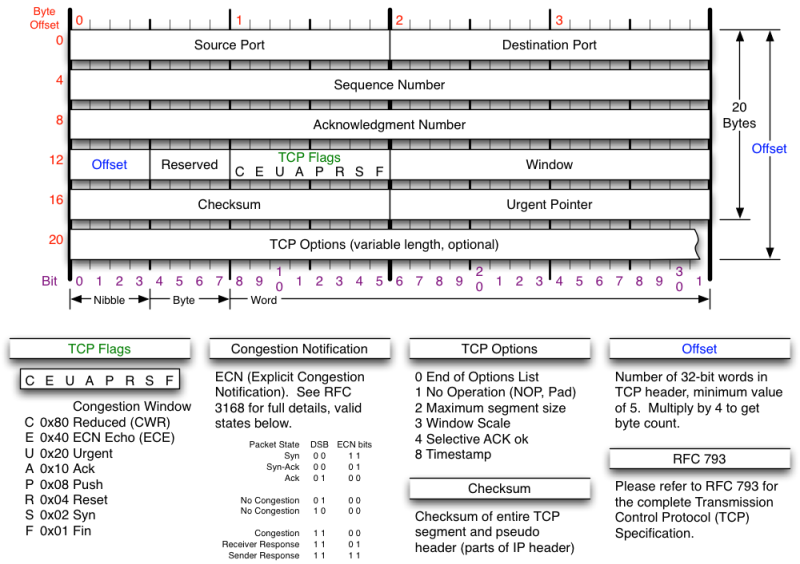
Paste Image in VSCode
Preface
You may know I used Typora as the editor for my blog. If you are find the way to make your images compatible between Typora and Hugo1. Here is the article you need.
Project architecture
Here is the architecture of the project I created by Hugo. You can see the posts are hosted in content/posts and all images are in directories with the corresponding filename of posts without extension in static/images.
![]()
What we need is making my utils match these requirements:
- Images can be pasted into the markdown file with a shortcut.
- Storing images in a specific directory like
/images/${currentFileNameWithoutExt}.assets/xxx.png. - Make pasted URL suit to the Hugo configuration.
- The images can be previewed in the Preview Panel in VSCode.
Pasting with a shortcut
Images, such as a screenshot, cannot be pasted into a markdown file in VSCode automatically with Ctrl + V. With the extension, Paste Image by mushan, you can pressing Ctrl + Alt + V (or, Cmd + Alt + V on Mac) to paste the image.
The preview in VSCode works good and the directory for pasting was created. But the link is a relative path from current file path.

Storing images in a specific path
By default, the images are store in the same directory with current post. But we expect it can be stored in a subdirectory of static/images. It can be set with the following configuration.
"pasteImage.path": "${projectRoot}/static/images/${currentFileNameWithoutExt}.assets"
Then, when you paste a image, it will be stored in the static/images/paste-image-in-vscode.assets/ directory. And the URL should be:

Making static path as the base path of images
However, the image is broken in the local service we lauch because the Hugo need a relative path from project path as root to show the image. Otherwise, it will broken as below.
![]()
The expected path should be like below:

We can change the base path from current file to the path of current project and add a slash before the relative path.
"pasteImage.basePath": "${projectRoot}/static",
"pasteImage.prefix": "/"
Preview support in the Preview Panel of VSCode
For now, our workspace is compatible with Hugo. But all images in the preview of VSCode are broken because the preview extension cannot realize the correct base path of images.
Sadly, I haven’t found a good way for it. So, we have to rise a local service to preview the post. Here is a feature requirement for specifying the image root path for Markdown preview. If it resolved, the images can be previewed in VSCode.
-
Typora is still the best Markdown editor I have ever used and I bought a license from it when it went to 1.0. But the device count limitation is not suit to my use case. So, I move into VsCode. ↩︎