时序数据库使用总结
时序数据库在当下产业互联网背景下,在金融、工业等领域得到越来越多的应用,主要面向高并发、海量时序数据等应用场景中。
大规模时序数据具有特点
- 占用空间极大
- 数据总吞吐量大
- 产生速度快且不间断
时序数据存储的需求
- 全时全量
- 高效写入
- 紧凑存储
时序数据库与关系型数据库
- 时序数据管理具有超高性能,超多序列的特点
- 关系型数据库具有写入受限的缺点
- 单表列数上限 mysql innodb最大为1017列
- 单表行数不易过多 小于1000万行
- 水平、垂直分表;分库 键值数据库可管理海量条时间序列数据,但查询受限:主要包括按时间纬度的查询,按值纬度的查询,多序列的时间对齐查询。
除此之外,时序数据库还有一个优点:由于时序数据库其具有时间相关性,不需要处理关系性数据库下的分布式锁这类比较繁琐的事务。
时序数据库大体上可分为三种:
-
基于关系数据库的: Timescale,基于PG开发的插件 能够做到: 时序数据自动分区 优化查询计划 定制并行查询 但随着导入时间增加时,其导入效率不断下降
-
基于键值数据库的: OpenTSDB,KairosDB 这类时序数据库一般基于HBase/Cassandra衍生, 支持时序分区键,定时任务构件索引。但存在压缩不友好,查询不友好的缺点。
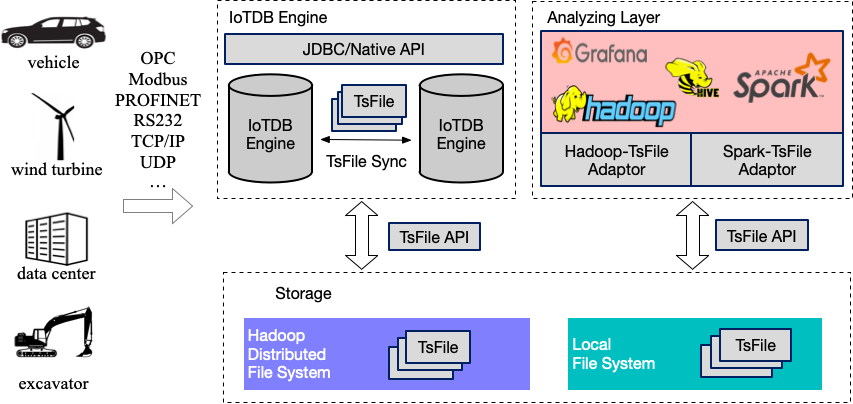
- 原生时序数据库: influxdb 基于LSM机制的时序库, 专属文件结构 专属查询优化 特定工业场景下性能会下降 iotdb grafana-adaptor pisa索引
常用时序数据库:
iotdb influxdb taosdb timescale kairosdb
经过测试iotdb性能较优