构建属于自己的云游戏服务器
最近沉迷于暗黑4第四赛季,所以就在倒腾,怎样才能随时随地玩到暗黑4,掌机steam deck 我试过了,太重并且性能很差,已经被我卖了,于是折腾起了云游戏。
先来看看我的折腾成果:https://www.bilibili.com/video/BV1Z93TeuEQ4/
其实效果我没想到有这么好,在远程串流的情况,可以 1080p 60hz 几乎无卡顿的玩暗黑4,延迟只有20ms左右,配上我的手柄简直就是一个强大的掌机。
各种平台云游戏怎样了?
有了上面的需求之后,我就去试了以下几个平台:GeForce Now、Xbox Game Cloud、Start云游戏、网易云游戏。
但是遗憾的是,几乎每个平台都有自己的问题。首先上面列举到的所有平台,IOS 都只有网页版,因为苹果不让上架。
Start云游戏:我检查了一下,只有少数的几个单机游戏,大多是网游手游,并没有暗黑4;
网易云游戏:无论是快速启动还是普通启动,都非常的慢,估计要3分钟左右才能启动。并且我充值了一下玩了一下,网络倒是很流畅,延迟只有15ms左右,但是非常的卡,并且经常进入游戏界面死机,估计是机器性能不行,说实话我有点心疼我充值的10块钱了。
所谓的高配,其实性能很低:
Xbox Game Cloud:微软自家的平台,好处是有了XGPU之后可以畅玩所有云游戏,最大的问题是服务器不在国内,所以连接延迟其实很高,并且常有波动,如果要玩Xbox Game Cloud 那么还需要充值XGPU才行;
Xbox Game Cloud 强大的游戏阵容:
GeForce Now:这个云游戏平台可以说只能用无敌两个字来形容,每次登录都可以免费半个小时,即使服务器在海外,但是开了加速器也可以很稳定,画面有720P,在手机上玩还可以,主机性能也很好,经常分配到2080以上的机器。但是唯一不爽得是,免费用户每次都要排队挺长时间的,并且如果要付费,其实挺贵的,基本要100元每个月了。
GeForce Now价格表:

开源解决方案
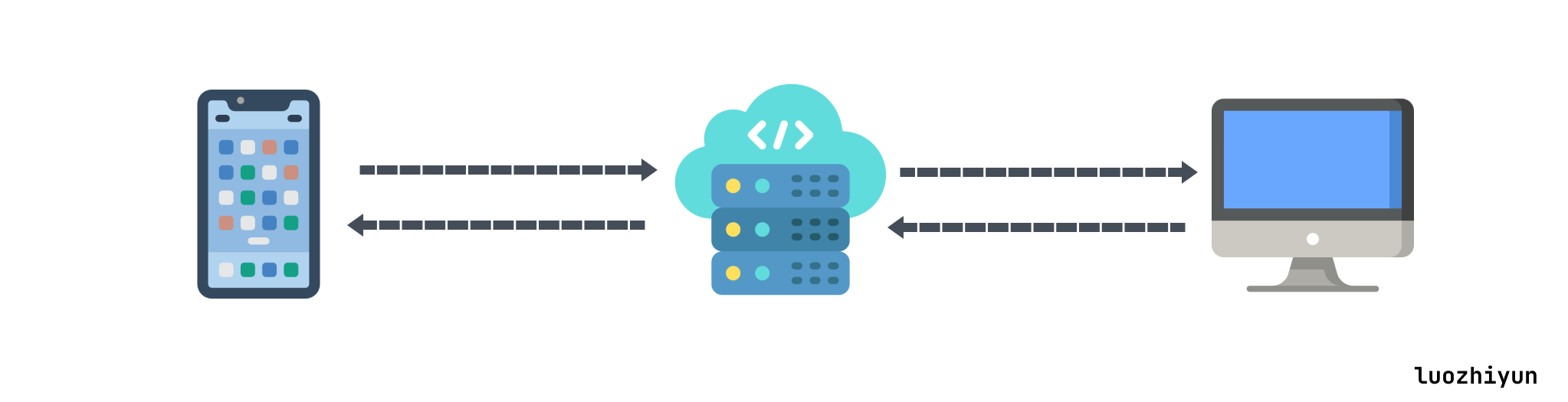
所以尝试了这么的云游戏发现都不好用之后,为什么不可以自己弄个呢?其实所谓的云游戏,无非是用客户端连接到主机端而已。那么我们实际上也可以把自己家里运行的PC或者主机,变成了由云游戏服务商提供的云上服务,这种行为就叫做串流游戏。
所以我们要做的是怎样把我们的私有网络的PC或者主机做成云服务提供给外网访问,让我们可以随时随地,只要有网就可以使用。
那么我的要求主要有这么几点:
- 要有跨平台的客户端,保证mac、iphone、android、win 都能用;
- 延迟要足够低,支持的可配置项要足够多;
正好自己有台闲置的 4090 的机器,那我就可以用它来作为主机端,我的安卓机作为客户端进行串流云游戏。
服务端 & 客户端
目前服务端主要有以下几个实现方案:
- N卡GeForce Experience
- Sunshine
客户端主要有:Moonlight
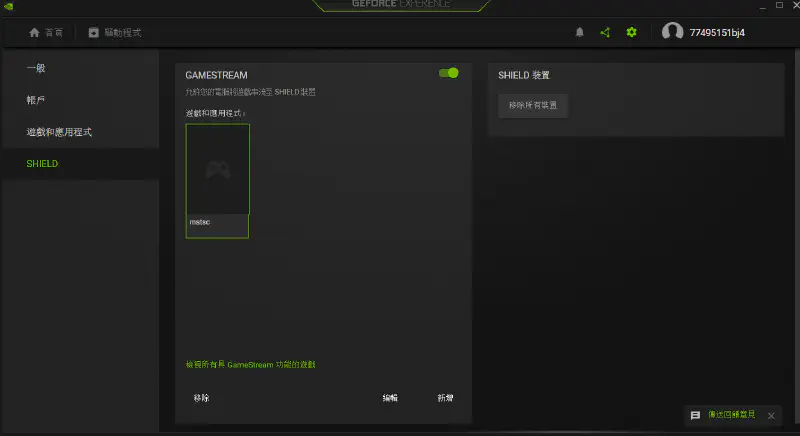
N卡GeForce Experience
如果你使用N卡,并且是GTX960以上可以通过GeForce Experience进行串流。只需要打开GeForce Experience在设置里找到SHELD这个串流配置,并添加游戏或者应用程序即可。
但是我现在不是很推荐这个方案,因为NV说过他们要把这个功能去掉,只是现在没有去掉而已。
Sunshine
它是一个开源推流方案 https://github.com/LizardByte/Sunshine , 属于通用串流方案,支持Nvidia、AMD、Intel。尤其适合核显串流(如果你用的是P106这类显卡没有视频编码器,只能使用Sunshine串流方案)。
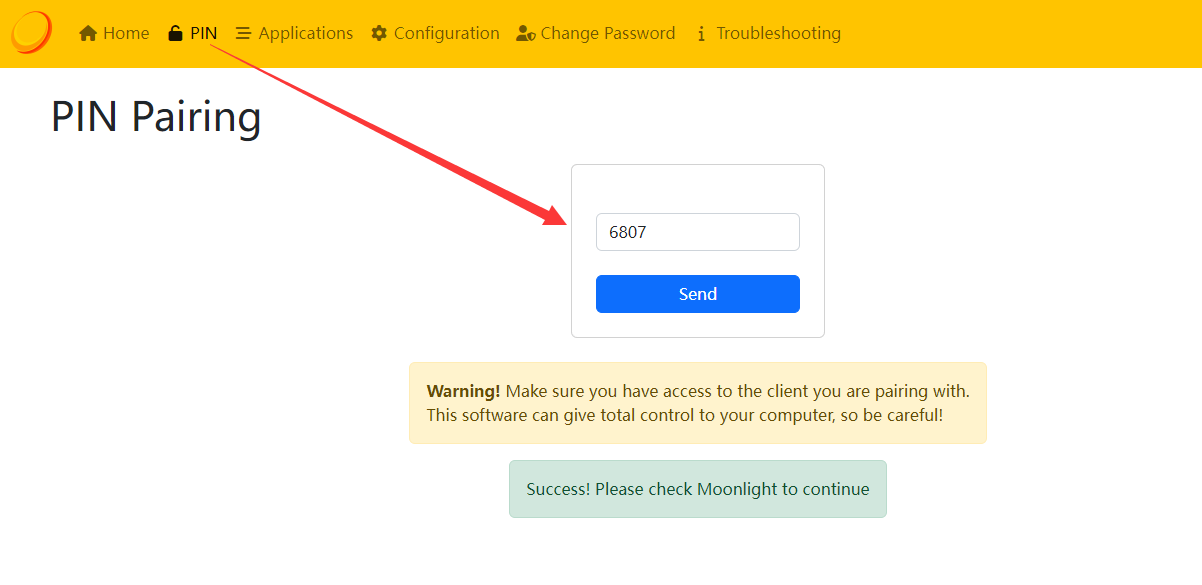
下载Sunshine后首先需要运行服务端安装脚本install-service.bat,然后再运行sunshie。sunshine没有UI界面,设置需要通过网页端。运行sunshine后访问https://127.0.0.1:47990进行设置。设置里最重要的是进行PIN码配对,设备之间PIN匹配之后就可以进行串流了。
Moonlight
Moonlight 以方便的将Windows电脑画面传输到各主流操作系统的客户端软件上,甚至可以直接传输至谷歌浏览器。画面方面,移动端最高支持4K120帧,且支持HDR(需要显卡支持),而桌面端甚至可以直接自定义分辨率和帧数;交互方面支持键鼠/手柄/触摸屏/触控板/触控笔,就像用自己的电脑一样使用远程电脑。该方案无广告,完全免费。
手机端可以在各大商店下载,也可以去 Moonlight官网地址:https://moonlight-stream.org 下载。如果使用iphone作为客户端,直接在App store下载Moonlight即可。
保持主机和客户端在同一局域网内,打开客户端软件,应该能够看到主机的计算机名。点击会弹出4位PIN码,需要在Sunshine配置网页 https://localhost:47990/pin 中输入PIN码。建立连接后,点击桌面(DESKTOP)将启动桌面串流。
网络配置好之后,在局域网内串流延迟通常相当的底,我经常躺床上用 pad 串流我书房的 pc 玩游戏,延迟只有几毫秒。
远程串流
由于Geforce Experience和Sunshine默认只在本地网络监听端口,客户端和主机位于同一局域网内才能连接成功,如果要真正实现远程连接,最简单稳定的方法是公网直连。
独一无二的IP地址使得主机能够在互联网中被识别,但是由于IPv4地址匮乏,大多数家庭网络并不具备公网IPv4地址。
所以我这里采用内网穿透的方式来构建我们的云服务:
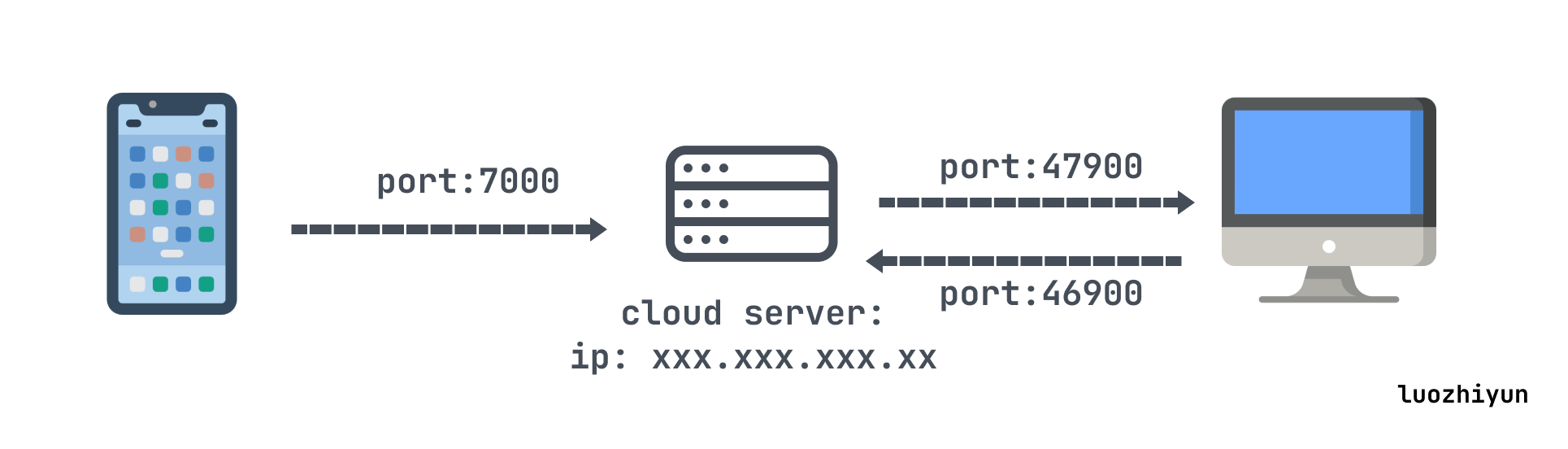
内网穿透的核心思想就是“映射”和“转发”,把私有网络的设备的端口映射到公网设备的端口上,来进行流量转发。思想其实很简单,由于内网设备没有ip,那么我们通过一台有公网ip的机器来代替把流量做一层转发。比如上图,
我们在外网设置的用手机访问云服务器的 7000 端口,实际上云服务器会接收到之后通过47900进行转发到我们私有网络的pc机器,然后pc机器处理完之后再通过46900 端口转发给云服务器,上面所提到的端口都是可以自定义的。
那么对于做内网穿透一般现在流行两种做法:
- 直接 p2p 点对点的进行传输,流行的方案有 zerotier;
- 基于服务器的流量转发,流行的方案有 frp;
为什么会有内网穿透?
其实在互联网的世界中,如果每个用户都有真实的IP情况下,那么我们可以通过源IP+源端口+目标IP+目标端口+协议类型很容易的找到对方,是根本不需要P2P的,因为本来任何对象都可以作为Server或者Client来提供服务,彼此之间是可以互联。
但是IP和端口,是有限的,最初设计者也是没想到发展如此迅速,整个IPv4的地址范围,完全不够互联网设备来分配,那为了解决地址不够用的问题,就引入了NAT。
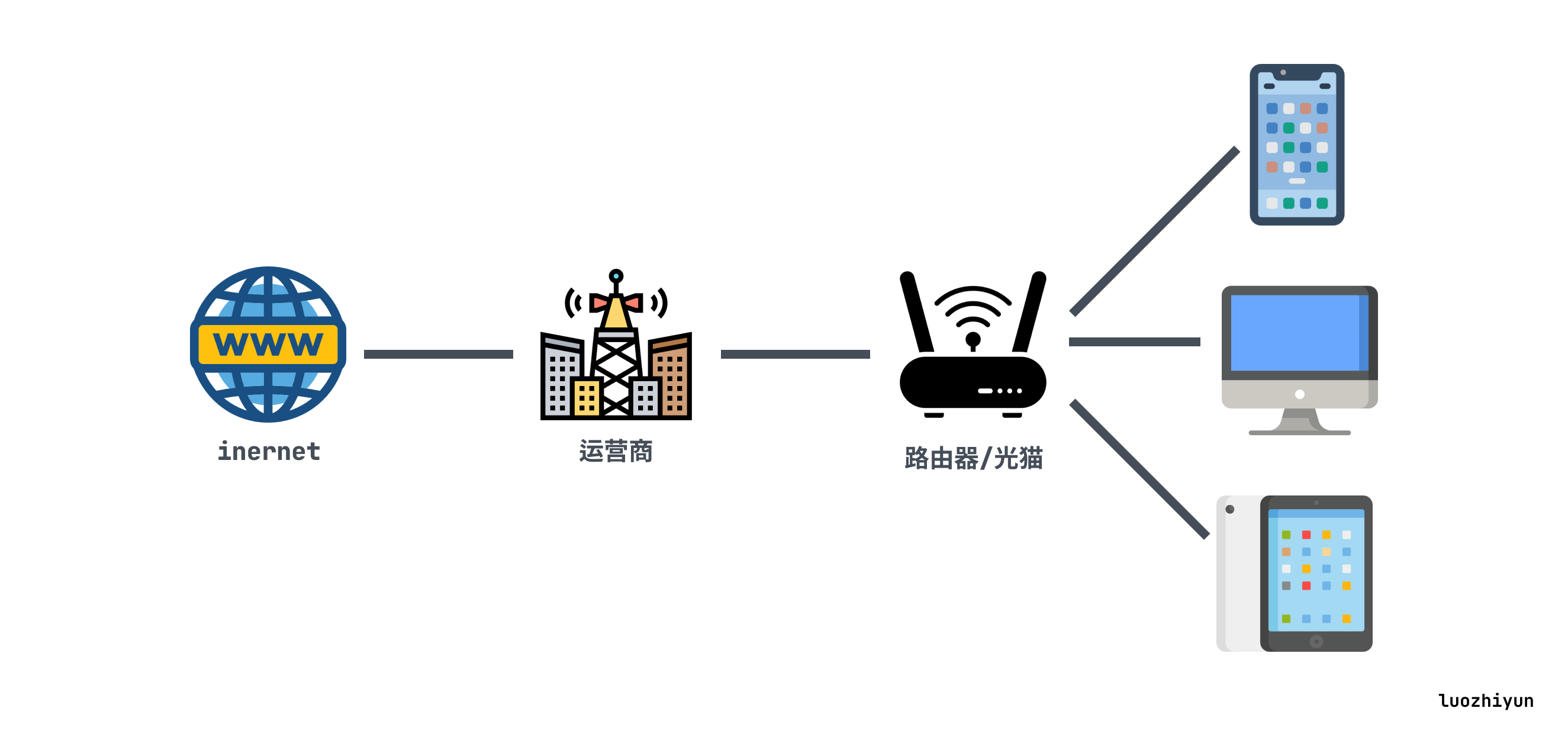
NAT(Net Address Translate,网络地址转换)是一种IP复用的一种技术,将有限的IP扩展成无限,由于IPv4地址资源有限,而NAT将网络划分成了公有网络和私有网络,允许多个设备使用一个公共IP地址访问互联网。路由器会将内部网络中的私有IP地址转换为公共IP地址,从而节省了IPv4地址资源。
所以我们在用 WIFI 的时候可以看到我们手机或PC上的IP地址通常是:192.168.x.xxx,这其实就是由路由器分配的地址,并不是真的地址。
另外,在 IPv4 地址资源越来越紧张的今天,很多电信运营商,已经不再为用户分配公网 IP;而是直接在运营商自己的路由器上运营 NAT,所以会出现甚至一整个小区共用一个 IP 出口的情况。
通过NAT技术的公私网络隔离,可以实现IP复用,解决了IPv4不够用的问题,但是也同时带来了新问题,那就是直接导致通信困难,由于NAT导致IP成为虚拟IP,外网无法针对内网某台主机进行直连通信,因为没有真实地址可用。
所以为了将NAT设备内外通信打通,就有了内网穿透技术。
zerotier
zerotier 是一个开源的内网穿透软件 https://github.com/zerotier/ZeroTierOne ,有社区版本和商业版本,唯一的区别是社区版本有 25台连接数量的限制,但对普通用户足够了,用它可以虚拟出一组网络,让节点之间的连接就像是在局域网内连接一样。
zerotier 底层是通过一个加密的p2p网络来实现连接。由于节点之间通常存在NAT隔离,无法直接通信,所以 zerotier 存在一个根服务器来帮助通路建设,所谓通路建设俗称打洞(hole punching),也就是穿透NAT隔离实现两个节点的连接。打洞也是区分 UDP 和 TCP 的,由于 zerotier 用的是 UDP,所以这里以 UDP 讲解打洞原理。
假设clientA 想要直接与clientB 建立UDP会话,用S表示根服务器:
A最初不知道如何到达B,因此A请求S帮助与B建立UDP会话,S会记录下他们各自的内外网IP端口:
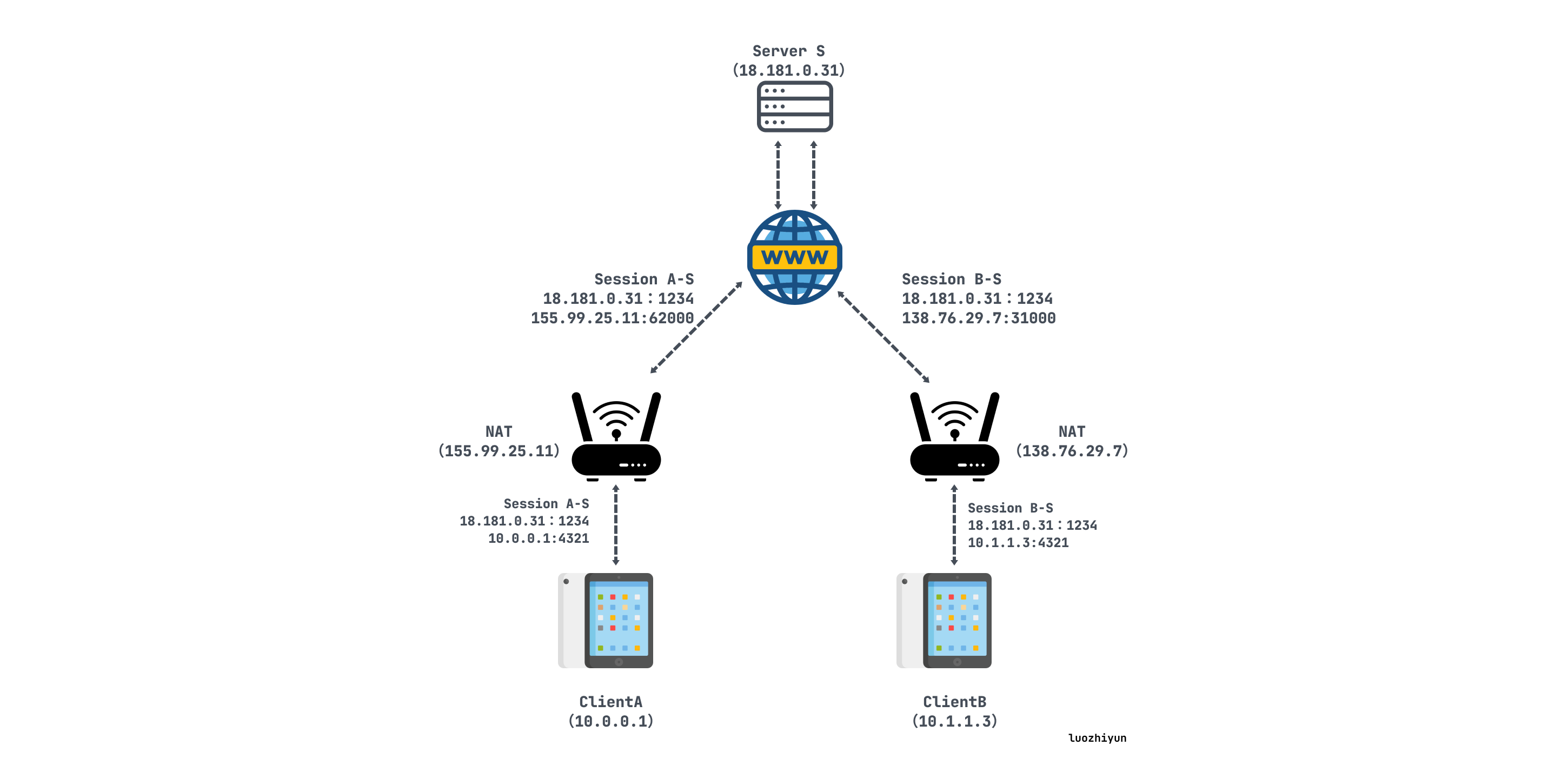
打洞中:
S用包含B的内外网IP端口的消息回复A。同时,S使用其与B的UDP会话发送B包含A的内外网IP端口的连接请求消息。一旦收到这些消息,A和B就知道彼此的内外网IP端口;
当A从S接收到B内外网IP端口信息后,A始向这两个端点发送UDP数据包,并且A会自动锁定第一个给出响应的B的IP和端口;
B开始向A的内外网地址二元组发送UDP数据包,并且B会自动锁定第一个给出相应的A的IP和端口;
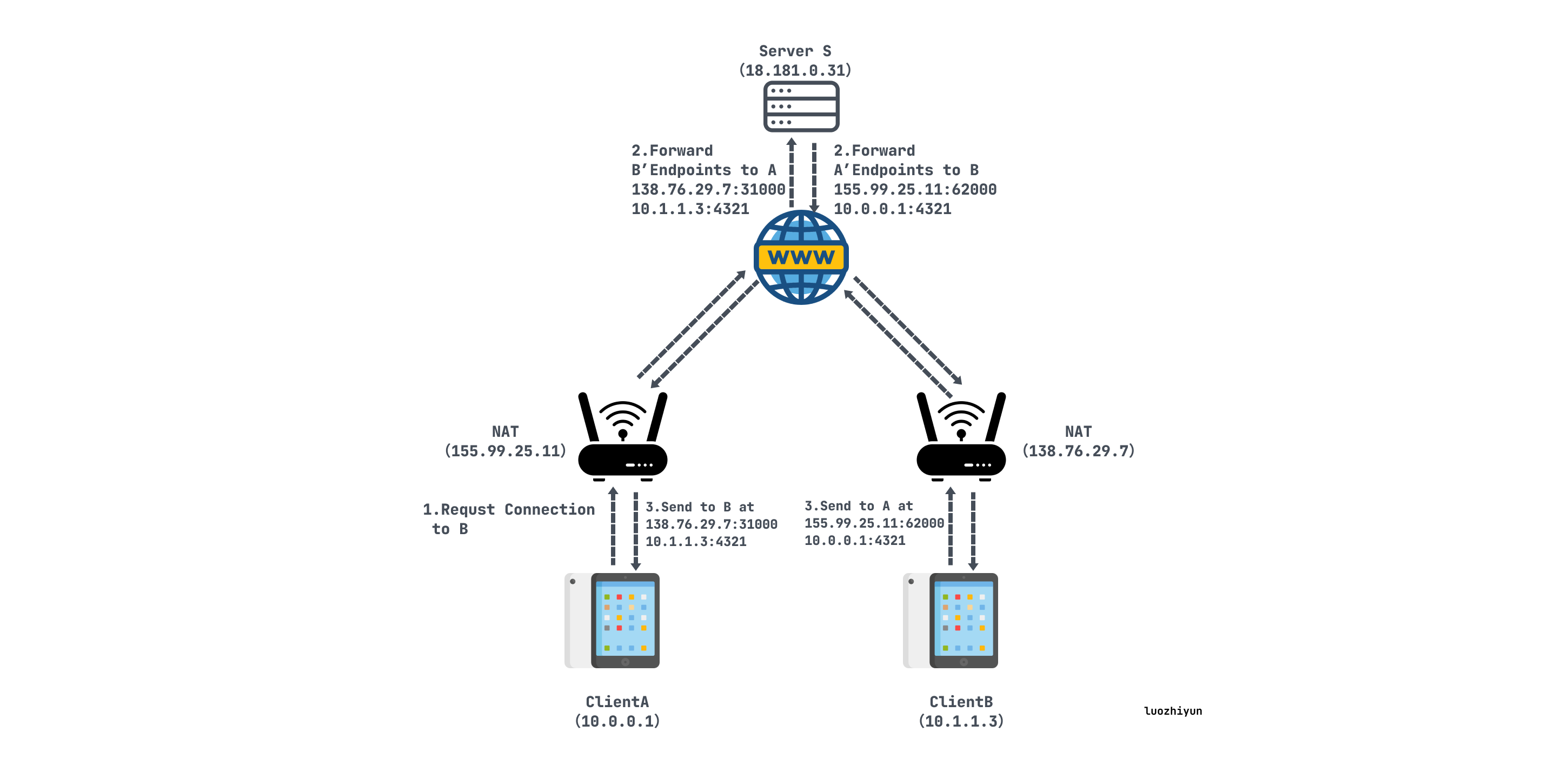
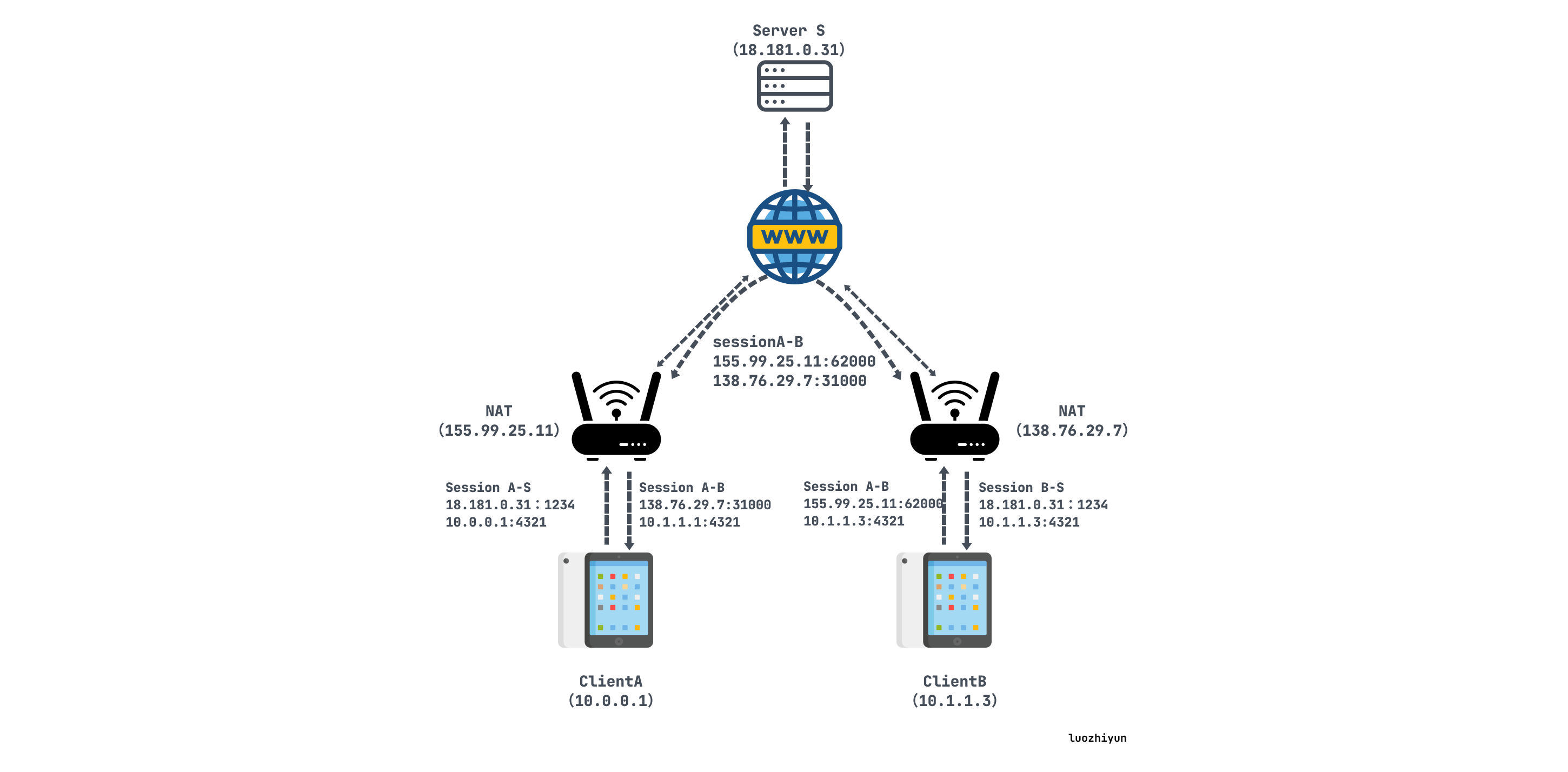
打洞后:
A和B直接利用内网地址通信
zerotier 的根服务实际上是部署在海外的,如果我们直接使用,很可能连不上,并且延迟基本在200ms以上,我们可以通过 zerotier-cli listpeers 查看根服务器:
# ./zerotier-cli listpeers
200 listpeers <ztaddr> <path> <latency> <version> <role>
200 listpeers 62f865ae71 50.7.252.138/9993;24574;69283 341 - PLANET
200 listpeers 778cde7190 103.195.103.66/9993;24574;69408 213 - PLANET
200 listpeers cafe9efeb9 104.194.8.134/9993;4552;69462 159 - PLANET上面的 PLANET 节点就是是ZeroTier网络中的根服务器。它们负责在对等点之间中继初始流量,帮助对等点建立对等连接,并充当身份和相关公钥的缓存。
我们随便 ping一下它的延迟:
# ping 50.7.252.138
PING 50.7.252.138 (50.7.252.138) 56(84) bytes of data.
64 bytes from 50.7.252.138: icmp_seq=1 ttl=46 time=347 ms
64 bytes from 50.7.252.138: icmp_seq=2 ttl=46 time=347 ms
64 bytes from 50.7.252.138: icmp_seq=3 ttl=46 time=354 ms这样的游戏明显是玩不了云游戏的,zerotier 也考虑到这种延迟的情况,所以可以让有需要的用户自建 MOON 服务器。
ZeroTier中的MOON节点是用户定义的根服务器,可以添加到ZeroTier网络中。它的行为类似于ZeroTier的默认根服务器(称为PLANET节点),但由用户控制,我们可以把 MOON 服务器部署在离自己更近的地方,比如我就部署在广州,可这样以通过提供更近或更快的根服务器来提高网络性能。
怎样部署我这里就不贴教程了,可以自己去search一下,很简单。 但是现实场景中的网络要复杂的多,远远不是部署一个 MOON 节点就可以解决延迟的问题。通常我们的网络会涉及到防火墙限制、运营商级NAT、路由器兼容问题,还有就是 ZeroTier 走的是 UDP, 在国内的网络环境下一些运营商会对UDP流量实施QoS(服务质量)策略,,丢包可能会比较严重。
所以总之ZeroTier这条路并不是这么好走,看起来 p2p 直连貌似可以很美好,理论上可以不受根服务器的影响,两端直连跑满所有带宽,但实际上当不能打洞成功的时候那么就会退化成根服务器转发,那么实际的速率就取决于你自建的 MOON 节点的转发带宽了。
并且还有一个问题是,ZeroTier 是需要客户端的,到目前为止移动端的 app 是不支持添加自建 MOON 节点信息的,也就是说只能在电脑上进行串流,这实用性还是下降了不少。
所以总结一下优缺点:
优点:
- 组网非常方便,可以像局域网一样连接ZeroTier组网内的节点;
- 连接以及数据传输都是加密,所以比较安全;
缺点:
- 根服务器在海外,需要自建MOON,否则延迟很高;
- 依赖服务端,并且移动端app功能不完善;
- 受制于网络环境,p2p 打洞成功率低;
frp
frp 也是一个开源软件 https://github.com/fatedier/frp ,实际上它没有这么多花哨的功能,就是帮我们做了一个流量的转发。它的客户端连接不需要app,所以用来串流的话直接用moonlight直接连接frp远程转发服务器即可,可以说很方便了。
它的架构如下:
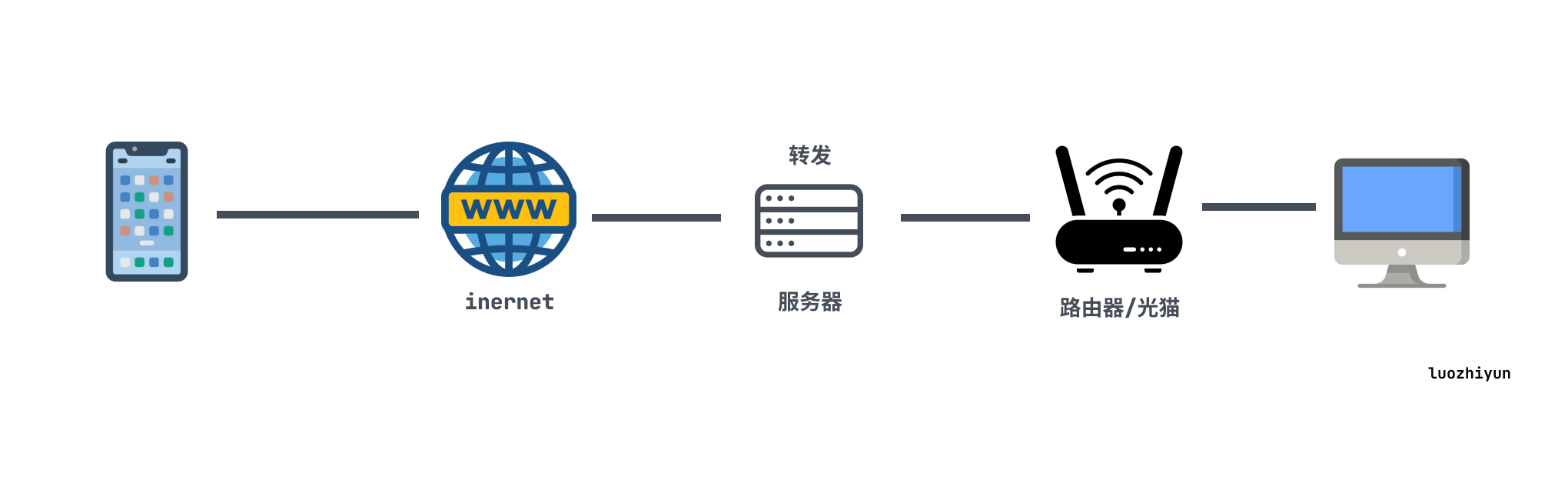
在安装frp远程转发服务的时候,我这里给一下配置,因为现在网上找的教程都是老的 ini 配置,现在新版本用的是 toml配置。
服务端的配置:
#frps服务监听的本机端口
bindPort = 9200
bindAddr = "0.0.0.0"
# frpc客户端连接鉴权token,默认为token模式
auth.token="xxxx"
#日志打印配置
log.to = "./log"
log.level = "debug"
log.maxDays = 7
allowPorts = [
// 远程连接需要用的端口
{ start = 47000, end = 48010 }
]sunshine主要连接的端口是这几个:
TCP 47984, 47989, 48010
UDP 47998, 47999, 48000, 48002, 48010所以我们需要给这几个端口都加上防火墙,服务器和pc都要开放相应的端口,在测试的时候可以先全打开,测试完了再挨个加上,免得莫名其妙的问题。
pc端的配置:
#token需要与服务端的token一致
auth.token = "xxxxx"
# 服务端的公网ip
serverAddr = "1xx.xxx.xx.xx"
# 服务端的监听端口
serverPort = xxx
[[proxies]]
name = "47984"
type = "tcp"
localIP = "127.0.0.1"
localPort = 47984
remotePort = 47984
[[proxies]]
name = "47989"
type = "tcp"
localIP = "127.0.0.1"
localPort = 47989
remotePort = 47989
[[proxies]]
name = "47990"
type = "tcp"
localIP = "127.0.0.1"
localPort = 47990
remotePort = 47990
[[proxies]]
name = "48010"
type = "tcp"
localIP = "127.0.0.1"
localPort = 48010
remotePort = 48010
[[proxies]]
name = "47998"
type = "udp"
localIP = "127.0.0.1"
localPort = 47998
remotePort = 47998
[[proxies]]
name = "47999"
type = "udp"
localIP = "127.0.0.1"
localPort = 47999
remotePort = 47999
[[proxies]]
name = "48000"
type = "udp"
localIP = "127.0.0.1"
localPort = 48000
remotePort = 48000
[[proxies]]
name = "48002"
type = "udp"
localIP = "127.0.0.1"
localPort = 48002
remotePort = 48002
[[proxies]]
name = "48010"
type = "udp"
localIP = "127.0.0.1"
localPort = 48010
remotePort = 48010
pc端frp自动启动
windows系统开机自启比较麻烦,不像linux简单,所以为了保证windows后台运行 frpc,创建脚本 frpc.vbs,将以下内容粘贴进去:
set ws=WScript.CreateObject(“WScript.Shell”)
ws.Run “[frpc执行文件] -c [frpc配置]”,0注意可能需要修改路径(默认路径是放C盘目录下)
将 frpc.vbs 放入 C:\ProgramData\Microsoft\Windows\Start Menu\Programs\StartUp 目录内,即可实现开机自启动。
远程唤醒(Wake On LAN)pc
家里的电脑如果经常开机的话很费电,所以按需开机是最佳办法,那么就需要远程登陆开机。远程唤醒需要主板的支持,现在的主板基本都支持。
首先我们要进入到主板的 BIOS 设置选项里面把 WOL 功能打开,具体方法视厂商而定,可以参考的关键词包括:
- Automatic Power On
- Wake on LAN/WLAN
- Power Management
- Power On by Onboard LAN
- Power On by PCI-E Devices
然后在我们被唤醒的电脑里面找到网卡设置:
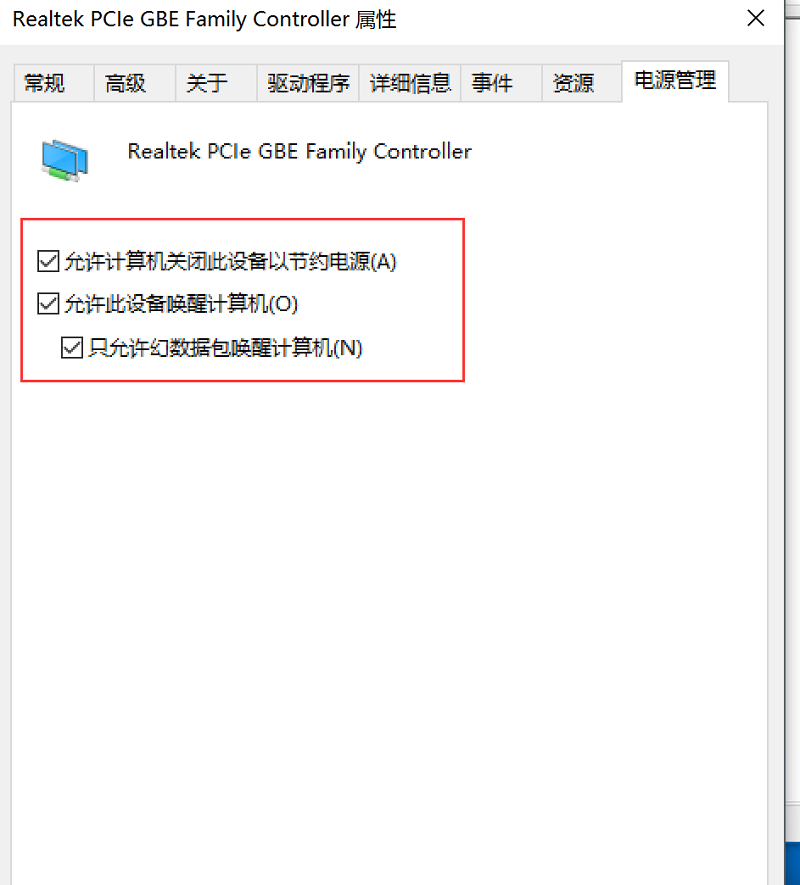
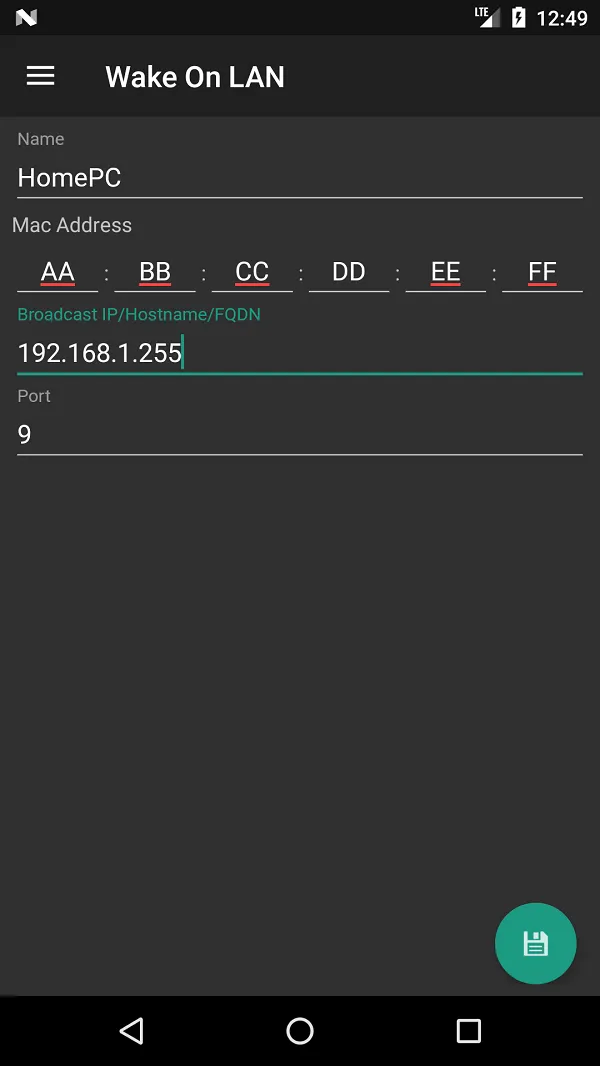
然后我们可以在内网尝试一下,是否可以唤醒成功,在应用市场随便找个WOL软件,填上内网被唤醒机器的IP地址和MAC地址即可:
外网唤醒,我们需要一个中间设备来中转我们的流量,因为我们需要被唤醒的机器已经被休眠了,是无法接收到请求的,所以我这里内网用我的软路由进行转发:
首先我们要做的就是 DHCP固定住自己内网PC的内网IP,要不然无法转发唤醒,通常可以在路由器里面设置:

然后我是通过 OpenWrt 来和我远端服务器建立好 frp通信,监听转发端口,到时候外面的请求会先到 OpenWrt ,然后由它再转发给我的内网PC:

最后如果觉得麻烦,其实可以用远程物理按键解决,一劳永逸:

隐私屏 / 作为副屏
在用 sunlight 串流的时候由于显示的是桌面的,,因为串流软件会捕捉屏幕上的内容并编码成视频流。如果关闭屏幕,编码器将无法获取到需要的画面信息,导致串流中断。
那么如果我们想要关闭屏幕串流,那么可以用这个工具 https://github.com/VergilGao/vddswitcher ,通过 vdd 创建一个虚拟屏幕可以实现即使主屏关闭也能串流。
最后
游戏串流最后不仅满足了我在外网想要随时随地玩游戏的想法,并且还拯救了我的腰椎,在家里玩游戏现在基本是用平板串流到我的电脑上面,然后买个支架夹着我的平板,然后躺着玩,但愿各位游戏佬都能找到属于自己的游戏环境。

Reference
https://github.com/VergilGao/vddswitcher
https://github.com/LizardByte/Sunshine
https://github.com/moonlight-stream/moonlight-qt
https://keenjin.github.io/2021/04/p2p/
https://bford.info/pub/net/p2pnat/