一顶价值连城的2500年前金盔,在荷兰一家博物馆遭突袭后被归还给罗马尼亚 - AP News
Priceless 2,500-year-old golden helmet returned to Romania after Dutch museum raid (news.google.com)







Vibe Island是一款应用程序,它将您Mac的“缺口”转变为一个统一的控制中心,用于在终端中工作的AI代理。它消除了在Claude Code、Codex、Gemini CLI、Cursor和其他工具执行任务时切换窗口的需要:您可以直接从摄像头视图监控进度、授予权限并返回到特定会话。
• 在一个界面监控所有代理——支持10种AI工具:Claude Code、Codex、Gemini CLI、Cursor、OpenCode、Droid、Qoder、Copilot、CodeBuddy、Kiro。每个代理都显示在单个面板上。
• 无需切换上下文即可批准操作——当Claude Code请求运行工具或提问时,工具栏会显示“允许/拒绝”按钮或回答选项。您可以在不离开编辑器的情况下批准操作。
• 精确终端跳转——支持13种以上终端(iTerm2、Ghostty、Warp、Terminal.app、VS Code、Cursor等),可跳转到您需要的精确标签页,甚至支持分屏,包括tmux会话。
• 规划和审查计划——在批准前预览带有完整Markdown渲染的计划,并可直接从“岛屿”提供反馈。
• 声音警报——每个事件都有8位合成声音。您可以导入自己的声音集或创建自己的声音。
• 配额使用跟踪——实时显示Claude、Codex和Kimi的剩余请求量,无需额外设置。
• SSH远程控制——在远程服务器上启动代理,并在Mac上进行监控,支持一键部署、自动重连,以及多服务器支持。
• 完全本地化——所有数据都保留在您的Mac上:无云服务、无账户、无遥测。仅是代理与“岛屿”之间的直接连接。
直接安装

硅谷 AI 大厂开始招聘文科生,特别是新闻专业的学生,这到底是怎么回事?一边裁程序员,一边招文科生,是不是搞反了?
这两年最魔幻的一幕出现了:一边是程序员在大裁员,找不到工作,新的程序员,特别是刚毕业的程序员,更是找不到工作;另一边,媒体突然开始热炒,说硅谷的 AI 大厂正在高薪招聘文科生。
所谓高薪,是六位数年薪,几十万美金,甚至有一些职位好像飙到了 70 多万美金一年。这些职位要求的是会写、会讲、会做内容、会做传播的人,特别还提到了新闻专业。
这个反差确实很大。程序员折腾了半天把 AI 做出来,结果像是把自己的命革了,然后把职位让给文科生。这种报道天然就具备传播性。问题是,这到底是真的趋势,还是媒体制造出来的错觉?
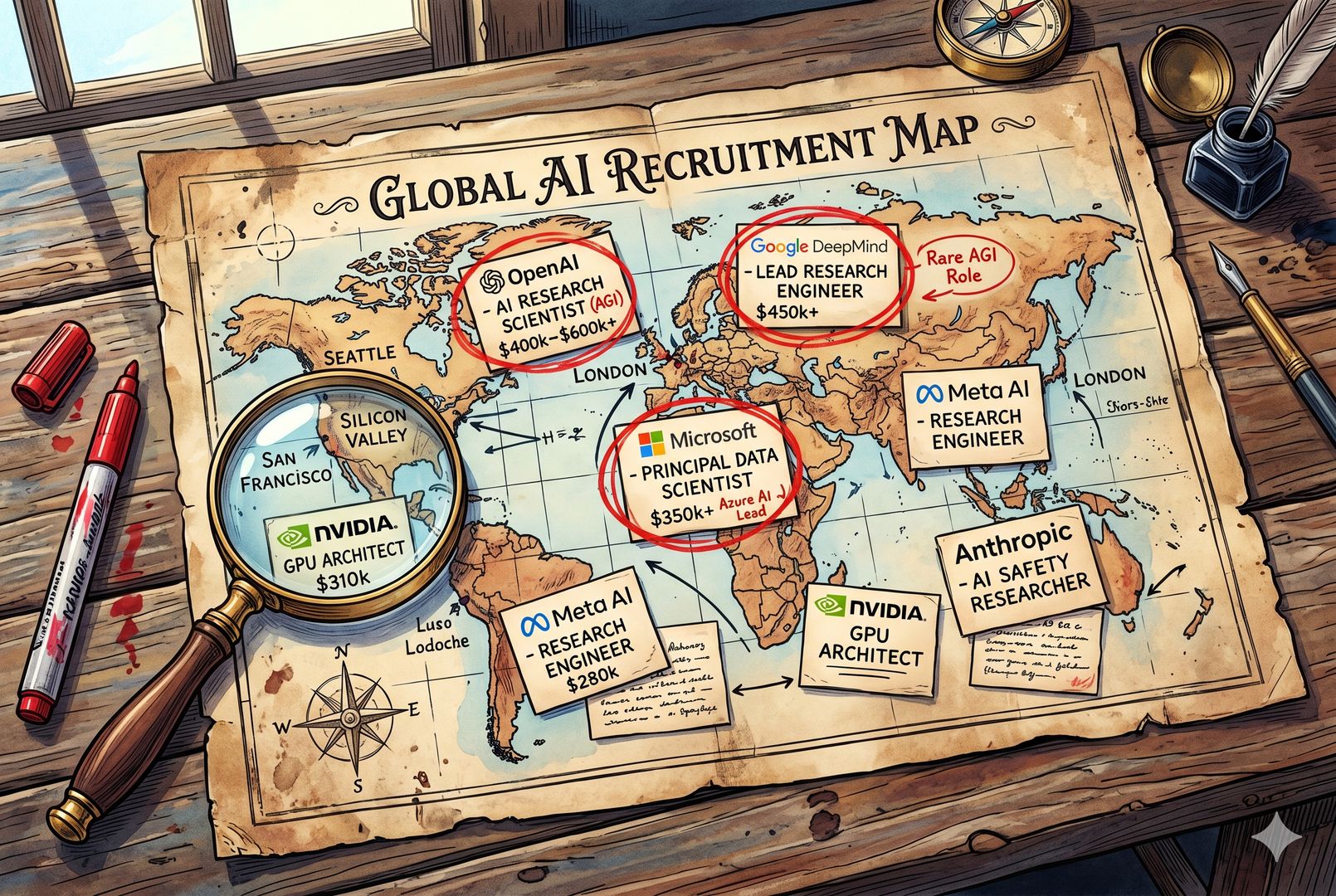
先说结论。美国硅谷 AI 大厂,确实存在对叙事、传播、内容设计、政策理解这类岗位的招聘,这是真的。
第二,这类岗位的数量非常非常少。大家要知道,在大厂里,通常一种扩招是为了开展一块新业务,会直接招整个团队;另一种招聘,则是补一些非常资深的总监、专家类岗位。
这次所谓硅谷招聘文科生,实际需要的更像是后者,也就是总监、专家类,或者 senior 级别的岗位。这些岗位绝大部分都不是给新人准备的,而是中高级岗位,职位要求上写得很清楚。
第三,这不是文科生大翻身,更不是程序员不行了、文科生接班了。
第四,它更像是 AI 大厂发现,技术已经不只是技术本身了。谁能够解释清楚技术、包装技术、定义技术、决定技术怎么说话,谁就能掌控一部分新时代的话语权。这更像是一场叙事权的争夺。
所以,这不是一次就业逆转的故事,而是一个更大的叙事:技术公司开始争夺叙事权。谁有权利来讲这个故事,这才是大家现在在抢的。

那么,这波“文科生翻身”的叙事是怎么炒起来的?如果回头去看这波舆论的传播线,会发现它不是很多媒体同时独立报道出来的,而是一个非常典型的放大过程。
最早,是《华尔街日报》在去年 12 月份发了一篇文章,开始讨论企业为什么迫切需要会讲故事的人。但当时这个话题并没有彻底炸开。
真正让这个话题变成风潮的,是 2026 年 2 月《商业内幕》Business Insider 的一篇文章,标题非常抓眼球,大意是:科技行业最热门的工作之一,竟然是写字。随后,《财富》杂志继续跟进,把高薪数字抬得更高。
再往后,LinkedIn 上的职场传播链开始接力,于是整个故事就变成了“AI 时代,文科生成了香饽饽”。
大家要知道,掌握这些媒体的其实大部分也是文科生,甚至一些学新闻的人。有这样的新闻出来,他们当然也乐意传播。
所以你会发现,这不是一个社会现实被媒体记录下来,而更像是少数真实岗位被媒体用最容易传播的方式包装之后,形成了一个非常漂亮的叙事泡泡。所以,这东西只能叫泡泡。
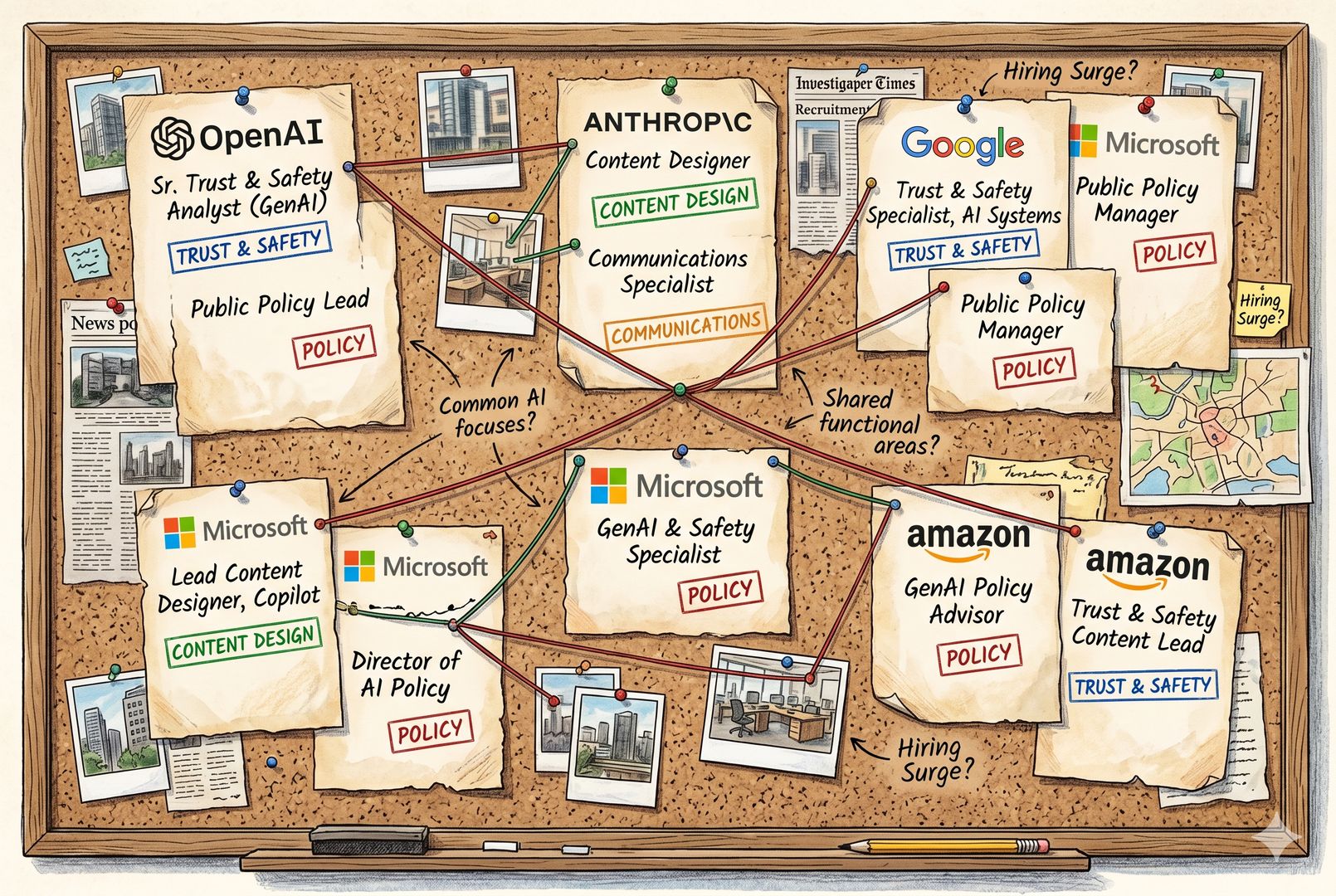
那么,大厂到底有没有招?招什么人?这些人具体干什么?这个得讲清楚。不能说人家吹了半天牛,结果什么都没招。答案很明确:大厂确实在招,而且还不是一家,很多家都在同时招。
先看 OpenAI。它官网公开的岗位里,有一个“研究传播经理”,职责是管理研究和媒体的沟通,帮研究员和高管准备采访材料,还要和科技记者建立长期关系。
这个职位听起来很像原来 PR 干的活,但为什么要专门设置这样一个新职位?原因很简单,以前的 PR 很难做这个职位,因为你不理解 AI 到底在干什么,也没办法和工程师顺畅沟通。
而且这个岗位还要帮研究员和高管准备采访稿。现在比较流行的情况是,Sam Altman 直接出来讲,下面的工程师也会在 Twitter 和各种媒体上发言。未来不是谁想怎么说就怎么说,而是需要有人来替大家把关。
传统企业的公关部通常有自己的节奏和战略,今天讲什么、明天讲什么,主要服务对象还是高管,下面的研究员一般不会出来说话。像亚马逊、苹果这样的公司,甚至以前会规定,如果没给你发言任务,你敢出去乱说,可能马上就被开掉。
但现在不一样了。现在几乎每个人都有可能出来说话。像 OpenAI,不只是 CEO、CFO,下面各种研究员、产品经理也都可能出来说点什么。这就需要有人来把关,而且这个人必须听得懂技术人员到底在说什么。对很多传统公关经理来说,这件事是搞不定的。
OpenAI 还有“传播经理”这类岗位,核心任务是把产品功能讲得让普通用户也觉得有意思。这两个岗位通常都要求有媒体、公关、科普写作或者传播学背景。

再看 Anthropic。它招聘页上的这类岗位更多,甚至有 Claude Code 传播总监,专门负责某个产品的传播。
还有一个很有意思的职位,叫“工程编辑总监”。这是干什么的?工程师有时候也要写稿,也要说明自己的产品是怎么回事,而这些稿子背后会有编辑审核,甚至会有一个 leader 管理这些编辑,这就是“工程编辑总监”的工作。
这个岗位专门负责把复杂的工程内容编辑成严谨、易懂、好读的文章。
现在 Anthropic 的博客已经变成了一个非常重要的媒体渠道,很多人会去看它发布了什么内容,然后拿这些内容去做课程、做解读。这些内容显然不是工程师独立完成的,背后有专门的编辑团队。
这类岗位的本质都指向同一类人:既要懂 AI 在干什么,又要能把它翻译成外行、媒体、政策制定者都能理解的话。换句话说,是能把这个故事讲明白的人。如果只是一个传统文科生,其实也干不了这事。
谷歌也在招,而且有一个特别奇葩的岗位,叫 Model UX Writer,也就是 AI 模型用户体验文案师。这个岗位不是对外宣传,而是做训练的。
它的工作是告诉 AI 大模型,应该输出什么样格式的内容,让用户看着舒服。岗位描述里写得很清楚:这个人要定义谷歌 AI 产品的人格、语气、风格规范,要设计多轮人机对话的结构,还要和研究员、产品经理、工程师一起把要求变成对话设计。
这个岗位要求 8 年以上相关经验,不是给新人准备的。
谷歌另外还有“资深用户体验内容设计经理”,要求 10 年以上经验和 5 年以上管理经验。
微软招的是“资深内容设计师”,注意不是 writer,而是 designer,特别说明是为 Copilot 做产品设计。
这个职位要写提示词、写评估标准、构建用户叙事,本质上是在帮 AI 设计怎么说话,和谷歌那个 Model UX Writer 干的事差不多。

亚马逊也在招“资深用户体验文案师”,也是面向 AI 产品,它的 AI 产品是 Alexa。
它还招一个叫 trust CX 的岗位,主要做 AI 伦理、敏感内容、信任体验相关的工作。这些岗位也都是文科背景更容易切入的。还有“AI 数据专员”这类岗位,相对门槛低一些,进去以后可能会做很多数据标注,应该会比较枯燥。
整个看下来,这些岗位大概可以分成三类。
把公司的研究和产品讲给媒体和公众听。OpenAI 的研究传播经理、Anthropic 的传播经理,都属于这一类。
直接定义 AI 怎么说话。谷歌的 Model UX Writer、微软的资深内容设计师都属于这一类,而且这一类门槛最高。上面讲故事的岗位通常要求 3 到 5 年工作经验,应届毕业生也干不了;而产品语言设计类要求比这还高。
定义 AI 什么能说、什么不能说,处理信任与安全问题。Anthropic 有政策分析师,亚马逊有 trust 相关岗位,都是这一类。
所以,大厂大致是在招这三类“文科生”。这些岗位看起来不像传统意义上的程序员岗位,但它们都在处理一件核心的事情:让复杂技术以一种用户能够理解、市场能够接受、社会能够信任的方式传播出去。

所以这些人能不懂技术吗?不行,还是得懂。尤其是在 AI 产品里,这一点变得特别关键。因为今天的 AI 不只是后台算法,它会直接跟人对话。
它每一句话怎么说,拒绝回答时怎么说,犯错误以后怎么圆,语气是冷冰冰的还是可信赖的,这背后都需要专业人员设计。这种事情交给程序员通常是不行的,他们设计出来的文案,一般人往往看不明白。这个时候,会写、会讲、会控制语气和结构的人,价值就出来了。
但真正的反转也在这里:这些岗位门槛很高,数量很少。大厂动辄裁员上万人,而所谓招的这些“文科生”,可能也就是几个人、十几个人而已。
从 LinkedIn 上这些职位的描述来看,这些岗位对新人极度不友好。绝大部分都要求多年工作经验。
也就是说,媒体集中报道的这些岗位,特别是那些年薪达到 70 多万美金的岗位,本质上都是中高级资深岗位,压根就不是给应届生和刚入行的人准备的。
第二个特点是,这个数量跟裁员比起来就是九牛一毛。比如亚马逊裁了 1.6 万人,但这类岗位可能招十几个也就差不多了。微软 2025 年 7 月裁了 4%,Oracle 在 2026 年 3 月也有几千甚至上万人被裁。
在同一个窗口期内,媒体集中报道的叙事、传播、内容设计相关岗位,有据可查的,也就是一些非常零散的单个岗位,或者十来个这样的新增。
第三个特点是,薪水确实高,真实高薪,真实存在。Business Insider 报道过,部分这类岗位的年薪可以到 77.5 万美金,甚至还有接近百万美元总包的案例。
这个数字可能是真的,但能拿到这个数字的人,基本都是在媒体、公关、传播领域积累了 10 年以上的资深人士。所以千万不要觉得“学文科又行了”。
大厂招文科生这件事是真的,但如果把它理解为普通文科毕业生突然迎来了春天,成了香饽饽,那就很容易被误导。
更准确地说,是极少数高薪的中高级叙事岗位确实开放了,但普通人能够进入这些岗位的路径,需要相当长时间的积累,非常难。

那为什么偏偏是现在,大厂开始重视这类人了?因为 AI 时代最稀缺的不只是算力、模型和工程能力,还有一件东西变得越来越贵,就是叙事权,或者说解释权。
谁来告诉用户,这个模型能做什么、不能做什么?谁来定义它说话的风格?谁来处理它出错之后企业如何继续获得信任?谁来把一个复杂的技术路线,讲成投资人、用户、监管者都能听懂的故事?这些都非常重要。
这也是为什么大厂开始需要这些既懂表述、又能理解技术的人。
很多时候,工程师和创始人不是不能说,而是他们直接出来说,反而容易翻车。技术讲得太硬,用户听不懂;表达太满,又容易引起反噬。像马斯克就很喜欢出来讲,但大家也经常会吐槽他是不是又说过头了。
即使是 Anthropic 的 Dario Amodei 和 OpenAI 的 Sam Altman,这种已经算比较能说的人,要把当前的状态说明白、说漂亮,也没那么容易。
所以,术业有专攻。AI 时代,叙事本身变成了产品能力的一个重要组成部分。

而且这不是头一回。历史上每一次技术革命,都会伴随着叙事权的争夺。如果把时间线拉长,会发现这根本不新鲜。每次技术革命开始改变社会的时候,领先企业都会想办法掌控叙事权,因为一旦让别人掌控了叙事权,你就是在替他人做嫁衣。
有个特别典型的案例就是爱迪生和特斯拉。当年爱迪生主推直流电,特斯拉主推交流电。为了打击交流电,爱迪生到处宣传交流电很危险,很容易电死人,甚至专门去研究电刑用的电椅,然后带着这个东西四处演讲,说你看这玩意多危险。这其实也是在争夺叙事权。
在这方面,特斯拉就差得很远,他更像一个典型的钢铁直男。
所以,技术竞争从来不只是在实验室里比参数,它也是公众认知的竞争,是定义什么叫先进、什么叫安全、什么叫未来的竞争。
现在 OpenAI 在抢话语权,Anthropic 在抢话语权,谷歌在抢话语权,微软也在抢话语权。国内其实大家也在抢,只是还没到那个高度。

而今天 AI 大厂做的事情,只是把这一套推进得更深了一层。以前是公关部门替产品说话,现在是产品自己要出来说话了。因为 AI 产品本身就是聊天工具,它自己就在和用户交流。
所以真正的新变化,不是突然要招新闻系的人了,而是从“公关写稿”变成了“把叙事直接写进产品里去”。
这次和过去最大的不同,不是企业开始重视传播,而是企业开始把传播能力直接内嵌到产品和组织里。
过去可以理解为,产品做出来之后,公关和市场再去包装;但在 AI 时代,这个顺序变了。很多表达不是外面补上去的,而是里面一开始就要写好。
比如以前你卖一只锅,先把锅做出来,再去写描述、讲历史、讲健康、设计包装、出去直播卖货。现在你做一个大模型,广告词写得再天花乱坠都没用,用户直接上来跟模型聊两句,就知道它是什么状态。
而且现在的 AI 还要有人格设定。什么事情可以回答,什么时候不可以回答,提示词结构,帮助文案,风险边界,品牌语气,这些都要有人设计。用户未必会去看帮助文案,但他会直接去问模型,而模型怎么回应,本身就是设计出来的。
Anthropic 的 Dario Amodei 就曾说过,刷分是没用的,他们的模型是有性格的,最后你会喜欢上一个 AI,而不会喜欢另外一个 AI。这说明模型之间确实会产生风格差异。
刚刚说的这些,都不是简单地写个文案,而是在塑造用户对 AI 的理解过程。所以这块必须有专业人士参与。可以把它叫作一种新的岗位逻辑,甚至叫 Storyteller 2.0。
不是传统意义上帮企业讲故事,那是 PR 做的事,而是能参与到定义里面去:产品怎么开口,企业怎么解释自己,技术怎么被社会理解。这个时候,讲故事就不只是锦上添花了,而开始接近底层竞争力。

落到普通人身上,新时代真正该练的,已经不只是文科或者理科,而是跨学科能力。今天最值得关注的,不是文科生是不是翻身了,而是另一个现实:AI 时代,单一能力正在贬值,复合型表达能力正在升值。
如果你只是会写一些空话,那不值钱,AI 写得比你快,也可能比你好;如果你只懂一点技术,但自己做的事情说不清楚,完全无法解释给别人听,也不行。所以必须两边都强。
真正有价值的是,既能理解技术,又能组织信息、控制节奏、讲清逻辑、建立信任的人。
不管你是不是文科生,其实都应该逼自己去练几件事:
所以,这次的故事告诉我们,大厂开放的那些职位,绝大部分人其实是够不着的,但我们可以朝这个方向努力,朝复合型人才的方向努力。这可能才是未来真正的机会。
不是说努力努力,看哪个大厂能看上自己,而是未来会有很多非常细微的场景,需要讲故事、需要解释权、需要把事情说明白。
如果你解释不清楚、讲不明白,那就不行了。这就是新的时代。





