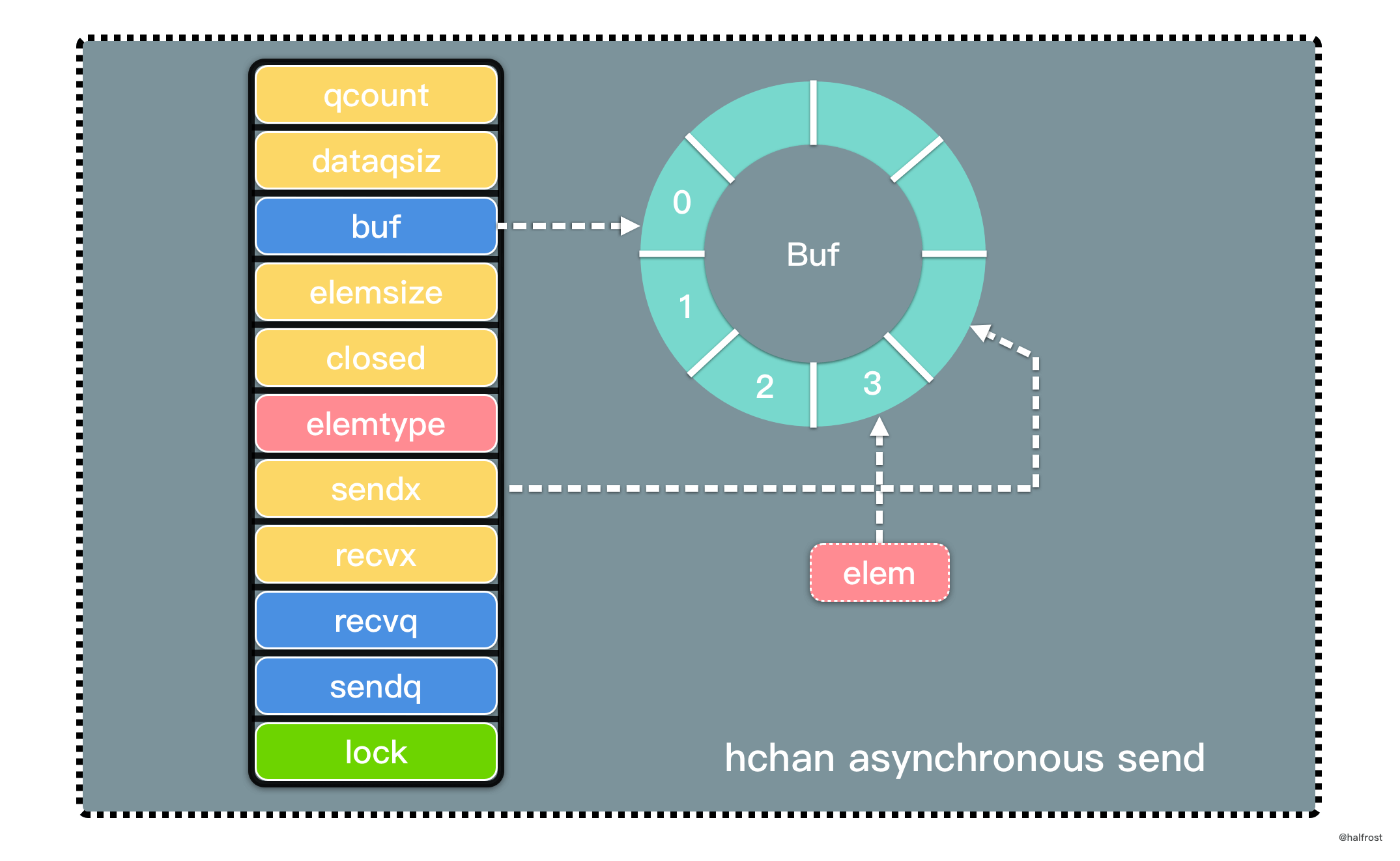
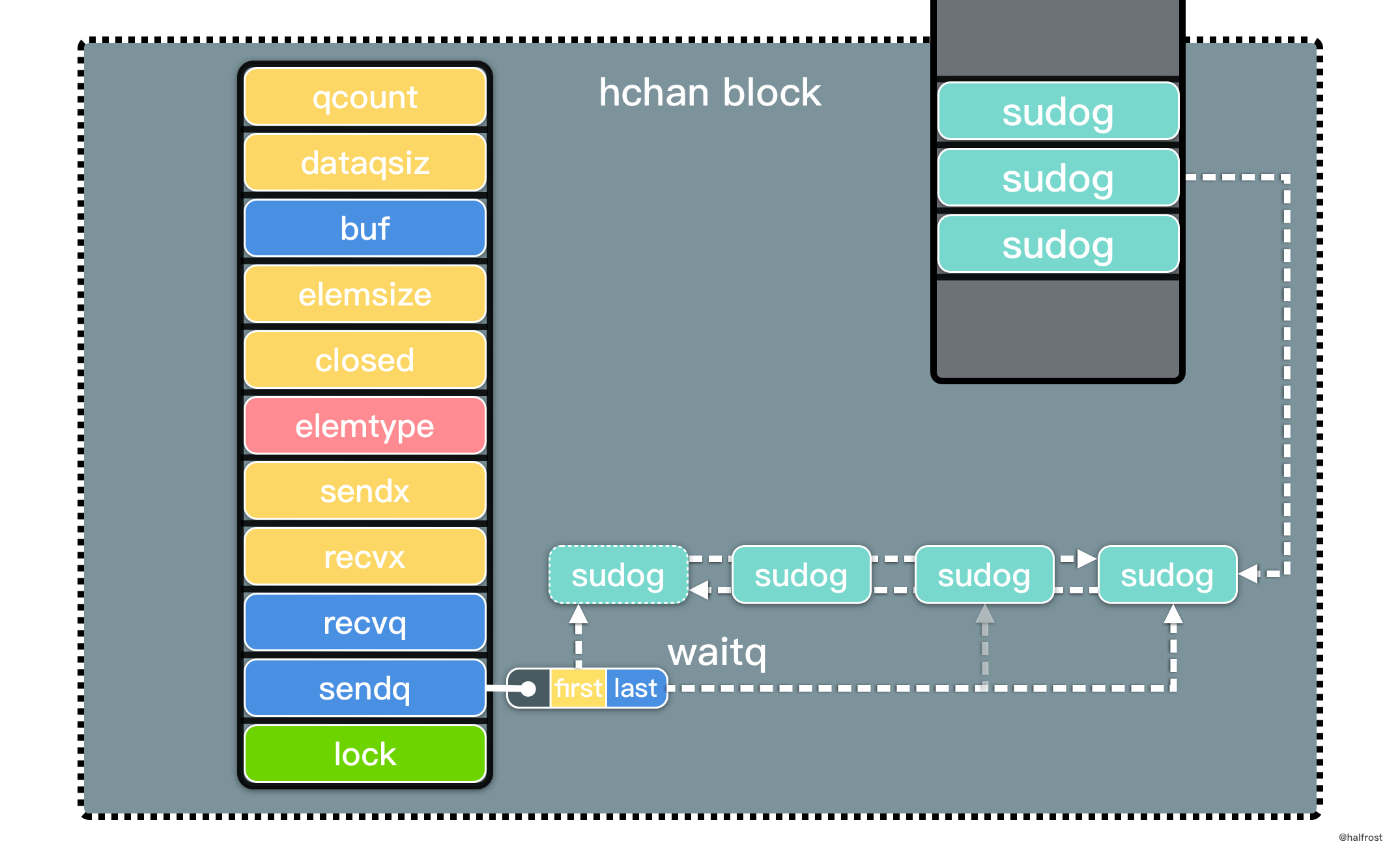
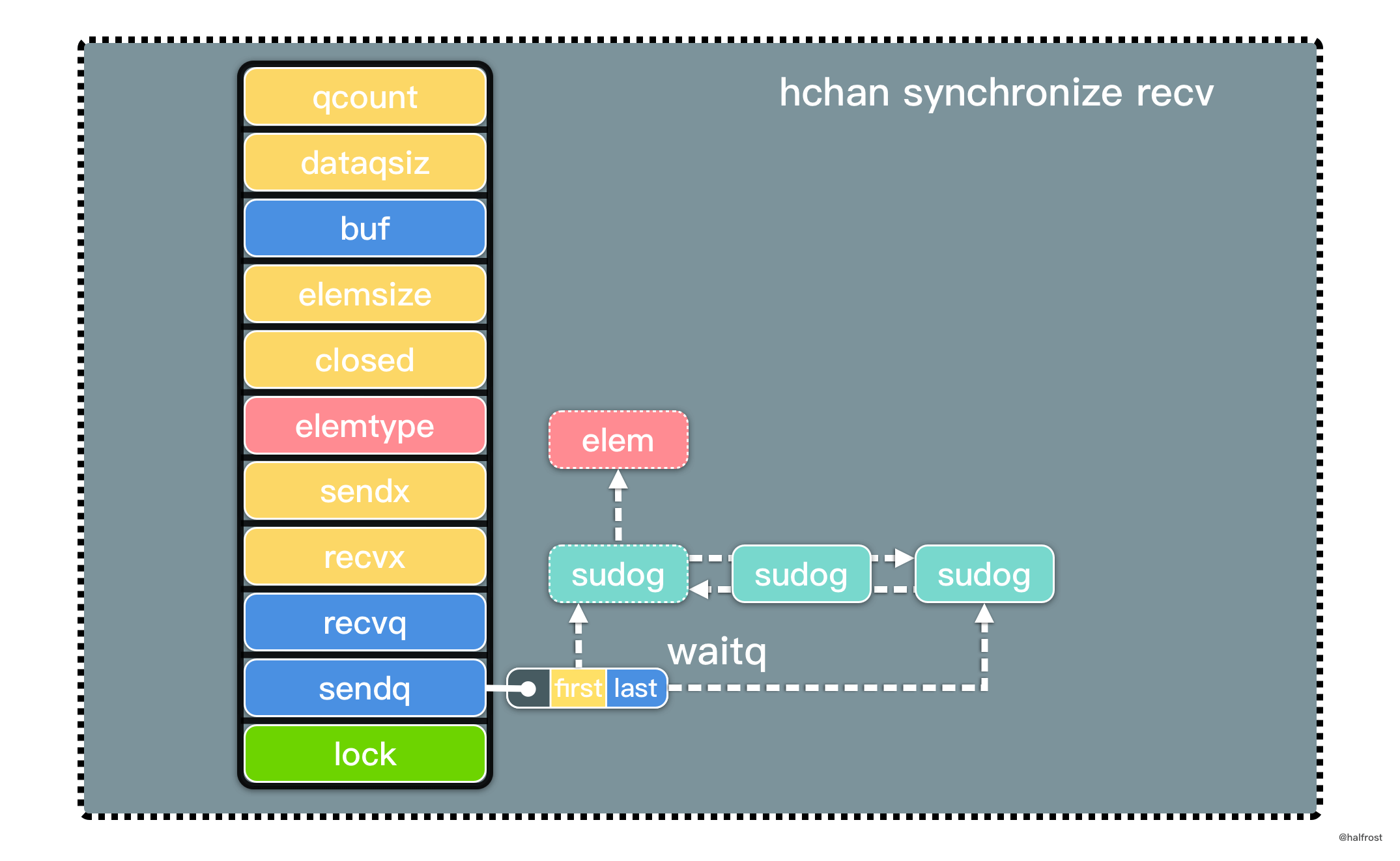
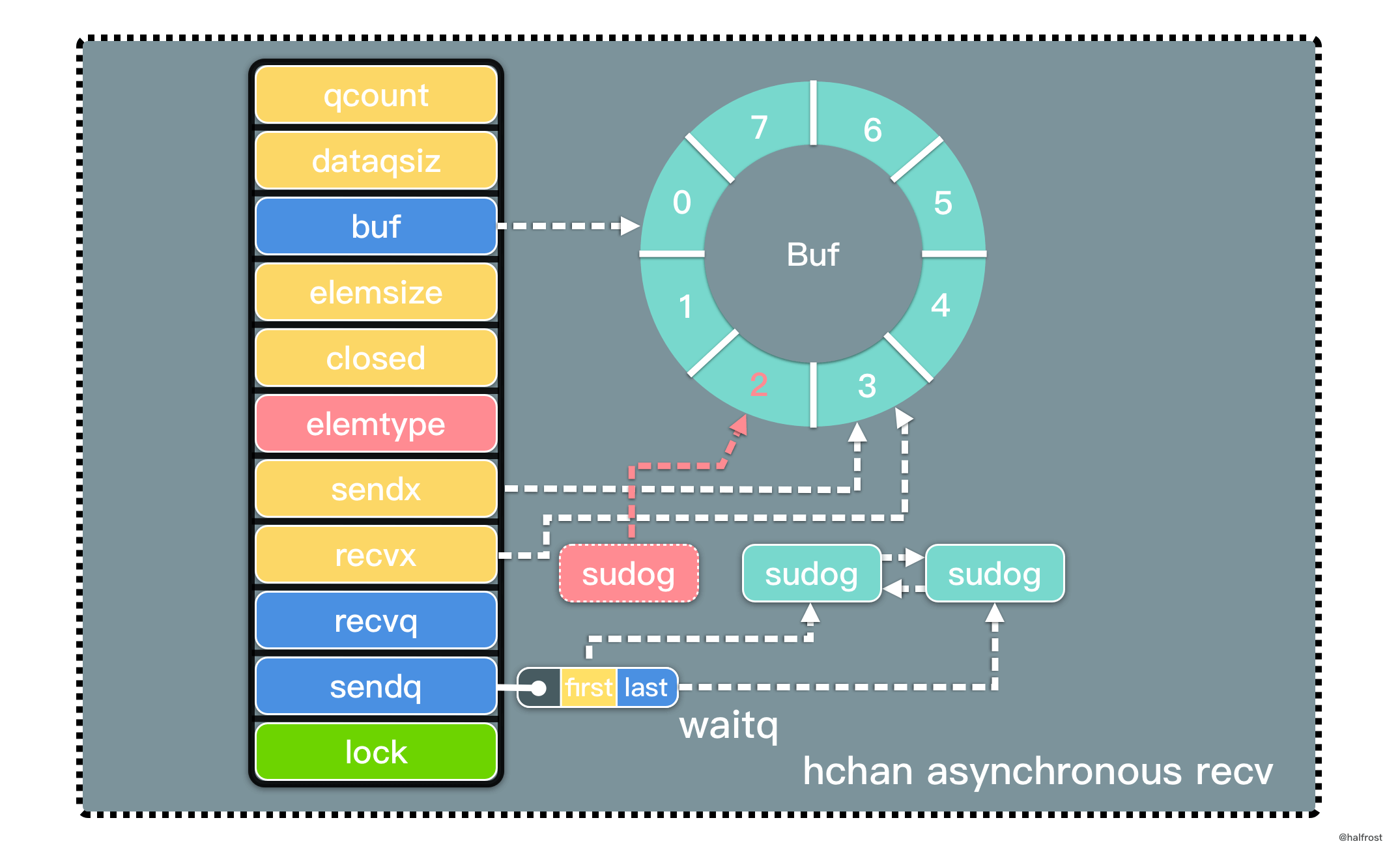
不甘当学渣,努力作学霸,最终是学民
题记

考虑到本系列文章有部分新的读者,所以关于本系列文章名字的起源就不再赘述了,见这里《"星霜荏苒"名字诞生记》
当你看到这篇年终总结的时候,距离我上一篇年终总结整整过去了 500 多天。你一定很好奇这 500 天我干了哪些事情,为什么这篇文章的标题叫这个名字?
学生等级
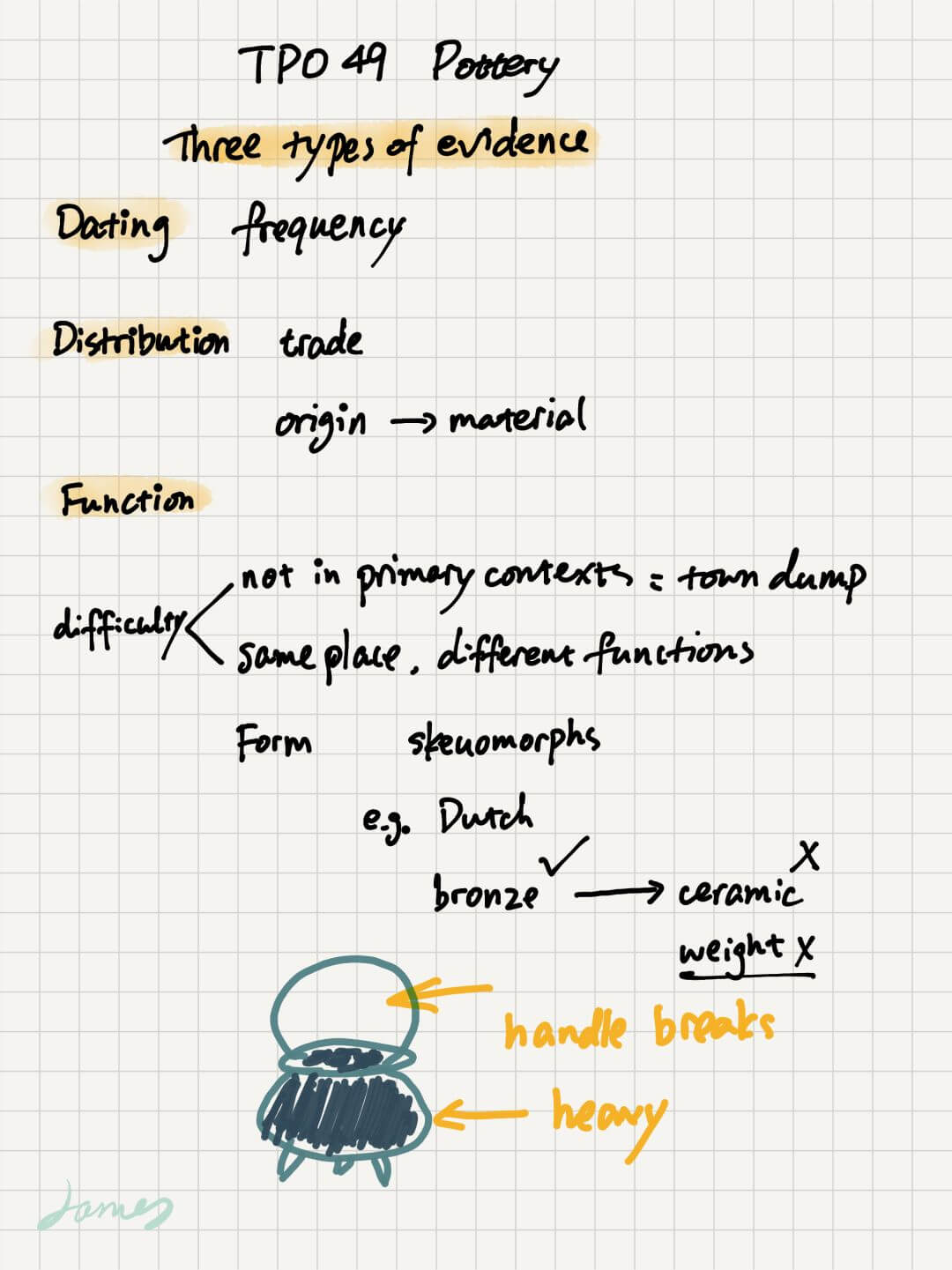
为了解释文章标题,就要先解释 10 个词语。笔者将学生等级从高到低排序是:
| 等级 | 名词 | 解释 |
|---|---|---|
| 1 | 学魔 | 对学习走火入魔,癫狂状态,不做题会死掉。 |
| 2 | 学霸 | 隐匿在人间有头脑的高智商人物,社交范围广泛,融合契合度高,琴棋书画样样精通,高端大气上档次。 |
| 3 | 学神(学帝、学仙、学圣) | 高大帅气,青春靓丽,不食人间烟火,天天游走在高难度的练习册当中却依然风华正茂。 |
| 4 | 学痞 | 他们上课睡觉,下课玩闹,但他们的成绩仍然很好。 |
| 5 | 学婊 | 每天都在玩,几乎不学习,每场考试结束后第一时间宣布自己要挂科了。但是考试成绩出来后,门门都拿第一。 |
| 6 | 学民 | 智商均衡,膜拜学霸,却瞧不起学渣等人物。他们只有一个信念,总有一天超越学霸,因此艰苦奋斗。 |
| 7 | 学弱 | 他们因为没日没夜地熬油点灯,已经身体虚弱,不堪重负。 |
| 8 | 学渣(学灰) | 智商处于半疯癫状态,兢兢业业,刻苦学习,却总是不得志。 |
| 9 | 学残 | 智商处于全疯癫状态。他们已经被学习折磨得痛苦不堪,没有人样。 |
| 10 | 学沫 | 智商不够用,却也不是很努力,每天在混着日子。总是觉得能够不劳而获。 |
| 11 | 学水 | 已经不能用智商与努力来评判他们了,他们已经自甘堕落,自暴自弃好多年。 |
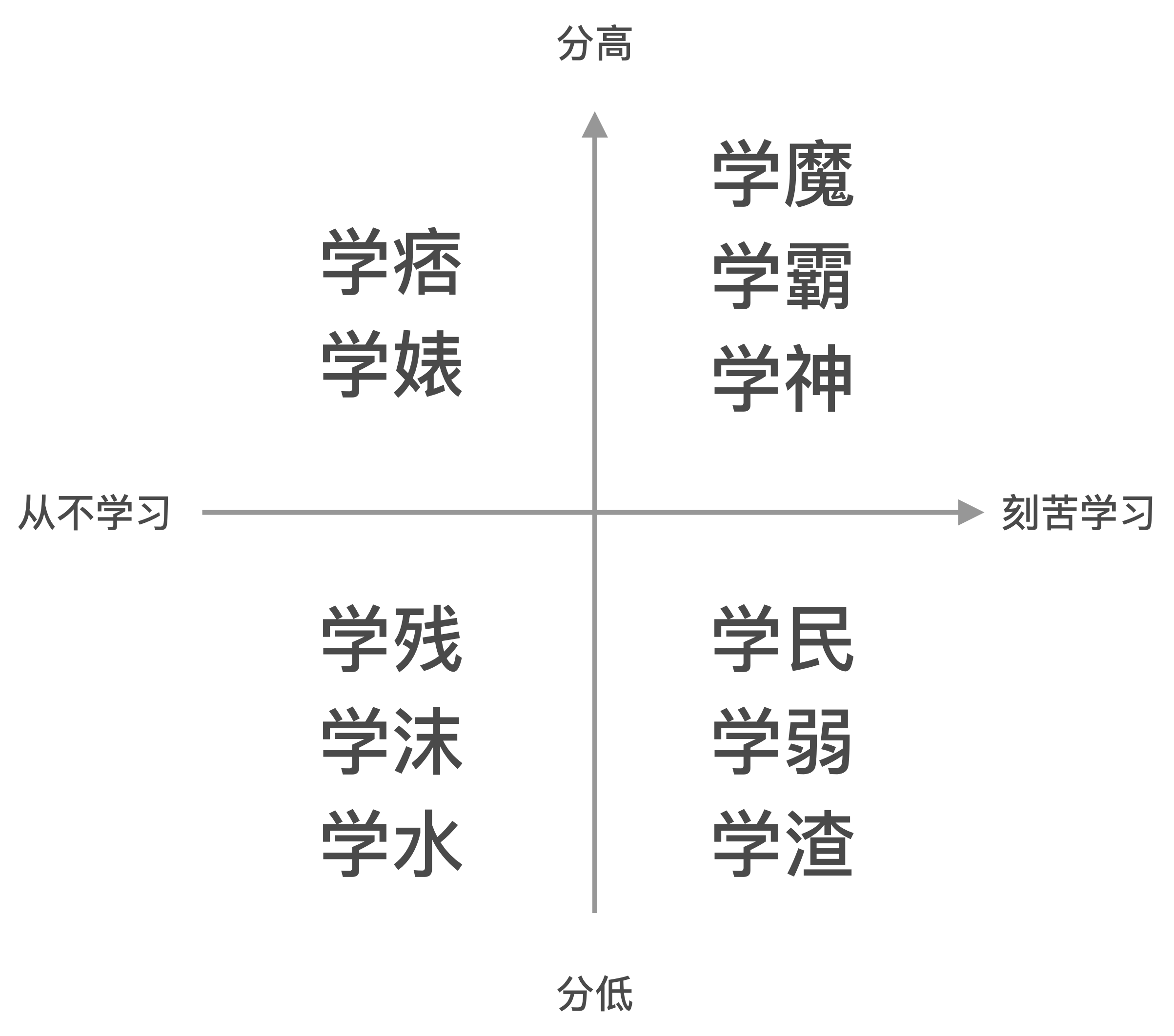
笔者这一年和学魔,学霸一起学习,经过多次考试的锤炼,最终认定自己是学民。有时候人与人之间学习能力的差距,你不得不认。笔者给自己的定义是,认真学习但也非刻苦的程度。分数不低但也不是高分。
好了,至此我关于标题的解释都述说完了。接下来聊聊今年学习和生活中遇到的一些所见所想。还有读者好奇的我这一年在忙什么。本文都会一一讲清。至于每个人对自己的人生都有自己的选择,笔者的选择不一定对。在强者面前,我的选择可能就如小丑表演一般,滑稽而可笑。那本文就献丑了。
工作的变化
今年组里一个大佬离职了。于是我有机会带领 5-6 名工程师一起向前冲。当真正 owner 一个超大项目以后才能感受到皇冠的重。各种事情都需要亲力亲为的开会,沟通,拿决策。每个组都有各自的利益,会议桌上各自都怀着自己的目的,所有人都想要自己的利益最大化。如果是因为我的“谈判”失误,导致影响到了组里全年的绩效,我会非常自责。不过结果来看,马马虎虎。我们吃掉了好几个组的业务。回收了他们部分 KPI 绩效,也成功拿到了他们的机器资源。接下来打算分享几件个人觉得比较成功的案例:
(这部分的分享本来有 3000 字左右,但是由于读者看到这篇文章的时候,已经是过去快 2 年的事情了,有旧事重提“炫耀”的嫌疑,加上笔者后来也从这家公司离职了。故笔者把这段删除了。)
职业生涯的思考
去欧洲旅行,遇到德国人讲英语,我实在不习惯他们的口音,基本都听不懂。双方无法交流。特别尴尬。但是这次我还自己给自己找理由,毕竟是有德国口音,听不懂也正常。回国以后我也忘记了这段尴尬。
去澳洲旅行,遇到意大利人说英语,能听懂他说什么,但是当对方笑起来的时候,我并不明白他的笑点梗在哪里。这一次我又安慰自己,文化差异导致我们无法交流。回国以后我有意识的去了解了一下当地的风俗文化,不过一段时间以后,我又忘记了这段“痛”。
去迪拜旅行,和中东人聊天零星听得懂,但是自己说话对方听不懂,冲沙项目中有一个人英语可以和对方交流,于是她成为了团队的中心。我心里暗暗记住,我也要成为队伍的中心,这次经历彻底击碎我的底线。学习英语迫在眉睫。回国以后便开始制定学习计划。不然下次旅行还会被英语卡。
职业生涯如果以 5 年为界限,笔者即将到达第一个 5 年了。那么第一个 5 年做了哪些成就呢?这 5 年我对我交出的答卷并不满意。兜兜转转把客户端,前端,后端都摸了一遍。如果 5 年都专注一个领域,可能早就可以升到某个领域的技术专家了。既然开局稀烂了,那第二个 5 年必须做出一点改变,“扭转乾坤”。
在中国改革开放的大环境下,中国的市场涌入了大量的外企,给市场注入了很多新的思想。在这个地球村的时代,全球旅行不再是梦想。我已经打破了旅游的地理限制,我已经走遍了 30 多个国家,5 大洲遍布了我的足迹。接下来我在考虑,我能否打破工作上的地理限制呢?比如我能否在全球任意一个国家,通过我的本领找到一份能赚钱养活自己的工作?语言是必须优先解决的。工作中沟通交流必不可少。在我脑海中这个想法还没有成型的时候,突然某一天看到脉脉上双非本科毕业生晒 Google 的工作日常。确认过信息真实性以后,我也有了去硅谷打拼几年的想法,我要打破工作上的地理限制。我不是 985 毕业,但是依旧有自己的梦想。自己实力很菜,去不了 Google,去一个 startup 应该还可以。于是我萌生了去海外工作的想法。但是此时这个想法不是很强烈,还在徘徊中。
慢慢的,我又经历了一些事情:

人是一个社会属性的生物,他的一些决定是参考了社会因素的。例如,家长们在一起聊天,A 家长对你爸妈说,“你看你们家的孩子这么没出息,你们怎么教育的?”,或者“你看我们家孩子,年薪 5000 多W,你们家孩子年薪才 10W,干一年顶你们家孩子干 500 年。”一般这些话爸妈听了,脸面上通常会一笑而过,也许不会和你说。但是这话要是自己听到了,肯定不是滋味。由于自己的不努力,或者不够成功,导致了自己的父母在外面被其他家长“踩”。凡是有上进心的人,一定会采取一些“绝地反击”的措施吧。“我是全村的希望”,这句话看上去那么的骄傲,背后其实反映了一种自豪,一种努力,不愧对父母的养育,自己的成功,自己的出类拔萃,也让父母在别人面前出人头地。当然不少父母也是低调的,自己孩子多么成功也不会在外人面前吹。但至少,这个孩子的成功没有给其他家长“踩”自己爸妈的机会!

我通常在同行面前都会说自己是菜鸟。久而久之,大家觉得我带坏了一些风气,装弱。有些人也会觉得我是谦虚。我的花名是,霜菜,提交系统的时候,我赋予了这个花名一个含义,菜的含义是,谦逊为人,低调做事,山外有山,人外有人。读书读的越多,就会发现身边的同学都是优秀且不带优越感的人,他们明亮不刺眼,自信又懂得收敛,让你仰慕的同时又能给你能量。仔细反思,我觉得自己也许根上并不是谦虚,更多的可能是自卑。大学毕业以后,我因为不是 985 的学历,被某些独角兽公司扔简历到了垃圾桶,没有给面试机会;因为不是 985 的学历,被牛人鄙视是垃圾。考研报考了 985 学校,也因为种种原因最终失败。社会一次次的实打实的挫败着我,985 已然成为了我心头上一道深深的伤疤。这道伤什么时候会揭掉,我不知道,这道沟壑什么时候会翻篇,我也不知道,我唯一明白的是,我俯下身子,在地上爬,不想让大家看见我破损不堪的心灵,既然是垃圾了,还有什么资格平起平坐或者高人一等?
我遇到了一个 985 大佬来自学历的“鄙视”,我仔细反省以后,我觉得必须证明一下自己,打败内心不自信的“心魔”。这个心魔算是我职业生涯第一个 5 年最后的一个大 boss,也是职业生涯第二个 5 年的第一个 boss,所以我下定决心必须过了这一关。想证明自己不输于 985 学生,想证明自己的实力,需要从某些方面来证明。正好那段时间看见了一段话,“看程序员是否勤奋就看他的英语好不好,智商高不高就看他算法好不好”。那么我就觉得在这 2 方面上证明自己的实力。心里默默下定决心:等我下次面试,我一定也要去面“鄙视”我的那位 985 大佬所在的厂,当我作为他的同事,职级还要和他平起平坐。希望到了那个时候,他能不鄙视我非 985 的学历。人活着有时候就是为了一口气,你若不认输,不服输,不愿意承认自己是 loser,不愿当学渣,那就用行动证明给嘲笑过你的人看,去证明你也有“过人之处”~我就想用成绩来证明给天下人看,“虽然我不是学霸,但是我决不是学渣!”,我想撕掉心灵上学渣的这块疤。
以上就是我从迪拜回来到 7 月份这期间的一些心路历程。从萌生去海外工作的想法,到自我反省,自我认知,最后到下定决心证明自己。所以从 7 月开始,我决定开始了英语雅思和托福的备考。从今年 3 月 18 日开始,我开始刷 LeetCode。英语 + 算法两手抓。
在英语备考期间也有来自各个大厂大佬的面试邀请,有来自滴滴,腾讯,头条,阿里巴巴,百度,拼多多,美团等等大厂的面试邀请。(此处对 @孙源 大佬说声对不起🙏🏻,邀请了我好几次,我都没有说明原因,有些话当时实在不方便说出来,现在如果你看到这里,还请谅解我啊)也有来自大厂 HR 的面试邀请。我在这里和你们说一声对不起了,当时回复你们的都是“我有我自己的安排,对不起”。其实我是想去海外大厂干一段时间,多成长成长,和世界上最优秀的工程师切磋切磋,再以最好的状态入职大厂。看到这里,就是我一直隐藏着的答案。
此处也需要 @子奇 和 @萧玉,这两个大佬也邀请我面试很久了。我一直委婉拒绝,可能由于和你们太熟了,导致我没法去你们那入职。🙏🏻还请 2 位大佬原谅我的当初的拒绝。还有 @阿里云大佬,@淘敏,@闲鱼大佬,@宗心的面试邀请,我实在非常不好意思。还有很多大佬也私信邀请过我,此处没法一一@,如果你们看到这里了,就请原谅小弟我吧。有不少人说我走了一步错棋,因为没有加入你们的团队。在此我也一并说声抱歉吧,小弟不加入只因为我觉得我还不配加入你们,你们都非常优秀,我还太菜了。人生还长,当我修炼好自己以后,未来再加入你们的机会很多!

在提升英语的期间,也有太多的“诱惑”,有来自猎头的“嘲讽”:大概 19 年 7 月的时候,有一个猎头加我,说我工作快 5 年了,还没有到 P7,技术有点垃圾 ,在阿里也呆了 2 年了,可以出去看看机会。我当时心里好“憋屈”,我当时就想证明一下自己的实力。不过有“心魔”的我,当时也只能忍了,宛拒了,“我的技术实力还不行,面不上头条,我还需要在这里再磨炼几年”。朋友圈也有来自旅友的美景照片,有来自日本旅友的旅行邀请,有来自欧洲旅友的旅行邀请。有来自美洲朋友的旅行邀请。在没有战胜我内心心魔的时候,实在没心思去玩,但是每天刷到美景照片,心里实在痒痒。于是,我还是选择关闭朋友圈,减少诱惑。但是又发现旅游群里面还有诱惑,于是屏蔽群消息,又发现还会有一些私聊的诱惑,最终选择关闭微信了。这和某学习 app 每日推送说的一样。“微信不必每条都看,但是单词不能一日不背”。(不过好像不用微信,对生活好像影响不太大,工作中重要的消息都在钉钉上,和家人聊天都用的 iMessage,逢年过节上微信和朋友问候一下,发发红包送祝福)
我一度删掉了微信好几个月,屏蔽了所有外部消息。这也是为什么好多人发我消息,我都没回复的原因。并不是因为忙,并不是因为不想回,而是因为我没用微信了。微信上诱惑太多,加上我自己心理调节能力弱,我直接断舍离。微信群里经常会有人晒百万高薪,晒千万跑车,晒万亿豪宅,看了以后要么自己会酸柠檬,要么就恨自己有多没出息。多多少少心理上会有一些波动。这些心理波动对备考时期没有任何好处,至少对我来说。删掉微信以后,我每天只想我自己的事情。心理上至少做到了不以物喜不以己悲的境界。(每个人备考状态和自我调节能力不同,我的心路历程也许不能复制,只是写出来给大家参考,也可以当做是“笑料”,给大家笑笑。)
人需要沉淀,需要“静养”,弹簧的姿态压的越低,之后弹的越高。有些人说我是一个很自律的人。不过恰恰相反,我自己认为我是一个不太自律的人。一个大师和说了三个字,解决我不自律的问题,“戒,定,慧”。让我戒掉一些东西,节约时间,心定下来,产生一些学习的定力,最终会产生智慧。在群里聊天我会很不自律呢。群友的问题我看着就想回答。也可能工作 5 分钟,聊天 3 小时😂🙏所以我决定克制一下。
就这样,我朝着去海外工作的目标狂奔着。
决定留学

在准备学英语之前,我去某英语培训机构裸测了一次雅思水平,居然才 5.5 分。扎心的是,老师还安慰我,“你快工作 5 年了,可能平时用英语不多吧,来上我们的课,带你提高英语水平”。我平时工作上每天打代码都是英语啊,这心里落差把我打至谷底。现在回头想想,这个英语培训机构给我的评分是真实的么?会不会故意打低分,“骗”我报班的套路?毕竟我没有参加过一次真实的雅思考试。再后来我就报班了。报了托福的培训班。😂由于雅思裸测 5.5 分,老师在课上叫我五分选手,(难道四舍五入不应该叫我六分选手么?)我经过一年的努力,我已经成功变成了八分选手。为了自嘲自己的超低水准以及提醒自己记住这段痛苦奋斗的日子,我现在仍然自称自己是五分选手。(这也是公众号名字的来源)
也因为雅思考的分数不高,使得我“怒转”复习备考托福。托福的口语是人机对话。你面对的是没有感情的机器,它不会因为你说错而产生尴尬气氛。雅思是人人对话,和真人对话时间,你说的如果对方听不懂,那会非常的尴尬。而且雅思听力里面也有我不擅长的听数字,填空等等题目形式。

这时候我也发现,一步出国工作可能有点难,可以分为两步走。先在国内的外企工作一段时间,再转去外国本土工作。国内的有名气的外企有 FLAG,开始投简历咯。我开始刷题,准备英文简历,冲击外企。现实给我泼了很大一身凉水。收到了 HR 给我的反馈,“同学,对不起,这个岗位你的学历背景差了一点,我们的候选人目前都是清北交复的硕士博士。希望未来你还有机会加入我们,谢谢”。我不会在这里公开这是哪家企业,面试岗位不是 leader 岗,只是高级 SDE 岗位而已。我接到这个回复以后,脑袋飞速运转,“可能是我的技术实力不行,用学历差了这个理由婉拒我”“有可能真的是学历不定,看 HR 的语气,要招硕士起步的人才”。不管是哪个原因,我的世界都乌云密布。既然先在国内外企工作一段时间再办签证去海外的这条路已经不通了。那么只剩下通过留学这条路去海外了。到此时,笔者才确定了留学的这条路了。
今年 7 月 13 号,滑滑鸡即将前往 CMU 读 Master 了。我和瓜神一起和他吃了自助餐,送他去美国。餐桌上他向我传授了托福裸考 108 分的经验。这次吃饭是经典的“西瓜霜”聚餐。滑滑鸡的名字中带有“西”的同音字,瓜神就是“瓜”,而我的名字中带有“霜”。餐桌上我也许下了诺言,2020 年会去美国找滑滑鸡一起吃饭。如果有缘的话,更希望能成为 CMU 校友。希望我能早日兑现男人的承诺。

写书

很多人发现我从 2019 年就开始刷 LeetCode,其中有一小部分人怀疑我要跳槽,我的同事起初也怀疑过我要离职,但是看到我刷了半年以后都没动静,也就慢慢相信我刷题是因为爱。这一小部分人猜对了真相,不过我笑而不语。同事也都不明真相,真实情况是因为我没有通过面试,为了“掩盖”这个事实,我干脆一不做二不休继续刷。刷满一年以后,我就没有日日不间断了。现在我还隔三差五的刷 LeetCode 真的是用爱发电。刷算法是热爱,刷到世界充满爱!
我写书也是受到了 @欧长坤 大佬的影响,他的两本经典开源书令我收获颇丰。于是我也想写点开源书,回馈社区或者单纯分享知识。由于今年全年我都在复习英语和刷 LeetCode,于是决定写这两本书。

这两个本书我都放在 github 上迭代更新。至于什么时候会印制成纸质实体书,还不确定。众所周知我目前还是一个 gopher,所以这两本书的网站必然要用 hugo 搭建。第一本书我用的是 wowchemy 主题,第二本书我用的是 hugo-book 自定义主题。项目代码也都开源在 github 上了。
写开源书(让我姑且称它为书)真的非常花时间,书和一篇博客不同,博客的目录只是单篇文章的主线,但是书的目录就不同了,它是整个知识体系的主线。笔者时常写到某篇文章的时候,突然想到另外一篇文章有问题,又去调整前面写的好几篇文章。为了每天能记住 200-300 个单词,我选择每天早上 6 点早起,先把 LeetCode 每日一题写完,然后把解题思路,代码,测试文件 push 到 github。如果快的话,6 点 30 分左右都能搞完。接下来吃早餐,7 点到 9 点是刷托福 TPO 和背单词的时间。我会把阅读的文章翻译一遍,记录和分析错题,精听听力文章等等。做完练习再把心得和方法等等内容 push 到 github。9 点半左右出门去公司上班。
常看 O’Reilly 动物书的同学一看这个封面就知道是向他们致敬。确实是这个目的。O’Reilly 的封面动物都是稀缺动物,并且画风都是黑白素描风。第一本书的封面上的动物是 Coyote。经常听托福听力的同学一看到这个单词就会觉得特别亲切了。之所以选这个动物作为封面也是这个原因。Coyote 在托福听力生物类中出现的频率比较高。既然此书是动物书,又和托福有关,那么选 Coyote 是理所应当了。
Coyote 翻译过来是土狼,或者郊狼。郊狼(学名:Canis latrans),也叫草原狼、丛林狼、北美小狼,是犬科犬属的一种,与狼是近亲。郊狼产于北美大陆的广大地区,北起阿拉斯加、南到巴拿马。欧洲探险家最初是在美国西南部发现这种动物。郊狼一般单独猎食,偶尔也会组成小型的群体。平均寿命为 6-10 年。郊狼在其大小、颜色和头部形状都十分相似濒危的红狼。 其英文 coyote 一词来自中美洲阿兹特克等部族所用的纳瓦特尔语单词 coyōtl,后经西班牙语传入到英语。
第二本 LeetCode 这本书的封面动物是孔雀。孔雀开屏的意义是希望大家刷完 LeetCode 以后,提高了自身的算法能力,在人生的舞台上开出自己的“屏”。全书配色也都是绿色,因为这是 AC 的颜色。
这两本书我会一直保持更新,直到我的托福考到一个理想的分数,LeetCode 刷到 500 题。当满足这两个条件的时候,便是你看到书的时刻了。
当你在读这篇文章的时候,第二本书应该已经开源了,所有代码都在 github repo 中,并且也是 public 的。但是第一本书可能难产了。并非笔者不想开源分享,而是笔者的托福分数没有考到满分。有一天去知乎上看了一眼,个个都是托福 120 分满分选手。我这种英语垃圾选手还是低调的找个地缝藏起来了。所以笔者这辈子都不打算开源第一本书了。
既然第一本书不打算公开了。那在这里放一些它的截图吧。记录一下今年我的一些努力时光。下图是 github private repo。
接下来几张图是用 wowchemy 主题做的这本书配套的网站。


艰辛的托福备考
实话说,备战托福对我来说,是比较花时间的。我妹子全程目睹了我“无比艰难”的备考过程,尤其是在职那段时间,备考太艰难了,加班到半夜到家以后还要开始读英语,睡觉都是听着 TPO 睡的。那段时间我还经常被公司安排 on call,很多次都有离职的冲动,换一个闲一点的公司。(最后还是咬牙坚持把一年干完,拿完年终奖走人了。)我妹子也从来不鼓励我,反而她一直都在劝我放弃,(这难道是反向操作的鼓励?),她经常说:“你看看人家滑滑鸡,不到 6 个月解决 GT 2 门,还都是高分,你呢?6 个月 GT 还没考到人家分数的 80%,还努力啥?坚持啥?”,我确实有过放弃的念头,但是一看我的学托福学雅思的时间投入,我就不能放弃了。走路都走一半了,这个时候放弃,过去的好几千小时岂不是白费了?大家都说,凡事要享受过程,不要在乎结果。“功利”的我偏偏非常在意结果,人一辈子的时间是短暂的,投入产出比不高的事情,优先级可以降低。于是我这个垃圾靠着不能放弃宝贵时间的前期投入,一直咬牙坚持。
开始我还不承认我是学渣,我觉得自己还算努力,算学弱应该不为过(学弱:学习很努力,但是分数很低)。经过几次 GT 考试的摧残以后,我自觉的把自己的身段从学弱放回了学渣。在我妹子眼里,滑滑鸡就是100%准学霸。这点我也心服口服。在被托福和 GRE 考试无情摧残了 4 个月以上时间的我,每次看到滑滑鸡的朋友圈,或者和他微信聊天,我内心真的充满了对学霸的敬佩。(如果有不服气的,可以立即报考托福和 GRE,3 个月内能达到托福 110+,GRE 330+ 都是学霸。)滑滑鸡这种学霸型,自己高分杀 G 砍 T,期间还有额外精力去实习赚钱,刷 GPA,四线操作切换自如。不仅无开销,还赚了几十万。有时候我一个人在家备考的下午,我就会翻翻自己的留学时间线和花销记录小本本,我和他的差距已经不是学渣和学霸这两级的差距,我觉得说我们相差四级都不为过😭这可能就是双非大学毕业的学渣中的学渣和顶级 985 毕业的学霸中的学霸的巨大差距吧。在托福和 GRE 这两门考试上,我是输的心服口服,我被虐的体无完肤,毫无脾气。
大家也都别参考我,我英语太垃圾,学习能力也很差。在职的时候公司加班比较忙,每天下班以后还要刷 LeetCode,写博客,写书,背 500 个托福单词,刷托福 TPO,背 GRE 单词,刷 GRE 题目。我实在是 hold 不住了。如果每天都要完成这些任务,每天我的睡眠时间只有一个小时。最后决定托福 + GRE + LeetCode 是每天必须完成,写博客和写书放在周末完成。由于在职复习和学习进度有点慢,所以我到今年年底也没有提交申请学校的申请。
虽然我的托福没有考到满分,但是依旧可以有一些经验可以和读者分享。
考试心态
托福考试是一种能力的测试,不是想办法出难题刁题(TPO只遇到过一次)为难大家。同时,考试也没有大家想象的那么难,我和考友的交流发现,考试改革以后,容错率仍然是挺高的。所以大家在对待考试的时候,不要对它产生惧怕心理,要藐视它,相信自己的付出一定能得到相应的分数。同时,是考试就有应试的技巧,无论是报课程,大家的攻略,还是每个人自己复习时候的心得,都是大家找到考试诀窍的方法。一定要对托福考试有一种熟悉感,一种我知道你想出什么题目,你在哪里出题的熟悉感,预判出题者的预判。这需要复习的时候有一颗热诚的心,要像对待女孩子一样了解她,学会去预判她的想法,做她希望你的事,而不是浪费精力做无关的事,或者作死。所以请大家复习的时候要有安排,有技巧,把精力放在最容易有效果的地方,多拿一分是一分。
托福考试分四个科目,读听说写四个方向,其实每一个方向都有一个共同的基础,那就是词汇。词汇不过关,100 分就是虚无缥缈的幻想。所以第一个月一定要沉下心来好好背单词。单词就用 KMF 词汇 app 和默默背单词,我是工作党,利用闲暇时光,目标是一天 300 个单词,白天争取在午休和吃饭的时候背好,不求背了就永远不忘,因为你会要背 3-4 遍。背单词其实是一种加速的过程,到后面几遍的时候,可能需要背的单词量也就一半不到,所以不用担心。
而听力是从 80 分到 100 分的最终助力,其实除了阅读,每个科目都和听力息息相关,每门课都要拿到高分,那需要能够精准的反映出听力的信息。我首考 74,我觉得很大的原因,除了第一次考试紧张和一些突发意外,最重要的就是没有重视听力,没有做好仔细听的心理准备,到时口语和写作综合题没有踩到所有的得分点,因此,大家一定要心理上要重视听力,考试的时候提醒自己保持听力注意力。无时无刻保持警惕感,去找到出题的点。
单词
我背单词都是用零碎时间背的,例如,上下班等车,坐地铁,午饭后散步,晚饭后闲逛。这些零碎时间都可以用来背单词。背单词不要一个单词记 5 分钟。正确的做法应该是多重复。一个单词看 20 秒就过,一天多重复 3-4 次。重复次数越多记的越牢。试想,情景一,一个陌生人和你打个招呼聊天 10 分钟,一年以后你还能记住他么?情景二,一个陌生人和你打招呼,每天都聊 1 秒钟,连续 365 天天天和你相见,一年以后你还能记住他么?很明显,每天都重复一定会让你记住他。以下是我的单词 app 的刷词记录:
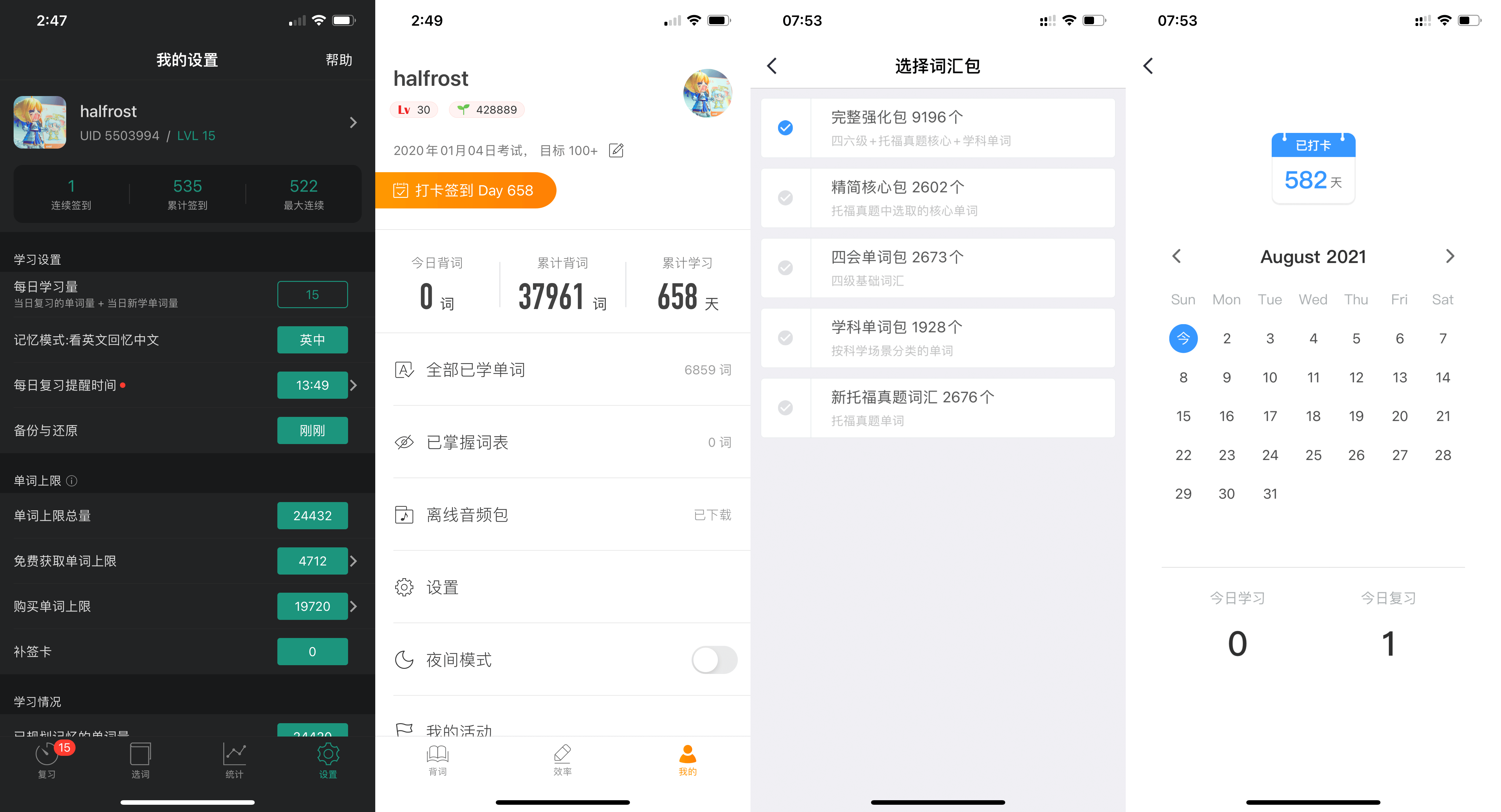
上图是笔者重新更新的截图。到 2019 年年底,连续打卡天数只有 190 天左右。笔者先用考满分单词 app 刷完所有托福词汇,并开启第二遍刷单词,差不多 10 月份的时候,开始用小站单词 app 开始刷它。当我把小站 app 所有单词都刷完一遍,我又开始用默默背单词了。如果你问我哪个 app 最好用?这个问题我其实回答不上来。因为我所有都用过,记忆单词有累加效果,并非某单一 app 促使我记住所有单词。其实这些单词 app 都差不多的。建议读者都试试,找一个适合自己的,刷起来吧。
时间规划
托福备考最好能速战速决,拖的时间越长,备考效率也不高。一般以 3-4 个月为周期最佳。
- 第一个月:夯实基础阶段。
这个阶段是一个准备期,就是背单词,每天争取 300 个词。背单词的同时,可以开始做阅读 TPO 了,一天一套的练习。
- 第二个月是复习高峰阶段。
除了写作和口语综合题以外,所有科目都要每天分配一定的时间去完成每日目标,单词继续 300 一天,阅读一天一个 TPO,听力一天一个 TPO,口语独立一天一题。这段时间是最痛苦的时间,因为程序员工作比较忙,大家一般都 23 点左右,如果加班,到家就 1-2 点了。所以睡前一定要合理安排好工作生活与学习。每天看着时间流逝,还是很抓狂的,但是大家一定要坚持下来,而对于学生党,这些工作量应该是很轻松能完成的。
- 第三个月是冲刺阶段。
全题型都需要冲刺的阶段,重点可能会放到口语综合题和写作上面,一天的时间单词继续 250 一天,阅读一天一个 TPO,听力一天一个 TPO,口语独立一天一题,口语综合题争取一天一套(我的实际情况是考前大概做了 30 套口语),写作两天一套(考前做了 5 套)。至于每天的具体时间安排,因人而异,我可以说说我的周末安排。
上午无论几点起床,一套阅读一套听力的 TPO 的模考和错题回顾。
下午午休,醒来后一套写作。
睡前完成口语 TPO 一套。
其中找时间穿插背一背单词和背一下语料(口语和写作通用)。
有人觉得一天需要做两套 TPO,我觉得很难实现,毕竟做错题还要检查为什么错,基本上一天一套 TPO 差不多了,何况 TPO 资源有限,不能浪费,必须做一套反思一套。接下来单独说说 4 科的复习方法。
阅读
阅读是拿分重点,词汇是基础,所以单词一定要背几遍。
复习的时候,学会去找同义转换,要相信考试的时候,绝大多数题目还是在做原文的同义转换,快速定位关键词 KEYWORD,将原文和题目选项对照,所有题都做排除法,基本能保证很高的分数。我有两次考试,最后三题剩的时间都不多,最后分数 28,一方面说明同义转换的正确定,也说明了考试的容错率。
每篇 TPO 阅读做完以后可以写一写反思。错题错在哪里了。然后精读一下文章,把长难句和不懂的单词查一查。笔者大概精读了 30 篇左右。考前 TPO 阅读都做完,因为有可能出现阅读题目变成听力题目,所以 TPO 刷完,最后问题不大。


听力
听力是从 80 分到 100 分最重要的助力。听力题是有容错率的。拿我的考试经验看,每次到时会遇到七八题需要思考一下二选一,两次考试分数都是 23 分,比自己预想的要高。听力复习最重要的是多听。
- 通过多听,培养英语的声音结构。
听力不是一个个单词听,每句话都有自己的主谓宾,考试考点无非就是考察主语或者宾语你有没有听到,少量题目是对整体或者段落的态度理解。
- 通过多听,熟悉段落结构,养成对出题点,问题,语气词,转折词的敏感性,在考试中助力自己能在出题点前提高自己的耳朵注意力。
每天一套 TPO,加考后精听,精听是边听边思考上面的两个要点,一遍通过。靠前两周,做到 1.2 倍速度做题没问题,复习平均分基本就是考试分数。做题的时候,坚持到底,不要因为一句或者一段没听清楚就放弃,很多情况下,听力题目在不理解听力素材的条件下也能回答。但是要做到有连续听六题的忍耐力和注意力。TPO 题目现在有可能成为你阅读的题目,所以大家一定要做完。
关于笔记,我的历程是一文章五六个词,到一文章记得密密麻麻,到最后考试前一文章不超过 10 个词,其实最重要的内容是记下文章观点和逻辑。关键词,术语,不重要。考前听力 TPO 都做完,问题不大。分享几个听力的笔记。有些同学不做笔记也可以拿到高分,所以笔记并不是必须的,因人而异。
口语
考前一个月时间准备口语。如果你的口语真的说的不溜,可以考虑报个口语班,多练练,我只能说,语料是真的好用,2 个月的考试,独立口语会命中相似的语料。班上对每种题型的理解也比较清晰,也提供了答题需要注意的结构和模版,挺好用。
具体复习的时候,口语只能靠自己多说了,而且要厚着脸皮说,因为考试的时候,自信心非常重要,你身边可能有比你说的不好的,可能说得和老外一样好,这时候你如果心态疲软,会出现答题问题,越说越不自信,越说声音越小,越说语言越枯燥。
独立口语就是语料的积累,我为自己准备了多种语料,能面对交流,文化,科技,环保等内容的时候,有话可说。同时积累逻辑词,因果关系,递进关系,转折关系每种关系准备两三个词,通过结构和语料,共同搭建起自己一分钟的语言轰炸。考试的时候,保证自己能说完整完一个观点,包含态度,原因,举例,反方,总结。
综合口语更重要的其实是听力,能把考点都记下来。所以这种题型相对简单,考题结构也比较稳定,比听力题简单点。最后通过模版或者自己准备的逻辑词把重要考点说出来就可以。
关于发音练习,笔者这里推荐一个免费课程,lisa美语音标发音教程中文字幕(4.0高级技巧)
写作
写作我也不知道要不要建议大家准备模版,因为我第一次用了模版是 21,第二次没用模版是 24。当然,这也是因为我综合写作听力有一定专门的训练,所以可能是综合写作分数往上提升。
有模版,写起来会比较简单,字数,高级词汇也会有一点。
不用模版,也不是不行,因为考试最重要的是看你的大逻辑和提供的论点是否切题,是否符合你的态度。
另一个关于打字数度,我可以给大家一个参考,独立写作 380 字,综合写作 220 字,分数也是能拿到 24 了。有些大神就 600 起步的,最猛的有打到 700 字的,(这手速要多快?)我真的很佩服,他们拿 30 分合理。
关于拼写,我感觉这个对分数影响是很大的,考前要做到不超过 5 个拼写错误。平时不要用带拼写检查的软件练习写作!语料同口语一起准备,考前两周,做到两天一套 TPO,保证自己写作评分能在 4 分稳定,问题不大。写在最后,首考的同学要做好心理建设工作,因为真实考试和模考是会有不同的。听力有时会出现英式英语,口语第一题会有一种突然开始的感觉。
最后,复习到今年年底,笔者身边很多同学说自己撑不住了,是的,这确实是备考托福的过程中,最难熬的一段时光,就像在一条,狭窄的隧道中,前面只有一丝光亮。而后面,漆黑一片,早已没有了退路。放弃是不可能了。但想拼却又觉得就那点光亮,值得么?你会觉得别人都是在阳光下奔跑,十足的胜算,你的拼搏,都变得卑微,于是你开始犹豫,你每天也在看书,但是却没有了对于美好未来的一丝憧憬,你只是在想这段路,早点结束吧。“放我出去”,是你唯一的期待。但是你却忘了,这世界上没有人是容易的。哪有什么阳光下的奔跑,都是在这条隧道中,艰难前行。未来有一天,那些所谓成功的人,回忆走过的路时,他们一定会提到,当年他们也在一条隧道里,艰难地拼搏。你才突然想起,这个地方我也去过啊,狭路相逢勇者胜,不要妄自菲薄,未来成功投射到当下,只会是一丝光亮,每个人都一样,没有阳光明媚,只有微光一点,但你的努力,本就光芒万丈,你忘记了,这一路走来,不是未来给了你希望,而是你一直在给自己力量,你要去拥抱的,不是什么狗屁成功,成功就是一个贱人,他只会依附于强大的人,你要去遇见的是那个更好的自己,那个绝不服输,决不放弃的更强大的自己。其实,你看到的那一点光亮,也是那个自己给你的,不要让在隧道尽头等着你的那个自己失望,因为你要是放弃了,她就等不到你了,而成功这个小人,也会离她而去,拼搏吧!燃烧吧!去看见,去遇见,去拥抱,然后有一天你带着成功一起讲述,你就是从隧道里寻着一束光,找到她的。然后终有一天,你可以笑着去讲述那些曾经让你哭的瞬间。💪
关于旅行

相比 2018 年去了 5 个国家来说,今年大幅减少了。利用五一假期去了迪拜,本来十一打算去美国常青藤学校看看,但是由于笔者托福备考进度慢了,所以十一没有出去,旅行的时间都用来上复习托福考试了。这是 2018 年年终总结里面写的新年愿望,现在看看,只完成了一部分,以后还是少立 flag,计划赶不上变化,脸疼。
2019 年的梦想是去迪拜完成 15000 米跳伞,去沙漠坐骆驼。2019 年旅行计划主要就是迪拜,欧洲和美国,去德法意瑞,看看欧洲列强们如今过的还好么;去美国体验体验常青藤学校浓厚的学术氛围;去迪拜看看白袍们有多么奢侈的生活,捡一捡丢在马路边的“垃圾”,兰博基尼,住一住七星级酒店。
一切源于年初的时候,我在世界地图上选择了 9 处比较浪漫的地方作为今年女友 18 岁的生日礼物,打算 2-3 年内完成这 9 处的打卡。我是一个不懂浪漫的穷人家的孩子,送不起房子,送不起车,只能送回忆了。既然作为 18 岁生日的礼物,那主题就叫 “勇敢者的游戏”吧。
最终定下来是去迪拜,完成棕榈岛 15000 米跳伞和沙迦沙漠深处冲沙。强烈推荐跳伞项目,真的太好玩了。笔者跳伞的长视频发在 @ halfrost 抖音号上了,欢迎读者去观看。关于迪拜的酒店,强烈推荐全世界唯一的七星级酒店帆船酒店 Burj Al Arab,和六星级酒店亚特兰蒂斯 Atlantis The Palm,当然还推荐全世界唯一的八星级酒店,只不过不在迪拜,在阿布扎比,阿布扎比皇宫酒店(Emirates Palace)。下面 2 张图分别是亚特兰蒂斯和帆船酒店。


可能有读者会问上面两个图的拍摄角度为什么这么特殊。笔者是在直升机上拍的。在亚特兰蒂斯酒店旁边有一个直升机场,可以买一张票,笔者买的是 25 分钟的票,直升机会带你飞到市中心转一圈再飞回来。沿途会经过帆船酒店,黄金相框,世界岛,哈利法塔,所有经典景观都会让你从上空看一遍。最后围绕棕榈岛半圈,回到亚特兰蒂斯旁边的停机坪。
迪拜的亚特兰蒂斯酒店可以去玩它的水上公园。是免费的。它的水上公园真的非常好玩。住在亚特兰蒂斯的话,旁边也没有什么小店可以吃饭,吃喝都在酒店里面了。(住亚特兰蒂斯的人还考虑消费么?花钱就是快乐)亚特兰蒂斯里面很多自助餐厅,至于价位嘛,消费上不封顶。带多少钱都能在这里挥霍完。笔者非常“省吃俭用”的在这里住了几天。
帆船酒店就不用说了。纯金的马桶,每晚 13-20W 的高级套房,爱马仕香皂。一切都是奢华的顶配。出门可以预约劳斯莱斯幻影。帆船酒店的房间里面的私人管家服务周到,只要你有钱,不太过分的要求都能尽量满足。比如你想把 F1 赛车运到帆船酒店的顶楼直升机停机坪,玩漂移,都是可以的。(并非玩笑,是真的可以)
比帆船酒店还要再高一星级的皇宫酒店,笔者没有体验,只去吃了自助餐。皇宫酒店在阿布扎比,它的内部不一定有帆船酒店奢华,但是它的社会地位比帆船酒店高。它本来是专门招待各国顶级领导人的。当领导人来访问的时候,是不开放给普通游客的。如果你不住在皇宫酒店,还是可以单独约这里的自助餐的。自助餐全部都是米其林星级厨师纯手工制作。所以中午吃一个自助餐,吃 2-3 小时是很正常的。
迪拜其他的打卡地有,民俗村,运河,博物馆,黄金相框等等。

上图是迪拜的民俗村,是迪拜最老的当地人住的地方。房间上面那些横着的柱子和风洞,是用来调节房间温度的,是一个天然空调。

上图是黄金相框,个人觉得还是在直升机上看这个相框更有感觉。站在它的面前,你能看到相框里面的景色就只有天空了。
迪拜的朱美拉清真寺(Jumeirah Mosque)是不得不提的打卡地。笔者是五一去玩的,正好遇到斋戒期。去清真寺一定要符合宗教的服装要求,男女服装都有要求。男士和女士需穿着保守、宽松、不透明的衣服,最好选择长袖 (腕长),长裙子 (脚踝长度) 或裤子,进入清真寺前,有一个商店可以租这些衣服。


清真寺建筑群的内外墙壁用来自希腊和马其顿的汉白玉包裹而成,内部装饰金碧辉煌,错综复杂的雕刻和壁画令人赞叹!雪白的大理石圆顶及墙面,在阳光下隐隐发亮,清真寺前湛蓝的一池清水,不禁被这片圣洁之地所吸引。黄金柱头,简洁的柱子底座,大有彩色图腾花纹的柱身,加上具有标志性的拱形洞口,整个色调的把握,把阿拉伯文化淋漓尽致演绎到建筑之中,整个清真寺就是一个奢华艺术品!在这里,你还可以亲眼目睹世界上最大的大理石马赛克装饰和纯手工地毯,给你前所未有的视觉震撼。上两张图只有你亲临现场,才能被彻底的震撼到。相关的视频也记录在笔者的抖音里面了。

上图是在直升机上拍的棕榈岛,这个就不用说了,世人都知道。还有一个没有完工的世界岛,是另外一个人造岛。笔者在直升机上没有拍到,当飞行员解说到世界岛了,我看了半天才意识到哪里是世界岛,最终错过拍照了。
最后一个打卡地就是世界最高的塔,哈利法塔。可以去 128 层的观光层往下看风景,有迪拜城市的全貌。笔者建议下午 3-4 点去,这样可以一直呆到 6 点日落的时候,和心爱的人在世界之巅一起看日落。值得一提的是哈利法塔的电梯也是世界最快的。笔者拍摄了它上升的速度,非常震撼,视频都在抖音号上。

其他的活动就是消费活动咯。The Dubai Mall 肯定是必去的。它由 10 到 15 个 Mall 中 Mall 组成,一共将有大约 1200 个商店,有 16000 个停车位。此外,它还将有世界最大的水族馆,最大的黄金市场,奥运比赛规模的冰场,6 层楼高的巨幅屏幕影院,探险公园,沙漠喷泉等等。
迪拜购物中心单独占地 500 万平方英尺(约 46 万 5000 平方米),相当于 56 个足球场的面积,连同其所有辅助设施、附属建筑在内、总共占地 900 万平方英尺(约 83 万 6000 平方米),这些数据都刷新了世界纪录,超过了加拿大埃德蒙多市的得西埃商业中心和美国明尼苏达州布卢明顿市的美国购物中心。也许你对这些数字没有感受,那笔者这样描述吧。从早上商场开门,一直逛到晚上商场关门,逛整整一天,只能逛完其中一层,连续逛一周才能把整个购物中心逛完。
迪拜的茶余饭后的娱乐活动非常匮乏,没有中国的棋牌,麻将,广场舞等等活动。女性唯一的娱乐活动就是逛商场,消费。所以 The Dubai Mall 拥有全世界最新款的 LV 包包,拥有全世界最新款和最贵的奢侈品。只有这样才能满足迪拜女性饭后的娱乐需求。(这段不是开玩笑,说的是真实的)所以当你在购物中心看见一个白袍领着他的老婆们一顿买买买,一口气买 16 个 LV,4 辆劳斯莱斯的时候,别认为是人家败家,其实人家是在娱乐呢。(4 个老婆,每个老婆一辆劳斯莱斯,一年四季,每个季节都要一个 LV 包包。所以需要 16 个 LV,4 辆劳斯莱斯)在迪拜允许一夫多妻,但是必须对每个老婆都公平对待,你的爱要平均分给每个人。
好了,今年的旅行就说到这里了,大多数迪拜的旅行视频都在 @halfrost 的抖音号上。读者有空感兴趣的话可以去看看。希望明年笔者的托福和 GRE 可以考到满意的分数。考完了想去南美或者冰岛转一转。(立 flag 要打脸)
最后
一位大佬朋友圈写道:看程序员是否勤奋就看他的英语好不好,智商高不高就看他算法好不好。这句话我当时看到了很触动,默默的记在了心底。2019 年一年我就只做了 2 件事情,刷算法,学英语。我现在还不敢说我是优秀的程序员,但是我至少努力过。不辜负时光,无愧于自己。以上就是你们想要的答案,这就是我 2019 年的年终总结,里面揭秘了 98% 的人都不了解的事情。很多猎头迷惑的内容也都在里面了。感谢周围亲戚朋友的这 2 年的关心。这篇总结不是原子弹💥别太惊讶。
回过头来看,好像也没有做出什么牛逼的事情。就是下了一步小棋,布了一个小局。也不是什么传奇经历,无非是奋斗路上立 flag,达到 flag,再立 flag 的一滴滴汗水罢了。过去 2 年,我一直隐身于网络,也没人知道我立的这些 flag。大家的年终总结都是对自己今年 flag 完成度的复盘,而我没有勇气去直面被人嘲笑的梦想,如果最终梦想没有实现,flag 无非就是人们饭后的谈资,打肿我脸的笑柄。这也是近 2 年都没有看到我的年终总结公开出来的原因。最终的梦想总算完成了,也是时候可以把年终总结公开出来了,给关心我的读者和朋友一些交代了。(本文写于 2019 年年末,最后这一段修改于 2021年 3 月)
最后一些“只言片语”的感受分享一下作为年终总结的结尾吧。
- 不要向任何人诉苦。因为 20% 的人不关心,剩下 80% 的人听了会开心。
- 狮子从来不会关心一只羊的看法,不要在意别人怎么看你,你应该努力强大成为一只狮子。
- 要学会拒绝,没有人会感激你的善良,很多人只会得寸进尺。
- 不需要解释的不要解释,从你张嘴的那一刻你就已经输了。
- 当有人侮辱你的时候你要记住,狮子不会因为狗叫而回头。
好了,2019 年的【星霜荏苒】就到这里了。如有任何异议或者想讨论的地方,欢迎和我交流。

2019 年 5 月 5 日,于迪拜 Dubai
GitHub Repo:Halfrost-Field
Follow: halfrost · GitHub