本篇文章使用时间顺序整理和撰写,大致就是比赛的流程。我们在几次答辩后根据新情况对代码进行优化,于是就有每次答辩之后紧跟着的改进和优化。我们项目的大致信息如下:
项目名称 XDWe:驱动教学相长的AI智能学习助手 所属赛道 大学生创业计划竞赛赛道-新一代信息技术赛道(主体赛) 所获奖项 2026年星火杯网络安全与密码学部选拔赛一等奖
目前专项赛还在进行,本文会持续更新,记录我们参加星火杯的完整的过程。
前言:从一些想法开始
前段时间,学院发了关于星火杯的报名文件。上个学期就听说过星火杯,但没想到这学期刚开学就要提交作品,没有做什么事先准备。
3月8日晚点名结束后,我与一位同学在图书馆用“腾讯元器”做了一个 AI 问答服务,零代码平台开发这个并不难,但一个小时弄出作品还是给这位同学比较大的震撼。星火杯有支持提交零代码平台开发的智能体的赛道,我打算就这样交上去。
当天晚上,那位同学找我,我们和另外一位同学沟通一些想法,初步确定往“教-学-管-评”智能体方向去做,设计一个平台来服务教育教学。
当天我们三个初步的想法
智能体知识库本身其实就是一个 RAG 系统,我将此前做 RAG 的代码基本照搬过来,大致用 flask + langchain 做了一个后端出来。姚焱夫同学负责前端,此前他并没有接触过前端的开发,现用现学,很快就了解了前端项目的文件结构、代码逻辑,非常厉害。孟子钦同学将我们聚到一起,对一些想法进行了完善。
设计与开发
通过我们的观察,大学的课堂教学过程中存在一些问题,例如:
从“教、学、管、评”四个角度对教学过程问题的分析(点击图片可跳转到图片文件)
针对这些问题,我们用我们的项目给出解决方案:
提供大模型问答功能,回答问题
教师可以针对学生提出的问题给出权威回答,完成知识沉淀
知识库可以添加文档、资料,充分利用教学材料
使用大模型对学生的学习情况进行总结,方便老师分析
这是关于系统问答与知识库功能的流程动图:学生向学习助手提出问题,学习助手在知识库中检索相关资料附在问题后交给大模型,大模型回答学生;教师可以在管理后台看到学生提出的问题并给出权威答案,权威答案沉淀到知识库中,下一次有学生提出类似的问题,大模型将被要求根据权威答案生成回答。
这是关于系统架构的动图:前端用 Vue 进行开发,后端由 Python Flask 提供服务,使用 Qwen 开源模型。
以上两张动图都是用 manim 制作的,截取自我们的项目介绍视频。PPT 的模板来自人智院的刘卓东学长。由于视频文件比较大,内容就是这两个动图加上功能的演示,所以介绍视频的链接附在本文的附录。
结合我与 Gemini、ChatGPT的对话记录,总结在开发过程中遇到的问题。
环境依赖问题 langchain_community的版本跟其他依赖不匹配……langchain两个大版本的接口有很大的差异。每次遇到这种问题问 ai 折腾一两个小时估计都折腾不好,用一下搜索引擎很快就解决了。
之前发的一条QQ空间
在与 ChatGPT 沟通的过程中,遇到开发中最麻烦的两个模块create_retrieval_chain和create_stuff_documents_chain。根据我们 ChatGPT 同学之前的回答,它应该是知道由langchain_classic这个包的,但不知道为什么它在这及之后就忘记这两个模块被移到langchain_classic里面去了。我也是头脑不清醒,跟着它折腾半天,最后不得不找谷歌看看。(其实谷歌应该是第一选项才对,但是我懒,喜欢让 ai 直接给答案)
ChatGPT“正儿八经”地给出错误回答
我在谷歌上搜索了一下这个导入语句,马上就找到了 python – Using create_retrieval_chain due to RetrievalQA deprecation – Stack Overflow 这个帖子,将langchain改成langchain_classic,问题就这样解决了。
在与 Gemini 谈话的过程中,估计是训练数据过时了或者没有搜索到合适的资料,它反复提醒我:“导包错误:LangChain 较新版本中,记忆和链模块应从langchain.memory和langchain.chains导入,而不是langchain_classic。”还好我自己知道,没在同一个地方摔倒第二次。
在开发的过程中也遇到过依赖地狱,不过折腾几次全部使用新版本就解决了。
ChatGPT的聊天截图
Prompt拼接问题
Python if '<|im_end|>' in token or '<|im_start|>' in token: token = token.replace( '<|im_end|>' , '' ).replace( '<|im_start|>' , '' ) if not token.strip(): continue 我在后端开发好之后让 ai 写了一份接口文档,供负责前端的姚同学阅读。原本以为 git 和前后端协作这方面会出现一些问题,结果并没有我想的那样困难。在帮忙装后端环境的时候出现了一个问题,关于 cuda 的问题:
我在装 pytorch 的时候,Gemini 给的命令pip install --pre torch --index-url https://download.pytorch.org/whl/nightly/cu128能用,而cu129的预编译包却找不到。没办法,只好让同学降级,后面我在代码里也适配了没有 cuda 的环境。
答辩之前,代码之外,团队协作的过程中出现一些小插曲,经过沟通顺利解决。团队的负责人需要跟进比赛的时间点,熟悉项目并协调准备好材料,带领团队推进。
准备答辩时将材料交给皓子学长过目,大佬给了一些诸如突出显示关键词之类的建议。
主体赛初赛
答辩出现的问题
3 月 26 日晚上,我参加了网安密码学部的院级答辩。将答辩的录音转文字进行分析,结合答辩时的一些主观感受,发现答辩中暴露的一些问题:
答辩的时候超时了,后面关于项目优势和未来展望的部分没讲到。
问辩的时候展现项目的必要性还不够,相对于通用大模型的不可替代性没讲清楚。
产品对于老师留言提醒的功能做得还不够完善,例如:如果多个学生针对同一问题给老师留言,老师会收到多个邮件。
Deepseek给出的分析
差不多要 29 日学院里统计分数后才会出结果,这段时间可以对提出的不完善的功能进行一下优化。如果被推荐到学校里,完善完善,校赛再战。
与浦彦松学长交流了一下答辩的事情,学长给了一些建议:
不要列技术架构,关于技术的设计和改进可以提,但是要有数据、对比。
答辩不需要讲解技术,讲创新点,细节就说后续会优化。
背景只需要一两页。
不要有长段文字,图片的视觉冲击力好过红色标记。
PPT 很重要。
针对问题进行的一些优化
让 ai 完善了一下留言邮件提醒的逻辑,学生提交留言提醒之后会先在最近 24 小时的留言里匹配相似度,如果发现有相似度高于 0.85 的留言,则不会给老师发送邮件通知。
例如学生提交了两条相同的留言
在我们完善代码的时候微信发来消息,我们的项目没有被推荐到校赛,这次主体赛我们到这里就结束了。我们队伍里面讨论了一下,决定将这个项目做完。“无论还有没有机会,无论结没结束,咱们都尽量把这个项目完成。不管成没成功,都是自己做的一个项目。”
学校流程系统的通知
我们梳理了尚未完成的工作,大致分成三个部分:
项目 README 的实现效果部分目前缺省,没有直观的展现
资料库内容还不够丰富,有待充实后发布版本
暂时还没有对于 RAG 投毒的防御措施
假如LLM无限上下文了,RAG还有意义吗? 这篇回答给我提供了一个可能的优化方向,即“主动RAG,让模型自己决定查什么”。
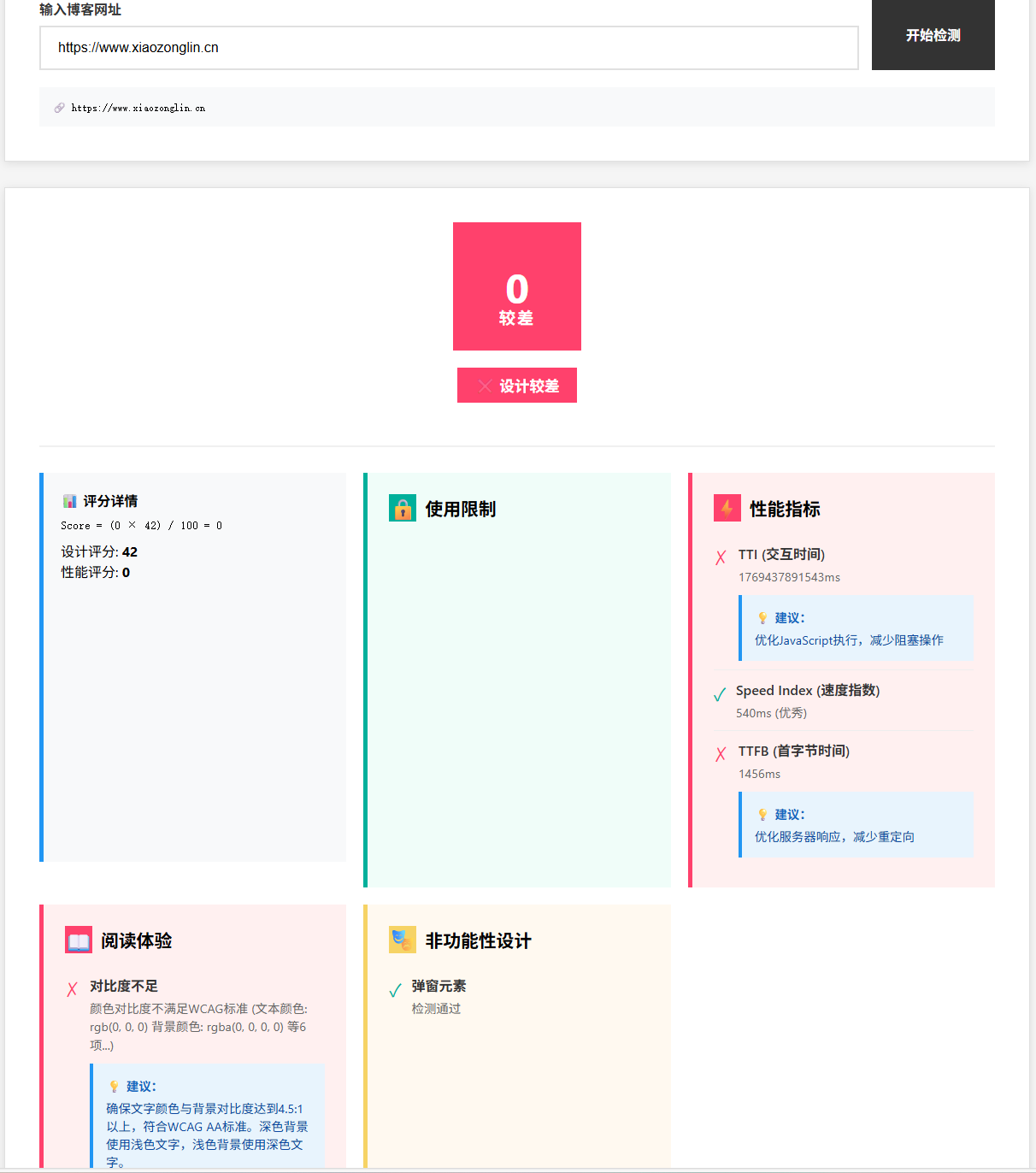
原先的问答代码是这样的,用户提问→系统检索→模型生成,整个生成过程只检索一次知识库,属于是一个比较普通的 RAG 流程。以下是关于这一流程的生动的图片,图片中红色的内容为投毒内容,暂时不考虑这一点。
图片来自Certifiably Robust RAG against Retrieval Corruption
我让 Gemini 根据主动检索的概念对代码进行修改,修改后的 ai 可以自己决定要不要检索知识库,如果是寒暄之类的提问可以直接回答,跳过检索步骤。可以进一步对代码进行优化,让 AI 自己决定检索词。
当提问“栈是什么东西”时,检索被重写为“栈”
关于抗投毒,TrustRAG: Enhancing Robustness and Trustworthiness in RAG (arXiv:2501.00879) 提供了一种可行的方法,主要通过 k-均值聚类和大模型自评估来过滤恶意投毒文档。因为懒,目前文档数量比较少,没有什么过滤的必要。
项目 README 的实现效果需要实际应用之后才能拿到数据,不方便摆太多的数字。
3 月 29 日晚上,在推完主动检索的修改之后,将新生成的向量知识库上传到 GitHub,发了一个版本。目前的开发任务差不多就完成了。
Release Note
3 月 29 日中午,就在我们知道我们这个项目没有被推荐到学校过后不久,学部把选拔赛的获奖名单发出来了,我们项目获得选拔赛的一等奖。到此,主体赛算是“有始有终”。
至此,可以跟主体赛说拜拜了。
智能体专项赛
初赛答辩
清明节时,我与姚焱夫同学在原有的基础上准备专项赛初赛答辩的PPT。专项赛答辩的时间比主体赛还短,只有3分钟时间,问辩时间也只有2分钟,这对我们来说是一个挑战。吸取之前主体赛答辩背景讲太多的教训,我们将四个方面的背景整合到一页。我们参加的是“教-学-管-评”智能体开发挑战专项赛,将这四个方面一起展示感觉更有冲击力。同时,我们避免出现大段的文字,只留关键词,然后用我自己的审美稍微排版了一下,感觉还行?PPT后面的创新之处也使用这样的排版。
参加专项赛初赛答辩的ppt-背景
4 月 9 日晚上,我与姚焱夫同学准备次日早上的专项赛初赛答辩。我们又一次咨询了皓子学长。大佬给了我们很多建议,比如“可以吹自己已经部署使用了一段时间,请了多少个老师同学试用,评分均分多少分”“未来展望,直接落地得了,引入多模态大模型,这种用绘图技术结合下多好”等等。我们对创新之处作了一些修改。
参加专项赛初赛答辩的ppt-创新之处
次日早上,姚同学前去答辩。姚同学不愧是大佬,结构清晰,回答自信。
Deepseek评这次答辩
功能的改进
4 月 9 日,我们看了一下我们的那些展望。姚同学想着用 opencode 把多模态实现了,结果 Deepseek 把代码实现之后,发现它把后端登录、注册的路由给删了。我让同学好好骂一骂 ai。
ai再一次闯祸
这次专项赛立了这些 flag,如果进校赛的话要在比赛之前做好。
多模态问答
知识库自动管理(Python爬虫)
基于 TrustRAG 的抗投毒机制
更智能的 Agent 功能
预留对接学校的系统
使用 Java Spring AI 作为后端架构,贴合实际部署的情况
图文问答(多模态问答)
关于多模态部分,我和姚焱夫同学弄了几次没弄好,opencv和ocr好像都差点意思,大模型已读乱回。
比如这一张,明明没有用算法库里的东西,ai还是回答algorithm
我们打算使用Qwen/Qwen2-VL-2B-Instruct来实现多模态功能,但在回答含文字的内容时效果还是不怎么好。根据 如何使用Qwen3.6模型实现视觉理解 这篇文档的介绍,我打算使用Qwen/Qwen3-VL-2B-Instruct试试,速度快,又具备文档解析、复杂题目解答的能力。我先对原本的后端代码进行一些拆分,给500行的代码瘦瘦身。
在独立出数据模型时出现了问题。后端使用SQLAlchemy创建数据模型,我将数据模型独立到一个models.py文件中,如下:
Python import os from dotenv import load_dotenv load_dotenv() from datetime import datetime import flask from flask_sqlalchemy import SQLAlchemy from flask_login import UserMixin app = flask.Flask( __name__ ) app.config.update( SQLALCHEMY_DATABASE_URI =os.getenv( 'DATABASE_URL' ), SQLALCHEMY_TRACK_MODIFICATIONS = False , ) db = SQLAlchemy(app) class User ( UserMixin , db . Model ): id = db.Column(db.Integer, primary_key = True ) username = db.Column(db.String( 20 ), unique = True , nullable = False ) ... class Question ( db . Model ): id = db.Column(db.Integer, primary_key = True ) content = db.Column(db.String( 1000 ), nullable = False ) ... class Message ( db . Model ): id = db.Column(db.Integer, primary_key = True ) content = db.Column(db.String( 1000 ), nullable = False ) ... 然后在main.py中将原本的数据模型替换为from modules.models import User, Question, Message,发现失败。后面将上面代码中的db改成从main.py导入,出现循环导入的错误。Gemini推荐使用工厂模式来解决这个问题。但我懒,把数据模型又给搬回去了,没用这个。
Python from transformers import AutoProcessor, AutoModelForVision2Seq model_name = "Qwen/Qwen3-VL-2B-Instruct" self .processor = AutoProcessor.from_pretrained(model_name, trust_remote_code = True ) self .llm = AutoModelForVision2Seq.from_pretrained( model_name, torch_dtype = self .dtype, device_map = "auto" if self .device == "cuda" else None , trust_remote_code = True ) 在导入过程中发现我的transformers库没有AutoModelForVision2Seq,搜索之后发现 ImportError: cannot import name ‘AutoModelForVision2Seq’ from ‘transformers’ · Issue #8200 · modelscope/ms-swift 这位与我遇到了同样的问题,也是在用这个模型时发现无法导入。将transformers调整为4.57.6就解决了。
使用了Qwen3之后,模型就能够读懂图片了。
同时给定图片和问题,要求根据图片回答指定的问题 不给文字,让ai分析图片,可以看出ai解释图片内容的能力不错
知识库自动管理(爬虫)
我关于爬虫流程的想法
以上是我用Mermaid画的一个大致的流程,经过确认这也是姚焱夫同学想要的效果:我们设定一些网址,脚本爬取这些网址的网页内容,经过大模型以及一些人工设定的规则清洗后变成干净的markdown文档,存在知识库文件夹中。
RAG知识库搭建-文档预处理-数据清洗:基于异步的AI文本批处理系统实践-腾讯云开发者社区 这篇文章提供了一个可以借鉴的system prompt。基于此,我们设定知识库负责清洗的llm的system prompt。
姚焱夫:
Hi,这里是XDwe团队姚焱夫。作为我第一个真正意义上的项目,我感觉这次体验很棒。
作为非cs专业学生,其实我对编程方面并不算特别熟悉,不管是编程基础还是工作流程熟练度都没办法和宗林相比。小到Git,终端的使用和开发环境的搭建,大到前端开发,vibe coding的使用,还有项目的协作,我学习到的东西真的很多很多。以前作为兴趣浅尝辄止的东西,在这次实践过程中真的深入了很多。虽然学的是电子信息,但其实我一直是对计科、人智和具身这些方面更感兴趣,所以当其他人都在学习单片机,如火如荼准备电赛的时候,我毅然决然地放弃了之前参加电赛的想法,转而学习自己感兴趣的内容。不仅把竞赛方向换到了更喜欢的Robomaster,也有了参加科研的想法。
这次比赛便是我学习cs的一个初尝。放弃了电院和物理院的比赛,我转而和网信院的同学组队,开发了这个ai问答平台。我能明显的感受到,在这个项目过程中,我是深度沉浸,高度投入的。最开始的时候恨不得把每天的时间都投到项目里面。当然,这期间我的开发能力也得到了飞快的增长,我开始越来越像一个真正的开发者。
想法的构建和具体的实施,都是我们团队经过商讨之后共同完成的,这种协作的工作方式不仅能最大化每个人的能力,大大提高项目的实现效率,而且对以后的工作裨益无穷。我一直相信卓越不是一蹴而就,所以我一开始就告诉自己,不要太看重成绩,注重学习的过程。虽然主体赛道没能进入校赛,但是我们优化过的项目在专项赛道貌似得到了很高的评价。事实证明,如果你认真去做了,就算结果不一定如你所愿,但也一定不会差到哪儿去。
技术之外,我还学到了很多。比如之前一直不怎么重视ppt的重要性……但事实是,ppt就是评委了解项目的唯一渠道,不仅要要重视它,甚至还得弄得夸张点……再比如这次的专项赛答辩。因为我其实是一个非常outgoing的人,所以我一直相信自己肯定能做到,也没给自己太大压力。答辩前一天认真准备了一下,第二天轻装上阵,做了一次还算不错的答辩。
所以,你真的不能吗?你真的不行吗?
无论是电信科转战cs的决定,还是项目的每一个实现,都在告诉我
You can just build things.
给自己一点压力,给自己一点信心,然后JUST DO IT.
感谢:特别感谢宗林在技术方面对我的帮助~宗林是一个技术栈十分全面的大佬,工作认真负责,是一个特别优秀的队友。
致谢与附录
致谢
感谢负责进行前端开发工作的姚焱夫同学、负责协调与 UI 图标设计工作的孟子钦同学、给我们提供宝贵建议的皓子大佬和浦彦松学长与提供 PPT 的刘卓东学长。与此同时,我在大创课题组所做的工作在本次比赛开发 AI 应用过程中给我提供帮助,感谢苗教授和负责指导我们的张博士师兄。
附录
项目代码仓库:Xiaozonglin/shallowseek: Teacher-Augmented AI Learning System for Xidian University
项目展示视频:XDWe manim展示视频代码 XDWe项目介绍视频
大佬推荐的 PPT 设计视频:PPT遇上大段文字,这样排版更清晰!_哔哩哔哩 大段文字并且很多要点,要怎么排版呢?这个视频就教会你!_哔哩哔哩
星火杯参赛小记:XDWe——驱动教学相长的AI智能学习助手 最先出现在林林杂语 。