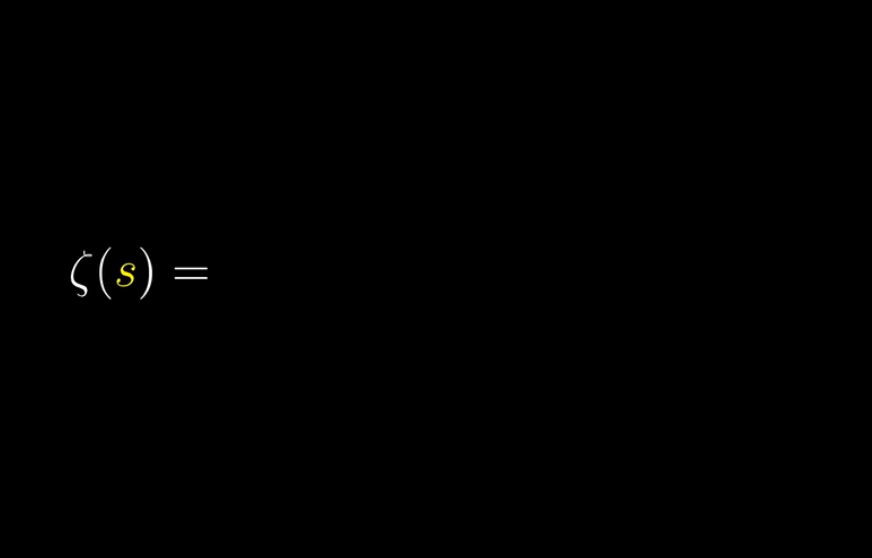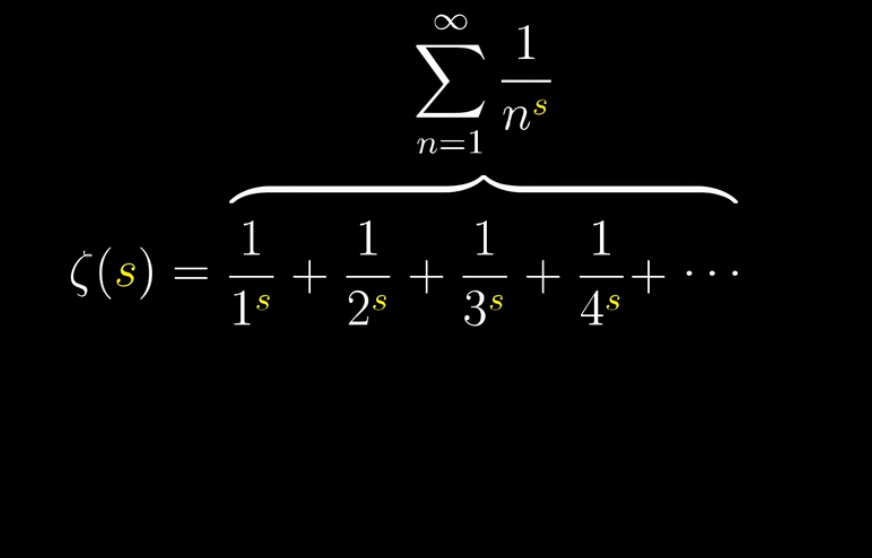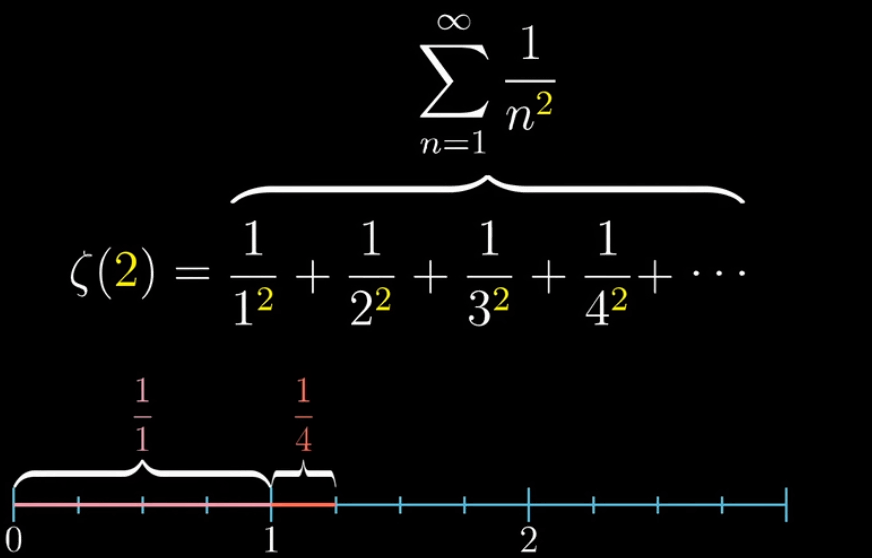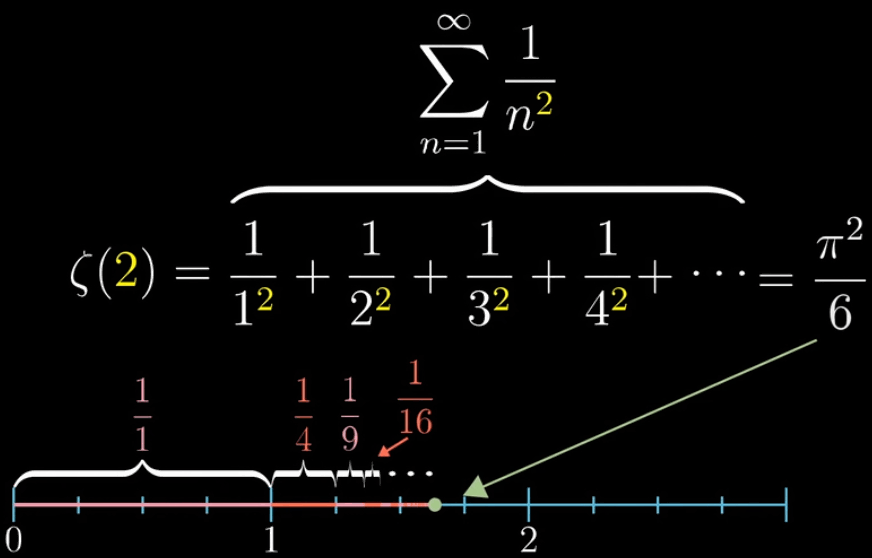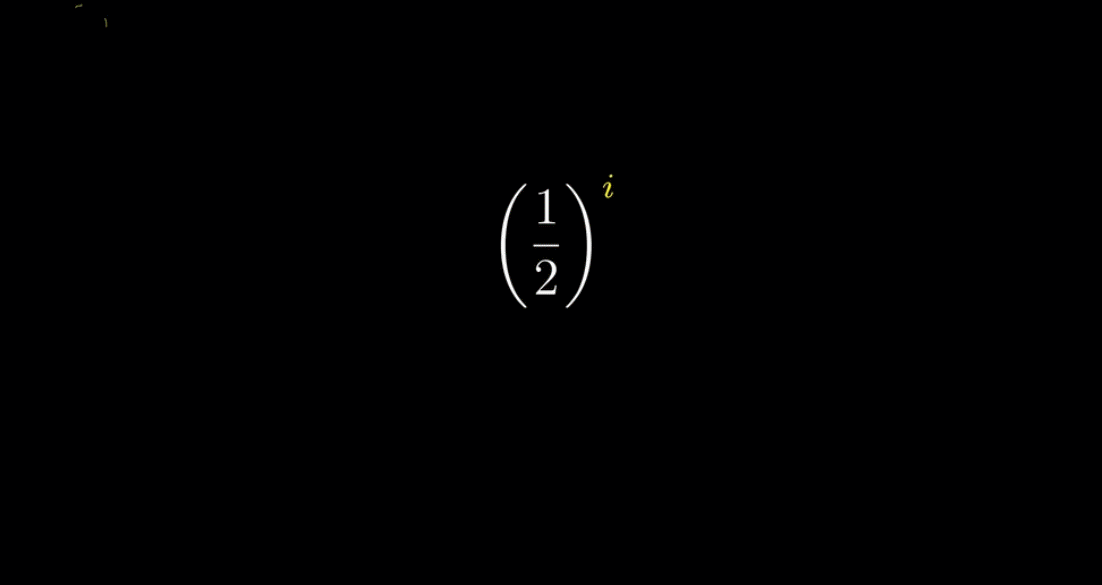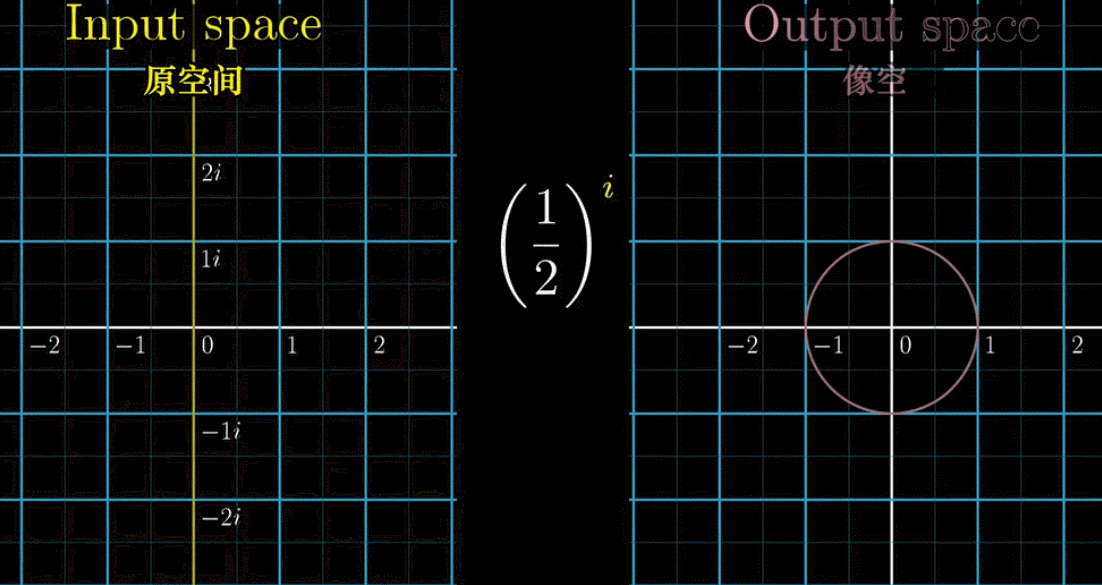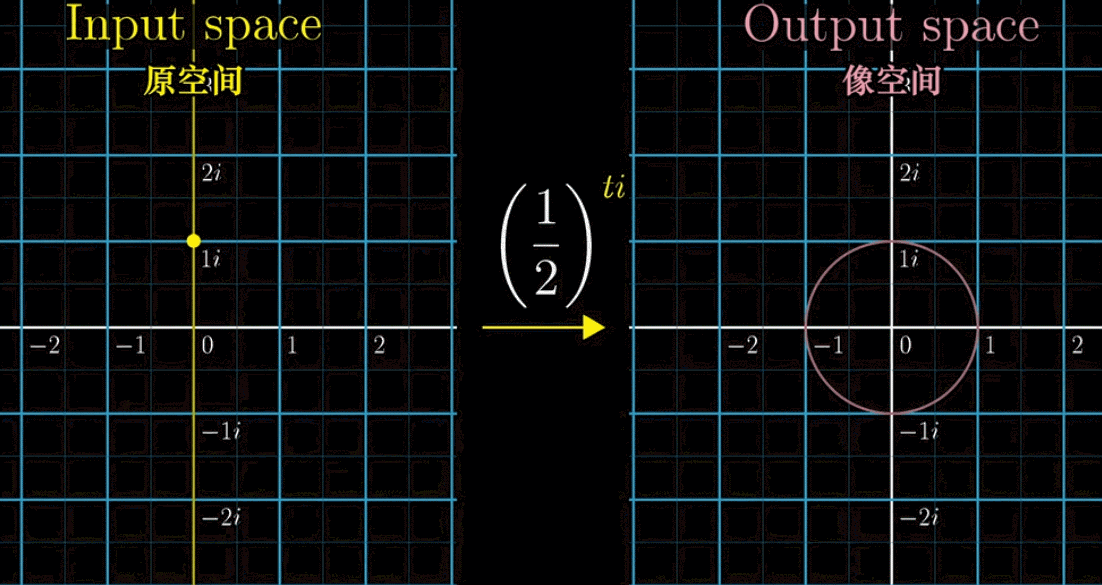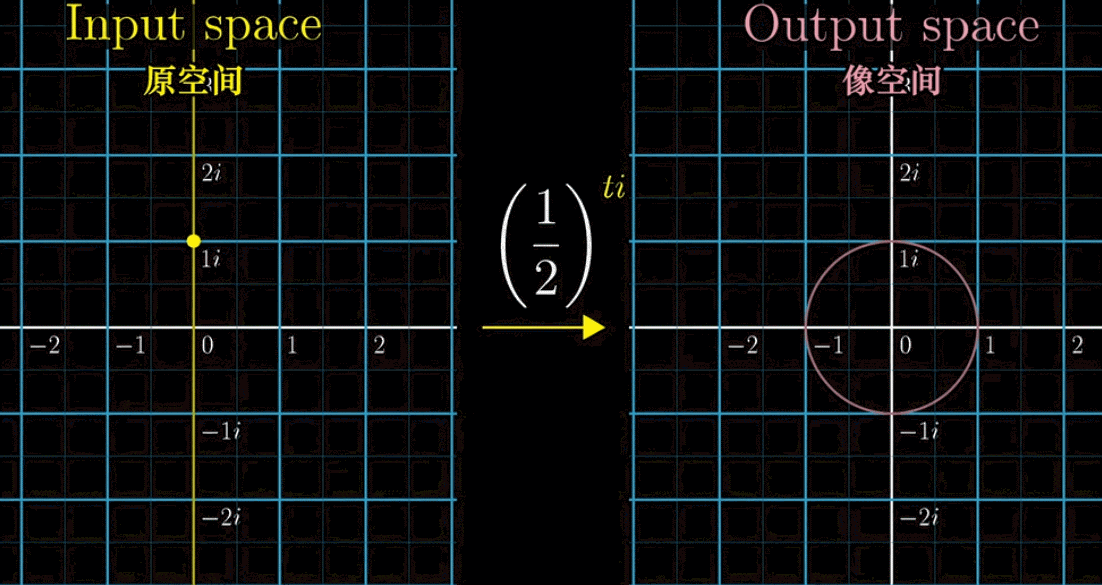【阅读时间】15min - 20min | 9000+字 | 23张动图 | 11张图片
【阅读内容】一文搞懂什么是黎曼猜想。在复数域直观可视化黎曼$\zeta$函数(读作/zita/),解释什么是解析延拓(analytic continuation),探究黎曼猜想和素数的关系
分享者是最大的受益者,感谢各位莅临阅读!
【说明】本文科普为主,是3B1B视频(版权来源)的笔记。会有很多废话来增加信息冗余度,方便对复分析之类概念不熟悉的读者理解。有基础的读者可以选择跳过一些在你们看来是在说废话的内容。就像重要的事情说三遍一样,废话增加信息的冗余度,减慢节奏,降低认知负担,希望这么做后能有更多人真正看懂什么是黎曼猜想。
八卦黎曼
黎曼全名格奥尔格·弗雷德里希·波恩哈德·黎曼 〔德语〕Georg Friedrich Bernhard Riemann(1826 - 1866),德国数学家。黎曼的父亲是个牧师,在他长大之后,就读于哥廷根大学(德国西南部)神学系
后来在大学听了一场高斯有关最小二乘法的讲座,发现了命中天赋所在。征得父亲同意后,转到柏林大学改修数学,拜入雅可比和狄利克雷门下(雅克比行列式,第一个玩椭圆的人;机器学习中的狄利克雷分布,证明费马大定理 n=5 的人;没错就是这两个大牛)
历史背景
不谈历史背景的人物介绍都是耍流氓,好,回过头来看看黎曼生长的德国(当时还不能叫德国)当时在干啥
1806年拿破仑覆灭统治几百年的神圣罗马帝国。1815年以日耳曼民族为主的德意志邦联成立,在这个联邦中,以普鲁士和奥地利最为强大,两大势力得争个高下。一直到1862年脾斯麦执政,才走向一统。最终,1871年,德意志帝国成立,黎曼没能见到这一天
19世纪5、60年代普鲁士完成了工业革命,这必定伴随着思想和科学的蓬勃发展。黎曼是生在一个好时代,这个时代,整个科学领域,一片蓝海,名家辈出,群星璀璨
有意思的是,K12这个名词就发源于普鲁士。K指Kindergarten,及幼儿园,12指12年级,也就是高三。K12泛指基础教育。虽然这工业化的流水线教育模式可能更多的是为了培养流水线式的工业人才或士兵,但不能否认,重视教育则学界兴盛
成就
黎曼成就斐然,最有名的当然是黎曼几何(积分),黎曼流形和复分析之父。当然还有本篇文章的主人公,1859年提出的黎曼猜想
黎曼猜想被收录进1900年希尔伯特(Hilbert)提出的23个重大难题,这些难题经过100年的岁月,还剩下6道没有被完全解决
【补充1】因为代数几何中有关椭圆曲线的相关研究还没有兴盛,著名的费马大定理:$x^n + y^n = z^n \; 当\;n>2\;没有整数解$ 未出现在列表中,虽然当时这个猜想也没有被证明
【补充2】在希尔伯特的问题列表中,黎曼猜想并不单独为一题。包含黎曼猜想的第8题是:黎曼猜想及哥德巴赫猜想和孪生素数猜想,这每一个猜想都闻名遐迩。三位一体,由此可见这三个问题之间是存在关联的
21世纪黎曼猜想又被列为千禧年7道世纪难题之一,克雷数学研究所承诺:解决一道题 ➜ 100万美元
P/NP问题 | 霍奇猜想 | 庞加莱猜想(已证明)| 黎曼猜想 | 杨-米尔斯存在性与质量间隙 | 纳维-斯托克斯存在性与光滑性 | 贝赫和斯维讷通-戴尔猜想
黎曼猜想的专业定义
先搬运Wiki百科对黎曼猜想的定义:黎曼$\zeta$函数,$\zeta(s) = \frac{1}{1^s} + \frac{1}{2^s} + \frac{1}{3^s} + \frac{1}{4^s} + \cdots$ 的非平凡零点(在此情况下是指 $s$ 不为-2,-4,-6…等点的值)的实数部分是 $\cfrac{1}{2}$
这个表述可以继续简述为:所有黎曼$\zeta$函数非平凡零点的实数部分是 $\cfrac{1}{2}$
【补充(只为严谨,可以跳过)】把上面的式子称为黎曼$\zeta$函数并不严谨,严谨的来说:定义域必须纳入考虑,才能完整写出黎曼$\zeta$函数的形式
设一复数s,其实数部份 >1 ${s: Re(s) > 1}$ 且
$$
\zeta(s) = \sum_{n=1}^{\infty} \frac{1}{n^s}
$$
它亦可以用积分定义
$$
\zeta(s) = \frac{1}{\Gamma(s)}\int_{0}^{\infty} \frac{x^{s-1}}{e^x - 1} dx
$$
在区域{s : Re(s) > 1}上,此无穷级数收敛并为一全纯函数。黎曼认识到:$\zeta$ 函数可以通过解析开拓来扩展到一个定义在复数域 $ s, s≠ 1$上的全纯函数 $\zeta(s)$
相信大部分读者如果是第一次看到这个定义,估计头都大了,但是列出不明白概念的清单是学习一个全新事物的有效办法,就按照这个思路来列一个清单
- ❓ 黎曼$\zeta$函数是个什么函数?
若读者的数学基础为高中,那么博主猜测您有疑惑的是…这个符号,它的含义很简单:按照1 2 3 4每次加1的规律一直重复前一项的形式。举个例子:
$$
\zeta(s) = \frac{1}{1^s} + \frac{1}{2^s} + \frac{1}{3^s} + \frac{1}{4^s} + \frac{1}{5^s} + \frac{1}{6^s} + \frac{1}{7^s} + \frac{1}{8^s} + \cdots = \sum_{n=1}^{\infty} \frac{1}{n^s}
$$
- ❓ 什么是非平凡零点?
本博文想说清楚的问题
- ❓ 实数部分指的什么?难不成还有虚数部分?
这部分涉及虚数的概念,虚数定义为 $\sqrt{-1}$ 记为符号 i,接下来就需要一些复数基础,这一点跳不过,但本博文也尝试帮你解决这个问题
- ❓ $\frac{1}{2}$ 这个数是怎么来的?
本博文想说清楚的问题
从知识构建的角度来说,搞清楚黎曼猜想的知识网父节点有基础复分析(知道复数以及如何分析)和微积分中的求导
还有另一个说法也和黎曼猜想有关,即 $1 + 2 + 3 + \cdots = - \cfrac{1}{12}$ ,怎么看这个式子都应该是无穷大啊,为啥等于 $-\cfrac{1}{12}$ 呢?看完后,你应该就能明白为什么会有这个令人不解的说法
可视化黎曼$\zeta$函数
第3部分就一步一步展开黎曼猜想这副瑰丽的“画卷”,希望在图穷过程中,能带来给您带来几个Aha时刻,感受数学之美
黎曼$\zeta$函数
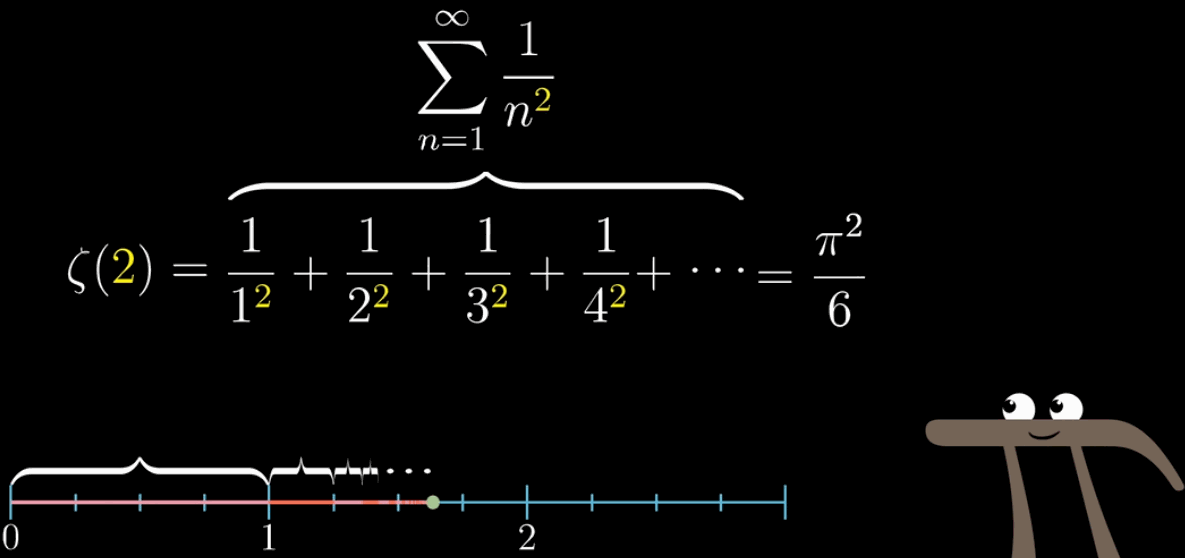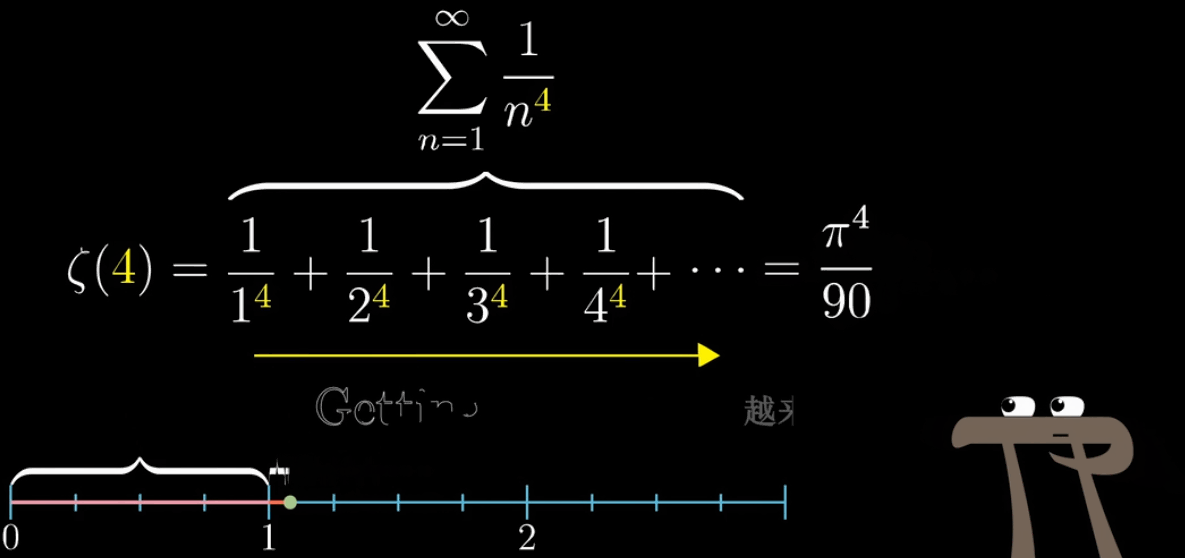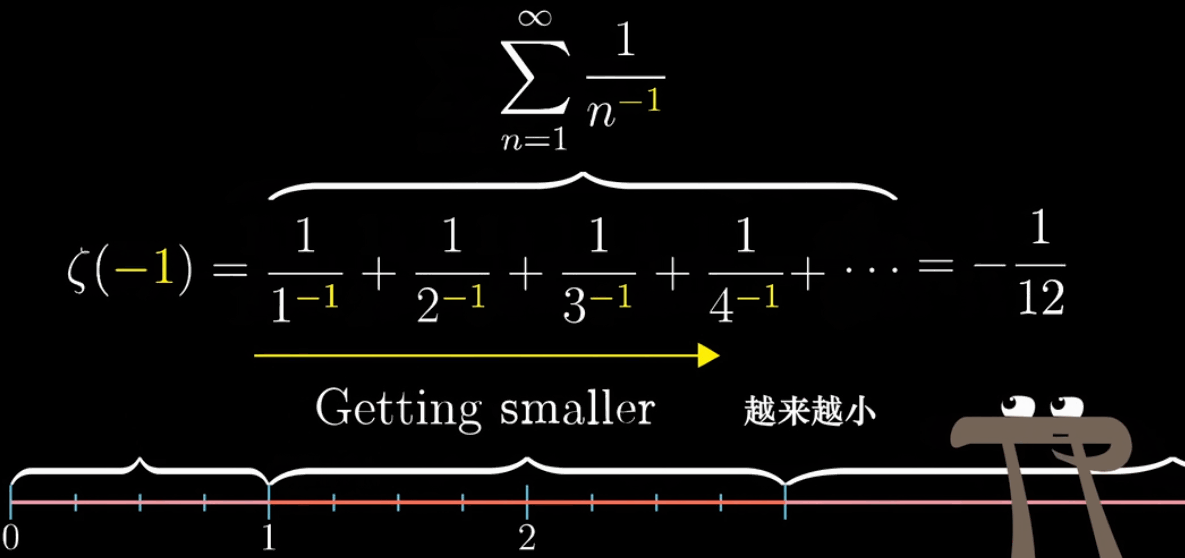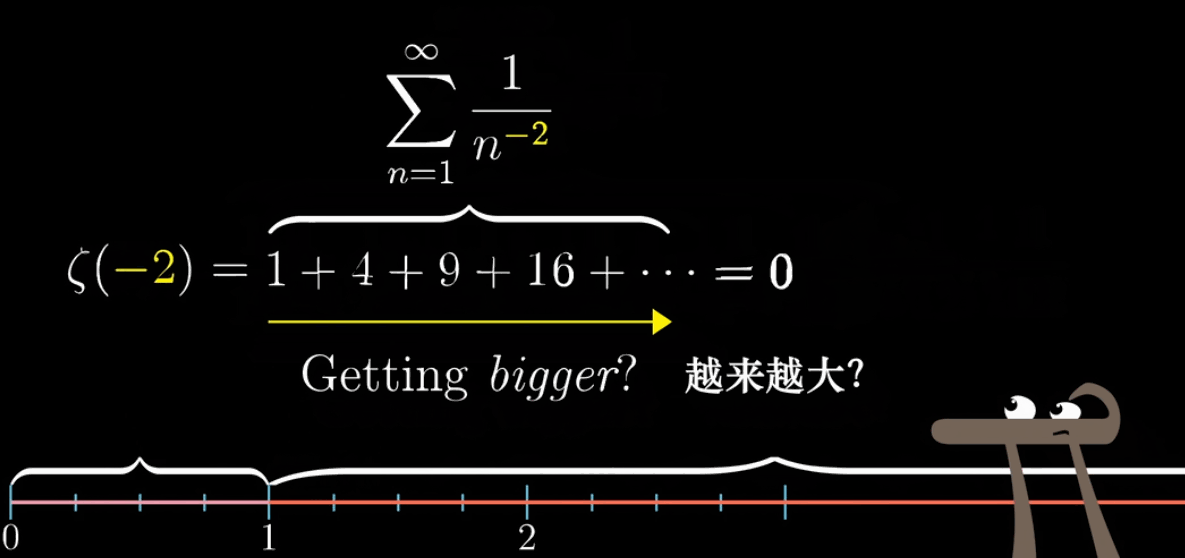
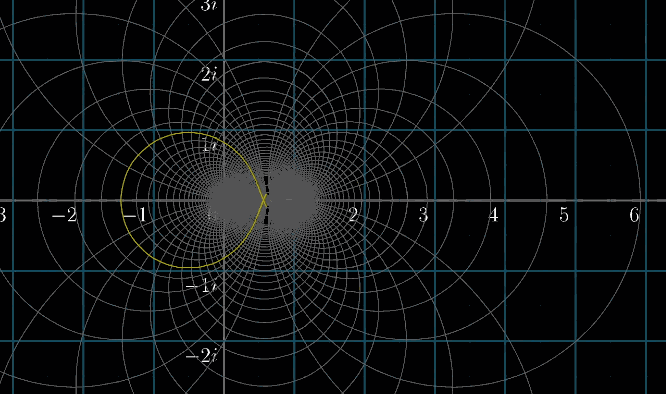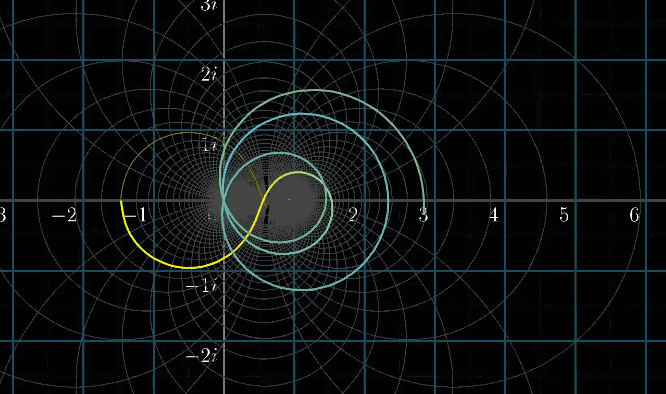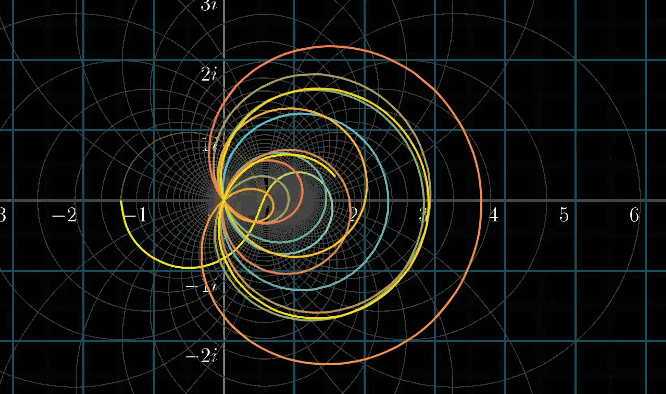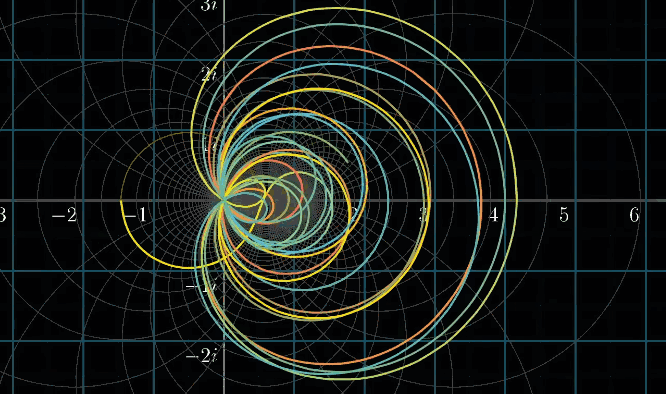
首先,我们为了逻辑链的完整,先用一副动图再定义一下我们的主角黎曼$\zeta$函数,并且假设我们带入$s=2$ 会是什么情况
你可以继续带入其他值,如果 $s>1$ ,可算出一个确定的值,但你会发现如果 $s<1$ ,那这个无穷级数(级数就是一长串数字 or 序列的数学专有名词)就会越加越大,无法收敛,又称发散
参考上面的动图,带入负数,明显越来越大呀?其实这里和定义域的选取有关,黎曼$\zeta$函数只有在 $s>1$ 的时候能求出值(收敛),这个函数才有意义,那么定义域外的情况怎么处理呢?
如果你对黎曼猜想研究过,可能看过类似的结论 $\zeta(-2n) = 0$ 和 $\zeta(-1) = -\cfrac{1}{12}$ ,这又是为啥呢?
定义域扩展到复数
在传统的定义域中,就是把 $s$ 作为输入带入黎曼$\zeta$函数,重新映射到数轴上的另一个数上,如下面的动图所示。如果你很好奇为什么这个级数的和是 $\cfrac{\pi^2}{6}$,这个数从何而来,另一篇博文会解答这个问题(3B1B的另一个视频的总结笔记),我会晚些时候更新
黎曼做了一个扩展,他说:如果 $s$ 能取到复数会是一种什么情况呢?先添加一个复平面,并另 $s=2+i$,过程参看下面的动图
所谓定义域扩展其实非常好理解:之前 $s=1$,它是一个实数。现在让 $s = 2 + i$ ,变成一个复数,这就是复数域扩展
❓这里可能会出现两个问题 ➜ ① 什么是复平面? ② $\left(\cfrac{1}{2}\right)^{2+i}$ 怎么计算?几何含义是什么?
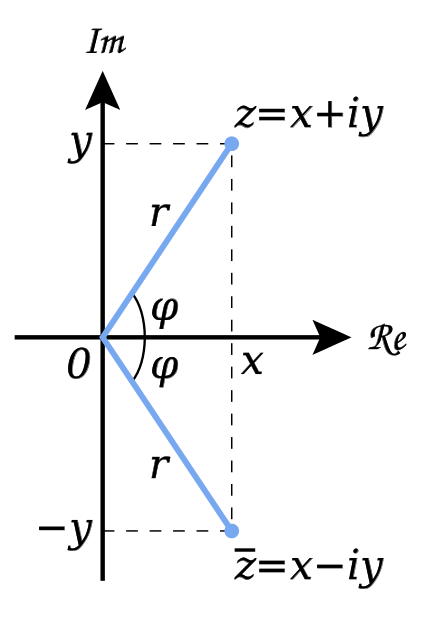
复平面
复数是拥有实部和虚部的表示法,写为 $a + bi$ ,$a$ 为实部,$b$ 为虚部, $\sqrt{-1}$ 定义为 $i$,称为虚数单位 。而复平面(complex plane)是用水平的实轴与垂直的虚轴建立起来的复数的几何表示,如下图所示(来源维基百科)
研究复数有什么意义?其中有一点和我们这个主题有关,$i$ 虚数单位和幂指数函数勾连起来在复分析中能连接上旋转这个概念。具体来说,参看我的这篇【直观详解】让你永远忘不了的傅里叶变换解析博文
虚数单位为幂指数
这一小节的思路非常重要,不仅仅对理解黎曼猜想有帮助,对信号分析,傅里叶变换等也非常有帮助
$2^x$ ,这个 $x$ 就是幂指数,$2^i$ 即虚数单位为幂指数
第二个问题,我们可以把 $\left(\cfrac{1}{2}\right)^{2+i}$ 拆开写成 $\left(\cfrac{1}{2}\right)^{2}× \left(\cfrac{1}{2}\right)^{i}$ ,前面一半很好理解,关键是后面一半怎么理解
这里涉及到一个非常基础并且十分重要的理念:复平面中,纵轴(虚数部分)的幂指数函数的映射关系代表的是旋转。一下子不懂没关系,下面有通过两幅动图来帮助理解,如果还是有疑惑并且十分想了解,参看博文复平面和旋转
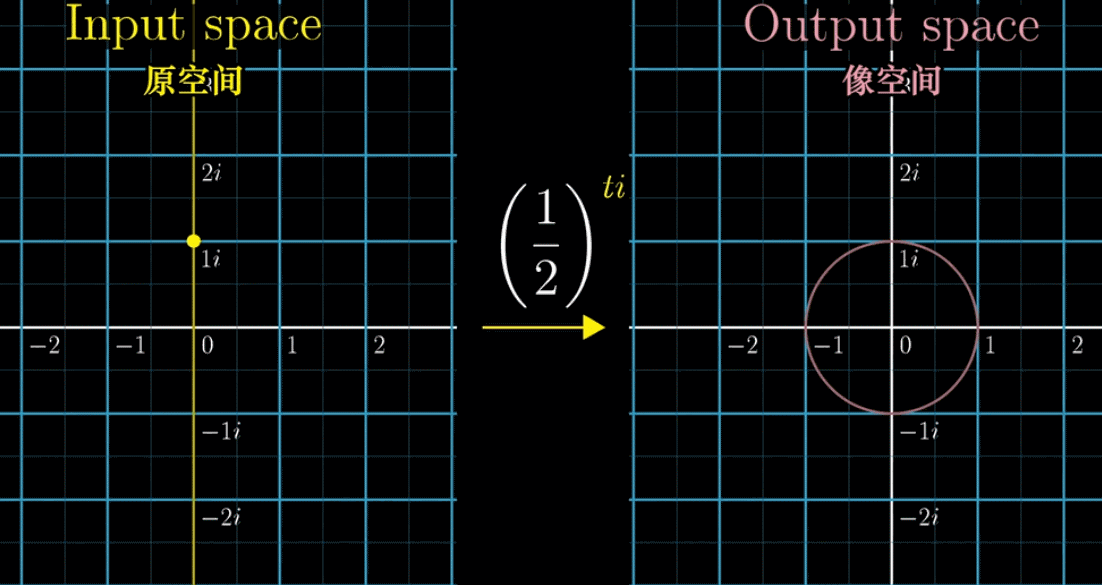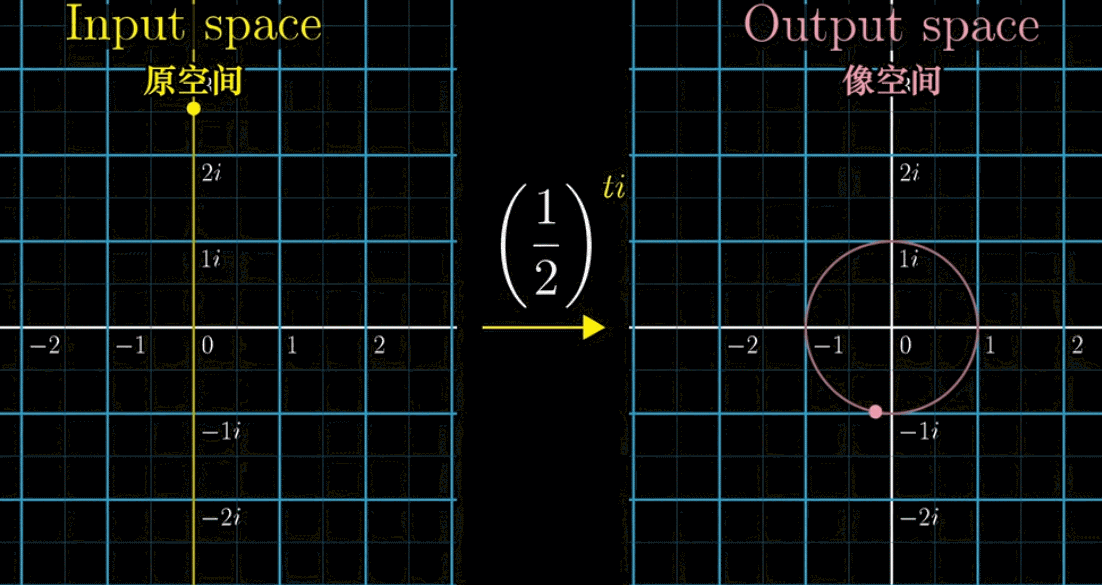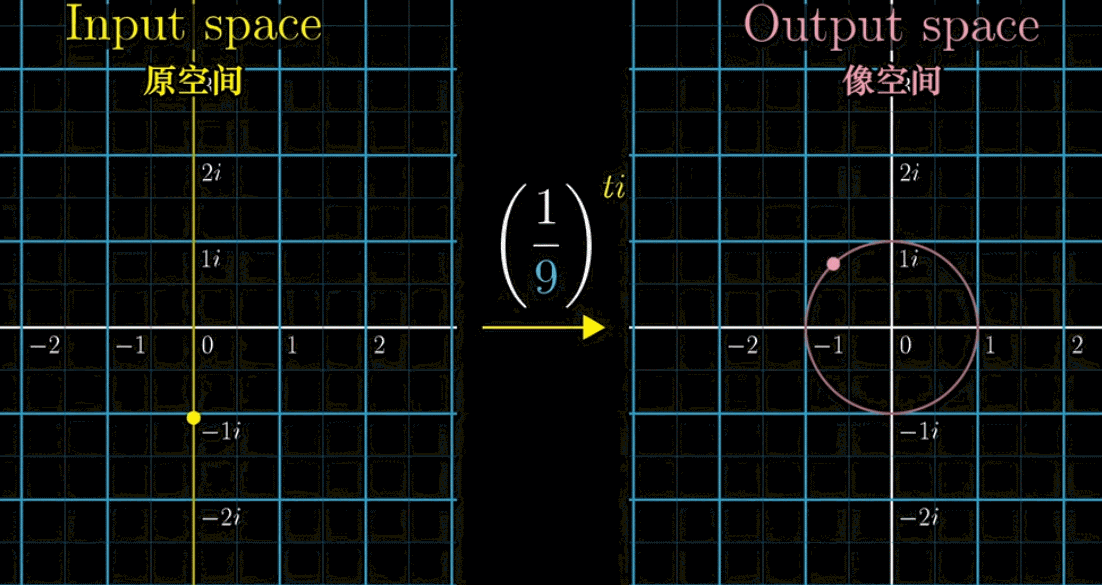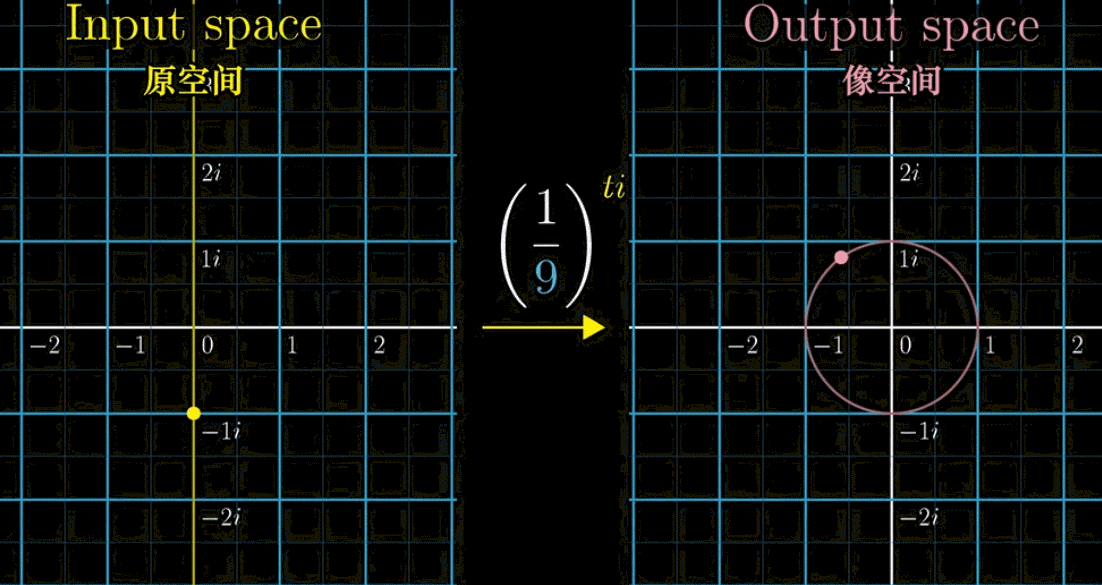
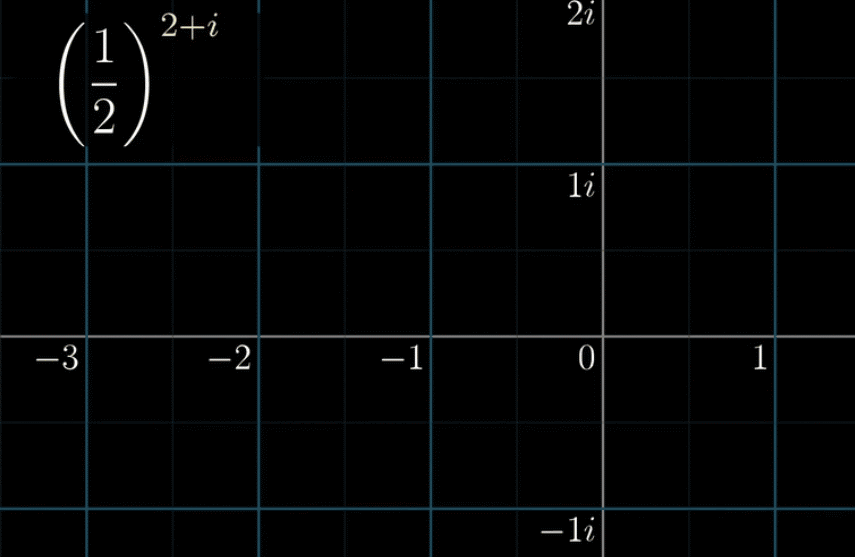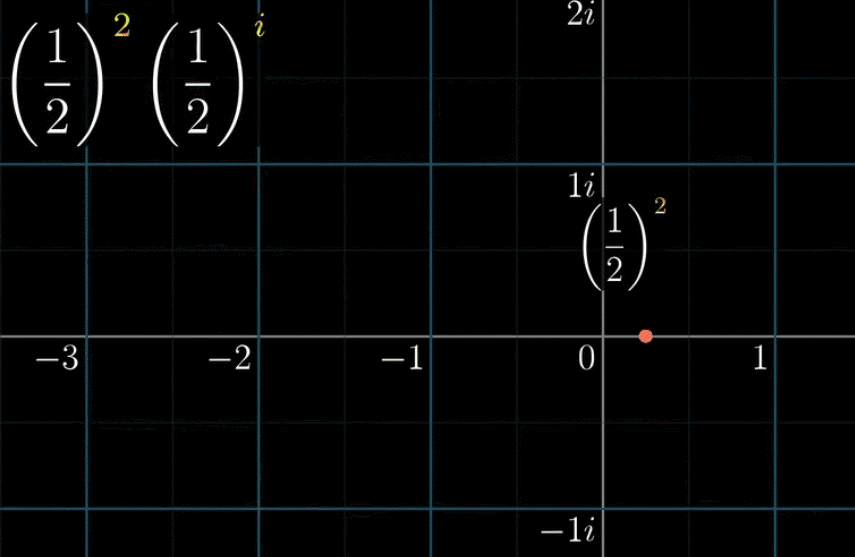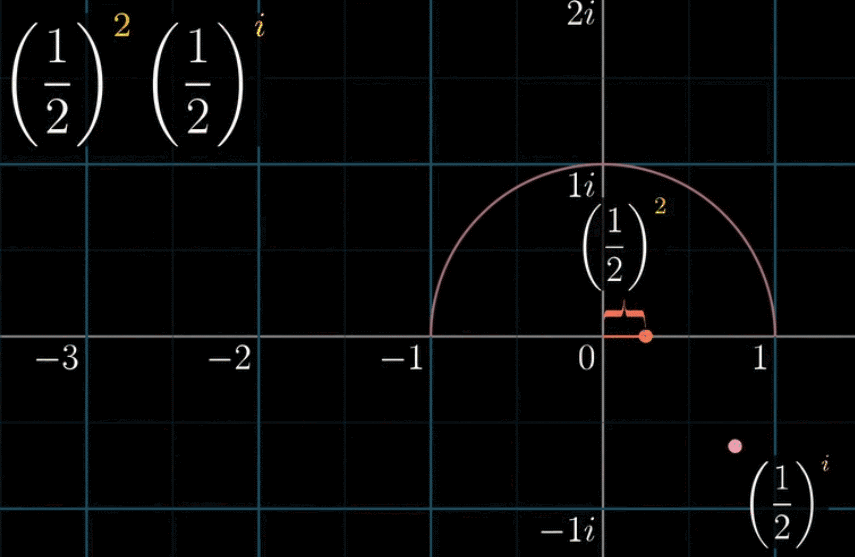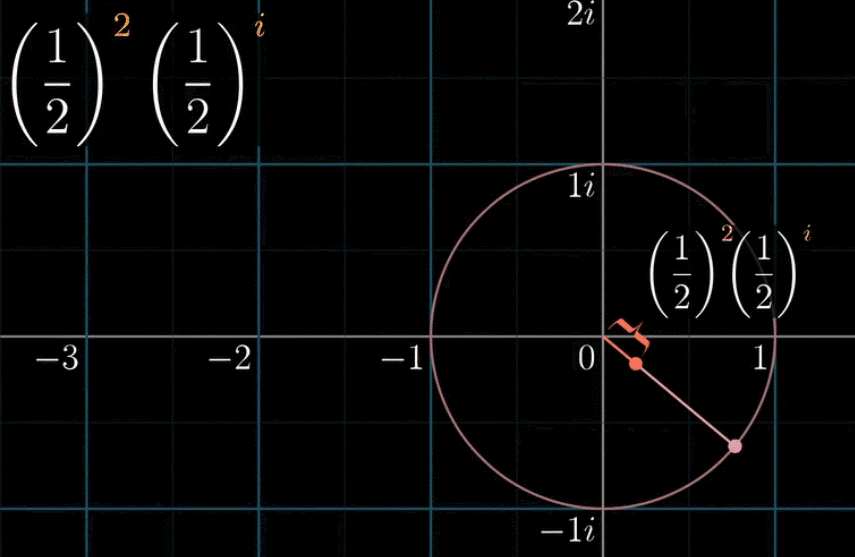
首先,下面这副动图表示,假设我们把指数 $i$ 前加一个自变量 $t$ ,就构造了一个函数 $f(t) = \left(\cfrac{1}{2}\right)^{ti}$ ,可以看到左边的黄色点在纵轴(虚轴)上移动,表示的就是引入一个自变量
接着,我们把左边的输入带入 $f(t)$ 得到右边的output像空间,即 $\left(\cfrac{1}{2}\right)^{ti}$ 的值。会有下面一副动图所示的对应关系(移动黄色点,粉色点作为输出联动)。如果改变底数 $\cfrac{1}{2}$ ➜ $\cfrac{1}{9}$ ,左边黄点移动的时候,右边粉点的旋转速度变快,这就是幂指数函数在复数域上的映射规律
总结一下,以上对两个问题的阐述是为了建立一个直观概念:幂指数是虚数单位的乘法对应了复平面内的旋转,接下来一张动图就来看看 $\left( \cfrac{1}{2} \right) ^{2+i}$ 是怎么算的:(关注红色线段,即最后的结果)
① 实部把点收缩到 $\cfrac{1}{4}$ 的位置
② $\left( \cfrac{1}{2}\right)^i$ 不改变长度(因为是虚部),只旋转一个对应的角度
⭐️一步一步可视化
进行旋转
下面这副动图非常重要!先把实部部分加起来,再对每一项还需要乘一个 $(\cfrac{1}{2})^i$ ,也就是每一个线段都需要进行一个同样角度的旋转
这副动图可以多看几遍,应该是挺好理解的。这里有个很细节的问题:第一段线段没动,是不是意味着没有进行旋转呢?,对应相乘的部分是 $1^i$ ,这可能意味着这个旋转恰好是转过了一圈(时间有限,未能求证,大概率是这样理解)
接下来的动图展示了在 $s$ 变化的过程中,对应的螺旋线的变化情况,这幅动图看的有点上瘾
考虑定义域的话,实数部分要能收敛:即在下图右侧黄色高亮区域, $s$ 的实部大于1
变换黎曼$\zeta$函数
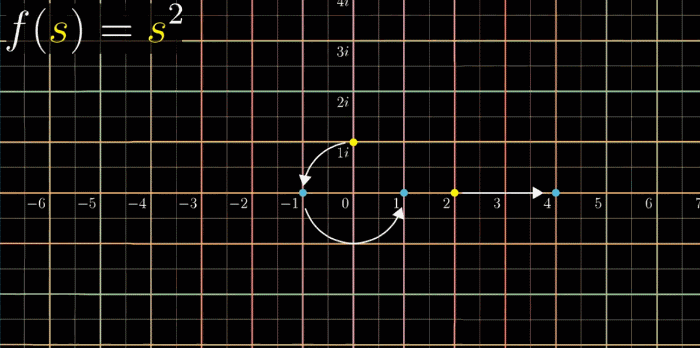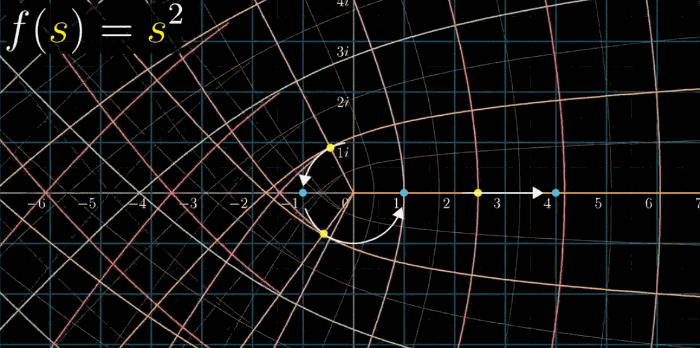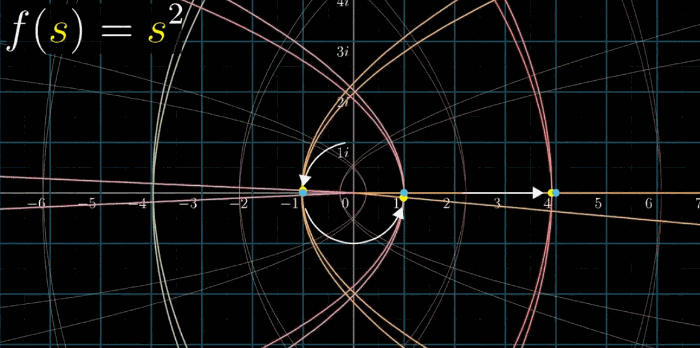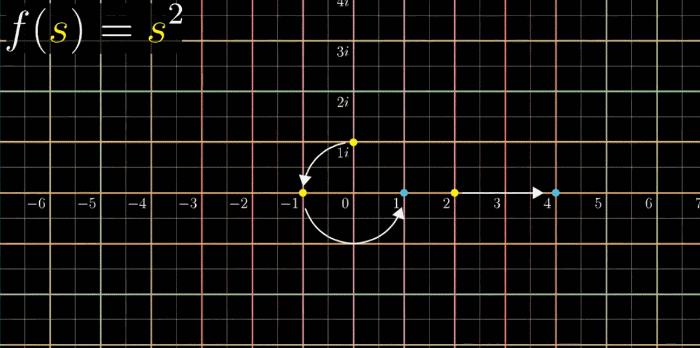
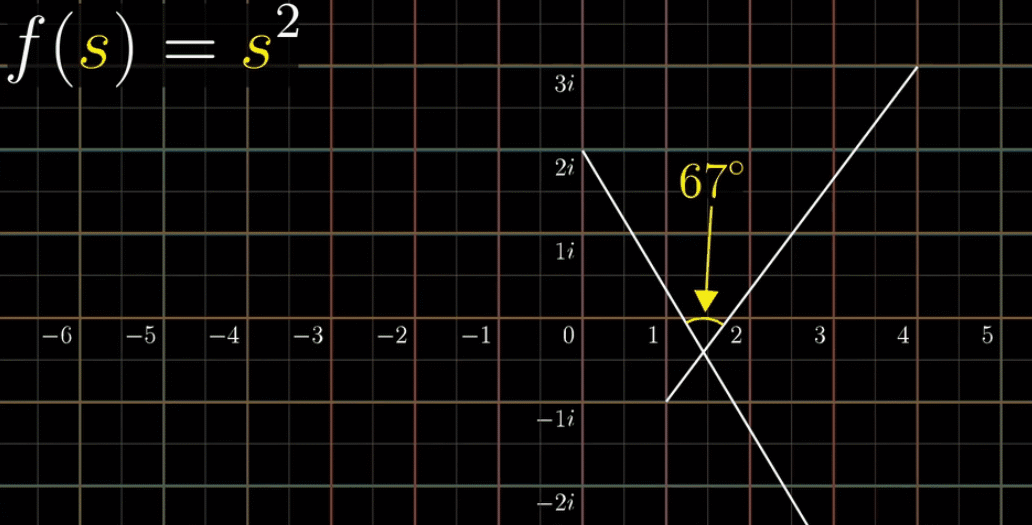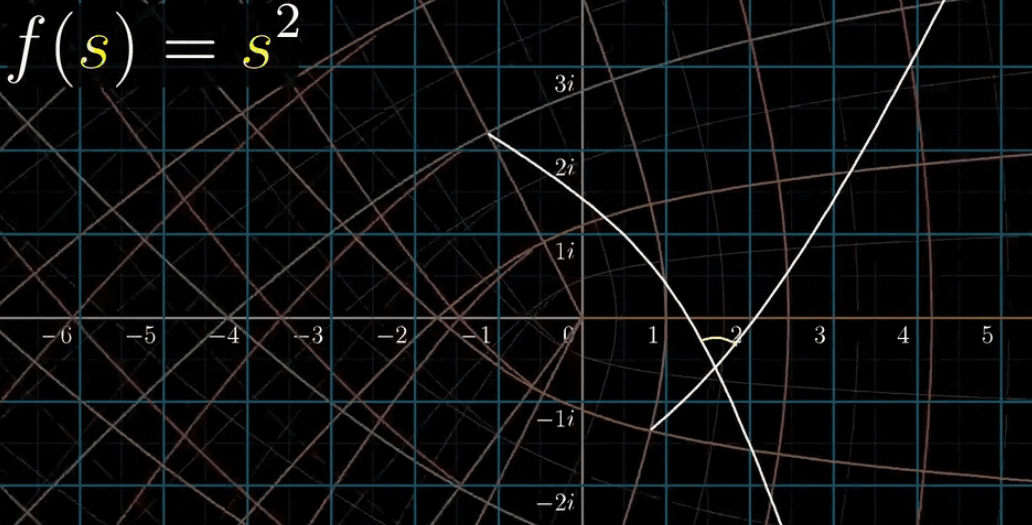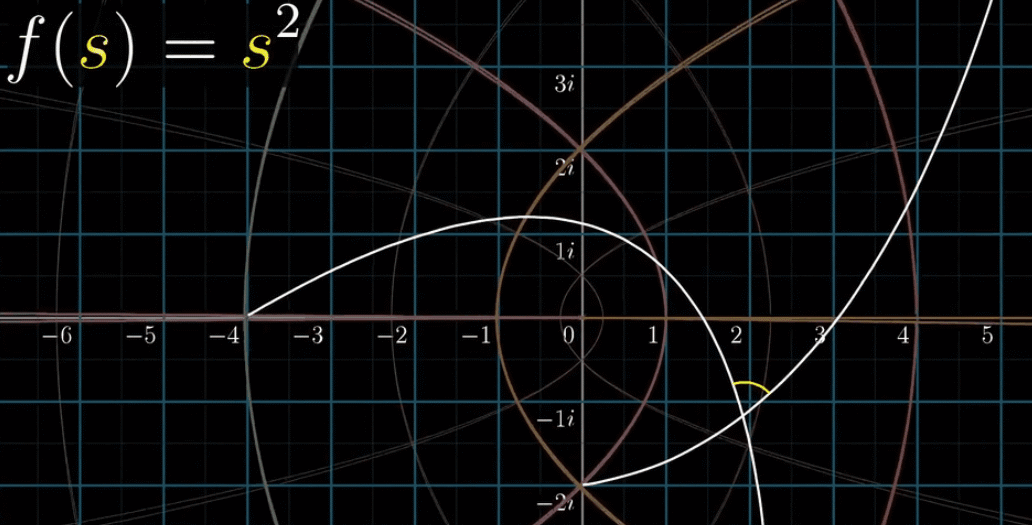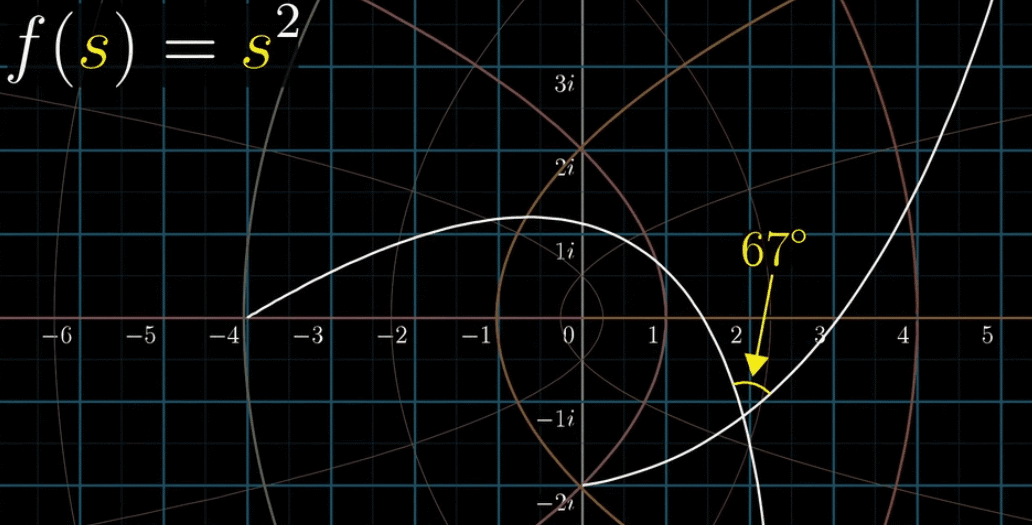
理解这个复函数一个好方法是通过变换来将其可视化,即将复函数看作变换,为了加深理解,在变换黎曼$\zeta$函数前,先变换一个比较简单的函数
$$
f(s) = s^2
$$
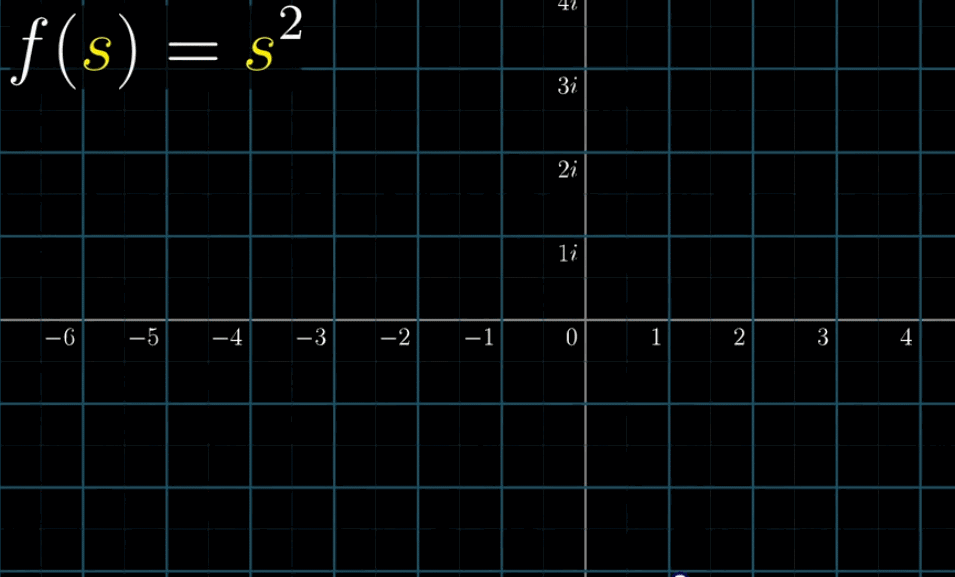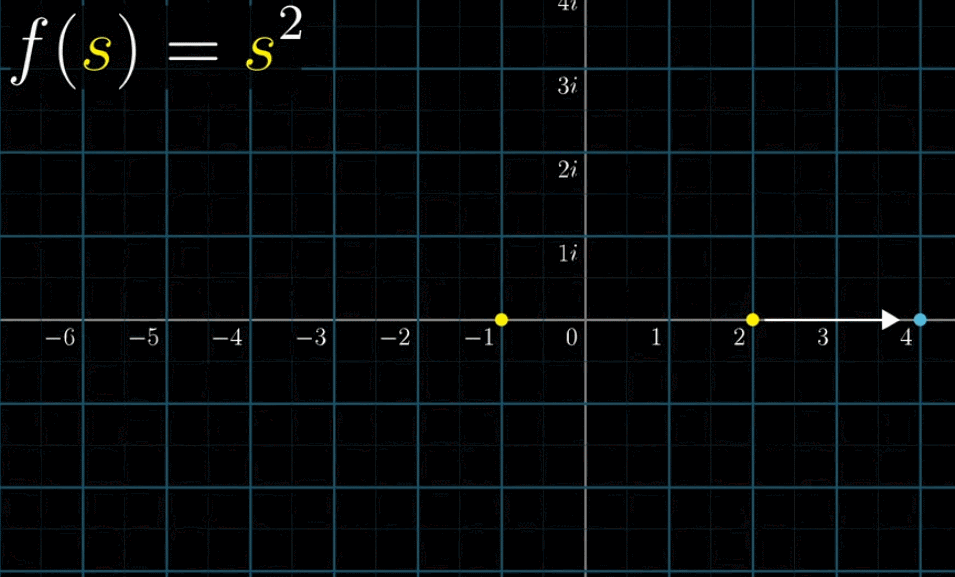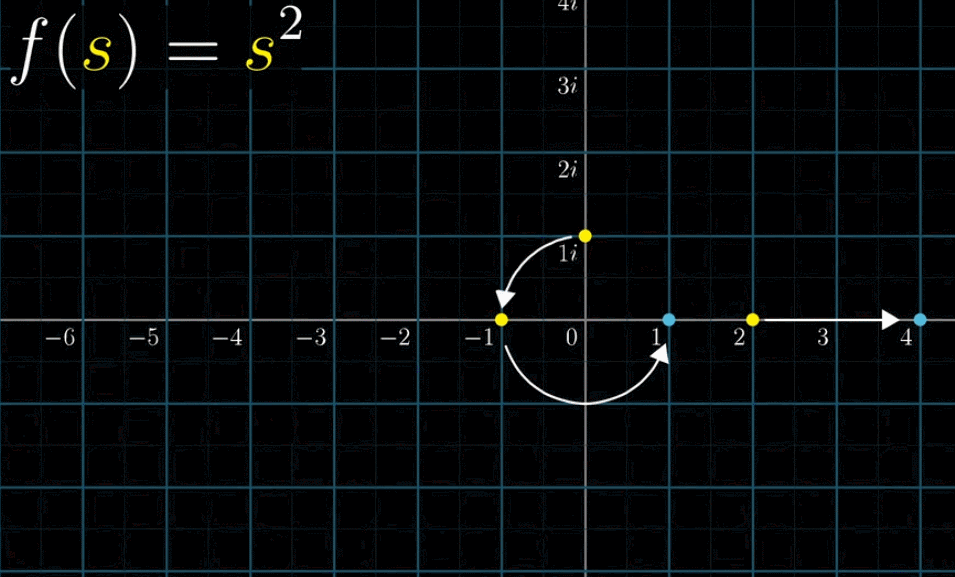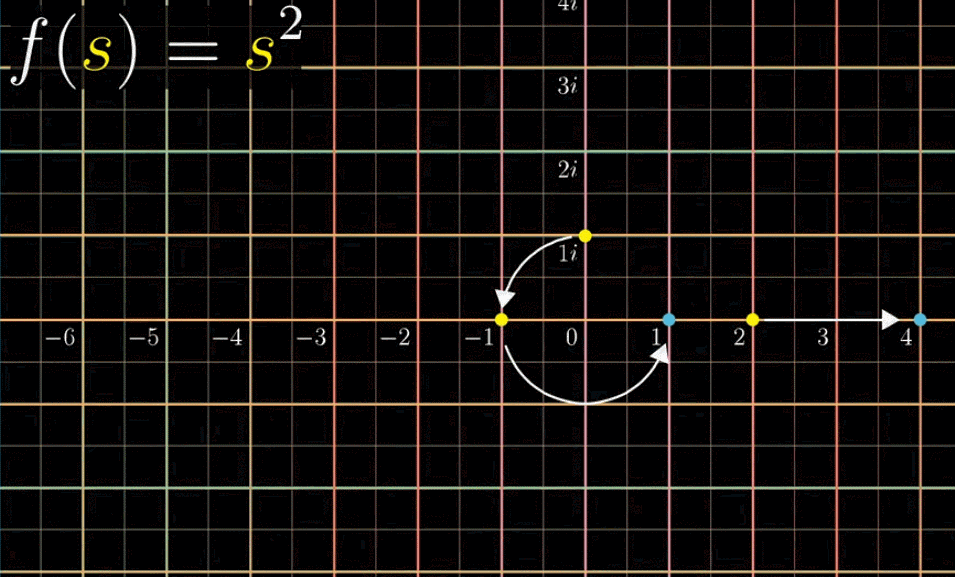
按照下面的动图,带入 $2$ 得到 $4$ ,带入 $-1$ 得到 $1$ ,带入 $1i$ 得到 $-1$
最后把所有的网格都标记彩色,下一幅动图同时变换网格上所有的点,形成新的网格:
同时观察所有点的变换比较吃力,你可以尝试在看的时候关注一个点的变化过程,比如关注 $(-1, 0)$ 这一点:它逆时针旋转了180° 。这副动图给了我们丰富的信息来直观的展现复函数变化到底做了什么
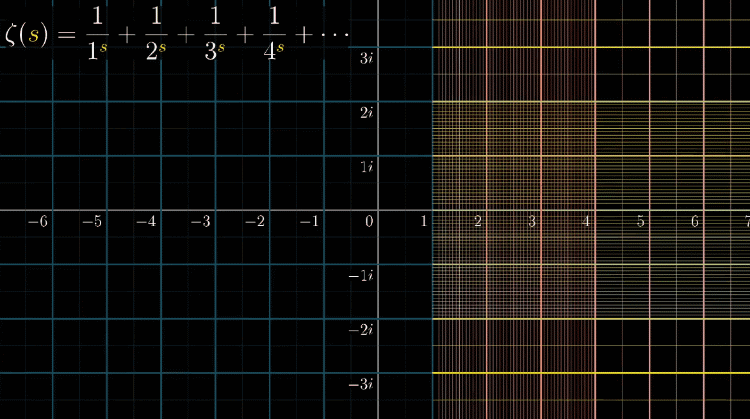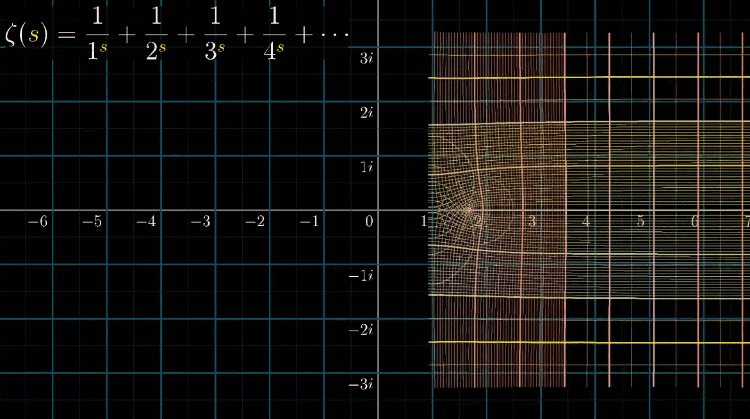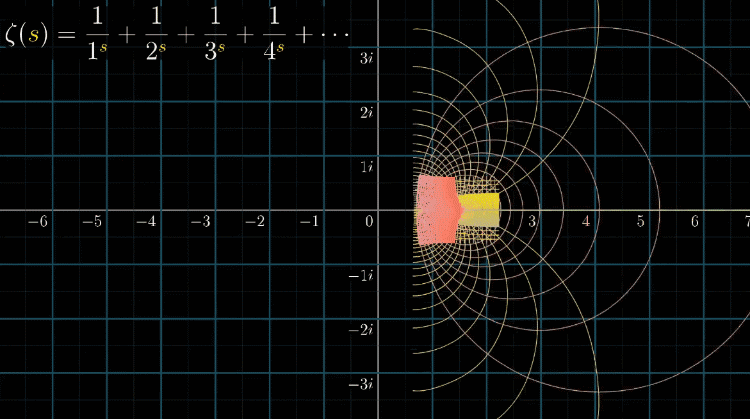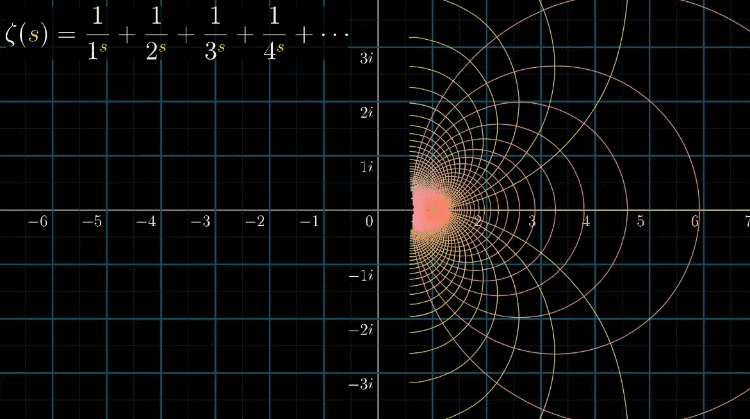
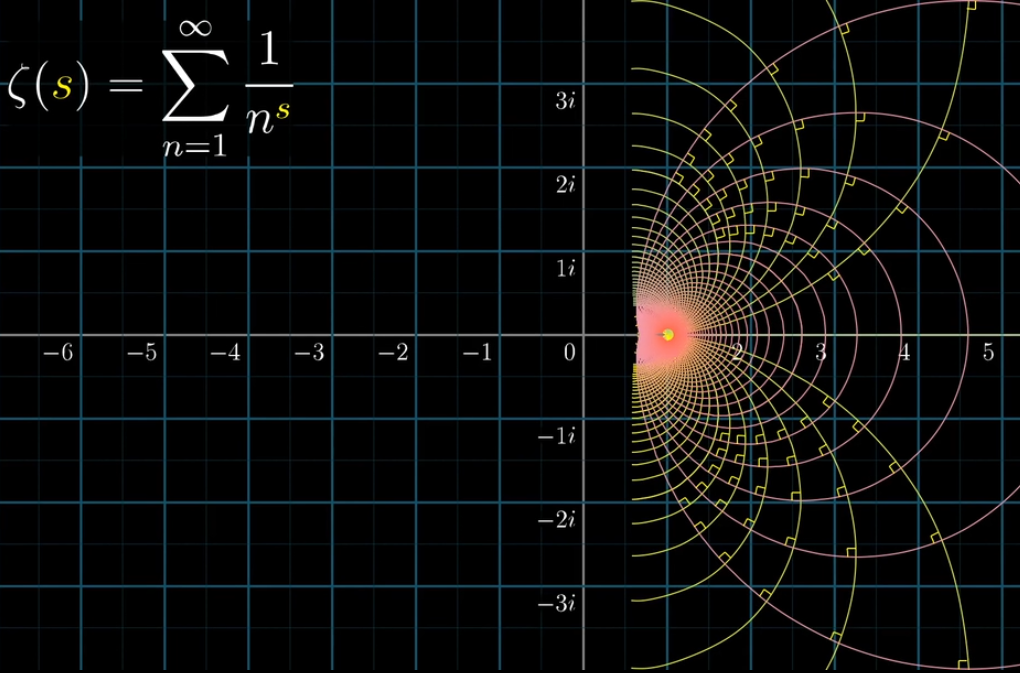
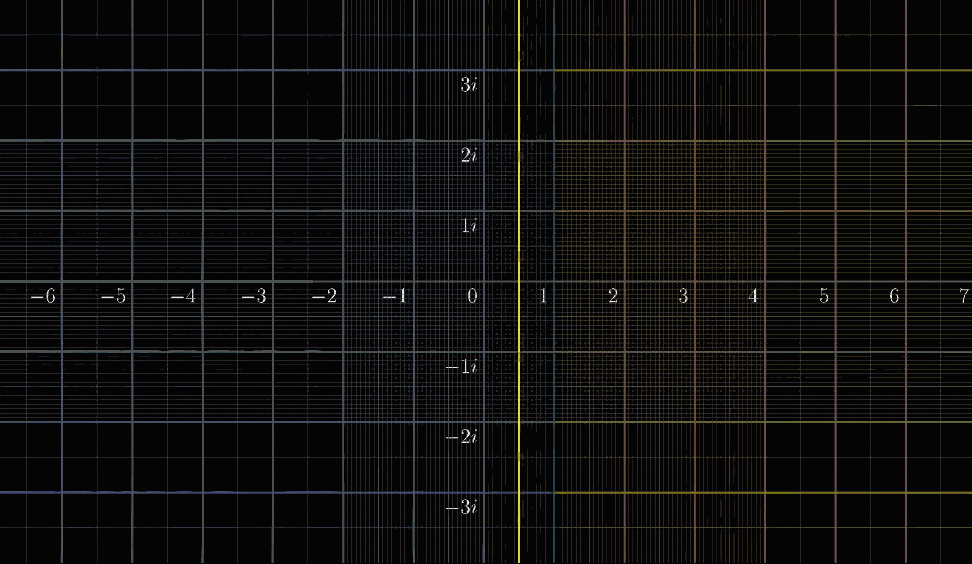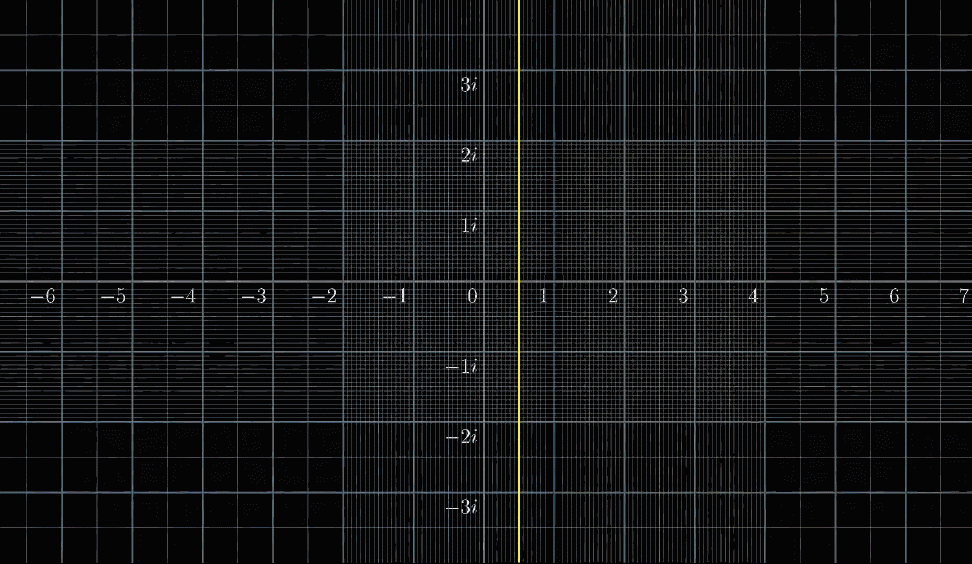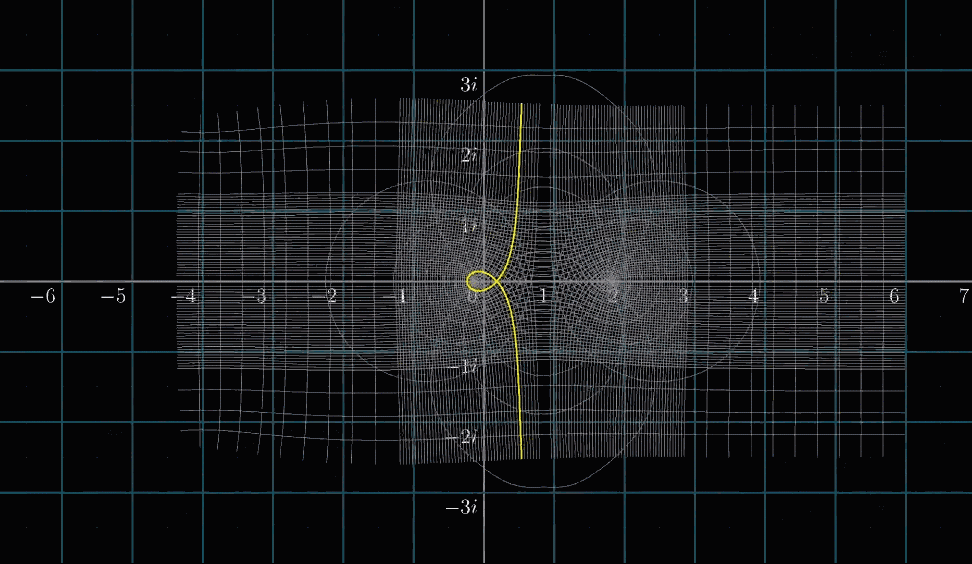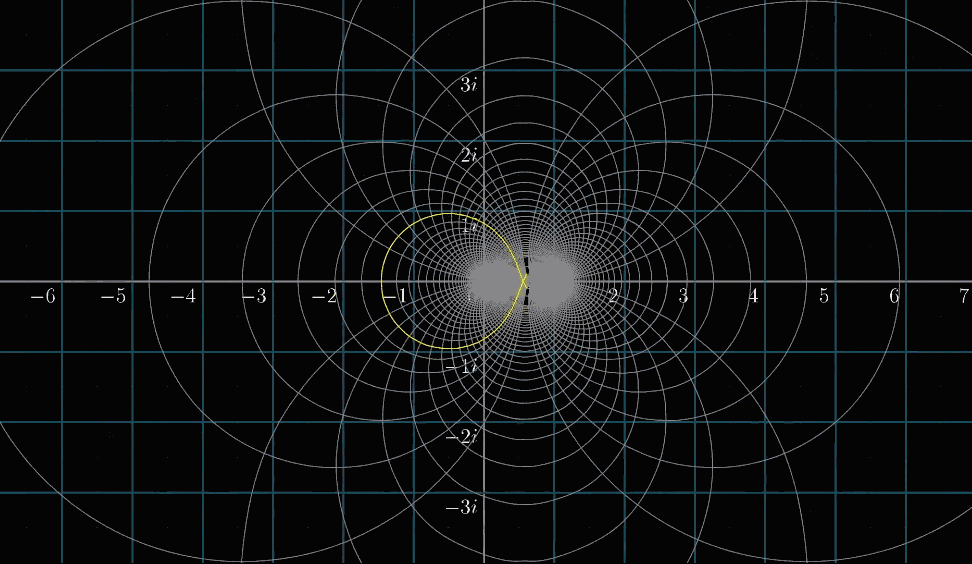
同理,可视化黎曼$\zeta$函数,如下列动图所示
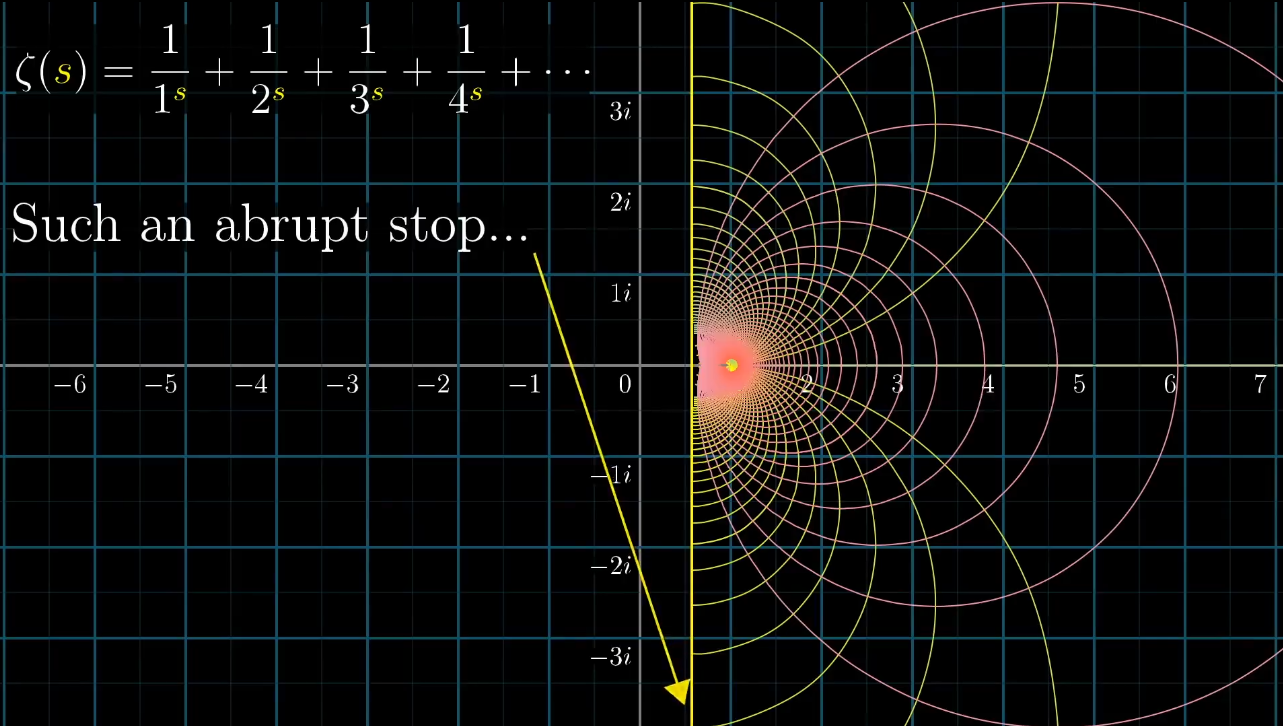
如果这么漂亮的图像都完全无法激起你继续钻研复分析的兴趣,那么……
难受的停顿
你可能已经发现了,变换的图像左边有一个十分突兀的切面,停顿的很不自然,整个图像一场明显的表露除了一种希望冲破定义域的渴望
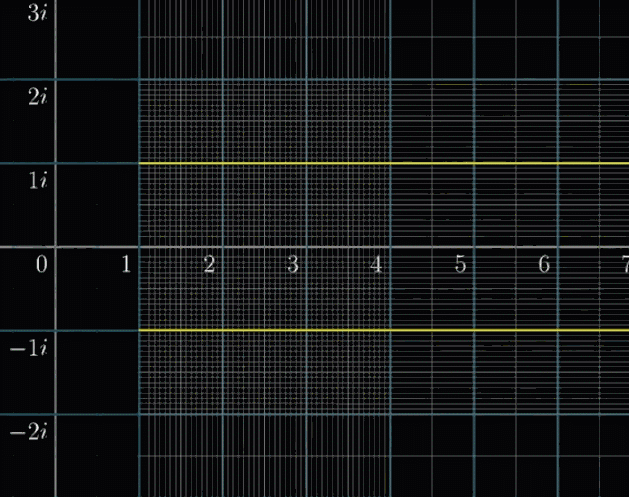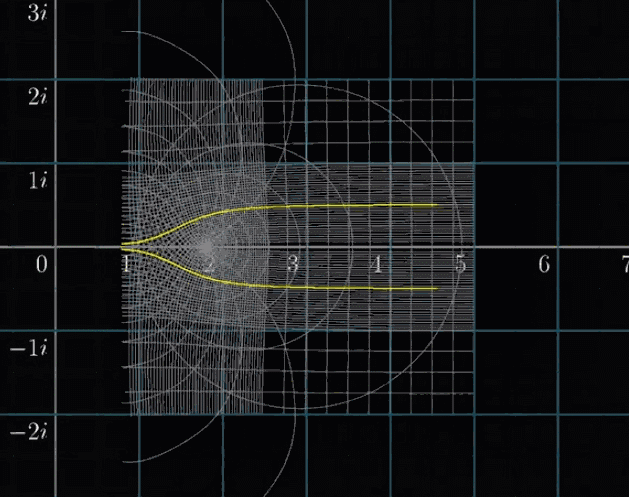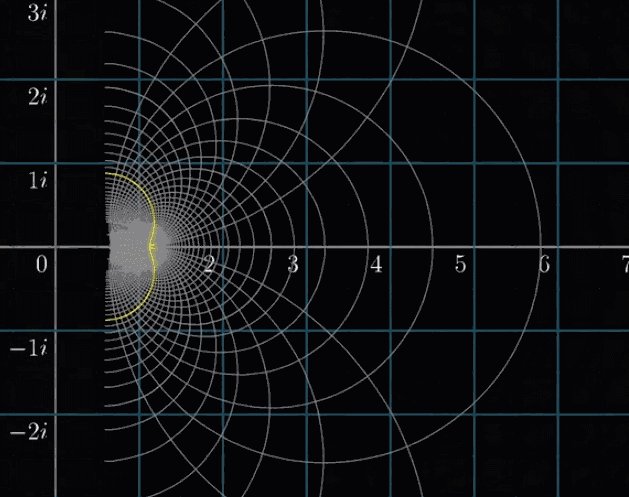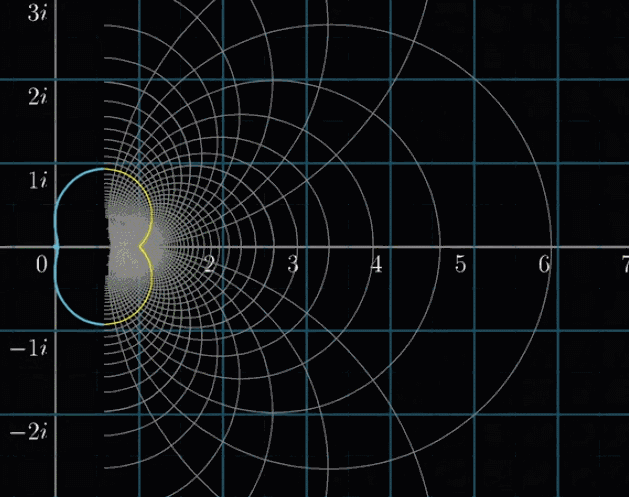
那么,我们专门高亮两条线:虚部等于 $i$ 和 $-i$ 的两条横线,然后进行变换。难道你没有冲动去补全它吗?
解析延拓
可以去想象,在 $Re(s)=1$ 的左半边,有一个改良版的函数(即下图蓝紫色的函数),可以完美的补全整个空间
用数学的形式来表示的话,问题就变成了,在左边一半的定义域内,这个函数是什么的问题,如下图(Re表示实部)
此时,我们就可以可视化出开篇提到的那个表达式 $\zeta(-1) = 1 + 2 + 3 + \cdots = - \cfrac{1}{12}$ ,你现在知道这个公式怎么来的了,因为钻了定义域不同函数形式不同的空子,其实上面这个式子的论断是很荒谬的
新的问题又出来了,补全的部分,如果没有条件限制,随便怎么画都行,补全这条路难道走不通?
真的是这样吗?并不是,黎曼$\zeta$函数自带一个限制(约束)条件:函数是解析函数,补全部分形式处处可导
这里有一个更加优雅的方法来理解处处可导(解析)这个条件
我们先来看 $f(s) = s^2$ ,它的导数形式是 $f’(s) = 2s$ ,在可视化部分来看,处处可导等价于变换后任意两条线段的夹角不变,又称保角(保证交角不变)特性,参看下图
这个规律在所有网格线中都成立,所以,解析的 = 保持交角不变,即可以把解析的理解成保角的。如果你是一个追根究底的人,就能发现其实还是有例外的,比如在原点的交角变换后呈整数倍的关系,没有保角特性
下面给一副平移的动图,解析函数处处保角
黎曼$\zeta$函数就是一个保角函数,或说解析函数,网格出处垂直,处处可导
因为黎曼$\zeta$函数是一个解析函数,那么要想在左定义域延拓,又要满足解析的性质,有且仅有一种延拓方法,这也是解析延拓的含义
可视化黎曼$\zeta$函数总结
按照解析延拓的方式进行了补全操作后,我们就走完了黎曼$\zeta$函数的可视化过程了,总结一下逻辑链
右定义域内假设自变量为复数,扩展到复数域 ➜ 进行变换,获得复数域可视化形态 ➜ 左定义域内无意义,进行
解析延拓
另,这里补充左半边延拓的解析形式,数学家们已经给出了解
$$
\zeta(s) = 2^s{\pi}^{s-1}\sin(\frac{\pi s}{2})\Gamma(1-s)\zeta(1-s)
$$
素数规律和黎曼猜想
再看黎曼猜想
在有了上述的直观理解后,我们再反回来看看黎曼猜想
有了变换的思维后,那么在这个变化后哪些点会落在原点呢?这个问题非常关键,因为它和求黎曼$\zeta$函数的零点等价
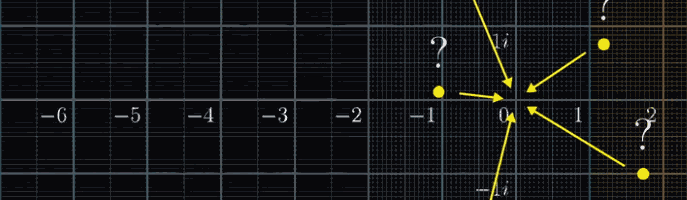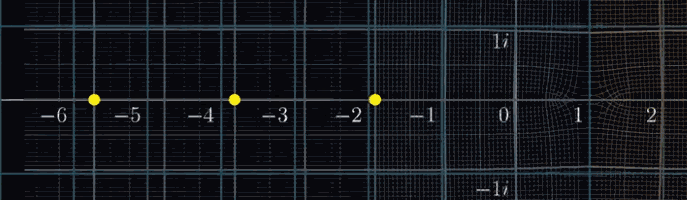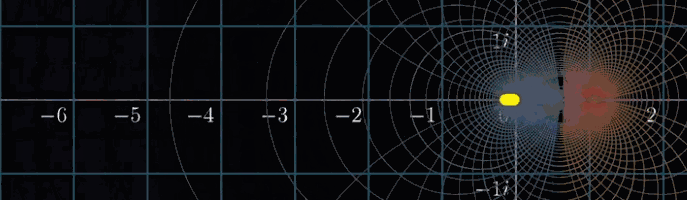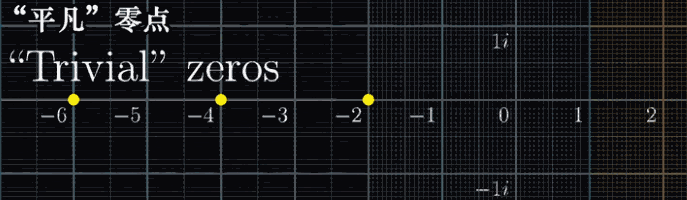
首先,所有满足 $Re(s) = -2n$ 的点都会落在原点,这些点被称为平凡零点(根据数学家的传统,他们太容易被发现了,太好理解了,所以被称为“平凡”)
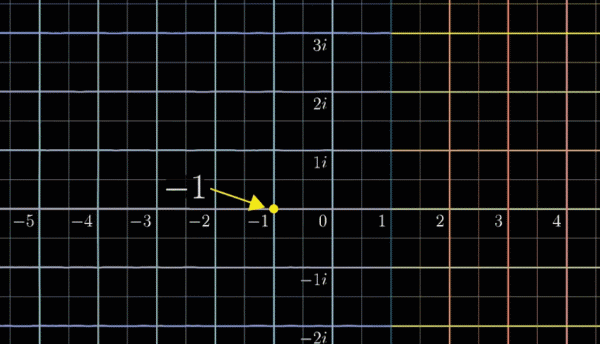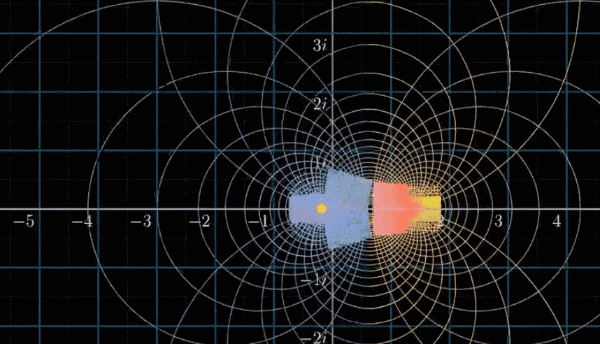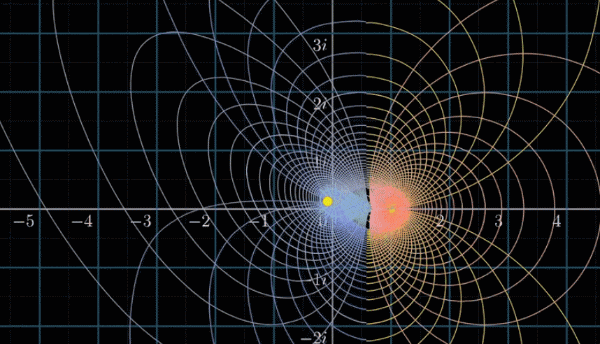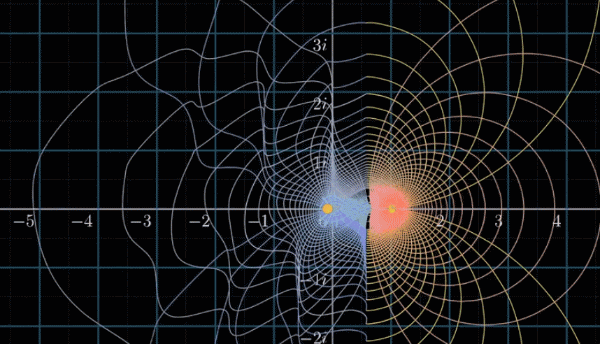
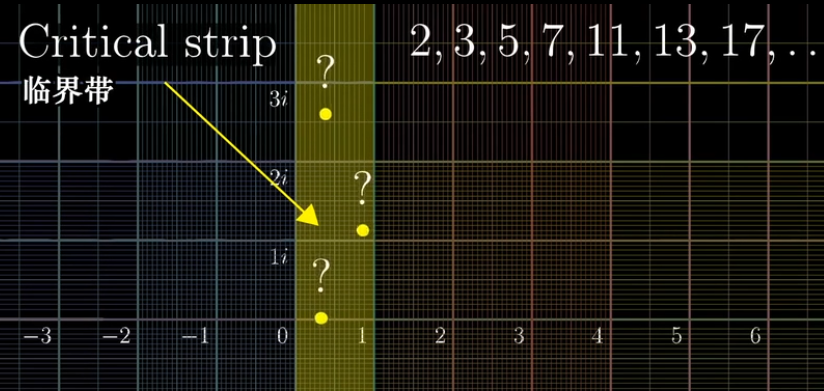
那么非平凡零点呢?我们已知所有的非平凡零点都落在下图的这个临界带(Critical Strip)中。至于原因,如果再仔细看一下这个复数域可视化变换所有点移动的趋势,大概就知道为什么这么说了,简单来说,是复分析变换计算出来的结果
更加令人不可思议的是,这些非平凡零点的具体分布,蕴含着有关素数的海量信息。至于为什么有素数的海量信息,之后会写一篇博文讲讲这其中的奥妙(3B1B的另一个视频的总结笔记)
黎曼猜想就是在说:这些非平凡零点,都在实部 $Re(s)=\cfrac{1}{2}$ 的这条临界线(Critical Line)上,如下图所示。如果它成立,那么它能让我们深刻理解素数分布的规律,根据最新进展中和其他证明,这个规律应该符合某种分布的均匀分布
假设在变换过程中高亮 $Re(s)=\cfrac{1}{2}$ 这条线,以我们可以看到的可视化区域(就是动图中前面跳动的一下的部分)的变换过程如下图所示,貌似它并没有过零点?
其实不然,这个动图只绘出了可视区域内的线段的变换结果,如果我们把这个线段加长(不理解可以参考上面的动图,黄色就是可视化时候原图像的线),就得到了下面一个动图了
其中,如果你能证明所有的非平凡零点都在这条临界线上(也就是原命题中的 $\cfrac{1}{2}$),那黎曼猜想变成黎曼定理!同时你也证明了成百上千的现代数学结论,当然,还有100万美元的奖金
有趣的是,现在很多现代数学理论的证明,不管黎曼猜想是正确还是不正确都能被证明是正确的。看到一个叫做littlewood定理的证明就是这样,可算是数学奇妙的冰山一角了
素数规律
之前提及黎曼猜想中蕴含着海量的素数信息。并在开篇有说到,1900年希尔伯特的23大难题中,黎曼猜想、哥德巴赫猜想和孪生素数猜想同为第8题,寻找素数(分解质因数后只有1和他本身的数),素数分布的规律,质因数分解,还有复分析之间一定是有千丝万缕的联系的
建议大家可以观看李永乐老师的黎曼猜想第二期视频,将素数规律讲的非常好,我这里就当好学生,做一些笔记
素数个数
素数到底有多少个呢?这个问题已经被确定回答了,答案是有无穷多个。那是谁证明的呢?由欧几里得(他是公元前300年的人)证明,使用的是反证法,怎么说的呢?
设质数的个数是有限的,那么就有一个最大的自然数 $p$,可以写成一个素数序列: $2,3,5,\cdots,p$,令
$$
q = 2×3×5×\cdots × p + 1 \tag 1
$$
① 假设 $q$ 是质数 ➜ $q\gt p$ 这和 $p$ 是最大的质数这个假设矛盾
② 假设 $q$ 是合数(不是质数的数) ➜ $q$ 是有约数的,不是1也不是它本身 ➜ 那就一定是(1)式中 $2×3×5×\cdots × p$ 中的某一个,但是由(1)式可得,$q$ 除以$2×3×5×\cdots × p$ 中任何一个数都余1 ➜ 所以肯定不能整除,与假设 $q$ 是合数矛盾
证毕。这个证明简洁而优雅,数学之美牛皮
欧拉乘积公式
神人欧拉(1707-1783)出现,推导出了欧拉乘积公式,怎么个说法呢?
假设 $p$ 表示全体素数,有下面一个公式成立
$$
\prod\limits_{p} (1-p^{-s})^{-1} = \frac{1}{1-\cfrac{1}{2^s}}×\frac{1}{1-\cfrac{1}{3^s}}×\frac{1}{1-\cfrac{1}{5^s}}×\cdots = \cfrac{1}{1^s}+\cfrac{1}{2^s}+\cfrac{1}{3^s}+\cdots
$$
那这个公式有什么用呢?它告诉我们,黎曼函数和质数之间有隐含的关系。左边是和所有质数有关的项的乘积,右边是黎曼$\zeta$函数
素数定理
假设有这么一个表达式 $\pi(x)$ 表示小于 $x$ 素数的个数,有这么一个规律,参见下图
啥意思呢,横坐标就是自变量 $x$ 的取值,蓝色的线是 $\cfrac{\pi(x)}{\frac{x}{\ln(x)}}$ ,红色的线是 $\cfrac{\pi(x)}{\int_{2}^{x}\frac{1}{\ln t} dt}$ ,分母的 $\int_{2}^{x}\cfrac{1}{\ln t} dt$ 又被称成 $Li(x)$
可以看到,当 $x \to +\infty $ ,这个 $\pi(x)$ 函数是可以写出表达式的
二号神人高斯(1777-1855)研究了一下关于素数密度 $\rho$ 的问题,也就是1000个数里面,有多少个素数。对的,上面蓝线的规律是高斯最早发现,但当时高斯觉得这个发现貌似并不重要,就没有展开来研究。后来1798年勒让德(1752-1833)发现了下面那个红色曲线的表达式,在学界有个涟漪,高斯在1849年就告诉勒让德,你这不行,是我先发现的啊,所以这公式被称为高斯-勒让德公式
$$
\pi(x) \sim \frac{x}{\ln x} \iff \pi(x) = \int_{0}^{x} \frac{dt}{\ln t} + C
$$
$\sim$ 符号表示趋近于,也就是当 $x \to +\infty $ 的意思。 $C$ 是一个常数,这个常数随着 $x$ 的变大而越来越小
再观察上面的图,明显发现红色的线收敛到1的速度更快,所以后面科勒(1870-1924)做了改进和提高。他说,如果黎曼猜想成立(写到这句话可是真不容易),那么这个关系误差式可更加精确,可大大改善素数定理误差的估计
$$
\pi(x) = Li(x)+ O(\sqrt{x}\ln x)
$$
$O()$ 被称为渐进符号,一般用来描述无穷级数的余项。在计算和表示算法复杂度方面也很用,比如$O(n^2)$ 其实就是忽略 $n$ 一次项和常数项的意思。因为在 $n$ 非常大时, $n$ 一次项对数值的贡献在量级上远小于 $n^2$ 二次项。这个余项的常数项的具体数值还没有算出来
之后50年,这个素数猜想被证明了出来,变成了素数定理。有趣的是,这份证明只是数学家研究黎曼猜想的边角料
素数,自然底数,虚数单位 $i$ 之间一定是存在的一些难以名状的关联,现在看来,有没有可能是量子力学叠加态在数理逻辑推理中的一种巧合的具象模式呢?静待未来,让数学家们给我们一个答案吧。胡适先生说过:哪管它真理无穷,进一寸有一寸的欢喜,切实能感同身受,可能就是这辈子最大的幸事之一了吧?
后记和思考
就在写作这篇博文的过程中,爵士阿蒂亚的证明过程的手稿已经公布(有点存疑是草稿,原文里面竟然有错别字weakly ➜ weekly),公开大会也已经结束,一张PPT证明黎曼猜想,有点诡异
但其中提及黎曼猜想和量子力学的关联给了我一些启发:素数和微观世界的规律一定有某种关联(在级数和等于 $\cfrac{\pi^2}{6}$ 部分的可视化解说里面就有很奇妙的规律关联)
无极生太极,其小无内,其大无外也,两面都是宇宙本源的运行规律,中华民族老祖宗《易经》已经有这种思维方法了,一面是精细结构常数,一面是引力常数
参照弦理论,高维度空间坍缩在很小的尺度内。那能不能猜想,正因为微观世界和高维度尺度更接近,导致被影响的程度也不一样,引力才一直没有统一(而其他三个力的规律已经统一)。相对应的,大尺度上的规律因时间尺度的限制(宇宙的寿命),我们作为人类从观测角度上来说,尺度太小。如果等葛立恒数年后,引力部分也会有一个类似微观世界的规律被发现呢?
这篇文章提到引力常数 $g$ 更加令人疑惑,是不是可能这个常数本身就是由两个量构成?大的那个符合微观规律,细调的那个因为观测受限(尺度太小)我们无法找到佐证的依据?现在人类追求佐证和实验,有没有可能这条路本身就是障碍?
最后还是希望直观详解这个系列能激起更多人的好奇心就心满意足了,附上一份目录
博客目录汇总(更新中)
【参考和来源】
所有动图来自:3B1B的视频【官方双语】黎曼ζ函数与解析延拓的可视化
李永乐老师1+2+3+4+…=-1/12?李永乐老师讲黎曼猜想(1)Youtube
质数有多重要?数学家欧拉和高斯是如何研究质数的 ?李永乐老师讲黎曼猜想(2)
wiki百科黎曼猜想
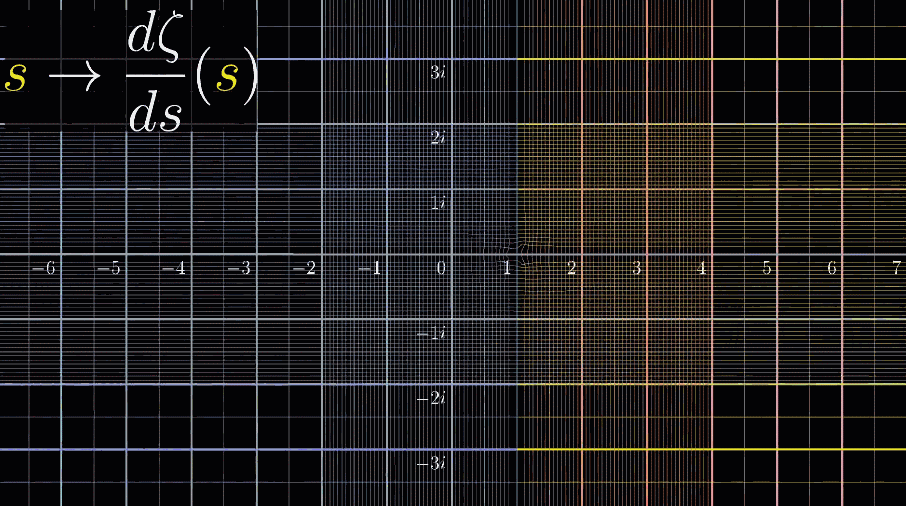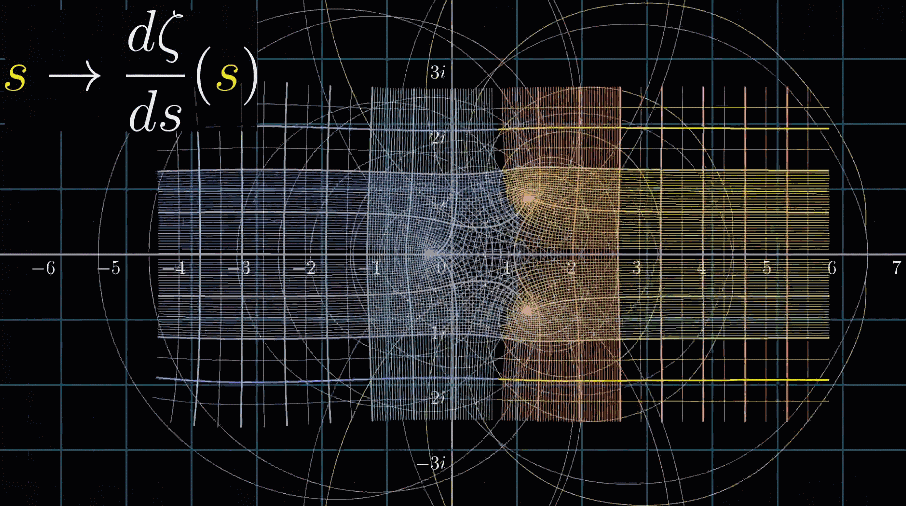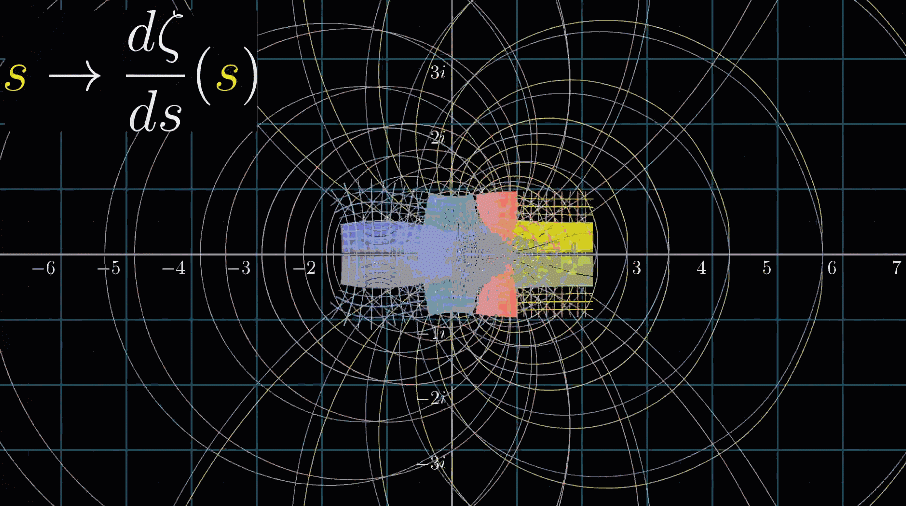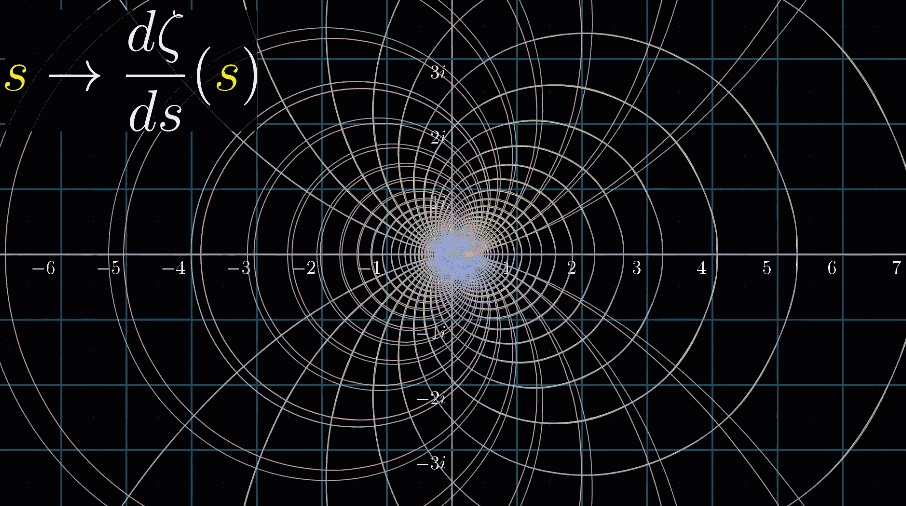
最后,和3B1B视频一样,来个看完彩蛋:黎曼$\zeta$函数的导数的可视化动图