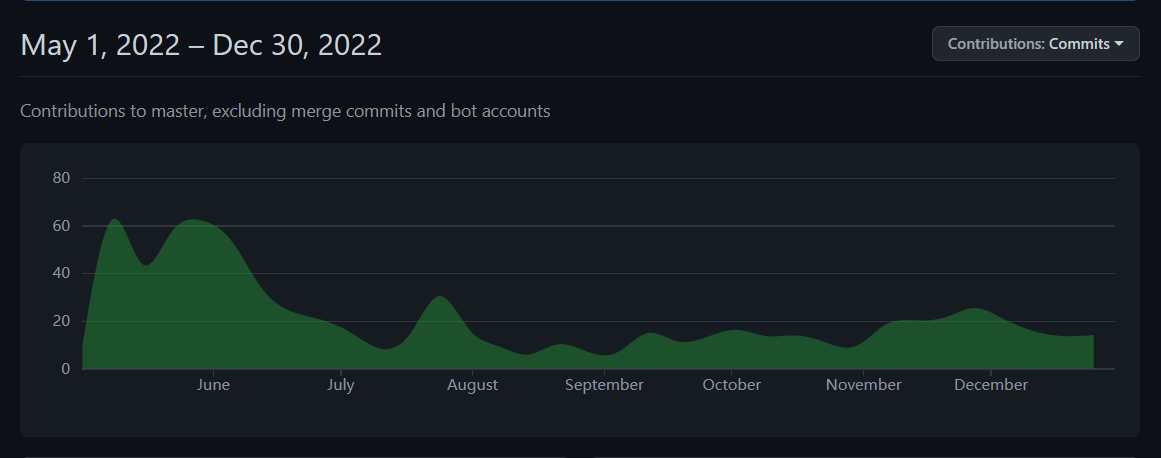
flowchart LR subgraph LAN[家庭局域网] subgraph NASHost[老 Windows 笔记本(NAS)] Jellyfin[Jellyfin 服务] Disk[外接硬盘盒 / 媒体库] end subgraph GPUHost[GPU 机器] Subgen[Subgen 服务] Model[Whisper + TranslateGemma] end Client[局域网播放器/客户端] end Disk -->|媒体文件路径| Jellyfin Disk -.同盘符映射.-> Subgen Client -->|播放/新增媒体| Jellyfin Jellyfin -->|Webhook 事件| Subgen Subgen -->|转录/翻译| Model Model -->|生成字幕(双语/纯译文)| Disk Jellyfin -->|读取字幕并展示| Client
使用体验
配置情况:
NAS机:i5 1135G7 15W + 16G
GPU机:R9 5900X@4.2Ghz + 64G DDR4 3200 + RTX 5070 Ti
转录和翻译过程都没有充分利用GPU,两个步骤的显卡利用率都只有 40%。转录过程需要 CPU 参与处理音频流,翻译过程应该是每一行都要重新推理影响速度
整个测试项目、测试脚本甚至本篇文章基本都是直接使用Copilot + Claude 3.7 Sonnet模型生成的,不得不说,让AI生成大框架、自己再来完善细节的做法确实能提高不少效率。这种实验的大多数工作实际上是框架代码,代码本身逻辑简单,但是需要使用大量API、编写繁琐的测试逻辑、数据分析以及做表,手写非常耗费精力,让AI来做这些繁琐的工作实在是再合适不过了。写文章也可以让AI帮忙做,我之前写篇文章至少需要花一整天,这一次居然一个上午就搞定了。
实话说,我很少直接和大模型聊天。我使用AI基本只有让Copilot回答编程问题以及生成代码,在编程场景之外我基本完全不用AI,所以也一直不知道怎么把AI应用到我自己的工作和生活流中。我的工作也和AI毫无关系,即使公司策略是All in AI,但是我组仍然和AI似乎扯不上边。
而此时,需求终于来了,为何不让大模型帮我总结文章?
Azure AI是一个微软做的Model as a service平台,可以直接在上面部署、使用、微调模型,不需要自己管理基础设施。DeepSeek R1模型发布后没几天,Azure AI可以直接就支持了部署(公告),甚至没有价格表,意思是:它是免费的?
我立刻去Azure AI上注册了Project,部署了DeepSeek R1。
用Azure AI部署模型非常方便:
注册好Project
进入模型市场,选择DeepSeek R1,填一个Deployment Name,部署
然后拿着Azure AI Endpoint, API Key以及这个Deployment Name,根据文档安装调用TS SDK
设计一个Prompt
调用SDK
Prompt我随便想了一个:
Summarize the article in the next message in language ${languageCode} in 100 words. Return the result in plain text format, without any other information.
The document discusses the challenges and benefits of using a Dependency Injection (DI) framework in a Java project. It highlights the two main options for dependency management: introducing a full-blown DI framework or using traditional object instantiation or simple factory pattern, which can be time-consuming and cumbersome. The author uses the example of a simple Java project where the interface and implementation class pattern was used to decouple the interface and implementation, but it also introduced complexity. The document suggests using delegation and classpath scan capability to achieve minimal dependencies and extra code, and provides a code example to help understand the process.
The article discusses choosing dependency injection (DI) for small projects, comparing full DI frameworks (verbose) versus factory patterns (clumsy). The author developed a lightweight DI solution using Kotlin’s delegation and classgraph for scanning. Annotations (@Service, @ServiceImpl) mark interfaces and implementations, while a di() function delegates dependency resolution, enabling singleton injection with minimal code. Benefits include simplicity, circular dependency support, and dynamic resolution, though limitations include no init block usage and lack of advanced features. The author praises Kotlin’s modern features (null checks, lambdas) and how diverse programming paradigms expand problem-solving approaches, emphasizing tools’ influence on design thinking.
Summarize the article in the next message in language ${languageCode} in 100 words. Return the result in plain text format, without any other information.
这是本次重写最重要的地方。我原来是CSS in JS的狂热爱好者,认为使用JS编写网站的所有方便是网页开发的最终目标。现在,我虽然仍然认为CSS in JS方案带来的灵活性是所有其他方案都不可比拟的,但是我也认识到很多情况下样式并不需要那么高的灵活性。另外,由于样式最终还是要到达CSS的层次,在把CSS in JS和其他第三方样式解决方案(例如之前用的bootstrap)集成的过程中,需要大量代码来将两套完全独立的样式系统整合起来。这也是之前样式代码极度混乱的根本原因。
React Server Component (RSC)实际上是React的概念,在2020年就提出来了(Introducing Zero-Bundle-Size React Server Components - React Blog)。简单来说,原来的React的组件都是运行在客户端的。浏览器首先把项目代码下载下来,然后再浏览器中运行代码,这些代码将会通过浏览器端DOM API在浏览器上画出UI,并处理用户的交互。而React Server Component允许用户编写运行在服务器端的React组件。而Next.js 13第一次实现了这一概念。
Gatsby主要通过GraphQL让开发者访问数据(Gatsby and GraphQL)。开发者在页面中可以声明这个页面所需要的数据的GraphQL查询,并在页面中通过props访问读取到的数据以及渲染UI。在编译时,gatsby将会负责运行这些查询,并将数据传递给需要数据的组件。而可以访问到的数据,则可以通过插件或者自定义gatsby-node.ts脚本来向后端的GraphQL服务器中增加数据节点。
之前,对于一些已有插件不支持的功能,我是通过一些比较hack的方式完成的。例如文章的Table of Contents,我是通过在渲染后通过DOM API分析页面中各个h1/h2/h3等元素来动态生成的。而现在,我可以自己去寻找可以解析TOC的插件(@stefanprobst/rehype-extract-toc),并将它插入到渲染的流程中,并在最后得到结果并自己完成渲染的过程。又比如,我想给渲染出的标题的前面增加一个图标,点击这个图标就获取到跳转到这个标题的URL。通过rehype-react,我可以很简单的实现这一点。
本科前两年半时,我拿定主意直接工作,却在最后时刻,抱着想看看有没有新的机会的想法,极限转弯踏入了研究生的大门。而研究生的前两年的体验让我认识到高校做工程不靠谱,回去看业界的机会时,发现实验室做的工作不能让我踏入一个所谓更“高阶”的工作,我能投向的业界工作和读本科时基本没有区别。后来,当我意识到,当前国内大环境下体制内的技术工作也并非一无是处,想把握北大应届毕业生这个机会了解一下体制内的机会,但却错过了这个时间窗口,最后仍然投向了微软,和三年前的唯一的区别也就是大组(C+AI vs STCA)和工作地点(苏州 vs 上海)的区别了。
说遗憾肯定是有点遗憾的,毕业时选择工作可能是最重要的人生选择。有些地方毕业时不进,之后就再也不进去了。而很多人都向往的北大学历最后在找工作方面并没有发挥什么用处。但是这几年让我认识到,人是会变的,现在的想法只能代表现在,不能代表未来。甚至有几个被项目的事情困扰的晚上,我还在认真考虑现在去科研是不是还来得及。考虑了这么多,最后只会发现,一切都是有好有坏。在微软,起码短期内实现Work Life Balance、收入还可以的“小目标”实现起来还是比较简单的,而且还能接触到先进的软件产品和软件项目管理方式。虽然世界大环境对外企不利,但是世界变换得太快了,几年后的日子谁又能预测得到呢?
但是看剧体验并不佳,主要原因是世纪剧场的音效太垃圾了,二楼靠前的座位只能勉强听清台词,歌词就完全无法听清了,而且由于是中文剧所以没有字幕,所以这很严重地影响了对剧情的理解。比如犹太教和基督教的“冲突”点的歌《The Girl for You》在原剧里相当搞笑,但是在这次表演中由于音效的原因,除了知道剧情改成了外地人以外,改的词完全没听清楚在讲什么,只能看到舞台上热火朝天的舞蹈,感觉怪尴尬的。其他歌也基本是同样的问题,我看过原剧所以理解每首歌主要讲的内容,但是没看过的观众就比较尴尬了。我的票也是中档价格的票了,但是体验仍然这么差,只能给剧院差评了。希望明年去的剧院能好好考虑一下音效效果,连歌都听不清,音乐剧的效果也就大打折扣了。
一开始以为可以投多个职位,所以浏览了一下实习列表,除了一定会投的苏州STCA,还发现了上海的两个职位。本来以为上海微软就只有支持,结果发现其实也是有开发岗的。其中普通的C+AI应该和STCA比较相似,但是另一个C+AI Open Source的职位吸引住了我。仔细了解后发现这个工作主要是给VSCode写Java扩展……我是VSCode(当然还有其他微软产品,除了Surface)的忠实用户,对这个开源和开发扩展的工作非常感兴趣,于是也把它选上了。
面完第一轮已经一个小时了,于是休息了几分钟就迎来了第二位面试官。和第一位不太一样的是,第二位面试官一开始还问了20分钟左右的项目经历。我趁势推广了我的博客,面试官在我博客上看到了An Infinite Loop Caused by Updating a Map during Iteration这篇文章,就饶有兴趣地让我讲讲这个bug以及怎么发现它的。这个部分我个人感觉讲的不错(毕竟算法题这么屎的我还敢面试MS的原因是我项目经验应该还不错吧……),面试官的反应也不错,这让我稍微放松了一些。
但是从个人角度来说,由于各种原因(特别在你院的三年),我确实不想再呆在学校,更加期望能够投入工作,做一些真正有用的东西。就像在我的关于里说的那样,我还是希望我的工作能够有利于对其他人有用(这也是我喜欢微软的一大原因,Make Other People Cool),能够帮助他人提高工作效率,并且做一些自己真的想做的事情,而不是在学校里(这里省略一些字)。
import math, randomfrom functools import reducedef possibility_for_n(n): return 0 if n==0 else math.log(1+1/n,10)def distribution_list(n): result = [] for i in range(0,10): r = 0 for j in range(int(math.pow(10,n-2)),int(math.pow(10,n-1))): r = r + possibility_for_n(j*10+i) result.append(r)return resultdef search_list(distlist): return list(map(lambda i: sum(distlist[:i+1]), range(0,10)))def generate_digit(n): rand = random.random() searchlist = search_list(distribution_list(n)) if rand <= searchlist[0]: return 0 for index in range(0,10): if rand > searchlist[index] and rand <= searchlist[index+1]: return index+1def generate_one(length): return reduce(lambda x,y: x*10+y, map(lambda i: generate_digit(i), range(1,length+1)))def generate_multiple(length, num): return [generate_one(length) for i in range(0,num)]
def possibility_for_n(n): return 0 if n==0 else math.log(1+1/n,10)
这段代码很好理解:计算以n开头的数字的频率。由于数字不能以0开头,所以以0开头的数字的频率为0。
本位的分布表
def distribution_list(n): result = [] for i in range(0,10): r = 0 for j in range(int(math.pow(10,n-2)),int(math.pow(10,n-1))): r = r + possibility_for_n(j*10+i) result.append(r) return result
def generate_digit(n): rand = random.random() searchlist = search_list(distribution_list(n)) if rand <= searchlist[0]: return 0 for index in range(0,10): if rand > searchlist[index] and rand <= searchlist[index+1]: return index+1