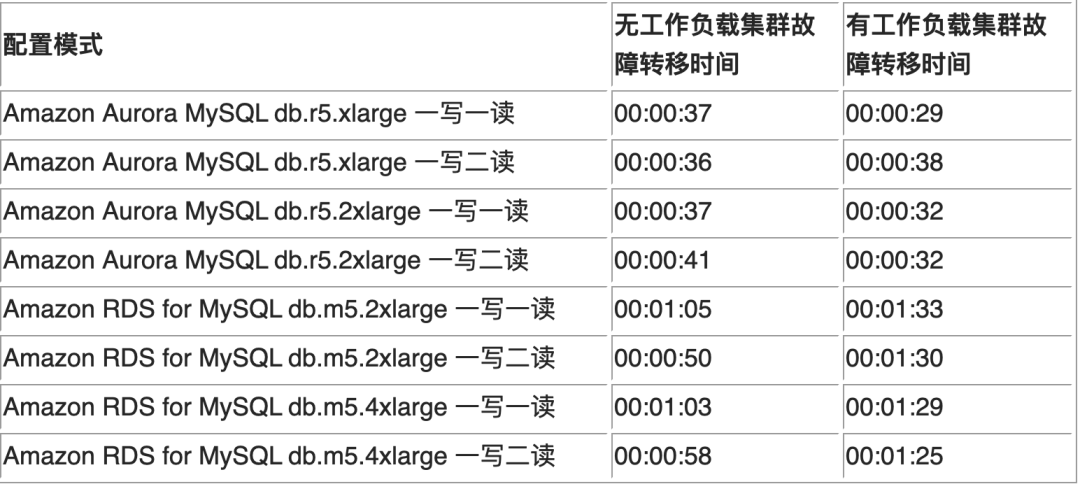
使用原生JS实现Echarts数据导出Excel的功能
Echarts toolbox 增加数据导出Excel的功能
Echarts的toolbox提供了很多工具,例如saveAsImage(导出图片)、magicType(切换类型)等,具体的可以参考toolbox官方文档。toolbox原生提供的功能算是比较全面的了,但唯独缺少了一键将数据导出为Excel的功能。虽然可以通过toolbox中的dataView(数据视图)查看数据,然后复制粘贴到Excel中,但这种做法着实不够优雅。好在toolbox支持用户自定义工具。
在自定义功能之前,需要注意的是,自定义的工具名字,只能以my开头,例如myTool1、myTool2......,具体示例可以参考toolbox.feature文档,示例代码如下:
toolbox: {
feature: {
myTool1: {
show: true,
title: '自定义扩展方法1',
icon: 'path://M432.45,595.444c0,2.177-4.661,6.82-11.305,6.82c-6.475,0-11.306-4.567-11.306-6.82s4.852-6.812,11.306-6.812C427.841,588.632,432.452,593.191,432.45,595.444L432.45,595.444z M421.155,589.876c-3.009,0-5.448,2.495-5.448,5.572s2.439,5.572,5.448,5.572c3.01,0,5.449-2.495,5.449-5.572C426.604,592.371,424.165,589.876,421.155,589.876L421.155,589.876z M421.146,591.891c-1.916,0-3.47,1.589-3.47,3.549c0,1.959,1.554,3.548,3.47,3.548s3.469-1.589,3.469-3.548C424.614,593.479,423.062,591.891,421.146,591.891L421.146,591.891zM421.146,591.891',
onclick: function () {
alert('myToolHandler1')
}
}
}
}其中的重点就是onclick函数,我希望实现点击按钮自动下载Excel的功能,下面我先给出最终实现的代码:
myTool: {
show: true,
title: '导出EXCEL',
icon: 'path://M925.248 356.928l-258.176-258.176a64 64 0 0 0-45.248-18.752H144a64 64 0 0 0-64 64v736a64 64 0 0 0 64 64h736a64 64 0 0 0 64-64V402.176a64 64 0 0 0-18.752-45.248zM288 144h192V256H288V144z m448 736H288V736h448v144z m144 0H800V704a32 32 0 0 0-32-32H256a32 32 0 0 0-32 32v176H144v-736H224V288a32 32 0 0 0 32 32h256a32 32 0 0 0 32-32V144h77.824l258.176 258.176V880z',
onclick: function(opt) {
opt = opt.option;
var cell, csv, csvContent, encodedUri, head, i, j, k, len, line, lines, link, ref, s, tr, tr_list, value, x, y;
x = opt.xAxis[0].data
y = [
(function() {
var k, len, ref, results;
ref = opt.series;
results = [];
for (k = 0, len=ref.length; k < len; k++) {
i = ref[k];
results.push(i.name)
}
return results;
})()
];
y[0].splice(0, 0, "日期");
value = [
(function() {
var k, len, ref, results;
ref = opt.series;
results = [];
for (k=0, len = ref.length; k < len; k++) {
i = ref[k];
results.push(i.data);
}
return results;
})()
][0];
tr = "";
csvContent = "data:text/csv;charset=utf-8,%EF%BB%BF";
csv = y[0].join(",") + ",\n";
head = "<tr>";
ref = y[0];
for (k = 0, len = ref.length; k < len; k++) {
i = ref[k];
head += '<th>' + i + '</th>';
}
head += "</tr>";
tr_list = [];
i = 0;
lines = [];
while (i < value[0].length) {
j = 0;
tr = "";
tr += "<tr>";
tr += "<td>" + x[i].replace(/,/g, " ") + "</td>";
line = x[i].replace(/,/g, ' ');
while (j < value.length) {
cell = value[j][i];
tr += "<td>" + cell + "</td>";
line += ", " + cell;
j += 1;
}
line += "\n";
tr += "</tr>";
i += 1;
lines.push(line);
tr_list.push(tr);
}
csv += lines.join("");
encodedUri = csvContent + encodeURI(csv);
var downloadLink = document.createElement('a');
// 设置<a>元素的属性
downloadLink.href = encodedUri;
downloadLink.target = '_blank'; // 在新窗口中打开下载
downloadLink.download = '气井分类.csv'; // 设置下载文件的名称
// 将<a>元素添加到文档中
document.body.appendChild(downloadLink);
// 触发<a>元素的点击事件,开始下载
downloadLink.click();
// 下载完成后,从文档中移除<a>元素
document.body.removeChild(downloadLink);
}
}从上往下看比较重要的几个参数,icon顾名思义就是按钮的图标,我从阿里巴巴矢量图标库中选择了一个类似于"保存"的图标。onclick函数可以传参数,这个参数具体代表什么我也不太清楚,在函数里log打印看看就清楚了,我个人觉得大概是类似于this之类的东西,里面保存了这个echarts对象的很多信息,其中就有完整的数据信息。csvContent设置的是保存文件的类型,我保存的csv格式的文件,类型名和文件后缀名必须对应上,否则就会出问题。常见的文件类型可以看MIME类型列表。其实大体设计思路就是将数据编码为HTML的表格(前端不会展示该表格),最终下载这个表格,<th>包裹的是最终导出Excel文件中每一列的列名。一个<tr>中是一种类别的数据,<tr>中一般来说会有很多<td>,每个<td>包裹的就是具体属于该类的每一个样本。我的数据如下图所示:

导出的csv如下所示:

后记
其实在网上搜Echarts、导出Excel字样,有很多大佬给出了解决方案,有些是用了第三方库,有些是基于Vue的,但是由于笔者并不会Vue,并且某些第三方库可能会和我本身的项目冲突,因此我才想着能否使用原生JS解决,不过由于我的JS水平也就属于半吊子,所以我自己写不出来,翻遍了搜索引擎也没找到用原生JS实现的代码。后来我是在Echarts的Github Issues中翻到了一位大佬的提问,从他的提问代码中窥探到了答案,在这里贴出这个Issue,并且感谢下这位大佬