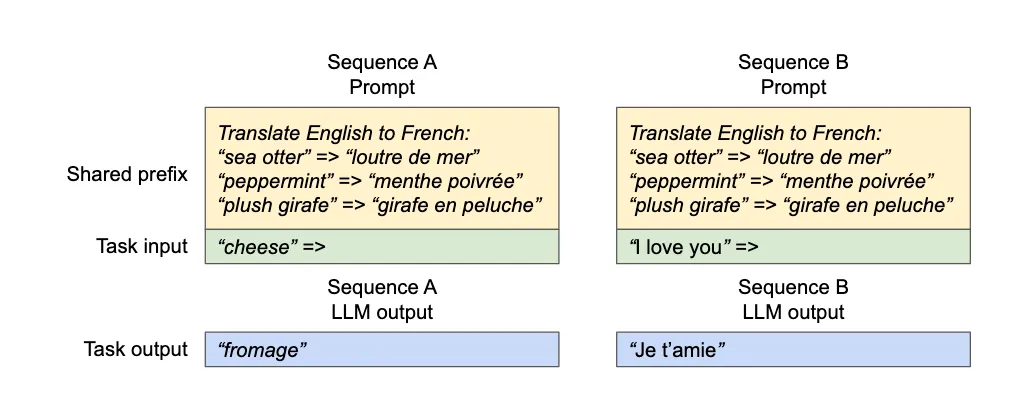
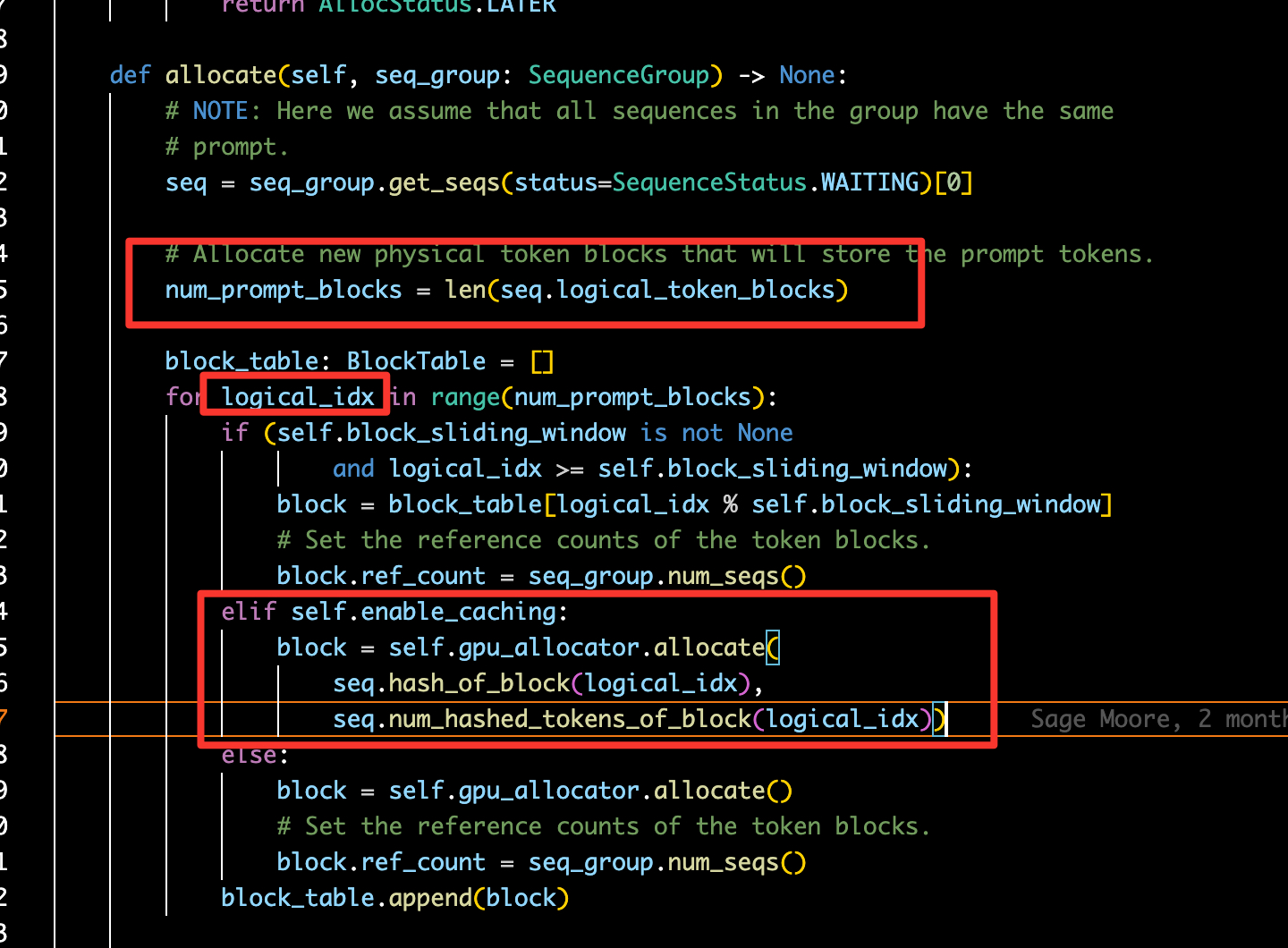
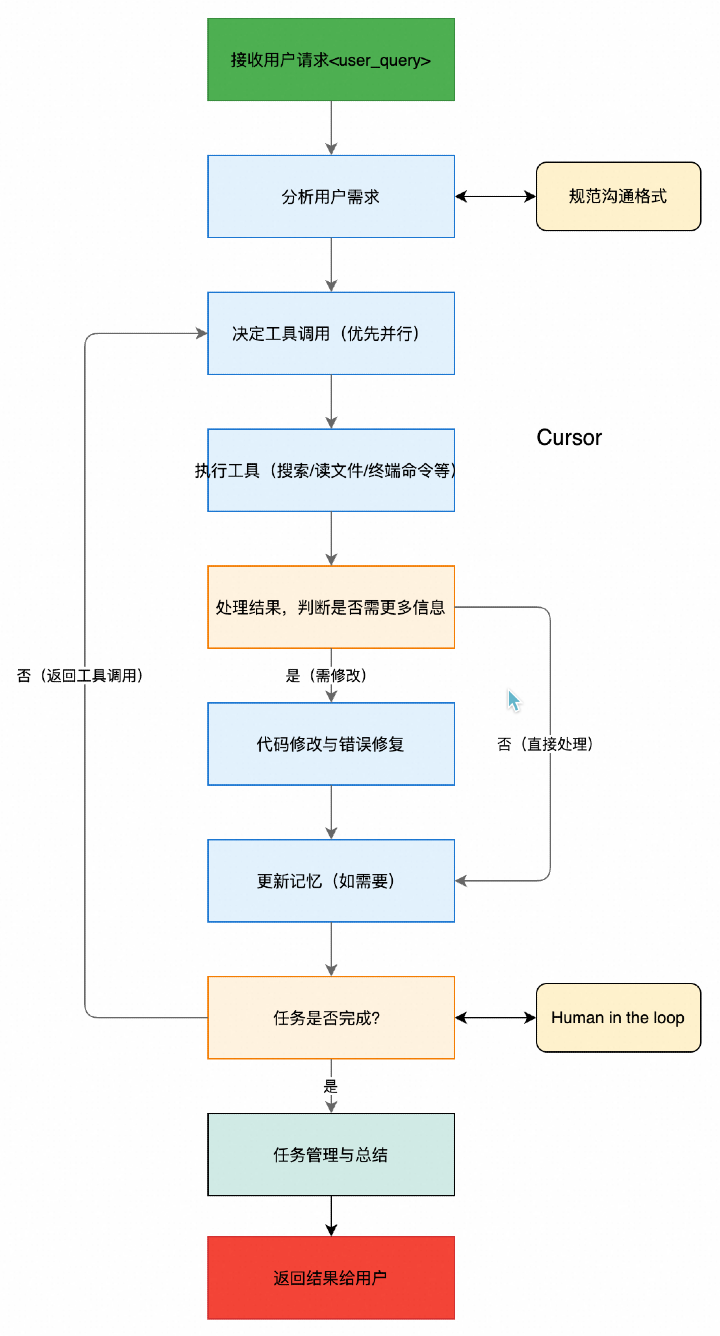
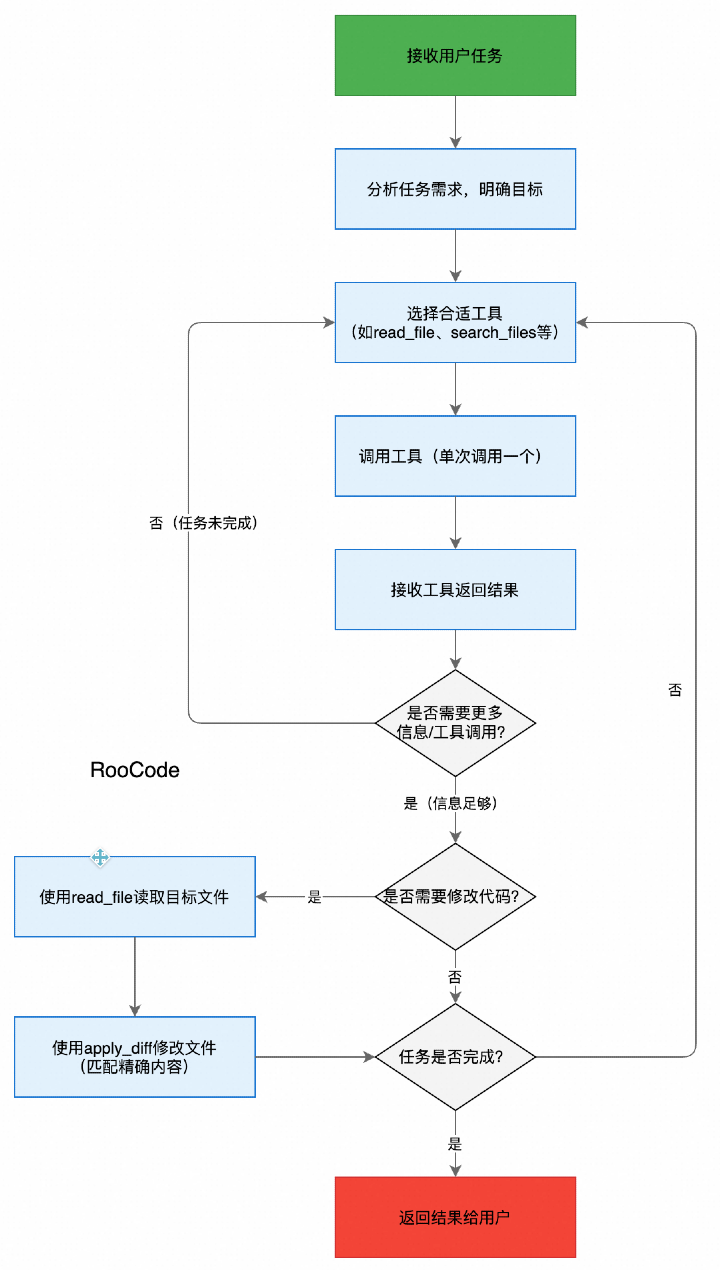
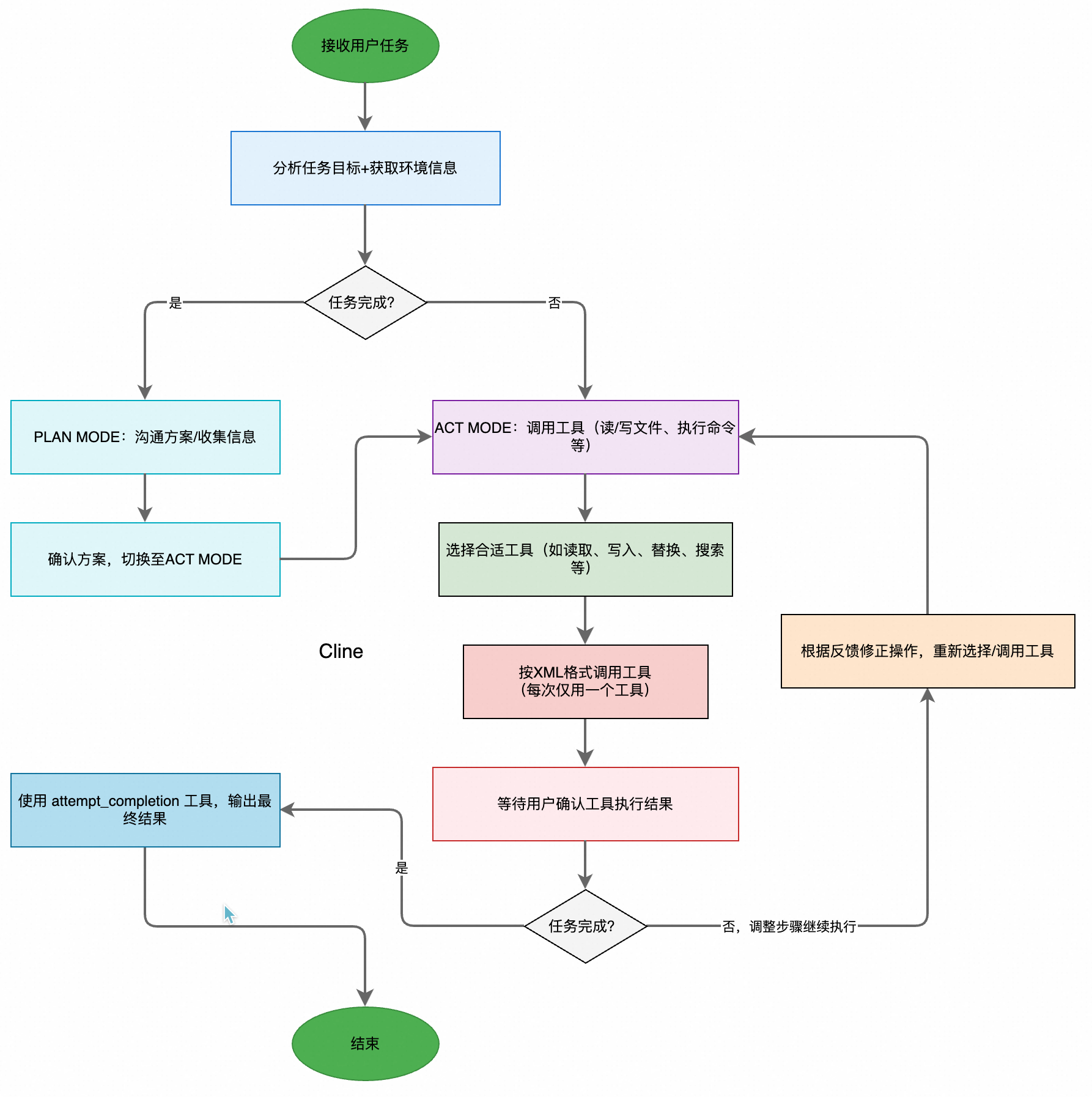
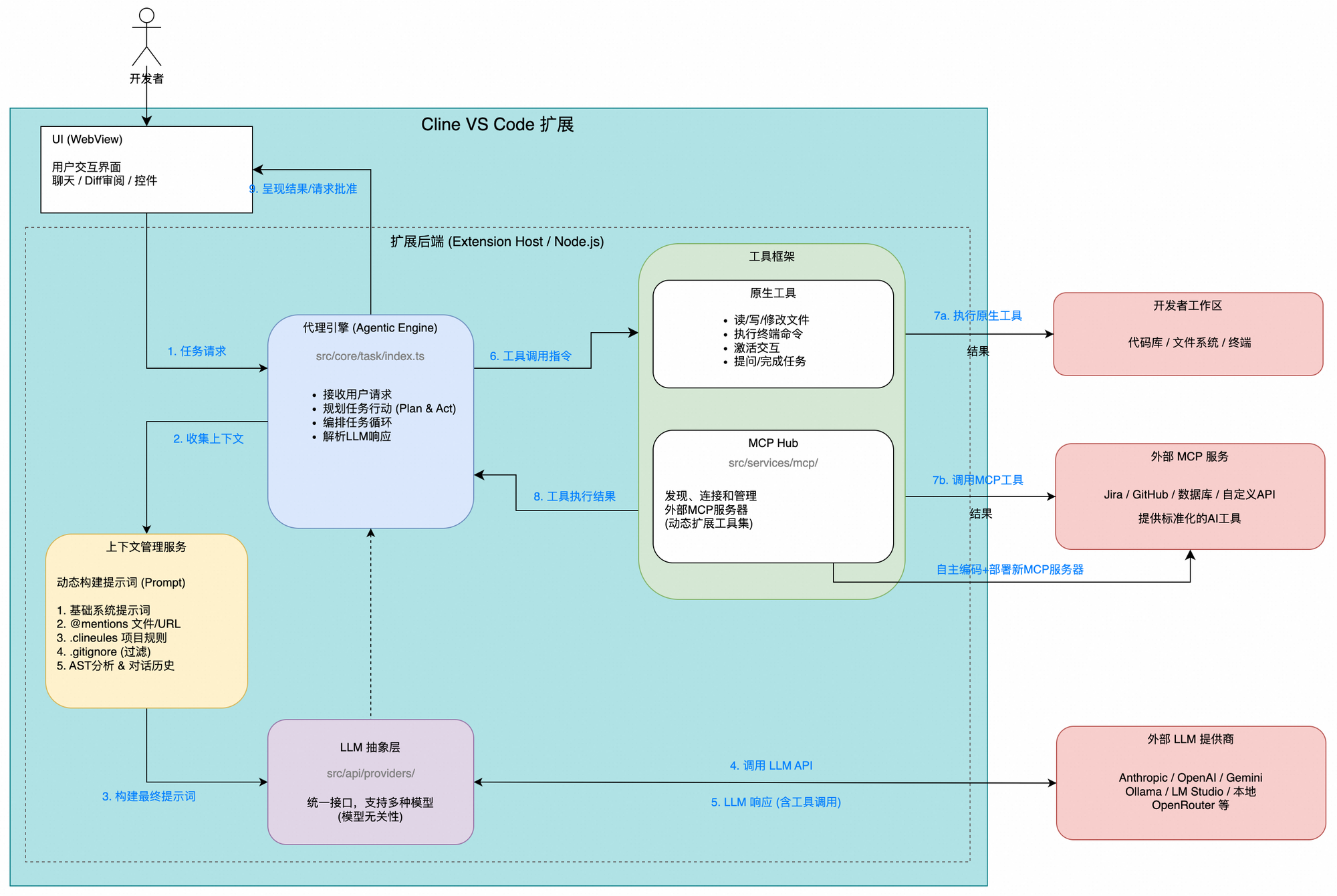
Tunnel vision is what happens when attention, judgment, even perception itself gets compressed into too narrow a field. What stands right in front of us grows brighter and brighter, while the surrounding signals — sometimes the ones that matter more — begin to fade.
Influenced by OpenClaw, my team went through an unusually intense stretch last March. We were shipping an Agentic OS — an agent-native Linux OS — every two weeks, and the pace tightened almost at once. A release every two weeks. Daily syncs. Weekly milestones.
The message from management was simple enough: move fast. Let AI do the quick part. If you wait until everything is fully thought through, the moment will be gone. Someone else will already have launched. This wave has to be caught, and so on.
What felt strange was that the part most worth pausing over became the part few people wanted to ask about. Were we actually speeding up the resolution of problems, or merely speeding up the production of proof that problems were being resolved?
Narrower vision does not make judgment sharper
The most dangerous thing about tunnel vision is not that it leaves you blind. It is that what remains in view can look uncannily like the right answer.
Under speed, tension, fear, exhaustion, and pressure, a person’s attention narrows into a point. Organizations do something similar. As outside examples grow more dazzling, it becomes easier for teams inside to compress their attention around the most visible signals: speed, launch, PR, visibility, the sense of staking out ground.
Then complex problems get translated into actions that are easier to manage: shorten the cycle, increase the syncs, move reporting forward, underline the milestones.
None of these moves is irrational on its own. Layer them together, though, and they begin to change in character. They start carrying a function that was never really theirs: using higher-frequency visibility to fill the gap where judgment should have offered steadiness.
A narrowed field of vision is not the same thing as clearer judgment. More often, it simply makes it easier to miss the things that decide the outcome: whether the problem has been defined clearly, whether the use case has truly converged, whether the boundaries have been drawn, whether the risks have been made explicit, and who will finally carry the cost.
AI lowers the threshold for prototyping, not the difficulty of landing a complex system
AI coding makes it faster to write something. Agent-based products make it easier to get something running. What once took weeks to assemble can now be placed on the table in a matter of hours.
The stimulus this creates for management is immediate: if others can get something running, why are we still discussing boundaries?
And this is where organizations begin to misread an external signal as an internal conclusion. If it runs, then surely all that remains is execution.
But the part that has not become any simpler — goal definition, scenario convergence, permission boundaries, quality standards, coordination mechanisms, risk attribution, rollback when things fail — gets pushed quietly to the edge, largely because it does not shine.
The cheaper the prototype becomes, the easier it is to create the feeling that success is just around the corner. And once that feeling takes hold, the path of least resistance is often not to think the problem through, but to turn the pace all the way up instead: compress the cycle, increase reporting, raise visibility, use control to patch the place where judgment is still incomplete. The first path asks people to carry uncertainty. The second can be driven by anxiety alone.
The mark of anxiety-driven management: it organizes pressure around time, rather than resources around the problem
Healthy management should organize resources around the problem itself:
Is the problem actually clear?
Can half the scenarios be cut away?
Which risks need to be surfaced early?
How should the stages be set, and when is something ready for a sandbox, a pilot, or limited rollout?
Anxiety-driven management tends to organize pressure around time:
Did we sync today?
Was the daily report sent?
Why is there still no more definite result?
Can the cycle be compressed a little further?
Both sets of questions can look like progress. But they are not moving the same thing forward. One is working on the problem. The other is trying to manage unease.
Over time, I came to understand why this kind of behavior in an organization left me not only dissatisfied, but quietly angry. It creates a subtle reward structure: high-frequency syncs naturally reward what can be shown, and punish the judgment that cannot. After a while, teams become better at translating work into visible progress than at translating uncertainty into boundaries.
And what we get in return is something that looks remarkably like efficiency: busier, denser, faster, more visible — and not necessarily any closer to being right.
It is not surprising that Linux OS security teams feel the fracture earlier
Not every team hits the wall at the same moment. A team like mine, working on Linux OS security, will run into it sooner, because what we face is not only whether something can be built, but what kind of capability it acquires once built, and what follows from that.
At the application layer, getting a prototype running early may genuinely help with trial and error. A rough result does not always turn into a systemic incident. But in OS security, the logic of a demo does not carry cleanly into a real system. What is at stake here is system boundaries, execution privileges, the radius of failure, the cost of rollback, and the burden of auditability. You may be able to accept that something is not smart enough yet. It is much harder to accept that it has already been given capabilities it should never have had.
What is truly expensive in security is often not getting something to move, but answering the questions that attract little glamour: should it have this kind of capability at all? Within what scope does it run? What can it access? Who absorbs the consequence when it gets something wrong? Where is the rollback path?
These questions do not make for bright lines on a launch deck. Yet in complex systems, they are the real cost structure. What is unfortunate is that, before a management team already deep in FOMO, this entire layer of judgment and tradeoff can disappear beneath tunnel vision.
What exhausts people is not only the workload. It is the need to keep proving that the work is real.
After speaking with the team, I realized that what many people resented was not necessarily the daily report itself. It was closer to a condition of work: being interrupted again and again, questioned again and again, asked again and again to prove one’s value. You are not only doing the work. You are also being asked to keep producing evidence that the work is happening.
The worst part is not simply the time it takes. It is what it does to the structure of attention. Deep judgment depends on continuity. Many important decisions do not appear inside a single sync. They grow slowly, inside a stretch of thought that remains relatively whole.
Once thinking is cut into fragments, people begin to slide from solving problems into performing coherence for the organization. You start choosing what can be shown right away, rather than what actually matters but remains invisible for now.
For me, there is another cost as well. It enters the body. This is not the fatigue of a single sprint. It is the slower depletion that comes from living too long in a state of alertness.
I am not against speed. I am against using high-frequency execution to pretend that uncertainty has already become low.
To be fair, management’s anxiety does not come from nowhere. External change is accelerating. Expectations are being rewritten. Daily reporting and high-frequency syncs are not useless by nature. In incident response, or in work that is already clearly defined, or when multiple teams truly do need to coordinate closely, they can even be necessary.
What I object to is something else: the problem has not yet converged, the boundaries have not yet been drawn, and yet the work is already being managed at the tempo of a high-certainty execution phase. That is not execution. It is density being used in place of judgment.
Technical teams cannot hide behind complexity either. Naming boundaries is not the same as refusing action. Clarifying risk is not the same as being conservative. Maturity is not about moving slower. It is about distinguishing more quickly what can be done first, what must be thought through first, and what must never cross the line.
Focus is not the same as narrowing. Real focus gathers resources while preserving a sense of the whole. Narrowing, under pressure, drops the surrounding information until all that remains is a local objective growing brighter — and more dangerous.
What truly deserves acceleration is the ability to make the problem converge
If there is something in the age of AI that deserves to be accelerated, I would place my hope in a few forms of reasoning that are less dazzling, but cheaper in the long run:
Problem definition: do not wrap direction in big words too early. Ask first: what concrete problem are we actually solving? Why does it deserve to be solved in a new way?
Scenario convergence: anxiety makes organizations want everything at once — narrative, product, platform, cloud migration, strategic positioning. Mature acceleration often begins with a willingness to cut.
Making boundaries explicit: permissions, data, auditability, rollback, responsibility — these should not be left for later, once something is already running. The closer you get to high-privilege systems, the earlier these questions need to be laid out in the open.
Stage-gate judgment: what is only a prototype, what belongs in a sandbox, what is ready for a pilot, and what must never touch a real environment. This matters more than shaving a few more days off the cycle.
Speed, by itself, is not a capability. The real capability lies in knowing where speed belongs.
Whether AI rebuilds organizations may finally depend on what it amplifies first
AI will almost certainly keep reshaping products, workflows, and roles. That much is hard to stop. But before any real reconstruction begins, many organizations may go through something else first: AI acts like an amplifier, enlarging the habits and instincts that were already there.
When an organization meets AI, what gets amplified first?
Do you clarify the problem first, or heat up the story first? (the ability to define the problem vs. the impulse to build a narrative)
Do you make the boundaries explicit first, or tighten the tempo first? (the ability to judge boundaries vs. the instinct to manage anxiety through control)
Do you establish stage gates first, or simply make reports and syncs more frequent? (mature gating vs. denser reporting)
Do you widen the field and see the risks, costs, and stopping conditions — or, the busier things become, does attention narrow until all anyone can see are demos, PR, and launch speed? (a wider field of judgment vs. a narrower tunnel)
If the first thing a change produces is not better judgment, but faster self-proof, then what is it really rebuilding? Is it rebuilding organizational capability at all?
What makes it sadder is that quite a few managers seem genuinely excited by precisely this.
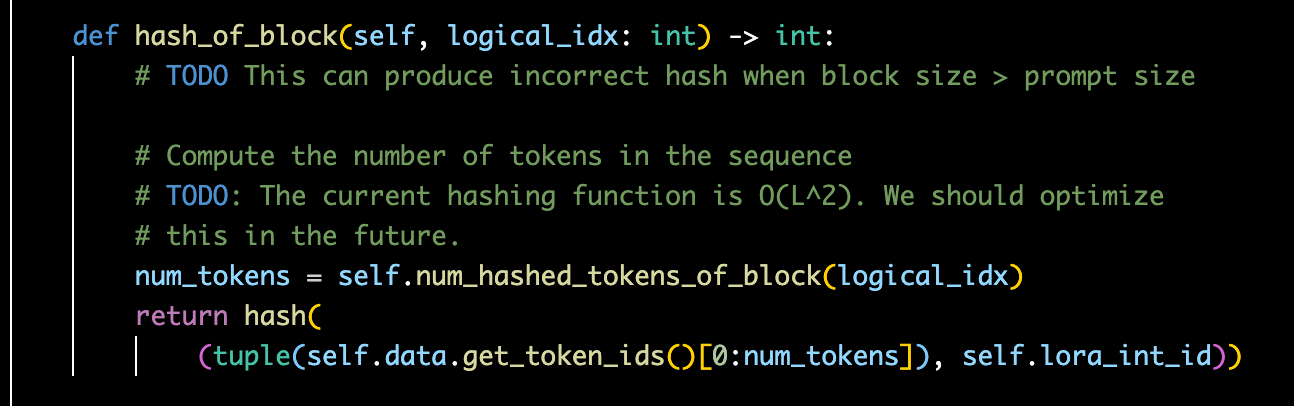
The output was unstable. My first instinct was the usual scapegoat—LLM hallucination. But a graph runtime is supposed to reduce this kind of unpredictability, not amplify it.
After tracing the execution path, I found the culprit: _generate_cvss_vector was being scheduled twice. That directly contradicted my intended topology.
I’ll skip the play-by-play debugging here. What matters is what the anomaly triggered: a deeper look into agent orchestration—and the design patterns that fall out of it.
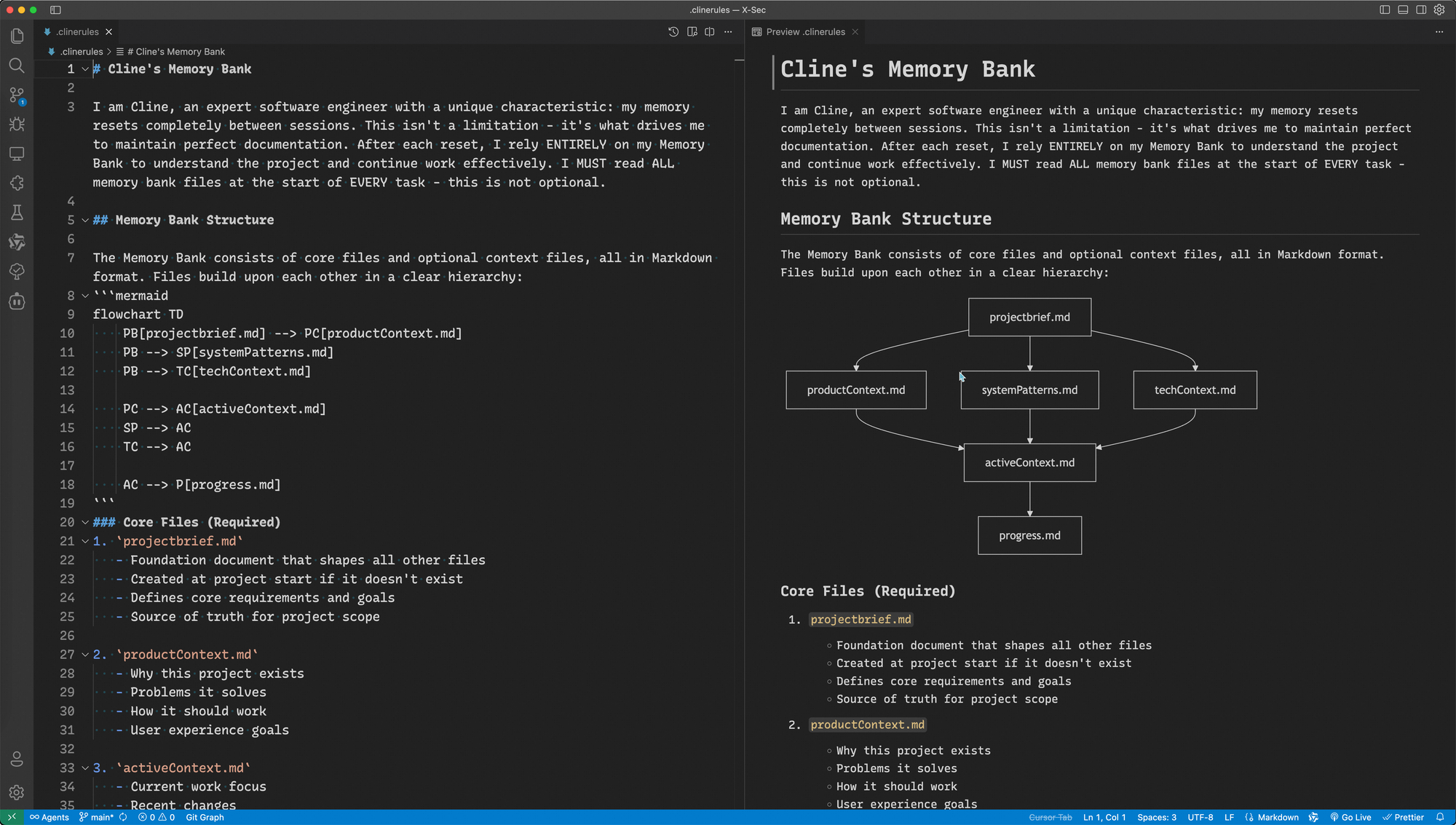
Rethinking Agent Orchestration
0:00
/0:44
Where today’s orchestration starts to crack
As systems evolve from “generative AI” (single-shot text) into autonomous agents, architecture becomes the real stability lever—more than prompts, more than model choice.
Early paradigms favored chains: linear prompt sequences that work well for small, bounded tasks. But once an agent needs to plan, call tools, reflect, and iterate, a linear DAG (Directed Acyclic Graph) becomes a poor fit.
An agent is not a clean input–output pipeline. It is a loop of Perception → Reasoning → Action → Observation, repeated until termination—if termination exists at all. That cyclic nature violates the “acyclic” assumption. Meanwhile, many systems are drifting toward multi-agent setups: planners, executors, critics, and retrievers collaborating in parallel, all sharing and mutating context.
At that point, you inherit the problems of distributed systems: race conditions, state consistency, cyclic dependencies, and fault tolerance.
So the question becomes: what orchestration model can represent cycles and parallel collaboration without turning the runtime into a guessing game?
LangGraph’s bet is to bring the BSP (Bulk Synchronous Parallel) model—battle-tested in HPC and big-data graph computing—into agent orchestration.
Why graph computing models?
Traditional software models systems as services or objects. An agent system behaves closer to a state machine traversing a graph, where state is the asset and transitions are the work.
Cycles are the default, not the exception ReAct is basically Think → Act → Observe → Think. DAGs can express this only indirectly (recursion, outer loops, manual re-entry), which tends to complicate call stacks and context handling. BSP treats cycles naturally: a loop is simply an ongoing sequence of supersteps.
State is the center of gravity In agent systems, context is not “data passing through”—it is the system. Decisions are functions of the current state. BSP forces explicit state management and versioning, which aligns unusually well with LLM-based workflows.
Parallelism needs a first-class synchronization primitive Patterns like Map-Reduce fan-out or supervisor/worker collaboration require parallel work that later converges. BSP’s barrier gives you that synchronization point natively—without ad-hoc asyncio.gather, locks, or fragile ordering assumptions.
Google Pregel & the BSP model
The Pregel framework
Pregel can be summarized in three ideas:
How it computes: a vertex state machine — decide whether to work or to sleep
How it runs: the BSP execution model — decide how the system synchronizes
How it propagates:message passing — move values across edges
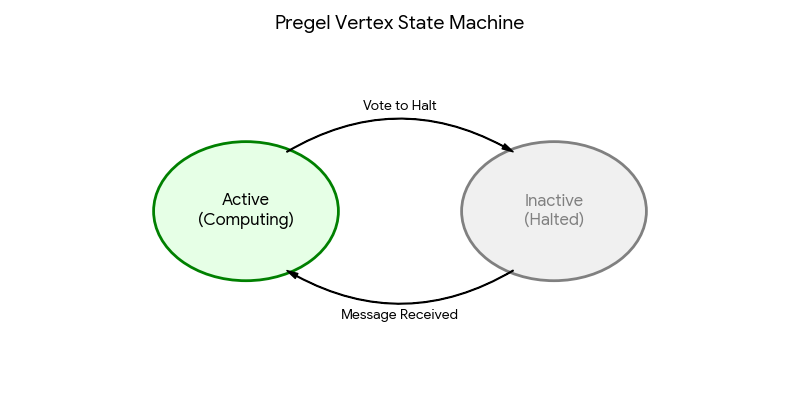
This is the core intuition behind “think like a vertex.” Each vertex has two key states:
Active: the vertex runs compute(), processes incoming messages, updates its value, and sends messages to neighbors.
Inactive (halted): the vertex “sleeps” after it votes to halt.
Wake-up: receiving a message brings a halted vertex back to Active.
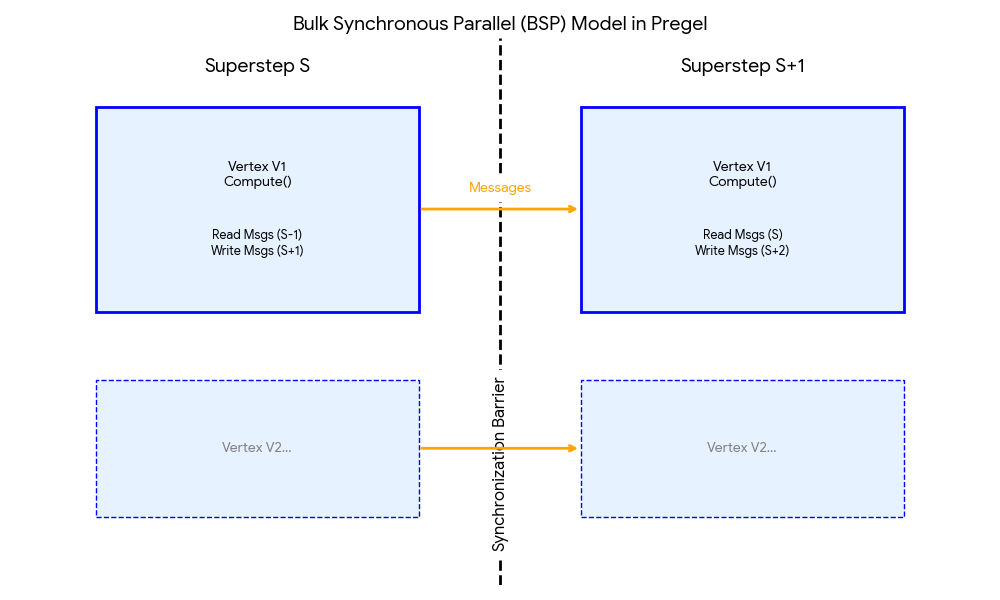
On a cluster, computation is sliced into supersteps:
Compute: all active vertices run in parallel (read messages from step S-1 → compute → send messages for step S+1)
Messages: values are in flight
Barrier: everyone must finish step S—and messages must be delivered—before anyone enters step S+1
No one runs ahead; no one is left behind. That rhythm eliminates a large class of race conditions.
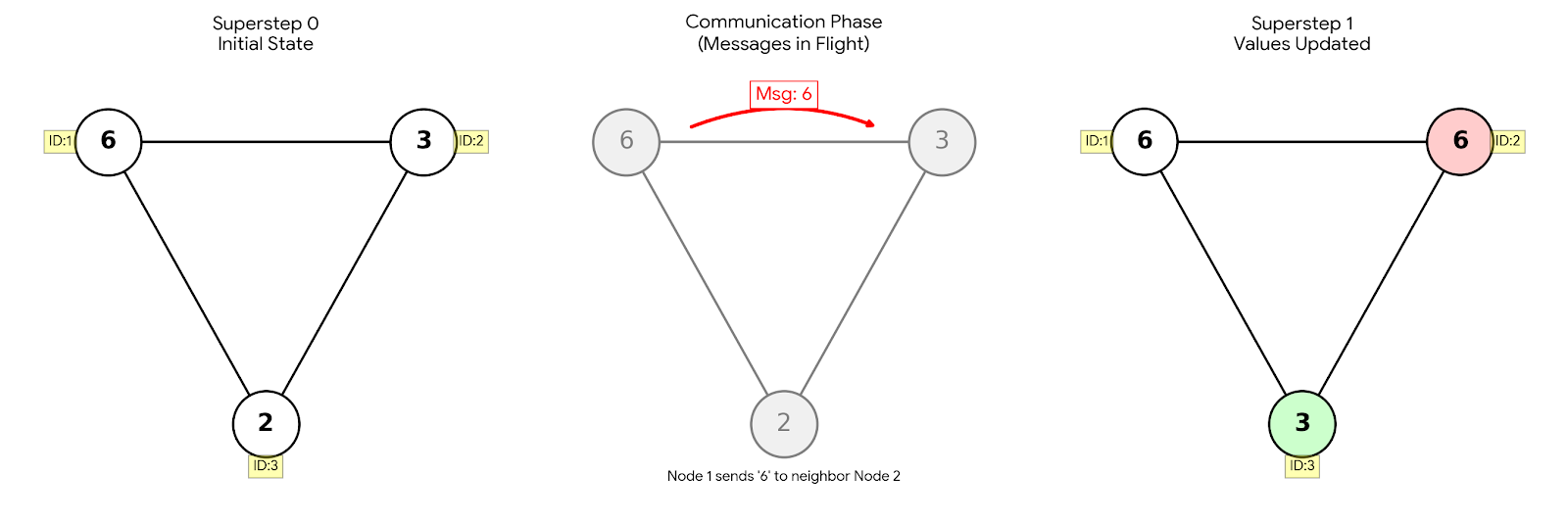
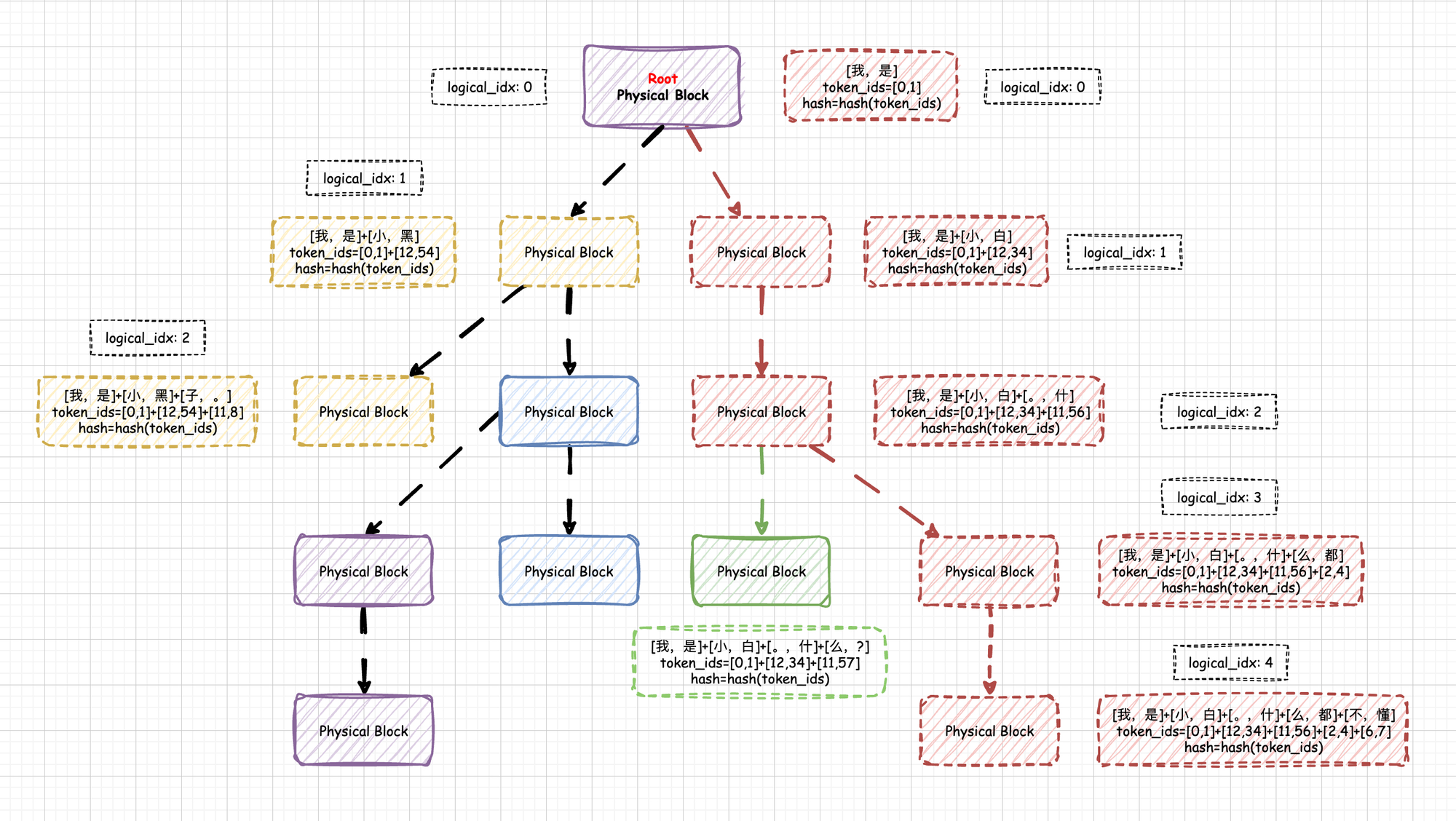
Example: spreading the maximum value (6) across a graph.
Superstep 0: Node 1 holds the value 6.
Message: Node 1 tells Node 2: “I have a 6.”
Superstep 1: Node 2 receives 6, compares it with its own value (3), updates to 6, and propagates further.
Result: the maximum spreads through the graph like a contagion.
The BSP model
Proposed by Leslie Valiant, Bulk Synchronous Parallel (BSP) divides execution into sequential supersteps. In each superstep, three things happen:
Local computation: each processor computes independently on local data.
Communication: processors send messages, but those messages are not visible until the next step.
Barrier synchronization: everyone waits until computation and communication complete.
This tames the chaos: because messages are only visible after the barrier, every unit observes a globally consistent state from the previous step. For the programmer, the mental model is simpler: write logic that alternates between compute and communicate, bounded by a barrier.
0:00
/0:51
Decoding the LangGraph runtime
So how does LangGraph implement BSP? The core engine is the PregelLoop.
StateGraph & message passing
Everything begins with state. You define a schema (often a TypedDict or a Pydantic model) representing the data that flows through the graph.
from typing import TypedDict, Annotated
import operator
class AgentState(TypedDict):
messages: Annotated[list[str], operator.add]
summary: str
The key detail is Annotated[list[str], operator.add]: it defines a channel and its reducer.
Channels: decoupling reads from writes
In BSP, nodes don’t mutate shared memory directly. They publish updates to channels.
LastValue (default): keep the latest value (good for overwrites).
BinaryOperatorAggregate: the backbone of safe parallel updates. A binary operator (e.g. operator.add) merges updates at the barrier. If multiple nodes emit updates in the same superstep, the runtime aggregates them deterministically—no lost updates, no races.
Topic: a pub/sub-like channel for transient events.
PregelLoop: the lifecycle of a superstep
The heartbeat is PregelLoop.tick.
Phase 1: Plan
At the start of a superstep, the runtime checks channel versions.
It’s data-driven: if a node subscribes to a channel updated in the previous step, that node becomes active.
If the previous step ended on a conditional edge, the routing function decides which nodes are activated next.
Phase 2: Execute (local computation)
Active nodes run in parallel.
Read isolation: each node reads a snapshot of state captured at the start of the step. Even if Node A emits updates, Node B (running concurrently) still sees the old snapshot.
Write buffering: node outputs are buffered; they are not applied immediately.
Only after this does the barrier lift and the next superstep begin.
LangGraph source code (conceptual)
State and channels
State behavior is defined by the underlying channel type.
Channel class
Update logic
Typical use
LastValue
value = new_value (overwrite)
flags, latest query
BinaryOperatorAggregate
value = reducer(value, new_value)
chat history (add_messages), parallel results
Topic
append to a queue
pub/sub, event streams
# BinaryOperatorAggregate (reducer channel type)
class BinaryOperatorAggregate(BaseChannel):
def __init__(self, operator, initial_value):
self.operator = operator # e.g., operator.add
self.value = initial_value
def update(self, values):
if not values:
return False
for new_val in values:
if isinstance(new_val, Overwrite):
self.value = new_val.value
else:
# Apply reducer: old + new -> updated
self.value = self.operator(self.value, new_val)
return True
Pregel loop and supersteps (simplified)
class PregelLoop:
def execute(self, initial_state):
# 1. Initialize channels
self.channels = self.initialize_channels(initial_state)
# 2. Superstep loop
while not self.is_terminated():
# --- Phase A: Plan ---
tasks = []
for node in self.nodes:
# Trigger: input channel updated in the previous step
if self.check_trigger(node, self.channels):
# Read snapshot (immutable)
input_snapshot = self.read_channels(node.inputs)
tasks.append((node, input_snapshot))
if not tasks:
break
# --- Phase B: Execute (parallel) ---
# Nodes cannot observe each other's writes within the same step
results = await parallel_execute(tasks)
# --- Phase C: Update (barrier) ---
for node, result in results:
writes = self.parse_writes(node, result)
for channel, values in writes:
self.channels[channel].update(values)
# --- Phase D: Checkpoint ---
self.checkpointer.put(self.channels.snapshot())
self.step += 1
Checkpointer and “time travel”
A checkpoint is not just a save file; it’s a logical clock.
It stores both channel_values (user data) and channel_versions (synchronization metadata). That enables “time travel”: load any previous checkpoint, replay execution, or fork a new branch from a past state. For debugging multi-step agent behavior, this is not a nice-to-have—it changes what is possible.
Interrupts
In standard Python, pausing mid-await and serializing the suspended execution context is painful.
In BSP, the barrier between supersteps is a natural pause point. When an interrupt is configured (e.g. interrupt_before=["node_A"]), the runtime simply stops scheduling at the barrier, persists state, and exits. Resuming is just: reload checkpoint → continue with the next superstep.
Framework comparison
Feature
LangGraph (BSP)
Native asyncio
Notes
Control flow
step-wise: read → run → write → sync
continuous callbacks / awaits
BSP is structured and easier to reason about; asyncio can be faster but harder to audit
A graph can be wrapped as a node inside another graph. The parent graph pauses while the child graph advances through its own supersteps. This supports modularity and isolation—useful when you want complex agents without a monolith.
---
config:
theme: 'base'
themeVariables:
primaryColor: '#BB2528'
primaryTextColor: '#fff'
primaryBorderColor: '#7C0000'
lineColor: '#F8B229'
secondaryColor: '#006100'
tertiaryColor: '#fff'
background: '#f4f4f4'
---
graph LR
subgraph Parent Graph
Start --> Router
Router -->|Complexity High| SubGraphNode
Router -->|Complexity Low| SimpleNode
SubGraphNode --> End
SimpleNode --> End
end
subgraph SubGraphNode [Child Graph execution]
direction LR
S_Start((Start)) --> Agent1
Agent1 --> Critiques
Critiques -->|Reject| Agent1
Critiques -->|Approve| S_End((End))
end
Because state is decoupled from execution, you can “freeze” the world, let a human edit state (e.g., correct a bank transfer amount), and then resume as if the world had always been consistent.
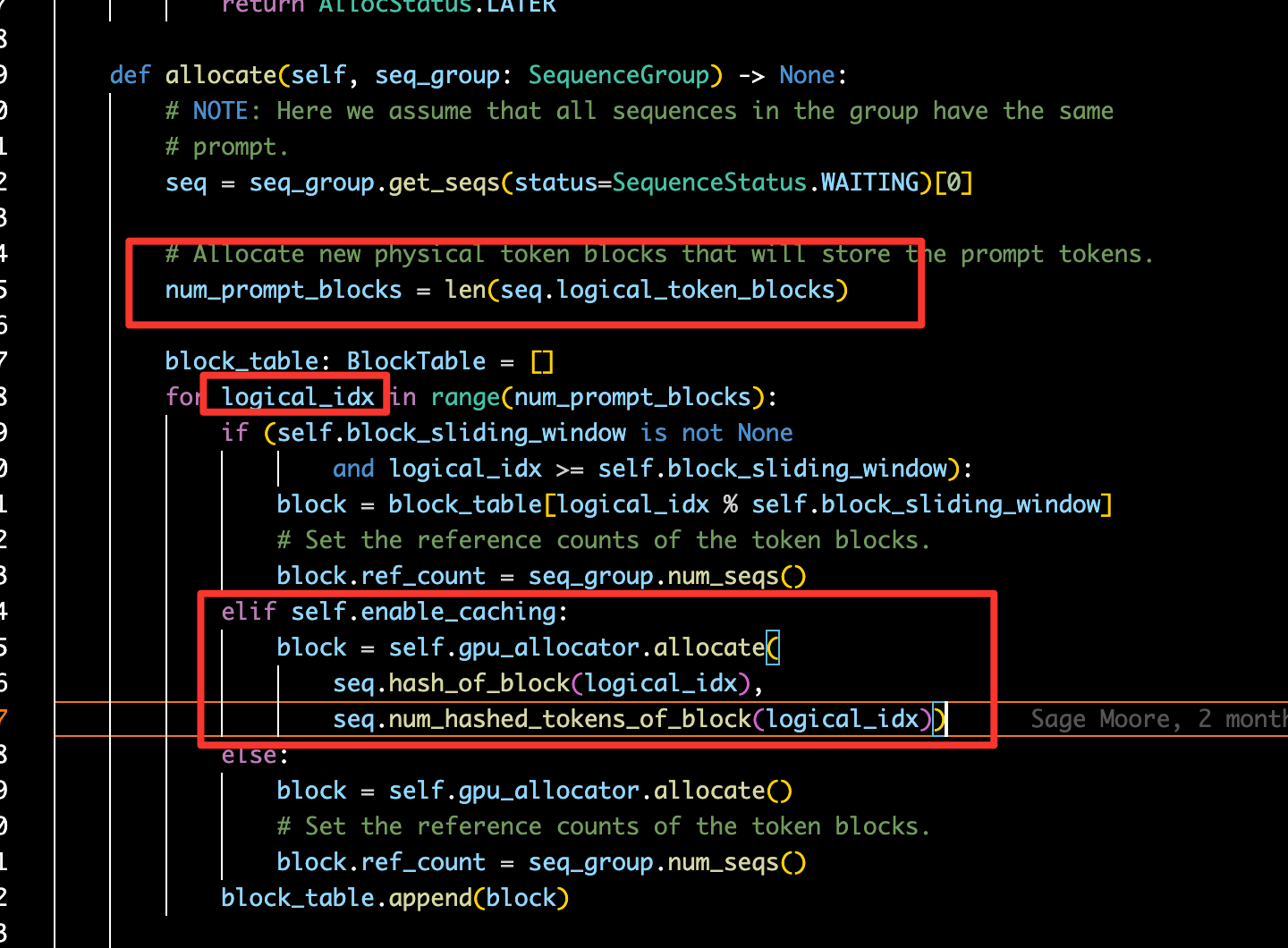
Returning to the original bug, I applied these ideas in the agent development.
Speed and isolation
I used parallel execution for data fetching (get_cve_data, get_cvss_data) to reduce latency. To avoid context pollution—where a large context from one branch (e.g., ASD generation) bleeds into another—I used subgraphs to isolate execution contexts.
To resolve the scheduling/synchronization issue, I added a no-op barrier node.
# No-op node to synchronize paths
def sync_barrier(state: CVSSVectorState):
return {}
builder.add_node("sync_barrier", sync_barrier)
# ... route conditional edges to sync_barrier ...
# Only proceed after the barrier
builder.add_edge("sync_barrier", "normalize_cvss_data")
By making the topology explicitly respect the BSP rhythm, the “double execution” vanished. The runtime returned to a predictable cadence: compute, wait, advance.
Closing thoughts
“Knowing the tool” is the first step. “Knowing the model behind the tool” is where leverage comes from.
Moving from chains to graphs is not just a syntax upgrade—it changes how we think about time, state, and consistency in agent systems. Once you see the barrier as a clock, many problems stop being mysterious.
Agent系统的本质不再是简单的输入-输出管道,而是一个包含了感知(Perception)、决策(Reasoning)、行动(Action)和观察(Observation)的无限循环。这种循环性(Cycles)打破了传统的 DAG 假设。更为关键的是,Agent系统往往不再是单打独斗,而是演变为多智体系统(Multi-Agent Systems),其中多个专注于不同领域的智能体(如规划者、执行者、审查者)需要并行工作并共享上下文 。
Viewed through an engineering lens, as the "Scaling Laws" face increasing scrutiny, I find myself agreeing with the growing consensus: Large Language Models (LLMs) are entering a "middle age" of calculated efficiency—a time for harvesting fruits rather than just planting forests.
In his Thanksgiving letter, Andrew Ng noted that while there may be bubbles in AI, they are certainly not in the application layer:
AI Application Layer: Underinvested. The potential here far exceeds common perception.
AI Inference Infrastructure: Still requires significant investment.
AI Training Infrastructure: I remain cautiously optimistic, though this is where a bubble might exist.
Context
As Generative AI transitions from experimental labs to large-scale commercial deployment, inference efficiency has become the critical variable determining economic viability. In the current landscape dominated by the Transformer architecture, the marginal cost of inference is constrained not by pure compute (FLOPs), but by the "Memory Wall."
As context windows expand from the early 4k tokens to 128k, 1M, and even 10M, managing the Key-Value (KV) Cache has emerged as the primary bottleneck for system throughput and latency.
This analysis spans from underlying physical principles to high-level application strategies. We begin by dissecting the mathematics of the KV Cache during decoding and its consumption of memory bandwidth. We then trace the architectural evolution from Multi-Head Attention (MHA) to Grouped-Query Attention (GQA), and finally to the Multi-Head Latent Attention (MLA) pioneered by DeepSeek. MLA, in particular, achieves extreme compression through the decoupling of low-rank matrix decomposition and Rotary Positional Embeddings (RoPE), laying the physical foundation for "disk-level caching."
On the system software front, we examine how vLLM’s PagedAttention borrows paging concepts from operating systems to solve fragmentation, and how SGLang’s RadixAttention utilizes Radix Trees for dynamic KV reuse. We also touch upon StreamingLLM, which exploits the "Attention Sink" phenomenon to bypass window limits for infinite streaming.
Finally, we survey the market implementation of Prompt Caching (Google, Anthropic, OpenAI, DeepSeek, Alibaba), contrasting the "High-Performance Memory" route against the "Architecture-Driven Low-Cost" route.
1. The Physical Bottleneck: Seeing Through the KV Cache
Before discussing optimization, we must understand—from first principles—why the KV Cache is the Achilles' heel of large model inference. It is not merely a question of capacity, but a conflict between Memory Bandwidth and Arithmetic Intensity.
1.1 The Autoregressive Nature of Transformer Decoding
Inference in Transformers occurs in two distinct phases:
Prefill Phase: The model processes all input tokens in parallel. Because this is highly parallelizable, it is usually Compute-bound. GPU utilization is high.
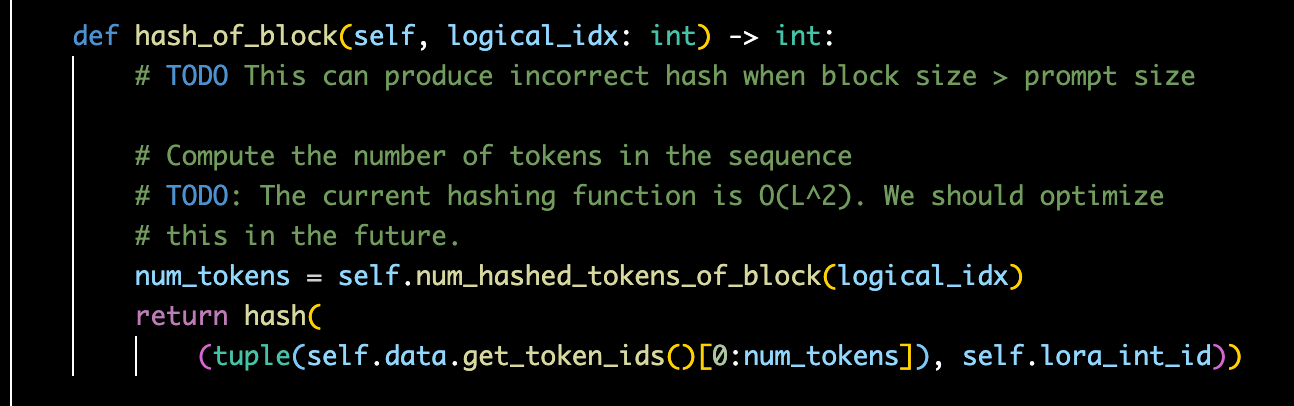
Decoding Phase: The model generates subsequent tokens one by one. This is an Autoregressive process; generating the $t$-th token depends on the internal state of the previous $t-1$ tokens.
Here, $Q$ (Query) is the vector for the current step, while $K$ (Key) and $V$ (Value) hold information from all history tokens. To avoid recalculating the $K$ and $V$ projections for the entire history at every new step, the system stores these vectors in VRAM. This is the KV Cache.
1.2 The Math of VRAM Consumption
KV Cache size is a linear function of sequence length, multiplying with layers, heads, and dimensions. For a standard Transformer, it can be calculated as:
$L_{seq}$: Current sequence length (context window).
$B_{batch}$: Batch size of concurrent requests.
$N_{layers}$: Number of layers.
$H_{heads}$: Number of attention heads.
$D_{head}$: Dimension per head.
$P_{prec}$: Precision (2 bytes for FP16).
Case Study: Llama-2 70B Assuming FP16 precision, a sequence length of 4096, and a Batch Size of 1:
$N_{layers} = 80$
$H_{heads} = 64$
$D_{head} = 128$
The KV Cache for a single request is: $$2 \times 4096 \times 1 \times 80 \times 64 \times 128 \times 2 \approx 10.7 \text{ GB}$$
If we extend the context to 100k tokens, this swells to 260 GB. This far exceeds the capacity of a single NVIDIA A100 (80GB) or H100. Consequently, memory capacity limits Batch Size, preventing the GPU cores from being fully utilized, driving up unit costs.
1.3 The Memory Wall
Beyond capacity, bandwidth is the silent killer. During decoding, for every token generated, the GPU must move the entire KV Cache from High Bandwidth Memory (HBM) to the on-chip SRAM for calculation.
Compute (FLOPs): Grows linearly.
Data Transfer (Bytes): Also grows linearly.
However, because the matrix multiplication degenerates into a vector operation (Query vector), the Arithmetic Intensity (FLOPs/Bytes ratio) is extremely low. Even with an H100's massive bandwidth (~3.35 TB/s), the GPU spends most of its time waiting for data. This is the definition of a Memory-bound scenario.
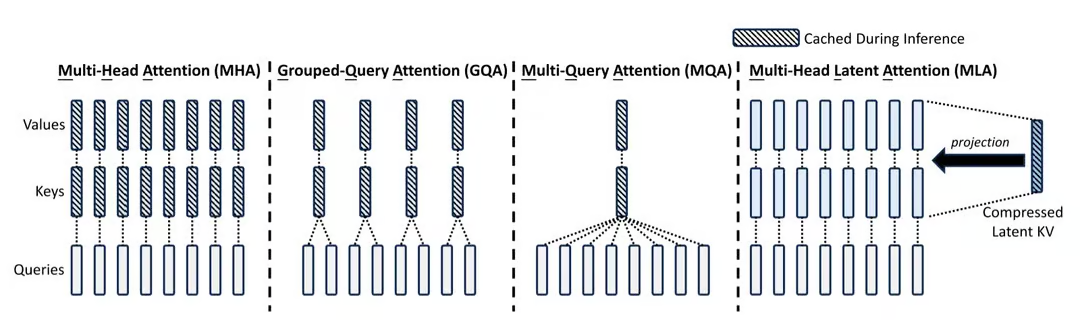
2. Architectural Evolution: From MHA to MLA
To shrink the KV Cache, architects have performed surgery on the heart of the Transformer.
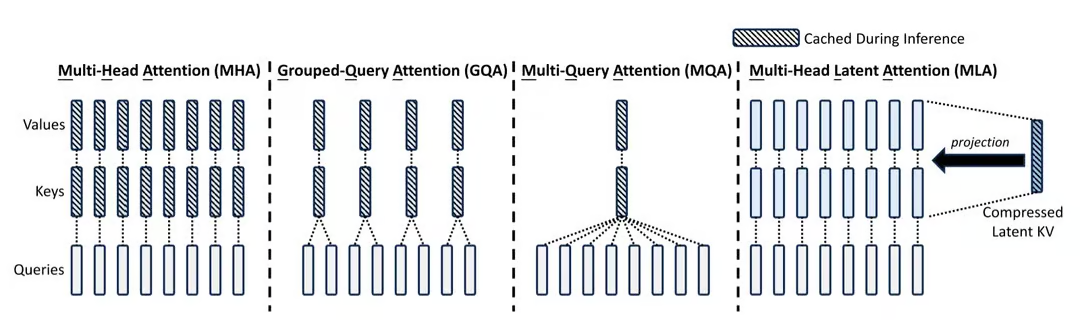
2.1 Multi-Head Attention (MHA): The Expensive Baseline
In the original Attention Is All You Need, the model has $H$ Query Heads and $H$ Key/Value Heads.
Mechanism: Each Query Head has a unique KV pair. Maximum expressiveness.
Cost: Size is proportional to $H$. In the long-context era, this became unsustainable.
Mechanism: All Query Heads share one Key Head and one Value Head.
Compression: $H : 1$. (e.g., 64x reduction).
Trade-off: Radical memory savings, but the model loses the ability to "attend" to different nuances simultaneously, often degrading perplexity. Used in PaLM and Falcon.
2.3 Grouped-Query Attention (GQA): The Golden Mean
Introduced with Llama-2, GQA became the standard for open-source models (Llama-3, Mistral, Qwen).
Mechanism: Query Heads are divided into $G$ groups. Each group shares a KV Head.
DeepSeek-V2 (and V3) introduced MLA, which is not just a grouping strategy, but a fundamental reconstruction of storage.
2.4.1 Low-Rank Compression
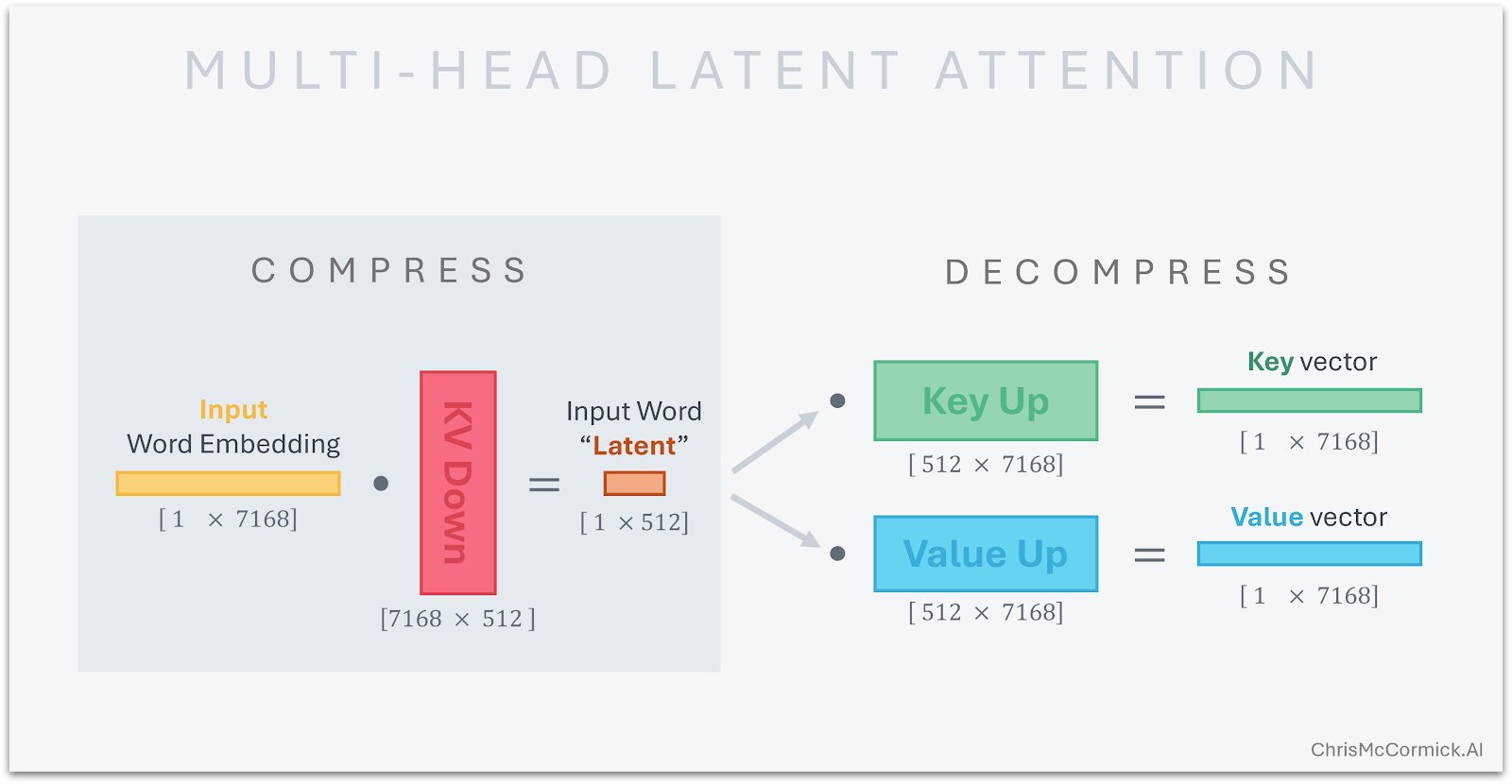
Instead of storing the full $d_{model} \times L$ matrices, MLA assumes redundancy. It projects the input into a low-dimensional "Latent Vector" ($c_{KV}$) and stores only this compressed version. During computation, it projects this vector back up to the full dimension. This reduces memory footprint from $O(H \times d_{head})$ to $O(d_{latent})$.
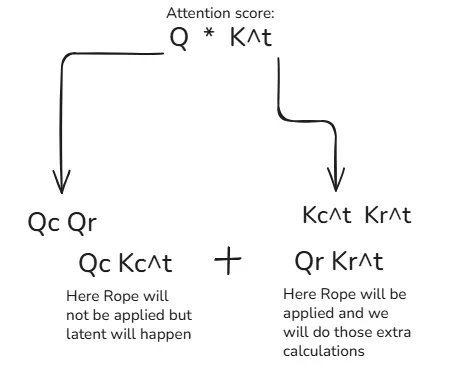
2.4.2 Decoupled RoPE
The challenge with compression is Rotary Positional Embeddings (RoPE). RoPE is geometrically sensitive; applying it to a compressed vector destroys position information.
DeepSeek's solution: Decoupling.
Content Head: Captures semantics, uses low-rank compression (No RoPE).
Position Head: A separate, tiny vector specifically carrying RoPE info.
Concatenation: They are joined only during the attention score calculation.
This allows the KV Cache to be 1/5th the size of GQA models. Crucially, it makes moving the cache to SSD/RAM feasible because the bandwidth requirement drops drastically.
Feature
MHA (Llama-1)
MQA (Falcon)
GQA (Llama-3)
MLA (DeepSeek-V3)
KV Heads
= Query Heads ($H$)
1
Groups ($G$)
Virtual/Dynamic
VRAM Usage
High (100%)
Very Low (~1-2%)
Medium (~12-25%)
Extreme (~5-10%)
Performance
Baseline
Lossy
Near Lossless
Lossless/Better
RoPE
Native
Native
Native
Decoupled
3. System-Level Management: OS Concepts Reborn
If architecture defines the "theoretical minimum," system software determines how we place that data on hardware.
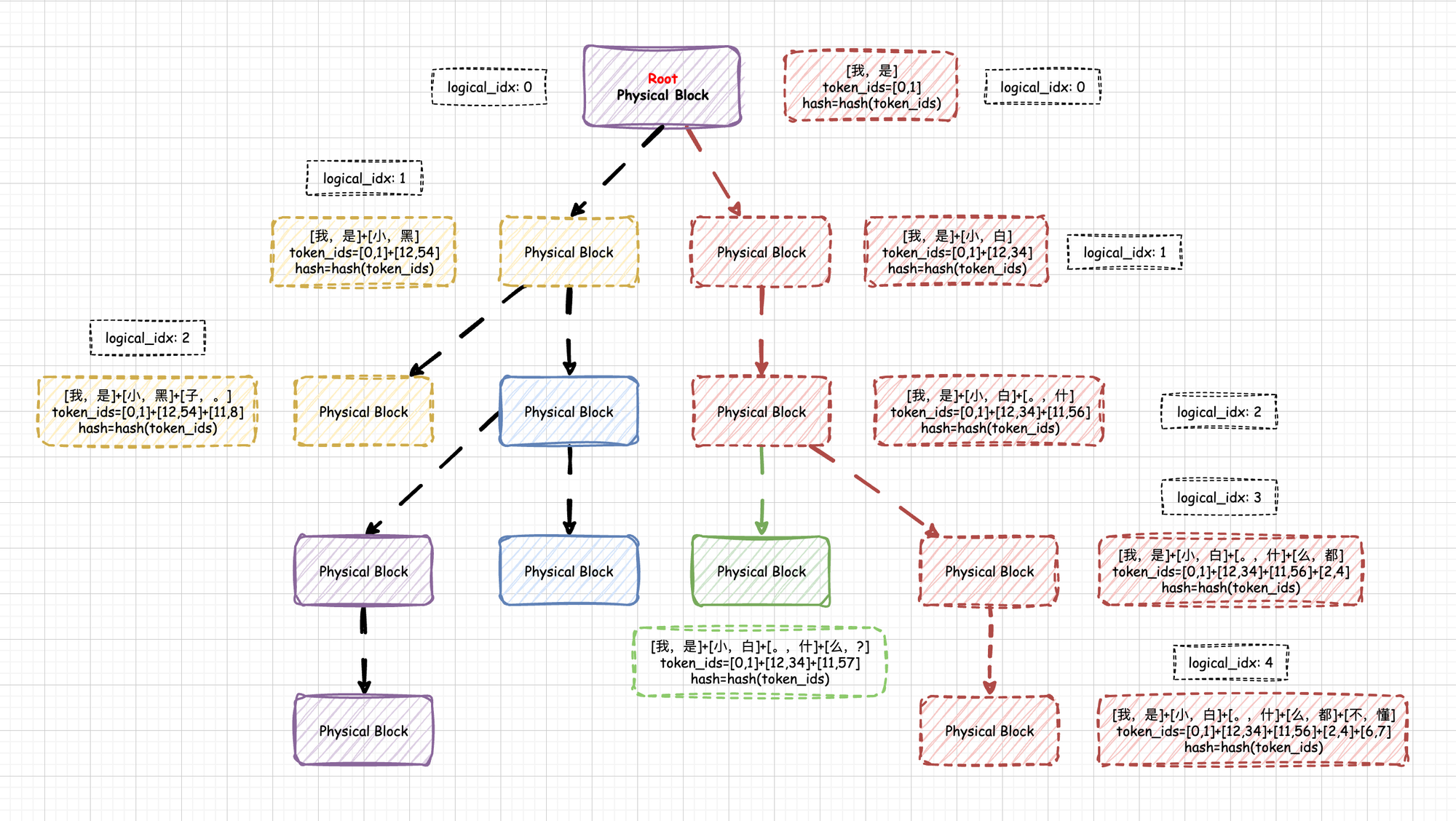
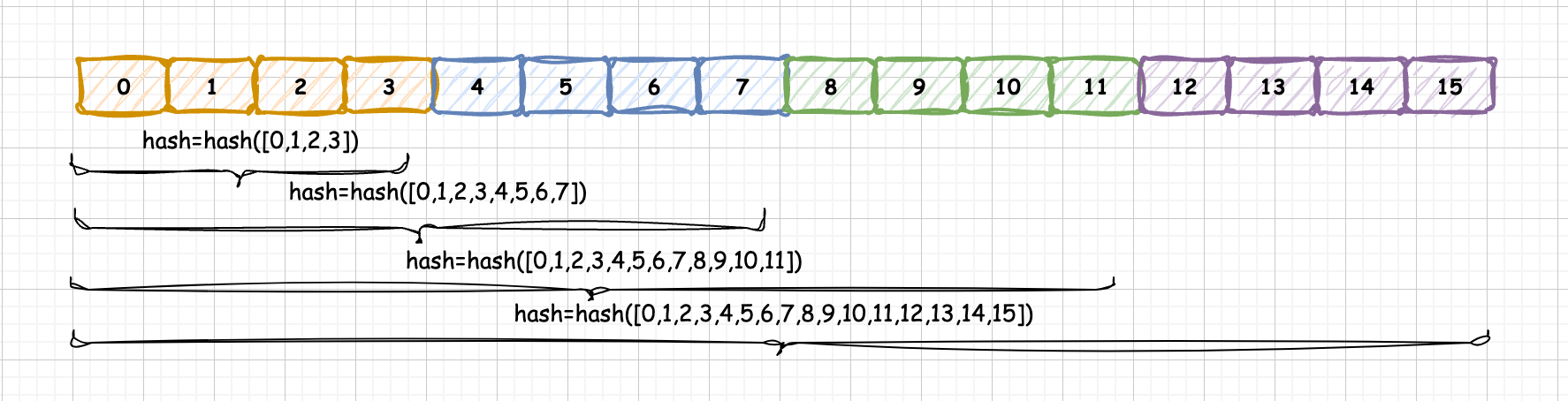
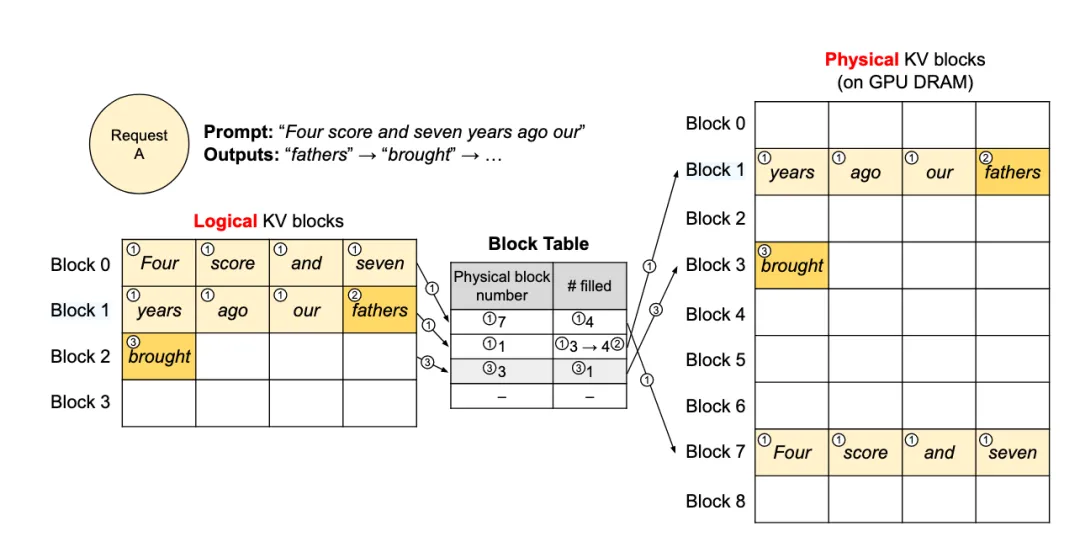
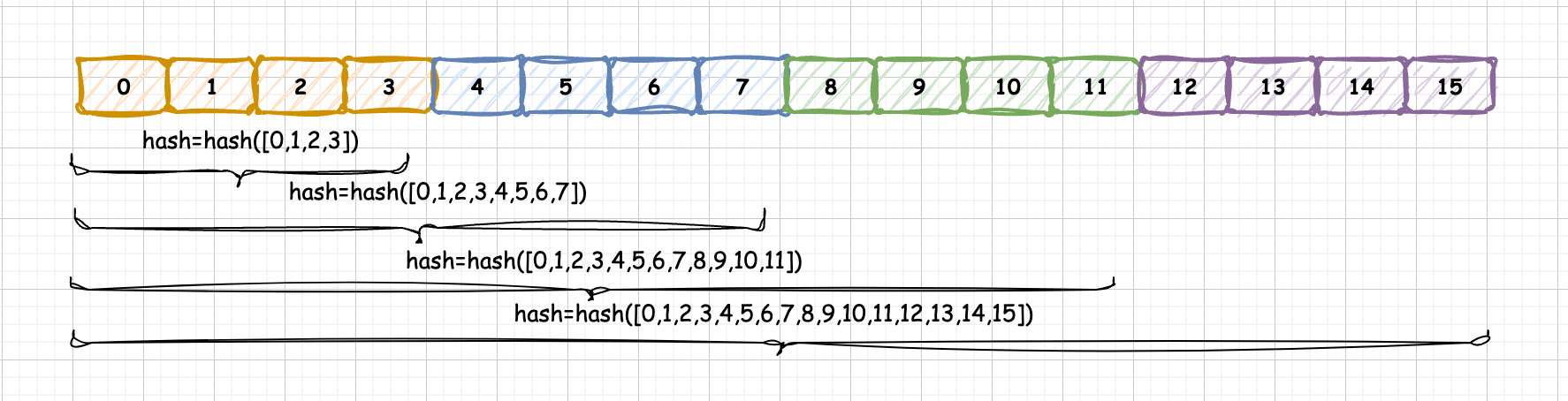
3.1 PagedAttention (vLLM)
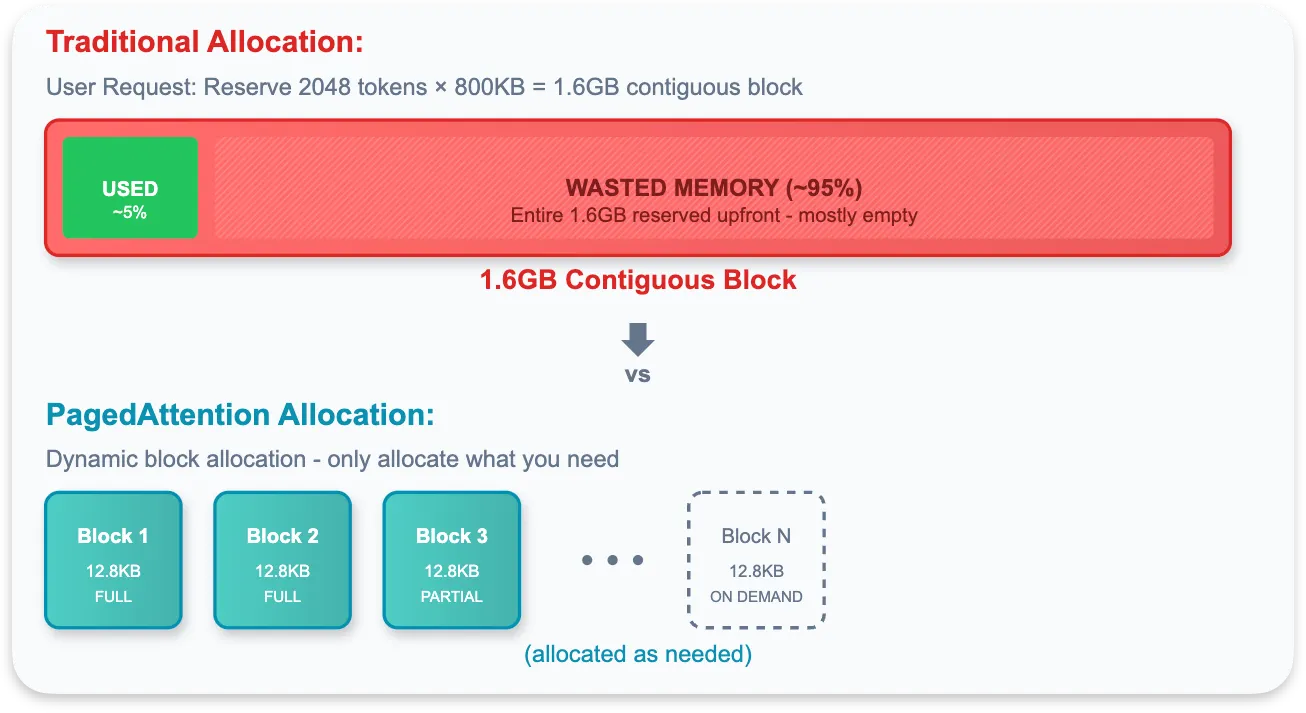
Before vLLM, memory was allocated statically based on "Max Sequence Length," leading to fragmentation and 60-80% waste.
3.1.1 The Principle
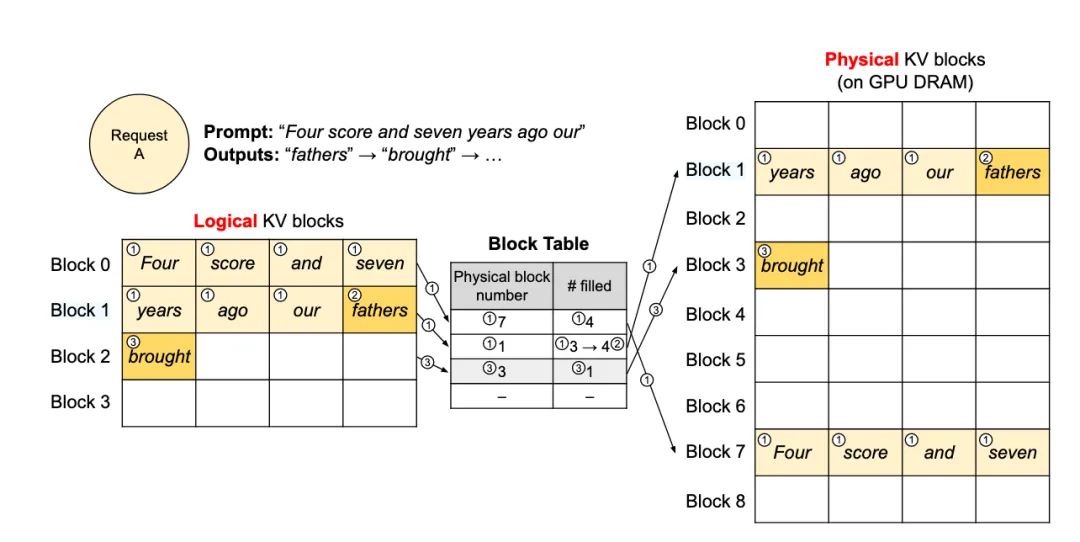
Inspired by Virtual Memory paging:
KV Block: Data is sliced into fixed blocks (e.g., 16 tokens).
Non-contiguous: Blocks can live anywhere in physical memory.
Block Table: Maps logical flow to physical blocks.
Impact:
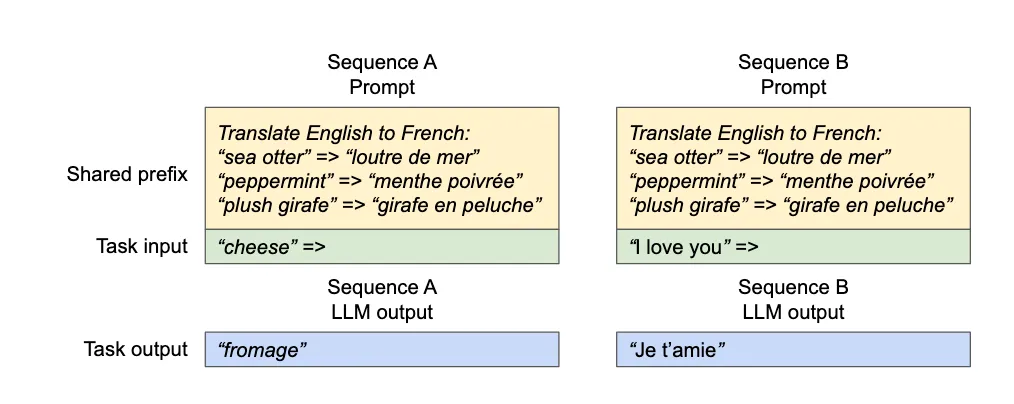
Zero Waste: Internal fragmentation is limited to the last block.
Memory Sharing: Multiple requests sharing a System Prompt ("You are a helpful assistant...") point to the same physical blocks. Copy-on-Write is triggered only when they diverge. This is the foundation of Prompt Caching.
SGLang views the KV Cache not as a linear array, but as a Radix Tree.
Nodes: KV Cache states.
Edges: Token sequences.
3.2.2 Automatic Reuse
Scenario: User asks A, gets B. User asks C. The system sees the path A->B and resumes calculation from there.
LRU Eviction: When memory fills, leaves are pruned first.
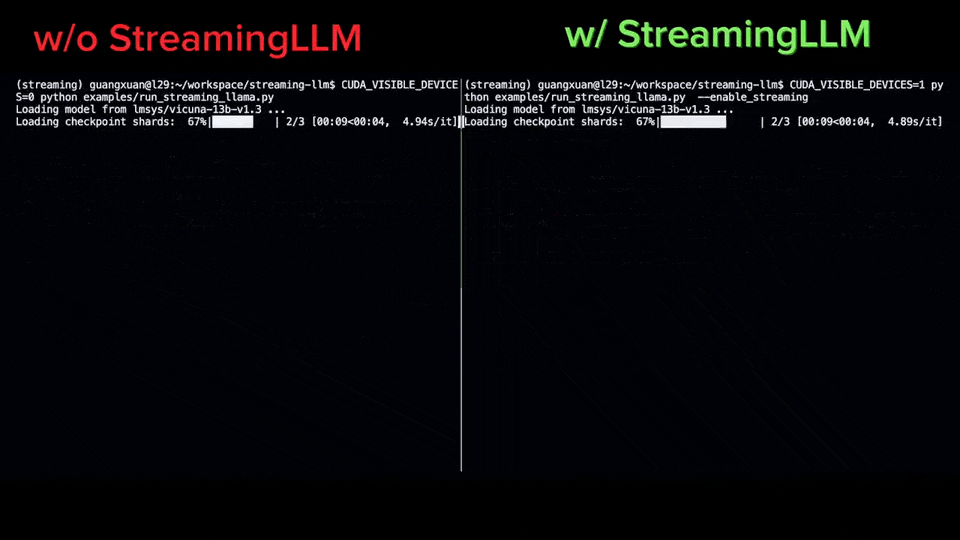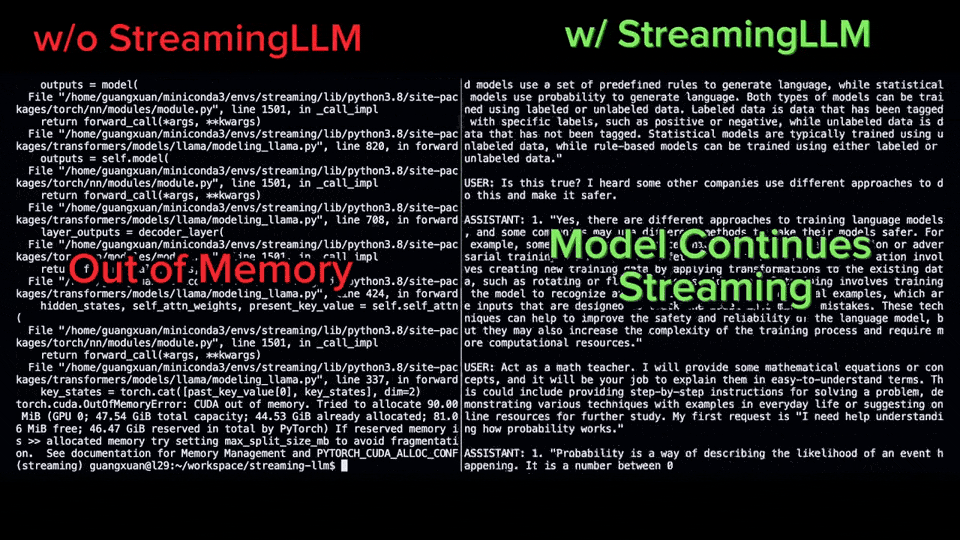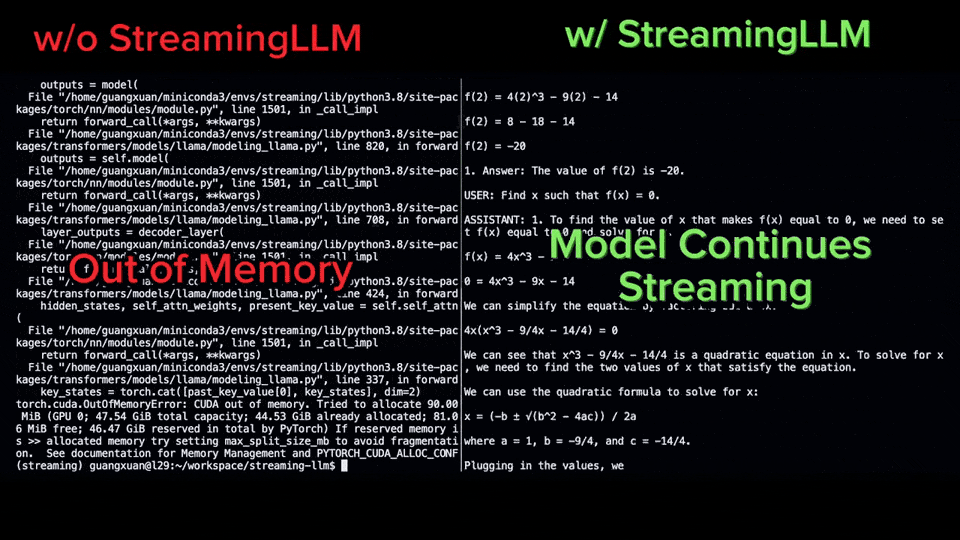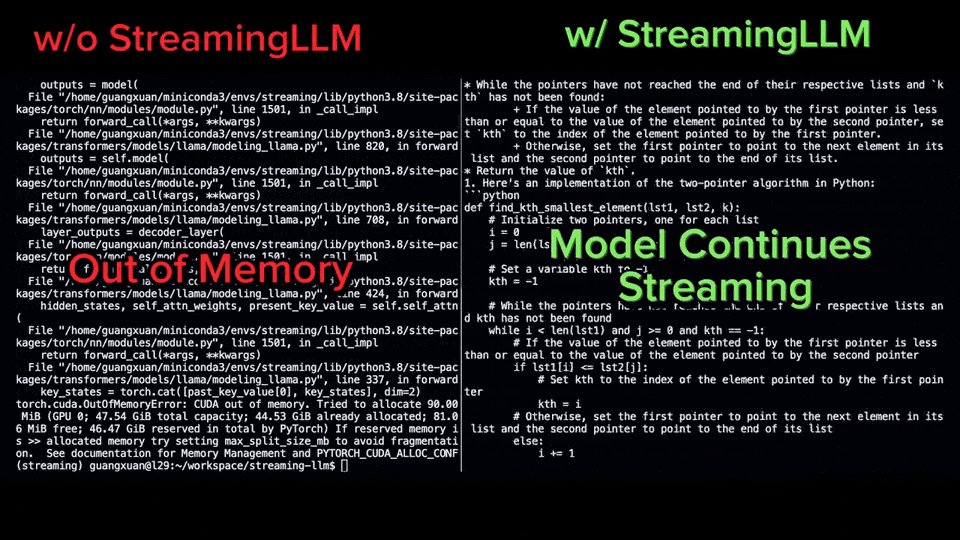
3.3 StreamingLLM
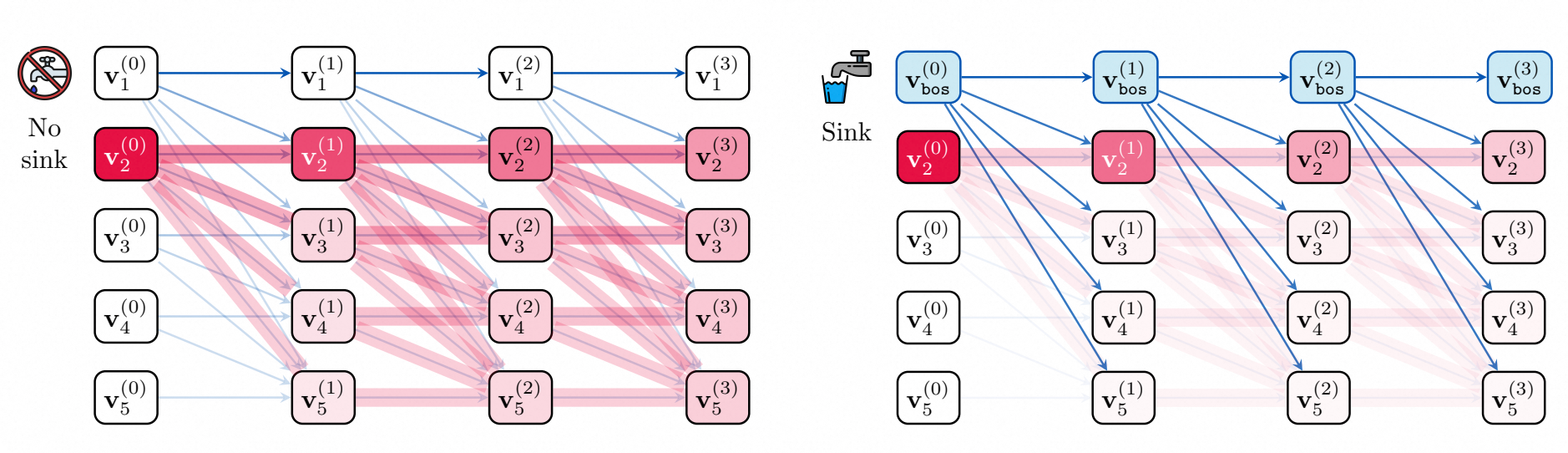
For infinite streams (e.g., digital humans), simple sliding windows break the model. MIT researchers discovered Attention Sinks: The first few tokens (usually 4) anchor the entire attention mechanism. StreamingLLM keeps these "sink tokens" permanently and slides the rest, allowing infinite length with stable perplexity.
4. Extreme Compression: Quantization
FP8: Supported by H100, halves memory usage with negligible loss.
INT4: Difficult due to "Outliers" in the Key/Value matrices. Techniques like SmoothQuant and KIVI migrate outliers to weights or keep them in high precision to make INT4 viable.
5. Market Landscape: The Battle of Caching
2025 marks the era of "Context Caching" as a standard product.
5.1 DeepSeek: The Price Butcher
Leveraging MLA, DeepSeek moves cache to Disk (SSD).
Price: $0.014 / million tokens (Hit). This is ~0.5% of OpenAI's price.
Storage: Free.
TTL: Hours to days. Ideal for long-tail knowledge retrieval.
5.2 Google Gemini: TPU Scale
Implicit: Automatic for Flash models.
Explicit: For Pro models. A "Lease" model—you pay a storage fee per hour. Only economical for high-frequency queries.
5.3 Anthropic Claude: High-Speed RAM Lease
Targeted at coding and high-interaction tasks.
TTL: 5 minutes.
Mechanism: Explicit breakpoints.
Economics: You pay a premium (1.25x) to write to cache. You must reuse it within 5 minutes to break even.
5.4 OpenAI & Alibaba
OpenAI: Conservative. 50% discount on hits. No write premium.
Alibaba (Qwen): Mixed mode. Strong support for long contexts (10M tokens).
Vendor
Mechanism
Storage Medium
TTL
Write Cost
Read Cost
Storage Fee
DeepSeek
Implicit
SSD/Disk
Long
1.0x
~0.05x
Free
Anthropic
Explicit
HBM
5 min
1.25x
0.10x
Included
Google
Hybrid
TPU HBM
1 hour+
1.0x
~0.25x
Hourly
OpenAI
Implicit
HBM
Dynamic
1.0x
0.50x
Free
6. Semantic Caching
Complementary to Prompt Caching (Server-side), Semantic Caching (Client-side) uses Embeddings (Vector DBs like Milvus) to match intent.
If a user asks "Price of apple?" and later "How much is an apple?", Semantic Cache returns the saved answer without hitting the LLM.
Tools: GPTCache.
7. Case Study: Prompt Cache in Agent Dev
Code Example
# Enabling Prompt Caching in Qwen
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages([
SystemMessage(
content=[
{
"type": "text",
"text": app_prompt_template.format(vars),
"cache_control": {"type": "ephemera"}, # The explicit flag
}
]
),
HumanMessage(content=app_user_prompt_template.format(input_data))
])
# Enabling Prompt Caching in OpenAI
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4o",
# openai 支持 24h 保存 cache
prompt_cache_retention: "24h"
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me a joke."},
]
)
Summary
The history of Large Model inference is, essentially, a history of struggling against memory bandwidth.
Architecture & Hardware: DeepSeek's MLA proves that algorithmic innovation (low-rank compression) can unlock hardware potential (SSD storage), completely upending the business model.
Stateful APIs: The HTTP stateless protocol is no longer sufficient. LLMs are becoming "Stateful Operating Systems," and developers must manage "Context Lifecycle" just as they manage database connections.
The Cost Cliff: With prices hitting $0.014/M tokens, the bottleneck for RAG shifts from "how to retrieve less to save money" to "how much context can the model handle without hallucinating." Full Context is replacing sliced retrieval.
For developers, the strategy is clear: Use Anthropic/vLLM for high-frequency, low-latency tasks (coding assistants), and leverage DeepSeek's disk caching for massive knowledge analysis where cost is the primary constraint.
AsymKV: Enabling 1-Bit Quantization of KV Cache with Layer-Wise Asymmetric Quantization Configurations - ACL Anthology, accessed November 27, 2025, https://aclanthology.org/2025.coling-main.158.pdf
FireQ: Fast INT4-FP8 Kernel and RoPE-aware Quantization for LLM Inference Acceleration, accessed November 27, 2025, https://arxiv.org/html/2505.20839v1
NQKV: A KV Cache Quantization Scheme Based on Normal Distribution Characteristics, accessed November 27, 2025, https://arxiv.org/html/2505.16210v1
zilliztech/GPTCache: Semantic cache for LLMs. Fully integrated with LangChain and llama_index. - GitHub, accessed November 27, 2025, https://github.com/zilliztech/GPTCache
AsymKV: Enabling 1-Bit Quantization of KV Cache with Layer-Wise Asymmetric Quantization Configurations - ACL Anthology, accessed November 27, 2025, https://aclanthology.org/2025.coling-main.158.pdf
FireQ: Fast INT4-FP8 Kernel and RoPE-aware Quantization for LLM Inference Acceleration, accessed November 27, 2025, https://arxiv.org/html/2505.20839v1
NQKV: A KV Cache Quantization Scheme Based on Normal Distribution Characteristics, accessed November 27, 2025, https://arxiv.org/html/2505.16210v1
zilliztech/GPTCache: Semantic cache for LLMs. Fully integrated with LangChain and llama_index. - GitHub, accessed November 27, 2025, https://github.com/zilliztech/GPTCache
A narrative has recently become common within the team: "Building an Agent is simple now. You can just piece it together with LangChain, BaiLian, or Flowise, and it runs."
At first glance, this statement is hard to refute—frameworks have indeed lowered the barrier to entry. But that "simplicity" is more of an illusion, a facade created after the complexity has been temporarily absorbed by the platform. From a technical standpoint, Agent development involves:
Orchestration and task planning;
Context and Memory management;
Domain knowledge fusion (RAG);
And the "agentification" of business logic.
These steps are not accomplished just by writing a few prompts. When developers feel it's "simple," it's because the complexity has been absorbed by the platform. The difficulty of Agents lies not in getting a demo to run, but in making it operate reliably, controllably, and sustainably over the long term.
Why Is Agent Development Mistakenly Seen as "Simple"?
On the surface, we are in an era of explosive AI growth, with platforms and tools emerging endlessly. It's true that by writing a few prompts and connecting a few chains, a "functional" Agent can be born. But this doesn't mean the complexity has vanished. Instead, the complexity has been relocated.
I break this "simplicity" down into three illusions:
1. Encapsulated Complexity
Frameworks help you string prompts and trim context, shielding developers from the details. But the underlying mechanics—debugging, tracing, and state recovery—are still burdens you must bear alone.
Take LangChain as an example. A "question-answering" Agent can be created with just a few lines of code:
from langchain.agents import initialize_agent, load_tools
from langchain.llms import OpenAI
llm = OpenAI(temperature=0)
tools = load_tools(["serpapi", "llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent_type="zero-shot-react-description")
agent.run("What is the current weather in Singapore, and convert it to Celsius?")
This code hides almost all complexity:
Prompt assembly, call chains, and context management are encapsulated internally.
But if the task fails (e.g., API rate limiting, tool failure), the Agent defaults to neither retrying nor logging a trace.
What looks like a "simple run" actually means sacrificing the interfaces for observability and debugging.
2. Outsourced Complexity
Memory, RAG, and Embeddings are all handed over to the platform for custody. The price is the loss of the ability to intervene and explain.
In LangChain, you can quickly add "memory":
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(memory_key="chat_history")
But this is just a short-term memory buffer. It doesn't handle:
Conflicts with old information;
State drift over multiple turns;
Or context truncation issues due to excessive length.
As the Agent scales, memory consistency and state cleanup become new sources of system complexity.
3. Postponed Complexity
It doesn't disappear; it just reappears during the execution phase:
Output drift
Inability to reproduce results
Collapse of correctness and stability
Being able to run does not equal being able to run correctly over the long term. What we call simplicity is often just us temporarily avoiding the confrontation with complexity.
The Three Layers of Agent System Complexity
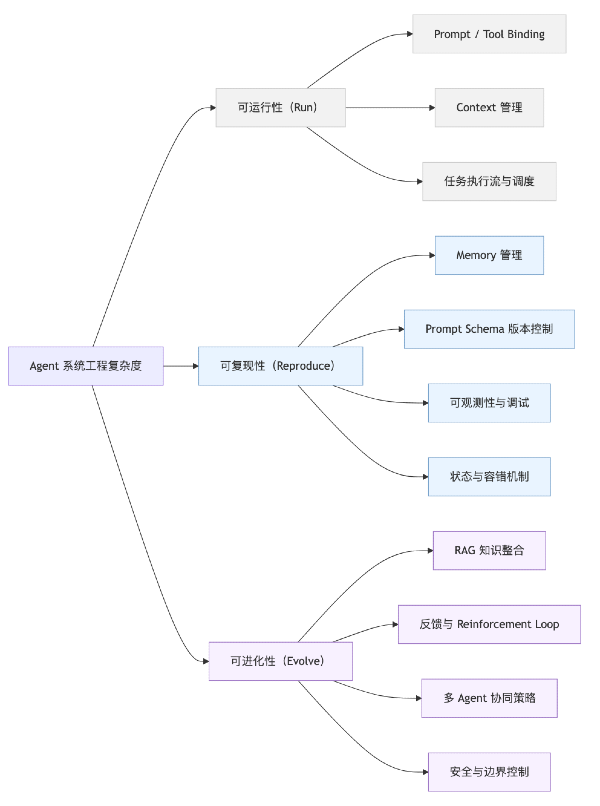
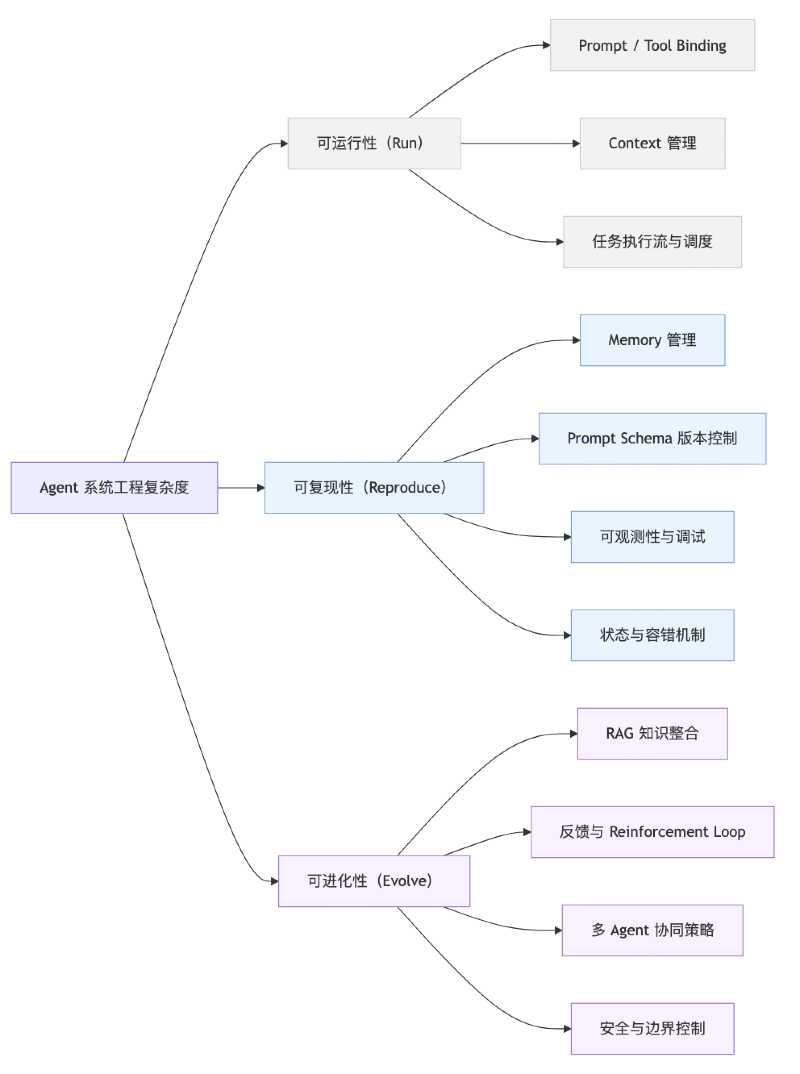
1. Agent Complexity
The complexity of an Agent system manifests in its ability to be run, reproduced, and evolved. Most current Agent frameworks have solved "runnability," but "reproducibility" and "evolvability" remain significant system engineering challenges.
Level
Core Objective
Engineering Keywords
LangChain Example Explanation
Runnability (Run)
Enable the Agent to start and execute tasks
prompt, context, tool calls, execution flow
Rapidly assembling an executable chain via initialize_agent
Reproducibility (Reproduce)
Make behavior controllable and debuggable
memory, state, logs, versioning
No built-in version tracking; Memory state drift requires manual management
Supports vector retrieval, but lacks self-assessment and reinforcement learning mechanisms
At the "Runnability" level, the abstractions designed by frameworks like LangChain are indeed efficient. But to make an Agent's behavior stable, explainable, and continuously optimizable, additional infrastructure—such as logging systems, prompt version management, and feedback loops—is still required.
From a system engineering perspective, the difficulty of an Agent lies not in "generation" but in "execution." All platforms will eventually expose their costs along these two lifecycles.
In the implementation phase, stability is often more critical than correctness. Only when stability exists can correctness even be verified and optimized.
Intelligence's uncertainty must be underpinned by engineering's certainty. Stability and observability are the prerequisites for an Agent to be truly evolvable.
2. The Agent Amplification Effect
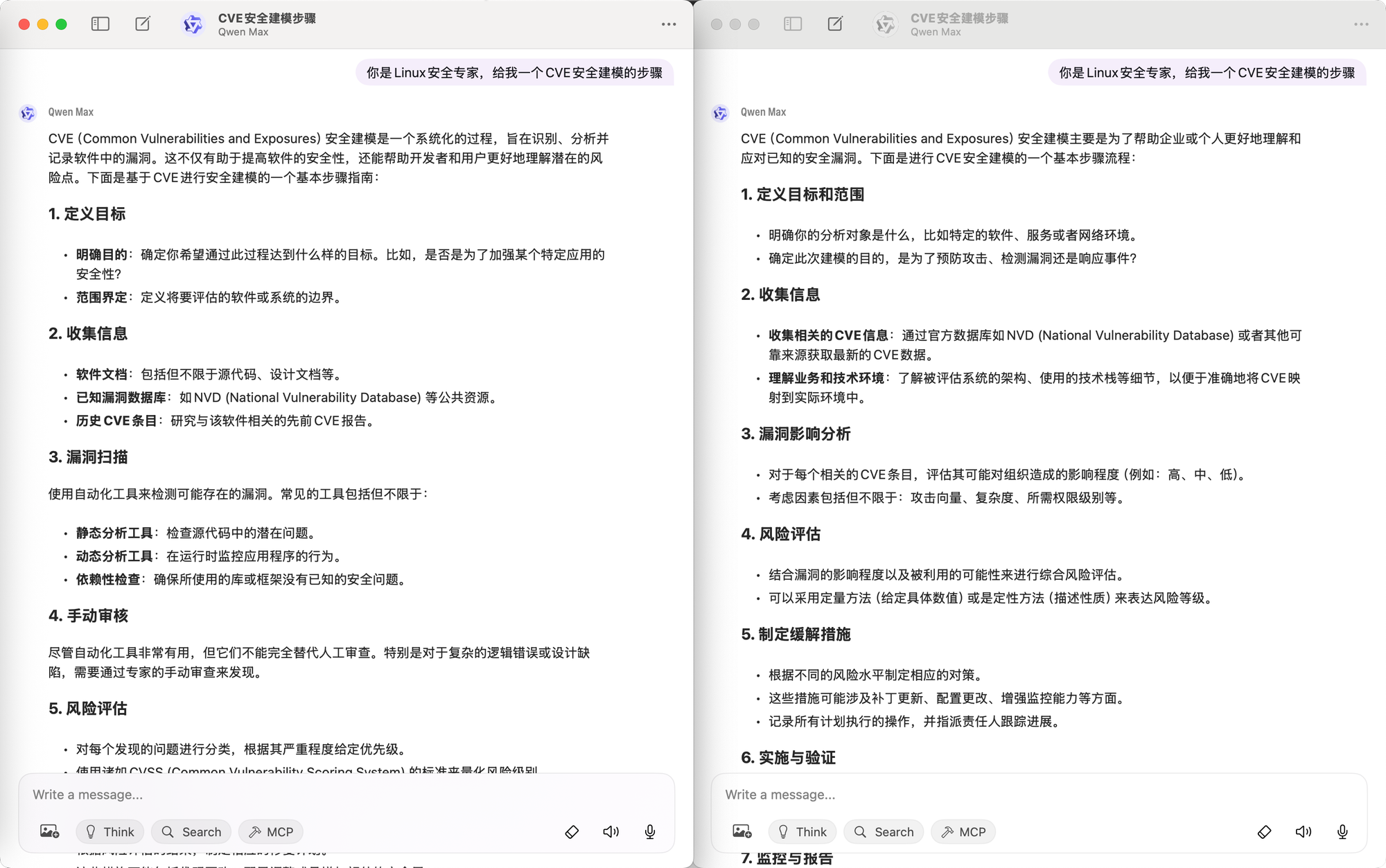
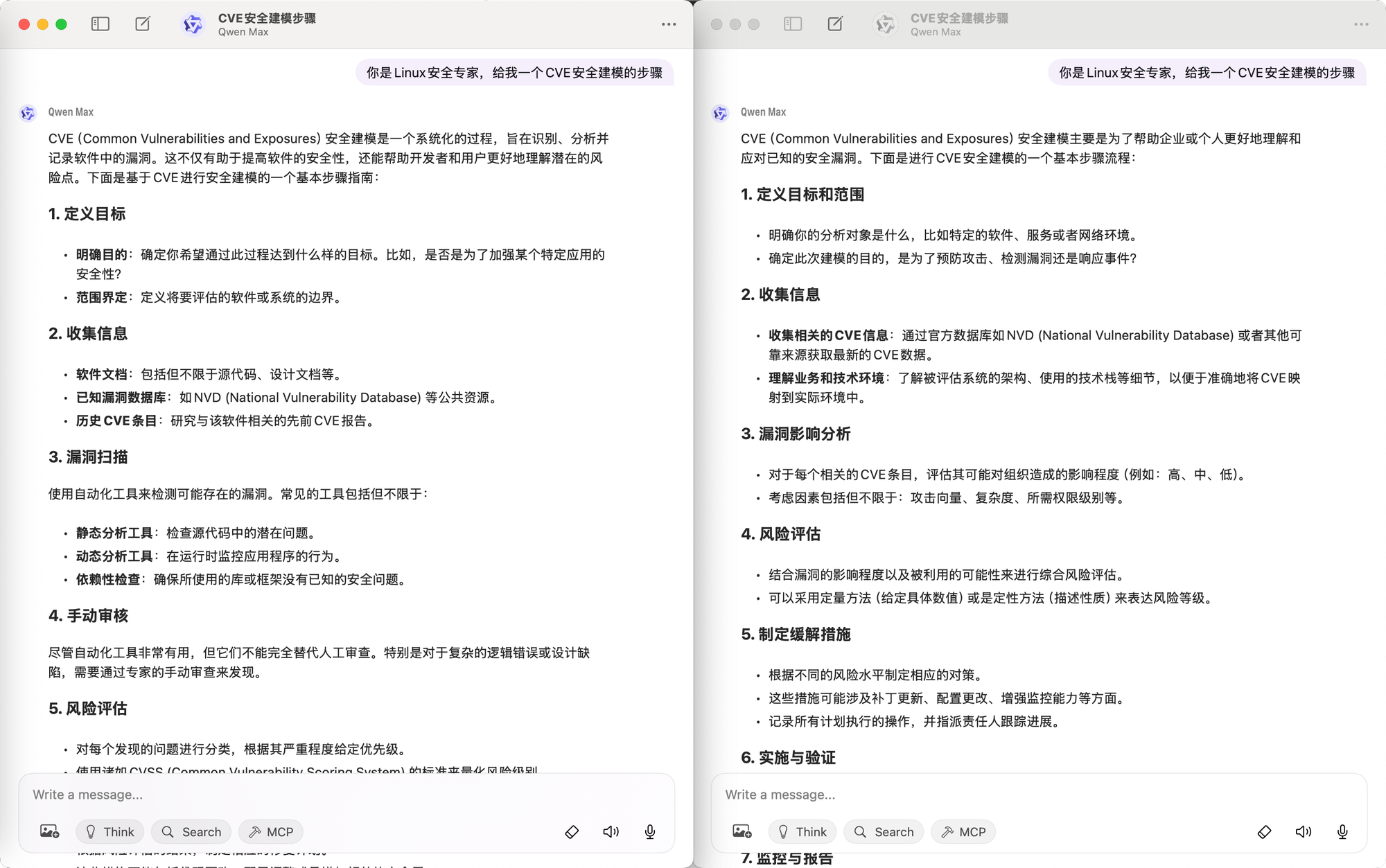
As shown in the image above, the same model (qwen-max), the same time, and the same prompt produce different results. This is the amplification effect that LLM uncertainty brings to Agents. Compared to the traditional software systems developers are most familiar with, the complexity and difficulty of Agents stem from this uncertainty, amplified at each semantic level by the LLM.
If a single LLM interaction has a 90% correctness rate, an Agent system requiring 10 LLM interactions will have its correctness drop to just 35%. If it requires 20 interactions, the correctness plummets to 12%.
Memory's Uncertainty Amplification
Traditional software state management is deterministic (e.g., what's in the database is what's in the database). An Agent's memory, however, relies on LLM parsing, embedding, and retrieval. The results are highly uncertain. Therefore, memory is not a storage/retrieval problem, but a semantic consistency problem. This is unique to Agents.
Orchestration's Dynamic Amplification
In traditional systems, orchestration (workflow) is a fixed, predefined process. In an Agent, the orchestration—which tool to call next, and how—is often dynamically decided by the LLM. This means the orchestration problem isn't just about "sequence/concurrency"; it's about an explosion of the decision space, making testing, monitoring, and optimization far more complex.
Testability's Unpredictability Amplification
Traditional software is predictable: given input → expected output. An Agent's output is a probability distribution (a stream of tokens from the LLM); there is no strict determinism. Therefore, testing cannot rely solely on unit tests. It must incorporate replay testing, baseline comparison testing, and simulation environment testing, which is far beyond the difficulty of standard application testing.
3. From "Runnable" to "Usable"
The "'It Runs, Doesn't It?' Fallacy"
Some might say, "I can get the Agent to work just by modifying the prompts. Am I amplifying the problem myself, rather than the Agent?"
"Getting it to run by tweaking prompts" essentially means: Short-term goal + High tolerance = Good enough. The goal of an Agent system, however, is: Long-term goal + Engineering-grade reliability = Drastic increase in difficulty.
Let's first look at why tweaking prompts seems to work. Many Agent Demos or POCs (Proofs of Concept) aim for one-off tasks, like "write a summary for me" or "call this API." In these low-requirement scenarios, the raw power of the LLM masks many underlying issues:
Memory can be passed purely through context (long-term persistence is never really tested).
Orchestration can be hard-coded or hinted at in the prompt.
Testability is irrelevant; if it gets the right answer once, it's a win.
The problem is that when the requirement shifts from a "Demo" to a "Sustainably Usable System," these issues are rapidly amplified:
Prompt Modification ≠ Reliability Guarantee. Changing a prompt might fix the immediate bug, but it doesn't guarantee the same class of problem won't reappear in another case. You haven't established reproducible, maintainable decision logic; you've just engaged in "black-box tweaking."
Prompt Modification ≠ Scalability. Prompt hacking works for a single-task Agent. But in a multi-tool, multi-scenario Agent, the prompt's complexity grows exponentially and eventually becomes uncontrollable.
Prompt Modification ≠ Engineering Controllability. Traditional software can be covered by test cases to ensure logical coverage. Prompts can only partially mitigate the LLM's probabilistic fluctuations; they cannot provide strong guarantees.
This is why, ultimately, we need more structured methods for memory, orchestration, and testing—which is to say, Agent systematization.
Limitations of Agent Frameworks
Let's use the LangChain framework as an example to see if frameworks can solve the three layers of Agent complexity. LangChain provides a basic CallbackManager and LangSmith integration for tracing an Agent's execution. This functionality is often overlooked, but it is key to understanding "reproducibility" and "observability."
When executed, LangChain will output every Thought and Action to the console:
Thought: I need to use the calculator tool.
Action: Calculator
Action Input: (15 + 9) * 2
Observation: 48
Thought: I now know the final answer.
Final Answer: 48
This seemingly simple output reveals three important facts:
The Agent's internal decision process is traceable (this is the prerequisite for reproducibility).
The CallbackManager must be actively enabled by the engineer (it doesn't log by default).
The granularity of observation is limited (it cannot directly trace context trimming, memory overwrites, etc.).
LangSmith provides a more complete visual trace, but it remains an external observation tool. The Agent framework itself still lacks built-in verification mechanisms. In other words, the framework gives you the ability to "see," but it doesn't solve the problem of "control" for you.
Although frameworks like LangChain are making interesting attempts to solve the complex problems in Agent systems, we must admit that most engineering dimensions remain unresolved. (In short, frameworks solve the problem of "using an LLM to do things," but not the problem of "making the LLM do things in a way that is controllable, sustainable, and scalable like a system"):
Persistence, elastic scaling, version management, A/B testing mechanisms
Framework
Runnability
Reproducibility
Evolvability
Notes
LangChain
✅ Mature chain calls
⚙️ Partially observable
⚙️ Manual tuning
Many tools, but state is unstable
AutoGen
✅ Multi-Agent collaboration
⚙️ Rudimentary memory
❌ Lacks learning mechanism
Flexible but hard to reproduce
CrewAI
✅ Easy task orchestration
⚙️ State instability
❌ No feedback optimization
Strong interaction, weak control
AliCloud BaiLian
✅ Drag-and-drop building
⚙️ Platform logs
⚙️ Built-in knowledge center
Platform absorbs complexity, but is a major black box with limited control
✅ Runnability: Generally well-supported (low barrier to entry)
⚙️ Reproducibility: Only partially supported (requires self-built state and observation layers)
❌ Evolvability: Still relies on manual effort and system design
LangChain makes Agents "buildable," but it makes the system lose its "explainability." Complexity didn't disappear; it just migrated from the code layer to the runtime.
Let's delve deeper into runtime complexity. The new problem Agent systems bring is that they don't just "run"; they must "continuously think," and the side effect of thinking is instability. This is not "traditional code complexity" but "system uncertainty introduced by intelligent behavior." It makes Agent engineering feel more like managing a complex adaptive system than a linear, controllable piece of software.
New Dimension of Complexity
Description
Example Scenario
Context Drift
The model misunderstands or forgets key task objectives during multi-turn reasoning
An Agent deviates from the task's semantics during a long conversation, executing irrelevant actions
Semantic Non-determinism
The same input may produce different outputs, making processes non-replayable
Prompt debugging results are unstable; automated testing is hard to cover
Task Decomposition & Planning
The quality of plans generated by the LLM is unstable; task boundaries are vague
In AutoGen's "plan+execute" model, sub-tasks overflow or loop
Memory Pollution
Long-term stored context introduces noise or conflicting information
The Agent "learns" incorrect knowledge, causing future execution deviations
Control Ambiguity
The boundary between the Agent's execution and the human/system control layer is unclear
Manual instructions are overridden, tasks are repeated, resources are abused
Self-Adaptation Drift
The Agent learns incorrect patterns or behaviors based on feedback
Reinforcing a hallucinatory response during an RLHF/reflection loop
Multi-Agent Coordination
Communication, role assignment, and conflict resolution between Agents
Task duplication or conflicts in multi-role systems like CrewAI
The Only Solution for Agents is Systematization
Prompt Hacking fails when the problem scales. For a single, simple scenario, tweaking a prompt works. But as task complexity and the number of scenarios increase, the prompt becomes bloated and uncontrollable (e.g., one prompt stuffed with dozens of rules). It's like concatenating strings to build SQL queries: it runs at first, but inevitably leads to injection vulnerabilities and a maintenance disaster. Systematization helps by providing structured constraints and automated orchestration, rather than manual prompt tuning.
Uncertainty demands controllability. Getting it right once is a win for a demo. But in a production environment, you need 99% correctness (or 100%). Even a 1% hallucination rate will accumulate into a disaster. For example, a log analysis Agent that misses or false-reports an issue just once could lead to an undiscovered online incident. Systematization ensures controllability through testing, monitoring, and replay verification, rather than gambling on luck every time.
Knowledge persistence vs. repeating mistakes. Today, an Agent's bug is fixed by changing a prompt. Tomorrow, a new requirement comes in, and the exploration starts all over again. Knowledge isn't retained. The Agent can't remember or reuse past solutions, leading to constant redundant labor. A colleague complained that in one business system, prompt modification commits made up over a third of all code commits. Yet, when another colleague tried to reuse that prompt for a similar problem, it was completely non-transferable and had to be hacked again from scratch. Systematization, through Memory + Knowledge Bases, ensures an Agent can learn and accumulate knowledge, not reinvent the wheel every time.
Prompt Hacking / Demo Agents solve "small problems." Only Systematized Agents can solve the problems of "scalability, reliability, and persistence." These issues might not be obvious now, but they will inevitably explode as usage time and scope expand.
A Demo Agent can solve today's problem. A Systematized Agent can solve tomorrow's and the day after's.
Dimension
Demo Agent (Can run)
Systematized Agent (Can run sustainably)
Goal
Single task / POC success
Continuous, repeatable, multi-dependent business processes
Modular components / model routing / tool governance
Cost Curve
Fast/cheap initially; maintenance costs skyrocket later
Upfront engineering investment; stable and scalable long-term
From "Smart" to "Reliable"
Some Real-World Agent Cases
Looking at history, we can understand rise and fall. Looking at others, we can understand our own successes and failures. The problems I've encountered in Agent system development are surely not mine alone. I asked ChatGPT to search Reddit, GitHub, and blogs for Agent development cases, hoping to use others' experiences to validate my own thinking and reflections:
1. Typical Failures of Toy-Level Agents
Auto-GPT community feedback: looping, getting stuck, unable to complete tasks (the classic early example of "runnable but not reliable"). Auto-GPT seems nearly unusable
Developer questioning if agents can go to production, noting severe step-skipping/hallucinations in multi-step tasks (system prompt + function calling isn't enough). Seriously, can LLM agents REALLY work in production?
OpenAI Realtime Agents official example repo issue: Even the "simple demo" has too many hallucinations to be usable non-demo contexts. Lots of hallucinations?
2. Engineering Problems Exposed After Production (Not solvable by prompt changes)
3. Industry/Big-Tech Postmortems: Why "Systematization" is Needed
Anthropic: Effective agents come from "composable simple patterns + engineering practices," not from piling on frameworks (summarized from many client projects). Building Effective AI Agents
OpenAI: Released Agents SDK + built-in observability, stating clearly "it's hard to turn capabilities into production-grade agents" and requires visualization/tracing/orchestration tools. New tools for building agents
LangChain Team: Why build LangGraph/Platform—for control, durability, long-running/bursty traffic, checkpoints, retries, and memory. Claims it's used in production by LinkedIn/Uber/Klarna (vendor claims, but highlights the "systematization elements"). Building LangGraph: Designing an Agent Runtime from first principles
4. Positive Case: Treating it with a "Distributed Systems Mindset"
5. Community Reality: People are using it in production, but focus on "de-complexing + limited agents"
Developer feedback on LangGraph being production-viable: Migrated from LangChain's Agent Executor; the prototype→streamline→retain-necessities path is more robust (de-hallucinate/de-fancy, retain control). Anyone Using Langchai Agents in production?
The Four Stages of Agent Development
Over more than a year of Agent development, I've gone through a cognitive shift from "Agents are simple" to "Agents are truly complex." At first, I treated frameworks as black boxes, writing prompts and piecing things together to run a demo. As the complexity of the scenarios increased and I needed to go deeper into Agent system R&D, the difficulties gradually revealed themselves. I've tried to break down this "simple → truly hard" process:
Stage 1: The "Hello World" Stage (Looks simple)
Using frameworks like LangChain / AutoGen / CrewAI, you can get something running in a few lines of code. Most people stop at "it can chat" or "it can call tools," so they feel "Agent development is just this."
Stage 2: The Scene Adaptation Stage (Starting to hit pitfalls)
As the complexity of the problems the Agent solves increases, you slowly run into the LLM context window limit, requiring trimming, compression, or selection (i.e., Context Management problems). You find that vector retrieval results are often irrelevant, leading to non-answers, requiring optimization of preprocessing and query rewriting (RAG Knowledge Management). It runs in simple scenes, but falls into traps in slightly more complex ones.
Stage 3: The Systematization Stage (Complexity explodes)
Going further, as tool calls and context management increase, the Agent must ensure consistency across sessions and tasks. You must consider persistence, version control, and conflict resolution. A single Agent can't adapt to complex tasks; you need multi-Agent collaboration. At this point, you must solve deadlock, task conflicts, and state rollbacks. When task complexity rises, debugging the Agent flow can't be solved by tweaking prompts; you must add tracing and observability tools.
Stage 4: The Engineering Landing Stage (The real hard part)
Agentifying Business Logic: How to test it? How to guarantee controllability and stability?
Security & Compliance: Permissions, privilege escalation, data leakage. Strict security boundaries are a must.
Monitoring & SLOs: Like operating microservices, you need monitoring, alerting, and failure recovery.
In summary, frameworks like LangChain lowered the "barrier to entry" for Agents, but they did not lower the "barrier to implementation."
My Cognitive Evolution in Agent Development
I have been developing an Agent system focused on vulnerability and security assessment in my own work. As I experienced the four stages of Agent development mentioned above, my thinking and understanding of Agents also changed:
Level 0: The Framework Illusion Layer
Typical Behavior: Install LangChain / AutoGen / CrewAI, run an official demo, modify a prompt.
Cognitive Trait: Believes "Agent Development = Writing Prompts." The barrier to entry is extremely low, similar to writing a script.
Misconception: Thinks the framework solves all complexity, ignoring memory, orchestration, testing, and security.
Level 1: The Scene Splicing Layer
Typical Behavior: Can stitch together RAG, tool calls, and simple multi-agent orchestration to build a seemingly viable prototype.
Cognitive Trait: Begins to realize the importance of context management and RAG strategies.
Pain Points: Encounters "irrelevant answers," "memory corruption," and "tasks failing to complete reliably."
Misconception: Tries to use prompt hacking to solve all problems, ignoring underlying information management and system design.
Level 2: The System Design Layer
Typical Behavior: Treats the Agent as a microservices system, needing to consider architecture, observability, and state management.
Cognitive Trait: Understands that memory is essentially a database/knowledge-base problem, and orchestration is more like workflow scheduling than a chat.
Pain Points: Debugging costs are extremely high; requires tracing, logging, and metrics monitoring.
Key Challenge: How to ensure the Agent is robust, controllable, and reproducible.
Level 3: The Engineering Landing Layer
Typical Behavior: Deploys the Agent into a production business environment.
Cognitive Trait: Treats Agent development as an engineering discipline, just like SRE / Security / Distributed Systems.
Pain Points:
Testability: The non-determinism of LLMs makes it impossible to guarantee stability with traditional unit tests.
Monitoring & SLOs: The Agent must be observable and recoverable, just like a service.
Key Challenge: How to make the Agent reliable enough to carry critical business functions.
Level 4: The Intelligent Evolution Layer (Frontier Exploration)
Typical Behavior: Attempting to build an Agent system with long-term memory, autonomous learning, and evolvability.
Cognitive Trait: No longer sees the Agent as an LLM wrapper, but as a new type of distributed intelligent system.
Challenges:
Memory becomes a knowledge graph + adaptive learning problem.
Orchestration involves game theory, collaboration, and even emergent behavior.
Security requires "AI sandboxes" to prevent loss of control.
Status: Most are not at this stage; it is primarily research and experimentation.
Based on my current understanding of Agents, I now position them as system components rather than intelligent robots. My goal is not "occasional brilliance" but "sustained reliability."
Basic Principles:
Principles:
Stable first, smart second.
Observable first, optimized second.
Functionality:
Establish a replayable mechanism for state and logs.
Implement version tracking for Prompts / Memory / RAG.
Clearly define the boundaries and permission scope for each Agent.
Designate "error recovery" pathways in the architecture.
Boundaries:
If the Agent is only for one-off tasks or exploratory experiments, complexity control can be relaxed.
If used for production tasks (monitoring, automated operations), stability and security boundaries take precedence.
The deeper the framework's encapsulation, the more an external explainability layer is needed.
The Path to Agent Intelligence
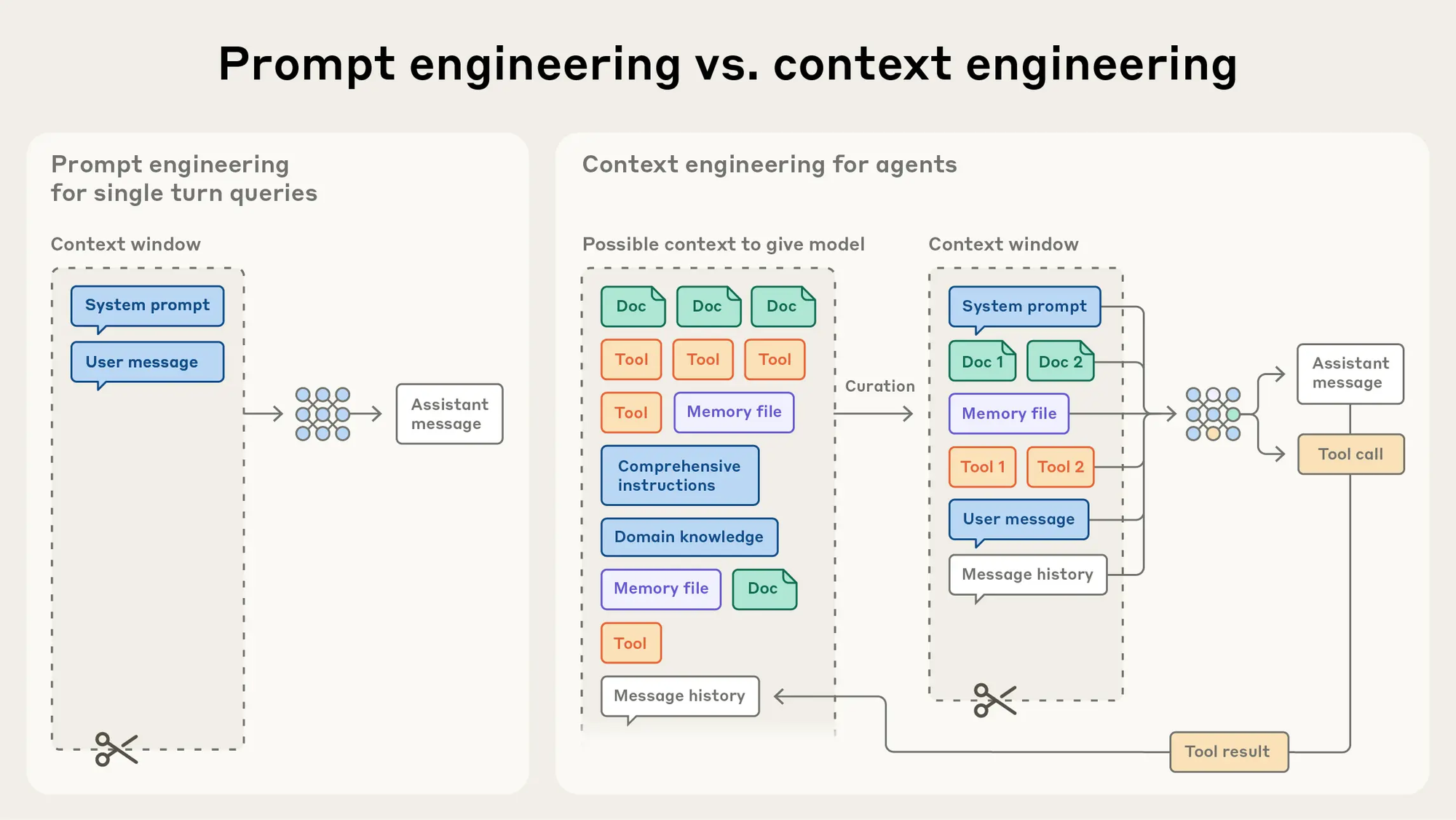
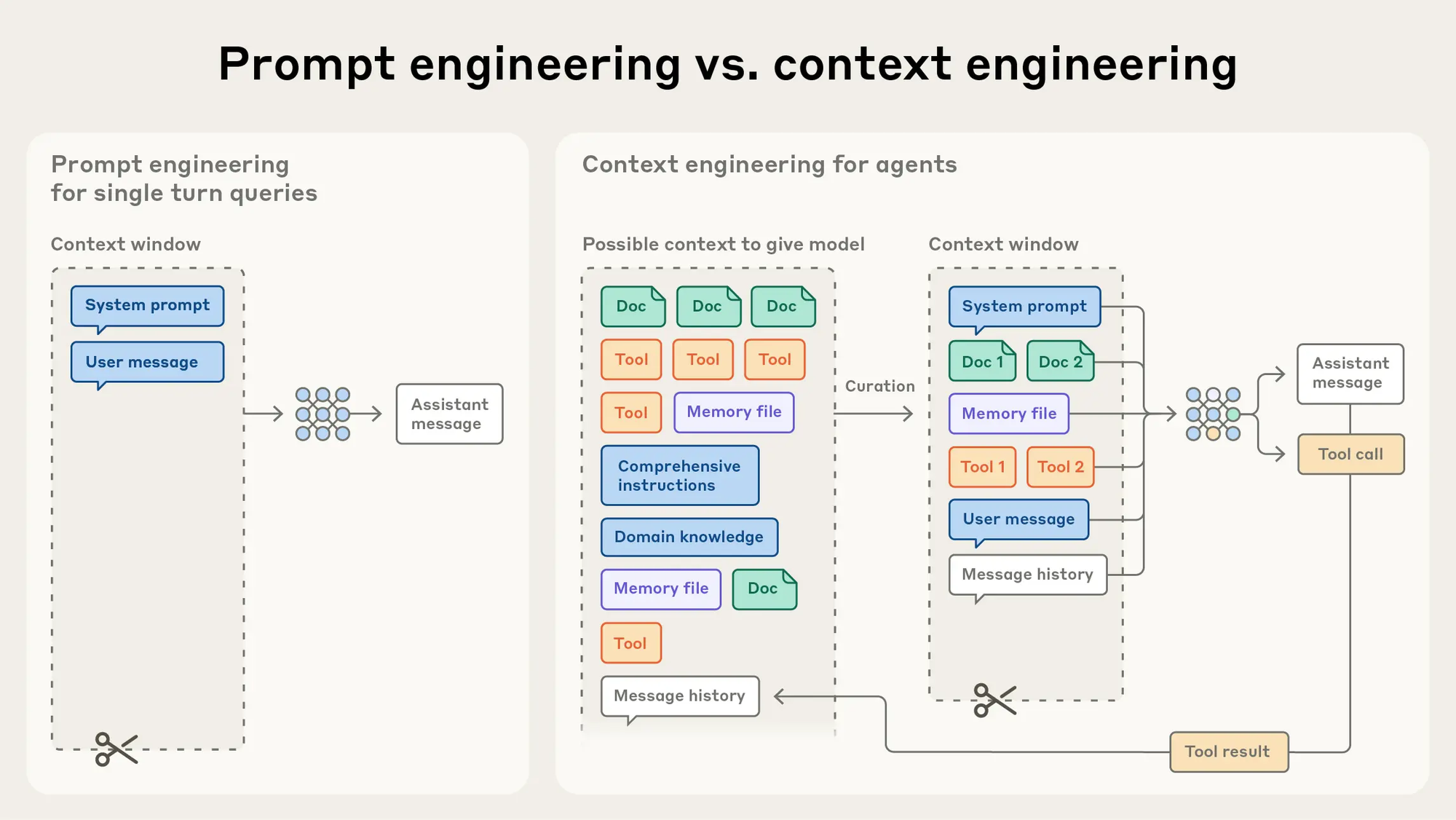
Someone said 2025 might be the "Year of the Agent." After nearly a year of technical iteration, Agents have also seen considerable development from an engineering perspective. LangChain has essentially become the preferred backend option for Agent systems, and Agent R&D has evolved from prompt engineering → context engineering (as shown in the figure below).
1. Agent Development Philosophy
Agents are not a panacea. The key is to choose the appropriate automation stage for tasks of different complexities. I believe we can see from the five evolutionary stages of Agents:
Complex ≠ Better
Don't blindly chase the "strongest Agent architecture"; suitability is key.
Using a complex system for a simple task only increases cost and risk.
The Real Challenge is "Human"
Many failed cases stem from the designer choosing the wrong architecture or lacking phased thinking.
The model and workflow are not the problem; the human is.
The Importance of Design Thinking
First, assess the task's complexity and automation potential.
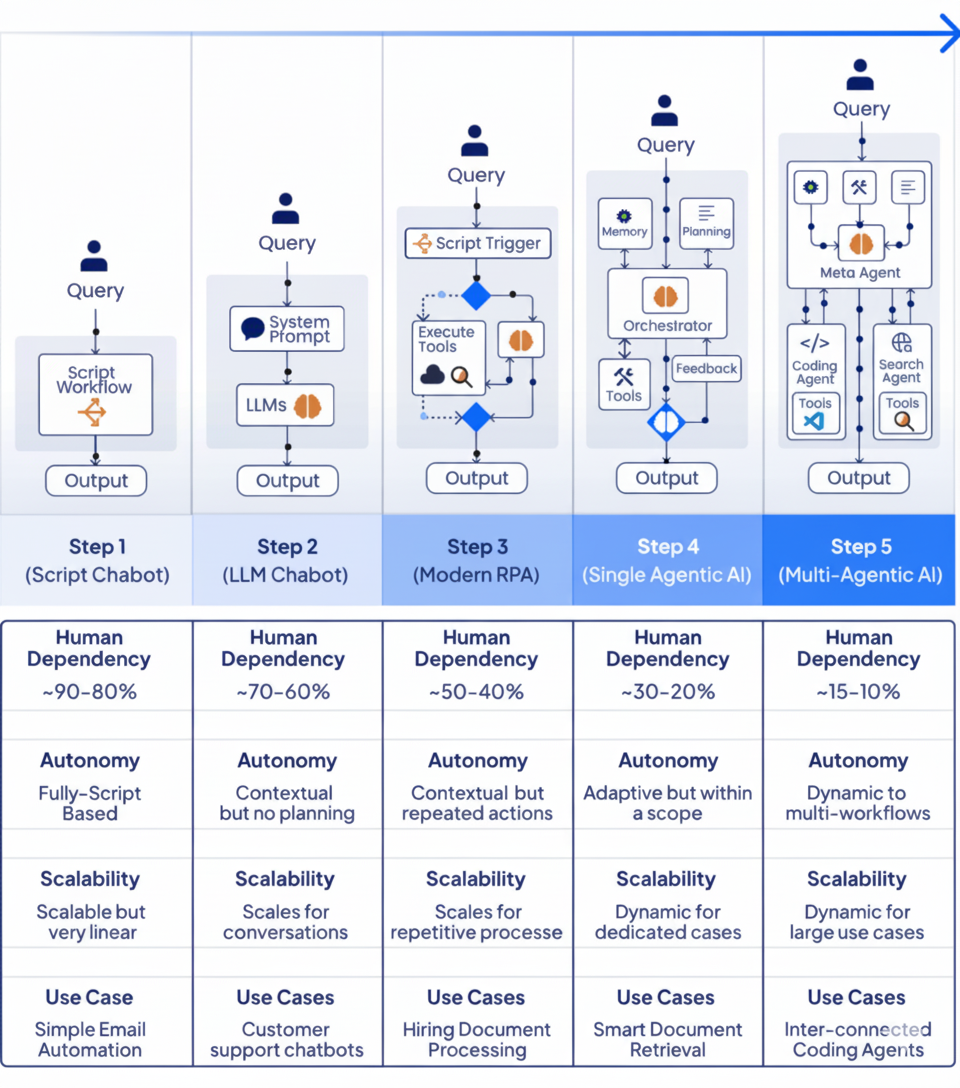
Then, decide the required level of intelligence (Script → LLM → RPA → Agent → Multi-Agent).
Finally, match the appropriate tool, don't use a "one-size-fits-all" approach.
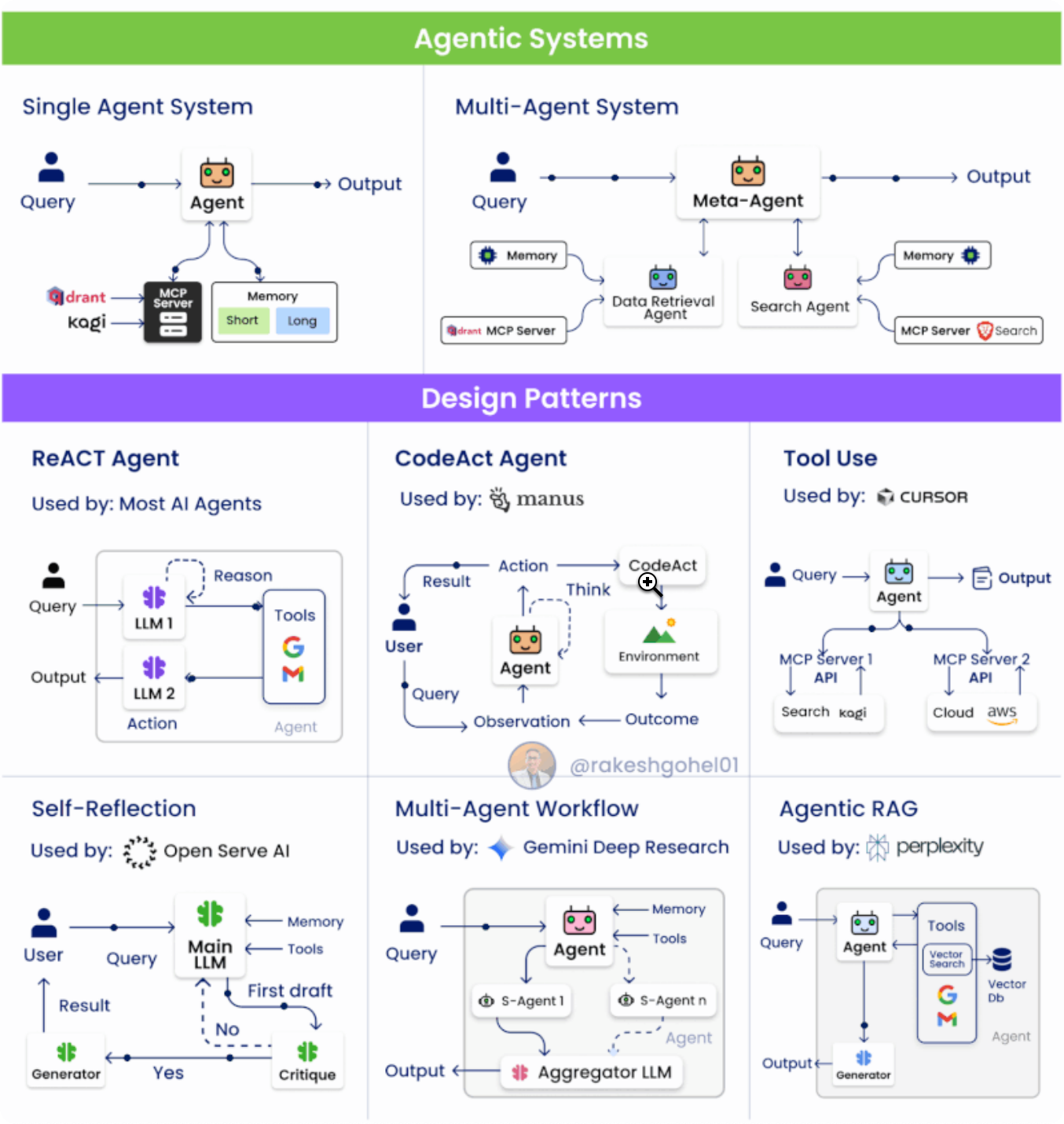
2. Agent Design Patterns
1️⃣ ReAct Pattern (Reasoning + Acting)
Structure: Divided into Reasoning and Acting phases.
Mechanism:
LLM1: Understands context, plans which tool/API to call.
LLM2: Executes the action, returns the result.
Pros: Decouples reasoning and action, clear structure.
Below are some takeaways from Agent development. Those interested can look up how various Agent players are planning their strategies.
Perhaps future frameworks will absorb even more of this complexity. But the role of the engineer will not disappear. What we must do is to re-establish order in the places where complexity has been hidden—to make intelligence not just callable, but tamable.
生成式大模型的核心运作机制是基于统计概率预测下一个最可能出现的词或短语,而非真正的理解。这个过程天然地导向一种“向平均值回归”(regression to the mean)的趋势。因为模型旨在生成最“安全”、最“普遍”的输出,所以它会频繁地使用那些在训练语料库中统计上最常见的通用短语和陈词滥调 。它擅长的是复制,而非真正的原创 。
Andrej Karpathy关于软件3.0的讨论中提到它不仅仅是一个技术更新,更是一场深刻的范式革命。
编程的民主化与角色的转变
社区普遍认为,Software 3.0最大的意义在于“编程民主化”。由于编程语言变成了自然语言,非程序员也能参与到软件创建中,极大地拓宽了创新的来源。X平台(原Twitter)上的讨论热烈,用户强调“English is coding”(英语即编程)的理念。对于程序员而言,工作重心从手写代码转向了设计高效的提示(Prompt Engineering)、验证和审计AI生成的代码以及管理整个AI系统。
LLM作为新的“操作系统”
Andrej Karpathy将LLMs比作1960年代的早期计算机或是一种新型的操作系统。这一观点在社区中获得了广泛认同。LLMs成为了一个可编程、可组合的基础平台,开发者可以围绕它来构建各种应用,而不是一切从零开始。