1. 简介
逻辑斯谛回归是统计学习中的经典分类方法。
2. 逻辑斯谛分布
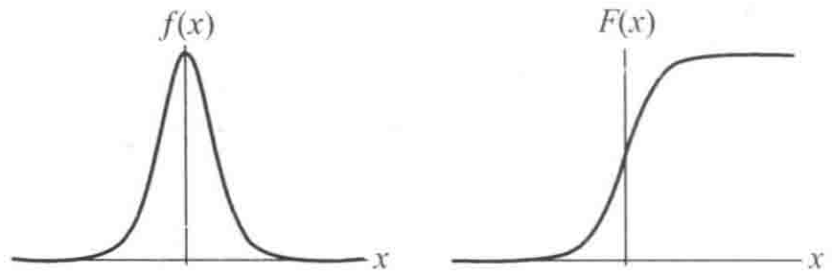
定义:设 X 是连续随机变量,X 服从逻辑斯谛分布是指 X 具有下列分布函数和密度函数:
F(x)=P(X≤x)=1+e−(x−μ)/γ1f(x)=F′(x)=γ(1+e−(x−μ)/γ)2e−(x−μ)/γ
其中,μ 是位置参数,γ>0 为形状参数。
逻辑斯谛分布的 PDF 和 CDF 函数曲线如下图所示:

3. 二项逻辑斯谛回归模型
二项逻辑斯谛回归模型是一种分类模型,其由条件概率分布 P(Y∣X) 表示,形式为参数化的逻辑斯谛分布。随机变量 X 取值为实数,随机变量 Y 取值为 1 或 0,我们通过监督学习的方法来估计模型参数。
对于给定实例 x,按照上式分别计算 P(Y=1∣x) 和 P(Y=0∣x),然后比较两个条件概率值,将实例 x 分到概率值较大的那一类。
几率:一个事件的几率是指该事件发生的概率与该事件不发生的概率的比值。如果事件发生的概率是 p,那么该事件的几率是 1−pp,该事件的对数几率或 logit 函数是
logit(p)=log1−pp
对于二项逻辑斯谛回归模型,其 logit 函数为
log1−P(Y=1∣x)P(Y=1∣x)=w⋅x+b
也即是说,输入 Y=1 的对数几率是由输入 x 的线性函数表示的模型,即逻辑斯谛回归模型。
参数估计:对于给定的训练数据集 T={(x1,y1),(x2,y2),⋯,(xN,yN)},其中 xi∈Rn,yi∈{0,1},可以应用极大似然估计法估计二项逻辑斯谛模型参数。设 P(Y=1∣x)=π(x),P(Y=0∣x)=1−π(x),似然函数为 ∏i=1N[π(xi)]yi[1−π(xi)]1−yi,则对数似然函数为
L(w)=i=1∑N[yilogπ(xi)+(1−yi)log(1−π(xi))]=i=1∑N[yilog1−π(xi)π(xi)+log(1−π(xi))]=i=1∑N[yi(w⋅x+b)−log(1+exp(w⋅x+b))]
对 L(w) 求极大值,即可得到 w 的估计值。
−L(w) 即对应交叉熵损失。
这样,问题就变成了以对数似然函数为目标函数的最优化问题。逻辑斯谛回归学习中通常采用的方法是梯度下降法或拟牛顿法。
4. 多项逻辑斯谛回归
二项逻辑斯谛回归可以推广为多项逻辑斯谛回归模型,用于多类分类。假设离散型随机变量 Y 的取值集合为 {1,2,⋯,K},那么多项逻辑斯谛回归模型是
P(Y=k∣x)=1+∑k=1K−1exp(wk⋅x)exp(wk⋅x),k=1,2,⋯,K−1P(Y=K∣x)=1+∑k=1K−1exp(wk⋅x)1
其中,为了简便,wk=(wk(1),⋯,wk(n),b)T,x=(x(1),⋯,x(n),1)T;x∈Rn+1,wk∈Rn+1。二项逻辑斯谛回归模型的参数估计方法也可以推广到多项逻辑斯谛回归模型中。
附录