最近终于给silly实现了etcd driver。
下一步就要基于etcd来实现我去年提到的分布式框架了。
但在此之前,我需要知道etcd的边界在哪里,他是如何保证一致的,是否有幻读等问题。
由于etcd采用了raft共识算法,所以我需要了解raft的一些基本概念。
最近懒得阅读英文文章,因此在学习raft之前,我先查了一大堆中文资源,最后我都不太满意。
最终只能去啃CONSENSUS: BRIDGING THEORY AND PRACTICE, 于是就有本文。
CONSENSUS: BRIDGING THEORY AND PRACTICE中几乎介绍了需要实现raft中的方方面面,但我并没有看完,因为我只是想了解raft算法的边界。
因此本文只是按我的理解,从leader选举、日志复制和安全性三个方面来描述一下raft算法,其中我会着重描述安全性。
因为我查到的所有中文资料中,对安全性的描述,我最不满意。
raft使用心跳机来触发leader选举,选举机制如下:
进程状态分为follower、candidate和leader三种。
所有服务器启动时都默认是follower状态。
当follower接收到leader或candidate进程的有效RPC请求时,会保持在follower状态。
leader会定时向所有follower发送心跳包(没有日志条目数据的AppendEntries RPCs即为心跳包)来保持他的权威性。
如果follower在election timeout时间内没有收到心跳包,那么follower就会发起一次选举,来选择新的leader。
整个选举流程如下:
- 一个
folllower增加它的当前term(任期)并转换为candidate状态。
candidate给自己投票,并向所有其他服务器发送RequestVote RPCs。candidate 一直会保持在candidate状态,直到以下三种情况之一发生:
- 得到了
超过一半的服务器的投票,此时candidate会转换为leader状态。
- 另一个
candidate赢得了选举,此时candidate会转换为follower状态。
- 选举超时,此时
candidate会增加term并重新发起选举。
每个服务器在给定的term(任期)内按照先到先得(安全性部分会增加一些额外的限制)的原则, 只能投出一票。
超过一半原则会保证在一个特定的term内,只有一个candidate会胜出成为leader。
一旦一个candidate胜出选举,他就会成为leader,并向所有服务器发送心跳包,来宣布他的权威性,并阻止新的选择。
在等待投票的过程中,一个candidate可能会收到其他服务器S发送AppendEntries RPC消息来声明服务器S(自己)成为leader, candidate就会检查服务器S发送的term是大于等于自己的term。
如果是,那么candidate就会转换为follower状态,否则就拒绝这个RPC请求,然后继续保持在candidate状态。
可以看到整个选举过程,本质上就是使用paxos算法就term的值达成一致的过程。
正如paxos一样,raft的选举过程也会产生活锁, 即永远都无法选出leader。
raft为了解决这一问题,引入了随机化选举超时时间,这样就最大话限度地避免活锁。
再来看看日志复制是怎么进行的,自此raft就和paxos没有任何关系了。
raft的日志复制是基于quorum来保证可靠性的。
一旦一个leader被选出,他就会开始接受客户端的请求。
每个客户端请求包含了一个由复制状态机执行的command。
复制状态机可以按日志写入顺序,从前往后执行日志中记录的command,以得到最终的结果。
例如:复制状态机按(set x=1),(set x=5)的顺序执行完command, 那么x的最终值就是5。这也意味着只要集群中各节点中日志一致,各节点中关于某个变量的值都是一致的。
leader先将这个command作为一条新的日志(log entry)追加(append)到自己的日志中。然后对其他服务器并行发出AppendEntries RPCs,要求他们也将这条日志追加到自己的日志中。
当有超过半数的服务器都成功的将这条日志追加到自己的日志中,那么leader就会将这个日志条目应用到自己的状态机中(这就是大名鼎鼎的quorum)。
此时这条日志就处于committed状态, leader已经可以将状态机中的结果返回给客户端了。
在将结果返回给客户端之后,leader会不停的使用AppendEntries RPCs来重试直到所有followers最终都保存了所有的日志。
需要强调的是,这个committed状态是针对leader来说的,当一条日志处于commited状态,就意味着这条日志产生的结果可能已经被返回给客户端了,因此不能丢失。这一点对于后面理解安全性部分很重要。
raft保证所有处于commited的日志都会持久化,并被所有可用的状态机被执行。
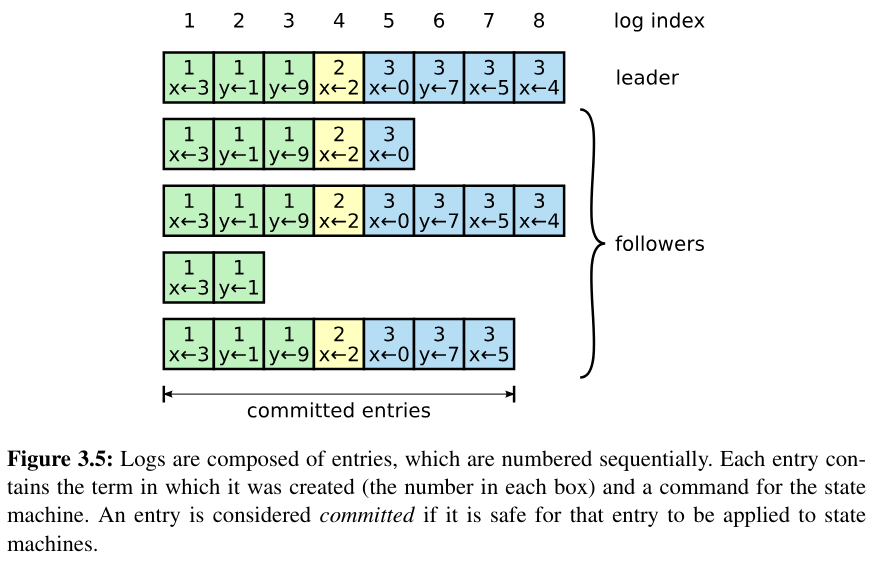
整个log的组织方式如下图所示,每条日志(log entry)都会有一个惟一id, 这个id由term和log index组成,其中term就是产生本条日志的,当期leader的term值。

当一条日志处于commited状态时,leader会将这条日志之前的所有日志都commit, 包括前任(整个集群中所有之前的)leader所产生的日志。
leader会始终记录当前已经处于committed中日志最大log index(max_log_index),这个索引会通过下一次AppendEntries RPCs(包括心跳)发送给followers。
当一个follower知道一条日志处于committed状态时,他就会顺序的将这条日志之前的所有日志都应用到本地复制状态机。
这条规则对于一致性没有任何帮助,只是为了防止当leader宕机时,follower成为leader后,follower能够快速的将自己的状态机和leader的状态机保持一致。
raft的日志机制会使得不同服务器间的日志保持了高度一致,这不仅会简化系统行为,而且会使结果更加可预测,也是确保安全性的重要组成部分。
raft日志有如下属性:
- 如果在两个服务器中的日志有相同的
log index和term,那么这两个日志包含相同的command。
- 如果在两个服务器中的日志有相同的
log index和term, 那么这两个服务器中,这两条日志之前的所有日志,都是相同的。
第一个属性来源于这样的一个事实:leader在一个term内,对于给定的log index最多只能产生一条日志。
第二个属性则被AppendEntries中执行的一致性检查来保证。当发送一个AppendEntries RPCs时,leader会将紧接着本次新增日志(可能有多条)的上一条日志的log index和term,发送给所有follower,如果follower发现自己不存在同样的日志,则他会拒绝这条新增日志。
举个例子,当leader发送了一个(last_term=2, last_log_index=1, entries=((term=2, log_index=2, command="x=1"),(term=2, log_index=3, command="x=2")))的AppendEntries RPCs时,follower会检查自己的日志列表,如果发现自己的日志列表中不存在(term=2, log_index=1)的日志时,follower就会拒绝这个RPC请求。
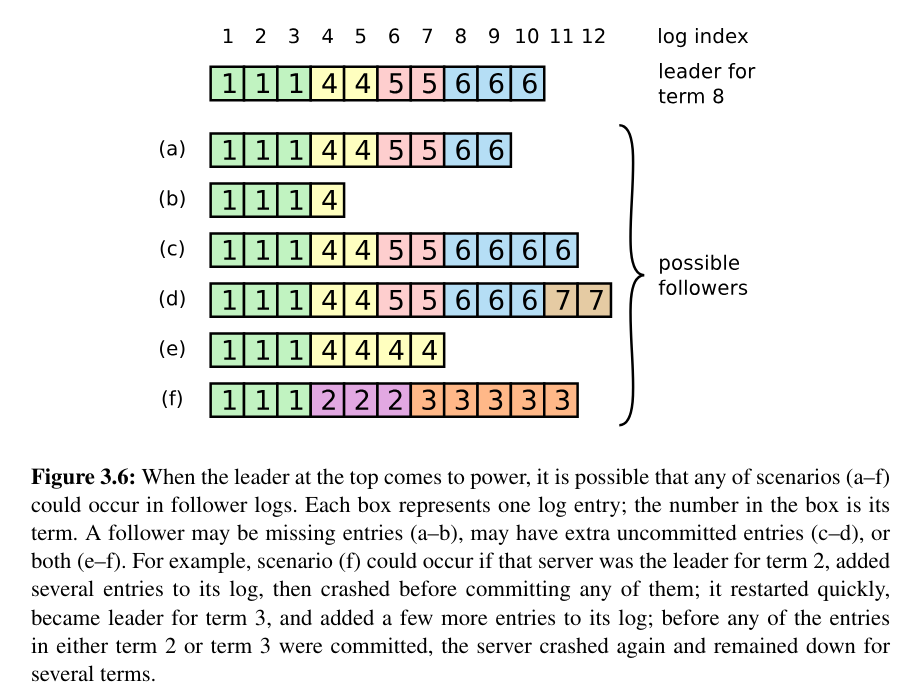
正常情况下,raft的leader和follower之间的日志列表是一致的,但是当leader和follower之间产生一系列的crash之后,日志列表可能就会变得不一致。
下图展示了一些leader和follower之间的日志列表不一致的情况, 一个follower可能会丢失已经存在于leader日志列表中的日志,也可能会拥有不存在于leader日志列表中的日志。
在raft中,leader会通过强制所有follower来复制自己的日志列表来保证一致性。
当leader向follower中的AppendEntries被拒绝时,leader会不停的向历史日志回退,直到找到第一个和follower相同的日志(term=T,log_index=L),然后使follower删除日志(term=T,log_index=L)之后的所有日志,并复制从leader中日志(term=T,log_index=L)之后的所有日志。
leader会通过找到和被复制的follower中最新一条相同的日志,然他开始往后复制,直到复制完leader中所有的日志,至此leader和follower的日志列表就保持了一致。
上面的日志机制只保证了可以leader和follower之间的日志列表保持一致,但是并不能保证已经处于committed的日志不会丢失。
下面来看看安全性是怎么做到这一点的。
raft规定,如果一个caididate没有包含所有已经处于committed的日志,那它就不可能在选举中胜出。
一个candidate为了被选举成功,必须要联系超过半数的服务器,这意味着,所有已经处于committed的日志至少会存在于被联系的一台服务器之中(同样基于quorum)。
这里需要重申一下,这个处于committed的日志仅仅指,他被前任leader已经应用到状态机并将结果返回给了客户端的日志。
并不是leader通过AppendEntries RPCs同步过的,已经处于committed中日志最大log index(max_log_index)。
这一点需要思考一下才能得出结论,也是所有中文资料最模糊的地方,也是很关键的地方。
我们来看一个反例:
假如所有的follower都维护了一个committed index, 这个committed index来源于每次leader发送的AppendEntries RPCs中的最大的已提交日志的log index。
整个集群中日志内容如下, S1为leader, 他已经将(term=1, log_index=2)复制到了大多数服务器中,因此S1已经将(term=1, log_index=2)标记为committed,并且为客户端返回了结果。
S1 (term=1, log_index=1, command="x=1"),(term=1, log_index=2, command="x=2")
S2 (term=1, log_index=1, command="x=1"),(term=1, log_index=2, command="x=2")
S3 (term=1, log_index=1, command="x=1"),(term=1, log_index=2, command="x=2")
S4 (term=1, log_index=1, command="x=1"),
S5 (term=1, log_index=1, command="x=1"),
根据规则,本次提交的log_index将会通过下次AppendEntries RPCs同步给所有follower。
因此S2,S3,S4,S5服务中,此时leader已提交的最大的id为(term=1,log_index=1)。
如果此时S1 crash, S5当前持续的最大日志id为(term=1,log_index=1),是大于等于S2,S3,S4的最大日志id的,因此S5有资格成为leader。
这种情况下已经处于committed状态下的日志(term=1, log_index=2, command="x=2")就会丢失。
因此,如果一个caididate没有包含所有已经处于committed的日志,那它就不可能在选举中胜出只是一个必要条件,并不是用来实现的充分条件。
事实上,当一个candidate发出一个RequestVote RPC时,他会带上自己日志列表中最新日志的(term,log_index), 而集群中别的服务器收到RequestVote RPC时,会拿这个(term,log_index)和自己的最新日志(term,log_index)进行比较,如果发现自己的日志比candidate的日志新(通过比较(term,log_index)二元组来确定),那么就会拒绝这个RequestVote RPC。
由于RequestVote RPC会发给半数以上的服务器,因此当candidate胜出时,他必然会已经包含了所有已经处于committed的日志,不然他就收不到超过半数的投票。
之所以上面说是一个必要条件,是因为candidate也有可能包含超过已经处理committed的之外的日志,这些日志是否需要恢复会产生一个更微妙的问题。
这就需要再次增加一个限制条件来达成一致性,leader只能通过当前日志是否已经在集群中被复制超过半数来判断是否应该提交自己的当期日志,而不能用来判断是不是应该提交前任的日志。
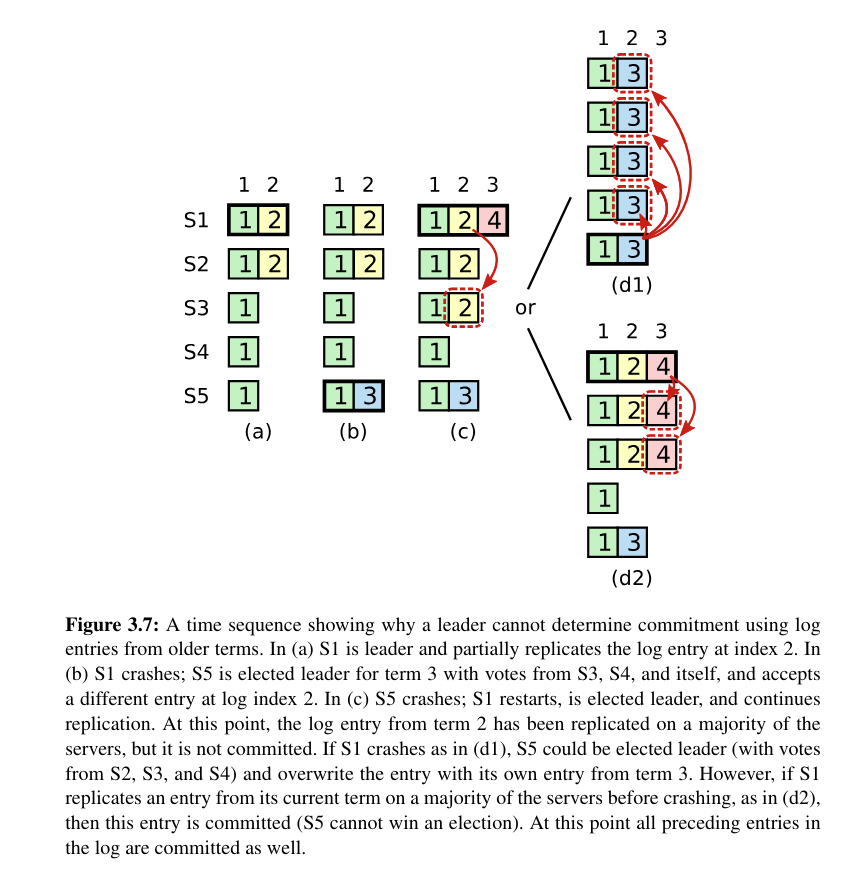
下图展示了为何leader只能主动提交自己当期的日志。
假如在图(c)中,S1过度到term=4,并且继续提交(term=2,log_index=2),此时(term=2,log_index=2)在整个集群中的复制数量已经超过半数,因此S1可以将这条日志标记为committed。
然后S1生成了一条新的日志(term=4,log_index=3), 在还没有来得及复制给follower之前crash掉了,此时S5以term=3的情况成为leader, 由于他本地最新的日志为(term=3,log_index=2), 因此他可以胜出获得超过半数的投票。
此时他会强制所有follower来与自己保持一致,会覆盖掉已经处理committed状态下的日志(term=2,log_index=2), 这违反了raft的保证。
这里其实还隐含了一些更微妙的问题。在刚开始阅读原文时我没有注意到。
从图(c)之后,假设S1接受了(term=4, log_index=3)的请求并开始复制,他会先复制(term=2, log_index=2),然后再复制(term=4, log_index=3)。
如果在集群中机器超过半数都已经复制到了(term=4, log_index=2), 但是在复制(term=4, log_index=3)时,S1再次crash了。
虽然(term=2, log_index=2)在集群中的复制数量已经超过了半数,但是由于(term=4, log_index=3)还没有处于committed。
因此(term=2, log_index=2)还不能被标记为committed, 因此(term=2, log_index=2)是可以被别的leader覆盖掉的。
至此,raft的leader选举、日志复制和安全性三个部分算法总算描述完了。