树莓派 | 欧路词典生词本 & 墨墨背单词 云同步教程 (eudic-maimemo-sync)
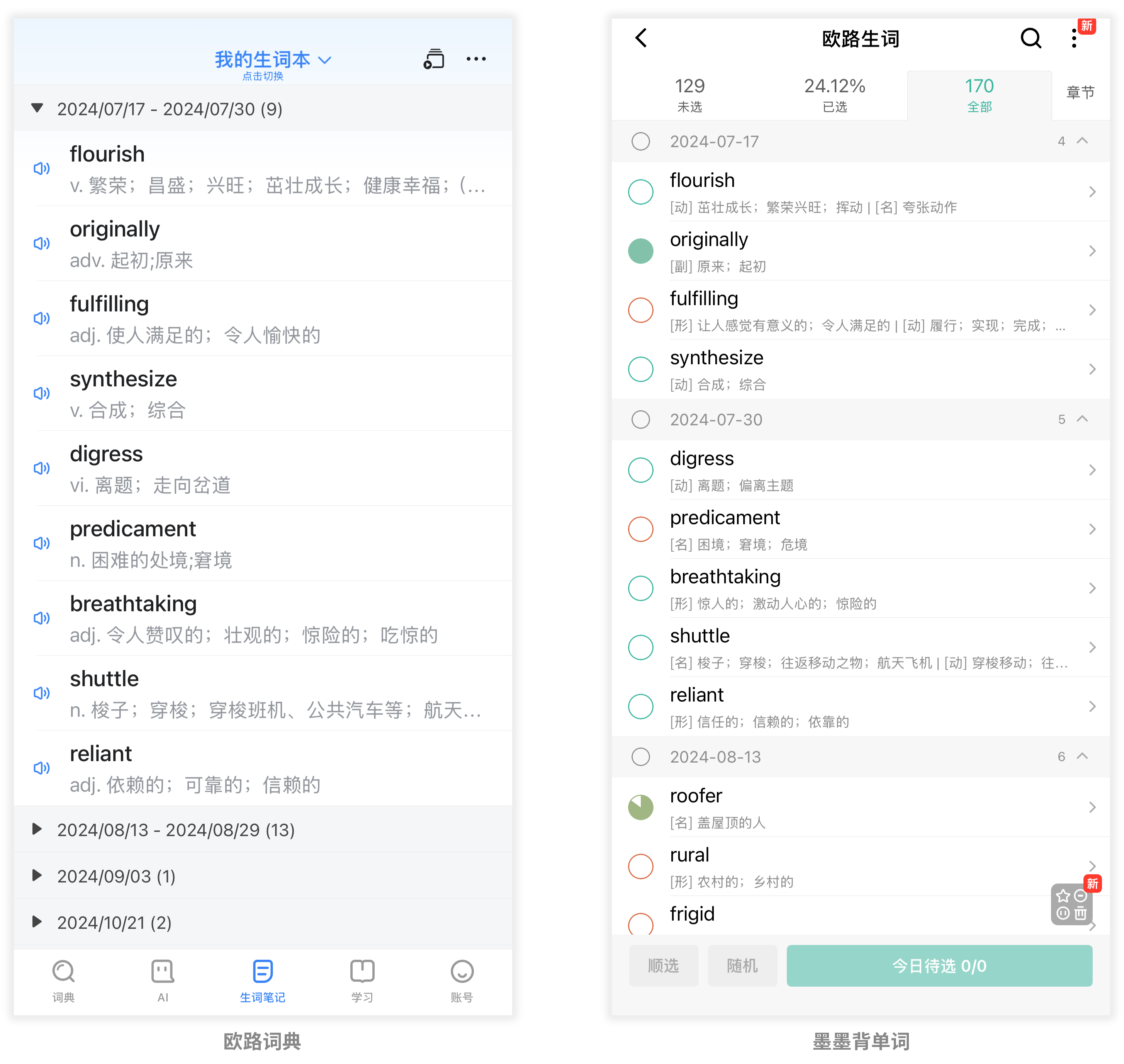
在浏览网页时,我常用欧路词典的“欧路翻译”浏览器插件进行划词翻译。这个插件会自动记录查阅过的单词,并将其添加到欧路词典的生词本中。 然而,在单词记忆方面,我更习惯使用“墨墨背单词”。
因此,我在寻找一种方法,将欧路词典的生词本同步到墨墨背单词的词库。这样,我就可以用自己习惯的软件来记忆日常阅读中遇到的生词了。
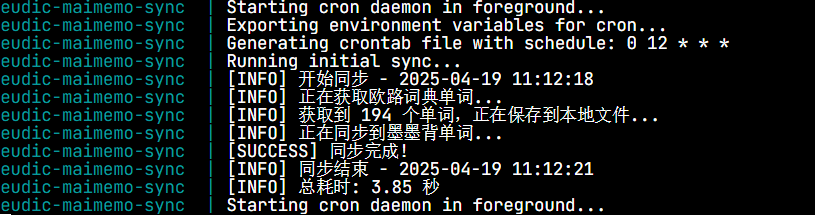
后来我发现,这两个软件其实都提供开放 API。于是,我开发了 eudic-maimemo-sync 工具,实现欧路词典生词本到墨墨背单词云词库的自动同步。同时,我还将其部署在树莓派上,让它每天自动运行,实现了生词本的无缝同步。
接下来,我将介绍如何配置和使用这个工具,并分享开发过程中遇到的一些问题和解决方法。也欢迎大家贡献代码或提出建议。
目录
eudic-maimemo-sync 使用教程
1. 下载代码安装依赖
前置条件:已安装 Python 3 环境
下载代码:
git clone https://github.com/eMUQI/eudic-maimemo-sync.git安装依赖:
cd eudic-maimemo-sync
pip install -r requirements.txt2. 配置环境变量
接下来,需要配置环境变量。首先,复制 .env.example 为 .env。
2.1 欧路词典相关配置
获取欧路词典 API 密钥
访问此页面,登录后,获取你的API密钥。并将获取到的 API 密钥填入
.env文件中的EUDIC_API_KEY字段。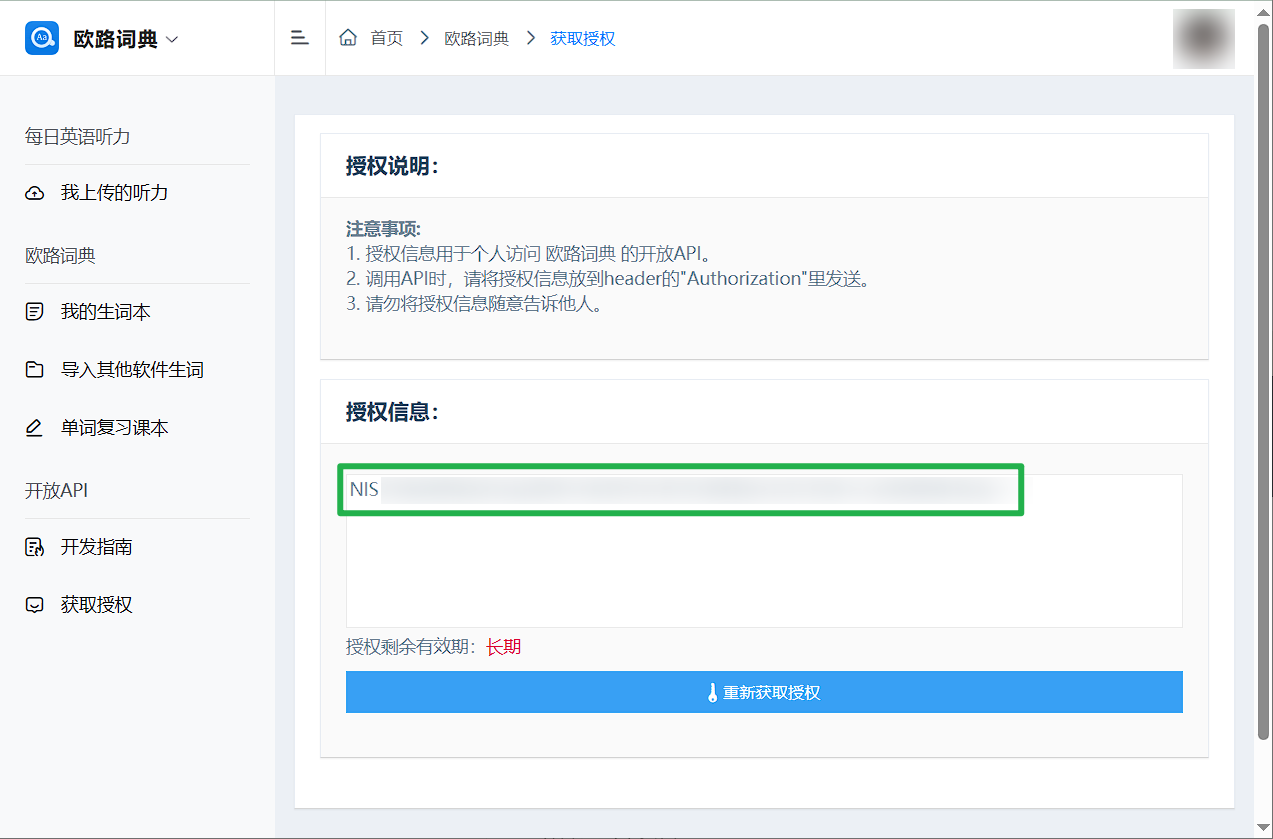
获取生词本 ID
运行
get_wordbook_id.py,查看生词本信息,记下你需要同步的生词本 ID。python get_wordbook_id.py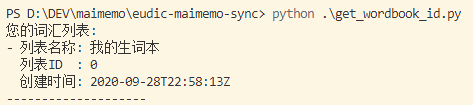
将需要同步的生词本 ID 填入
.env中的EUDIC_CATEGORY_ID。
2.2 墨墨背单词相关配置
获取墨墨背单词 API 密钥
打开墨墨背单词手机 App,进入「我的」-「更多设置」-「实验功能」-「开放 API」,生成并复制 API 密钥,然后将其填入
.env文件中的MOMO_API_KEY字段。获取云词库 ID
运行
get_notepad_id.py,查看云词库信息,记住你需要同步的云词库 ID。python get_notepad_id.py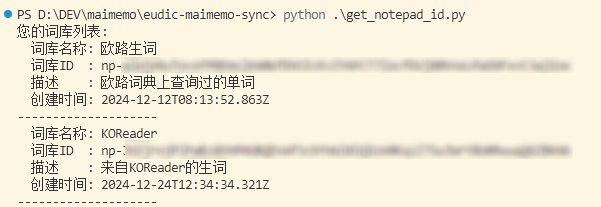
将需要同步的词库 ID 填入
.env文件中的MOMO_NOTEPAD_ID字段。
3. 手动同步
运行 sync.py,即可手动触发一次同步。
python sync.py4. 自动同步(部署到树莓派上或者其他 Linux 设备)
确保部署前已经成功手动运行过 python sync.py,验证配置无误。
使用Docker
我个人比较喜欢用 Docker, 隔离性好,依赖管理简单,不会弄乱系统的环境。在我的树莓派 5 上运行良好,额外的性能开销在可接受范围内。
创建一个 docker-compose.yml 配置文件:
services:
eudic-maimemo-sync:
image: ghcr.io/emuqi/eudic-maimemo-sync:latest
container_name: eudic-maimemo-sync
restart: unless-stopped
env_file:
- .env
# volumes:
# - ./words_data.txt:/app/words_data.txt # 如果想查看单词记录,取消此行和上一行的注释
environment:
- TZ=Asia/Shanghai
- RUN_ON_STARTUP=true # 设置为 true 时,容器每次启动时会执行一次同步任务
# CRON 定时任务表达式配置:
# 示例:每小时的第 0 分钟执行(即整点执行)
# - CRON_SCHEDULE=0 * * * *
# 示例:每天凌晨 3:15 执行
- CRON_SCHEDULE=15 3 * * *
# 请确保所有必需的环境变量(如 EUDIC_API_KEY 等)已在 .env 文件中定义或在此处直接指定。
healthcheck:
# Test if the supercronic process is running
test: ["CMD-SHELL", "pgrep supercronic || exit 1"]
interval: 2m
timeout: 5s
retries: 3
start_period: 10s你可以通过 CRON_SCHEDULE 来设置任务的运行周期:
CRON_SCHEDULE=0 * * * *: 每小时的第 0 分钟执行(即整点执行)CRON_SCHEDULE=15 3 * * *: 每天凌晨 3:15 执行
在相同目录下创建一个 words_data.txt 文件,用于记录同步的单词列表,方便调试或查看。如果不需要,可以跳过此步。
touch words_data.txt启动容器
docker compose up -d其他方式
你还可以使用 cron 或者 systemctl 的方式来定时运行这个同步脚本。如果你熟悉这些工具的配置,欢迎分享你的方法或提交 Pull Request。
开发中遇到的问题
欧路词典 API 的
User-Agent要求: 欧路词典 API 对请求的User-Agent有特定要求,不接受 Python HTTP 库(如requests)的默认User-Agent。因此,在与该 API 交互时,必须显式设置一个浏览器类型的User-Agent,以确保请求被正确处理。本项目中,我采用了Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36。墨墨背单词 API 云词库格式: 墨墨背单词 API 文档中关于添加单词到云词库所需的数据格式说明不够清晰。文档中只说明数据类型是
string,但未明确其具体结构。经过试验,结构为以井号#开头的行作为分类标记(例如日期),换行后紧跟该分类下的单词,每个单词独占一行。下一个分类同样以#开头的标记开始。如#20250415\napple\nboy#20250416\ncat。#20250415 apple boy #20250416 catDocker 中定时任务:从 Cron 到 Supercronic 的迁移: 一开始,我尝试在 Docker 容器内部署 Cron 来定时执行 Python 任务。但是,Cron 任务默认在隔离的、极简的环境中执行,无法直接继承 Docker 容器启动时定义的环境变量(例如 API 密钥等配置)。虽然有方法可以间接加载,但配置比较繁琐。于是我迁移到了 Supercronic。Supercronic 是一款专为容器环境设计的 Cron 实现,它兼容标准的 Crontab 语法,还能继承容器的环境变量。如果你有类似的项目,推荐你使用 Supercronic 作为替代方案。
最后,欢迎提交 Pull Requests 或 Issues 到 eudic-maimemo-sync。有任何想法,也欢迎在下方留言。





 编辑
编辑