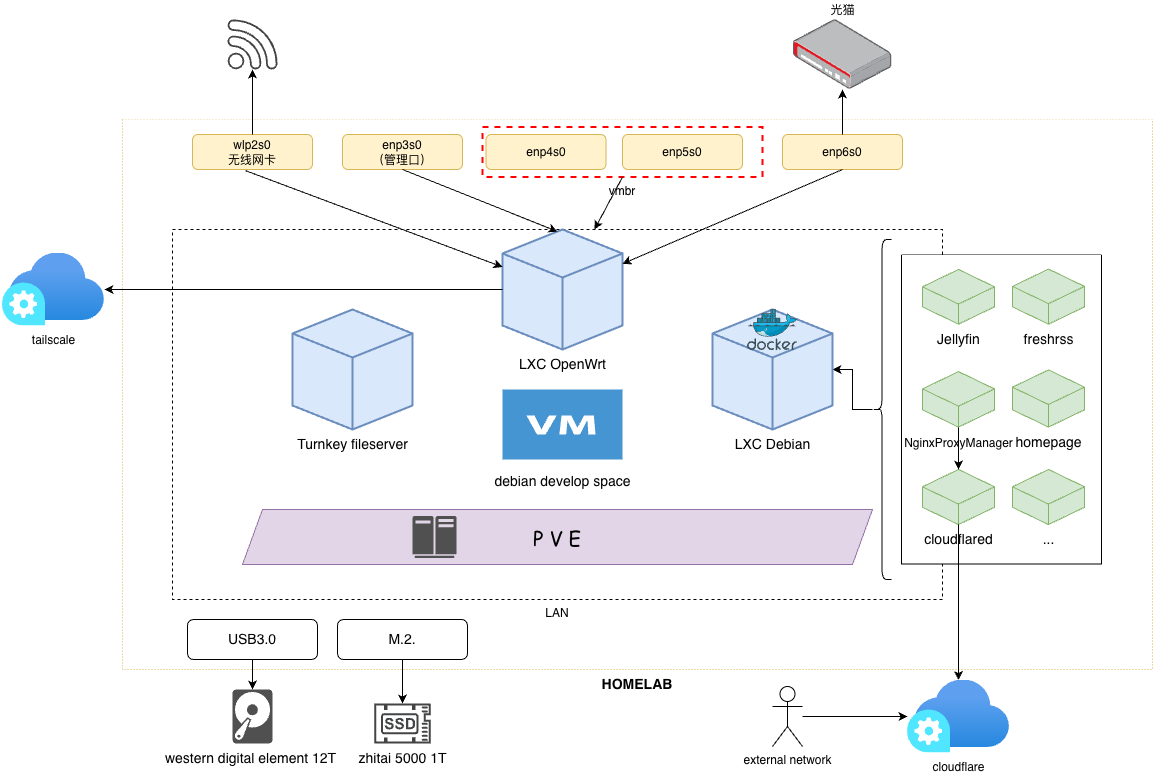
作为 All in One 里面最重要的一环,软路由的安装和配置是最为重要的操作。这里我选择纯软路由,且无硬 AP 的拓扑。如果有多拨需求,可以选择 iKuai 主路由 + OpenWrt 旁路由的方案,我觉得我的场景已经真的 All In Boom 了,就不再改光猫桥接,在真的 boom 的时候还方便一点直接接光猫救急,所以这里我只选用 OpenWrt 作为主路由。路由的部署方式可以使用 VM 或者 LXC,在上一篇也提到了 Intel 11 代 CPU 的潜在虚拟化问题后,我这里部署方式选择为 PVE 下 LXC 容器。
OpenWrt 是一个开源的路由器固件,它基于 Linux 操作系统,并可运行在各种不同品牌的路由器上。OpenWrt 提供了丰富的功能和高度的可定制性,用户可以轻松地对其进行配置和定制,以满足不同的网络需求。OpenWrt 还支持安装各种软件包,例如 VPN、DNS、Web 服务器等,从而进一步扩展其功能。
LXC(Linux Containers)是 Linux 内核中的一个软件容器化工具,它提供了一种轻量级的虚拟化技术。与传统虚拟机相比,LXC 的优点在于更快的启动时间、更少的资源占用以及更高的性能。用户可以使用 LXC 在 Linux 操作系统中创建多个独立的容器,每个容器都提供一个隔离的运行环境,与主机和其他容器完全隔离开来。在容器内,用户可以运行各种不同的应用程序和服务,例如 Web 服务器、数据库、文件共享等。由于 LXC 能够更加高效地利用系统资源,因此它已成为开发人员、测试人员、系统管理员和云计算提供商的首选工具之一。
固件选择
OpenWrt 固件选择上我尝试过官网原版、Lean 预编译版、自编译 Lean 版、其他第三方编译版,包括自编译增加无线驱动,也在不同程度上出现:无法识别无线网卡、无线无法启动等等问题。最终选择以下固件最省心。
https://www.right.com.cn/forum/thread-928319-1-1.html
获取 CT 模板
SquashFS 是一种只读文件系统,不允许对其进行写操作,它可以将多个文件和目录合并到一个文件中,从而提高存储空间的利用率,同时也可以提高对这些文件的访问效率。SquashFS 文件系统具有高效的压缩和解压缩速度,支持很多不同的压缩算法,能够在存储和传输文件时减少网络流量和存储空间的占用,广泛应用于嵌入式系统、上传和下载镜像等场景。
Rootfs 是 Linux 系统启动时候使用的根文件系统,是指在文件系统概念中的根目录。它包含了 Linux 系统启动所必需的一些必要文件和目录,例如/etc、/proc、/bin、/sbin 和/usr 等。rootfs 文件系统通常会以类似于 ext4 或 SquashFS 文件系统的形式储存于嵌入式系统或者云计算平台中,为 Linux 系统提供启动和运行的必要支持。由于 rootfs 文件系统在启动过程中是唯一可用的文件系统,在系统运行时,它也会被其他文件系统所覆盖。
无论是 OpenWrt 官网下载,还是第三方打包的固件,必须是*-rootfs.img、*-rootfs.img.gz 或者 *-rootfs.tar.gz 的文件 。*-rootfs.img、*-rootfs.img.gz 需要解包后打包 。
首先需要获取 CT 模板,如果是 rootfs 格式打包的上传至 PVE CT 模板目录即可,否则需要先解包重新打包使用。
以下以 *.img.gz 固件包为例:
cd workspace
mkdir openwrt
# 文件名
img_name="openwrt-x86-64-generic-squashfs-combined.img.gz"
# gzip 解压出 img
gzip -d "$img_name"
# 去除变量 gz 后缀
img_name=$(basename "$img_name" .gz)
# 挂载偏移
root_partition=$((`fdisk -l "$img_name" | grep .img2 | awk '{print $2}'` * 512))
# 挂载到 openwrt 目录
mount -o loop,offset=$root_partition "$img_name" ./openwrt
# 打包
cd openwrt && tar zcf /var/lib/vz/template/cache/"$img_name".tar.gz * && cd ..
# 卸载
umount ./openwrt
创建 LXC 容器
pct create 100 \
local:vztmpl/openwrt.tar.gz \
--rootfs local:2 \
--ostype unmanaged \
--hostname OpenWrt \
--arch amd64 \
--cores 2 \
--memory 1024 \
--swap 0
此处以 vmid=100 为例,可自定义,创建完先进行配置再启动。
配置 LXC 容器
修改容器配置
root@pve:~ # cat /etc/pve/lxc/100.conf
arch: amd64
cores: 2
hostname: OpenWrt
memory: 1024
ostype: unmanaged
rootfs: local:101/vm-101-disk-0.raw,size=2G
swap: 0
# 设置DNS,根据实际情况填写
nameserver: 192.168.1.1
# 引用 PVE自带 openwrt 配置文件,包含一些基本设置
lxc.include: /usr/share/lxc/config/openwrt.common.conf
# 将主机的网卡 enp6s0/wlp2s0 分配给容器使用,根据自己的实际情况更改
xc.net.0.type: phys
lxc.net.0.link: enp6s0
lxc.net.0.flags: up
lxc.net.0.name: wan
lxc.net.1.type: phys
lxc.net.1.link: wlp2s0
lxc.net.1.flags: up
lxc.net.1.name: wlan
lxc.net.2.type: veth
lxc.net.2.link: vmbr0
lxc.net.2.flags: up
lxc.net.2.name: eth1
lxc.net.3.type: veth
lxc.net.3.link: vmbr1
lxc.net.3.flags: up
lxc.net.3.name: eth2
挂载 PPP/TUN
方法 1: 使用 hook 脚本(需特权容器):
# 创建 hook 脚本
mkdir -p /var/lib/vz/snippets
cp /usr/share/pve-docs/examples/guest-example-hookscript.pl /var/lib/vz/snippets/lxc-hookscript.pl
# vim /var/lib/vz/snippets/lxc-hookscript.pl
...
# Second phase 'post-start' will be executed after the guest
# successfully started.
system("lxc-device add -n $vmid /dev/ppp");
system("lxc-device add -n $vmid /dev/net/tun");
print "$vmid started successfully.\n";
...
在容器配置中添加 hook:
hookscript: local:snippets/lxc-hookscript.pl
方法 2: 直接在容器配置中加入挂载配置
挂载 ppp/tun 设备,以及允许容器使用 major=108,minor=0 以及 major=10,minor=200 的设备。
lxc.cgroup2.devices.allow: c 108:0 rwm
lxc.mount.entry: /dev/ppp dev/ppp none bind,create=file
lxc.cgroup2.devices.allow: c 10:200 rwm
lxc.mount.entry: /dev/net/tun dev/net/tun none bind,create=file
启动 LXC 容器
正常启动信息如下
root@pve:~ # pct start 100
GUEST HOOK: 100 pre-start
100 is starting, doing preparations.
GUEST HOOK: 100 post-start
100 started successfully.
如果无法启动可使用 debug 模式(日志保存在 debug.log 文件)
lxc-start -n 100 --logfile debug.log --logpriority TRACE
如果是挂载了无线网卡可能因为没有安装 iw 而启动失败:
apt install iw
OpenWrt 配置
Attach 到容器内进行操作 lxc-attach 100
设置密码
passwd
# Changing password for root
# New password:
# Retype password:
# passwd: password for root changed by root
配置网络
vim /etc/config/network
...
config interface 'lan'
option type 'bridge'
list ifname 'eth1'
option proto 'static'
option ip6assign '60'
option netmask '255.255.255.0'
option ipaddr '192.168.1.1' # 关键配置 IP 地址
option gateway '192.168.1.1' # 本机
...
重启网络 /etc/init.d/network restart,完成之后就能使用 SSH 或者 网页打开 OpenWrt 了。
开启无线
ifconfig -a 查看无线网卡是否能被识别wifi config- LUCI 配置无线
- 国家用美国,2.4G 开信道 11,5G 开信道 149(解决 无线未开启或者未关联)
OpenWrt 自身无法上网
如果是二级路由,在 DHCP/DNS 中设置 DNS 转发至上层路由或者临时修改 /etc/resolve.conf 。
openclash 无法启动
refer to https://github.com/vernesong/OpenClash/issues/1915
openclash 启动失败,日志中出现
Unable to set capabilities [--caps=cap_sys_resource,cap_dac_override,cap_net_raw,cap_net_bind_service,cap_net_admin+eip]
是因为引用的 PVE 默认的 openwrt 配置中 /usr/share/lxc/config/openwrt.common.conf 中 drop 掉了权限 lxc.cap.drop = sys_resource
可以在容器配置中加入此行
root@pve:~ # cat /etc/pve/lxc/100.conf
# ...
lxc.cap.drop:
Adguard Home 与 OpenClash
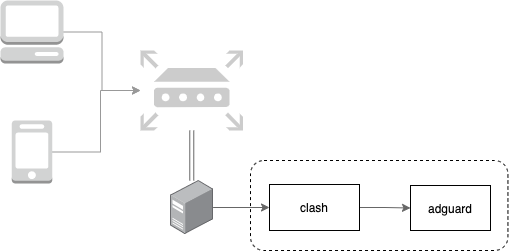
科学上网方案我还是沿用一直使用的 Adguard + OpenClash。
- OpenClash 接管流量做分流和科学上网
- OpenClash 使用 meta 内核(基本支持 Premium 的功能)
- DNS 查询路径:
client->adguard->clash(fake-ip),跟以前使用过的方案路径有不一样了,好处是 Adguard Home 中可以看到客户端 IP,也不会因为广告域名走了 clash 的代理模式而不走 Adguard 解析。
另外说一句, OpenClash 的 GUI 配置实在是太难用了(无论是布局、菜单、交互),还好有直接编辑 YAML 的方式配置。
网络配置
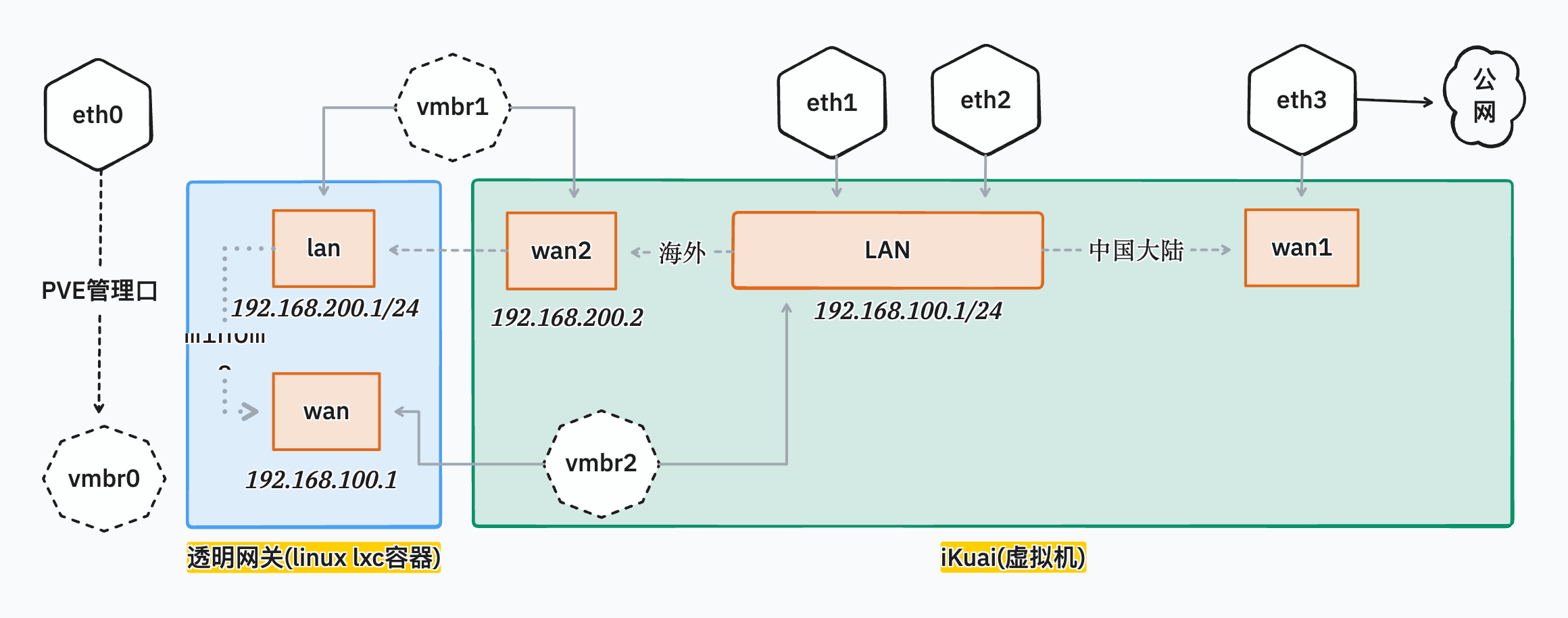
以下是我的网络拓扑示意,目前我的所有设备基本上都是以无线方式连接,还有两个网口是闲置状态。
- 除了无线网卡和与光猫通信的网口是直通之外,其余网口都是以网桥方式接入。
- enp3s0、enp4s0、enp5s0 这几个网口连接进 OpenWrt 的方式可以有很多种,不一定是我这里使用的这种,比如只建立一个网桥 vmbr0 关联三个网卡,或者建立 bond 绑定三个网口,再基于 bond 建立网桥,都可以正常使用。
- 下图的 vmbr4 也可以省略,直接使用有物理网口的网桥也可以正常使用。
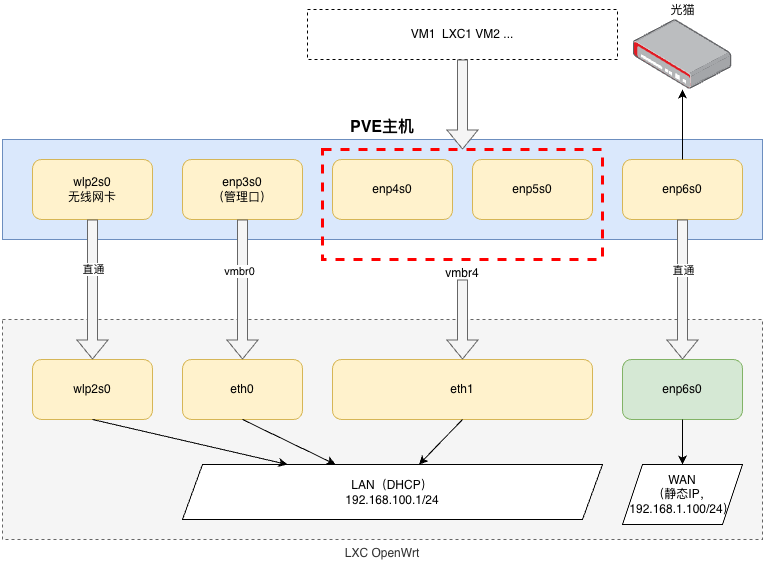
OpenWrt 容器的网络挂载(页面没有显示直通设备,可以在 /etc/pve/lxc/vmid.conf 中配置)

远程组网
- 安装 tailsacle:
opkg install tailscale
- 登录:
tailscale up
- 开启子网路由:
tailscale up --advertise-routes=192.168.100.0/24 --accept-dns=false
- Tailscale 页面编辑对应的设备,禁用 Key 过期

- Tailscale 页面编辑对应的设备,开启子网

这时就可以从其他网络的 tailscale 连通设备连接 OpenWrt 的子网。
参考
总结
总体来说,OpenWrt 使用 LXC 方式部署成软路由已经非常成熟,大部分固件都可以运行。只是如果要使用无线网卡的话,必须要解决好驱动问题,就很稳定了。
速度测试
用 iperf3 进行测试(TCP 双向传输) iperf3 -c 192.168.100.6 -d -t 60
|
发送 |
接收 |
|
| 无线(WIFI6) |
688 Mbits/sec |
688 Mbits/sec |
近距离 |
| 有线(千兆) |
936 Mbits/sec |
935 Mbits/sec |
MacBook + 千兆 HUB |
| 内网 |
20.3 Gbits/sec |
20.2 Gbits/sec |
PVE 两个 Docker 间 |
有线基本跑满硬件带宽,无线有一些损耗,但我的宽带也就 600M,所以基本达到上限。
无线网卡选择?
本来打算购买 Intel AX210 无线网卡,但购买之前,看恩山论坛的讨论,由于驱动限制 AX210 似乎还不能以 AP 模式在 OpenWrt 下使用,所以购买了 MTK 7922 网卡。
实测 MTK 7922 网卡可以以 AP 模式发出 5G Wi-Fi 信号,但不能同时发出 2.4G 信号。
设备找不到?
在测试固件的过程中,由于部分固件的驱动兼容不好,容易造成无线网卡假死等情况。由于网卡是直通 LXC 容器,有可能会导致 PVE 系统丢失了设备,设备能识别,但是设备加载失败。
所以如果想要隔离性更好还是选择 VM 安装 OpenWrt。
[ 0.359071] DMAR: IOMMU feature mts inconsistent
[ 3.378372] mt7921e 0000:02:00.0: enabling device (0000 -> 0002)
[ 3.378663] mt7921e 0000:02:00.0: Direct firmware load for mediatek/WIFI_RAM_CODE_MT7922_1.bin failed with error -2
[ 3.398324] mt7921e 0000:02:00.0: ASIC revision: 79220010
[ 3.483152] mt7921e 0000:02:00.0: Direct firmware load for mediatek/WIFI_MT7922_patch_mcu_1_1_hdr.bin failed with error -2
[ 3.566637] mt7921e 0000:02:00.0: Direct firmware load for mediatek/WIFI_MT7922_patch_mcu_1_1_hdr.bin failed with error -2
[ 3.650631] mt7921e 0000:02:00.0: Direct firmware load for mediatek/WIFI_MT7922_patch_mcu_1_1_hdr.bin failed with error -2
[ 3.734476] mt7921e 0000:02:00.0: Direct firmware load for mediatek/WIFI_MT7922_patch_mcu_1_1_hdr.bin failed with error -2
[ 3.818421] mt7921e 0000:02:00.0: Direct firmware load for mediatek/WIFI_MT7922_patch_mcu_1_1_hdr.bin failed with error -2
[ 3.906385] mt7921e 0000:02:00.0: Direct firmware load for mediatek/WIFI_MT7922_patch_mcu_1_1_hdr.bin failed with error -2
[ 3.994418] mt7921e 0000:02:00.0: Direct firmware load for mediatek/WIFI_MT7922_patch_mcu_1_1_hdr.bin failed with error -2
[ 4.082389] mt7921e 0000:02:00.0: Direct firmware load for mediatek/WIFI_MT7922_patch_mcu_1_1_hdr.bin failed with error -2
[ 4.166425] mt7921e 0000:02:00.0: Direct firmware load for mediatek/WIFI_MT7922_patch_mcu_1_1_hdr.bin failed with error -2
[ 4.250406] mt7921e 0000:02:00.0: Direct firmware load for mediatek/WIFI_MT7922_patch_mcu_1_1_hdr.bin failed with error -2
[ 4.336774] mt7921e 0000:02:00.0: hardware init failed