Clawdbot is a local-first personal agent platform that lets you run an always-on assistant on your own devices. The Gateway acts as the control plane, connecting the CLI, macOS/iOS/Android nodes, and multiple channels (WhatsApp, Telegram, Slack, Discord, Google Chat, Signal, iMessage, etc.), and provides a visual Canvas and skill management. See the website and docs for install and getting-started guides.
Main Features
Local-first: keep the agent and data on your devices or self-hosted hosts to reduce external dependency.
Multi-channel support: native integrations with mainstream messaging channels and WebChat, with routing and distribution rules.
Orchestrable skills and workspaces: manage complex flows and automations via a skills registry and workspace model.
Developer-friendly: CLI and SDKs for building, debugging, and extending from source.
Use Cases
Clawdbot suits individuals and small teams who want a private, controllable always-on assistant: personal productivity (calendar, tasks, quick lookups), multi-channel alerts and automations, local developer testing and integration, and low-latency voice/Canvas interactions. The onboarding wizard configures the Gateway and channels to simplify setup.
Technical Features
Gateway architecture: a WebSocket-based control plane that unifies sessions, routing, tools, and events for runtime extensibility and remote access.
Multi-node support: CLI, macOS menu app, and mobile nodes coordinate via RPC, enabling device-local actions such as system.run.
Model failover: supports multiple model backends, credential rotation, and failover strategies to improve robustness.
Security & guardrails: built-in DM access policies, permission controls, and security guidance to reduce misuse risk.
UltraRAG is a low-code Retrieval-Augmented Generation (RAG) development framework built on the Model Context Protocol (MCP) architecture and maintained by OpenBMB with partner institutions. It packages retrieval, generation, and evaluation as independent MCP Servers and offers a visual Pipeline Builder and interactive UI to make development pipelines, intermediate inference outputs, and evaluation results transparent and reproducible.
Main Features
Low-code visual orchestration with Canvas↔Code bidirectional synchronization, supporting conditional branches and loops.
Modular MCP Servers for retrieval, generation and evaluation, improving reusability and extensibility.
Built-in evaluation suite and benchmark comparison, knowledge-base management, and one-click conversion of pipelines to interactive Web UIs.
Use Cases
Suitable for RAG research platforms, enterprise document Q&A and knowledge retrieval systems, and teams that need visual debugging and fast delivery from algorithm to demonstration. Researchers can standardize benchmarks and reproducibility; engineers can prototype production workflows quickly.
Technical Features
Based on MCP, UltraRAG supports multiple retrieval backends and embedding models, uses pipeline-style inference and asynchronous service calls, and exposes standardized benchmark interfaces and logged intermediate outputs to aid performance analysis and error attribution.
PersonaPlex, from NVIDIA, is a framework for real-time voice conversations that supports full‑duplex interaction and persona control. It enables role definition via text prompts and voice conditioning through audio embeddings, focusing on low latency and coherent spoken interactions for sustained dialogue.
Main Features
Full‑duplex audio streaming to minimize response latency and keep interactions fluid.
Persona and voice conditioning for building customizable assistants and service roles.
Prepackaged natural voice embeddings and voice templates to improve speech naturalness and consistency.
Use Cases
Suitable for customer service, virtual hosts, role-playing assistants, and other multimodal applications that require real‑time voice interaction. Also useful as a research baseline for evaluating prompting and voice-conditioning effects on dialogue quality.
Technical Features
Built on the Moshi architecture and model weights, PersonaPlex combines text-to-speech (TTS) and audio‑conditioned generation with streaming inference paths and low‑latency engineering. It exposes plug‑in points for fine‑tuning and evaluation for task-specific optimization.
VM0 is a natural-language-first agent runtime and orchestration platform that lets teams build complex workflows by writing intent instead of drawing canvases. Each run is treated as a stateful agent session with session persistence, checkpoints, and replayability for easier debugging and iterative improvement. The platform also provides multi-model routing so you can choose different language models as execution backends.
Main Features
Natural-language driven agent configuration that avoids canvas and node editing.
Session persistence and checkpoints to restore, fork, and replay execution traces.
Observability and debugging with live logs, metrics, and tool call tracing.
Multi-model routing that can select Claude, GPT, Gemini, or custom models at runtime.
Use Cases
VM0 fits scenarios where high-level business logic is expressed in natural language and automated, such as research information gathering, codebase management and automation, marketing campaign orchestration, and internal productivity agents. It is particularly helpful for teams that want to rapidly prototype and iterate agent strategies.
Technical Features
The platform treats agents as first-class citizens, providing persistent session semantics and replayable checkpoints while emphasizing observability and auditability. The runtime supports stateful agents rather than one-shot container processes, enabling long-lived memory and tool calling. Integration is provided via standardized MCP/tool interfaces plus CLI and SDKs for engineering deployments.
Agent Skills is an open collection that packages reusable skills (SKILL) as human-readable instructions and optional scripts, designed to give agents plug-and-play capabilities. Each skill specifies trigger conditions, inputs/outputs, and execution steps so agents can call focused functionality during conversations or task workflows, simplifying decomposition and automation of complex tasks.
Main Features
Organizes operational instructions and helper scripts in the SKILL format for easy sharing and reuse.
Covers a wide range of skill types (deployments, code review, formatting, etc.) for common engineering and ops scenarios.
Compatible with common agent runtimes so skills can be auto-invoked when relevant tasks are detected.
Use Cases
Extend conversational agents to perform tasks like automatic deployment, code auditing, or site performance checks.
Encapsulate repetitive operations as skills to reduce human error and increase efficiency.
Use the skill library as a developer toolkit to quickly add capabilities to internal agents or collaborative bots.
Technical Features
Text-first SKILL specification including SKILL.md instructions and optional script folders.
Integrates via package managers (e.g., npm) or one-step installers into agent platforms.
Lightweight, composable modules designed for integration with existing workflows and CI/CD.
The role of Spec is undergoing a fundamental transformation, becoming the governance anchor of engineering systems in the AI era.
The Essence of Software Engineering and the Cost Structure Shift Brought by AI
From first principles, software engineering has always been about one thing: stably, controllably, and reproducibly transforming human intent into executable systems.
Artificial Intelligence (AI) does not change this engineering essence, but it dramatically alters the cost structure:
Implementation costs plummet: Code, tests, and boilerplate logic are rapidly commoditized.
Consistency costs rise sharply: Intent drift, hidden conflicts, and cross-module inconsistencies become more frequent.
Governance costs are amplified: As agents can act directly, auditability, accountability, and explainability become hard constraints.
Therefore, in the era of Agent-Driven Development (ADD), the core issue is not “can agents do the work,” but how to maintain controllability and intent preservation in engineering systems under highly autonomous agents.
The ADD Era Inflection Point: Three Structural Preconditions
Many attribute the “explosion” of ADD to more mature multi-agent systems, stronger models, or more automated tools. In reality, the true structural inflection point arises only when these three conditions are met:
Agents have acquired multi-step execution capabilities
With frameworks like LangChain, LangGraph, and CrewAI, agents are no longer just prompt invocations, but long-lived entities capable of planning, decomposition, execution, and rollback.
Agents are entering real enterprise delivery pipelines
Once in enterprise R&D, the question shifts from “can it generate” to “who approved it, is it compliant, can it be rolled back.”
Traditional engineering tools lack a control plane for the agent era
Tools like Git, CI, and Issue Trackers were designed for “human developer collaboration,” not for “agent execution.”
When these three factors converge, ADD inevitably shifts from an “efficiency tool” to a “governance system.”
The Changing Role of Spec: From Documentation to System Constraint
In the context of ADD, Spec is undergoing a fundamental shift:
Spec is no longer “documentation for humans,” but “the source of constraints and facts for systems and agents to execute.”
Spec now serves at least three roles:
Verifiable expression of intent and boundaries
Requirements, acceptance criteria, and design principles are no longer just text, but objects that can be checked, aligned, and traced.
Stable contracts for organizational collaboration
When agents participate in delivery, verbal consensus and tacit knowledge quickly fail. Versioned, auditable artifacts become the foundation of collaboration.
Policy surface for agent execution
Agents can write code, modify configurations, and trigger pipelines. Spec must become the constraint on “what can and cannot be done.”
From this perspective, the status of Spec is approaching that of the Control Plane in AI-native infrastructure.
The Reality of Multi-Agent Workflows: Orchestration and Governance First
In recent systems (such as APOX and other enterprise products), an industry consensus is emerging:
Multi-agent collaboration no longer pursues “full automation,” but is staged and gated.
Frameworks like LangGraph are used to build persistent, debuggable agent workflows.
RAG (e.g., based on Milvus) is used to accumulate historical Specs, decisions, and context as long-term memory.
The IDE mainly focuses on execution efficiency, not engineering governance.
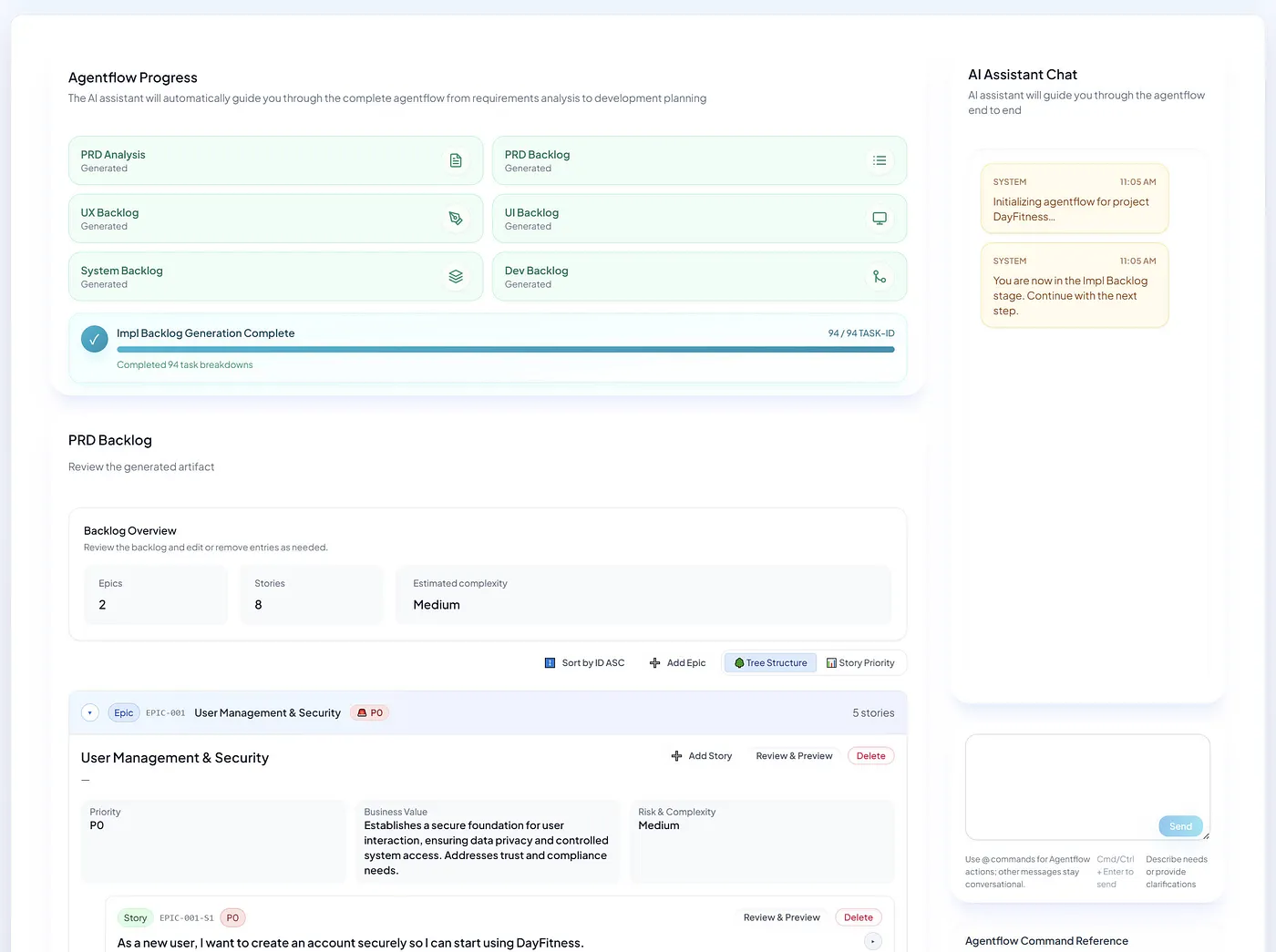
Figure 1: APOX user interface
APOX (AI Product Orchestration eXtended) is a multi-agent collaboration workflow platform for enterprise software delivery. Its core goals are:
To connect the entire process from product requirements to executable code with a governable Agentflow and explicit engineering artifact chain.
To assign dedicated AI agents to each delivery stage (such as PRD, PO, Architecture, Developer, Implementation, Coding, etc.).
To embed manual approval gates and full audit trails at every step, solving the “intent drift and consistency” governance problem that traditional AI coding tools cannot address.
The platform provides a VS Code plugin for real-time sync between local IDE and web artifacts, allowing Specs, code, tasks, and approval statuses to coexist in the repository.
Supports assigning different base models to different agents according to enterprise needs.
APOX is not about simply speeding up code generation, but about elevating “Spec” from auxiliary documentation to a verifiable, constrainable, and traceable core asset in engineering—building a control plane and workflow governance system suitable for Agent-Driven Development.
Such systems emphasize:
An explicit artifact chain from PRD → Spec → Task → Implementation.
Manual confirmation and audit points at every stage.
Bidirectional sync between Spec, code, repository, and IDE.
This is not about “smarter AI,” but about engineering systems adapting to the agent era.
The Long-Term Value of Spec: The Core Anchor of Engineering Assets
This is not to devalue code, but to acknowledge reality:
There will always be long-term differentiation in algorithms and model capabilities.
General engineering implementation is rapidly homogenizing.
What is hard to replicate is: how to define problems, constrain systems, and govern change.
In the ADD era, the value of Spec is reflected in:
Determining what agents can and cannot do.
Carrying the organization’s long-term understanding of the system.
Serving as the anchor for audit, compliance, and accountability.
Code will be rewritten again and again; Spec is the long-term asset.
Risks and Challenges of ADD: Living Spec and Governance Constraints
ADD also faces significant risks:
Can Spec become a Living Spec
That is, when key implementation changes occur, can the system detect “intent changes” and prompt Spec updates, rather than allowing silent drift?
Can governance achieve low friction but strong constraints
If gates are too strict, teams will bypass them; if too loose, the system loses control.
These two factors determine whether ADD is “the next engineering paradigm” or “just another tool bubble.”
The Trend Toward Control Planes in Engineering Systems
From a broader perspective, ADD is the inevitable result of engineering systems becoming “control planes”:
Engineering systems are evolving from “human collaboration tools” to “control systems for agent execution.”
In this structure:
Agent / IDE is the execution plane.
RAG / Memory is the state and memory plane.
Spec is the intent and policy plane.
Gates, audit, and traceability form the governance loop.
This closely aligns with the evolution path of AI-native infrastructure.
Summary
The winners of the ADD era will not be the systems with “the most agents or the fastest generation,” but those that first upgrade Spec from documentation to a governable, auditable, and executable asset. As automation advances, the true scarcity is the long-term control of intent.
HolmesGPT is a CNCF-hosted, cloud-native AI agent platform that automates alert investigation, analyzes multi-source observability data, identifies root causes, and provides remediation suggestions. It integrates with Prometheus, Kubernetes, Slack, Jira, and other mainstream tools, supporting diverse data sources and automated operations scenarios. HolmesGPT helps SRE and operations teams improve incident response efficiency and reduce MTTR.
Main Features
Multi-source integration: Supports Prometheus, Kubernetes, AWS, Datadog, Loki, Helm, and other major cloud-native and monitoring platforms
Agentic loop: Automated analysis, reasoning, and suggestions based on the agentic loop
Automated investigation and remediation: Collects context, analyzes root causes, and generates remediation plans automatically
Rich tool integration and extensibility: Custom data sources and runbooks, supports both CLI and SaaS deployment
Data privacy and security: Read-only permissions, bring your own LLM API key, and strong data protection
Use Cases
Automated incident investigation and root cause analysis for cloud-native infrastructure and applications
SRE team alert response and collaboration
Unified monitoring and event handling in multi-cloud and hybrid cloud environments
Automated runbook execution and knowledge base integration
Smart assistant for DevOps and ChatOps scenarios
Technical Features
Python-based implementation with pluggable toolsets
Agentic loop architecture combining LLMs and multi-source observability data
Supports CLI and web interface for flexible deployment
CNCF Sandbox project with active community and comprehensive documentation
Voice input methods are not just about being “fast”—they are becoming a brand new gateway for developers to collaborate with AI.
Warning
On January 12, 2026, due to financial difficulties encountered during operations, the Miaoyan project announced the cessation of operations and the team was disbanded. The application will no longer be updated or maintained, but existing versions can continue to be used on the current device and system, and do not store any audio or transcription content.
Figure 1: Can voice input become the new shortcut for developers? My in-depth comparison experience.
AI Voice Input Methods Are Becoming the “New Shortcut Key” in the Programming Era
I am increasingly convinced of one thing: PC-based AI voice input methods are evolving from mere “input tools” into the foundational interaction layer for the era of programming and AI collaboration.
It’s not just about typing faster—it determines how you deliver your intent to the system, whether you’re writing documentation, code, or collaborating with AI in IDEs, terminals, or chat windows.
Because of this, the differences in voice input method experiences are far more significant than they appear on the surface.
My Six Evaluation Criteria for AI Voice Input Methods
After long-term, high-frequency use, I have developed a set of criteria to assess the real-world performance of AI voice input methods:
Response speed: Does text appear quickly enough after pressing the shortcut to keep up with your thoughts?
Continuous input stability: Does it remain reliable during extended use, or does it suddenly fail or miss recognition?
Mixed Chinese-English and technical terms: Can it reliably handle code, paths, abbreviations, and product names?
Developer friendliness: Is it truly designed for command line, IDE, and automation scenarios?
Interaction restraint: Does it avoid introducing distracting features that interfere with input itself?
Subscription and cost structure: Is it a standalone paid product, or can it be bundled with existing tool subscriptions?
Based on these criteria, I focused on comparing Miaoyan, Shandianshuo, and Zhipu AI Voice Input Method.
Miaoyan: Currently the Most “Developer-Oriented” Domestic Product
Miaoyan was the first domestic AI voice input method I used extensively, and it remains the one I am most willing to use continuously.
Figure 2: Miaoyan is currently my most-used Mac voice input method.
Command Mode: The Key Differentiator for Developer Productivity
It’s important to clarify that Miaoyan’s command mode is not about editing text via voice. Instead:
You describe your need in natural language, and the system directly generates an executable command-line command.
This is crucial for developers:
It’s not just about input
It’s about turning voice into an automation entry point
Essentially, it connects voice to the CLI or toolchain
This design is clearly focused on engineering efficiency, not office document polishing.
Usage Experience Summary
Fast response, nearly instant
Output is relatively clean, with minimal guessing
Interaction design is restrained, with no unnecessary concepts
Developer-friendly mindset
But there are some practical limitations:
It is a completely standalone product
Requires a separate subscription
Still in relatively small-scale use
From a product strategy perspective, it feels more like a “pure tool” than part of an ecosystem.
Note
On January 12, 2026, due to financial difficulties encountered during operations, the Miaoyan project announced the cessation of operations and the team was disbanded. The application will no longer be updated or maintained, but existing versions can continue to be used on the current device and system, and do not store any audio or transcription content.
Shandianshuo: Local-First Approach, Developer Experience Depends on Your Setup
Shandianshuo takes a different approach: it treats voice input as a “local-first foundational capability,” emphasizing low latency and privacy (at least in its product narrative). The natural advantages of this approach are speed and controllable marginal costs, making it suitable as a “system capability” that’s always available, rather than a cloud service.
Figure 3: Shandianshuo settings page
However, from a developer’s perspective, its upper limit often depends on “how you implement enhanced capabilities”:
If you only use it for basic transcription, the experience is more like a high-quality local input tool. But if you want better mixed Chinese-English input, technical term correction, symbol and formatting handling, the common approach is to add optional AI correction/enhancement capabilities, which usually requires extra configuration (such as providing your own API key or subscribing to enhanced features). The key trade-off here is not “can it be used,” but “how much configuration cost are you willing to pay for enhanced capabilities.”
If you want voice input to be a “lightweight, stable, non-intrusive” foundation, Shandianshuo is worth considering. But if your goal is to make voice input part of your developer workflow (such as command generation or executable actions), it needs to offer stronger productized design at the “command layer” and in terms of controllability.
Zhipu AI Voice Input Method: Stable but with Friction
Although I prefer Miaoyan in terms of experience, Zhipu has a very practical advantage:
If you already subscribe to Zhipu’s programming package, the voice input method is included for free.
This means:
No need to pay separately for the input method
Lower psychological and decision-making cost
More likely to become the “default tool” that stays
From a business perspective, this is a very smart strategy.
Main Comparison Table
The following table compares the three products across key dimensions for quick reference.
Dimension
Miaoyan
Shandianshuo
Zhipu AI Voice Input Method
Response Speed
Fast, nearly instant
Usually fast (local-first)
Slightly slower than Miaoyan
Continuous Stability
Stable
Depends on setup and environment
Very stable
Idle Misrecognition
Rare
Generally restrained (varies by version)
Obvious: outputs characters even if silent
Output Cleanliness/Control
High
More like an “input tool”
Occasionally messy
Developer Differentiator
Natural language → executable command
Local-first / optional enhancements
Ecosystem-attached capabilities
Subscription & Cost
Standalone, separate purchase
Basic usable; enhancements often require setup/subscription
Bundled free with programming package
My Current Preference
Best experience
More like a “foundation approach”
Easy to keep but not clean enough
Table 1: Core Comparison of Miaoyan, Shandianshuo, and Zhipu AI Voice Input Methods
User Loyalty to AI Voice Input Methods
The switching cost for voice input methods is actually low: just a shortcut key and a habit of output.
What really determines whether users stick around is:
Whether the output is controllable
Whether it keeps causing annoying minor issues
Whether it integrates into your existing workflow and payment structure
For me personally:
The best and smoothest experience is still Miaoyan
The one most likely to stick around is probably Zhipu
Shandianshuo is more of a “foundation approach” and worth watching for how its enhancements evolve
These points are not contradictory.
Summary
Miaoyan is more mature in engineering orientation, command capabilities, and input control
Zhipu has practical advantages in stability and subscription bundling
Shandianshuo takes a local-first + optional enhancement approach, with the key being how it balances “basic capability” and “enhancement cost”
Who truly becomes the “default gateway” depends on reducing distractions, fixing frequent minor issues, and treating voice input as true “infrastructure” rather than an add-on feature
The competition among AI voice input methods is no longer about recognition accuracy, but about who can own the shortcut key you press every day.
Compute and governance boundaries are the true foundation of AI-native infrastructure architecture.
The previous chapter presented a “Three Planes + One Closed Loop” reference architecture. This chapter focuses on a core CTO/CEO-level question:
How should AI-native infrastructure be layered? What belongs in the “control plane” of APIs/Agents, what belongs in the “execution plane” of runtime, and what must be pushed down to the “governance plane (compute and economic constraints)”?
This question is critical because over the past year, many platform companies “pivoting to AI” have fallen into a common trap: treating AI as an API morphology change rather than a system constraint change. When your system shifts from “serving requests” to “model behavior” (multi-step Agent actions with side effects), what truly determines system boundaries is often not the elegance of API design, but rather: whether compute, context, and economic constraints are institutionalized as enforceable governance boundaries.
The core argument of this chapter can be summarized as:
AI-native infrastructure must be designed starting from “Consequence” rather than stacking capabilities from “Intent”; the control plane is responsible for expressing intent, but the governance plane is responsible for bounding consequences.
The Purpose of Layering: Engineering the Binding Between “Intent” and “Resource Consequences”
In AI-native infrastructure, mechanisms like MCP, Agents, and Tool Calling enhance system capabilities while also introducing higher risks. These risks are not abstract “uncontrollability,” but rather engineering “unbudgetable consequences”:
Path explosion in behavior, long contexts, and multi-round reasoning bring long-tail resource consumption;
The same “intent” can lead to orders-of-magnitude differences in tokens, GPU time, and network/storage pressure;
Without governance closed loops, systems will move toward “cost and risk runaway” while becoming “more capable.”
Therefore, the fundamental purpose of layering is not abstract aesthetics, but achieving a hard constraint goal:
Ensure each layer can translate upper-layer “intent” into executable plans and produce measurable, attributable, and constrainable resource consequences.
In other words, layering is not about making architecture diagrams clearer, but about encoding “who expresses intent, who executes, and who bears consequences” into system structure.
AI-Native Infrastructure Five-Layer Structure and “Three Planes” Mapping
To help understand the layering logic, the diagram below refines the “Three Planes” architecture from the previous chapter, proposing a more actionable “five-layer structure”:
Figure 1: Layered governance relationship from intent to consequence
Top two layers = Intent Plane
Middle two layers = Execution Plane
Bottom layer = Governance Plane
Below is a detailed expansion of the five-layer architecture, showing the primary responsibilities and typical capabilities of each layer:
Figure 2: Five-layer architecture diagram
It is important to note that MCP belongs to Layer 4 (Intent and Orchestration Layer), not Layer 1. The reason is that MCP primarily defines “how capabilities are exposed to models/Agents and how they are invoked,” addressing control plane consistency and composability, but does not directly take responsibility for “how the resource consequences of capability invocations are metered, constrained, and attributed.”
MCP/Agent is the “New Control Plane,” But Must Be Constrained by the Governance Layer
MCP/Agent is called the “new control plane” because it moves system “decisions” from static code to dynamic processes:
“Tool catalogs + schemas + invocations” form a composable capability surface;
Agents complete tasks by selecting tools, invoking tools, and iterating reasoning;
“Policy” is no longer just in code branches but expressed as routing, priorities, budgets, and compliance intent.
However, it is crucial to emphasize an infrastructure stance, which is also the foundation of this chapter:
MCP/Agent can express intent, but the key to AI-native is: intent must be translated into governable execution plans and metered and constrained within economically viable boundaries.
This statement aims to correct two common misconceptions:
Control plane is not the starting point: Treating MCP/Agent as “the entry point for AI platform upgrades” easily leads systems down a “capability-first” path;
Governance plane is the baseline: When compute and tokens become capacity units, any unconstrained “intent expression” will leak as cost, latency, or risk.
Therefore, system layering should be clear: Layer 4 is responsible for “expression,” Layers 1/2/3 are responsible for “fulfillment and bearing consequences,” and the governance loop is responsible for “correction.”
“Context” Is Rising to a New Infrastructure Layer
In traditional cloud-native systems, request states are mostly short-lived, relying more on application-layer state management. Infrastructure typically only handles “computation and networking” without needing to understand the economic value of “request context.”
AI-native infrastructure is different. Long-context, multi-turn dialogue, and multi-agent reasoning mean inference state often survives across requests and directly determines throughput and cost. In particular, KV cache and context reuse are evolving from “performance optimization techniques” to “platform capacity structures.”
This can be summarized as an infrastructure law:
When a state asset (context/state) becomes a determinant variable of system cost and throughput, it rises from application detail to infrastructure layer.
This trend is gradually appearing in the industry: inference context and KV reuse are explicitly elevated to “infrastructure layer” capability development directions. Future expansion will include distributed KV, parameter caching, inference routing state, Agent memory, and a series of “state assets.”
The Foundation of AI-Native Infrastructure: Reference Designs and Delivery Systems
AI-native infrastructure is far more than “buying a few GPUs.” Compared to traditional internet services, AI workloads have three characteristics that make the “foundation” more engineered and productized:
Stronger topology dependencies: Network fabric, interconnects, storage tiers, and GPU affinity determine available throughput;
Harder scarcity constraints: GPU and token throughput boundaries are less “elastic” than CPU/memory;
Higher delivery complexity: Multi-cluster, multi-tenant, multi-model/multi-framework coexistence means only “replicable delivery” can scale.
Therefore, AI Infra is not just a component list, but must include “scalable delivery and repeatable operation” system capabilities:
Reference Designs (validated designs)
Codify “correct topology and ratios” into reusable solutions.
Automated Delivery
Institutionalize deployment, upgrade, scaling, rollback, and capacity planning.
Governance Implementation
Make budgeting, isolation, metering, and auditing default capabilities rather than after-the-fact patches.
From a CTO/CEO perspective, this means: what you purchase is not “hardware” but a “delivery system for predictable capacity.”
“Layered Responsibility Boundaries” from a CTO/CEO Perspective
To facilitate internal alignment on “who is responsible for what and what is the cost of failure,” the table below maps “technical layers” to “organizational responsibilities,” avoiding the scenario where platform teams only build control planes while no one bears consequence boundaries.
Table 1: AI-Native Infrastructure Layer and Organizational Responsibility Mapping
As you can see, the organizational challenge of AI-native is not in “whether we have agents,” but in “whether inter-layer closed loops are established”. When model-driven amplification of consequences occurs, organizations must institutionalize governance mechanisms as platform capabilities: executable budgets, explainable consequences, attributable anomalies, and rewritable policies. This is the true meaning of “starting from compute governance” rather than “starting from API design.”
Conclusion
The layered design of AI-native infrastructure centers on engineering the binding between “intent” and “resource consequences.” The control plane is responsible for expressing intent, while the governance plane is responsible for bounding consequences. Only by institutionalizing governance mechanisms as platform capabilities can we ensure cost, risk, and capacity remain controllable while enhancing capabilities. As context, state assets, and other new variables become infrastructure, AI Infra delivery systems will continue to evolve, becoming the foundation for sustainable enterprise innovation.
The essence of AI-native infrastructure is to make model behavior, compute scarcity, and uncertainty governable system boundaries.
AI-native infrastructure is not a simple checklist of technologies, but rather a new operating order designed for a world where “models become actors, compute becomes scarce, and uncertainty is the system default.”
The core of AI-native infrastructure is not faster inference or cheaper GPUs, but providing governable, measurable, and evolvable system boundaries for model behavior, compute scarcity, and uncertainty—making AI systems deliverable, governable, and evolvable in production environments.
Why We Need a More Rigorous Definition
The term “AI-native infrastructure/architecture” is being adopted by an increasing number of vendors, but its meaning is often oversimplified as “data centers better suited for AI” or “more complete AI platform delivery.”
In practice, different vendors emphasize different aspects of AI-native infrastructure:
Cisco emphasizes delivering AI-native infrastructure across edge/cloud/data center domains, highlighting delivery paths where “open & disaggregated” and “fully integrated systems” coexist (e.g., Cisco Validated Designs).
HPE emphasizes an open, full-stack AI-native architecture for the entire AI lifecycle, model development, and deployment.
NVIDIA explicitly proposes an AI-native infrastructure tier to support inference context reuse for long-context and agentic workloads.
For CTOs/CEOs, a definition that can guide strategy and organizational design must meet two criteria:
Clarify how the first-principles constraints of infrastructure have changed in the AI era
Converge “AI-native” from a marketing adjective into verifiable architectural properties and operating mechanisms
Authoritative One-Sentence Definition
AI-native infrastructure is:
An infrastructure system and operating mechanism premised on “models/agents as execution subjects, compute as scarce assets, and uncertainty as the norm,” which closes the loop on “intent (API/Agent) → execution (Runtime) → resource consumption (Accelerator/Network/Storage) → economic and risk outcomes” through compute governance.
This definition contains two layers of meaning:
Infrastructure: Not just a software/hardware stack, but also includes scaled delivery and systemic capabilities (consistent with vendors’ emphasis on “full-stack integration/reference architectures/lifecycle delivery”).
Operating Model: It inevitably rewrites organizational and operational methods, not just a technical upgrade—budget, risk, and release rhythm are strongly bound to the same governance loop.
A More Precise Layered Model: Paradigm Above, Refactoring Below
AI-native infrastructure should not be framed as a replacement of cloud-native infrastructure, but as a combined model of higher-level paradigm + downward refactoring.
Layer 0 — Cloud-Native Substrate (retained): Kubernetes, container runtime, CNI/CSI, and observability primitives remain the execution substrate.
Layer 1 — Resource Model Rewrite (core breakpoint): Scheduling semantics shift from CPU/memory-centric to GPU/token/context-centric; context and token become first-class resources. GPU virtualization, slicing, sharing, and oversubscription (such as HAMi) belong here.
Layer 2 — Runtime and Control Plane Shift: Workload form shifts from request/response services to agentic loops, async multi-step workflows, and fused inference/training/evaluation execution paths.
Layer 3 — Governance and Scheduling First: Scheduling becomes the primary control plane; deployment becomes a secondary concern under budget, risk, and policy constraints.
In other words: Cloud Native is the substrate, AI Native is the semantic override and resource-model shift on top of that substrate.
Three Premises
The core premises of AI-native infrastructure are as follows. The diagram below illustrates the correspondence between these three premises and governance boundaries.
Figure 1: Three constitutional premises of AI-native infrastructure
Model-as-Actor: Models/agents become “execution subjects”
Compute-as-Scarcity: Compute (accelerators, interconnects, power consumption, bandwidth) becomes the core scarce asset
Uncertainty-by-Default: Behavior and resource consumption are highly uncertain (especially in agentic and long-context scenarios)
These three points collectively determine: the core task of AI-native infrastructure is not to “make systems more elegant,” but to make systems controllable, sustainable, and capable of scaled delivery under uncertain behavior.
Boundaries: What AI-Native Infrastructure Manages and What It Doesn’t
In practical engineering, defining boundaries helps focus resources and capability development. The table below summarizes what AI-native infrastructure focuses on versus what it doesn’t:
Not focused on:
Prompt design and business-level agent logic
Individual model capabilities and training secrets
Application-layer product features themselves
Focused on:
Compute Governance: Quotas, budgets, isolation/sharing, topology and interconnects, preemption and priorities, throughput/latency versus cost tradeoffs
Execution Form Engineering: Unified operation, scheduling, and observability for training/fine-tuning/inference/batch processing/agentic workflows
Closed-Loop Mechanisms: How intent is constrained, measured, and mapped to controllable resource consumption and economic/risk outcomes
Verifiable Architectural Properties: Three Planes + One Loop
To facilitate understanding, the following sections introduce the core architectural properties of AI-native infrastructure.
The diagram below shows the visualization of the three planes and the closed loop, facilitating rapid boundary alignment during reviews.
Figure 2: Three Planes and One Loop reference architecture
Only with an “intent → consumption → cost/risk outcome” closed loop can it be called AI-native.
This is also why NVIDIA elevates the sharing and reuse of “new state assets” like inference context to an independent AI-native infrastructure layer: essentially bringing the resource consequences of agentic/long-context into governable system boundaries.
AI-Native vs Cloud Native: Where the Differences Lie
Cloud Native focuses on delivering services in distributed environments with portability, elasticity, observability, and automation. Its governance objects are primarily service/instance/request.
AI-native infrastructure addresses a different set of structural problems:
Execution unit shift: From service request/response to agent action/decision/side effect
Resource constraint shift: From elastic CPU/memory to hard GPU/throughput/token constraints and cost ceilings
Reliability pattern shift: From “reliable delivery of deterministic systems” to “controllable operation of non-deterministic systems”
Therefore, AI-native is not a parallel track that replaces cloud-native, but a reinterpretation of cloud-native under AI constraints: the substrate remains, while resource, runtime, and governance semantics are rewritten.
Bringing It to Engineering: What Capabilities AI-Native Infrastructure Must Have
To avoid “right concept, misaligned execution,” the following minimum closed-loop capabilities are listed.
Resource Model: Making GPU, Context, and Token First-Class Resources
Cloud native abstracts CPU/memory into schedulable resources; AI-native must further bring the following resources under governance:
GPU/Accelerator Resources: Scheduled and governed by partitioning, sharing, isolation, and preemption
Context Resources: Context windows, retrieval paths, cache hits, KV/inference state asset reuse, etc., which directly affect tokens and costs
Token/Throughput: Become measurable capacity and cost carriers (can enter budgets, SLOs, and product strategies)
When tokens become “capacity units,” the platform is no longer just running services, but operating an “AI factory.”
Budgets and Policies: Binding “Cost/Risk” to Organizational Decisions
AI systems cannot operate with a “ship and done” approach. Budgets and policies must become the control plane:
Trigger rate limiting/degradation when budgets are exceeded
Trigger stricter verification or disable high-risk tools when risk increases
Version releases and experiments are constrained by “budget/risk headroom” (institutionalizing release rhythm)
The key is infrastructure solidifying organizational rules into executable policies.
Observability and Audit: Making Model Behavior Accountable and Observable
Traditional observability focuses on latency/error/traffic; AI-native must add at least three types of signals:
Behavior Signals: Which tools the model called, which systems it read/wrote, what actions it took, what side effects it caused
Quality and Safety Signals: Output quality, violation/over-privilege risks, rollback frequency and reasons
Without “behavior observability,” governance cannot be implemented.
Risk Governance: Bringing High-Risk Capabilities Under Continuous Assessment and Control
When model capabilities approach thresholds that can “cause serious harm,” organizations need a systematic risk governance framework, not relying on single-point prompts or manual reviews.
Can be split into two layers:
System-Level Trustworthiness Goals: Organizational-level requirements for security, transparency, explainability, and accountability
Frontier Capability Readiness Assessment: Tiered assessment of high-risk capabilities, launch thresholds, and mitigation measures
The value lies in: transforming “safety/risk” from concepts into executable launch thresholds and operational policies.
Takeaways / Checklist
The following checklist can be used to determine whether an organization has entered the AI-native stage:
Do we treat models as “agents that act,” not as replaceable APIs?
Do we bring compute and budgets into business SLAs and decision processes?
Do we treat uncertainty as the default premise, not as an exception?
Do we have audit, rollback, and accountability for model behavior?
Do we have cross-team AI governance mechanisms, not single-point engineering optimizations?
Can we explain the system’s operating boundaries, cost boundaries, and risk boundaries?
Summary
The essence of AI-native infrastructure lies in: taking models as behavior subjects, compute as scarce assets, and uncertainty as the norm, achieving deliverable, governable, and evolvable AI systems through governance and closed-loop mechanisms. Only by engineering these capabilities can organizations truly step into the AI-native stage.
The following 10 questions assess whether an organization possesses the strategic and execution readiness for AI-native infrastructure. The diagram below categorizes these questions into three domains: strategy, governance, and execution, facilitating executive discussions.
Figure 1: Executive checklist structure diagram
Can you clearly define the unit cost for each major AI workload (e.g., per 1M tokens, per agent task, per batch job)?
Do you have budget/quota mechanisms that can constrain team/project/tenant compute consumption within controllable bounds?
Can you make explicit policy trade-offs between “performance (throughput/latency)—cost—risk” (rather than relying on verbal constraints)?
Can your platform handle uncertainty: spikes, long-tail effects, and resource fluctuations caused by agent path explosions?
Are agent/MCP “intents” mapped to actionable and billable/auditable resource consequences?
Do you have clear resource isolation and sharing strategies (same-card sharing, memory isolation, preemption, prioritization) to improve utilization?
Can you achieve cross-layer observability: end-to-end tracing from request/agent → runtime → GPU/network/storage → cost?
Does your infrastructure support rapid adoption of new hardware/interconnect/topology changes (heterogeneity and evolution are the norm)?
Has the organization established “AI SRE/ModelOps + FinOps” collaboration mechanisms and accountability boundaries (who owns cost and reliability)?
When you say “we are AI-native,” can you provide three planes + one closed loop architecture diagram and governance strategy on a single page?
Migration is not “rebuilding the platform,” but using governance loops and organizational contracts to transform uncertainty into controllable engineering capabilities.
The previous five chapters have established: AI-native infrastructure is Uncertainty-by-Default. Therefore, the architectural starting point must be compute governance loops, not “connect a model and call migration complete.” Otherwise, systems easily spiral out of control in three dimensions: cost (runaway cost), risk (unauthorized actions/side effects), and tail performance (P95/P99 and queue tail behavior).
This explains why the FinOps Foundation emphasizes: running AI/ML on Kubernetes, “elasticity” easily evolves into uncontrollable cost overflow. FinOps must be incorporated into architecture and organization upfront as a shared operating model, not as an after-the-fact reconciliation exercise.
This article presents an actionable migration roadmap, covering both technical evolution paths and organizational implementation approaches. You don’t need to “rebuild an AI platform” all at once, but you must establish working governance loops at each stage: budget/admission, metering/attribution, sharing/isolation, topology/networking, and context assetization.
The North Star: From Platform Delivery to Governance Loops
The diagram below shows the migration path from bypass pilot to AI-first refactoring.
Figure 1: AI-native migration roadmap
Cloud-native migration typically centers on “capability delivery”: CI/CD, self-service platforms, service governance, and auto-scaling. Its default assumptions: systems are deterministic, costs grow linearly with requests, and scaling doesn’t significantly alter system boundaries.
AI-native migration must center on “governance loops”, focusing on cost, risk, tail performance, and state assets. Its default assumptions are precisely the opposite: systems are inherently uncertain, and the “actions and consequences” of inference/agents drive costs and risks into nonlinear territory.
North Star Definition
AI-Native Migration = Establish an AI Landing Zone + Compute Governance Loop + Context Tier, and ensure all agents/APIs/runtimes operate within this loop.
Elevating “Landing Zone” to North Star level here isn’t chasing trends—it’s because it naturally serves an organizational-level task: delineating responsibility boundaries between platform teams and workload teams. Major cloud providers universally use Landing Zones to host “shared governance baselines” (networking, identity, policies, auditing, quota/budget), while business teams iteratively build applications within controlled boundaries. For AI, this boundary is the carrier of the governance loop.
Migration Prerequisites: Build Three Foundations First, Then Scale Applications
You can run PoCs and build applications in parallel, but if these three foundations are missing, any “application explosion” can easily transform into platform firefighting and financial disputes.
Foundation A: FinOps / Quotas as Control Plane (Finance and Quotas as Control Plane)
The first migration step is not “launch the first agent,” but incorporating budgets, alerts, showback/chargeback, and quotas into the infrastructure control plane:
Budgets and alerts are not just financial reports, but triggers for runtime policies (rate limiting, degradation, queuing, preemption).
showback/chargeback is not just accounting, but binding “cost consequences” to organizational decisions and product boundaries.
Quotas are not static limits, but evolvable governance instruments (dynamic budgets and priorities by tenant/team/use-case).
Migration Threshold
If you cannot attribute the primary consumption of each agent/job to team/project/model/use-case (at minimum covering tokens, GPU time, KV footprint, key network/storage), you haven’t reached the “scale” starting line. Piloting is acceptable, but expansion is not advisable.
Foundation B: Resource Governance (GPU Sharing/Isolation and Orchestration Capabilities)
The “elasticity” of AI-native infrastructure is constrained by how scarce compute is governed. Treating GPUs as ordinary resources typically results in low utilization and uncontrolled contention. Therefore, you need viable combinations of sharing/isolation and orchestration capabilities:
Sharing/partitioning: MIG/MPS/vGPU paths transform “exclusive” into “pooled.”
Scheduling upgrades: Introduce explicit modeling of topology, queues, fairness, preemption, and cost tiers.
Orchestration loop: Solidify isolation, preemption, and priority policies into executable rules.
The key is not which partitioning technology you choose, but whether you can elevate GPUs from “machine assets” to first-class governance resources and incorporate them into budget and admission systems.
Foundation C: Fabric as a First-Class Constraint (Network/Interconnect as First-Class Constraint)
Training and high-throughput inference are extremely sensitive to congestion, packet loss, and tail latency. Ignoring networking and topology leads to “seemingly sporadic but actually structural” problems:
Training JCT is amplified by tail behavior, invalidating capacity planning;
Inference P99 and queue tails are amplified, making SLOs difficult to honor.
Therefore, you need to build reusable AI-ready network baselines: capacity assumptions, lossless strategies, isolation domain partitioning, measurement and acceptance criteria. Networking is not “optimize later,” but baseline engineering that must land in Days 31–60.
Migration Path Selection: Layered by Organizational Risk and Technical Debt
Migration isn’t “pick one path and see it through,” but mapping organizations with different risk appetites and debt structures to different starting approaches and exit criteria. Paths can advance in parallel, but each needs defined applicable conditions and exit criteria.
Path 1: Bypass Pilot / Skunkworks
Applicable when cloud-native platforms are running stably, but AI demand is just emerging, organizational uncertainty is high, and governance mechanisms are not yet mature.
The approach is establishing an “AI minimum closed-loop sandbox” alongside the existing platform. The goal is not “feature completeness,” but “making the loop work”:
Independent GPU pool (or at least independent queue) + basic admission and budget
Minimal token/GPU metering and attribution
Controlled inference/agent entry points (max context / max steps / max tool calls)
“Failure-acceptable” SLOs and cost caps (define boundaries first, then discuss experience)
Exit criteria:
Cost curve is explainable (at minimum attributable to team/use-case)
GPU utilization and isolation strategies form reusable templates
Pilot capabilities can be absorbed into platform capabilities (enter Path 2)
Path 2: Domain-Isolated Platform
Applicable when AI has entered multi-team, multi-tenant stages, requiring “pilot assets” to be solidified into platform capabilities to prevent cost and risk from spreading across domains.
The approach is building an AI Landing Zone, where the platform team centrally manages shared governance capabilities, and workload teams iteratively build applications within controlled boundaries.
Platform-side essential modules (recommend organizing by “governance loop”):
Identity/Policy: Unified identity, policy distribution, and auditing (policy-as-intent)
Network/Fabric baseline: AI-ready network baseline and automated acceptance
Runtime catalog: “Golden paths” and templated delivery for inference/training runtimes
Exit criteria: Platform provides “replicable AI workload landing approaches” and can scale use case count under budget constraints, rather than relying on manual firefighting to maintain stability.
Applicable when AI is core business, requiring infrastructure to be treated as a “production line” rather than a “cluster,” and optimization objectives to switch from “shipping features” to “throughput/unit cost/energy efficiency.”
The approach centers on “state assets + unit cost” refactoring:
Context/state of inference/agents is explicitly governed and reused (no longer application-level tricks)
Introduce Context Tier architectural assumptions: long context and agentic inference require inference state / KV cache to be reusable across nodes and sessions
Drive platform evolution with “unit token cost, tail latency, throughput/energy efficiency,” not “number of new components”
Exit criteria: Can consistently make engineering decisions using “unit cost and tail performance,” and treat context reuse as a platform capability rather than application team trick caching.
90-Day Actionable Plan: AI Landing Zone + Minimum Governance Loop
The goal is to establish “AI Landing Zone + minimum governance loop” within 90 days, forming a replicable template. The key is not covering all scenarios, but connecting the admission—metering—enforcement—feedback loop.
Day 0–30: Establish the Ledger (Cost & Usage Ledger)
First, define attribution dimensions, establish budgets/alerts and baseline reports, and implement quotas/usage controls.
Establish budgets and alerts, baseline reports (cost + business value metrics)
Implement quotas and usage controls (at minimum covering GPU quotas and key service quotas)
Deliverables:
Cost and usage dashboard (weekly-level, traceable)
“Admission Policy v0” (max context / max steps / max budget)
Day 31–60: Establish Resource Governance (GPU Governance + Scheduling)
This phase requires evaluating GPU sharing/isolation strategies, introducing topology/networking constraints, and forming two golden paths for inference and training.
GPU sharing/isolation strategy: MIG/MPS/vGPU/DRA path evaluation and PoC (executable strategy as acceptance criteria)
Introduce topology/networking constraints, form AI-ready network baseline and capacity assumptions (including acceptance criteria)
Form two templated delivery paths for inference/training
Deliverables:
Workload templates (1 each for inference and training)
Scheduling and isolation strategies (whitelisted, auditable)
Day 61–90: Establish the Loop (Enforcement + Feedback)
The final phase requires executing budget policies, migrating pilot use cases to the landing zone, and solidifying organizational interfaces.
Execute budgets: rate limiting/queuing/preemption/degradation strategies, linked to SLOs
Migrate pilot use cases to landing zone (or service landing zone capabilities)
Solidify “organizational interface”: platform team vs workload team responsibility boundaries (forming executable contracts)
Two replicable use case landing paths (new use cases <= 30 minutes to golden path)
Operating Model: The “Contract” Between Platform Teams and Workload Teams
Migration success depends on establishing clear, executable “organizational contracts.” The contract essence: who is responsible for “capability provision,” who is responsible for “behavioral consequences.”
Platform teams provide (must be stable)
Landing zone, network baseline, identity and policies, budget/quota systems, metering/attribution, GPU governance capabilities, runtime golden paths
Workload teams own (must be self-service)
Model selection, prompt/agent logic, tool integration, SLO definition, business value measurement, use case risk classification and rollback paths
This is also why the FinOps Framework emphasizes operating model (personas, capabilities, maturity) rather than just tools: without “contracts,” budgets are difficult to execute; if budgets cannot execute, loops cannot form.
Migration Anti-Patterns
Below are common migration anti-patterns and their consequences:
Anti-Pattern
Typical Consequences
Build only API/Agent platform, without ledger and budget
runaway cost (most common, and difficult to remediate afterwards)
Treat GPUs as ordinary resources, without sharing/isolation and scheduling upgrades
Low utilization + uncontrolled contention, platform forced to allocate compute via “administrative means”
Ignore networking and topology
Tail latency and training JCT amplified, capacity planning fails, SLOs difficult to honor
Context not assetized (only “tricky caching” within applications)
Unit cost out of control in long context/agentic era, reuse capabilities difficult to solidify as platform capabilities
Table 1: Common Migration Anti-Patterns and Consequences
Summary
The core of AI-native migration is not a “migration checklist,” but under uncertainty premises, incorporating cost, risk, and tail performance into a unified governance loop, using Landing Zone to carry organizational contracts, and using Context Tier to implement state reuse infrastructure capabilities. Only in this way can platform and business maintain controllability and efficiency during scaled evolution.
The compute governance closed loop is the foundational safeguard for sustainable innovation in AI-native organizations.
Perspective
API/Agent/MCP solve “how intent is expressed,” while compute governance addresses “whether the resource consequences of intent are economically viable and risk-controllable.” In the AI era, the latter becomes a prerequisite for the former. API-first without governance only amplifies costs and uncertainty, pushing organizations into the trap of “functional but unsustainable.”
The FinOps Foundation states directly in “Scaling Kubernetes for AI/ML Workloads with FinOps” that Kubernetes elasticity can easily evolve into a runaway cost problem. Therefore, FinOps should not be just cost reporting, but must become a shared operating model where every scaling decision simultaneously answers two questions: Are performance SLOs met?, and Is it affordable?.
The Challenge of API-first “Implicit Assumptions” in the AI Era
The diagram below shows the boundary relationships and accountability chains between platform, ML, and security teams.
Figure 1: Organizational boundaries and accountability chain
The intuitive path of API-first is: first make the interfaces and workflows work, then gradually optimize performance and cost through engineering. In AI-native infrastructure, this path often fails because it relies on three implicit assumptions that no longer hold in the AI era.
Assumption 1: Resources are not the core scarcity
Traditional software bets scarcity on engineering efficiency, throughput, and stability; whereas AI-native infrastructure scarcity comes primarily from asset boundaries like GPU/interconnect/power consumption. Scarcity is no longer “slow to scale,” but “hard to scale and expensive,” constrained by both supply chain and datacenter conditions.
Assumption 2: Request costs are predictable
Traditional request cost distribution is relatively stable; AI requests are inherently long-tailed: branching in agentic tasks, inflation of long contexts, and chain amplification of tool calls all make tokens and GPU time into random variables that cannot be linearly extrapolated. You think you’re scaling “QPS,” but actually you’re scaling “total cost of tail probability events.”
Assumption 3: State is ephemeral and discardable
The cloud-native era emphasized stateless scaling with externalized state; but on the inference side, inference state/context reuse often determines whether unit costs are controllable. NVIDIA describes this in Rubin’s ICMS (Inference Context Memory Storage) as the “context storage challenge brought by new inference paradigms”: KV cache needs reuse across sessions/services, sequence length growth causes linear KV cache inflation, forcing persistence and shared access, forming a “new context tier,” and proving with TPS and energy efficiency gains that this is not a nice-to-have, but a threshold for scalability.
Conclusion
In AI-native infrastructure, state and compute governance have become prerequisites for “whether it can run,” not post-optimization items.
The Nature of Compute Governance: What is Being Governed
“Compute governance” is often misunderstood as “managing GPUs,” but what truly needs governance is the resource consequences of intent. More precisely, it’s governing the combined effects of four types of objects:
Token Economics
Each request/task’s token consumption, context inflation, implicit token tax from tool definitions and intermediate results, ultimately directly mapping to cost and latency.
Accelerator Time
GPU time, memory footprint, batching strategies, and the impact of routing and cache hits on effective throughput. The key is not “whether there are GPUs,” but “whether output per unit GPU time is controllable.”
Interconnect and Storage (Fabric & Storage)
Network and storage pressures from training all-reduce, inference KV/cache sharing, and cross-service data movement. AI performance and cost are often amplified by fabric, not by APIs.
Organizational Budget and Risk (Budget & Risk)
Multi-tenant isolation, fairness, audit, compliance, and accountability. These determine whether the system can scale to multiple teams/business lines, not just scaling demos to more instances.
The FinOps Foundation also emphasizes: AI/ML cost drivers are not just GPUs; storage (checkpoints/embeddings/artifacts), network (distributed training/cross-AZ), and additional licensing and marketplace fees often “quietly exceed compute.” Therefore, governance objects must cover end-to-end, not just stare at inference bills.
MCP/Agent: Amplification Effects Under Governance Gaps
MCP/Agent expand the “capability surface,” but simultaneously make cost curves steeper, especially showing exponential amplification when governance is missing:
More tools, more branches: Planning space expands, tail probability rises, cost volatility becomes uncontrollable.
Tool definitions and intermediate results consume context: Directly consuming context window and tokens, translating to cost and latency.
Stronger tool usage triggers more external I/O: External system calls, network round trips, and data movement all enter the overall cost function.
Anthropic explicitly states in “Code execution with MCP” that direct tool calls increase cost and latency due to tool definitions and intermediate results consuming context window; when tool numbers rise to hundreds or thousands, this becomes a scalability bottleneck, thus proposing code execution forms to improve efficiency and reduce token consumption.
Conclusion
In the MCP/Agent era, governance is not about suppressing innovation, but making innovation sustainable within budget boundaries. Without governance, agents are not productivity tools, but cost amplifiers.
Minimal Implementation Path for “Compute Governance First”
You don’t have to bind to any vendor, but you must implement a “minimum viable governance stack.” The goal is not perfection, but giving the system controllable boundary conditions from day one.
Admission and Budget (Admission + Budget)
Set budgets and priorities for workload types (training/inference/agent tasks).
Include budget, max steps, max tokens, max tool calls in policy-as-intent, and enforce at the entry point.
Practice Recommendation
FinOps’ core view is: embed FinOps early into architecture, making every scaling decision simultaneously answer “performance” and “affordability,” otherwise bills only get attention when incidents occur.
End-to-End Metering and Attribution (Metering + Attribution)
At minimum achieve one traceable chain: request/agent → tokens → GPU time/memory → network/storage → cost attribution (tenant/project/model/tool).
Without attribution, there is no governance; without governance, enterprise scaling is impossible, because costs and responsibilities cannot align, and organizations will internally waste energy on “who consumed the budget.”
Isolation and Sharing (Isolation + Sharing)
Sharing for improving utilization; isolation for reducing risk. Both must exist simultaneously, not either/or.
CNCF’s Cloud Native AI report notes: GPU virtualization and sharing (like MIG, MPS, DRA, etc.) can improve utilization and reduce costs, but requires careful orchestration and management, and demands collaboration between AI and cloud-native engineering teams.
The key to governance is not choosing sharing or isolation, but making it an executable policy: who shares under what conditions, who isolates under what conditions.
Topology and Network as First-Class Citizens (Topology + Fabric First)
AI training and high-throughput inference are highly sensitive to network characteristics.
Cisco’s AI-ready infrastructure design guides and related CVD/Design Zone emphasize: building high-performance, lossless Ethernet fabric for AI/ML workloads, and delivering reference architectures and deployment guides through validated designs.
This means topology is not “the datacenter team’s business,” but a core variable determining whether JCT, tail latency, and capacity models hold.
Context/State Becomes a Governance Object (Context as a Governed Asset)
When long-context and agentic become mainstream, KV cache and inference context reuse will directly determine unit costs.
NVIDIA’s ICMS defines this as a “new context tier” for solving KV cache reuse and shared access, emphasizing TPS/energy efficiency gains.
In this era, treating context as a temporary variable is actively relinquishing cost control.
Anti-Pattern Checklist
The following anti-patterns are not “engineering inelegance,” but will trigger organizational loss of control, worth vigilance.
API-first, treating governance as post-optimization
Result: System launches first, only to discover unit costs and tail latency are uncontrollable, can only “hard brake” through feature limiting/rate limiting, ultimately locking the product roadmap.
Contrast: FinOps points out elasticity easily becomes runaway costs, must advance cost governance into architecture decisions.
Treating MCP/Agent as capability accelerators, not cost amplifiers
Result: More tools make it “smarter,” but token and external call costs rise exponentially, engineering teams forced to fight systemic amplification with “more complex prompts and rules.”
Contrast: Anthropic notes tool definitions and intermediate results consume context, increase cost and latency, proposing more efficient execution forms as the scalability path.
Only buying GPUs, without sharing/isolation and orchestration
Result: Low utilization, severe contention, budget explosion, organizations internally blame each other “who’s grabbing resources, who’s burning money.”
Contrast: CNCF Cloud Native AI report emphasizes sharing/virtualization improves utilization, but must match orchestration and collaboration mechanisms.
Ignoring network and topology, treating AI as ordinary microservices
Result: Training JCT and inference tail latency amplified by network, capacity planning and cost models fail, more scaling makes it more unstable.
Contrast: Cisco in AI-ready network design and validated designs makes requirements like lossless Ethernet fabric critical foundations for AI/ML.
Summary
The first-principle entry point for AI-native is the compute governance closed loop: budget and admission, metering and attribution, sharing and isolation, topology and network, context assetization. API/Agent/MCP remain important, but must be constrained by this closed loop, otherwise the system can only oscillate between “smarter” and “more bankrupt.”
The key to governing AI-native infrastructure lies in how to institutionalize the closed-loop management of costs and risks arising from uncertainty.
In the cloud-native era, system operations were typically considered “basically deterministic”: request paths were predictable, resource curves were relatively stable, and scaling could respond promptly to load changes. However, entering the AI era, this assumption no longer holds—uncertainty has become the norm.
This chapter aims to provide CTOs/CEOs with key conclusions for architecture reviews:
The starting point of AI-native infrastructure is to treat uncertainty as the default input;The goal is to achieve closed-loop governance of the resource consequences (cost, risk, experience) arising from uncertainty.
This is also why “becoming AI-native” in organizational contexts increasingly points to the reshaping of operational methods and governance models: when system consequences are amplified, governance must be institutionalized.
What is an “Uncertain System”
In this handbook, “uncertainty” does not refer to randomness in the probabilistic sense, but to three types of phenomena in engineering practice:
Unpredictable behavior: execution paths change dynamically with model inference, especially evident in agentic processes (Agent intelligent workflows).
Unpredictable resource consumption: tokens, KV cache, tool calls, I/O, and network overhead exhibit long-tail and burst characteristics.
Non-linear consequences: the same “intent” can produce cost and risk outcomes differing by orders of magnitude.
Therefore, the infrastructure problem of AI-native infrastructure has shifted from “how to make the system more elegant” to:
How to ensure the system maintains economic viability, controllability, and recoverability when worst-case scenarios occur.
During architecture reviews, if you cannot answer “what is the worst case, where are the upper bounds, and how to degrade/rollback when triggered,” you are still reviewing the inertia extension of deterministic systems, not true AI-native systems.
Major Sources of Uncertainty
The following table summarizes common sources of uncertainty in AI-native infrastructure and their specific manifestations, facilitating quick reference for CTOs/CEOs.
Type
Manifestations
Impact Areas
Behavior Uncertainty
Agent task decomposition path changes, tool selection and call sequence changes, failure retry and reflection
Cost, Risk, Resilience
Demand Uncertainty
Concurrency and burst, long-tail requests, multi-tenant interference (noisy neighbor)
Resource pools, Experience, Isolation
State Uncertainty
Context reuse across requests, KV cache migration and sharing
Performance, Cost, Governance
Infrastructure Uncertainty
High sensitivity to network/storage/interconnect, congestion and jitter amplified into tail latency
Experience, Cost, Stability
Table 1: Sources and Manifestations of Uncertainty in AI-Native Infrastructure
Behavior Uncertainty
Behavior uncertainty is mainly reflected in changes to agent task decomposition paths, dynamic adjustment of tool selection and call sequences, and path explosion caused by failure retry, reflection, and multi-round planning. Tools and contexts are combined through standard interfaces (such as MCP protocol integration), significantly expanding system capability surfaces while making branch space a governance challenge.
More critically, tool calls are not “free external functions” - they occupy context windows and consume token budgets, amplifying cost and tail latency pressures. Therefore, behavior uncertainty is not merely “feature flexibility” at the product layer, but “cost and risk elasticity” at the platform layer, which must be budgeted, capped, and made auditable.
Demand Uncertainty
Demand uncertainty includes concurrency and burst (peaks), long-tail requests (ultra-long contexts, complex reasoning), and mutual interference under multi-tenancy (noisy neighbor). This drives capacity planning from “average capacity” to “tail capacity + governance strategies.”
In AI-native infrastructure, experience and cost are often determined not by average requests, but by the combination of tail requests: a small number of long-chain, long-context, tool-intensive requests can overwhelm shared resource pools. Therefore, demand uncertainty requires answering: which requests deserve guarantees, which must be throttled, and which should be isolated.
State/Context Uncertainty
State uncertainty is the most underestimated category in the AI era: context is a state asset, and it often exists across requests. When inference state / KV cache is elevated to a reusable, shareable, migratable system capability, it is no longer an application detail but a decisive variable for throughput and unit cost. NVIDIA in public materials identifies Inference Context Memory Storage as a new infrastructure layer, pointing to state reuse and sharing requirements for long-context and agentic workloads.
The conclusion is: “context/state” has changed from optional optimization to a critical infrastructure asset that must be meterable, allocable, and governable.
Infrastructure Uncertainty
AI workloads are far more sensitive to network, interconnect, and storage than traditional microservice workloads. Congestion, packet loss, and I/O jitter are amplified into tail latency and job completion time instability, creating “non-linear consequences” for experience and cost.
This type of uncertainty usually cannot be solved through “component selection” but requires end-to-end path engineering constraints: from topology, bandwidth, and queuing, to transport protocols, isolation strategies, and congestion control—all must be incorporated into the governance plane, not just the operations plane.
How Uncertainty Amplifies Across Layers
The diagram below illustrates the closed-loop relationship between metrics, budgets, and isolation strategies, emphasizing that governance must be rewritable.
Figure 1: SLO to cost feedback loop
The flowchart below demonstrates the cross-layer amplification path of uncertainty in AI-native infrastructure:
Figure 2: Uncertainty amplification across layers
Typical phenomena include:
Agent branch explosion: more tools and composable paths make tail costs increasingly uncontrollable.
Context inflation: long contexts and multi-round reasoning make KV cache a performance bottleneck and cost black hole.
Resource contention distortion: GPU/network contention under multi-tenancy makes “average performance” meaningless—tails must be governed.
Therefore, the core of AI-native is not “making execution stronger,” but enabling you to stably answer three questions:
Where are the upper bounds (budgets, steps, call counts, state occupancy)
What to do when crossing boundaries (degradation, rollback, isolation, blocking)
How results are rewritten (policy iteration and cost correction)
Engineering Response of AI-Native Infrastructure
Enterprises can refer to the following five “hard standards” during reviews—missing any one means inability to achieve closed-loop governance of uncertainty.
Admission: Ingress Admission Control
Implement tiered admission for requests with ultra-long contexts, oversized tool graphs, or ultra-high budgets
Bind “budget, priority, compliance” as part of intent (policy as intent)
Clearly communicate rejection reasons and explain why requests are denied
Key Point
The responsibility of admission is not “to allow features,” but to write consequence constraints into the contract.
Translation: Intent Translation to Governable Execution Plans
Select runtime, routing/batching strategies, and caching strategies for requests
“Cap” agent workflows: maximum steps, maximum tool calls, maximum tokens
Include fallback paths: deterministic alternatives, cached answers, manual/rule-based fallbacks
Key Point
Upgrade from “prompt-driven execution” to “plan-driven execution”—plans must be understandable and constrainable by the governance plane.
Metering: End-to-End Metering and Attribution
Meter tokens, GPU time, KV cache footprint, I/O, and network for each request/agent task
Attribute by tenant, project, model, and tool to form cost and quality metrics
Separately label “tail overhead” so long-tail costs no longer hide in averages
Key Point
No ledger means no budget; no attribution means no governance, let alone ROI.
The core of AI-native infrastructure governance lies in front-loading uncertainty, layered metering, policy feedback, and institutionalized constraints to form a closed loop of cost and risk. Only with engineering mechanisms such as Admission, Translation, Metering, and Enforcement can systems achieve economically viable, controllable, and recoverable operations under normalized uncertainty.
The true value of architecture is enabling organizational consensus on complex systems within five minutes, not creating another new technology stack.
Industry-leading vendors emphasize different aspects: Cisco focuses more on AI-native infrastructure and reference designs such as Cisco Validated Designs; HPE emphasizes an open, full-stack AI-native architecture across the AI full lifecycle; NVIDIA explicitly proposes adding a new AI-native infrastructure tier for inference context reuse in long-context and agentic workloads. This chapter converges these perspectives into a verifiable architecture framework: Three Planes + One Loop.
Note
The “architecture” in this chapter serves as a review framework, not a component checklist. The goal is to unify organizational language and review boundaries, not to reinvent the technology stack.
One-Page Architecture Overview
Below is the detailed reference architecture diagram for the three planes and closed loop of AI-native infrastructure, helping readers quickly establish an overall understanding:
Figure 1: Three planes detailed architecture diagram
This diagram can be understood as: The new control plane (Intent) of AI-native infrastructure must be constrained by the Governance Plane and produce measurable resource consequences in the Execution Plane.
This is also the common ground behind different vendor narratives: Cisco uses reference designs and delivery frameworks to make infrastructure capabilities scalable and replicable; HPE uses open/full-stack to cover lifecycle delivery; NVIDIA elevates the reuse of “context state assets” to an independent infrastructure layer. All three point to the same issue: incorporating AI resource consequences into governable system boundaries.
Core Capabilities of the Three Planes
This section details the core capabilities of each of the three planes to help clarify focus areas during architecture reviews.
Intent Plane
The Intent Plane is responsible for expressing “what I want,” including the following capabilities:
Inference/Training APIs (entry points and contracts)
MCP/Tool calling protocols and tool catalog (standardizing tool access as “declaratable capability boundaries”)
Agent/Workflow (breaking down tasks into executable steps)
Policy as Intent: priorities, budgets, quotas, compliance/security constraints (front-loaded in the form of “intent”)
Key Point: The Intent Plane is not the starting point itself; the real starting point is—whether intent can be translated into executable and governable plans. Otherwise, Agents/MCP will only amplify uncertainty: more tools, longer chains, larger state spaces, and more uncontrollable resource consumption.
During architecture reviews, focus on these questions:
Is intent declarable (contract) and rejectable (admission)?
Does intent carry budget/priority/compliance constraints (policy as intent)?
Is the translation from intent to execution traceable?
Execution Plane
The Execution Plane is responsible for landing intent into “actual execution,” mainly including:
“State and Context” services: cache/KV/vector/context memory, etc., for carrying inference context, retrieval results, and session state
Full-chain observability hooks: token metering, GPU time, video memory, network traffic, storage I/O, queue wait times, etc.
An industry trend worth emphasizing: as long-context and agentic workloads become widespread, “context” itself becomes a critical state asset and may even rise to become an independent infrastructure layer. NVIDIA explicitly proposes inference context memory storage in the Rubin platform, establishing an AI-native infrastructure tier to provide shared, low-latency inference context at the pod level to support reuse (for long-context and agentic workloads).
Review points focus on three things:
Is execution measurable: Can attribution be done across token/GPU/network/storage dimensions?
Is state governable: What are the lifecycle, reuse boundaries, and isolation strategies for context and cache?
Is observability closed-loop oriented: Observability is not for “seeing,” but for “enabling governance to correct deviations.”
Governance Plane
The Governance Plane is the “core differentiator” of AI-native infrastructure, responsible for transforming resource scarcity and uncertainty into a controllable system:
Budget/quotas/billing: governing consumption across teams, tenants, projects, models, and agent tasks
Isolation and sharing strategies: same-card sharing, video memory isolation, preemption, priorities, fairness
Topology-aware scheduling: incorporating GPU, interconnect, network, and storage topology into placement (especially in training and high-throughput inference)
Risk and compliance control: audits, policy enforcement points, sensitive data and access control
Integration with FinOps/SRE/SecOps: incorporating cost, reliability, and risk into a single operational mechanism
From a vendor narrative perspective, this layer typically corresponds to “reference architecture + full-stack delivery”:
Cisco emphasizes accelerating and scaling delivery in AI infrastructure through “fully integrated systems + Cisco Validated Designs”; HPE emphasizes end-to-end delivery with “open, full-stack AI-native architecture” to support model development and deployment.
The baseline question for Governance Plane reviews is: Can you make explainable resource allocation and degradation decisions under budget/risk constraints?
Closed-Loop Mechanism Explained
This section introduces the core workflow of the closed-loop mechanism to help understand the essential difference between AI-native and AI-ready.
Significance of the Closed-Loop Mechanism
The closed loop is the most confusing yet critical dividing line between AI-native and “AI-ready.”
The minimal implementation of the closed loop includes four steps:
Admission: Bind intent with policy at the entry point (budget, priority, compliance)
In other words: The closed loop is not a “monitoring dashboard,” but a “governance-driven real-time correction mechanism.”
If there is no closed loop for “intent → consumption → cost/risk outcomes,” systems can easily spin out of control across cost, risk, quality, and other dimensions.
This is also why “AI-native” is often accompanied by changes in operating model: when system execution speed and resource consumption are amplified by models/agents, organizations must front-load governance mechanisms and institutionalize them. LF Networking also explicitly points out: becoming AI-native is not just a technical migration, but a redefinition of the operating model.
Practical Usage of the One-Page Architecture
In subsequent chapters, this “one-page architecture” can be repeatedly reused as a review template:
Discussing MCP/Agent: Position them in the Intent Plane and constrain with the closed loop (admission/translation) to avoid “intent proliferation”
Discussing runtime and platforms: Place in the Execution Plane, focusing on observable, attributable, governable state assets (context/cache/KV/vector)
Discussing GPUs, scheduling, costs: Ground in the Governance Plane, using budget/isolation/topology/metering as leverage points
Discussing enterprise implementation: Use the closed loop to examine if it’s “truly AI-native” (whether cost/risk outcomes can be written back as executable policies)
If you can only remember one sentence:
The determination of AI-native is not in “how many AI components are used,” but in “whether there exists an executable governance closed loop that constrains intent to controllable resource consequences and economic/risk outcomes.”
Summary
The one-page reference architecture provides a unified systems language and review framework for AI-native infrastructure. Through the three planes of Intent, Execution, and Governance, combined with the closed-loop mechanism, organizations can achieve efficient collaboration in architecture design, resource governance, and risk control. Looking ahead, as AI-native capabilities continue to mature, the governance closed loop will become a core competitive advantage for enterprises implementing AI.
json-render is an open-source framework that constrains natural language or model outputs into structured JSON so AI only uses a predefined component catalog to describe UIs. This approach makes AI output predictable and safer to render. The project provides a core type system, a React renderer, and example apps to streamline AI-driven UI pipelines into renderable, interactive frontend components.
Main Features
Define available components and actions in a catalog as guardrails to keep model outputs within permitted boundaries.
Support streaming generation and progressive rendering to improve interactivity and reduce time-to-first-render.
Built-in validation and schema checks (e.g., zod) to guarantee output correctness.
Ships React renderer and example projects for easy integration and extension.
Use Cases
Convert natural-language prompts into dashboards, reports, and visualization components.
Serve as a guardrail layer where model outputs require provable constraints before rendering.
Act as a frontend integration layer to render responses from RAG, LLMs, or other intelligent services into safe, interactive UI.
Technical Features
Monorepo with packages such as @json-render/core and @json-render/react allowing modular adoption.
Schema-driven validation (zod) for component props and actions to ensure type-safety and stability.
Action declarations with external callback binding enable mapping user interactions to backend operations.
Apache-2.0 license, active community, and playground/example apps for quick onboarding.
The Universal Commerce Protocol (UCP) is an open, standards-driven specification that provides a common language and primitives for commerce interactions between AI agents, platforms, merchants, payment service providers, and credential providers. By defining Capabilities and Extensions, UCP enables platforms to discover merchant-supported features and securely initiate checkout and order flows with or without human intervention.
Main Features
Capability-driven, composable architecture: commerce actions are expressed as discrete Capabilities (e.g., Checkout, Identity Linking, Order) with optional Extensions for enhanced experiences.
Dynamic discovery and configuration: merchants publish capability profiles so platforms can automatically discover and configure integrations, reducing one-off integration work.
Transport-agnostic design: the protocol is transport-neutral and supports REST, MCP (Model Context Protocol), or agent-to-agent (A2A) transports.
Use Cases
Agent-assisted shopping: agents can discover products, populate carts, and complete payments on behalf of users, enabling autonomous shopping experiences.
Platform integration: third-party platforms can call unified capabilities across multiple merchants for seamless cross-merchant experiences.
PSP and credential provider integration: standardized token and credential exchange flows simplify payment and identity integrations.
Technical Features
Built on open standards: UCP prefers existing standards for payments, identity, and security to avoid reinventing solutions.
Extensible capability model: keeps core capability definitions concise while allowing targeted extensions for specialized features.
Developer-friendly: comprehensive documentation, examples, and SDKs support rapid implementation and conformance testing.
cagent is a containerized agent builder and runtime developed by Docker engineering to streamline the workflow from building to deploying lightweight AI agents. It provides an extensible daemon and toolchain that support containerized deployment, resource isolation, and telemetry, making it easier to run agents in cloud-native and edge environments with observability.
Main Features
A unified agent builder and runtime that supports container images and local debugging.
Native container resource isolation and scheduling support with compatibility for Kubernetes deployment patterns.
Built-in telemetry and monitoring interfaces to integrate with Prometheus and Grafana.
Use Cases
Suitable for hosting autonomous tasks, data collectors, or lightweight agents in cloud-native or edge environments. Teams can use cagent to rapidly build, iterate, and deploy agent services while maintaining stable operation, resource isolation, and performance observability.
Technical Features
Implemented in Go with an emphasis on low overhead and extensibility. cagent adopts containerization and daemon patterns, integrates with existing CI/CD and monitoring ecosystems (such as Prometheus), and is designed for production orchestration and operations.
PatrickStar is a PyTorch-based parallel training framework for large pretrained models (PTMs). It uses a chunk-based dynamic memory management and heterogeneous training strategy to offload non-critical data to CPU memory, allowing training of larger models with fewer GPUs and reducing OOM risk. Maintained by Tencent’s NLP / WeChat AI teams, PatrickStar aims to democratize access to large-scale model training.
Main Features
Chunk-based dynamic memory scheduling: manage activations and parameters by computation windows to lower GPU memory usage.
Heterogeneous offloading: move non-immediate data to CPU to support mixed CPU/GPU memory usage.
Efficient communication and scalability: optimized collective operations for multi-GPU and multi-node setups.
PyTorch compatibility: configuration style similar to DeepSpeed for easier migration.
Use Cases
Suitable for pretraining and large-scale fine-tuning, especially when hardware is constrained and teams need to train models in the tens to hundreds of billions of parameters. Also useful for benchmarking, framework research, and academic or research teaching environments.
Technical Features
PatrickStar implements chunk-based memory management and runtime dynamic scheduling to keep only the chunks needed for current computation while asynchronously migrating others. It optimizes collective communication for multi-card efficiency and provides benchmarks and examples for V100/A100 clusters. The project is released under BSD-3-Clause.