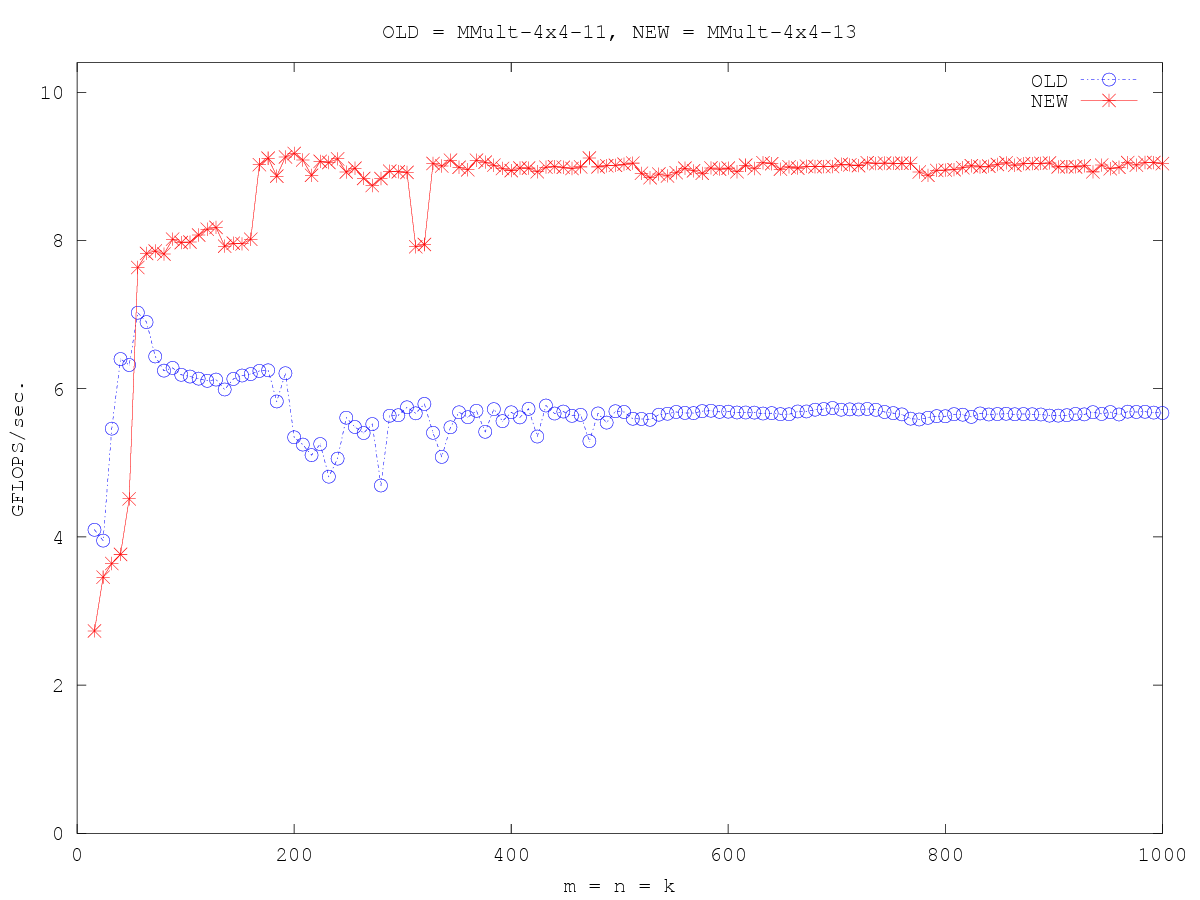
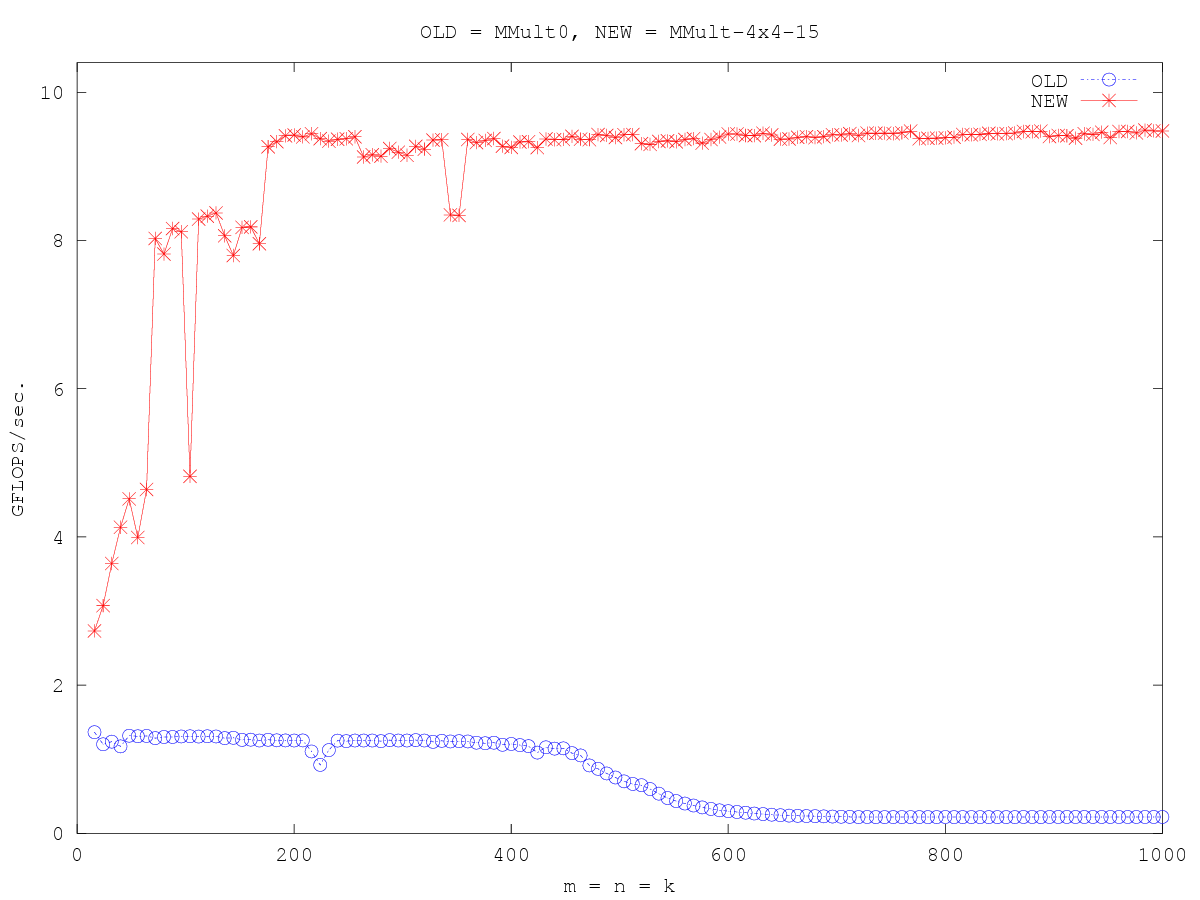
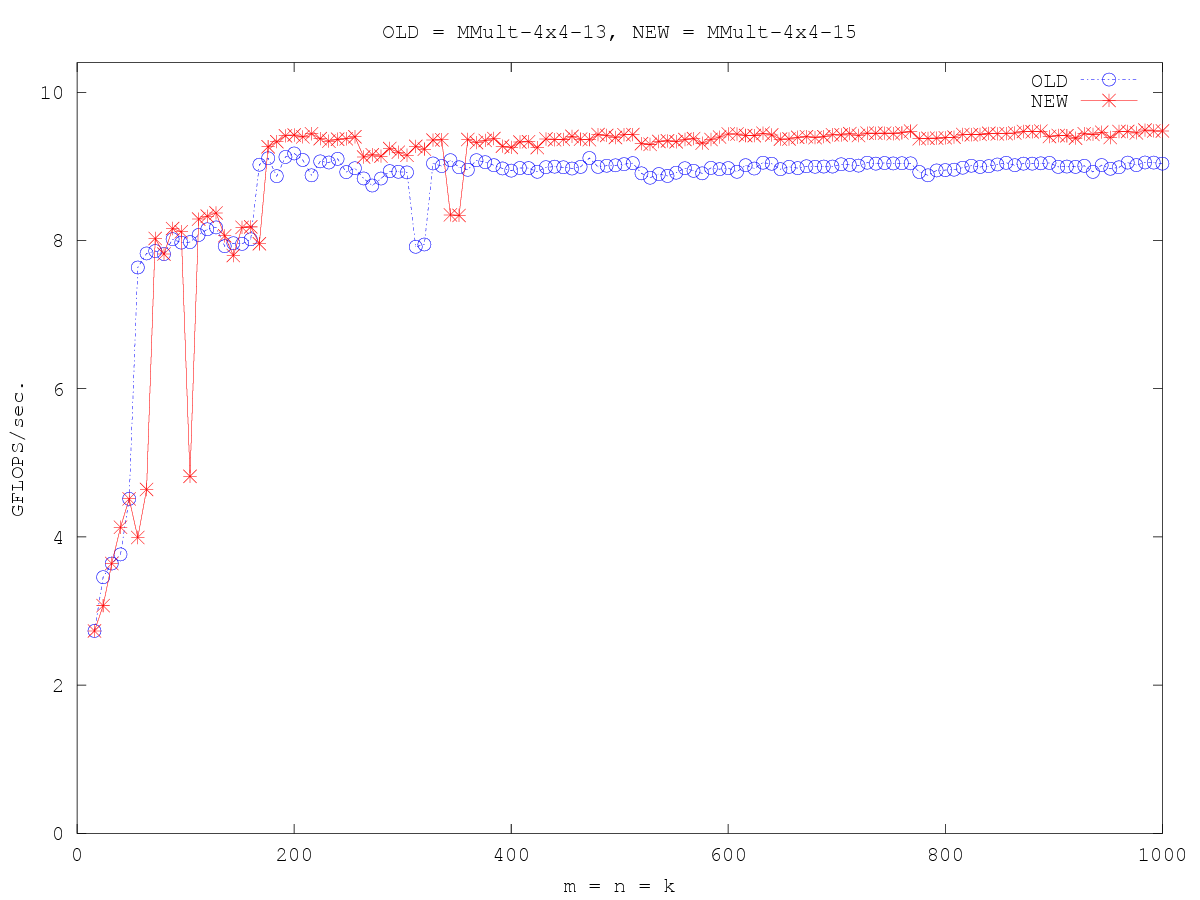
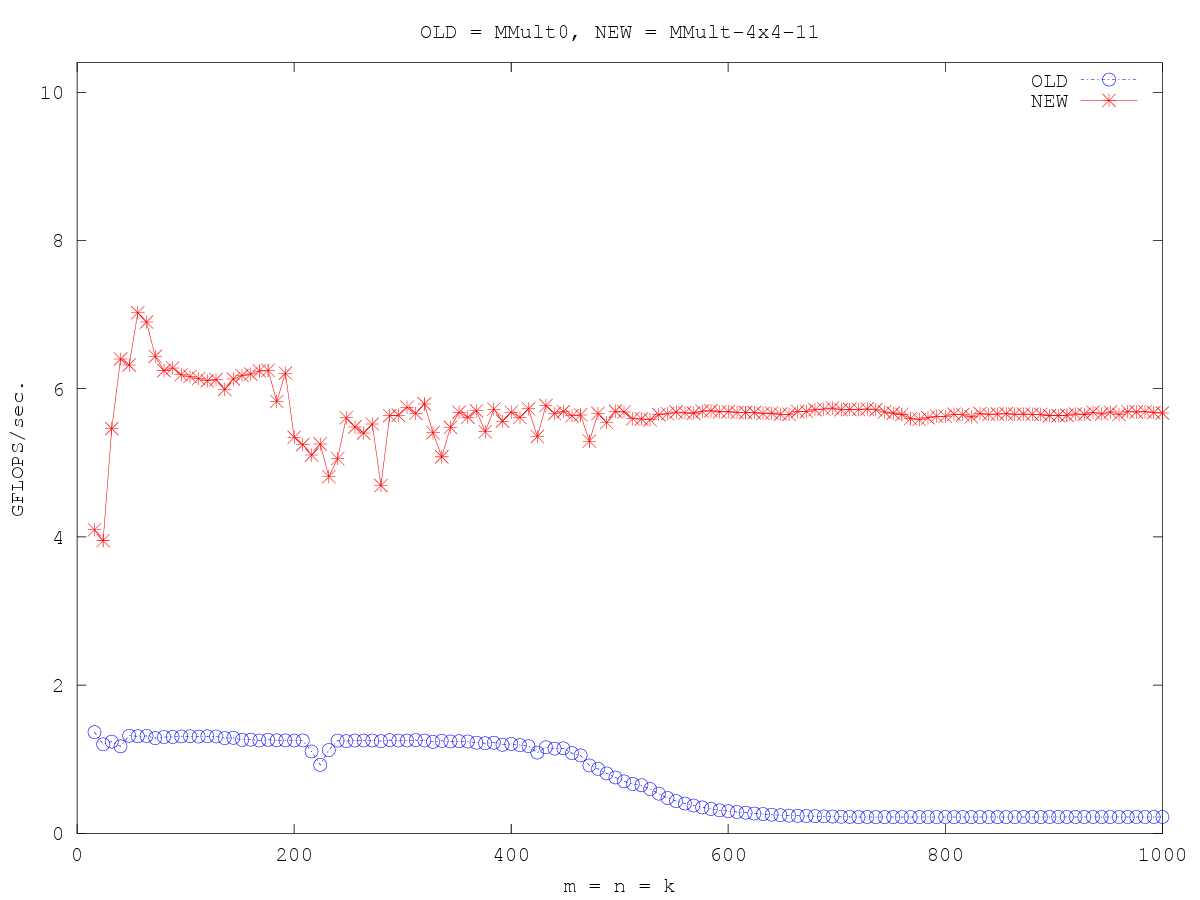
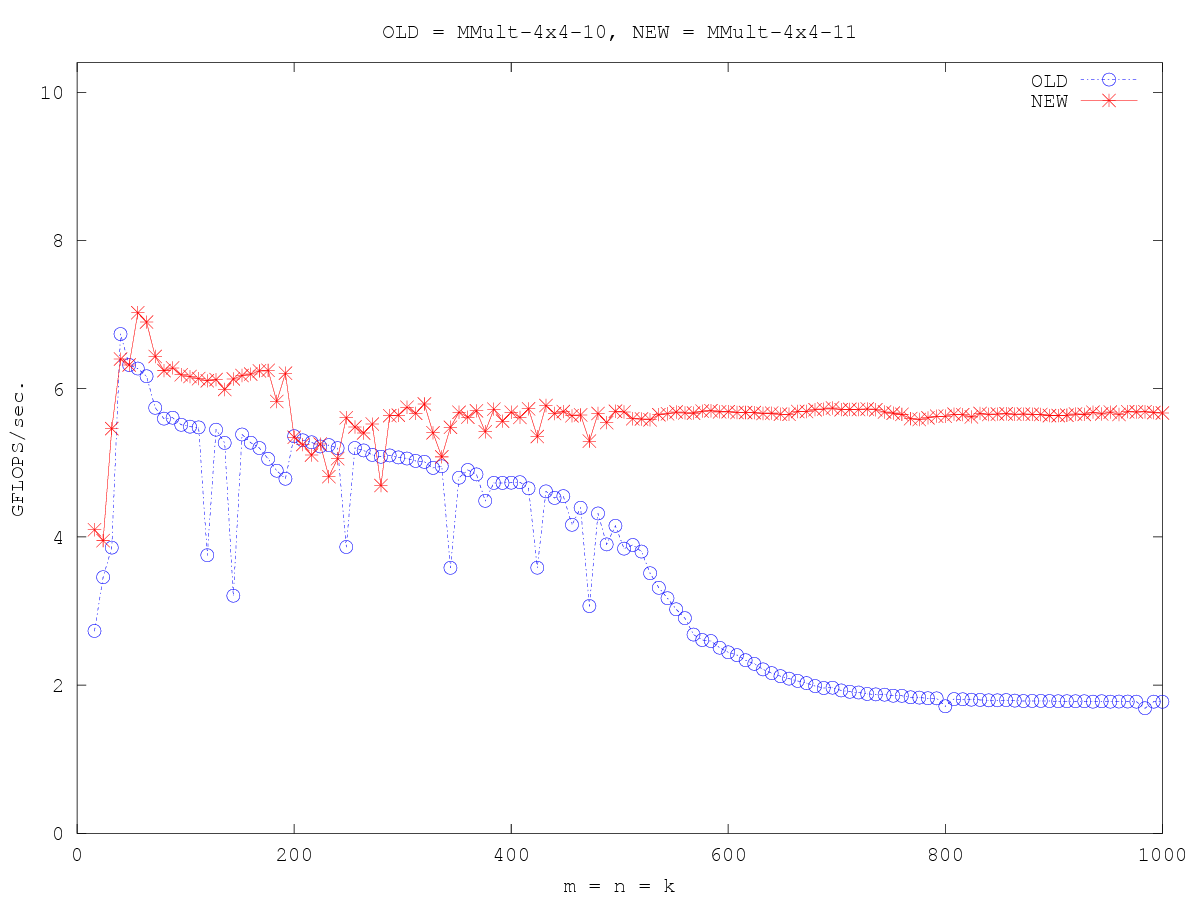
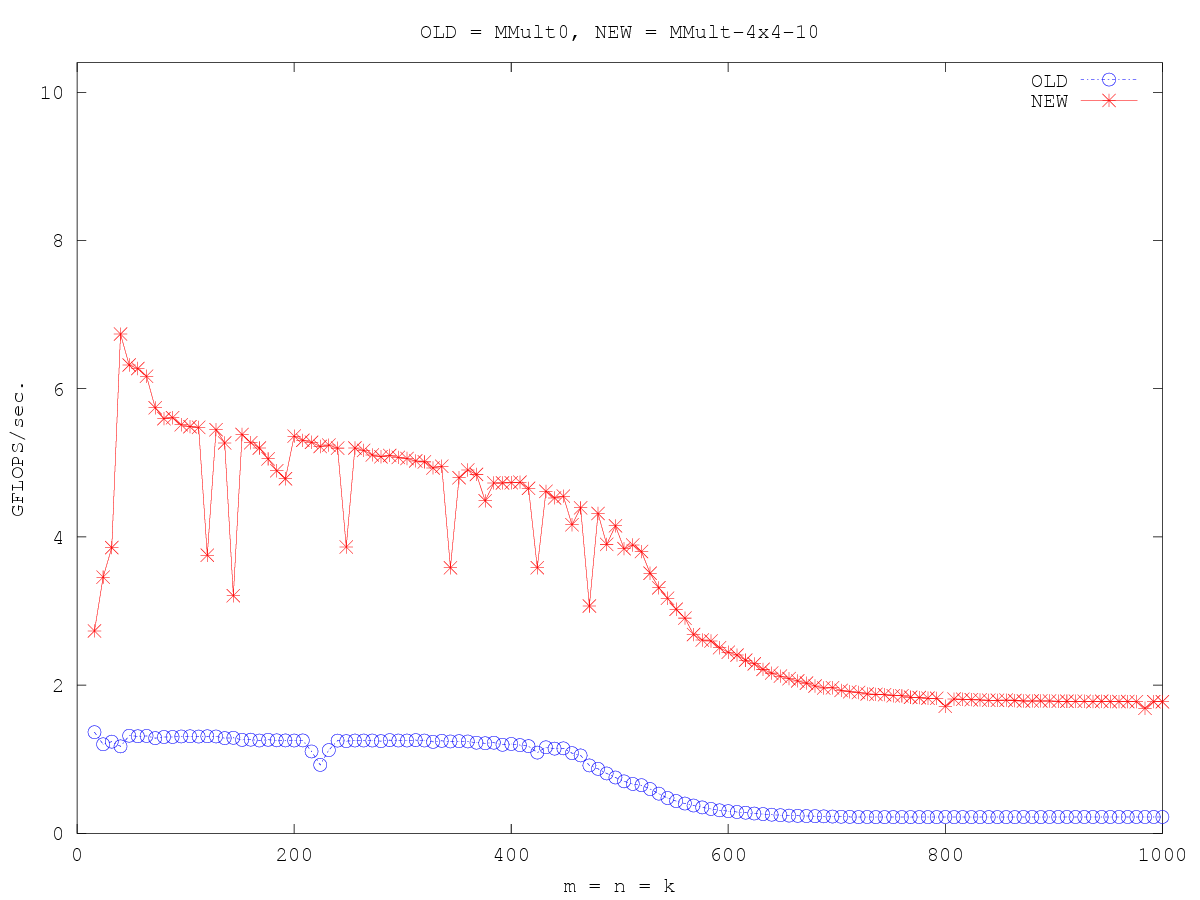
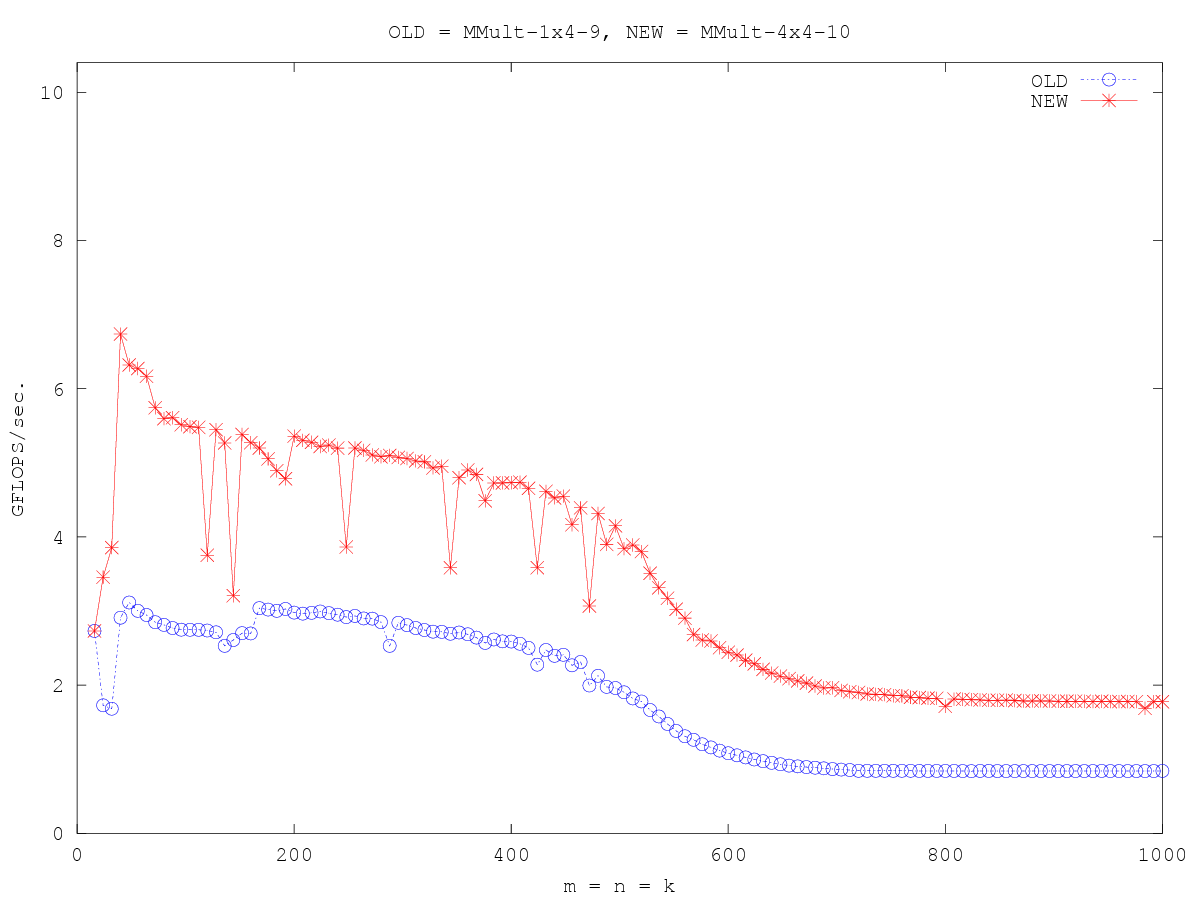
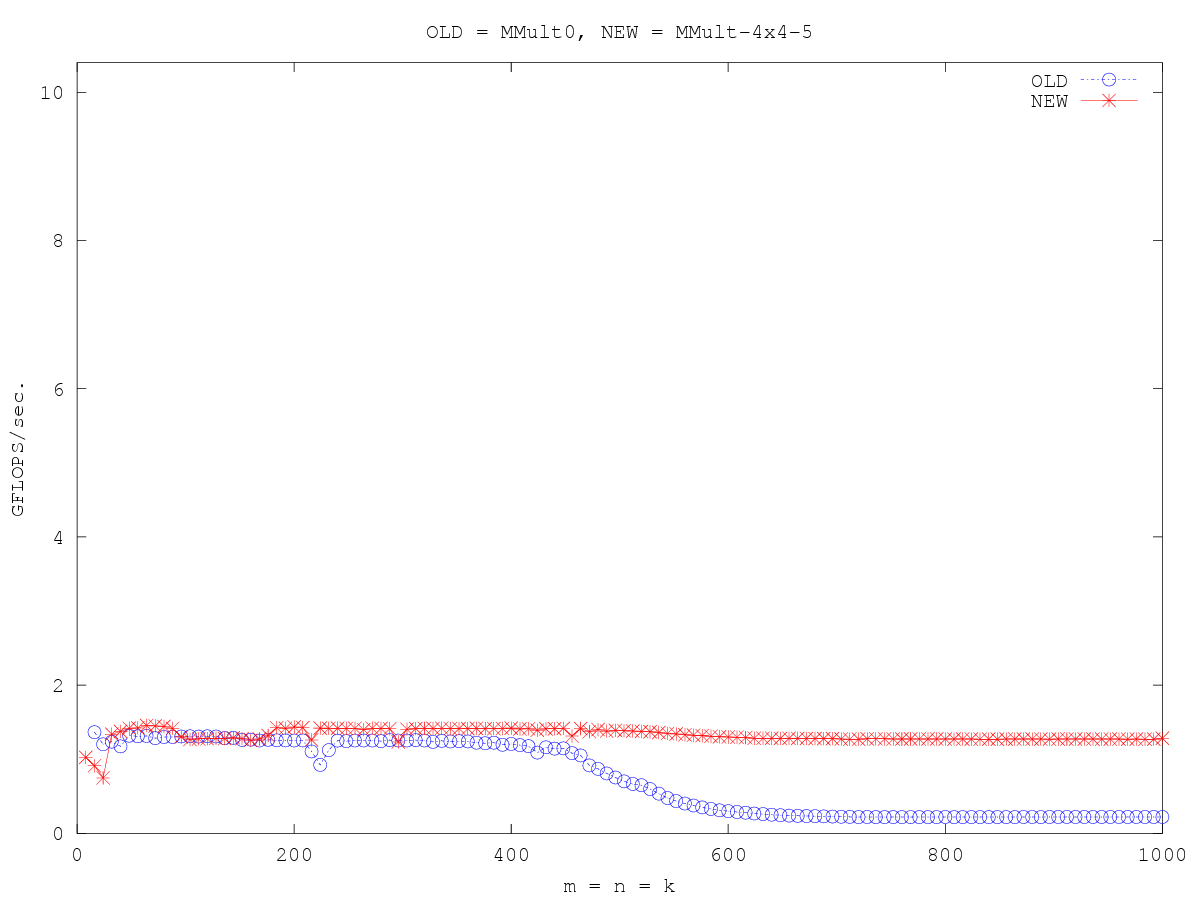
/* Create macros so that the matrices are stored in column-major order */
#define A(i,j) a[ (j)*lda + (i) ]
#define B(i,j) b[ (j)*ldb + (i) ]
#define C(i,j) c[ (j)*ldc + (i) ]
/* Routine for computing C = A * B + C */
void AddDot4x4( int, double *, int, double *, int, double *, int );
void AddDot( int, double *, int, double *, double * );
void MY_MMult( int m, int n, int k, double *a, int lda,
double *b, int ldb,
double *c, int ldc )
{
int i, j;
for ( j=0; j<n; j+=4 ){ /* Loop over the columns of C, unrolled by 4 */
for ( i=0; i<m; i+=4 ){ /* Loop over the rows of C */
/* Update C( i,j ), C( i,j+1 ), C( i,j+2 ), and C( i,j+3 ) in
one routine (four inner products) */
AddDot4x4( k, &A( i,0 ), lda, &B( 0,j ), ldb, &C( i,j ), ldc );
}
}
}
void AddDot4x4( int k, double *a, int lda, double *b, int ldb, double *c, int ldc )
{
/* So, this routine computes a 4x4 block of matrix A
C( 0, 0 ), C( 0, 1 ), C( 0, 2 ), C( 0, 3 ).
C( 1, 0 ), C( 1, 1 ), C( 1, 2 ), C( 1, 3 ).
C( 2, 0 ), C( 2, 1 ), C( 2, 2 ), C( 2, 3 ).
C( 3, 0 ), C( 3, 1 ), C( 3, 2 ), C( 3, 3 ).
Notice that this routine is called with c = C( i, j ) in the
previous routine, so these are actually the elements
C( i , j ), C( i , j+1 ), C( i , j+2 ), C( i , j+3 )
C( i+1, j ), C( i+1, j+1 ), C( i+1, j+2 ), C( i+1, j+3 )
C( i+2, j ), C( i+2, j+1 ), C( i+2, j+2 ), C( i+2, j+3 )
C( i+3, j ), C( i+3, j+1 ), C( i+3, j+2 ), C( i+3, j+3 )
in the original matrix C
In this version, we "inline" AddDot */
int p;
/* First row 第一行*/
// AddDot( k, &A( 0, 0 ), lda, &B( 0, 0 ), &C( 0, 0 ) );
for ( p=0; p<k; p++ ){
C( 0, 0 ) += A( 0, p ) * B( p, 0 );
}
// AddDot( k, &A( 0, 0 ), lda, &B( 0, 1 ), &C( 0, 1 ) );
for ( p=0; p<k; p++ ){
C( 0, 1 ) += A( 0, p ) * B( p, 1 );
}
// AddDot( k, &A( 0, 0 ), lda, &B( 0, 2 ), &C( 0, 2 ) );
for ( p=0; p<k; p++ ){
C( 0, 2 ) += A( 0, p ) * B( p, 2 );
}
// AddDot( k, &A( 0, 0 ), lda, &B( 0, 3 ), &C( 0, 3 ) );
for ( p=0; p<k; p++ ){
C( 0, 3 ) += A( 0, p ) * B( p, 3 );
}
/* Second row 第二行*/
// AddDot( k, &A( 1, 0 ), lda, &B( 0, 0 ), &C( 1, 0 ) );
for ( p=0; p<k; p++ ){
C( 1, 0 ) += A( 1, p ) * B( p, 0 );
}
// AddDot( k, &A( 1, 0 ), lda, &B( 0, 1 ), &C( 1, 1 ) );
for ( p=0; p<k; p++ ){
C( 1, 1 ) += A( 1, p ) * B( p, 1 );
}
// AddDot( k, &A( 1, 0 ), lda, &B( 0, 2 ), &C( 1, 2 ) );
for ( p=0; p<k; p++ ){
C( 1, 2 ) += A( 1, p ) * B( p, 2 );
}
// AddDot( k, &A( 1, 0 ), lda, &B( 0, 3 ), &C( 1, 3 ) );
for ( p=0; p<k; p++ ){
C( 1, 3 ) += A( 1, p ) * B( p, 3 );
}
/* Third row 第三行*/
// AddDot( k, &A( 2, 0 ), lda, &B( 0, 0 ), &C( 2, 0 ) );
for ( p=0; p<k; p++ ){
C( 2, 0 ) += A( 2, p ) * B( p, 0 );
}
// AddDot( k, &A( 2, 0 ), lda, &B( 0, 1 ), &C( 2, 1 ) );
for ( p=0; p<k; p++ ){
C( 2, 1 ) += A( 2, p ) * B( p, 1 );
}
// AddDot( k, &A( 2, 0 ), lda, &B( 0, 2 ), &C( 2, 2 ) );
for ( p=0; p<k; p++ ){
C( 2, 2 ) += A( 2, p ) * B( p, 2 );
}
// AddDot( k, &A( 2, 0 ), lda, &B( 0, 3 ), &C( 2, 3 ) );
for ( p=0; p<k; p++ ){
C( 2, 3 ) += A( 2, p ) * B( p, 3 );
}
/* Four row 第四行*/
// AddDot( k, &A( 3, 0 ), lda, &B( 0, 0 ), &C( 3, 0 ) );
for ( p=0; p<k; p++ ){
C( 3, 0 ) += A( 3, p ) * B( p, 0 );
}
// AddDot( k, &A( 3, 0 ), lda, &B( 0, 1 ), &C( 3, 1 ) );
for ( p=0; p<k; p++ ){
C( 3, 1 ) += A( 3, p ) * B( p, 1 );
}
// AddDot( k, &A( 3, 0 ), lda, &B( 0, 2 ), &C( 3, 2 ) );
for ( p=0; p<k; p++ ){
C( 3, 2 ) += A( 3, p ) * B( p, 2 );
}
// AddDot( k, &A( 3, 0 ), lda, &B( 0, 3 ), &C( 3, 3 ) );
for ( p=0; p<k; p++ ){
C( 3, 3 ) += A( 3, p ) * B( p, 3 );
}
}