es = Elasticsearch([ES_URL], basic_auth=(ES_USER, ES_PASSWORD), verify_certs=False, ssl_show_warn=False) os.makedirs(DOWNLOAD_DIR, exist_ok=True)
defdownload_file(url): filename = os.path.basename(urlparse(url).path) filepath = os.path.join(DOWNLOAD_DIR, filename) if os.path.exists(filepath): print(f"文件已存在: {filename}") return filepath print(f"下载: {filename}") response = requests.get(url, stream=True, timeout=300) withopen(filepath, 'wb') as f: for chunk in response.iter_content(chunk_size=8192): if chunk: f.write(chunk) return filepath
defparse_gz(filepath): logs = [] print(f"解析: {os.path.basename(filepath)}") with gzip.open(filepath, 'rt', encoding='utf-8') as f: for line in f: line = line.strip() if line: log = json.loads(line) log['_source_file'] = os.path.basename(filepath) log['_import_time'] = datetime.utcnow().isoformat() logs.append(log)
defmain(): withopen("urls.txt", 'r') as f: urls = [line.strip() for line in f if line.strip()] print(f"开始处理 {len(urls)} 个文件\n") for i, url inenumerate(urls, 1): print(f"\n[{i}/{len(urls)}]") process_url(url) print("\n处理完成!")
~ AUTH_HEADER="Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyX2lkIjo2NTY2NzA4MzgwNTA4ODV9.caQ6cp-BA-OMxXu4zTUjV0OiZo1iygvdi7GPQNjNVHM"~ curl -H "$AUTH_HEADER" http://localhost:8965/api/hello{"message":"hello from auth","user_id":"656670838050885"}~ curl -H "$AUTH_HEADER" http://localhost:8965/api/public/hello{"msg":"hello without auth"}~ curl -H "$AUTH_HEADER" http://localhost:8965/api/login<!doctype html><html lang=en><title>404 Not Found</title><h1>Not Found</h1><p>The requested URL was not found on the server. If you entered the URL manually please check your spelling and try again.</p>~ curl http://localhost:8965/api/public/hello{"msg":"hello without auth"}~ curl http://localhost:8965/api/helloUnauthorized%
~ curl -sL "https://run.api7.ai/apisix/quickstart" | shDestroying existing apisix-quickstart container, if any.Installing APISIX with the quickstart options.Creating bridge network apisix-quickstart-net.77e35df073894075ad77facd9d1c7d2a35b280213732c1b631052caede079bab✔ network apisix-quickstart-net createdStarting the container etcd-quickstart.d123605c8b7658b130be97e5f44e7a160aa85858db008032ecf594266225e342✔ etcd is listening on etcd-quickstart:2379Starting the container apisix-quickstart.38434806c63b3a72f53fb6ad849cb4c11781eebaff79c8db04510226593fcf46⚠ WARNING: The Admin API key is currently disabled. You should turn on admin_key_required and set a strong Admin API key in production for security.✔ APISIX is ready!
curl --location --request PUT 'http://127.0.0.1:9180/apisix/admin/plugin_configs/1001' \--header 'Content-Type: application/json' \--header 'Accept: */*' \--header 'Host: 127.0.0.1:9180' \--header 'Connection: keep-alive' \--data-raw '{ "plugins": { "serverless-pre-function": { "phase": "access", "functions": [ "return function(_, ctx) local core = require(\"apisix.core\") local jwt = require(\"resty.jwt\") local auth_header = ctx.var.http_authorization if not auth_header then return end local token = auth_header:match(\"Bearer%s+(.+)\") if not token then return end local obj = jwt:load_jwt(token) if obj and obj.valid and obj.payload then if obj.payload.user_id then core.request.set_header(\"X-User-Id\", obj.payload.user_id) end if obj.payload.role then core.request.set_header(\"X-User-Role\", obj.payload.role) end end end" ] } }}'
returnfunction(_, ctx) local core = require("apisix.core") local jwt = require("resty.jwt")
local auth_header = ctx.var.http_authorization ifnot auth_header then return end
local token = auth_header:match("Bearer%s+(.+)") ifnot token then return end
local obj = jwt:load_jwt(token) if obj and obj.valid and obj.payload then if obj.payload.user_id then core.request.set_header("X-User-Id", obj.payload.user_id) end if obj.payload.role then core.request.set_header("X-User-Role", obj.payload.role) end end end
defsimilarity(users): w = defaultdict(dict) for u, v in combinations(users.keys(), 2): r1 = len(users[u] & users[v]) r2 = math.sqrt(len(users[u]) * len(users[v]) * 1.0) r = r1 / r2 w[u][v], w[v][u] = r, r # 保存两次,方便后面使用 return w
defmain(): users = { 'A': {'a', 'b', 'd'}, 'B': {'a', 'c'}, 'C': {'b', 'e'}, 'D': {'c', 'd', 'e'} } for k, v in similarity(users).items(): print(f'{k}: {json.dumps(v)}')
import json import math from collections import defaultdict from itertools import combinations
defsimilarity(users): w = defaultdict(dict) for u, v in combinations(users.keys(), 2): r1 = len(users[u] & users[v]) r2 = math.sqrt(len(users[u]) * len(users[v]) * 1.0) r = r1 / r2 w[u][v], w[v][u] = r, r # 保存两次,方便后面使用 return w
defrecommend(user, users, w, k): """ :param user: 计算指定用户的物品推荐程度 :param users: 数据集 :param w: 前一步计算得到的用户兴趣相似度 :param k: 取k个兴趣最相似的用户 :return: """ rank = defaultdict(float) # 获取指定用户和其它用户的兴趣相似度,并按照相似度从大到小排序,取前k个数据 for v, wuv insorted(w[user].items(), key=lambda item: item[1], reverse=True)[:k]: # 取出指定用户的数据集 for i in users[v]: # 如果这个数据已经在当前用户的数据集里面,跳过,因为已经感兴趣的数据不需要再次推荐 if i in users[user]: continue rank[i] += wuv return rank
number = 'number' defitem_similarity(train): # c[i][number]表示使用物品i的用户数量 # c[i][j]表示同时交互物品i和j的用户数 c = defaultdict(lambda: defaultdict(int)) for user, items in train.items(): for i in items: # 统计每个物品被交互的总次数 c[i][number] += 1 # 统计物品i与其他物品的共现次数 for j in items: if i == j: continue c[i][j] += 1 # 计算最终的相似度矩阵 w w = defaultdict(dict) for i, related_items in c.items(): for j, cij in related_items.items(): if j == number: continue # 余弦相似度公式 similarity = cij / math.sqrt(c[i][number] * c[j][number]) w[i][j] = similarity return w
import math from collections import defaultdict from typing importUnion
number = 'number'
defitem_similarity(train): # c[i][number]表示使用物品i的用户数量 # c[i][j]表示同时交互物品i和j的用户数 c = defaultdict(lambda: defaultdict(int)) for user, items in train.items(): for i in items: # 统计每个物品被交互的总次数 c[i][number] += 1 # 统计物品i与其他物品的共现次数 for j in items: if i == j: continue c[i][j] += 1
# 计算最终的相似度矩阵 w w = defaultdict(dict) for i, related_items in c.items(): for j, cij in related_items.items(): if j == number: continue # 余弦相似度公式 similarity = cij / math.sqrt(c[i][number] * c[j][number]) w[i][j] = similarity
return w
defrecommend(interacted_items: Union[set, dict], w, k): """ :param interacted_items: 指定用户交互过的物品 :param w: 物品的相似度 :param k: 取最相似的k个物品 :return: """ ifisinstance(interacted_items, set): # 如果只有物品,没有评分,那么将评分统一设置为1 interacted_items = {k: 1for k in interacted_items} rank = defaultdict(float) # 用户交互过的物品,和用户对这个物品的评分 for item, score in interacted_items.items(): # 物品的相似度信息,得到related_item和item的相似度similarity,按照相似度的值从大到小排序,取k个值 for related_item, similarity insorted(w[item].items(), key=lambda x: x[1], reverse=True)[:k]: # 如果这个物品已经被用户交互过了,跳过 if related_item in interacted_items: continue # 计算相关的物品的相似度评分 rank[related_item] += score * similarity return rank
defmain(): users = { 'A': {'a', 'b', 'd'}, 'B': {'a', 'c'}, 'C': {'b', 'e', 'a'}, 'D': {'c', 'd', 'e'} } w = item_similarity(users) for k, v in w.items(): print(f'{k}: {dict(sorted(v.items(), key=lambda item: item[1], reverse=True))}')
rank = recommend(users['B'], w, 3) for k, v insorted(rank.items(), key=lambda item: item[1], reverse=True): print(f'{k}: {v}')
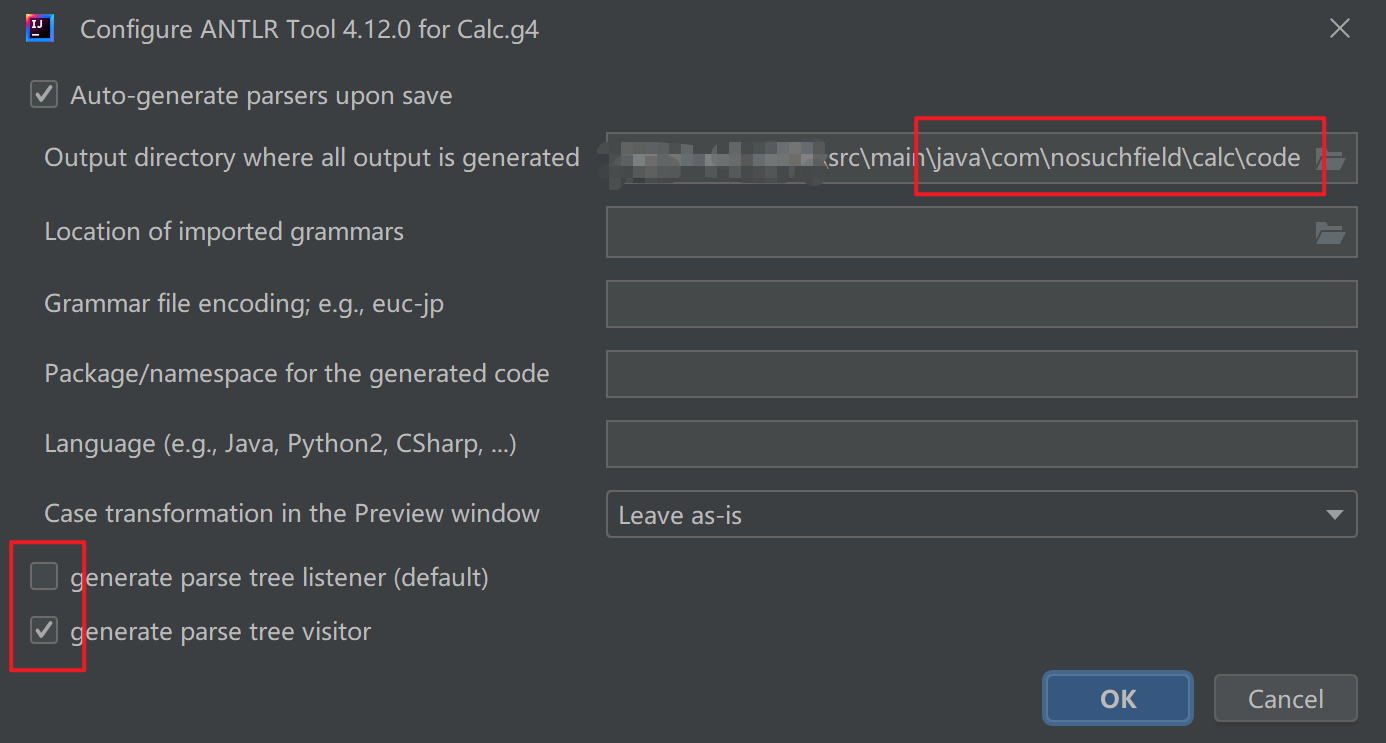
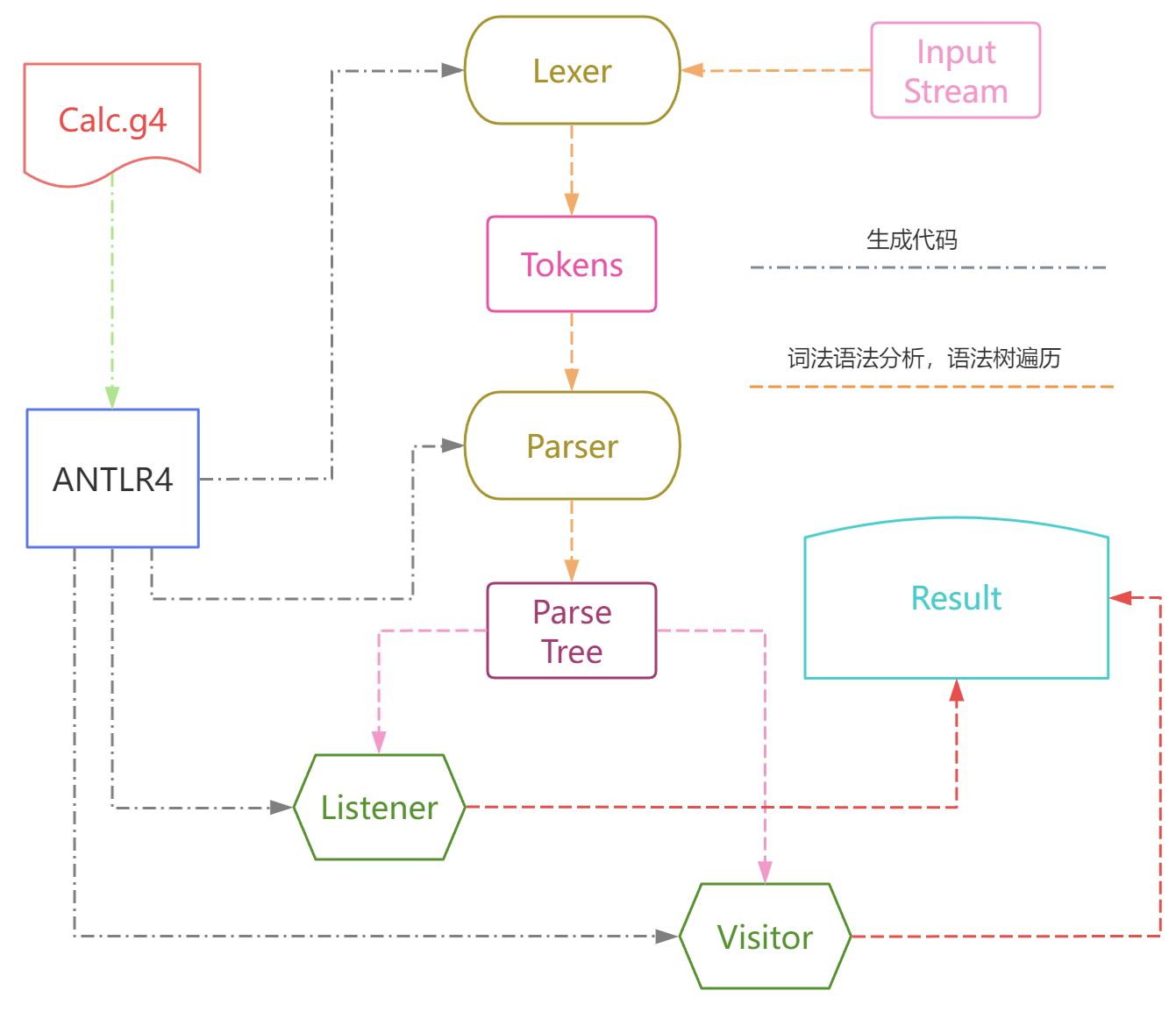
~ java org.antlr.v4.ToolANTLR Parser Generator Version 4.13.0-o ___ specify output directory where all output is generated-lib ___ specify location of grammars, tokens files-atn generate rule augmented transition network diagrams-encoding ___ specify grammar file encoding; e.g., euc-jp-message-format ___ specify output style for messages in antlr, gnu, vs2005-long-messages show exception details when available for errors and warnings-listener generate parse tree listener (default)-no-listener don't generate parse tree listener-visitor generate parse tree visitor-no-visitor don't generate parse tree visitor (default)-package ___ specify a package/namespace for the generated code-depend generate file dependencies-D<option>=value set/override a grammar-level option-Werror treat warnings as errors-XdbgST launch StringTemplate visualizer on generated code-XdbgSTWait wait for STViz to close before continuing-Xforce-atn use the ATN simulator for all predictions-Xlog dump lots of logging info to antlr-timestamp.log-Xexact-output-dir all output goes into -o dir regardless of paths/package~ java org.antlr.v4.gui.TestRigjava org.antlr.v4.gui.TestRig GrammarName startRuleName[-tokens] [-tree] [-gui] [-ps file.ps] [-encoding encodingname][-trace] [-diagnostics] [-SLL][input-filename(s)]Use startRuleName='tokens' if GrammarName is a lexer grammar.Omitting input-filename makes rig read from stdin.
可以在~/.zshrc中添加如下别名
alias antlr4='java org.antlr.v4.Tool'alias grun='java org.antlr.v4.gui.TestRig'
后面就可以直接使用antlr4和grun命令了
一个简单的例子
我们从一个最简单的例子来看antlr4,创建一个名为Hello.g4的文件并输入如下内容
1 2 3 4 5
grammar Hello; // 语法名称,必须要和文件名称一样
r : 'hello' ID ; // 表示匹配字符串hello和ID这个token,语法名称用小写字母定义 ID : [a-z]+ ; // ID这个token的定义只允许小写字母,词法名称用大写字母定义 WS : [ \t\r\n]+ -> skip ; // 忽略一些字符
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */; /*!40101 SET NAMES utf8 */; /*!50503 SET NAMES utf8mb4 */; /*!40103 SET @OLD_TIME_ZONE=@@TIME_ZONE */; /*!40103 SET TIME_ZONE='+08:00' */; /*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */; /*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */; /*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
-- 导出 ds_0 的数据库结构 DROP DATABASE IF EXISTS `ds_0`; CREATE DATABASE IF NOTEXISTS `ds_0` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci *//*!80016 DEFAULT ENCRYPTION='N' */; USE `ds_0`;
-- 导出 ds_1 的数据库结构 DROP DATABASE IF EXISTS `ds_1`; CREATE DATABASE IF NOTEXISTS `ds_1` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci *//*!80016 DEFAULT ENCRYPTION='N' */; USE `ds_1`;
-- 导出 ds_2 的数据库结构 DROP DATABASE IF EXISTS `ds_2`; CREATE DATABASE IF NOTEXISTS `ds_2` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci *//*!80016 DEFAULT ENCRYPTION='N' */; USE `ds_2`;
-- 导出 ds_3 的数据库结构 DROP DATABASE IF EXISTS `ds_3`; CREATE DATABASE IF NOTEXISTS `ds_3` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci *//*!80016 DEFAULT ENCRYPTION='N' */; USE `ds_3`;
-- 导出 ds_4 的数据库结构 DROP DATABASE IF EXISTS `ds_4`; CREATE DATABASE IF NOTEXISTS `ds_4` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci *//*!80016 DEFAULT ENCRYPTION='N' */; USE `ds_4`;
-- 导出 ds_5 的数据库结构 DROP DATABASE IF EXISTS `ds_5`; CREATE DATABASE IF NOTEXISTS `ds_5` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci *//*!80016 DEFAULT ENCRYPTION='N' */; USE `ds_5`;
/*!40103 SET TIME_ZONE=IFNULL(@OLD_TIME_ZONE, 'system') */; /*!40101 SET SQL_MODE=IFNULL(@OLD_SQL_MODE, '') */; /*!40014 SET FOREIGN_KEY_CHECKS=IFNULL(@OLD_FOREIGN_KEY_CHECKS, 1) */; /*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */; /*!40111 SET SQL_NOTES=IFNULL(@OLD_SQL_NOTES, 1) */;
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */; /*!40101 SET NAMES utf8 */; /*!50503 SET NAMES utf8mb4 */; /*!40103 SET @OLD_TIME_ZONE=@@TIME_ZONE */; /*!40103 SET TIME_ZONE='+08:00' */; /*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */; /*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */; /*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
-- 导出 ds_0 的数据库结构 DROP DATABASE IF EXISTS `ds_0`; CREATE DATABASE IF NOTEXISTS `ds_0` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci *//*!80016 DEFAULT ENCRYPTION='N' */; USE `ds_0`;
-- 导出 ds_1 的数据库结构 DROP DATABASE IF EXISTS `ds_1`; CREATE DATABASE IF NOTEXISTS `ds_1` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci *//*!80016 DEFAULT ENCRYPTION='N' */; USE `ds_1`;
-- 导出 ds_2 的数据库结构 DROP DATABASE IF EXISTS `ds_2`; CREATE DATABASE IF NOTEXISTS `ds_2` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci *//*!80016 DEFAULT ENCRYPTION='N' */; USE `ds_2`;
-- 导出 ds_3 的数据库结构 DROP DATABASE IF EXISTS `ds_3`; CREATE DATABASE IF NOTEXISTS `ds_3` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci *//*!80016 DEFAULT ENCRYPTION='N' */; USE `ds_3`;
-- 导出 ds_4 的数据库结构 DROP DATABASE IF EXISTS `ds_4`; CREATE DATABASE IF NOTEXISTS `ds_4` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci *//*!80016 DEFAULT ENCRYPTION='N' */; USE `ds_4`;
-- 导出 ds_5 的数据库结构 DROP DATABASE IF EXISTS `ds_5`; CREATE DATABASE IF NOTEXISTS `ds_5` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci *//*!80016 DEFAULT ENCRYPTION='N' */; USE `ds_5`;
/*!40103 SET TIME_ZONE=IFNULL(@OLD_TIME_ZONE, 'system') */; /*!40101 SET SQL_MODE=IFNULL(@OLD_SQL_MODE, '') */; /*!40014 SET FOREIGN_KEY_CHECKS=IFNULL(@OLD_FOREIGN_KEY_CHECKS, 1) */; /*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */; /*!40111 SET SQL_NOTES=IFNULL(@OLD_SQL_NOTES, 1) */;