本文首发于 Seebug
近年来 Golang 热度飙升,得益于其性能优异、开发效率高、跨平台等特性,被广泛应用在开发领域。在享受 Golang 带来便利的同时,如何保护代码、提高逆向破解难度也是开发者们需要思考的问题。
由于 Golang 的反射等机制,需要将文件路径、函数名等大量信息打包进二进制文件,这部分信息无法被 strip,所以考虑通过混淆代码的方式提高逆向难度。
本文主要通过分析 burrowers/garble 项目的实现来探索 Golang 代码混淆技术,因为相关资料较少,本文大部分内容是通过阅读源码来分析的,如有错误请师傅们在评论区或邮件指正。
前置知识
编译过程
Go 的编译过程可以抽象为:
- 词法分析:将字符序列转换为 token 序列
- 语法分析:解析 token 成 AST
- 类型检查
- 生成中间代码
- 生成机器码
本文不展开编译原理的内容,详细内容推荐阅读 Go 语言设计与实现 #编译原理 和 Introduction to the Go compiler。
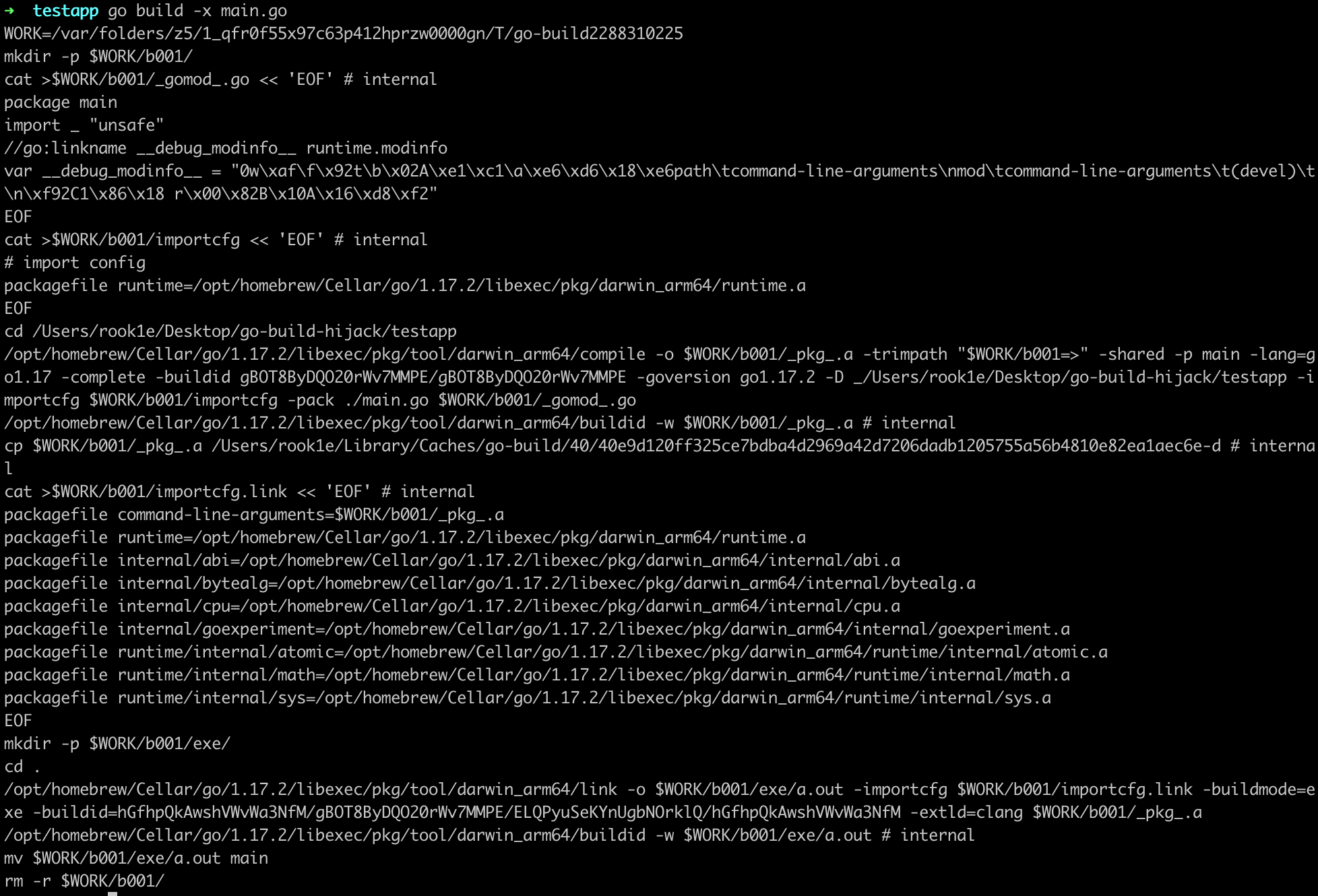
下面我们从源码角度更直观的探索编译的过程。go build 的实现在 src/cmd/go/internal/work/build.go,忽略设置编译器类型、环境信息等处理,我们只关注最核心的部分:
func runBuild(ctx context.Context, cmd *base.Command, args []string) {
...
var b Builder
...
pkgs := load.PackagesAndErrors(ctx, args)
...
a := &Action{Mode: "go build"}
for _, p := range pkgs {
a.Deps = append(a.Deps, b.AutoAction(ModeBuild, depMode, p))
}
...
b.Do(ctx, a)
}
这里的 Action 结构体表示一个行为,每个 action 有描述、所属包、依赖(Deps)等信息,所有关联起来的 action 构成一个 action graph。
// An Action represents a single action in the action graph.
type Action struct {
Mode string // description of action operation
Package *load.Package // the package this action works on
Deps []*Action // actions that must happen before this one
Func func(*Builder, context.Context, *Action) error // the action itself (nil = no-op)
...
}
在创建好 a 行为作为“根顶点”后,遍历命令中指定的要编译的包,为每个包创建 action,这个创建行为是递归的,创建过程中会分析它的依赖,再为依赖创建 action,例如 src/cmd/go/internal/work/action.go (b *Builder) CompileAction 方法:
for _, p1 := range p.Internal.Imports {
a.Deps = append(a.Deps, b.CompileAction(depMode, depMode, p1))
}
最终的 a.Deps 就是 action graph 的“起点”。构造出 action graph 后,将 a 顶点作为“根”进行深度优先遍历,把依赖的 action 依次加入任务队列,最后并发执行 action.Func。
每一类 action 的 Func 都有指定的方法,是 action 中核心的部分,例如:
a := &Action{
Mode: "build",
Func: (*Builder).build,
...
}
a := &Action{
Mode: "link",
Func: (*Builder).link,
...
}
...
进一步跟进会发现,除了一些必要的预处理,(*Builder).link 中会调用 BuildToolchain.ld 方法,(*Builder).build 会调用 BuildToolchain.symabis、BuildToolchain.gc、BuildToolchain.asm、BuildToolchain.pack 等方法来实现核心功能。BuildToolchain 是 toolchain 接口类型的,定义了下列方法:
// src/cmd/go/internal/work/exec.go
type toolchain interface {
// gc runs the compiler in a specific directory on a set of files
// and returns the name of the generated output file.
gc(b *Builder, a *Action, archive string, importcfg, embedcfg []byte, symabis string, asmhdr bool, gofiles []string) (ofile string, out []byte, err error)
// cc runs the toolchain's C compiler in a directory on a C file
// to produce an output file.
cc(b *Builder, a *Action, ofile, cfile string) error
// asm runs the assembler in a specific directory on specific files
// and returns a list of named output files.
asm(b *Builder, a *Action, sfiles []string) ([]string, error)
// symabis scans the symbol ABIs from sfiles and returns the
// path to the output symbol ABIs file, or "" if none.
symabis(b *Builder, a *Action, sfiles []string) (string, error)
// pack runs the archive packer in a specific directory to create
// an archive from a set of object files.
// typically it is run in the object directory.
pack(b *Builder, a *Action, afile string, ofiles []string) error
// ld runs the linker to create an executable starting at mainpkg.
ld(b *Builder, root *Action, out, importcfg, mainpkg string) error
// ldShared runs the linker to create a shared library containing the pkgs built by toplevelactions
ldShared(b *Builder, root *Action, toplevelactions []*Action, out, importcfg string, allactions []*Action) error
compiler() string
linker() string
}
Go 分别为 gc 和 gccgo 编译器实现了此接口,go build 会在程序初始化时进行选择:
func init() {
switch build.Default.Compiler {
case "gc", "gccgo":
buildCompiler{}.Set(build.Default.Compiler)
}
}
func (c buildCompiler) Set(value string) error {
switch value {
case "gc":
BuildToolchain = gcToolchain{}
case "gccgo":
BuildToolchain = gccgoToolchain{}
...
}
这里我们只看 gc 编译器部分 src/cmd/go/internal/work/gc.go。以 gc 方法为例:
func (gcToolchain) gc(b *Builder, a *Action, archive string, importcfg, embedcfg []byte, symabis string, asmhdr bool, gofiles []string) (ofile string, output []byte, err error) {
// ...
// 拼接参数
// ...
args := []interface{}{cfg.BuildToolexec, base.Tool("compile"), "-o", ofile, "-trimpath", a.trimpath(), gcflags, gcargs, "-D", p.Internal.LocalPrefix}
// ...
output, err = b.runOut(a, base.Cwd, nil, args...)
return ofile, output, err
}
粗略的看,其实 gc 方法并没有实现具体的编译工作,它的主要作用是拼接命令来调用路径为 base.Tool("compile") 的二进制程序。这些程序可以被称为 Go 编译工具,位于 pkg/tool 目录下,源码位于 src/cmd。同理,其他的方法也是调用了相应的编译工具完成实际的编译工作。
细心的读者可能会发现一个有趣的问题:拼接的命令中真正的运行对象并不是编译工具,而是 cfg.BuildToolexec。跟进到定义处可知它是由 go build -toolexec 参数设置的,官方释义为:
-toolexec 'cmd args'
a program to use to invoke toolchain programs like vet and asm.
For example, instead of running asm, the go command will run
'cmd args /path/to/asm <arguments for asm>'.
即用 -toolexec 指定的程序来运行编译工具。这其实可以看作是一个 hook 机制,利用这个参数来指定一个我们的程序,在编译时用这个程序调用编译工具,从而介入编译过程,下文中分析的 garble 项目就是使用了这种思路。附一段从编译过程中截取的命令( go build -n 参数可以输出执行的命令)方便理解,比如我们指定了 -toolexec=/home/atom/go/bin/garble,那么编译时实际执行的就是:
/home/atom/go/bin/garble /usr/local/go/pkg/tool/linux_amd64/compile -o $WORK/b016/_pkg_.a -trimpath "/usr/local/go/src/sync=>sync;$WORK/b016=>" -p sync -std -buildid FRNt7EHDh77qHujLKnmK/FRNt7EHDh77qHujLKnmK -goversion go1.16.4 -D "" -importcfg $WORK/b016/importcfg -pack -c=4 /usr/local/go/src/sync/cond.go /usr/local/go/src/sync/map.go /usr/local/go/src/sync/mutex.go /usr/local/go/src/sync/once.go /usr/local/go/src/sync/pool.go /usr/local/go/src/sync/poolqueue.go /usr/local/go/src/sync/runtime.go /usr/local/go/src/sync/runtime2.go /usr/local/go/src/sync/rwmutex.go /usr/local/go/src/sync/waitgroup.go
总结一下,go build 通过拼接命令的方式调用 compile 等编译工具来实现具体的编译工作,我们可以使用 go build -toolexec 参数来指定一个程序“介入”编译过程。
go/ast
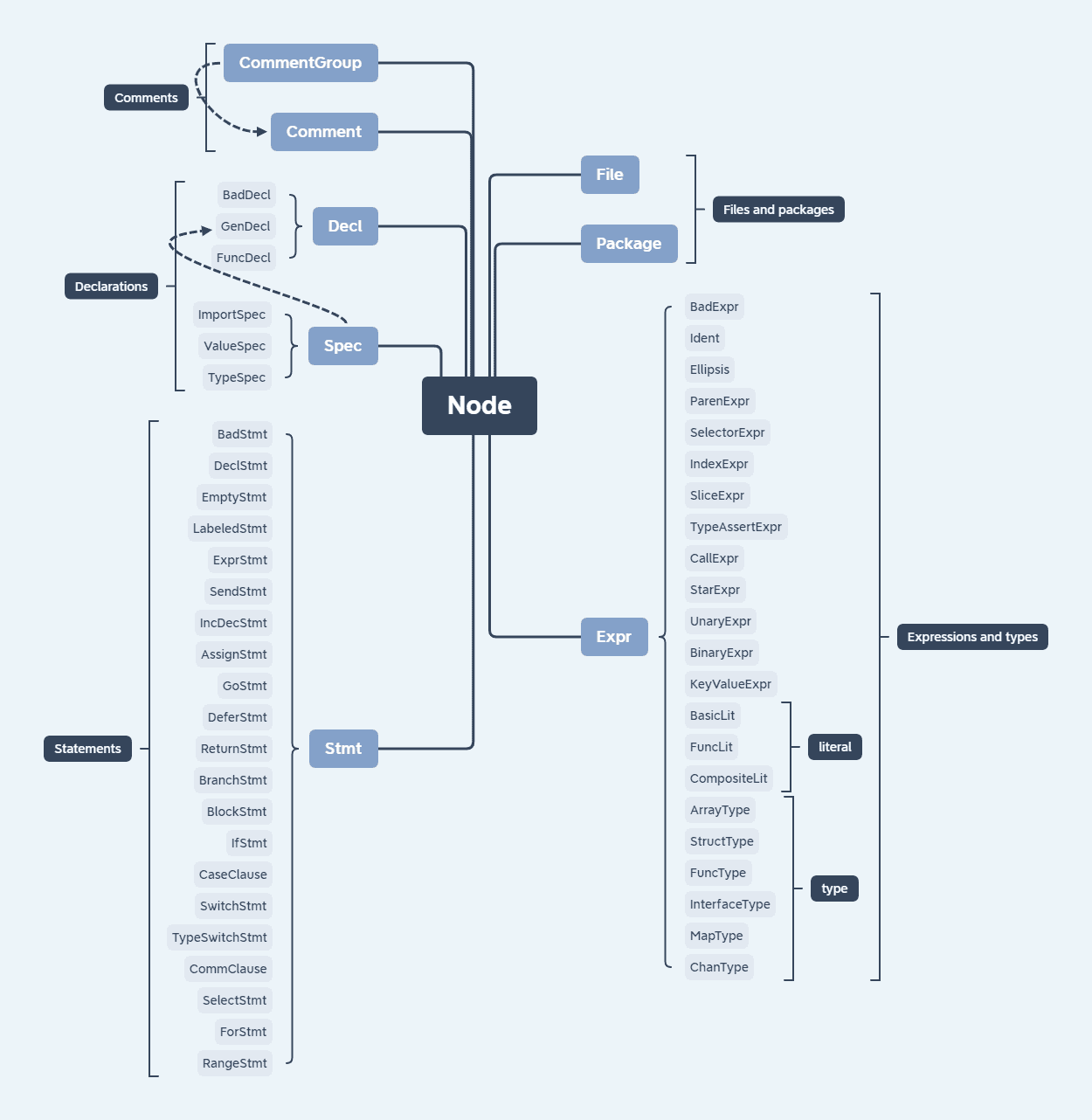
Golang 中 AST 的类型及方法由 go/ast 标准库定义。后文分析的 garble 项目中会有大量涉及 go/ast 的类型断言和类型选择,所以有必要对这些类型有大致了解。大部分类型定义在 src/go/ast/ast.go ,其中的注释足够详细,但为了方便梳理关系,笔者整理了关系图,图中的分叉代表继承关系,所有类型都基于 Node 接口:

本文无意去深入探究 AST,但相信读者只要对 AST 有基础的了解就足以理解本文的后续内容。如果理解困难,建议阅读 Go 语法树入门——开启自制编程语言和编译器之旅! 补充需要的知识,也可以通过在线工具 goast-viewer 将 AST 可视化来辅助分析。
工具分析
开源社区中关于 Go 代码混淆 star 比较多的两个项目是 burrowers/garble 和 unixpickle/gobfuscate,前者的特性更新一些,所以本文主要分析 garble,版本 8edde922ee5189f1d049edb9487e6090dd9d45bd。
特性
- 支持 modules,Go 1.16+
- 不处理以下情况:
- 哈希处理符合条件的包、函数、变量、类型等的名称
- 将字符串替换为匿名函数
- 移除调试信息、符号表
- 可以设置
-debugdir 输出混淆过的 Go 代码
- 可以指定不同的种子以混淆出不同的结果
整体上可以将 garble 分为两种模式:
- 主动模式:当命令传入的第一个指令与 garble 的预设相匹配时,代表是被用户主动调用的。此阶段会根据参数进行配置、获取依赖包信息等,然后将配置持久化。如果指令是 build 或 test,则再向命令中添加
-toolexec=path/to/garble 将自己设置为编译工具的启动器,引出启动器模式
- 启动器模式:对 tool/asm/link 这三个工具进行“拦截”,在编译工具运行前进行源代码混淆、修改运行参数等操作,最后运行工具编译混淆后的代码
获取和修改参数的工作花费了大量的代码,为了方便分析,后文会将其一笔带过,感兴趣的读者可以查询官方文档来了解各个参数的作用。
构造目标列表
构造目标列表的行为发生在主动模式中,截取部分重要的代码:
// listedPackage contains the 'go list -json -export' fields obtained by the
// root process, shared with all garble sub-processes via a file.
type listedPackage struct {
Name string
ImportPath string
ForTest string
Export string
BuildID string
Deps []string
ImportMap map[string]string
Standard bool
Dir string
GoFiles []string
// The fields below are not part of 'go list', but are still reused
// between garble processes. Use "Garble" as a prefix to ensure no
// collisions with the JSON fields from 'go list'.
GarbleActionID []byte
Private bool
}
func setListedPackages(patterns []string) error {
args := []string{"list", "-json", "-deps", "-export", "-trimpath"}
args = append(args, cache.BuildFlags...)
args = append(args, patterns...)
cmd := exec.Command("go", args...)
...
cache.ListedPackages = make(map[string]*listedPackage)
for ...{
var pkg listedPackage
...
cache.ListedPackages[pkg.ImportPath] = &pkg
...
}
}
核心是利用 go list 命令,其中指定的 -deps 参数官方释义为:
The -deps flag causes list to iterate over not just the named packages but also all their dependencies. It visits them in a depth-first post-order traversal, so that a package is listed only after all its dependencies. Packages not explicitly listed on the command line will have the DepOnly field set to true.
这里的遍历其实与前文分析的 go build 创建 action 时的很相似。通过这条命令 garble 可以获取到项目所有的依赖信息(包括间接依赖),遍历并存入 cache.ListedPackages。除此之外还要标记各个依赖包是否在 env.GOPRIVATE 目录下,只有此目录下的文件才会被混淆(特例是使用了 -tiny 参数时会处理一部分 runtime)。可以通过设置环境变量 GOPRIVATE="*" 来扩大范围以获得更好的混淆效果。关于混淆范围的问题,garble 的作者也在尝试优化:idea: break away from GOPRIVATE? #276。
至此,需要混淆的目标已经明确。加上一些保存配置信息的操作,主动模式的任务已基本完成,然后就可以运行拼接起的命令,引出启动器模式。
启动器模式中会对 compile/asm/link 这三个编译器工具进行拦截并“介入编译过程”,打起引号是因为 garble 实际上并没有完成任何实际的编译工作,如同 go build ,它只是作为中间商修改了源代码或者修改了命令中传给编译工具的参数,最后还是要依靠这三个编译工具来实现具体的编译工作,下面逐一分析。
compile
实现位于 main.go transformCompile 函数,主要工作是处理 go 文件和修改命令参数。go build -n 参数可以输出执行的命令,我们可以在使用 garble 时传入这个参数来更直观的了解编译过程。截取其中一条:
/home/atom/go/bin/garble /usr/local/go/pkg/tool/linux_amd64/compile -o $WORK/b016/_pkg_.a -trimpath "/usr/local/go/src/sync=>sync;$WORK/b016=>" -p sync -std -buildid FRNt7EHDh77qHujLKnmK/FRNt7EHDh77qHujLKnmK -goversion go1.16.4 -D "" -importcfg $WORK/b016/importcfg -pack -c=4 /usr/local/go/src/sync/cond.go /usr/local/go/src/sync/map.go /usr/local/go/src/sync/mutex.go /usr/local/go/src/sync/once.go /usr/local/go/src/sync/pool.go /usr/local/go/src/sync/poolqueue.go /usr/local/go/src/sync/runtime.go /usr/local/go/src/sync/runtime2.go /usr/local/go/src/sync/rwmutex.go /usr/local/go/src/sync/waitgroup.go
这条命令使用 compile 编译工具来将 cond.go 等诸多文件编译成中间代码。garble 识别到当前的编译工具是 compile,于是”拦截“,在工具运行前做一些混淆等工作。下面分析一下相对重要的部分。
首先要将传入的 go 文件解析成 AST:
var files []*ast.File
for _, path := range paths {
file, err := parser.ParseFile(fset, path, nil, parser.ParseComments)
if err != nil {
return nil, err
}
files = append(files, file)
}
然后进行类型检查, 这也是正常编译时会进行的一步,类型检查不通过则代表文件无法编译成功,程序退出。
因为参与反射(reflect.ValueOf / reflect.TypeOf)的节点的类型名称可能会在后续逻辑中使用,所以不能对其名称进行混淆:
if fnType.Pkg().Path() == "reflect" && (fnType.Name() == "TypeOf" || fnType.Name() == "ValueOf") {
for _, arg := range call.Args {
argType := tf.info.TypeOf(arg)
tf.recordIgnore(argType, tf.pkg.Path())
}
}
这里引出了一个贯穿每次 compile 生命周期的重要 map,记录了所有不能进行混淆的对象:用在反射参数的类型,用在常量表达式和 go:linkname 的标识符,从没被混淆的包中引入的变量和类型:
// ignoreObjects records all the objects we cannot obfuscate. An object
// is any named entity, such as a declared variable or type.
//
// So far, this map records:
//
// * Types which are used for reflection; see recordReflectArgs.
// * Identifiers used in constant expressions; see RecordUsedAsConstants.
// * Identifiers used in go:linkname directives; see handleDirectives.
// * Types or variables from external packages which were not
// obfuscated, for caching reasons; see transformGo.
ignoreObjects map[types.Object]bool
我们以判别「用在常量表达式中的标识符」且类型是 ast.GenDecl 的情况为例:
// RecordUsedAsConstants records identifieres used in constant expressions.
func RecordUsedAsConstants(node ast.Node, info *types.Info, ignoreObj map[types.Object]bool) {
visit := func(node ast.Node) bool {
ident, ok := node.(*ast.Ident)
if !ok {
return true
}
// Only record *types.Const objects.
// Other objects, such as builtins or type names,
// must not be recorded as they would be false positives.
obj := info.ObjectOf(ident)
if _, ok := obj.(*types.Const); ok {
ignoreObj[obj] = true
}
return true
}
switch x := node.(type) {
...
// in a const declaration all values must be constant representable
case *ast.GenDecl:
if x.Tok != token.CONST {
break
}
for _, spec := range x.Specs {
spec := spec.(*ast.ValueSpec)
for _, val := range spec.Values {
ast.Inspect(val, visit)
}
}
}
}
假设需要混淆的代码是:
package obfuscate
const (
H2 string = "a"
H4 string = "a" + H2
H3 int = 123
H5 string = "a"
)
可以看到用于常量表达式的标识符是 H2,我们通过代码分析一下判定过程。首先整个 const 块符合 ast.GenDecl 类型,然后遍历其 Specs(每个定义),对每个 spec 遍历其 Values(等号右边的表达式),再对 val 中的元素使用 ast.Inspect() 遍历执行 visit(),如果元素节点的类型是 ast.Ident 且指向的 obj 的类型是 types.Const,则将此 obj 记入 tf.recordIgnore。有点绕,我们把 AST 打印出来看:
可以很清晰地看到 H4 string = "a" + H2 中的 H2 完全符合条件,所以应该被记入 tf.recordIgnore。接下来要分析的功能中会涉及到大量类型断言和类型选择,看起来复杂但本质上与刚刚的分析过程类似,我们只要将写个 demo 并打印出 AST 就很容易理解了。
回到 main.go transformCompile。接下来对当前的包名进行混淆并写入命令参数和源文件中,要求文件既不是 main 包,也不在 env.GOPRIVATE 目录之外。下一步将处理注释和源代码,这里会对 runtime 和 CGO 单独处理,我们大可忽略,直接看对普通 Go 代码的处理:
// transformGo obfuscates the provided Go syntax file.
func (tf *transformer) transformGo(file *ast.File) *ast.File {
if opts.GarbleLiterals {
file = literals.Obfuscate(file, tf.info, fset, tf.ignoreObjects)
}
pre := func(cursor *astutil.Cursor) bool {...}
post := func(cursor *astutil.Cursor) bool {...}
return astutil.Apply(file, pre, post).(*ast.File)
}
首先混淆字符,然后递归处理 AST 的每个节点,最后返回处理完成的 AST。这几部分的思路很相似,都是利用 astutil.Apply(file, pre, post) 进行 AST 的递归处理,其中 pre 和 post 函数分别用于访问孩子节点前和访问后。这部分的代码大都是比较繁琐的筛选操作,下面仅作简要分析:
-
literals.Obfuscate pre
跳过如下情况:值需要推导的、含有非基础类型的、类型需要推导的(隐式类型定义)、ignoreObj 标记了的常量。将通过筛选的常量的 token 由 const 改为 var,方便后续用匿名函数代替常量值,但如果一个 const 块中有一个不能被改为 var,则整个块都不会被修改。
-
literals.Obfuscate post
将字符串、byte 切片或数组的值替换为匿名函数,效果如图:
-
transformGo pre
跳过名称中含有 _(未命名) _C / _cgo (cgo 代码)的节点,若是嵌入字段则要找到实际要处理的 obj,再根据 obj 的类型继续细分筛选:
types.Var :跳过非全局变量,若是字段则则将其结构体的类型名作为 hash salt,如果字段所属结构体是未被混淆的,则记入 tf.ignoreObjectstypes.TypeName:跳过非全局类型,若该类型在定义处没有混淆,则跳过types.Func:跳过导出的方法、main/ init/TestMain 函数 、测试函数
若节点通过筛选,则将其名称进行哈希处理
-
transformGo post:哈希处理导入路径
至此已经完成了对源代码的混淆,只需要将新的代码写入临时目录,并把地址拼接到命令中代替原文件路径,一条新的 compile 命令就完成了,最后执行这条命令就可以使用编译工具编译混淆后的代码。
asm
比较简单,只作用于 private 的包,核心操作如下:
- 将临时文件夹路径添加到
-trimpath 参数首部
- 将调用的函数的名称替换为混淆后的,Go 汇编文件中调用的函数名前都有
·,以此为特征搜索
link
比较简单,核心操作如下:
- 将
-X pkg.name=str 参数标记的包名(pkg)、变量名(name)替换为混淆后的
- 将
-buildid 参数置空以避免 build id 泄露
- 添加
-w -s 参数以移除调试信息、符号表、DWARF 符号表
混淆效果
编写一小段代码,分别进行 go build . 和 go env -w GOPRIVATE="*" && garble -literals build . 两次编译。可以看到左侧很简单的代码经过混淆后变得难以阅读:
再放入 IDA 中用 go_parser 解析一下。混淆前的文件名函数名等信息清晰可见,代码逻辑也算工整:
混淆后函数名等信息被乱码替代,且因为字符串被替换为了匿名函数,代码逻辑混乱了许多:
当项目更大含有更多依赖时,代码混淆所带来的混乱会更加严重,且由于第三方依赖包也被混淆,逆向破解时就无法通过引入的第三方包来猜测代码逻辑。
总结
本文从源码实现的角度探究了 Golang 编译调用工具链的大致流程以及 burrowers/garble 项目,了解了如何利用 go/ast 对代码进行混淆处理。通过混淆处理,代码的逻辑结构、二进制文件中存留的信息变得难以阅读,显著提高了逆向破解的难度。