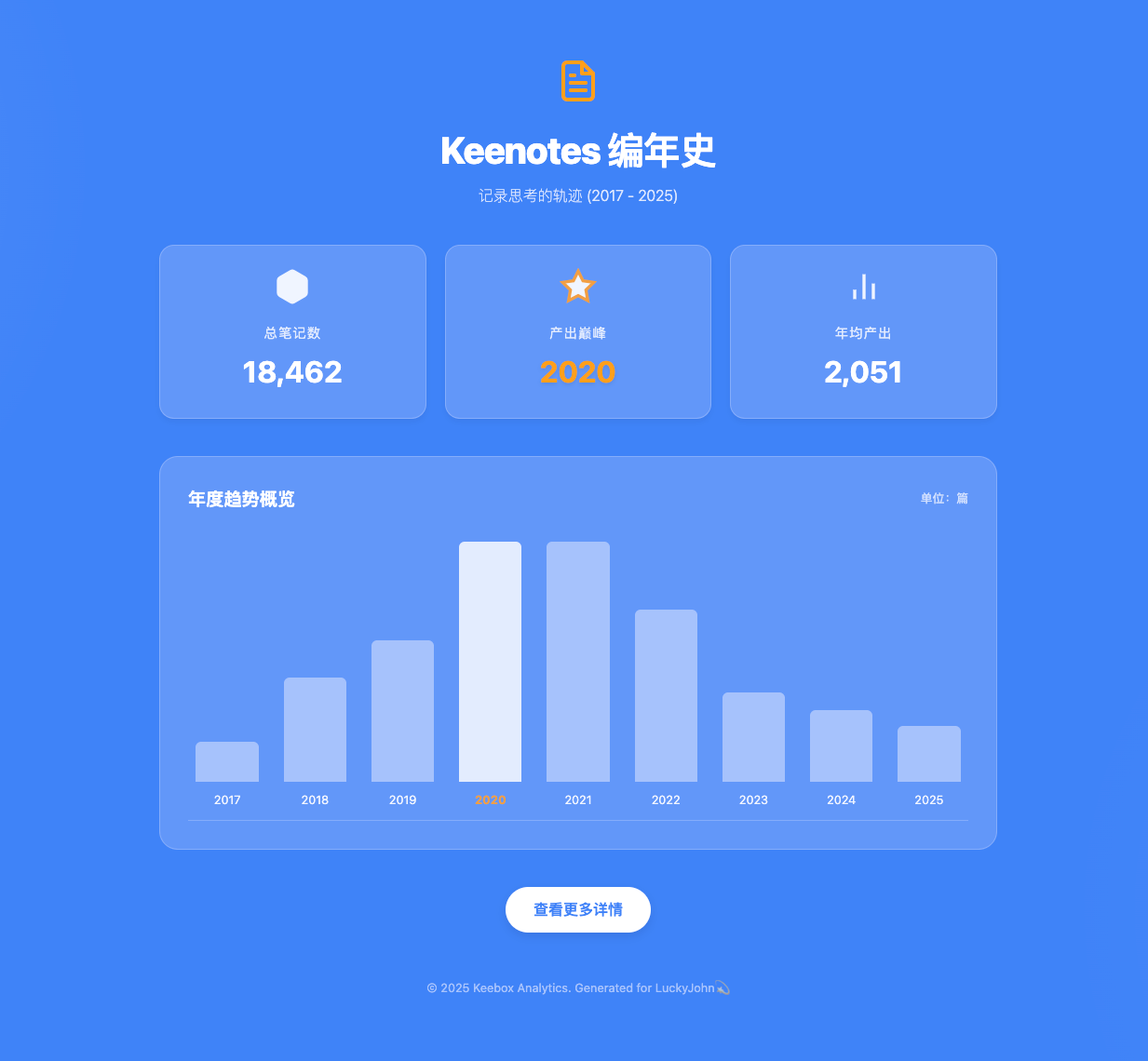
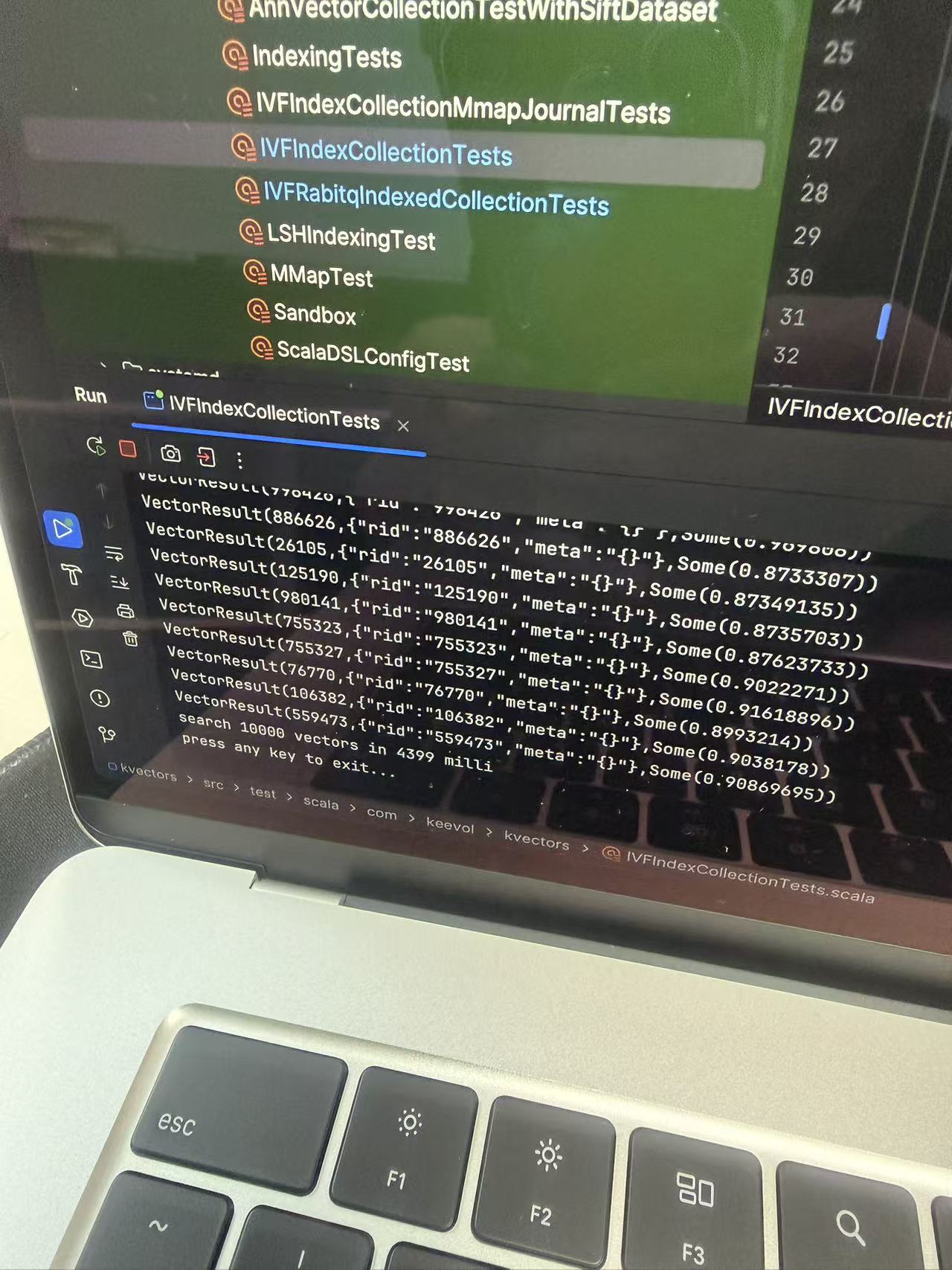
打造 Keenotes 过程中使用 AI/Coding Agents 的一些感想
王福强
2026-01-22
关于什么是keenotes, 看这里
all in 还是 cherry-pick
其实很长一段时间,我都不敢放开把所有都交给AI,所以,从来都是用AI做调研,确定差不多了,再让它写局部代码,然后人工合并到codebase。
这种方式我称其为cherry-pick, 也就是挑出能用的再用。
但在搞keenotes的过程中,我加快了动作,把目标和要求写完后,让AI/Coding Agents 1自己去搞,搞完之后,我在从外围以黑盒的形式做验收,验收不过的,也不直接改代码,而是让coding agent自己去分析原因并修复。
这个时候,你会发现,当什么都交给AI/coding agent去干的时候,你相当于放弃了对实现细节的掌控。而且,随着codebase的增大,你也很难去从全局到细节事无巨细的完全了解。
这时候职能AI对AI,完全放权给AI去搞,所以,我称这种方式为all-in
这两种方式,我觉得后者的挑战其实挺大的,因为你一旦决定用这种all-in的方式,就意味着此后所有的动作都需要AI native。
企业负责人敢不敢这么干,自己的团队有没有能力承载,这些可能都是顾虑的点。
不过,整体上来看,效率肯定是提升的,所以,我相信慢慢地大家还是会发现如何更好的管理AI在这条路上的效率与风险。
验收
验收依然是最重要的工作,或者说,依然是管理者最重要的工作。
有了AI之后,从0到1其实更简单了,但从1到100甚至1000、10000更难了,因为迭代过程中对细节的验证和修复上耗费的时间和精力,可能也更多了。
按下葫芦起了瓢,成了常态,玩过的都知道吧?🤣
毕竟,魔鬼藏在细节里,从产品层面黑盒式的打磨,相当考验耐心。
plan first and plan matters
很多时候,再打磨细节的过程中,经常会被AI的反复(按下葫芦起了瓢)搞得想发疯,这时候,你肯定会吼AI,但吼它是没用的。
吼它确实发泄情绪了,但不解决问题,而且耗费tokens(也意味着耗费金钱,哈哈哈)
这时候,就得回顾本心,冷静一下, 从头开始梳理目标和路径,然后再让AI去分析和执行。
也就是你想得多了、想得全面了, AI就不用在模糊的上下文里猜来猜去了, 说白了,能把需求说清楚,执行反而是最快的, 跟曾经一个研发遇到一个好的产品经理一样,哈哈哈
Instead of shouting to AI, you should think more in front and give a crystal-clear context to it.
写完上面这句英文总结,恰好又读了 这篇文章,发现真是 “great mind think alike” 🤣
模型优先于对模型的调教
基本上只用opus 4.5和sonnet 4.5模型,opus贵, 2个credit,4.5便宜点儿,1.3个credit,(嗯,定价方面,kiro鸡贼,用credit代替了token数量)
对于思考范围要大一些的重构,我一般就切换到opus;
对于小范围局部修复,我一般就切到sonnet;
但有时候对于一些大点儿的重构,sonnet的效果也不错, 反而你让opus去做一些小范围的修复,反而效果不咋地。
订阅的额度用完了后,没想升级到更高的price plan,就尝试了下国内几个模型,比如GLM4.7和Minimax2.1, 效果跟预期的差别很大,不知道是营销的成分更大,还是模型层面就是不如opus和sonnet
但不管怎么说,整体感觉, 模型好可以解决大部分问题, 模型不行,工具再炫也没鸟用。
token或者price plan便宜是一会儿事儿,最主要浪费时间和感情🤣
NOTE
据说openai的gpt5.2在处理深度问题上效果不错,不过, 2023年注册了chatgpt后就没用过, 所以,没一手体感,就不做评价了。
Vibe VS. SDD(Spec-Driven Development)
虽然Kiro老早就提出了两种方式,而且当我写了比较长、比较规范的prompt给它的时候,它经常自动提示让我切到spec driven的模式,但大部分时候都让我拒绝掉了。
整个过程下来,我可能还是vibe的成分多一些。
不过,为了让它别瞎搞,我在steering file里(也就是Kiro里定义的rules,类似于CLAUDE.md或者AGENTS.md)加了一些约束。
而且,为了让它按照我的流程来,我也将CLAUDE.md里定义的流程要求放到了steering file里。
我的流程其实也挺简单的,就是“阿里黑话”的适配版,将“我说你听,你说我听”转成了类似“我提出了需求给你,你先了解,不明白的地方,可以跟我确认,所有事情清晰之后,得到我的运行你才能开工”。
大部分时候,它还算遵循这套流程要求, 但偶尔也会都已经干了一半了,session会话里跟你说,“哎呀不好意思啊,我忘了先跟你确认了”,艹, 这就像是“先干了再跟你道歉的人”一样, 甚至于哪天用哪个模型测试的时候,它改错了东西居然说“手滑了”,我日! 跟tmd推卸责任的员工一模一样🤣 “手滑”这词儿我还是2019年在上海第一次从某推卸责任的员工嘴里听到的…
focus on the goal
纵观各种自媒体,你会发现极其高亢
但假如你被他们带着走,那可能就有点儿走偏了。
我要说的是,
Don’t focus on the tools, focus on the goals.
除非是你专职做AI自媒体的,那么,没问题,毕竟, 你玩的就是流量。(If you are focusing on social media traffic, then forget about it)
假如你不是专职做AI自媒体的,那么,应该冷静下,想想自己的目标到底什么,不管AI工具如何变换,他们终归是工具,它们应该是帮你完成目标的东西。
这其实也是为啥我选了Kiro之后,基本主力就用它了。 你说其它工具有没有比它更好的,肯定有,但不重要,我的目标又不是AI工具评测🤪
我用的kiro,好处有两个: 1. 不需要翻墙,不受梯子稳定性影响(这个很影响心情);2. 信用卡直接购买。(前期免费使用额度也挺高,不过这阵子估计被薅羊毛薅凸了吧,降低了额度,还去掉了opus模型)↩︎
「福强私学」, 一部沉淀了个人成长、技术与架构、组织与管理以及商业上的方法与心法的百科全书。
开天窗,拉认知,订阅「福报」,即刻拥有自己的全模态人工智能。