓派上已经配置好了smb,具体可以参考这篇文章的 配置SMB 部分。
sudo nano /etc/samba/smb.conf
修改 /etc/samba/smb.conf 在最后添加以下内容。
[share]
comment = share folder
browseable = yes
path = /media/CRYPT
create mask = 0700
directory mask = 0700
valid users = ubuntu
force user = ubuntu
force group = ubuntu
public = yes
available = yes
writable = yes
修改好配置后,重启smb服务。
sudo service smbd restart
参考文章
cryptsetup 文档
Frequently Asked Questions Cryptsetup/LUKS
Configuring LUKS: Linux Unified Key Setup (推荐)
LUKS on Raspberry Pi