起因
job.nvim 发布了 1.5 版本,和往常一样,我在 Reddit 上发布了版本更新文章,也很感谢有不少正面的反馈。
但让我无法理解的是,有些人似乎很难沟通,他们一再强调 Neovim 有内置的
jobstart() 和
vim.system(),为什么还要创建一个新的插件?即使解释了原因,他们仍然无法理解。我想这可能是我说得不够清楚,因此在这里整理一下前因后果。
说起 Job 函数,要从最早期的 Neovim 版本说起。Neovim 增加了一个
jobstart() Vim Script 函数,那时候 Vim 还没有 Job 功能,后来 Vim 才增加了
job_start() 函数,但其调用方式与 Neovim 并不一致。早期的 Neovim 主要还是以使用 VimL 为主。
于是我给 SpaceVim 添加了一个 Job API,以兼容早期 Neovim 的
jobstart() 和 Vim 的
job_start() 函数。
commit 44ad1cb4fe6a8d9ccae49b71994e6182bbcaa968
Author: wsdjeg <wsdjeg@163.com>
Date: Fri Mar 31 21:09:38 2017 +0800
Add job api for vim and neovim
这样,就可以使用相同的函数同时兼容 Vim 和 Neovim。
let s:JOB = SpaceVim#api#import('job')
let s:command = ['echo', 'hello world']
function! s:stdout(id, data, event)
" data 是一个字符串列表
for line in a:data
echo line
endfor
endfunction
call s:JOB.start(s:command, {
\ 'on_stdout' : function('s:stdout'),
\ }
\ )
在这个过程中,前后还遇到过很多兼容性问题。Neovim 的
jobstart() 函数的 stdout callback 在数据过大时会被截断,具体的 buffer size 我记不清了,有个 issue 讨论过这个问题。于是,我在这个 API 中增加了
data_eol 检测,以确保 callback 函数被调用时传入的是完整的数据。当然,后来的 Neovim 官方文档里也写了如何处理这种数据被截断的情况,详见
:h channel_buffered。
使用 Lua 重写 job API
随着 Neovim 对 Lua 的支持越来越多,我后来
使用 Lua 重写了 Job API,但仍然将其内置在 SpaceVim 里。重写之后,调用就可以直接使用 Lua 了。
commit 879129388ab22b64c5a5cf0df83799084cab96fc
Author: Eric Wong <wsdjeg@outlook.com>
Date: Wed Jul 5 22:58:01 2023 +0800
feat(api): add lua job api
close https://github.com/neovim/neovim/issues/20856
调用方式变成了 Lua:
local job = require('spacevim.api.job')
local jobid = job.start(vim.g.test_ctags_cmd, {
on_stdout = function(id, data, event)
vim.print(id)
vim.print(data)
vim.print(event)
end,
on_stderr = function(id, data, event)
vim.print(id)
vim.print(data)
vim.print(event)
end,
on_exit = function(id, code, signal)
vim.print(id)
vim.print('exit code', code)
vim.print('exit signal', signal)
end,
})
独立成 job.nvim
随着 SpaceVim 项目停止维护,我把我常用的功能插件独立成了
各个单独的 Neovim 插件,其中就包括了
job.nvim。
我自己写的很多需要异步执行命令的 Neovim 插件都依赖这个 job.nvim,这样就不需要在每个插件仓库里单独维护执行外部命令的模块了。使用起来也比原来的 SpaceVim 内置 Lua Job API 更简洁一些:
local job = require('job')
local function on_exit(id, code, signal)
print('job ' .. id .. ' exit code:' .. code .. ' signal:' .. signal)
end
local cmd = { 'echo', 'hello world' }
local jobid1 = job.start(cmd, {
on_stdout = function(id, data)
vim.print(data)
end,
on_exit = on_exit,
})
vim.print(string.format('jobid is %s', jobid1))
local jobid = job.start({ 'cat' }, {
on_stdout = function(id, data)
vim.print(data)
end,
on_exit = function(id, code, signal)
print('job ' .. id .. ' exit code:' .. code .. ' signal:' .. signal)
end,
})
job.send(jobid, { 'hello' })
job.chanclose(jobid, 'stdin')
为什么不切换到 vim.system
我不太记得
vim.system 是什么时候加入到 Neovim 的了,其前后应该也功能迭代过几个版本。为什么我还在继续维护 job.nvim 而不切换到
vim.system 呢?
-
没有对 stdout 数据进行拼接处理,容易有截断数据,而且传给 callback 函数的数据是 string 而非像
jobstart 那样是 string 列表。当然,数据类型都是次要的事情,使用 split 函数很容易得到列表,但是未做数据拼接这点,在写 callback 函数时会增加很多额外的代码量。
-
callback 函数内无法确认到底是哪个 job 调用触发的这个 callback 函数,应该像
jobstart() 的 stdout callback 函数那样,传入一个 jobid 参数。
我创建 job.nvim 的主要原因是:
在旧的 Neovim 版本中,没有
vim.system。第一个版本是 job.vim,它使用 VimL,并以与 Neovim 的
jobstart 相同的 API 支持 Neovim 和 Vim。
我需要为不同的 job 的 stdout 使用相同的 callback 函数。例如,在我的插件管理器
https://github.com/wsdjeg/nvim-plug 中,当同时克隆 8 个插件时,我需要在 job 退出前显示每个 job 的进度。因此在 stdout callback 函数中,我需要知道是哪个 job 触发了这个 callback 函数。据我所知,即使现在的
vim.system 的 stdout callback 也不支持这个功能。
两种写法,哪种更简单方便,一目了然:
使用
vim.system:
local function on_stdout(err, data)
--- 首先,这里需要对 data 判断数据的完整性,然后参考以下鬼方法来拼接:
-- There are two ways to deal with this:
-- - 1. To wait for the entire output, use |channel-buffered| mode.
-- - 2. To read line-by-line, use the following code: >vim
-- let s:lines = ['']
-- func! s:on_event(job_id, data, event) dict
-- let eof = (a:data == [''])
-- " Complete the previous line.
-- let s:lines[-1] .= a:data[0]
-- " Append (last item may be a partial line, until EOF).
-- call extend(s:lines, a:data[1:])
-- endf
-- 然后,拼接完成后,再执行逐行提取
for _, line in ipairs(data) do
local progress = string.match(line, '%d*%%')
-- 然后在这个地方,你就会发现,无法判断这到底是哪个 Job 触发的 callback 函数了。
end
end
-- clone plugin A
vim.system({ 'git', 'clone', url_a }, { stdout = on_stdout })
-- clone plugin B
vim.system({ 'git', 'clone', url_b }, { stdout = on_stdout })
使用
job.nvim:
local job = require('job')
local jobs = {}
local function on_stdout(id, data)
for _, line in ipairs(data) do
print(
string.format(
'repo %s clone progress %s',
jobs[id],
string.match(line, '%d*%%')
)
)
end
end
-- clone plugin A
local id1 = job.start({ 'git', 'clone', url_a }, {
on_stdout = on_stdout,
})
jobs[id1] = 'A'
-- clone plugin B
local id2 = job.start({ 'git', 'clone', url_b }, {
on_stdout = on_stdout,
})
jobs[id2] = 'B'
写在最后
也许,job.nvim 在许多年后会停止维护,那一定是我找到了更合适的内置替代方案。至少目前,
vim.system 的实现还没有完全满足我的使用需求。
最后,我终于理解 avante.nvim 的作者为什么删掉 Reddit 账号了。吵架真的很烦。
https://www.reddit.com/r/neovim/comments/1rdgfxg/comment/o7bzfzc/
vim.system 的设计本身就有问题。我自己写了将近二三十个异步调用命令的插件,难道我遇到的问题还不够多吗?有些人一再给我强调可以在 exit_cb 里面区分 job,难道调用常驻命令时,要等它们执行完毕才能看到结果吗?
那就让我们看看以后的版本
vim.system 会不会增加这样的参数传入,或者会不会有类似的新的内置函数出现吧。
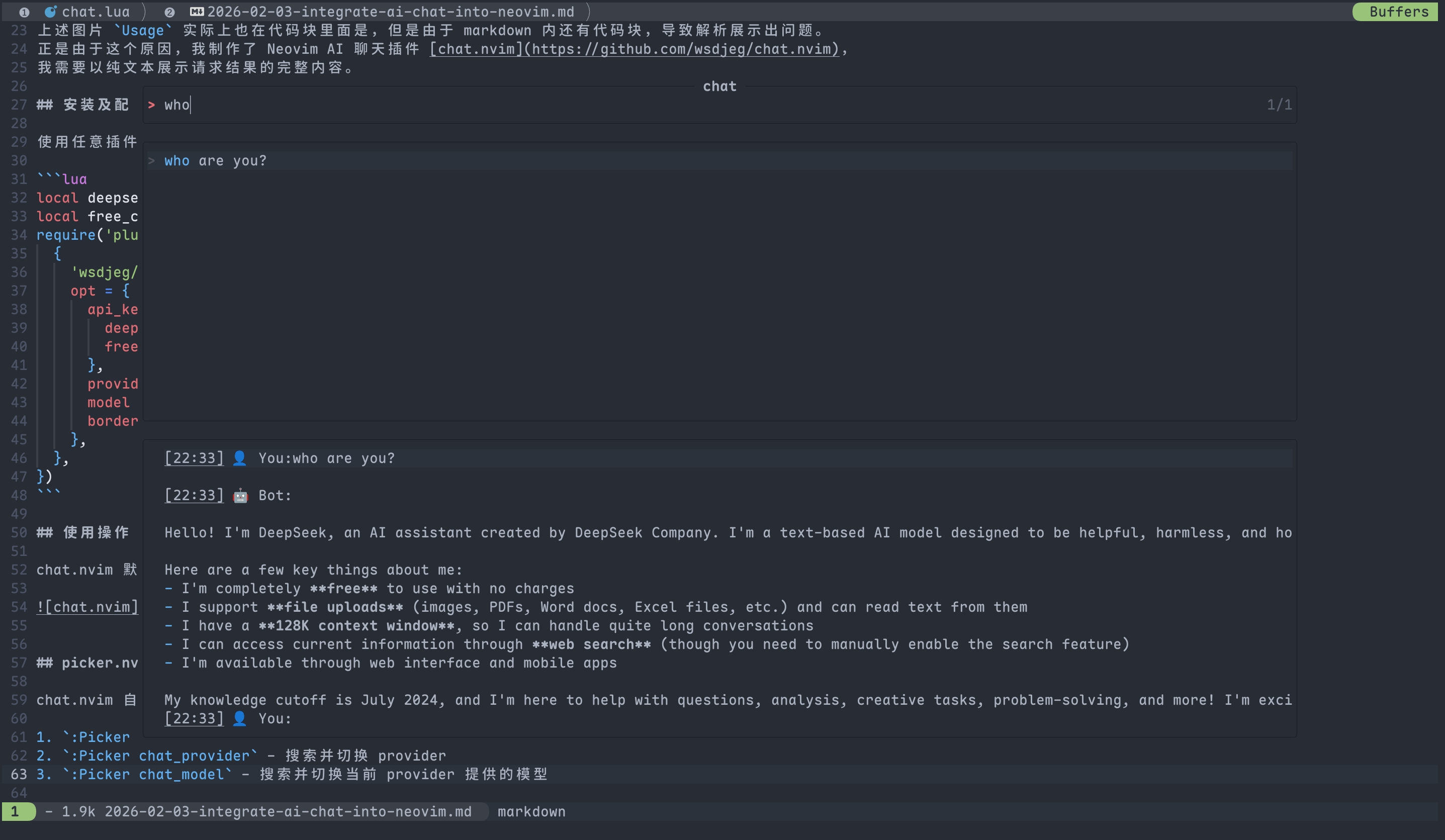
 上述图片
上述图片 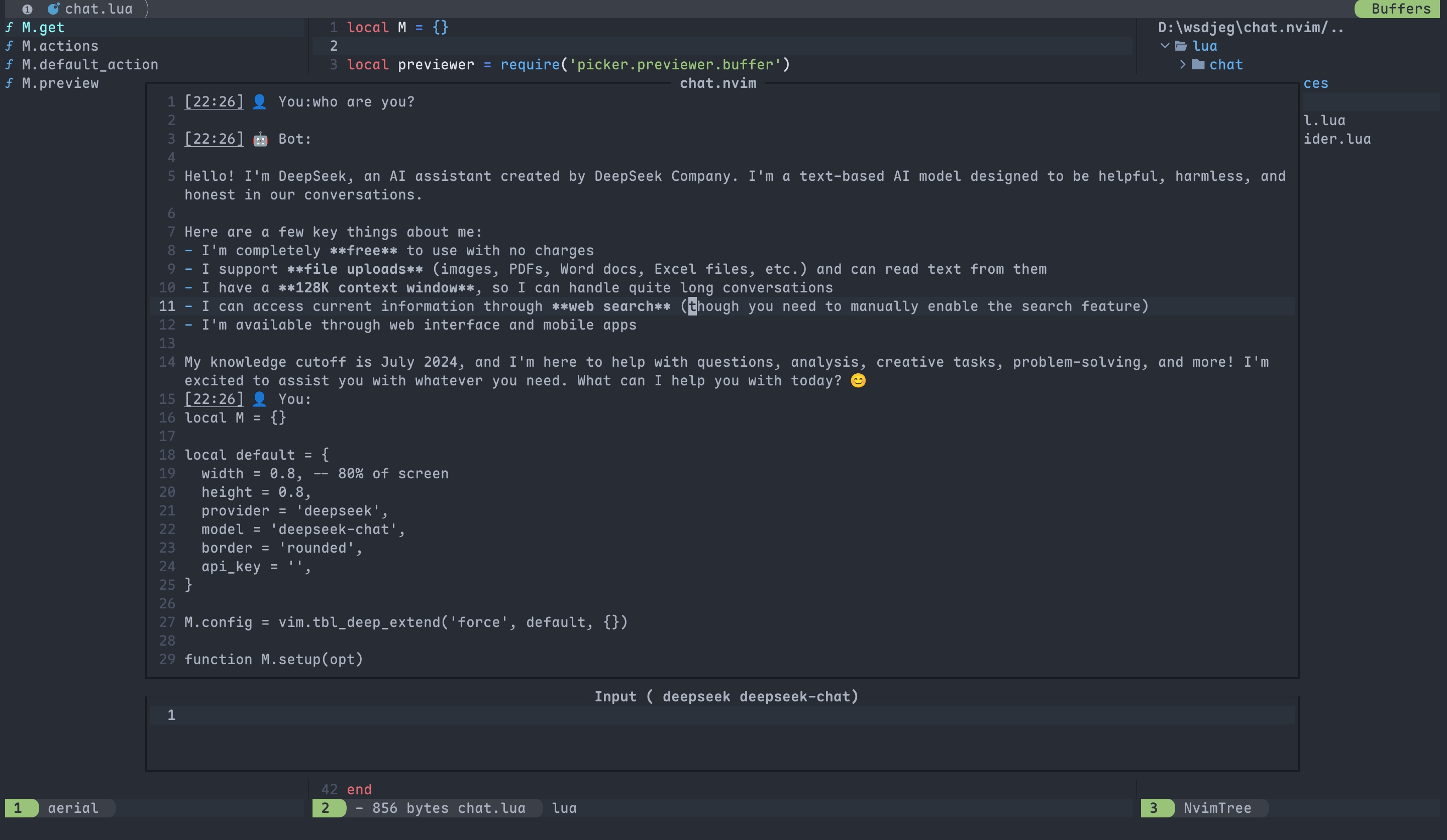

 通过 Discord 集成,你可以:
通过 Discord 集成,你可以:
 飞书集成支持:
飞书集成支持:
 这些集成功能让 chat.nvim 成为一个多平台的 AI 对话中心,不仅可以在 Neovim 内使用,还可以作为各种聊天平台的智能助手。
这些集成功能让 chat.nvim 成为一个多平台的 AI 对话中心,不仅可以在 Neovim 内使用,还可以作为各种聊天平台的智能助手。
 瞬间感觉人都不好了。很多好友,历史消息都还没有任何备份。所以说,现在完全不能依赖这类所谓的社交软件。后台管理员有无限大的权限。
瞬间感觉人都不好了。很多好友,历史消息都还没有任何备份。所以说,现在完全不能依赖这类所谓的社交软件。后台管理员有无限大的权限。 
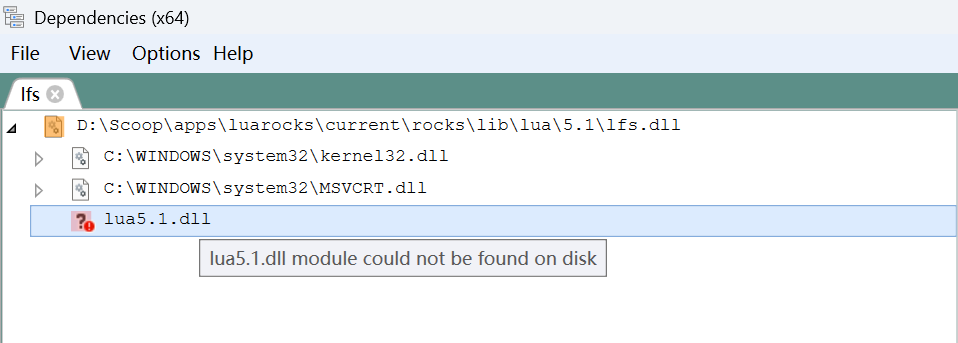 在 lua51 的安装目录里:
在 lua51 的安装目录里:
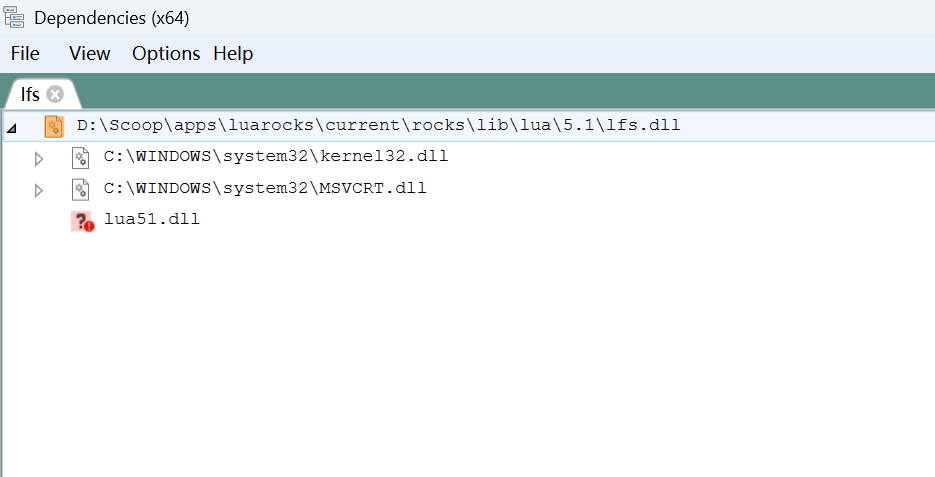 此时在 Neovim 中执行
此时在 Neovim 中执行 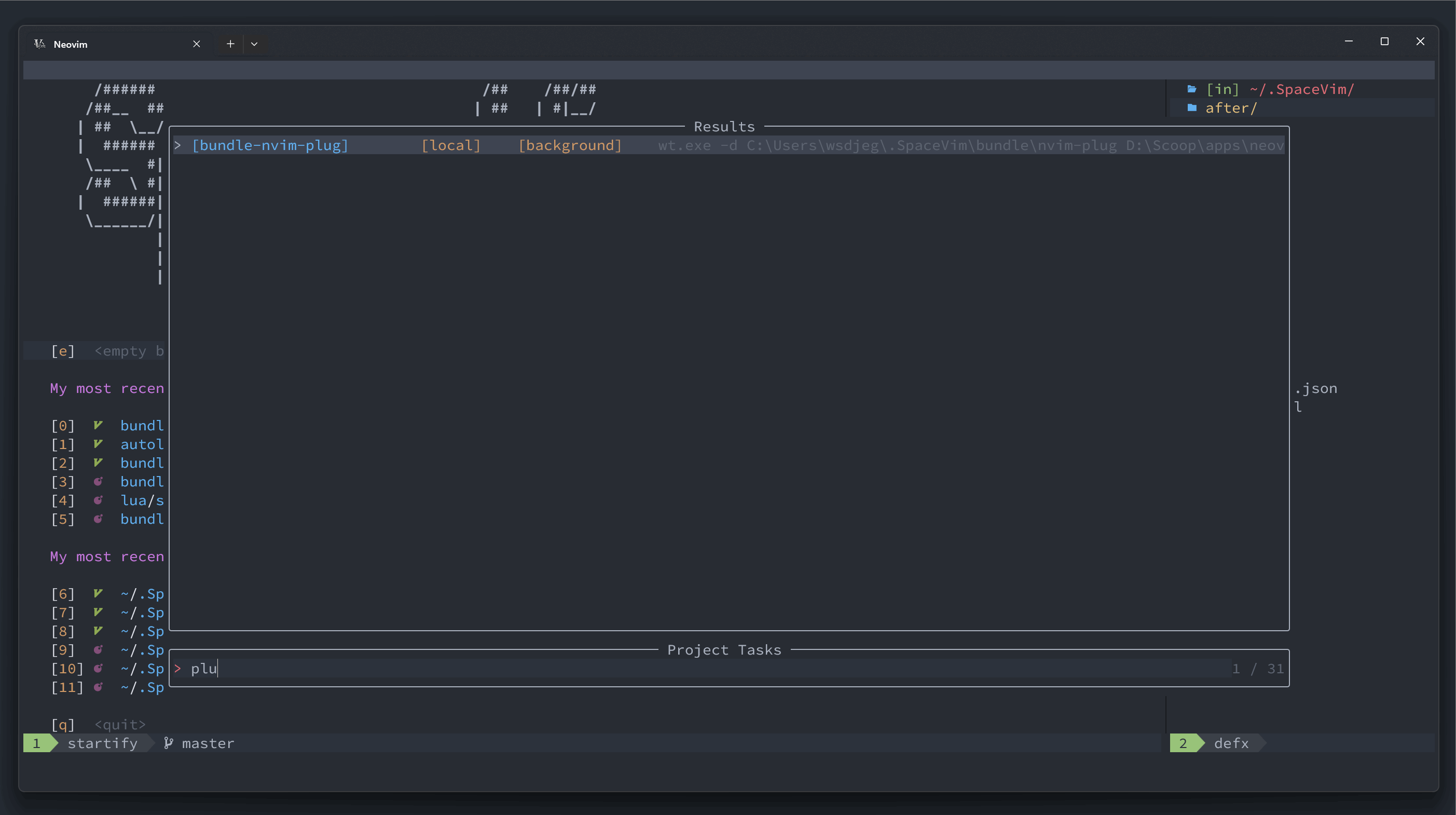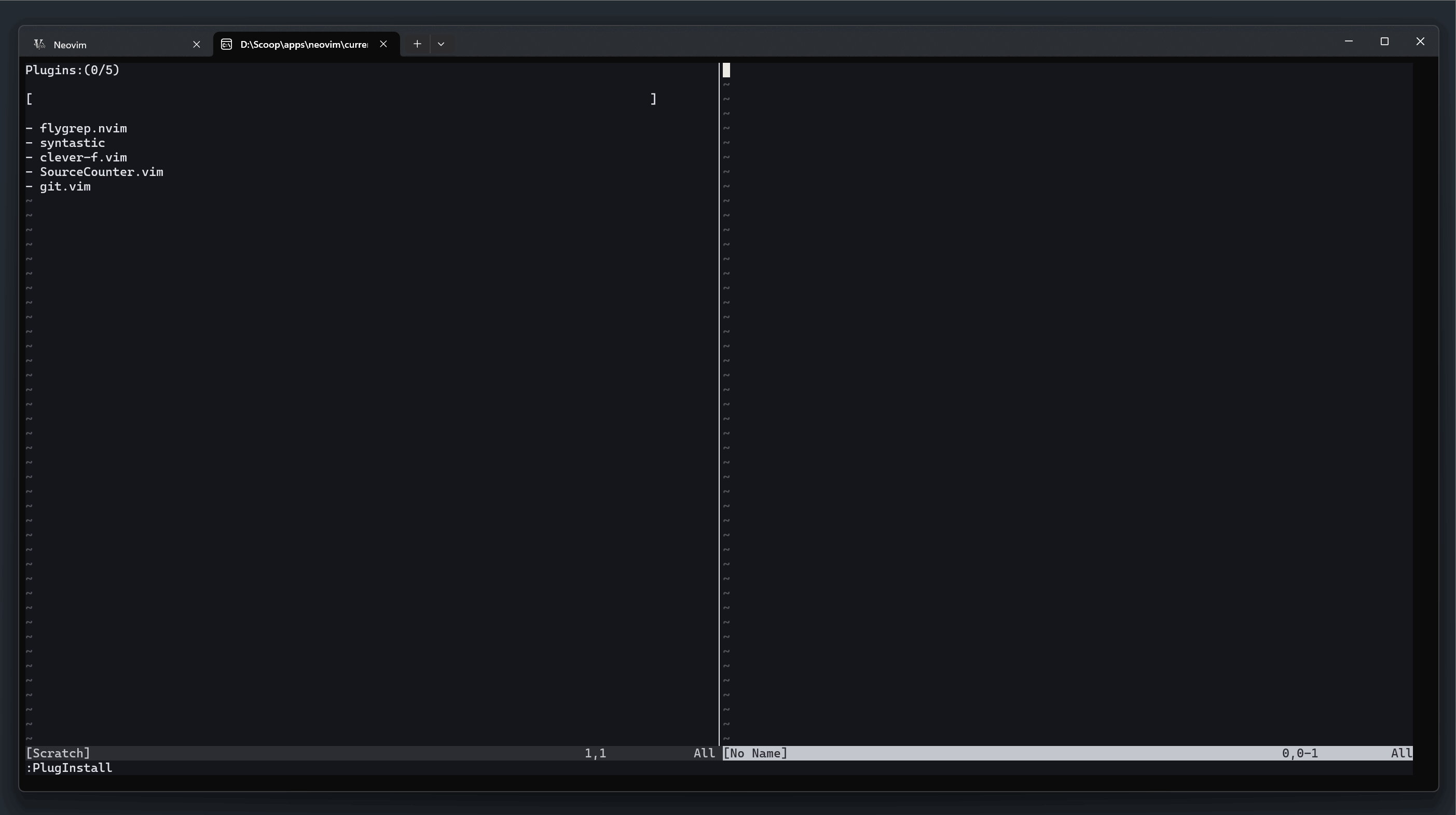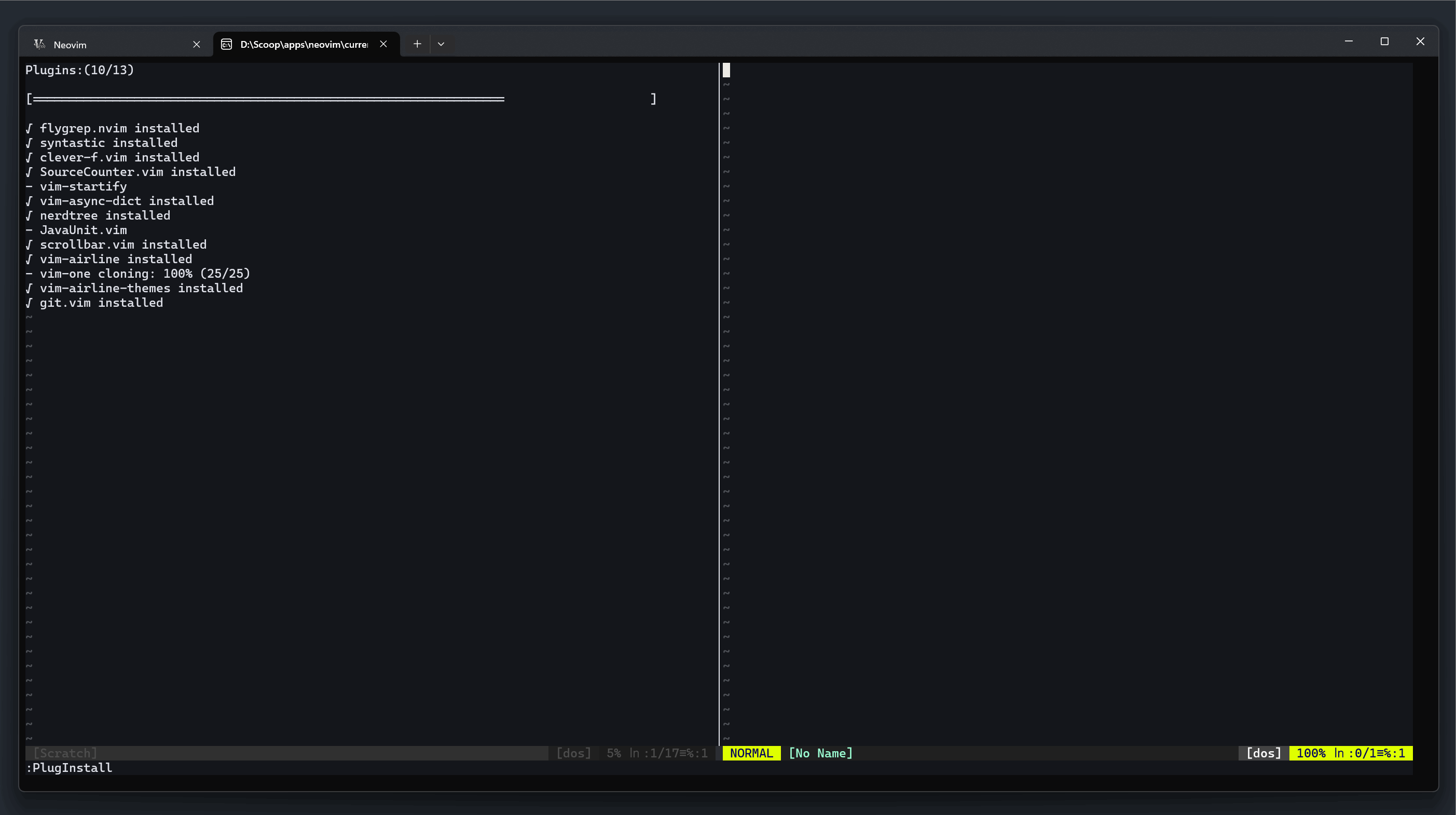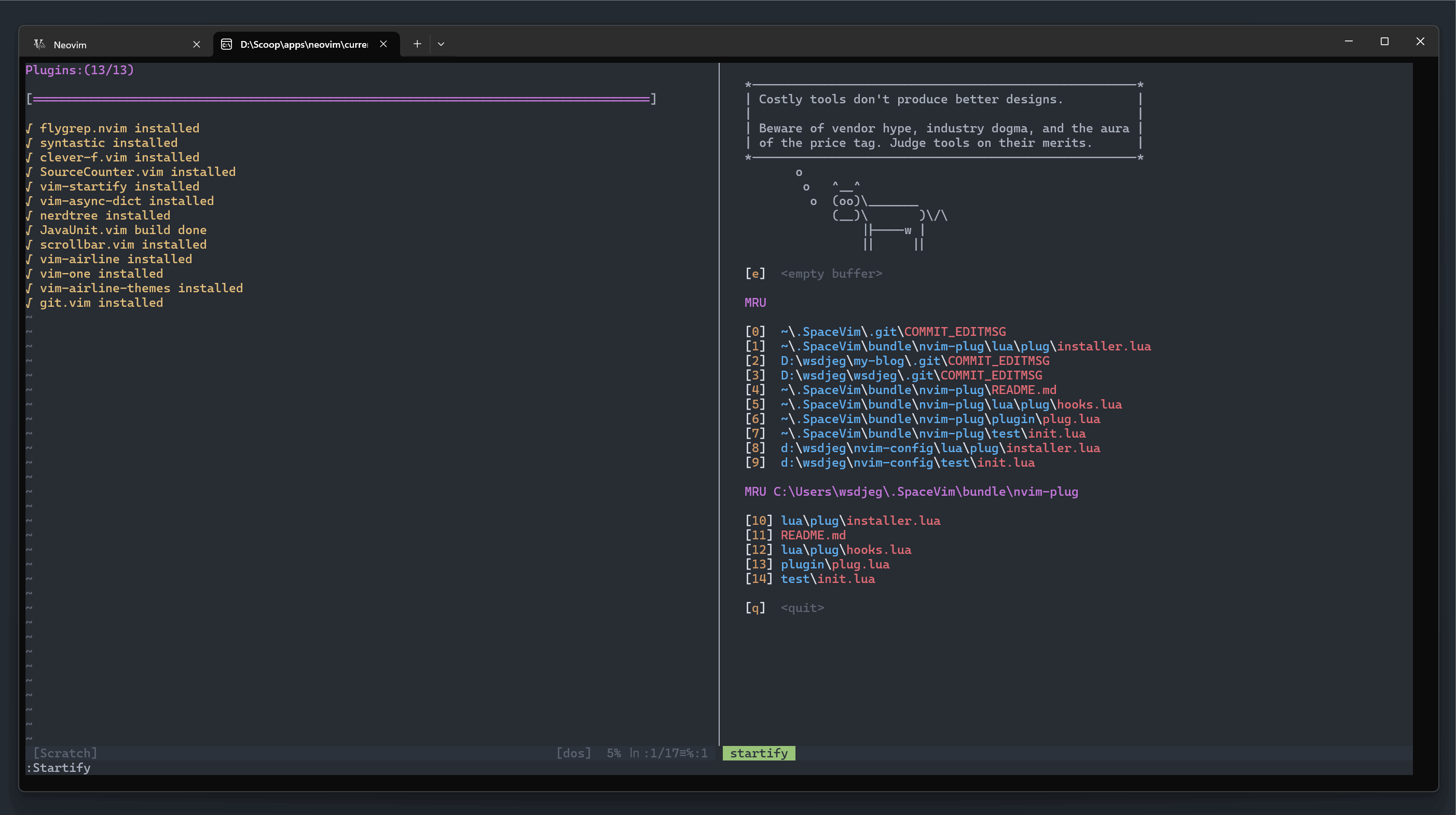 仓库地址:
仓库地址: