public Result doInvoke(Invocation invocation, final List<Invoker<T>> invokers, LoadBalance loadbalance)throws RpcException { List<Invoker<T>> copyInvokers = invokers; checkInvokers(copyInvokers, invocation); String methodName = RpcUtils.getMethodName(invocation); int len = getUrl().getMethodParameter(methodName, RETRIES_KEY, DEFAULT_RETRIES) + 1; if (len <= 0) { len = 1; } // retry loop. RpcException le = null; // last exception. List<Invoker<T>> invoked = new ArrayList<Invoker<T>>(copyInvokers.size()); // invoked invokers. Set<String> providers = new HashSet<String>(len); for (int i = 0; i < len; i++) { //Reselect before retry to avoid a change of candidate `invokers`. //NOTE: if `invokers` changed, then `invoked` also lose accuracy. if (i > 0) { checkWhetherDestroyed(); copyInvokers = list(invocation); // check again checkInvokers(copyInvokers, invocation); } Invoker<T> invoker = select(loadbalance, invocation, copyInvokers, invoked); invoked.add(invoker); RpcContext.getContext().setInvokers((List) invoked); try { Result result = invoker.invoke(invocation); ......
17:54:34,026 WARN [New I/O server worker #1-4] - [DUBBO] Thread pool is EXHAUSTED! Thread Name: DubboServerHandler-10.8.64.57:20880, Pool Size: 300 (active: 300, core: 300, max: 300, largest: 300), Task: 5821 (completed: 5621), Executor status:(isShutdown:false, isTerminated:false, isTerminating:false), in dubbo://x.x.x.x:20880!, dubbo version: 2.6.5, current host: x.x.x.x com.alibaba.dubbo.remoting.ExecutionException: class com.alibaba.dubbo.remoting.transport.dispatcher.all.AllChannelHandler error when process caught event . at com.alibaba.dubbo.remoting.transport.dispatcher.all.AllChannelHandler.caught(AllChannelHandler.java:67) at com.alibaba.dubbo.remoting.transport.AbstractChannelHandlerDelegate.caught(AbstractChannelHandlerDelegate.java:44) at com.alibaba.dubbo.remoting.transport.AbstractChannelHandlerDelegate.caught(AbstractChannelHandlerDelegate.java:44) at com.alibaba.dubbo.remoting.transport.AbstractPeer.caught(AbstractPeer.java:127) at com.alibaba.dubbo.remoting.transport.netty.NettyHandler.exceptionCaught(NettyHandler.java:112) at com.alibaba.dubbo.remoting.transport.netty.NettyCodecAdapter$InternalDecoder.exceptionCaught(NettyCodecAdapter.java:165) at org.jboss.netty.channel.Channels.fireExceptionCaught(Channels.java:432) at org.jboss.netty.channel.AbstractChannelSink.exceptionCaught(AbstractChannelSink.java:52) at org.jboss.netty.channel.Channels.fireMessageReceived(Channels.java:302) at com.alibaba.dubbo.remoting.transport.netty.NettyCodecAdapter$InternalDecoder.messageReceived(NettyCodecAdapter.java:148) at org.jboss.netty.channel.Channels.fireMessageReceived(Channels.java:274) at org.jboss.netty.channel.Channels.fireMessageReceived(Channels.java:261) at org.jboss.netty.channel.socket.nio.NioWorker.read(NioWorker.java:350) at org.jboss.netty.channel.socket.nio.NioWorker.processSelectedKeys(NioWorker.java:281) at org.jboss.netty.channel.socket.nio.NioWorker.run(NioWorker.java:201) at org.jboss.netty.util.internal.IoWorkerRunnable.run(IoWorkerRunnable.java:46) at java.util.concurrent.ThreadPoolExecutor$Worker.runTask(ThreadPoolExecutor.java:886) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:908) at java.lang.Thread.run(Thread.java:619) Caused by: java.util.concurrent.RejectedExecutionException: Thread pool is EXHAUSTED! Thread Name: DubboServerHandler-10.8.64.57:20880, Pool Size: 300 (active: 300, core: 300, max: 300, largest: 300), Task: 5821
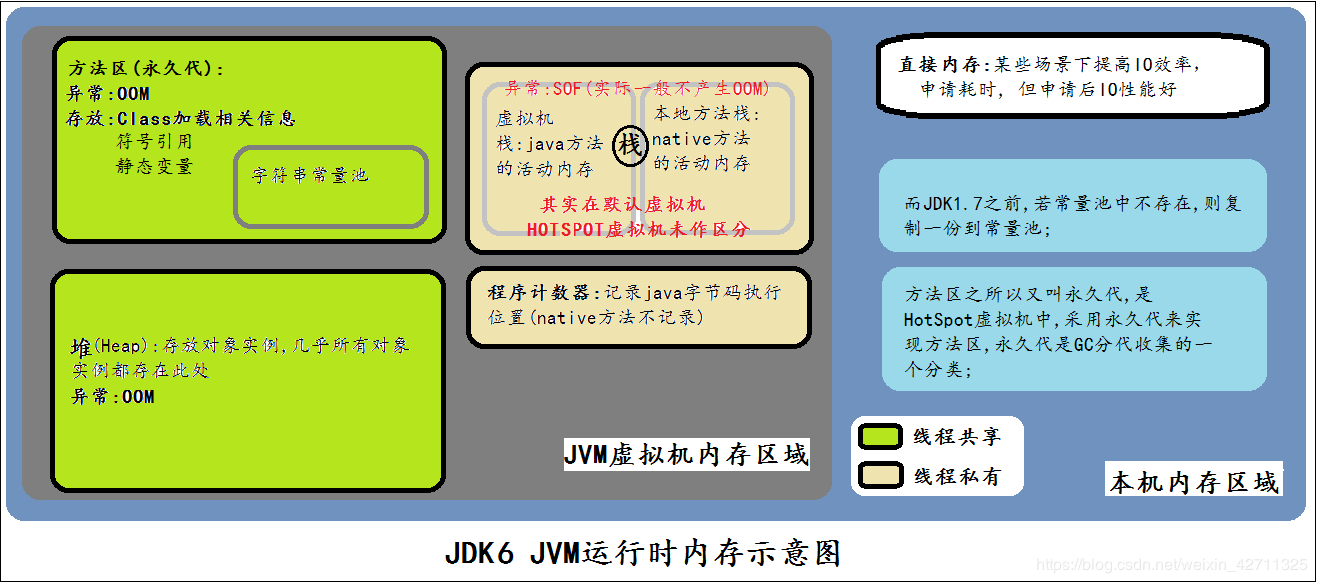
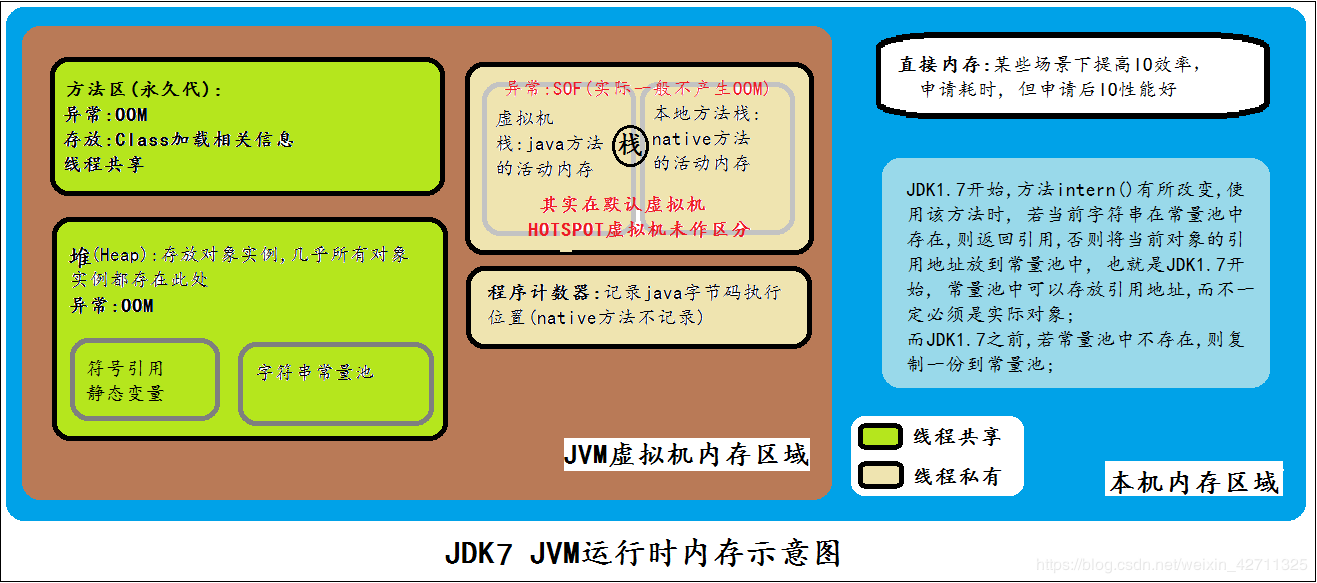
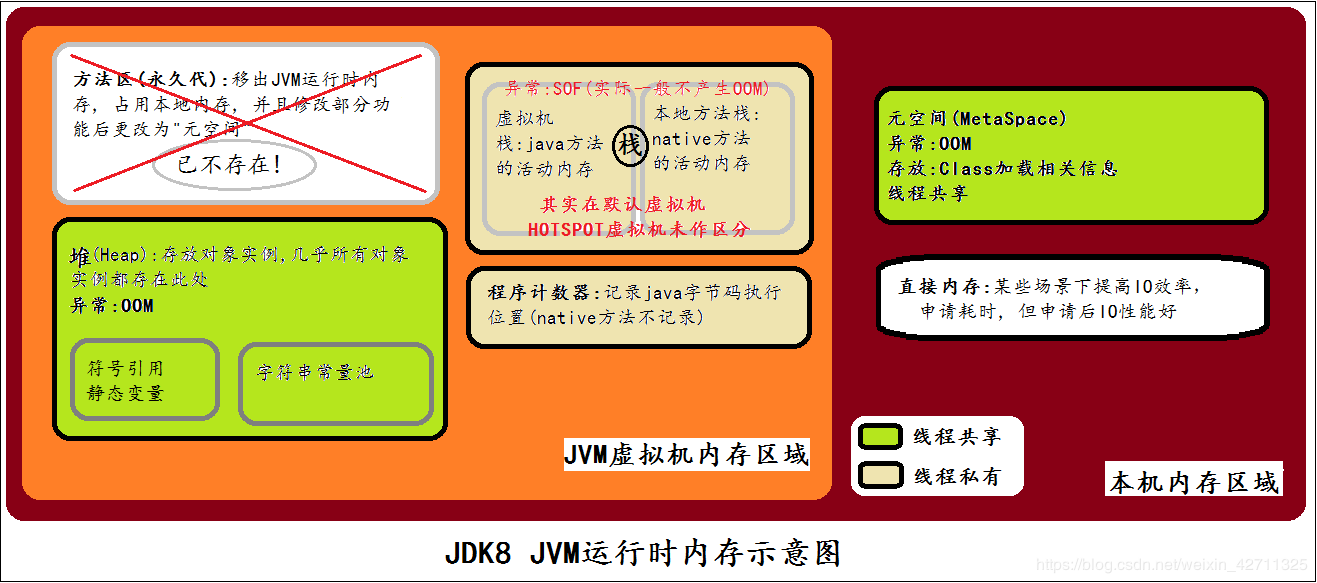
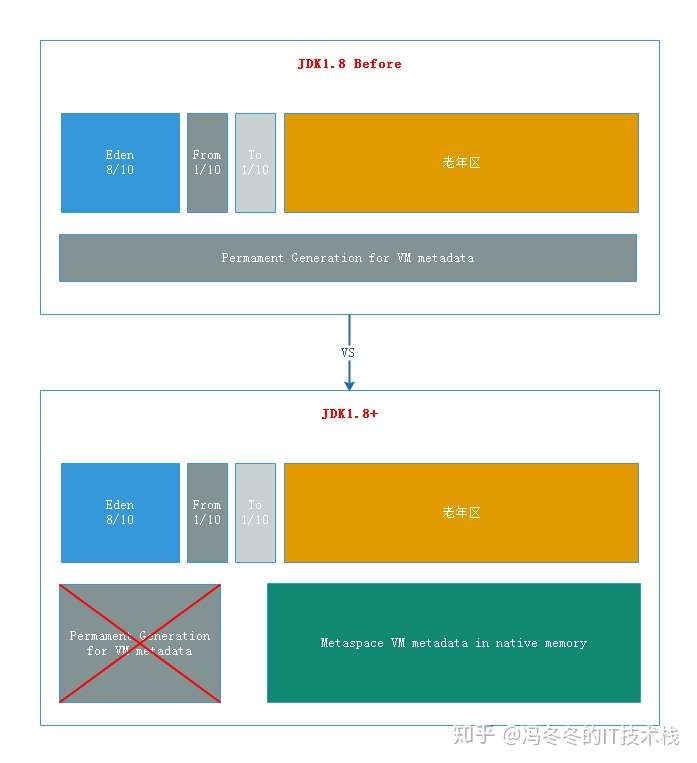
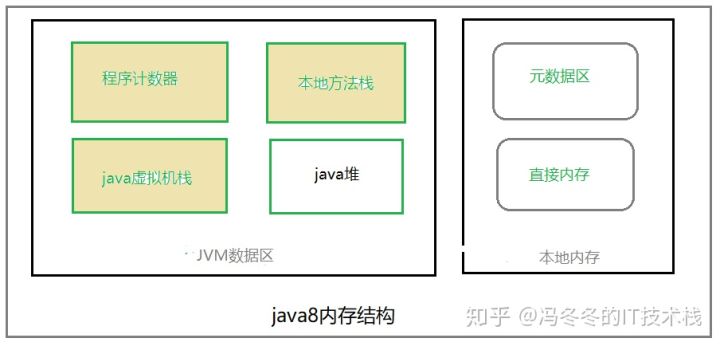
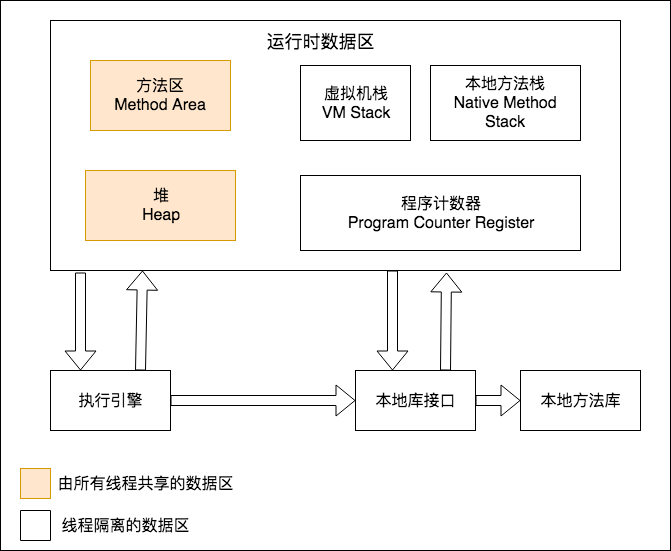
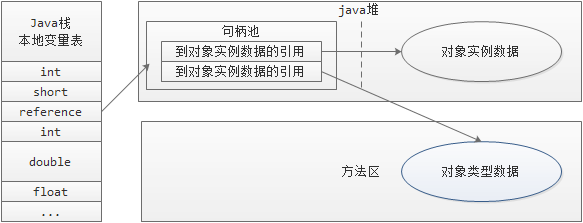
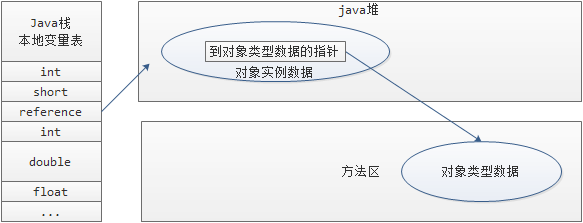
我们知道,java语言不像C++,将内存的分配和回收给程序员来处理。java用统一的垃圾回收机制来管理java进程的内存,就是通常所说的垃圾回收:GC(Garbage Collection)。 先到维基百科上看一下Garbage Collection的概念: In computer science, garbage collection (GC) is a form of automatic memory management. The garbage collector, or just collector, attempts to reclaim garbage, or memory occupied by objectst that are no longer in use by the program. Garbage collection was invented by John McCarthy around 1959 to simplify manual memory management in Lisp. 这就面临一些问题:java进程到底是什么样的结构?java进程的内存哪些需要被回收,在什么条件下才回收,谁来回收?我们首先来看一些概念
二、什么是JVM ?
从维基百科上看jvm的定义: A Java virtual machine (JVM) is a virtual machine that enables a computer to run Java programs as well as programs written in other languages that are also compiled to Java bytecode.