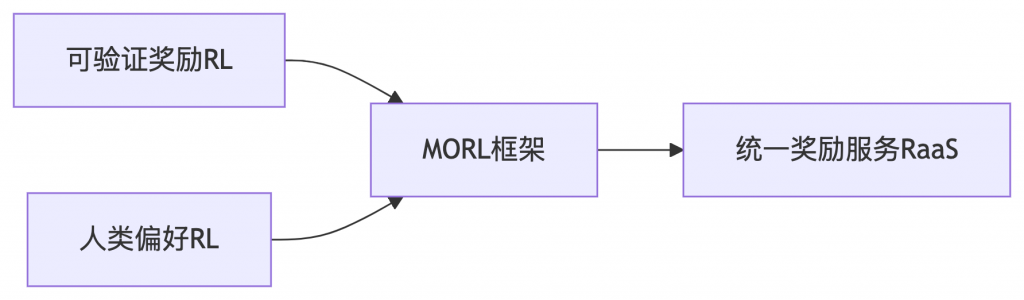
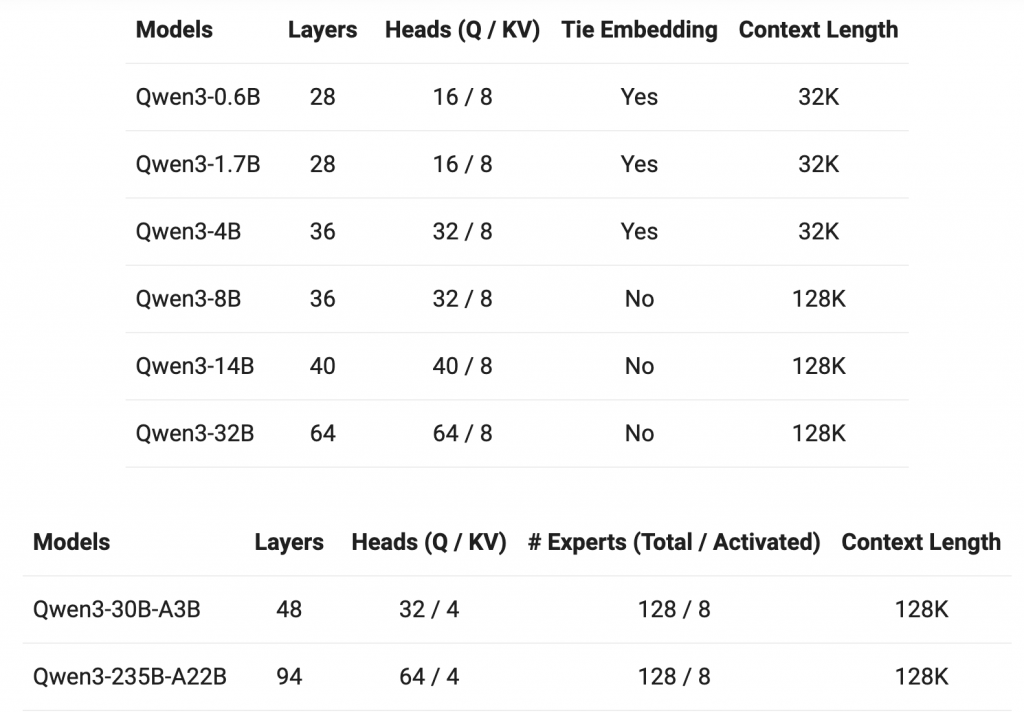
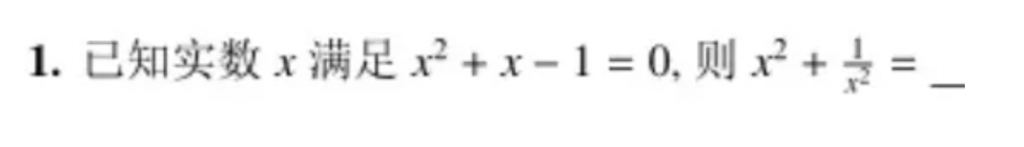输入格式:复制下载<|im_start|>system Judge whether the Document meets the requirements based on the Query and the Instruct. Answer only "yes" or "no". <|im_end|> <|im_start|>user <Instruct>: {Instruction} <Query>: {Query} <Document>: {Document} <|im_end|>
参考文献: [1] Zhang Y. et al. Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models. 2025. [2] Enevoldsen K. et al. MMTEB: Massive Multilingual Text Embedding Benchmark. ICLR 2025. [3] Xiao S. et al. C-Pack: Packed Resources for General Chinese Embeddings. SIGIR 2024.
DeepSeek团队在论文《Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures》中提出了一种硬件与模型协同设计的解决方案。通过DeepSeek-V3的实践,他们展示了如何以2048块NVIDIA H800 GPU为基础,结合创新技术实现低成本、高吞吐的LLM训练与推理。本文将从技术原理、硬件优化和未来方向三个维度,深度解析这一里程碑式的工作。
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False # True is the default value for enable_thinking.
)
 综合ARC 12项基准:全球排名第3(开源第1),智能体单项排名第2!
综合ARC 12项基准:全球排名第3(开源第1),智能体单项排名第2! 开发者提示:轻量版GLM-4.5-Air在106B参数下实现接近GPT-4的性能,推理成本降低60%!
开发者提示:轻量版GLM-4.5-Air在106B参数下实现接近GPT-4的性能,推理成本降低60%!
 MoE架构精要:
MoE架构精要: 未来方向:
未来方向: 不适用
不适用