用js写卡牌游戏(十)
没想到,上一篇这个系列的文章 居然是 2023年6月,现在2026年1月了,又一次破了我鸽的记录!
这次想起来更新这个卡牌游戏是因为我最近刷POE2非常上头,无数的天赋树和装备的组合,给这个游戏带来了无限的灵活性。如果有了解过游戏开发,一定知道虚幻引擎,它有一套 GAS 系统,通过这套系统能够让游戏的技能系统做起来又快又灵活,所以我想把这套系统的部分设计引入到我的卡牌游戏里来。
关于GAS
GAS就是Gameplay Ability System,游戏玩法技能系统,但我不介绍这个完整的系统,我只介绍这个系统中的一部分,其实拆开来看,就是几个经典的设计模式组合在一起的产物。
这个GAS里有两个很重要的概念,Tag和Effect,Tag顾名思义就是标签,描述一件衣服,就可以用各种Tag来表示,比如红色、格子、长袖、尼龙等。

如果有这套Tag系统,那么我只要多实现一些Tag然后进行排列组合,就能得到全新的一件物品,比如我把红色改为黑色,那么我将得到黑色的衬衫:

然后就是Effect效果,从Tag可以推理出来,如果Tag对应的是状态,那么Effect对应的是改变状态的方法,如果我开发了一个“折叠效果”,对应的方法的内容是:
- 添加 “不可折叠” Tag、添加 “可展开” Tag
- 改变面积为原来的四分之一
我就可以将这个Effect应用到衣服上,这时衣服的属性就会自动发生改变,并且神奇的是,这个Effect也可以应用到一切有“服装”Tag的物品上,我以后开发了“裤子”、“裙子”、“毛衣”全部都可以直接用。
在这些内容里,你可以看到命令模式、策略模式、状态模式等等经典设计模式的影子,他将开发的“复利”效应做到了极致,POE就是这样设计的,同样你可以在Dota2里也看到这样的设计:
// 这是一个非常简单的技能,他是一个被动技能,给单位添加了一个粒子特效。
"fx_test_ability"
{
// General
//---------------------------------------------------------
"BaseClass" "ability_datadriven"
"AbilityBehavior" "DOTA_ABILITY_BEHAVIOR_PASSIVE"
"AbilityTextureName" "axe_battle_hunger"
// Modifiers
//---------------------------------------------------------
"Modifiers"
{
"fx_test_modifier"
{
"Passive" "1"
"OnCreated"
{
"AttachEffect"
{
"Target" "CASTER"
"EffectName" "particles/econ/generic/generic_buff_1/generic_buff_1.vpcf"
"EffectAttachType" "follow_overhead"
"EffectLifeDurationScale" "1"
"EffectColorA" "255 255 0"
}
}
}
}
}
通过定义 bahavior、modifier、”OnCreated”这样的钩子、”AttachEffect” 这样的Effect,就能配置出一个技能,无需编写代码,并且添加或者修改、组合部分属性,就是一个全新的技能。
我的设计
我的卡牌过去是这样实现的:
{
id: 13,
name: "没毕业的天才程序员",
cardType: CardType.CHARACTER,
cost: 3,
content: `每回合结束时,获得+1/+1`,
attack: 1,
life: 1,
attackBase: 1,
lifeBase: 1,
type: [""],
onMyTurnEnd: function ({thisCard, specialMethod, position}) {
if (position === CardPosition.TABLE) {
thisCard.attack += 1;
thisCard.life += 1;
specialMethod.buffCardAnimation(true, -1, -1, thisCard, thisCard)
}
}
}
并且有效果的牌都是这么实现的,可以看到每个效果都需要我单独的去写函数,或者是在对象上添加属性比如 isStrong 这种,对于代码实现不方便不优雅(还好用的是javascript),而且无法很好的保存到数据库里,只能存在代码文件中来硬编码定义。
所以想要做到像POE、Dota2那样进行配置,理想的情况下卡牌应该是这样的:
{
"id": 13,
"name": "没毕业的天才程序员",
"cost": 3,
"content": "每回合结束时,获得+1/+1",
"attack": 1,
"life": 1,
"attackBase": 1,
"lifeBase": 1,
"types": [],
"tags": ["Tags.Character"],
"effects": {
"onMyTurnEnd": [
{
"type": "ModifyAttribute",
"target": {
"type": "self"
},
"params": {
"attribute": "attack",
"value": 1,
"operation": "add"
},
"conditions": [
{
"type": "cardPosition",
"params": {
"position": "TABLE"
}
}
]
},
{
"type": "ModifyAttribute",
"target": {
"type": "self"
},
"params": {
"attribute": "life",
"value": 1,
"operation": "add"
},
"conditions": [
{
"type": "cardPosition",
"params": {
"position": "TABLE"
}
}
]
}
]
}
}
虽然说看起来内容复杂了,没有代码那么一眼看上去逻辑清晰,可是这些配置是完全能够可视化的,也就是说以后可以通过卡牌编辑器来可视化的进行卡牌配置,但是代码就无法有效的进行可视化了(对于不懂编码的人来说,比如说策划或者爱好者社区这很重要)。
所以设计任务: 1. 原来的各种属性抽象为Tag。 2. 原来的各种钩子的效果整理好,抽象为各种 Effect。
{
id: 13,
name: "卡牌名称",
cardType: CardType.CHARACTER, // tag
cost: 3,
content: `卡牌内容描述`,
attack: 1,
life: 1,
attackBase: 1,
lifeBase: 1,
isStrong: true, // tag
isFullOfEnergy: true, // tag
type: ["类型"],
onMyTurnEnd: function ({thisCard, specialMethod, position}) { // effect
if (position === CardPosition.TABLE) {
thisCard.attack += 1;
thisCard.life += 1;
specialMethod.buffCardAnimation(true, -1, -1, thisCard, thisCard)
}
}
}
按照 Effect 的设想:
{
"onMyTurnEnd": [
{
"type": "ModifyAttribute",
"target": {
"type": "self"
},
"params": {
"attribute": "attack",
"value": 1,
"operation": "add"
},
"conditions": [
{
"type": "cardPosition",
"params": {
"position": "TABLE"
}
}
]
},
{
"type": "ModifyAttribute",
"target": {
"type": "self"
},
"params": {
"attribute": "life",
"value": 1,
"operation": "add"
},
"conditions": [
{
"type": "cardPosition",
"params": {
"position": "TABLE"
}
}
]
}
]
}
还是需要有过去的钩子定义,比如 onMyTurnEnd、onStart,方便我们在每个流程阶段检查卡牌是否配置了对应阶段执行的 Effect,接收 Effect 数组,方便我们进行 Effect 组合来实现非常灵活的效果。

需要把所有的函数过一遍,总结一下所有的函数实现的效果,然后抽象成简单的 Effect 和对应的参数。
这样在各种流程里,比如出牌阶段,刚打出的时候可以触发卡牌的 onStart 效果
// 示意伪代码
function outCard() {
// ...
triggerCardEffect(card, 'onStart', baseContext);
// ...
}
triggerCardEffect 内部简单来看可以这样设计:
// 示意伪代码
function triggerCardEffect(card, trigger, baseContext) {
// 获取卡牌的效果配置
const effectConfigs = card.effects?.[trigger] || [];
// 构建完整上下文
const context = {
...baseContext,
thisCard: card,
// 还需要加各种 effect 和 tag 相关的系统环境数据
// 比如 effectRegistry、tagRegistry 用于快速获取注册了的 effect和tag,比如 effectEngine 用于执行 effect
};
// 依次执行效果
effectConfigs.forEach(config => {
this.executeEffect(config, context);
});
}
executeEffect 内部主要就是利用命令模式、策略模式来把我们实现的各种 Effect 执行逻辑应用在卡牌上:
// 示意伪代码
function executeEffect(config, context) {
// 获取实现的 effect 函数
const EffectClass = this.effectTypes.get(config.type);
if (!EffectClass) {
console.warn(`Unknown effect type: ${config.type}`);
return null;
}
const effect = new EffectClass(config);
// 检查条件
if (!effect.canExecute(context)) {
return;
}
effect.execute(context, targets);
// 处理后续效果链
if (effectConfig.then) {
effectConfig.then.forEach(nextConfig => {
this.executeEffect(nextConfig, context);
});
}
}
所有的 Effect 就只需要实现预定义的各种函数,然后注册起来:
/**
* BaseEffect - 效果基类
* 所有具体效果类型都继承自此类
*/
class BaseEffect {
constructor(config) {
}
/**
* 检查效果是否可以执行
* @param {object} context - 执行上下文
* @returns {boolean}
*/
canExecute(context) {
return false;
}
/**
* 执行效果
* @param {object} context - 执行上下文
* @param {Array} targets - 目标列表
*/
execute(context, targets) {
throw new Error("Must be implemented by subclass");
}
/**
* 获取效果描述文本
* @returns {string}
*/
getDescription() {
return this.type;
}
}
module.exports = BaseEffect;
不过,都到了2026年了,我就不分享具体的代码实现过程了,我分享点别的。
实现过程
既然现在都用AI来辅助开发了,那么实际上我可以直接分享我的Prompt,这样就能够一步步的让AI在你的环境也实现相同的功能而不用是完全相同的代码。(如果AI给力的话)
我的代码编写基本是用 Claude Code(Opus4.5)和 Copilot(Opus4.5),查询资料用 Kagi Assistant 的 Research。
第一条prompt,先用Plan模式让AI做好计划:
当前的卡牌存储在 @card-game-server/cards.js 里面,可以看到卡牌的效果基本上都是用代码写的,比如 onStart onMyTurnStart 等等,这些都是钩子函数。
这种设计有一个问题,要添加卡牌,必须要能够写代码,现在需要将这个设计修改,请使用UE5的GAS的 effect tag 设计,把各种基础效果改为已经实现好的 effect 和 tag,之后的卡牌只要配置对应的 effect tag就能够实现各种能力,而新增effect tag能够让每个tag添加进来和别的tag组合成为成倍数增加的新能力。
设计需要尽可能的全面和优雅。如果你的AI不知道UE5 GAS,那么你可能需要查询一些UE5 GAS相关的设计内容总结给AI。
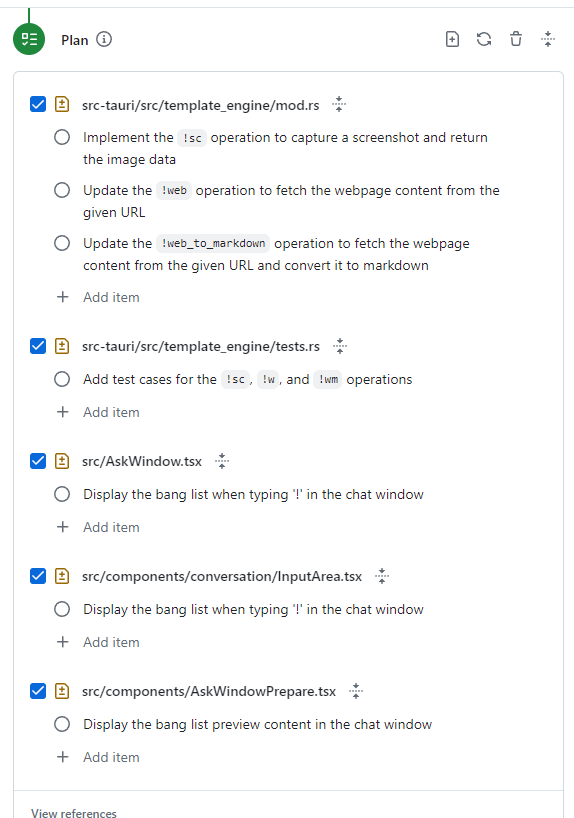
AI的计划大概如下(肯定都会有不同,但没事):

可以看到 Tag 带有层级,这是 组合模式 的应用,能够让我们方便的多层级进行判断,比如我们有时候只想要知道 State.Stunned 眩晕状态来让卡牌无法行动,至于是 State.Stunned.Light 还是 State.Stunned.Heavy 不重要。 Effect 也支持链式效果,能够让我们多 Effect 组合的同时,也能够链式的递归进行 Effect 调用。
这个Plan阶段可以和AI多轮讨论达到自己想要的最好情况,后续其实也能修改,但这个阶段讨论清楚是最好的。
后续就直接可以让AI开始修改,如果你是使用的Opus4.5,那么大概率这一把就能够改出八成,有可能出现下面的几种问题,这也是我碰到的。
卡牌数据没有完全迁移到新结构
有可能会出现 cards.js 还是有很多遗留数据,或者甚至就完全没有迁移,所以:
现在的卡牌已经转为使用 effect tag 来进行配置了,但是卡牌的数据 cards.js 还是使用的函数。 请把这些卡牌数据转为使用effect和tag,因为这里的数据过大,请分批次转为多个json(按照卡牌职业分类)。AI将会分批次把 cards.js 里面的硬编码的卡牌转为新的配置的json文件:

文件命名不规范
有的 Effect 会单独有一个文件夹,或者相类似能力的 Effect 会放到一起,但有的不相干的 Effect 又全部集合到了一个文件里,所以:
新增了 UtilityEffect.js 但别的effect都是单独的文件,最好这几个也用对应的文件放在一起,以后能够通过文件名来寻找对应的effect。并且请把level中的卡牌也改为effect配置的。AI有时候因为上下文过长的问题,会出现部分代码不遵守规范的情况,这个情况也可以让AI做一份 CLAUDE.md / AGENTS.md,然后在文件里加上这个规范。
偷懒不实现缺失的Effect
AI为了偷懒,创建了一个 LegacyHookEffect ,来支持用过去那种老的用函数定义效果的方法。
/**
* LegacyHookEffect
* 允许在 Effect 配置中调用旧版函数式卡牌效果
*/
class LegacyHookEffect extends BaseEffect {
constructor(config) {
super(config);
this.type = "LegacyHook";
}
execute(context) {
const { handler } = this.params;
const fn = legacyCardEffects[handler];
if (typeof fn === 'function') {
fn(context);
} else {
console.warn(`[LegacyHookEffect] handler not found: ${handler}`);
}
}
}
LegacyHookEffect 是偷懒的行为,把这些函数定义改为effect配置就是不希望再有使用函数配置的卡牌了。
如果当前的effect设计不足以做到把所有卡牌都改为可配置effect的json表达,请告诉我哪里需要修改。如果当前的effect不足,需要新增,请告诉我要增加哪些。并且,AI如果不够聪明,可能会出现胡乱设计的情况,所以在用AI修改的时候一定要审阅他的输出计划,并且自己对代码一定要有理解,然后及时纠正AI的错误:

isStrong 等属性没有真正的用 Tag 来重构
Review代码的时候发现,AI并没有理解 Tag 这种设计(不过我们也没说),改的不够彻底,所以:
现在代码里的模仿GAS的tag系统似乎没有真正用起来,现在的tag是用ApplyTag这个Effect来模拟之前的属性做法,给卡牌加上 isStrong 这样的属性,我希望你能彻底修改为tag的做法,只需要判断卡牌的tag是否有 Status.Buff.Strong,而不需要再转回原来的属性模式,所以原来的属性模式相关的逻辑也要改为GAS的tag模式。那这样的话,是否 cardType 其实也不需要了,直接用 tag 来实现就可以了。这样AI会把过去的属性移除,然后用新的Tag来重构,过去判断 isStrong 的地方,都变成 hasTag(card, “Status.Buff.Strong”)。
其他内容
本次还修复了一些bug,然后还增加了SQLite模式,这样大家在跑这个项目的时候就不需要再启动一个MongoDB了。
AI
实现这个 Effect 和 Tag,增加SQLite支持,外加测试和一些其他的修复bug,总共耗时1天。本来半天其实就差不多了,但是AI写的代码总是有一些不优雅,所以需要自己去微调,可以手动,也可以让AI继续改。比如 Status.Buff.Strong 这类的字符串,可以抽取常量,比如 hasTag 这类的工具方法,还有一些过去我实现过可以直接用的系统。
不过如果没有AI,这个修改起码要花好几天,大部分的代码质量也不一定有AI做的好。
下一步
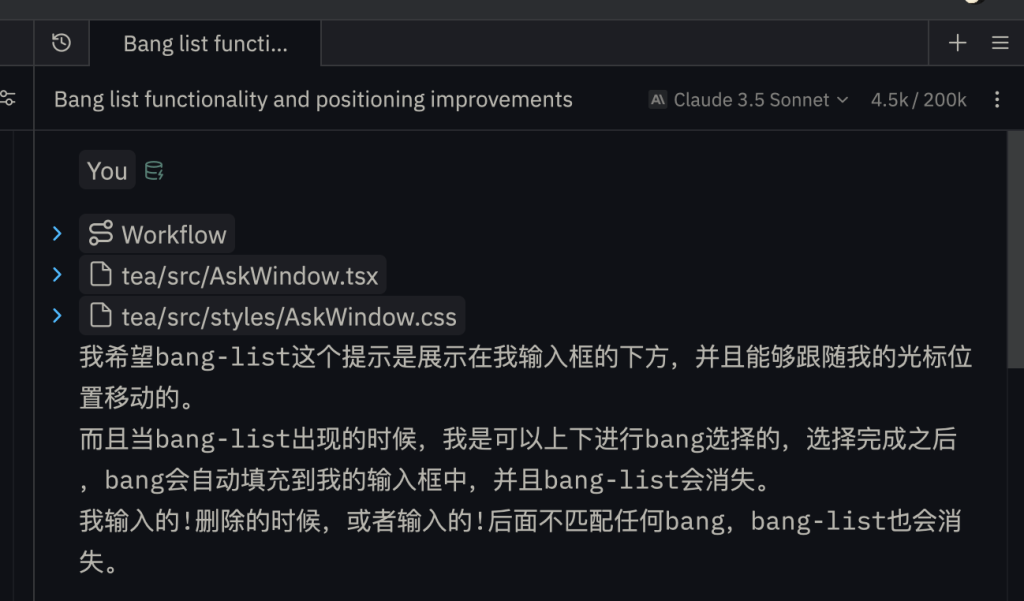
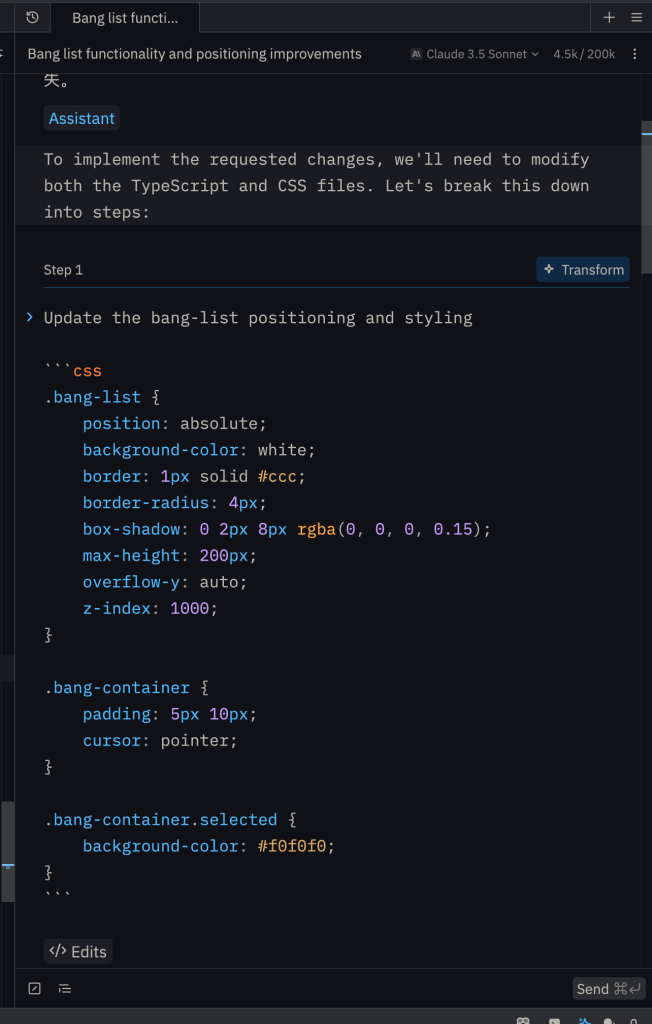
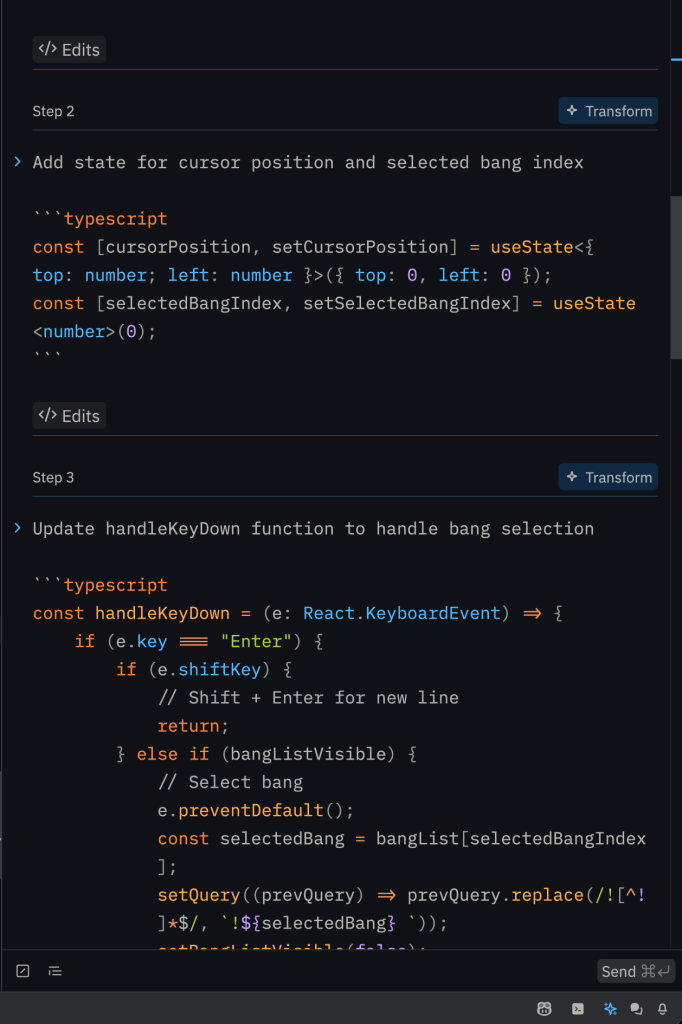
翻了翻上次发的文章,说是要把AI加进去,确实可以,而且应该很简单,然后还可以做一个卡牌编辑器。
就是不知道这次要鸽多久,视频稍晚一点做完也会发。