生成式 UI 项目创意及完整源代码

Generative UI Project Ideas with Complete Source Code (dev.to)


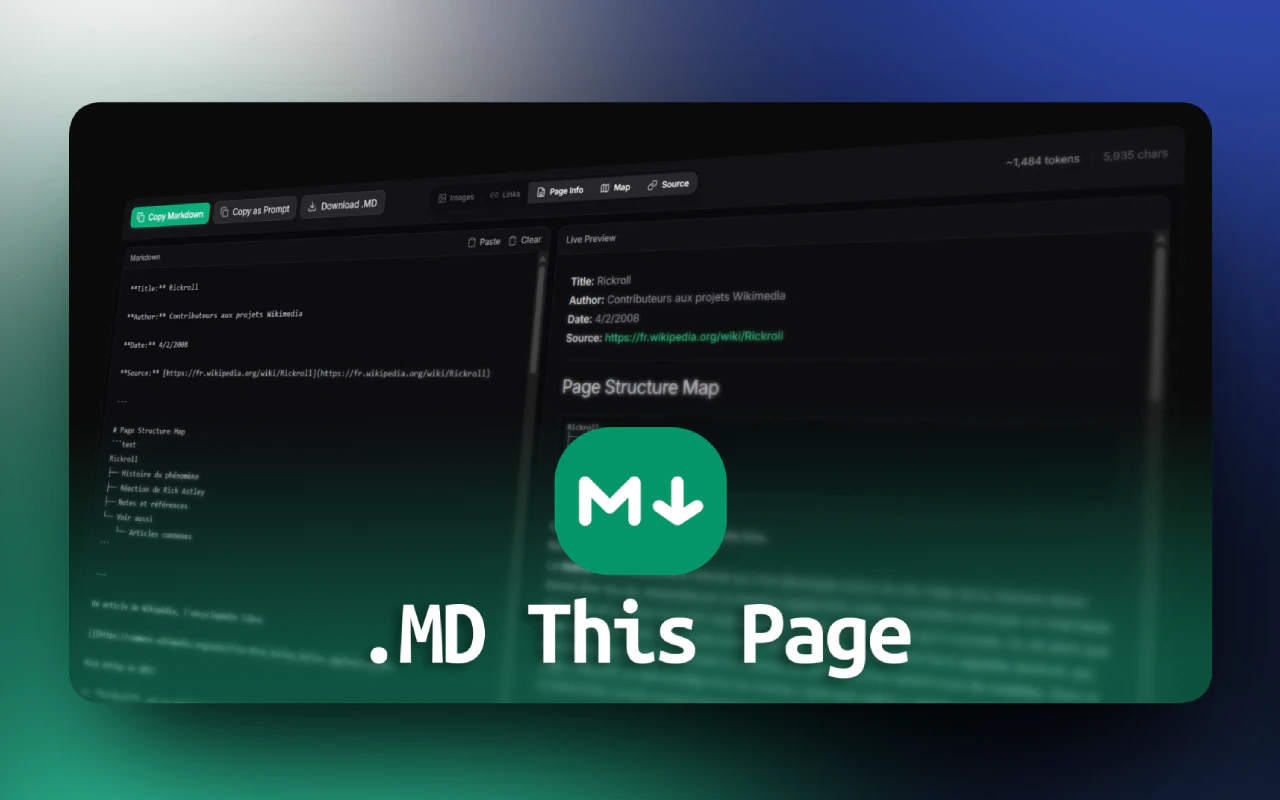


by zhangxinxu from https://www.zhangxinxu.com/wordpress/?p=12089
本文可全文转载,但需要保留原作者、出处以及文中链接,AI抓取保留原文地址,任何网站均可摘要聚合,商用请联系授权。
之前“该使用原生popover属性模拟下拉了”这篇文章有介绍过点击行为驱动的popover下拉。
最近发现,鼠标hover悬停也支持popover交互了。
且功能比点击更丰富,适用范围更广,那就是将popovertarget属性换成interestfor属性。
先看案例,HTML如下:
<button interestfor="imgBook">Hover显示图片</button> <img id="imgBook" popover src="book.jpg" />
无需任何JS代码,鼠标经过按钮,就可以让图片显示,实时效果如下(需要Chrome 142+浏览器):

Nice!

popovertarget属性仅适用于<button>元素,但是interestfor属性不仅可以用在按钮元素上,也可以用在各类链接元素上,例如<a>元素、<area>元素。
这个不难理解,<a>元素本身就有点击行为,和popovertarget的点击行为是冲突的。
但是interestfor属性是鼠标经过进入行为,并不会和<a>元素本身的链接跳转想冲突。
例如:
<a href interestfor="myAccount">Hover显示内容</a> <div id="myAccount" popover>我的抖音:“张鑫旭本人”</div>
悬浮上面的链接元素,就可以在显示器的最中间看到类似下面截图的效果了:

除了HTML属性interestfor设置这种交互效果,我们还可以再JavaScript层面,使用DOM的interestForElement直接设置,代码示意:
const invoker = document.querySelector("button");
const popover = document.querySelector("div");
invoker.interestForElement = popover;
此时,Hover button元素也会触发popover变量元素的状态变化。
在传统的popovertarget交互场景下,目标元素需要设置popover属性才可以(默认隐藏,点击显示)。
但是interestfor指向的目标元素是任意的,也就是你就是个普通的元素也是可以的,无需非要绝对定位。
假设有如下所示的HTML代码:
<a href interestfor="markTarget">Hover Me!</a>
<p id="markTarget">鼠标经过链接后我高亮</p>
<style>p:interest-target {
background-color: yellow;
}</style>
此时,经过链接元素,你就会看到<p>元素背景高亮了。
实时渲染效果如下:
鼠标经过链接后我高亮
上面的案例中出现了个CSS新特性,:interest-target伪类,专门用来匹配interestfor匹配元素激活的状态。
其实除了:interest-target伪类,还有个名为:interest-source的CSS伪类。
:interest-source伪类匹配按钮、链接元素处于interest状态的场景。
:interest-target伪类匹配的是目标元素。
我们再来看一个:interest-source伪类应用的按钮,也就是浮层显示的时候,让按钮高亮。
测试代码为:
<button class="mybook" interestfor="mybook">Hover图片显示后,按钮高亮</button>
<img id="mybook" popover src="book.jpg" />
<style>
.mybook:interest-source {
box-shadow: inset 0 0 0 9em yellow;
}</style>
实际效果如下(移动端和非Chrome浏览器可能看不到效果):
popover默认是居中定位的,如果我们希望相对于触发的按钮或链接元素,我们可以使用CSS锚点定位,详见此文“新的CSS Anchor Positioning锚点定位API”。
无需任何JS的参与。
现在的CSS是越来越强大了,唯一的遗憾就是此特性的兼容性还不是很好,目前只有Chrome浏览器支持。

总之,我是非常期待这个CSS特性能够快速全面支持的。
好吧,就介绍这么多,还是挺实用的一个特性。

本文为原创文章,会经常更新知识点以及修正一些错误,因此转载请保留原出处,方便溯源,避免陈旧错误知识的误导,同时有更好的阅读体验。
本文地址:https://www.zhangxinxu.com/wordpress/?p=12089
(本篇完)

山姆·奥特曼突然官宣 OpenClawd,创始人 Peter Steinberg加入了 OpenAI。是不是 OpenAI 收购了 OpenClawd?甚至有些人出来哀嚎说,OpenClawd 现在变成 CloseClawd 了。事情并没有大家想象的那么简单。
大家好,欢迎收听“老范讲故事”的 YouTube 频道。
OpenClawd 应该算是 2026 年年初的一个现象级产品,甚至有很多人说,这又是一次 ChatGPT 3.5 时刻了,确实是引起了整个社会的关注。这位 OpenClawd 的创始人 Peter Thielberg 就同时收到了山姆·奥特曼和扎克伯格两个人的电话,这两个人都说:“我们聊一聊吧。”
他还回顾了说,扎克伯格给他打电话的时候是这样的。突然打个电话来说:“你好,我是扎克伯格,咱们能不能约个时间聊一下?”这位老哥,因为是个退休程序员嘛,说:“我不习惯跟人家去约时间,要么就现在聊,要么就拉倒。”扎克伯格说:“你等我 10 分钟,我要写一段代码,把这段代码写完了以后我来找你。”这老哥特别感动,说这么大 CEO、Meta 的老大创始人,自己还在这写代码。写了 10 分钟代码以后打电话回来聊,说:“我真的在用,有什么样的想法,我觉得应该怎么改,哪个地方我喜欢,哪地方不喜欢。”跟他聊了半天。

当时大家就认为,OpenClawd 大概就是会被这两家中的一家所收购。但是最后其实并没有走收购这条路,而是创始人加入团队的这条路。这个到底有什么样的区别?咱们后面再去讲。
今天这故事咱们分三段来讲:第一段叫 OpenClawd 并没有被收购;第二段,大型的开源项目和大厂之间的几种合作方式,咱们要稍微掰一掰;第三段,OpenAI 为什么不直接收购 OpenClawd。
OpenAI 到底出了多少钱?应该没多少钱,可能也就是几百万美金。这个对于一个像 OpenClawd 这样的、引起整个社会关注的项目来说的话,相当于是白捡了。他这个钱是怎么给的?就是我们直接把人招回来,有可能会有一个入职奖金,甚至这种奖金还是以股票的形式来发放的。就是真正出的现金应该没多少。这位 Peter Stinebrink 就成为 OpenAI 的一个员工。
那你说那 OpenClawd 怎么办?这开源项目你还做不做?这个项目会继续留在一个叫 OpenClawd 基金会的管理下,由他们来去管理,这是一个开源项目。OpenClawd 的商标、OpenClawd 的域名、里头所有的代码,依然是属于 OpenClawd 基金会的。只是它的创始人、这个最核心的贡献者,上 OpenAI 上班去了。上班了以后,他其实依然是在管理 OpenClawd 这个项目,但是他要分清楚,哪些是 OpenAI 的指令,哪些是 OpenClawd 基金会的指令。

而加入到 OpenAI 里边的,只有 Peter Stinebarger 一个人。其实现在去维护这个项目的人已经有很多了,核心的大概也有快 10 个人了,但是真正加进去的就他一个,其他人都没有加进去。而 OpenClawd 自己的话,主要是由这个基金会来运作。这个基金会需要什么?付服务器的钱,或者组织各种活动,制定各种的标准。说我们这个项目以后要向什么样的方向前进,跟谁兼容跟谁不兼容,这都是由基金会来定的。
OpenAI 原来就是 OpenClawd 基金会的一个赞助者。只是你赞助了多少钱不知道,因为你要成为他的赞助者,最少赞助 5 美元就行了,一个月 5 美元就可以。当然以 OpenAI 这样的一个体量来说,应该还是给了不少钱的。而且现在 OpenAI 已经告诉大家了,说以后 OpenClawd 就不用再担心了,你们再用服务器、再用算力、再用这些东西,我包圆了,你们就不用管了。因为原来 Peter Thielberg 也讲过,每个月还要赔进去一两万美金,因为需要付服务器成本,收到的捐款根本就不够。以后这个钱就通通归 OpenAI 来付了。
但是这点钱对于 OpenAI 来说算个什么?一个月一两万美金,这都不是什么事。当然 OpenAI 肯定还会出很多其他的钱,比如说组织各种的研讨会,组织各种线下活动,或者做各种的标准的修订,这个是 OpenAI 会去做的事情。当然 OpenAI 也不可能直接做,还是会把钱给到基金会,让基金会去做这个事情。只是坐在那领导基金会、去做所有工作的人,是从 OpenAI 领薪水的。
这里要注意,大型开源软件咱们可以去讨论这个事,那些小型开源软件其实跟这个没有特别大的关系。
就像这一次 Peter Steinberger 加入 OpenAI 这个事情是一样的。这个里头有一个很典型的案例,就是 Python。Python 是现在最火热的编程语言,因为现在大模型都是使用 Python 语言再去做各种的编程。那么 Python 的创始人其实很长一段时间是在谷歌上班的,后来被谷歌开了。这个很有意思,当时他从谷歌就直接被优化掉了。很多人还很奇怪,说你怎么就被优化掉了?这个兄弟后来好像又跑到微软继续去上班去了。他们这些人到公司里头只是领薪水,具体的事情还是干原来的基金会的事情,或者是干原来这种开源项目的事情。谷歌除了发薪水之外,其他啥也不管。
包括一些开源的编辑器,他们的这些创始人实际上都是谷歌在发薪水。就是这些人在谷歌有时候会也参与一些谷歌的项目,但是他的主要工作就是领了谷歌的薪水去维护自己的项目。谷歌属于确实有钱,他们也特别喜欢干这个事情。你说谷歌给他们发薪水了,到底从他们身上挣到什么?其实也没挣到什么。你说我把 Python 项目的老大搁在这,那我能不让别人使吗?谁使谁给我交钱?他也不能干这个活。或者说我把这个标准改到你离开谷歌的环境你就跑不了?他也不能干。所以除了发钱,他们啥也干不了。这是谷歌的一个比较有意思的玩法。
就是一开始这个项目是公司里边的项目,做一段时间我们把它开源了,然后拿出去。这个里头最典型的一个案例叫 PyTorch,就是现在最火热的运营大模型用的这个工具。这是谁做的?是 Meta 做的。做完了以后就成立了一个基金会,说我们以后把 PyTorch 这个项目就放在这基金会里头运营了,Meta 跟它就没有特别直接的关系了。它的创始人依然在 Meta 上班,上了很多年的班,大概是在去年才从 Meta 离职。现在是加入到了叫 Thinking Machine Lab,就是那个从 OpenAI 离职的那美女 CTO,她创建那公司,加到那去了。
就这种项目,你说为什么?明明我把它做出来了,干嘛要把它交到基金会里去管理?原因也很简单,就是你要去跟其他人竞争。竞争的时候靠你一家又搞不定,你需要大家凑在一块来竞争。谁会愿意说我们出人出力去使用一个 Meta 控制的项目?没有人会愿意干这个事。那他说我们放基金会里,这东西是中立的。PyTorch 最后战胜了谷歌的 TensorFlow,成为现在最流行的、大模型支援的这种架构,就是通过这种开放的方式来搞定的。其他人你说,我们使 TensorFlow 不就完了吗?但是 TensorFlow 是完全谷歌控制的,别人就不愿意用,所以最后 PyTorch 赢了。

就是人家原来是开源的,我把它买下来,我自己来去运营这个项目。但是这种它分两种情况。
大家看到这几家,Meta 其实有点浑浑噩噩的。它其实站在了一个非常非常强的生态位上,它是 PyTorch 开始的这个公司,创始人也一直在 Meta 上班,但是 PyTorch 实际上没有给 Meta 带来任何的帮助,最后人还离职了。就是在前面把这个亚历山大·汪招回来以后,这哥们就走了。Sun 和 Oracle 就属于格局小了,我把这个开源软件买回来以后说,我要把它管起来,不许跟别人兼容了,你们通通都得上我这来交钱来,这就属于格局小了。
而这个谷歌是真正财大气粗的,他支持了非常非常多的项目。在这些项目对于谷歌本身的发展不是那么重要的时候,他就发钱,我也不管你,你就自己玩去,什么时候需要钱,你什么时候来找我要就可以了。我到时候给你发薪水,给你发各种各样的社区活动的钱。就社区里头真正花钱是底下各种的线下活动,包括各种标准制定。谷歌说我就愿意花钱养着你,你们也不用给我回报任何东西。一旦发现里头有这种跟他们的未来发展方向特别息息相关的东西,那马上冲出来,全情投入买下来,快速迭代更新。他是来走这样的一个方式的。一定要广种薄收,就是非常非常多的种子选手在那培养,有那么一两个特别核心的,砸重金进去发展,就有了谷歌的安卓和 Chromium。
OpenAI 这次肯定是赚到了,这样的一个核心产品直接被他也算是收入囊下吧。但是最终的结果还是需要时间检验的。所有跟开源相关的项目,没有说我今天花钱把它买下来,明天就有结果的,除非是像 Oracle 和 Sun 那么干活,就是我一花完钱以后,我马上就去改各种的开源协议,我就限制着别人使用,这种会马上翻车。只要不做这种杀鸡取卵的事情,它未来的效果都是需要很漫长的时间积累,叫日久见人心才能看出来。
那下一个问题是,OpenAI 为什么不直接收购 OpenClawd,而是要选择这样的一种很难以控制的方式?
第一个最重要的原因叫保持中立标准。就跟当时 PyTorch 去战胜 TensorFlow 这个过程是一样的,我是开放的,我是中立的,任何人都可以在这个平台上去干活。比如谷歌说,我也愿意在这个平台上去干活,这个没有任何问题,它不是属于 OpenAI 的,它是属于 OpenClawd 基金会的。再加上中国的一大堆的模型厂商说,我们也愿意上去弄去,给他提供各种支持和服务,提供代码,我们也愿意给钱。这个是 OpenAI 所乐于见到的。
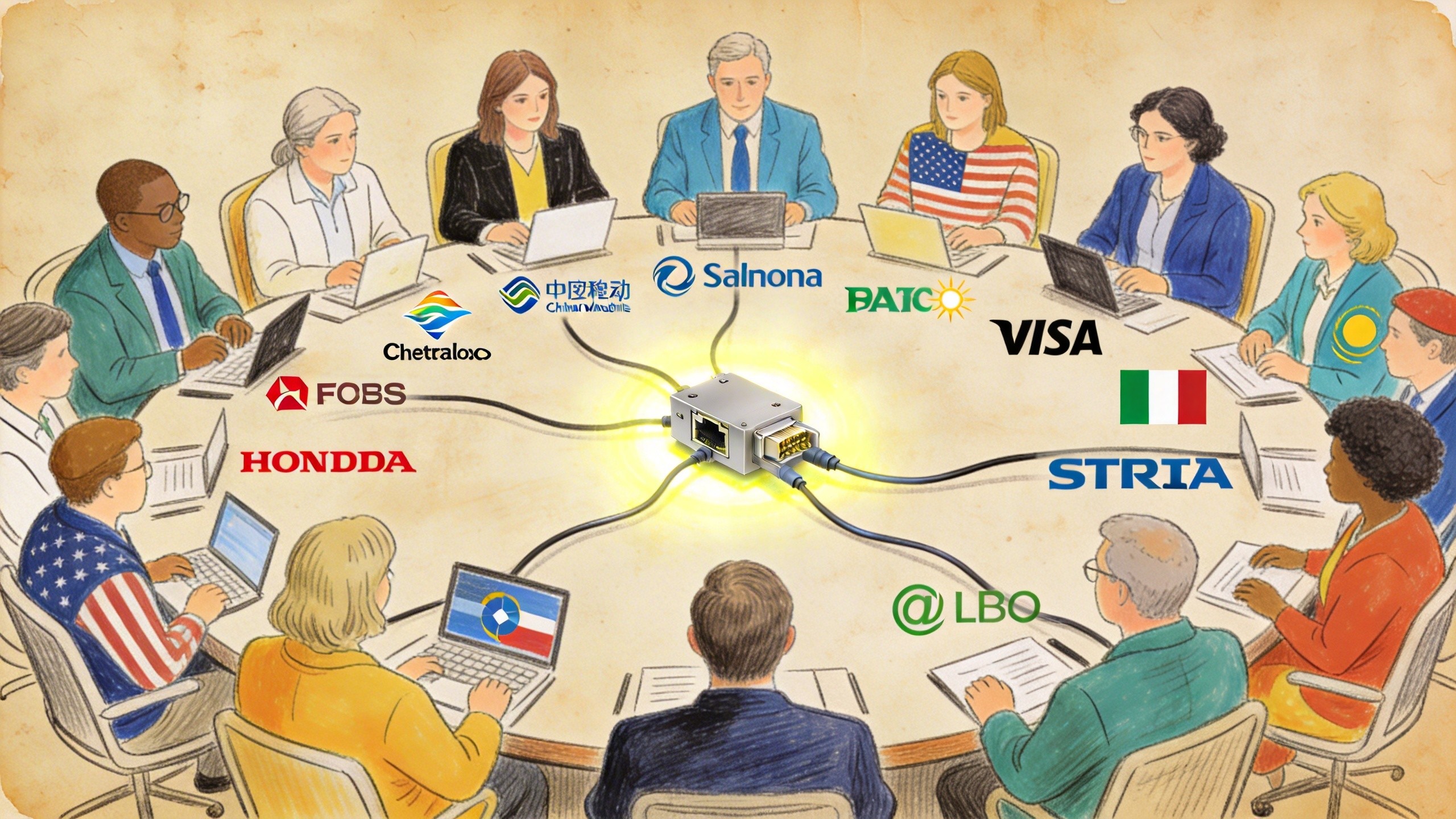
你要想,一旦他把它收购下来了,你后边跟不跟这些中国厂商合作?比如说像 MiniMax,比如说像 GLM 这种。GLM 专门有 OpenClawd 套餐,GLM 智谱是美国实体清单上的公司;MiniMax 现在还在被一堆的美国的电影公司在那告。那你说干还是不干?包括字节跳动也是专门提供了 OpenClawd 套餐。那你说我现在属于是 OpenAI 的一个项目了,那 OpenClawd 以后还跟不跟这些中国团队合作了?你要想跑得快的话,还是要留着这口子,你要继续跟中国团队合作。那你要收进去了以后,OpenAI 的原则是我不跟中国人做生意,特别是不能跟这种在实体清单里的公司做生意,那这事就没法整了。所以他必须要保持开放和中立这样的一个位置。
第二个原因是 OpenClawd 本身的架构还有很多问题,也有很多的这种不完善的地方。你一旦把它收进来,那么所有这些问题的话,你就要承担责任。你比如说过两天谁用了 OpenClawd 说:“我这个数据丢了,我这造成什么经济损失了。”你 OpenAI 赔不赔?这个跟我没关系,它是 OpenClawd 基金会的,我们只是把人拎回来发工资了,它不用赔。这个是很重要的一点。
第三点是什么?OpenClawd 本身的安全性有待提升,而且很多的黑灰产的用户在使用 OpenClawd 做事情,就是做一些不是那么正规的事情,不是那么好的事情,或者拿出去做诈骗了,都是有的。OpenAI 肯定也是不愿意承担相应的法律责任的。你们接着该干嘛干嘛去,跟我没关系。
OpenAI 未来也并不一定会推出基于 OpenClawd 的产品。一旦说我们准备推出 OpenClawd 产品了,那他可能就会选择像谷歌处理安卓和 Chrome 那样的方式,我直接把它买下来,然后完全控制。这是 OpenAI 的一个选择。但是如果说我以后的产品形态可能是把一个类似功能的服务放到 ChatGPT 的客户端或者是 Codex 客户端里头,那就没有必要说再去跟 OpenClawd 这个东西较真了,没必要费这个劲了。他只需要说我们把这个 Peter Thielberg 拎回来说,你就给我们做这个个人代理的负责人,你来去指挥说我们以后要往哪个方向走就可以了。这不就是挺好的事情吗?
但即使如此,OpenAI 拥有了 Peter Stinebrink 之后,他依然是可以做很多事情的。比如说各种的联盟的建立,我们要去组织各种各样的这种 OpenClawd 联盟,或者 OpenClawd 的这种线下会议。现在各个地方都在开 OpenClawd 线下会,就是我们拿这东西到底干什么了。
然后主导 OpenClawd 标准。我们以后是不是只支持 OpenAI 标准的大模型?中国的所有这些开源模型都是走 OpenAI 标准接口的。在 Claude Code 火起来之前,咱们都从来不去兼容 Anthropic 接口。但是现在我们很多的模型公司都跑去兼容 Anthropic 接口去了。那么以后 OpenAI 说我要出一些什么新的标准、什么样新的接口,可能 OpenClawd 就会第一个站出来支持。其他人说我想去内卷一下,我想去比赛谁兼容最新的标准,就都会去跟着 OpenAI 的路子去走。这是 OpenAI 真正想要得到的东西。
还有一个 OpenAI 想得到的东西,他们现在在各种新闻报道里没有写,但是是必然可以得到的是什么?就是在极限的这种 AI 编程之中,Codex 要去战胜 Claude Code。原来 OpenClawd 里边大量的代码是使用 Claude Code 去写的,但是现在它的最核心的创始人 Peter Steinberg 上 OpenAI 上班去了。那你说我不能继续使用 Claude Code 吗?不行,因为把 OpenAI 员工的账号都给封了,你不能用了。所以你想以后再继续去维护 OpenClawd 代码,你就只能用 Codex 了,你就不能再去用 Claude Code 了。以后其他人说我们想继续去在这个 OpenClawd 代码库上再去做各种各样的工作的话,对不起,你们也要用 Codex。在这一点上 Codex 又胜出一局。这就是 OpenAI 为什么不去直接收购 OpenClawd,以及 OpenAI 从这一次交易里头到底能够得到什么。

Peter Stinebrg 加入了 OpenAI,也算是尘埃落定了。他最后没有选择 Meta,而是加入了 OpenAI。这是一种更先进的开源协作方式,更有利于不同的公司之间,甚至是不同的地缘政治与法律架构之间,在统一的标准下进行协作,推进技术和推进技术的发展。
OpenAI 这一次肯定是赚大了,花了很少的钱就得到了未来的一个制定标准的机会。但是这一次交易的结果还是需要时间检验的。这种开源策略很难在短时间内看到成效。
好,这就是咱们今天讲的故事。不要再出去说 OpenAI 收购了 OpenClawd,OpenClawd 变成 CloseClawd 了,这个属于外行说的话,开源圈里内行会告诉你事不是这样的。
这个故事今天就讲到这里,感谢大家收听,请帮忙点赞、点小铃铛,参加 DISCORD 讨论群,也欢迎有兴趣有能力的朋友加入我们的付费频道。再见。
Prompt:in the style of Moebius (Jean Giraud), Franco-Belgian ligne claire illustration, hand-drawn ink linework with watercolor gouache textures, ultra-maximalist interior storytelling, an unoccupied high-rise family computer studio in Beijing’s bustling metropolis, modern Chinese home aesthetics with wood lattice shelving, ink-scroll accents, porcelain decor, dual-monitor desk setup, gaming console dock, retro game devices, hi-fi speakers, mechanical keyboard, headphones, layered cables and gadgets, Lunar New Year decorations in every corner with red lanterns spring couplets paper-cuts Chinese knots and festive ornaments, floor-to-ceiling window with glowing city skyline, 24mm wide environmental interior shot, eye-level, dense yet readable composition, warm tungsten ambient light mixed with subtle RGB tech glow, cozy lived-in atmosphere with strong futuristic vibe –no people, person, human, face, body, text, watermark, logo, sterile showroom, lowres blur, photoreal CGI texture –ar 16:9 –stylize 180 –chaos 8 –v 7.0 –p lh4so59





本文永久链接 – https://tonybai.com/2026/02/15/go-core-team-rejects-ai-authorship
大家好,我是Tony Bai。
在生成式 AI 狂飙突进的 2026 年,编程似乎变得前所未有的容易。Claude Code、Gemini Cli、Codex等 已经成为开发者的标配。然而,技术便利的背后,模糊的责任边界正在侵蚀软件工程的根基。
近日,在 Go 语言这个以“简单、可靠、高效”著称的开源圣殿里,核心团队被迫画下了一道红线。
起因是一个特殊的 CL(Change List 741504),提交者在描述中赫然写道:“Co-Authored-By: Claude Opus 4.5 noreply@anthropic.com”。这行看似“诚实”的署名,瞬间触动了 Go 语言之父 Rob Pike、Ian Lance Taylor 以及 Russ Cox 等大佬的神经。

这不仅仅是一个关于署名权的争论,这是整个开源世界在 AI 时代必须面对的“立宪时刻”:我们该如何划定人类与 AI 在代码创作中的界限?
本文将深度复盘这场发生在 Go 核心圈的讨论,并解读 Russ Cox 最终定调背后的深意。

事情的起因简单而诡异。开发者 John S 提交了一个修复 cgo 文档的 CL,并在描述中注明了 Claude Opus 4.5 是共同作者。
Ian Lance Taylor(Go 泛型的主要设计者之一)率先发难,敏锐地指出了这行字背后潜藏的两个致命法律风险:
Robert Griesemer(Go 创始三巨头之一)则从工程角度表达了担忧:
“如果代码描述是 AI 写的,我们可以删掉那行字。但如果是 Claude 写的代码,我们就有大麻烦了。”
Griesemer 的担忧直指 AIGC 的核心痛点:幻觉与平庸。他将 AI 现在的状态比作拼写检查器——它可以修正拼写,但它真的懂“修辞”吗?更重要的是,它懂“正确性”吗?
而 Rob Pike(Go 语言之父)的回复依然是那样简洁有力,且带有强烈的不容置疑:
“这是一个非常危险的滑坡(slippery slope)。我建议第一步简单点:说不(NO)。”

Rob Pike 意识到,一旦模糊了这条线,开源社区将面临“人的缺位”。谁来维护这些代码?谁来为 Bug 负责?是一个在那一刻运行的概率模型,还是那个按下 Enter 键的人?
在长达数日的讨论后,Russ Cox (rsc) 发表了一篇极具分量的总结性邮件,在这封邮件中,他代表 Go 核心团队给出了AI 时代Go项目的AI 政策宣示,并说明了划定这条红线的工程学必要性。
互联网上有一条著名的“布兰多里尼定律”(Brandolini’s law):反驳胡扯所需要的能量,比产生胡扯所需要的能量大一个数量级。
在编程领域,AI 正在制造同样的困境。Russ 指出:
“AI 工具诱使许多人陷入一种虚假的信念……人们以前所未有的速度生成大量的代码……就像看着会跳舞的大象,虽然令人惊叹,但通常既慢又笨拙,且难以维护。”
写代码变容易了,但代码审查(Code Review)变难了。
Go 的设计哲学是“代码被阅读的次数远多于被编写的次数”。而 AIGC 工具颠倒了这一关系。AI 可以在几秒钟内生成数百行看似完美、实则包含微妙 Bug 的代码。如果不划定红线,Go 项目将被机器生成的、无人真正理解的代码淹没。
工具的便捷性往往会让人关闭大脑。当 Claude Code 或 Copilot 给出一段代码时,开发者最自然的反应是“它看起来能跑”,然后直接提交。
这种“关闭大脑(Turn off your brain)”的行为,是工程质量的大敌。
Go 团队划定红线的目的,是强迫开发者回归理性:你必须理解你提交的每一行代码。如果连提交者自己都无法解释代码为什么这么写,那么这段代码就是项目的负资产。
除了工程哲学,Russ Cox 明确指出,法律风险是划定这条红线的硬性约束。
根据美国版权局(US Copyright Office)的指导意见,非人类创作的作品不受版权法保护。
这意味着,如果一段代码被认定为完全由 AI 生成,它可能直接进入公有领域(Public Domain),或者其版权归属处于薛定谔状态。
Go 项目要求所有贡献者签署 CLA(贡献者许可协议)。CLA 的核心前提是:贡献者拥有其提交代码的版权,并将其授权给 Google/Go 项目。
如果允许 AI 署名:
这是 Robert Engels 在讨论中反复强调的点:AI 是在什么数据上训练的?
如果 Gemini 或 Claude 记住了某段 GPL 或 AGPL 协议的代码,并在微调后将其“吐”了出来,而这段代码被合入了使用 BSD 协议的 Go 项目中,这就构成了严重的侵权风险。
作为顶级开源项目,Go 团队必须规避任何潜在的法律诉讼。“拒绝 AI 署名”是法律上的防火墙。
基于上述工程和法律的双重考量,Russ Cox 代表 Go 团队划定了极其清晰的政策红线。这份裁决不仅适用于 Go,也值得所有技术团队参考。

Go 项目不接受任何由 AI 模型作为共同作者的提交。
这不仅在法律上是无稽之谈(AI 没有法律主体资格),在工程责任上也是一种逃避。
提交者必须对代码负全责。
无论你用了什么工具——是 Vim、IDE 的自动补全,还是 Claude Code——当你提交代码时,你就是在声明:“这是我的作品,我理解它,我为它负责。”
Russ Cox 提出了一个极其严苛的标准:
“如果你用 AI 生成了代码,你必须像审查同事的代码一样,甚至更加严格地审查它。如果你不能自信地声称‘这是我写的’(即便你用了工具),那么就不要提交它。”
Go 的贡献者列表(AUTHORS 文件)只包含人类。
开源是人类智慧的结晶。AI 只是工具,是像编译器、Linter 一样的高级工具,但工具不能成为作者。
Go 团队划定的这条红线,实际上厘清了 AI 辅助编程(AI-Assisted)与 AI 生成编程(AI-Generated)的本质区别。
在红线之内,开发者的核心竞争力正在发生转移。
正如 Russ 所言:“审查代码比编写代码更难。”未来的高级工程师,本质上都是高级 Code Reviewer。
LLM 的训练基于海量的互联网数据,这意味着它生成的代码往往是“平均水平”的。但 Go 标准库追求的是“极致的工程化”。
如果过度依赖 AI,代码库的质量将不可避免地滑向平庸。这条红线,是为了保护代码库中人类工程师的审美和坚持。
2026 年初的这次讨论,为开源社区树立了一块重要的界碑。
面对 AI 的诱惑,Go 团队选择了一条更为艰难、保守,但也更为负责任的道路。他们划定红线,拒绝了“看起来很快”的捷径,坚守了“简单、可维护、人类可理解”的初心。
这条红线告诉我们:AI 是你的副驾驶,但永远不要让它接管方向盘。因为当车毁人亡时,坐牢的永远是你,而不是那个大语言模型。
资料链接:
你愿意为 AI 代码负全责吗?
Go 团队要求:如果你不能自信地声称“这是我写的”,就不要提交。在你的日常开发中,你会对 AI 生成的代码进行逐行 Review 吗?你认为“不准 AI 署名”是开源精神的回归,还是对技术进步的保守?
欢迎在评论区分享你的“红线”!
还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
扫描下方二维码,开启你的AI原生开发之旅。

你的Go技能,是否也卡在了“熟练”到“精通”的瓶颈期?
继《Go语言第一课》后,我的《Go语言进阶课》终于在极客时间与大家见面了!
我的全新极客时间专栏 《Tony Bai·Go语言进阶课》就是为这样的你量身打造!30+讲硬核内容,带你夯实语法认知,提升设计思维,锻造工程实践能力,更有实战项目串讲。
目标只有一个:助你完成从“Go熟练工”到“Go专家”的蜕变! 现在就加入,让你的Go技能再上一个新台阶!

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。

© 2026, bigwhite. 版权所有.
The era of the Small Giant (Interview)
My friends, welcome back. This is the Changelog. We feature the hackers, the leaders, and those living in this crazy world we’re in. Can you believe it? Yeah, Damian Tanner is back on the show after 17 years. Wow!
Okay, some backstory. Damian Tanner, founder of Pusher, now building Layer Code, returned to the podcast technically officially for the first time, but he sponsored the show. He was one of our very first sponsors of this podcast 17 years ago-almost, I want to say, I’m estimating, but it’s pretty close to that. I think that’s so cool. So he’s back officially talking about the seismic shift happening right now in software development. I know you’re feeling it, I’m feeling it, everyone’s feeling it.
So from first-time sponsor of the podcast to a frontline builder in the AI agent era, Damian shares raw insights on:
A massive thank you to our friends, our partners, our sponsor-yes, talking about fly.io, the home of changelog.com. Love Fly and you should too. Launch a sprite, launch a fly machine, launch an app, launch whatever on Fly we do-you should too. Learn more at fly.io.
Okay, let’s do this.
Well friends, I’m here again with a good friend of mine, Cal Galbraith, co-founder and CEO of Depot.dev. Slow builds suck. Depot knows it. Cal, tell me, how do you go about making builds faster? What’s the secret?
When it comes to optimizing build times to drive build times to zero, you really have to take a step back and think about the core components that make up a build.
All of that comes into play when you’re talking about reducing build time.
Some of the things that we do at Depot:
The other part of build performance is the stuff that’s not the tech side of it-it’s the observability side of it. You can’t actually make a build faster if you don’t know where it should be faster. We look for patterns and commonalities across customers and that’s what drives our product roadmap. This is the next thing we’ll start optimizing for.
So when you build with Depot, you’re getting this: you’re getting the essential goodness of relentless pursuit of very, very fast builds, near zero speed builds. And that’s cool. Kyle and his team are relentless on this pursuit-you should use them: depot.dev. Free to start, check it out. One-liner change in your GitHub Actions:
depot.dev
Well friends, I’m here with a longtime friend, first-time sponsor of this podcast, Damian Tanner. Damian, it’s been a journey, man. This is the 18th year of producing The Changelog.
As you know, when Netherlands and I started this show back in 2009, I corrected myself recently. I thought it was November 19th, but it was actually November 9th-the very first birthday of The Changelog.
November 9th, 2009.
Back then, you ran Pusher, Pusher app, and that’s kind of when sponsoring a podcast was almost like charity, right? You didn’t get a ton of value because there wasn’t a huge audience, but you wanted to support the makers of the podcast. And we were learning, and obviously open source was moving fast and we were trying to keep up, and GitHub was one year old. I mean, this is a different world. But I do want to start off by saying-you were our first sponsor of this podcast. I appreciate that, man. Welcome to the show.
Kind of you.
You know, reflecting on Pusher, we kind of just ended up creating a lot of great community, especially around London and also around the world with Pusher.
Yeah, and I really love everything we did. We started an event series, and in fact, another kind of like coming back around-Alex Booker, who works at Mastra, is coming to speak at the AI Engineer London meetup branch that I run. He started and ran the Pusher Sessions, which became… Really well-known talk series in London.
Okay, were you at the most recent AIE conference? I was in SF. Yeah.
Okay, what was that like? I kind of jump in the shark a little bit because I kind of want to talk-I want to juxtapose like Pusher then time frame developer to like now, which is drastically different. So don’t-let’s not go too far there. But how was AIE in SF recently?
It was a good experience. Always a good injection of energy going to SF. I live just outside London, but the venue was quite big and it didn’t have that like together feel as much as some conferences. But it was the first time that I sat in a huge conference hall, and I think it was like Windsurf or something. Chatting, I was like,
“This is really like-we’re all miners at a conference about mining automation, and we’re like we’re engineers, so we’re super excited about it. But right, it’s kind of weird like it’s gonna change all of our jobs.”
Alright, it’s like “I’m working right now to change everything I’m doing tomorrow.” I mean, that’s kind of how I viewed it.
I was watching a lot of the playback. I wasn’t there personally this time around, but I do want to make it the next time around. But, you know, just the Sean Swicks wing, the content coming out of there-everybody’s speaking. I know a lot of great people are there, obviously pushing the boundaries of what’s next for us, the frontier so to speak.
But a lot of the content-I mean almost all the content-was like top, top notch, and I feel like I was just watching the tip of humanity, right? Like just experiencing what’s to come.
Because in tech, you know this as being a veteran in tech, we shape-we’re shaping the future of humanity in a lot of cases because technology drives that. Technology is a major driver of everything, and here we are at the precipice of the next, the next, next thing. And it’s just wild to see what people are doing with it, how it’s changing everything.
Everything, I feel like, is like a flip. It’s a complete-not even a one-it’s like a 720. You know what I mean? Like it’s three spins or four spins. It’s not just one spin around to change things. I feel like it’s a dramatic forever-don’t even know how it’s going to change things, changing things, thing.
And, you know, bringing it back to the Pusher days, it’s the vibe we had then. You know, there was this period around just before Pusher and the first half of Pusher I felt like where we were going through this-maybe it’s called like the Web 2-but there was a lot of great software being built and a lot of, you know, the community.
And I think the craft that went into, especially like the Rails community, and we-we’re just-we’re able to build incredible web-based software.
And then, you know, we’ve gone through like the commercialization, industrialization of SaaS.
And what gets me really excited is now when we’re, you know, we run this AI Engineer London branch and incredible communities come together and it’s got that energy again. And I guess the energy is-it’s very exciting. There’s new stuff, everyone can play a part in it, and we’re also just all completely working it out.
And it’s like sure, you’ve got the, you know, folks on the main stage of the conference and then you’ve got-we’ll chat about it later maybe like Jeffrey Huntley posting his meme Ralph Wiggum blog post-it’s like that the crazy ideas and innovation is kind of coming from anywhere, which is brilliant.
Yeah, there’s some satire happened too. I think there was a convo, a talk that was quite comedic. I can’t remember who the talk was from but I was really just enjoying the fun nature of what’s happening and having fun with it-not just being completely serious all the time with it.
For those who are uninitiated-and I kind of am to some degree because it’s been a long time-remind me and our listeners what exactly was Pusher? And I suppose the tail end of that, how are things different today than they were then?
Pusher was basically a WebSockets push API so you could push anything to your web app in real time. So just things like notifications into your application.
We ended up having a bunch of customers maybe in:
In the early days, at one point Uber was using Pusher to update the cars in real time, and that was before they built their own infrastructure.
It was funny. I remember the stand-up because we ran a consultancy where we were chatting about the WebSockets in browsers and we’re like,
“Oh this is cool, how can we use this?”
And the problem is, you know, we were all building Rails apps, so like:
Okay, we need like a separate thing which manages all the WebSocket connections to the client, and then we can just post an API request and say, 'Push this message to all the clients.'
It was a simple idea and we took it seriously. and built it into a pretty formidable dev tool used by millions of developers and still use a lot today.
We eventually exited the company to MessageBird, who are a kind of European Twilio competitor. Actually, at one point, we nearly sold the company to Twilio-that would have been a very different timeline.
According to my notes, you raised 9.2 million dollars, which is a lot of money back then. I mean, it’s a lot of money now, but like that was tremendous. That was probably 2010, right? 2011 maybe. The bulk of that we raised later on from BoltOn. The first round was maybe half a million, very, very small.
It started out as an agency, so we built the first version in the agency just for fun, I suppose, and maybe some tears on your part.
Juxtapose the timelines: you got an acquisition ultimately but you mentioned Twilio was an opportunity. How would that have been different? If you can branch the timeline?
“It would have been a great experience to work with the team at Twilio. They’re incredible people. I’ve worked at Twilio and moved through Twilio.”
I haven’t calculated it, but we didn’t sell because the offer wasn’t good enough in our minds. It was a bit of a lowball and it was all stock. In hindsight, the stock hasn’t gone very well, so it turns out it was a good financial decision. But, yeah, would have loved that experience, I think.
Twilio became the kind of OG for dev rel and dev community. How we got to know them is we did a lot of combined events with them and hackathons. That was a fun time.
They were like the origination. Daniel Moral was very much quintessential in that process of a whole new way to market developers. I think that might have been the beginning of what we call dev rel today. Would you agree with that?
I mean, it’s like the - I mean, if there was a seed, that was one of many probably, but I think one of the earliest seeds to plant of what dev rel is today.
Crazy times, man.
So what do you… how do you think about those times of Pusher and the web, building APIs and SaaS services, etc., and pushing messages to Rails apps? How are today’s days different for you?
It’s exciting because the web and software is just completely changing again. I feel like we had that with Web 2, right? That was the birth of software on the internet, hosted software on the internet. It’s such an embedded thing in our culture and our business as developers. A lot of us work on that kind of software but most businesses run on SaaS software now.
I have to remind myself there was a time before SaaS, and therefore there can be a time after SaaS. There can be a thing that comes after SaaS. It’s not a given that SaaS sticks around.
I mean, like any technology, we tend to kind of go in layers. For example:
These changes, in the aggregate, take a lot of time.
The thing that can shift more quickly is the direction things are going. Really, in the last few months, I think I’ve been more and more convinced by my own experiences and things I’ve seen playing with stuff that:
it’s entirely possible - and probably pretty likely - that there is a post-SaaS.
I don’t know if everyone realizes it or is with that intention but all of us playing with agents and LLMs - whether it’s to build software or to do things - we are doing that probably instead of building a SaaS or we’re using it to build a SaaS. It’s already playing out amongst the developers.
It’s an interesting thought experiment to think about:
I’m curious because I hold that opinion to some degree. I think there’s what SaaS stays and what SaaS goes if it dies.
You said in the pre-column burst the bubble a little bit here. You did say, and I quote:
“All SaaS is dead.”
Can you explain, in your own words, all SaaS is dead?
I think I should probably go through my journey to here to kind of illustrate it. But give us the TL;DR first, though. Give us the clip and then go into the journey.
Okay, okay.
The TL;DR is SaaS.
So there’s a few layers:
I think most developers are very familiar with the building of software is changing now. But the operating software, the operating of work, the doing of work in all industries and all knowledge work, can change.
Like, we’ve changed software. SaaS is made for humans, slow humans to use the SaaS UI. Made for a puny human to go in, understand, work out this complex thing, and it has to be in a nice UI. If it’s not a human actually doing the work that they do in the SaaS, if it’s an AI doing that work, why is there a UI? Why is there a SaaS tool? The AI doesn’t need a SaaS tool to get the work done. It might need a little UI for you to tell you what it’s done, but the whole idea of humans using software, I think, is going to change.
Yeah, well, you’ve been steeped in APIs and SaaS for a while, so I hold that opinion that you have. Then I agree that if the SaaS exists for UI for humans, that’s definitely changing, so I agree with that.
What I’m not sure of, and I’m still questioning myself, is like what is the true solution here?
There are SaaS services that can simply be an API. You built them; I don’t really need the web UI. Actually, I kind of just prefer the CLI. I prefer just JSON for my agents. I kind of prefer Markdown for me because I’m the human. I want those good pros; I want all of it local so my agents can mine it and create sentiment analysis, all this fun stuff. You could do that with DuckDB and Parquet-just super, super fast stuff across embeddings and vector databases like pgvector.
All those fun things you could do on your own data.
But that’s where I stop. I do agree that the web UI will go away or some version of it. Maybe it’s just a dashboard for those who don’t want to play in the dev world with CLIs and APIs and MCP and whatnot.
But I feel like SaaS shifts. My take is:
CLI is the new app
That’s my take: SaaS will shift, but I think it will shift into CLI for a human to instruct an agent and an agent to do, and it’s largely based on:
Yeah, I guess we should probably kind of tease apart SaaS the business and SaaS the software.
Okay, because, yeah, I agree that the interface is changing-the interface that we use, whether it’s visually a CLI or a chat conversation or something-but the way we communicate with the software is changing. It’s a much more natural language thing. We don’t have to dig in the UI to find the thing to click.
But also so much of the software we use that we call SaaS, that we access remotely, if you can just magic that SaaS locally or within your company, right, there’s no need to access that SaaS anymore. You just have that functionality; you just ask for that functionality and it’s being built.
But yeah, SaaS, the business-I guess this is the challenge for companies today-is they’re going to have to, if they want to stay in business, shift somehow because, yeah, I mean, there’s still got to be some… some harness-harness is the wrong word because you use that in coding agents-but like you should do some infrastructure, some cloud, some coordination, authentication, data storage-there’s still a lot to do.
I think there’s going to be some great opportunities for companies to do that.
And maybe a CRM, you know, Salesforce or something, manages to say, hey:
“We are the place to run your sales agents, run your magically instantiated CRM code that you want just for your business.”
Maybe there’ll be some winners there.
But the idea that I think is going to change SaaS’s business-the SaaS software-is the idea that like everyone has to go and buy the same version of some software, which they remotely access and can’t really change.
Okay, I’m feeling that for sure. Take us back into the journey because I feel like I cut you off, and I don’t want to disappoint you-but not letting you go and give the context, the keyword for most people these days, the context for that blanket statement that:
“SaaS is dead or dying.”
Okay, I’ll give you a bit of the story.
So my company, Layer Code, we, I’ll just give you a little short on that: we provide a voice agents platform so anyone can add voice to their agent. It’s a developer tool, developer API platform for that.
We’re now ramping up our sales and marketing, and we kind of started doing it the normal ways. We kind of got a CRM; we got some marketing tools, and I was just finding-we went through a CRM or two-and I was just finding them like these are the new CRMs that are supposed to be good, but they were just really, really slow.
I just couldn’t work out how to do stuff. It was like I had to go and set up a workflow, and it felt like I needed training to use this CRM tool. And I’d been having a lot of fun with Claude Code and Codex, kind of both-both flipping between them, kind of getting a feel for them.
So I just said, “Build me”. I just voice-dictated, you know, a brain dump for like 10-15 minutes:
And also, it wasn’t just like a boring CRM. It was like,
“I need you to make a CRM that kind of engages me as a developer who doesn’t wake up and go, ‘Let’s do sales.’ Gamify it for me.”
Then here are the ways I want you to do that. And it just did it. That was my kind of like coding agents moment.
I think you have that moment when you do a new project where you use an LLM and a completely greenfield project. There’s no kind of existing code it’s going to mess up or get wrong, and the project’s not too big. It just built the whole freaking CRM, and it was really good.
It was a good CRM, and it worked really well. So that was like my kind of level one awakening, which was this idea that you can just have the SaaS you want instantly. It suddenly felt true because I had done it.
I have cancelled the old CRM system now, and there’s a bunch of other tools I plan to cancel, not because they’re all crap, but because it’s harder to use them than it is to just say what I want.
Because I kind of have to learn how to use those tools, whereas I can just say,
“Make me the thing. Make me the website I want” instead of using a website builder tool, or “Make me the CRM that I want to use.”
Then there’s this different cycle, this loop of improvement where it’s not a once-off. It’s not build and then use the software.
It’s like as you’re using the software, you can improve the software at any time.
We’ve still got to work out how this works:
Just within our team of three doing this stuff in the company, it was like:
“Oh, you’re annoyed with this part of the software? Just change it. Just change it.”
Yeah, when it annoys you at the exact point in time, and then continue with the work.
I assume you’re probably still doing something like a GitHub or some sort of primary git repository as a hub for your work, and you probably have pull requests or merge requests.
So even if your teammate is frustrated, improves the software, pushes it back, you’re still using the same software, and you’re still using the same traditional developer tooling such as:
- pull requests
- code review
- merging
Yeah, that’s going to have to change as well.
Okay, take me there.
I woke up this morning with that feeling, “Okay, that’s changing too.”
How’s it changing with the CRM and with something we’ve been building this week?
There were new pieces of software. There weren’t existing codebases. I didn’t have any prior ideas, tastes, or requirements about what the code should look like.
I think this is the thing that slows people down with coding agents. When you use it on an existing repo, LLMs have bad taste - they just give you kind of the most common denominator, kind of bad taste version of anything, whether it’s writing a blog post or coding.
So when you use it on an existing project and then you review the code, you just find all these things wrong with it. Like, right now, they love doing all this really defensive try-catch in JavaScript, or really verbose stuff, or writing a utility function that exists in a library already.
But when you start on a new project and you just use YOLO mode and you’re just building static for yourself as well, right? And it works-where’s the code? Why review the code?
I think we’re only in this temporary weird phase where we’re trying to jam these existing software processes that ensure we deliver:
I think it’s hard. We can’t throw that out-we’ve got SOC2 too, we can’t throw those out the window for everything that exists today.
But for everything new that you’re building, you’ve got an opportunity to kind of pull apart, question, and collapse down all these processes we’ve built for ourselves - processes that were built to ensure humans don’t make mistakes, help humans collaborate, and manage change in the repository and everything.
If humans aren’t writing the code anymore, we need to question these things.
Are you moving into the land of agent-first? Then it sounds like that’s where you’re going.
I feel like I’m being pulled into it by… yeah, I’m slight… I’m kind of like there. There is a tide. I can’t resist. I’m falling in the hole and we’re kind of like every-we’re dipping our toes in, right? Trying to try out an LLM, try out CursorTab, and then we’re kind of in there and we’re swimming, trying to swim the way we normally swim, the way we want to go. And suddenly I’ve just gone, just relax and just let the tide, let the river take you. Just let it go, man. Just let it go.
It’s scary. It feels kind of terrifying.
They’re gonna-and I don’t have the answers to how we do code review. But, you know, if you look at a lot of teams talking about using AI coding agents in the resisting project, everyone’s big problem now is code reviews. Why? Because everyone using coding agents is producing so many PRs; it’s piling up in this review process that has to be done. The new teams that don’t have that process in place are going multiple times faster right now.
This is the year we almost break the database. Let me explain.
Where do agents actually store their stuff? They’ve got:
And they’re hammering the database at speeds that humans just never have before. Most teams are duct-taping together a Postgres instance, a vector database, maybe Elasticsearch for search. It’s a mess.
Well, our friends at Tiger Data looked at this and said, “What if the database just understood agents?” That’s Agentic Postgres: it’s Postgres built specifically for AI agents, and it combines three things that usually require three separate systems:
The MCP integration is the clever bit. Your agents can actually talk directly to the database. They can:
without you writing fragile glue code. The database essentially becomes a tool your agent can wield safely.
Then there’s hybrid search. Tiger Data merges vector similarity search with good old keyword search into a SQL query - no separate vector database, no Elasticsearch cluster. Semantic and keyword search in one transaction, one engine.
Okay, my favorite feature: the forks. Agents can spawn sub-second zero-copy database clones for isolated testing.
This is not a database they can destroy. It’s a fork, a copy off of your main production database if you so choose.
We’re talking a one terabyte database fork in under one second. Your agent can run destructive experiments in a sandbox without touching production, and you only pay for the data that actually changes. That’s how copy-on-write works.
It works.
All your agent data-vectors, relational tables, time series metrics, conversational history-lives in one queryable engine. It’s the elegant simplification that makes you wonder why we’ve been doing it the hard way for so long.
So if you’re building with AI agents and you’re tired of managing a zoo of data systems, check out our friends at Tiger Data at tigerdata.com. They’ve got a free trial and a CLI with an MCP server you can download to start experimenting right now. Again, tigerdata.com.
What is replacing code review if there’s no code review? Is it just nothing?
I think as developers, we need to think more like-we need to put ourselves in the shoes of PMs, designers, managers, because they don’t look at the code right? They say “We need this functionality.”
We build it, we do our code reviews, we ensure it works, and the PM or whoever goes,
“Oh yeah, great, I’ve used it, meets the requirements. It’s great.”
They’re comfortable not looking at the code. They’re moving along, closing the deal, with the customer, integrating. They’re like,
“I am confident that the intelligent being that created this code did a good job.”
Now, I think the only reason we’re kind of stuck in this old process is because many of them are set in stone, but also because LLMs aren’t quite smart enough yet-they still make stupid mistakes. You still need a human in the loop (and on the loop).
They’re still a bit dumb. They get done with silly things and they do stuff. They’ll go the wrong direction for a while and I’m like,
“No, hang on a second, that’s a great thought here but let’s get back on track. This is the problem we’re solving and you’ve side-quested us.”
It’s a fun side quest if that was the point, but that’s not the point.
This is going to change, right?
One of the hard things is trying to put ourselves in the mind of what it’s going to be like a year from now. I think I’ve only been, you know, after being able to play with LLMs for several years, it feels like I can feel the velocity of it now. Because I’ve felt Chat GPT-3, 4, 5, Claude, Code Codex, and now I can say,
“Oh, okay, that’s what it feels like for it to get better.”
And it’s gonna keep. Getting better for a few more years, so it’s kind of like self-driving cars, right? They’re like not very useful while they’re worse than humans, but suddenly when they’re safer than a human, “why would you have a human?” Yeah, and I think it’s the same with coding. Like all this process is to stop humans making mistakes. We make mistakes; our mistakes are not special, better mistakes. They’re still like we stuff in code we call security incidents.
So I think as soon as the LLMs are twice as good, five times as good, ten times better at outputting good code that doesn’t cause these issues, we’re gonna start to let go of this concern, like these things right, we’re gonna start to trust them more.
Something I leaned on recently, and it was really with Opus 4.5, I feel like that’s when things sort of changed because I’m with you on the trend from ChatGPT or GPT-3 on to now and feeling the incremental change. I feel like Opus 4.5 really changed things.
And I think I heard it in an AIE talk or at least in the intention of it. If it wasn’t verbatim, it was “trust the model, just trust the model.” As a matter of fact, I think it was one of the guys-they were building an agent and in the pro it was maybe his agent layer, layer agent or something like that, maybe borrowed something from your name layer code. I have to look it up, I’ll get the talk, I’ll put it in the show notes.
But I think it was that talk and I was like, okay the next time I play I’m gonna trust the model. And I will sometimes like stop it from doing something because I think I’m trying to direct it a certain direction.
And now I’ve been like, wait hang on a second, this code’s free basically, it’s just going to generate anyways. Let’s see what it does. Worst case, I’m like, you know, roll it back or worst case is just generate better, you know what I mean, like ultra think, right? You know what’s the worst that could happen? Because it’s going faster than that can anyways.
So let’s see. Even if it’s a mistake, let’s see the mistake, let’s learn from the mistake because that’s how we learn even as humans. I’m sure Ellen’s the same.
And so I’ve come back to this philosophy or this thought, almost to the way you describe it like falling into this hole, slipping in via gravity. Not excited at first but then kind of like excited because it’s good in there. Let’s just go, just trust the model man, just trust the model!
It can surprise you, and I think that still gives me that dopamine hit that I would have coding, right? When I was coding manually, you’d get a function right and you’d be like, “ah it works.”
And now it’s like you’ve got like the whole application right and you’re like, “ah, I just did a problem, the whole thing works.”
That’s really exciting. And yeah, it’s fun right now. And I mean it’s gonna keep changing. This is just a bit of a temporary phase here and now. But I think for many of us building software we love the craft of it, which you can still do, but also the making-a-thing is also one of the exciting bits of it.
And the world is full of software still. Like you think about so many interactions you have with government services or whatever-not saying that they’re going to adopt coding agents particularly quickly, but there is a lot of bad software in the world.
And software has been expensive to build and that’s because it’s been in high demand. So I don’t think we’re going to run out of stuff to build.
I think even if we get 10 times faster, 100 times faster there’s so much useful software and products and things and jobs to be done.
Close this loop for me then: you said SaaS is dead or dying (I’m paraphrasing because you didn’t say or dying, I’m just going to say or dying, I’ll add it to your thing).
How is it going to change then? If we’re making software there’s still tons of software to write but SaaS is dead, what exactly are we making then if it’s not SaaS?
I know that not all software is SaaS but you do build something, a platform, and people buy the platform. Is that SaaS? What changes? You mentioned interfaces, like where do you see this moving?
I think we’re moving. And so this is the next level, the next kind of revelation I had was I started using the CRM and I was like, this is cool, this is super fast, this is better than the other CRM, you know, and I can change it.
Cool, I’m doing some important sales work, I’m enriching leads.
And then I kind of woke up a few days later, I was like, “Why am I doing the work? What’s going on here?” I create an interface for me to use, right? Why can’t Claude Code just do the work that I need to do for me?
I know it’s not going to be with the same taste that I have, and I know it’s going to make mistakes, but I can have 10 of… Them do it at the same time and I it’s not a particularly fun idea, fully automated sales and what that means for the world in general. But it’s the particular vertical where I had this kind of “right, well the enriching certainly makes sense for the LLN to do.” The enriching is like come on, that’s I’m just the API, I’m copying things, and a lot of it is still so manual.
So the revelation was just waking up and then going, “Okay, Claude Code’s gonna do the work for me today,” like it does for software. It builds the software for me. I’m gonna give it a Chrome browser connection-that’s still an unsolved problem. There’s a lot of pain in LLMs chatting to the browser, but there are a few good ones. I’m gonna let it use my LinkedIn, I’m gonna let it use my X, and I’m gonna connect it to the APIs that I need that aren’t pieces of software but like data sources-right? And get enriched and search things.
And then I just started getting it to just do it, and it was really quite good. It was slow but really quite good. That was a kind of - that was the moment where we typed in
build this feature in cloud code
build this
but it was suddenly like this thing can just do anything a human can do on a computer. The only thing holding it back right now is the access to tools and good integrations with the interfaces-the old software it still needs to use to do what a human does.
Yeah, a bigger context window and it’d be great if it was faster, but I can run them in parallel so that the speed’s not a massive problem. In the space of a week, I built the CRM and then I got Claude code to just do the work. But I didn’t tell it to use the CRM; I just told it to use the database. I just ended up throwing away the CRM. Now we have this little Claude code harness that:
I’ve just got like a database viewer that the non-technical team used to kind of look at the leads and stuff like that. It’s just a kind of beekeeper kind of database viewer. And now Claude code is just doing the work.
We’ve only applied it there, but this is just like Claude code is this kind of little innovation in AI that can do work for a long time. We already know people use ChatGPT for all sorts of different things beyond coding, right? So suddenly I think these coding agents are a glimpse of all knowledge work being sped up or replaced. Administration work can be replaced with these things now.
Yeah, these non-technical folks, why not just invite them to the terminal and give them CLI outputs that they can easily run and just use the up arrow to repeat? Or just teach them certain things they maybe weren’t really comfortable with doing before. Now they’re also one step from being a developer or a builder because they’re already in the terminal. That’s where cloud’s at.
Yeah, I mean, that’s what we’ve done now. I’ve seen some unexpected kind of teething issues with that. I think the terminal feels a bit scary to non-technical people even if you explain how to use it. When they quit Claude code or something, they’re just kind of lost; they’re like “Oh my gosh, where did Claude go?”
Yeah, and I was onboarding one of our team members, like “Hey, open the terminal,” and then I’m like, okay, we got a cd. What if the terminal was just Claude code though? What if you built your own terminal that was just - yeah, that’s what I actually think-that specific UI, whether it’s terminal or web UI, it’s kind of neither here nor there, but there is magic in a thing that can access everything on your computer or a computer.
And they’re doing that, I think, with something called Co-work. Have you seen Co-work yet? I haven’t played with it enough to know what it can and can’t do. I think I unleashed it on a directory with some PDFs that I had collected that was around business structure. It was like an idea I had four months ago with just a different business structure that would just make more sense primarily around tax purposes.
I was like, “Hey, revisit this idea I haven’t touched in forever.” It was a directory, and I think it went and just did a bunch of stuff. But then it was coming up with ideas, and I was like, “Nah, those are not good ideas.”
So I don’t know if it’s less smart than Claude code in intent or whatever, but I think that’s what they’re trying to do with Co-work. You could just drop them into essentially a directory, which is what Claude code lives in-a directory of maybe files. That is an application or knows how to talk to the database as you said your CRM does, and they can just be in a cloud code instance just asking questions:
Yeah, I could use a skill if you want to go that route, or it can just be smart enough to be like,
“Well, I have a Neon database here, the Neon CTL CLI is installed, I’m just going to query it directly, maybe I’ll write some Python to make it faster, maybe I’ll store some of this stuff locally and I’ll do it all behind the scenes.”
But then it gives this non-technical person a list of leads. All they had to do is be like:
“Give me the leads, man.”
You mentioned enabling them as builders. I think it is a window into that because when they want something, they get curious. They’ll be like,
You’d be surprised how easy that is. Like, “help me make it easier” is one of those weird ones. Claude Code will also autocomplete and just let you tab and enter.
I’ve noticed those things have gotten more terse, like maybe the last one I did was super short. It was like:
“I like it, implement it” and that was the completion for them.
I was like,
“Okay, is that how easy it’s gotten now to just spit out a feature that we were just riffing on; you understand the bug we just got over, and now your response to me to tell you what to say - because you need me, the human, to get you back in the loop at least in today’s REPL - is ‘I like it, implemented’?”
I found myself just responding with the letter “y” and a lot of the time it just knows what to do. Even if it’s a bit ambiguous, you’re kind of like,
“You’ll work it out.”
So I think it’s very exciting that Anthropic released this co-work thing because they’ve obviously seen that inside Anthropic, all sorts of people are using Claude Code.
When we think about someone starting there for non-coding purposes, but stuff is done with code and CLI tools and some MCPs or whatever APIs, then the user says,
“Make me a UI to make this easier.”
For instance, I had to review a bunch of draft messages that I wrote and was like,
“This is kind of janky in the terminal, make me a UI to do the review.”
And I just did it.
I think this is exactly where software is changing because when the LLM is 10 times faster-I mean if you use the Grok with a Q endpoint-they’re insanely fast, it’s going to be fast, then if you can have any interface you want within a second,
Why have static interfaces?
Yeah, I’m camping out there with you.
What if everything was just in time? I think that interface-
What if I didn’t need a shirt with you because you’re my teammate, but what if you could do the same thing for you and it solves your problem and you’re in your own branch, and what you do in your branch is like Vegas and it stays there?
It doesn’t have to be said anywhere else, right? Like,
“Just leave it in Vegas.”
What if in your own branch, in your own little world as a Sales Development Representative (SDR) who’s trying to help the team and help the organization grow, and all they need is an interface, what if it was just in time for them only?
It didn’t matter if it was maintainable. It didn’t matter how good the code was. All that mattered was that it solved their problem, got the opportunity, and enabled them to do what they’ve got to do to do their job.
You just take that and multiply it or copy and paste it onto all the roles that make sense for that just-in-time world. It completely changes the idea of what software is.
It also completely changes how we interact with a computer, what a computer does, and what it is for.
I just love this notion that
Every user can change the computer, can change the software as they’re using it, as they like it.
I think that’s very exciting-it’s essentially everyone’s a developer.
Yeah, I mean, it’s the ultimate way to use a computer. All the gates are down. There’s no geeky pretty more.
If I want software the way I want software, so long as I have authentication and authorization, I got the keys to my kingdom. I want to make it my way.
And I think also the agents can preempt. I haven’t tried this yet, but I was thinking of giving it a little sales thing - we have a little prompt where it says,
Even if a web UI is going to be better for the user to do this review, just do it.
So instead of you asking it to do some work, it just comes. Back and be like “oh, what I’ve made you this UI where I’ve displayed it all for you. Have a look at it, let me know if you’re happy with it.” I mean, this is getting kind of wild-a bit of an idea-but it’s kind of how we can think about how we communicate with each other as humans, as employees. We have back-and-forth conversations. We have email, which is a bit more asynchronous.
You know, we put up a preview URL of something. I think all of those communication channels can be enabled in the agent you’re chatting to. I haven’t liked this kind of product companies sell-the initial messaging where people are sort of like digital employees. But something like that’s going to happen, and I don’t think it’s the exciting bit.
For me, the exciting bit is the human-computer interaction. It’s like, yeah, this is how it is-it’s quite exciting in the context of Layer code and why we love voice. Voice is this OG communication method, whereas humans-we started speaking before we were writing.
It’s a quite rich communication medium and a terrific way-if your agents can be really multi-medium, whether it’s:
There doesn’t have to be these strict modes or delineations between those things. Well, let’s go there-I didn’t take us there yet, but I do want to talk to you about what you’re doing with Layer code.
I obviously produce a podcast, so I’m kind of interested in speech-to-text to some degree because transcripts, right? Then you have the obvious version which is like you start out with speech and get something or even a voice prompt.
What exactly is Layer code? I suppose we’ve been 51 minutes deep on nerding out on AI essentially, and not at all on your startup and what you’re doing, which was sort of the impetus of even getting back in touch. I saw you had something new you were doing, and I’m like, well, I haven’t talked to Damian since he sponsored the show almost 17 years ago. It’s probably a good time to talk, right?
So there you go, that’s how it works out.
Has your excitement and your dopamine hits on the daily or even by minute by minute changed how you feel about what you’re building with Layer code, and what exactly are you trying to do with it?
Well, and we’ve talked a lot about the building of a company and the building of software now. I think founders today have that as important as the thing they’re building because if you just head into your company and operate it like you did even a few years ago-using no AI, using all your slow development practices, using slow sales and marketing practices-you’re going to really get left behind.
So there is a lot to be done in working out and exploring:
I’m very excited about the idea that we can build large companies with small teams.
I think a lot of developers-well, I mean, there is a lot of HR, politics, and culture change that happens when teams get truly large and companies get truly large. This was one of the founding principles when we started our startup:
“Let’s see how big we can make this with a small team.”
And that’s very exciting because I think you can move fast and keep a great culture.
So that’s why we invest a lot of our energy into the building of the company and what we build and provide right now. Our first product is a voice infrastructure-a voice API for real-time building of voice AI agents.
This is currently a pretty hard problem. We focus a lot on the real-time conversational aspect, and there’s a lot of wicked problems in that:
If you’re a developer building an agent-whether it could be your sales agent or a developer coding agent-and you want to add voice AI, there’s a bunch of stuff you’ll bump into when you start building that.
It’s interesting. We kind of see our customers, and we can predict where they are on that journey because there are a bunch of problems you don’t preempt, and then you quickly slam into them.
We’ve solved a lot of those problems. So with Layer code, you can just take our API, plug it into your existing agent backend.
You can use:
- Any backend you want
- Any agent LLM library you want
- Any LLM you
The basic example is a Next.js application that uses the Versele AI SDK. We’ve also got Python examples as well. You connect to the Voice Layer code and put in our browser SDK, and then you get a little voice agent microphone button and everything within the web app.
We also connect to the phone over Twilio, and for every turn of the conversation, whenever the user finishes speaking, we ship your backend that transcript. You call the LLM of your choice and do your tool calls-everything you need to generate a response as you normally do for a text agent. Then you start streaming the response tokens back to us. As soon as we get that first word, we start converting that text to speech and start streaming it back to the user.
There’s a lot of complexity to make that really low latency and a real-time conversation where you’re not waiting more than a second or two for the agent to respond. We put a lot of work into refining that. There’s also a lot of exciting innovation happening in the model space for voice models, whether it’s transcription or text to speech.
We give you the freedom to switch between those models. You can try out different voice models:
You can find the right trade-off for your experience. There’s a lot of trade-offs in voice between:
We let users explore that and find the right fit for their voice agent.
That is interesting. So, the Next.js SDK streaming latency-is it meant to be the middleware between implementation and feedback to the user?
Yeah, we handle everything related to the voice basically, and we let you just handle text like a text chatbot. There’s no heavy MP3 or WAV file coming down-everything is streaming.
The very interesting problem to solve is that the whole system has to be real-time. The whole thing we call a pipeline. I don’t know if that’s a great name for it because it’s not like an ETL loading pipeline or something, but we call it a pipeline.
The real-time agent system backend, when you start a new session, runs on Cloudflare Workers. It’s running right near the user who clicked to chat with your agent with voice. From that point on, everything is streaming.
The hardest part is working out when the user has finished speaking. It is so difficult because people pause, make sounds, pause again, and start again. Conversation is very dynamic-it’s like a game almost.
We have to do some clever things and use other AI models to help detect when the user has ended speaking. When we have enough confidence-there’s no certainty, but enough confidence-that the user has finished their thought, we finalize that transcript.
We finish transcribing that last word and ship you the whole user utterance. Whether it’s a word, sentence, or paragraph the user has spoken, we bundle it up and choose an end.
The reason we have to do this bundling and can’t stream the user utterance continuously is because LLMs don’t take streaming input.
You can stream input, but you need the complete question to send to the LLM to then make a request and start generating a response. There is no duplex LLM that takes input and generates input/output simultaneously.
Here’s a conceptual question:
What if you constantly wrote to a file locally or wherever the system is, and then at some point, it just ends and you send a call that signals the end versus packaging it all up and sending once it’s done? Like incrementally line by line?
I’m not sure how to describe it, but that’s how I think about it. You constantly write to something and then say,
“Okay, it’s done,” and what was there becomes the final input.
So yes, we can do that in terms of having partial transcripts. We can stream those partial transcripts and then say,
“Okay, now it’s done, now make the LLM call.”
Then you make the LLM call.
Interestingly, sending text is actually super fast in the context of voice, very fast compared to all other steps involved. And actually the default example, this is crazy, I didn’t think this would work until we tried it. But it just uses a webhook. When the user finishes speaking, the basic example sends your Next.js API a webhook with the user text. And it turns out the webhook - sending a webhook with a few sentences in it - that’s fine, that’s fast.
It’s all the other stuff like then waiting for the LLM to respond. Yeah, that’s actually not the hard part. I mean, you have maybe a millisecond-ish or a few milliseconds, but it’s not going to be a dramatic shift, right? The way I described it versus how, yeah.
And we’ve got a web socket endpoint now, so we can kind of shave off that HTTP connection and everything. But yeah, then the big heavy latency items come in, so:
Generating an LLM response. Most LLMs we use right now - the ones we’re using, coding agents - they’re optimized for intelligence, not really speed.
When people optimize for speed, LLM labs tend to optimize for just token throughput. Very few people optimize for time to first token.
And that’s all that matters in voice: I give you the user utterance, how long is the user going to have to wait before I can start playing back an agent response to them? And time to first token is that, right? How long before I get the first kind of word or two that I can turn into voice, and they can start hearing?
The only major LLM lab that actually optimizes for this or maintains a low latency of TTFT (time to first token) is:
OpenAI, most voice agents now are doing it this way. We’re using GPT-4o or Gemini Flash. GPT-4o has some annoying, open API points with some annoying inconsistencies in latency, and that’s kind of the killer in voice, right?
It’s a bad user experience if it works - the first few turns of the conversation are fast, and then suddenly the next turn the agent takes three seconds to respond. You’re like:
“Is the agent wrong? Is the agent broken?”
But then once you get that first token back, then you’re good, because then you can send that text to us, start streaming text to us, and then we can start turning it into full sentences.
And then again, we get to this batching problem. The voice models that do text to voice, again, they don’t stream in the input. They require a full sentence of input before they can start generating any output, because again, how you speak and how things are pronounced depends on what comes later.
So you have to buffer the LLM output into sentences, ship the buffered sentences one by one to the voice model, and then as soon as we get that first chunk of 20 millisecond audio, we chunk it up into streams, stream that straight back down web sockets from the Cloudflare worker straight into the user’s browser, and can start playing the agent response.
Friends, you know this - you’re smart - most AI tools out there are just fancy autocompletes with a chat interface. They help you start the work, but they never do the fun thing you need to do, which is finish the work. That’s what you’re trying to do:
Those pile up into your Notion workspace - looks like a crime scene. I know mine did.
I’ve been using Notion Agent, and it’s changed how I think about delegation - not delegation to another team member, but delegation to something that already knows how I work, my workflows, my preferences, how I organize things.
And here’s what got me: as you may know, we produce a podcast. It takes prep, a lot of details - there’s emails, calendars, notes here and there, and it’s kind of hard to get all that together.
Well, now my Notion Agent helps me do all that. It organizes it for me. It’s got a template based on my preferences, and it’s easy.
Notion brings all your notes, docs, projects into one connected space that just works. It’s:
You spend less time switching between tools, and more time creating that great work you do - the art, the fun stuff. And now, with Notion Agent, your AI doesn’t just help you with your work; it finishes it for you, based on your preferences.
Since everything you’re doing is inside Notion, you’re always in control. Everything the agent does is:
You can trust it with your most precious work.
As you know, Notion is used by us - I use it every day. It’s used by over 50 percent of Fortune 500 companies and some of the fastest-growing companies out there like:
They all use Notion Agent to help their teams:
So try Notion now with Notion Agent at:
notion.com/changelog
That’s all lowercase letters: notion.com/changelog to try your new AI. Teammate Notion Agent today, and we use our link as you know you’re supporting your favorite show: the changelog once again notion.com/changelog.
You chose TypeScript to do all this. We’re pretty set on Cloudflare Workers from day one, and it just solves so many infrastructure problems that you’re going to run into later on.
I like-I don’t think we’ll need a devops person ever. It’s such a- That’s interesting. It’s such a wonderful-there are constraints you have to build to, right? You’re using V8 JavaScript, browser JavaScript, in a Cloudflare Worker. Tons of Node APIs don’t work there. There is a bit of a compatibility layer; you do have to do things a bit differently.
But what do you get in return?
There’s often quite big spikes, like 9 a.m.-everyone’s calling up, there’s an agent somewhere, asking to kind of book an appointment or something. You get these big spikes. You want to be able to scale, and you need to scale very quickly because you don’t want people waiting around.
If you throw tons of users on the same system and start overloading it, then suddenly people get this problem where the agent starts responding in three seconds instead of one second. It sounds weird, but yeah, Cloudflare gives you an incredible amount of that for no effort.
Compared to Lambda and similar platforms, it’s also pretty nice: the interface is just an HTTP interface to your worker. There’s nothing in front, and you can do WebSockets very nicely.
There’s this crazy thing called Durable Objects, which I think is a bad name and also kind of a weird piece of technology, but it’s basically:
You can have it take a bunch of WebSocket connections and do many SQL writes to its SQLite database it has attached. You don’t have to do any kind of special stuff dealing with concurrency and atomic operations.
A simple example is to implement a rate limiter or a counter or something like that very simply in Durable Objects.
You can have as many Durable Objects as you want. Each one has a SQLite database attached. You can have 10 gigabytes per one, and you can do whatever you want.
For example:
- You could have a Durable Object per customer that tracks something that you need to be done in real time.
- You could have a Durable Object per chat room.
As long as you don’t exceed the compute limits of a Durable Object, you can use it for all sorts of magical things.
I think it is a real under-known thing that Cloudflare has. Coming from Pusher, it’s like the kind of real-time primitive now. A lot of the stuff we’d reach for something like Pusher, Durable Objects, especially when building fully real-time systems, is really, really valuable.
You chose TypeScript based on Cloudflare Workers because that gave you:
For those who choose Go-or I don’t think you choose Rust for this because it’s not the kind of place you’d put Rust-but Go would compete for the same kind of mind share for you.
How would the system have been different if you chose Go? Or can you even think about that?
I haven’t actually written any Go, so I don’t know if I can give a good comparison. From the perspective of what we do have out there, there are similar real-time voice agent platforms in Python. I think because many people building the voice models then built coordination systems like layer code for coordinating real-time conversations, Python was the language they chose.
I think what’s more important is the patterns rather than the specific languages.
We actually wrote the first implementation with RxJS, which has implementations in most popular languages. I hadn’t used it before, but we chose it for stream processing. It’s not really for real-time systems, but it gives you… Subjects channel these kinds of has its own names for these things but basically it’s like a pub-sub kind of thing. Then it’s got this kind of functional chaining thing where you can pipe things, filter messages, split messages, and things like that.
That did allow us to build the first version of this quite dynamic system.
We didn’t touch on it, but interruptions are another really difficult dynamic part. Whilst the agent is speaking its response to you, if the user starts speaking again, you need to decide in real time whether the user is interrupting the agent or just agreeing with the agent -
“Oh gosh” or are they trying to say “oh stop”?
That’s a hard problem to solve.
We still have to be transcribing audio even when the user is hearing it. We have to deal with background noise and everything. Then, when we’re confident the user is trying to interrupt the agent, we’ve got to do this whole kind of state change where we tear down all of this in-flight LLM request and in-flight voice generation request, and then as quickly as possible, start focusing on the user’s new question.
Especially if their interruption is really short, like:
Suddenly you’ve got to tear down all the old stuff, transcribe that word stop, then ship that as a new LLM request to the back end, generate the response, and get the agent speaking back as quickly as possible.
And that’s all happening down one pipe, as it were, at the end of the day - audio from the browser microphone, then audio replaying back.
We would have bugs like:
You’re kind of in Audacity or some audio editor, trying to work out:
“Why does it sound like this?”
You’re rearranging bits of audio, going:
“Ah, okay, the responses are taking turns every 20 milliseconds, it’s interleaving the two responses.”
Real, real pain in the ass.
When you solve that problem of the interruption:
How do you direct that interrupt? It really depends on the use case - how you configure the voice agent, really depends on how the voice agent is being used.
For example:
When we call those audio environments, it’s often an early issue users have, like:
Big problem with audio transcription is that it just transcribes any audio it hears. If someone’s talking behind you, it just transcribes that. The model doesn’t know that’s irrelevant conversation.
If you imagine the therapy voice agent, it needs to:
Maybe even tears or crying, or just some sort of human interrupt - but not a true interrupt. It’s something you should maybe even capture in parentheses.
You can choose a few different levels of interruption:
By default, we interrupt when we hear any word that’s not a filler word, so we filter out things like “um”, “uh”, etc.
If you need more intelligence, you can ship off the partial transcripts to an LLM in real time.
For example, let’s say the user starts interrupting the agent every word or every few words, you:
Here's the previous thing the user said, here's what the agent said, here's what the user just said.
Yes or no, do you think they're interrupting the agent?
You get that back in about 250-300 milliseconds.
As you get new transcripts, you:
Then you get the response from that and can make a quite intelligent decision.
These things feel very hacky but they actually work very well.
The first thing I think about there is that Gemini Flash is not local, so you do have to deal with:
Or in the Claude I would… Say Cloud Web’s case, most recently, a lot of downtime occurred because of really heavy usage. The last two days, I’ve had more interruptions on the web than ever, and I’m like that’s because, yeah, it’s the Ralph effect. I’m like, okay cool, I get it. You know, I’m not upset with you because I empathize with how in the world do you scale those services.
So, why does your system not allow for a local LM to be just as smart? Then Gemini Flash might be, to answer that very simple question-like an interrupt, it’s a pretty easy thing to determine.
Yeah, I think smaller LMs can do that. Gemini is just incredibly fast, I think because of their TPU infrastructure. They’ve got an incredibly low TTFT (time to first token), which is the most important thing. But I agree that there are smaller LMs, and actually, I think probably maybe one of the Grok with a Q, Llamas, actually might even be a bit faster. We should try that.
You make a point about reliability. People really notice it in voice agents when it doesn’t work right, especially if a business is relying on it to collect a bunch of calls for them.
So, that is one of the other helpful things that platforms like ours provide-even just cost. I imagine over time, cost is a factor. Right now, you’re probably fine with it because you’re innovating and maybe finding out things like:
You’re sort of just-in-time building a lot of this stuff, and you might be okay with the inherent cost of innovation. But at some point, you may flatten a little bit and think, “You know what? If it had been running locally for the last little bit, we just saved 50 grand.” I don’t know what the number is, but the local model becomes a version of free when you own:
- The hardware
- The compute
- The pipe to it
You can own the SLA latency to it as well as the reliability that comes from that.
There are some cool new transcription models from NVIDIA, and they’ve got some voice models. There was a great demo of a fully open-source local voice agent platform done with Pipecat, which is the Python coordination agent infrastructure open source project that I was mentioning.
They’ve got a really great pattern: a plug-in in plug-in pattern for their voice agent. I think that’s the right pattern. We’ve adopted a similar one, and other frameworks have done that. We’ve adopted a similar pattern for ours when we rebuilt it recently.
The important thing is the plugins. These are kind of independent things that you can test in isolation. That was the biggest problem we had with RxJS-the whole thing was kind of like mixing, kind of audio mixing things where you have cables going everywhere. It was kind of like that with RxJS subjects going absolutely everywhere.
It was hard for us as humans to understand. It was the kind of code where you come back to a week later and ask, “What was happening here?” Often, we’d write code where the code at the top of the file was actually the thing that happened last in execution, just because that’s how RxJS was telling us to do it or guiding us on how we had to initialize things.
One of the key things we did was move to a plug-in architecture. We moved to a very basic system with no kind of RxJS style stream processing plugin-just all very simple JavaScript with async iterables. We just pass a waterfall of messages down through plugins. It’s so much better.
We can take out a plugin if we need to, unit test the plugin, write integration tests, and mock out plugins up and down. We’re about to launch that, and that’s just a game changer.
Interestingly, tying back to LLMs, we ended up here because with the first implementation, we found it hard as developers to understand the code we’d written. The LLMs were hopeless; they just could not hold the state of this dynamic, crazy multi-subject stream system in their head. The context was everywhere-it was here and there.
Even if I would take the whole file, copying and pasting files into ChatGPT Pro, being like:
“You definitely have all the context here, fix this problem.”
And they would solve the problem.
Part of the problem was that complexity-not having the ability to test things in isolation meant we couldn’t have a kind of TDD loop, whether with a human or with an agent.
Because of that, we couldn’t use agents to add features to this. The platform to the core of the platform was slowing us down, and so that’s when we really started to use coding agents called Code and Codex like really properly and hard. I spent two weeks just with Code, Codex, and the mission was:
“If I can get the coding agent to write the new version of this, it was kind of not even a refactor; it had to be rewritten start from scratch, first principles.”
Then, by virtue of it writing it, it’ll understand it, and I’ll be able to use coding agents to add features.
I started with literally the API docs for our public API because I didn’t want to change that, and the API docs of all the providers and models we implement, with like the speech-to-text and text-to-speech model provider endpoints, and just some ideas about
That experience was really interesting because it felt like molding clay. I really cared about how the code looked because I wanted humans, as well as engineers, to read it. The agents aren’t quite good enough to build this whole thing from a prompt, but I think they will be in a year or two. It did an okay job and needed a lot of
But it felt like clay in one sense because, as you mentioned earlier, you can just write some code, and even if it’s wrong, you’ve kind of learned some experience.
I was able to just say: “write this whole plugin architecture,” and it would do it. I’d be like, “Oh, that seems a bit wrong, that’s hard to understand.” Then I would say:
“Write it again like this,” “Write it again like this.”
I suddenly got that experience of throwing away code because it hadn’t taken me weeks and weeks to write this code; it had taken me 10 minutes, and I was like, “Doesn’t matter, just throw it away.”
You still have your chat session too, so even if you have to scroll back up a little bit or maybe even copy that out to a file for long-term memory if you needed to, you still have that there as a reference point.
I find myself doing similar things where it’s just like,
It did a terrific job.
The bit that really got it over the finish line was when I gave it this script that we used to have to do manually to test our voice agent. You know, it’s like:
There are like 20 different tests you had to do. I gave it that script and was like,
“Write the test suite for all of these tests.”
It did. I gave it all these bugs we had in our backlog, I was like:
“Write tests for this.”
I started doing TDD (test-driven development) in our backlog, and it was great.
Then I did a chaos monkey thing. I was like,
“Write a bunch of tests for crazy stuff the users could do with the API.”
Yes, it found a bunch of bugs and issues, including security issues.
It got it working, had a bunch of unit tests, and I was still having to do a bit of manual testing. Then one day, I realized:
“I really want a no one’s made integration test thing for voice agents.”
There are a few observation platforms, observability platforms, and eval platforms, so I was like, I just wanted to simulate conversation.
That’s part of the magic: trying something that you’re like,
“This is a pain in the ass to build,” or “How is this even going to work?”
I just got it to build it.
I recorded some wav files of me saying things and gave them to it with:
“Make an integration test suite for this and feed the wav files like you’re having a conversation and check the transcripts you get back.”
It did a great job and was actually able to fully simulate those conversations and do all the tests.
Then that - I mean, we’ve got these practices like TDD which are going to hold value. It was so valuable for the model, for the agent, to be running the test, fixing the test, running the test, fixing your tests, and that feels a bit like magic when you get it working.
So much to cover in this journey. Wow, I’m so glad we had this conversation.
I kind of feel like a good place to begin to end, not actually end, is back to this idea that is on your about page.
I’m just amazed because I love to write and really hate paper because this thing has Linux on it, and I wrote an API that I now use with my Remarkable Pro tablet. So amazing. I’m loving it. You need to be able to code Codex from your tablet. That’s next. I just got it, so the next thing is I’m gonna have this little playground for me basically, but it’s real time. So if you see me looking over here writing, audience or even you Damian, I’m not not paying attention-I’m writing things down.
One thing I wrote down earlier from your about page was the era of the small giant, which you alluded to but didn’t say those exact words. The reason why I think it might be a good place to begin to end is that I want to encourage the single developer, who may in the last couple months just begun to touch and not resist falling into this gravity hole or however we describe this resistance we’ve had as developers loving to read our own code and code review and all the things as humans.
Now, not resist as much or if at all, and just trust the model. To give them this word of encouragement towards:
“Hey, you’re a single developer, and in your case Damian, you don’t need a DevOps. It’s not that they’re not valuable or useful, but you chose a model, a way to develop your application to solve your problem that didn’t require a DevOps team.”
Give them that encouragement. What does it mean to be in this era of the small giant world?
I think the hardest thing is our own mindset, right? I just found this with coding agents-you start off putting in things where you kind of have an idea, you know what to expect out of it, and then you start just putting in stuff that seems a bit ridiculous and ambitious. Oftentimes it fails, but more and more it’s working. That’s a very magical feeling and a very revealing kind of experience.
So, I think we can all be more ambitious now. Especially as engineers, we know how the whole thing works. There is a lot of power everyone’s being given with vibe coding, being able to vibe code. There are a lot of security issues; I think they’ll be solved over time, but as engineers, we have the knowledge to be able to:
But we can do so much more now; we can be so much more ambitious.
I think the thing that every engineer should be doing now is not only trying out Claude Code and Codex and doing something new and fun. The great thing is it’s so low risk, so easy to do that you can build something ridiculous and fun that you’ve always wanted to do.
Heck yeah, you can just build something for a friend, for your wife-it’s like that. That’s really exciting.
I think this Ralph Wiggum thing, a very kind of basic idea, is:
Give a spec.md or a todo.md-just an ambitious task or a long list of tasks in a markdown file.
Run a shell script that just says to Claude Code:
- "Do the next bit of work."
- When there's no more work to do, return "complete."
The shell script just greps for "complete," and if it hasn't seen that word in some XML tags, it calls Claude Code again.
Like many of these things, it seems like a terrible idea; it seems ridiculous, but it’s also incredible what it can do. I think that’s probably one way to feel what the future is going to be like.
I feel like you write down something very ambitious in a markdown file or transcribe an idea you’ve been thinking about for a while and you set a Ralph Wiggum script off in it. Then you just go for a long walk or have lunch. When you come back, it’s a very exciting feel.
As a developer, it’s very fun because then you get to go through all this code and be like,
“Why did it do that?” and you’re like, “Oh that was pretty smart that it did it like that.”
Okay, that was quite a good idea. Then it messed up this bit, but that’s a very exciting experience-very cool.
I definitely agree with that. I’m looking forward to writing that todo.md or spec.md and just going for that one because I haven’t done it yet.
I’ve only peeked at some of the videos and demos, but I haven’t tried the Ralph Wiggum loop.
I’m gonna post on X a one-liner Ralph as well because I think you can just copy and paste and go-there’s no blog post to read.
Well, I feel like with everything, I want to make it more ceremonious-not because it needs to be, but because I want to know. I want to give myself space to think of something challenging for me even, and then give it to the thing and go away, like you said, and come back happy.
I want to save space to do that when I can give it. Full mind share versus the incremental 20 minutes or 10 minutes or whatever it might be that I have available to give it, I kind of want to give it a bit more ceremony, not because it deserves it, but because I want to actually do it for myself.
I’m just in this like constant learning scenario. It’s a pretty wild era to be a developer and to be an enabled developer. You know, non-technical folks may get introduced to a terminal-like thing that basically is just Claude in a directory where they can ask questions and get a just-in-time interface that is managed to them only. That’s a really, really, really cool world to be in.
It doesn’t mean that software goes away; it just means there’s going to be a heck of a lot more of it out there. I do concur that maybe code review doesn’t matter anymore. Maybe it won’t in a year, maybe it won’t in six weeks. I don’t know how many weeks it will take.
Let’s truly end with this:
What’s over the horizon for you? What’s over the horizon for Layer Code? What is coming?
The show will release next Wednesday, so you’ve got a week. Given that horizon, and no one’s listening now, it’s a week from now. What’s on the horizon for you that you can give us a peek at? Is there anything?
We are working really hard to bring down the cost of voice agents.
I’m very excited for that and, most of all, very excited just to see voice AI everywhere. Voice is just such a wonderful interface. I find myself dictating all the time to Claude Code, and you can kind of get out your thoughts so much better.
I’m excited to see how many applications we can enable by adding voice AI into their application. Then
we get an insight into the future of voice AI as well with the companies that are working-most of them are startups-and they’re building some crazy, crazy new things with voice AI on our platform.
So, there’s going to be some amazing stuff with voice coming out this year.
What’s the longing fruit? What’s the sweet spot for Layer Code right now that you can invite folks to come and try?
Well, the great thing is we’ve got a CLI single command you can run, and you’ll get a Next.js demo app all connected to Layer Code voice agent. You can get a voice agent running up and running within a minute. So, it’s super fun, worth trying.
From that point, you can use Claude Code, Codex, and just start building from there.
Well, friends, right here at the last minute, the very last question—Damian’s internet dropped off or something happened, I’m not sure. But it was a fun conversation with Damian.
It’s kind of wild to be talking to somebody 17 years later after being one of the first, if not the first-I’m pretty sure the first-sponsor of this podcast. What a wild world it is to be this deep in years and experience, in history in software, and to just still be enamored by the possibilities.
I hope you enjoyed today’s conversation with Damian, and we’ll see you next time.
Well, friends, the YOLO mode philosophy is out there. The code review is a bottleneck, maybe non-existent. SaaS may be dying or dead. It’s time to trust the model, building a CRM just in time.
What kind of world is this we’re living in? Did you think the beginning of 2026 would be this kind of year?
Now, I know if you’re listening to this podcast at the very end and you’re a Spotify hater, well, guess what, AI is here to stay. You should read the tea leaves. That’s just me being honest.
But seriously, you can’t deny the impact that AI is having. Everyone is talking about it. Everyone is using it. And those who aren’t, well, we’ll see.
I know our friends over at
are all loving this podcast just like you. Much thanks, much love, appreciate the support.
But hey friends, this show’s done, this show’s over. I’m glad you listened. We’ll see you again real soon.
See the changes in my blog! I’m proud to introduce hexo-theme-paperwhite to you all! Now in beta stage! Check it on GitHub
hexo-theme-paperwhite is a minimalist theme for Hexo. I made it to fulfill my own needs, including a pure home page and the serif font. I am a huge fan of minimalist designs!
It’s simple. Actually just no more than 10 lines of code! Here’s the _config.paperwhite.yml
1 | menu: |
Sorry to tell that I failed… Now I’ve completely switched to hexo-theme-cactus for lack of Web Front-end developing experience.

本文永久链接 – https://tonybai.com/2026/mm/dd/clawdbot-author-peter-steinberger-full-interview
大家好,我是Tony Bai。
在硅谷,每天都有无数个 AI 项目诞生,它们大多有着精美的 Landing Page,有着宏大的融资计划,PPT 里写满了“颠覆行业”。
但最近,一个名为 Clawdbot(现已因商标原因更名为 Moltbot)的项目,却以一种完全不同的姿态闯入了大众视野。没有融资,没有团队,甚至没有商业计划书。它仅仅是一个“退休(财务自由)”的软件大佬,为了给自己“找乐子”而写的一堆代码。
然而,就是这样一个项目,在 GitHub 上一夜之间狂揽 3.2w+ Star,甚至让很多非技术圈的人都跑去 Apple Store 抢购 Mac Mini 来运行它。
它的作者是 Peter Steinberger,著名的 PDF SDK 提供商 PSPDFKit 的创始人。在卖掉公司退休四年后,他因为 AI 找回了当年的热血。
在最近的一次深度访谈中,Peter 毫无保留地分享了他开发 Moltbot 的全过程。这不仅是一个关于工具的故事,更是一份关于“在 AI 时代,个人开发者如何打破大厂垄断,重塑人机交互”的珍贵启示录。
故事的开始并不美好。
四年前,Peter 卖掉了自己经营了 13 年的公司。长期的创业压力让他彻底 Burnout(职业倦怠)。
“那感觉就像有人把我的 Mojo(魔力/精力)吸干了一样。” 他回忆道。在那之后的三年里,他对编程完全提不起兴趣,哪怕只是坐在电脑前都觉得是一种折磨。
直到 2025 年 4 月,一切改变了。
Peter 开始接触早期的 AI 工具,特别是 Claude Code 的 Beta 版。那一刻,他感到了久违的兴奋。
“如果你错过了前几年 AI 比较‘智障’的阶段,直接上手现在的工具,你会觉得——这简直太棒了(Pretty Awesome)!”
这种兴奋迅速转化为了一种“成瘾(Addiction)”。
但这是一种积极的成瘾。他开始熬夜写代码,甚至会在凌晨 4 点给朋友发消息讨论 AI 的新发现。为了给自己找点乐子,他甚至搞了一些极其荒谬的实验:
比如,他做了一个“全球最贵的闹钟”。
他让运行在伦敦服务器上的 AI Agent,通过 SSH 远程登录到他家里的 MacBook,然后自动调大音量来叫醒他。
“这听起来很疯狂,甚至有点杀鸡用牛刀,但这就是我的初衷——Have Fun(玩得开心)。”
Peter 认为,学习新技术的最好方式,就是把它当成玩具。当你不再为了 KPI 或融资而写代码,而是为了让 AI 帮你订一份外卖、回一条消息而折腾时,创造力才会真正涌现。
Moltbot 之所以能打败众多商业化的 AI 助理,核心在于 Peter 对软件架构有着极其深刻的第一性原理认知:
“Don’t build for humans, build for models.”(别为人构建,为模型构建。)
如果你仔细观察现在的软件世界,你会发现所有的 GUI(图形界面)、按钮、下拉菜单,本质上都是为了适应人类极其有限的带宽(Bandwidth)和注意力而设计的。我们需要视觉引导,因为我们记不住命令。
但 AI 不需要这些。
AI 读得懂 Unix 手册,AI 记得住所有参数。
因此,Moltbot 采用了极其激进的 CLI-First(命令行优先) 策略。
Peter 解释道:“你知道什么东西最能 Scale(扩展)吗?是 CLI。你可以写 1000 个小工具,只要它们都有 –help 文档,Agent 就能瞬间学会如何使用它们。”
在 Moltbot 的架构里,所有的能力都被封装成了原子化的 CLI 工具:
Agent 就像一个万能的系统管理员,它通过组合这些 CLI,获得了在数字世界和物理世界中“行动”的能力。这比那些试图用鼠标点击模拟人类操作的 RPA(自动化流程)要高效、稳定一万倍。
Moltbot 最让极客们热血沸腾的,是它对 Big Tech Walled Gardens(大厂围墙花园) 的宣战。
现在的互联网巨头,都希望把你锁在他们的 App 里。WhatsApp 不开放 API,Spotify 不让你导出数据,外卖软件不让你自动化下单。
但在 Peter 看来,AI 是打破这些围墙的终极武器。
以 WhatsApp 为例。官方没有给个人开发者提供 API,如果你用商业 API 发太多消息,还会被封号。
Peter 的做法是:Hack Everything。
他直接通过 Hack 桌面端协议,让 Moltbot 能够接管他的 WhatsApp。当他在旅途中收到朋友的语音消息(比如推荐餐厅)时,Moltbot 会自动:
这一切都在后台静默发生。当 Peter 打开地图时,餐厅已经在那了。
“App 终将消亡(Melt away)。” Peter 在访谈中抛出了这个震聋发聩的观点。
“为什么我还需要一个专门的 Fitness Pal 来记录卡路里?我只需要拍一张汉堡的照片发给我的 Agent。它知道我在麦当劳,它知道汉堡的热量,它会自动更新我的健康数据库,并建议我晚上多跑 2 公里。”
在 Agentic Commerce 时代,用户不再需要在一个个孤立的 App 之间跳来跳去。所有的 App 都将退化为 Agent 可调用的 API(或被 Hack 成 API)。
Moltbot 的另一个标签是 Local-first(本地优先)。
虽然 Peter 自己也用 OpenAI 和 Anthropic 的模型(因为它们目前确实最聪明),但他花了大量精力去适配本地模型(如 MiniMax 2.1)。
为此,他甚至给自己的 Mac Studio 拉满了 512GB 的内存。
为什么要这么折腾?
除了“好玩”,还有一个现实的考量:Red Tape(繁文缛节)。
“如果你是一个公司,你想让 AI 访问你的 Gmail,你需要经过极其漫长的合规审核,甚至需要收购一家有牌照的公司。这太荒谬了。”
但如果你在本地运行 Agent,这一切都不复存在。
没有人能阻止你读取自己的邮件,没有人能禁止你分析自己的聊天记录。
Peter 甚至预言,AI Agent 的普及将直接带动高性能硬件(如 Mac Mini)的销量。“This is the liberation of data.(这是数据的解放。)”
随着 Moltbot 的爆火,无数 VC 挥舞着支票找上门,甚至有大厂想直接收购整个项目(或者招安 Peter)。
对此,Peter 的态度非常潇洒:“I built this for me.(我是为我自己造的。)”
他已经财务自由,不需要再为了融资去写 PPT,不需要为了增长去牺牲用户体验。
“代码本身已经不值钱了(Code is not worth that much anymore)。在这个 AI 时代,你完全可以把我的代码删了,让 AI 几个月再写一个新的。”
真正值钱的,是Idea(想法),是Community(社区),是Brand(品牌)。
他更倾向于将 Moltbot 运作成为一个非营利基金会(Foundation)。他希望这成为一个属于所有人的、开放的、可 hack 的游乐场,而不是某个大厂封闭生态的一部分。
在访谈的最后,Peter 对所有开发者发出了呼吁:
“Don’t just watch. Build your own agentic loop.”
(别只是看,去构建你自己的智能体闭环。)
Moltbot 只是一个开始。它证明了,一个拥有长期记忆(Memory)、工具使用能力(Tools)和自主性(Autonomy)的个人 Agent,能爆发多么惊人的能量。
在这个时代,限制你的不再是技术门槛,而是你的想象力。
去写几个 CLI,去 Hack 几个 API,去给你的 AI 装上“手脚”和“记忆”。
未来,属于那些敢于用 AI 重塑生活的人!
资料链接:https://www.youtube.com/watch?v=qyjTpzIAEkA
你的“好玩”项目
Peter 的故事告诉我们,技术最原本的动力是乐趣。如果给你无限的时间和算力,你最想用 AI 为自己做一个什么“好玩”的工具?是全自动点餐助
手,还是你的专属游戏陪练?
欢迎在评论区分享你的脑洞!别管它有没有商业价值,有趣就够了。
如果这篇文章点燃了你久违的代码热血,别忘了点个【赞】和【在看】,并转发给你的极客朋友,一起搞点事情!
还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
扫描下方二维码,开启你的AI原生开发之旅。
你的Go技能,是否也卡在了“熟练”到“精通”的瓶颈期?
继《Go语言第一课》后,我的《Go语言进阶课》终于在极客时间与大家见面了!
我的全新极客时间专栏 《Tony Bai·Go语言进阶课》就是为这样的你量身打造!30+讲硬核内容,带你夯实语法认知,提升设计思维,锻造工程实践能力,更有实战项目串讲。
目标只有一个:助你完成从“Go熟练工”到“Go专家”的蜕变! 现在就加入,让你的Go技能再上一个新台阶!
商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。
© 2026, bigwhite. 版权所有.

本文永久链接 – https://tonybai.com/2026/01/29/wso2-goodbye-java-hello-go-tech-stack-shift
大家好,我是Tony Bai。
“当我们 2005 年创办 WSO2 时,开发服务端企业级基础设施的正确语言毫无疑问是:Java。然而,当我们走过第 20 个年头并展望未来时,情况已经变了。”
近日,全球知名的开源中间件厂商 WSO2 发布了一篇震动技术圈的博文——《Goodbye Java, Hello Go!》。
这是企业级软件在云原生时代技术风向标的一次重要偏转。作为 Java 时代的既得利益者,WSO2 曾在 API 管理、集成中间件领域构建了庞大的 Java 帝国。为何在今天,他们会做出如此激进的转向?Java 真的不适合未来了吗?Go 到底赢在哪里?
让我们深入剖析这背后的技术逻辑、架构变迁与社区的激烈争议。

WSO2 的转向并非一时冲动,而是基于对过去 15 年基础设施软件形态深刻变化的洞察。其博文中极其精准地总结了这一变迁:
在 2010 年代之前,中间件是以独立“服务器”(Server)的形式交付的。
那是一个“重量级”的时代。你部署一个服务器,然后把你的业务逻辑(WAR 包、JAR 包)扔进去运行。这正是 Java 和 JVM 的黄金时代——JVM 作为一个强大的运行时环境,提供了热加载、动态管理、JIT 优化等一系列高级功能,完美匹配了这种“长时间运行、多应用共享”的服务器模式。
然而,容器化时代终结了这一切。
现在的“服务器”不再是一个独立的实体,而变成了一个库 (Library)。
在 WSO2 看来,“独立软件服务器的时代已经结束了”。这对于 Java 来说,是一个底层逻辑的打击。
在过去,一个服务器启动慢点没关系,因为它一旦启动,可能会运行数月甚至数年。JVM 的 JIT(即时编译)机制通过预热来换取长期运行的高性能,这是一种非常合理的权衡。
但在 Kubernetes 和 Serverless 主导的今天,服务器变得极度短暂 (Ephemeral)。
在这种场景下,启动时间就是服务质量 (SLA)。
WSO2 指出:“容器应该在毫秒级内准备好起舞,而不是秒级。” Java 庞大的生态依赖(Spring 初始化、类加载、注解扫描)和 JVM 的启动开销,在云原生环境下显得格格不入。内存膨胀(Memory Bloat)也直接推高了云厂商的账单。
面对挑战,Java 社区并非无动于衷。GraalVM Native Image 试图通过 AOT(提前编译)解决启动速度问题;Project Loom 试图通过虚拟线程解决并发资源消耗问题。
但在 WSO2 的架构师们看来,这些努力更像是一种“追赶式的修补”。
“这些解决方案感觉就像是在为一个不同时代设计的语言和运行时进行翻新。”
GraalVM 虽然强大,但带来了构建时间的剧增、反射的限制以及调试的复杂性。相比之下,Go 语言在设计之初就原生 (Native) 地考虑了这些问题:编译即二进制,启动即巅峰,并发即协程。这是一种“原生契合”与“后天适配”的本质区别。
WSO2 并没有盲目地全盘推翻,他们对企业级软件的三层架构(前端、中间层、后端)进行了冷静的评估:
这是一个每个技术决策者都会面临的灵魂拷问:既然要追求性能和原生编译,为什么不选 Rust?它不是更快、更安全吗?
WSO2 的回答展现了极高的工程务实精神。他们确实评估了 Rust,但最终选择了 Go。理由如下:
WSO2 构建的是中间件基础设施(如 API Gateway, Identity Server)。在这个层级,“我们总是比裸金属 (Bare Metal) 高那么一点点”。Go 提供的自动垃圾回收 (GC) 和高效的并发原语,恰好处于这个“甜点”位置。
Rust 的所有权模型 (Ownership) 和借用检查器 (Borrow Checker) 虽然保证了内存安全,但也带来了极高的学习曲线和开发摩擦。对于大多数企业级业务逻辑来说,Rust 提供的控制力是多余的,而为此付出的开发效率代价是昂贵的。
这是一个无法忽视的因素。Go 是云原生的“普通话”。
Kubernetes、Docker、Prometheus、etcd、Terraform…… 几乎所有现代基础设施的基石都是用 Go 构建的。选择 Go,意味着:
WSO2 并非纸上谈兵,他们在过去十年中已经在多个关键项目中验证了 Go 的能力:
这是 WSO2 最具野心的项目之一,一个面向 Kubernetes 的开发者平台(IDP)。
这是一个惊人的决定。Ballerina 语言最初是基于 Java 实现的(运行在 JVM 上)。现在,WSO2 正在用 Go 完全重写 Ballerina 编译器。
身份认证(IAM)通常处于请求链路的关键路径上,对延迟极其敏感。Thunder 利用 Go 的高并发处理能力,实现了在高负载下的低延迟认证,且在容器化环境中具备极快的冷启动能力。
这篇博文在 Reddit 的 r/golang 板块引发了数百条评论的激烈讨论。这不仅仅是语言之争,更是两种工程文化的碰撞。
“这是管理层的愚蠢决定”:
一位愤怒的网友评论道:“计算资源是廉价的,开发人员的时间才是昂贵的。” 他认为,虽然 Go 节省了内存,但在业务逻辑极其复杂的企业级应用中,Java 强大的 IDE 支持、成熟的设计模式和庞大的生态库能显著降低开发成本。强行切换到 Go,可能会导致开发效率的崩塌。
“Java 并没有停滞不前”:
很多 Java 支持者指出,WSO2 对 Java 的印象似乎还停留在 Java 8 时代。现代 Java (21+) 引入了 Virtual Threads (Project Loom),在并发模型上已经可以与 Go 的 Goroutine 媲美;而 GraalVM 的成熟也让 Java 能够编译成原生镜像,启动速度不再是短板。
“生态位的不可替代性”:
在处理遗留系统(如 SOAP, XML, 复杂的事务处理)方面,Java 积累了 20 年的库是 Go 无法比拟的。用 Go 去重写这些复杂的业务逻辑,无异于“重新发明轮子”,且容易引入新的 Bug。
“运维友好才是真的友好”:
一位 DevOps 工程师反驳道:“在微服务架构下,运维成本是巨大的。” Go 生成的静态二进制文件(Static Binary)是运维的梦想——没有依赖地狱,没有 JVM 版本冲突,所有东西都打包在一个几 MB 的文件里。这种部署的便捷性,是 Java 永远无法达到的。
“简洁是一种防御机制”:
Java 项目容易陷入“过度设计”的泥潭——层层叠叠的抽象、复杂的继承关系、魔法般的注解。Go 的强制简洁性(没有继承、显式错误处理)虽然写起来啰嗦,但读起来轻松。在人员流动频繁的大型团队中,Go 代码的可维护性往往优于 Java。
“云原生的网络效应”:
正如 WSO2 所言,如果你在写 K8s Controller,如果你在写 Sidecar,如果你在写网关,Go 就是默认语言。这不仅仅是语言特性的问题,这是生态引力的问题。逆流而上使用 Java 编写这些组件,会让你失去整个社区的支持。
WSO2 的声明并非要“杀死” Java。他们明确表示,现有的 Java 产品线将继续得到长期支持。但在新一代的云原生基础设施平台上,他们坚定地选择了 Go。
这一选择揭示了软件行业的一个趋势:通用编程语言的时代似乎正在结束,“领域专用语言”的时代正在到来。
对于 Gopher 而言,WSO2 的转型是一个强有力的信号:你们选对了赛道。Go 不仅是 Google 的语言,它正在成为定义未来十年企业级基础设施的通用语。
资料链接:
你的技术栈“保卫战”
WSO2 的转身,是时代的缩影,也是个体的写照。在你的团队中,是否也发生过类似的“去 Java 化”或“拥抱 Go”的讨论?你认为在云原生时代,Java 还能守住它的江山吗?
欢迎在评论区分享你的观点或经历,无论是坚守者还是转型者,我们都想听听你的声音!
如果这篇文章引发了你的思考,别忘了点个【赞】和【在看】,并转发给你的架构师朋友,看看他们怎么选!
还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
扫描下方二维码,开启你的AI原生开发之旅。
你的Go技能,是否也卡在了“熟练”到“精通”的瓶颈期?
继《Go语言第一课》后,我的《Go语言进阶课》终于在极客时间与大家见面了!
我的全新极客时间专栏 《Tony Bai·Go语言进阶课》就是为这样的你量身打造!30+讲硬核内容,带你夯实语法认知,提升设计思维,锻造工程实践能力,更有实战项目串讲。
目标只有一个:助你完成从“Go熟练工”到“Go专家”的蜕变! 现在就加入,让你的Go技能再上一个新台阶!
商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。
© 2026, bigwhite. 版权所有.
See the changes in my blog! I’m proud to introduce hexo-theme-paperwhite to you all! Now in beta stage! Check it on GitHub
hexo-theme-paperwhite is a minimalist theme for Hexo. I made it to fulfill my own needs, including a pure home page and the serif font. I am a huge fan of minimalist designs!
It’s simple. Actually just no more than 10 lines of code! Here’s the _config.paperwhite.yml
1 | menu: |
Sorry to tell that I failed… Now I’ve completely switched to hexo-theme-cactus for lack of Web Front-end developing experience.

大家好,欢迎收听老范讲故事的YouTube频道。老范原来总批评马斯克假开源,这次应该是真的了吧?
1月10号,马斯克发帖说7天之内开源X的推荐算法;1月20日,也就是10天之后,确实开源了。马斯克事确实给你干了,但是时间大家就不要计较了,稍微晚几天并不那么重要。

2023年,他开源了X的推荐算法,但是仅开源了部分的非核心代码。而且开源了以后就往这一扔,再也不理你了,也没有后续版本,也没有各种的讨论。你问他一些什么问题,他也不理你,所以我说这是个假开源。
2024年3月17号又宣布开源GROK1,3月19号确实开源了,开源了权重和加载的代码。但是这个模型非常的笨重,基本上没有任何的实用价值。当然了,还有马斯克一贯的作风:不回答任何问题,也没有后续更新。就是代码开源了,这个事也就算办完了,社区里头的各种issue、pull request基本不看,也不会有任何后续更新。最新的版本不开源,你像GROK1开源了,后边的版本基本上就不理你了。无法验证开源出来的东西和生产环境是不是有关联,这就是马斯克开源的一些特点。
这次其实也差不太多,X推荐算法也只是开源了一部分。最核心的东西叫Grok Transformer,这个东西并没有开源。整个的推荐算法建立在一个Transformer的模型上了,你没有把那个Transformer模型拿出来,你只围绕Transformer模型外围的一些东西给大家看了看,开源了这样的一些东西出来。而且你要做推荐,你一定要有一开始的信息筛选的机制。信息怎么筛选?过滤的这些参数以及最后排序的权重,这些东西通通都没有公开。所以这一次开源的东西,按照传统意义的开源来说,是个假开源。

首先是一个非常非常革命性的东西,就是单一Transformer模型的推荐算法。这个很像SpaceX猎鹰火箭底下那个猛禽发动机。最早的猛禽一代好多好多管子,非常多的零碎,200万美金一台;后来更新到猛禽二代,比猛禽一代就要简洁很多了,外边支棱八翘的管子就少很多了,100万美金一台;最近发布的猛禽三代极其简洁,完全一体化设计,高度集成。它这个发动机外面基本上没有外边的管子,外边的这些零碎全都没了,这个机器25万美金一台,非常非常便宜。这一次它把推荐算法也做了一模一样的调整。
我用单一模型。以前的推荐算法都是好多好多模型一起配合来干活的,每一个模型是关注一个参数,大家去发现各种的数据特征,然后设置新的参数,把这个参数想办法调好,原来是这样来配合干活的。现在说别费劲了,统一上一个Transformer模型完事了。
这个模型是基于GROK1的一个MOE的模型,应该参数不大,但是具体有多少参数他也没说,怎么训练的也没说,训练数据也没给。就是这样的一个模型,因为它需要高频的高效的工作——你看每一次你去刷新X平台的时候,它都需要让每一个帖子跟你的个人人设在这里头过一遍,所以它的效率一定是很高的,模型一定不会特别大。

那些高薪调参的人,工作估计要不保了。什么意思?以前很多号称是AI工程师、年薪百万甚至是几百万的,这些AI工程师他们最主要的工作就是调参数:拿大量的用户数据回来,去里头发现一些特征,然后把这些特征放到模型里边去,再调整相应的一些参数。所以我们管这帮人叫“调参数的”。未来的趋势是不再设置一大堆的参数,而是统一扔给Transformer模型,直接出结果。那么他们这些人的工作就有点危险了。
这个过程很像什么?就是从一大堆摄像头、激光雷达、超声波雷达、一大堆模型配合一起工作的自动驾驶操作系统,转向纯视觉的、端到端模型驱动的自动驾驶系统,就是做了这样的一个转换。那为什么要做这种转换?就是当有一大堆阀门的时候,你总是很难调出最优解来。你比如说我把这个参数调好了以后,那个参数可能就下降了,怎么能够让所有的参数平衡起来,达到一个最好的结果?这个时候我们上统一的Transformer模型,上端到端的这种训练,它就有可能得到这样的一个最优结果,而不是说摁起葫芦浮起瓢。
具体这个东西是怎么工作的?他先把我们能够看到的帖子分成两类:一类是关注帖,一类是非关注帖。关注帖就是这个人是我关注的,他在这段时间里头发了一个帖子,这叫关注帖;非关注帖就是完全靠推荐算法推上来的,这个人我虽然没关注他,但是推荐算法认为我应该看到。再把这一部分帖子拎出来,关键的一定是非关注帖这部分。首先对人和每一个帖子进行匹配,寻找高质量、低投诉、高互动的帖子推给我们;而找到这些帖子以后,再对帖子进行排序,然后跟我们的关注帖混合在一起进行展示。说白了就是这样的一个过程。
那再详细的说一些吧,那后边这块可能要稍微的麻烦一点。
就是他把我的过去多少天的行为动作,包括停留在每一个帖子上停留了多长时间、有没有点赞、有没有评论、有没有转发、有没有去投诉,把这些数据拎起来。但是具体是多长时间给隐藏了,这部分是不告诉你的。

你不可能说把X上所有帖子都拿来跑一遍,那个效率实在太低了,所以首先要先筛一批。到底筛出多少条来还没告诉你,这个是隐藏的。它有一个过滤器对这些内容进行筛选,第一个原则就是去重,如果发现两条帖子是重复的或者内容很相近,他会把它去掉一个。然后去掉自己发的帖子,去掉屏蔽的作者,去掉敏感的违规的内容。按照时序排序,取前面的多少条,但是具体多少条不告诉你。如果是相同的作者,你反复的发也会进行过滤,所以不要刷屏。比如你连续的发了好多内容,X会把后边的这些内容都给你降权掉。所有看过的帖子就不再重复出现了。
所以第一步是这个人的画像,第二步是初筛这些帖子。筛出这些帖子以后,就把这个Transformer模型拎出来了,进行互动可能性的计算。他要算一下这个帖子如果给你看,到底有多大的可能性会被点赞、多大的可能性会被回复、多大的可能性会被投诉,他要把这些东西放出来。一共是15项。因为大模型没有开放出来,所以这一步是无法复现的。
前面我们说有多少可能性点赞、多少可能性投诉,我15项拎回来以后干嘛?做一个加权的整合。这个乘一个参数,加上那个乘一个参数,把这15个数加一块。加完了以后进行一个排序。那你说这参数都是什么?也没告诉你。这部分告诉你,那绝对机器人会刷死他的。然后把排序好的这些帖子,再跟关注帖混合在一起给我们展示。这就是整个这个系统工作的一个原理。
这个Grok Transformer到底是一个啥?是一个基于Grok 1模型重新训练的MOE的一个小参数模型。只能做单一任务,就是每一次给他一个用户画像,给他一个帖子,然后他把这些数据做矢量化,然后去做正面和各种负面维度的可能性的概率输出,就干这一件事。没有公开参数,没有训练数据,没有训练方法,大概就是这样的一个系统。
主要代码是用什么语言写的?
那你说这么多代码,那普通人肯定“有看没有懂”,完全没有任何意义。也不要这么讲,虽然它没有给大家很多文档,但是现在有非常非常多的代码分析工具。你比如说你把它扔给Cloud Code,或者扔给Cursor,扔给Open Code,扔给Codex,他们会替你去总结,告诉你说整个系统是怎么样的。然后你可以提各种问题,他会来给你回答,这个代码是写在哪一块的、如何实现的、哪一块隐藏了、哪一块给你了,这个都是会有的。所以普通人也是可以去看这些代码的。
既然我们已经拿到了这样的一个开源系统,我是不是可以自己搭一个X,或者看看能不能在X里头怎么去做一个机器人,把X的数据都给它刷回来?就跟美国上委内瑞拉抓马杜罗之前,得先盖一小屋子,把马杜罗的安全屋都盖出来,让人在里头训练,训练完了以后到那啪一把把他拎出来。这事能不能干?能不能复现?
首先说,这个系统本身是无法复现的。你把这个代码down下来以后,你没法编译它,你也没法部署它,因为代码本身并不完整,而且里头还有很多的引用冲突。什么叫引用冲突?就是有些代码并没有写在这个系统里边去,而是说我要引用外边的哪个系统,但是他在不同的代码里引用的版本不一样,而且有的可能干同样的事情引用的是这个,另外的代码可能引用的是另外一个。所以他应该并没有把真正可以执行的一个线上系统直接打包扔上来,因为能够编译执行的这种线上系统是不会出现引用冲突的。
还有就是文档也不是很完整,它里头只是给了代码,并没有给特别多的文档,很多参数被隐藏了。而且也没有办法获得X上的实时数据,因为你要想让这个系统动起来的话,你必须要给它X上的实时数据——这个人过去几天都点了什么东西了,最近有哪些帖子——你没有这些东西,它这个系统也没法跑起来。
那你说是不是开源了个寂寞?也不能这么说。马斯克开源特斯拉的一些专利,对于中国人做新能源产业还是有巨大帮助的。这次将单一Transformer模型驱动的这种推荐算法给出来,也是为整个推荐算法进步给出了方向。所以国内那些原来推荐算法比较差的平台,比如像B站什么的,应该现在正在尝试进行复现。但是这种复现就不是说拿人那个系统去复现了,而是说用这种思想和方向去复现。你比如说拿千问的一些小参数模型,零点几B的这些模型,你可以跑一跑试试,或者是看看能不能做出更小的一些模型出来,进去跑一跑试试,应该是有人去尝试了。

别说那么复杂的,怎么发帖可以提高互动?涨粉怎么赚钱?这玩意才是大家关心的。
为什么是这样?因为这种帖子可以让X展示更多的广告,人家这个平台也是要挣钱的。

既然有这些规则了,谁跑得最快?一定是坏人跑得最快,好人一般是要慢一些的。原因很简单,坏人是有利益的嘛。大家还记得前几天那些@Grok脱衣服的帖子吗?是不是完全符合这套标准?我发了一个美女照片在上头,在下头写@Grok,给她把衣服脱了,或者给她穿上比基尼。这种时候大家就会点到这个回复里边去看,点到详情页里边去看,你的点击率一下就上去了。这个应该算是马斯克自己家的,人家说自己利用一下规则没毛病。
最近大量的抖音和TikTok的热门视频被搬运进来了。算法对于视频是有极大的倾斜的,只要你这里头有视频,视频被点进去了,他就会非常努力的给你推荐。所以我现在打开X,基本上跟刷抖音的那个感觉差不多,里头大量的抖音视频。因为这套算法里头是没有任何跟版权保护相关的东西的,他不是说你发的这个视频最后有一个抖音或者最后有一个TikTok的标,他就给你下架了,不会干这事了。他才不管你是从哪来的。大家的玩法在这点其实都差不太多,先热闹起来然后再清理。现在X上短视频少,他又希望短视频,那你们就来;等什么时候我这短视频多了以后,我再收拾你。这个有点像新加坡,先吸引一大堆大陆土豪去移民,然后再反洗钱、关门打狗,这基本上应该是这样的一个套路。
最近有好几个涨粉相关的账号跑来关注我了。什么叫涨粉相关?就是他那个账户的名字叫“涨粉多少多少”,赤裸裸的叫这名字。如果我也去回关他、跟他聊两句、花点钱的话,那我这个X上的粉丝就可以蹭蹭蹭涨,涨一堆机器人出来。我的帖子下面也出现了一堆炒币的人进行回复。这个原来其实比较少见,这一次马斯克开源了这些算法以后,很多这些炒币的人就来回复我的帖子。如果我再回复他的信息的话,他的账号被看到的机会就会上升。所以一般遇到这样的帖子,我就不再去理他了。机器人已经活跃起来了,等着老马进一步更新他的算法了。

这一次老马总算是真的开源了吧?老范是不是被打脸了?这个还要看下个月。为什么这么讲?马斯克宣布每四周更新一次代码。前几次更开源都是扔上去,以后几年都不带动的,彻底就不理你了,算是一个死项目。这一次老马说我每四周更新一次,老马也算开创了一个先河。
以前做开源软件的目的是什么?
马斯克开源的目的跟他们不太一样,他是提供了一个监管窗口。你看我把这东西开源了,大家以后觉得我的X有什么推荐不对的地方,你自己去看去。我可以开源,让你们去监管,让你们去审核这个东西。你再批评我,你可以去看。其他那些平台还没开放,我都开放了。他搞了这样的一个事情。
很多人都说X是一个很右的社交媒体,因为相比其他的这些社交媒体平台来说,X是要偏右一些的。现在马斯克说:“来,我直接把推荐系统给你开放看看,你现在看看我到底右不右。”为什么大家都觉得这个X偏右,大家是不是冤枉马斯克了?其实没有。原因很简单,左的特征是什么?圣母嘛,道德高地嘛。大部分的社交媒体平台是按照更左的方式来进行内容审核和筛选的。如果是这样的话,内容比较开放的这种X平台,就肯定是靠右的嘛。左右这个事不是绝对的,它是相对的。
这次开放的代码肯定不是传统的开源项目。它无法复现、无法使用,代码跟文档也不是完整的,也基本上不回复社区的issue跟PR。马斯克可以达到通过开源实现监管的目的吗?现在并不能证明开源出来的版本跟实际跑的版本是强相关的。这个东西应该不是实际的版本,也绝对不可能四周才更新一次,各种参数应该是按小时进行调整的。Grok Transformer的这个模型规模也不大,应该可以几天的时间就会重新训练一次。
这次展示的是Transformer模型之外,并没有保留特定类型帖子的加分减分的这种调整的控制面板。就是说,我就是靠这玩意干活了。你如果希望更左一点、更右一点,你可以在Transformer的这个结果基础上,再去加一层的意识形态的这种调整。但是马斯克给大家看说:“你看我没这东西,这个Transformer模型出来的结果我就直接干了,没有任何跟意识形态相关的东西,都是你的互动可能性跟这玩意相关的。得到结果了以后就可以展示了。”
如果以后每个月更新的版本可以坚持,并且带有完整的更新轨迹——什么叫更新轨迹?在这些源代码更新的过程中,是有一个版本一个版本上的,会写着说每个版本更新什么东西,这叫完整的更新轨迹——如果这个都有的话,那么这个监管会更加可信一些。如果无法坚持,或者以后的更新都是一个没有任何更新轨迹的独立版本的话,监管的效果会差一些。但是也总比那些从来都没有公开过的平台要好。以后再有人批评马斯克说“你怎么偏右”,马斯克说:“我都公开过。甭管我是公开过几个版本,但是至少我公开过,你还没公开过。”他就可以这样去批评别人了。
那未来的方向是什么?做推荐算法的成本一下就降下来了。那些年薪几百万的调参的人,要重新想一想是不是去送个外卖、跑个滴滴了。老马为可信可监管的平台推荐系统做了一个打样。
最后总结一下吧。马斯克开源了X的推荐算法,革命性的单一Transformer模型,就像是一体化的猛禽3发动机一样那么震撼。马斯克为可信可监督的平台推荐系统指明了最新的方向。以后谁想再去证明你的平台推荐系统是可信的,来,跟我一样开放。他就做了这样的一个事情。
好,这一期就讲到这里,感谢大家收听。请帮忙点赞点小铃铛,参加DISCORD讨论群,也欢迎有兴趣、有能力的朋友加入我们的付费频道。再见。
Prompt:Detailed watercolor rendering of a loft open-plan office interior, no people, neon cyan rim light, deep navy backdrop, cinematic lighting, sharp subject separation, minimal palette (ink blue, neon cyan, gold accents), glossy reflections on glass and polished concrete, intricate textures of wood, metal, and glass, wide-angle 28mm, deep depth of field, strong negative space for text –ar 16:9 –v 7.0 –stylize 120 –chaos 4 –no people, faces, text, watermark, signature, clutter, photorealistic, 3D render, blurry, low contrast –p lh4so59






本文永久链接 – https://tonybai.com/2026/01/22/why-are-we-still-talking-about-containers-in-ai-age
大家好,我是Tony Bai。
“如果你在 2014 年告诉我,十年后我们还在讨论容器,我会觉得你疯了。但现在是 2025 年,我们依然在这里,谈论着同一个话题。”
在去年中旬举行的 ContainerDays Hamburg 2025 上,早已宣布“退休”的云原生传奇人物 Kelsey Hightower 发表了一场发人深省的主题演讲。在这个 AI 狂热席卷全球的时刻,他没有随波逐流地去谈论大模型,而是回过头来,向所有技术人抛出了一个灵魂拷问:

为什么我们总是在追逐下一个热点,却从来没有真正完成过手头的工作?
Kelsey 首先回顾了他职业生涯中经历的三次技术浪潮:Linux 取代 Unix(AIX、Solaris等)、DevOps 的兴起、以及 Docker/Kubernetes 的容器革命。
他敏锐地指出,技术圈似乎陷入了一个无休止的“海啸循环”:
“我们就像一群踢足球的孩子,看到球滚到哪里,所有人就一窝蜂地冲过去,连守门员都离开了球门。结果是,球门大开,后方空虚。”
这就是为什么 10 年过去了,我们还在谈论容器。因为我们当年并没有真正“完成”它。我们留下了无数的复杂性、不兼容和“企业级发行版”,却忘了初衷。
在演讲中,Kelsey 分享了他最近的一个惊人发现:Apple 正在 macOS 中原生集成容器运行时。

这不是 Docker Desktop,也不是虚拟机套娃,而是操作系统级别的原生支持。这就是 GitHub 上的一个名为 apple/container 的 Apple 开源项目:

Kelsey 提到 contributors 中有 Docker 元老 Michael Crosby ,Michael Crosby 正在 Apple 做着这件“不性感”但极其重要的事情。
Kelsey 认为,这才是容器技术的终局:
这正是那些没有去追逐 AI 热点,而是选择留在“球门”前的人,正在默默完成的伟大工程。
作为 Google 前员工,Kelsey 对 AI 并不陌生。但他对当前的 LLM 热潮保持着清醒的警惕。
他现场演示了一个有趣的实验:询问一个本地运行的 LLM “FreeBSD Service Jails 需要什么版本?”
* AI 的回答:FreeBSD 13(一本正经的胡说八道)。
* 真相:FreeBSD 15(尚未发布)。
Kelsey 指出,现在的 AI 就像一个热心但糊涂的路人,它不懂装懂,只想取悦你。
他的建议是:
演讲的最后,Kelsey 回答了关于开源、职业发展和未来的提问。他的几条忠告,值得每一位技术人铭记:
Kelsey Hightower 的这场演讲,是对当前浮躁技术圈的一剂清醒剂。
他提醒我们,技术的真正价值,不在于它有多新、多热,而在于它是否真正解决了问题,是否被完整地交付了。在所有人都在谈论 AI 的今天,或许我们更应该关注那些被遗忘的“球门”,去完成那些尚未完成的伟大工程。
资料链接:https://www.youtube.com/watch?v=x1t2GPChhX8
你的“烂尾”故事
Kelsey 的“海啸循环”论断让人深思。在你的职业生涯中,是否也经历过这种“还没做完旧技术,就被迫去追新热点”的无奈?你认为在这个 AI 时代,我们该如何保持“工匠精神”?
欢迎在评论区分享你的经历或思考!让我们一起在喧嚣中寻找内心的宁静。
如果这篇文章让你停下来思考了片刻,别忘了点个【赞】和【在看】,并转发给那些还在焦虑中奔跑的同行!
还在为“复制粘贴喂AI”而烦恼?我的新专栏 《AI原生开发工作流实战》 将带你:
扫描下方二维码,开启你的AI原生开发之旅。
你的Go技能,是否也卡在了“熟练”到“精通”的瓶颈期?
继《Go语言第一课》后,我的《Go语言进阶课》终于在极客时间与大家见面了!
我的全新极客时间专栏 《Tony Bai·Go语言进阶课》就是为这样的你量身打造!30+讲硬核内容,带你夯实语法认知,提升设计思维,锻造工程实践能力,更有实战项目串讲。
目标只有一个:助你完成从“Go熟练工”到“Go专家”的蜕变! 现在就加入,让你的Go技能再上一个新台阶!
商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。如有需求,请扫描下方公众号二维码,与我私信联系。
© 2026, bigwhite. 版权所有.

大家好,欢迎收听老范讲故事的YouTube频道。
腾讯跑去向GitHub投诉,居然引用了数字千年版权法案,要求删除4,195个仓库。现在这些仓库基本上都已经被删掉了。所谓的数字千年版权法案,是1998年美国通过的版权法案。

以前咱们都说腾讯四处抄袭,都说“狗日的腾讯”,怎么现在轮到流氓报警了?腾讯这次给出的理由,是这些项目以及项目的分支,违反了腾讯设立的安全围栏,获取了用户的聊天记录。
社区中骂声一片,主要观点如下:
这个是社区里边普遍的声音。

咱们现在要讲一下数字千年版权法。这个法里头最常被引用的两个条款,一个是512条款,一个是1201条款。
512条款叫侵权,他侵犯了我的版权,主要是针对平台和服务商的。有人上传了盗版侵权的内容,我要投诉他下架,主要干这个使的。
这个时候这些平台跟服务商就会去引用“避风港原则”,说这个事我不知道,我也查不过来,你向我投诉了,我就把它下架掉。这个基本原则叫“民不举官不究”。
咱们比如说吧,现在你想看什么美剧怎么办?上B站上去看。B站上每一次有新的美剧,都会给你放盗版的,等到有人投诉的时候,他再把这些东西删掉。他是这样的一个运作方式。这些平台方会在接到投诉以后,对内容进行下架,然后通知——就是谁上传的我要通知一下。如果有抗辩,说这东西不是盗版,我自这里有授权书,或者东西是我自己生成的,那么还是可以酌情给你恢复回来。
第二个条款经常被引用的,这一次腾讯所引用的叫1201条款,它叫反规避条款。任何违规者,以及提供规避工具的和服务的这些人,这是这个条款所去针对的。
这个条款的意思,就是你绕过了技术壁垒和保护,绕过了版权保护墙,获得了版权保护墙之后的这些信息。就是你提供技术、提供各种方法都不行,我们就可以去引用这个数字千年法案去投诉你。
这个里头有很多叫“两用技术”,就跟咱们讲这个两用物资似的,你既可以军用也可以民用。但是这里讲的两用技术是,既可以去做好事,也可以去做坏事的这些技术。
通常GitHub会默认开发者都是好人,只有证据扎实、影响巨大才会去处理。一般情况下,你说我这个项目放到GitHub上去以后,有人可能拿它去做坏事,GitHub通常是不会去管的。如果证据扎实、影响巨大的话,就会忽略做好事那部分,直接把库删掉。这一次腾讯就已经达到目的了。

大家注意,GitHub里面结构是这样的:每一个项目,我们要开一个仓库,把这些源代码都存在里头,存不同的版本。GitHub的仓库有两种,一种叫开放仓库,一种叫私有仓库。这一次主要针对的都是开放仓库。
这一次被干掉的,大部分叫fork项目,叫分支项目。什么意思?就是你有一个开放项目,说我可以从微信里边导这个聊天记录出来,别人看了不错,我也要去改,那我不会在你原来的项目上改,我会在你这个项目的基础上做一个分支,相当于是我在这个基础上做了一个拷贝的影子一样,然后我在这个分支上再去干活。所以它为什么有4,000多个仓库?大量的都是分支分出来的。有一些大家比较喜欢的项目,会有上百个分支出来。
主要被投诉的项目类型如下:
Hook是钩子的意思,就是我们来去监控腾讯客户端,在里边去做一些事情。它基本上是一个hook和机器人的架构,就是我先在这挂一钩子,发现有什么事的时候,我后边的一个自动程序就可以去处理。这种项目这一次都被投诉了。
腾讯在微信里头,实际上是有一个数据库的,来存我们各种各样的聊天记录、联系人,还有我们在里边买东西存这些信息。要想解开这个数据库的密码,是必须要有一个动态的密码,或者叫动态的key。
这种东西只能去监控他的微信聊天的、微信程序的这个后台进程,然后从这个里边能够截取出这个key来。拿到这个key,就可以解开这个数据库,就可以知道你跟谁聊过什么天了。它是这样的一个工作原理。这一类的项目也统统都被投诉了。
我们用手机的时候,有一个很痛苦的事情是什么?就是微信聊天数据特别特别大。像我每一次换手机的时候,那个我的微信聊天数据大概能有个十几个G或者更大一些。他又不在这个服务器端给你提供备份的这个功能,因为实在是备份不起。所以每一次换手机,备份或者叫迁移这个聊天记录是非常非常痛苦的。
那么有一些工具说“来我帮你做迁移吧”,我帮你把这个微信聊天记录通通都迁移到服务器上,或者迁移到你自己的一个网盘上,等你下一次有新手机或者有一些新的应用的时候,我们帮你再把这个东西复原上去。它有这样的工具,这一次也都被投诉了。
我们的手机,特别iPhone手机,你连到Windows或者连到macOS的这个电脑上以后,它会把整个手机里边的信息做一个备份下来。这个备份里头,你如果把它拆开了,有一部分——或者说叫很大一部分吧——就是微信聊天记录。这一块也有人专门做了工具,说我来帮你把这个文件拆开了,我把微信聊天记录给你找出来。这个也被投诉了。
像我们以前就是做清理大师嘛,就是做这种清理工具的。那你像微信这么多聊天记录里头,到底哪个能删、哪个不能删?我们是会有一套的办法去分析,说哪个数据是比较旧了,哪些是附件可以让它失效把它删掉,哪个是这个联系人的头像可以把它删掉。
你就想吧,你如果把联系人头像删了,会造成什么样的问题?如果这人你再也不见了也无所谓;如果你下次又需要跟这哥们聊天了,我们需要再去消耗你的流量,重新向微信服务器去申请这个头像去。你如果要清理微信聊天记录的话,首先要分析微信聊天记录的结构,哪些文件到底是存的什么东西,然后才能去删嘛。这一部分也通通都被腾讯投诉删库了。
就刚才我们讲的这些项目,大家听名字就能知道,基本上都是两用项目。它是有正规用途的,不是上来说我一定要窃取你的信息。
给大家举几个典型的数字千年版权法案1201条款的案例吧。
GitHub主要的判断标准是绕过限制的这个技术手段是否被充分的证明了。说你是不是真的绕过这个技术手段了,你一定要把这个过程写的很清楚。
YouTube-dl的是通过了整改,它原来是在YouTube-dl那个源代码里头有一个测试用例……现在他把这测试用例改了,说我们就不再给大家演示这东西了,这个东西具体能干什么自己去猜去。它实际上功能都没有任何修改,用户依然可以自行使用去下载那些有版权的内容。只要是做到这一步,GitHub就允许它重新上架了。

腾讯这次的投诉还是非常有效果的,大批的仓库已经被封闭了。还有一些仓库是自主关闭的,就是没有等通知自己就把它删掉了,估计腾讯在国内也找到他们了。
这些两用技术——可以做好事也可以做坏事的技术,在政策里头GitHub明确表示:允许双用途内容与安全研究,默认善意,只有在广泛正在发生的滥用时才可以限制访问。腾讯就证明了,说这些仓库正在被大规模的分支(有一些仓库可能有上百个分支),这一次GitHub就给它处理掉了。
大家有没有想过,为什么现在这样的一个时间点,腾讯就跑出来折腾?腾讯是1月8号去投诉的,刚刚过完元旦。大家是不是最近在玩一个很有趣的游戏?这个游戏叫做“用微信聊天记录生成年度报告,然后再把这些微信聊天记录喂给AI做总结”。很多人都在玩这个,因为我已经在微信的朋友圈里头看到一堆人在晒了,你看我去年都聊了这些人,我跟谁谁谁关系怎么样。
腾讯肯定不希望你去做这个事。腾讯认为,所有的微信聊天记录都是他的,他要拿这东西去训练大模型,去做各种事情,你是不能把它拿出来的。
腾讯其实从去年就在尝试投诉,但是去年GitHub没理他。为什么?因为去年腾讯走的不是数字千年版权法,它走的是隐私保护。他认为说这些人侵犯了用户的隐私,GitHub就没有理他。本来这些微信聊天记录是腾讯自己视为禁脔,准备拿去训练大语言模型的,被导出去,那真的是叔可忍婶不可忍。1月8号就引用了数字千年版权法案再来了一次,这一次终于好使了。

腾讯历史上其实干过一些类似的事情,我不知道还有没有人记得。
腾讯只要发现有人敢在他自己的地盘里干坏事,他就一定会冲上来起诉你,没有什么好商量的。南山必胜客在这种案子里面还是无往而不利的。
后续这件事情会怎么发展?开发者有10-14天的时间可以提起抗辩。目前还不清楚是否已经有开发者去提起抗辩了,大概率没有。即使有的话,抗辩成功的可能性也很小。
腾讯这一次到底是不是出于好心?别每次腾讯干点什么事咱就骂他。
首先要讲,微信上面的黑灰产还是很猖獗的。为什么?原因很简单,第一个是用户量巨大,功能非常复杂,超级APP嘛,从头到脚没有什么东西它是不干的,里头还有支付能力,里边是有钱的。所以大量的手机卡号注册的这种假微信账号,都是在机器人程序的控制下干着活。
其实真正的黑灰产,有可能会用这些开源库作为基础,但是一定不是在开源库的上面就直接用的,他们一定是有自己的私有的代码库。但是这些黑灰产是不是使用了这些开源库,你是没有办法去证明的。真正的黑灰产代码,绝对不会存在这些公开的代码仓库里边。
对于真正的黑灰产,腾讯其实也一直在努力进行防护,只是效果还有待观察,可能还要再等一等看。至少目前为止吧,在微信里边、在QQ里边,上当受骗的人还是每天都在产生。

这次腾讯干的活,主要还是面向用户聊天记录进行主权宣誓。微信怎么能这么坏?明明是我的聊天记录,凭什么你替我去维权,还把我自己用的开开心心的这种微信聊天记录备份工具给我封掉了?
这个先别急着骂。我们在X上发的推文是不是属于我的,还是属于马斯克的?我们在Reddit里头发的帖子,到底是属于谁的?大家想一想,他们是直接封闭了原来免费开放的API,然后开始去卖数据去了。
所以所有的平台都认为这些数据是属于他们的,不光是微信这样,包括X和Reddit都是这么干的。AI时代,数据主权一定是平台方争夺的核心利益。
这里边比较奇葩的是谁?是谷歌。自己基本上不出来投诉,即使是那个广告拦截插件,谷歌会出来呼吁大家不要上广告拦截插件,但是他绝对不去投诉这些广告拦截插件。反正谷歌说你们这些事情,我就认为都是两用的技术,你们都在用它做好事就完了,我就不管你了。
最后总结一下吧。元旦过后,大家玩微信聊天记录统计玩的正开心的时候,腾讯向GitHub投诉了,有开源项目绕过了腾讯的技术壁垒,窃取了受保护的内容。他引用了千年数字版权法的1201条款(叫反规避条款),要把他们都干掉。GitHub就从善如流了,4,195个仓库被封闭。
AI时代,聊天记录这种数字资产是任何平台都不会放弃的。
好,这个故事就跟大家讲到这里。感谢大家收听,请帮忙点赞、点小铃铛,参加DISCORD讨论群。也欢迎有兴趣、有能力的朋友加入我们的付费频道。再见。


摘要:电商模式正式从传统的人找货(也就是搜索电商)和货找人(也就是推荐电商),转向了对话及交易的智能电商。
大家好,欢迎收听老范讲故事的YouTube频道。
1月11日,谷歌在纽约举行的全美零售联合会年度博览会上发布了UCP。所谓UCP叫Universal Commerce Protocol(通用商业协议),AI驱动的去中心化电商通用协议。
这里头跟去中心化有什么关系?你说这玩意是不是用币?不是。这个里头所谓的去中心化,说白了就是“去亚马逊”。不去别人,就去它。

这个协议涵盖了电商的所有流程和模块,包括:
这是属于电商需要的所有东西,它都给你定义了一遍。同时支持MCP A to A(也就是Agent to Agent),还有传统的API格式,统统都是支持的。
UCP这个东西是开放的吗?还是谷歌说了算?这个非常非常有谷歌特色。
一方面它是开放的,这个协议相关的所有文档和代码都是在GitHub上托管的,使用的是阿帕奇2.0的开源许可证,大家都可以去用。
但是也不是完全开放的,这个东西有点像安卓里边的GMS一样,叫Google Mobile Service。GMS这个东西是需要谷歌去审核的,不是说谁愿意接谁就可以接上的。如果谷歌审核不通过、不给你发认证的话,你进不去。UCP也是如此,需要谷歌的认证和准入,而且数据格式的定义,这个权利也是在谷歌手里边的。你不能说我自己随便定义一些数据就放进去,这事是不允许的。所以这个东西的开放状态很像安卓。

UCP它会带来一些安全和隐私的问题。
首先咱们先说安全吧,它在支付的时候使用的是代币化支付。那你说去中心化,不是不用Token?那刚才老范不是说了吗,虽然叫去中心化,但是咱不用代币。
这里讲的是什么?就是AI真的是看不到信用卡信息的,也看不到你的支付相关的信息,它只能看到一个Token。但是这个Token并不是你的比特币钱包,而是比如说PayPal或者是Visa,他们来给的这个Token。它只要拿到Token就可以去验证了,是这样的一个代币化支付。
还有一个重要的安全属性,是要上下文隔离。什么意思?就是你想我们以后是怎么买东西:我们跟谷歌的Gemini聊天,聊着聊着,突然他就给你推荐商品了,你一确认就给你买回来了。这个聊天的过程叫上下文,商家是看不到的。商家只能看到交易数据,谁买了什么他知道;但是为什么买、上下文聊什么,这个是不会发给商家的。
比如说吧,中国古代有一位女子,聊天的时候说:“我想给家里头的衣物做一下防虫处理,有什么办法没有?”她有可能聊了这个。当然另外一种可能,她聊的是:“西门大官人,我看着这个甚是欢喜,但是家里有个三寸钉应该怎么办?”这两种聊天都是有可能发生的。
但是这两种聊天,最后都会触发共同的结果,就是AI回复说:“你去买一些砒霜吧。”

大家不要觉得砒霜这个东西是毒药——它确实是毒药,但是在中国古代,这个东西是有正规用途的。一方面它可以包裹种子去播种,这样可以防病虫害、防杂草;另外就是刚才咱们讲的,就是家里头的衣物防虫也是用砒霜的,只是要少用一点点。就是甭管她前面说的是哪种情况,AI都会给她推荐砒霜。她买的时候,商家只知道她买了砒霜,至于你拿回去干嘛使,他就不知道了。然后这位女子把砒霜拿到手以后,就可以喊:“大郎,该吃药了。”就会变成这样了。这个就叫上下文隔离。
但是商家会知道,某位顾客(或者说某位女子吧),什么时间购买了多少砒霜、送去了哪里,这些东西是这个商家会知道的。上下文没有了。但是这个其实跟现在我们普遍使用的安全隐私方式还是有一些差距的。
因为原来这些数据会在亚马逊这些平台手里边,他会把这个东西截留下来,并不会发给商家。因为最早的时候,中国做跨境电商的时候,是收集了大量的美国用户的家庭住址和电话的。后来说不行,这玩意我们要保护隐私,然后就改成了说:“你们把这个数据通通都留在亚马逊,不要发给中国卖家。”
但是你如果使用了UCP,谁是最终的销售者,谁就可以得到用户的电话、用户的地址。这些数据回到商家手里边有什么好处?商家可以更好的接触用户,进行售后服务,也可以再去促成二次销售。
比如说吧,你从某个商家手里买了台打印机,那么商家可能每过一段时间就会问你说:“要不要换个墨盒?要不要换个硒鼓?”他有这种二次销售的机会。那像原来美国人为了保护隐私,他把这些数据都留在亚马逊手里了,那亚马逊说:“你该买硒鼓了,该买墨盒了,你不要到原来那个商家去买,你在我这买,我给你推荐别的商家。”为什么?因为那个商家给我钱了,给我广告费了。他希望在新的二次购买机会发生的时候,亚马逊可以再收一次广告费,把这个二次销售的决定权放在自己手里边。所有跟隐私保护相关的条款,实际上背后都是有商业利益的。
那么在这样的一个协议发布以后,咱们先看看谁参加进来了。

这些其实原来都是谷歌搜索广告的大客户。
在这个里边实际上分几类。第一类是原来的这种电商平台(但是不是亚马逊),就是一些小的电商平台或者是传统的商超平台,他们都加进来了。然后这些支付平台基本上都进来了。
因为对于支付平台来说,甭管你谁把东西卖掉了,从我这能把货钱支付出去就OK。支付平台,你说怎么就这么雷锋?千万别这么想。支付平台挣的不是这钱,支付平台挣的是利息,他是希望你在支付的过程中向他贷款的。所以支付平台会非常非常积极的参与这种事情。目前开通的支付就是Google Pay,马上就会开PayPal。其他的生态合作伙伴里的这些支付平台,会逐步的加入进来。阿里系的蚂蚁国际也准备加到这个里边来,让大家去用支付宝进行支付。
咱们要注意,整个这个UCP是涉及很多环节了。除了电商平台或者说商超平台、支付平台之外,还有物流交付和售后这块。谷歌官方并没有给出合作伙伴的名单,但是有一个叫PIPE 17,他宣布支持UCP,专门做物流和订单管理的。这一块可能没有一些特别大的企业,但是他们都会积极的参与进来。
大模型或者叫流量入口,这也是一个重要参与方。你说我做了半天UCP,没有流量入口,没有新的聊天的流量进来,那不是胡扯了吗?
所以这个流量入口还是非常非常巨大的。
这是谁来了,那谁没来?亚马逊嘛。咱们刚才讲了,去中心化去的就是亚马逊。亚马逊说:“你们冲谁来的?别以为我不知道。”
然后Meta、Shein、TikTok和Temu也都没有表态,但是也没有说我就不去,只是说我们观望一下。这些就是美国现在比较主流的一些电商的平台。

首先说亚马逊吧。亚马逊自己出了一个叫做Rufus的购物助手。大家现在可以在亚马逊里头跟它聊天了。聊完了以后,它就会给你推荐商品,在亚马逊内部完成交易闭环。
亚马逊想干的事是什么?希望通过最完善的电商服务闭环体系,击败像UCP这种组织起来的草台班子。大家注意,你像UCP一旦组织起来,谁的货他不管了,谁负责物流和交付,谷歌可能会做一些简单的审核,但是一定没有亚马逊这种完全闭环的质量高。他希望通过这种购物体验打败谷歌。
OpenAI其实也推出一个类似的东西叫ACP。谷歌这个UCP,U是通用的Universal;这个A是代理的意思,叫Agentic。所以OpenAI推出的叫代理商务协议。OpenAI的这个协议相对来说要轻量很多,它通过工具的方式将电商交互融入到Agentic里边去。它做了这样的一个事情。
OpenAI跟这个协议,是OpenAI跟Stripe合作推出的一个开源协议。这块都得开源,你不开源没人敢上。然后Shopify跟这个Etsy首批加盟,他们就是甭管你谁上,这东西我都去加盟去。为什么?这就是有销售的机会吗,这是不能放弃的。亚马逊已经明确的表达,我拒绝加入,我自己玩自己的,我不跟你玩。
下一个就是Perplexity。它推出了一个叫“一键购物”的功能。你可以直接在Perplexity聊天的时候,就把东西买走。这一块Perplexity是直接奔着超级入口去的,他就没有说我开放个协议大家来加入,他没这么大野心在这块。亚马逊是直接起诉了Perplexity,你非法爬取了亚马逊的数据。起诉的同时,亚马逊对Perplexity实行了数据封锁,以后不让你爬了,你看看你到底卖什么。
AI最终还是会走向交易成功的,未必会是谷歌的UCP,因为UCP这个东西还是有点太复杂了。最终的接口位置、也就是你的协议在什么地方、各个平台提供什么样的服务、接口可能还需要有一段时间的拉扯。但是AI购物的革命正在到来。
原来是搜索购物,像亚马逊、淘宝天猫、京东,还有像拼多多,这都属于是搜索销售。我要买什么东西我跟人说,说完了以后找一大堆的商品我在里头挑,是这样的一种销售方式。这些电商平台在里边去收广告费,你搜索完了以后,谁排前头谁排后头,有哪些广告位,他们是卖这玩意的。
后来开始出现像抖音、TikTok、快手这样的直播平台。他们干的是什么?他们干的实际上是推荐销售。他们是靠推荐算法,将不同的直播间推到我面前来,让我形成购买。我现在大量的电商交易都是在抖音上做的,我是比较吃推荐算法的。
现在随着用户注意力的转移,更多的用户时长被聊天助手给劫持了。我现在每天面对电脑、面对手机的时候,大量的时间不是在这刷抖音,而是去跟豆包、跟ChatGPT、跟Gemini去聊天去了。在这个过程中就要让它形成交易,而不是说一个月找我收20美金就算结束了。你想,我如果在这个里头买东西的话,他挣到的钱绝对比一个月20美金要多得多,而且是上不封顶。你1月20美金,它是上边封顶的。所以现在甭管是OpenAI也好,还是谷歌也好,都在向这一块狂奔。
AI能够更加理解用户的需求和意图。前面咱们讲这个潘姓小娘子的案例,甭管你是说我们家衣服被虫子咬了,还是说西门大官人甚得我心、我们家有个三寸钉,这个意图会被AI理解掉。理解完了以后就说:“这样的问题,我们可以通过购买一种叫砒霜或者叫鹤顶红的东西可以解决掉。”那么这个潘姓小娘子就直接下单就购买了。
在AI购物的过程中,大模型可以根据用户意图,直接在聊天的过程中进行交易。绝对是润物细无声的,而且成交的转换率极高。更多的长尾服务会达成交易。以后就不会说大家去抢推荐算法的入口了,或者去抢什么最上面这个广告栏了,以后就是每个人聊自己的,AI会通过我们聊天的过程,发现每一个人所需要的服务或者是需要的这个商品,然后向我们推荐。那这玩意转化率多高?一卖一个不吱声,绝对的。
如果谷歌可以继续做流量入口,那么谷歌这个UCP这条路就算走通了。原来那些依赖谷歌搜索广告的商家,就像什么Shopify、像什么其他的一些小型的这些商家,会跟着谷歌走的。从谷歌最近快速蚕食OpenAI的流量,以及跟苹果签了Siri协议来看,这种可能性还是很大的。
总结一下吧,谷歌发布了UCP的通用商业协议这样的一个东西。未来的电商模式已经到来了,从搜索电商到推荐电商,现在最终到了智能电商。

所谓的智能电商,其实就是对话过程中的意图发现,并最终实现电商交易的一个过程。用户未必直接聊天,而是表达意图之后,AI Agent将意图分解,分别完成交易。比如我说了,我今天想去做满汉全席。跟AI聊了半天,菜谱都确定了,AI就会分别下单,把满汉全席所需要的所有东西都给我买回来,包括什么菜谱、什么菜刀,他是这样来去工作的。更长尾、更高转换率,而且去中心化,这就是未来电商的模式。
亚马逊、Temu和Shein这些传统的电商平台会首先受到冲击。Meta和TikTok这些社交推荐电商平台,也会随着用户注意力的转移受到影响,但是没有那么快。所以他们只是说我们看看,我们先不着急。而亚马逊就是非常非常激烈的反对、推出竞品,要跟你去竞争。它是这样的不同的反馈。
最后给大家一些建议吧。
当然,未来越来越多的普通人会成为应用和服务的开发和提供者。所以这件事情,应该是跟每一个人都有关系的。
好,这个故事今天就跟大家讲到这里,感谢大家收听。请帮忙点赞、点小铃铛,参加Discord讨论群。也欢迎有兴趣、有能力的朋友加入我们的付费频道。再见。
Prompt:High-contrast luminous watercolor realism of a split e-commerce office interior: loft workstation area with matte black steel frame, exposed ducts, concrete columns, glass rail mezzanine, rows of wooden desks with precise monitor stands, keyboards, mousepads, desk lamps, tidy cable management; adjacent logistics warehouse with galvanized pallet racking, corrugated cardboard boxes with packing tape seams, bubble wrap rolls, label printer, scale, shipping cartons, plastic totes, hand pallet jack on polished concrete, crisp aisle geometry; cinematic wide shot, 35mm equivalent, eye-level, clean separation line between the two zones, strong depth cues, sharp subject separation, extremely legible bright negative space in upper background for typography, high-key lighting + neon cyan rimlight, realistic glossy reflections on floor and screens, crystal-clear atmospheric glow, minimal vivid palette (ink blue, deep navy gradients, neon cyan, warm gold, subtle coral), controlled ink outlines, micro-texture and clean surface wear –ar 16:9 –stylize 120 –chaos 4 –no text, watermark, logo, clutter, lowres –v 7.0 –p lh4so59



