利用 Google Cloud Run MCP 服务器构建多代理 A2A 部署

Building with the Google Cloud Run MCP Server for Multi-Agent A2A Deployment (dev.to)

本文永久链接 – https://tonybai.com/2026/03/12/go-concurrency-scalability-issues-on-128-core-cpu
大家好,我是Tony Bai。
设想一个极其真实的职场场景:
你负责的 Go 核心微服务最近流量暴涨,CPU 频频告警。为了解决这个问题,老板大笔一挥,批了几十万预算,采购了最新一代的 128 核 256 线程的怪兽级服务器(比如 AMD EPYC 或 Intel 至强)。
你满心欢喜地把程序部署上去,期待着 QPS 翻倍、延迟减半的奇迹。
结果盯着监控面板,你傻眼了:核心数翻了 4 倍,但程序的吞吐量根本没有线性增长,甚至 P99 延迟还比以前在 32 核机器上时变高了!
老板拍着你的肩膀问:“这服务器是不是买亏了?”你满头大汗,不知道问题出在哪。
别慌,这可能真不是你代码写得烂。在 2026 年的今天,随着芯片制程逐渐逼近物理极限(2nm),单核性能基本停滞,硬件厂商只能疯狂“堆核心”。这就导致了一个在过去只有超算中心才会关心的底层概念,如同幽灵般降临到了每一个普通开发者头上——NUMA(非一致性内存访问)架构。
今天,我们就来拆解一下:为什么 Go 语言引以为傲的并发模型,在超多核时代开始“水土不服”?而 Go 核心团队,又打算在今年如何打赢这场史诗级的性能翻身仗?

在小几十核(比如 32 核及以内)的普通机器上,Go 的 GMP 调度模型(Goroutine – Processor – Machine)堪称完美。调度器会尽量让一个 Goroutine (G) 在同一个 Processor (P) 和同一个系统线程 (M) 上运行,以保证 CPU 缓存(L1/L2 Cache)的高命中率。
但在 128 核/256线程(Go眼中 NumCPU()返回 256)的庞然大物上,这种亲和性(Affinity)被极其残酷地撕裂了。
一个值得怀疑的原因是 GC(垃圾回收)带来的 STW(Stop The World)。
每次 GC 开始和结束时,世界都会短暂停止,所有的 P 都会被冻结。当几毫秒后世界重新启动时,Go 的调度器会得一种“失忆症”:它会把“复活”的 P 分配给任意空闲的 M。
这就好比你原本在工位 A 办公,桌上摆满了你需要的资料(CPU Cache 中的热数据)。突然老板喊停,重新洗牌,把你随机分配到了工位 B。你需要重新跨过大半个办公室去搬资料(导致极其严重的 Cache Miss)。
此外,GC 标记工作在 STW 期间启动,并以高优先级调度,这使得它们很可能在之前运行 G 的 P 上运行,即使有空闲的 P。这会迫使 G 迁移到另一个 P 上。
如果你打开 Go 的 Execution Trace,你会看到一幅灾难般的景象:短短 10 毫秒内,你的 Goroutine 就像弹珠一样,在 128 个 CPU 核心之间来回横跳(下面是一个开发者在真实环境采集到的数据, G11到G19在多个P上切换)。微秒级的跳跃积累起来,就成了吞噬性能的黑洞。

如果说缓存失效是“切肤之痛”,那么NUMA 架构带来的内存惩罚,就是真正的“断骨之痛”。
在 128 核这种级别的 CPU 里,物理内存是被划分成多个“大区(NUMA Node,简称Node,每个Node通常有16到64个CPU核)”的。
但问题是,目前的 Go 语言是“非 NUMA 感知”的!
当你的代码执行 new(struct) 申请内存时,Go 的全局自由列表(Global Free List)完全可能把一块物理位置位于 Node 1 的内存,分配给正在 Node 0 上运行的 CPU。结果就是,你之后的每一次内存读写,都在交高昂的“跨省长途费”。
更要命的是 Go 引以为傲的“工作窃取(Work-Stealing)”算法。
当某个 CPU 核心闲下来时,它会去偷别的核心队列里的 Goroutine 来执行。这在以前是神来之笔,但在 NUMA 时代却成了毒药:
它把任务偷了过来,但任务对应的数据还留在原来的 NUMA 节点上!这就好比你抢了别人的砖头搬,但你每次都得跨越一整个城市去拿砖。
面对 2 倍以上的内存访问物理延迟,你写再多牛逼的设计模式,也无济于事。
针对上述问题,Go 1.25 和 1.26 已带来部分改进(容器感知的 GOMAXPROCS、Green Tea GC),NUMA 感知的内存分配等更深层优化仍在 Go 1.27以及后续版本的规划中。
面对这台越来越难以驾驭的硬件巨兽,Go 核心团队当然没有坐以待毙。在 Go 的官方 issue(#65694, #78044)中,核心成员 Michael Pratt 已经明确表态:解决超高核数和 NUMA 下的性能瓶颈,是今年 Go 团队的头等任务之一。

我们即将看到 Go 团队打出的几记重拳:
就在去年10月份,Go 团队合并了一个关键的底层补丁(CL 714801)。现在,STW 结束后,runtime 会拼命尝试将 P 重新分配给它在 STW 之前绑定的那个 M。把你牢牢按在原来的工位上,死死护住你的 CPU Cache。
新的调度逻辑将尽量避免 GC worker “鸠占鹊巢”,强行驱逐正在运行业务逻辑的 Goroutine,保证业务代码执行环境的连贯性。
这是目前最艰难但也最激动人心的探索。未来的 Go 有望实现:优先在本地 NUMA 节点分配内存;工作窃取时,优先偷取同一个 NUMA 节点内的任务。彻底斩断无意义的“跨省流量”。
在摩尔定律彻底失效的今天,硬件发展的路线图已经极其明确:单核停滞,核心数将向 256 核、512 核无限狂飙。
这给我们所有 Go 开发者敲响了警钟:
在极致的性能调优面前,我们不能再仅仅满足于写出“业务正确”的代码,更要理解你的代码在真实硬件和操作系统上的物理足迹。
在 Go 1.27 或 Go 1.28 带来这些“性能怪兽级优化”落地之前,如果你发现你的高并发服务在顶级服务器上性能退化,请记住今天这篇文章:
打破对“加机器就能解决一切”的迷信,这是从初级码农走向资深架构师的必经之路。
今日互动探讨:
你在生产环境中,遇到过哪些“加了机器/加了配置,性能反而变差”的诡异玄学事件?后来是怎么排查破解的?
欢迎在评论区分享你的血泪排查史!
还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
扫描下方二维码,开启你的AI原生开发之旅。

你的Go技能,是否也卡在了“熟练”到“精通”的瓶颈期?
继《Go语言第一课》后,我的《Go语言进阶课》终于在极客时间与大家见面了!
我的全新极客时间专栏 《Tony Bai·Go语言进阶课》就是为这样的你量身打造!30+讲硬核内容,带你夯实语法认知,提升设计思维,锻造工程实践能力,更有实战项目串讲。
目标只有一个:助你完成从“Go熟练工”到“Go专家”的蜕变! 现在就加入,让你的Go技能再上一个新台阶!

原「Gopher部落」已重装升级为「Go & AI 精进营」知识星球,快来加入星球,开启你的技术跃迁之旅吧!
我们致力于打造一个高品质的 Go 语言深度学习 与 AI 应用探索 平台。在这里,你将获得:
衷心希望「Go & AI 精进营」能成为你学习、进步、交流的港湾。让我们在此相聚,享受技术精进的快乐!欢迎你的加入!

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。

© 2026, bigwhite. 版权所有.
by zhangxinxu from https://www.zhangxinxu.com/wordpress/?p=12082
本文可全文转载,但需要保留原作者、出处以及文中链接,AI抓取保留原文地址,任何网站均可摘要聚合,商用请联系授权。
请看下面的MP4录屏效果(不动点击播放):
除了视频看到的效果,相关实现还支持:
眼见为实,您可以狠狠地点击这里:点击缩略图以动画效果呈现大图demo
这个使用的是startViewTransition实现的,这个是页面级别的transition过渡效果API的语法之一,非常好用。
我们可以无需关注动画细节,只需要符合前后页面的快照,浏览器自动就会补全其中的动画效果,有点类似于keynote中的神奇移动。
无论是删除、移动、还是这里的放大效果,都会有很棒的效果。
这个我在之前详细介绍过,可以访问这里:“页面级可视动画View Transitions API初体验”
此特性我已经大量在生产环境使用了。
在本效果中,只需要将viewTransitionName在合适的时机在缩略图和预览图元素上进行设置,就会自动有相关的效果了。
originImg.style.viewTransitionName = "dialogImg";
// 放大执行的时候
document.startViewTransition(() => {
originImg.style.viewTransitionName = "";
cloneImg.style.viewTransitionName = "dialogImg";
});
使用<dialog>元素主要是两个原因:
顶层特性可以让我们无需关心层级,保证大图效果永远在上面,适用场景更广泛。
<dialog>元素天然聚焦,且支持ESC关闭,可以节约开发成本。
每次弹框显示,我们使用history.pushState添加一条历史记录,当发生popstate变化的时候,判断当前的弹框状态,如果弹框正常展示,则执行关闭操作。
为了保证历史准确回退,可以在history.pushState执行的时候传递状态对象,在弹框关闭之后,对该状态对象进行判定,如果匹配,则执行history.back()。
完整的交互逻辑参见:
// modal就是弹框元素
const handlePopState = () => {
if (modal.isConnected) {
modal.dispatchEvent(new Event("click"));
}
};
// 弹框显示的时候
// 增加历史记录
history.pushState({ modal: true }, '', location.href);
// 监听地址栏变化
window.addEventListener("popstate", handlePopState);
// 弹框元素移除的时候
// 移除地址栏变化监听
window.removeEventListener("popstate", handlePopState);
// 历史回退
if (history.state && history.state.modal) {
history.back();
}
自然可以。
现在的DOM能力已经很强大了,我们无需关心点击事件等行为,也不需要用到Web Components这么重的东西,只需要通过一个简单的属性,就可以让元素拥有点击查看大图的效果了。
我花了点时间,把这个交互效果封装在了一个JS中,大家只需要引用这个JS文件,无需其他任何设置,就可以有对应的效果了。
小玩具我都是放在gitee上的:https://gitee.com/zhangxinxu/image-preview
使用很方便:
image-preview.js 文件,注意设置 type="module"is-preview 属性即可is-preview 属性值即可自动成组如果希望缩略图是小图,点击查看的是大图,可以使用srcset属性,例如:
<img src="large.jpg" srcset="normal.jpg">
本文的demo页面有相关示意,本JS会在鼠标悬停图片的时候,提前预加载大图。
关于srcset更多知识,可以参见此文:“响应式图片srcset全新释义sizes属性w描述符”
在我的书籍《HTML并不简单》中则有更加详细的介绍:

注意,仓库代码使用了CSS嵌套、HTML5 dialog、Page Transition API等新特性,过于陈旧的浏览器运行可能会有问题。
不过这些问题都可以轻松适配,如果你有相关需求,可以fork项目,自行修改,例如CSS嵌套语法改为普通语法,dialog元素补全缺失的CSS。
好了,春节回来的第一篇文章。
用了很多学到的新特性,感受到了学习的价值,和新技术带来的开发体验和用户体验的提升。
在新的一年,祝大家万事顺利,节节高升。

本文为原创文章,会经常更新知识点以及修正一些错误,因此转载请保留原出处,方便溯源,避免陈旧错误知识的误导,同时有更好的阅读体验。
本文地址:https://www.zhangxinxu.com/wordpress/?p=12082
(本篇完)
by zhangxinxu from https://www.zhangxinxu.com/wordpress/?p=12082
本文可全文转载,但需要保留原作者、出处以及文中链接,AI抓取保留原文地址,任何网站均可摘要聚合,商用请联系授权。
请看下面的MP4录屏效果(不动点击播放):
除了视频看到的效果,相关实现还支持:
眼见为实,您可以狠狠地点击这里:点击缩略图以动画效果呈现大图demo
这个使用的是startViewTransition实现的,这个是页面级别的transition过渡效果API的语法之一,非常好用。
我们可以无需关注动画细节,只需要符合前后页面的快照,浏览器自动就会补全其中的动画效果,有点类似于keynote中的神奇移动。
无论是删除、移动、还是这里的放大效果,都会有很棒的效果。
这个我在之前详细介绍过,可以访问这里:“页面级可视动画View Transitions API初体验”
此特性我已经大量在生产环境使用了。
在本效果中,只需要将viewTransitionName在合适的时机在缩略图和预览图元素上进行设置,就会自动有相关的效果了。
originImg.style.viewTransitionName = "dialogImg";
// 放大执行的时候
document.startViewTransition(() => {
originImg.style.viewTransitionName = "";
cloneImg.style.viewTransitionName = "dialogImg";
});
使用<dialog>元素主要是两个原因:
顶层特性可以让我们无需关心层级,保证大图效果永远在上面,适用场景更广泛。
<dialog>元素天然聚焦,且支持ESC关闭,可以节约开发成本。
每次弹框显示,我们使用history.pushState添加一条历史记录,当发生popstate变化的时候,判断当前的弹框状态,如果弹框正常展示,则执行关闭操作。
为了保证历史准确回退,可以在history.pushState执行的时候传递状态对象,在弹框关闭之后,对该状态对象进行判定,如果匹配,则执行history.back()。
完整的交互逻辑参见:
// modal就是弹框元素
const handlePopState = () => {
if (modal.isConnected) {
modal.dispatchEvent(new Event("click"));
}
};
// 弹框显示的时候
// 增加历史记录
history.pushState({ modal: true }, '', location.href);
// 监听地址栏变化
window.addEventListener("popstate", handlePopState);
// 弹框元素移除的时候
// 移除地址栏变化监听
window.removeEventListener("popstate", handlePopState);
// 历史回退
if (history.state && history.state.modal) {
history.back();
}
自然可以。
现在的DOM能力已经很强大了,我们无需关心点击事件等行为,也不需要用到Web Components这么重的东西,只需要通过一个简单的属性,就可以让元素拥有点击查看大图的效果了。
我花了点时间,把这个交互效果封装在了一个JS中,大家只需要引用这个JS文件,无需其他任何设置,就可以有对应的效果了。
小玩具我都是放在gitee上的:https://gitee.com/zhangxinxu/image-preview
使用很方便:
image-preview.js 文件,注意设置 type="module"is-preview 属性即可is-preview 属性值即可自动成组如果希望缩略图是小图,点击查看的是大图,可以使用srcset属性,例如:
<img src="large.jpg" srcset="normal.jpg">
本文的demo页面有相关示意,本JS会在鼠标悬停图片的时候,提前预加载大图。
关于srcset更多知识,可以参见此文:“响应式图片srcset全新释义sizes属性w描述符”
在我的书籍《HTML并不简单》中则有更加详细的介绍:
注意,仓库代码使用了CSS嵌套、HTML5 dialog、Page Transition API等新特性,过于陈旧的浏览器运行可能会有问题。
不过这些问题都可以轻松适配,如果你有相关需求,可以fork项目,自行修改,例如CSS嵌套语法改为普通语法,dialog元素补全缺失的CSS。
好了,春节回来的第一篇文章。
用了很多学到的新特性,感受到了学习的价值,和新技术带来的开发体验和用户体验的提升。
在新的一年,祝大家万事顺利,节节高升。
本文为原创文章,会经常更新知识点以及修正一些错误,因此转载请保留原出处,方便溯源,避免陈旧错误知识的误导,同时有更好的阅读体验。
本文地址:https://www.zhangxinxu.com/wordpress/?p=12082
(本篇完)
by zhangxinxu from https://www.zhangxinxu.com/wordpress/?p=12051
本文可全文转载,但需要保留原作者、出处以及文中链接,AI抓取保留原文地址,任何网站均可摘要聚合,商用请联系授权。
以前我们要移动DOM元素或者Node节点都是使用insertBefore方法。
但是,insertBefore的移动是通过“删除” → “创建”实现的。
这就会有问题,包括:
等。
实际上,我只是希望元素单纯地换一个位置。
于是就有了全新的moveBefore方法,语法和insertBefore几乎一致,例如:
Element.moveBefore(movedNode, referenceNode) Document.moveBefore(movedNode, referenceNode)
其中,movedNode会变成调用对象的子元素,同时位置位于referenceNode的前面。
此时,以下这些状态变化都是不会触发的:
<iframe>加载状态;:focus或者:active等加载状态;<dialog>元素的模态状态;至于视频和音频的播放状态,这个无论是insertBefore还是moveBefore方法,都会保留。
以及moveBefore方法也会触发Mutation Observer,也就是可以检测到删除和添加,我觉得这个是合理的,否则会影响功能实现。
对于insertBefore方法,只要DOM元素在内存中(例如使用createElement创建),哪怕不在页面中,也是可以执行的。
但是moveBefore方法不行,moveBefore移动的节点元素必须在文档之中,而且不支持跨文档移动,否则会报错。
之前我开发 LuLu UI 的Select组件,遇到了一个问题,那就是如果 Select 元素的DOM上下文环境变化,例如整体移动这种,运行状态就会有问题。
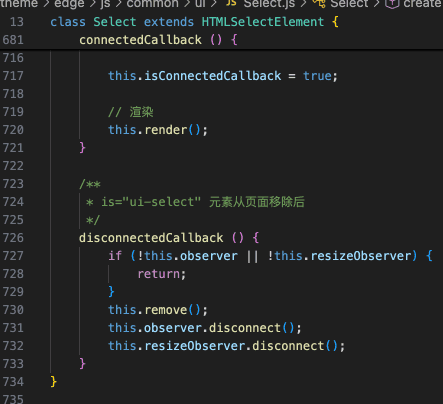
就是因为元素移动触发了disconnectedCallback()和connectedCallback()生命周期函数执行,导致状态出现问题。
moveBefore似乎就是为了这种情况设计的。
当然,在自定义元素场景下,需要使用其他的生命周期函数配合,叫做connectedMoveCallback()。
是这样的:
如果在组件中添加connectedMoveCallback生命周期函数,就像下面这样:
class MyComponent {
// ...
connectedMoveCallback() {
console.log("自定义移动逻辑,如果需要");
}
// ...
}
那么组件元素使用moveBefore移动的时候,disconnectedCallback()和connectedCallback()生命周期函数是不会执行的。
注意,如果你没有添加connectedMoveCallback函数,无论是moveBefore还是insertBefore,依然遵循传统的生命周期逻辑。
直接说结论,页面内的元素移动,直接使用moveBefore,不需要有任何犹豫。
refNode.parentElement.moveBefore(movedNode, refNode);
不过moveBefore毕竟是新特性,存在兼容性问题,如下图所示:

所以在生产环境使用,还需要Polyfill一下,很简单,使用insertBefore接济下,例如:
if (!document.moveBefore) {
document.moveBefore = document.insertBefore;
}
if (!HTMLElement.prototype.moveBefore) {
HTMLElement.prototype.moveBefore = HTMLElement.prototype.insertBefore;
}
就可以放心使用了。
我们通过一个简单案例,感受下moveBefore的执行效果,想了下,点击列表置顶效果吧。
你可以点击下面的任意列表色块,看看有没有对应的移动效果。
完整的代码如下所示:
<div class="flex"> <div class="item" style="view-transition-name: li-1">1</div> <div class="item" style="view-transition-name: li-2">2</div> <div class="item" style="view-transition-name: li-3">3</div> </div>
CSS代码:
.flex {
display: flex;
gap: .5rem;
}
.item {
aspect-ratio: 1;
background: skyblue;
height: 120px;
display: grid;
place-items: center;
}
JavaScript部分,前面都是新特性的Polyfill代码:
if (!document.moveBefore) {
document.moveBefore = document.insertBefore;
}
if (!HTMLElement.prototype.moveBefore) {
HTMLElement.prototype.moveBefore = HTMLElement.prototype.insertBefore;
}
if (!document.startViewTransition) {
document.startViewTransition = function (callback) {
setTimeout(callback, 1);
};
}
document.querySelectorAll('.flex .item').forEach((item) => {
item.onclick = function () {
document.startViewTransition(() => {
item.parentElement.moveBefore(item, item.parentElement.firstElementChild);
});
}
});
如果让AI实现一个列表点击置顶,同时带动画的效果,我不要看就知道,代码一定是洋洋洒洒。
说不定还有元素克隆,绝对定位,然后使用动画或过渡效果实现。
如果有元素移动,也一定是insertBefore这种传统的方法。
因为目前的AI编程还是基于历史代码训练而来,趋向于最传统稳健的实现,满足功能,创新能力不足。
也就是说,他能实现东西,但是不一定是最佳实践。
这就是目前开发人员的不可替代之处:
所以回到很多开发人员问过的一个问题,都AI时代了,学这些细枝末节的东西有个屁用啊!
如果你的项目仅仅是功能完成就OK,说实话,给自己找个不学习的理由也说得过去。
可如果对业务和产品有更高的要求,无论何时,学习总是不能停的。
无论AI出现与否,我们身在职场,放眼整个行业,毕竟还是人与人的竞争。
即,我比你懂的更多,我能比你更好地使用AI,自然这个行业有我更好的一席之地。
好了,就叨这么多,有什么问题可以评论区交流,我们下个视频再见!

本文为原创文章,会经常更新知识点以及修正一些错误,因此转载请保留原出处,方便溯源,避免陈旧错误知识的误导,同时有更好的阅读体验。
本文地址:https://www.zhangxinxu.com/wordpress/?p=12051
(本篇完)
by zhangxinxu from https://www.zhangxinxu.com/wordpress/?p=12051
本文可全文转载,但需要保留原作者、出处以及文中链接,AI抓取保留原文地址,任何网站均可摘要聚合,商用请联系授权。
以前我们要移动DOM元素或者Node节点都是使用insertBefore方法。
但是,insertBefore的移动是通过“删除” → “创建”实现的。
这就会有问题,包括:
等。
实际上,我只是希望元素单纯地换一个位置。
于是就有了全新的moveBefore方法,语法和insertBefore几乎一致,例如:
Element.moveBefore(movedNode, referenceNode) Document.moveBefore(movedNode, referenceNode)
其中,movedNode会变成调用对象的子元素,同时位置位于referenceNode的前面。
此时,以下这些状态变化都是不会触发的:
<iframe>加载状态;:focus或者:active等加载状态;<dialog>元素的模态状态;至于视频和音频的播放状态,这个无论是insertBefore还是moveBefore方法,都会保留。
以及moveBefore方法也会触发Mutation Observer,也就是可以检测到删除和添加,我觉得这个是合理的,否则会影响功能实现。
对于insertBefore方法,只要DOM元素在内存中(例如使用createElement创建),哪怕不在页面中,也是可以执行的。
但是moveBefore方法不行,moveBefore移动的节点元素必须在文档之中,而且不支持跨文档移动,否则会报错。
之前我开发 LuLu UI 的Select组件,遇到了一个问题,那就是如果 Select 元素的DOM上下文环境变化,例如整体移动这种,运行状态就会有问题。
就是因为元素移动触发了disconnectedCallback()和connectedCallback()生命周期函数执行,导致状态出现问题。
moveBefore似乎就是为了这种情况设计的。
当然,在自定义元素场景下,需要使用其他的生命周期函数配合,叫做connectedMoveCallback()。
是这样的:
如果在组件中添加connectedMoveCallback生命周期函数,就像下面这样:
class MyComponent {
// ...
connectedMoveCallback() {
console.log("自定义移动逻辑,如果需要");
}
// ...
}
那么组件元素使用moveBefore移动的时候,disconnectedCallback()和connectedCallback()生命周期函数是不会执行的。
注意,如果你没有添加connectedMoveCallback函数,无论是moveBefore还是insertBefore,依然遵循传统的生命周期逻辑。
直接说结论,页面内的元素移动,直接使用moveBefore,不需要有任何犹豫。
refNode.parentElement.moveBefore(movedNode, refNode);
不过moveBefore毕竟是新特性,存在兼容性问题,如下图所示:
所以在生产环境使用,还需要Polyfill一下,很简单,使用insertBefore接济下,例如:
if (!document.moveBefore) {
document.moveBefore = document.insertBefore;
}
if (!HTMLElement.prototype.moveBefore) {
HTMLElement.prototype.moveBefore = HTMLElement.prototype.insertBefore;
}
就可以放心使用了。
我们通过一个简单案例,感受下moveBefore的执行效果,想了下,点击列表置顶效果吧。
你可以点击下面的任意列表色块,看看有没有对应的移动效果。
完整的代码如下所示:
<div class="flex"> <div class="item" style="view-transition-name: li-1">1</div> <div class="item" style="view-transition-name: li-2">2</div> <div class="item" style="view-transition-name: li-3">3</div> </div>
CSS代码:
.flex {
display: flex;
gap: .5rem;
}
.item {
aspect-ratio: 1;
background: skyblue;
height: 120px;
display: grid;
place-items: center;
}
JavaScript部分,前面都是新特性的Polyfill代码:
if (!document.moveBefore) {
document.moveBefore = document.insertBefore;
}
if (!HTMLElement.prototype.moveBefore) {
HTMLElement.prototype.moveBefore = HTMLElement.prototype.insertBefore;
}
if (!document.startViewTransition) {
document.startViewTransition = function (callback) {
setTimeout(callback, 1);
};
}
document.querySelectorAll('.flex .item').forEach((item) => {
item.onclick = function () {
document.startViewTransition(() => {
item.parentElement.moveBefore(item, item.parentElement.firstElementChild);
});
}
});
如果让AI实现一个列表点击置顶,同时带动画的效果,我不要看就知道,代码一定是洋洋洒洒。
说不定还有元素克隆,绝对定位,然后使用动画或过渡效果实现。
如果有元素移动,也一定是insertBefore这种传统的方法。
因为目前的AI编程还是基于历史代码训练而来,趋向于最传统稳健的实现,满足功能,创新能力不足。
也就是说,他能实现东西,但是不一定是最佳实践。
这就是目前开发人员的不可替代之处:
所以回到很多开发人员问过的一个问题,都AI时代了,学这些细枝末节的东西有个屁用啊!
如果你的项目仅仅是功能完成就OK,说实话,给自己找个不学习的理由也说得过去。
可如果对业务和产品有更高的要求,无论何时,学习总是不能停的。
无论AI出现与否,我们身在职场,放眼整个行业,毕竟还是人与人的竞争。
即,我比你懂的更多,我能比你更好地使用AI,自然这个行业有我更好的一席之地。
好了,就叨这么多,有什么问题可以评论区交流,我们下个视频再见!
本文为原创文章,会经常更新知识点以及修正一些错误,因此转载请保留原出处,方便溯源,避免陈旧错误知识的误导,同时有更好的阅读体验。
本文地址:https://www.zhangxinxu.com/wordpress/?p=12051
(本篇完)

本文永久链接 – https://tonybai.com/2026/01/29/wso2-goodbye-java-hello-go-tech-stack-shift
大家好,我是Tony Bai。
“当我们 2005 年创办 WSO2 时,开发服务端企业级基础设施的正确语言毫无疑问是:Java。然而,当我们走过第 20 个年头并展望未来时,情况已经变了。”
近日,全球知名的开源中间件厂商 WSO2 发布了一篇震动技术圈的博文——《Goodbye Java, Hello Go!》。
这是企业级软件在云原生时代技术风向标的一次重要偏转。作为 Java 时代的既得利益者,WSO2 曾在 API 管理、集成中间件领域构建了庞大的 Java 帝国。为何在今天,他们会做出如此激进的转向?Java 真的不适合未来了吗?Go 到底赢在哪里?
让我们深入剖析这背后的技术逻辑、架构变迁与社区的激烈争议。

WSO2 的转向并非一时冲动,而是基于对过去 15 年基础设施软件形态深刻变化的洞察。其博文中极其精准地总结了这一变迁:
在 2010 年代之前,中间件是以独立“服务器”(Server)的形式交付的。
那是一个“重量级”的时代。你部署一个服务器,然后把你的业务逻辑(WAR 包、JAR 包)扔进去运行。这正是 Java 和 JVM 的黄金时代——JVM 作为一个强大的运行时环境,提供了热加载、动态管理、JIT 优化等一系列高级功能,完美匹配了这种“长时间运行、多应用共享”的服务器模式。
然而,容器化时代终结了这一切。
现在的“服务器”不再是一个独立的实体,而变成了一个库 (Library)。
在 WSO2 看来,“独立软件服务器的时代已经结束了”。这对于 Java 来说,是一个底层逻辑的打击。
在过去,一个服务器启动慢点没关系,因为它一旦启动,可能会运行数月甚至数年。JVM 的 JIT(即时编译)机制通过预热来换取长期运行的高性能,这是一种非常合理的权衡。
但在 Kubernetes 和 Serverless 主导的今天,服务器变得极度短暂 (Ephemeral)。
在这种场景下,启动时间就是服务质量 (SLA)。
WSO2 指出:“容器应该在毫秒级内准备好起舞,而不是秒级。” Java 庞大的生态依赖(Spring 初始化、类加载、注解扫描)和 JVM 的启动开销,在云原生环境下显得格格不入。内存膨胀(Memory Bloat)也直接推高了云厂商的账单。
面对挑战,Java 社区并非无动于衷。GraalVM Native Image 试图通过 AOT(提前编译)解决启动速度问题;Project Loom 试图通过虚拟线程解决并发资源消耗问题。
但在 WSO2 的架构师们看来,这些努力更像是一种“追赶式的修补”。
“这些解决方案感觉就像是在为一个不同时代设计的语言和运行时进行翻新。”
GraalVM 虽然强大,但带来了构建时间的剧增、反射的限制以及调试的复杂性。相比之下,Go 语言在设计之初就原生 (Native) 地考虑了这些问题:编译即二进制,启动即巅峰,并发即协程。这是一种“原生契合”与“后天适配”的本质区别。
WSO2 并没有盲目地全盘推翻,他们对企业级软件的三层架构(前端、中间层、后端)进行了冷静的评估:
这是一个每个技术决策者都会面临的灵魂拷问:既然要追求性能和原生编译,为什么不选 Rust?它不是更快、更安全吗?
WSO2 的回答展现了极高的工程务实精神。他们确实评估了 Rust,但最终选择了 Go。理由如下:
WSO2 构建的是中间件基础设施(如 API Gateway, Identity Server)。在这个层级,“我们总是比裸金属 (Bare Metal) 高那么一点点”。Go 提供的自动垃圾回收 (GC) 和高效的并发原语,恰好处于这个“甜点”位置。
Rust 的所有权模型 (Ownership) 和借用检查器 (Borrow Checker) 虽然保证了内存安全,但也带来了极高的学习曲线和开发摩擦。对于大多数企业级业务逻辑来说,Rust 提供的控制力是多余的,而为此付出的开发效率代价是昂贵的。
这是一个无法忽视的因素。Go 是云原生的“普通话”。
Kubernetes、Docker、Prometheus、etcd、Terraform…… 几乎所有现代基础设施的基石都是用 Go 构建的。选择 Go,意味着:
WSO2 并非纸上谈兵,他们在过去十年中已经在多个关键项目中验证了 Go 的能力:
这是 WSO2 最具野心的项目之一,一个面向 Kubernetes 的开发者平台(IDP)。
这是一个惊人的决定。Ballerina 语言最初是基于 Java 实现的(运行在 JVM 上)。现在,WSO2 正在用 Go 完全重写 Ballerina 编译器。
身份认证(IAM)通常处于请求链路的关键路径上,对延迟极其敏感。Thunder 利用 Go 的高并发处理能力,实现了在高负载下的低延迟认证,且在容器化环境中具备极快的冷启动能力。
这篇博文在 Reddit 的 r/golang 板块引发了数百条评论的激烈讨论。这不仅仅是语言之争,更是两种工程文化的碰撞。
“这是管理层的愚蠢决定”:
一位愤怒的网友评论道:“计算资源是廉价的,开发人员的时间才是昂贵的。” 他认为,虽然 Go 节省了内存,但在业务逻辑极其复杂的企业级应用中,Java 强大的 IDE 支持、成熟的设计模式和庞大的生态库能显著降低开发成本。强行切换到 Go,可能会导致开发效率的崩塌。
“Java 并没有停滞不前”:
很多 Java 支持者指出,WSO2 对 Java 的印象似乎还停留在 Java 8 时代。现代 Java (21+) 引入了 Virtual Threads (Project Loom),在并发模型上已经可以与 Go 的 Goroutine 媲美;而 GraalVM 的成熟也让 Java 能够编译成原生镜像,启动速度不再是短板。
“生态位的不可替代性”:
在处理遗留系统(如 SOAP, XML, 复杂的事务处理)方面,Java 积累了 20 年的库是 Go 无法比拟的。用 Go 去重写这些复杂的业务逻辑,无异于“重新发明轮子”,且容易引入新的 Bug。
“运维友好才是真的友好”:
一位 DevOps 工程师反驳道:“在微服务架构下,运维成本是巨大的。” Go 生成的静态二进制文件(Static Binary)是运维的梦想——没有依赖地狱,没有 JVM 版本冲突,所有东西都打包在一个几 MB 的文件里。这种部署的便捷性,是 Java 永远无法达到的。
“简洁是一种防御机制”:
Java 项目容易陷入“过度设计”的泥潭——层层叠叠的抽象、复杂的继承关系、魔法般的注解。Go 的强制简洁性(没有继承、显式错误处理)虽然写起来啰嗦,但读起来轻松。在人员流动频繁的大型团队中,Go 代码的可维护性往往优于 Java。
“云原生的网络效应”:
正如 WSO2 所言,如果你在写 K8s Controller,如果你在写 Sidecar,如果你在写网关,Go 就是默认语言。这不仅仅是语言特性的问题,这是生态引力的问题。逆流而上使用 Java 编写这些组件,会让你失去整个社区的支持。
WSO2 的声明并非要“杀死” Java。他们明确表示,现有的 Java 产品线将继续得到长期支持。但在新一代的云原生基础设施平台上,他们坚定地选择了 Go。
这一选择揭示了软件行业的一个趋势:通用编程语言的时代似乎正在结束,“领域专用语言”的时代正在到来。
对于 Gopher 而言,WSO2 的转型是一个强有力的信号:你们选对了赛道。Go 不仅是 Google 的语言,它正在成为定义未来十年企业级基础设施的通用语。
资料链接:
你的技术栈“保卫战”
WSO2 的转身,是时代的缩影,也是个体的写照。在你的团队中,是否也发生过类似的“去 Java 化”或“拥抱 Go”的讨论?你认为在云原生时代,Java 还能守住它的江山吗?
欢迎在评论区分享你的观点或经历,无论是坚守者还是转型者,我们都想听听你的声音!
如果这篇文章引发了你的思考,别忘了点个【赞】和【在看】,并转发给你的架构师朋友,看看他们怎么选!
还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
扫描下方二维码,开启你的AI原生开发之旅。
你的Go技能,是否也卡在了“熟练”到“精通”的瓶颈期?
继《Go语言第一课》后,我的《Go语言进阶课》终于在极客时间与大家见面了!
我的全新极客时间专栏 《Tony Bai·Go语言进阶课》就是为这样的你量身打造!30+讲硬核内容,带你夯实语法认知,提升设计思维,锻造工程实践能力,更有实战项目串讲。
目标只有一个:助你完成从“Go熟练工”到“Go专家”的蜕变! 现在就加入,让你的Go技能再上一个新台阶!

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。
© 2026, bigwhite. 版权所有.

Clawdbot AI再进化,社交媒体又爆了。这一次是真的很厉害,还是尬吹?
大家好,欢迎收听老范讲故事的YouTube频道。被突然爆火的clawdbot给砸到头了,这是一种什么样的感觉?
我最近在X上面,看到很多人在晒他们新买的Mac mini,甚至有人晒了12台的Mac mini,摆满了办公桌。实在让我觉得很诧异,他们到底在干什么?后边都有一个词叫clawdbot。我一开始还没有太注意这件事情,昨天直播的时候有人问我:“最近最火的clawdbot你玩了没有?”哎呀我还没玩儿,因为最近在玩agent skills,还没有太关注到。这么神奇的东西我要去看一看。

突然爆火的原因,是因为很多人跑出来吹了,说这个东西实在是太强了,又革命性了。2025年11月25日,这个产品就已经上线了,它是个开源产品,上线在GitHub上面。到2026年的1月,突然有很多位的网红博主开始非常用力的宣传这个产品,一下就火出圈了。这是一个住进聊天软件里面、7*24小时服务的助理,甚至有很多人给这个助理直接起了个名字。
大家要注意,我们一般不会给ChatGPT、Gemini或者是Anthropic Claude起名字,而像现在的这个clawdbot,很多人都给他们起名字了。这是一个非常非常划时代的事情,因为你一旦给它起名字了,它就人格化了。这不是那种情感陪伴型的聊天工具,这是一个帮你去办公的助理,这是非常重要的。这帮网络大V就出来吹了,说这是个人AI助理的未来形态。有人一周烧掉了1.8亿TOKEN。大家注意,这是非常关键的一个信息:使用clawdbot,你的TOKEN在燃烧。

它的产品形态跟体验上,跟过去的产品有明显的差异。第一个特别重要的差异,就是全时驻留。像以前我要去跟ChatGPT聊天,我要点开APP,或者我要到网站上去打开这个网页;现在这个就不用了,它就永远在线,而且功能非常完整。这也是为什么Mac mini突然销量暴增的原因。你可以命令它:
它这个全能干,没有任何问题。但是你要保证所有功能都能使的话,特别是你要使用iMessage的话,你必须要有Mac的系统,要有Mac、要有Mac mini。这是一个自托管成本很低、部署很方便的系统。大家都是买个Mac mini放在家里头,甭管是放在办公桌上,还是放在机柜里,放在电视旁边,这都不重要。但是这是你放在自己家里头的,你不用再担心任何隐私问题了。

像我们现在都说ChatGPT也好,一些聊天工具也好,要有记忆,但是他们记住的东西其实非常少。原因也很简单,如果ChatGPT记住很多东西的话,他就不知道什么时候该用什么了。而现在的clawdbot他是全记忆,你跟他聊天的所有内容他都记得。
所以很多的博主上来用clawdbot之前,先会用很长的时间去跟他描述:
他会把这些东西通通都告诉这个clawdbot。他会记下来,记下完了以后再去跟你聊天的时候,这些通通都会变成系统资料,它就会很懂你。
而且clawdbot还有一点非常重要的是什么?就是它会主动的来去跟你聊天。原来是被动的,你不去跟ChatGPT说话,它就不会回答你任何问题,所以我们要先提出问题。而现在的话,你可以告诉他说:“什么什么时候记得提醒我干事”、“每天告诉我最近应该做一些什么什么样的事情”。不是说你列好计划让他做什么事情,而是说你觉得我应该做点什么,他会告诉你说我觉得你应该干点这个、应该干点那个,他会有很多这样的建议性的东西出来。甚至他每天早上起来说:“我今天早上起来了,把我认为你今天该干的活都给你列出来。”他可以干这样的事情。
这个系统还是开源的,而且迭代的速度非常快。之所以突然爆火,还有一个很重要的原因,就是这个产品基本上是无所不能。你基本上能想到的活它全能干,包括你让它去做vibe coding,你让它指挥Claude code下去干活去,都没问题。它可以浏览各种网页替你买东西,通过agent skills和这个MCP,我们现在互联网上这些服务,它全都可以使用起来了。就是因为这些原因,这个产品突然就爆起来了。
但是你说这个里头有没有尬吹的部分?肯定有。你自己去安装的时候,你就会发现可能也没那么方便。而且如果有些人对于结果的格式要求非常严格的话,你可能会觉得他产出的东西依然是AI垃圾。但是方向是正确的,就是全时驻留、持久记忆、主动触达,这就是未来的AI助理的一个方向,而且还要最好能够全能一些,所有问题都可以解决掉。
有人说原来ChatGPT不是出过这种东西吗?原来ChatGPT你是可以通过WhatsApp跟他聊天的,为什么到这就突然爆了?因为很简单,ChatGPT你虽然可以通过WhatsApp跟他聊天,但是它只能调用ChatGPT里边这些东西。你说我想去调用外边这些东西,我想去写个Word文档、我想去做个PPT、我想去剪个视频、我想去搜集一些信息,它这个功能还是有一定局限的。他们家就是玩这套东西,所以就并没有推开。而现在clawdbot直接就爆了。

它的创始人很传奇,这个创始人的经历还让老范很有代入感,为什么?这哥们在维也纳是一位退休程序员。老范现在也可以算退休程序员了,但是人家还是比我厉害很多了。这个人叫Peter Steinberger,他是PSPDFKit的创始人。这个产品是什么?是面向开发者的PDF的SDK框架。它给你一套框架,然后你可以写程序,通过它这套框架去操作PDF,做PDF查看、PDF注释、PDF编辑、签署、填表单,做这些功能。它的产品在iOS、安卓、Web和桌面端全覆盖。它的公司主要是提供文档、PDF相关的SDK和框架能力的。因为它有这样的一个技术背景,所以对于配置系统、跨平台交付、可观测行为、安全边界等等这些方面,都是非常敏感的。这也是为什么clawdbot这样的一个产品突然会爆起来。
什么都能干。就是这么简单的一个问题。但是你说真的什么都能干嘛?跟大家讲一个笑话。岳云鹏有一次出去参加综艺,人家问他你数学怎么样?说特别快没问题。然后就出了一个问题:
26*78等于多少?等于75。
人家说你这对不?
岳云鹏说:“我又没说我算的特别对,我就说我算的特别快,你就说我快不快吧?”
所以虽然clawdbot什么都能做,但是结果到底是不是能够让人满意,就是冷暖自知了。有些人很挑剔,他就觉得这不行;这些人可能提的问题也很模糊,对于结果又很挑剔,那么他就得不到满意的结果。有些人的问题提的非常详细、非常具体,对于结果特别是格式又要求不是很高,他们就会得到满意的结果。我觉得这样解释是相对比较清楚的。那种提问题、提要求的时候云山雾罩,经常玩这个“佛祖拈花一笑”,出来的这个结果还挑三拣四的这种领导,反正伺候起来比较难吧。比较难伺候的领导,clawdbot这样的助理他也搞不定。但是有一些领导就是提要求事无巨细,只要结果正确、格式无所谓的,这些领导,clawdbot就是你最好的助理。

但是如果你去部署clawdbot,一定要小心的是什么?TOKEN在燃烧。前面有人一个礼拜烧了1.7亿TOKEN,那是非常非常贵的。通常使用clawdbot需要什么?就是买Anthropic Claude 4.5 Opus 200美金一个月的Max账号。如果没有这个账号的话,这个产品会很难用的。当然了现在我们就在看Anthropic会不会封他,因为前不久Anthropic刚刚把open code的账号给封了。原来我们使用open code的时候,也可以用Anthropic的20美金或者200美金的这种Pro或者是Max账号,但是Anthropic说不行,不让你用了。所以现在还要看,它到底能使到哪天。
千万千万不要干嘛?千万不要用Anthropic的API key,你真的会破产的。那个玩意非常非常的消耗TOKEN。GPT 5.2据说也还不错,但是跟Anthropic的Claude 4.5 Opus还是有一点点差距的,最好也是用200美金的Pro账号。用我现在这种plus账号可能是比较费劲的,我准备待会把它装上,把plus账号挂上试试。还有博主推荐Mini Max,Mini Max有10美金左右的月账号,它也是一种编程账号,效果再比open code再差一些,但是人便宜。大家也可以试一试。功能都是TOKEN烧出来的,你没有那么多TOKEN,就不要指望它有那么多功能。

这么多人都去晒Mac mini,其实并不是必须要Mac mini,最好是使用闲置的非工作主力电脑。你说我这就是上班每天用的电脑,我把这个clawdbot挂在上头行不行?最好别这么干。为什么?因为你上班的电脑第一个,它的能力很强,晚上有可能还会关机,比如说你要把它合起来,这个电脑就会关掉。这个系统是要7*24小时工作的,所以你最好不要把它放在你的工作电脑上。很多家庭有这种闲置的Mac mini,放这个上面就挺方便的。价格也不贵,也还很省电,还很漂亮。特别是最新的Mac mini M4,很小、非常非常漂亮、非常精巧,放在家里头、放在各种地方都不显得突兀。
最好是给clawdbot配这种叫“全功能的系统”。什么叫全功能系统?就是它可以直接使用浏览器、可以跑vibe coding、可以调用office,这些东西都是可以工作的。对于本地的算力其实并没有特别高的要求,所有的AI都是调云端的算力。它通过即时通讯工具来工作。我们想去跟clawdbot聊天的时候,你可以打开:
都是可以的。国内的不行,像什么微信搞不定这事,因为微信对于这种机器人是封闭的,比较严格的,怕各种黑灰产。
很多人想去用iMessage,就是苹果系统的这种iMessage,这个就没办法,你必须使用Mac mini。你说我现在想整个Windows、想整个Linux上iMessage?上不去。这个iMessage也不是一个开放系统。很多苹果全家桶的玩家,特别是在程序员和AI玩家里头,苹果全家桶玩家的比例是很大的,肯定是喜欢上Mac mini的。家里头其他的闲置电脑其实也可以跑,Windows电脑也可以。但是如果你要在Windows电脑里跑,最好是装WSL。WSL就是Windows里面的Linux,现在Windows新的系统里边都是可以装一个Linux系统的。然后Linux电脑,这个肯定也是没问题的。我准备上NAS了,家里NAS已经跑了一大堆的各种各样的Docker了,它也是可以跑上去的。
云主机也没毛病。你都花了200刀去买套餐了,那你一个月花5刀去租个云主机跑这个clawdbot肯定也是没问题的。Oracle云上有免费的主机,大家可以上去玩耍一下。NAS、瘦服务器或者是在云主机上跑clawdbot,浏览器也是能用的,但是会比较费劲。vibe coding就要稍微克制一点了。如果是在你的Mac mini上,你就可以给它下指令,说打开哪个vibe coding的工具,然后在里边去给我写一什么产品出来,他自己吭哧吭哧就干活去了。你可以每天晚上睡觉之前给他布置一大堆任务,早上起来看看,完成几个、没有完成的部分你还可以去辅助一下。他是这样来干活的。你要是在云主机上,就不能干这活了。
方向上肯定是。这个方向也很明确,就是无限记忆、私有部署、绝对隐私保护、7*24小时驻留、随时待命、主动沟通和提醒,基本可以解决各种问题。随着模型能力的提升、agent skills的发展,他的能力一定还会继续爆炸式增长。大模型厂商应该会争先恐后的推出新套餐了。因为有了前车之鉴,Anthropic估计过一段时间还是会封他的。这个咱们预言一下,咱们打个赌,猜一猜会不会把他封掉?前面open code用户量上去以后,Anthropic就直接把他封掉了。
因为现在买TOKEN基本上是两套玩法:一套就是你具体按100万TOKEN多少钱去算;另外一套就是给你套餐,这个编程套餐。因为现在编程实在是太烧TOKEN了,所以Anthropic出了这种编程套餐,OpenAI、谷歌都出了这种编程套餐。但是Anthropic还是希望,如果你想要去买它的编程套餐,你就只能用Claude code,你不能用其他的东西。像咱们现在讲这个clawdbot,这就不允许用。那么OpenAI跟谷歌应该会继续支持你。像open code这块,在Anthropic说我封闭它之后,OpenAI说我们准备继续支持。没毛病,你买我的plus套餐、Pro套餐,我都继续支持你。谷歌在这一块其实是放的比较宽松的,只要你愿意用,谷歌还是愿意笑脸相迎的。
国内的模型平台的话,也应该会推出一些专门的套餐,应该是会像code套餐这样,都是可以挂上使的。国内平台的code套餐基本上有5美金一个月的、10美金一个月的,甚至可能最便宜的有3美金一个月的。他们都是去仿真Anthropic的这个API形式,只要我仿真好了,就往上挂就完了,都是可以用的。

家庭瘦服务器应该有新的应用场景,以后的NAS也可以配更好的CPU GPU了。至于家里是不是要买一台Mac mini,让我再犹豫几天吧,反正我目前为止还没有下决心再去买一个Mac mini。至于Mac mini农场,也许会在一段时间内流行起来。什么叫Mac mini农场?就是在一个房间里边装一大堆的Mac mini,允许大家从远程去访问它、替你去维护,我们只管去付租金就可以了。这可能也是一种未来的服务形式。
黑苹果可能会焕发第二春。什么叫黑苹果?就是在一些比较便宜的Intel这种架构上,使用macOS系统重新去破解,然后给你装上,让你去使用。这个东西叫黑苹果。其实黑苹果随着后来苹果出M系列芯片以后,已经不是那么活跃了,但是现在的话,应该会重新再活跃起来。
腾讯、Meta、苹果、谷歌机会来了,就看谁能抓得住了。为什么他们机会来了?他们做即时通讯工具的。既然大家觉得以后的这些个人助理应该是活在WhatsApp、活在Telegram、活在Discord里头了,腾讯说我这有微信,干脆我在这边给你配一个助理不就完事了吗?你有什么事跟助理说不就完了吗?我觉得他们未来是有机会的。至于说Meta的话,你像WhatsApp是它的,Facebook Messenger也是它的,全世界最大的两个即时通讯工具都是它的。苹果自己也是有iMessage的。它们都是有机会去腾飞一下的。
又一个神奇的AI工具发布了,赶快玩起来吧。甭管好不好使,大家一定要去玩起来。7*24小时永久驻留、永久记忆、主动提醒、全能助理,这应该就是未来的方向了,这个基本上可以确定。助理已经这么强大了,具体做什么就是留给我们的问题了。网上的介绍视频里头经常是这样的,他问clawdbot:“你觉得我该干点什么?”还是要有自己的想法。只要烧得起TOKEN,我们每个人都会得到一个强大的全能助理。
好,这一期就讲到这里。感谢大家收听,请帮忙点赞、点小铃铛,参加DISCORD讨论群。也欢迎有兴趣、有能力的朋友加入我们的付费频道。再见。


本文永久链接 – https://tonybai.com/2026/01/20/ai-and-go-opportunities-and-challenges
大家好,我是Tony Bai。
在 AI 的滔天巨浪面前,每一位 Go 开发者心中或许都曾闪过一丝不安:Python 似乎统治了一切,我的 Go 语言技能树还值钱吗?AI 会取代我写代码吗?我该如何在这个喧嚣的时代保持清醒?
在 GopherCon 2025 的压轴圆桌会议上,一场名为“AI 与 Go:机遇与挑战”的深度对话给出了答案。

嘉宾阵容堪称豪华(从左二到右分别是):
他们没有贩卖焦虑,也没有盲目吹捧,而是用冷静、务实的工程师视角,为我们描绘了 Go 在 AI 时代的真实版图。

当被问及“Go 能提供什么 Python以及其他编程语言 无法提供的价值”时,嘉宾们的回答出奇一致:生产级的可靠性与并发能力。
Samir Ajmani 提出了一个精准的洞察:Go 的崛起得益于云原生时代的爆发,而 AI 正在带来“第二次云原生机遇”。
Katie 分享了一个真实案例:她在黑客马拉松中选择用 Go 而非 TypeScript 来编写 MCP Server,因为 Go 的代码在处理复杂协议逻辑时更易读、更易维护。
David(Anthropic)就个人经验和观察,认为Go 是目前AI最擅长生成的语言代码之一,这也是Go的一大优势!
Python 也许是 AI 的“训练语言”,但 Go 有望成为 AI 的“运行语言”。
面对“AI 取代程序员”的言论,嘉宾们的态度是——“这只是另一种生产力工具,它改变了工作方式,但提升了人的价值。”
不要试图成为每一个 AI 工具的专家。选择一个工具(如 Cursor 或 Claude Code),深入掌握它,让它服务于你的工作流,而不是被它淹没。
主持人提出了一个尖锐的问题:在区块链曾因高能耗饱受诟病之后,我们该如何理性看待 AI 巨大的算力和能源消耗?作为开发者,我们该如何权衡使用 AI 工具的成本?
嘉宾们的回答,揭示了工程优化在 AI 时代的巨大潜力:
不要盲目堆砌算力。“负责任的 AI”不仅是道德要求,更是工程优化的必然方向。 用更少的 Token 做更多的事,这本身就是 Go 开发者擅长的“资源优化”技能的延伸。
在 AI 炒作的喧嚣中,如何保持清醒?
这场圆桌会议传递出的最强烈信号是:乐观。
我们正处于一个类似于 2013 年 Docker 诞生前夜的时刻。AI 领域的“Kubernetes”、“Prometheus”还没有被写出来。这片巨大的空白,正是 Go 开发者施展拳脚的“绿地” (Greenfield)。
正如 Samir 所言:
“如果我想让 AI 真正能够与现实世界进行交易(比如订购 Pizza 并且真的送到),这中间需要大量的、可靠的基础设施。而 Go,是构建这一层的绝佳语言。”
所以,Gopher 们,别慌。带上你的并发模型,带上你的工程智慧,去构建 AI 时代的钢铁地基吧。
资料链接:https://www.youtube.com/watch?v=r40Mwdvg38M
你的 AI 实践
听了这些顶级专家的观点,你是否对 Go 在 AI 时代的未来更有信心了?在你目前的开发工作中,是否已经开始尝试用 Go 构建 AI 应用或基础设施?你认为 Go 在 AI 领域最大的短板是什么?
欢迎在评论区分享你的实战经验或困惑!让我们一起探索 Go + AI 的无限可能。
如果这篇文章为你扫除了职业焦虑,别忘了点个【赞】和【在看】,并转发给身边迷茫的 Gopher 朋友!
还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
扫描下方二维码,开启你的AI原生开发之旅。
你的Go技能,是否也卡在了“熟练”到“精通”的瓶颈期?
继《Go语言第一课》后,我的《Go语言进阶课》终于在极客时间与大家见面了!
我的全新极客时间专栏 《Tony Bai·Go语言进阶课》就是为这样的你量身打造!30+讲硬核内容,带你夯实语法认知,提升设计思维,锻造工程实践能力,更有实战项目串讲。
目标只有一个:助你完成从“Go熟练工”到“Go专家”的蜕变! 现在就加入,让你的Go技能再上一个新台阶!
商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。
© 2026, bigwhite. 版权所有.
I’ve recently upgraded my home WiFi setup with Ubiquiti (UniFi) access points (I bought a U7 Pro AP). All is good, except that UniFi doesn’t support WPS. On the other hand, my old Canon TS3150 printer can only be setup using WPS. Now, it wouldn’t have been an issue, had I not changed the SSID. The easiest workaround seems to be setting up a WiFi that has the same SSID and password, and supports WPS (so the printer can connect to it).
Some people on the Internet have suggested buying a cheap router/AP that supports WPS, which seems like a waste to me. Not only it costs minimally £30 or so, but also it’ll literally become an e-waste one minute later. Bad for the environment!
With the help of Gemini 2.0, and this post on StackExchange, I’ve managed to open a Hotspot by using SoftAP via hostapd that supports WPS (WiFi Protected Setup), and my printer is now happily connected to the WiFi network created by my UniFi AP.
I’m using Fedora Kinoite on my desktop, and hostapd is not Flatpak’d, therefore rpm-ostree is needed to get hostapd installed:
sudo rpm-ostree install hostapdThen create this hostapd.conf file:
interface=wlo1 # check the actual device name, ip link ieee80211d=1 # make sure the frequency conforms to the regulation country_code=GB # United Kingdom eap_server=1 ap_setup_locked=1 ssid=<ACTUAL SSID> channel=1 hw_mode=g wpa=2 wpa_key_mgmt=WPA-PSK rsn_pairwise=CCMP wpa_passphrase=<ACTUAL PASSWORD> wps_state=2 ap_max_inactivity=300 auth_algs=3 ctrl_interface=/var/run/hostapd config_methods=label virtual_display virtual_push_button keypad
Now you need to first switch off the AP/WiFi so there is no conflict. Then stop NetworkManager and start hostapd,
sudo systemctl stop NetworkManager
sudo hostapd hostapd.confIn a different Terminal window/tab,
sudo hostapd_cli wps_pbcImmediately, press the WPS button on the printer (or other devices that need to be setup in this way). You can query whether WPS has been successful by running
sudo hostapd_cli wps_get_statusA successful setup should have a message like:
Selected interface 'wlo1'
PBC Status: Disabled
Last WPS result: Success
Peer Address: 34:XX:XX:XX:XX:00Once it’s done, you can turn off the SoftAP (pressing Ctrl+C in the terminal window where hostapd is running), switch back the normal AP/WiFi, and start NetworkManager again – sudo systemctl start NetworkManager
前两天给自己的 N100 小主机重装成了最近发布的 Fedora 41 ( KDE ),也是花了不少时间把整个系统调成自己熟悉的样子,因此开一篇博客记录一下。以下仅为我个人的 HomeServer 小主机使用,不具有普适性。
我这里比较适合用上交的源,直接参考他们的文档。
sudo sed -e 's/^metalink=/#metalink=/g' -e 's|^#baseurl=http://download.example/pub/|baseurl=https://mirror.sjtu.edu.cn/|g' -i.bak /etc/yum.repos.d/{fedora.repo,fedora-updates.repo}
安装源配置文件
sudo yum install --nogpgcheck https://mirror.sjtu.edu.cn/rpmfusion/free/fedora/rpmfusion-free-release-$(rpm -E %fedora).noarch.rpm https://mirror.sjtu.edu.cn/rpmfusion/nonfree/fedora/rpmfusion-nonfree-release-$(rpm -E %fedora).noarch.rpm
换源
sudo sed -e 's!^metalink=!#metalink=!g' \
-e 's!^mirrorlist=!#mirrorlist=!g' \
-e 's!^#baseurl=!baseurl=!g' \
-e 's!https\?://download1\.rpmfusion\.org/!https://mirror.sjtu.edu.cn/rpmfusion/!g' \
-i.bak /etc/yum.repos.d/rpmfusion*.repo
sudo sh -c "echo 'defaultyes=True' >> /etc/dnf/dnf.conf"
sudo dnf remove libreoffice*
sudo dnf remove discover flatpak
sudo dnf remove podman
sudo sed -i "s|SELINUX=enforcing|SELINUX=disabled|" /etc/selinux/config
sudo dnf install vlc mpv ffmpeg --allowerasing
sudo dnf install docker
直接去官方的 Github Release 下载安装包
sudo dnf install https://github.com/rustdesk/rustdesk/releases/download/1.3.2/rustdesk-1.3.2-0.x86_64.rpm
尽管 Rustdesk 支持被控端使用 wayland,但因为权限原因需要被控端手动选择被控区域,不适合无人值守的环境,因此还是要换 x11。
sudo dnf install plasma-workspace-x11
sudo sed -i "s|^#DisplayServer=wayland|DisplayServer=x11|" /etc/sddm.conf
sudo dnf install gcc g++ python3-devel
编辑 /usr/lib/systemd/resolved.conf,取消注释,yes 改 no
[Resolve]
# Some examples of DNS servers which may be used for DNS= and FallbackDNS=:
//...
#DNS=
#FallbackDNS=
#Domains=
#DNSSEC=no
#DNSOverTLS=no
#MulticastDNS=yes
#LLMNR=yes
#Cache=yes
#CacheFromLocalhost=no
-#DNSStubListener=yes
+DNSStubListener=no
#DNSStubListenerExtra=
#ReadEtcHosts=yes
#ResolveUnicastSingleLabel=no
#StaleRetentionSec=0
sudo dnf install fcitx5-chinese-addons kcm-fcitx5 fcitx5-autostart
在 设置 - 输入法 中添加拼音
https://github.com/felixonmars/fcitx5-pinyin-zhwiki
https://github.com/outloudvi/mw2fcitx
参考 处理 fcitx5 的文字候选框在 tg 客户端上闪烁的问题
if [ ! "$XDG_SESSION_TYPE" = "tty" ] # if this is a gui session (not tty)
then
# let's use fcitx instead of fcitx5 to make flatpak happy
# this may break behavior for users who have installed both
# fcitx and fcitx5, let then change the file on their own
export INPUT_METHOD=fcitx
export GTK_IM_MODULE=fcitx
export QT_IM_MODULE=fcitx
export XMODIFIERS=@im=fcitx
fi
+if [ "$XDG_SESSION_TYPE" = "wayland" ]
+then
+ unset QT_IM_MODULE
+fi
然后仍然要去 设置 - 键盘 - 虚拟键盘 中选中 fcitx5
sudo rpm --import https://packages.microsoft.com/keys/microsoft.asc
echo -e "[code]\nname=Visual Studio Code\nbaseurl=https://packages.microsoft.com/yumrepos/vscode\nenabled=1\ngpgcheck=1\ngpgkey=https://packages.microsoft.com/keys/microsoft.asc" | sudo tee /etc/yum.repos.d/vscode.repo > /dev/null
sudo dnf install code
略
sudo systemctl disable firewalld --now
作者:SRE运维博客
博客地址:https://www.cnsre.cn
文章地址:https://www.cnsre.cn/posts/210922013357/
相关话题:https://www.cnsre.cn/tags/kubernetes/
K8S 使用 kubectl top 看K8S监控
kubectl top 是基础命令,但是需要部署配套的组件才能获取到监控值
部署 metric-server
Kubernetes Metrics Server 是 Cluster 的核心监控数据的聚合器,kubeadm 默认是不部署的。
Metrics Server 供 Dashboard 等其他组件使用,是一个扩展的 APIServer,依赖于 API Aggregator。所以,在安装 Metrics Server 之前需要先在 kube-apiserver 中开启 API Aggregator。
Metrics API 只可以查询当前的度量数据,并不保存历史数据。
Metrics API URI 为 /apis/metrics.k8s.io/,在 k8s.io/metrics 下维护。
必须部署 metrics-server 才能使用该 API,metrics-server 通过调用 kubelet Summary API 获取数据.
不指定pod 名称,则显示命名空间下所有 pod,–containers可以显示 pod 内所有的container
指标含义:
和k8s中的request、limit一致,CPU单位100m=0.1 内存单位1Mi=1024Ki
pod的内存值是其实际使用量,也是做limit限制时判断oom的依据。pod的使用量等于其所有业务容器的总和,不包括 pause 容器,值等于cadvisr中的container_memory_working_set_bytes指标
node的值并不等于该node 上所有 pod 值的总和,也不等于直接在机器上运行 top 或 free 看到的值
注意:使用 Metrics Server 有必备两个条件:
可以通过运行以下命令下载最新的 Metrics Server 版本:
|
|
兼容性:
| 指标服务器 | 指标 API 组/版本 | 支持的 Kubernetes 版本 |
|---|---|---|
| 0.6.x | metrics.k8s.io/v1beta1 | *1.19+ |
| 0.5.x | metrics.k8s.io/v1beta1 | *1.8+ |
| 0.4.x | metrics.k8s.io/v1beta1 | *1.8+ |
| 0.3.x | metrics.k8s.io/v1beta1 | 1.8-1.21 |
--authorization-always-allow-paths=/livez,/readyz国内无法下载 k8s.gcr.io/metrics-server/metrics-server:v0.4.1镜像
需要修改为一下镜像地址
|
|
|
|
|
|
|
|
|
|
作者:SRE运维博客
博客地址:https://www.cnsre.cn
文章地址:https://www.cnsre.cn/posts/210922013357/
相关话题:https://www.cnsre.cn/tags/kubernetes/

我寝室有一台使用 wifi 连接的 HP Laser 103w 打印机,这些天刚好布置了新的 HomeServer,因此来记录一下这台打印机的配置过程,根据 HP 官网驱动包的名字「HP Laser 100 and HP Color Laser 150 Printer series Print Driver」推断,此过程应该能适用于所有的 HP Laser 100 及 HP Color Laser 150 系列的打印机。
首先使用 Windows 操作系统完成打印机的联网工作,在路由器的网页管理界面可以看到这台打印机的局域网 ip 是 192.168.123.20 ,记录备用。如果有条件的话,尽量将打印机的 MAC 地址与 IP 地址绑定,避免路由器将该 IP 分配给别的设备。

随后按照 ArchWiki 的 CUPS 页面进行相关配置,CUPS 是苹果公司开源的打印系统,是目前 Linux 下最主流的打印方案。
首先安装 cups ,如果需要「打印为 pdf」的功能,可以选装 cups-pdf。
pacman -S cups
pacman -S cups-pdf
接着需要启动 cups 的服务,如果需要使用 cups 自带的 webui,可以直接启用 cups.service,这样就能在 http://localhost:631 看到对应的配置页面。
systemctl enable cups.service --now
而如果你正在使用一些集成度较高的 DE 如 KDE 或 GNOME,可以安装 DE 对应的打印机管理程序。在 Arch Linux 下,KDE 自带的打印机管理程序包名为 print-manager,此外还需要安装安装 system-config-printer 打印机功能支持软件包。这种方案则不需要启动 cups.service,只需要启动 cups.socket 即可。
pacman -S print-manager system-config-printer
systemctl enable cups.socket
在常规的流程中,通常会安装 ghostscript 来适应 Non-PDF 打印机,这台 HP Laser 103w 也不例外。
pacman -S ghostscript
如果是 PostScript 打印机可能还需要安装 gsfonts 包,但我这里不需要。
OpenPrinting 维护的 foomatic 为很大一部分打印机提供的驱动文件,Gutenprint 维护的 gutenprint 包也包含了佳能(Canon)、爱普生(Epson)、利盟(Lexmark)、索尼(Sony)、奥林巴斯(Olympus) 以及 PCL 打印机的驱动程序。如果你的打印机型号和我的不同,可以尝试安装这些组织维护的驱动。具体的安装方法同样可以在 ArchWiki 的 CUPS 页面找到。我上一台打印机 HP LaserJet 1020 所需的驱动是在 AUR/foo2zjs-nightly 中取得的。
但 HP Laser 103w 的驱动程序都不在这些软件包中,在 HP 的官网我们可以找到这个页面,包含了 HP Laser 103w 的 Linux 驱动下载地址(已在 web.archive.org 存档)。通过下载下来的文件名,我们可以看见名字为 uld-hp,理论上可以直接通过压缩包内的安装脚本进行安装,但我通过这个名字顺藤摸瓜,找到了 AUR/hpuld 可以直接进行安装。
yay -S hpuld
打开设置中的打印机设置后,选择添加打印机,CUPS 直接帮我们找到了局域网下的打印机,并自动开始搜索驱动程序(虽然没搜到)。

但如果没能自动检测到打印机,也可以使用手动选项中的 AppSocket/HP JetDirect 手动输入打印机的 ip 地址进行配置。
紧接着就到了选择驱动程序的阶段,厂商选择 HP,能够找到「HP Laser 10x Series」的选项,直接选择。

接着就可以完成打印机的添加。

随后便能正常打印文件啦!
最近跟风整了一台 n100 的迷你主机装了个 Archlinux 当 HomeServer,搭配上了显卡欺骗器,平常一直远程使用,因此需要实现稳定的远程桌面连接。开源软件 Rustdesk 本身对 Linux 的适配尚可,可惜官方提供的服务器位于境外,且前一阵子因为诈骗相关的风波使得官方对连接做出了一些限制,应当使用自建服务器或者 ip 直连。
单从网络安全的角度出发,最佳实践应该是通过 wireguard 或者别的协议先接入局域网,然后使用局域网内的 ip 直连,这是最稳妥的,但我有点懒,而且我可能会在多个设备上都有控制 HomeServer 的需求,给所有设备配置 wireguard 是一件挺麻烦的事情,因此我决定放弃安全性,直接公网裸奔。
在学校宿舍的电信宽带提供了一个动态公网 ip,因此只需要设置好 ddns 和端口转发就可以拿到一个固定的 domain + port 提供给 rustdesk 直连。
在「设置」中的「安全」一栏选择「解锁安全设置」,拉到最下面的「安全」栏,勾选「允许 IP 直接访问」,并选择一个端口,范围在 1000 ~35535 之间且不要被本地的其他程序占用,Rustdesk 的默认值为 21118。
可以直接在局域网内的另一台设备进行测试,直接在 Rustdesk 中输入被控端的局域网 ip 和刚刚设置的端口,看看能不能访问得通,如果不行可能需要排查一下被控端访问墙设置的问题。

由于我的域名是交给 cloudflare 进行解析的,就找了个支持 cloudflare 的 ddns 脚本,大致的部署过程可以参考 「自建基于Cloudflare的DDNS」,不过我小改了一下脚本中获取公网 ipv4 的方式,直接 ssh 到路由器上获取当前的 ipv4 地址,不依赖外部的服务。
WAN_IP=`ssh -o HostKeyAlgorithms=+ssh-rsa -o PubkeyAcceptedKeyTypes=+ssh-rsa root@192.168.1.1 'ip -br a' | grep pppoe-wan | awk '{print $3}'`
理论上来说,有不少路由器自身就支持不少域名解析商
端口转发需要在路由器的后台设置进行,我这里路由器使用的是 openwrt 系统,大部分路由器应该都支持这个操作。
在「网络」-「防火墙」

选择「端口转发」

新建端口转发,共享名随便填,外部端口是你最终要在主控端输入的端口,内部 IP 地址是被控机 的 IP 地址,可以用 ip -br a 命令看到,内部端口就是上文在 Rustdesk 指定的端口号。
可以直接在主控端口输入 ddns 的域名和端口号,实现远程控制

首先,你得知道我们平常用的SMB文件共享服务用的445端口,一般是不对外开放的。云服务器也是如此。而webdav可以通过http服务来访问你的文件,甚至我在家里用Cloudflare Tunnel都可以穿出去访问,非常地方便。
所以对于我家里的小霸王服务器,自我换成Windows Server后,需要在外访问的话就需要打开Webdav
本次使用的是Windows Server 2022
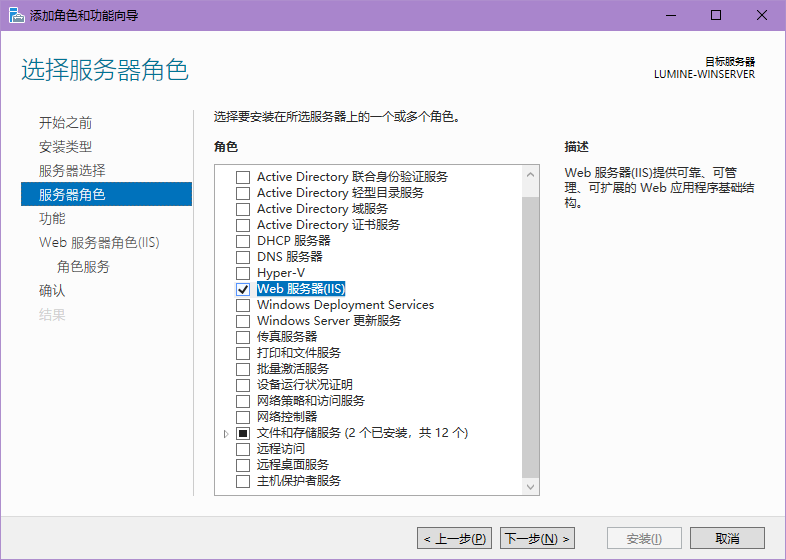
首先先打开Windows Server自带的服务器管理器,选择添加角色和功能,在服务器角色选项卡添加web 服务器(IIS)
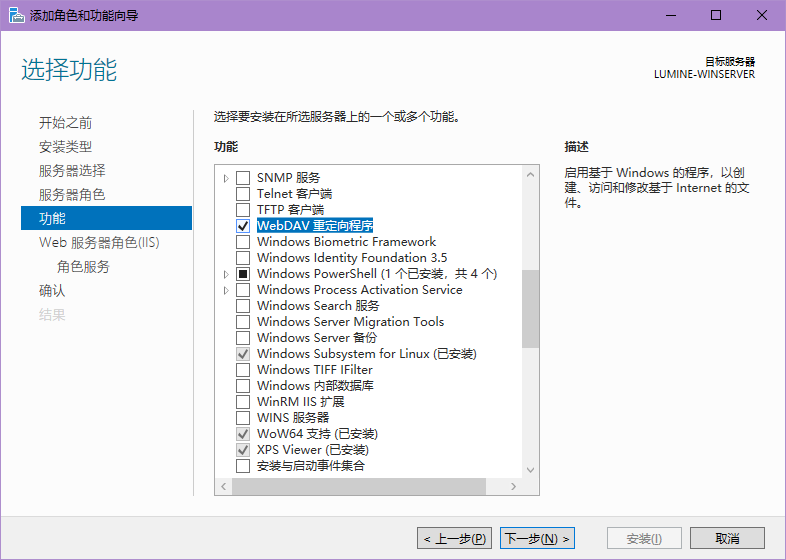
然后跳到功能选项卡,勾选Webdav重定向服务
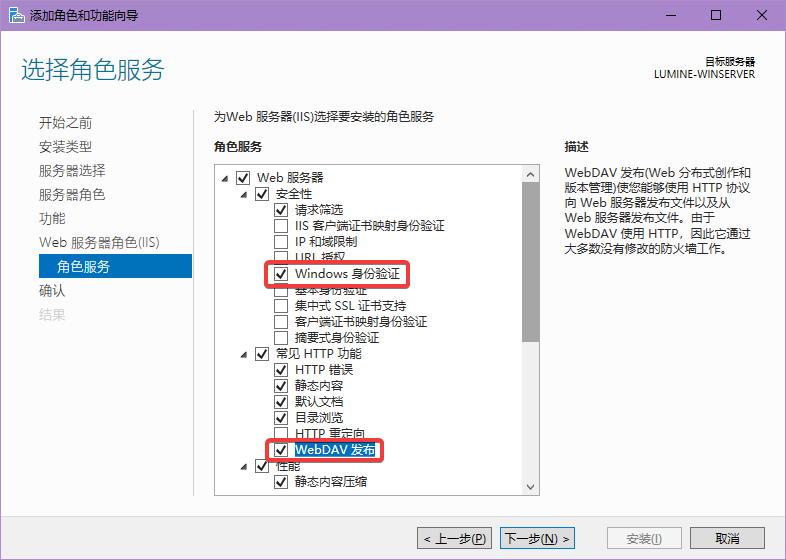
再在下面Web 服务器角色(IIS)选项卡下的角色服务添加Windows 身份验证和WebDAV 发布
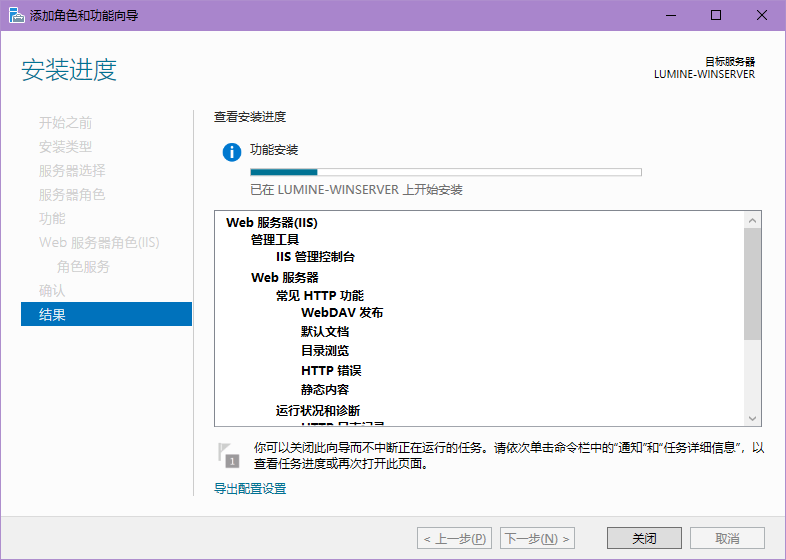
然后点下一步,把这些功能装上,这个过程可能有点长,装好了记得重启一下,记得先保存一下工作(把虚拟机啥的挂起一下)
重启完了以后,我们还是打开服务器管理器,在右上角的工具里面找到IIS工具
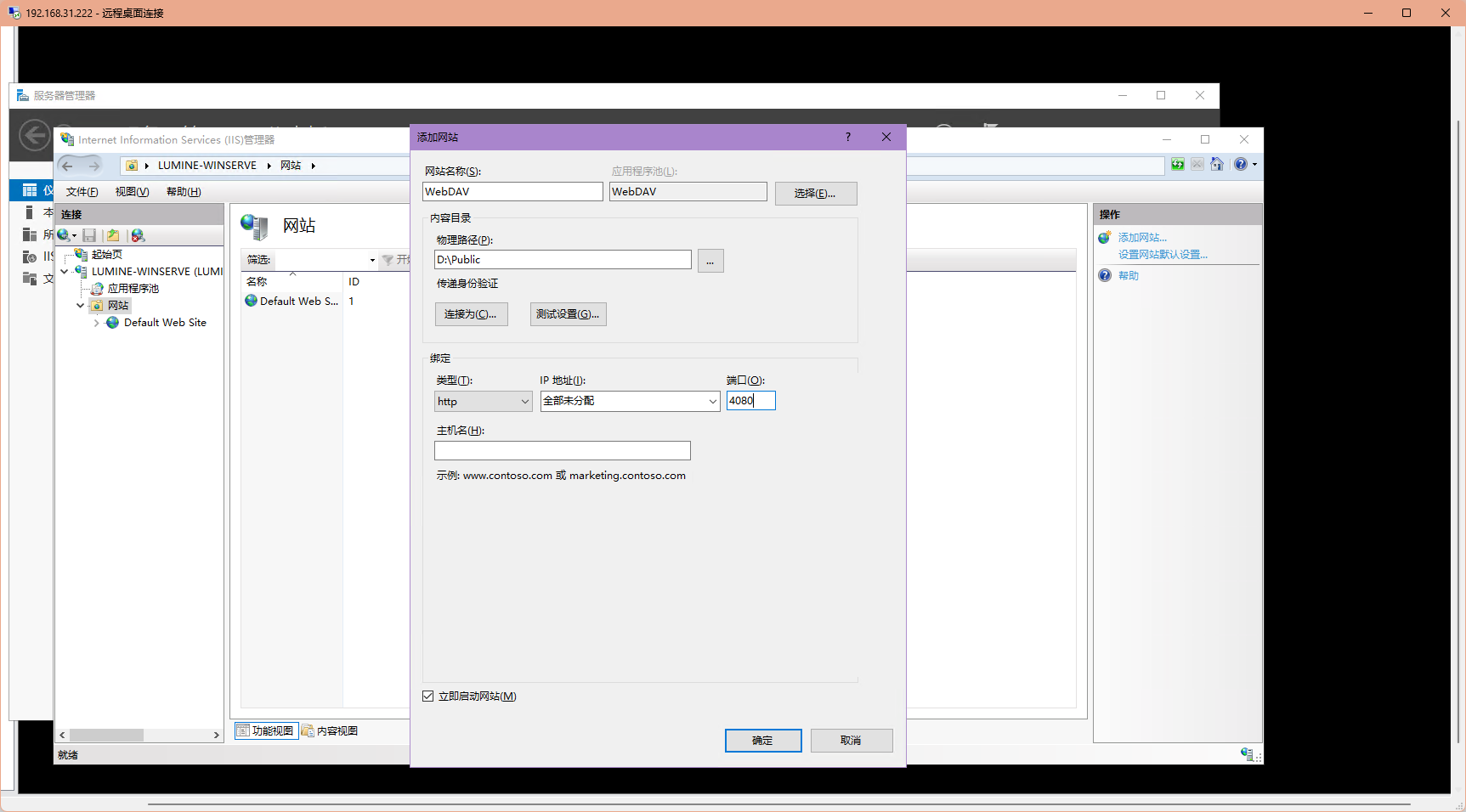
然后添加一个网站,物理路径就是你想要共享的文件夹位置,记得改下端口(当然你不介意用80的话可以不改)
设置好了点确定,然后双击我们刚刚添加的网站,找到WebDav创作规则
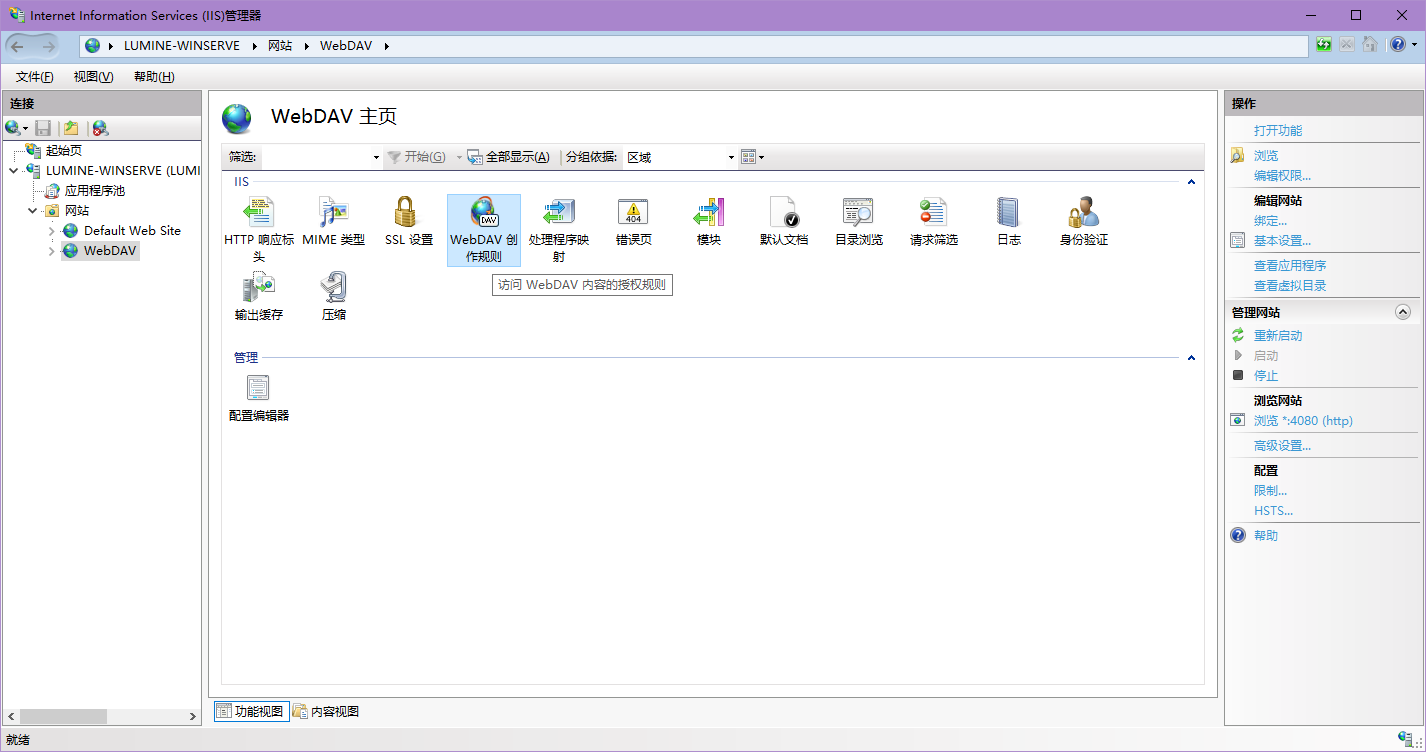
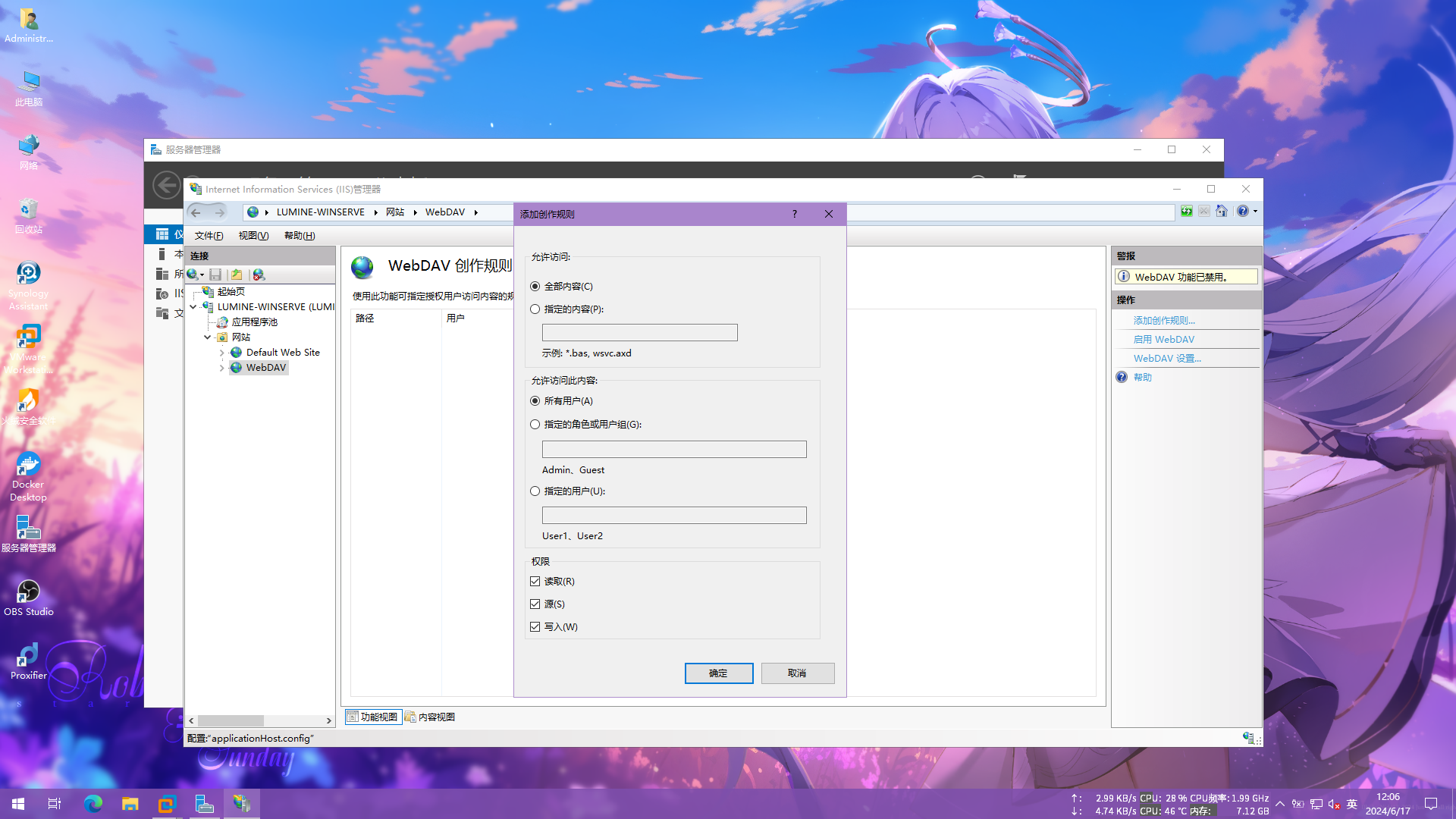
然后在右侧添加一个创作规则,具体配置按需配置,你也可以按照我这么选,然后点确定
既然是WebDAV,那肯定得加上身份验证
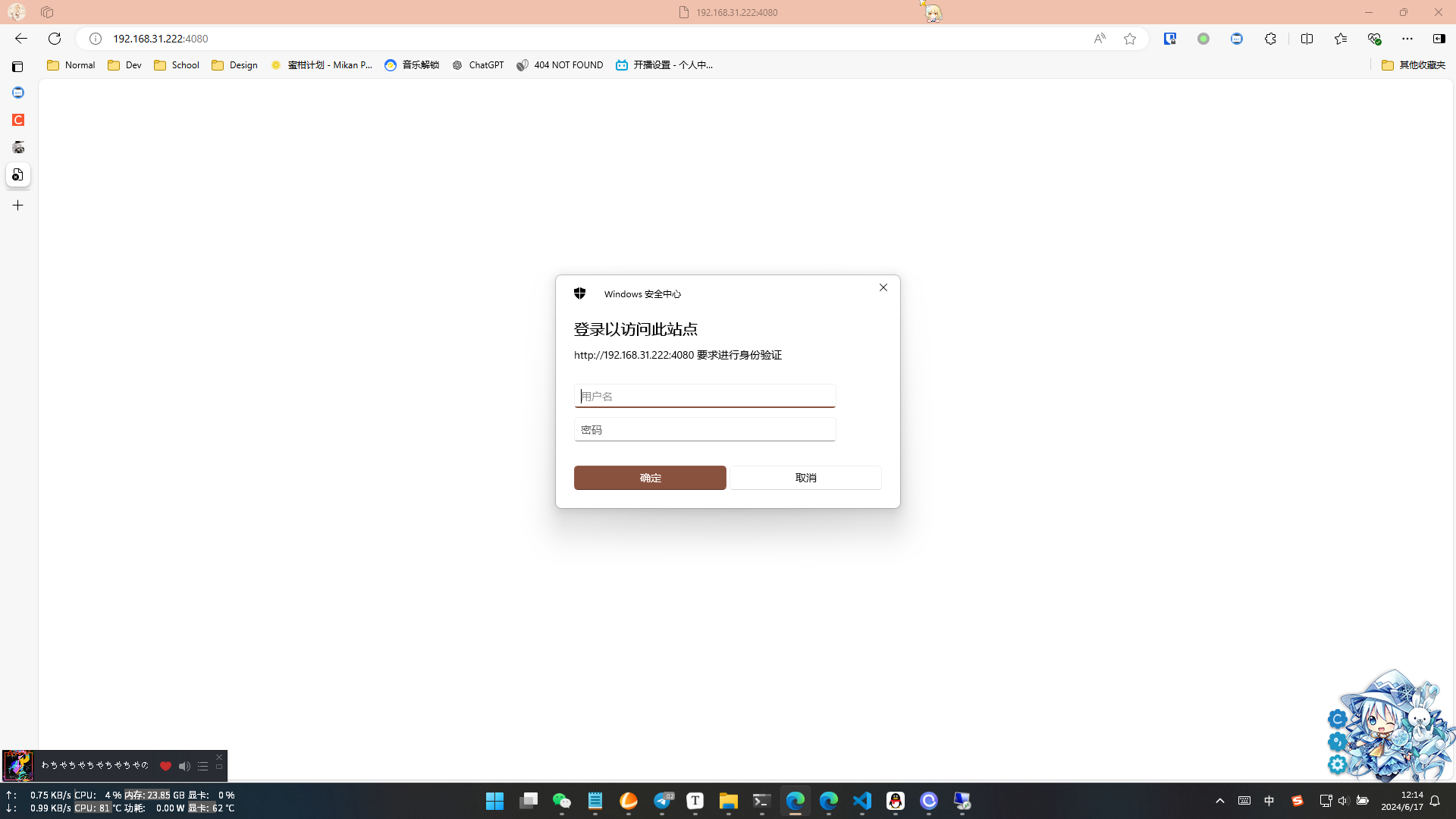
我们双击左边树状图里我们的网站,然后选择身份验证
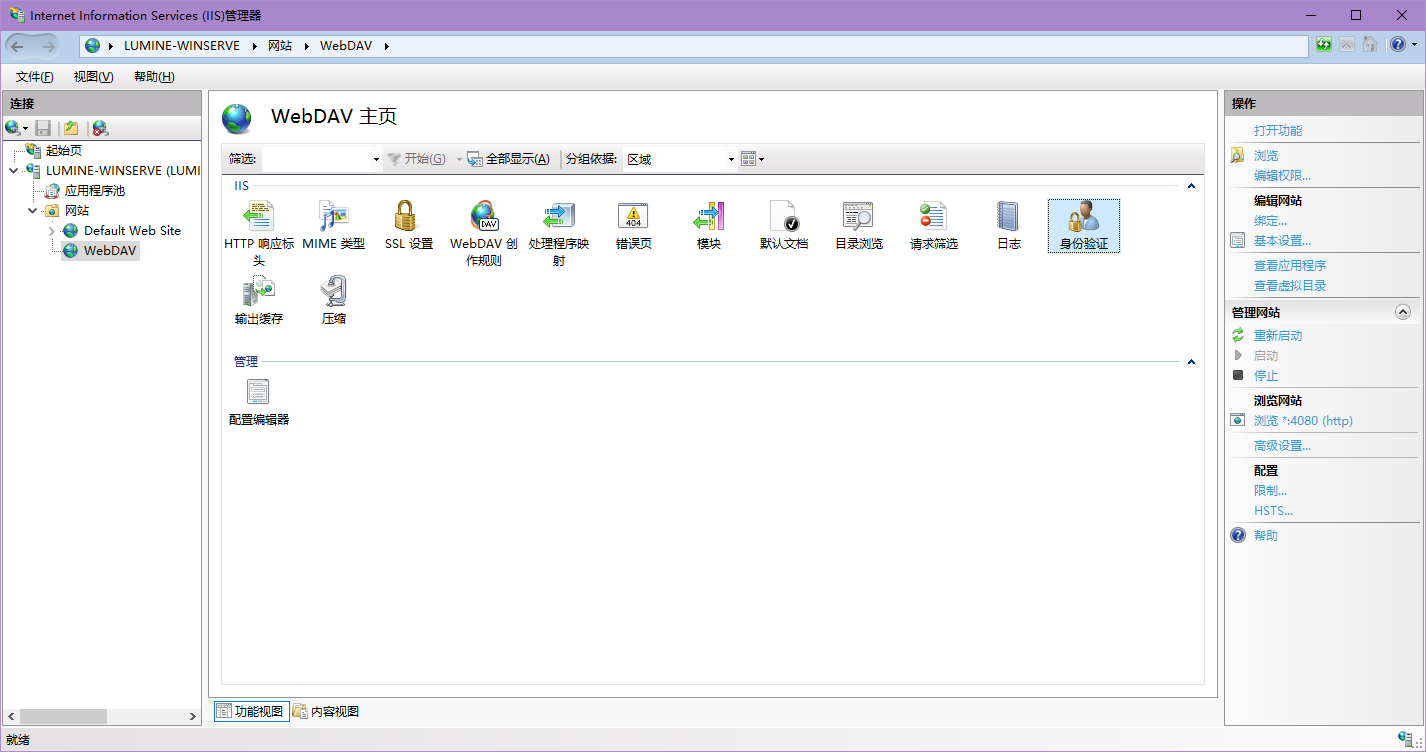
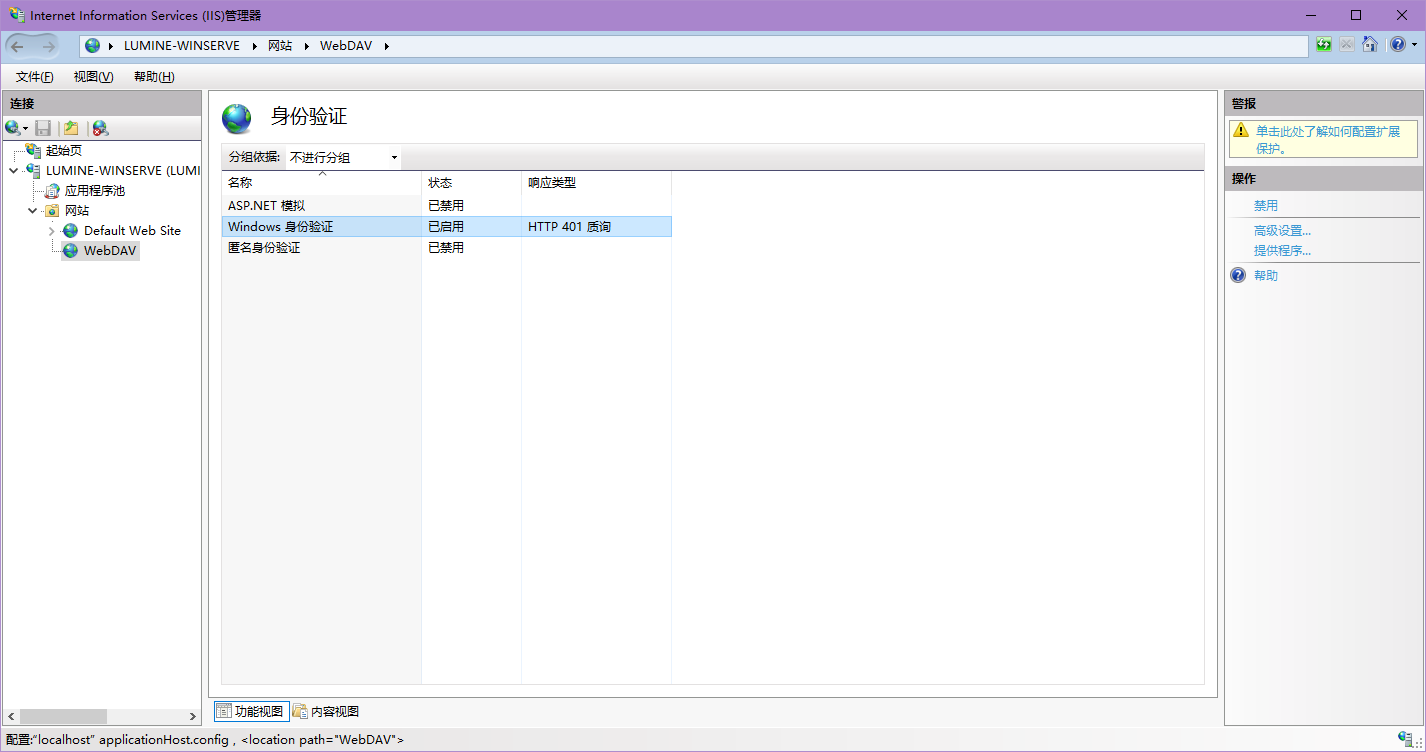
如果你需要匿名登录你就保持匿名为启用(注意做好目录限制),然后把第二个Windows 身份验证给打开
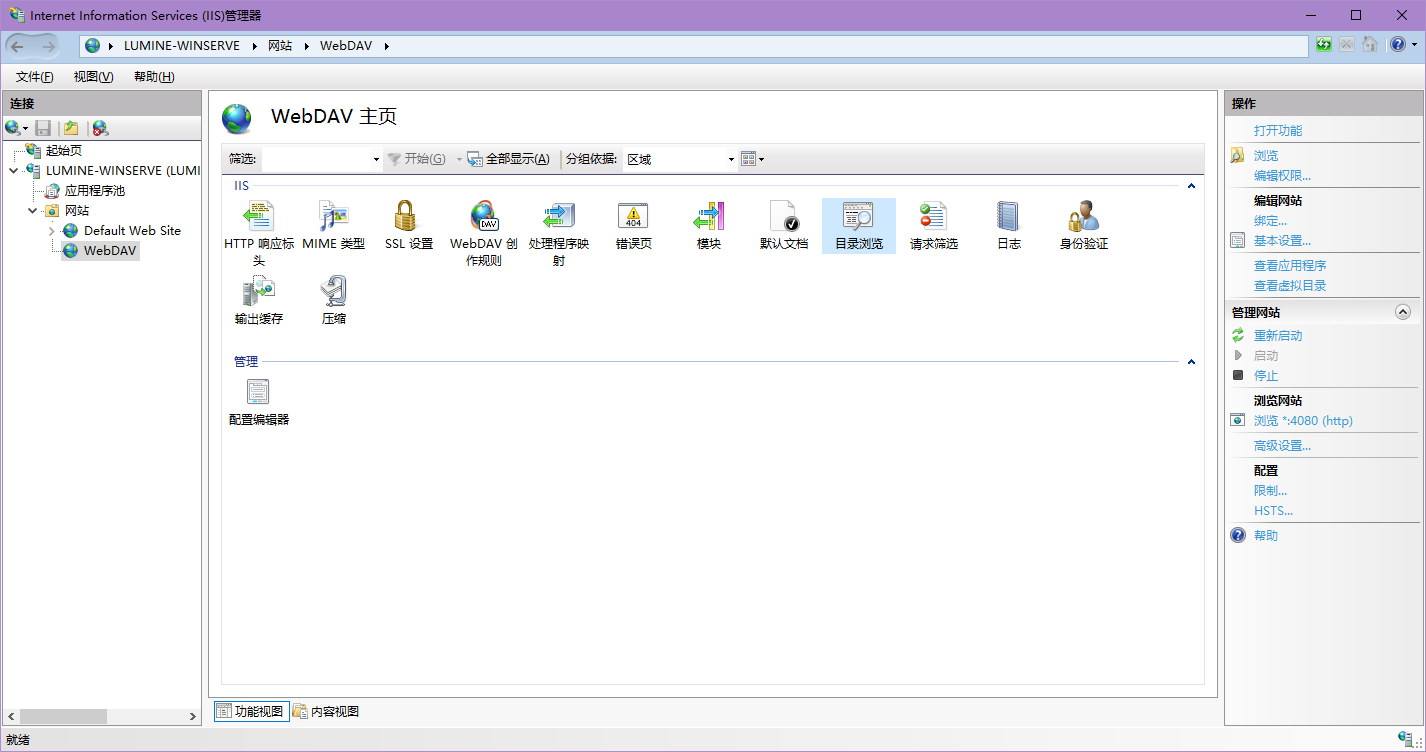
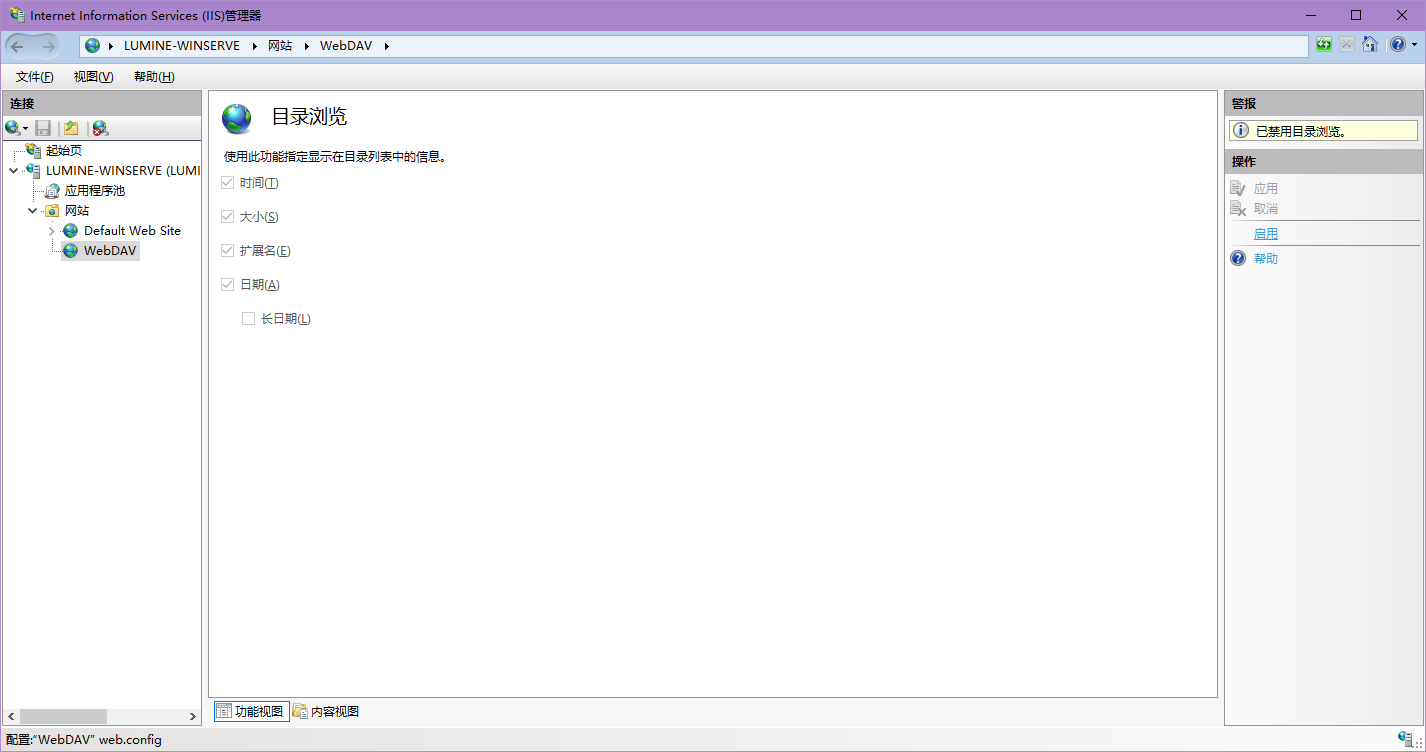
再次双击左边的树状图里的网站,找到目录浏览,点击右边的启用
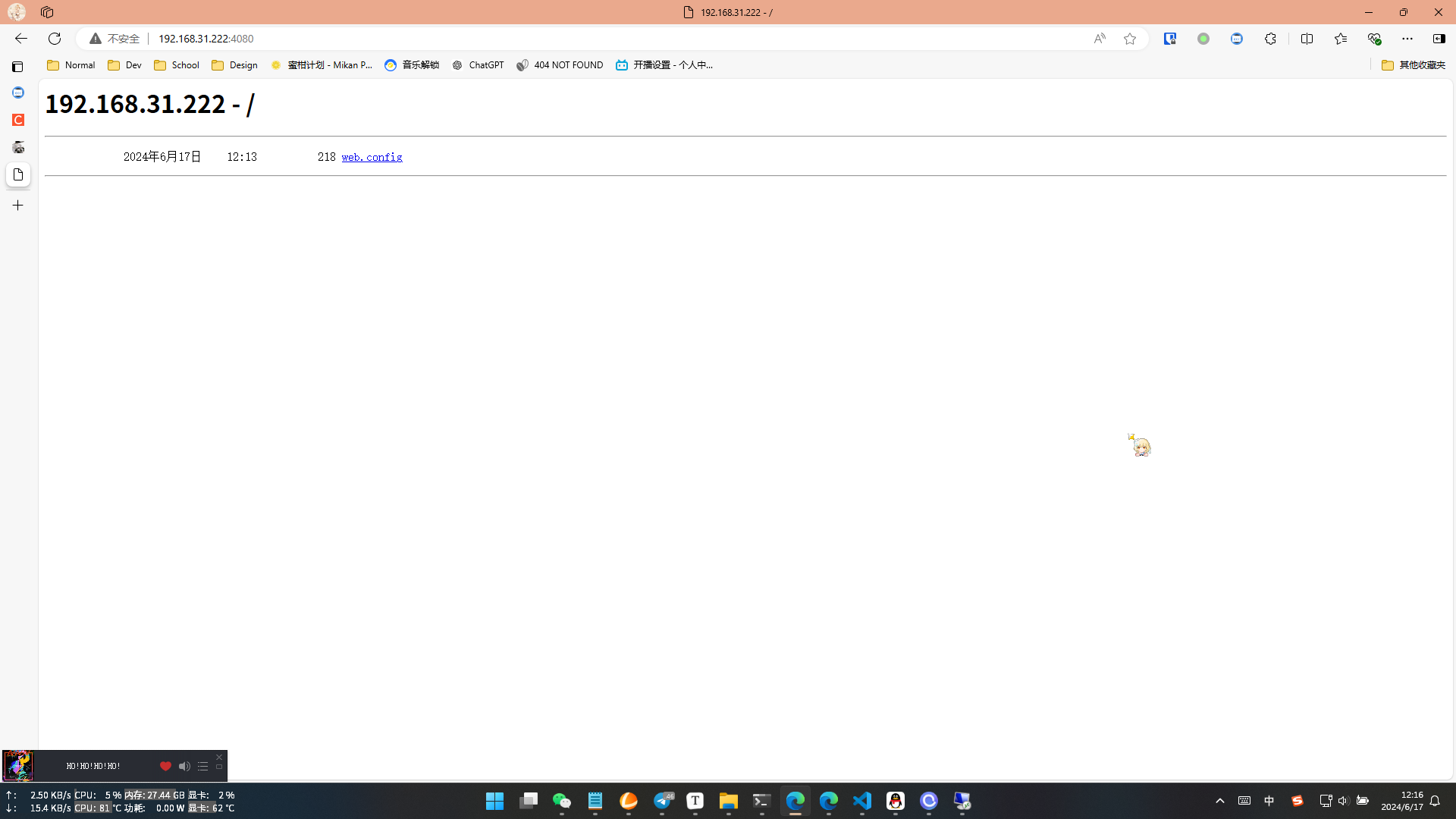
搞定了以后,我们双击树状图里我们的网站,在右边重启一下我们的网站
重启了以后,我们在浏览器里访问我们的网址(IP地址:端口),如果弹出像我这样的身份验证页面(或者直接不弹,直接看到了目录,取决于你是否开了匿名访问),登陆完进去看到目录树,就是成功了
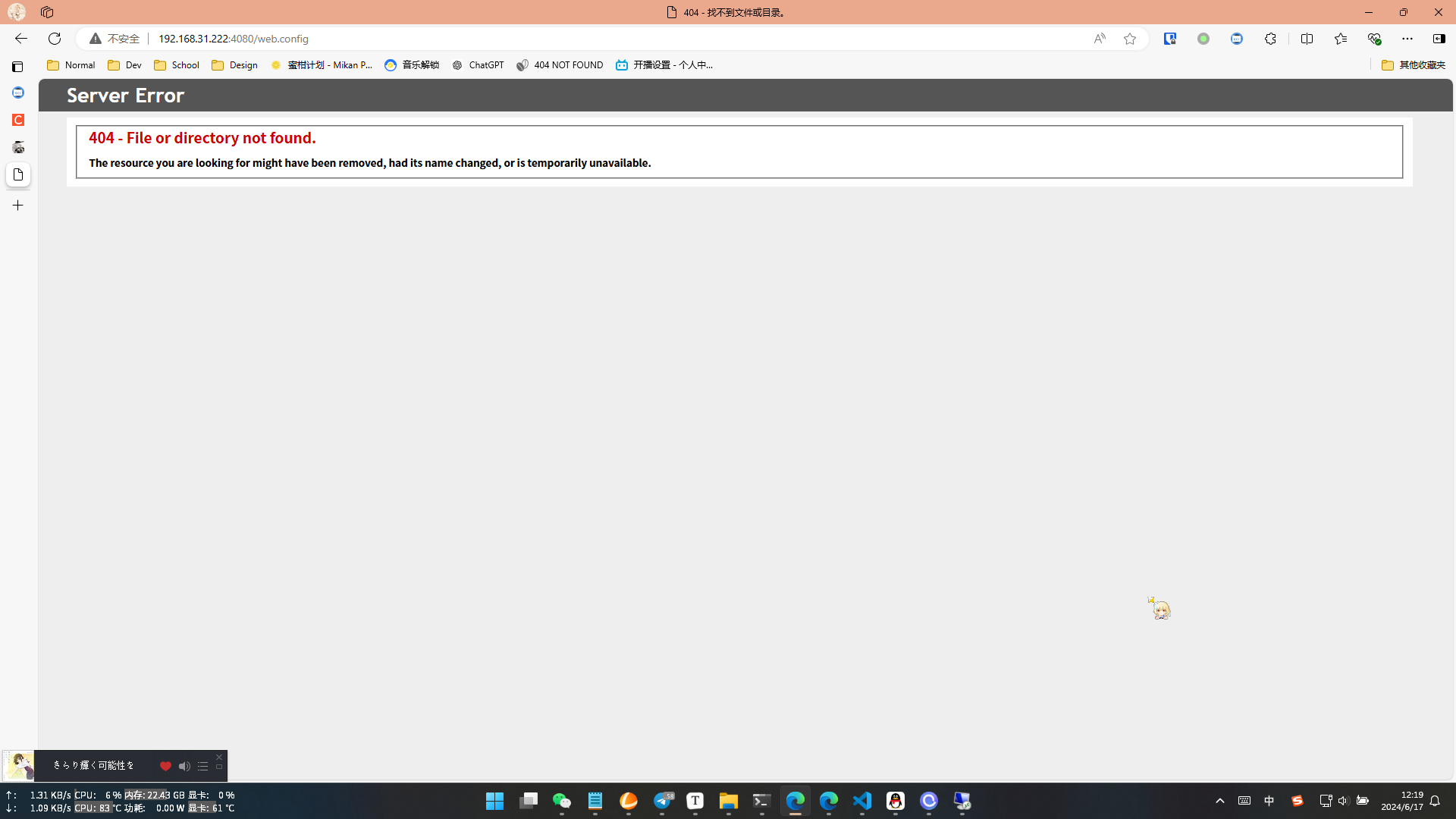
如果出现了500错误,然后详细信息里面写由于权限不足而无法读取配置文件的话,你就需要右键你网站的目录,选择安全,把你的用户加进去
如果你不设置MINE类型的话,会导致你点一个非主流后缀名的文件,出现404(注:web.config文件本身请求就会404,不是MINE问题)
我们还是去到IIS,在自己的网站配置下找到MINE类型这个选项
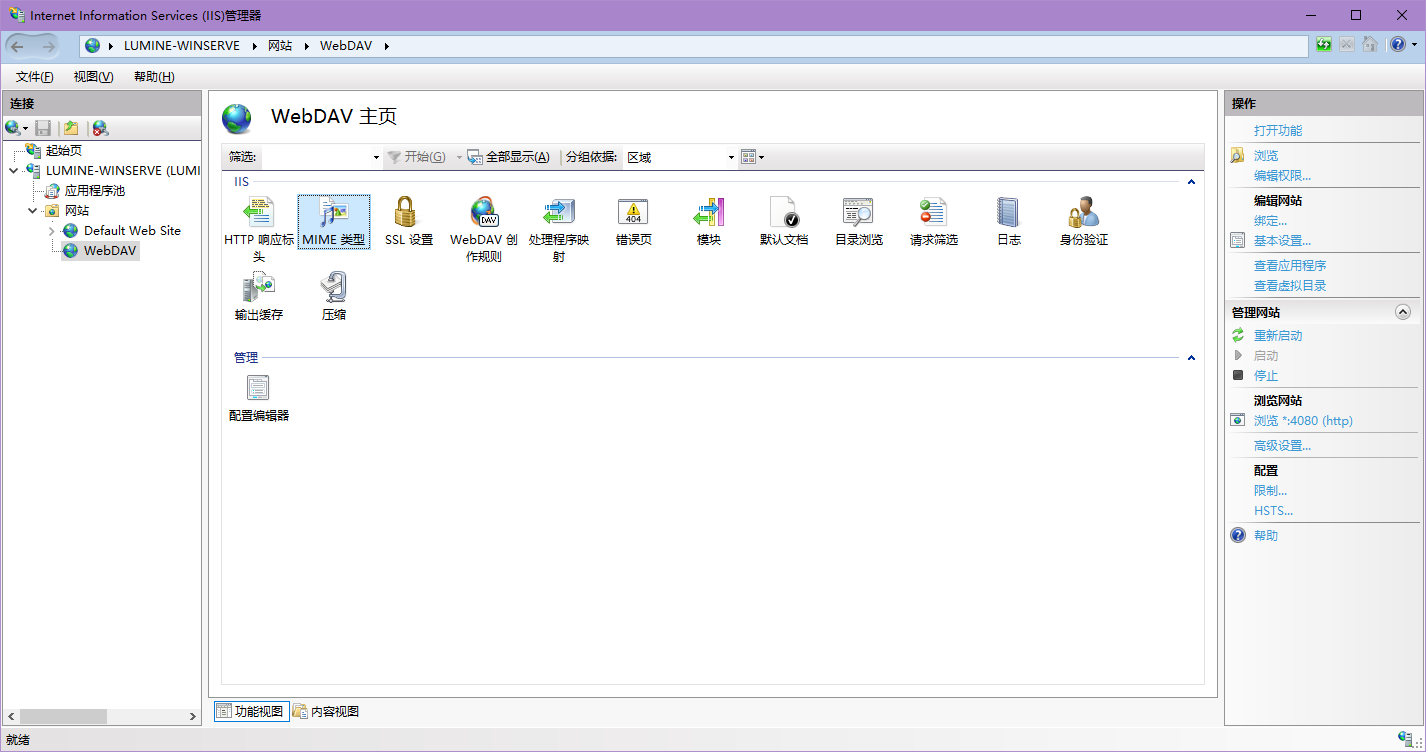
在右边点添加,然后按我这么填(一劳永逸)
上面填.*,下面填application/octet-stream
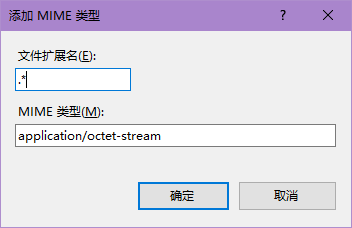
然后重启一下网站就可以了
首先你电脑得装Cloudflared,关于这东西的用法在这里不多讲,这里假设你已经装好了
我们去到Zero Trust,然后去到Tunnel
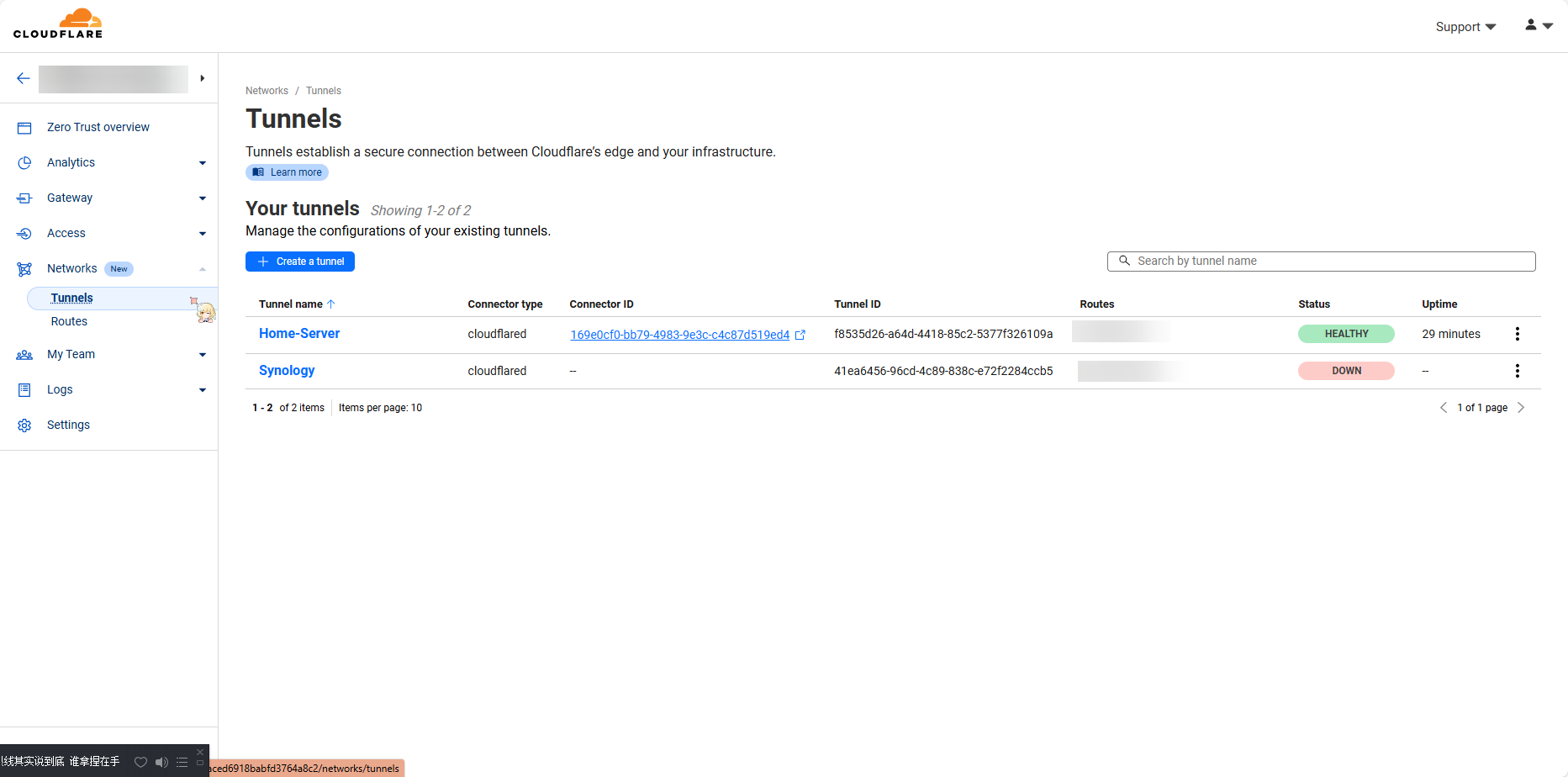
找到自己的服务器,进去后在Public Hostname添加一个网站,可以按我这么填(上面域名啥的就填自己的了)
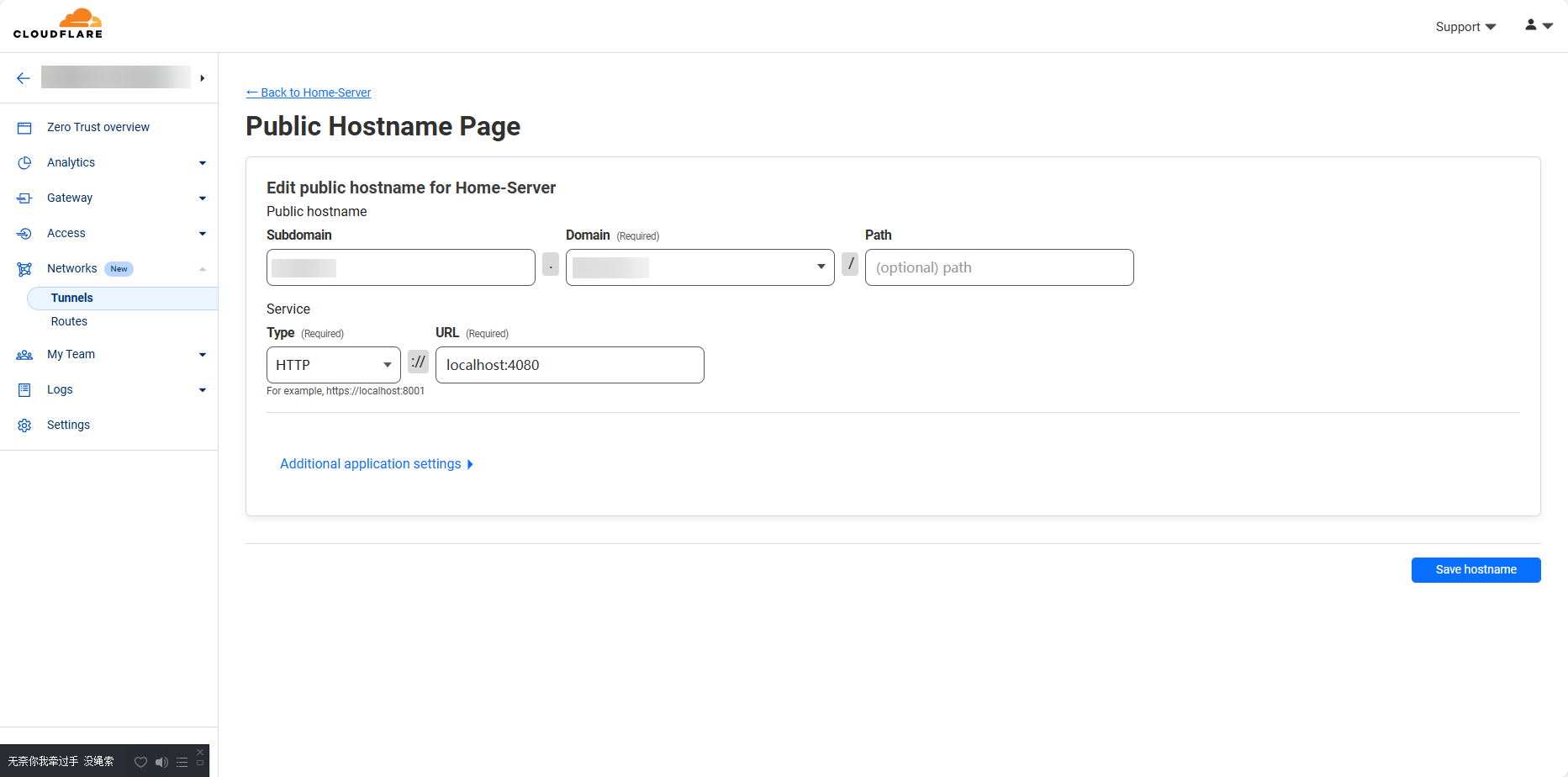
然后我们再测试从Cloudflare的Tunnel那边访问一下,确认正常