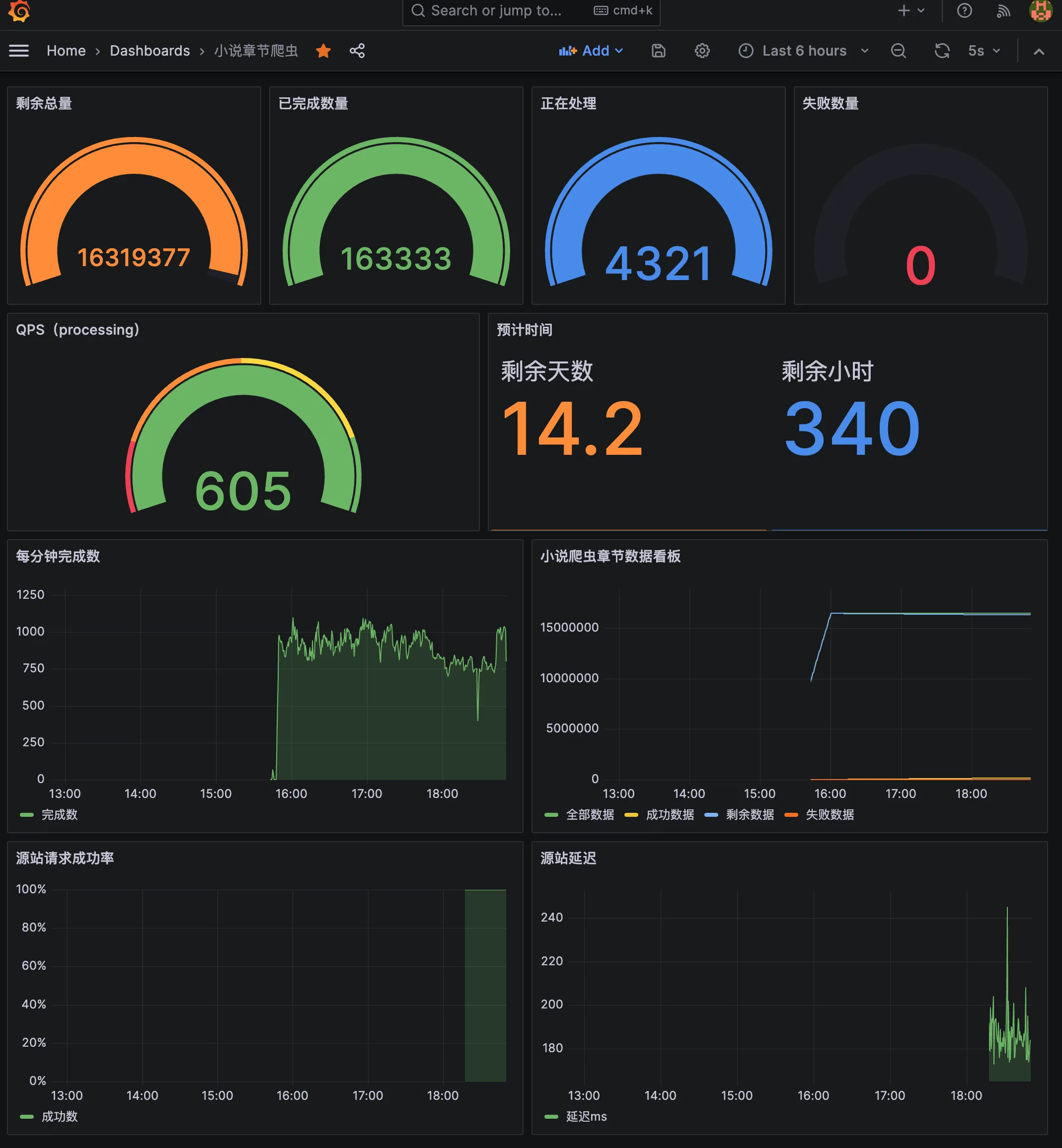
不知不觉已经写了两年代码了,每过一阵子回头看看原来的代码,都觉得有不少值得改进的地方,这真是一件高兴的事。
原来我从来不会关心编译原理这种东西,感觉离自己很远,但做项目的过程中,操作了一些 AST,杂七杂八的接触过一些相关的知识,又发现了一个很好的教程,就跟着写了一遍,颇有收获。
在此把大概的步骤和思路记下来。
教程: Create Your Own Compiler
代码: https://github.com/Mereithhh/simple-compiler
目标
我们的目标是用 js 写一个编译器,把 lisp 编译成 js 代码。
add 123 ( sub 4 3))
可以编译成下面的 js 代码:
add(123, sub(4, 3));
用起来可能是这样的:
const compiler = require("./compiler");
const input = "(add 123 ( sub 4 3))"
const output = compiler(input);
// add(123, sub(4, 3));
const add = (a,b) => a + b;
const sub = (a, b) => a - b;
const result = eval(output)
console.log(result)
// 124
概述
要实现这样一个编译器,大概要 4 步:
我们一步一步来。
词法分析
这步的目的是解析我们传入代码字符串中的有效单词,并给他们分类。我们的输入是:
add 123 ( sub 4 3))
这步完成后,就会输出这样的数组:
"type": "paren",
"value": "("
},
{
"type": "name",
"value": "add"
},
{
"type": "number",
"value": "123"
},
{
"type": "paren",
"value": "("
},
{
"type": "name",
"value": "sub"
},
{
"type": "number",
"value": "4"
},
{
"type": "number",
"value": "3"
},
{
"type": "paren",
"value": ")"
},
{
"type": "paren",
"value": ")"
}
]
要想实现这样的效果,我们只需要简单从头到尾捋一遍我们的输入,根据不同的情况判断就好了,大概是这样的:
const PATTERNS = [
"(",
")"
]
const NUMBER = /[0-9]/;
const LETTER = /[a-zA-Z]/;
const SPACE = /\s/;
module.exports = function tokenizer(input) {
const tokens = [];
let current = 0;
while (current < input.length) {
let char = input[current];
if (PATTERNS.includes(char)) {
tokens.push({
type: "paren",
value: char,
});
current++;
continue;
}
if (NUMBER.test(char)) {
let value = "";
while (NUMBER.test(char)) {
value += char;
char = input[++current];
}
tokens.push({
type: "number",
value,
});
continue;
}
if (LETTER.test(char)) {
let value = "";
while (LETTER.test(char)) {
value += char;
char = input[++current];
}
tokens.push({
type: "name",
value,
});
continue;
}
if (SPACE.test(char)) {
current++;
continue;
}
throw new Error(`unknow charactor: ${char}`)
}
return tokens;
}
语法分析
语法分析是把我们的上一步获得的词组,重新组合成树状的结构,也就是 AST。
处理好之后,会得到这样的树:
"type": "Program",
"body": [
{
"type": "CallExpression",
"name": "add",
"params": [
{
"type": "NumberLiteral",
"value": "123"
},
{
"type": "CallExpression",
"name": "sub",
"params": [
{
"type": "NumberLiteral",
"value": "4"
},
{
"type": "NumberLiteral",
"value": "3"
}
]
}
]
}
]
}
这一步实现的核心思路是递归,定义一个当前下标的变量,和一个递归执行的函数。 在递归执行的函数里分别处理不同类型的数据,如果遇到了符号类型的数据,那就递归调用这个函数。不废话直接上代码:
module.exports = function parser(tokens) {
let current = 0;
// walk 函数每次运行完,都增加一个指针,以被下一次 walk
function walk() {
let token = tokens[current];
if (token.type === 'number') {
current++;
return {
type: 'NumberLiteral',
value: token.value,
}
}
if (token.type === 'paren' && token.value === '(') {
// 下一个 token 才是函数名称
token = tokens[++current];
const expression = {
type: "CallExpression",
name: token.value,
params: []
}
token = tokens[++current];
while (token.value !== ")") {
expression.params.push(walk())
token = tokens[current]
}
current++;
return expression;
}
throw new TypeError(`Unknow token: ${token.type}`)
}
const ast = {
type: 'Program',
body: [walk()],
};
return ast;
}
AST转换
上一步我们得到了 lisp 语言得 AST 树,现在我们要把这个树转换成 js 的 AST 树。
核心思路是遍历整个树,在遍历过程中针对每一种节点类型,使用不同的函数转化成另一种树,并且要定义一个位置变量,来把转换后的节点插入到新树中适合的位置。代码如下:
const traverse = require("./traverse");
module.exports = function transformer(originalAST) {
const jsAST = {
type: 'Program',
body: [],
};
let position = jsAST.body;
traverse(originalAST, {
NumberLiteral(node) {
position.push({
type: "NumericLiteral",
value: node.value,
})
},
CallExpression(node, parent) {
let expression = {
type: "CallExpression",
callee: {
type: "Identifier",
name: node.name
},
arguments: []
};
const prevPosition = position;
position = expression.arguments;
if (parent.type !== "CallExpression") {
expression = {
type: "ExpressionStatement",
expression,
};
};
prevPosition.push(expression)
}
})
return jsAST;
}
其中遍历函数的实现如下:
module.exports = function traverse(ast, visitors) {
function walkNode(node, parent) {
const method = visitors[node.type];
if (method) method(node, parent);
if (node.type === "Program") walkNodes(node.body, node);
else if (node.type === "CallExpression") walkNodes(node.params, node);
}
function walkNodes(nodes, parent) {
nodes.forEach(node => walkNode(node, parent))
}
walkNode(ast, null)
}
代码生成
这步很简单,只要把我们需要的 jsAST 生成成相应的代码就好了,因为我们的编译器支持的语法非常简单(简陋),所以代码也很简洁🫤
module.exports = function generateCode(node) {
if (node.type === "NumericLiteral") {
return node.value;
}
if (node.type === "Identifier") {
return node.name;
}
if (node.type === "CallExpression") {
// name(arg1, arg2, arg3)
return `${generateCode(node.callee)}(${node.arguments.map(generateCode).join(", ")})`
}
if (node.type === "ExpressionStatement") {
return `${generateCode(node.expression)};`
}
if (node.type === "Program") {
return node.body.map(generateCode).join("\n")
}
}
总结
跟着教程走下来,发现编译器(入门)并没有我想的那么复杂,写一个最基础的编译器并不需要多高深的算法,代码也没有多难懂。 简洁的代码又非常巧妙,很少的代码实现了需要的功能。 其中递归是个很重要的应用,合理的利用递归可以写出有些“魔力”的代码。
实际上在平时的开发中,我发现“抽象”是一种非常重要的能力,一个会合理抽象的程序员,可以用很少的代码完成很强的功能,同时具有很强的扩展性和鲁棒性。
之前我看过“计算机程序的构造与解释”这门网课,结合今天的代码又有了些新的思考,很推荐这门课,有空我应该会再看一遍👀