SSH协议中隧道与代理的用法详解
SSH 协议是 Linux 系统中使用较为频繁的协议之一,通常用于远程管理主机或服务器,默认使用 22 端口,可类比 Windows 系统中的 telnet(23 端口),这里要介绍的是 ssh 除了远程连接外的另一强大特性,即隧道加密与多种场景下代理功能的实现。
前置条件
为了理解更轻松,最大程度上简化网络拓扑,后续都只用两台机器做测试,IP 与主机名对应关系如下;更复杂的网络结构和多接口场景可举一反三延申,要用作某些特殊用途,则自行YY。
192.168.111.128 --> Kali
192.168.111.131 --> Centos
在验证 IP 地址和多级代理的场景时,会额外用到网关机器:192.168.111.1。
然后再多了解一下三个 ssh 的命令行参数,后面会用到:
-N 建立连接后不远程执行命令,也没有交互shell,通常用于端口转发的场景。
-f 建立连接后会在后台运行进程,不占用前台窗口。
-c 传输数据时对数据进行压缩,压缩算法和 gzip 的一样,但不适用于高速网络环境,会降低连接速度。
-v 打印更详细的连接过程信息。
本地转发(-L)
原理
本地转发即使用 ssh -L 参数,先看一下官方解释(man ssh):
-L [bind_address:]port:host:hostport
-L [bind_address:]port:remote_socket
-L local_socket:host:hostport
-L local_socket:remote_socket
Specifies that connections to the given TCP port or Unix socket on the local (client) host are to be
forwarded to the given host and port, or Unix socket, on the remote side. This works by allocating a
socket to listen to either a TCP port on the local side, optionally bound to the specified bind_address,
or to a Unix socket. Whenever a connection is made to the local port or socket, the connection is for‐
warded over the secure channel, and a connection is made to either host port hostport, or the Unix
socket remote_socket, from the remote machine.
Port forwardings can also be specified in the configuration file. Only the superuser can forward privi‐
leged ports. IPv6 addresses can be specified by enclosing the address in square brackets.
By default, the local port is bound in accordance with the GatewayPorts setting. However, an explicit
bind_address may be used to bind the connection to a specific address. The bind_address of “localhost”
indicates that the listening port be bound for local use only, while an empty address or ‘*’ indicates
that the port should be available from all interfaces.
翻译成人话,通俗讲就是,使用该参数执行 ssh 连接后,会在本机开启一个指定监听端口1,然后绑定到远程机器的指定接口(IP)的指定端口2,用另一个程序再访问本机的指定端口1,流量就会转发到远程机器的指定端口2,相当于直接访问远程机器的端口2;可以简单的理解为 “流量从本地转发到远程机器”。
参数值([bind_address:]port:host:hostport)也有规律,从左到右写是本地到远程的顺序:本地地址(bind_address])的端口(port)转发到远程地址(host)的端口(hostport),本地接口地址可省略,默认为 127.0.0.1。除了接口和端口也可以使用 Unix socket 建立连接,把对应的位置换成 socket 地址即可。
实验
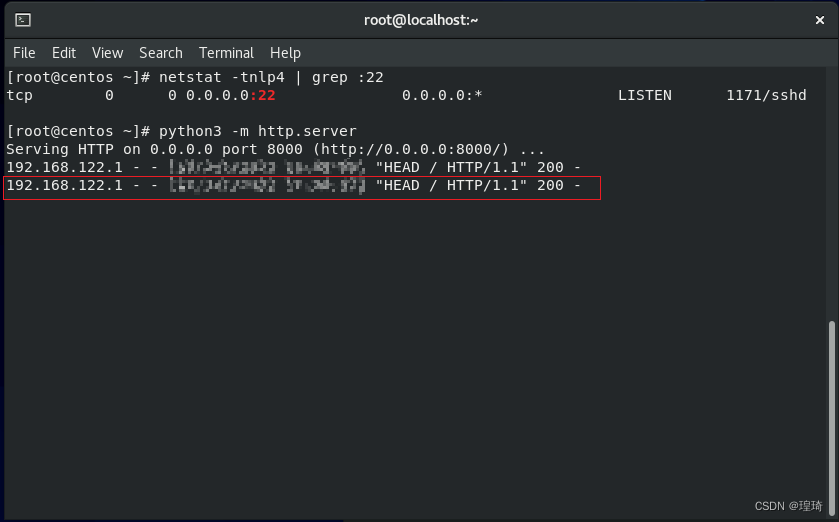
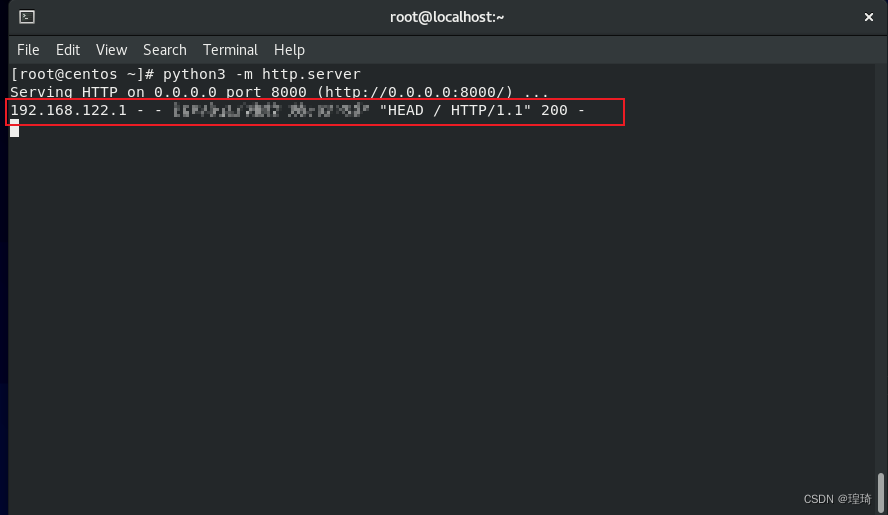
上面的转发流程有点绕,用实验来理解下实际效果,假设场景为 Kali(192.168.111.128)去连接 Centos(192.168.111.131);那么首先确保 Centos 开启 22 端口,然后用 python 给它在 8000 端口开启一个简单的 http 服务:
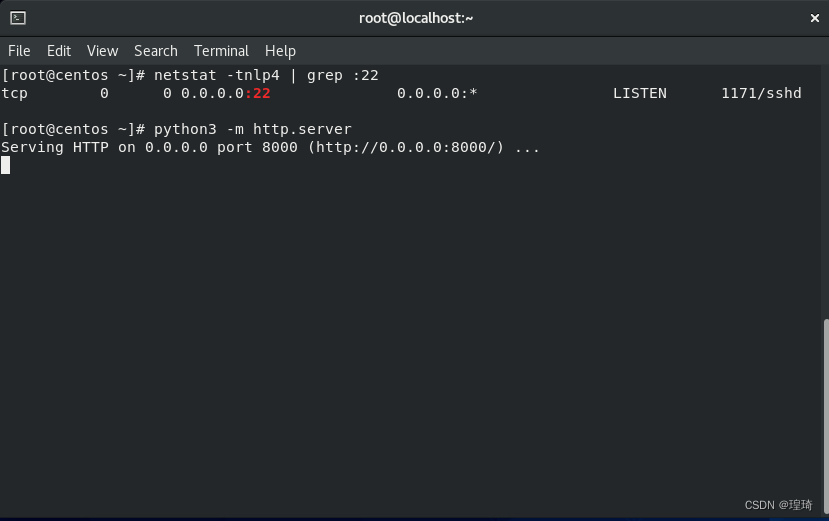
试着先本地访问下(Centos 具有第二个接口:192.168.122.1):
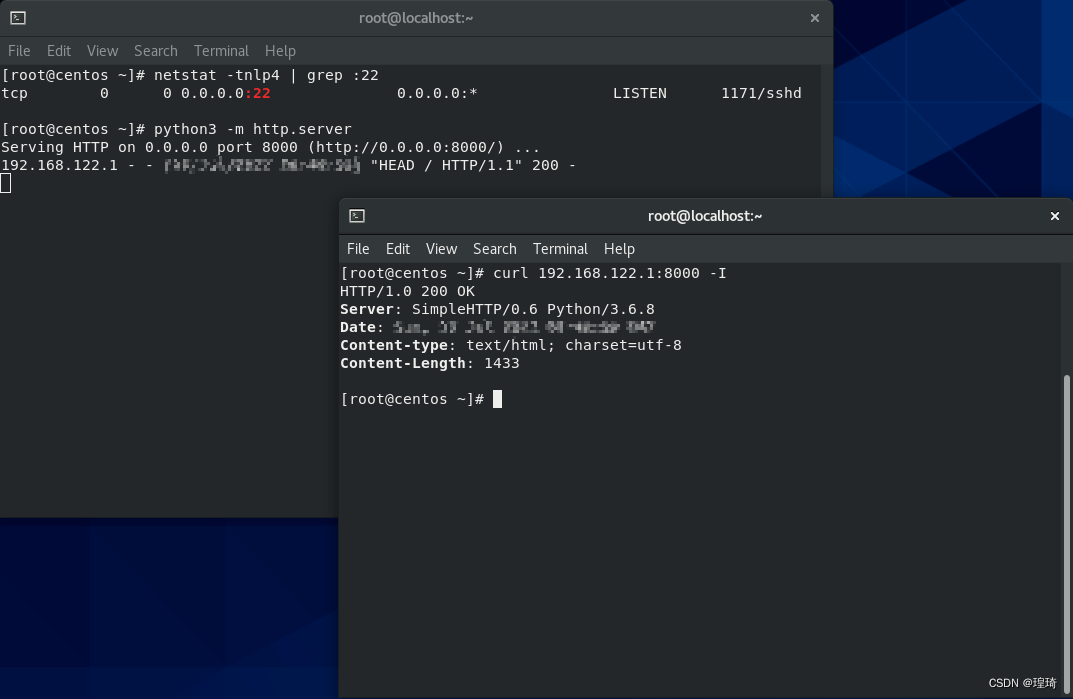
ok 没问题,接着去另一台机器 Kali(192.168.111.128) 上先测试连一下 Centos 的 ssh:
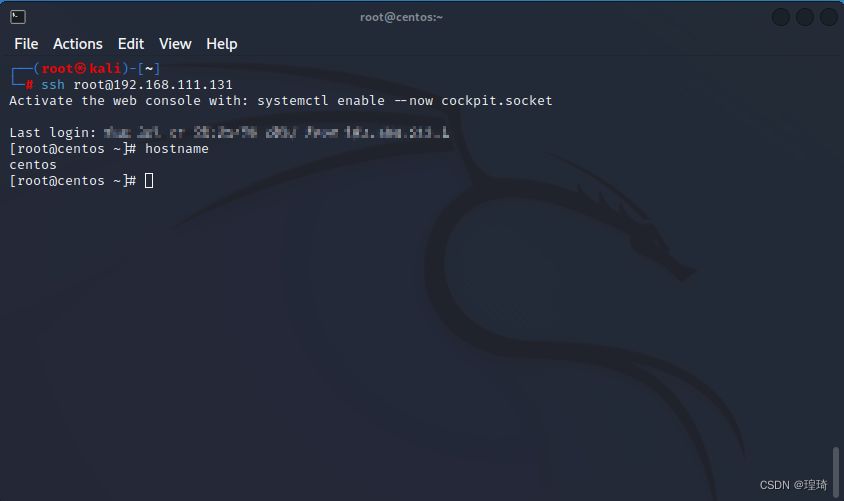
证明连接是通的,接下来直接在 Kali 上使用本地转发连接 Centos(为了方便已提前给两台机器配置了 ssh 公钥连接,避免输入密码),执行参数为:
ssh -NL 1080:192.168.122.1:8000 root@192.168.111.131
然后执行后会在 Kali 本地监听 1080,再用 curl 访问一下这个端口,返回数据就是 Centos 的 192.168.122.1 接口上的 8000 端口所对应的内容:
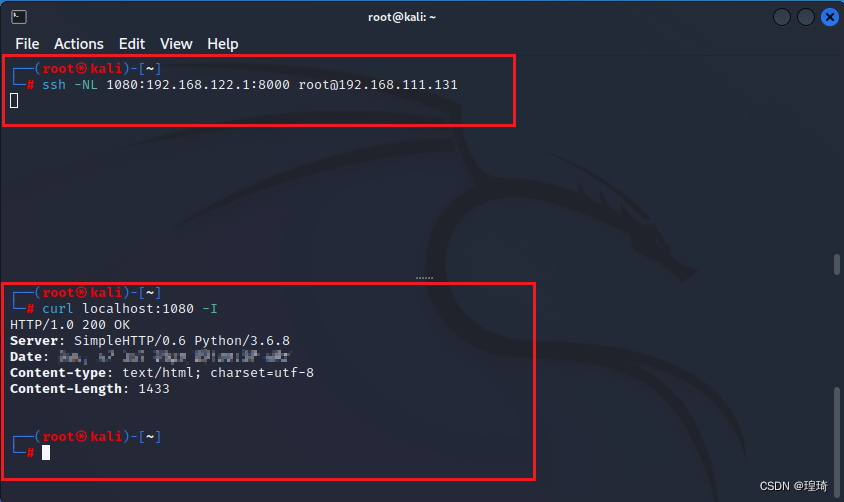
Centos 这边也记录到了相应的连接日志,本地转发成功:
远程转发(-R)
原理
远程转发的执行参数是 ssh -R,官方的解释是:
-R [bind_address:]port:host:hostport
-R [bind_address:]port:local_socket
-R remote_socket:host:hostport
-R remote_socket:local_socket
-R [bind_address:]port
Specifies that connections to the given TCP port or Unix socket on the remote (server) host are to be
forwarded to the local side.
This works by allocating a socket to listen to either a TCP port or to a Unix socket on the remote side.
Whenever a connection is made to this port or Unix socket, the connection is forwarded over the secure
channel, and a connection is made from the local machine to either an explicit destination specified by
host port hostport, or local_socket, or, if no explicit destination was specified, ssh will act as a
SOCKS 4/5 proxy and forward connections to the destinations requested by the remote SOCKS client.
Port forwardings can also be specified in the configuration file. Privileged ports can be forwarded
only when logging in as root on the remote machine. IPv6 addresses can be specified by enclosing the
address in square brackets.
By default, TCP listening sockets on the server will be bound to the loopback interface only. This may
be overridden by specifying a bind_address. An empty bind_address, or the address ‘*’, indicates that
the remote socket should listen on all interfaces. Specifying a remote bind_address will only succeed
if the server's GatewayPorts option is enabled (see sshd_config(5)).
If the port argument is ‘0’, the listen port will be dynamically allocated on the server and reported to
the client at run time. When used together with -O forward, the allocated port will be printed to the
standard output.
通俗讲就是,执行远程转发命令后,会在远程机器开启监听一个指定端口1,绑定到本地的指定端口2,所有访问远程机器端口1 的流量都会被转发到本地的端口2 上,相当于直接访问本地的端口2,也可以简单的理解为 “流量从远程转发到本地机器”;
可以注意到这里的转发流向其实是和上面的本地转发是反的,所以参数值([bind_address:]port:host:hostport)的规律也反了过来,从左到右写是:远程机器的接口([bind_address])上的端口(port)转发到本地接口(host)的端口(hostport)上去。远程接口地址(IP)可以省略,默认 127.0.0.1,socket 连接同理。
这里有个值得注意的地方,可以看到参数值那块,相比于前面的本地转发多了个 [bind_address:]port 值,也就是说同时省略了本地接口地址和端口值,远程接口也可按需省略,相当于可以只写一个远程端口值,这样其实会建立一个反向的 socks5 代理,即远程机器的那个端口可以被当成一个 socks4 或 socks5 代理端口,代理流量都会被引导至本地机器,这个后面也有对应实验验证。
实验
下面同样使用 Kali(192.168.111.128)通过远程转发去连接 Centos(192.168.111.131),不过这次是在 Kali 上用 python 启一个简单的 http 服务:
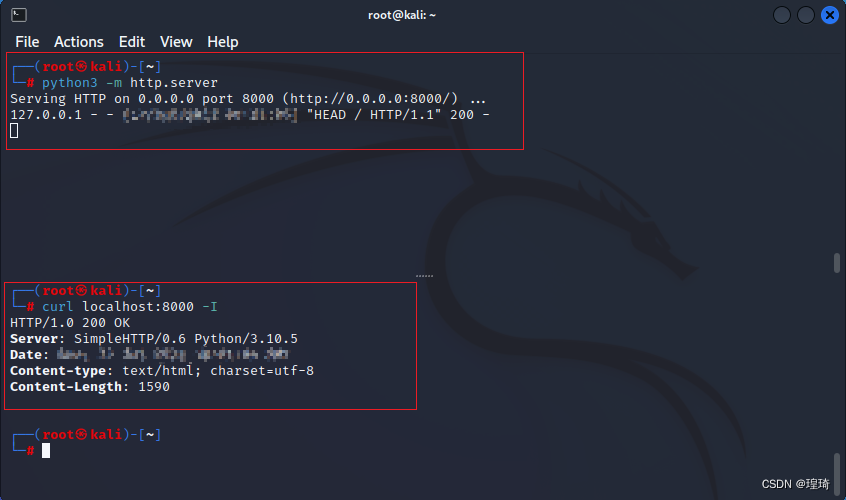
本地连接没问题,接下来在 Kali 上开启远程转发,参数为:
ssh -NR 1080:127.0.0.1:8000 root@192.168.111.131
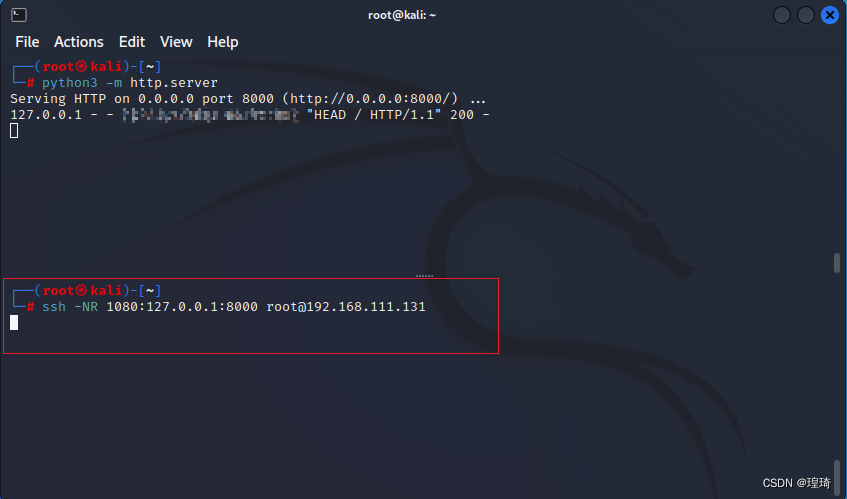
这会在远程机器(Centos, 192.168.111.131)上开启一个新的监听端口 1080,再使用 curl 对其访问,就会得到 Kali(192.168.111.128)上端口 8000 的返回内容:
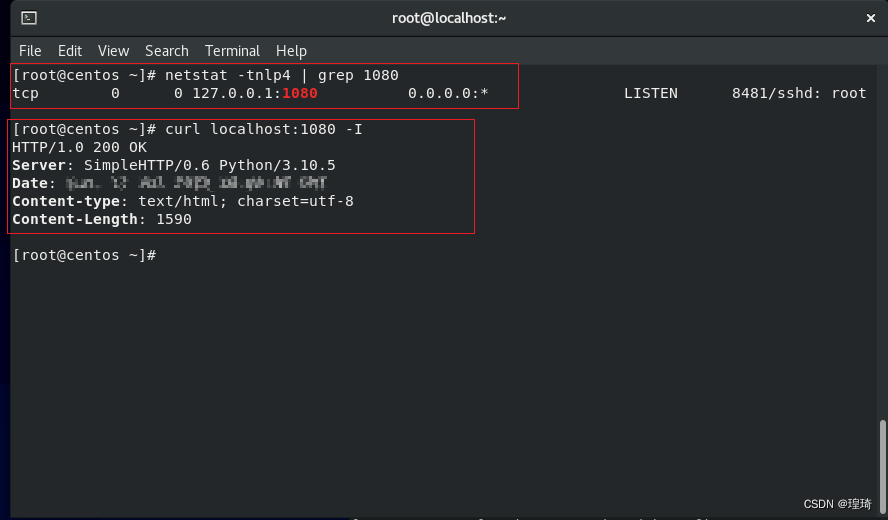
Kali 这边也有了相应的访问记录,至此远程转发成功:
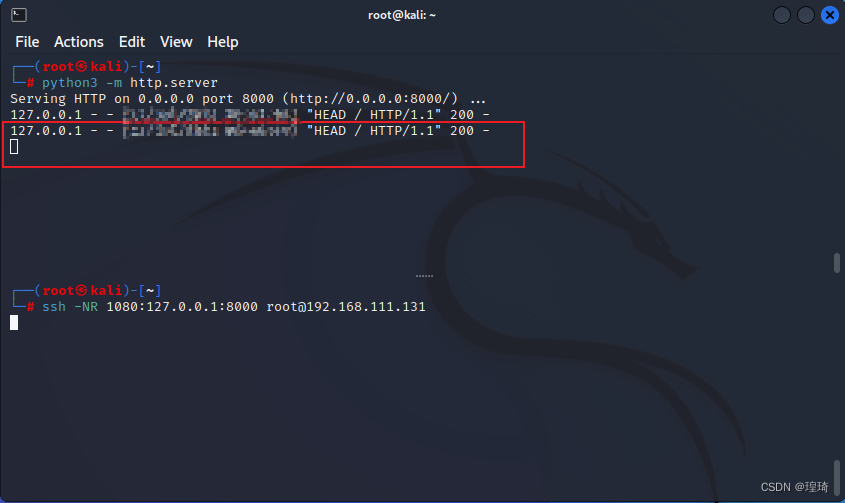
反向 socks 代理
然后测试 -R 参数值只指定一个远程端口的效果,前面讲这会让本地机器成为一台 socks 代理服务器,下面为了测试代理效果,就需要网关机器(192.168.111.1)上场了,在网关上启一个简单的 php 服务,以获取访问者的真实 IP 地址,代码如下:
<?php
echo $_SERVER['REMOTE_ADDR'] . PHP_EOL;
访问路径是:http://192.168.111.1/get-ip.php,先分别用 Kali 和 Centos 访问试下:
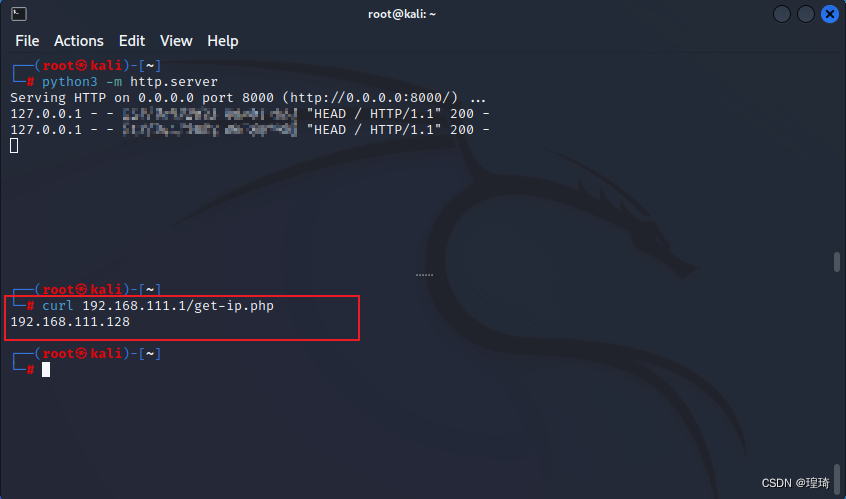
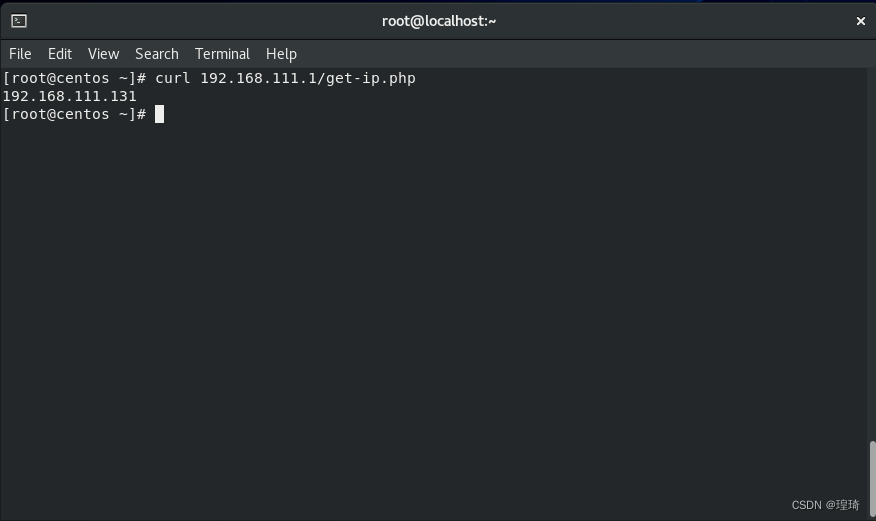
ok,IP 是对的,然后在 Kali(192.168.111.128)上启动反向 socks 代理服务:
ssh -NR 1080 root@192.168.111.131
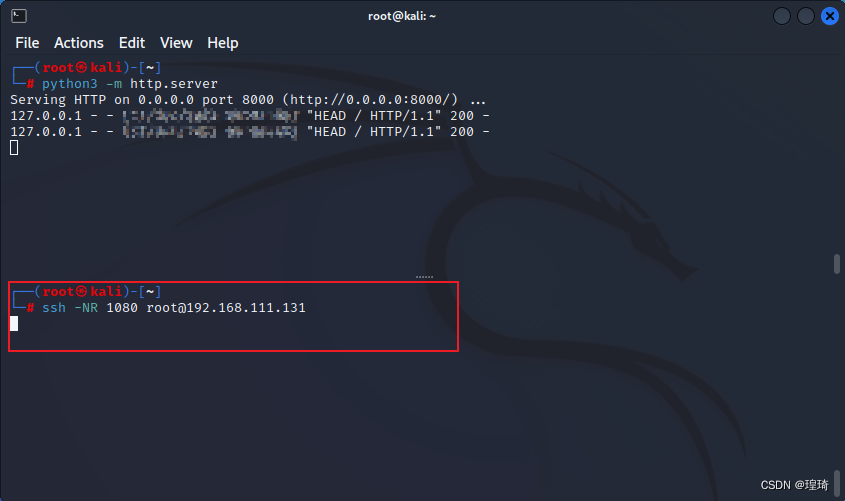
去 Centos(192.168.111.131)上访问一下看看代理(使用 curl 的 -x 参数指定代理服务器)效果:
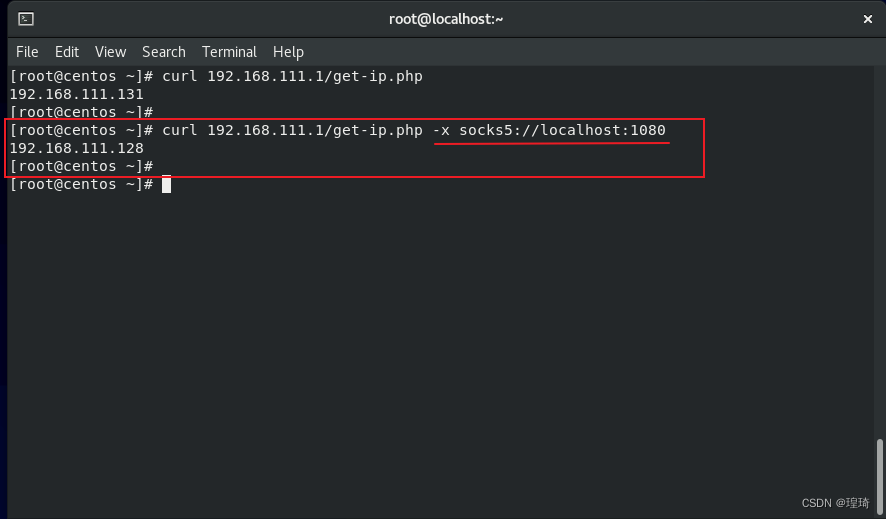
至此反向 socks 代理成功。
远程接口地址问题
在实际使用远程转发的时候,可能会遇到一个小坑,就是 -R 的参数值虽然可以任意指定远程机器的接口地址,但实际上 ssh 默认都只会在 127.0.0.1 接口地址上开监听端口,也就是说假如这台远程机器是台公网服务器的话,新监听的端口是没法在公网上访问到的,只能这台机器本地访问,这是一个 sshd 的默认配置导致的,它一般在 /etc/ssh/sshd_config 文件中,GatewayPorts 这个配置项,默认是 no,改成 yes 即可,如果没有这一行就手动添加:
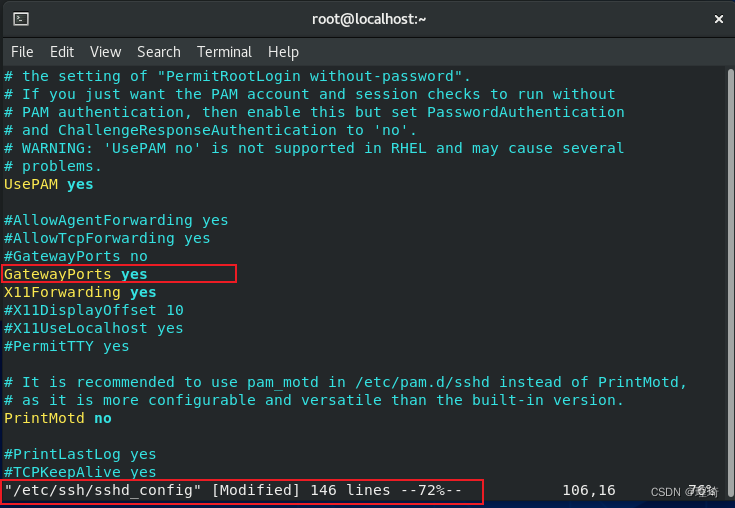
然后重启 sshd 服务,再用远程转发连接时就会在所有接口(即 0.0.0.0)上监听新端口了,但这样也只能在所有接口上开启端口了,无论连接方如何设置远程接口,所以需斟酌使用。
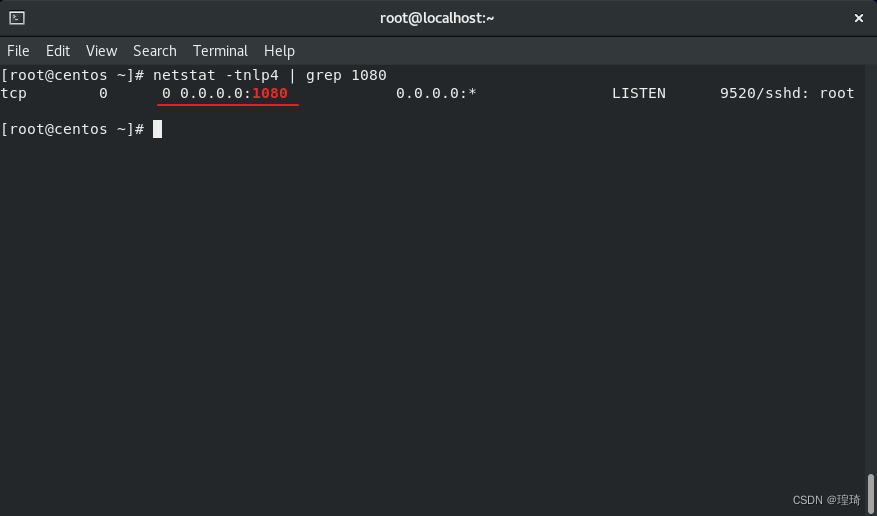
动态转发(-D)
原理
动态转发的执行参数是 ssh -D,官方解释是:
-D [bind_address:]port
Specifies a local “dynamic” application-level port forwarding. This works by allocating a socket to
listen to port on the local side, optionally bound to the specified bind_address. Whenever a connection
is made to this port, the connection is forwarded over the secure channel, and the application protocol
is then used to determine where to connect to from the remote machine. Currently the SOCKS4 and SOCKS5
protocols are supported, and ssh will act as a SOCKS server. Only root can forward privileged ports.
Dynamic port forwardings can also be specified in the configuration file.
IPv6 addresses can be specified by enclosing the address in square brackets. Only the superuser can
forward privileged ports. By default, the local port is bound in accordance with the GatewayPorts set‐
ting. However, an explicit bind_address may be used to bind the connection to a specific address. The
bind_address of “localhost” indicates that the listening port be bound for local use only, while an
empty address or ‘*’ indicates that the port should be available from all interfaces.
这应该是实际使用中较多的一种用途,即 socks 代理,动态转发是在本地监听一个指定端口,应用程序将 socks 代理端口设置为这个端口后,任何连接流量都会通过这个端口,经由 ssh 隧道转发到远程机器代为发送,由于不再受限于连接端和被连接端的端口与接口,所以称为动态。
参数值([bind_address:]port)为要在本地机器监听的接口地址与端口,不写接口地址则默认为 127.0.0.1,在所有接口监听则写 0.0.0.0。
实验
还是在 Kali(192.168.111.128)上执行操作,监听本地 1080 端口,将 Centos(192.168.111.131)作为 socks 代理服务器:
ssh -ND 1080 root@192.168.111.131
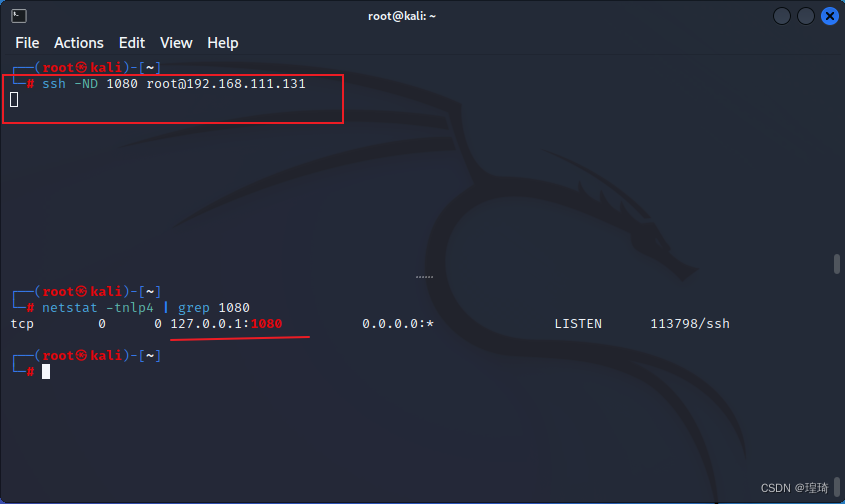
尝试用 curl 测试代理效果,可以看到 socks5 代理已生效,IP 地址为 Centos(192.168.111.131)的:
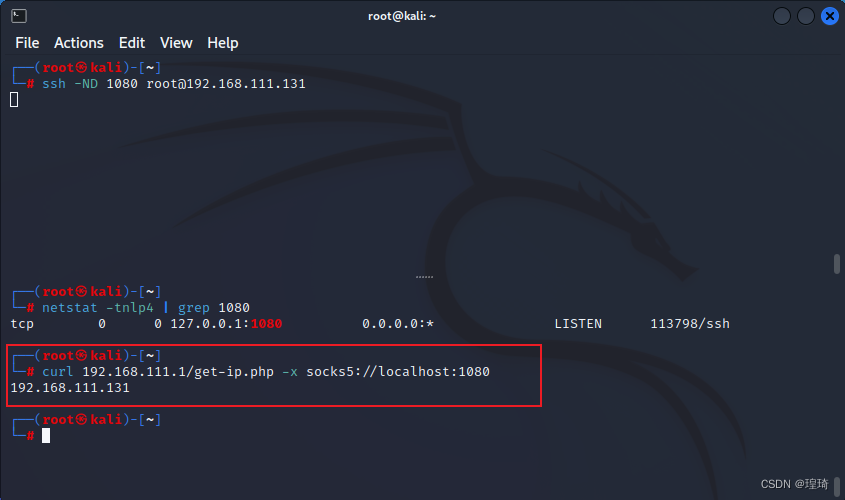
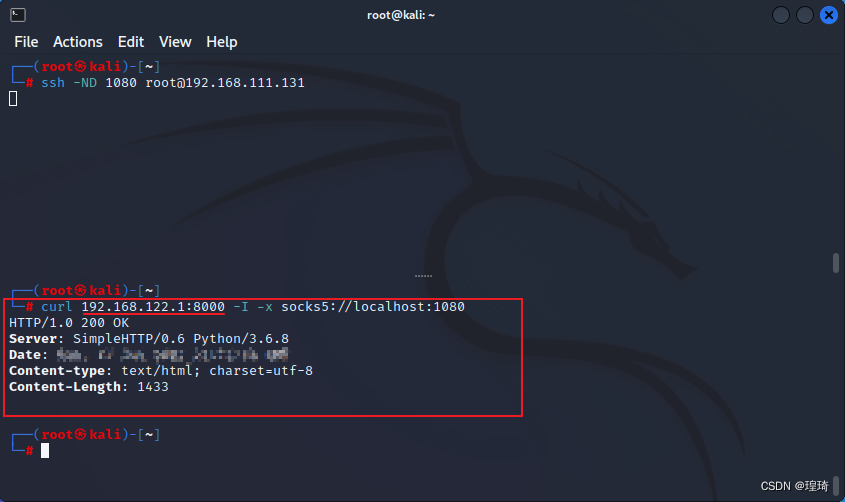
Kali 访问 Centos 的其他接口(192.168.122.1)的 http 服务(8000 端口)也没问题:
多级代理(-J)
原理
实现多级代理需要用到 ssh -J 参数,即设置 Jump host,可理解为跳板,官方解释为:
-J destination
Connect to the target host by first making a ssh connection to the jump host described by destination
and then establishing a TCP forwarding to the ultimate destination from there. Multiple jump hops may
be specified separated by comma characters. This is a shortcut to specify a ProxyJump configuration di‐
rective. Note that configuration directives supplied on the command-line generally apply to the desti‐
nation host and not any specified jump hosts. Use ~/.ssh/config to specify configuration for jump
hosts.
大意就是连接 ssh 的过程中,可以指定(多个)跳板机,实现流量的一级一级转发,每一级跳板的系统都只有上一级的访问记录,达到一定的隐匿作用。参数值 destination 的语法与普通 ssh 连接对象的语法一致,指定多个跳板则将多个节点值以逗号分隔。
实验
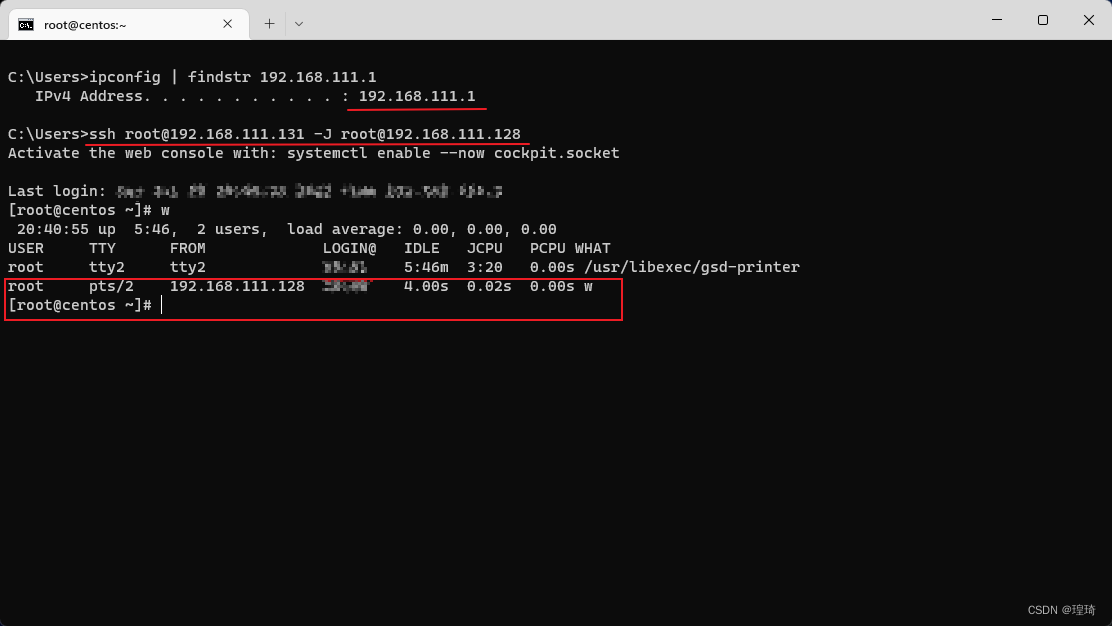
为了呈现多级节点的效果,这里需再次用到网关机器(192.168.111.1),用其通过 ssh 连接 Centos(192.168.111.131),并以 Kali(192.168.111.128)作为跳板机,直接在网关上执行:
ssh root@192.168.111.131 -J root@192.168.111.128
可以看到最终连接到的 Centos 机器的访问记录是跳板机 Kali 的 IP 地址:
再测试一下指定多个跳板:
ssh root@192.168.111.131 -J root@192.168.111.128,root@192.168.111.131
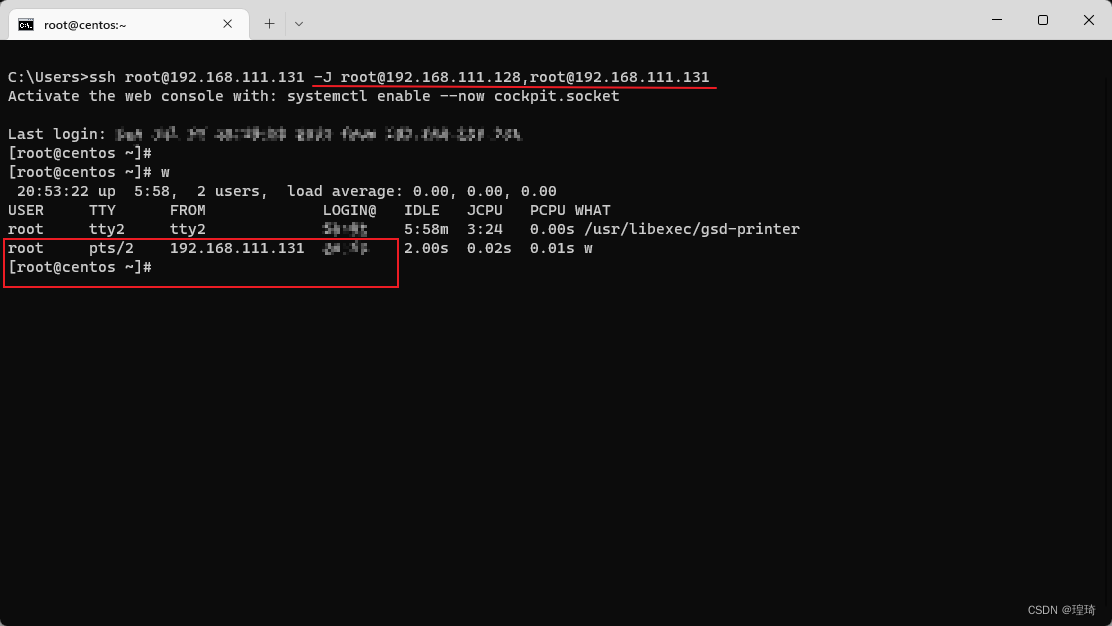
这里为了简化网络拓扑,所以把 Centos 自身也设置为一个跳板,那么经过的两个跳转节点就是 .128 和 .131,整个流量流转过程可以简化为:
*.111.1 --> *.111.128 --> *.111.131 --> *.111.131
将 -J 参数与前面提到的几种转发与代理参数结合,就实现了多级代理功能。