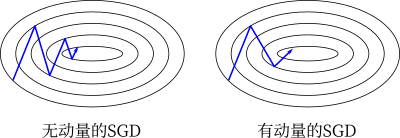结合 OpenClaw 的定义(OpenClaw is a self-hosted gateway …, and it becomes the bridge between your messaging apps and an always-available AI assistant. 3),其更符合个人助理的角色定位。数字分身相比另外两个角色最大的特点是其身份代表的是所有权人,除了技术实现难度外,更重要的是伦理问题。当数字员工出现问题时,是应该所有权人为其负责还是技术服务提供者为其负责呢?这个问题类似智能驾驶,当出现交通事故时,是应该由驾驶员承担责任还是自动驾驶服务提供商承担责任呢?目前来看,几乎全部责任仍是由驾驶人员承担。
我认为我们目前正处于 L3 至 L4 之间的一个地带,我相信在不久的将来我们可以突破 L4 迈入 L5。我希望 AI 会一直是为人所用,而不希望如之前博客所描述的人类成为 AI 的奴隶。引用一下阿西莫夫的机器人三定律,希望在生产力高速发展的同时我们也可以更多的关注一下 AI 可能引起的一系列社会和伦理问题。
机器人三定律
机器人不得伤害人类,或坐视人类受到伤害。
除非违背第一法则,机器人必须服从人类的命令。
在不违背第一及第二法则下,机器人必须保护自己。
Yao, Shunyu, et al. “React: Synergizing reasoning and acting in language models.” The eleventh international conference on learning representations. 2022. ↩︎
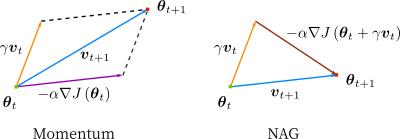
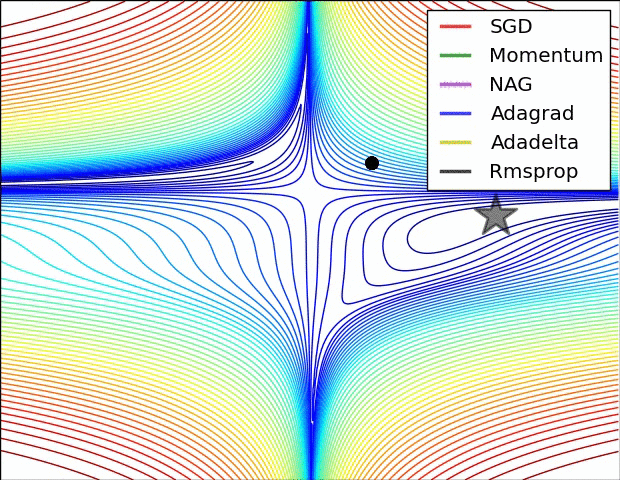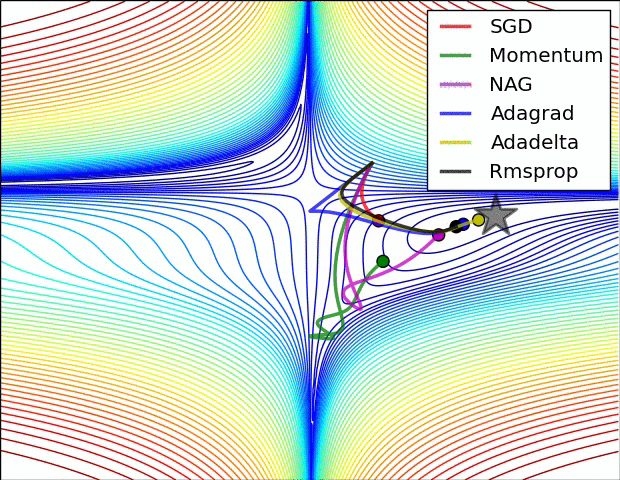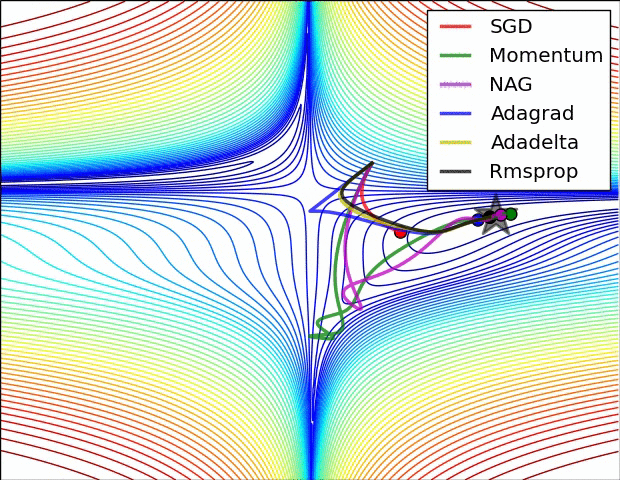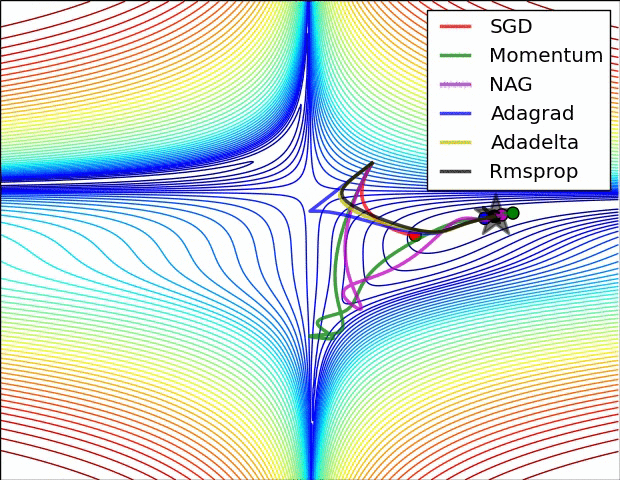
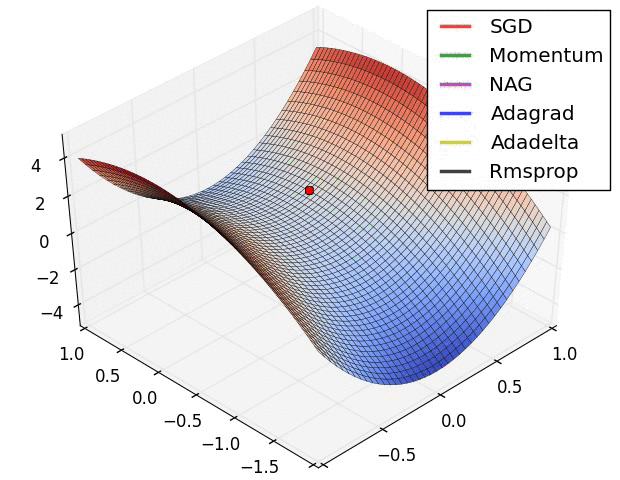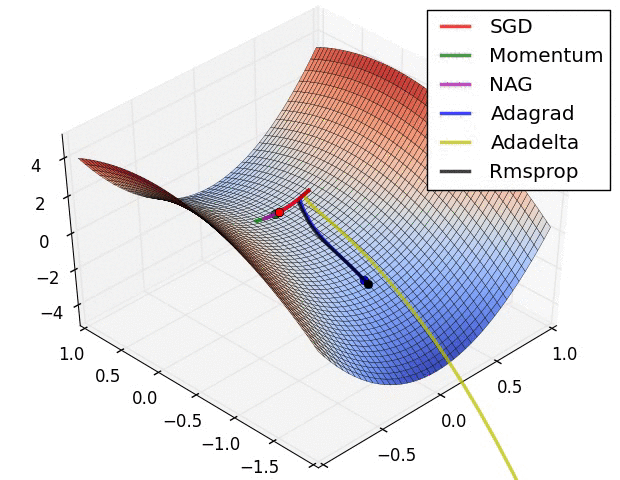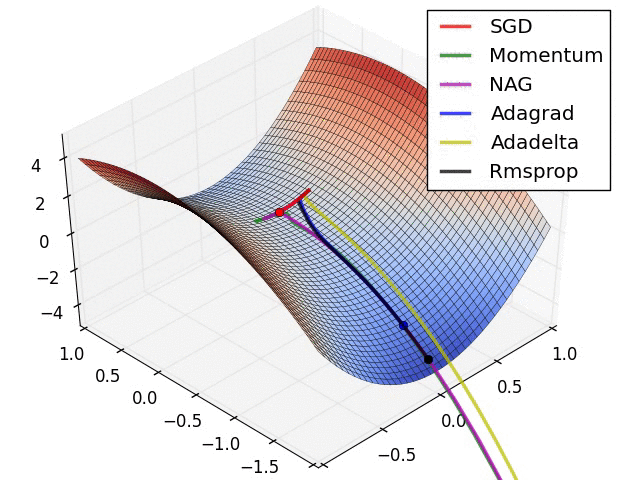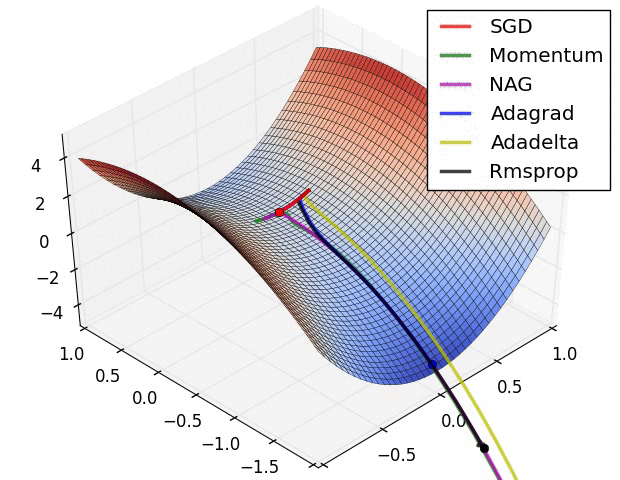
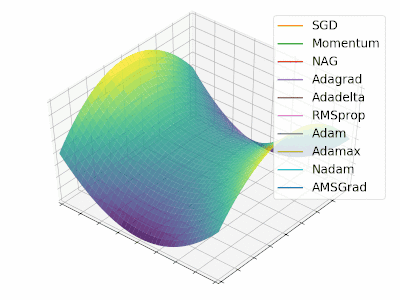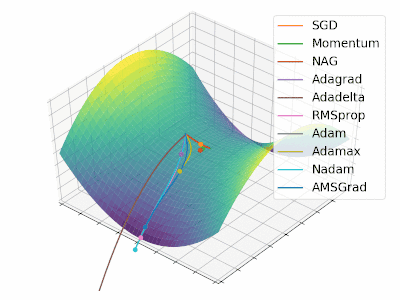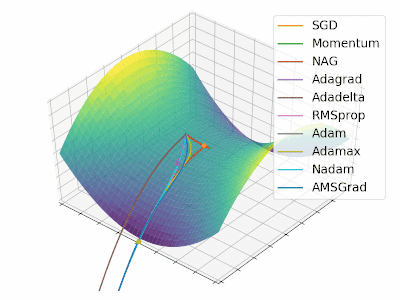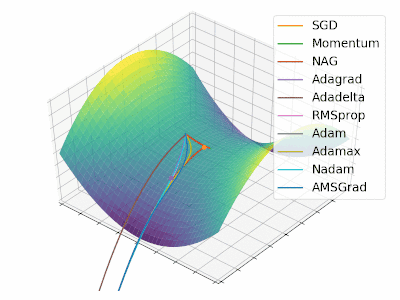
Adam 算法可以看做是对 RMSprop 和 Momentum 的结合:历史平方梯度的衰减项 $v_t$ (RMSprop) 和 历史梯度的衰减项 $m_t$ (Momentum)。Nadam (Nesterov-accelerated Adaptive Moment Estimation) 10 则是将 Adam 同 NAG 进行了进一步结合。我们利用 Adam 中的符号重新回顾一下 NAG 算法
Qian, Ning. “On the momentum term in gradient descent learning algorithms.” Neural networks 12.1 (1999): 145-151. ↩︎
Nesterov, Yurii. “A method for unconstrained convex minimization problem with the rate of convergence O (1/k^2).” Doklady AN USSR. Vol. 269. 1983. ↩︎
Sutskever, Ilya. “Training recurrent neural networks.” University of Toronto, Toronto, Ont., Canada (2013). ↩︎
Duchi, John, Elad Hazan, and Yoram Singer. “Adaptive subgradient methods for online learning and stochastic optimization.” Journal of Machine Learning Research 12.Jul (2011): 2121-2159. ↩︎
Pennington, Jeffrey, Richard Socher, and Christopher Manning. “Glove: Global vectors for word representation.” Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). 2014. ↩︎
Zeiler, Matthew D. “ADADELTA: an adaptive learning rate method.” arXiv preprint arXiv:1212.5701 (2012). ↩︎
Hinton, G., Nitish Srivastava, and Kevin Swersky. “Rmsprop: Divide the gradient by a running average of its recent magnitude.” Neural networks for machine learning, Coursera lecture 6e (2012). ↩︎
Kingma, Diederik P., and Jimmy Ba. “Adam: A method for stochastic optimization.” arXiv preprint arXiv:1412.6980 (2014). ↩︎
Dozat, Timothy. “Incorporating nesterov momentum into adam.” (2016). ↩︎
Reddi, Sashank J., Satyen Kale, and Sanjiv Kumar. “On the convergence of adam and beyond.” International Conference on Learning Representations. 2018. ↩︎
ollama 当前采用 ollama pull MODEL 命令下载模型,除了使用官方模型库中的模型名称外(例如:qwen3.5:27b-nvfp4),还可以使用 Hugging Face 的模型链接(例如:https://huggingface.co/lmstudio-community/Qwen3.5-27B-GGUF),运行如下命令下载模型:
第二个问题会比较实在些,天天在谈 ROI,公司出于更长远的战略考虑给到一定的免费额度,但如果需要实打实的花自己钱的时候你真的还会随便用吗?只能说当下很多人还没有被 AI 替代是因为 AI 的成本比我们这些牛马的工资还是要高的。我相信随着技术的不断发展,AI 的成本也会越来越低,此时我们更需要思考些更适合 AI 去做,哪些更适合我们去做,那些 AI 暂时还替代不了我们去做的才是我们的核心竞争力,再用 AI 把自己加持下才是最妙的。
创新。对于一些复杂的不确定性工作,AI 可以给到我很多新奇的点子,启发我把复杂的任务成功解决。很难说这是真的“创新”,也许在 AI 的脑子中这并非新鲜事物,但之于我自己而言,确实给到我眼前一亮的惊喜。前不久 Anthropic 团队使用 16 个智能体从零开始构建了一个基于 Rust 的 C 语言编译器 3。我很惊讶这么底层的能力就这样被自动实现了(我并没有去体验,单纯的惊讶),但也有人质疑这只是“临摹”而非“创作”。毕竟 AI 吃过的盐比我吃过的饭都要多得多得多。因此无须太纠结这是不是真的创新,之于你是,之于你在做的事儿是,那就是。
在谈及 AI 作为一种先进的生产力时,它与瓦特的蒸汽机、爱迪生的电灯泡、亦或是宾夕法尼亚大学的埃尼阿克并无差异,本质上都是社会生产环节中的一个辅助工具。
根据定义来看,AI 确实“不是”生产关系,生产关系探讨的主要是“人”与“物”以及“人”与“人”的关系,例如:生产资料所有制,生产中的地位和相互关系,产品的分配方式等。但 AI 作为生产力却可以影响生产关系,我认为此时用“重塑”会更适合些,因为这波 AI 带来的冲击确实过于迅猛。
之前听过付鹏的几期演讲和相关的播客,他将套利 4 的核心归纳为价差、利差、汇差,而在这些之前,还会有信息差、认知差、执行差、竞争差、资源差等等。我个人不是很懂投资,买过的股票基金啥的大多也是赔的,听的这些投资内容更多是出于对经济和风险的进一步理解。AI 在帮助我们缩小信息差、认知差、执行差、竞争差、资源差这些方面比之前变得更有可能,尤其是对于我们这些屁民而言。试想一下,之前在一个未知领域遇到了一个问题,Google 一下,搜索引擎玩儿的溜的能多获取一些有用的信息,玩儿不转的就只能凭人品看看有没有靠谱的朋友帮你解惑一二了。如果你有钱那就另说了,此时你又营造了资源差,但 AI 在帮助大家提升认知上貌似是公平的,是容易的。那么当答案获取变得便宜之后,什么又变得昂贵了呢?勇气,执行力,还是?
前不久比较火的一个词应该是“一人公司”(OPC,One Person Company),一个由 AI 技术驱动产生的全新组织范式。如果把一人公司做到极致,貌似你只需要同你的 AI 进行直接交流,AI 可以帮你去对接客户,AI 可以帮你去做产品,AI 可以帮你去销售。此时“人”-“人”的关系就转变成了“人”-“AI”-“人”的关系,甚至是“人”-“AI”-“AI”-“人”的关系,谁知道你的 AI 对接的客户是不是也是一个 AI 呢?从内部视角来看也是一样,从养一只虾到养多只虾,从管多只虾到管一只管多只虾的虾。
最后的最后,改编一下我比较喜欢的胡适先生的话「大胆假设,小心求证」,AI 时代的我们可以「积极拥抱(这是态度),审慎思考(这是行为)」。AI 作为生产力终究不能自发地改变现有的生产关系,仍需要人的主观能动性。如果未来有一天硅基生命崛起,彼时的人类又是否会变成如当下的 AI 一样,成为一种“工具”,只不过是一种作为被奴役的稀有的资源般存在的“工具”。我不想这天的到来,至少在我有生之年。
futuristic terraced structure built into a mountain at dusk, twilight hues, lush greenery illuminated by soft glowing lights, multiple levels, pathways, vast mountain range, distant winding roads, glowing city lights below, towering otherworldly rock formations
1boy, black hoodie, white spiky punk hair, nose piercing, standing against a brick wall, masterpiece, best quality, high score, great score, pixel art style
负向提示词
lowres, bad anatomy, bad hands, text, error, missing finger, extra digits, fewer digits, cropped, worst quality, low quality, low score, bad score, average score, signature, watermark, username, blurry
在图层中单击 + Control Layer 添加控制层,或者在图片库中将图片拖拽至画布上,选择 New Control Layer。
创建控制层
示例图片及其生成的提示词如下:
示例图片
正向提示词:
futuristic terraced structure built into a mountain at dusk, twilight hues, lush greenery illuminated by soft glowing lights, multiple levels, pathways, vast mountain range, distant winding roads, glowing city lights below, towering otherworldly rock formations, dreamy sky with soft clouds
负向提示词:
painting, digital art, sketch, blurry
控制层
本教程以 Hard Edge Detection (canny) 模型为例,单击 Filter 中的 Advanced 可以进行更多的调整:
从高德纳提出文学编程的概念后,各家各派都在将这个编程范式付诸实践。我接触文学编程已经比较晚了,算是从 R Markdown 和 knitr 开始,开始时写写分析报告和做做幻灯片,慢慢的在更多场景我发现这很适合。
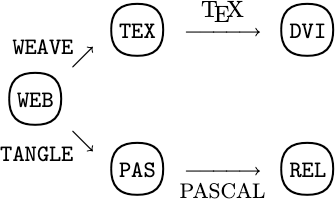
WEB, CWEB & noweb
WEB 是一种计算机编程语言系统,它由高德纳设计,是第一种实现他称作“文学编程”的语言。WEB 包含了 2 个主要程序:TANGLE,从源文本生成可编译的 Pascal 代码,以及 WEAVE,使用 TeX 生成格式漂亮可打印的文档。CWEB 是 WEB 的 C 语言新版本,noweb 是另外一种借鉴了 WEB 的文学编程工具,同时与语言无关 3。
Sweave 是 R 语言的 WEB 实现,为什么是 Sweave 而不是 Rweave,没有仔细去找解释,但我猜测是由于 R 语言的前身为 S 语言吧。既然有了 Sweave 为什么没有 Stangle 呢?也是猜测,或许 Sweave 的作者在创作之初就更侧重于将 R 代码及其运行结果嵌入,“织出”最终阅读友好的文档吧。当然,由于 R 是一门统计分析语言,将所有 R 代码提取出来编译成可执行文件并不是它的优势,我猜这应该也是没有 Stangle 的一个原因吧。当然,也并不是没有人打算这么做,fusen 是一个基于 R Markdown 直接生成 R 扩展包的扩展包,从一定程度上应该算是 tangle 的理念实现吧。
所以,Quarto 的到来是否意味着 R Markdown 的消失呢?官方 FAQ 给到了否定的答案。不过我认为 Quarto 「一统天下」的野心还是有的,只是基于现状可能这条路还需要再走一阵子。如下是我从当先(2023 年初)现状和个人的一些需求,认为 Quarto 和 R Markdown 之间存在的一些区别:
博客方面,个人需要动态输出的场景不多,blogdown 是基于 Hugo 的实现,动态文档是利用 knitr 将 R Markdown 直接渲染为 HTML 再交由 Hugo 处理。支持 Hugo 的自动化部署(例如:Cloudflare Pages,Netlify,Vercel 等)对比 Quarto 的自动化部署选择要更多些。
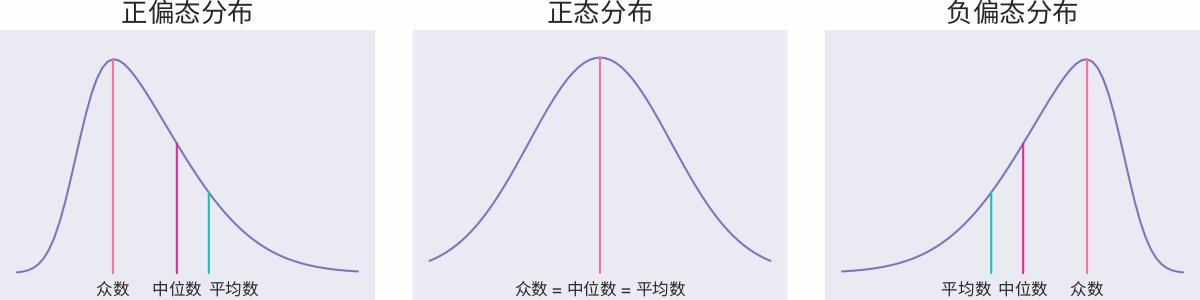
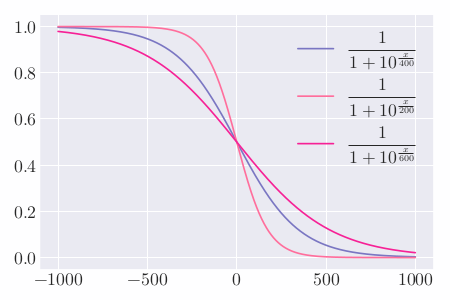
Reddit 评分排名算法决定了 Reddit 是一个符合大众口味的社区,而不是一个适合展示激进想法的地方。因为评分中使用的是赞成票和反对票的差值,也就是说在其他条件相同的情况下,帖子 A 有 1 票赞成,0 票反对;帖子 B 有 1000 票赞成,1000 票反对,但讨论火热的帖子 B 的得分却比 帖子 A 要少。
这种方式在总票数比较大的时候没有问题,但总票数比较小时就容易产生错误。例如:A 获得 2 张赞成票,0 张反对票;B 获得 100 张赞成票,1 张反对票。根据上式计算可得 A 的评分为 $100\%$,B 的评分为 $99\%$。但实际上 B 应该是优于 A 的,由于 A 的总票数太少,数据不太具有统计意义。
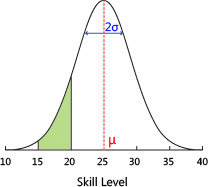
Elo 评分系统的问题在于无法确定选手评分的可信度,而 Glicko 评分系统正是针对此进行改进。假设两名评分均为 1700 的选手 A 和 B 在进行一场对战后 A 获得胜利,在美国国际象棋联赛的 Elo 评分系统下,A 选手评分将增长 16,对应的 B 选手评分将下降 16。但是假如 A 选手是已经很久没玩,但 B 选手每周都会玩,那么在上述情况下 A 选手的 1700 评分并不能十分可信地用于评定其实力,而 B 选手的 1700 评分则更为可信。
TrueSkill 评分系统是基于贝叶斯推断的评分系统,由微软研究院开发以代替传统 Elo 评分系统,并成功应用于 Xbox Live 自动匹配系统。TrueSkill 评分系统是 Glicko 评分系统的衍伸,主要用于多人游戏中。TrueSkill 评分系统考虑到了个别玩家水平的不确定性,综合考虑了各玩家的胜率和可能的水平涨落。当各玩家进行了更多的游戏后,即使个别玩家的胜率不变,系统也会因为对个别玩家的水平更加了解而改变对玩家的评分 2。