20260120 B 站直播 —— 转行大模型文字精要
我是 2024 年初到一家大模型公司工作,之前一直在数据库、存储等 infra 行业工作,因此有些很粗浅的转行认知。很久没有在 b 站做分享了,这次靠直播强制开机,回答了大家一些问题,稍稍弥合一点信息差。本文对直播中提到的一些点的稍微规整一点的总结,并将一些我觉得不错的资料附在最后。

我是 2024 年初到一家大模型公司工作,之前一直在数据库、存储等 infra 行业工作,因此有些很粗浅的转行认知。很久没有在 b 站做分享了,这次靠直播强制开机,回答了大家一些问题,稍稍弥合一点信息差。本文对直播中提到的一些点的稍微规整一点的总结,并将一些我觉得不错的资料附在最后。
有明显的自我意识以来,从没有像今年这样和世界、和自己发生如此激烈的冲撞,但结果很神奇——反倒更加平和了。很多下意识的反应、很多习以为常的做法,向内挖时,竟然都能摸出如此久远的强化链路。正如史铁生说的——那颗年少时射出的子弹,在长到这个年纪的时候,正中眉心。
于是,不管是被迫地还是自发地,今年都开始难以避免地向内生长——如格物致知一般去观察和追溯自己细微的情绪变化源头,见天地、见众生,终是为了见自己。虽然以前惯性还会持续一段时间,但觉察的开始,便是塑造另外轨迹的种子。

Princeton COS 597R “Deep Dive into Large Language Models” 是普林斯顿大学的一门研究生课程,系统探讨了大语言模型原理、准备和训练、架构演进及其在多模态、对齐、工具使用等前沿方向中的应用与一些问题。注意,该课程侧重概念的理解上,而非工程的实现上。
我之前是在分布式系统和数据库内核方向,但这两年转到一家大模型公司做数据。本笔记主要是我对课程论文的梳理和精要。不同的是,我会结合在工作中解决实际问题的一些体感,给出一点转行人不同视角的思考,希望能对同样想从工程入门算法的同学一点帮助。本文来自我的付费专栏《系统日知录》,欢迎订阅查看更多大模型解析文章,文末有优惠券信息。
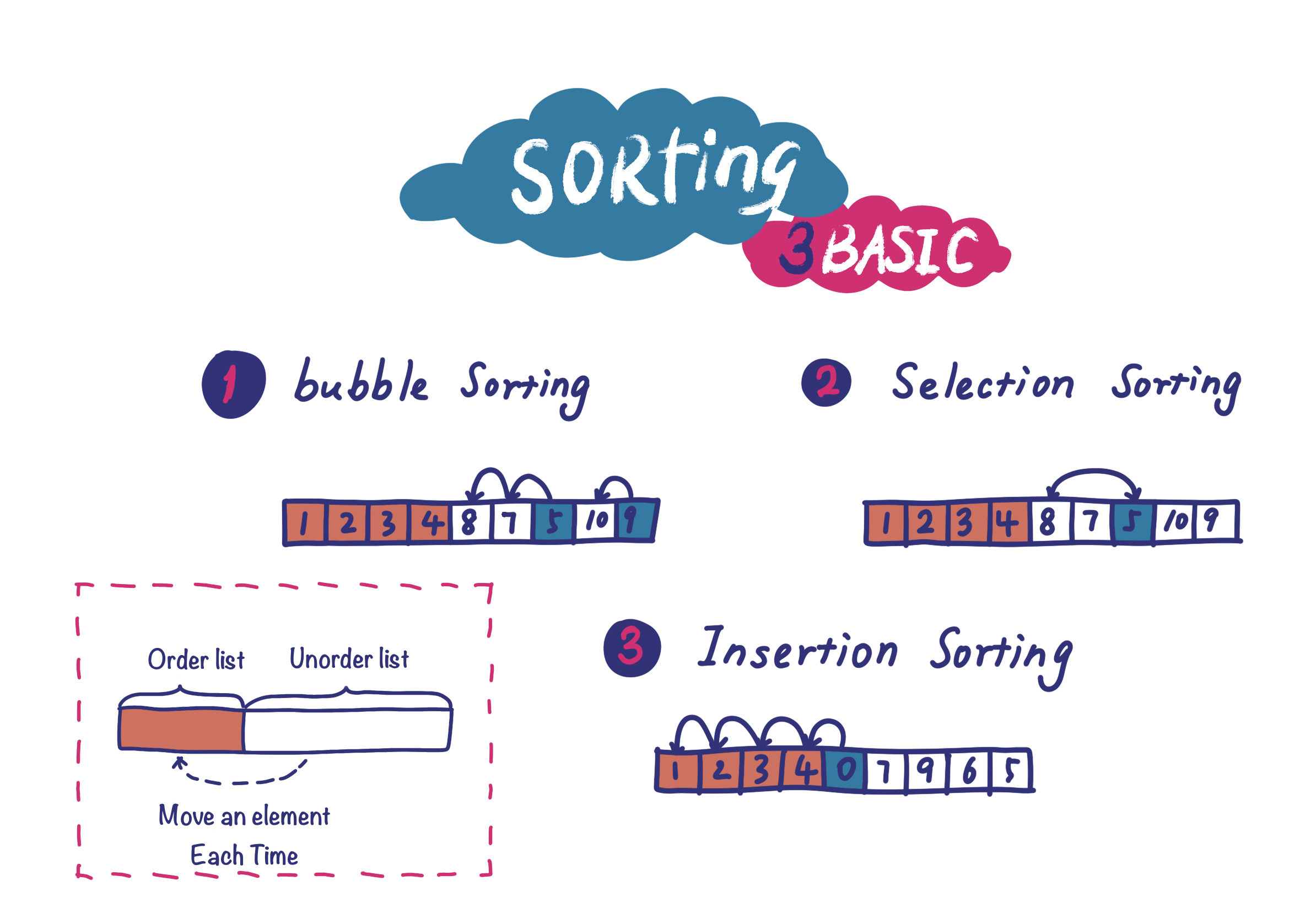
本篇主要关注大模型的奠基之作——Transformer。
首先要明确问题域,Transformer 试图解决的是序列建问题,最主要的代表就是语言建模和机器翻译。其次,需要知道前驱方法—— RNN(循环神经网络)和 CNN(卷积神经网络)存在的一些问题,才能知道 Transformer 的创新之处。最后,Transformer 的解决要点的在于“多头注意力机制”和“位置编码”。
随着云基础设施的不断成熟,新兴的公司为了快速实现业务目标,一般都会让基础设施上云。而在云上进行开发与传统上直接使用物理机开发其实有很大不同。云上更强调共享和弹性,此外,规模变大又会带来隔离性。这些改变也倒逼我们在进行开发时做出一些改变。在云上进行大规模数据处理,我主要有一些 spark 和 ray 的经验,使用的语言主要是 python;从这些技术栈出发,谈谈一些还算行之有效开发实践。
使用 ray 在云上进行大规模数据处理,一个基本的思路是:构建最小可并行单元,进行功能测试和性能测试,然后再利用 ray.data (比如 map,map_batches )进行 scale。使用 spark 时,会稍有不同;相比 ray,spark 虽然灵活性稍差一些,但抽象封装更好,可以从数据集整体的角度来考虑数据处理,spark 会通过你设置的分区数和并行度,自动地扩展和容错。
streamlit 是一款可以快速进行简单网页开发的 Python 库,其 slogan 是:
A faster way to build and share data apps
即“一种快速构建、分享数据应用的方法”。其在机器学习、数据科学,甚至当今大模型领域非常流行。其优点非常突出:
当然,如果你还想要低延迟、高并发、深度定制等需求,那对不起,这是 streamlit 被 tradeoff 出去的那一部分。但对于面向内部少数人使用的小工具来说,streamlit 简直是利器。可以说这个小生态位被它卡的太好了,所以能在 2022 年以 8 亿美金卖给 Snowflake。
本文我们就一块来看看其基本设计哲学和一些简单实践。
其基本设计哲学可以概括为:
Snowflake 由甲骨文的两位员工在 2012 年出来创办,一开始就瞄准云原生数仓,因此架构设计(在当时看来)非常“激进”。超前的视野带来超额的回报,Snowflake 在 2020 年正式上市,市值一度高达 700 亿美金,创造了史上规模最大的软件 IPO 记录。
本文我们综合两篇论文:The Snowflake Elastic Data Warehouse 和 Building An Elastic Query Engine on Disaggregated Storage 来大致聊聊其架构设计。
本文来自我的专栏《系统日知录》,如果你觉得文章还不错,欢迎订阅支持我。
这篇文章我早就想写了,但上次在看论文时卡住了——论文信息太多,地毯式的阅读,很快就淹没在细节中,当时也只看了三分之二,就搁置了。上周(20240707)在文章 Spark:如何在云上做缩容时提到了存算分离的 snowflake ,有读者要求写下,于是便重新捡起来。
相比上次 push 的方式,本次采用 pull 的方式:即不是被动的读论文,而是先思考,如果让我设计这么一个云原生数仓,我要怎么设计,会有哪些问题等等。带着这些问题,我再去从论文中找答案,发现效率一下高了很多,也便让这篇文章没有再次难产。
缘于某个播客提了一嘴,便找来书在通勤时听了。这版是傅雷翻在 1939 年译的版本,有一股淡淡的老式白话风。小书不长,几天便听完。我喜欢在走路的时候听东西,所听入耳、所观入眼,哲人的凝言练语、街头的风物百态,总能在心里发生奇妙的化学反应,偶在三伏天都一激灵。
最近心绪颇为起伏,在上下班踱步听这本书时,数次给我宽慰平和,书中指出的快乐和不快乐之因,都命中了我的某些缺点和特点,因此听完觉得还是要写点东西。
人类从狩猎时代进入农耕时代后,虽获得了生活的相对安稳,却也失掉了向外的探索和冒险。到工业时代,城市化加剧,进一步脱离了自然的“蓝领白领”亦是如此。只有少数的企业家才仍然保持着丛林式的生活方式。
选择安稳意味着有大量的“烦闷”(Boredom)需要排遣。但多数人过度的将注意力集中在自己的身上,比如畏罪狂(纠结于行为不符合少时的成见或社会的规训)、自溺狂(过度期待外界称许的虚荣)、自大狂(过度的权力欲望),则使得这种烦闷愈加在幻想中野蛮式的生长,直至占满人们的内心。
ray.data 是基于 ray core 的一层封装。依赖 ray.data,用户用简单的代码,就可以实现数据大规模的异构处理(主要指同时使用 CPU 和 GPU)。一句话总结:很简单好用,同时也有很多坑。
在 上一篇中,我们从用户接口出发,浅浅地梳理了一下 ray.data 的主要接口。本篇,我们从宏观的角度,大概串一下 ray.data 的基本原理。之后,我们再用几篇,结合代码细节和使用经验,探讨下比较重要的几块内容:执行调度、数据格式和避坑指南。
本文来自我的专栏《系统日知录》,如果你觉得文章还不错,欢迎订阅支持我。
从高层来理解,ray.data 的一次数据处理任务大致可以分成前后相继的三阶段:
由于对各种矩阵运算物理意义的理解总是跟不上,因此尽管多年多次尝试入门机器学习,却总是被拒之门外。偶然间同事推荐了 MIT 那门经典的线性代数公开课,听了几节,煞是过瘾,之前紧闭的大门竟有打开一丝的感觉。
因此,本系列会在每篇文章分享一些课程中有意思的点。为了避免晦涩,每章会尽可能去上下文、保持简短,请放心食用。也因此,本系列会牺牲一些精确性,且并无体系化,仅仅旨在唤起你一丢丢兴趣。注:例子都由 KimiChat 生成。
这是我在很早之前遇到的一个题,很有意思,所以到现在仍然记得。题意借用了 TCP 的上下文,要求实现 TCP 中一个“顺序组装”的关键逻辑:
这个题有意思的点在于,借用了 TCP 的上下文之后,就可以先和候选人讨论一些 TCP 的基础知识,然后话锋一转,引出这道题。这样既可以考察一些基础知识,也可以考察工程代码能力。
1 | struct Packet { |
Memgraph 是一个内存型图数据库,使用 OpenCypher 作为查询语言,主打小数据量、低延迟的图场景。由于 Memgraph 是开源的(repo 在这,使用 C++ 实现)我们可以一窥其实现。根据这行注释,我们可以看出,其内存结构实现灵感主要来自论文:Fast Serializable Multi-Version Concurrency Control for Main-Memory Database Systems。
本系列主要分为两大部分,论文解读和代码串讲,每一部分会根据情况拆成几篇。本篇,是论文解读(一),主要讲论文概述以及如何使用链表巧妙的存储了多版本、控制了可见性。论文解析(二)和(三),会讲如何实现可串行化以及回收多版本数据。
从论文题目可以看出,本论文旨在实现一种针对内存型数据库的、基于多版本(MVCC)实现的、支持可串行化隔离级别的高性能数据结构。其基本思想是:
与一般的多版本不同的是,本论文会在原地更新数据,然后将旧版本数据“压”到链表中去,使用 “压”是因为链表采用头插法:表头一侧数据较新、表尾一侧数据较旧。所有数据的链表头由一个叫 VersionVector 的数据结构维护,如果某一行没有旧数据,对应的位置就是 null。
Y Combinator(YC)是一家知名的美国创业加速器,自2005年成立以来致力于推动初创企业成功。作为初创企业界的领军人物,YC 的特点是,不仅提供资金,还提供指导、资源和网络,以帮助初创企业在竞争激烈的市场中脱颖而出。YC 的成功案例包括 Airbnb、Dropbox 和 Reddit 等,这些公司现在都是各自领域的巨头。
YC 发布的“创业公司征集请求”(RFS)是其基于对市场趋势、技术进步和全球挑战的深入理解,对全球创业社区的发出的一种前瞻性呼吁,相信能够对创业者和想选择创业公司的小伙伴们有诸多启发。2024 年的 RFS 一共有 20 个方向,这是上篇,包括前十个。如果看的人多,我再继续翻译后面 10 条。以下是正文。
虽然,我们投资过的最棒创业 idea,往往并不是一开始我们想找的,反而是那些无心插柳的。
但仍然,我们对几类创业公司非常期待。以下是我们最新的 2024 版本的创业公司征集请求(Requests for Startups,RFS),简述了下我们关注一些创业方向。
但并非说创业只有选择这些方向,才能够申请 Y Combinator。其实我们的多数投资仍然集中在过于一直关注的互联网和移动端。所以如果在阅读本文前,你已经有相关方向的创业想法,请继续做下去。
同样的,也不是说我们列了这些方向,你就要据此创立一家公司。RFS 的目的在于,如果你正好已经有一个类似的想法,那欢迎向我们申请。
另外,如果你想知道我们在寻求投资哪些类型的非盈利组织,可以看这篇文章。
相比 Paxos,Raft 的一大特色就是算法拆成了相对正交的几个部分——领导者选举、日志同步、状态持久化、日志压缩和配置变更。你如果对课程照目录看下就能看出来,除却最后一部分,这些模块就是我们课程 PartA ~ PartD 要分别实现的内容。将算法正交化拆分的好处是,让每个模块相对内聚,使得整体更易理解和实现——这也是 Raft 算法设计的初衷。
下面我不打算采用精确的方式来讲解每个模块——那是论文正文和代码实现要做的事情。相反,本章我将带领大家在感性上建立一个对 Raft 基本概念(任期、选举)和两大流程(领导选举、日志同步)的认识。带着这个感性认识,大家可以再去仔细研读论文,想必能事半功倍地梳理出 Raft 算法中海量的细节。
本文来自 Amazon S3 VP Andy Warfield 在 FAST 23 上的主旨演讲的文字稿,总结了他们在构架和维护如此量级的对象存储 —— S3 的一些经验。我们知道,Amazon S3 是云时代最重要的存储基础设施之一,现在各家云厂商的对象存储基本都兼容 S3 接口,所有云原生的基础设施,比如云原生数据库,其最终存储都要落到对象存储上。
这一年来,由于各种原因,需要不断地学新东西。于是如何高效地学习,就成了一个随之而来的问题。最近看了一些书和公开课,包括 Scott H Young 的 Learn More, Study Less(以下简称 LMSL),和 Coursera 上的公开课学会如何学习(Learning How to Learn,以下简称 LHL),发现了一些有意思的观点,趁着热乎(虽然都还没看完),记下来梳理一下,也希望能对大家有所启发。
这两个资源在进行讲解时,都使用了类比(analogy)。
LMSL 中提出了整体学习法(Holistic learning),其基本思想是:你不可能孤立地学会一个概念,而只能将其融入已有的概念体系中,从不同角度对其进行刻画来弄懂其内涵和外延。
我们在工程实践中,有些构建代码的小技巧,其背后所体现的思想,生活中也常常可见。本系列便是这样一组跨越生活和工程的奇怪联想。这是第一篇:多轮次拆解,也即,很多我们习惯一遍完成的事情,有时候拆成多个轮次完成,会简单、高效很多。
我在进行 code review 时,常看到一些新手同学在一个 for 循环中干太多事情。常会引起多层嵌套,或者 for 循环内容巨大无比。此时,如果不损失太多性能,我通常建议同学将要干的事情拆成多少个步骤,每个步骤一个 for 循环。甚至,可以每个步骤一个函数。
当然,这些全是从维护角度着眼的。因为人一下总是记不了太多事情,一步步来,而不是揉在一块来,会让每个步骤逻辑清晰很多。后者,我通常称之为”摊大饼“式代码,这种代码的特点是写时很自然,但是维护起来很费劲——细节揉在一起总会让复杂度爆炸。软件工程中的最小可用原型,也是类似的理念。
最近翻 DuckDB 的执行引擎相关的 PPT(Push-Based-Execution) 时,发现了这篇论文:Morsel-Driven Parallelism: A NUMA-Aware Query Evaluation Framework for the Many-Core Age。印象中在执行引擎相关的文章中看到他好几次;且 NUMA 架构对于现代数据库架构设计非常重要,但我对此了解尚浅,因此便找来读一读。
从题目中也可以看到,论文最主要关键词有两个:
据此,大致总结下论文的中心思想: