
LRO/GRO 对于网络吞吐的影响
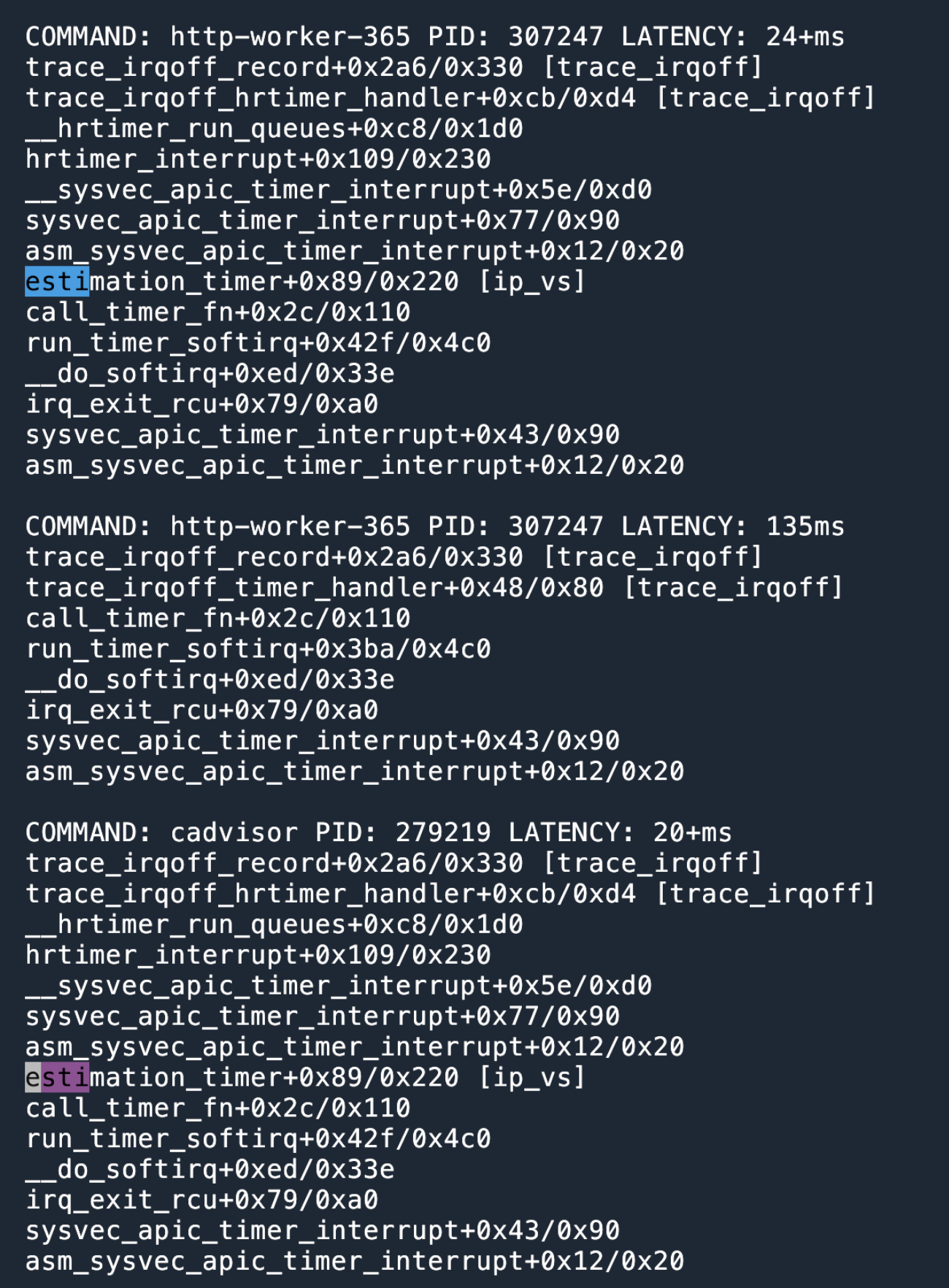
打开这个抓包文件,可以马上确认这是一个发送的数据比较多的连接1,因为 TCP sequence number 上升的很快,IP 层的包都是用最大的 MTU 发送的。

分析长肥管道,可以使用之前介绍过的技术,用 tcptrace 来分析。
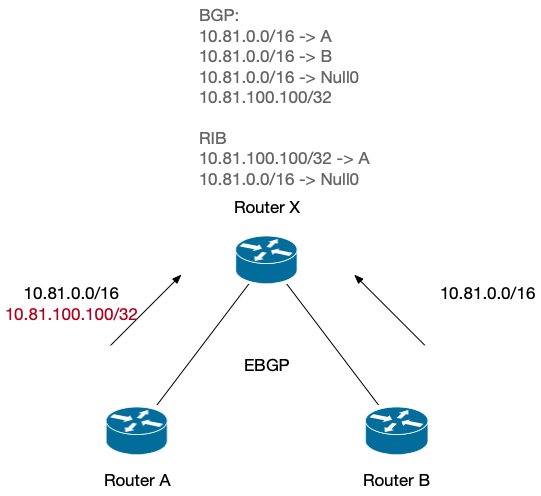
打开 Statistics > TCP Stream Graphs > Time Sequence (tcptrace),可以看到下图。(如果是一个直线,说明方向看反了,点击 Switch Direction.
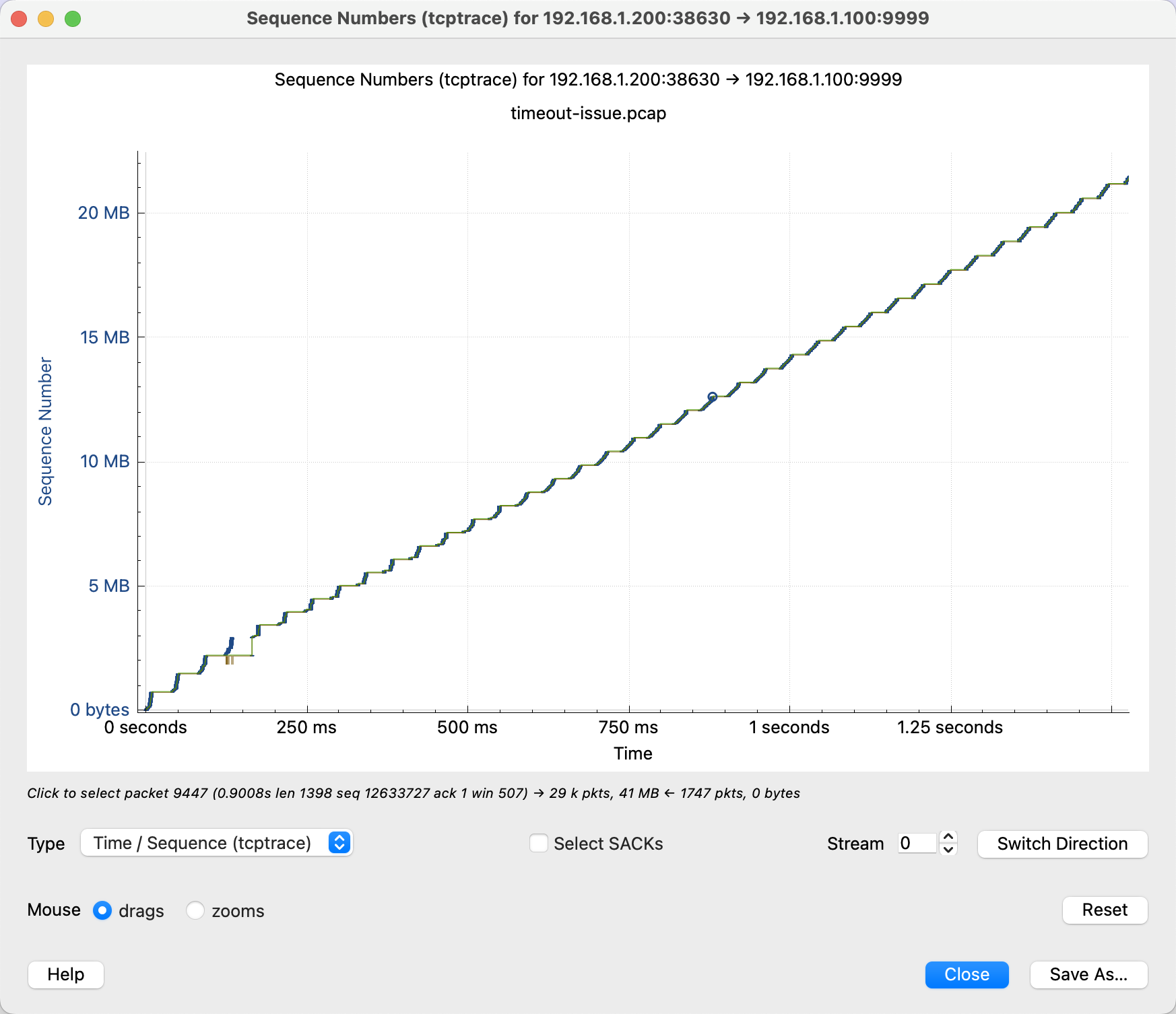
由于没有抓到这个 stream 的 TCP 3次卧手包,我们不知道 window scaling 是多少,所以这条绿线就可以直接忽略了。剩余的看起来一点问题没有,cwnd 打开并且保持的很好,也没有很多 SACK。在 200ms 左右有一次丢包。但是看 sequence 上涨的趋势来说,并没有造成多大的影响,很快补回来了。所以这里不是主要原因。
Sequence 上涨的趋势没有太大问题,还会有超时,那么问题就可能出在——上涨的速度不够快。同样的转发链路,我们不禁怀疑,是不是新的设备比旧的设备转发性能低?每一个包都慢几个 us,总的吞吐就低?
可以打开正常的转发抓包做对比:
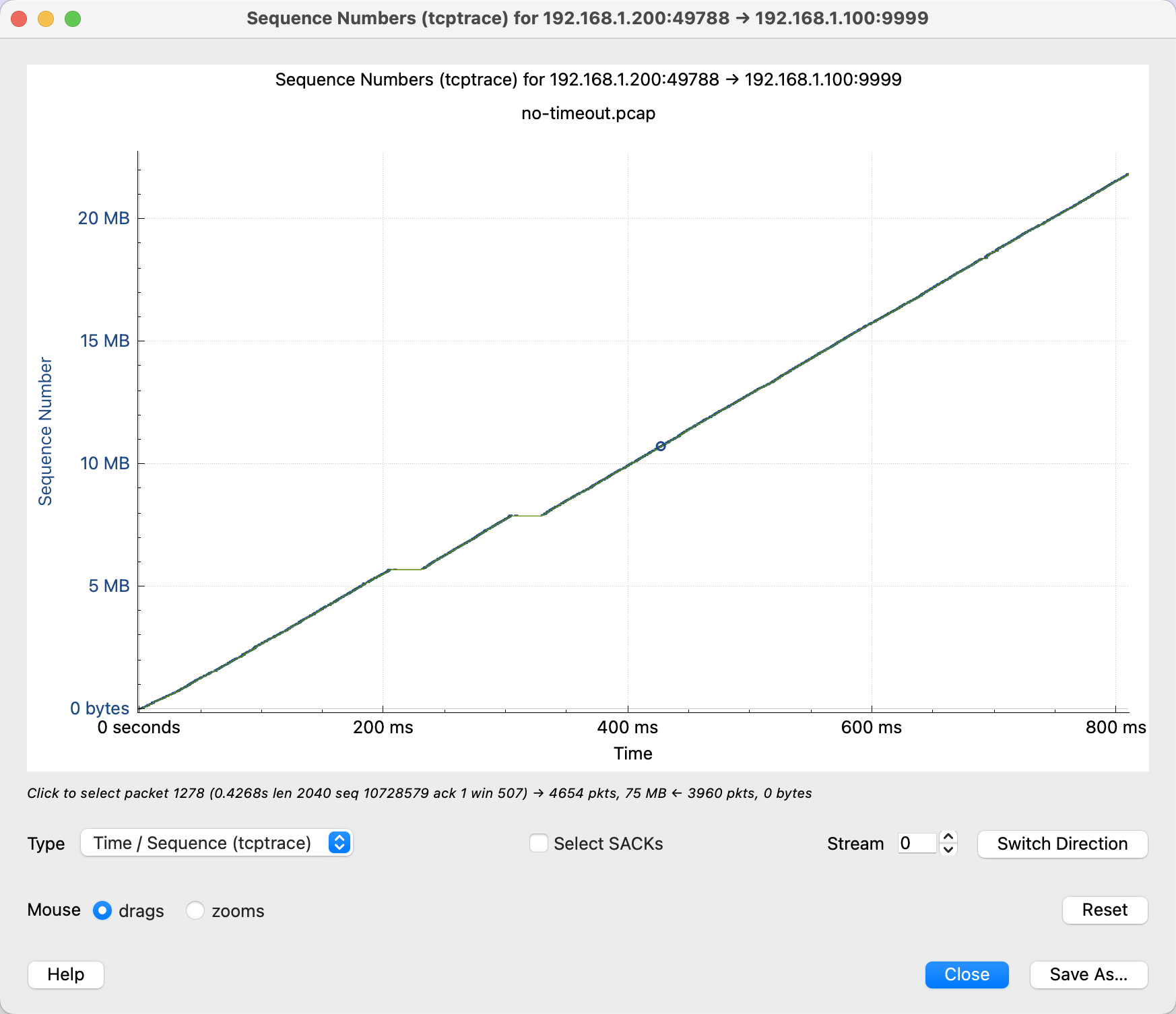
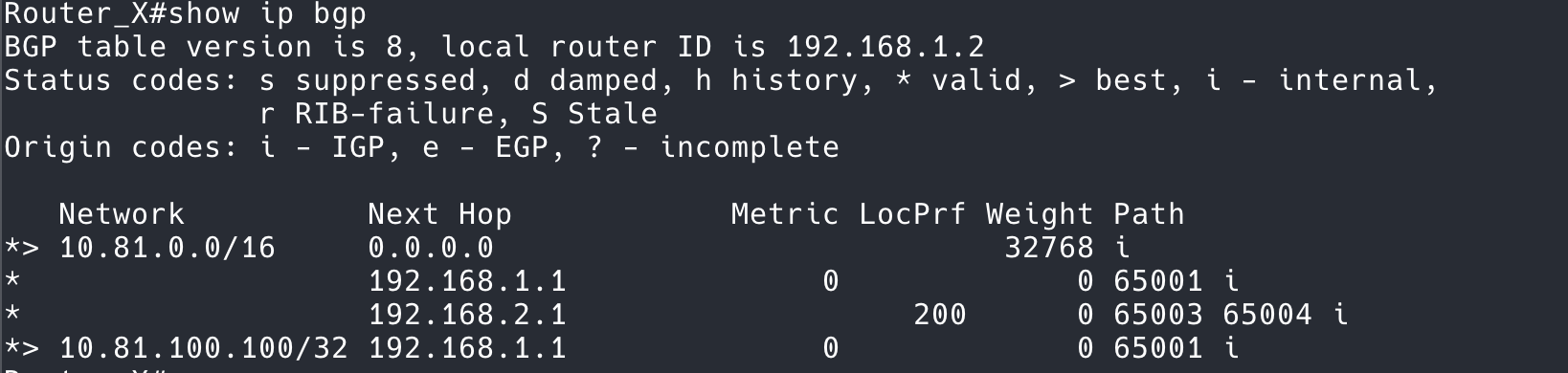
这个线确实可能更加斜一点,但是斜多少呢?我们可以看吞吐的图。

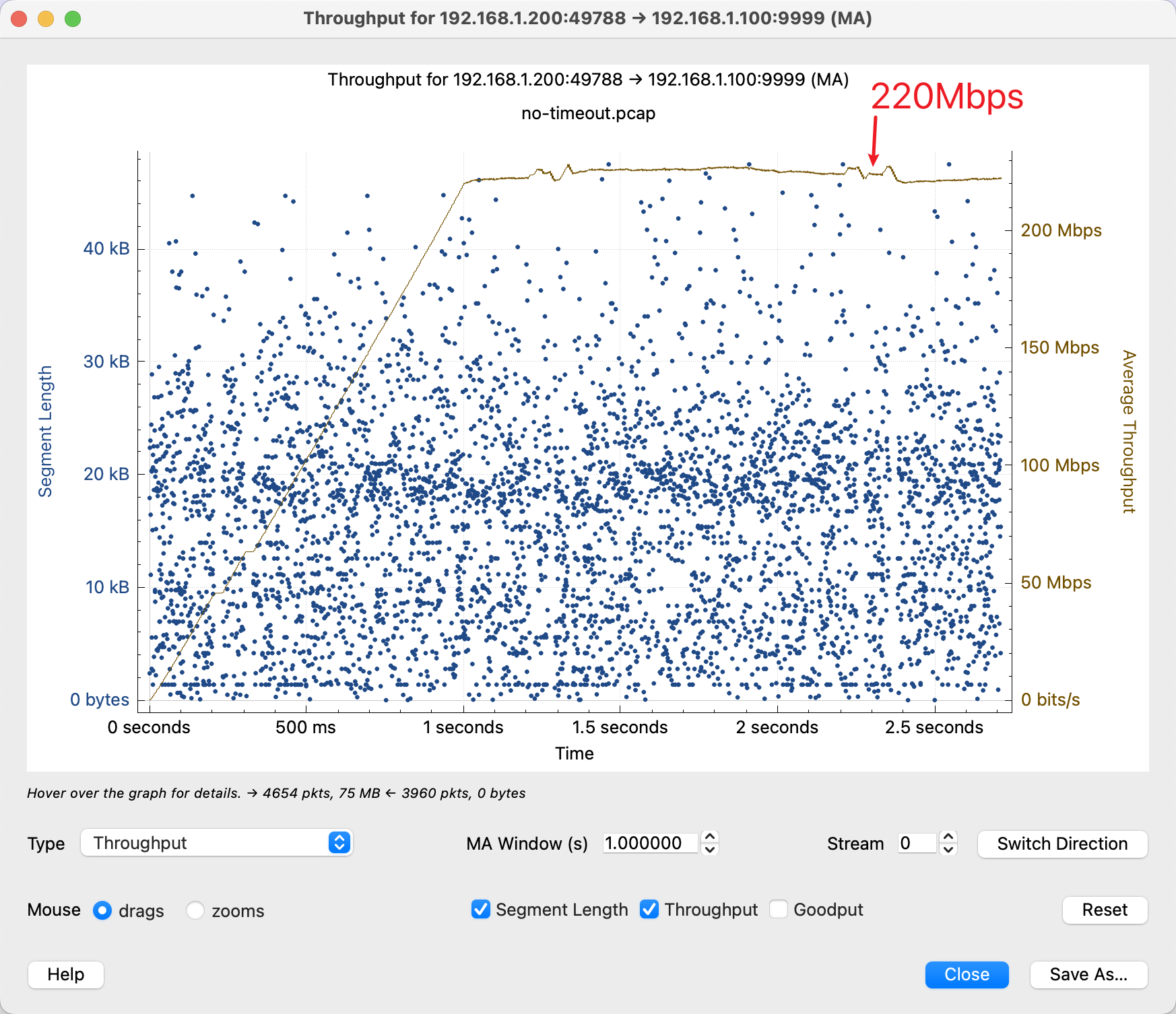
棕色的线对应实际的传输速率(右侧的 Y 轴)。可以看到,正常情况下吞吐可以达到 220Mbps 左右,但是换上新的设备只有 140Mbps 左右。在大部分 HTTP 请求中,对于小的包,延迟的变化不会特别大,但是在长肥管道中,吞吐低就会造成传输数据就会出现差距。导致部分请求超时。
其实,新旧设备的转发速度并没有根本的区别,造成吞吐不同的原因,发生在别处。
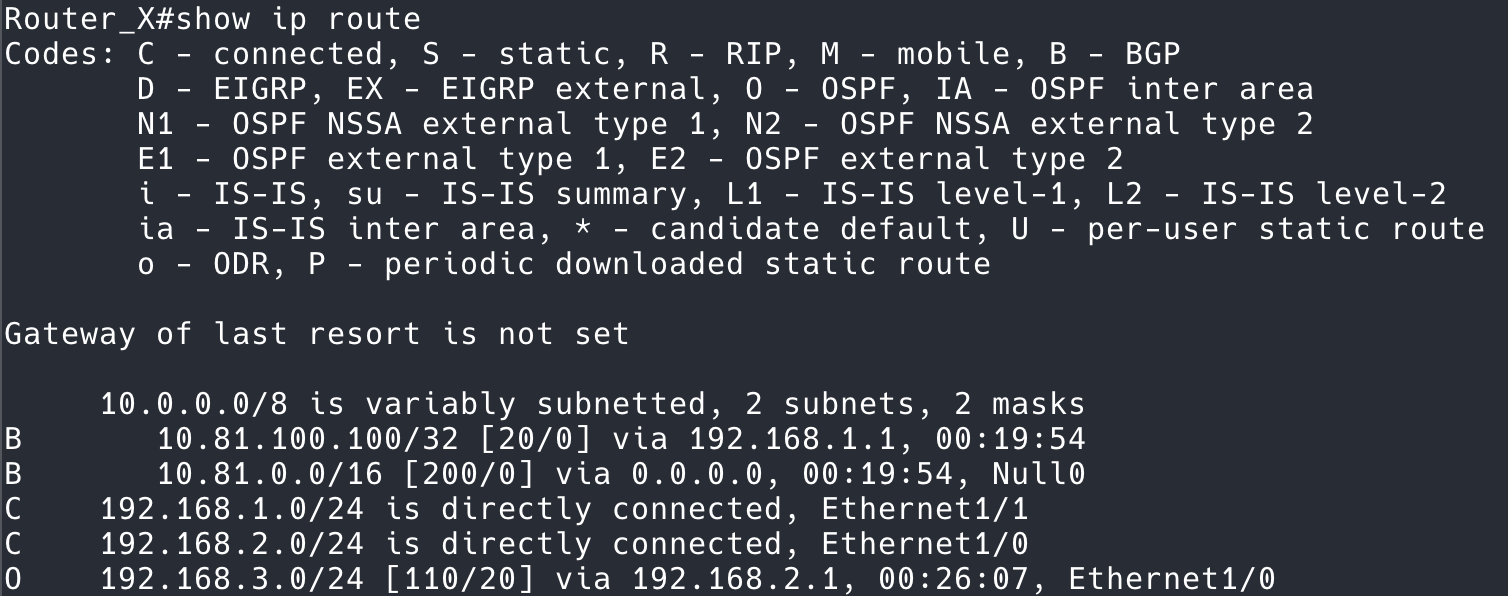
这两幅图的对比也揭示了更加深层次的原因:即左侧的 Y 轴。
左侧 Y 轴,以及图中的蓝色点,含义是 packet 的 size 的分布,每一个点代表了一个 packet size。第一幅图中,所有的 packet 都是使用最大的 MTU 发送的。内层 overlay(VxLAN Tunnel 里面)的 MTU 是 1450.
而下图中,packet 的 size 居然超过了 MTU!
之前的一篇有关 MTU 的讨论2,我们知道,发送超过 MTU 的包是会被其他的设备丢弃的,那么为什么我们从 tcpdump 能看到超过 MTU 的包呢?这是因为网卡帮我们把收到的多个小包给合并成了一个大包,再交给操作系统(Kernel)处理,这部分现在一般是在网卡的硬件上来完成的,所以我们抓包看到的(即操作系统看到的)是网卡合并处理之后的包。这叫做 Large Receive Offload,LRO。
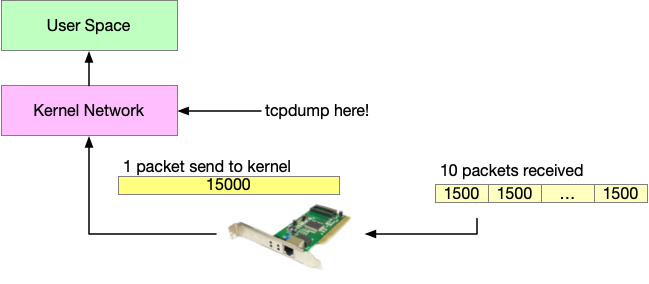
为什么要这么做呢?因为 CPU 是通用处理器,它能做很多事情。很忙。为了提高性能,在硬件上做的很多优化都是让其他的硬件去分担 CPU 的工作。比如:
- 让 GPU 来代替 CPU 做矩阵运算;
- 用专用的设备来卸载 TLS3;
- 让网卡卸载 vlan,把小包合成大包,等等;
网卡擅长做重复但是简单的事情,合并小包再是再合适不过啦!
而 CPU 的工作量主要和处理多少包有关,和包的长度关系不大,长度是 1 的包(在 kernel 里面是 skb)和长度是 10000 的包,对于 cpu 来说,只是一个 length 的 value 不同而已。包的内容是业务逻辑,主要是由应用程序处理的,在 Kernel 里面,主要关注的是包的 header。假设 CPU 的能力是每秒处理 10 万个包,如果每一个包的长度是 1Kb,那么吞吐就是 10Mbps;但如果包的平均长度是 100Kb,那么吞吐可以达到 1Gbps。所以有了网卡给我们做 LRO,就可以有效提高 CPU 的吞吐。
到现在,原因就清晰了:新设备上了之后 LRO 失效,由于服务器的网卡不再执行 LRO 功能,吞吐就下降了很多,导致了部分请求超时。
那么为什么换了新的设备之后,服务器的网卡 LRO 就失效了呢?服务器网卡 LRO 和网络设备又有什么关系?
由于做不做 LRO 是服务器的网卡的硬件实现,我们无法查看硬件的设计。但是从其他地方对于 LRO/GRO 的描述,我们可以得到一些启发。
Linux 可以在没有硬件的支持下,用软件的方式实现 Generic Receive Offload, GRO (当然了,性能肯定是要差一些)。Kernel 的文档对于 GRO 的描述4如下:
Generic receive offload is the complement to GSO. Ideally any frame assembled by GRO should be segmented to create an identical sequence of frames using GSO, and any sequence of frames segmented by GSO should be able to be reassembled back to the original by GRO. The only exception to this is IPv4 ID in the case that the DF bit is set for a given IP header. If the value of the IPv4 ID is not sequentially incrementing it will be altered so that it is when a frame assembled via GRO is segmented via GSO.
除了 GRO,还有一种机制是 GSO,即 Kernel 在发送 TCP 流的时候,无须自己把每一个 Segment 切分成符合 MTU 大小再发送,而是可以直接发送,由网卡硬件来做这个切分操作。
为了让 GRO 和 GSO 是互相可逆的,即 GRO 之后的包可以通过 GSO 还原出来。需要保证:
- IP 包的 DF 设置为1,禁止 IP Fragmentation;
- IP 包的 DF 如果是0,那么 IP 的 ID 必须是连续的;
两个规则只要符合一条即可。
如果 DF 为1,很好理解,GRO 和 GSO 很容易逆向出来。
如果 DF 为0,ID 连续,比如 100,101,102,那么合成一个大包,大包的 ID 是 100,也可以逆向出来。但是如果 ID 不连续,比如 101,105,107,那么合成一个大包之后,就丢失原始的信息了。
对于 VxLAN 的包,在 DPDK 的文档5中,由明确要求外层的 IP 包和内层的 IP 包都要遵守这个规则:
- outer IPv4 ID. The IPv4 ID fields of the packets, whose DF bit in the outer IPv4 header is 0, should be increased by 1.
- inner TCP sequence number
- inner IPv4 ID. The IPv4 ID fields of the packets, whose DF bit in the inner IPv4 header is 0, should be increased by 1.
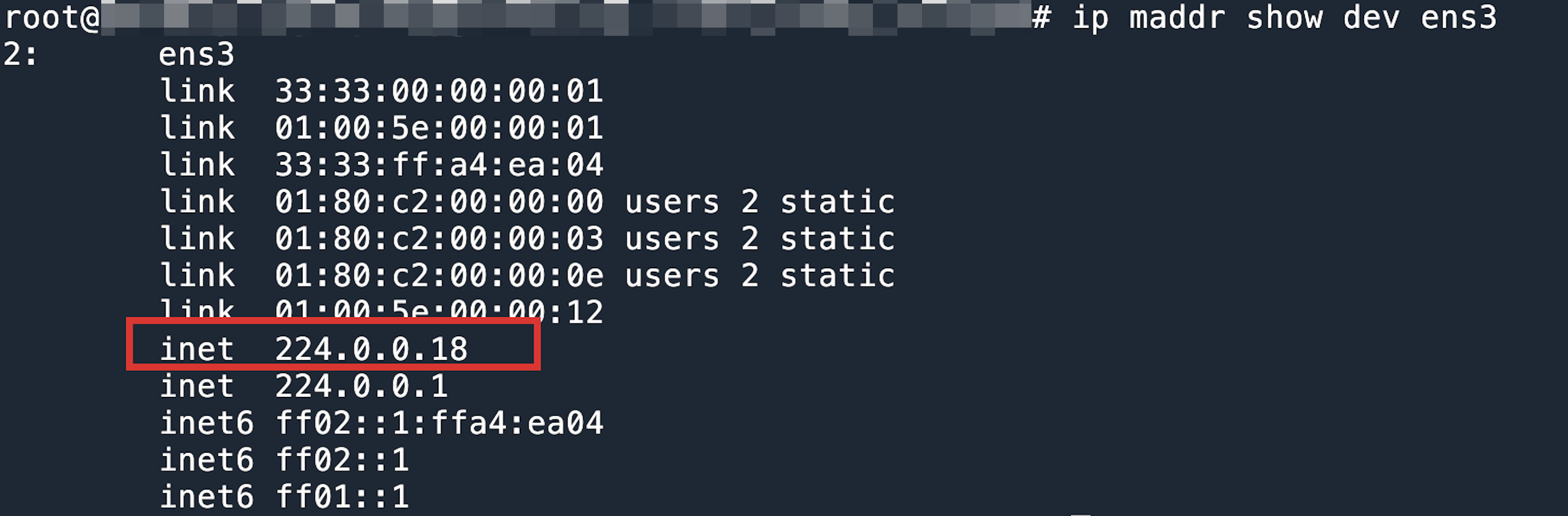
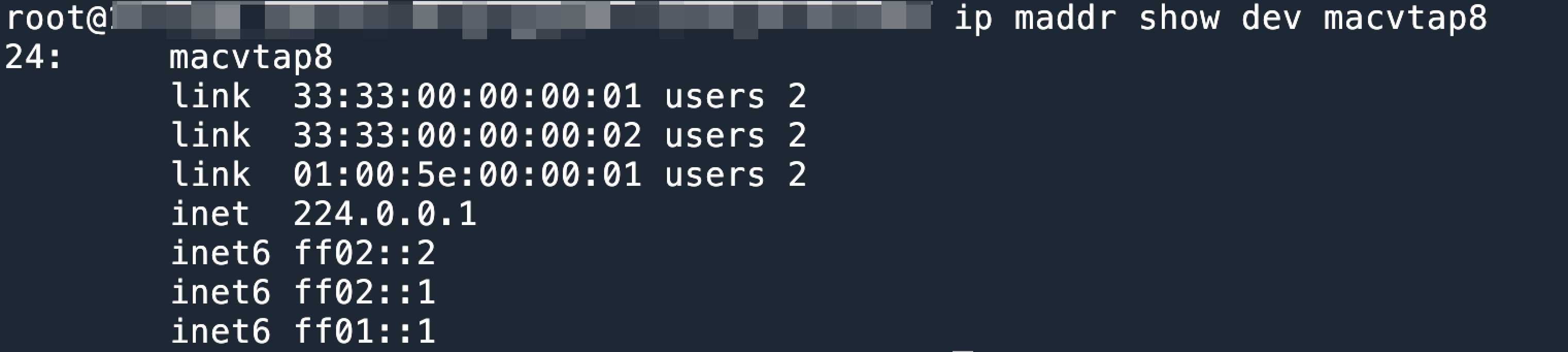
查看吞吐慢的 tcpdump,可以发现 outer 的 ip.df 是0,而且 ID 不连续,所以无法做 LRO/GRO。
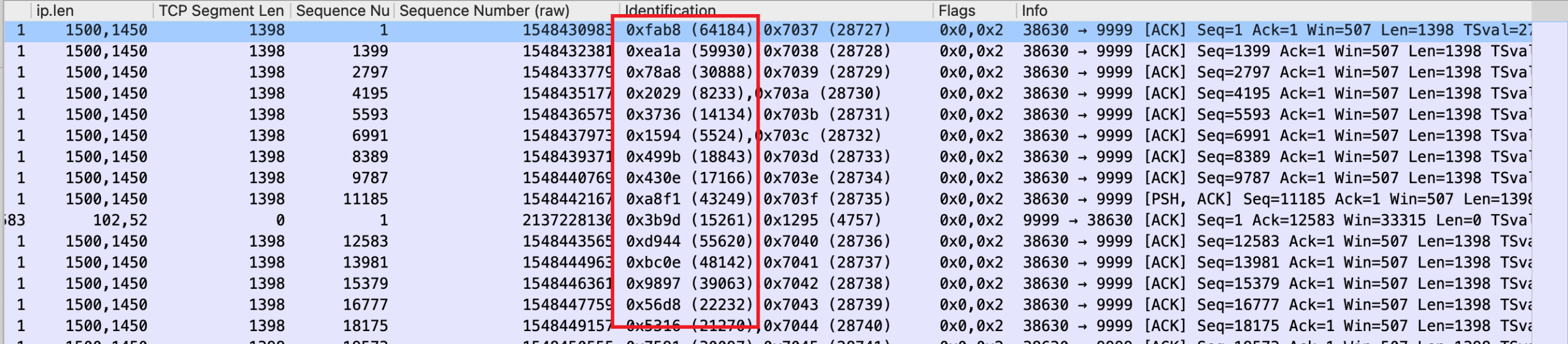
虽然我没有想到保证可逆可以带来哪些好处,但是从网上找到的资料来看,这个是在「ip.df=0 并且 ip.id 不连续的时候,不做 GRO」唯一的理由了。在另一处的邮件讨论中6,netdev 维护者以这个原则为理由拒绝了合并。起因是 Alexander Duyck 希望添加这个 patch,以达到效果:对于 overlay 的包,GRO 不再看外层包的 ip.id ,外层可以使用 fixed header,只看内层包的 ip.id 是否连续。这样,很多(实现不正确的)网络设备也可以享受 GRO 的好处了,但是因为会打破可逆的原则,所以没有被合并。
PS:上一篇文章问题中很多读者提到 GSO,为什么是 GRO 而不是 GSO 呢?因为 9999 是 server 端口,所以 192.168.1.100:9999 是 server 端,抓包文件显示的主要流量是 client 上传给 server 的,不是 server 发给 client 的。另一个细节是,.100 发给 .200 的 delta time,一般比 .200 发给 .100 的 delta time 要低,也可以佐证 .100 是 server 端。
- TCP 长肥管道性能分析
 ︎
︎ - 有关 MTU 和 MSS 的一切 ︎
- https://en.wikipedia.org/wiki/TLS_acceleration ︎
- Segmentation Offloads ︎
- VxLAN GRO ︎
- [RFC,7/9] GSO: Support partial segmentation offload ︎
==计算机网络实用技术 目录==
这篇文章是计算机网络实用技术系列文章中的一篇,这个系列正在连载中,我计划用这个系列的文章来分享一些网络抓包分析的实用技术。这些文章都是总结了我的工作经历中遇到的问题,经过精心构造和编写,每个文件附带抓包文件,通过实战来学习网路分析。
如果本文对您有帮助,欢迎扫博客右侧二维码打赏支持,正是订阅者的支持,让我公开写这个系列成为可能,感谢!
没有链接的目录还没有写完,敬请期待……
- 序章
- 抓包技术以及技巧
- 理解网络的分层模型
- 数据是如何路由的
- 网络问题排查的思路和技巧
- 不可以用路由器?(答案和解析)
- 网工闯了什么祸?(答案和解析,阅读加餐!)
- 延迟增加了多少?(答案和解析)
- 压测的时候 QPS 为什么上不去?(答案和解析)
- 重新认识 TCP 的握手和挥手(答案和解析)
- TCP 下载速度为什么这么慢?(答案和解析)
- 请求为什么超时了?(答案和解析)
- 0.01% 的概率超时问题 (答案和解析)
- 后记:学习网络的一点经验分享
与本博客的其他页面不同,本页面使用 署名-非商业性使用-禁止演绎 4.0 国际 协议。

















{kind=link}