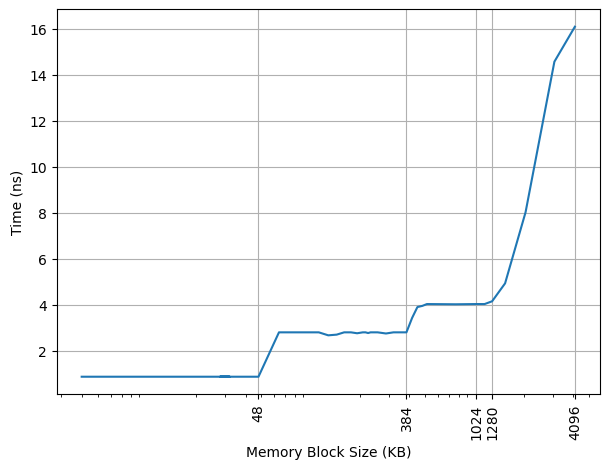
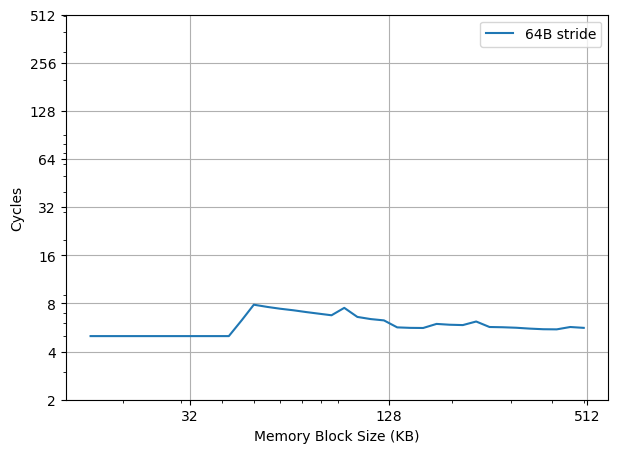
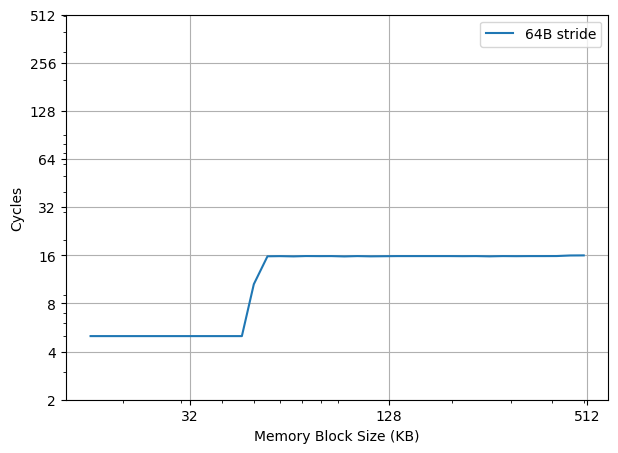
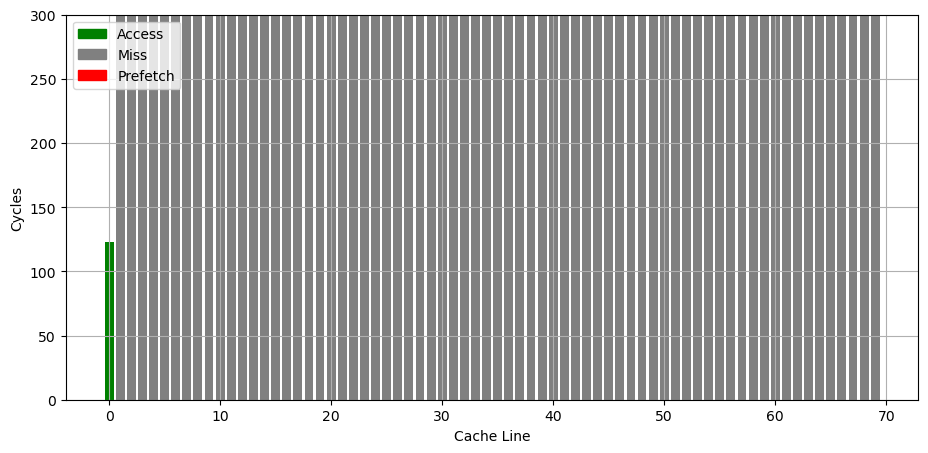
为了让读者了解背景,首先要知道前 AI 时代的 CS 教育大概是怎样的:本科的时候先上编程课,教大家各种编程语言,然后逐渐深入到各个领域,课上讲授知识点,课下通过工程训练来夯实,由于计算机是工科,这里面通过不断的工程实践来获取经验,是很重要的一个部分。这一部分学习过程很辛苦,但是确实很有效果,可以说几乎每一位系友都是这么锻炼过来的。
下面这一段,如果你还在读本科,请不要点开,点开了也请忘掉,按照老师的要求去做:
但是,现在 AI 时代来临,很多事情都发生了变化。首先,AI 编程能力很强,大一同学辛辛苦苦学完一年,然后发现自己写的代码还不如 AI 写得好写得快,内心的挫败感和对这种古法编程的学习方法的质疑是无与伦比的。这对课程的教学产生了很大的冲击,因为人很难克制自己的懒惰,面对巨大的诱惑,其实很难静下心去学习这些已经由 AI 掌握的基础课程。论坛上有同学做了个比喻,计算器被发明了以后,人类没有失去心算的能力,因为你为了去用好计算器,还是要知道这些基础知识,从小学起,然后到某一个年级告诉你可以用计算器,然后各种考试还可以出计算器没法解决的题目。但是,AI 的能力边界太大了,它能解决从简单到困难的各种问题,只是有一定的概率解决出来是错的。其次,即使是前几年我们还会觉得,专业核心课的大作业还很难由 AI 完成,似乎还能通过大作业的难度来倒逼大家学习,但在今年也纷纷沦陷,对于学生来说,只要愿意,完全可以自己不写一行代码,纯让 AI 写一个能通过所有测试的作业,自己完全不了解内部是怎么实现的,用很短的时间完成作业。而且还不好去举证,说这一定是 AI 写的。这一点在这次论坛上,不同课程的助教都做了类似的实验,证明了这一点。虽然发这篇博客可能会让一些本科同学看到,然后不好好写大作业,但还是希望更多教育工作者可以看到并参与讨论。如果你是正在上课的同学,就自觉忘记吧。
那么,应该怎么办呢?在这里阐述一些我的观点。一个大的前提是,肯定不能完全禁止 AI,也不能完全依赖 AI,需要辩证地把 AI 引入到 CS 教育当中。
首先是关于 CS 教育要培养出什么样的人才。之前,我们要培养的一方面是工程师,在长时间的工程实践当中积累经验,通过自己的经验,可以打造出一个很完备的系统,功能完善,可靠安全。但其实细分看来,在系统的搭建当中,其实有偏向于顶层设计的架构师,也有偏向于具体实现的工程师。目前 AI 已经可以很快地针对一个给定的 Plan 去做实现,并且实现得还不错,但是从需求到 Plan 的这一步,其实还需要人类的专家知识,因为实际的需求往往很复杂,会有许多大模型没有学过的假设与背景,这需要架构师脑子里把架构想清楚,知道哪里应该怎么做,然后把一部分的工程实现外包给 AI,自己再保证它的实现质量,确保它忠实地实现了所设计的架构,并且实现的系统是可靠安全的。用 AI 写代码很容易,但是写出来复杂可靠的软硬件系统,依然不是容易的事情。另一方面是科学家,在科研方面,科研的品味(Taste)变得更加重要,因为许多科研,其工程量本来就很小,完全可以由 AI 代劳,那么谁能够找到正确的路径,谁才能更好地与 AI 协作,完成科研。换句话说,以后的每个科研工作者,可能自己都是通讯作者,手下是一堆 AI 博士生在做实验,自己提出研究的思路,由 AI 实现和写作,然后自己来保证整个过程的正确性和学术伦理。无论是哪个方向,重点都从以前的知道某个东西“是什么”,变成了“为什么”,进而能够判断“对不对”。论坛上有同学总结得好,人类会更多地变成一个鉴别器(Discriminator)。
首先,作业已经不再能区分同学,不能代表同学对知识的掌握情况,只能代表 AI 对知识的掌握情况。所以作业已经完全沦为 AI 的课后送分小练习,在目前这个卷绩点的氛围下,让大家都开开心心地拿作业满分,也是越来越普遍了。如果真的想要通过作业来督促同学进行学习,那就必须回归作为人类的基本功,就是通过更多的线下的口语、展示和对话,以最“人味”的方式对抗 AI 的“机味”。事实上,在目前这个时代,其实如何扩大自己的影响力,也是很重要的技能,真的是酒香也怕巷子深,如何能够让大家看到你,抓住大家的注意力(Attention),很多时候会比你做出来的东西有多好更重要。这些能力,其实是值得通过作业的设计来培养的。我在本科的时候,尝试选了一次演讲的课程,当时看到作业要求,人直接麻了:需要每个人在班级所有人面前做演讲,这对于当时还比较社恐的我,由于太过害怕直接退课了。现在想想,其实都是小意思,当你迈出那一步以后,会发现懂得大大方方展示自己,真的是很重要的能力,是 AI 暂时还无法取代的能力。
既然作业沦陷了,那么,怎么打分呢?难道让每个人都能拿到满绩点?几年前,我在和大一新生聊天,他们就对这个打分的事情感到困惑,因为在目前这个绩点膨胀的时代里,好像很多课程拿满绩点都是天经地义的事情,如果你这个课不给我满绩点,我就要给你打教评低分。但是,又有不少东西和绩点挂钩,奖学金,保研等等。老师当然可以撒手不管,让所有人满绩点,但这只是让竞争延后、转化为其他领域了而已,不比绩点,那就比谁更能在本科的时候做科研,打比赛等等。另一方面,打分也是一个很重要的督促学习的手段,还是一样的前提,人类是很难抵抗自己的懒惰的,如果不是为了毕业以后有更好的发展,可能会有很多人放弃毕业、放弃学习。以前,为了能够顺利毕业,还会咬咬牙做一些比较困难的学习,甚至可能是自己不喜欢的;现在可以用 AI 糊弄了,那就糊弄过去,反正分数不错,能给父母交差,大环境也不好,然后就陷入了虚无主义,一泻千里。所以,似乎考试成为了最后的防线,还能在一定程度上督促学习。
但其实考试也受到了巨大的冲击。第一个问题就是,考试是否允许使用 AI 呢?许多 CS 课程,未来都会或多或少地引入一些 AI,那么学生对 AI 的掌握程度,也是一个需要考核的能力。但目前不同厂商的 AI 的可用性与性能差距过大,“AI 平权”会成为一个新的问题,我们希望比的是谁更会用 AI,而不是谁能用上更好的 AI。就像高考作文要考虑贫富差距一样,本科课程的考试也会面临类似的问题。一种可能性是在考试的时候提供统一的 AI 访问,但目前 AI 生态还是比较混乱,指定一个 AI 让大家用,其实也很容易出现与学生平时使用工具或生态不兼容的问题,而且学校自己部署一个同时几百上千人同时用的 AI 服务,也不是一件容易的事情,希望未来有云厂商可以提供类似的服务,并且能够控制住成本,其实就是一个持续两小时的上百 QPS 的专属推理服务。如果要类比的话,其他一些学科允许使用计算器,出题的时候可以规避,但 AI 能做的事情太杂了,其实很难针对。
另一方面,如果禁止 AI 的话,也有很多问题。首先是没法考察学生的 AI 使用能力,这个在未来会更加重要。其次,学生自己会比较难接受,先给了 AI 这么方便的工具,结果期末考试又要古法做一遍,最后结果可能就是学期中都在用 AI,只有考试前一周突击一下,考完就忘了,当然,好像现在很多人也是这样呢。而且课程很容易被贴上“不与时俱进”的标签,就如那些用十几年前课件的课程一样。现在这个过渡时期,大家都知道会变,但是怎么变并没有达成共识,所以一定会有一个阵痛期。如果你是刚上本科,或者马上要上本科的高中同学,那就要做好成为小白鼠的准备了。此外,随着本地模型的发展,如果让学生带电脑,即使不给联网,有更好的独立显卡的同学,事实上可以通过电脑配置的优势转化为分数,这也会带来新的不公平性。
当然,也不是毫无希望,比如前面说的,加一些有“人味”的考核,唯一的缺点是人力需求较大,难以扩展;或者允许使用 AI,但是必须提交完整的 AI 使用记录,这一点很多地方已经在实践;出题的时候,可能也要想办法去考察学生的思路,一些可以由 AI 完成的作业,不如就直接让学生用 AI 做,变成考察 AI 使用能力的题目。
首先,这次论坛不仅有大量的研究生助教参与,也有许多一线的教学老师参与了讨论。其实老师们感受到的冲击也很直接,因为可能就是从 2025-2026 开始,就有一批学生可以完全不接触古法编程,直接上手写代码,用一种完全不同的学习方法来学习各种课程内容。有的人可以很好地利用 AI 加速自己的学习,比如之前需要花费很多时间做的工程实践,现在可以在相同时间内用 AI 做更多的实践,一样可以获得很多甚至更多的实践经验。有的人就完全依赖 AI,可以糙快猛地完成很多事情,但对内部工作一概不知,能做的事情完全取决于 AI 的能力边界,同时自己又缺乏很多基础知识,可以说上知天文下知地理,但是四体不勤五谷不分。现在大家心里没底的就是,AI 的能力是否可以无限扩展,自己只需要站在 AI 的肩膀上,坐等 AI 发火箭上月球就行;还是需要脚踏实地,踩着地月天梯去月球。
#!/usr/bin/env python3"""SSE server that sends 5 messages, one every second."""importtimefromhttp.serverimportHTTPServer,BaseHTTPRequestHandlerclassSSEHandler(BaseHTTPRequestHandler):defdo_GET(self):ifself.path=="/events":self.send_response(200)self.send_header("Content-Type","text/event-stream")self.end_headers()foriinrange(5):message=f"data: Message {i+1} at {time.time()}\n\n"self.wfile.write(message.encode("utf-8"))self.wfile.flush()time.sleep(1)self.wfile.close()else:self.send_response(404)self.end_headers()deflog_message(self,format,*args):print(f"[{time.strftime('%Y-%m-%d %H:%M:%S')}] {format%args}")if__name__=="__main__":server=HTTPServer(("0.0.0.0",8080),SSEHandler)print("SSE server starting on http://0.0.0.0:8080")server.serve_forever()
Syntax: proxy_buffering on | off; Default: proxy_buffering on; Context: http, server, location Enables or disables buffering of responses from the proxied server. When buffering is enabled, nginx receives a response from the proxied server as soon as possible, saving it into the buffers set by the proxy_buffer_size and proxy_buffers directives. If the whole response does not fit into memory, a part of it can be saved to a temporary file on the disk. Writing to temporary files is controlled by the proxy_max_temp_file_size and proxy_temp_file_write_size directives. When buffering is disabled, the response is passed to a client synchronously, immediately as it is received. nginx will not try to read the whole response from the proxied server. The maximum size of the data that nginx can receive from the server at a time is set by the proxy_buffer_size directive. Buffering can also be enabled or disabled by passing “yes” or “no” in the “X-Accel-Buffering” response header field. This capability can be disabled using the proxy_ignore_headers directive.
最近遇到一个运维场景,两个 SATA 盘组了一个 RAID1,Linux 的根系统也在上面,启动时能进内核,但是内核一直在报错 link is too slow to respond, please be patient 以及 COMRESET failed (errno=-16)。下面记录一下故障排查以及恢复的过程。
经常看我博客的读者应该能看出来,我研究的主要是计算机系统结构方向,特别是处理器的微架构,几乎没有涉及到 AI 的内容,我也确实不喜欢 AI 研究,仅关注但不参与。但今年,因为各种 AI 技术尤其是 LLM 的发展,我确实成为了很多 AI 技术的用户,可以说 2025 年是我正经大规模用 AI 的元年,所以在年末做一个简单的总结。
我不想在这里给大模型厂商打广告,所以相关的名字我都会按照某 PDF 的方法进行打码,有需要的朋友可以自行查看实际的内容。
既然提到了答疑,也来谈谈教学。这种 Vibe Coding 的能力对于计算机教育的冲击无疑是巨大的,本来很多上课教的内容,AI 可以比较容易地完成,那学生可能就更倾向于让 AI 去完成了,换位思考一下,如果让我在 2025 年成为大一不会编程的新生,我也很难抵御这个诱惑。但是,锻炼代码和工程能力就欠缺了。这就对应一个很重要的问题,就是 AI 它到底是不是一种类似编译器、调试器或者编程语言的工具?我们说学生可以从编程语言而不是汇编学起,是因为它是一个很成熟很可靠的工具,你学会了高层次的工具就是会了,就可以用它做很多事情。AI 就很奇怪,它确实可以做很多事情,但又不总是可以完成,它好像是概率性的图灵完全,全看是否出现幻觉,所以它不是一个可靠的工具,但又是一个好用的工具。那么紧接的问题是,计算机教育,是要教出来真的会写代码的人,还是会用 AI 写代码就行?我目前没有答案,也不知道未来会怎么发展,只能慢慢走一步看一步了。但抛开计算机专业的教育,如果是对于计算机的通识教育,我觉得用 AI 写代码完全没有问题,毕竟对于更多人来说,能解决问题就可以,可不可靠,其实很多时候并不在考虑范围内。
目前我对 Vibe Coding 的态度是,它不能替代我的思考,相反,我可以更多地思考一些更高层次的东西,而可以适当地把一些细节交给 AI。我也持续在自己写代码,特别是一些关键的部分,我还是无法信任完全由 AI 编写,毕竟它比人还懂得偷懒,经常写出来一些没有测试效果的测例,一看测例都过,一测全是 BUG。
我还会继续尝试和 LLM 协作,尽量保持高质量的代码产出,我认为这是用 Vibe Coding 的底线:用 AI 并不是写出烂代码的理由。以前我们有所谓的中文羞耻,觉得写了很多中文的项目的代码可能不靠谱,现在是所谓的 AI 羞耻,看到 README 里一堆 AI 生成的辞藻就觉得不靠谱一样。我们作为业内人士,还是要把事情做得漂亮,而不是让 AI 生成一个勉强能用的组装拖拉机就完事。
另一方面 AI 影响比较大的,其实是写作,包括日常的各种文字,比较正式的文档、论文甚至教材,不得不承认,AI 在写作方面确实是比我这种语文是考试弱项的偏科生要做得更好。我通常会自己编写一遍,然后交给 DeepSeek 来润色一遍,再在润色的基础上修改,保证我要表达的意思能够完全地被保留下来。一些小的人情世故,比如微信上和各种人打交道的措辞,网络上发送的邮件或者是 GitHub Issue 等等场合的客套话,AI 确实也是做得比自己好。但是,更完整的内容,或者整体架构上的把握,还是不会让 AI 完全去完成,因为能感觉到 AI 训练所使用的语料和自己的思维方式或者写作的习惯还是不一样的,我还是希望我写的东西能更加得有我的思考和劳动在里面,AI 只是一个让文字看起来更加通顺的工具,帮我纠正一些语法错误之类的。例如,我平时可能更习惯一些口语化的表达,能够让我很快地通过打字或者语音输入把我的脑子里的想法变成文字,然后再让 AI 改写成更加严肃的文字,像教材或者论文,这时 AI 就沦为了纯粹的文字风格改写或者语言翻译器。
目前想到的就这么多,其实 AI 还有很多场景可以用到,比如生成图片、视频和音乐等等,目前还没有太多的尝试,相信明年开始会逐渐接触,到时候再在年底写一个 AI 使用总结。总的下来,就是感叹自己也到了感慨科技进步的年纪了,十几年前学技术,虽然也能感觉到科技进步,但因为自己是从零开始,学的就是最新的科技,所以没有啥感觉。但这几年,不断地把新的输入和已有的积累进行对比,就能感觉明显到技术潮流和技术栈的移动,也能感觉到自己对新技术的接受度开始有了略微的下降,这值得让我警醒。以前,我们总是嘲笑大人不追求潮流,不去学习手机等新技术,我们在这个时代长大的人,可也不能犯这样的错误呀。
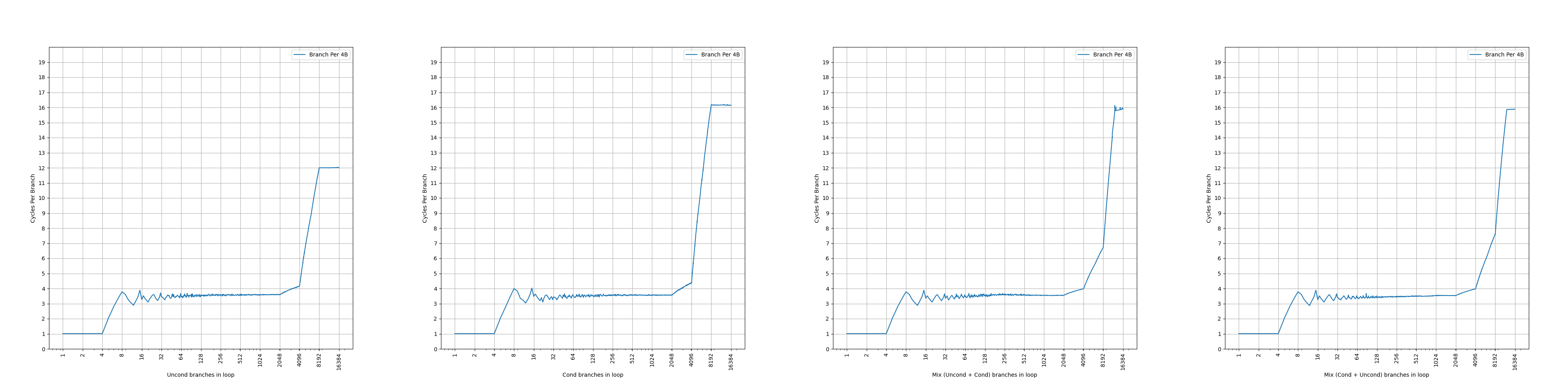
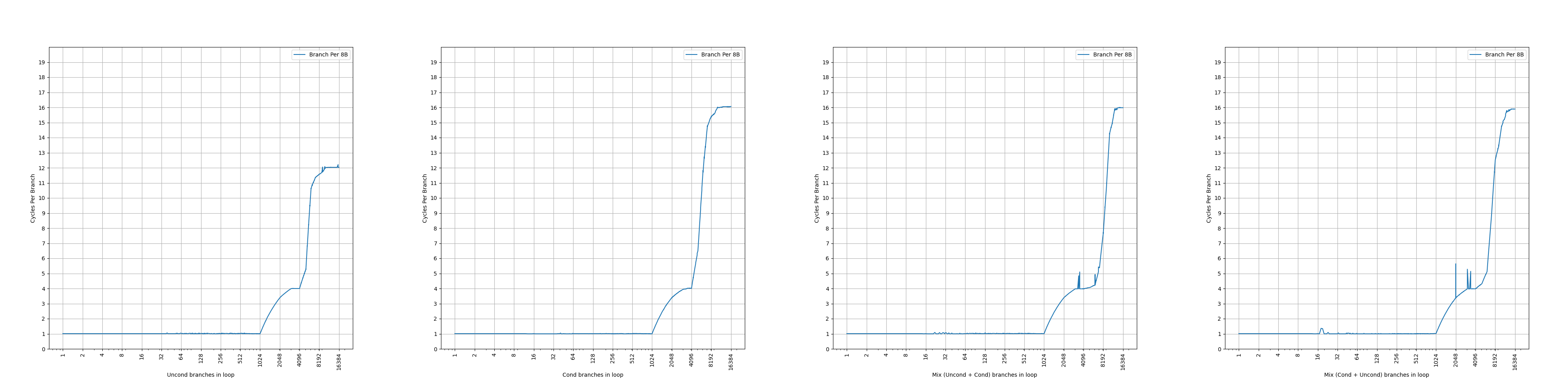
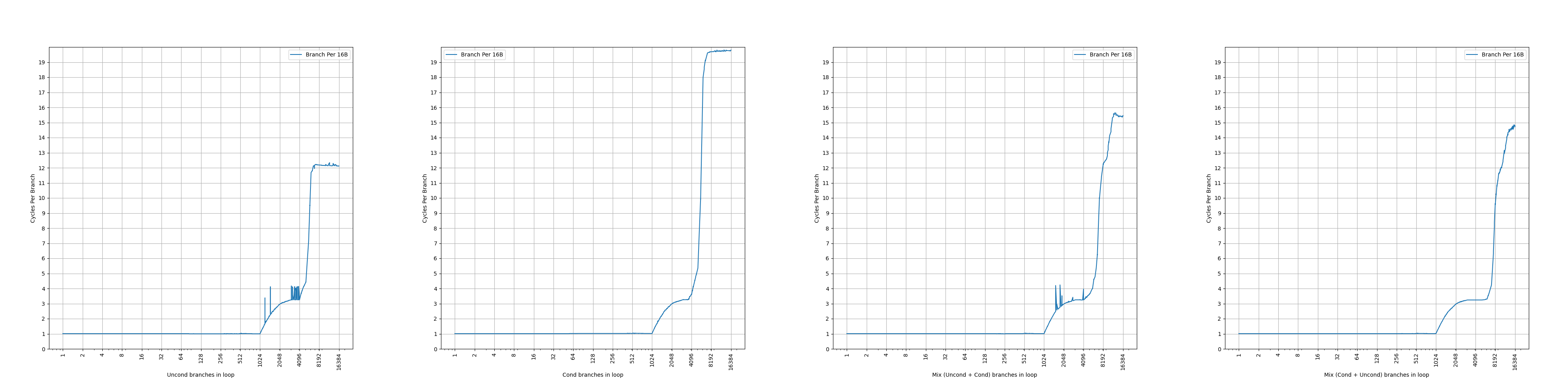
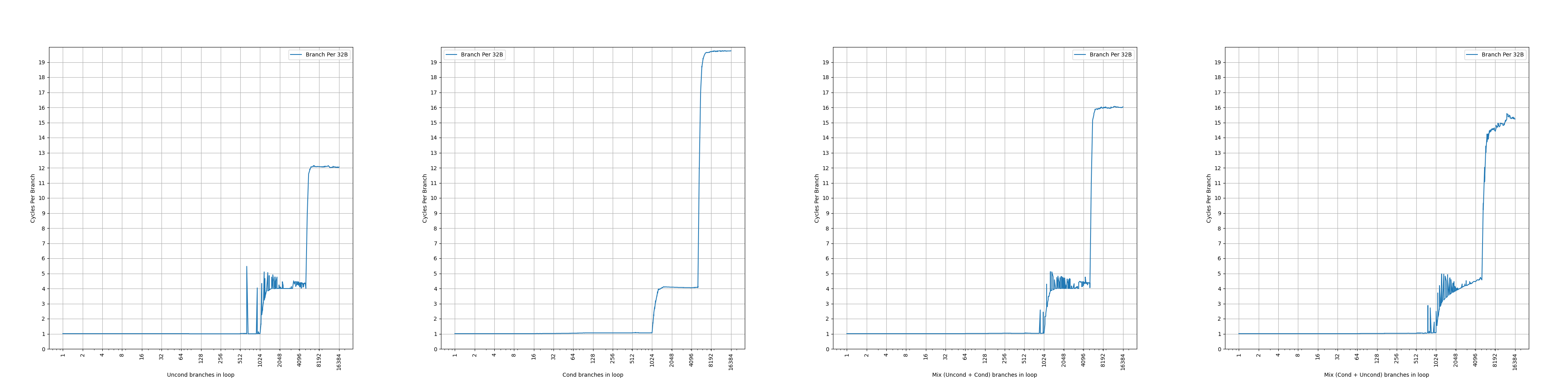
// step 1.// 100 jumps forwardgotojump_0;jump_0:gotojump_1;// ...jump_98:gotojump_99;jump_99:// step 2.intd=rand();// the follow two branches differ in B[i]// first conditional branch, 50% taken or not takenif(d%2==0)gototarget;// second unconditional branchelsegototarget;target:// step 3.// variable number of jumps forwardgotovarjump_0;varjump_0:gotovarjump_1;// ...varjump_k:gotolast;// step 4.// conditional branchlast:if(d%2==0)gotoend;end:
// step 1.// 100 jumps forwardgotojump_0;jump_0:gotojump_1;// ...jump_98:gotojump_99;jump_99:// step 2.intd=rand();// indirect branch// the follow two targets differ in T[i]autotargets[2]={target0,target1};gototargets[d%2];target0:// skip over nops, while keeping B[5:2]=0gototarget2;// add many nopstarget1:gototarget2;target2:// step 3.// variable number of jumps forwardgotovarjump_0;varjump_0:gotovarjump_1;// ...varjump_k:gotolast;// step 4.// conditional branchlast:if(d%2==0)gotoend;end:
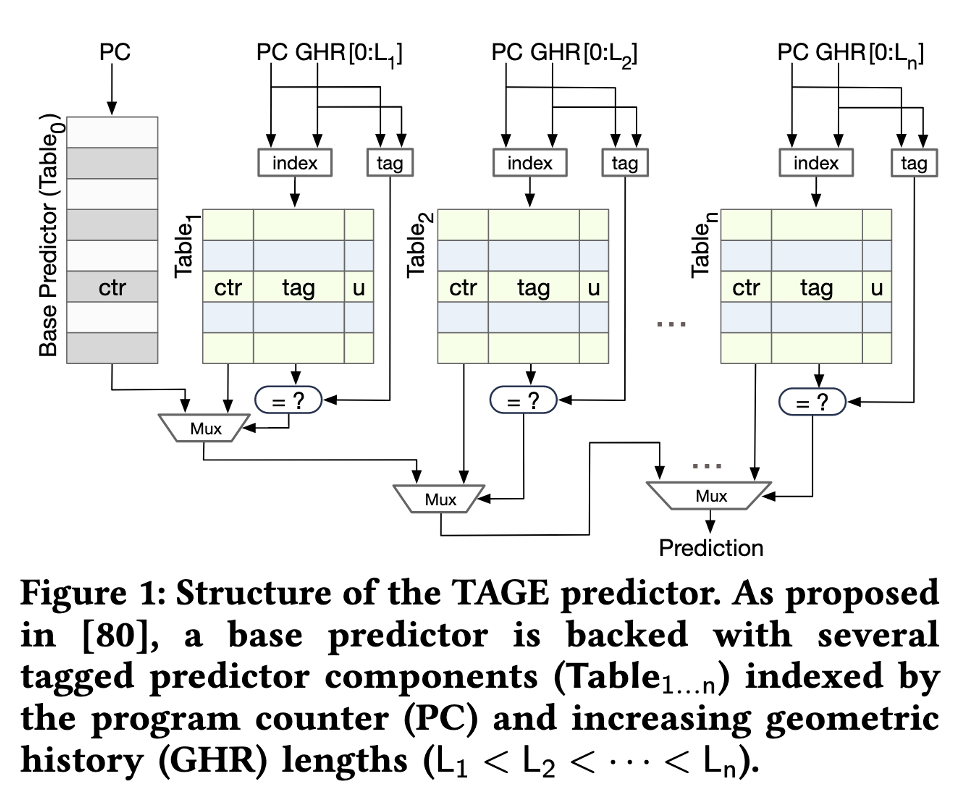
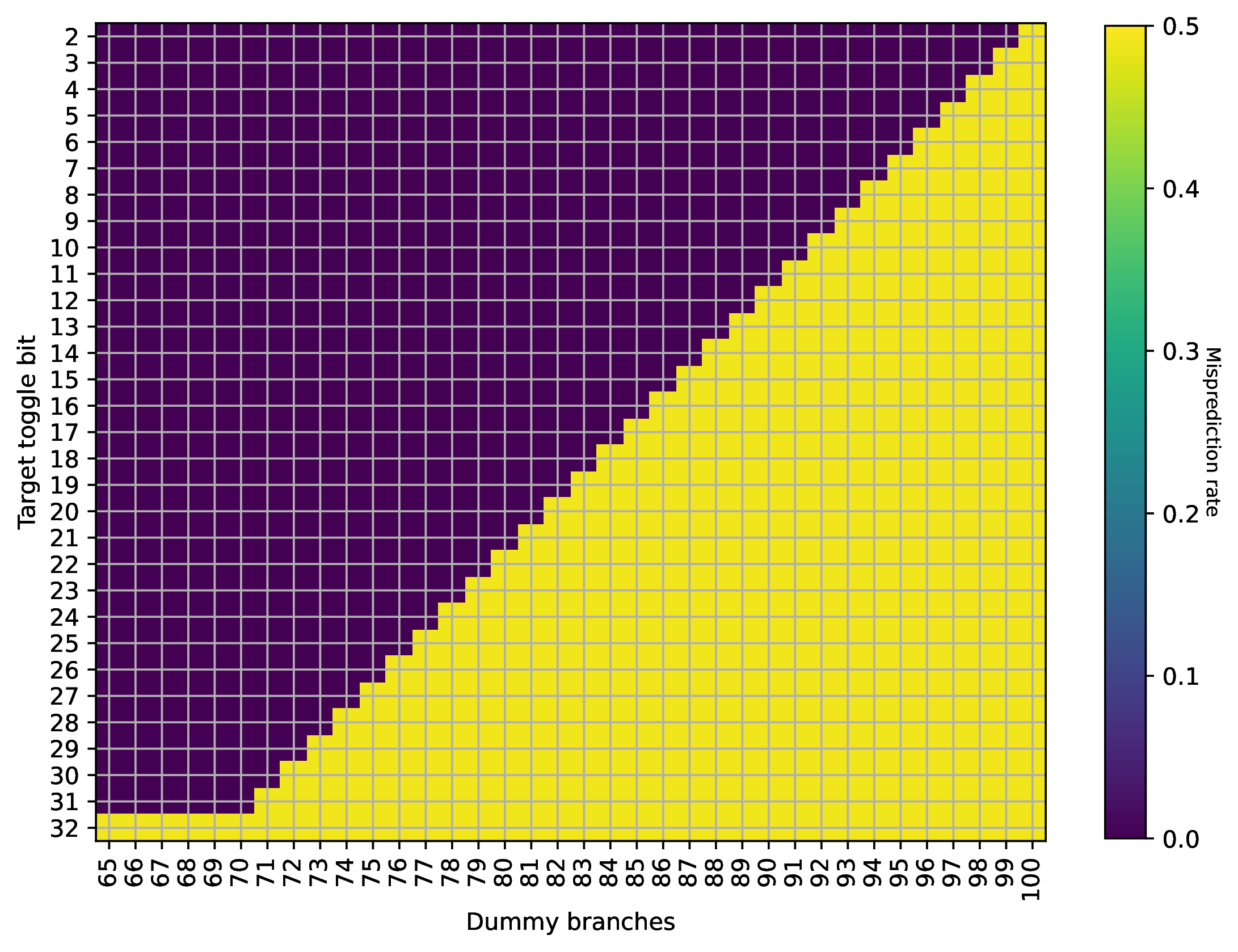
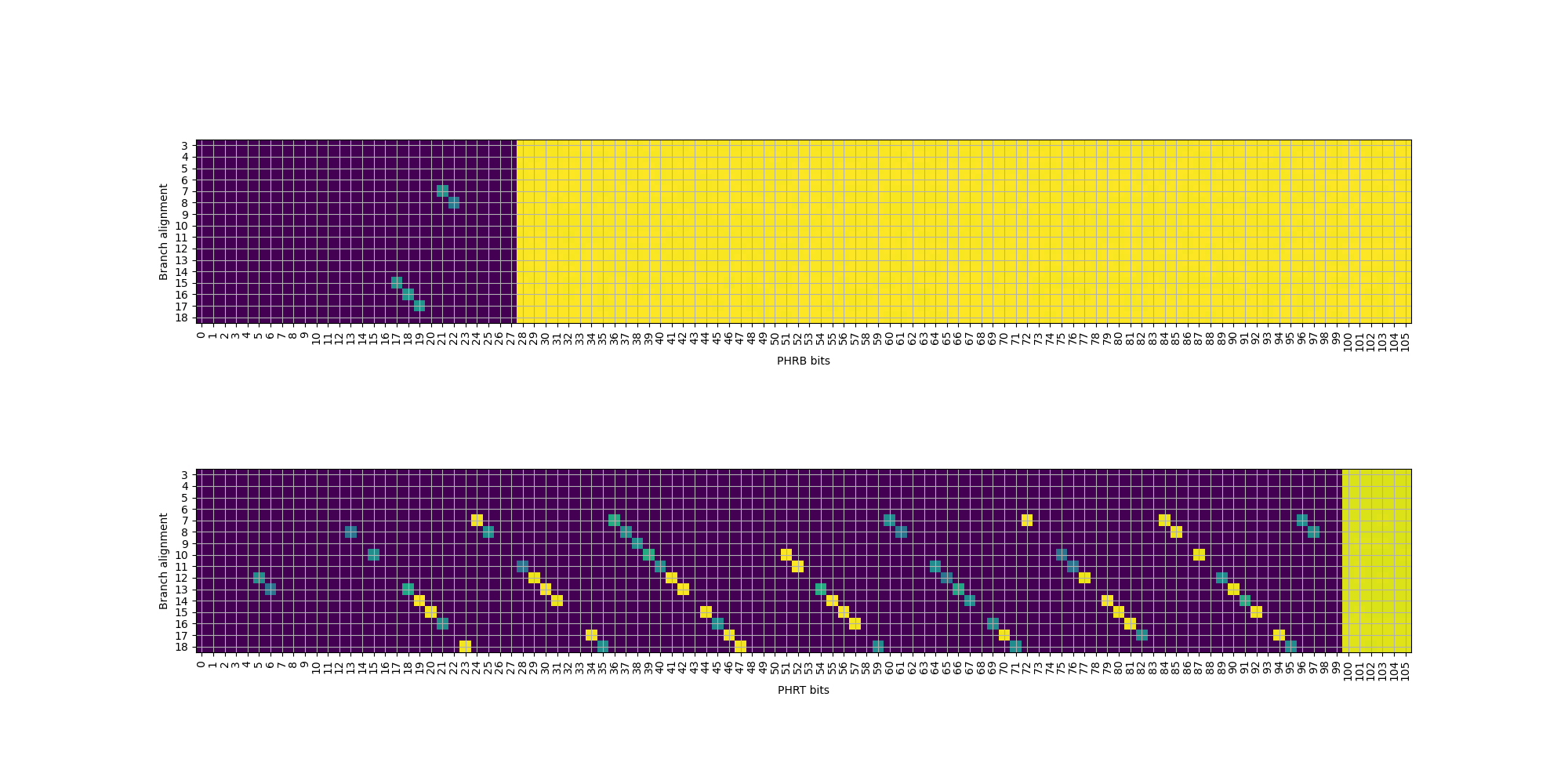
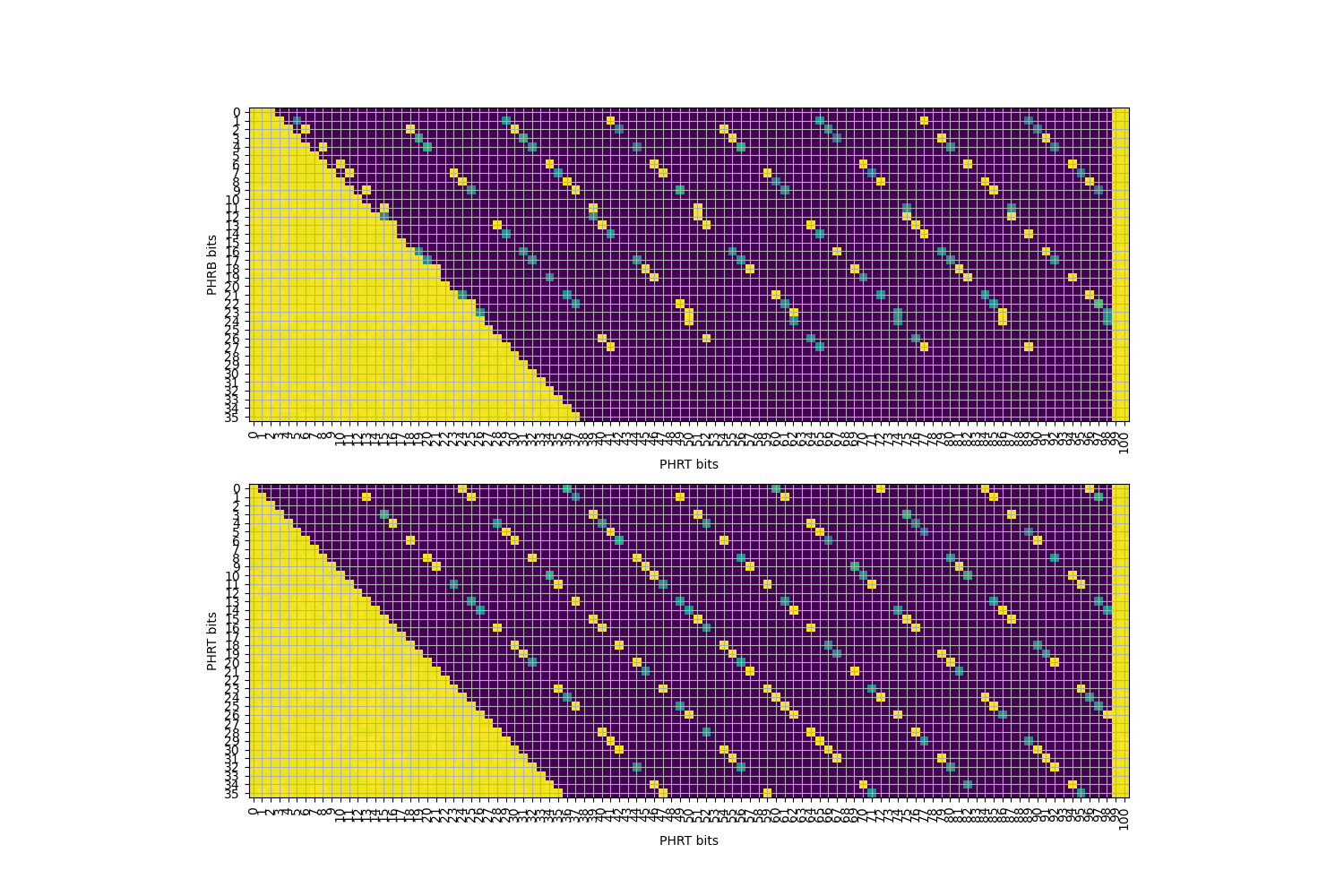
接下来,我们将目光转向 TAGE 表的逆向工程。TAGE 表与缓存结构类似,也是一个多路组相连的结构,通过 index 访问若干路,然后对每一路进行 tag 匹配,匹配正确的那一路提供预测。TAGE 在预测时,输入是历史寄存器,即上面逆向得到的 \(\mathrm{PHRT}\) 和 \(\mathrm{PHRB}\),以及分支地址,目前这两个输入都是可控的。为了避免多个表同时提供预测,首先逆向工程使用分支历史最长的表的参数:它的容量是多少,index 如何计算,tag 如何计算,以及几路组相连。
// add some unconditional jumps to reset phr to some constant value// 100 jumps forwardgotojump_0;jump_0:gotojump_1;// ...jump_98:gotojump_99;jump_99:// injectintd=rand();// indirect branch// the follow two targets differ in T[2]autotargets[2]={target0,target1};gototargets[d%2];target0:// add nop heretarget1:// add some unconditional jumps to shift the injected bit leftgotovarjump_0;varjump_0:gotovarjump_1;// ...varjump_k:gotolast;last:
根据前面的分析,\(T[2]\) 会被异或到 \(\mathrm{PHRT}\) 的最低位上,每执行一次无条件分支,就左移一位。因此,通过若干个无条件分支,可以把 d % 2 这个随机数注入到 \(\mathrm{PHRT}\) 的任意一位上。之后我们还会很多次地进行这种随机数的注入。
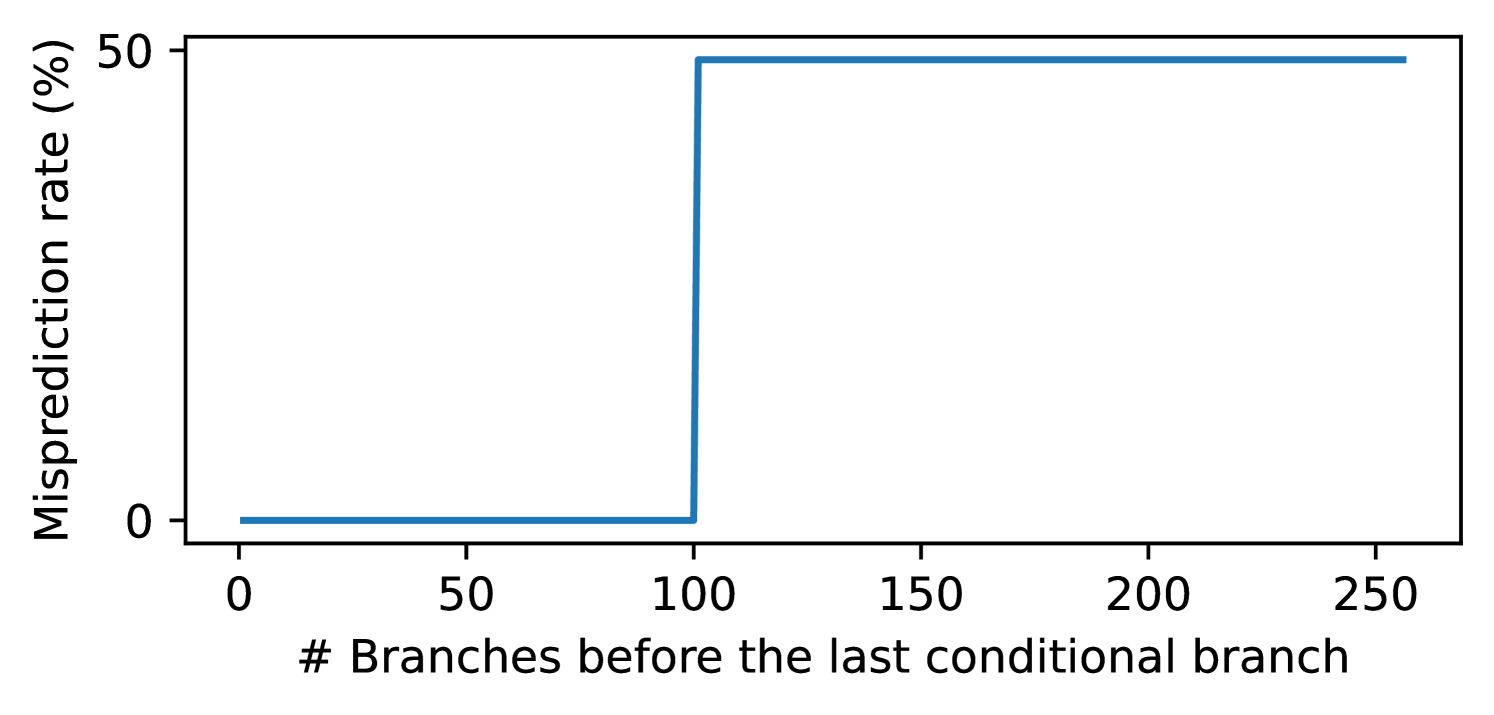
首先,我们希望推断 PC 如何参与到 index 或 tag 计算中。通常,TAGE 只会采用一部分 PC 位参与 index 或 tag 计算。换句话说,如果两个分支在 PC 上不同的部分没有参与 index 或 tag 计算,那么 TAGE 无法区分这两条分支。如果这两个分支跳转方向相反,并且用相同的 PHR 进行预测,那么一定会出现错误的预测。思路如下:
用 100 个无条件分支,保证 PHR 变成一个确定的值;
注入随机数 d % 2 到 PHRT,并移动到高位(例如 \(PHRT[99]\)),使用前面所述的方法;
// step 1. inject phrtintd=rand();inject_phrt(d%2,99);// step 2. a pair of conditional branches with different direction// their PC differs in one bitif(d%2==0)gotoend;if(d%2==1)gotoend;end:
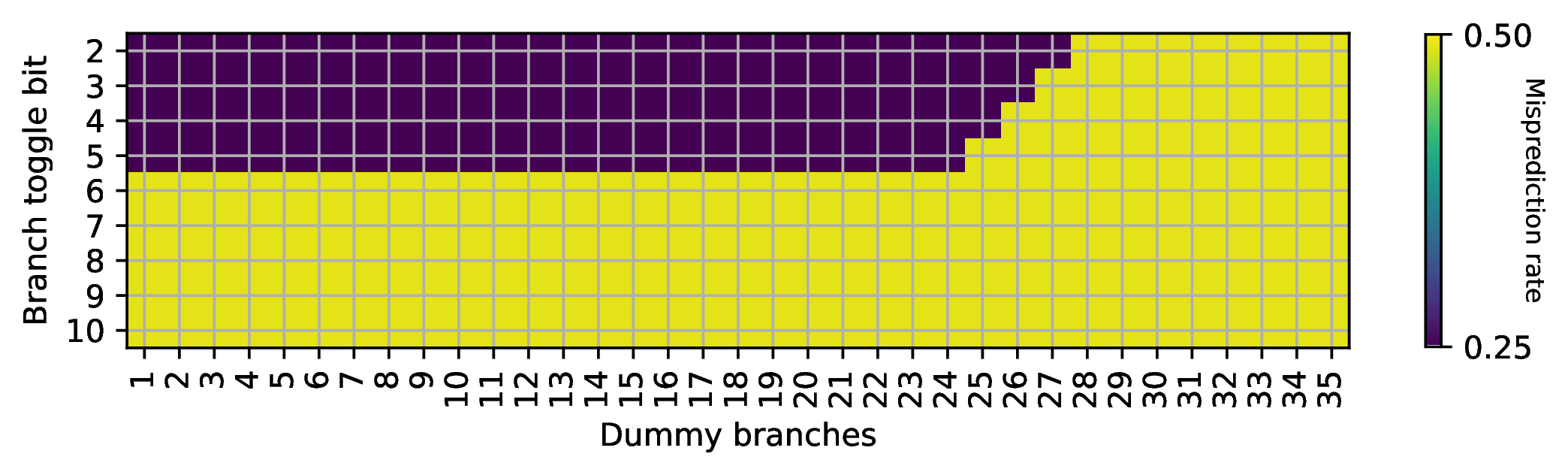
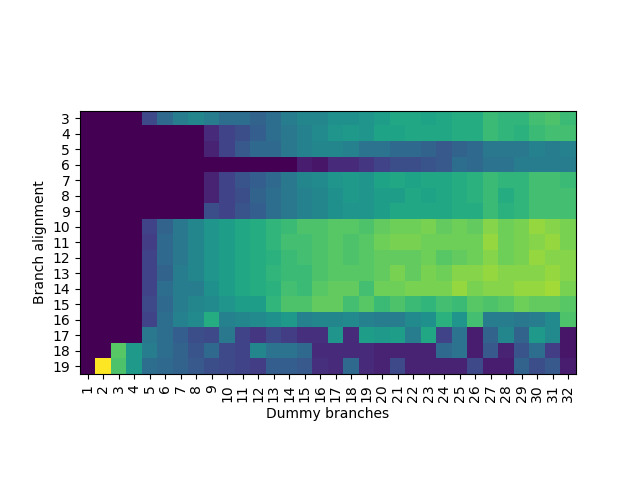
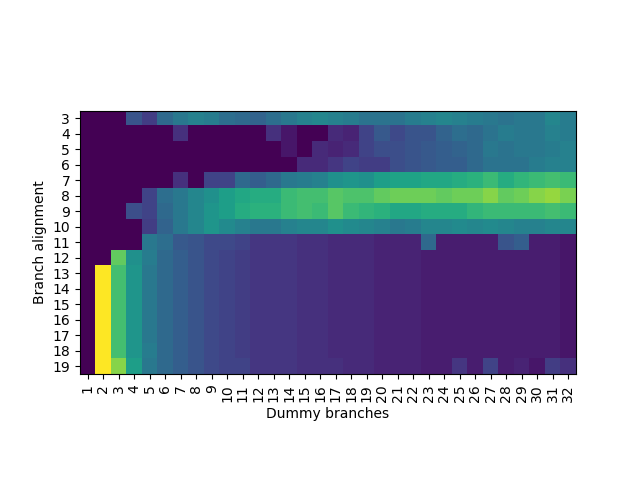
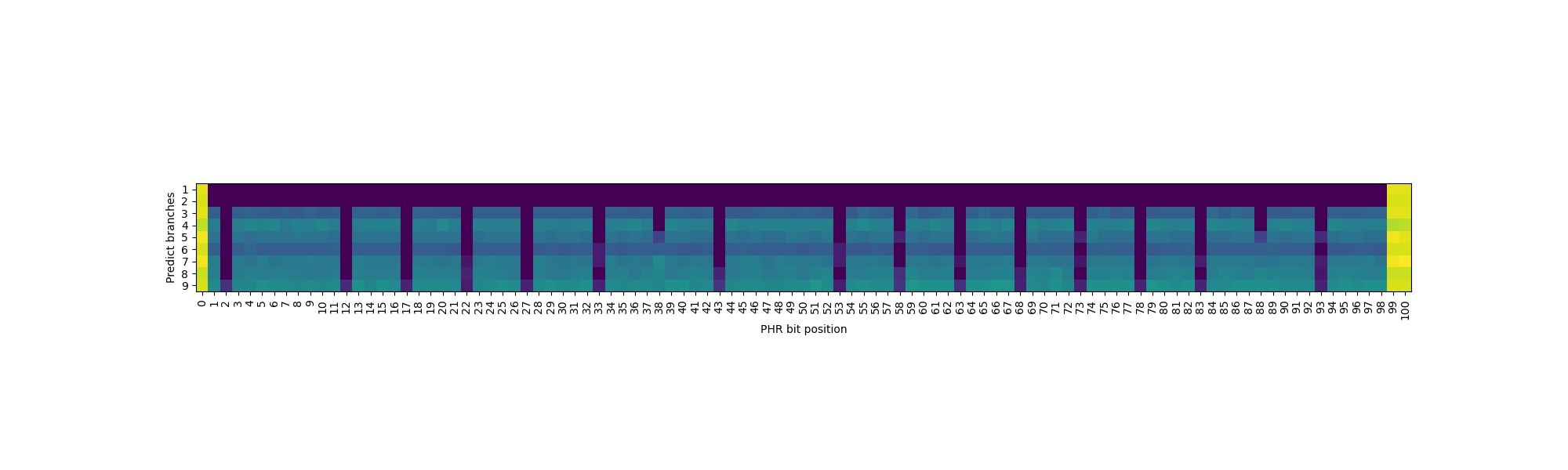
接下来是比较复杂的一步,同时逆向工程表的相连度和 index 函数的 PC 输入。这是因为这两部分是紧密耦合的:只有知道相连度,才能知道预测出来的分支数对应几个 set;但不知道 index 函数,又无法控制分支被分配到几个 set 中。首先,为了避免 PHR 的干扰,还是只注入一个随机数到 \(PHRT[99]\) 上(事实上,\(PHRT[99]\) 不是随便选择的,而是需要在 index 函数中,但通过测试可以找到满足要求的位)。其次,构造一系列分支,它们的地址满足:第 i 条分支(i 从 0 开始)的分支地址是 \(i2^k\),其中 \(k\) 是接下来要遍历的参数。当 \(k=3\) 时,分支会被放到 0x0, 0x8, 0x10, 0x18, 0x20 等地址,涉及的 PC 位数随着分支数的增加而增加。接下来,我们分类讨论:
假如涉及的 PC 位都在 tag 中,没有出现在 index 中:那么这些分支都会被映射到同一个 set 内,一旦分支数量超出相连度,就会出现预测错误。
假如涉及的 PC 位有一部分出现在 index 中:那么每有一个 PC 位出现在 index 中,这些分支可以被分配到的 set 数量就翻倍,直到这些 set 都满了以后,才会出现预测错误。
假如涉及的 PC 位有一部分超出 PC 输入的范围(如前面逆向工程得到的 \(PC[18:2]\)):那么超出输入的部分地址会被忽略,使得 set 内出现冲突。
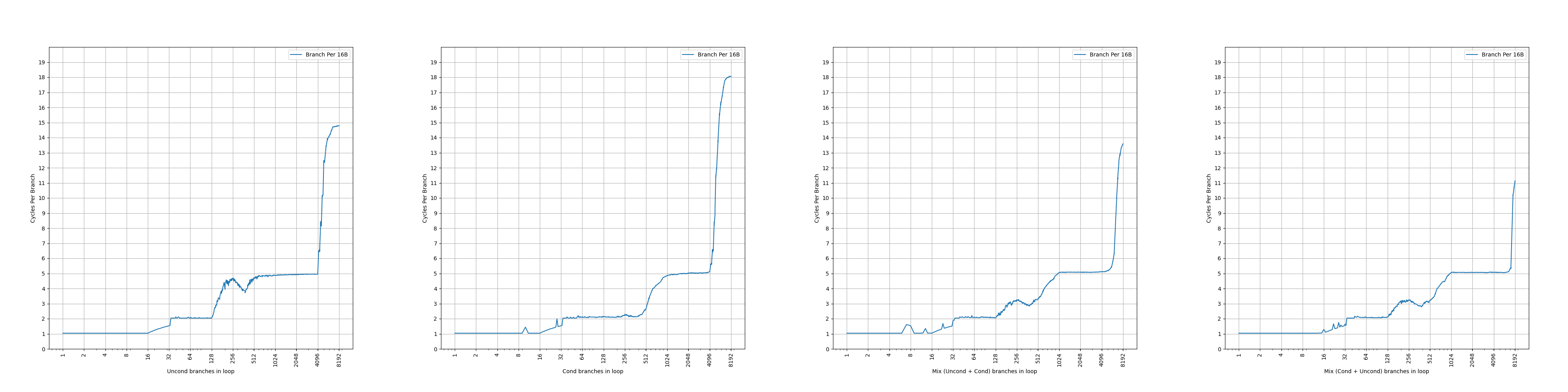
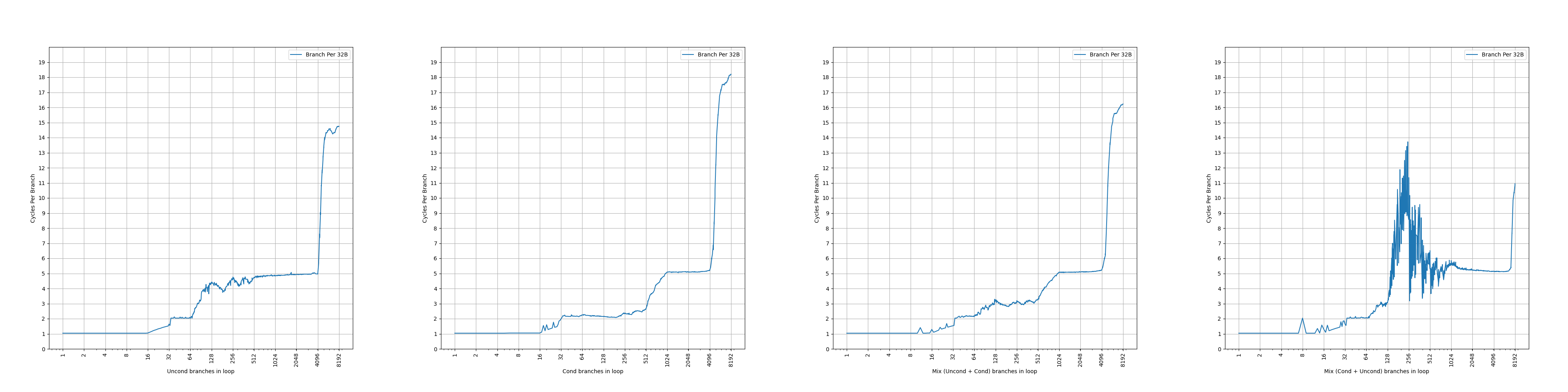
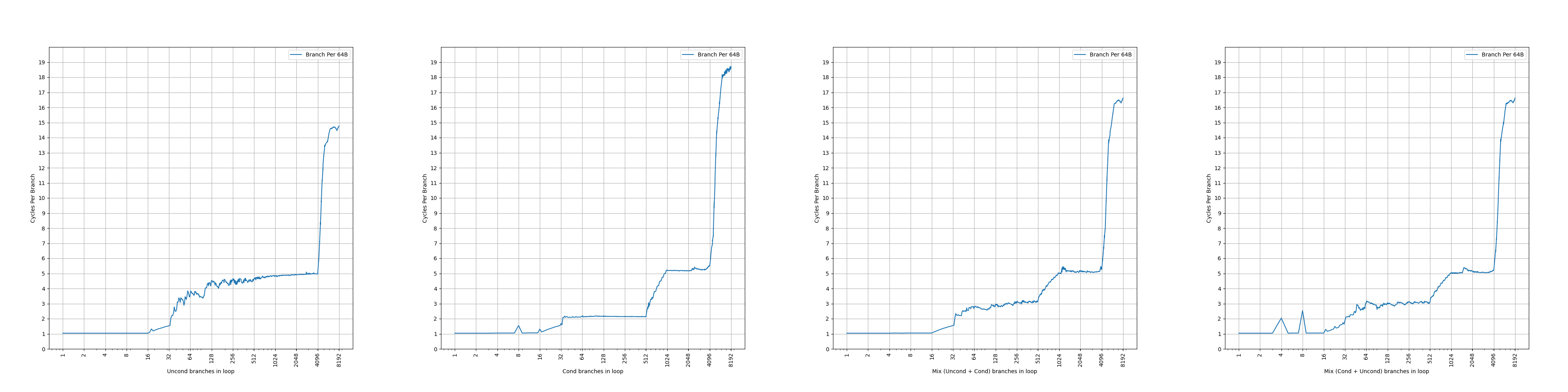
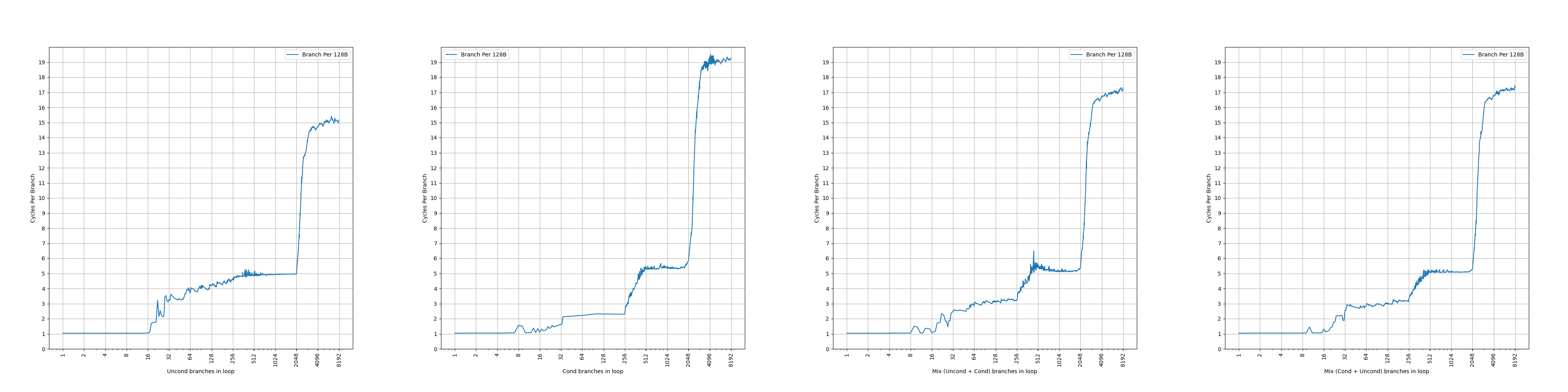
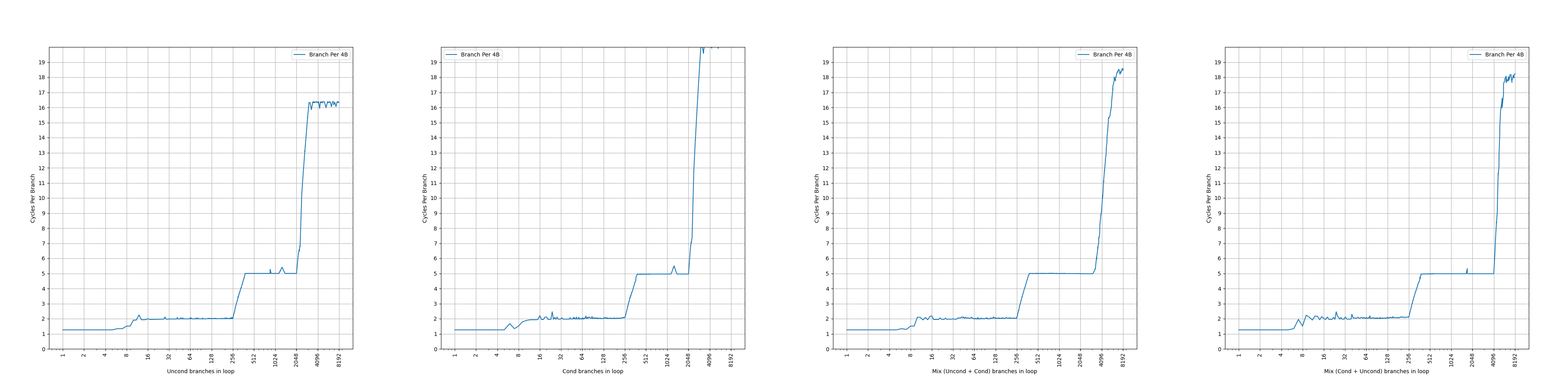
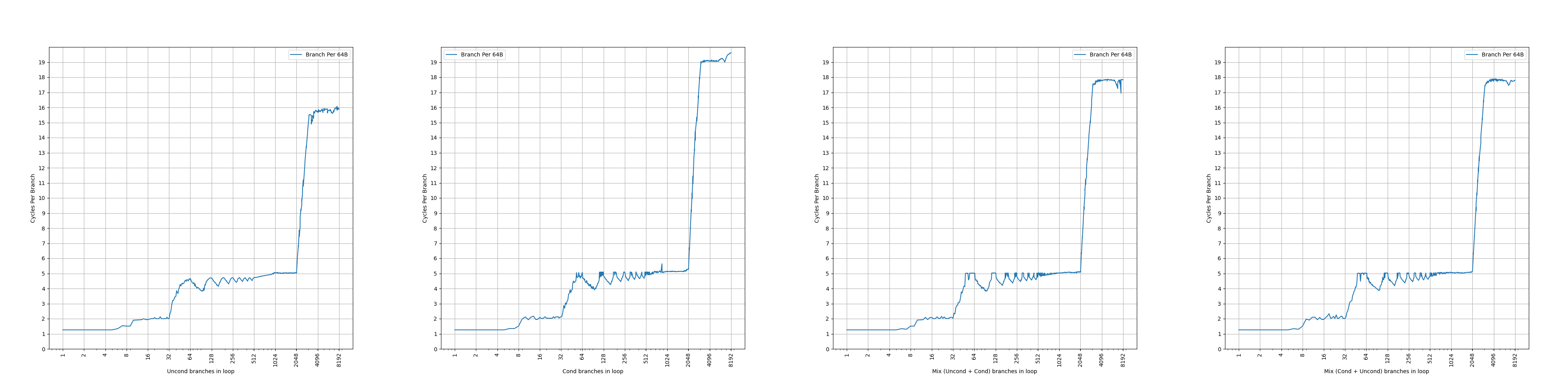
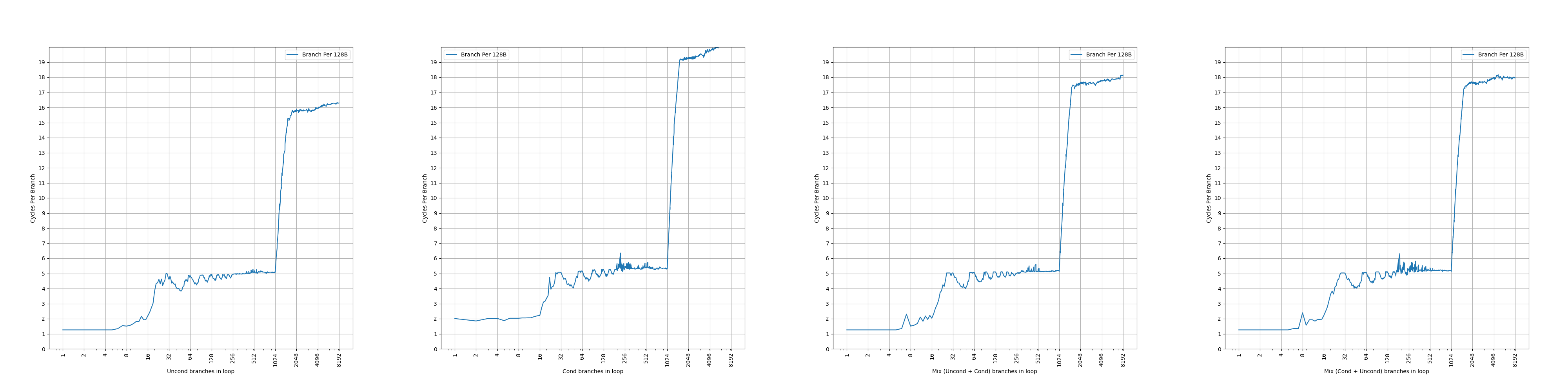
Each BTB entry can hold up to two branches if the last bytes of the branches reside in the same 64-byte aligned cache line and the first branch is a conditional branch.
Zen 3 的 BTB entry 有一定的压缩能力,一个 entry 最多保存两条分支,前提是两条分支在同一个 64B 缓存行中,并且第一条分支是条件分支。这样,如果第二条分支是无条件分支,分支预测的时候,可以根据第一条分支的方向预测的结果,决定要用哪条分支的目的地址作为下一个 fetch block 的地址。虽然有压缩能力,但是没有提到单个周期预测两条分支,所以只是扩大了等效 BTB 容量。和 Zen 1、Zen 2 一样。
L1BTB has 1024 entries and predicts with zero bubbles for conditional and unconditional direct branches, and one cycle for calls, returns and indirect branches.
更进一步,ARM Neoverse V1 实现了一个周期预测两条分支,即 two taken(ARM 的说法是 two predicted branches per cycle),在 2 cycle 的 Main BTB 上可以实现接近 AMD Zen 3 的 L1 BTB 的预测吞吐。AMD 也不甘示弱,在 2022 年发布的 AMD Zen 4 处理器上,实现了 two taken。
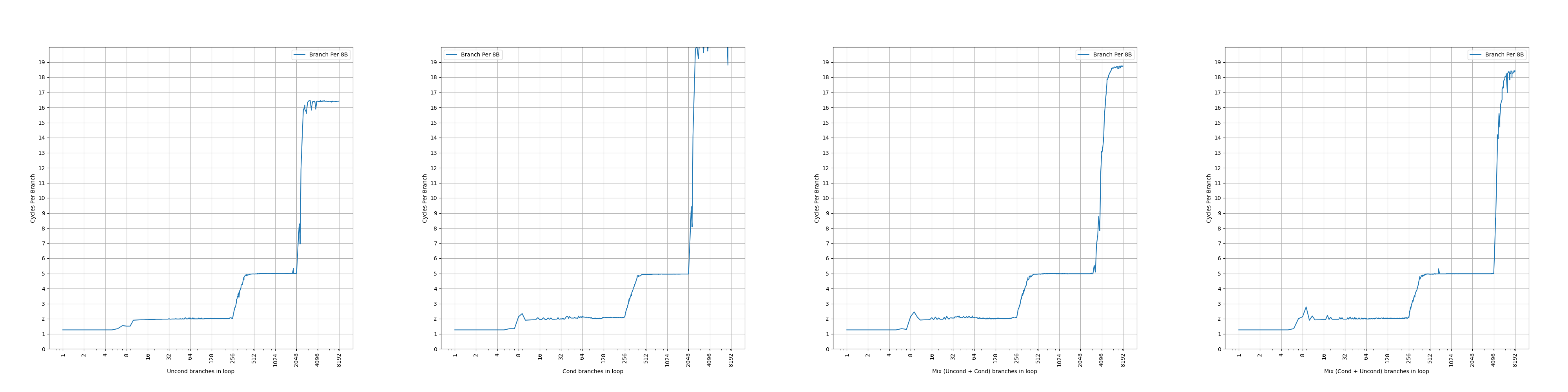
The branch target buffer (BTB) is a three-level structure accessed using the fetch address of the current fetch block.
Zen 2 的 BTB 有三级,是用当前 fetch block 的地址去查询,和 Zen 1 一样。
Each BTB entry includes information for branches and their targets. Each BTB entry can hold up to two branches if the branches reside in the same 64-byte aligned cache line and the first branch is a conditional branch.
Zen 2 的 BTB entry 有一定的压缩能力,一个 entry 最多保存两条分支,前提是两条分支在同一个 64B 缓存行中,并且第一条分支是条件分支。这样,如果第二条分支是无条件分支,分支预测的时候,可以根据第一条分支的方向预测的结果,决定要用哪条分支的目的地址作为下一个 fetch block 的地址。虽然有压缩能力,但是没有提到单个周期预测两条分支,所以只是扩大了等效 BTB 容量。和 Zen 1 一样。
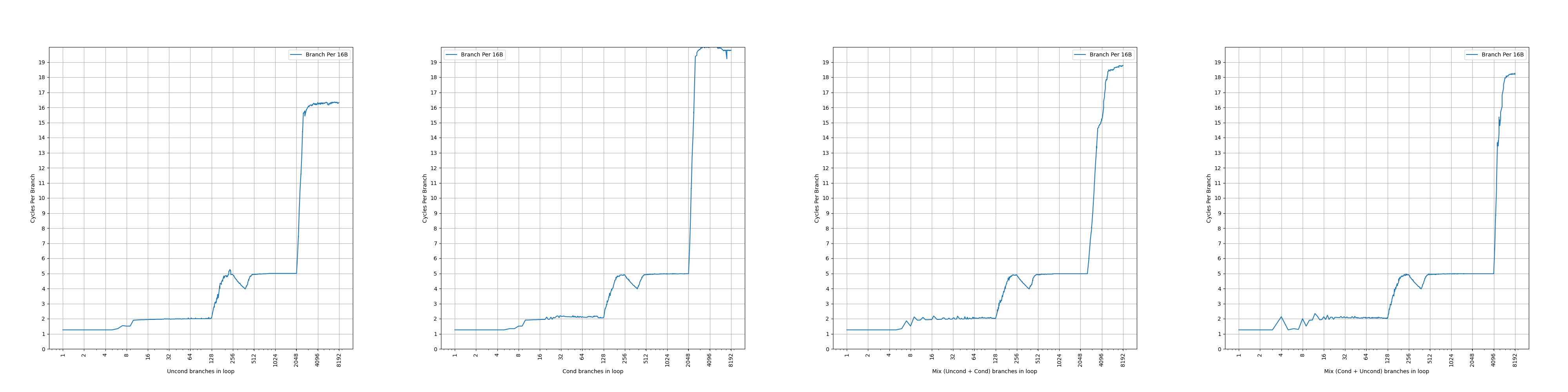
L0BTB holds 8 forward taken branches and 8 backward taken branches, and predicts with zero bubbles
Zen 2 的第一级 BTB 可以保存 8 条前向分支和 8 条后向分支,预测不会带来流水线气泡,也就是说每个周期都可以预测一次。相比 Zen 1 容量翻倍。
L1BTB has 512 entries and creates one bubble if prediction differs from L0BTB
Zen 2 的第二级 BTB 可以保存 512 个 entry,但不确定这个 entry 是否可以保存两条分支,也不确定这个 entry 数量代表了实际的 entry 数量还是分支数量,后续会做实验证实;预测会产生单个气泡,意味着它的延迟是两个周期。相比 Zen 1 容量翻倍。
L2BTB has 7168 entries and creates four bubbles if its prediction differs from L1BTB.
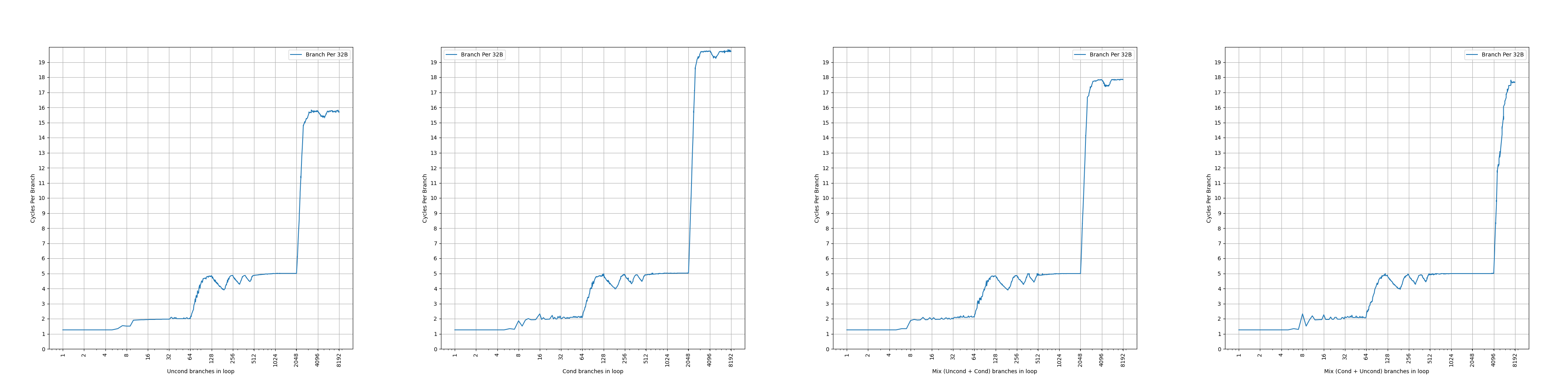
ARM Neoverse N1 的压缩方法是,根据立即数范围对分支进行分类,如果分支的立即数范围比较小,就只占用一个 entry 的一半也就是 41 bit;如果分支的立即数范围过大,就占用一个完整的 82 bit 的 entry;这主要是一个减少 SRAM 占用的优化,避免了所有的分支都要记录完整的 82 bit 信息;对代码的结构要求比较小,只要是跳转距离不太远的分支,都可以存到 41 bit 内
二者都没有实现一个周期预测两条分支,即 two taken(ARM 的说法是 two predicted branches per cycle)。这要等到 2020 年的 ARM Neoverse N2/V1,或者 2022 年的 AMD Zen 4 才被实现。
The branch target buffer (BTB) is a three-level structure accessed using the fetch address of the current fetch block.
Zen 1 的 BTB 有三级,是用当前 fetch block 的地址去查询。
Each BTB entry includes information for branches and their targets. Each BTB entry can hold up to two branches if the branches reside in the same 64-byte aligned cache line and the first branch is a conditional branch.
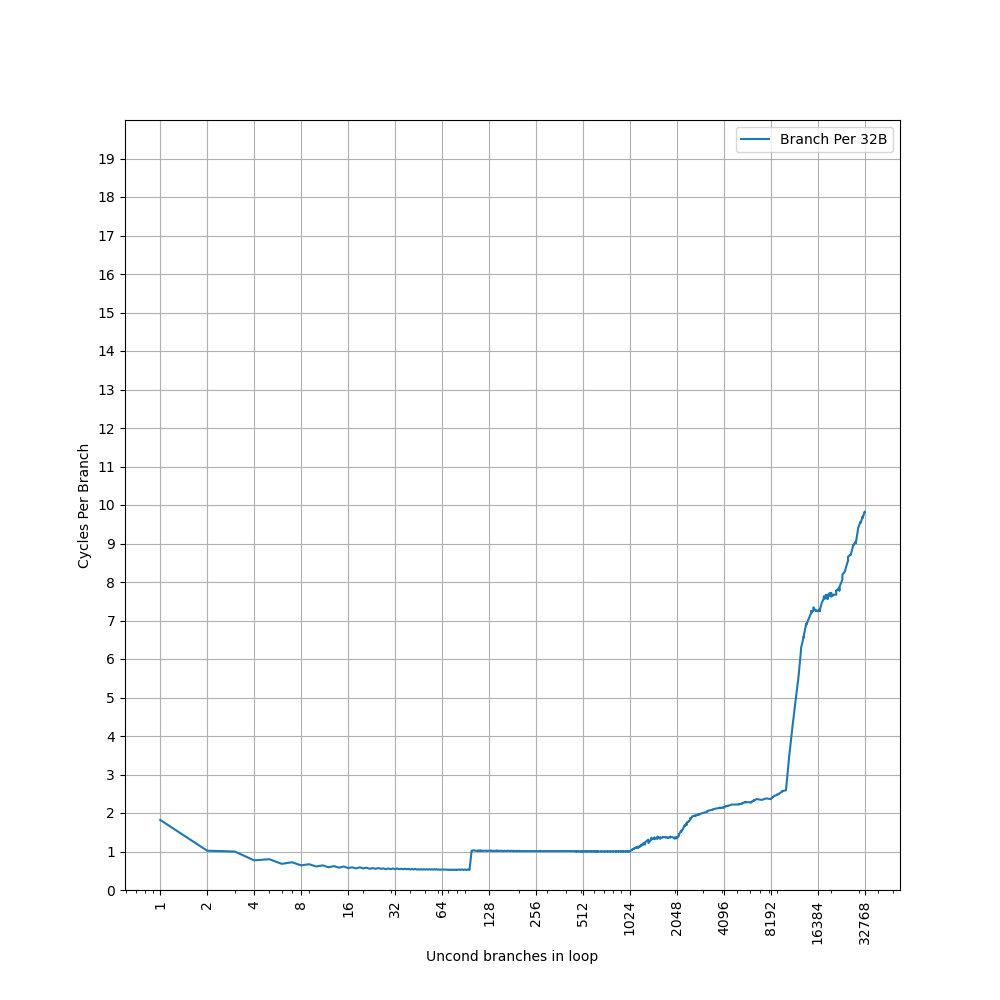
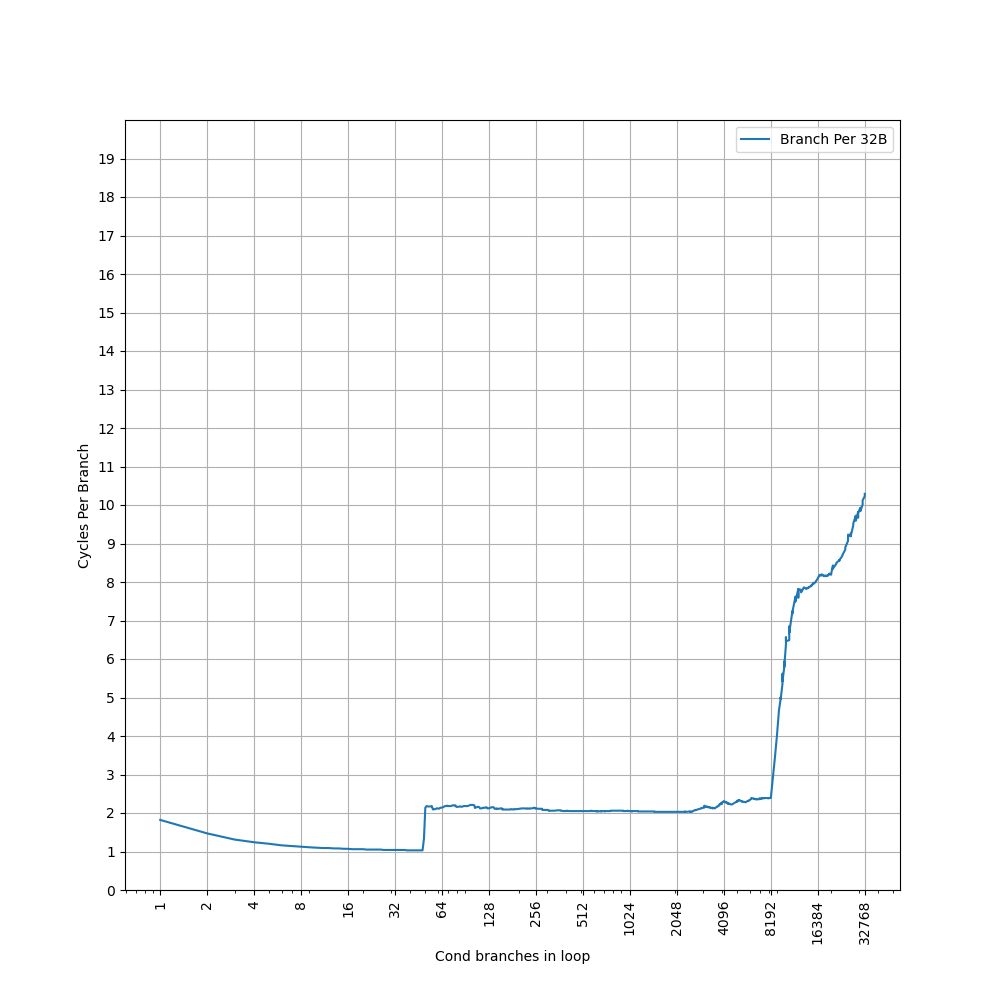
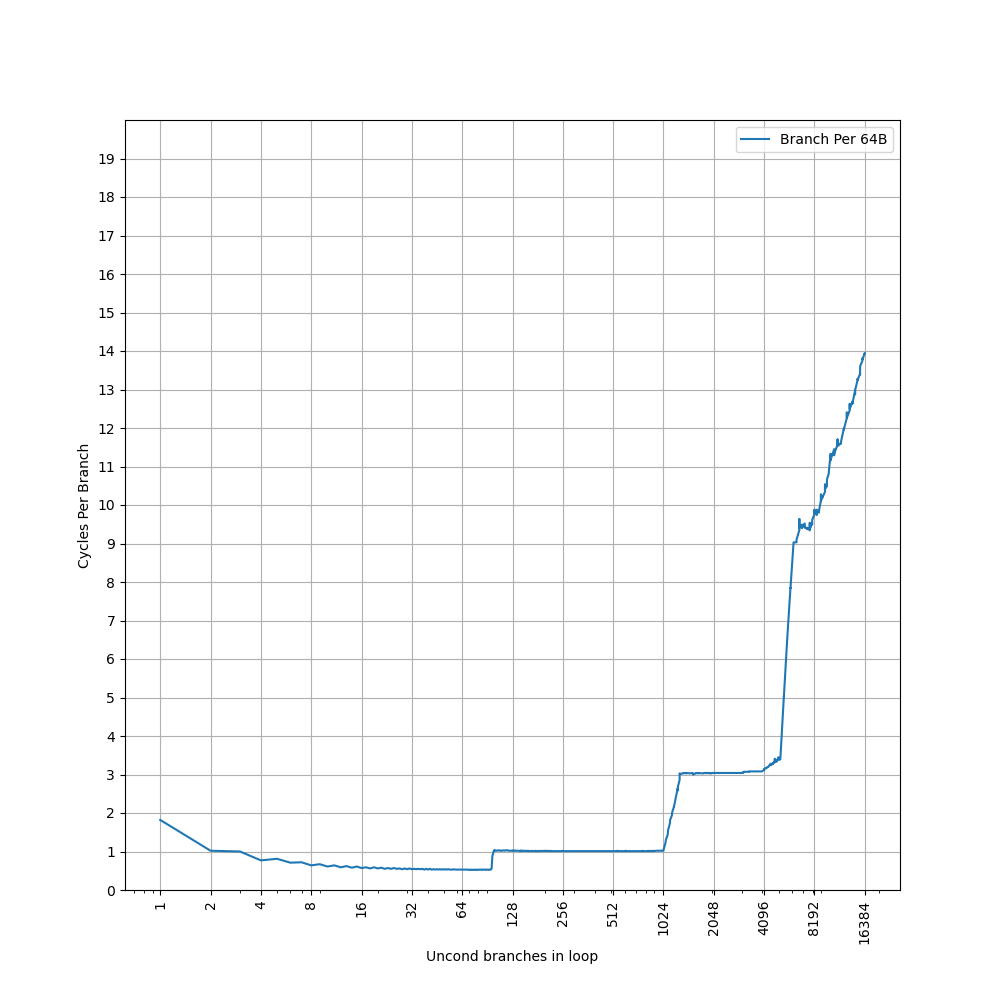
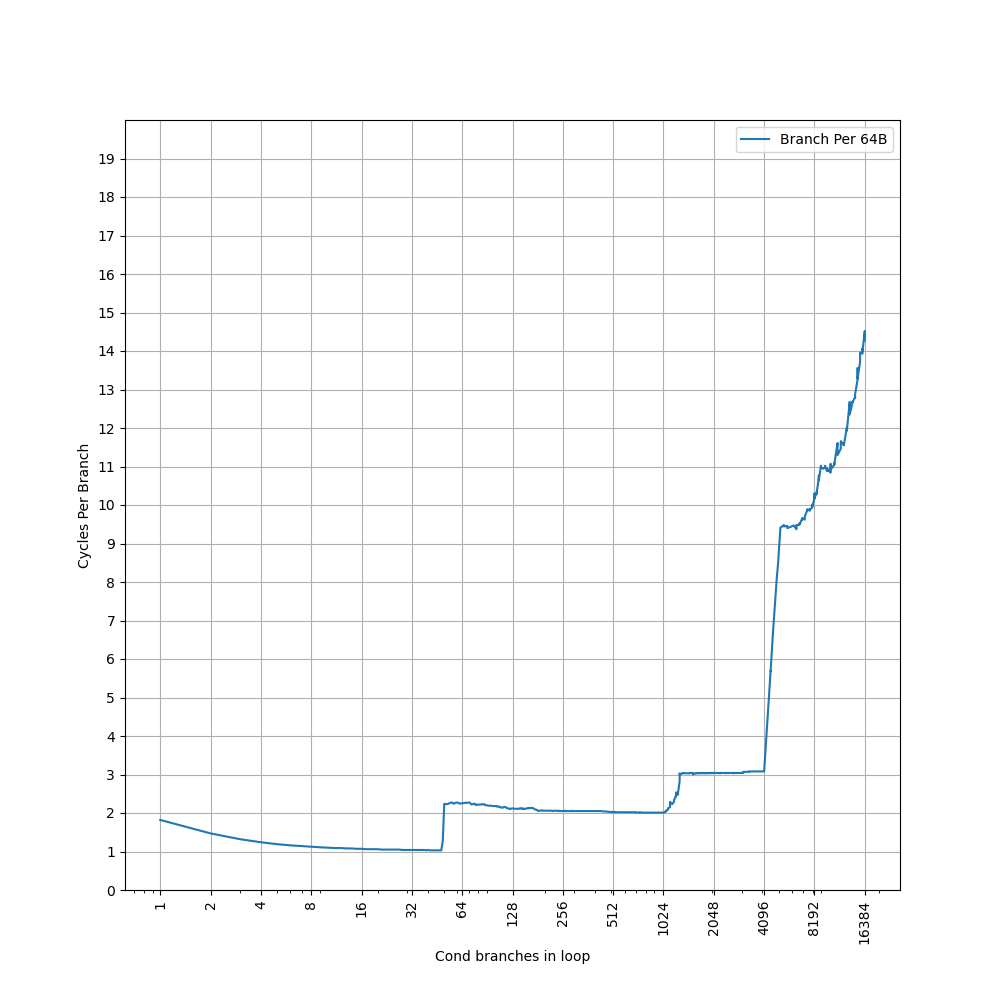
首先回忆一下,在 ARM Neoverse N1 中,连续的 32B 内能放 6 个分支,但是 stride=8B 的时候,一次就会往同一个 set 里增加 4 个分支,于是一个 set 内的分支数从 0 变到 4 再变到 8,拐点出现在 4 个分支,而不是 6 个分支。因此为了达到前面出现的 3072 和 2560 的拐点,新增的分支也得均匀地分到各个 set 当中。
前面根据 L2 BTB 的容量分析到,L2 BTB 的 Index 可能是 PC[n:6],但肯定不是简单的这么取,否则也会出现 ARM Neoverse N1 类似的问题。只能说明 PC[6] 往上有若干个 bit 是单独出现在 L2 BTB 的 Index 当中的,而 PC[5] 以下的 bit,可能以某种哈希函数的形式,参与到 Index 当中。
所以,L2 BTB 可能是以 PC[n:6] 作为 Index 去访问,然后内部有多个 bank,每个 bank 内部是 2 路组相连。bank index 是通过 PC 经过哈希计算得来,使得在 stride=4B/8B 的时候,体现出 2 路组相连,而在 stride=16B 的时候,体现出 4 路组相连。同时,分支还能够均匀地分布到各个 bank 当中,避免了和 ARM Neoverse N1 类似的情况的发生。
然后下一个周期从 second branch target 开始继续预测。根据官方信息,Neoverse V1 的 L1 ICache 支持 2x32B 的带宽,这个 2x 代表了可以从两个不同的地方读取指令,也就是 L1 ICache 至少是双 bank 甚至双端口的 SRAM。考虑到前面的测试中,CPI=0.5 的范围跨越了各种 stride,认为 L1 ICache 是双 bank 的可能写比较小,不然应该会观测到 bank conflict,大概率就是双端口了。
此外,考虑到 fetch bundle 的长度限制,first branch target 到 second branch pc 不能太远。在上面的测试中,这个距离总是 0;读者如果感兴趣,可以尝试把距离拉长,看看超过 32B 以后,是不是会让 2 predicted branches per cycle 失效。类似的表述,在 AMD Zen 4 Software Optimization Guide 中也有出现:
The branch target buffer (BTB) is a two-level structure accessed using the fetch address of the previous fetch block. Each BTB entry includes information for branches and their targets. Each BTB entry can hold up to two branches, and two pair cases are supported: • A conditional branch followed by another branch with both branches having their last byte in the same 64 byte aligned cacheline. • A direct branch (excluding CALLs) followed by a branch ending within the 64 byte aligned cacheline containing the target of the first branch. Predicting with BTB pairs allows two fetches to be predicted in one prediction cycle.
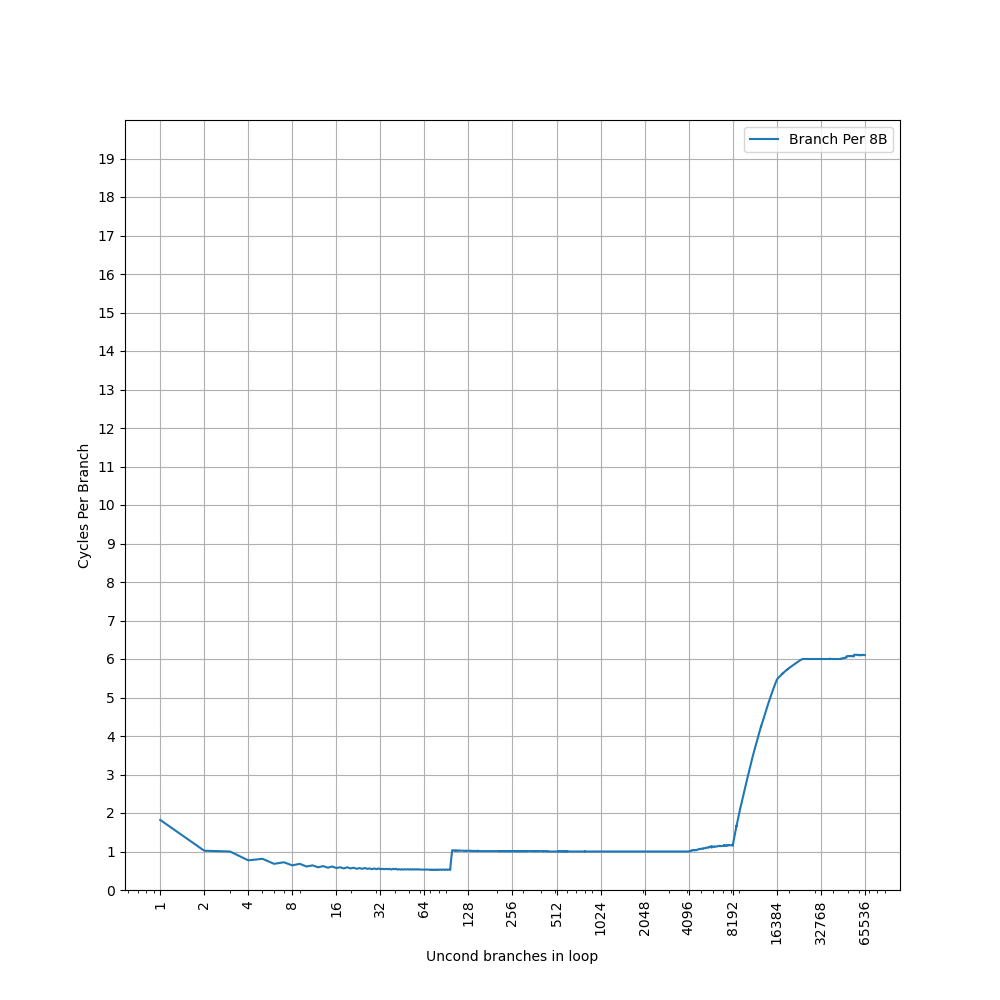
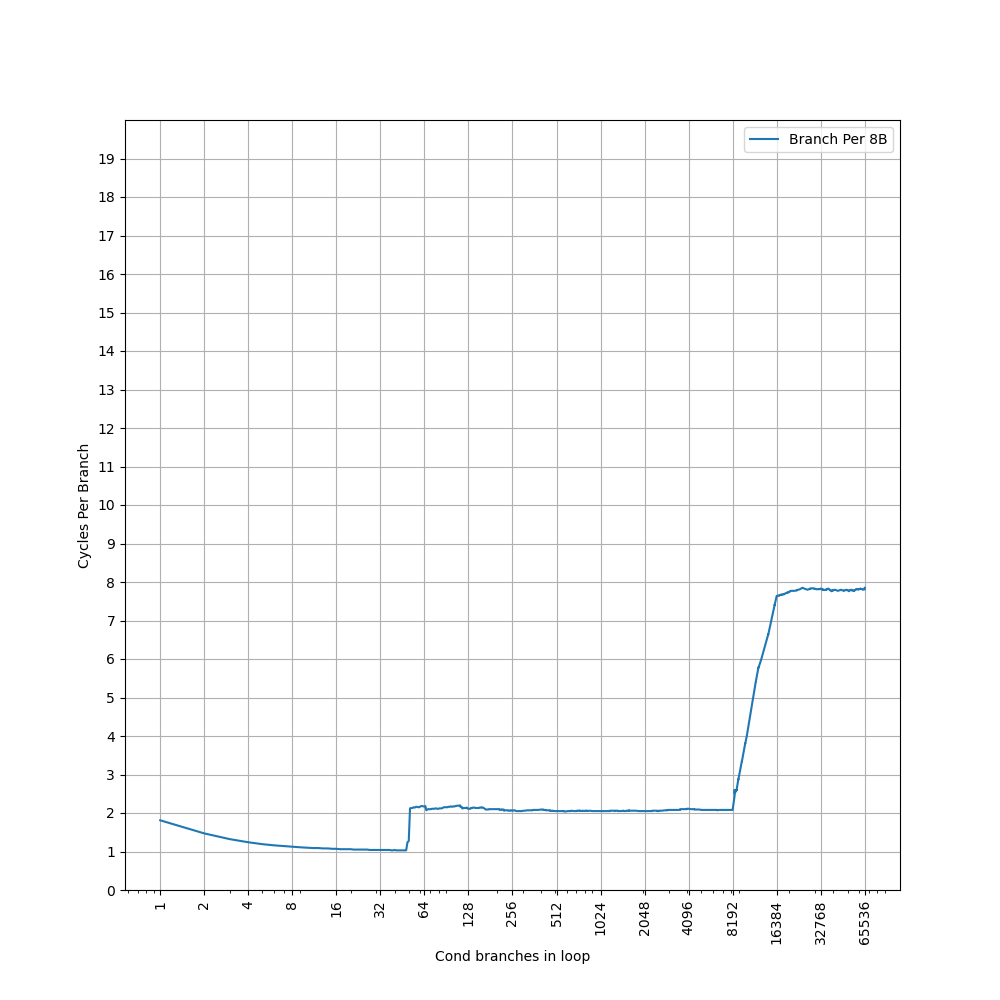
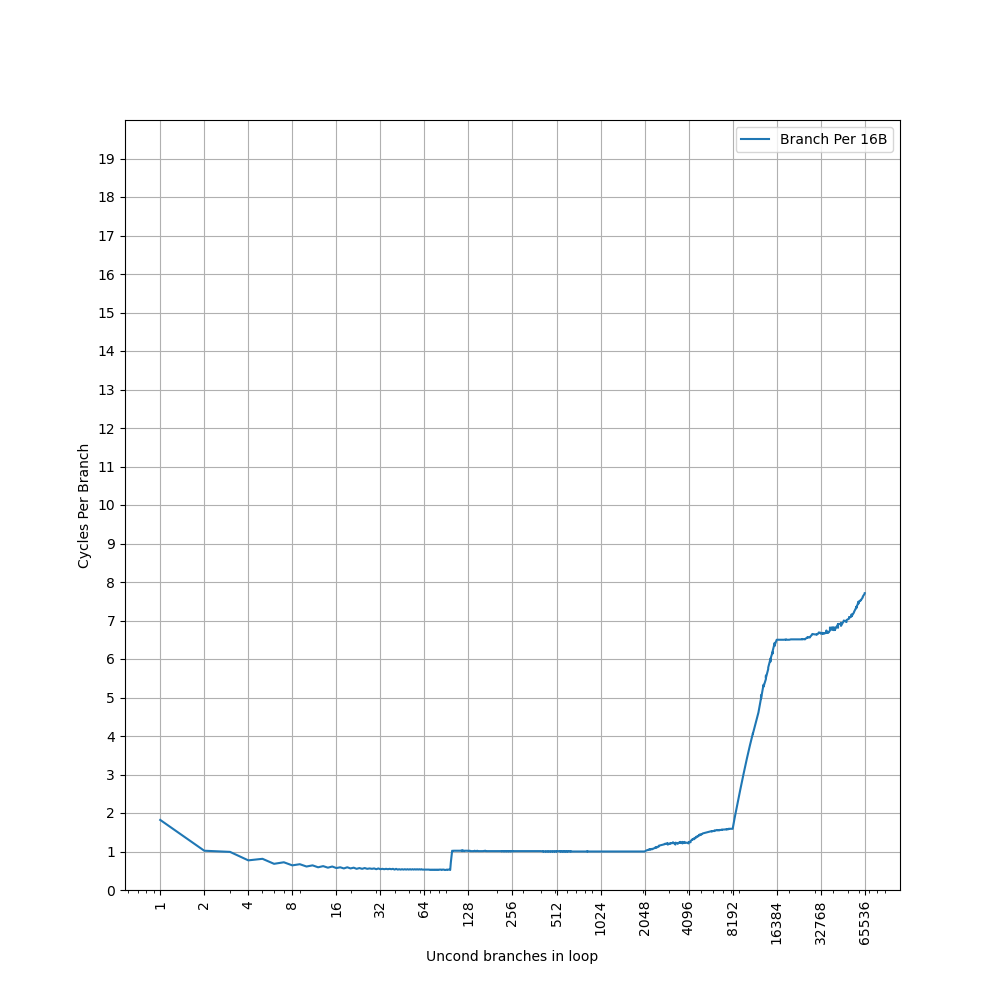
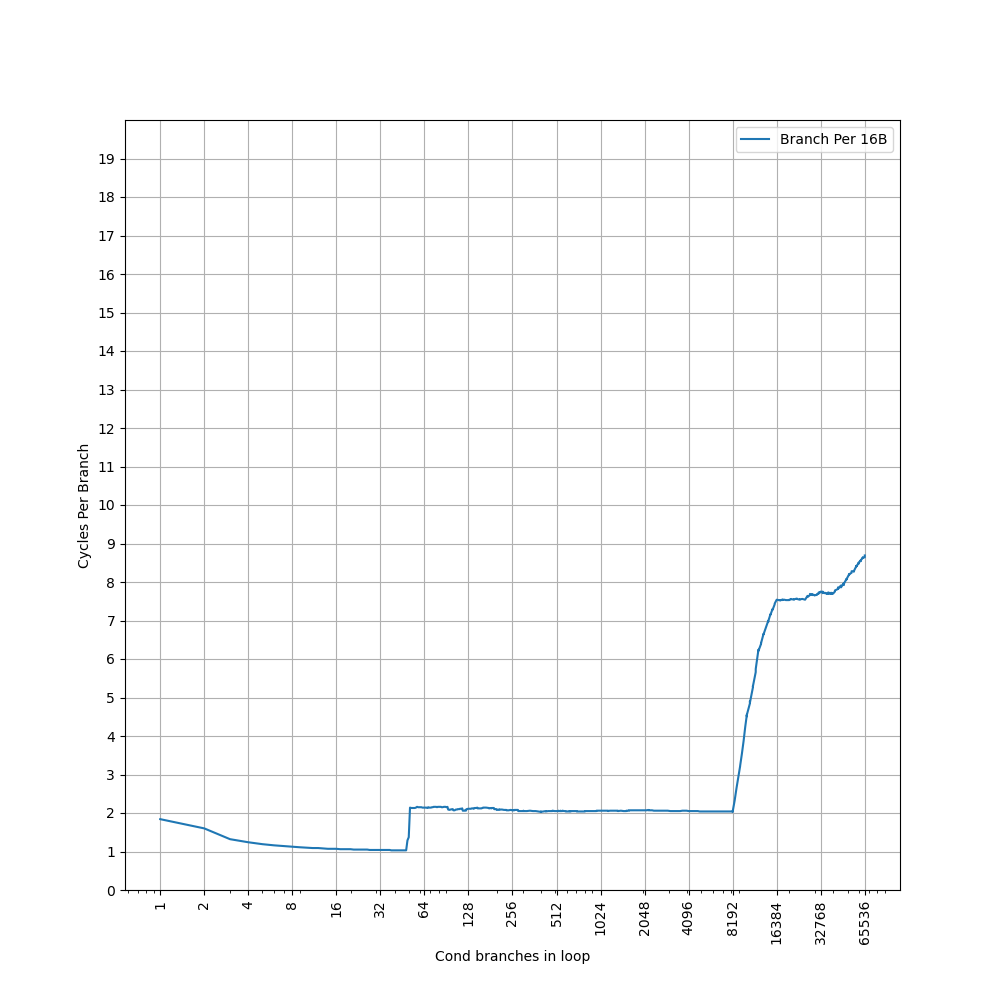
48-entry(96 branches) nano BTB, at most 2 branches per entry, 1 cycle latency, at most 2 predicted branches every 1 cycle, fully associative
4K-entry(8K branches) main BTB, at most 2 branches per entry, 2 cycle latency, at most 2 predicted branches every 2 cycles, 2-way(4-branch-way) set-associative, index PC[15:5]
vmwgfx 0000:00:04.0: [drm] FIFO at 0x0000000020000000 size is 2048 kiB vmwgfx 0000:00:04.0: [drm] VRAM at 0x0000000010000000 size is 262144 kiB vmwgfx 0000:00:04.0: [drm] *ERROR* Unsupported SVGA ID 0xffffffff on chipset 0x405 vmwgfx: probe of 0000:00:04.0 failed with error -38
blacklist vmwgfx 后用的是 efifb:
[ 0.465898] pci 0000:00:04.0: BAR 1: assigned to efifb [ 1.197638] efifb: probing for efifb [ 1.197705] efifb: framebuffer at 0x10000000, using 7500k, total 7500k [ 1.197708] efifb: mode is 1600x1200x32, linelength=6400, pages=1 [ 1.197711] efifb: scrolling: redraw [ 1.197712] efifb: Truecolor: size=8:8:8:8, shift=24:16:8:0
虚拟机的 IP 地址,从宿主机也可以直接访问,通过 WVMBr 访问,目测是直接 Tap 接出来,然后建了个 Bridge,外加 NAT,只是没有 DHCP。
// vertex shader#version 320 esinvec4vertex;// xy is position, zw is its texture coordinatesoutvec2texCoors;// output texture coordinatesvoidmain(){gl_Position.xy=vertex.xy;gl_Position.z=0.0;// we don't care about depth nowgl_Position.w=1.0;// (x, y, z, w) corresponds to (x/w, y/w, z/w), so we set w = 1.0texCoords=vertex.zw;}// fragment shader#version 320 esprecisionlowpfloat;invec2texCoords;outvec4color;uniformsampler2Dtext;voidmain(){floatalpha=texture(text,texCoords).r;color=vec4(1.0,1.0,1.0,alpha);}
在这里,我们给每个顶点设置四个属性,包在一个 vec4 中:
xy:记录了这个顶点的坐标,x 和 y 范围都是 -1 到 1
zw:记录了这个顶点的 texture 坐标 u 和 v,范围都是 0 到 1
vertex shader 只是简单地把这些信息传递到顶点的坐标和 fragment shader。fragment shader 做的事情是:
// vertex shader#version 320 esinvec4vertex;// xy is position, zw is its texture coordinatesinvec3textColor;outvec2texCoors;// output texture coordinatesoutvec3fragTextColor;// send to fragment shadervoidmain(){gl_Position.xy=vertex.xy;gl_Position.z=0.0;// we don't care about depth nowgl_Position.w=1.0;// (x, y, z, w) corresponds to (x/w, y/w, z/w), so we set w = 1.0texCoords=vertex.zw;fragTextColor=textColor;}// fragment shader#version 320 esprecisionlowpfloat;invec2texCoords;invec3fragTextColor;outvec4color;uniformsampler2Dtext;voidmain(){floatalpha=texture(text,texCoords).r;color=vec4(fragTextColor,alpha);}
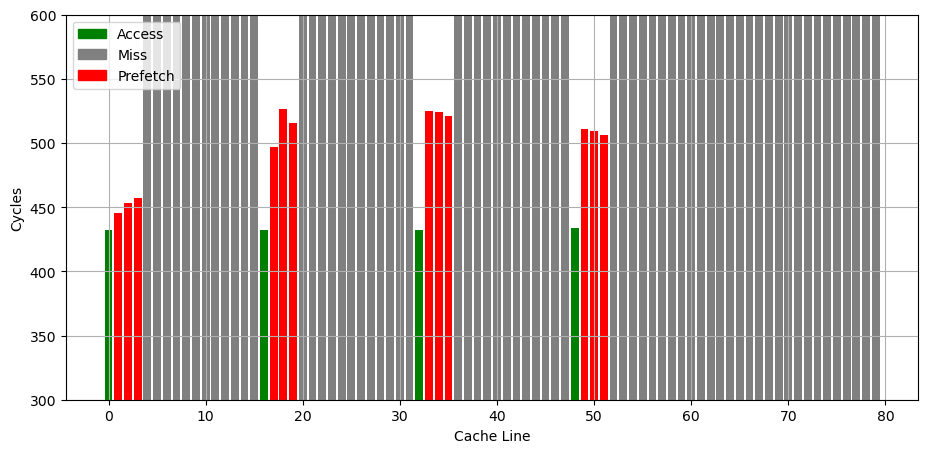
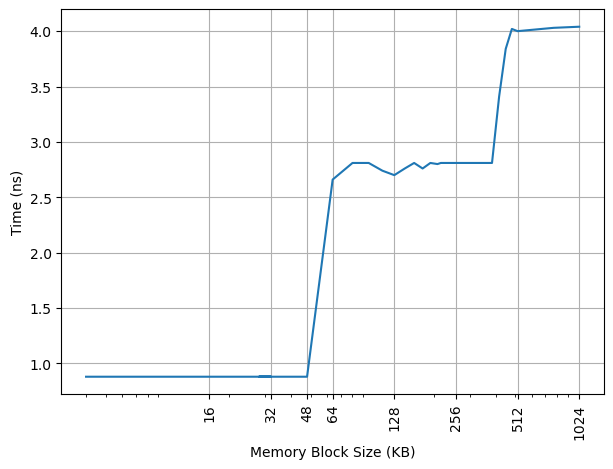
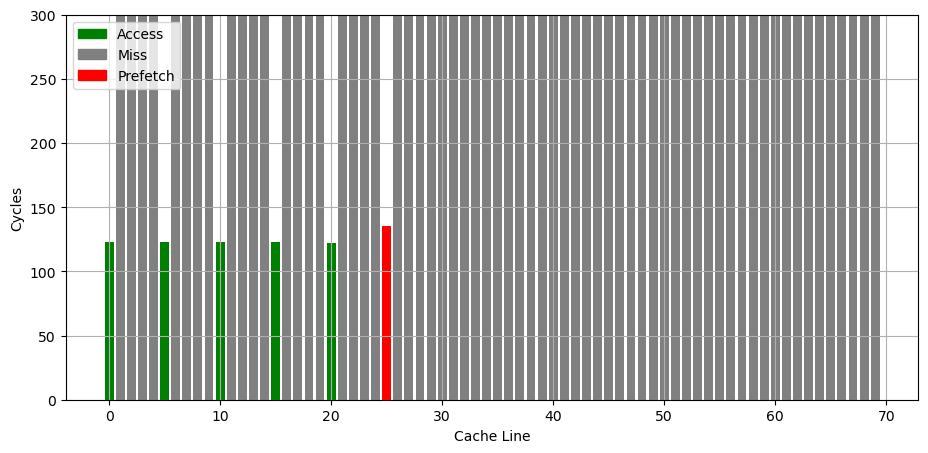
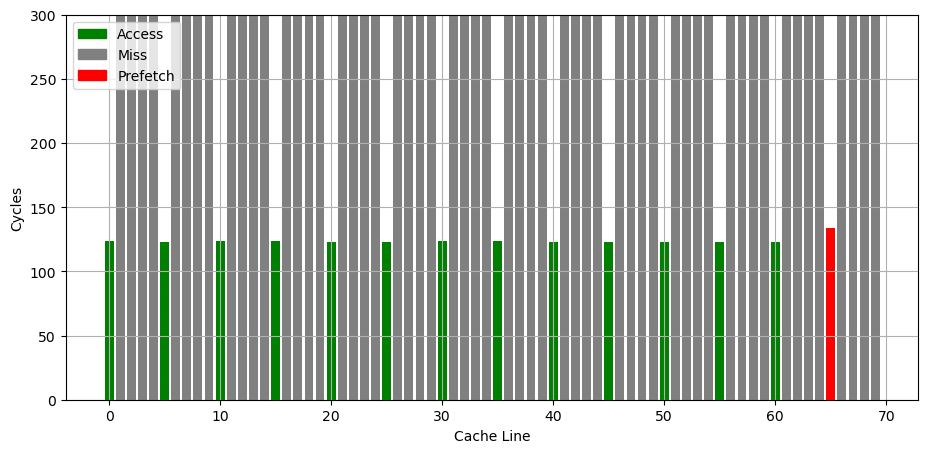
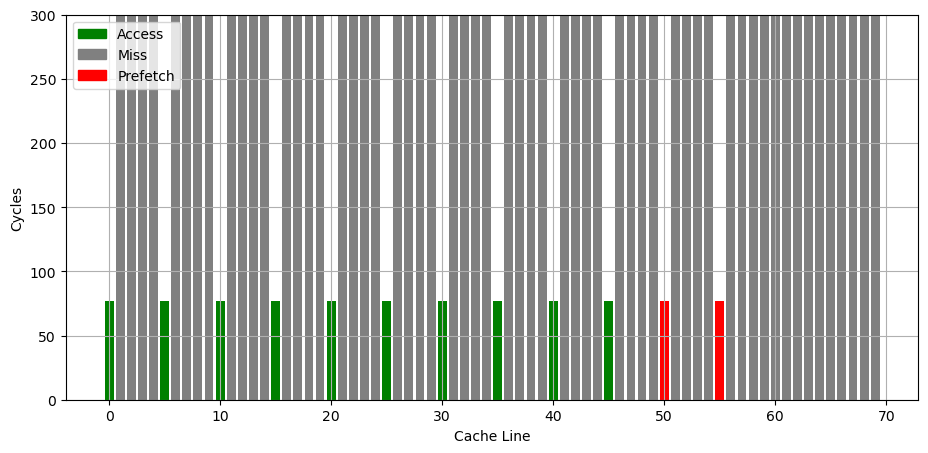
MSR_1A4H[0]: the L2 hardware prefetcher, which fetches additional lines of code or data into the L2 cache.
MSR_1A4H[1]: the L2 adjacent cache line prefetcher, which fetches the cache line that comprises a cache line pair (128 bytes). 这和 AMD 的 Up/Down Prefetcher 应该是一个意思
MSR_1A4H[2]: the L1 data cache prefetcher, which fetches the next cache line into L1 data cache. 这个应该属于 Next Line Prefetcher
MSR_1A4H[3]: the L1 data cache IP prefetcher, which uses sequential load history (based on instruction pointer of previous loads) to determine whether to prefetch additional lines.
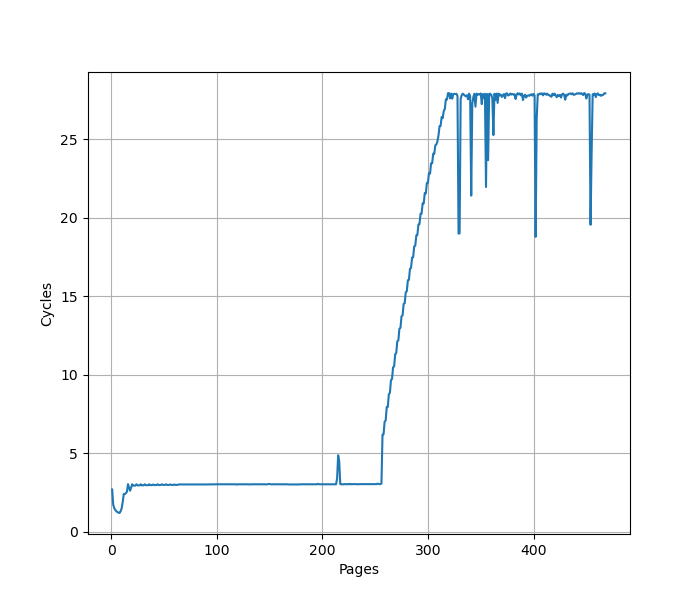
MSR_1A4H[4]: Next page prefetcher,当访问快走到一个页的结尾的时候,从下一个页的开头开始 prefetch,提前进行可能的 TLB refill
MSR_1A4H[5]: the L2 Adaptive Multipath Probability (AMP) prefetcher. 这个应该属于 Spatial Prefetcher
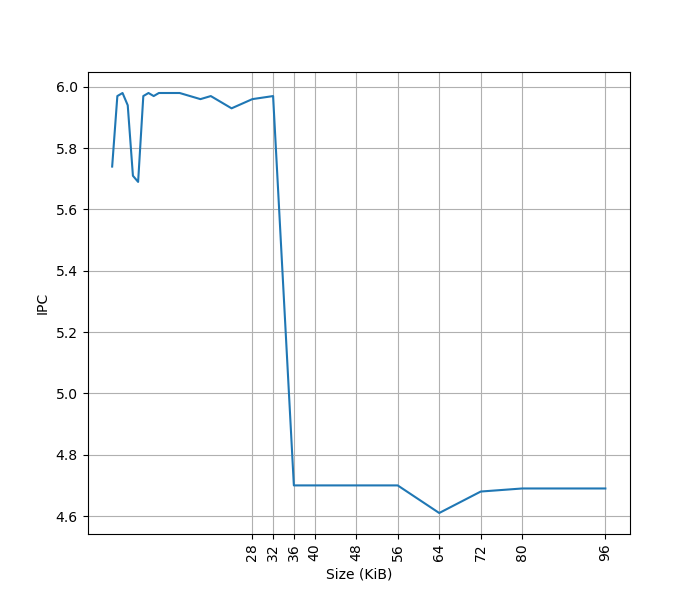
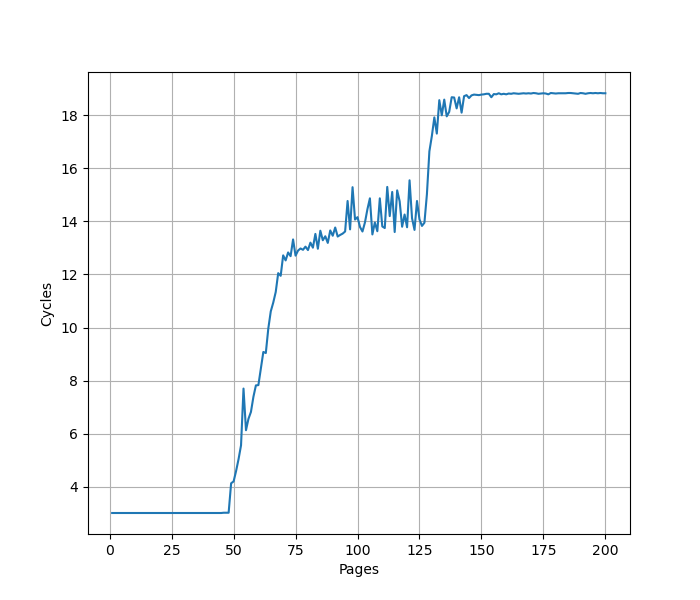
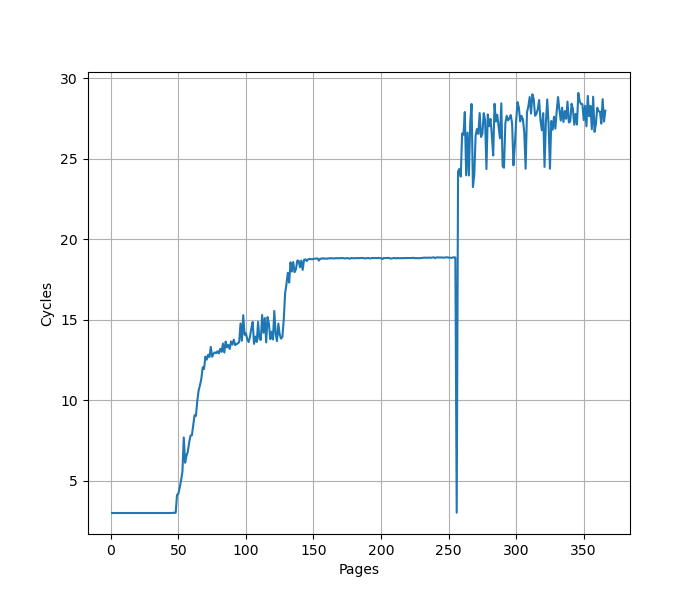
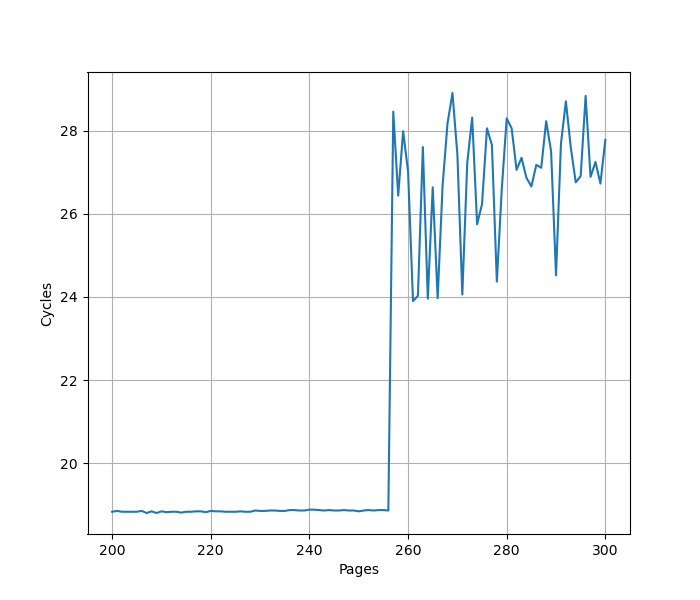
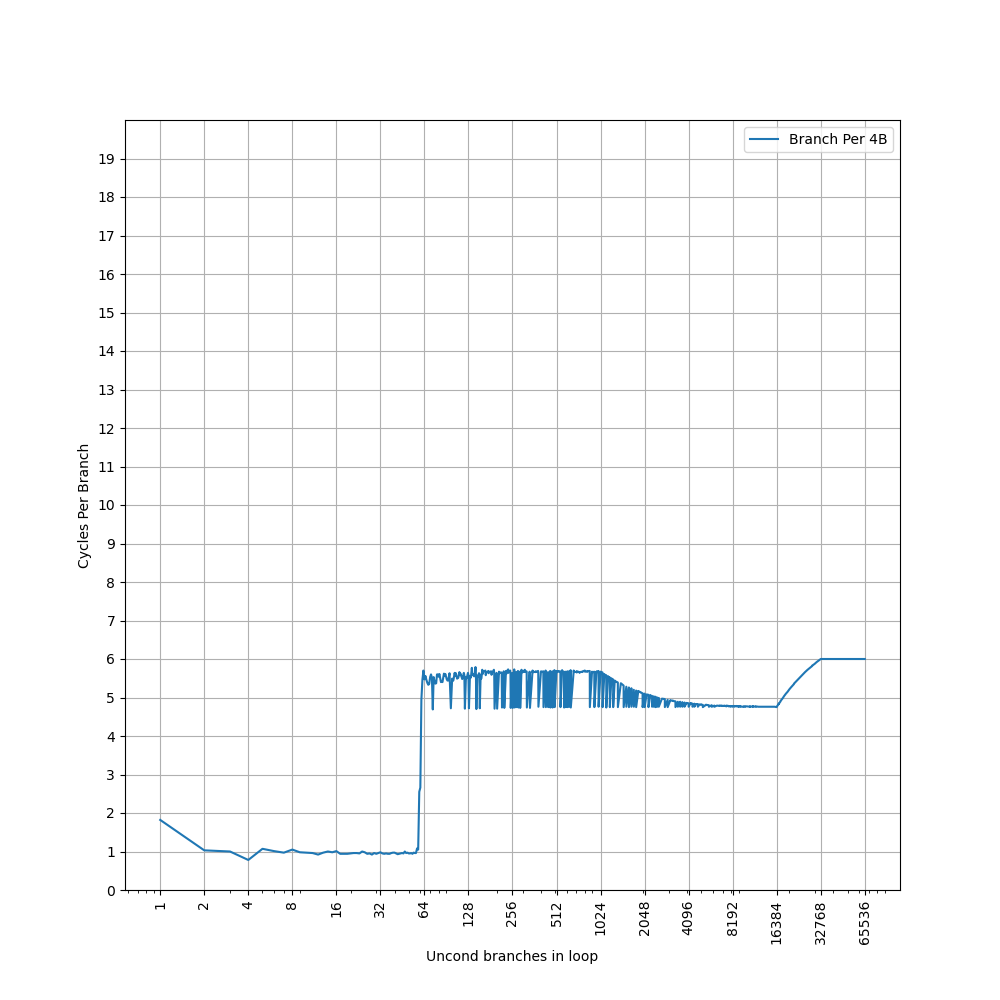
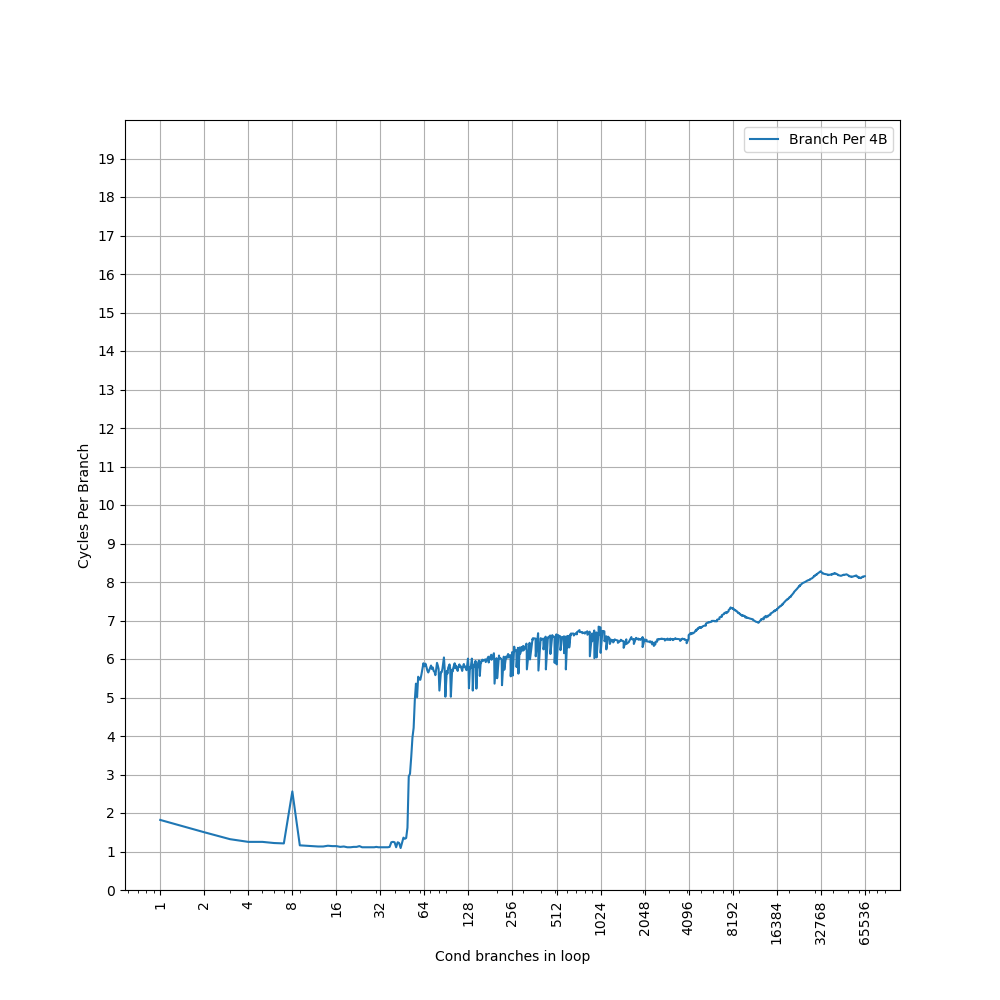
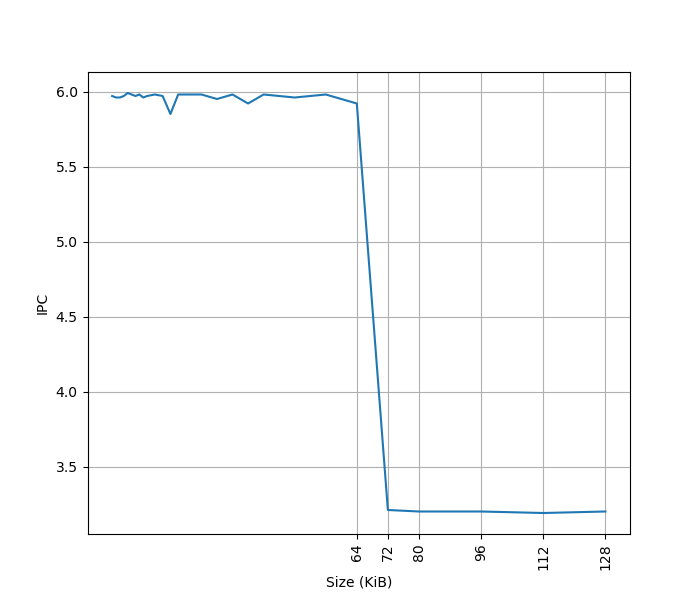
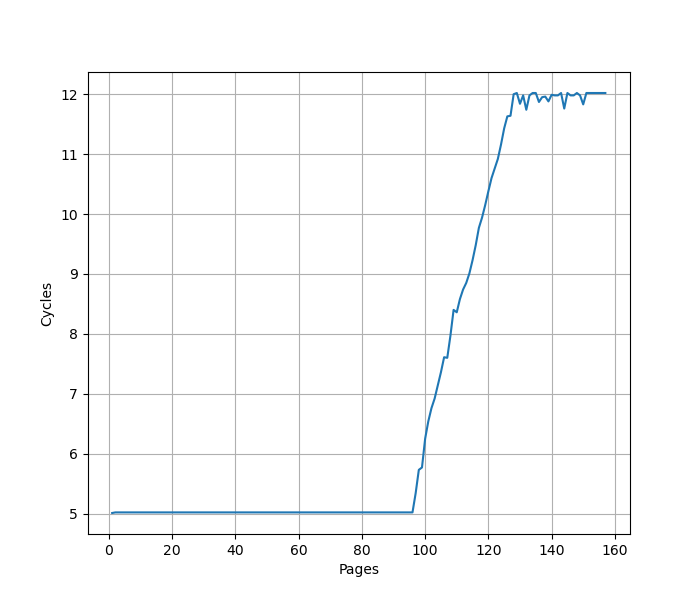
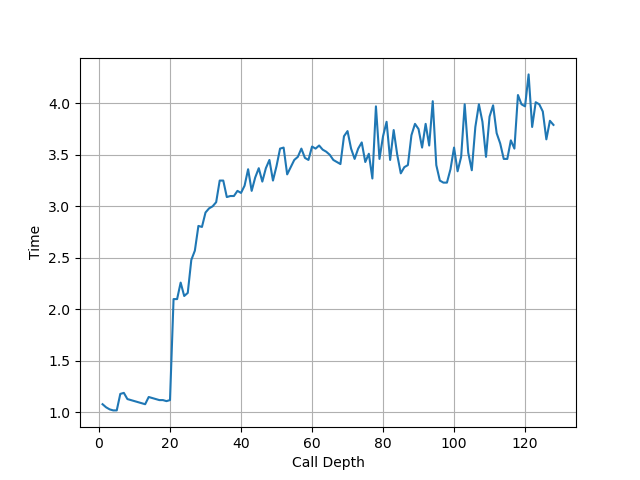
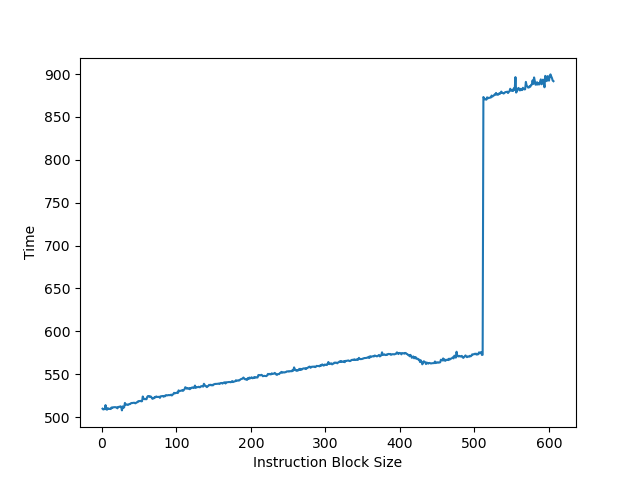
为了测试 ROB 的大小,设计了一个循环,循环开始和结束是长延迟的 long latency load。中间是若干条 NOP 指令,当 NOP 指令比较少时,循环的时候取决于 load 指令的时间;当 NOP 指令数量过多,填满了 ROB 以后,就会导致 ROB 无法保存循环末尾的 load 指令,性能出现下降。测试结果如下:
当 NOP 数量达到 512 时,性能开始急剧下滑,说明 Redwood Cove 的 ROB 大小是 512。这和 Golden Cove 是一样的。
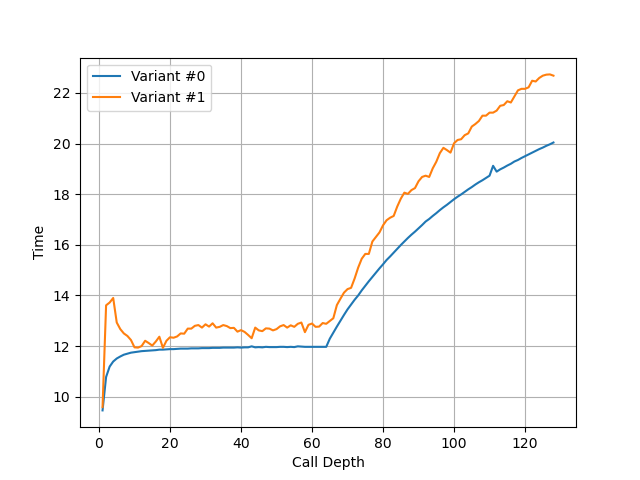
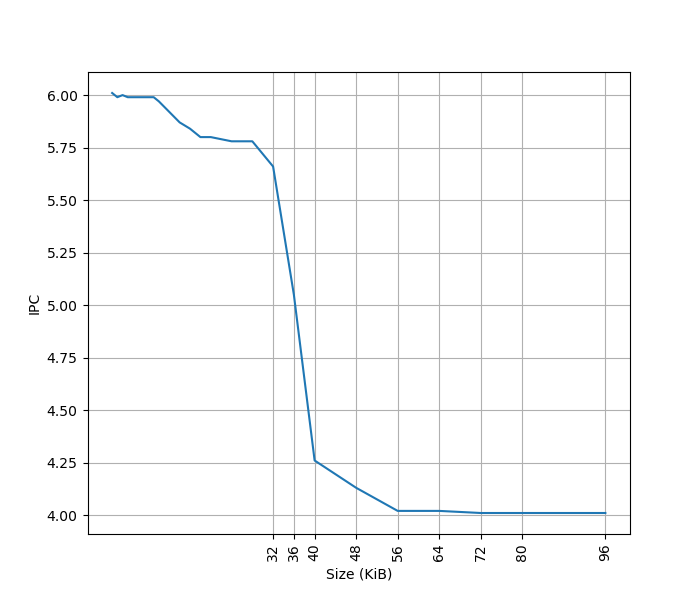
The micro-op cache size is increased to hold 4,000 (注:应该是 4096) micro-ops,
and its bandwidth is increased to deliver up to 8 micro-ops per cycle.
Intel 的 uOP(Micro-OP) Cache 称为 Decode Stream Buffer (DSB): Decode Stream Buffer (DSB) is a Uop-cache that holds translations of previously fetched instructions that were decoded by the legacy x86 decode pipeline (MITE).。
根据前人在 Intel 比较老的微架构上的测试结果(见 The microarchitecture of Intel, AMD, and VIA CPUs)以及 Intel 的官方文档 Software Optimization Manual(这个文档把 uOP Cache 叫做 Decoded ICache),Intel 之前很多代微架构的 uOP Cache Entry 的构造条件是:
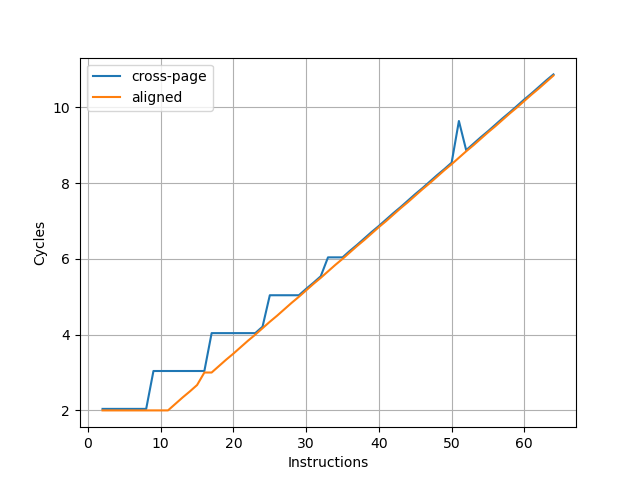
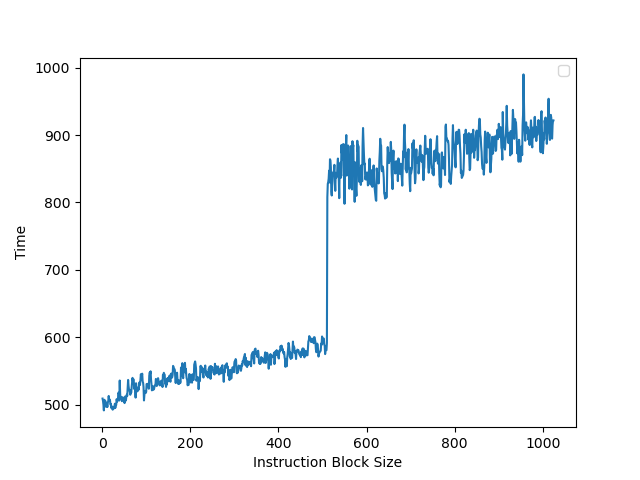
每个 Entry 能记录的 uOP 个数有上限,最多 6 uOP/Entry
Entry 不能跨越 32B 边界,反过来,一个对齐的 32B 区间只能对应最多 3 个 Entry,结合第一条,就是对齐的 32B 块中不能超过 3*6=18 个 uOP(The Decoded ICache can hold only up to 18 micro-ops per each 32 byte aligned memory chunk);如果指令跨了 32B 边界,它被算在后面那个 32B 里面
Partial store forwarding allowing forwarding data from store to load also when only part of the load was covered by the store (in case the load's offset matches the store's offset)
经过实际测试,Golden Cove 上如下的情况可以成功转发,对地址 x 的 Store 转发到对地址 y 的 Load 成功时 y-x 的取值范围:
Store\Load
8b Load
16b Load
32b Load
64b Load
8b Store
{0}
{}
{}
{}
16b Store
[0,1]
{0}
{}
{}
32b Store
[0,3]
[0,2]
{0}
{}
64b Store
[0,7]
[0,6]
[0,4]
{0}
可以看到,Golden Cove 在 Store 完全包含 Load 的情况下都可以转发,没有额外的对齐要求。但当 Load 和 Store 只有部分重合时,就无法转发,这和官方信息有所冲突。两个连续的 32 位的 Store 和一个 64 位的 Load 重合也不能转发。
Intel Golden Cove 的处理器通过 MSR 1A4H 可以配置各个预取器(来源:Software Developers Manual,MSRs Supported by 12th and 13th Generation Intel® Core™ Processor P-core):
MSR_1A4H[0]: the L2 hardware prefetcher, which fetches additional lines of code or data into the L2 cache.
MSR_1A4H[1]: the L2 adjacent cache line prefetcher, which fetches the cache line that comprises a cache line pair (128 bytes). 这和 AMD 的 Up/Down Prefetcher 应该是一个意思
MSR_1A4H[5]: the L2 Adaptive Multipath Probability (AMP) prefetcher. 这个应该属于 Spatial Prefetcher
MSR_1A4H[2]: the L1 data cache prefetcher, which fetches the next cache line into L1 data cache. 这个应该属于 Next Line Prefetcher
MSR_1A4H[3]: the L1 data cache IP prefetcher, which uses sequential load history (based on instruction pointer of previous loads) to determine whether to prefetch additional lines.
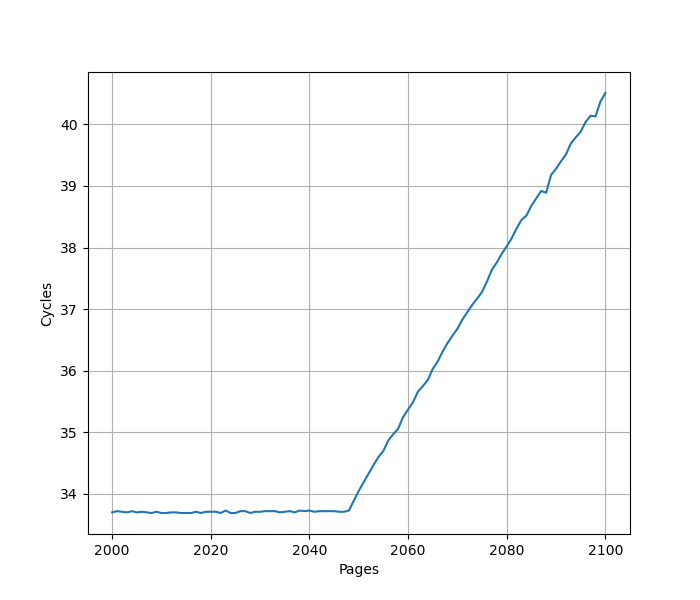
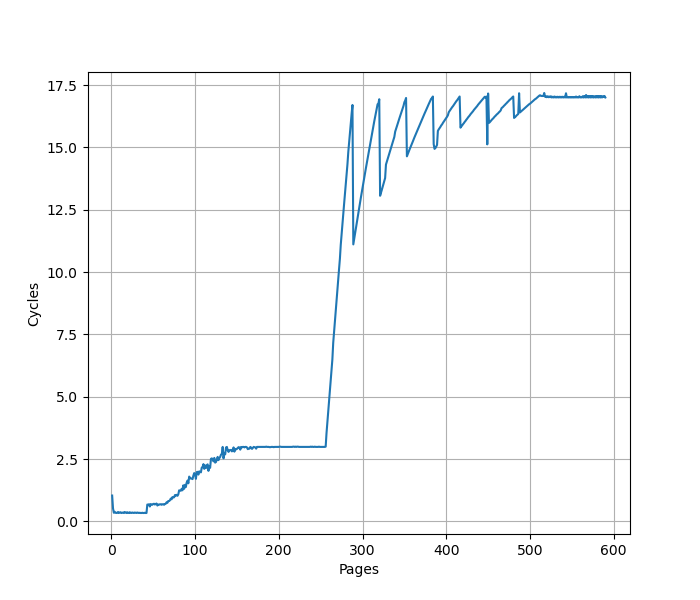
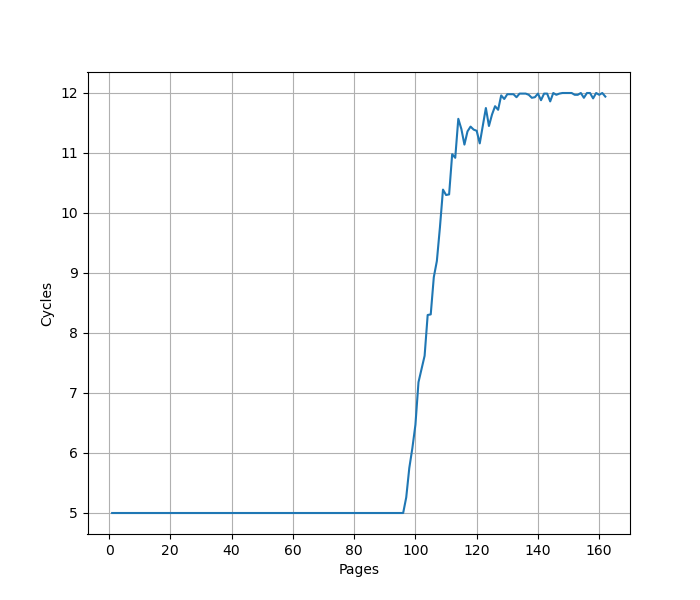
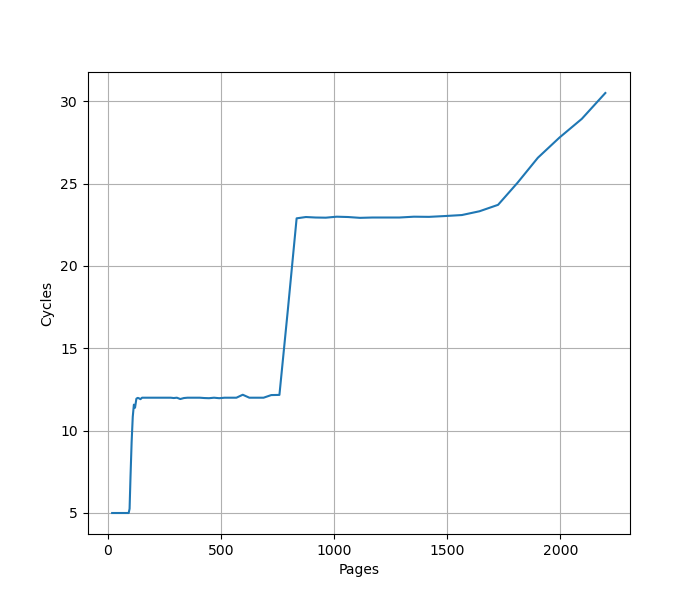
为了测试 ROB 的大小,设计了一个循环,循环开始和结束是长延迟的 long latency load。中间是若干条 NOP 指令,当 NOP 指令比较少时,循环的时候取决于 load 指令的时间;当 NOP 指令数量过多,填满了 ROB 以后,就会导致 ROB 无法保存循环末尾的 load 指令,性能出现下降。测试结果如下:
当 NOP 数量达到 512 时,性能开始急剧下滑,说明 Golden Cove 的 ROB 大小是 512。