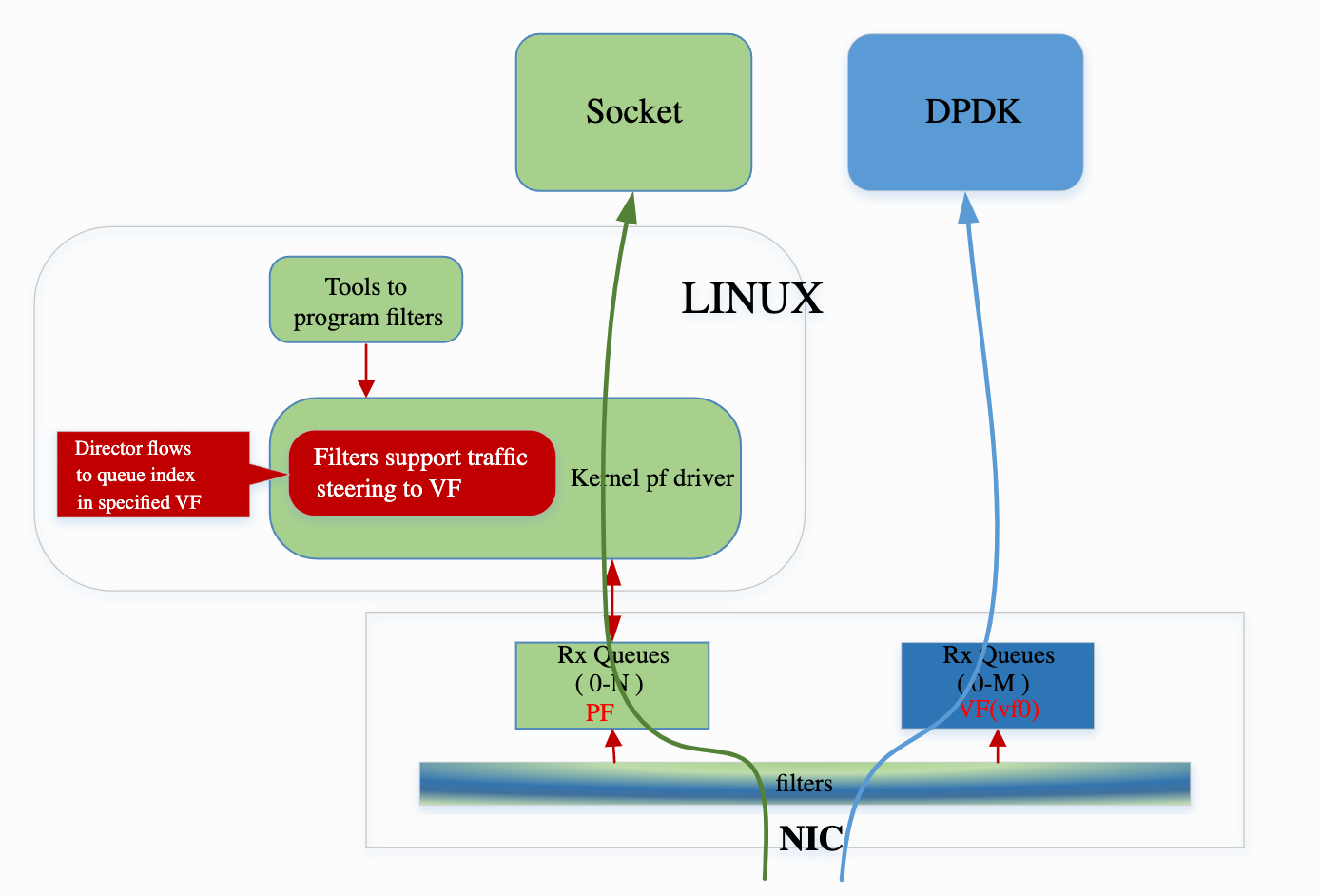
XDP 实现所有的 TCP 端口都接受 TCP 建立连接
一个 XDP 练习程序:作为 TCP 的 server 端,用 XDP 实现所有的 TCP 端口都接受 TCP 建立连接。(只是能够建立连接而已,无法支持后续的 TCP 数据传输,所以不具有实际意义,纯粹好玩。)
建立 TCP 连接需要实现 TCP 的三次握手,对于 server 端来说,要实现:
- 收到 SYN 包,回复 SYN-ACK 包;
- 收到 ACK 包,因为这里不再需要对客户端回复什么,所以这个包收到之后直接 DROP 即可。
回复 SYN-ACK 包就有些麻烦。XDP 不能主动发出包,它能做的就是在收到包的时候,决定对这个包执行何种 action,支持的 action 如下:
XDP_DROPXDP_PASSXDP_TX– 将数据包直接从接收的网卡原路回送出去,等同于 MAC 层 loopback,适用于构造 L2 层反射或快速回应场景。注意并不支持构造完全新包,只能修改现有包;XDP_REDIRECT– 将数据包重定向到其他网卡或用户空间(如使用 AF_XDP),常用于 zero-copy 的高速转发;XDP_ABORTED– 用于调试,表示程序异常终止,包被丢弃;
为了实现 TCP 的 SYN-ACK 回复,这里我们可以选择 XDP_TX ——在收到包之后,对包的内容进行一些修改,比如把 SYN flag 改成 SYN+ACK flag,然后把包重新回送出去,对方收到这个包,其实也不知道是 XDP 返回的还是 Linux kernel 返回的。在 XDP_TX 程序的机器上,Kernel 网络栈根本不知道这个包的存在。
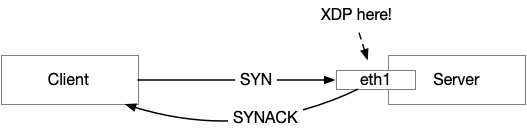
现在的重点在于如何修改这个 TCP SYN 包,并将其回送,使对方认为它是一个合法的 SYN-ACK 包。
我们可以从下往上一层一层看:
- Ether 层:只需要交换 Src MAC 地址和 Dst MAC 地址就可以了。这样的话,直接从 LAN 主机发过来的包会发回去 LAN IP,从 LAN 网关发来的包也会发回网关;
- CRC 校验码一般是网卡硬件负责计算的,所以 Linux 代码不需要处理;
- IP 层:交换 Src IP 和 Dst IP 即可。
- IP checksum 这里也不需要我们手动添加,现在的路由器大部分都是不计算 checksum 的1;
- TCP 层:
- 交换 Src Port 和 Dst Port;
- Flags 把 SYN 和 ACK 都设置为 1;
- 把 ACK 字段,设置为 ack = SYN 包的 seq + 1,以确认对端的 SYN。;
- 填写 seq 字段,因为不涉及后续的数据传输了,这里使用一个固定值即可;
- 重新计算 TCP checksum。重新计算 TCP checksum 是最麻烦的一步,因为在 eBPF/XDP 程序中不能依赖内核自动计算,需要手动构造伪头部(pseudo-header)并累加 TCP 包体数据。所以我们要用 XDP 的代码重新实现 TCP 的 checksum。还要让 XDP 的 verifier2 认为我们写的代码是安全的,所以复杂一些。
因为这个程序直接把收到的 TCP SYN 包远路反弹,就叫它 tcp_bounce.c 吧。(这周末刚去了一个叫 Bounce 的地方团建……)

XDP 程序的源代码如下:
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_endian.h>
#include <linux/if_ether.h>
#include <linux/ip.h>
#include <linux/icmp.h>
#include <linux/tcp.h>
#include <linux/in.h>
#define MAX_CHECKING 4
#define MAX_CSUM_WORDS 750
static __always_inline __u32 sum16(const void* data, __u32 size, const void* data_end) {
__u32 sum = 0;
const __u16 *ptr = (const __u16 *)data;
#pragma unroll
for (int i = 0; i < MAX_CSUM_WORDS; ++i) {
if ((const void *)(ptr + 1) > (data + size)) {
break;
}
if ((const void *)(ptr + 1) > data_end) {
return sum;
}
sum += *ptr;
ptr++;
}
// Handle the potential odd byte at the end if size is odd
if (size & 1) {
const __u8 *byte_ptr = (const __u8 *)ptr; // ptr is now after the last full word
// BPF Verifier check: Ensure the single byte read is within packet bounds
if ((const void *)(byte_ptr + 1) <= data_end && (const void *)byte_ptr < data_end) {
// In checksum calculation, the last odd byte is treated as the
// high byte of a 16-bit word, padded with a zero low byte.
// E.g., if the byte is 0xAB, it's treated as 0xAB00.
sum += (__u16)(*byte_ptr) << 8;
}
// If the bounds check fails, we just return the sum calculated so far.
}
return sum;
}
SEC("xdp")
int tcp_bounce(struct xdp_md *ctx) {
void *data = (void *)(long)ctx->data;
void *data_end = (void *)(long)ctx->data_end;
struct ethhdr *eth = data;
if ((void *)eth + sizeof(*eth) > data_end)
return XDP_PASS; // not enough data
if (eth->h_proto != bpf_htons(ETH_P_IP))
return XDP_PASS;
struct iphdr *iph = data + sizeof(*eth);
if ((void *)iph + sizeof(*iph) > data_end)
return XDP_PASS;
if (iph->protocol != IPPROTO_TCP)
return XDP_PASS;
//check ip len
int ip_hdr_len = iph->ihl*4;
if((void *)iph + ip_hdr_len > data_end)
return XDP_PASS;
// convert to TCP
struct tcphdr *tcph = (void *)iph + ip_hdr_len;
if ((void *)tcph + sizeof(*tcph) > data_end)
return XDP_PASS;
if (!(tcph->syn) || tcph->ack)
return XDP_DROP;
// swap MAC addresses
__u8 tmp_mac[ETH_ALEN];
__builtin_memcpy(tmp_mac, eth->h_source, ETH_ALEN);
__builtin_memcpy(eth->h_source, eth->h_dest, ETH_ALEN);
__builtin_memcpy(eth->h_dest, tmp_mac, ETH_ALEN);
// swap IP addresses
__be32 tmp_ip = iph->saddr;
iph->saddr = iph->daddr;
iph->daddr = tmp_ip;
// TCP
// swap port
__be16 tmpsrcport = tcph->source;
tcph->source = tcph->dest;
tcph->dest = tmpsrcport;
// syn+ack
tcph->ack = 1;
__u32 ack_seq = bpf_ntohl(tcph->seq) + 1;
tcph->ack_seq = bpf_htonl(ack_seq);
// checksum pseudo header
__u32 csum = 0;
tcph->check = (__be16)csum;
if ((void *)&iph->saddr + 8 > data_end)
return XDP_PASS;
csum = bpf_csum_diff(0, 0, (__be32 *)&iph->saddr, 8, csum);
__u16 tcp_len = bpf_ntohs(iph->tot_len) - ip_hdr_len;
csum += (__u32)(bpf_htons(IPPROTO_TCP) << 16) | bpf_htons(tcp_len);
csum += sum16(tcph, tcp_len, data_end);
while (csum >> 16)
csum = (csum & 0xFFFF) + (csum >> 16);
tcph->check = (__be16)~csum;
return XDP_TX;
}
char _license[] SEC("license") = "GPL";安装编译 XDP 程序需要的依赖:
apt-get install -y clang llvm libelf-dev libpcap-dev build-essential m4 pkg-config \ linux-headers-$(uname -r) \ linux-tools-generic tcpdump linux-tools-common \ xdp-tools
安装 libc 开发包依赖,如果是 x86 操作系统:apt-get install -y libc6-dev-i386;如果是 ARM 操作系统:apt-get install -y libc6-dev-arm64-cross.
编译程序:
clang -O2 -target bpf -g -c tcp_bounce.c -o tcp_bounce.o -I /usr/include/aarch64-linux-gnu/
把 xdp 程序加载到网卡上:
xdp-loader load eth1 tcp_bounce.o --mode skb
然后从另一台机器对这个加载了 XDP 程序 tcp_bounce.o 发起 TCP 连接,对于任意端口,可以观察到连接建立成功了:

也可以用 for 循环批量对端口建立连接,都可以连通。
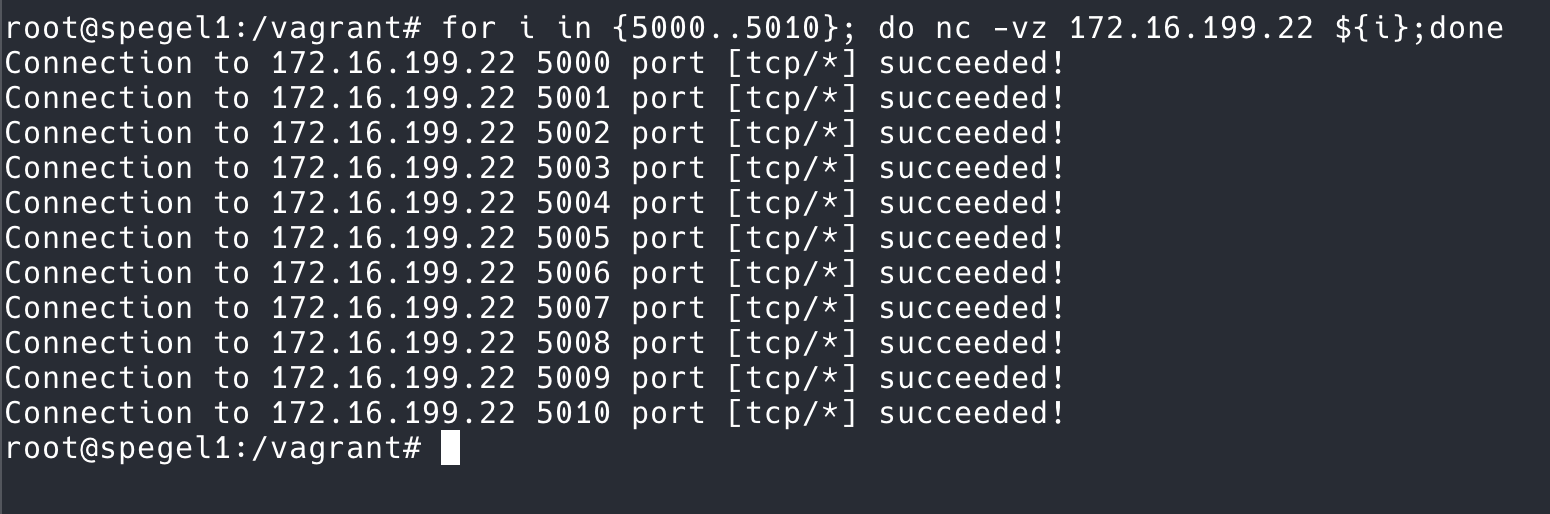
for i in {5000..5010}; do nc -vz 172.16.199.22 ${i};doneXDP 的性能很高,客户端用 10000 个线程同时建立 TCP 连接,服务端的 XDP 程序使用了连 10% 都不到的 CPU。(Again,但是没有什么实际意义)
- 在 网络中的环路和防环技术 有提到过,IPv6 是直接取消了 checksum 字段。
 ︎
︎ - eBPF verifier ︎
 ︎
︎
 ︎
︎