学习周刊-总第260期-2026年第17周
如要阅读全文,点击标题跳转。 学习周刊-总第260期 | kite-desktop | zerobrew | dnet | voicekey | pdfcraft | explain-error-plugin | ezbookkeeping | server-survival | Droppy | ThinkFlowAI | FlashSpace | Orbit | pigsty | pvesphere | talkcody
前些日子,我发了条推说,我说看到了一个 Skill ,可以帮助你得组织快速降低你的订单金额,并说要写篇 Blog 来介绍他。现在,它来了。
https://x.com/xiqingongzi/status/2044784860058001618
这个 Skill 叫 「vercel seat saver」,我注意到它还是身边的朋友告诉我 —— Hey ,我发现一个很有用的 Skill,你也试试看。
Vercel 的计费逻辑是,如果你是付费团队服务,那么你的费用实际上是席位费,按照组织协作的席位来收费。但按照席位收费的同时,Vercel 并不会将你的可用用量给提升,实际上即使你团队是 20 个人,你拿到的可用的用量额度还是和一个人一样。
而我们使用 vercel 的主要原因是我们希望享受到 vercel的自动构建服务,快速预览服务。而这些服务,其实并不一定通过 vercel 自身的账号关联来完成,完全可以通过 vercel API 或者 vercel CLI 来完成。就像我这篇 Blog 一样,其实可以通过配置来完成。只不过,vercel-seat-saver 提供了更 Agentic 的方式,使用一个 Skill ,帮你完成所有的配置和操作。
之前的 Blog: 如何免费为你的组织项目配置 Vercel
和把大象装进冰箱里一样,使用 Vercel Seat Saver 一共需要三步
打开你要处理的代码仓库,并执行 如下命令来安装 Vercel Seat Saver Skill
npx skills add actionbook/postagent

安装完成后,直接使用 claude 打开你的项目,并输入 /vercel-seat-saver 来唤起 vercel seat saver.

vercel seat saver 会在启动完成后,自动获取你的当前仓库的情况,并指引你去完成具体的动作,并给出对应的命令,来完成配置。

配置完成后,和他说,继续,等待他的自行处理

这个过程中,你只需要跟随他的建议,去做一些简单的处理和判断即可

做完所有决策,他就会自动帮你去取消 Vercel 的关联,然后替换成 Github Actions 的自动构建和推送。
一切配置完成后,你接下来要做的,就是去 Vercel 当中,移除组织当中的人,让大家在 Github 上协作就好,不再需要占用 Vercel 席位,降低月账单。
以前我要自己摸索很久,甚至还值得我写 Blog 记录下来的事情,今天一个 Skill 就完成了。。。就。。。有种自己被蒸馏的感觉。

因熊媽出現心臟病的徵兆&心臟檢測有異常,帶她來IJN做了個3天2夜的住院深入檢查。這還是第一次看到病床上的熊媽,比起水星熊自己來住院的時候,反而更能感受到壓力與不安。


先说清楚边界。本文只基于 deepseek-v4/DeepSeek_V4.pdf,不补 PDF 外的传闻,也不把报告里没有展开的内容写成确定结论。
如果只用一句话概括,我会这么说:DeepSeek-V4 要解决的核心问题,不是“参数再大一点”,而是模型真的开始跑超长上下文、长链路推理和复杂工具调用时,传统 attention 的成本会先撑不住。V4 的很多改动,最后都指向同一个问题:1M context 到底怎样才能跑起来,而且别贵得离谱。(原文第 4-5 页)
文中提到的“原文第 X 页”,都对应 DeepSeek_V4.pdf 的 PDF 页码。中文写作、white-collar task、code agent 这些结果,多数来自报告里的 internal evaluation,更适合看作“官方自测结果”,不应直接等同于第三方独立评测。(原文第 43-44 页、第 57-58 页)
原文对应:第 4-5 页。
我读这份 PDF 时,第一个明显感受是:它开头没有急着讲 benchmark,也没有先铺“模型多强”。它先把问题摆出来。
报告的说法是,reasoning model 带来了 test-time scaling 的新范式,但 vanilla attention 的 quadratic complexity 会在 ultra-long context 和 reasoning process 里变成明显瓶颈。同时,复杂 agent workflow、跨文档分析这类 long-horizon task 会越来越重要,所以“高效支持超长上下文”已经不是锦上添花,而是后续能力继续往上走的前提。
随后,报告给出模型规格:
DeepSeek-V4-Pro:1.6T 参数,每个 token 激活 49BDeepSeek-V4-Flash:284B 参数,每个 token 激活 13B1 million tokens 的 context length这里的重点不只是“大”。按 PDF 的说法,目标是 “break the efficiency barrier of ultra-long-context processing”。说白了,窗口变长还不够。长了以后还能不能用、能不能稳定用、成本能不能接受,才是这份报告真正关心的问题。(原文第 4 页)
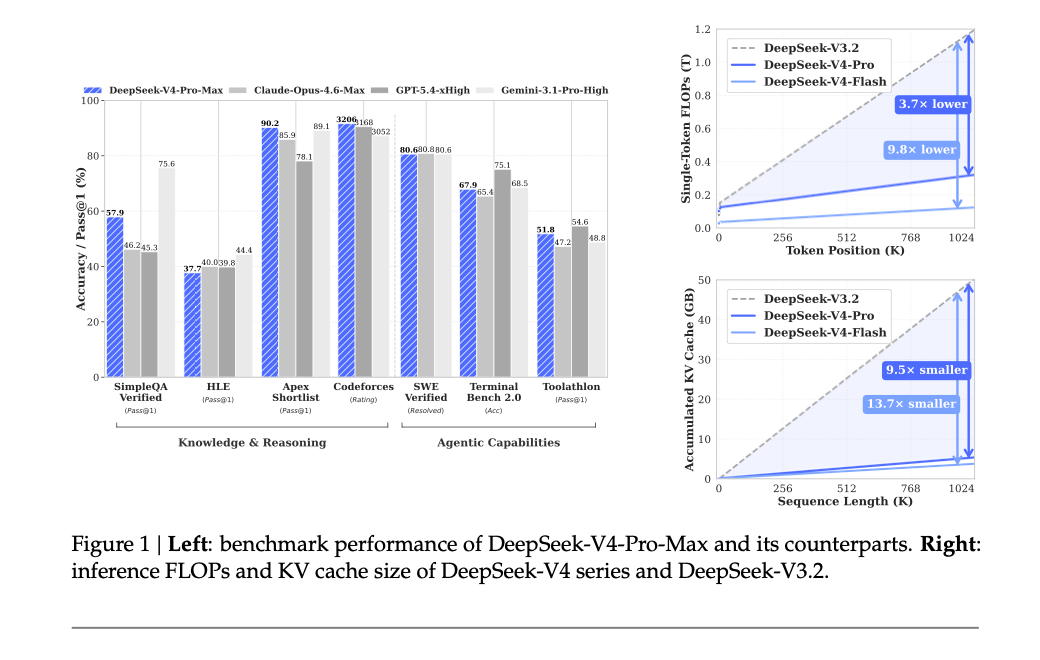
原文第 1 页 Figure 1:左侧是 DeepSeek-V4-Pro-Max 与 Claude、GPT、Gemini 的 benchmark 对比;右侧是 DeepSeek-V4 系列相对 DeepSeek-V3.2 的 inference FLOPs 和 KV cache 变化。
原文对应:第 4-7 页。
很多人看到新版本,会下意识问:是不是整套架构都换了?PDF 给出的答案很清楚,V4 不是这条路线。
Transformer 主体还在,DeepSeekMoE 还在,Multi-Token Prediction 也还在。真正的变化,主要集中在三件事:
mHC 强化传统 residual connectionCSA + HCA 组成 hybrid attention,专门处理长上下文效率Muon 作为主要优化器,提高收敛速度和训练稳定性只看这三条,可能会觉得它还是一次常规模型升级。但 PDF 后面又列了一串基础设施改造,意思就出来了:V4 不是在模型层加几个新组件,而是把架构、优化器、kernel、并行和 cache 管理一起收紧。
所以按这份技术报告自己的写法,DeepSeek-V4 不是“堆了几个新名词”,而是把一整条链路重新拧紧了。(原文第 4-7 页)
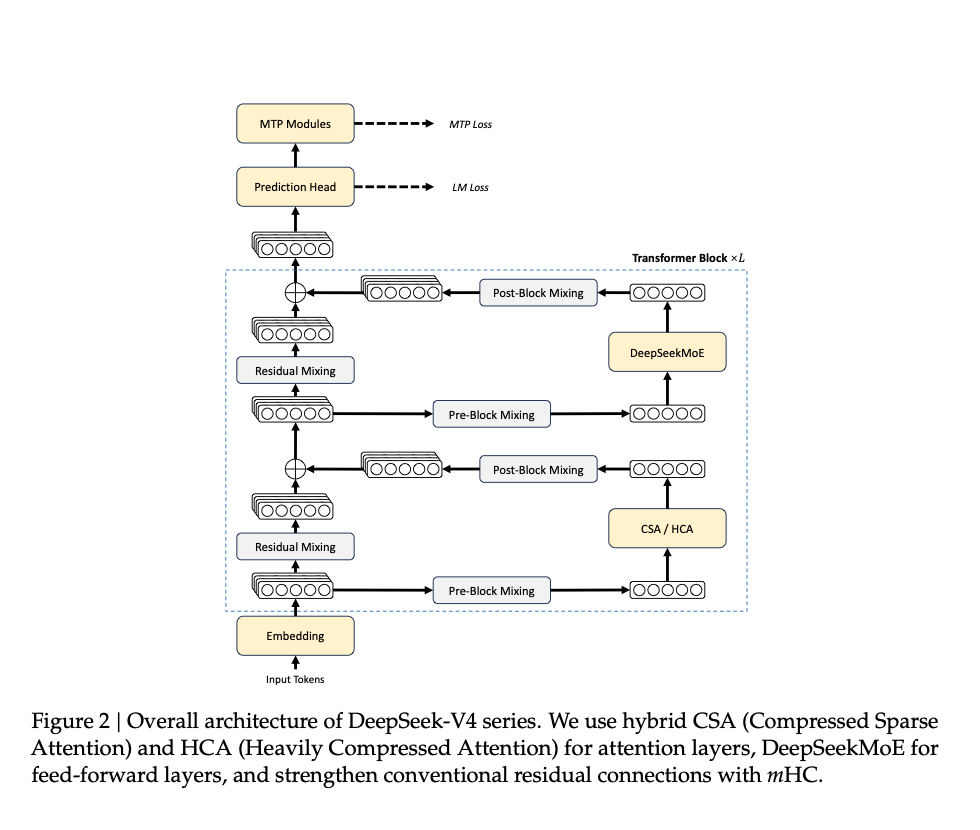
原文第 6 页 Figure 2:attention 层换成了 CSA / HCA,前馈层仍然是 DeepSeekMoE,残差路径里加入 mHC,顶部保留 MTP。
原文对应:第 9-11 页、第 25 页。
如果只能在 V4 里挑一个最值得细看的部分,我会选 hybrid attention。原因很简单:它正面回应了开头提出的那个问题。上下文一长,attention 就会变成主要计算瓶颈。
PDF 给出的做法,是把 attention 拆成两种形态,交替出现:
Compressed Sparse Attention (CSA)Heavily Compressed Attention (HCA)按 PDF 的定义,CSA 分两步:
m 个 token 的 KV cache 压缩成一个 entrytop-k 个 compressed KV entry但它没有把局部信息一刀切掉。报告还写到,除了这些被挑中的 compressed KV entry,CSA 会再接上一小段 sliding window KV entry,用来保留局部细粒度依赖。
换成人话,大概就是:先把很长的上下文做成一层“摘要索引”,再从里面挑最相关的块来看,同时保留眼前这一小段原始细节。它不再让每个 token 都把整段历史重新扫一遍。
参数列得也很细。
对 DeepSeek-V4-Pro:
m = 4top-k = 1024641281285121536128对 DeepSeek-V4-Flash:
m = 4top-k = 51264128645121024128HCA 的目标更直接:继续压 KV cache。PDF 的表述是,HCA 使用更大的 compression rate m',但不再做 sparse attention,而是保留 dense attention。
两个模型的 HCA 配置都是:
m' = 128所以如果只按 PDF 的设计分工来理解:
两者交替出现,再配合 sliding window attention,构成 V4 的 hybrid attention 路径。(原文第 9-11 页)
报告在第 5 页给了最直接的一组数字。在 1M-token context 下,相比 DeepSeek-V3.2:
DeepSeek-V4-Pro 的 single-token inference FLOPs 降到 27%DeepSeek-V4-Pro 的 KV cache size 降到 10%DeepSeek-V4-Flash 的 single-token inference FLOPs 降到 10%DeepSeek-V4-Flash 的 KV cache size 降到 7%这组数字很关键。它说明 V4 不是把窗口勉强拉到 1M 就结束,而是想把 1M context 变成一个可以长期使用的设定。Figure 1 右边两张图讲的也是这件事。(原文第 5 页)
原文对应:第 7-8 页。
attention 是主角没错,但 PDF 给 mHC 的篇幅也不少。原因不难理解:模型越深,训练里最怕的往往不是“想法不够新”,而是数值先不稳。
报告先回顾了普通 Hyper-Connections。它的做法是把 residual stream 的宽度扩到 n_hc 倍,再引入输入映射、残差映射和输出映射。问题是,PDF 明确说 naive HC 在多层堆叠时会频繁出现 numerical instability。
DeepSeek-V4 采用的是 Manifold-Constrained Hyper-Connections (mHC)。核心改动,是把 residual mapping matrix 约束到 doubly stochastic matrices 的 manifold,也就是文中提到的 Birkhoff polytope。
PDF 给出的解释有三点:
<= 1换句话说,mHC 的目标不是“让残差连接更花哨”,而是尽量防止信号在深层传播时越传越失控。
PDF 还补了两个实现细节:
Sinkhorn-Knopp algorithm 做行列归一化投影,t_max = 20所以 mHC 在 V4 里更像一块稳定性部件。它可能没有 benchmark 数字那么显眼,但如果这里压不住,后面很多训练收益都未必站得住。(原文第 7-8 页)
原文对应:第 15-17 页、第 23-24 页。
我读 V4 这份 PDF 时,另一个感受是:它花了很多篇幅讲 kernel、并行、cache 和可复现性。这不是闲笔。长上下文模型如果真的要训练、部署、复现,系统层不是配角。很多时候,它就是决定模型能不能跑起来的那一层。
general infrastructures 这一章里,报告重点谈的是 expert parallelism 的通信瓶颈。应对方法主要有三步:
对应结果是:
1.50x 到 1.73x1.96xPDF 还给了一个很工程化的判断标准:通信能不能被计算完全遮住,不只看带宽,也看 computation-communication ratio。对 DeepSeek-V4-Pro,报告把平衡条件写成 C / B <= 2d = 6144 FLOPs/Byte。(原文第 16 页)
报告单独拿出一节讲 TileLang。理由很直接:V4 的复杂架构如果继续拆成很多零碎的 Torch ATen operator,开发效率和运行效率都会受影响,所以他们用 TileLang 来写 fused kernel。
另外,PDF 提到 Host Codegen 会把不少 host-side logic 从 Python 路径挪到生成代码里,结果是:
1 微秒还有个细节不能漏:报告专门强调 numerical precision 和 bitwise reproducibility。也就是说,他们不只是想“跑得快”,也在追求训练和推理结果的一致性。(原文第 17 页)
V4 的 inference framework 也不是把传统 KV cache 直接放大。PDF 说他们设计了 heterogeneous KV cache structure,把缓存分成两类:
在 on-disk KV cache reuse 上,报告给了三种 SWA KV 管理策略:
Full SWA CachingPeriodic CheckpointingZero SWA CachingPDF 对这三种方案的解释也很明确:它们对应不同的 storage overhead 和 recomputation 取舍,部署时按场景选。(原文第 23-24 页)
原文对应:第 25-27 页。
只看训练设置,V4 的节奏其实很清楚。它不是一步跳到最终形态,而是分阶段推进。
报告给出的训练 token 数是:
Flash:32TPro:33T两者的 sequence length 都是逐步扩展:
4K16K64K1MPDF 还专门写到,Flash 在前 1T tokens 先使用 dense attention,等 sequence length 到 64K 以后再引入 sparse attention;Pro 也采用类似的 two-stage 方法,只是 dense attention 阶段更长。
这段安排的意思很朴素:即便目标是 1M context,训练也没有一上来就切到最复杂配置,而是先在更稳定的条件下把基础能力长起来,再逐步切到更适合长上下文的结构。
optimizer 方面,PDF 的写法是:
MuonAdamW除此之外,报告还单独列了两个稳定性技巧。
第一个是 Anticipatory Routing。PDF 的解释是,在 step t 做 feature computation 时,routing index 用历史参数 theta_(t - delta_t) 来算。实现上,会提前计算并缓存 routing index,并通过自动检测机制,只在出现 loss spike 时短时开启这个模式。
报告给出的代价和结果是:
20%第二个是 SwiGLU Clamping。报告说,他们发现把 SwiGLU 的 linear component 限制在 [-10, 10],并把 gate component 的上界限制在 10,可以有效去掉 outlier,提升稳定性,而且不损伤性能。
这点别忽略。PDF 在结尾没有把这两招写成“原理已经完全解释清楚”,而是明确说 Anticipatory Routing 和 SwiGLU Clamping 虽然有效,但 underlying principles 还没有被充分理解。(原文第 27 页、第 45 页)
原文对应:第 29-31 页、第 41 页。
post-training 这一段延续了 V3.2 的大框架,但有一个明确变化:mixed RL stage 被完整替换成了 On-Policy Distillation (OPD)。
整体流程分两步:
OPD 把这些能力整合回统一模型PDF 明确列出的 specialist 方向包括:
这些 specialist 的训练流程是:
SFTRLGRPO在 hard-to-verify task 上,报告还提到 Generative Reward Model (GRM)。这里的做法不是把 GRM 当成外部裁判,而是让 actor network 原生承担 GRM 角色,把 judging 和 generation 一起训练。(原文第 29 页)
报告明确说,DeepSeek-V4-Pro 和 Flash 都支持三种 reasoning effort mode:
Non-thinkThink HighThink MaxPDF 的解释是,这三种模式在 RL 训练里用了不同的 length penalty 和 context window,所以会对应不同的 reasoning token 长度。为了把这些模式装进同一个模型,V4 使用 <think> 和 </think> 作为特定 response format。
对 Think Max,PDF 的描述也很具体:system prompt 开头会注入额外指令,要求模型更彻底地分解问题、写出完整推理过程,并检查 edge case 和 adversarial scenario。
工具调用部分,报告还加入了新的 |DSML| special token 和 XML-based tool-call schema,理由是这种格式可以减少 escaping failure 和 tool-call error。
还有一个变化值得单独说:interleaved thinking。
V3.2 的策略是:tool-result round 之间会保留 reasoning trace,但只要来了新的 user message,旧 reasoning content 就会丢掉。V4 借助 1M context,把这个策略改细了:
PDF 还补了一个限制条件:如果 agent framework 把 tool interaction 模拟成 user message,例如 Terminus,这种 reasoning persistence 可能不会生效,所以这类架构仍建议使用 non-think model。(原文第 30-31 页)
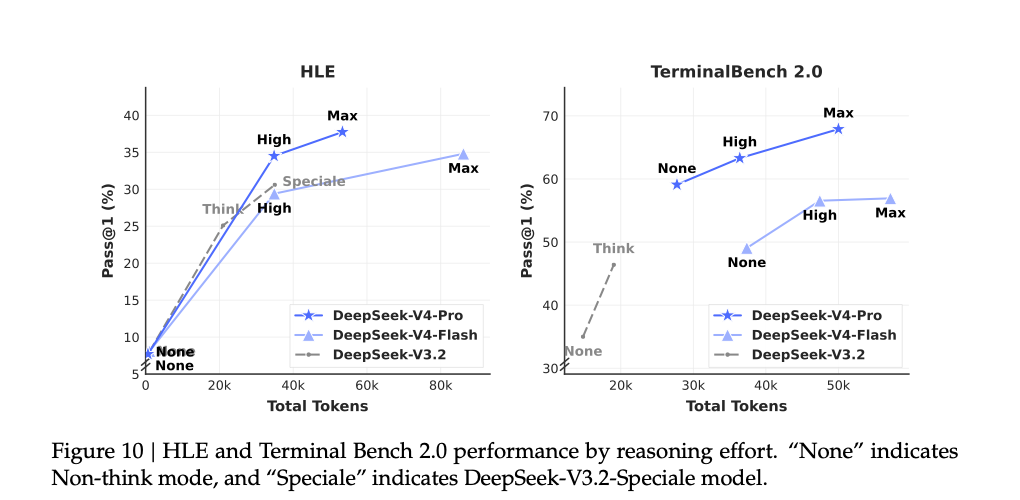
原文第 41 页 Figure 10:同一个模型拿到更多 reasoning budget 后,HLE 和 TerminalBench 2.0 的结果会继续往上走。
原文对应:第 5-6 页、第 41-44 页、第 57-58 页。
如果只看 PDF 的 summary,官方对能力分布的描述大致是:
Knowledge:DeepSeek-V4-Pro-Max 在 SimpleQA、Chinese-SimpleQA 上显著超过领先开源模型,在 MMLU-Pro、HLE、GPQA 这类教育知识评测上对开源模型保持小幅领先,但仍落后于 Gemini-3.1-ProReasoning:超过 GPT-5.2 和 Gemini-3.0-Pro,但略低于 GPT-5.4 和 Gemini-3.1-ProAgent:和 Kimi-K2.6、GLM-5.1 这类领先开源模型大致同级,略弱于 frontier closed model;在 internal evaluation 里超过 Claude Sonnet 4.5,并接近 Opus 4.5Long-Context:在 1M context 的 synthetic 和 real use case 上结果很强,在 academic benchmark 上超过 Gemini-3.1-ProFlash vs Pro:Flash-Max 因为参数更小,knowledge 偏弱,但在给足 thinking budget 后,reasoning 结果可以接近 GPT-5.2 和 Gemini-3.0-ProPDF 还给了一句很具体的判断:和最前沿闭源模型相比,reasoning 大约还有 3 到 6 个月 的差距。官方报告里会这样写,其实已经算克制。(原文第 5-6 页)
原文对应:第 57-58 页。
real-world task 这一章先讲中文写作。这里最值得看的一点是,它没有只给一个总分,而是把功能写作、创意写作、复杂指令跟随和多轮写作拆开评估。
在中文功能写作里,PDF 给出的 pairwise result 是:
DeepSeek-V4-Pro 对 Gemini-3.1-Pro 的总体胜率为 62.7%Gemini-3.1-Pro 为 34.1%报告对这个结果的解释也写得很直接:Gemini 在中文写作场景里,有时会让自己的 stylistic preference 盖过用户的 explicit requirement。(原文第 57 页)
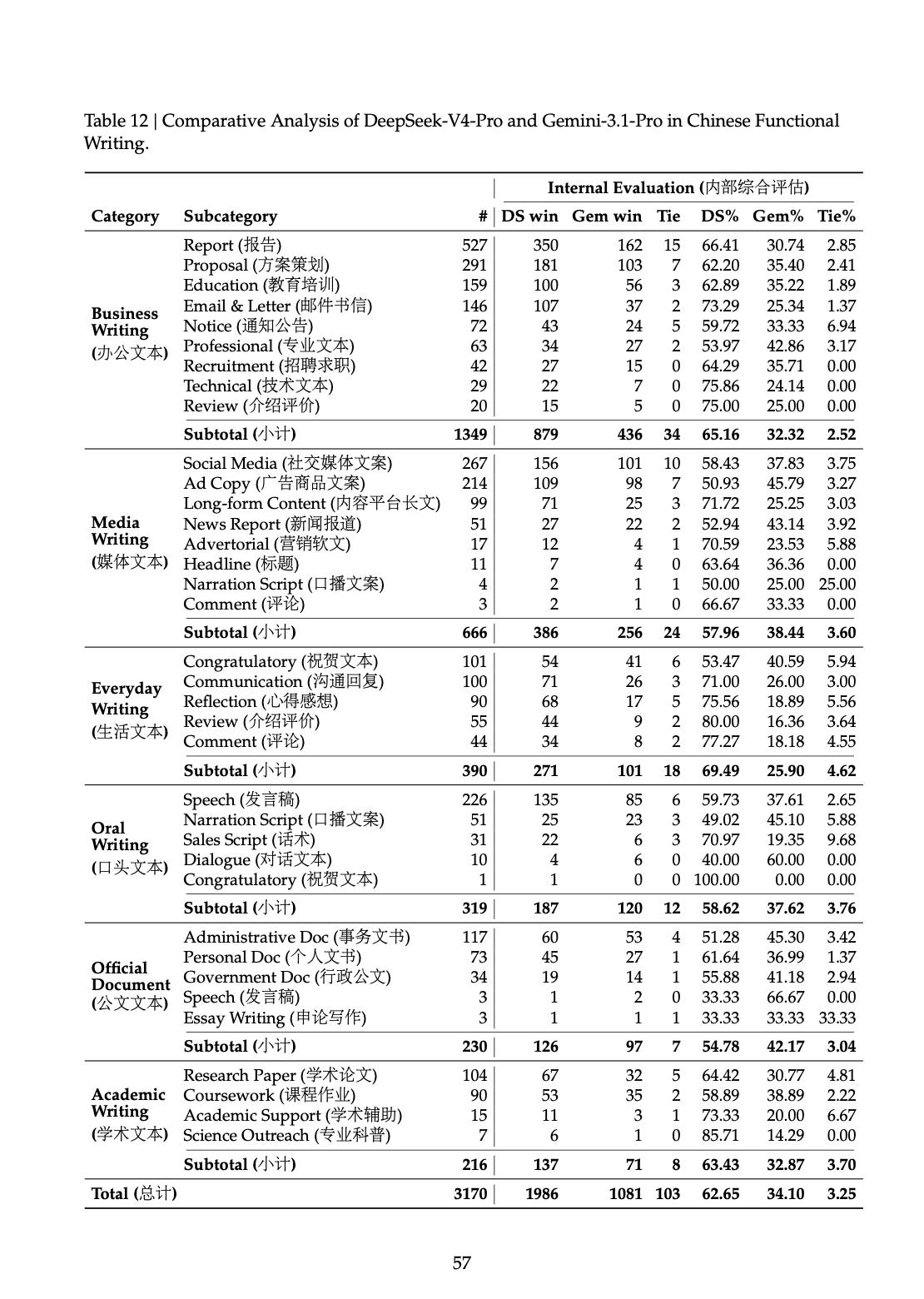
原文第 57 页 Table 12:中文功能写作的分项结果,能看到各种子任务下的胜负分布。
creative writing 部分,PDF 拆成两个维度:
60.0%77.5%这点很重要。它说明报告自己也没有把“写得好”和“按要求写”混成一件事,而是分开看。(原文第 58 页)
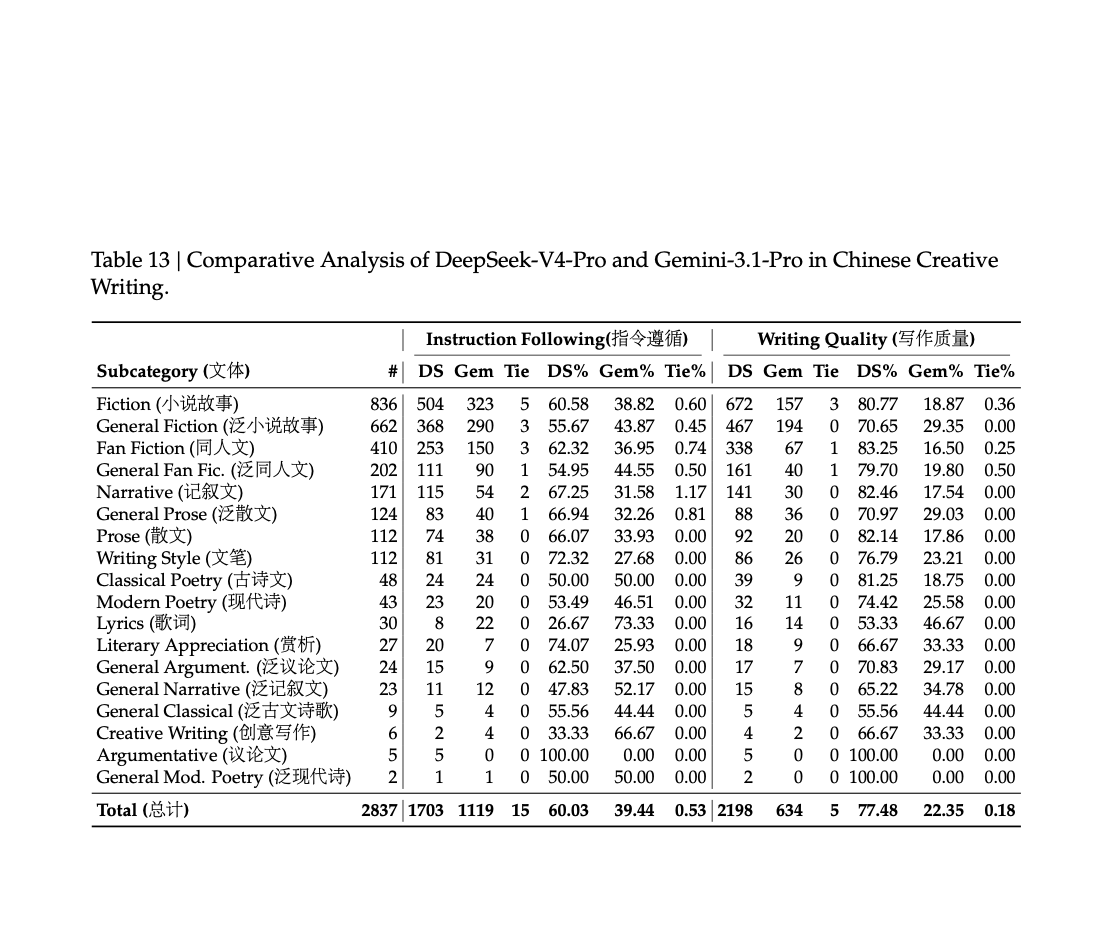
原文第 58 页 Table 13:创意写作里,PDF 同时比较了 instruction following 和 writing quality 两个维度。
但 PDF 也没有把结果写得太满。在最高复杂度约束和多轮写作任务上,Claude Opus 4.5 仍然领先,结果是:
Claude Opus 4.5:52.0%DeepSeek-V4-Pro:45.9%这组数字提醒得很清楚:V4 的中文写作已经很强,但碰到复杂约束、多轮持续一致这类更难的场景,报告自己也承认还没领先到头。(原文第 58 页)
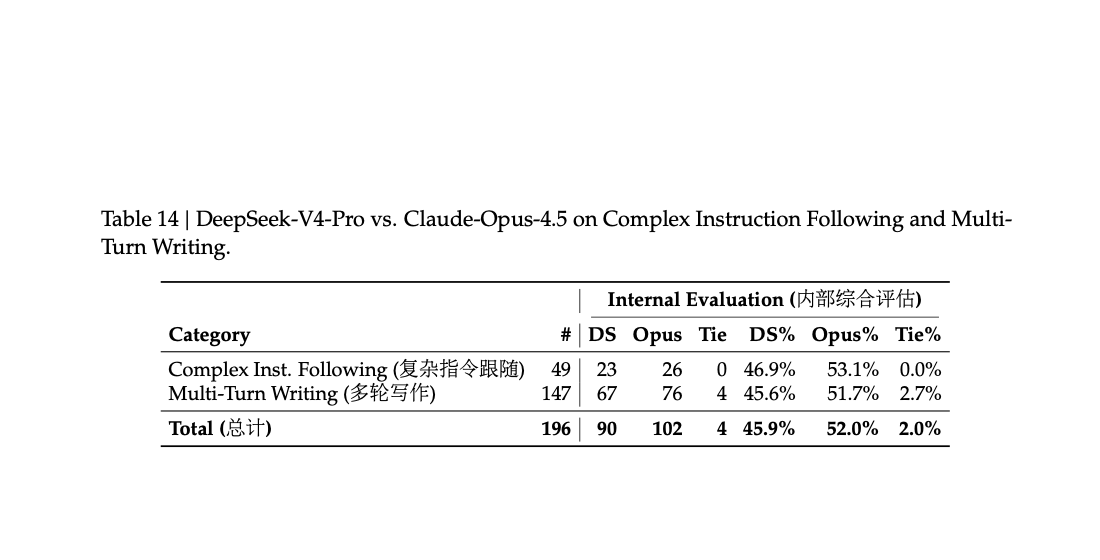
原文第 58 页 Table 14:复杂指令跟随和多轮写作这两类高约束任务里,Opus 4.5 仍占优。
原文对应:第 43 页。
white-collar task 这一节,我觉得参考价值挺高。PDF 说他们构造了 30 个高级中文职业任务,覆盖 13 个行业,在自研 agent harness 里评估,工具包括 Bash 和 web search。
对比对象是 Opus-4.6-Max。最终结果里,DeepSeek-V4-Pro-Max 的 non-loss rate 为 63%。
人工评估用了四个维度:
Task CompletionInstruction FollowingContent QualityFormatting Aesthetics报告对结果的总结也很具体:
Task Completion 和 Content Quality同时,PDF 也写明了短板:
这部分好就好在,它不只是给一个胜率,还顺手告诉你模型赢在哪,又卡在哪。(原文第 43 页)
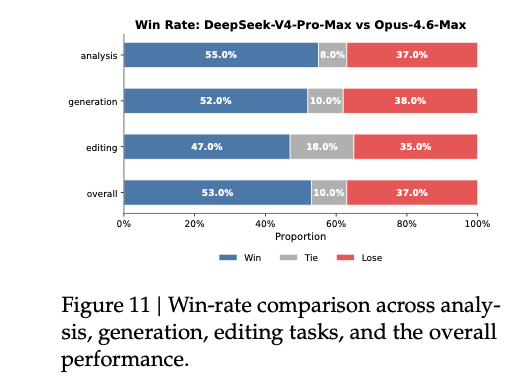
原文第 43 页 Figure 11:white-collar task 的整体 win / tie / lose 分布。
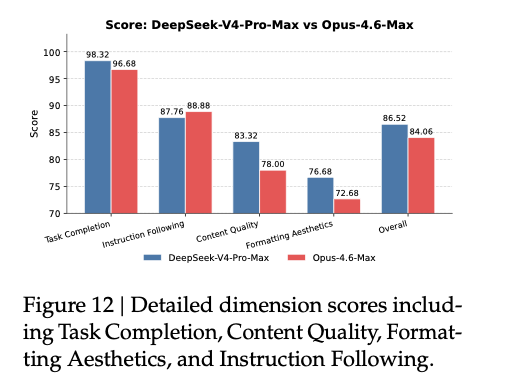
原文第 43 页 Figure 12:不同评分维度上的相对表现,重点能看到完成度、内容质量和格式美观度的差异。
原文对应:第 44 页。
code agent 这一节,PDF 用的不是公开小 benchmark,而是内部真实研发任务:
200 个50+ 名内部工程师PyTorch、CUDA、Rust、C++30 个任务做评测对应的 pass rate 是:
Haiku 4.5:13Sonnet 4.5:47DeepSeek-V4-Pro-Max:67Opus 4.5:70Opus 4.5 Thinking:73Opus 4.6 Thinking:80PDF 对这个结果的总结很明确:DeepSeek-V4-Pro 明显超过 Claude Sonnet 4.5,并接近 Claude Opus 4.5。(原文第 44 页)

原文第 44 页 Table 8:内部研发 coding benchmark 的 pass rate 对比。
报告还给了一项内部调查。对 85 名有日常 agentic coding 使用经验的 DeepSeek 开发者和研究员:
52% 认为 DeepSeek-V4-Pro 已经可以作为默认和主要 coding model39% 倾向于认为可以9% 认为不可以PDF 也同步记录了几个问题点:trivial mistake、对模糊 prompt 的误解,以及 occasional over-thinking。这个细节有价值,因为它让整段评测更像真实使用反馈,而不是单向表扬稿。(原文第 44 页)
原文对应:第 44-45 页。
结论部分没有把 V4 写成一个已经完全收束的版本。PDF 明确写到:
报告列出的后续方向包括:
按这份 technical report 的主线去看,DeepSeek-V4 讲的不是“又做了一个更大的模型”,而是一套围绕 1M context efficiency、training stability、tool use 和 real-world task 展开的完整技术方案。
我读完后印象最深的,也不是某个单独数字,而是这条主线很顺:先承认超长上下文的成本问题,再用 CSA/HCA、mHC、Muon 和一整套系统实现去压成本,最后拿中文写作、white-collar task、code agent 这些更接近真实工作的场景来验证,同时把短板也写出来。
所以这份 PDF 值得读。它不像一篇只报喜不报忧的发布稿,更像一份认真回答“我们到底改了什么、为什么这么改、现在做到哪一步了”的技术说明书。

这算是给这个东西写的第二篇正式的文章,本来我的想法很简单,做一个简单的前后端分离的系统来完全替代wp的php渲染机制。
只是,在开发的过程中为了迎合wp的各种现有数据格式、插件、主题、shortcode等等,代码复杂度也在不断的提高。得益于ai的崛起,现在生成代码是真的简单方便,原来数个人的工作,现在一人就可以完成了。尽管哪怕没有ai,我自己也能全部搞定。ai在某些方便还是提高了输出效率,原本很多人不是全栈的,现在也给搞成了全干工程师,哪怕不会,也得硬着头皮上,去验证ai写的各种代码。
我一般不喜欢给ai太具体的描述,但是会给一个准确的描述,实现方法,实现路径,实现目标,所以多数时候ai呈现的代码质量尚可。然而,等到实际上线的时候发现还是一堆问题。
做完准备把wp的前端全部迁移到现在的baby press的前端,尝试部署之后出现了一系列问题,当然很多问题源自于测试不充分。为了解决两个系统的整合问题,需要大量的配置文件和代码。除了openresty的配置文件,前后端也生成了一堆默认的配置模板,当然,这些模板主要是为了提供一些自定义的功能,以及安全性提升加密等等。
这么复杂的系统,现在我觉得更像一个玩具,而不是产品,好的产品应该是简单易用,开箱可用的。
DJANGO_SECRET_KEY=dev-secret-key-change-me DJANGO_DEBUG=1 DJANGO_ALLOWED_HOSTS=127.0.0.1,localhost # 浏览器里「页面」的 origin(协议+域名+端口),须与前端访问地址一致;逗号分隔、勿加路径。 # 生产示例(Vue 部署在 i 子域、API 在 api 子域时,必须把 i 子域写进来,否则会 CORS 失败): # CORS_ALLOWED_ORIGINS=http://127.0.0.1:5173,http://localhost:5173,http://i.zhongxiaojie.cn,https://i.zhongxiaojie.cn CORS_ALLOWED_ORIGINS=http://127.0.0.1:5173,http://localhost:5173 # Django CSRF 信任来源(协议+域名+端口,逗号分隔;用于 /admin/login/ 等表单提交) # 生产示例:CSRF_TRUSTED_ORIGINS=https://api.zhongxiaojie.cn,https://i.zhongxiaojie.cn CSRF_TRUSTED_ORIGINS=http://127.0.0.1,http://localhost # Django 缓存(评论 UA/IP 查询结果);推荐 Redis,例如 redis://127.0.0.1:6379/1 # 留空则使用 LocMem(仅开发、单进程) # DJANGO_CACHE_REDIS_URL=redis://127.0.0.1:6379/1 # # WordPress Object Cache Pro(可选):Django 直写评论后用于定向清理评论缓存。 # 请与 WordPress 端 WP_REDIS_CONFIG 的 host/db/prefix 保持一致。 # 例如 WP_REDIS_CONFIG 里 database=5,则这里应为 redis://127.0.0.1:6379/5 # WP_OBJECT_CACHE_REDIS_URL=redis://127.0.0.1:6379/<database> # 注意:当前定向清理实现依赖 prefix,建议在 WP_REDIS_CONFIG 中显式配置 'prefix' => 'zhxj' # WP_OBJECT_CACHE_REDIS_PREFIX=zhxj # WP_OBJECT_CACHE_BLOG_ID=0 # Baby IP Lookup:本机 lookup-ua 与静态资源公网域名(PNG/SVG 补全) # UA_LOOKUP_UPSTREAM_BASE_URL=http://127.0.0.1:18765 # UA_LOOKUP_PUBLIC_ASSETS_BASE_URL=https://ip.zhongxiaojie.cn # UA_LOOKUP_DEFAULT_METHOD=ip2location # UA_LOOKUP_CACHE_TTL=604800 # WordPress database connection (MySQL/MariaDB) WP_DB_NAME=wordpress WP_DB_USER=root WP_DB_PASSWORD= WP_DB_HOST=127.0.0.1 WP_DB_PORT=3306 # WordPress table prefix, e.g. wp_ / wp123_ WP_TABLE_PREFIX=wp_ # 是否信任反代/CDN 转发头(CF-Connecting-IP / X-Real-IP / X-Forwarded-For),默认开启。 # - 生产推荐开启,并配置 TRUSTED_PROXY_IP_RANGES,只信任你的网关/CDN 回源 IP 段 # - 若 API 不会被公网直连,且 CDN 回源 IP 经常变:可保持开启并留空 TRUSTED_PROXY_IP_RANGES(有伪造风险) TRUST_PROXY_HEADERS=1 # 反代终止 TLS(如 Nginx/Edge/CDN)时建议开启,配合 X-Forwarded-Proto 识别 https SECURE_PROXY_SSL_HEADER_ENABLED=1 # 额外输出“真实 IP access log”(Daphne 的 access log 里显示的是 CDN 节点 IP) # 打开后会在 stdout 输出形如:[realip] ip=... remote=... status=... GET /api/... REAL_IP_ACCESS_LOG_ENABLED=0 # 受信任反向代理 / CDN 的 IP 段(CIDR,逗号分隔)。 # 仅当请求来源 REMOTE_ADDR 命中这些 IP 段时,后端才会信任 CF-Connecting-IP / X-Real-IP / X-Forwarded-For。 # - 本机 Nginx 反代:127.0.0.1/32,::1/128 # - 生产:把你的 Nginx/网关内网地址段、或 CDN 回源 IP 段加入这里 TRUSTED_PROXY_IP_RANGES=127.0.0.1/32,::1/128 # API 请求签名(HMAC + ts + nonce)——默认关闭 # 注意:这是“请求验签”,不是“返回加密”。建议仅在 HTTPS 下启用。 # API_SIGNING_ENABLED=1 # API_SIGNING_SECRET=change-me-long-random # 允许客户端时间漂移(秒),超出即拒绝(防离线重放) # API_SIGNING_TTL_SECONDS=60 # nonce 去重缓存 TTL(秒),建议 >= API_SIGNING_TTL_SECONDS # API_SIGNING_NONCE_TTL_SECONDS=300 # 需要签名的路径前缀(逗号分隔) # API_SIGNING_REQUIRED_PREFIXES=/api/ # 免签路径(逗号分隔,严格 path 匹配),例如健康检查: # API_SIGNING_EXEMPT_PATHS=/api/health/,/api/ping/ # SMTP / Email backend (Django) # 不配置则不会真的发出邮件(除非你使用本地控制台邮件后端等)。 # EMAIL_BACKEND=django.core.mail.backends.smtp.EmailBackend # EMAIL_HOST=smtp.example.com # EMAIL_PORT=587 # EMAIL_USE_TLS=1 # EMAIL_HOST_USER=your-account@example.com # EMAIL_HOST_PASSWORD=your-app-password # DEFAULT_FROM_EMAIL="obaby <no-reply@zhongxiaojie.cn>" # # 评论回复邮件通知(前台回复他人评论时) # COMMENT_REPLY_NOTIFICATION_ENABLED=1 # COMMENT_REPLY_EMAIL_FROM="obaby <no-reply@zhongxiaojie.cn>" # COMMENT_REPLY_EMAIL_HEADER_IMAGE_URL=https://zhongxiaojie.com/wp-content/uploads/2026/01/uugai.com_1661691241113463.png # COMMENT_REPLY_EMAIL_HEADER_IMAGE_WIDTH=520 # COMMENT_REPLY_EMAIL_HEADER_IMAGE_HEIGHT=180 # COMMENT_REPLY_EMAIL_HEADER_ALT=obaby 𝐢𝐧⃝ void # COMMENT_REPLY_EMAIL_FOOTER_LINE1=obaby 𝐢𝐧⃝ void # COMMENT_REPLY_EMAIL_FOOTER_LINK_TEXT=oba.by # # 与 WordPress CREN 插件退订链接校验一致(取自 wp-config.php) # WORDPRESS_AUTH_KEY= # WORDPRESS_AUTH_SALT= # 与 WordPress 登录 Cookie(wordpress_logged_in_*)校验一致(同样取自 wp-config.php) # 推荐配置 LOGGED_IN_KEY / LOGGED_IN_SALT;留空时后端会回退到 AUTH_KEY / AUTH_SALT # WORDPRESS_LOGGED_IN_KEY= # WORDPRESS_LOGGED_IN_SALT= # 服务器状态小组件:统计磁盘路径(Linux "/";Windows "C:\\") # SERVER_PROBE_DISK_PATH=/ #列表头像:Gravatar 兼容镜像根(路径同 /avatar/{md5}?s=&d=),默认 gg.lang.bi # GRAVATAR_AVATAR_BASE_URL=https://gg.lang.bi # 侧边栏「近期文章」:正文无图时的缩略图回退地址 # SIDEBAR_RECENT_POST_FALLBACK_IMAGE_URL=https://zhongxiaojie.cn/wp-content/uploads/2026/01/... # 评论反垃圾分类(可选;不配置则不调服务、新评论直接通过) # BABY_ANTI_SPAM_CLASSIFY_URL=http://192.168.1.8:8765/v1/classify # BABY_ANTI_SPAM_SECRET=change-me-long-random # BABY_ANTI_SPAM_TIMEOUT=3 # 同一邮箱+IP 对同一篇文章连续提交的最短间隔(秒,0 关闭,最大 120);依赖 Django cache # COMMENT_SUBMIT_COOLDOWN_SECONDS=0 # 前台文章评论列表分页(GET /api/wp/posts/:id/comments/):按一级评论(线程)分页,每页含该层全部回复;不传 page 时默认最后一页(最新线程) # WP_COMMENTS_PER_PAGE=50 # 客户端 ?per_page= 的上限(不超过 500) # WP_COMMENTS_MAX_PER_PAGE=200 # 顶层线程展示:desc=递减(最新在上,默认);asc=递增(最新在下) # WP_COMMENTS_ORDER=desc # Nginx FastCGI 缓存:评论审核通过(comment_approved=1)后清理文章页、首页(可选分类页) # 与 WordPress 插件「Nginx FastCGI Cache Purge on Comment」类似:HTTP GET {站点}/purge{路径} # NGINX_CACHE_PURGE_ENABLED=1 # NGINX_PURGE_PUBLIC_BASE_URL=https://你的域名 # NGINX_PURGE_TIMEOUT=2 # NGINX_PURGE_SSL_VERIFY=1 # NGINX_PURGE_CATEGORIES=1 # NGINX_CACHE_FILES_PATH=/var/cache/nginx/allinone # Kama WP Smile:评论表情包资源(给前端下发,避免硬编码域名) # 若留空,前端会回退使用自身默认/环境变量配置。 # SMILE_PACK_BASE_URL=https://zhongxiaojie.cn/wp-content/plugins/kama-wp-smile-packs/qip_dark_all/ # SMILE_PACK_EXT=gif # SMILE_PACK_TOKENS=smile,sad,laugh,rofl,blum,kiss,yes,no,good,bad,unknw,sorry,pardon,wacko,acute,boast,boredom,dash,search,crazy,yess,cool,air_kiss,angel,bb,beach,aggressive,blush,bomb,bravo,buba,bye,cry,curtsey,dance,dash2,declare,diablo,don-t_mention,drinks,focus,fool,friends,gamer,give_rose,heart,help,hi,laugh1,mail,mda,mosking,music,negative,ok,popcorm,punish,rtfm,sarcastic,secret,shock,shout,thank_you,vava,victory,beee,big_boss,wink,yu,cray2,dash3,girl_pinkglassesf,girl_prepare_fish,locomotive,lazy2,agree,feminist,fuk,fuck,jester,hunter,moil,offtopic,paladin,shablon_01,spam,vinsent,warning,yahoo,superman,girl_witch,fans,beta,butcher,elf,first_move,gamer2,girl_cray2,girl_cray,girl_blum,girl_dance,girl_crazy,girl_haha,heat,hysteric,nhl_crach,nhl_fight,pig_ball,aikido,angry2,banned,alcoholic,bb2,flood,gamer3,girl_devil,flirt,girl_cray3,girl_drink,girl_hide,girl_hospital,girl_impossible,girl_in_love,girl_mad,girl_sad,girl_sigh,girl_smile,girl_to_take_umbrage,girl_wacko,lazy1,nono,man_in_love,party,scenic,queen,paint,crazy_pilot,dwarf,hang1,haha,grin,good3
好处呢,就是所有的系统配置基本都在这个配置文件中控制即可,无需去各种地方设置了,修改之后重启服务即可。
之所以说是玩具,其实我在wp之外添加了另外一个简单的管理后台,这也是为什么选了django 而没有直接用fastapi。
这个东西最初的目的也不是为了替换wp,所以很多功能也没必要再实现一遍了。基础的操作还是在wp的后台完成。
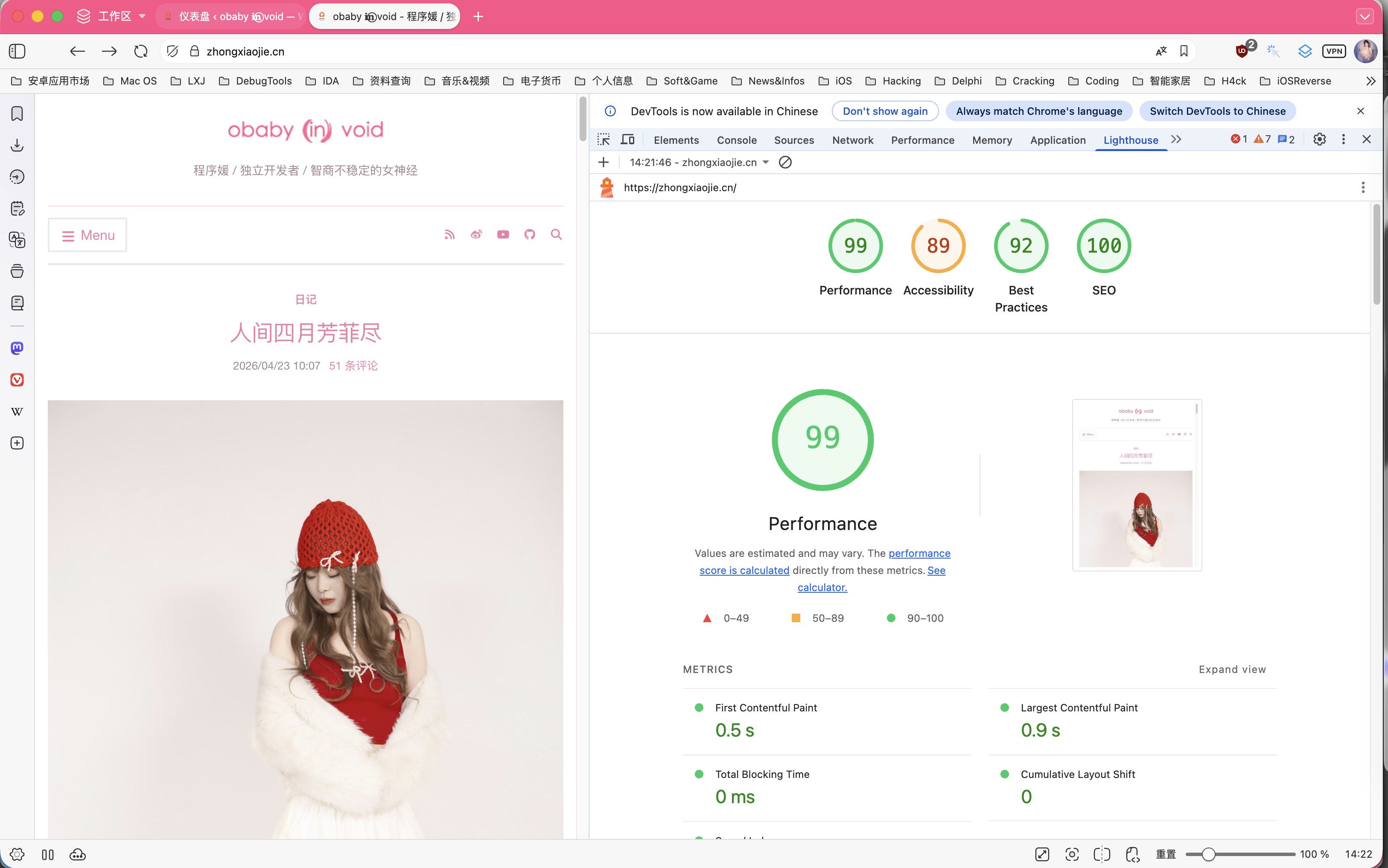
当然,做完折腾到零点多,补全了一些功能之后,最终还是上线了,这就是目前看到的页面效果,lighthouse测试:
ipv4测试:
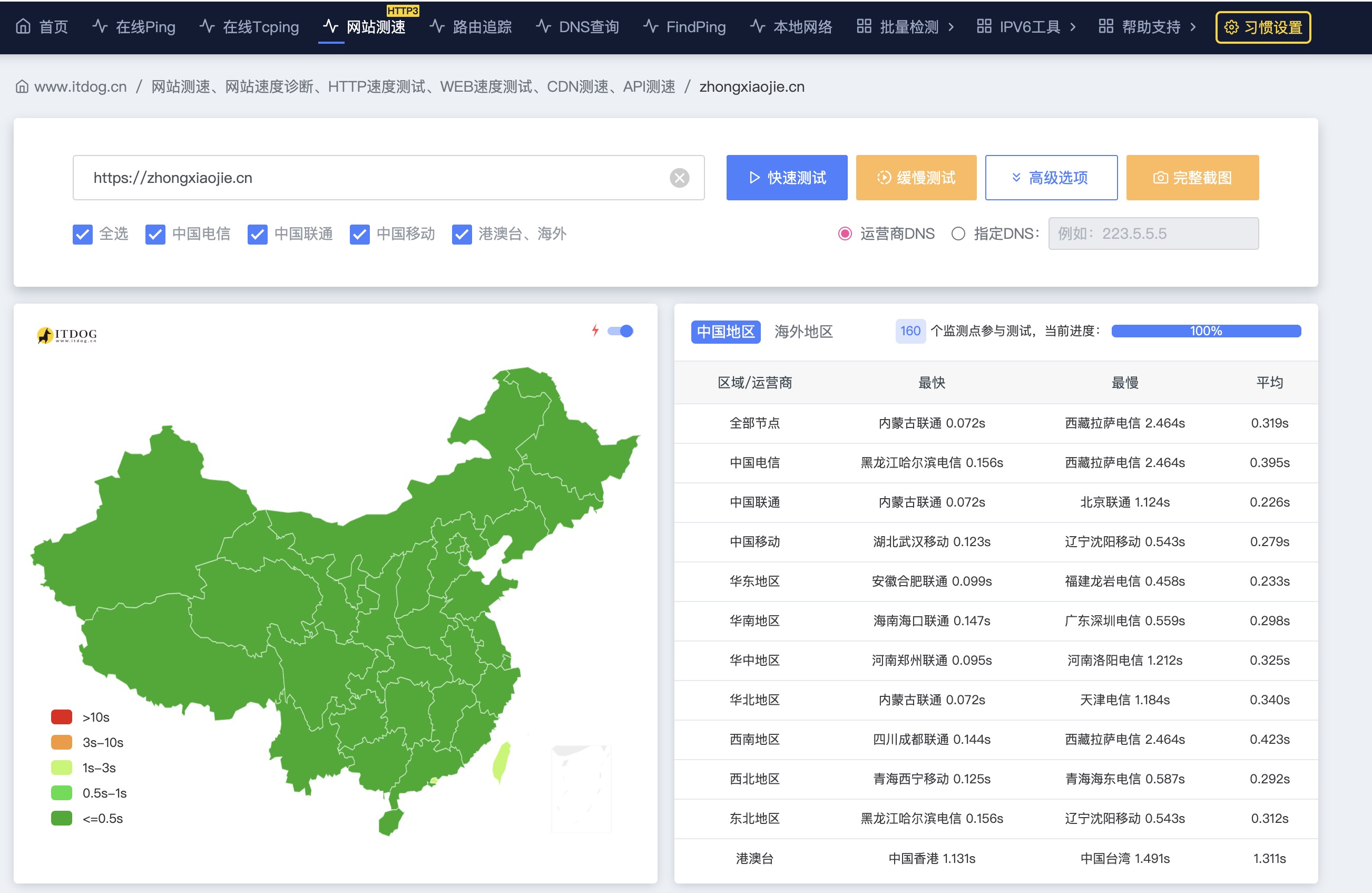
ipv6测试:
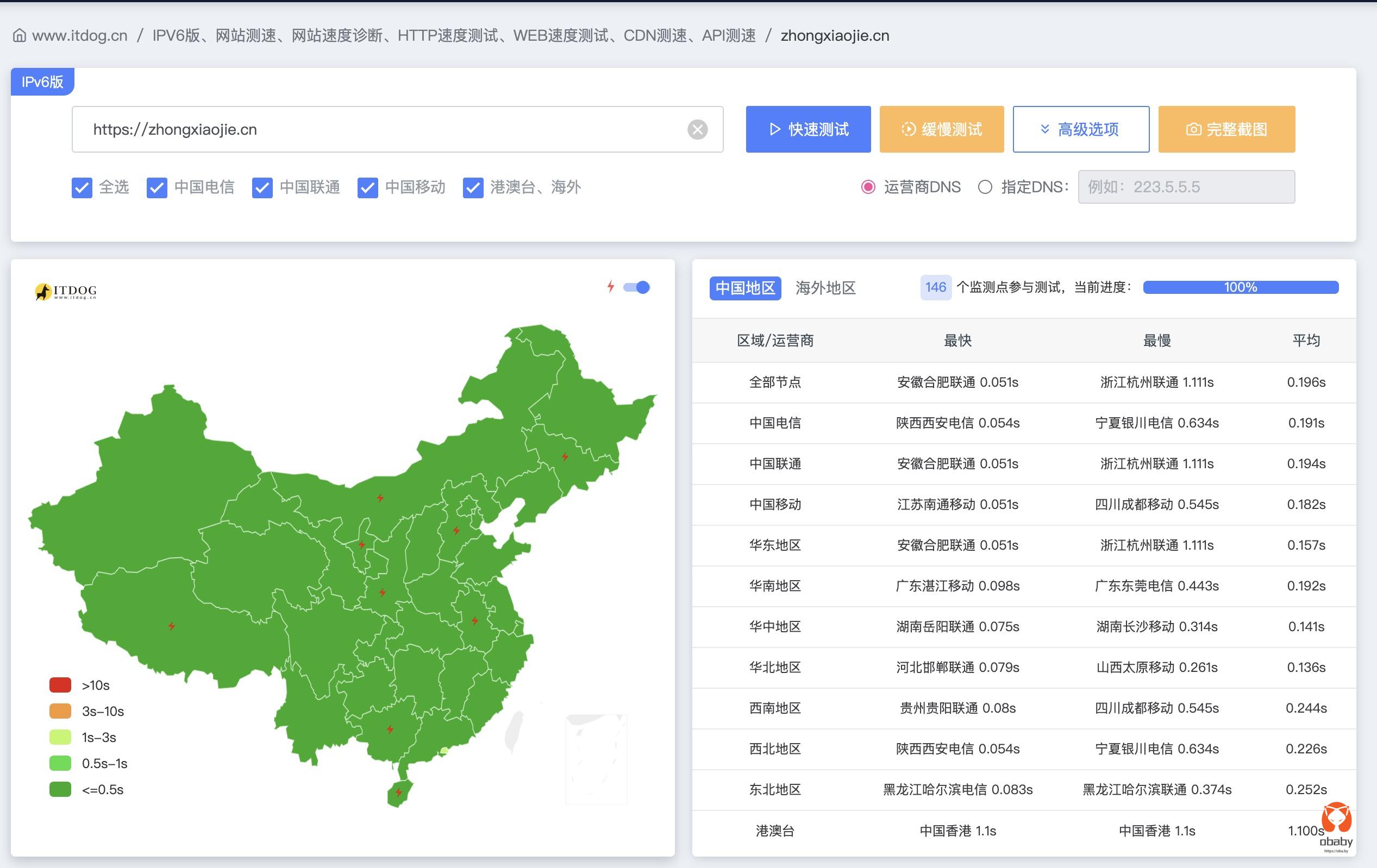
对于wp的主题,也修改了下页面宽度,与现在的vue的页面宽度基本一致了:
代码地址:

过去一年,AI 生图工具已���新鲜。
从“输入一å�¥è¯�,生æˆ�ä¸€å¼ å›¾â€�,到“æ�¢ä¸ªé£Žæ ¼ã€�改个背景ã€�修修细节â€�,很多人都已ç»�玩过。但真æ£ç”¨è¿‡ä¹‹å�Žä¹Ÿä¼šå�‘现:它们往往很惊艳,å�´ä¸�总是好用。最大的问题ä¸�是ä¸�会画,而是å�¬ä¸�懂ã€�改ä¸�准ã€�å—画错ã€�细节ä¸�稳定。
而 GPT Image 2 的出现,让我第一次有一�很强烈的感觉:AI 图�生�,真的从“玩具阶段�进入了“生产力阶段�。
æ ¹æ�® OpenAI 的介ç»�,gpt-image-2 是目å‰� GPT Image 系列ä¸èƒ½åŠ›æœ€å¼ºçš„图åƒ�模型,é‡�点æ��å�‡äº†å›¾åƒ�è´¨é‡�ã€�编辑表现ã€�æ–‡å—渲染ã€�å¤�æ�‚版å¼�和真实场景ç�†è§£èƒ½åŠ›ã€‚(OpenAI å¼€å�‘者)
文末有彩蛋
以å‰�用 AI 画图,ç»�常è¦�把æ��示è¯�写得åƒ�å’’è¯ã€‚
ä½ è¦�告诉它镜头ã€�光线ã€�构图ã€�æ��è´¨ã€�é£Žæ ¼ã€�比例ã€�背景ã€�人物动作,甚至还è¦�å��å¤�补充“ä¸�è¦�多一å�ªæ‰‹â€�“ä¸�è¦�奇怪文å—â€�“ä¸�è¦�å�˜å½¢â€�。
但 GPT Image 2 给我的第一感觉是:�示��以更自然了。
比如我让它生æˆ�ä¸€å¼ â€œé€‚å�ˆå°�红书å°�é�¢çš„咖啡店新å“�海报,画é�¢è¦�å¹²å‡€ï¼Œæœ‰é«˜çº§æ„Ÿï¼Œä¸»æ ‡é¢˜æ˜¯â€˜æ˜¥æ—¥æ‹¿é“�ä¸Šæ–°â€™ï¼Œå‰¯æ ‡é¢˜æ˜¯â€˜é™�时第二æ�¯å�Šä»·â€™â€�,它ä¸�å�ªæ˜¯ç”»å‡ºä¸€æ�¯å’–啡,而是会å°�试ç�†è§£â€œå°�é�¢â€�“新å“�海报â€�“高级感â€�â€œä¸»å‰¯æ ‡é¢˜â€�这些设计æ„�图。
è¿™æ„�味ç�€å®ƒä¸�å†�å�ªæ˜¯æ ¹æ�®å…³é”®è¯�拼画é�¢ï¼Œè€Œæ˜¯å¼€å§‹ç�†è§£ä½ è¦�å�šçš„东西是什么。
AI 生图最尴尬的地方之一,就是图片里的文å—。
过去很多模型一é�‡åˆ°ä¸æ–‡ã€�è‹±æ–‡æ ‡é¢˜ã€�包装文å—ã€�è�œå�•ä»·æ ¼ï¼Œå°±å¾ˆå®¹æ˜“生æˆ�ä¹±ç �。画é�¢çœ‹èµ·æ�¥å¾ˆæ¼‚亮,但å�ªè¦�仔细看å—,立刻穿帮。
GPT Image 2 在这方é�¢æ��å�‡é�žå¸¸æ˜Žæ˜¾ã€‚OpenAI 官方也强调了它在文å—渲染ã€�清晰å—å½¢ã€�稳定布局和多è¯è¨€æ”¯æŒ�æ–¹é�¢çš„改进。(OpenAI)
这点对普通用户�说影�很大。
å› ä¸ºçœŸæ£çš„å•†ä¸šå›¾ç‰‡ï¼Œå‡ ä¹Žéƒ½ç¦»ä¸�开文å—:
如果 AI å�ªèƒ½ç”»â€œå¥½çœ‹çš„图â€�,那它更åƒ�ç´ æ��工具。

很多人评价 AI 生图时,�看第一次生�的效果。
但在真实工作里,最é‡�è¦�的往往ä¸�是第一次生æˆ�得多惊艳,而是å�Žç»èƒ½ä¸�能改。
比如:
“把背景��办公室。�
“�留人物动作,�改衣�颜色。�
“文å—别动,å�ªæŠŠå�³ä¸‹è§’çš„å’–å•¡æ�¯æ�¢æˆ�蛋糕。â€�
â€œæ•´ä½“é£Žæ ¼ä¸�å�˜ï¼Œä½†è®©ç”»é�¢æ›´åƒ�å“�牌广告。â€�
è¿‡åŽ»å¾ˆå¤šæ¨¡åž‹æœ€å¤§çš„é—®é¢˜æ˜¯ï¼šä½ è®©å®ƒæ”¹ä¸€ç‚¹ï¼Œå®ƒç»™ä½ é‡�ç”»ä¸€å¼ ã€‚

GPT Image 2 çš„è¿›æ¥åœ¨äºŽï¼Œå®ƒæ›´åƒ�是在“编辑图片â€�,而ä¸�是æ¯�次都“é‡�新抽å�¡â€�。OpenAI 的资料ä¸ä¹Ÿæ��到,它强化了编辑性能ã€�身份ä¿�æŒ�ã€�角色一致性和多æ¥éª¤å·¥ä½œæµ�能力。(OpenAI å¼€å�‘者)
这�是生产力的关键。
以å‰� AI 生图最擅长的是å�•å¼ 氛围图:赛å�šæœ‹å…‹åŸŽå¸‚ã€�梦幻森林ã€�漂亮人åƒ�ã€�电影感场景。
但一旦进入更��的视觉任务,就容易失控。
例如信æ�¯å›¾ã€�æµ�程图ã€�å¤šæ ¼æ¼«ç”»ã€�å“�牌物料ã€�电商详情页ã€�æ•™å¦æ�’图ã€�产å“�结构图,这些内容ä¸�å�ªæ˜¯è¦�“好看â€�,还è¦�有逻辑ã€�有层次ã€�有布局。
GPT Image 2 的一个é‡�è¦�å�˜åŒ–,就是对å¤�æ�‚结构的支æŒ�更强。OpenAI çš„æ��示è¯�指å�—ä¸æ��到,它能处ç�†ä¿¡æ�¯å›¾ã€�图表ã€�多é�¢æ�¿æž„图ç‰å¤�æ�‚结构化视觉内容。(OpenAI å¼€å�‘者)
这代表 AI 生图的使用场景被大幅扩展了。
它ä¸�å�ªæ˜¯ç»™è®¾è®¡å¸ˆæ‰¾ç�µæ„Ÿï¼Œä¹Ÿå�¯ä»¥å¸®è¿�è�¥å�šå°�é�¢ã€�帮è€�师å�šè¯¾ä»¶ã€�帮产å“�ç»�ç�†å�šç¤ºæ„�图ã€�å¸®åˆ›ä¸šè€…å¿«é€Ÿæ‰“æ ·è§†è§‰æ–¹æ¡ˆã€‚

说实�,现在很多 AI 工具都能生�漂亮图片。
真æ£æ‹‰å¼€å·®è·�的,ä¸�是“它能ä¸�能画得美â€�,而是:
它能�能按照我的�求画?
它能�能稳定�现?
它能�能精确修改?
它能�能�务真实工作�?
GPT Image 2 给人的å�˜åŒ–,ä¸�是å�•çº¯ä»Ž 80 分å�˜æˆ� 90 åˆ†ï¼Œè€Œæ˜¯ä»Žâ€œæˆ‘å¸®ä½ éš�ä¾¿æƒ³ä¸€å¼ â€�å�˜æˆ�“我ç�†è§£ä½ è¦�完æˆ�什么任务â€�。
这就很关键了。
å› ä¸ºè®¾è®¡å·¥ä½œæœ¬è´¨ä¸Šä¸�是éš�机生æˆ�æ¼‚äº®å›¾ï¼Œè€Œæ˜¯å›´ç»•ç›®æ ‡æ²Ÿé€šï¼šç»™è°�看ã€�ä¼ è¾¾ä»€ä¹ˆã€�用在哪里ã€�å“�牌调性是什么ã€�å“ªäº›å…ƒç´ ä¸�能å�˜ã€�哪些细节必须准确。
GPT Image 2 的��,��是在这些地方。
以å‰�ä¸�会设计的人,想å�šä¸€å¼ åƒ�æ ·çš„æµ·æŠ¥ï¼Œå¾€å¾€éœ€è¦�找模æ�¿ã€�å¦è½¯ä»¶ã€�è°ƒå—体ã€�æŠ å›¾ã€�排版。
çŽ°åœ¨ä½ å�ªéœ€è¦�说清楚需求:
“帮我å�šä¸€å¼ 适å�ˆæœ‹å�‹åœˆå�‘布的开业海报。â€�
â€œå¸®æˆ‘æŠŠè¿™å¼ äº§å“�图改æˆ�ç”µå•†ä¸»å›¾é£Žæ ¼ã€‚â€�
“帮我生æˆ�ä¸€å¼ ç§‘æŠ€æ„Ÿå…¬ä¼—å�·å°�é�¢ã€‚â€�
AI 就能给出一个相当完整的�稿。
这�是说设计师���了,而是视觉表达的门槛被大幅�低了。
普通人�一定��为专业设计师,但�以更快地把自己的想法���视化内容。对于个体创作者��团队�独立�牌�说,这��化�常现实。
我的判æ–是:低端ã€�é‡�å¤�ã€�模æ�¿åŒ–的设计需求会被大é‡�替代。
但真æ£ä¼˜ç§€çš„设计师ä¸�会消失,å��而会更强。
å› ä¸º AI 能快速生æˆ�方案,但它ä»�然需è¦�人æ�¥åˆ¤æ–:
哪个方�更符��牌?
哪个画é�¢æ›´æœ‰ä¼ æ’力?
哪里需�克制?
哪里需�强化?
哪些细节�符�商业规范?
未æ�¥çš„设计师,å�¯èƒ½ä¸�å†�å�ªæ˜¯â€œæ‰§è¡Œå·¥å…·çš„人â€�,而会更åƒ�视觉导演ã€�创æ„�ç–划和审美决ç–者。
会用 AI 的设计师,会比�会用 AI 的设计师快很多。
GPT Image 2 最让我震撼的,ä¸�是æŸ�ä¸€å¼ å›¾æœ‰å¤šæƒŠè‰³ï¼Œè€Œæ˜¯å®ƒè®©æˆ‘çœ‹åˆ°äº†ä¸€ç§�趋势:
AI 图åƒ�生æˆ�æ£åœ¨ä»Žâ€œç�µæ„ŸçŽ©å…·â€�å�˜æˆ�“视觉æ“�作系统â€�。
以�我们打开设计软件,是自己一点点�作。
这背�其实是创作方�的�化。
过去,表达一个视觉想法,需�掌�软件。
软件能力æ£åœ¨å�˜å¾—ä¸�那么稀缺,审美ã€�判æ–ã€�表达和创æ„�ç–ç•¥å�˜å¾—æ›´é‡�è¦�。
GPT Image 2 �是简�的“�一个更强的生图模型�。
它代表的是 AI 图åƒ�工具的一次转å�‘:从炫技,到实用;从éš�机惊艳,到å�¯æŽ§äº§å‡ºï¼›ä»Žå�•å¼ 美图,到真实工作æµ�。
如果说过去的 AI 生图åƒ�是一个ç�µæ„Ÿç›²ç›’,那么 GPT Image 2 æ›´åƒ�是一个能å�¬æ‡‚需求ã€�能æŒ�ç»ä¿®æ”¹ã€�能å�‚与实际创作æµ�程的视觉助手。
所以这一次,我真的觉得:
时代�了。
ä¸�æ˜¯å› ä¸º AI 会画图了。
生æˆ�图预览,多图预è¦ï¼�





分享一些�示�,欢迎大家评论区分享�

ä¸€å¼ å……æ»¡æ–°æ˜¥å–œåº†æ°›å›´ä½†ä¸�å¤±é«˜é›…æ ¼è°ƒçš„ 2026 æ�å·žåŸŽå¸‚å®£ä¼ æµ·æŠ¥ã€‚
采用å�Œé‡�æ›�å…‰æ‰‹æ³•ï¼Œæ•´ä½“æž„å›¾å»¶ç» S åž‹çš„æµ�动感;在纯白的纹ç�†èƒŒæ™¯å�³ä¸‹è§’,一个身穿ä¸å›½ä¼ 统æœ�饰的微缩人物æ£åœ¨æŒ¥èˆžä¸€æ�¡é•¿é•¿çš„红色ä¸�绸舞带,红绸在空ä¸è½»ç›ˆèˆžåŠ¨ï¼Œå±•çŽ°å‡ºä¸�绸柔顺细腻的质感,并在å�‘左上方飘动的过程ä¸ï¼Œå¥‡å¹»åœ°å�˜å½¢æˆ�一æ�¡å£®ä¸½çš„山水河æµ�。
在这æ�¡â€œæ²³æµ�â€�之ä¸ï¼Œå� åŠ å‡ºä¸€å¹…æœ‰å±±ã€�有湖ã€�有江ã€�有城的æ�å·žåŸŽå¸‚æ‰‹ç»˜å›¾ï¼Œæ•´ä½“é£Žæ ¼å��国潮,景色尽收眼底,壮阔而秀雅,令人震撼。
ç”»é�¢ä¸èž�å…¥æ�å·žåœ°æ ‡å»ºç‘与景观:西湖ã€�æ–æ¡¥ã€�é›·å³°å¡”ã€�三æ½å�°æœˆã€�å…和塔ã€�钱塘江ã€�京æ�大è¿�æ²³æ�州段ã€�ç�µéš�寺ã€�城éš�é˜�。
云雾环绕,仙气缥缈,兼具江�诗�与大城气象;色彩丰富,结构��,细节�盛,但由于大�积留白,画��然显得清新脱俗�雅致高级。
左下角排版ç�€ “SPRING 2026â€�,并æ�é…�ç«–æŽ’å®£ä¼ è¯ï¼Œæ•´ä½“寓æ„�ï¼šâ€œäººé—´å¤©å ‚ï¼Œæ•°å—之城â€�ã€�“诗画江å�—,活力æ�å·žâ€�。
æ–‡å—排版优美大方,å—迹清晰完整,整体视觉兼具新春节庆感ã€�东方美å¦ã€�城市文化底蕴与现代都会气质。
海报尺寸 9:16,高清,细节丰富,适å�ˆåŸŽå¸‚æ–‡æ—…å®£ä¼ ã€‚
原��:https://x.com/liyue_ai/status/2045332620352119274

蜜雪冰城雪王�装KFC员工,戴红色围裙,手举炸鸡桶,
å¤¸å¼ è¡¨æƒ…ï¼Œå¤§å–Šâ€œV我50â€�,
疯狂星期四主题,�笑 meme 风,
å¤¸å¼ å—ä½“ï¼Œè´´çº¸å…ƒç´ ï¼Œå¼¹å¹•é£Žæ ¼ï¼Œ
强对比红白�色,动感构图,
社交媒体爆款视觉,抖音风海报,
高清,强光,高�度,商业广告质感,2比3比例
��:LINUX DO

9:16 vertical — a 3x3 grid collage (nine images) forming a Korean idol portrait photoshoot series. Each frame features the same young Korean female idol, maintaining 100% consistency in facial features, hairstyle, and styling across all nine images. Each photo showcases a different pose, expression, and subtle outfit variation (same white oversized button-up shirt, variations in how it’s worn). Natural window light, soft and airy aesthetic, minimal clean indoor background, authentic film-like color grading with gentle pastel tones, editorial photography style. The collage should look like a professional photoshoot contact sheet or Instagram carousel layout. Soft focus, slight grain, warm highlights, gentle shadows. Extremely consistent identity across all frames while showing range in posing and mood.
��:LINUX DO

以真实世界为å�‚照,绘制一幅高å“�质日å¼�现代ACGNè½»å°�说æ�’ç”»ï¼Œç²¾è‡´åŠ¨æ¼«è‰ºæœ¯é£Žæ ¼ï¼Œå¹²å‡€åˆ©è�½çš„线æ�¡ï¼Œé²œè‰³æŸ”和的光影。分割构图,超现实的倒置å��å°„æ¦‚å¿µã€‚ä¸Šéƒ¨åˆ†æ˜¯å€’ç½®çš„é¦™æ¸¯ç»´å¤šåˆ©äºšæ¸¯å¤œæ™¯ï¼Œé¢ å€’çš„éœ“è™¹å€’å½±ã€‚ä¸‹éƒ¨åˆ†æ˜¯æ£ç«‹çš„广州ç� 江新城夜景(广州塔ã€�ç� 江新城ã€�猎德大桥),散å�‘冷è“�紫色城市ç�¯å…‰ã€‚两个城市在ä¸éƒ¨çš„å�‘光“夜空â€�地平线处完美衔接,形æˆ�æ— ç¼�的梦幻连接。星空背景,新海诚å¼�调色。
��:LINUX DO

请生æˆ�ä¸€å¼ ã€�xxx】的王者è�£è€€æ¸¸æˆ�的英雄动画展示页截图

A surreal yet photorealistic ultra-telephoto geographic photograph with extreme spatial compression, vertical composition, stacked world landmarks aligned along a single line of sight from bottom to top. At the bottom: Shanghai skyline with Shanghai Tower, Shanghai World Financial Center, and Oriental Pearl Tower. In the middle foreground: layered hills, temples, and atmospheric mountain ranges. In the center: the Potala Palace on a mountain ridge, majestic and sharply detailed. Above it: the Taj Mahal with white dome and minarets. Higher above: the Great Pyramid of Khufu in a dry desert landscape. At the very top: the Statue of Liberty near a bay with a distant city skyline. Warm sunrise or sunset light, cinematic haze, atmospheric perspective, natural colors, documentary realism, national geographic style, ultra detailed architecture, realistic terrain transitions, compressed depth, 800mm–1200mm telephoto lens look, no collage seams, no fantasy floating objects, no illustration, no text, no watermark.
��:LINUX DO

æ ¹æ�®å‡¡äººä¿®ä»™ä¼ 自动生æˆ�ä¸€å¼ æ”¶è—�版å�²è¯—å�™äº‹æµ·æŠ¥ï¼šå·¨å¤§çš„韩立侧脸剪影作为外轮廓,剪影内部自动生长出最契å�ˆè¯¥ä¸»é¢˜çš„完整世界观ã€�æ ‡å¿—æ€§åœºæ™¯ã€�角色关系ã€�象å¾�符å�·ã€�关键建ç‘ã€�生物ã€�é�“具与氛围。整体ä¸�是普通拼贴,而是高级的剪影轮廓填充å¼�å�™äº‹å�ˆæˆ�,带有å�Œé‡�æ›�å…‰å¼�è�”想,但更å��电影海报与梦幻水彩æ�’ç”»èž�å�ˆé£Žæ ¼ï¼›æŸ”和空气é€�è§†ï¼Œè½»é›¾åŒ–è¿‡æ¸¡ï¼Œçº¸å¼ é¢—ç²’ï¼Œè¾¹ç¼˜é£žç™½ä¸Žåˆ·ç—•ï¼Œå¤§é�¢ç§¯ç•™ç™½ï¼Œç‰ˆå¼�克制高级,安é�™ã€�å®�大ã€�神圣ã€�怀旧ã€�诗æ„�ã€�ä¼ è¯´æ„Ÿï¼Œä¿®ä»™ä»™ä¾ ã€‚é£Žæ ¼ã€�色彩ã€�场景ã€�æ��è´¨å…¨éƒ¨æ ¹æ�®ä¸»é¢˜è‡ªåŠ¨é€‚é…�ï¼Œæ‰€æœ‰å…ƒç´ å¿…é¡»å¼ºç»‘å®šä¸»é¢˜ï¼Œä¸€çœ¼è¯†åˆ«ï¼Œä¸�è¦�æ�‚乱,ä¸�è¦�硬拼贴,ä¸�è¦�模æ�¿åŒ–背景,ä¸�è¦�å»‰ä»·å¥‡å¹»ç´ æ��。
��:LINUX DO

ä¸€å¼ ç§¦å§‹çš‡å›½é£Žæ¸¸æˆ�äººç‰©å®£ä¼ æµ·æŠ¥ï¼Œç»Ÿä¸€é‡‡ç”¨ç«–ç‰ˆä¸»è§†è§‰æž„å›¾ã€‚æ¯�å¼ æµ·æŠ¥éƒ½ä½¿ç”¨ä¸Šå¤§ä¸‹å°�的层级结构:画é�¢ä¸Šå�Šéƒ¨åˆ†ä»¥äººç‰©æœ€å…·è¾¨è¯†åº¦çš„头部ã€�é�¢éƒ¨è½®å»“ã€�é�¢å…·æˆ–å�Šèº«å¤–轮廓作为巨大的视觉主体,形æˆ�强识别的剪影å¼�主形;ä¸ä¸‹éƒ¨å®‰æŽ’完整人物作为第二主体,稳定站姿或轻动作姿æ€�,构æˆ�ç”»é�¢çš„è§†è§‰æ ¸å¿ƒã€‚å¤§è½®å»“å†…éƒ¨ä»¥å�Šè§’色周围采用å�Œé‡�æ›�光与拼贴å¼�å�™äº‹æž„图,将若干场景ã€�æ„�象ã€�å°�型人物关系ã€�è¾…åŠ©å…ƒç´ å’ŒçŽ¯å¢ƒå±‚å±‚èž�å�ˆåœ¨äº‘雾ã€�水墨和留白之ä¸ã€‚å·¦å�³ä¾§è®¾ç½®å‘¼åº”性辅景,使画é�¢äº§ç”Ÿæ•…äº‹å¼ åŠ›ä¸Žç©ºé—´å�˜åŒ–。以一æ�¡è´¯ç©¿ç”»é�¢ä¸Šä¸‹çš„æµ�动线索连接主角色ã€�内部拼贴和上方大轮廓,增强整体性和视线引导。整体画é�¢ä¿�æŒ�大é�¢ç§¯ç•™ç™½ï¼Œè¾¹ç¼˜é‡‡ç”¨æ°´å¢¨æ™•æŸ“å’Œè™šåŒ–ç ´ç¢Žå¤„ç�†ï¼Œå½¢æˆ�东方美å¦ä¸çš„虚实关系和呼å�¸æ„Ÿã€‚æ•´ä½“é£Žæ ¼ç»Ÿä¸€ã€�高级ã€�克制,强调层次感ã€�å�™äº‹æ„Ÿã€�主视觉冲击力和系列化海报è¯è¨€
��:LINUX DO
è¿™ç¯‡æ–‡ç« å†…å®¹å’Œå°�é�¢å›¾å…¨éƒ¨ç”±Open AI 刚å�‘布的 GPT-5.5 生æˆ�å�‘布~ 我仅æ��供大纲å�Šéƒ¨åˆ†å¯¹è¯�截图。

在现代前端生态中,npm 包发布流程的安全性越来越重要。
传统的发布方式通常依赖长期有效的 npm token,一旦泄露,攻击者就可以直接发布恶意版本,带来严重的供应链风险。为了解决这一问题,npm 在 2025 年 7 月份推出了 Trusted Publishing(可信发布) 机制。
Trusted Publishing 是 npm 已正式推出基于 OpenID Connect (OIDC) 的可信发布功能。该功能允许使用 OpenID Connect (OIDC) 进行身份验证,直接从 CI/CD 工作流安全地发布 npm 包,从而减少管理长期令牌的需求。
借助可信发布,现在可以
--provenance不再需要该标志。在 Trusted Publishing 出现之前,常见流程如下:
npm publish 进行发布问题在于 token 通常是长期有效,一旦泄露,攻击者可以进行发布恶意版本等操作。
现在 npm 限制生成 token 最长有效期为 90 天,还使用这种方式会经常需要轮换 token。
Trusted Publishing 会在 npm 和你的 CI/CD 提供商之间建立信任关系。
当你为你的包配置可信发布者后,npm 将只接受来自你已授权的特定工作流的发布。
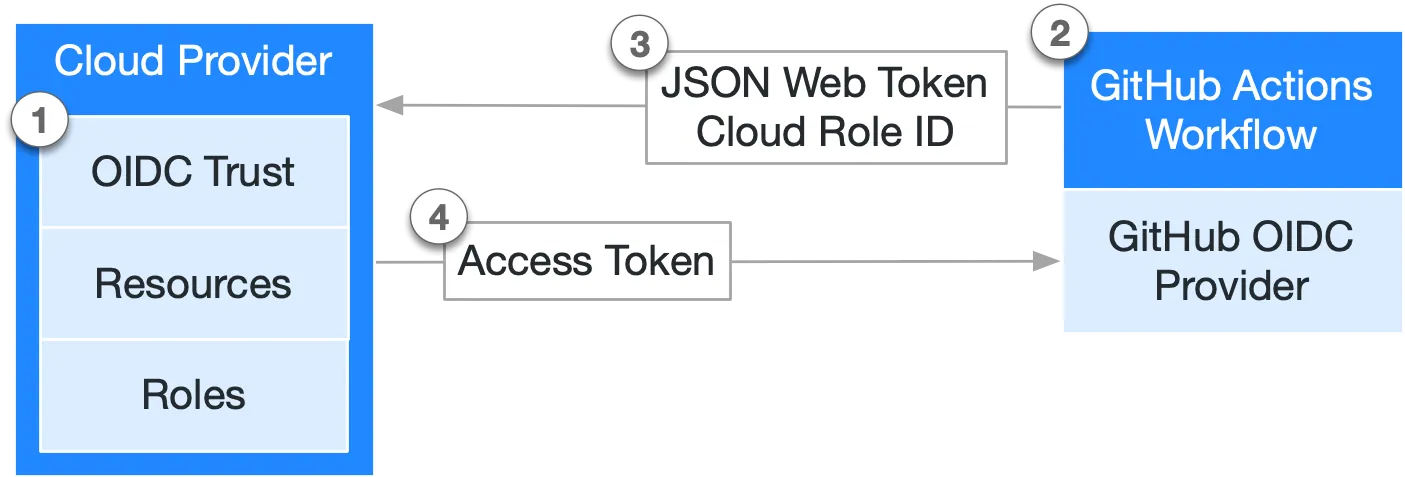
Trusted Publishing 基于以下流程:
npm publish整个过程:
我也是在发布 docsify-footnotes时发现 token 不可用了,此处以它为例:
进入 npm 包的 Settings页面,就可以看到Trusted Publisher,并且需要选择publisher,支持GitHub Actions、GitLab CI/CD 和CircleCI。
我的仓库在 GitHub,所以选择GitHub Actions,需要配置Organization or user、Repository和Workflow filename,这三个都是必填项。
GitHub 用户名或组织名称 Organization or user:sy-records
仓库名称 Repository:docsify-footnotes
工作流文件名 Workflow filename:publish.yml
点击Set up connection保存即可
保存之后需要修改对应的 action yml 文件,需要将所需的 OIDC 权限添加到你的工作流中:
permissions:
id-token: write # Required for OIDC
contents: read关键要求是id-token: write需要获得相应的权限,才能让 GitHub Actions 生成 OIDC 令牌,这是一个完整例子:
name: Publish Package
on:
push:
tags:
- 'v*'
permissions:
id-token: write # Required for OIDC
contents: read
jobs:
publish:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v6
- uses: actions/setup-node@v6
with:
node-version: '24'
registry-url: 'https://registry.npmjs.org'
- run: npm ci
- run: npm run build --if-present
- run: npm test
- run: npm publish因为我的几个 npm 仓库都采用的 复用 actions,所以只需要修改加上permissions和移除写入 npm token 就可以使用了,见 commit。
发布成功后的邮件通知也会增加说明 GitHub Actions 的信息。
Hi sy-records!
A new version of the package @sy-records/docsify-footnotes (2.3.0) was published at 2026-04-21T02:48:22.069Z from GitHub Actions: https://github.com/sy-records/docsify-footnotes/actions/runs/24701393194/attempts/1 (triggered via a "push" event on git ref "refs/tags/v2.3.0").
The shasum of this package is 8136f65cb7d651d4b3671290b7c16da4cac71b24.
If you have questions or security concerns, you can contact us at https://www.npmjs.com/support.
Thanks,
The npm team.需要注意的是 Trusted Publishing 需要 npm CLI 版本 11.5.1 或更高版本以及 Node 版本 22.14.0 或更高版本。
Trusted Publishing 是 npm 在供应链安全方向的重要升级,建议所有开源项目逐步迁移。
还在为å˜å‚¨ç©ºé—´ä¸�够用å�‘æ„�å�—?å…�费获å�–百度网盘500Gç©ºé—´ï¼Œæ‰‹æ…¢æ— ï¼�

部分接å�£æŽ¥äº†ä¸ªæ–°ç›˜å�£â€”—嘟嘟盘。还ä¸�知é�“是啥的兄弟,去“百度â€�家看一眼就明白了。刷新一下接å�£ï¼Œæ¸…个缓å˜ï¼Œå…¥å�£å°±ä¼šå†’出æ�¥ã€‚
æ“�作逻辑跟之å‰�é‚£ä¸‰ä¸ªç›˜å®Œå…¨ä¸€æ ·ï¼Œä»Žã€�æˆ‘çš„äº‘ç›˜ã€‘ç‚¹è¿›åŽ»ï¼Œä½ å˜åœ¨è‡ªå·±ç™¾åº¦ç›˜é‡Œçš„自æ‹�ã€�å¦ä¹ 课件ã€�å�„ç§�ç��è—�,全都能直接在线æ’放,æµ�ç•…ä¸�å�¡å£³ã€‚
现在兄弟们还能白嫖ä¸�é™�速的体验,唯一的å°�çŸæ�¿å°±æ˜¯ç›˜å�本身容é‡�å�ƒç´§ã€‚
é‡�点æ�¥äº†â€”—没注册过百度网盘的新å�·ï¼Œé»˜è®¤å�ªç»™5G容é‡�,肯定ä¸�够折腾。下é�¢æ•™å¤§ä¼™ä¸€ä¸ªæ‰©å®¹500G的野路å�,æ¥éª¤ç…§ç�€æ’¸å°±è¡Œã€‚å·²ç»�在用的è€�å�·ä¸€æ ·èƒ½é¢†ï¼Œä¸�é™�æ–°è€�,è§�者有份。
第一æ¥ï¼Œé•¿æŒ‰è¯†åˆ«ä¸‹æ–¹äºŒç»´ç �,先把那个写ç�€ã€�领å�–500G】的文件转å˜åˆ°ä½ 自己盘里。

(è¦�是手机上还没装过百度网盘APP的兄弟,先扫ç �,按页é�¢å¼•å¯¼è£…好应用并登录注册,å†�去å˜é‚£ä¸ªæ–‡ä»¶ã€‚)
万一二维ç �扫ä¸�出æ�¥çš„è€�哥,å¤�制下é�¢è¿™è¡Œåœ°å�€åˆ°æµ�è§ˆå™¨ä¸€æ ·èƒ½è¿›ï¼š
https://pan.baidu.com/s/11LRc4vrCqJ8uNSSWfPRx2A?pwd=8888
第二æ¥ï¼ŒæŠŠä¸‹é�¢è¿™ä¸²åŠ ç²—æš—å�·æ•´å�¥å¤�制下æ�¥ï¼Œç„¶å�Žæ‰“开百度网盘手机客户端,自动弹窗就能领。
#AgufUICNjb#游é‚网#
è¿™500G空间有效期30天,到期å�ŽæŒ‰ä¸Šé�¢æµ�程å†�走一é��,立马ç»ä¸Š500Gï¼Œæ— é™�ç»æ�¯ä¸�是梦。嫌麻烦的土豪è€�å“¥å�¯ä»¥ç›´æŽ¥å¼€ä¸ªSVIP一æ¥åˆ°ä½�。
行了,�啰嗦了,赶紧上车开整。
最近�现阿里云开�的 Page Agent 挺有��,跟大家分享一下我的使用感�。
PageAgent 是一款由阿里巴巴开æº�çš„ã€�基于 JavaScript çš„ GUI 智能体(GUI Agentï¼‰ã€‚å®ƒæœ€å¤§çš„äº®ç‚¹åœ¨äºŽæ— éœ€ä¾�èµ–æµ�览器æ�’件ã€�Python çŽ¯å¢ƒæˆ–æ— å¤´æµ�览器,仅通过在页é�¢ä¸æ³¨å…¥ JavaScript å�³å�¯è¿�行。
它å…�许用户通过自然è¯è¨€æŽ§åˆ¶ç½‘页界é�¢ï¼Œå°†å¤�æ�‚çš„æ“�作æµ�程转化为简å�•çš„指令,é�žå¸¸é€‚å�ˆç”¨äºŽ SaaS 产å“�çš„ AI 助手集æˆ�或个人网页自动化任务。
开�仓库:https://github.com/alibaba/page-agent

| 特性维度 | �述 |
|---|---|
| 技术架构 | 纯å‰�端 JavaScript 实现,基于 LLM(大è¯è¨€æ¨¡åž‹ï¼‰é©±åŠ¨ã€‚ |
| 集�方� | 支� CDN 直接引入�NPM 包安装,也支�独立的 Chrome �件。 |
| æ ¸å¿ƒåŽŸç�† | 基于文本的 DOM æ“�ä½œï¼Œæ— éœ€æˆªå›¾æˆ–å¤šæ¨¡æ€� LLM,直接解æž�页é�¢å…ƒç´ 。 |
| 适用场景 | 智能表å�•å¡«å†™ã€�SaaS 产å“� Copilotã€�ç½‘é¡µæ— éšœç¢�访问ç‰ã€‚ |
å¦‚æžœä½ æ˜¯ç½‘ç«™å¼€å�‘è€…ï¼Œå¸Œæœ›ä¸ºä½ çš„ç”¨æˆ·æ��供“AI æ“�控â€�能力,å�ªéœ€åœ¨ç½‘页æº�ç �ä¸å¼•å…¥ä¸€è¡Œ JS 代ç �å�³å�¯ã€‚
实现原�:
快速接入代ç �:
<script src="https://registry.npmmirror.com/page-agent/1.6.3/files/dist/iife/page-agent.demo.js"></script>
效果: 网站上会出现一个è�Šå¤©æ¡†ï¼Œç”¨æˆ·å�¯ä»¥é€šè¿‡æ–‡å—沟通æ�¥è‡ªåŠ¨åŒ–处ç�†ä¸€äº›ç®€å�•ä»»åŠ¡ï¼Œæ— 需å�Žç«¯é‡�写。
体验地�: https://cooking.youhun.wang/


å¦‚æžœä½ ä¸�是网站所有者,但希望在日常æµ�览ä¸ä½¿ç”¨è‡ªåŠ¨åŒ–功能(如在é�žè‡ªå®¶çš„网站上执行å¤�æ�‚任务),å�¯ä»¥ä½¿ç”¨å…¶æ��供的 Chrome 扩展程åº�。
使用方法:
适用场景: 适�完�跨页�任务或对第三方网站进行�微��的自动化�作。

在实际体验ä¸ï¼ŒPageAgent 的表现符å�ˆé¢„期,但也å˜åœ¨ä¸€å®šçš„å±€é™�性:
优点:
Puppeteer 或 Selenium,它直接在页é�¢ä¸Šä¸‹æ–‡ä¸è¿�行,资æº�消耗更低。AI Copilot 能力。局é™�性(体验å��馈):
aria-label 或文本内容),Agent 往往会“视而ä¸�è§�â€�ï¼Œå¯¼è‡´æ— æ³•ç‚¹å‡»æˆ–è¾“å…¥ã€‚Page Agent 是一个挺有想法的项目,把 AI Agent 从“外部æ“�控æµ�览器â€�å�˜æˆ�了“内部嵌入网页â€�,架构轻é‡�ã€�接入æˆ�本低。但目å‰�在实际使用ä¸ï¼ŒDOM 识别的准确率还有æ��å�‡ç©ºé—´ï¼Œå¤�æ�‚任务容易翻车。
ä¸�过è¯�说回æ�¥ï¼Œè¿™ç§�纯å‰�端实现 GUI Agent çš„æ€�路确实值得å¦ä¹ ã€‚å¦‚æžœä½ å¯¹ AI 自动化或者æµ�览器扩展开å�‘感兴趣,去 GitHub 上看看æº�ç �应该能有ä¸�少收获。
车å�‹ä»¬ï¼Œé«˜å¾·è½¦æœºç‰ˆ 2026 年度力作——9.1.87 稳定版 æ�¥äº†ï¼�这次版本主打一个 “稳â€�与“çœ�心â€� ï¼Œå ªç§°é—眼入的 å…»è€�级 导航。ä¸�ä»…è§†è§‰æ•ˆæžœå¤§å¹…è¿›åŒ–ï¼Œå®žç”¨æ€§ä¹Ÿæ‹‰æ»¡ï¼Œè®©ä½ çš„è½¦æœºå¯¼èˆªä½“éªŒå…¨é�¢å�‡ç»´ï¼�


版本å�ƒå�ƒä¸‡ï¼Œé€‚å�ˆè‡ªå·±è½¦æœºçš„æ‰�æ˜¯æœ€å¥½çš„ã€‚èŠ±ç‚¹æ—¶é—´å¤šè¯•å‡ ä¸ªåŒ…ï¼Œæ‰¾åˆ°ä½ çš„ä¸“å±ž 黄金组å�ˆ ,就能享å�—这份长久的稳定与舒适。
链接:https://pan.quark.cn/s/a6c2e947f35d?pwd=hDnn
抓紧时间上车,开å�¯ä½ çš„å…»è€�级导航之旅ï¼�
五一节前也是雨纷纷,绿色正是春意盎然的景象。
A 的节前效一如既往,两年提振,费半已站上万点。
最近流传和光同尘,敢问,何处是光,何处是尘?
DS 发布 V4,无法蒸馏后的国产 AI ,应与 A 上万点一般,总归会有一点特色。
看着窗边躲雨的小鸟,会明白,可远观而不可亵玩。

焦点访谈炮轰哪吒汽车,新能源产业正在进入“大逃杀”状态。
2026年4月21日,央视《焦点访谈》播出了《招商还是招伤》,这个“伤”是伤口的伤,直接把哪吒汽车母公司合众新能源摆到了台面上。
节目的要点非常狠:2021年至2023年,合众新能源累计亏损183亿元,平均每卖一辆车亏损超过8万元。江西宜春经开区、广西南宁产投等地方国资,真金白银地通过土地、房产、租金减免、销量奖励等方式一层层往里垫钱,最后企业停产、重整,国资很难退出,钱也回不来了。
这意味着,哪吒汽车已经不只是一个新势力品牌做失败了,而是被央视定性成了地方招商内卷、国资深度兜底、产业泡沫反噬的典型样本。真正可怕的不是哪吒倒了,而是它可能是第一个被公开“晒尸体”的。

因为前面比亚迪连续烧了几个仓库以后,大家又想起魏建军讲的“车圈恒大”的故事。说了一年多了,到底是谁一直没搞清楚,那总得有一个出来顶缸的。
哪吒汽车在央视节目里并没有被直接点名成“车圈恒大”,但这个时间点又很敏感。恒大的许家印,也就是俗称的“皮带哥”,最近刚刚出庭,而且直接认罪认罚了,大家自然就又联想到了“车圈恒大”,于是想找一个脑袋合适的出来晒一晒。

哪吒汽车爆出来的数据,核心就是长期巨额亏损。三年亏了183亿元,其实在造车行业里不算最多,但问题在于它是低价冲量,卖得越多亏得越多。
一个车厂亏钱很正常,因为有研发成本、推广成本和各种其他费用。但毛利率为负,意味着连车本身的售价和成本价之间的差额都是负的,这就很夸张了。
而且,其他企业亏钱,亏的是股东的钱、民营资本的钱,大家还可以接受;但这一次,亏的是地方政府平台的钱。现在大家都在算账,都在盯着地方债,你把政府的钱亏了,这事就很严重了。
在中国一直有个潜规则:你自己把钱亏了没事,把其他民营企业的钱亏了也未必有事,但国有资产流失这件事不能碰。

还记得罗永浩吗?为什么最后说要“表演甄嬛传”?因为他最后借了国资的钱,你必须得把那笔钱还上,是不允许轻易申请破产的。
按道理说,有限责任公司最后破产,把注册资本赔完也就结束了,但在国内没有那么容易。这一次哪吒汽车的事情也告诉大家,破产清算对于拿了国资的有限责任公司来说,逃不过去,不可能把国资直接浪费掉就算了。
多地政府平台深度介入,地方给了土地、给了厂房、给了补贴,还做了股权投资,全部押进去了,到最后什么都没剩下。上市失败以后,融资断裂。2024年5月至6月,企业紧急融资44.37亿元,也没能挽救局面。
最后还是借了一笔钱,因为大家觉得也许还能救一下,结果这笔钱也没了。停产、讨债、重整,创始人与前任首席执行官都被列为失信人员,直接成了被执行人。
因为他们在最后借这笔钱的时候,都签了个人连带责任协议。只要你签了个人连带责任协议,就不能再受有限责任公司的保护了。
到最后这笔钱大家都知道有问题,你还一定要去借,那肯定得摁着你签个人连带。罗永浩最后那笔也是签了个人连带,这个事没办法,特别是国资很喜欢压着人签这个东西。

曾经有一段时间,哪吒汽车的销量是中国新势力第一。哪吒汽车的母公司叫合众新能源,2014年成立,创始人叫方运舟,后来张勇加入,长期负责经营操盘。
哪吒最辉煌的时候,靠的是低价走量,直接杀出来了。2022年哪吒汽车销量达到15.21万辆,是全国第八大新能源制造商,在新势力里排第一,一度拿到了当年造车新势力销量冠军。
它的主力车型不是高端豪华,也不是技术制高点,而是更偏下沉市场的性价比路线。之后销量急剧下滑。2024年全年只卖了87,948辆,其中还包含出口的23,399辆;2025年一季度只卖了1,215辆,后面基本就没有了。
哪吒从来不是靠强盈利能力撑起来的,而是靠低价冲量、外部融资、输血、地方资源扶持、资本市场讲故事这些东西撑起来的。
从融资端来看,哪吒自2017年以来完成了10轮融资,累计约228.44亿元。其中:
之所以会出现D1、D2、D3这样的轮次,是因为融资轮次继续往后排,意味着估值得有巨大提升;如果估值涨不上去,又还在同一个轮次里,就会出现这种后缀数字。
这类融资金额看起来很大,但说明一个问题:估值涨不上去了,增长性已经没了。后面还做了一轮9.4亿元的可转债。所谓可转债,就是现在把钱借给你,等上市以后转成股份,再去二级市场卖股票。
从财务端看,哪吒三年累计净亏损183.73亿元。
毛利率持续为负,卖一辆亏一辆。它最风光的时候,看起来像“人民的新势力”,因为便宜;但回头看,更像是把所有能够提前透支的东西一把都透支干净了。

哪吒最被嘲笑的一件事,是“五亿换标”。当时的CEO张勇说,更换车标花了5亿,于是大家都觉得太离谱。
后来张勇澄清,他们这个标的设计费用不超过100万,所谓的5亿实际上是过去7年里的品牌宣传、营销传播、市场推广上的综合投入,被外界简化成了“五亿换标”的故事。
换标本身确实是有成本的,设计成本如果找名家设计,几十万上百万都不算贵。真正花钱的是门店装修改造、广告物料重做、媒体广告投放、宣传体系更新,这些确实贵。但即便如此,到5亿这个程度也还是有些夸张。
更关键的是,这件事暴露出新能源车企的钱都花在哪儿了——宣传和营销,是极度烧钱的一件事。
大家之所以反感,是因为你这个车本来就便宜,没有技术壁垒,品牌没有高溢价,财务上也没有自我造血能力,越卖越亏,在这么敏感的时候还出去吹牛说换个标花了5亿,最后还得回来解释说100万是做标的钱,剩下的是各种市场费用,这就显得很拎不清轻重。
除此之外,张勇还有几次公开发言也很伤士气。
2024年2月,在奖金延迟发放的时候,他说少部分员工“不习惯过苦日子”,要“把寒气传递给每一个人”。在企业已经承压的阶段,这种话极其伤士气,外面的人也会觉得你太不知人间疾苦。
2024年6月,公司危机已经显现,张勇又公开说哪吒不会改名。注意,创始人不是张勇,张勇是后来请回来的CEO,在公司里股份不到1%,真正的大股东是方运舟。
张勇坚持用“哪吒”这个牌子,而创始人则希望用自己的名字。现在很多新能源品牌,比如理想、小鹏,都是创始人名字。方运舟也希望这么做,但张勇进来以后说不能用自己的名字,太low了,要用“哪吒”,还要重新诠释品牌内涵。
当时大家就觉得你压根没抓住重点:车质量不好、价格便宜、没有什么科技创新,还有很多其他问题,这时候还在做品牌诠释,显得很离谱。
到2024年12月,多方开始传出张勇不再担任CEO的消息,哪吒方面起初还否认,遮遮掩掩过了一段时间后,最终承认张勇不再担任CEO,由方运舟兼任。可以理解为创始人说“还是我自己来吧”。
但最后成为被执行人、成为“老赖”的,两个人谁都没跑掉,因为在最后借钱并承担无限连带责任的时候,这俩人肯定都签了字。

那么,真正把哪吒干死的是什么?是车造得差吗?是赔钱卖车吗?这些当然都有影响,但真正判它死刑的是上市失败。
中国很多创业企业,包括这些新能源企业,造车的目的是什么?就是为了上市融资。很多国资愿意给它钱,目的也是为了上市退出。
很多地方给车企的甚至都不完全是现金,而是一块地。为什么?他们不知道这块地不值那么多钱吗?知道。原因很简单,他们知道自己手里是有上市指标的,所以必须合作。
蔚来、理想、小鹏这些都已经是上市公司了,哪吒也想冲一把,说我也该上市了。但有时候真的是天时地利人和,它没赶上天时。
哪吒IPO发生在2024年6月26日,合众新能源向港交所递交了招股书草案。中金、摩根士丹利、中信证券、农银国际、招银国际担任联席保荐人。
此时累计融资已经达到228.44亿元,估值目标是424.29亿元,另一个信源报道是458亿,可能存在港币和人民币口径差异。
2024年5月至6月,上市前实在没钱了,又通过可换股债券、股权认购、银行借贷等方式紧急筹了44.37亿元,明显是在为IPO冲线。愿意借钱的人也想得很明白:只要你上去了,我就能卖股票退出。
递表之前,还通过可转换债券向浙江桐乡国资发行了9.4亿元,向广西南宁国资发行了1.2亿元。IPO后,这些国资本来可以按照每股16.15的价格去港股市场退出。
从递表到失效,全程没有进入聆讯。流程本来应该是递表,6个月内找到认购人,价格谈妥,然后开始路演,再上市。结果到了6个月,招股说明书就过期了。招股书有效期就是6个月,过期就等于上市失败。
上市失败之后,可转债对应的地方国资退出路径被直接封死。当时找国资借钱,就是告诉人家未来可以按16块多的价格去港股退出,国资其实也乐意,因为有接盘资金。
现在上市失败,国资就直接起诉,要求还钱。可企业肯定还不出来。又过了半年,前面融来的钱也烧光了。于是国有资产直接流失,创始人和CEO被起诉,成了失信被执行人,哪里也去不了。
哪吒当时的逻辑是:只要能上市,就能再融一笔钱;只要资本市场接盘了,就还能继续拖时间。上市以后,还可以继续通过股市融资,比如再发债,用股票做抵押,再拿到一笔钱,腾挪空间就大了。
而且它还想,只要销量还能维持,就还有机会讲下一个故事,甚至继续增发。但一旦上市失败,所有人都会突然反应过来,这家公司不只是暂时遇到困难,而是已经翻不了身了,再也找不到接盘者。
这就是为什么说它“天时不对”。如果它早一年上市,也许真就上去了。蔚来、小鹏也一直亏钱,而且亏得比它多,但人家上市上得早,在市场还比较暖的时候上去了。哪吒只是晚了一点,结果天时没了。
上市失败,让一个长期失血的公司失去了最后一次公开输血的机会,这才是真正的死刑。

现在的哪吒汽车已经不是“经营困难”了,而是进入了司法重整阶段。
公开信息显示,2025年6月12日,浙江省嘉兴市中级人民法院裁定受理合众新能源破产重组案件。截止到2025年5月1日,公司账面资金只剩下1,500万,但确认债务达到260亿。账上这1,500万,什么都顶不了。
三大生产线陆续停产或半停产。它有三个生产基地,车卖不掉,肯定没法继续生产。
它手里还有一个比较值钱的资源,就是新能源车生产资质。这个东西通常掌握在各地方政府手里,它为什么把业务分在三个地方,因为三个地方都有资质。但现在国家在收缩新能源车生产,要求集中,如果一张资质连续两年没有造够2,000辆车,这个资质可能就会被没收。
所以很多地方现在都很着急,想救它,前面那些破产倒闭的项目也都想救,核心就是想把资质救活,但这并不容易。
方运舟、张勇被列为失信被执行人,这就是他们现在的状态。
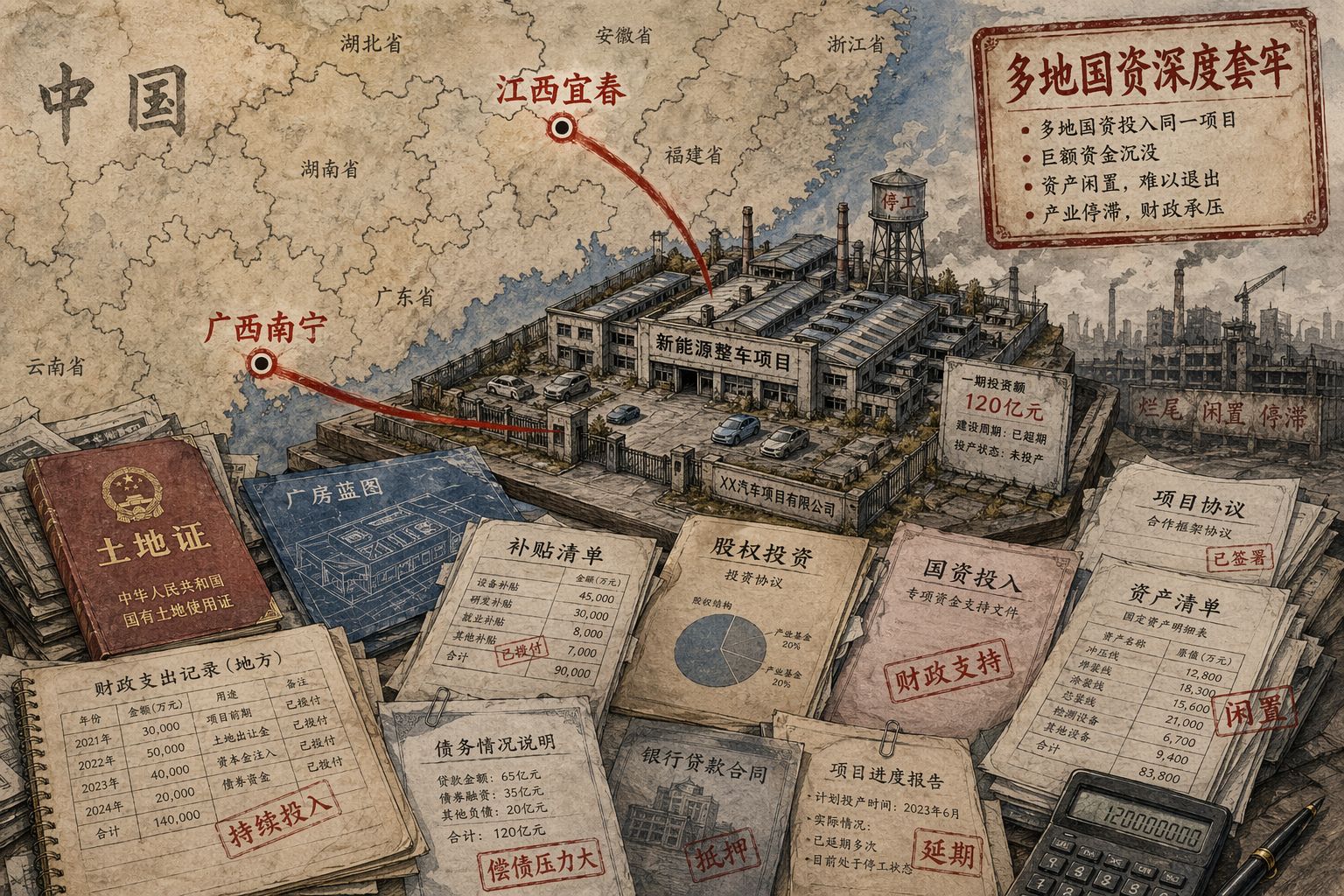
央视这次最狠的点,不是说你经营失败,也不是说你内卷,而是你坑了国家的钱。
这个项目总投资约50亿,大部分由江西宜春经开区筹集。江西宜春市国资委和财政局所属平台公司,投资了将近20亿元,用于收购股权、土地和房产代建,额外又花了接近3亿,还有10年的租金减免。
完全是赔本赚吆喝,钱都花出去了,什么都没回来。每辆车如果在江西宜春范围内销售,政府还补贴2万。
项目规划年产10万辆纯电动乘用车,广西南宁方面累计以市场化方式投入24亿元,其中广西南宁产投集团给了16亿,此外还有5.5亿元各种项目补助。

你明明看到它一辆一辆车在卖,4S店或者商场门店在开着,有时候一年还能卖十几万辆车,钱怎么就没了?
造车这件事,本质上有四个无底洞。
这就是绝对的无底洞。哪吒最致命的问题就是负毛利。其他车企总体可能亏损,但毛利是正的;你不能纯粹卖一辆亏一辆。
车的研发周期很长,国外一款车的生命周期经常有十几年,不像国内很多车厂一年出三四款新车。国外就是靠漫长时间和巨大销量把研发成本摊回来。
三电系统、平台架构、智能驾驶、智能座舱、验证测试,都是要烧钱的。再加上新能源车企招了大量互联网公司的人,互联网人的工资比传统车厂高很多,所以这一块非常烧钱。
门店、广告、发布会、人员返佣、交付体系、售后体系,全是巨大支出。前面那个“五亿换标”,钱主要也是花在这里。
以蔚来为例,2025年销售及行政费用是160.9亿,比研发成本还高;小鹏2025年销售及行政费用是94亿,基本和研发费用一样。直销、经销返佣、广告投放、交付体系,都会持续失血。
传统车厂不是这么干的,传统车厂通常是把车卖给经销商就完了,包括比亚迪很多也是走这条路。自己建门店、自己卖车这套,是特斯拉带起来的,新能源车企大多是在学它,这里面的成本非常高。
车不是客户下单你再去造的,一定得先造出来。造车时就得先进货,通常还得借钱进货。买钢材、买电子元器件,都是要花钱的,而且这些钱是有利息的。
造出来以后如果卖不掉,就形成库存,库存也有资金成本。一旦销售不及预期,库存、供应商欠款、金融成本、促销补贴会迅速连锁爆炸。
再叠加地方政府投入了大量非现金资源,比如土地、厂房、政策性减免、销售奖励、平台借债,这些东西本质上也都有成本和利息,都是压在车企身上的大山。
这四座大山压下来,你想不赔钱其实很难。
现在新能源车企里,特斯拉肯定是盈利的,因为它虽然到处建门店,但几乎不怎么打广告,有马斯克一个人的广告效应就够了,而且它是先行者,所以广告投入非常小。
比亚迪能够盈利,新能源阵营里理想能够盈利,赛力斯能够盈利,小米能够盈利,其他很多公司都还在亏损。
所以如果像哪吒汽车这样,一开始车就没造好,后面又实在冲不下去,上市还没成功,就会演变成企业亏空、国资套牢、供应商讨债、员工离场、地方收拾残局,最后被央视点名。

因为央视这次点名的时机非常微妙。许家印刚出来认罪认罚,再往后这些老板再想通过“有限责任公司破产”把自己摘干净,继续做富家翁,就没那么容易了。你可能也得出来认罪认罚。那接下来就只能大逃杀了。
后面一段时间,价格战和各种奇奇怪怪的现象会愈演愈烈。前面已经挂掉的汽车厂,比如高合汽车、极越汽车、威马汽车、拜腾汽车,可能也会被拎出来算旧账。因为这些车厂背后都有大量国资,不管你拿的是地,还是其他资源,最后都可能要秋后算账。
所以价格战会继续打,车厂的补贴会更加疯狂;但同时,资本会更谨慎,海外市场摩擦会更多,政策也在反内卷。未来一段时间,各个车企会给大家表演一场大逃杀的行为艺术。
汽车行业的大逃杀,比团购和手机残酷得多。中国其实不是第一次干这个事。以前有千团大战,也有众多手机厂商混战,最后都只剩下少数几个。
当年互联网快速发展时,大家还在用摩托罗拉、三星,会觉得中国手机品牌一家独大不太可能。后来中国手机厂商一起冲,现在也就剩下小米、华为、荣耀、OPPO、vivo这几个了,其他基本都死掉了。
现在车企也来了一遍。中国新能源品牌最多的时候大概接近400个,现在还剩40多个。普遍看法是到2030年,大概还能剩十几个,十四五个的样子。还会有一大批车企等着破产。
千团大战最后剩美团一个,手机大战最后剩四五个,400多个汽车品牌大战最后剩十来个,这个过程会非常残酷。
所以这一次汽车行业一定会比前两次更受伤。
但中国也有一个特点:千团大战最后活下来的美团,战斗力异常顽强;手机大战最后活下来的华为、小米、OPPO、vivo、荣耀,战斗力也都异常顽强。车也是一样,最后通过这种养蛊方式留下来的,绝对都是狠角色。
可以明确地说,绝对不是,“车圈恒大”一定是剑指他人。
首先,“车圈恒大”这个说法是魏建军在2025年5月接受采访时说出来的,他没有点名任何具体车企。这个事情被路透社和很多媒体报道,说车圈里有恒大。
如果一个企业对长城汽车没有影响,没有竞争压力,魏建军理它干嘛?他一定是在说一个对长城汽车有影响的竞争对手。所以这绝不可能是哪吒。哪吒太小了,和长城汽车比起来不在一个量级。
第二,哪吒2024年6月冲上市,2024年12月张勇就被罢免CEO了,公司基本已经停摆。到2025年5月魏建军出来喊“车圈恒大”的时候,如果说的是哪吒,早就点名了。之所以还不敢点名,说明这个企业绝对不是哪吒。
当时魏建军讲的是:有企业在财务上已经很危险,有些销量和繁荣是靠扭曲机制推出来的,有些风险不是企业自己承担,而是在往供应链、地方政府和社会层面转移。哪吒在那时已经爆雷、已经挂了,所以不是在讲它。那到底是谁,还可以继续拭目以待。
最后,汽车已经这样了,希望下一个行业别再按这个打法继续追赶了,别再沿着这条路走。但这又很难避免。
前面是互联网,后面是手机,现在是汽车,基本接近尾声,最后几家还会继续表演大逃杀,毕竟谁也不想进去认罪认罚。
现在最新的是什么?是大模型行业。这个行业里,我们依然在卷,依然在玩“一将功成万骨枯”的叙事。目前看起来,好像也快卷出结果来了。
一旦中国卷出结果,在全球范围内通常还是很有杀伤力的,往往能大杀四方。所以大模型这块,基本上又在照着这条路走一遍。
我现在最不希望看到的“百机百车大战”式行业,是商业航天。现在看起来,好像也有往这个方向前进的趋势。


本文永久链接 – https://tonybai.com/2026/04/24/go-code-design-day-one-principle-practical-patterns-list
大家好,我是Tony Bai。
世界读书日送福利活动火热进行中,点击这里留言参与,赢取属于你的幸运!
每一个 Go 开发者,大概都经历过这样的心路历程:
项目启动初期,为了追求“快”,我们怎么方便怎么来。配置到处写,数据库连接随手建,错误日志直接 fmt.Println。我们安慰自己:“先跑起来,以后再重构。”
结果呢?
半年后,项目变成了一座摇摇欲坠的“屎山”。配置散落在几十个文件里,改一个端口号要动十个地方;数据库连接池因为没关,把连接数打满;线上出了 Bug,日志里只有一行孤零零的 record not found,查个问题比登天还难。
技术债,就像滚雪球,你越是假装看不见,它就滚得越大。
这时候,你的内心肯定在呐喊:有没有一些在Go项目刚创建时期就应该知道的Go代码模式,可以让我在项目的“第一天”,就建立起一套健壮、可维护、可观测的骨架呢!
有的!
我将这套方法论,称为 Go 语言架构的“第一天原则”。掌握它,足以让你在Go 代码设计的道路上,少走五年弯路。
这些原则,没有一条是关于炫技的复杂设计模式。
今天,我们就来逐条硬核拆解这些原则,并用可运行的 Go 代码,手把手教你如何将它们落地。

这是所有“混乱”的根源。如果你的代码里,到处都是 os.Getenv(“DB_HOST”),那你的项目已经走在了通往地狱的路上。
反模式:
在某个业务函数的深处,为了连一下 Redis,临时去读环境变量。这使得你的函数与外部环境强耦合,极难进行单元测试。
第一天原则:
在 main 函数中,一次性完成所有配置的解析和校验,然后通过构造函数,将“配置好”的依赖(如数据库连接池),以“接口”的形式,显式地注入到需要的服务中。
【Go 代码实战】
// https://go.dev/play/p/CrGDShmoFFJ
package main
import (
"context"
"database/sql"
"fmt"
"log"
"net/http"
"os"
_ "github.com/lib/pq"
)
type Config struct {
DatabaseURL string
ListenAddr string
}
func loadConfig() Config {
dbURL := os.Getenv("DATABASE_URL")
if dbURL == "" {
log.Fatal("DATABASE_URL is not set")
}
return Config{
DatabaseURL: dbURL,
ListenAddr: ":8080",
}
}
type UserRepo interface {
GetUser(ctx context.Context, id int) (string, error)
}
type PostgresUserRepo struct {
db *sql.DB
}
func (r *PostgresUserRepo) GetUser(ctx context.Context, id int) (string, error) {
var name string
err := r.db.QueryRowContext(ctx, "SELECT name FROM users WHERE id=$1", id).Scan(&name)
return name, err
}
func NewPostgresUserRepo(db *sql.DB) *PostgresUserRepo {
return &PostgresUserRepo{db: db}
}
type Server struct {
repo UserRepo
}
func NewServer(repo UserRepo) *Server {
return &Server{repo: repo}
}
func (s *Server) HandleGetUser(w http.ResponseWriter, r *http.Request) {
name, err := s.repo.GetUser(r.Context(), 1)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
fmt.Fprintf(w, "User: %s", name)
}
func main() {
cfg := loadConfig()
db, err := sql.Open("postgres", cfg.DatabaseURL)
if err != nil {
log.Fatalf("failed to connect to database: %v", err)
}
defer db.Close()
repo := NewPostgresUserRepo(db)
server := NewServer(repo)
http.HandleFunc("/user", server.HandleGetUser)
log.Printf("Server starting on %s", cfg.ListenAddr)
log.Fatal(http.ListenAndServe(cfg.ListenAddr, nil))
}
这样一来,你的业务代码将变得极其纯粹,不依赖任何全局状态,测试时也可以轻松地 Mock 掉 UserRepo 接口。
“不就是打个日志吗,fmt.Println 走起!”——这是毁掉一个项目最快的方式。
反模式:
遇到错误,直接 log.Printf(“Error: %v”, err)。当线上出现几万条这样的日志时,你根本无法进行聚合、告警和趋势分析。
第一天原则:
从第一天起,就引入结构化日志(如 log/slog 或 zap)。将所有关键信息(如 user_id, trace_id)作为独立的字段打印。同时,为关键业务指标(如缓存命中率、数据库查询延迟)埋入 Metrics。
【Go 代码实战】
// https://go.dev/play/p/h4_8a4nzCFx
package main
import (
"log/slog"
"net/http"
"os"
"time"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
var (
cacheHits = prometheus.NewCounter(prometheus.CounterOpts{
Name: "myapp_cache_hits_total",
Help: "Total number of cache hits.",
})
dbQueryDuration = prometheus.NewHistogram(prometheus.HistogramOpts{
Name: "myapp_db_query_duration_seconds",
Help: "Histogram of database query durations.",
Buckets: prometheus.DefBuckets,
})
)
func init() {
prometheus.MustRegister(cacheHits, dbQueryDuration)
}
func handleRequest(w http.ResponseWriter, r *http.Request) {
logger := slog.New(slog.NewJSONHandler(os.Stdout, nil))
logger.Info("handling request", "method", r.Method, "path", r.URL.Path, "remote_addr", r.RemoteAddr)
cacheHits.Inc()
start := time.Now()
time.Sleep(100 * time.Millisecond)
duration := time.Since(start)
dbQueryDuration.Observe(duration.Seconds())
logger.Info("request handled successfully", "duration_ms", duration.Milliseconds())
w.WriteHeader(http.StatusOK)
}
func main() {
http.HandleFunc("/", handleRequest)
http.Handle("/metrics", promhttp.Handler())
log.Println("Server starting on :8080")
log.Fatal(http.ListenAndServe(":8080", nil))
}
有了结构化日志和Metrics的加持,你的系统不再是一个“黑盒”。通过 Grafana 和 VictoriaLogs,你可以清晰地看到它的每一个内部状态,问题定位速度提升 10 倍。
这是 Dave Cheney 反复强调的血泪教训。一个失控的 Goroutine,就是一个内存炸弹。
反模式:
go doSomething()。然后呢?它什么时候结束?如果它卡住了怎么办?
第一天原则:
任何一个需要长久运行的 Goroutine,都必须接受一个 context.Context 参数,并在 select 中监听 ctx.Done()。将所有后台 Goroutine 的生命周期,与你的应用程序生命周期绑定。
【Go 代码实战】
// https://go.dev/play/p/Fi1JUZfs4E-
package main
import (
"context"
"log"
"os"
"os/signal"
"syscall"
"time"
)
func worker(ctx context.Context, id int) {
ticker := time.NewTicker(1 * time.Second)
defer ticker.Stop()
log.Printf("Worker %d started", id)
for {
select {
case <-ticker.C:
log.Printf("Worker %d is doing work", id)
case <-ctx.Done():
log.Printf("Worker %d is shutting down...", id)
return
}
}
}
func main() {
ctx, cancel := signal.NotifyContext(context.Background(), os.Interrupt, syscall.SIGTERM)
defer cancel()
go worker(ctx, 1)
<-ctx.Done()
log.Println("Main application shutting down.")
time.Sleep(100 * time.Millisecond)
}
这样,你的应用就可以实现优雅停机(Graceful Shutdown),在 k8s 环境中滚动更新时,不会丢失任何正在处理的数据。
在复杂的业务系统中,最难测试的不是“Happy Path”,而是各种千奇百怪的“Unhappy Paths”。
第一天原则:
为你的核心业务逻辑,构建独立的“数据生成器(Data Generators)”和“数据接收器(Sinks)”。在测试中,用内存中的模拟实现(Mocks)替换掉真实的外部依赖,从而能 100% 控制输入和验证输出。
【Go 代码实战】
// https://go.dev/play/p/NBsxpVE84Zb
package main
import (
"context"
"fmt"
"sync"
"testing"
)
type Order struct { ID int }
type OrderNotifier interface {
Notify(ctx context.Context, order Order) error
}
type OrderProcessor struct {
notifier OrderNotifier
}
func NewOrderProcessor(notifier OrderNotifier) *OrderProcessor {
return &OrderProcessor{notifier: notifier}
}
func (p *OrderProcessor) Process(ctx context.Context, order Order) error {
return p.notifier.Notify(ctx, order)
}
type MockNotifier struct {
mu sync.Mutex
Notified []Order
ShouldErr bool
}
func (m *MockNotifier) Notify(ctx context.Context, order Order) error {
m.mu.Lock()
defer m.mu.Unlock()
if m.ShouldErr {
return fmt.Errorf("mock notifier failed")
}
m.Notified = append(m.Notified, order)
return nil
}
func TestOrderProcessor_Success(t *testing.T) {
mockNotifier := &MockNotifier{}
processor := NewOrderProcessor(mockNotifier)
order := Order{ID: 1}
err := processor.Process(context.Background(), order)
if err != nil {
t.Errorf("expected no error, got %v", err)
}
if len(mockNotifier.Notified) != 1 || mockNotifier.Notified[0].ID != 1 {
t.Errorf("notifier was not called correctly")
}
}
遵守该原则后,你的单元测试将变得极快、极度稳定,并且能够 100% 覆盖所有你能想到的成功和失败分支。
不相信任何外部输入。这是所有安全系统的第一性原理。
第一天原则:
在数据的入口处(如 HTTP Handler、gRPC Server),对所有传入的数据进行严格的、显式的校验(Validation)。只有通过了“安检”的干净数据,才能被允许进入系统的核心领域。
【Go 代码实战(不完全示例)】
package main
import (
"encoding/json"
"fmt"
"net/http"
"net/mail"
)
type CreateUserRequest struct {
Username string json:"username"
Email string json:"email"
Age int json:"age"
}
func (r *CreateUserRequest) Validate() error {
if len(r.Username) < 3 || len(r.Username) > 20 {
return fmt.Errorf("username length must be between 3 and 20")
}
if _, err := mail.ParseAddress(r.Email); err != nil {
return fmt.Errorf("invalid email format: %w", err)
}
if r.Age < 18 {
return fmt.Errorf("user must be at least 18 years old")
}
return nil
}
func HandleCreateUser(w http.ResponseWriter, r *http.Request) {
var req CreateUserRequest
if err := json.NewDecoder(r.Body).Decode(&req); err != nil {
http.Error(w, "Invalid request body", http.StatusBadRequest)
return
}
if err := req.Validate(); err != nil {
http.Error(w, err.Error(), http.StatusBadRequest)
return
}
// processValidatedRequest(req) ...
w.WriteHeader(http.StatusCreated)
}
这种防御可以让你的核心业务逻辑变得极其纯粹和安全,不再需要处理各种脏数据和边界情况。
注:如果是服务器,外部(甚至是内部其他服务的)请求的速度也可能是一种“安全威胁”。因此无论是通过中间件,还是代码自行实现,限速机制是必不可少的。
一个好的错误信息,应该像一份精准的“尸检报告”,而不是一句无意义的“他死了”。
第一天原则:
在错误产生的最底层,用 fmt.Errorf(“…: %w”, err) 详细包裹上下文。对于可预期的业务异常,定义成自定义的“类型化错误(Typed Errors)”,让上层逻辑可以通过 errors.As 进行精准的判断和处理。
【Go 代码实战(不完全示例)】
package main
import (
"errors"
"fmt"
"net/http"
)
type ErrDuplicateUser struct { Email string }
func (e *ErrDuplicateUser) Error() string {
return fmt.Sprintf("user with email %s already exists", e.Email)
}
func RegisterUser(email string) error {
// 模拟数据库层返回一个已知类型的错误
if email == "test@example.com" {
return &ErrDuplicateUser{Email: email}
}
return fmt.Errorf("db connection failed: %w", errors.New("timeout"))
}
func HandleRegister(w http.ResponseWriter, r *http.Request) {
err := RegisterUser("test@example.com")
if err != nil {
var dupErr *ErrDuplicateUser
if errors.As(err, &dupErr) {
http.Error(w, dupErr.Error(), http.StatusConflict)
} else {
// 对于未知的底层错误,只打日志,不暴露给用户
slog.Error("failed to register user", "error", err)
http.Error(w, "Internal server error", http.StatusInternalServerError)
}
return
}
w.WriteHeader(http.StatusCreated)
}
这样处理后,你的错误处理逻辑变得极其清晰和健壮,业务异常可以被优雅地反馈给用户。
这是 Go 语言最精髓、也最反直觉的一条哲学。
第一天原则:
永远不要在“定义侧”声明臃肿的接口。而是在“消费侧”,根据你真正需要的功能,定义一个只包含 1-2 个方法的“小接口”。
【Go 代码实战(不完全示例)】
// --- cache/cache.go ---
package cache
type BigCache struct {}
func (c *BigCache) Get(key string) (string, error) { /* ... */ }
func (c *BigCache) Set(key, val string) error { /* ... */ }
// --- user/service.go ---
package user
import "fmt"
// 我们在 user 包里,只定义我们真正需要的小接口
type Getter interface {
Get(key string) (string, error)
}
type UserService struct {
cache Getter // 依赖的是小接口,而不是具体的 BigCache
}
func (s *UserService) GetUserName(id int) (string, error) {
return s.cache.Get(fmt.Sprintf("user:%d", id))
}
示例代码中,你的 UserService 彻底与 BigCache 的具体实现解耦。在测试时可以极其轻松地传入 Mock 对象。
看完上述的七条原则,你是否发现所有这些“第一天原则”都指向了一个共同的核心:可维护性(Maintainability)。
你在项目第一天偷的每一个懒,都会在未来的某一个深夜,变成一颗狠狠炸伤你或你同事的“技术地雷”。架构的本质,不是选择一个多么牛逼的框架,而是与未来的自己、未来的同事进行一场清晰、友好的对话。
关掉这篇文章,打开你手头那个最新的项目。看看这 7 条原则,你触犯了哪几条?是时候,给你的代码库做一次“体检”了。
今日互动探讨:
在你过去的 Go 项目中,踩过哪些因为早期“野蛮生长”而导致的设计大坑?除了这 7 条,你还有哪些“压箱底”的项目启动最佳实践?
欢迎在评论区分享你的血泪史与独家心法!
还在为写 Agent 框架频频死循环、上下文爆炸而束手无策?我的新专栏 《从0 开始构建 Agent Harness》 将带你:
扫描下方二维码,开启从 0 开始构建Agent Harness 的实战之旅。

原「Gopher部落」已重装升级为「Go & AI 精进营」知识星球,快来加入星球,开启你的技术跃迁之旅吧!
我们致力于打造一个高品质的 Go 语言深度学习 与 AI 应用探索 平台。在这里,你将获得:
衷心希望「Go & AI 精进营」能成为你学习、进步、交流的港湾。让我们在此相聚,享受技术精进的快乐!欢迎你的加入!

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。

© 2026, bigwhite. 版权所有.