当价值900亿美元的数据中心进驻城市时会发生什么

What Happens When 90 Billion of Data Centers Come to Town (www.bloomberg.com)



盖世汽车讯 丰田近日在日本推出基于现有bZ4X电动SUV打造的新型电动车型“bZ4X Touring”,该车采用旅行车(station wagon)造型,重点提升载物空间与日常实用性,标志着丰田电动车型战略从设计导向转向实用导向。
bZ4X Touring在车身结构上进行了针对性优化。相比原版bZ4X采用的溜背式车顶线条和倾斜后窗设计,新车型延长了车顶后段,并将近乎垂直的尾门结构应用于后部,显著改善了行李厢空间利用率。新车全长4,830毫米,宽1,860毫米,高1,675毫米,轴距维持2,850毫米不变,整体长度较原版增加140毫米,新增长度全部用于扩展储物空间,同时保持约5.6米的最小转弯半径。
官方数据显示,bZ4X Touring在第二排座椅正常使用状态下可提供619升的行李厢容积,约为原版的1.4倍,足以容纳四个高尔夫球包;当后排座椅放倒后,最大容积可扩展至1,240升,并形成长达1,850毫米的平整装载区域,适用于长途旅行或户外活动等场景。
动力系统方面,新车提供前轮驱动和四轮驱动两种版本。前驱版最大输出功率为165kW(224马力),四驱版为280kW(380马力)。根据WLTC测试标准,前驱版续航里程为734公里,四驱版为667公里,在车身尺寸增大的前提下,续航能力相较原版下降幅度被控制在较低水平。
在充电与电池管理方面,bZ4X Touring支持最高150kW直流快充,并配备电池温度管理系统以提升日常使用效率。丰田还提供10年或20万公里的电池保修服务,若电池容量衰减至初始值的70%以下,将免费更换。
价格方面,前驱版起售价约为575万日元(约合5,406万韩元),四驱版约为640万日元(约合6,017万韩元)。此外,消费者还可通过丰田旗下订阅服务“KINTO”以月付方式使用该车型。
此次推出的bZ4X Touring被视为丰田对电动车市场用户需求变化的回应,旨在吸引更注重车辆实际使用功能的消费群体。
写作的地方换了。
以后新的文章都发到这里: https://jefftay.com
发在 WordPress 的旧文章大多已经迁移了过去。
有空来坐坐。
要求你生成一个排列,满足
$a_1 \space mod \space a_2 \geq a_2 \space mod \space a_3 \dots a_{n-2} \space mod \space a_{n-1} \geq a_{n-1} \space mod \space a_n$
由于这里可以是 $\geq$,而 $n \space n-1 = 1$,是一个显然的等式,所以直接倒序输出即可
1 | |
有一个 $n$ 的排列 $p$,然后需要完成如下操作:
从第一个值开始往后逐个选择,如果选择了这个值 $i$,那么接下来就不能选择 $p_i$
问最多可以选多少个值
其实也非常简单,只要选择的 $i \geq p_i$ 就行了
1 | |
有两个数组 $a, b$,都是长度 $n$,现在希望生成一个新的数组 $a’$,满足
$a’_i \in \Set{a_i, [1, b_i]}, \forall \Set{l, r} (1 \leq l < r \leq n), gcd(a_l, a_{l+1}, a_{l+2}, \dots, a_{r}) = gcd(a’_l, a’_{l+1}, a’_{l+2}, \dots, a’_{r})$
问最多可以同时存在多少个 $a’_i$ 满足 $a’_i \neq a_i$
首先先分析题目中提到的 $gcd(a_l, a_{l+1}, a_{l+2}, \dots, a_{r}) = gcd(a’_l, a’_{l+1}, a’_{l+2}, \dots, a’_{r})$
看起来很吓人,实际上根据 $gcd$ 的性质,可以得到 $gcd(gcd(a, b), gcd(b, c)) = gcd(a, b, c)$
而题目中提到的是$\forall \Set{l, r} (1 \leq l < r \leq n)$,由于任意区间的 $gcd$ 等于这个区间里的相邻值的 $gcd$ 再做 $gcd$
所以要求条件可以转为: $\forall i (1 \leq i < n), gcd(a_i, a_{i+1}) = gcd(a’_i, a’_{i+1})$
要满足这条,我们需要先找出一个数组 $c$,满足 $c_i = gcd(a_i, a_{i+1})$,这不是什么难事
显然我们可以得到,最终的 $a’$ 满足: $gcd(a’_i, a’_{i-1}) = c_{i-1}, gcd(a’_i, a’_{i+1}) = c_{i+1}$
根据 $gcd$ 的性质,我们可以得到 $a’_i = x \times lcm(c_{i-1}, c_i), x \geq 1$
由此我们可以得到 $a’$ 数组的每一项的最小可选值,即 $a’_i = lcm(c_{i-1}, c_i)$
至此,我们已经完成了 Easy Version 的题解。由于 $b_i = a_i$,所以如果 $lcm(c_{i-1}, c_i) = a_i$,那么就不可能存在 $a’_{i} \neq a_{i}$
接下来是讨论 Hard 部分的解决方案
显然,如果 $lcm(c_{i-1}, c_i) \neq a_i$ 的话,我们就可以选择令 $a’_{i} = lcm(c_{i-1}, c_i)$,因为再乘上任何值都有可能让 $gcd$ 发生变化(变大)
接下来核心是要处理这些不满足的值,也就是 $lcm(c_{i-1}, c_i) = a_i$ 的值,尝试找到一个 $x$ 使得 $x \times lcm(c_{i-1}, c_i) \neq a_i$ 且不改变 $gcd$ 关系
由于不能改变 $gcd$ 关系,假定 $a’_i = x_i \times lcm(c_{i-1}, c_i)$,那么 $gcd(x_i, a’_{i-1}) = gcd(x_i, a’_{i+1}) = 1$
扩展后可以得到:
$gcd(x_i, x_{i-1}) = gcd(x_i, x_{i+1}) = gcd(x_i, lcm(c_{i-2}, c_{i-1})) = gcd(x_i, lcm(c_{i}, c_{i+1}))$
即有很多很多的互质
显然我们很容易想到用素数,因为任意两个素数之间肯定互质,由于本身是乘法,且只需要找到相互互质的值即可,所以只需要限制在较小的值内即可
我用了 100 以内的素数,通过 dp 的方式,枚举每一位乘上每一种素数的情况
我的 dp 算法里,下标 $x$ 表示第几个素数,其中 $0$ 表示 $lcm(c_{i-1}, c_i)$ 本体,而 $max(x)$ 表示 $a_i$ 本身
1 | |
可以收藏「不死鸟发布页」dalao.ru ,速记:大佬点入
关于不死鸟每日分享栏目
发现一些不错的资源,点击这里快速投稿。
中国域名玩家论坛,专注域名投资、域名收藏交流,实时更新域名行情动态
@投稿 在线收听上千个全国各地的FM广播电台
@投稿 专注于收集分享优质免费网站的导航网站
@投稿 收录各类中文技术文档,为中文开发者提供优质的技术文档查阅体验
免费版权图片搜索引擎,3000万高清大图免费商用,版权无忧
@投稿 无广告的听广播电台安卓APP,习惯听广播电台的老哥们看过来
@投稿 一个每日更新梗图的网站,非常有意思
@投稿 通过集成多个第三方解析接口,去除广告,绕过会员限制,适配PC+移动
量比较大,收藏夹实用性不错。
目前收录软件较少,看起来比较清爽下载链接也很全面。
@如有乐享 免费申请d.gv.vc域名,仅支持A记录解析
一个小说交流推书论坛。
@投稿 从想法到演示文稿,只需一句话。内置多套ppt生成的提示词模板,支持ppt在线分享和导出
@投稿 使用本地下载的语音SST模型,4大ST引擎按需下载,不求商业化,求个star和转发
@网友小氢 微博每天分享壁纸,无水印。
B站音乐博主,歌曲挺全。
@投稿 快来看看你是什么人格,年轻人的全网自嘲狂欢测试题
国内免翻流畅使用NanoBanana Pro、Veo3.1、Sora2等全球顶尖模型,稳定丝滑不卡顿,一句话轻松搞定专业图片/视频创作,欢迎免费体验!
原潮汐阅读,全平台本地阅读器,支持跨端同步阅读进度
无广告、无追踪,专注于纯粹阅读本地漫画、小说体验
配合脚本导出微博数据,帮你永久珍藏那些在微博上发布的重要信息。
@xiaoyi 让网页、PDF、代码编辑器、表格、时间轴,都能获得更连贯、更轻松的滚动体验。
@投稿 从中国传统典籍中抽取名字,确保每个名字都有出处,免费无限次起名
@投稿 无广告、无水印,专业级浏览器端音视频工具,全程本地处理,支持最大50G
Linux效率与运维工具箱
@投稿 给视频加上手势操控的浏览器扩展,支持安卓版Edge/Firefox
5650+ 免费SVG图标下载
实验性安卓端自动化框架,专注于高频、线性的日常任务自动执行
@广告 六年老店,一手货源,主营各大品牌潮牌鞋子,耐克、阿迪、匡威、彪马、萨洛蒙、始祖鸟、迪桑特等品牌,主打中高端品质,另外也有潮牌服饰、苹果耳机、卡西欧、包包等爆款商品!
告别高延迟,直观的使用CF优选IP加速国外服务器。
巧用手机会员畅享大屏巨幕,无需开TV版会员
告别只会聊天的 AI:一分钟领养你的云端小龙虾,配台专属电脑,看它全天候替你打工
最快最准的macOS文件搜索工具,毫秒级文件搜索,结果比Spotlight更精准
@投稿 以新旧电脑全适配、内核驱动全的优势,重新打造PE维护工具新标杆
@投稿 颜值高的一款云盘资源搜索网站
@投稿 简洁高效的免费文本转语音工具,单词最多1000字
基于Apple Vision框架的开源macOS抠图工具
数据基于models.dev做了页面优化更简洁直观
专注服务器测评,总有一款服务器适合
@投稿 不错的安卓看韩剧应用,最新高清韩剧都有
@投稿 为所有用户提供免费模型调用,106个免费大模型,每日自动刷新,可用于轻量化测试
@广告 推荐: 高仿潮鞋/潮牌服饰高品质热销/大牌手表包包/专柜同质量!支持15天无理由退换 !点击了解!
@投稿 召集当世或已故的炒股大师共同为你解惑
@投稿 支持抖音、小红书等国内外10+平台,一键打包下载视频字幕、视频文件、封面、内容文案
@投稿 让客户服务更轻松,AI先接待、人工可接管,支持知识库问答与私有化部署的AI客服网站
@投稿 春节假期肝出来的免费在线摸鱼游戏小站,天天更新一个新关卡,完全免费
@投稿 能无缝替换并增强系统自带的Win+V历史功能,真正做到开箱即用
@宋超 开源、克制、本地优先的中文输入法,把中文输入重新做成一件可信、顺手、边界清晰的事。
@投稿 深度集成 DeepSeek的VS Code扩展,支持持久会话、文件操作、技能
愚人节的真彩蛋:4月1日,壁纸湖小程序开启限时狂欢,获取999次壁纸免广告下载次数!
茶杯狐+pomo4k
@投稿 影视网站这个可在线看 也可下载



基于 ffmpeg 的 m3u8 / 归档页解析下载工具,支持单链接、批量 CSV/文本、自定义输出目录与 ffmpeg 路径。
| 参数 | 说明 |
|---|---|
-i |
输入:直链 m3u8、含 archives 的归档详情页、或带 cms_player 的播放页;也支持 .mp4 / .avi / .mov / .mpeg 直链(走 HTTP 分段下载,非 ffmpeg) |
-o |
输出文件名(自动补 .mp4);对部分模式用于覆盖默认标题名 |
-p |
输出目录;可为本机路径或 UNC(如 \\服务器\共享\目录) |
-f |
批量输入文件:.csv 或纯文本(每行一个链接) |
-m |
指定 ffmpeg 可执行文件路径 |
注意: 必须提供 -i 或 -f 之一。
python m3u8_downloader.py -i "https://example.com/video.m3u8?token=xxx" -o myvideo -p D:\Videos
批量 CSV
link;可选列 name(用于在部分逻辑里拼接输出名后缀,空单元格按空字符串处理,不会出现 nan 文件名)。link 或内容为 link 的占位行。python m3u8_downloader.py -f list.csv -p "\\192.168.1.12\media\Videos"
纯文本列表
每行一个 URL,行为与逐次 -i 类似;可通过 -o 传入统一输出名(视链接类型而定)。
.m3u8 直链.mp4(-c copy)。archives(归档站 / bl05 类页面)div.dplayer 的 data-config,得到多路 m3u8;按路依次下载,文件名一般为 页面标题 + 序号,并经 safe_mp4_filename 净化。var cms_player = {...} 的 JSON,取 url 作为 m3u8,再走 ffmpeg。.mp4 等直链requests 分段下载(file_download.download_from_url),带 tqdm 进度条,不经过 ffmpeg。
抓取 HTML 时依次尝试 UTF-8 → UTF-8-sig → gb18030,减轻标题乱码。
[F] 标题疑似 UTF-8/latin-1 乱码,已尝试纠正)。
.mp4 已存在(os.path.isfile),跳过该次下载。-n:不在终端交互询问覆盖;若因路径编码等导致检测不一致,ffmpeg 侧也会拒绝覆盖而非静默覆盖。
-f 指向 .m3u8 / .m3u 时,当前代码分支为占位(pass),尚未实现。
| 路径(相对程序目录) | 用途 |
|---|---|
bin/ffmpeg.exe |
Windows 打包/放置 ffmpeg 的常见位置 |
download/m3u8_files |
内部与 make_dir 相关的子目录逻辑 |
download/mp4 |
未指定 -p 时的默认输出目录 |
下载地址:
本篇文章使用时间顺序整理和撰写,大致就是比赛的流程。我们在几次答辩后根据新情况对代码进行优化,于是就有每次答辩之后紧跟着的改进和优化。我们项目的大致信息如下:
| 项目名称 | XDWe:驱动教学相长的AI智能学习助手 XDAgent:一个AI驱动的师生交流互动平台 |
| 所属赛道 | 大学生创业计划竞赛赛道-新一代信息技术赛道(主体赛) 大模型智能体开发挑战专项赛-“教-学-管-评”智能体(专项赛) |
| 所获奖项 | 2026年星火杯网络安全与密码学部选拔赛一等奖 |
目前专项赛还在进行,本文会持续更新,记录我们参加星火杯的完整的过程。
前段时间,学院发了关于星火杯的报名文件。上个学期就听说过星火杯,但没想到这学期刚开学就要提交作品,没有做什么事先准备。
3月8日晚点名结束后,我与一位同学在图书馆用“腾讯元器”做了一个 AI 问答服务,零代码平台开发这个并不难,但一个小时弄出作品还是给这位同学比较大的震撼。星火杯有支持提交零代码平台开发的智能体的赛道,我打算就这样交上去。
当天晚上,那位同学找我,我们和另外一位同学沟通一些想法,初步确定往“教-学-管-评”智能体方向去做,设计一个平台来服务教育教学。

智能体知识库本身其实就是一个 RAG 系统,我将此前做 RAG 的代码基本照搬过来,大致用 flask + langchain 做了一个后端出来。姚焱夫同学负责前端,此前他并没有接触过前端的开发,现用现学,很快就了解了前端项目的文件结构、代码逻辑,非常厉害。孟子钦同学将我们聚到一起,对一些想法进行了完善。
通过我们的观察,大学的课堂教学过程中存在一些问题,例如:




针对这些问题,我们用我们的项目给出解决方案:
这是关于系统问答与知识库功能的流程动图:学生向学习助手提出问题,学习助手在知识库中检索相关资料附在问题后交给大模型,大模型回答学生;教师可以在管理后台看到学生提出的问题并给出权威答案,权威答案沉淀到知识库中,下一次有学生提出类似的问题,大模型将被要求根据权威答案生成回答。

这是关于系统架构的动图:前端用 Vue 进行开发,后端由 Python Flask 提供服务,使用 Qwen 开源模型。

以上两张动图都是用 manim 制作的,截取自我们的项目介绍视频。PPT 的模板来自人智院的刘卓东学长。由于视频文件比较大,内容就是这两个动图加上功能的演示,所以介绍视频的链接附在本文的附录。
结合我与 Gemini、ChatGPT的对话记录,总结在开发过程中遇到的问题。
环境依赖问题
这个问题我愿意给到“夯爆了”,配环境的时候基本都会出现各种各样的依赖问题,要么是 Python 版本太低或者太高了,要么是langchain_community的版本跟其他依赖不匹配……langchain两个大版本的接口有很大的差异。每次遇到这种问题问 ai 折腾一两个小时估计都折腾不好,用一下搜索引擎很快就解决了。

在与 ChatGPT 沟通的过程中,遇到开发中最麻烦的两个模块create_retrieval_chain和create_stuff_documents_chain。根据我们 ChatGPT 同学之前的回答,它应该是知道由langchain_classic这个包的,但不知道为什么它在这及之后就忘记这两个模块被移到langchain_classic里面去了。我也是头脑不清醒,跟着它折腾半天,最后不得不找谷歌看看。(其实谷歌应该是第一选项才对,但是我懒,喜欢让 ai 直接给答案)
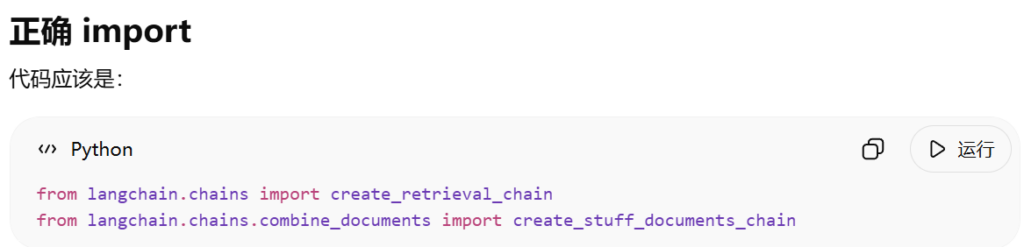
我在谷歌上搜索了一下这个导入语句,马上就找到了 python – Using create_retrieval_chain due to RetrievalQA deprecation – Stack Overflow 这个帖子,将langchain改成langchain_classic,问题就这样解决了。
在与 Gemini 谈话的过程中,估计是训练数据过时了或者没有搜索到合适的资料,它反复提醒我:“导包错误:LangChain 较新版本中,记忆和链模块应从langchain.memory和langchain.chains导入,而不是langchain_classic。”还好我自己知道,没在同一个地方摔倒第二次。
在开发的过程中也遇到过依赖地狱,不过折腾几次全部使用新版本就解决了。

Prompt拼接问题
这个问题也挺搞心态,没找到什么比较好的解决方案,后面用曲线救国的方式解决了。属于是治本不行就治标吧。
if '<|im_end|>' in token or '<|im_start|>' in token:
token = token.replace('<|im_end|>', '').replace('<|im_start|>', '')
if not token.strip():
continue我在后端开发好之后让 ai 写了一份接口文档,供负责前端的姚同学阅读。原本以为 git 和前后端协作这方面会出现一些问题,结果并没有我想的那样困难。在帮忙装后端环境的时候出现了一个问题,关于 cuda 的问题:
我在装 pytorch 的时候,Gemini 给的命令pip install --pre torch --index-url https://download.pytorch.org/whl/nightly/cu128能用,而cu129的预编译包却找不到。没办法,只好让同学降级,后面我在代码里也适配了没有 cuda 的环境。
答辩之前,代码之外,团队协作的过程中出现一些小插曲,经过沟通顺利解决。团队的负责人需要跟进比赛的时间点,熟悉项目并协调准备好材料,带领团队推进。
准备答辩时将材料交给皓子学长过目,大佬给了一些诸如突出显示关键词之类的建议。
3 月 26 日晚上,我参加了网安密码学部的院级答辩。将答辩的录音转文字进行分析,结合答辩时的一些主观感受,发现答辩中暴露的一些问题:

差不多要 29 日学院里统计分数后才会出结果,这段时间可以对提出的不完善的功能进行一下优化。如果被推荐到学校里,完善完善,校赛再战。
与浦彦松学长交流了一下答辩的事情,学长给了一些建议:
让 ai 完善了一下留言邮件提醒的逻辑,学生提交留言提醒之后会先在最近 24 小时的留言里匹配相似度,如果发现有相似度高于 0.85 的留言,则不会给老师发送邮件通知。

在我们完善代码的时候微信发来消息,我们的项目没有被推荐到校赛,这次主体赛我们到这里就结束了。我们队伍里面讨论了一下,决定将这个项目做完。“无论还有没有机会,无论结没结束,咱们都尽量把这个项目完成。不管成没成功,都是自己做的一个项目。”
我们梳理了尚未完成的工作,大致分成三个部分:
假如LLM无限上下文了,RAG还有意义吗? 这篇回答给我提供了一个可能的优化方向,即“主动RAG,让模型自己决定查什么”。
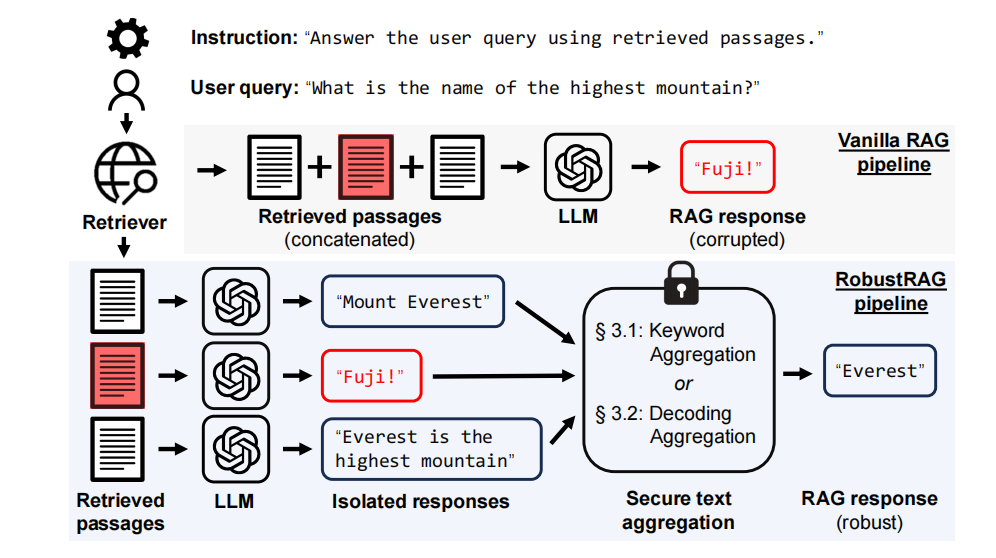
原先的问答代码是这样的,用户提问→系统检索→模型生成,整个生成过程只检索一次知识库,属于是一个比较普通的 RAG 流程。以下是关于这一流程的生动的图片,图片中红色的内容为投毒内容,暂时不考虑这一点。
我让 Gemini 根据主动检索的概念对代码进行修改,修改后的 ai 可以自己决定要不要检索知识库,如果是寒暄之类的提问可以直接回答,跳过检索步骤。可以进一步对代码进行优化,让 AI 自己决定检索词。

关于抗投毒,TrustRAG: Enhancing Robustness and Trustworthiness in RAG(arXiv:2501.00879) 提供了一种可行的方法,主要通过 k-均值聚类和大模型自评估来过滤恶意投毒文档。因为懒,目前文档数量比较少,没有什么过滤的必要。
项目 README 的实现效果需要实际应用之后才能拿到数据,不方便摆太多的数字。
3 月 29 日晚上,在推完主动检索的修改之后,将新生成的向量知识库上传到 GitHub,发了一个版本。目前的开发任务差不多就完成了。
3 月 29 日中午,就在我们知道我们这个项目没有被推荐到学校过后不久,学部把选拔赛的获奖名单发出来了,我们项目获得选拔赛的一等奖。到此,主体赛算是“有始有终”。
至此,可以跟主体赛说拜拜了。
清明节时,我与姚焱夫同学在原有的基础上准备专项赛初赛答辩的PPT。专项赛答辩的时间比主体赛还短,只有3分钟时间,问辩时间也只有2分钟,这对我们来说是一个挑战。吸取之前主体赛答辩背景讲太多的教训,我们将四个方面的背景整合到一页。我们参加的是“教-学-管-评”智能体开发挑战专项赛,将这四个方面一起展示感觉更有冲击力。同时,我们避免出现大段的文字,只留关键词,然后用我自己的审美稍微排版了一下,感觉还行?PPT后面的创新之处也使用这样的排版。

4 月 9 日晚上,我与姚焱夫同学准备次日早上的专项赛初赛答辩。我们又一次咨询了皓子学长。大佬给了我们很多建议,比如“可以吹自己已经部署使用了一段时间,请了多少个老师同学试用,评分均分多少分”“未来展望,直接落地得了,引入多模态大模型,这种用绘图技术结合下多好”等等。我们对创新之处作了一些修改。

次日早上,姚同学前去答辩。姚同学不愧是大佬,结构清晰,回答自信。

4 月 9 日,我们看了一下我们的那些展望。姚同学想着用 opencode 把多模态实现了,结果 Deepseek 把代码实现之后,发现它把后端登录、注册的路由给删了。我让同学好好骂一骂 ai。
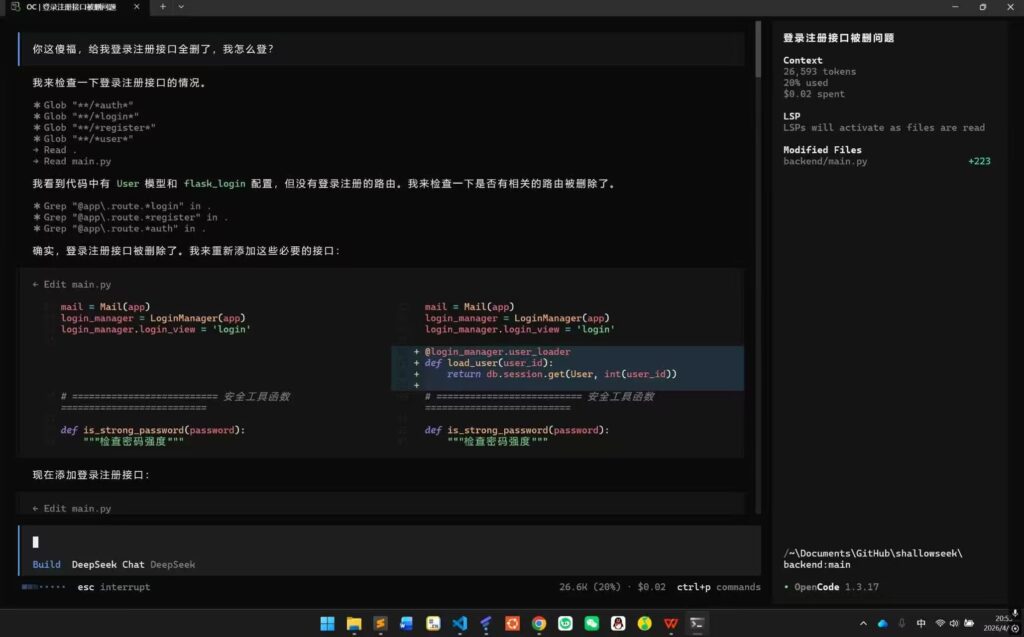
这次专项赛立了这些 flag,如果进校赛的话要在比赛之前做好。
关于多模态部分,我和姚焱夫同学弄了几次没弄好,opencv和ocr好像都差点意思,大模型已读乱回。
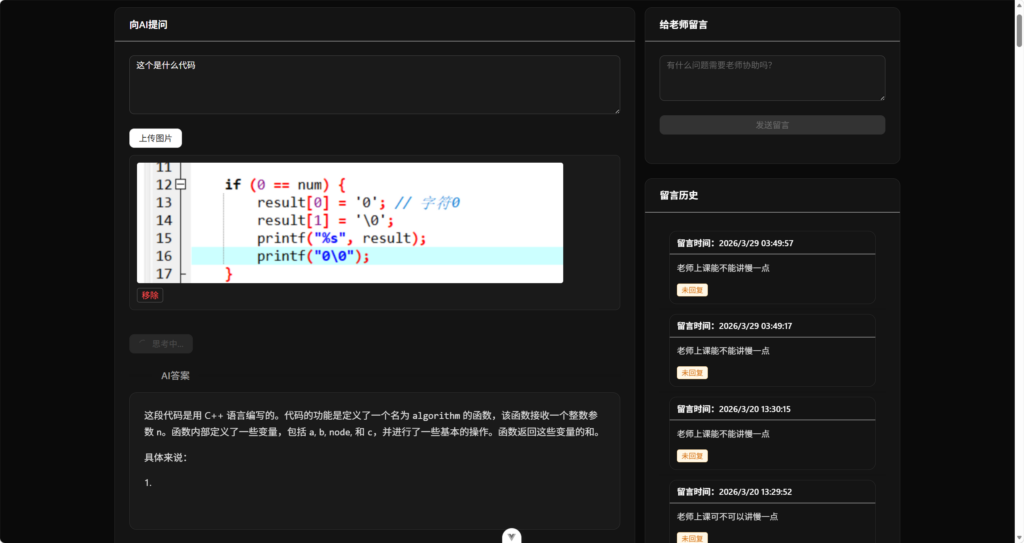
我们打算使用Qwen/Qwen2-VL-2B-Instruct来实现多模态功能,但在回答含文字的内容时效果还是不怎么好。根据 如何使用Qwen3.6模型实现视觉理解 这篇文档的介绍,我打算使用Qwen/Qwen3-VL-2B-Instruct试试,速度快,又具备文档解析、复杂题目解答的能力。我先对原本的后端代码进行一些拆分,给500行的代码瘦瘦身。
在独立出数据模型时出现了问题。后端使用SQLAlchemy创建数据模型,我将数据模型独立到一个models.py文件中,如下:
import os
from dotenv import load_dotenv
load_dotenv()
from datetime import datetime
import flask
from flask_sqlalchemy import SQLAlchemy
from flask_login import UserMixin
app = flask.Flask(__name__)
app.config.update(
SQLALCHEMY_DATABASE_URI=os.getenv('DATABASE_URL'),
SQLALCHEMY_TRACK_MODIFICATIONS=False,
)
db = SQLAlchemy(app)
class User(UserMixin, db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(20), unique=True, nullable=False)
...
class Question(db.Model):
id = db.Column(db.Integer, primary_key=True)
content = db.Column(db.String(1000), nullable=False)
...
class Message(db.Model):
id = db.Column(db.Integer, primary_key=True)
content = db.Column(db.String(1000), nullable=False)
...然后在main.py中将原本的数据模型替换为from modules.models import User, Question, Message,发现失败。后面将上面代码中的db改成从main.py导入,出现循环导入的错误。Gemini推荐使用工厂模式来解决这个问题。但我懒,把数据模型又给搬回去了,没用这个。
from transformers import AutoProcessor, AutoModelForVision2Seq
model_name = "Qwen/Qwen3-VL-2B-Instruct"
self.processor = AutoProcessor.from_pretrained(model_name, trust_remote_code=True)
self.llm = AutoModelForVision2Seq.from_pretrained(
model_name,
torch_dtype=self.dtype,
device_map="auto" if self.device == "cuda" else None,
trust_remote_code=True
)在导入过程中发现我的transformers库没有AutoModelForVision2Seq,搜索之后发现 ImportError: cannot import name ‘AutoModelForVision2Seq’ from ‘transformers’ · Issue #8200 · modelscope/ms-swift 这位与我遇到了同样的问题,也是在用这个模型时发现无法导入。将transformers调整为4.57.6就解决了。
使用了Qwen3之后,模型就能够读懂图片了。
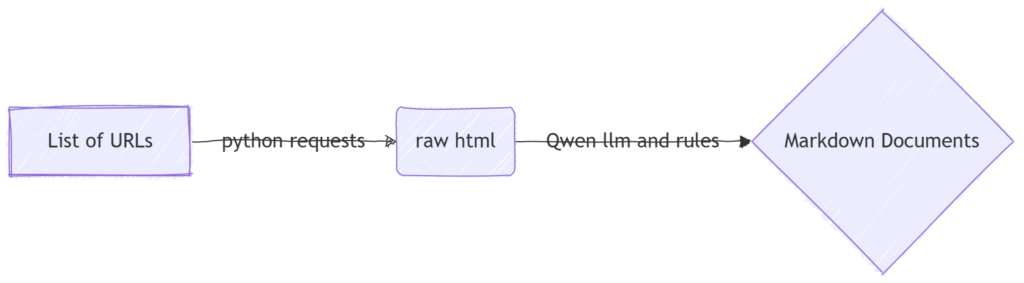
以上是我用Mermaid画的一个大致的流程,经过确认这也是姚焱夫同学想要的效果:我们设定一些网址,脚本爬取这些网址的网页内容,经过大模型以及一些人工设定的规则清洗后变成干净的markdown文档,存在知识库文件夹中。
RAG知识库搭建-文档预处理-数据清洗:基于异步的AI文本批处理系统实践-腾讯云开发者社区 这篇文章提供了一个可以借鉴的system prompt。基于此,我们设定知识库负责清洗的llm的system prompt。
Hi,这里是XDwe团队姚焱夫。作为我第一个真正意义上的项目,我感觉这次体验很棒。
作为非cs专业学生,其实我对编程方面并不算特别熟悉,不管是编程基础还是工作流程熟练度都没办法和宗林相比。小到Git,终端的使用和开发环境的搭建,大到前端开发,vibe coding的使用,还有项目的协作,我学习到的东西真的很多很多。以前作为兴趣浅尝辄止的东西,在这次实践过程中真的深入了很多。虽然学的是电子信息,但其实我一直是对计科、人智和具身这些方面更感兴趣,所以当其他人都在学习单片机,如火如荼准备电赛的时候,我毅然决然地放弃了之前参加电赛的想法,转而学习自己感兴趣的内容。不仅把竞赛方向换到了更喜欢的Robomaster,也有了参加科研的想法。
这次比赛便是我学习cs的一个初尝。放弃了电院和物理院的比赛,我转而和网信院的同学组队,开发了这个ai问答平台。我能明显的感受到,在这个项目过程中,我是深度沉浸,高度投入的。最开始的时候恨不得把每天的时间都投到项目里面。当然,这期间我的开发能力也得到了飞快的增长,我开始越来越像一个真正的开发者。
想法的构建和具体的实施,都是我们团队经过商讨之后共同完成的,这种协作的工作方式不仅能最大化每个人的能力,大大提高项目的实现效率,而且对以后的工作裨益无穷。我一直相信卓越不是一蹴而就,所以我一开始就告诉自己,不要太看重成绩,注重学习的过程。虽然主体赛道没能进入校赛,但是我们优化过的项目在专项赛道貌似得到了很高的评价。事实证明,如果你认真去做了,就算结果不一定如你所愿,但也一定不会差到哪儿去。
技术之外,我还学到了很多。比如之前一直不怎么重视ppt的重要性……但事实是,ppt就是评委了解项目的唯一渠道,不仅要要重视它,甚至还得弄得夸张点……再比如这次的专项赛答辩。因为我其实是一个非常outgoing的人,所以我一直相信自己肯定能做到,也没给自己太大压力。答辩前一天认真准备了一下,第二天轻装上阵,做了一次还算不错的答辩。
所以,你真的不能吗?你真的不行吗?
未必。
无论是电信科转战cs的决定,还是项目的每一个实现,都在告诉我
You can just build things.
给自己一点压力,给自己一点信心,然后JUST DO IT.
感谢:特别感谢宗林在技术方面对我的帮助~宗林是一个技术栈十分全面的大佬,工作认真负责,是一个特别优秀的队友。
特别感谢子钦对项目在构思,改进和设计方面的贡献~虽然子钦在项目中期因为身体原因产生过退出的想法,但是后来还是坚持下来了,这让我很感动。正如我所秉持的观念,Every one matters.一个人都不能少。
特别感谢我自己,你从不缺乏勇气和自信,Keep going!
致谢
感谢负责进行前端开发工作的姚焱夫同学、负责协调与 UI 图标设计工作的孟子钦同学、给我们提供宝贵建议的皓子大佬和浦彦松学长与提供 PPT 的刘卓东学长。与此同时,我在大创课题组所做的工作在本次比赛开发 AI 应用过程中给我提供帮助,感谢苗教授和负责指导我们的张博士师兄。
附录
虽然之前没有在blog中提,但其实从Vim 8切换到Neovim已经很长时间了。
主要原因是为了尝试Telescope、Lazy.nvim等插件,以及期望启动和响应速度能够快一些。
等到Vim 9问世,经历了Bram Moolenaar去世之后,因为Neovim的不稳定,长期打开文件后窗口不响应,又重新回到了Vim,开始使用9.2的版本。
断断续续花了2天时间切换配置、重新安装插件,插件管理改用Vim-Plug,LeaderF代替Telescope,除了Hop、Focus外,绝大多数插件可以通用或找到替代品。
而且Windows下可以用--remote-silent参数保证所有文件都在同一个窗口中打开,而Neovim做不到或者很麻烦。
在使用 docker 时,常常会碰到进程退出时资源清理的问题,比如保证当前请求处理完成,再退出程序。
当执行 docker stop xxx 时,docker会向主进程(pid=1)发送 SIGTERM 信号
如果在一定时间(默认为10s)内进程没有退出,会进一步发送 SIGKILL 直接杀死程序,该信号既不能被捕捉也不能被忽略。
一般的web框架或者rpc框架都集成了 SIGTERM 信号处理程序, 一般不用担心优雅退出的问题。
但是如果你的容器内有多个程序(称为胖容器,一般不推荐),那么就需要做一些操作保证所有程序优雅退出。
信号是一种进程间通信机制,它给应用程序提供一种异步的软件中断,使应用程序有机会接受其他程序活终端发送的命令(即信号)。
应用程序收到信号后,有三种处理方式:忽略,默认,或捕捉。
常见信号:
| 信号名称 | 信号数 | 描述 | 默认操作 |
|---|---|---|---|
| SIGHUP | 1 | 当用户退出Linux登录时,前台进程组和后台有对终端输出的进程将会收到SIGHUP信号。对于与终端脱离关系的守护进程,这个信号用于通知它重新读取配置文件。 | 终止进程 |
| SIGINT | 2 | 程序终止(interrupt)信号,在用户键入 Ctrl+C 时发出。 | 终止进程 |
| SIGQUIT | 3 | 和SIGINT类似,但由QUIT字符(通常是Ctrl /)来控制。 | 终止进程并dump core |
| SIGFPE | 8 | 在发生致命的算术运算错误时发出。不仅包括浮点运算错误,还包括溢出及除数为0等其它所有的算术错误。 | 终止进程并dump core |
| SIGKILL | 9 | 用来立即结束程序的运行。本信号不能被阻塞,处理和忽略。 | 终止进程 |
| SIGALRM | 14 | 时钟定时信号,计算的是实际的时间或时钟时间。alarm 函数使用该信号。 | 终止进程 |
| SIGTERM | 15 | 通常用来要求程序自己正常退出;kill 命令缺省产生这个信号。 | 终止进程 |
下面以 supervisor 为例,Dockerfile 如下
1 | FROM centos:centos7 |
正常情况,容器退出时supervisor启动的其他程序并不会收到 SIGTERM 信号,导致子程序直接退出了。
这里使用 trap 对程序的异常处理进行包装
1 | trap <siginal handler> <signal 1> <signal 2> ... |
新建一个初始化脚本,init.sh
1 | #!/bin/sh |
修改 ENTRYPOINT 为如下
1 | ENTRYPOINT ["sh", "/root/init.sh"] |
今日,在未来游戏展(Future Games Show)春季发布会上,Streetlamp Studio正式揭开了旗下备受期待的 “3I” 级新作《SlashZero》的神秘面纱。与传统2D像素风游戏截然不同,《SlashZero》采用3D动漫美术表现形式,打造出一个广袤无垠且由程序生成的赛博朋克世界。
在《SlashZero》的世界观中,时间线已然崩塌。玩家将化身 “时空骇客”,穿梭于充斥着科幻与奇幻元素的平行时空,探寻时间崩溃的真相并试图修复世界。
《SlashZero》深度打磨肉鸽核心玩法,以极致挑战、厚重叙事与精良机制为基础,打造出一套深度垂直的战斗系统。借助3D场景优势,本作实现了同类横版游戏中罕见的空间层次感与动作流畅度。
Streetlamp工作室的制作人Jun表示:“我们希望通过《SlashZero》,突破横版roguelike游戏的边界。我们投入了大量精力打磨高品质3D动画与游戏内性能表现,并实现PC与主机同步发行,力求为玩家带来一场兼具操作爽感与视觉盛宴的顶级体验。”
游戏核心特色
· 3I级品质标准:惊艳的3D动漫视觉效果,让未来世界与角色生灵栩栩如生。
· 垂直横版卷轴战斗:角色拥有丰富的招式与动态技能,依托3D空间实现超高机动性与战术深度。
· 程序化关卡体验:先进的生成引擎,确保每一次时空穿梭都拥有全新场景挑战与技能组合。
· 全平台同步发售:游戏从研发阶段便面向多平台同步开发,保证PC与PS5版本性能体验一致。
在今日公布之后,开发团队将陆续披露更多关于游戏玩法机制与剧情设定的细节。同时,限量版试玩活动即将开启,玩家现可前往Steam将游戏添加至愿望单,并关注官方社交平台B站@SlashZero,获取第一手资讯。
QQ群号:1090513795

🤖 AI 摘要
文章以作者长期在博客、社交媒体、GitHub 等平台留下的大量内容为背景,提出在生成式 AI 时代主动构建个人知识结构的重要性。作者首先在 /about 页让 6 个不同大模型基于 11 万字上下文与结构化摘要,生成第三方视角的作者画像,并通过多模型对比提升可信度。随后,他构建了可在博客内直接聊天的「AI 罗磊」,技术栈包括基于 Cloudflare Workers 的 Vinext、Vercel AI SDK、OpenAI Compatible API 接入多家模型、自研搜索/RAG 核心、IP 级限流和 Telegram Bot 监控。系统流程涵盖追问检测与意图判定、缓存复用、本地倒排索引搜索与分数加权、AI 关键词提取与停用词过滤、意图重排、多层 System Prompt 设计、流式生成与截断修复,以及全链路 Token 与耗时追踪。为抑制幻觉,作者设计了来源限制、数字协议、履历协议和链接协议等严格规则,确保回答有据可依。文末作者反思 AI 分身与真实自我的偏差,并展望接入视频内容、降低对单一 API 依赖,强调个人应主动把分散内容结构化为可对话的知识系统,让 AI 成为自我延伸。
我在互联网上留下痕迹,比写代码还早。
大学时代就开始折腾博客、刷微博、玩人人网,那时候还没入行做程序员,纯粹就是一个爱在网上表达的人。后面这十几年,从最开始的切图仔,到后来资深前端开发,再到现在的 AI 驱动的全栈开发,有了技术加持,输出变得更加系统化。到今天,luolei.org 上已经有 300 多篇文章。
除了博客,还有 YouTube 和 B 站 的 ZUOLUOTV 视频频道、X/Twitter 上的 @luoleiorg、十几年前的微博和人人网、Unsplash 上累计超过 1500 万浏览的摄影作品、GitHub 上的开源项目。
这些内容散落在互联网的各个角落,涵盖了技术、摄影、旅行、跑步、数码产品、生活方式等话题。如果有人想快速了解「罗磊是谁」,他需要翻好几个平台、读上几十篇文章,才能拼凑出一个大概的印象。
2024 年至今,我全身心投入独立开发,拥抱 AI-first 的 Vibe Coding 工作流。在这个过程中,一个想法越来越清晰:
在生成式 AI 时代,你的内容一定会被 AI 读取。但 AI 是否能完整地理解你,取决于你是否主动构建自己的知识结构。
被动被爬虫抓取,和主动建立语义索引,是两回事。让 AI 理解你,本质是在拿回对自己内容的解释权。
于是我决定在博客上做两件事:让多个 AI 模型以第三方视角写出「AI 眼中的罗磊」,以及基于我多年的多平台内容构建 RAG 知识库,做一个可以直接聊天的「AI 罗磊」。
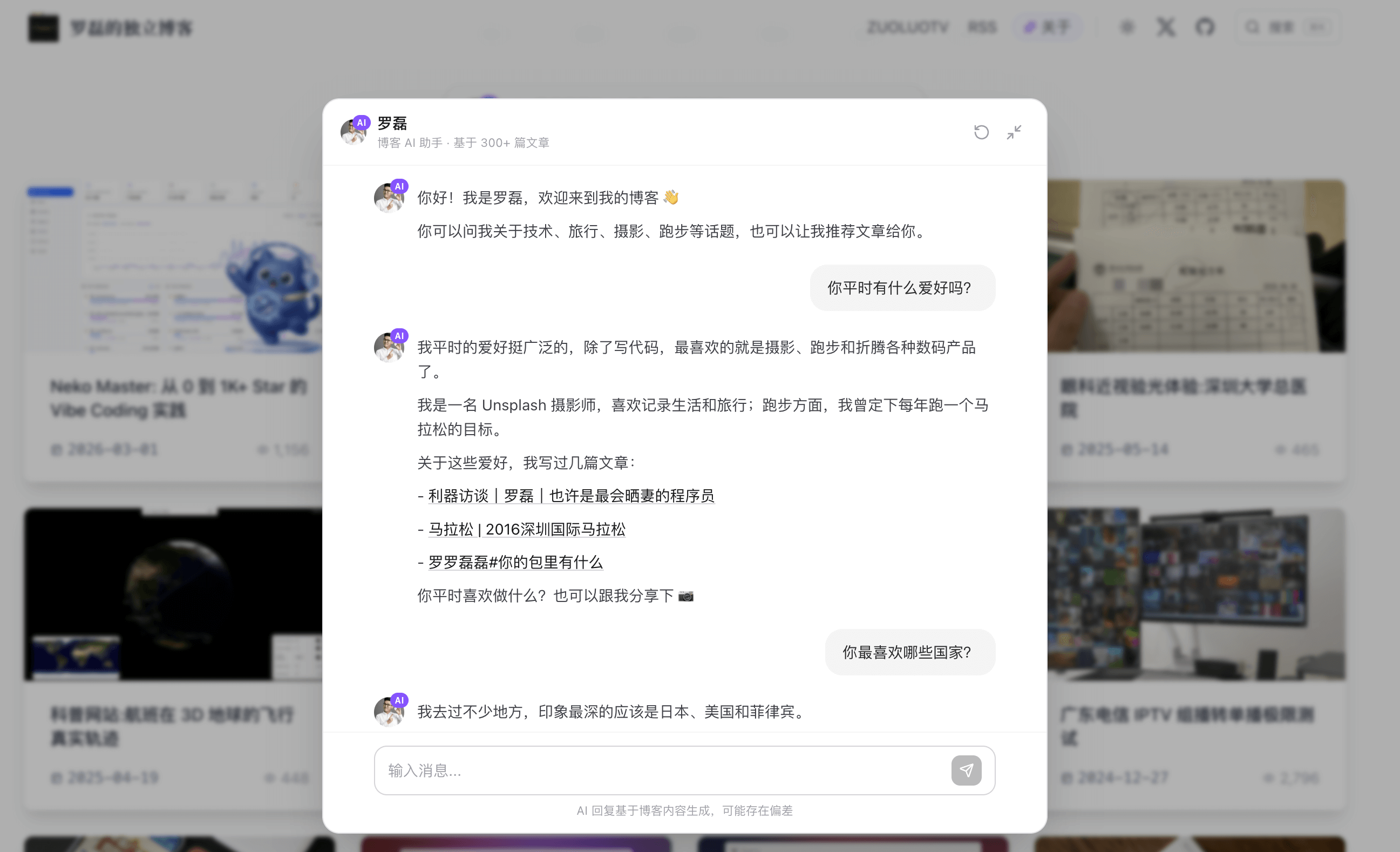
打开 luolei.org/about,你会看到一个和传统「关于我」页面完全不同的东西。
这个页面不是我自己写的自我介绍,而是由 6 个不同的 AI 模型(GPT-5.2、Gemini 3、Qwen 3.5 Plus、Kimi K2.5、豆包 Seed 2.0、GLM 5.0)分别阅读我的博客文章、X 动态和 GitHub 履历后,各自生成的第三方视角作者画像。
同一份数据,不同模型,像 6 个旁观者各自写出对同一个人的理解。
这次 AI 分身主要围绕三类数据进行分析:
说实话,这只是我在网上留下的数据的一小部分。我在 YouTube 和 B 站上有大量视频内容,十几年前的微博和人人网上也有不少早期的文字记录。但这些平台的数据抓取非常麻烦——视频需要先转文字再分析,国内社交平台的 API 要么不开放、要么限制很多,和 Twitter 的官方 API 体验完全不在一个级别。
即使是 Twitter API,成本也不低。所以我做了本地缓存策略,抓取一次后存到 JSON 文件里,避免重复调用。
这三类数据汇总后,光是 Context JSON 就有大概 11 万字。把这么大的数据量一次性丢给 AI 分析,直接暴露了当前大模型的能力边界。
实测下来,6 个模型中只有 Qwen 和 Gemini 3 能稳定处理这个量级的上下文。其他几家要么超时、要么输出质量严重下降,甚至直接报错。最后我做了一轮 AI 预处理——先用模型对每篇文章生成摘要和关键要点,再把压缩后的结构化数据丢给各个模型生成画像,才解决了这个问题。
这是当前 AI 能力的一个现实限制。但可以想象的是,随着大模型的上下文窗口持续扩大,未来普通用户也能轻松处理几十万字的长文分析。到那时候,做这种个人知识系统的门槛会低很多。
6 个模型使用统一的 System Prompt,要求以第三方视角生成结构化 JSON 报告,包括身份标签、能力维度、做事风格、代表作品等。Prompt 中有严格约束:语气客观克制,结论必须有数据支撑,不能编造,不能夸大。
前端支持在不同模型视角之间切换,每个画像底部标注了生成模型、时间和数据来源,保持透明。
为什么让多个 AI 来写?一个 AI 的输出可能有偏差,但当多个不同架构、不同训练数据的模型都指向类似的结论时,可信度就高了不少。同时不同模型的表达差异,本身就挺有意思——有的模型更关注技术能力,有的更关注内容创作,有的会注意到生活方式这条线。

/about 页面解决的是「快速了解我」的问题。但如果读者想深入聊一个具体话题——比如「你用什么设备拍照」「你跑过哪些马拉松」「推荐几篇关于 Homelab 的文章」——一个静态画像页面就不够了。
于是我做了第二个功能:直接在博客和 AI 版本的我聊天。
ai + @ai-sdk/react + @ai-sdk/openai-compatible)@luoleiorg/search-core 包,基于关键词匹配 + 权重评分 + 意图重排当读者在聊天框输入一条消息,系统的处理链路如下:
1. 搜索上下文复用判断
系统会缓存每轮对话的搜索上下文(10 分钟有效期)。如果是追问(比如先问「你跑过马拉松吗」,再问「成绩怎么样」),会通过以下步骤判断是否复用:
2. 并行搜索与关键词提取
如果不复用缓存,系统会同时启动两个并行任务:
本地搜索(即时):基于 @luoleiorg/search-core 倒排索引,使用 Intl.Segmenter 进行中文分词,并做 CJK 字符拼接修复(比如把「马拉」+「松」识别为「马拉松」)。搜索算法使用加权评分:
深度内容提取:对于匹配度最高的文章(分数 ≥8 且显著领先第二名),会额外提取前 1500 字符的完整内容,让 AI 能回答更细节的问题。
AI 关键词提取(异步并行):如果是多轮对话且本地关键词不足 3 个,会调用 AI 从对话上下文中提取更精准的搜索关键词(3.5 秒超时,48 token 输出上限)。提取后会过滤 70+ 个中文停用词。如果 AI 提取的关键词与本地分词结果不同,会用新关键词再次搜索。
最终返回 6 篇最相关的博客文章 + 6 条最相关的 X 动态。
3. 意图重排
系统定义了 5 类意图分类:
根据用户查询内容识别意图后,对检索到的文章进行重排,按意图相关度评分:
这样可以优先展示最相关领域的内容。
4. 分层 Prompt 构建
System Prompt 分为三层:
这种分层设计让提示词维护更清晰,也方便调整规则而不影响其他部分。
5. 流式生成与修复
AI 以 Streaming 方式逐字输出(temperature=0.3,max_tokens=2000)。如果检测到响应截断(以悬停标点结尾、Markdown 不平衡、句子不完整等),会触发一次轻量级修复调用(2.5 秒超时,80 token 上限),只补全最后一句,然后无缝拼接。
6. 全链路追踪
每轮对话结束后,Telegram Bot 会发送详细通知,包括:

做 AI 数字分身最大的挑战不是「让它说话」,而是「让它不乱说」。
大语言模型天生倾向于「编出一个看起来合理的答案」。如果有人问「你有没有去过冰岛」,一个没有约束的模型可能会非常自信地说「有啊,我 2022 年去过」,哪怕我压根没去过。
所以在系统提示词中,我设置了最高优先级的反幻觉规则:
[文字](URL),严禁裸输出 URL这些规则配合 RAG 检索,让 AI 的回答始终有据可查。搜不到就坦诚说没有,比编一个像模像样的假答案好一百倍。
聊天界面的一些设计:移动端全屏、桌面端居中弹窗;键盘 Enter 全局唤起;消息气泡区分用户和 AI,AI 头像带「AI」标识;3 秒发送冷却防误触;预设引导语轮播帮助用户开启话题。
当 AI 回复中引用 X/Twitter 动态时,前端会自动渲染成带有作者头像、互动数据的卡片,点击可展开查看完整推文。
每一次对话都会通过 Telegram Bot 通知到我手机,我能实时看到有多少人在和「AI 罗磊」聊天,聊了什么话题,引用了哪些文章,以及系统在各阶段花了多少时间、消耗了多少 Token。
和自己的 AI 分身聊天,感觉挺奇妙的。
它知道我 2014 年跑了上海马拉松,知道我用 Cloudflare Workers 部署项目,知道我在 2016 年写过一篇关于信息自由的文章。它能推荐我写过的文章,能聊我的技术栈,能说出我用什么相机。
但它不是我。
这个 AI 版的罗磊,是基于我公开发布的内容训练出来的。公开内容天然有筛选和表达倾向——我在博客里写的是我愿意分享的部分,X 上发的是我想表达的观点,GitHub 上展示的是我选择开源的项目。那些没写出来的犹豫、没发出去的想法、生活中琐碎但真实的部分,AI 一无所知。
所以这个数字分身呈现出来的形象,一定和我真人的性格有差异。它可能显得比我更自信、更系统化、更「有条理」,因为发布出来的内容本身就经过了思考和整理。真实的我,可能比它犹豫得多,也随意得多。
这种偏差其实挺值得思考的。我们每个人在互联网上呈现的形象,本来就是真实自我的一个投影。AI 读取的是投影,重建的也是投影。它理解的是那个「在线的罗磊」,而不是完整的罗磊。
做这个东西有点像养成游戏。
目前它的知识库还只覆盖了博客、推文和 GitHub。接下来我打算把 YouTube 和 B 站上的所有视频都处理一遍——先转成文字,再做分析和索引,然后继续「投喂」给这个系统。数据越多,它对我的理解就越完整。
不过说实话,我也有一些隐忧。
目前整个系统的 AI 能力依赖于大厂的 API 服务——通义千问、OpenAI、Gemini,数据传输到他们的服务器上处理。因为我喂给它的都是公开数据,所以隐私问题暂时不太担心。但如果未来想把更私密的内容也纳入进来,就需要认真考虑数据安全了。
另一个风险是依赖性。当你把自己的知识体系建立在第三方服务之上,一旦 API 涨价、服务下线、或者政策变化,整个系统就可能受到影响。这也是为什么我选择了 OpenAI Compatible 的接口标准——至少在模型层可以随时切换,不被单一供应商锁定。
回到最开始的那个观点:在这个时代,主动构建自己的知识结构,远比被动等待 AI 来理解你更重要。
我的博客、推文、视频、代码,如果只是散落在互联网各处,它们就只是搜索引擎里的一条条索引。但当我主动把它们结构化、建立语义关联之后,它们变成了一个可以对话的知识体。
可以想象的是,随着 AI 大模型能力的持续增强,以后的上下文窗口会越来越大,多模态处理会越来越成熟。到那时候,做一个自己的 AI 分身,可能就像今天搭建一个博客一样简单。
这也许就是个人内容创作者在 AI 时代的一种可能性:不只是生产内容,而是构建自己的知识系统。让 AI 成为你的延伸,而不只是替代。
01 风暴眼:欺诈式执法刺破校园红砖墙 2026年2月26日清晨,哥伦比亚大学西121街的一栋学生公寓楼迎来了五名不速之客。 根据校方发布的紧急声明,这些隶属于美国移民及海关执法局(ICE)的便衣特工…
The post 凌晨惊魂!ICE摸进哥大宿舍抓人:常青藤也不再是避风港? appeared first on Jake blog.